
1. Введение
Если вы предпочитаете запускать скрипты из пакета напрямую, без пошагового руководства, вы можете найти их в репозитории GoogleCloudPlatform/devrel-demos .
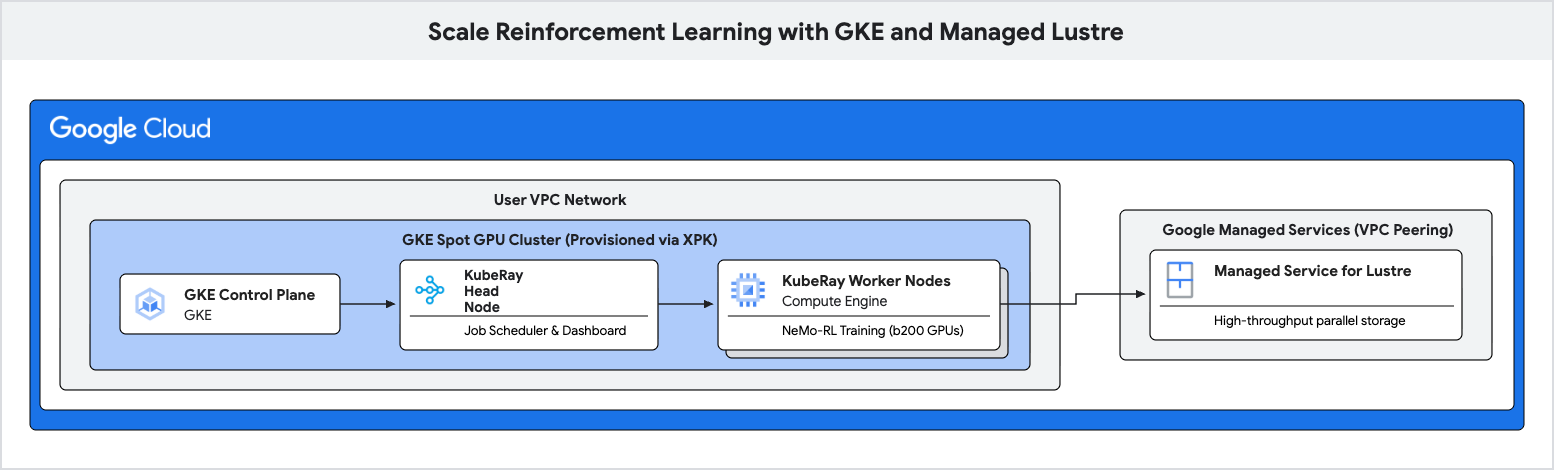
В этом практическом занятии вы узнаете, как развернуть высокопроизводительный конвейер обучения для обучения с подкреплением (Reinforcement Learning, RL) с использованием Google Kubernetes Engine (GKE) и Managed Lustre .
В задачах обучения с подкреплением, особенно в тех, которые используют такие алгоритмы, как групповая относительная оптимизация политики (GRPO), генерируются огромные объемы данных во время «генерации опыта» и требуют частого сохранения контрольных точек. Стандартное объектное хранилище может создавать узкие места во время этих всплесков операций ввода-вывода, в результате чего дорогостоящие ускорители простаивают.
Для устранения этих узких мест и достижения более высокой пропускной способности обучения вы будете использовать Managed Lustre — параллельную файловую систему.
Что вы будете делать
- Настройте переменные среды для кластера Ray на базе графического процессора.
- Создайте кластер Spot GPU в GKE с помощью инструмента XPK .
- Создайте управляемый экземпляр Lustre .
- Разверните кластер KubeRay и смонтируйте файловую систему Lustre.
- Submit a NeMo-RL training workload.
- Обеспечьте высокую пропускную способность и низкую задержку при создании контрольных точек с помощью облачного мониторинга.
Что вам понадобится
- Веб-браузер, например Chrome .
- Проект Google Cloud с включенной функцией выставления счетов.
Данный практический семинар предназначен для опытных технических специалистов, инженеров платформ и исследователей в области искусственного интеллекта, знакомых с GKE и концепциями хранения данных.
Ориентировочная общая продолжительность: от 45 до 60 минут плюс 2 часа тренировочного времени.
2. Прежде чем начать
Создайте проект в Google Cloud.
- В консоли Google Cloud выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов.
Запустить Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud и поставляемая с предустановленными необходимыми инструментами.
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» .
- После подключения к Cloud Shell подтвердите свою аутентификацию:
gcloud auth list - Confirm your project is configured:
gcloud config get project - Если параметры вашего проекта заданы не так, как ожидалось, настройте их следующим образом:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Install XPK
В этом практическом занятии для подготовки кластера GKE используется xpk . Инструкции по установке xpk см. в руководстве по установке xpk .
В Cloud Shell его можно установить с помощью следующей команды:
pip install xpk
Включить API
Выполните эту команду в Cloud Shell, чтобы включить все необходимые API:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Настройка переменных среды
Для обеспечения единообразия команд в этом практическом задании настройте несколько переменных окружения.
Создайте файл с именем env.sh и заполните его вашей конфигурацией. Вы можете использовать следующий шаблон:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Замените <YOUR_PROJECT_ID> и <YOUR_HF_TOKEN> на ваши фактические значения.
Подключите файл, чтобы загрузить переменные в текущую сессию:
source env.sh
4. Создайте кластер GKE с помощью XPK.
На этом этапе вы используете xpk для развертывания кластера GKE с использованием спотовых графических процессоров.
xpk — это инструмент для подготовки гиперкомпьютеров с поддержкой ИИ , который упрощает создание кластеров GKE для автоматизированных рабочих нагрузок. Указав тип устройства и количество узлов, он создает необходимые VPC, подсети и пулы узлов.
Выполните команду создания кластера:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Дождитесь создания кластера. Это может занять несколько минут.
Включите дополнение RayOperator.
После создания кластера включите надстройку RayOperator для управления кластерами KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Verify Lustre CSI Driver
XPK должен автоматически включить драйвер Lustre CSI с помощью флага --enable-lustre-csi-driver . Убедитесь, что он включен:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Если возвращается false , выполните команду включения резервного режима:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Provision Managed Lustre Instance
На этом шаге вы создадите экземпляр управляемой службы для Lustre. Lustre — это параллельная файловая система, обеспечивающая высокую пропускную способность для создания контрольных точек.
Выделение диапазона IP-адресов для управляемых сервисов
Для работы Lustre требуется соединение VPC с управляемыми сервисами Google. Сначала выделите глобальный диапазон IP-адресов:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Establish VPC Peering
Подключите вашу VPC к сетевой инфраструктуре сервисов:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Create Lustre Instance
Теперь создайте экземпляр Lustre. Эта команда выполняется асинхронно.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Verify Lustre Status
Для подготовки экземпляра Lustre требуется приблизительно 10-15 минут . Проверить статус можно с помощью:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Дождитесь, пока состояние не станет ACTIVE , прежде чем продолжить.
6. Deploy Ray Cluster on GKE
На этом этапе вы развернете кластер KubeRay на узлах GKE и смонтируете файловую систему Lustre, используя PersistentVolume (PV) и PersistentVolumeClaim (PVC).
Fetch Lustre IP
Перед созданием тома необходимо получить IP-адрес точки монтирования вашего экземпляра Lustre:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Создание глянцевых ПВХ и ПВХ
Создайте файл с именем rl-lustre-volume.yaml используя следующую конфигурацию. Она определяет, как GKE подключается к вашему экземпляру Lustre.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Примените конфигурацию тома:
kubectl apply -f rl-lustre-volume.yaml
Create RayCluster Configuration
Создайте файл с именем ray-cluster.yaml . В нем указываются головной и рабочий узлы KubeRay, используется тип ускорителя nvidia-b200 , а том Lustre монтируется в каталог /lustre .
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Apply the Ray cluster configuration:
kubectl apply -f ray-cluster.yaml
Проверьте состояние кластера.
Отслеживайте создание подов:
kubectl get pods -w
Дождитесь, пока головной и рабочий модули Running .
7. Предоставьте данные о нагрузке по обучению с подкреплением.
На этом этапе вы отправите задание на обучение NeMo-RL GRPO в свой кластер Ray.
Connect to the Ray Dashboard
Для отправки заданий и просмотра метрик необходимо подключиться к панели мониторинга Ray. Поскольку панель мониторинга находится в GKE, используйте переадресацию портов для доступа к ней из Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Создайте исполняемый скрипт.
Создайте файл с именем run_nemo_rl.sh . Этот скрипт будет выполняться на рабочих узлах кластера Ray. Мы используем cat << EOF для заполнения переменных окружения, которые вы установили ранее.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Создать файл игнорирования луча
Создайте файл .rayignore , чтобы предотвратить загрузку Ray больших или ненужных папок:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Create Runtime Environment Configuration
Создайте JSON-файл для передачи переменных окружения в задание Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Разместить вакансию
Используйте Ray CLI для отправки задания на конечную точку панели мониторинга. Если команда ray не найдена в Cloud Shell, вы можете установить ее с помощью pip install ray :
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
В терминале Cloud Shell вы увидите поток логов. Задача загрузит модель, инициализирует рабочие процессы Ray и запустит цикл обучения GRPO.
8. Мониторинг результатов тренировок.
На этом этапе вы сможете понаблюдать за производительностью файловой системы Lustre во время обучения и создания контрольных точек.
Check Training Logs
По мере прохождения обучения вы будете видеть в логах сообщения о сохранении контрольных точек в /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 . Обратите внимание, что создание контрольных точек происходит асинхронно и не блокирует работу рабочих процессов Ray на длительное время.
Чтобы оценить скорость создания контрольных точек, ищите в логах строки, указывающие на количество сохраненных контрольных точек.
Просматривайте показатели Lustre в облачной консоли.
To see metrics for your Lustre instance:
- В консоли Google Cloud найдите «Управляемая служба для Lustre» .
- Щелкните по имени вашего экземпляра (
rl-demo-gpu-lustre). - Перейдите на вкладку «Мониторинг» .
Here you can observe:
- Пропускная способность (байты/сек) : отслеживайте пики во время создания контрольных точек.
- Пропускная способность : отслеживайте, сколько места занимают контрольно-пропускные пункты.
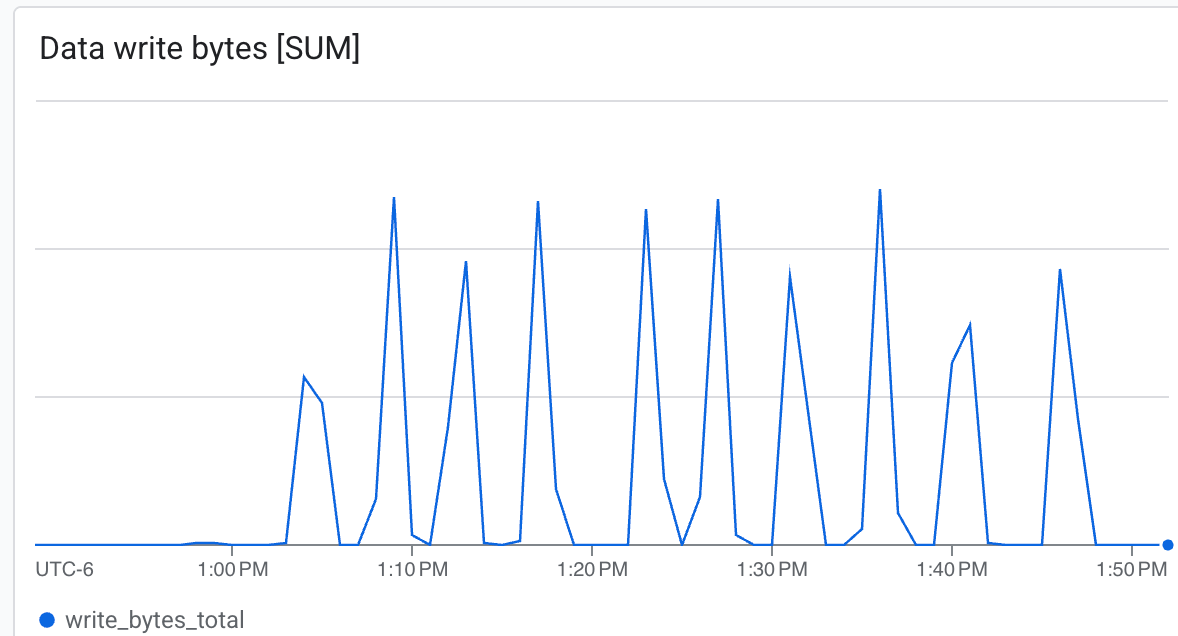 Lustre способен записывать данные с очень высокой скоростью, создавая контрольные точки за минимальное время .
Lustre способен записывать данные с очень высокой скоростью, создавая контрольные точки за минимальное время .
9. Ресурсы для уборки
Выполните следующие команды в Cloud Shell, чтобы удалить ресурсы, созданные в этом практическом задании.
Delete Managed Lustre Instance
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Удаление кластера GKE с помощью XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Clean up IP Aliases (Optional)
Если вы хотите полностью очистить диапазоны IP-адресов, созданные для пиринга VPC:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Ресурсы будут удалены асинхронно. Вы можете проверить их статус в консоли Cloud Console.
10. Поздравляем!
Вы успешно завершили практическое занятие по масштабируемому обучению с подкреплением с использованием GKE и Managed Lustre !
Что вы узнали
- Как использовать
xpkдля развертывания кластера GKE с графическими процессорами и экземплярами Spot. - Как включить драйвер Lustre CSI и дополнения RayOperator.
- Как развернуть экземпляр Lustre в рамках управляемой службы Google Cloud.
- Как развернуть кластер KubeRay и смонтировать хранилище Lustre.
- How to submit a NeMo-RL GRPO training workload.
- Как отслеживать производительность хранилища во время обучения.
Следующие шаги
- Explore more NVIDIA NeMo-RL features.
- Узнайте больше о гиперкомпьютере Google Cloud AI .
- Ознакомьтесь с документацией по управляемым услугам Lustre .