
1. บทนำ
หากต้องการเรียกใช้สคริปต์ที่แพ็กไว้โดยตรงโดยไม่ต้องทำตามบทแนะนำทีละขั้นตอน คุณจะดูสคริปต์ได้ในที่เก็บ GoogleCloudPlatform/devrel-demos
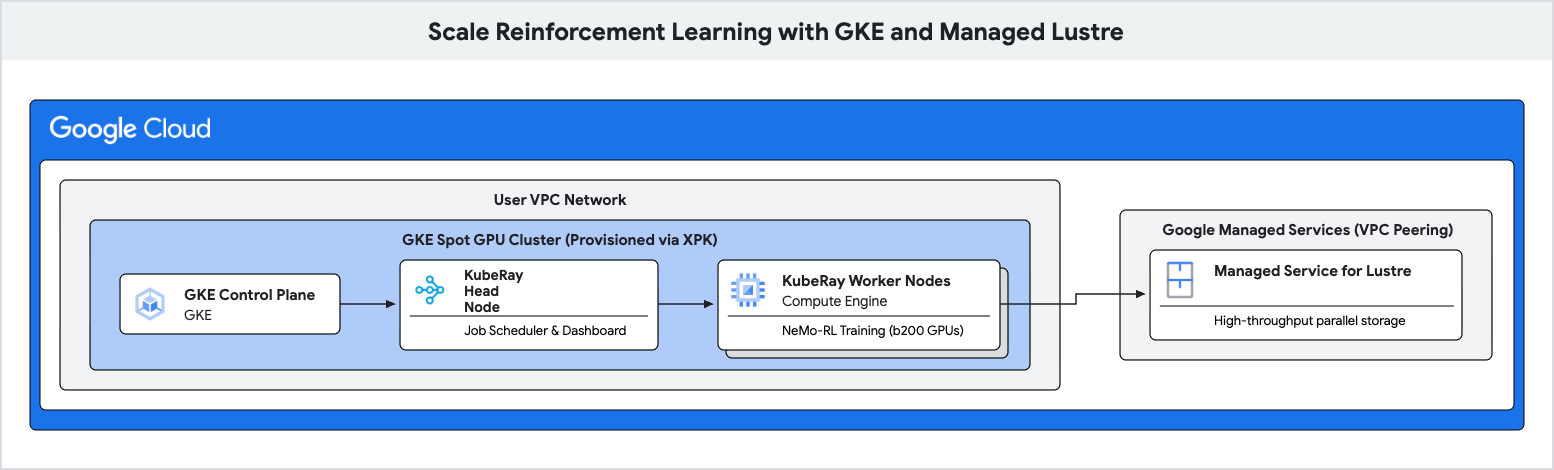
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีทำให้ไปป์ไลน์การฝึกที่มีประสิทธิภาพสูงสําหรับการเรียนรู้แบบเสริมกำลัง (RL) ใช้งานได้โดยใช้ Google Kubernetes Engine (GKE) และ Managed Lustre
เวิร์กโหลดการเรียนรู้แบบเสริมกำลัง โดยเฉพาะอย่างยิ่งเวิร์กโหลดที่ใช้อัลกอริทึม เช่น การเพิ่มประสิทธิภาพนโยบายแบบสัมพัทธ์ของกลุ่ม (GRPO) จะสร้างข้อมูลจำนวนมหาศาลในระหว่าง "การสร้างประสบการณ์" และต้องมีการตรวจสอบจุดย้อนกลับบ่อยครั้ง ที่เก็บข้อมูลออบเจ็กต์มาตรฐานอาจทำให้เกิดคอขวดในช่วงที่มีการใช้งาน I/O สูง ซึ่งจะทำให้ตัวเร่งความเร็วที่มีราคาสูงไม่ได้ใช้งาน
คุณจะใช้ Managed Lustre ซึ่งเป็นระบบไฟล์แบบขนานเพื่อขจัดจุดคอขวดเหล่านี้และเพิ่มอัตราการส่งข้อมูลการฝึก
สิ่งที่คุณต้องดำเนินการ
- กำหนดค่าตัวแปรสภาพแวดล้อมสำหรับคลัสเตอร์ Ray ที่ใช้ GPU
- จัดสรรคลัสเตอร์ GPU แบบสปอตใน GKE โดยใช้เครื่องมือ XPK
- สร้างอินสแตนซ์ Managed Lustre
- ทำให้คลัสเตอร์ KubeRay ใช้งานได้และติดตั้งระบบไฟล์ Lustre
- ส่งภาระงานการฝึก NeMo-RL
- สังเกตการณ์การส่งข้อความปริมาณมากและเวลาในการตอบสนองของจุดตรวจสอบต่ำโดยใช้ Cloud Monitoring
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ เช่น Chrome
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
Codelab นี้เหมาะสำหรับผู้ใช้ที่มีความรู้ด้านเทคนิคขั้นสูง วิศวกรแพลตฟอร์ม และนักวิจัย AI ที่คุ้นเคยกับแนวคิดของ GKE และพื้นที่เก็บข้อมูล
ระยะเวลารวมโดยประมาณ: 45-60 นาที บวกเวลาฝึกอบรม 2 ชั่วโมง
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว
เริ่มต้น Cloud Shell
Cloud Shell คือสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งโหลดเครื่องมือที่จำเป็นไว้ล่วงหน้า
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ยืนยันการตรวจสอบสิทธิ์โดยทำดังนี้
gcloud auth list - ตรวจสอบว่าได้กำหนดค่าโปรเจ็กต์แล้ว
gcloud config get project - หากไม่ได้ตั้งค่าโปรเจ็กต์ตามที่คาดไว้ ให้ตั้งค่าดังนี้
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
ติดตั้ง XPK
Codelab นี้ใช้ xpk เพื่อจัดสรรคลัสเตอร์ GKE ดูวิธีการติดตั้ง xpk ได้ที่คู่มือการติดตั้ง xpk
คุณติดตั้งได้ใน Cloud Shell โดยใช้คำสั่งต่อไปนี้
pip install xpk
เปิดใช้ API
เรียกใช้คำสั่งนี้ใน Cloud Shell เพื่อเปิดใช้ API ที่จำเป็นทั้งหมด
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. กำหนดค่าตัวแปรสภาพแวดล้อม
ตั้งค่าตัวแปรสภาพแวดล้อม 2-3 ตัวเพื่อให้คำสั่งใน Codelab นี้สอดคล้องกัน
สร้างไฟล์ชื่อ env.sh และป้อนข้อมูลการกำหนดค่า คุณใช้เทมเพลตต่อไปนี้ได้
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
แทนที่ <YOUR_PROJECT_ID> และ <YOUR_HF_TOKEN> ด้วยค่าจริง
เรียกใช้ไฟล์เพื่อโหลดตัวแปรลงในเซสชันปัจจุบัน
source env.sh
4. สร้างคลัสเตอร์ GKE โดยใช้ XPK
ในขั้นตอนนี้ คุณจะใช้ xpk เพื่อจัดสรรคลัสเตอร์ GKE ด้วย GPU แบบสปอต
xpk เป็นเครื่องมือจัดสรร AI Hypercomputer ที่ช่วยลดความซับซ้อนในการสร้างคลัสเตอร์ GKE สำหรับภาระงานอัตโนมัติ การระบุประเภทอุปกรณ์และจำนวนโหนดจะสร้าง VPC, ซับเน็ต และกลุ่มโหนดที่จำเป็น
เรียกใช้คำสั่งสร้างคลัสเตอร์
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
รอให้ระบบสร้างคลัสเตอร์ การดำเนินการนี้อาจใช้เวลาหลายนาที
เปิดใช้ส่วนเสริม RayOperator
เมื่อสร้างคลัสเตอร์แล้ว ให้เปิดใช้ส่วนเสริม RayOperator เพื่อจัดการคลัสเตอร์ KubeRay โดยทำดังนี้
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
ยืนยัน Lustre CSI Driver
XPK ควรเปิดใช้ไดรเวอร์ Lustre CSI โดยอัตโนมัติผ่านแฟล็ก --enable-lustre-csi-driver วิธีตรวจสอบว่าเปิดใช้แล้ว
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
หากแสดง false ให้เรียกใช้คำสั่งเปิดใช้การสำรอง
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. จัดสรรอินสแตนซ์ Lustre ที่มีการจัดการ
ในขั้นตอนนี้ คุณจะได้สร้างอินสแตนซ์ Managed Service for Lustre Lustre เป็นระบบไฟล์แบบขนานที่ให้ปริมาณงานสูงสำหรับการตรวจสอบ
จัดสรรช่วง IP สำหรับบริการที่มีการจัดการ
Lustre ต้องใช้การเชื่อมต่อเพียร์ VPC กับบริการที่มีการจัดการของ Google ก่อนอื่น ให้จัดสรรช่วง IP ทั่วโลกโดยทำดังนี้
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
สร้างการเพียร์ VPC
เชื่อมต่อ VPC กับเครือข่ายบริการ
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
สร้างอินสแตนซ์ Lustre
ตอนนี้ให้สร้างอินสแตนซ์ Lustre คำสั่งนี้จะทำงานแบบไม่พร้อมกัน
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
ยืนยันสถานะ Lustre
อินสแตนซ์ Lustre จะใช้เวลาประมาณ 10-15 นาทีจึงจะพร้อมใช้งาน คุณตรวจสอบสถานะได้โดยใช้
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
รอจนกว่าสถานะจะเป็น ACTIVE ก่อนดำเนินการต่อ
6. ติดตั้งใช้งานคลัสเตอร์ Ray บน GKE
ในขั้นตอนนี้ คุณจะทำให้คลัสเตอร์ KubeRay ใช้งานได้ในโหนด GKE และติดตั้งระบบไฟล์ Lustre โดยใช้ PersistentVolume (PV) และ PersistentVolumeClaim (PVC)
ดึงข้อมูล IP ของ Lustre
ก่อนสร้างวอลุ่ม คุณต้องรับ IP จุดต่อเชื่อมของอินสแตนซ์ Lustre โดยทำดังนี้
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
สร้าง PV และ PVC ของ Lustre
สร้างไฟล์ชื่อ rl-lustre-volume.yaml โดยใช้การกำหนดค่าต่อไปนี้ ซึ่งจะกำหนดวิธีที่ GKE เชื่อมต่อกับอินสแตนซ์ Lustre
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
ใช้การกำหนดค่าระดับเสียง
kubectl apply -f rl-lustre-volume.yaml
สร้างการกำหนดค่า RayCluster
สร้างไฟล์ชื่อ ray-cluster.yaml ซึ่งจะระบุโหนดหัวหน้าและโหนด Worker ของ KubeRay โดยใช้nvidia-b200ประเภทตัวเร่งและติดตั้งวอลุ่ม Lustre ที่ /lustre
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
ใช้การกำหนดค่าคลัสเตอร์ Ray
kubectl apply -f ray-cluster.yaml
ยืนยันสถานะคลัสเตอร์
ตรวจสอบการสร้างพ็อด
kubectl get pods -w
รอจนกว่าพ็อดส่วนหัวและพ็อดของ Worker จะเป็น Running
7. ส่งภาระงานการเรียนรู้แบบเสริมกำลัง
ในขั้นตอนนี้ คุณจะส่งงานการฝึก GRPO ของ NeMo-RL ไปยังคลัสเตอร์ Ray
เชื่อมต่อกับแดชบอร์ด Ray
หากต้องการส่งงานและดูเมตริก คุณต้องเชื่อมต่อกับแดชบอร์ด Ray เนื่องจากแดชบอร์ดอยู่ใน GKE ให้ใช้การส่งต่อพอร์ตเพื่อเข้าถึงจาก Cloud Shell โดยทำดังนี้
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
สร้างสคริปต์การดำเนินการ
สร้างไฟล์ชื่อ run_nemo_rl.sh สคริปต์นี้จะดำเนินการใน Worker ของคลัสเตอร์ Ray เราใช้ cat << EOF เพื่อป้อนตัวแปรสภาพแวดล้อมที่คุณตั้งค่าไว้ก่อนหน้านี้
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
สร้างไฟล์ Ray Ignore
สร้างไฟล์ .rayignore เพื่อป้องกันไม่ให้ Ray อัปโหลดไดเรกทอรีขนาดใหญ่หรือไดเรกทอรีที่ไม่จำเป็น
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
สร้างการกำหนดค่าสภาพแวดล้อมรันไทม์
สร้างไฟล์ JSON เพื่อส่งตัวแปรสภาพแวดล้อมไปยังงาน Ray โดยทำดังนี้
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
ส่งงาน
ใช้ Ray CLI เพื่อส่งงานไปยังปลายทางแดชบอร์ด หากไม่พบคำสั่ง ray ใน Cloud Shell คุณสามารถติดตั้งได้ด้วย pip install ray ดังนี้
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
คุณจะเห็นบันทึกที่สตรีมในเทอร์มินัล Cloud Shell งานจะโหลดโมเดล เริ่มต้นใช้งาน Worker ของ Ray และเริ่มลูปการฝึก GRPO
8. ตรวจสอบประสิทธิภาพการฝึก
ในขั้นตอนนี้ คุณจะสังเกตประสิทธิภาพของระบบไฟล์ Lustre ระหว่างการฝึกและการตรวจสอบ
ตรวจสอบบันทึกการฝึก
เมื่อการฝึกดำเนินไป คุณจะเห็นบันทึกที่ระบุว่าระบบกำลังบันทึกจุดตรวจไปยัง /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 โปรดทราบว่าการสร้างจุดตรวจสอบจะเกิดขึ้นแบบไม่พร้อมกันและจะไม่บล็อก Worker ของ Ray เป็นเวลานาน
หากต้องการดูความเร็วของการตรวจสอบจุด ให้มองหาบรรทัดบันทึกที่ระบุจุดตรวจสอบที่บันทึกไว้
ดูเมตริก Lustre ใน Cloud Console
วิธีดูเมตริกสำหรับอินสแตนซ์ Lustre
- ใน คอนโซล Google Cloud ให้ค้นหา Managed Service for Lustre
- คลิกชื่ออินสแตนซ์ (
rl-demo-gpu-lustre) - คลิกแท็บการตรวจสอบ
โดยคุณจะดูข้อมูลต่อไปนี้ได้
- อัตราการส่งข้อมูล (ไบต์/วินาที): ดูจุดสูงสุดระหว่างการตรวจสอบ
- ความจุ: ตรวจสอบว่าจุดตรวจสอบใช้พื้นที่เท่าใด
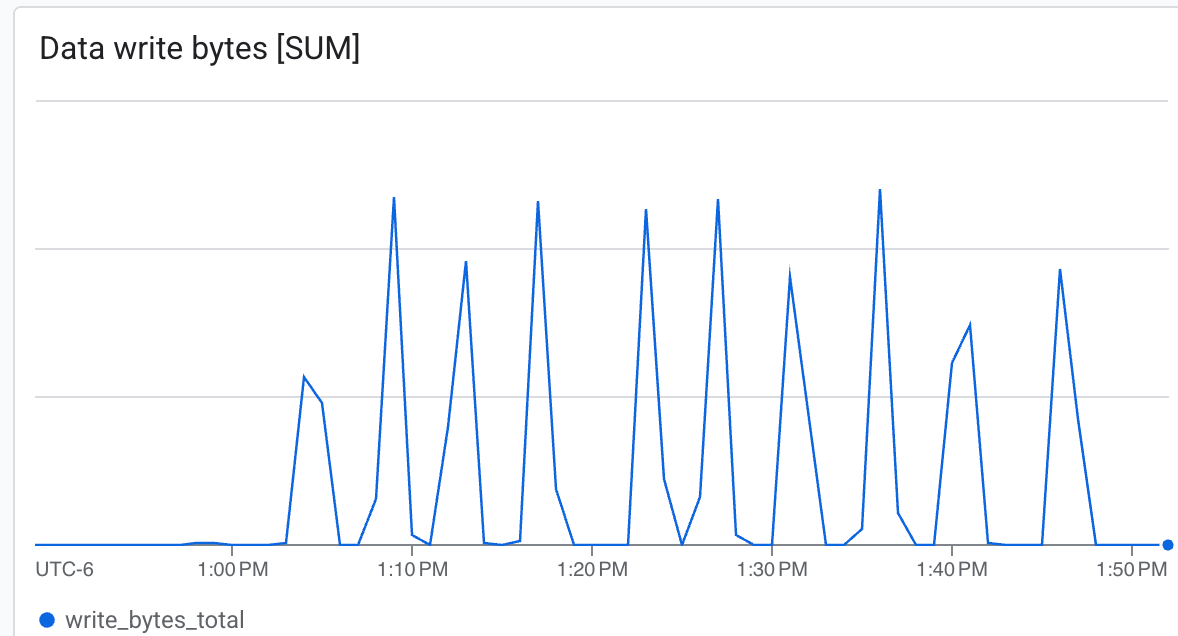 Lustre สามารถเขียนด้วยความเร็วสูงมากและเขียนจุดตรวจสอบในเวลาที่น้อยที่สุด
Lustre สามารถเขียนด้วยความเร็วสูงมากและเขียนจุดตรวจสอบในเวลาที่น้อยที่สุด
9. ล้างข้อมูลทรัพยากร
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อลบทรัพยากรที่สร้างขึ้นในโค้ดแล็บนี้
ลบอินสแตนซ์ Lustre ที่มีการจัดการ
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
ลบคลัสเตอร์ GKE โดยใช้ XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
ล้างนามแฝง IP (ไม่บังคับ)
หากต้องการล้างช่วง IP ที่สร้างขึ้นสำหรับการเชื่อมต่อ VPC แบบเพียร์ทั้งหมด ให้ทำดังนี้
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
ระบบจะลบทรัพยากรแบบอะซิงโครนัส คุณตรวจสอบสถานะได้ใน Cloud Console
10. ขอแสดงความยินดี
คุณทำ Codelab Scale Reinforcement Learning with GKE and Managed Lustre เสร็จสมบูรณ์แล้ว
สิ่งที่คุณได้เรียนรู้
- วิธีใช้
xpkเพื่อจัดสรรคลัสเตอร์ GPU ของ GKE ด้วยอินสแตนซ์สปอต - วิธีเปิดใช้ไดรเวอร์ Lustre CSI และส่วนเสริม RayOperator
- วิธีจัดสรรอินสแตนซ์บริการที่มีการจัดการของ Google Cloud สำหรับ Lustre
- วิธีติดตั้งใช้งานคลัสเตอร์ KubeRay และติดตั้งพื้นที่เก็บข้อมูล Lustre
- วิธีส่งภาระงานการฝึก GRPO ของ NeMo-RL
- วิธีสังเกตประสิทธิภาพของพื้นที่เก็บข้อมูลระหว่างการฝึก
ขั้นตอนถัดไป
- สำรวจฟีเจอร์อื่นๆ ของ NVIDIA NeMo-RL
- ดูข้อมูลเพิ่มเติมเกี่ยวกับ Hypercomputer ของ Google Cloud AI
- อ่านเอกสารประกอบของ Managed Service for Lustre