
1. Giới thiệu
Nếu muốn chạy trực tiếp các tập lệnh được đóng gói mà không cần hướng dẫn từng bước, bạn có thể tìm thấy các tập lệnh này trong kho lưu trữ GoogleCloudPlatform/devrel-demos.
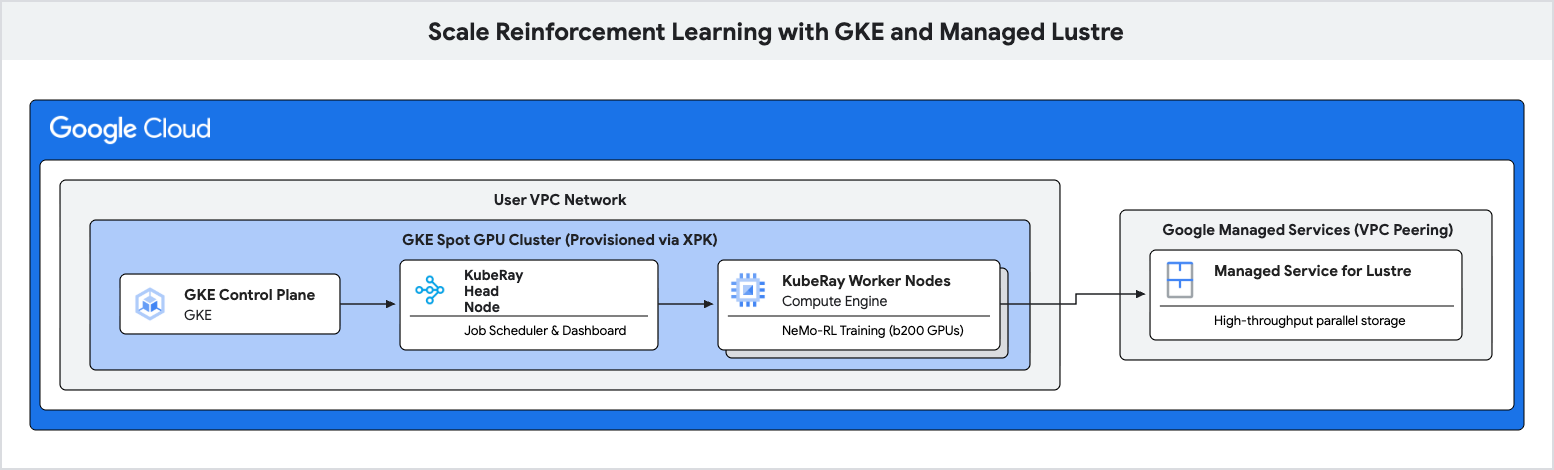
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách triển khai một quy trình huấn luyện hiệu suất cao cho Học tăng cường (RL) bằng cách sử dụng Google Kubernetes Engine (GKE) và Managed Lustre.
Các khối lượng công việc Học tăng cường, đặc biệt là những khối lượng công việc sử dụng các thuật toán như Tối ưu hoá chính sách tương đối theo nhóm (GRPO), tạo ra lượng dữ liệu khổng lồ trong quá trình "Tạo trải nghiệm" và yêu cầu kiểm tra thường xuyên. Bộ nhớ đối tượng tiêu chuẩn có thể gây ra tình trạng tắc nghẽn trong các đợt I/O này, khiến các trình tăng tốc đắt tiền không hoạt động.
Bạn sẽ sử dụng Managed Lustre, một hệ thống tệp song song, để loại bỏ những điểm tắc nghẽn này và đạt được thông lượng huấn luyện cao hơn.
Bạn sẽ thực hiện
- Định cấu hình các biến môi trường cho một cụm Ray dựa trên GPU.
- Cung cấp một cụm GPU Spot trên GKE bằng công cụ XPK.
- Tạo một phiên bản Lustre được quản lý.
- Triển khai một cụm KubeRay và gắn hệ thống tệp Lustre.
- Gửi khối lượng công việc huấn luyện NeMo-RL.
- Theo dõi thông lượng cao và độ trễ thấp của điểm kiểm tra bằng Cloud Monitoring.
Bạn cần có
- Một trình duyệt web như Chrome.
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
Lớp học lập trình này dành cho người dùng kỹ thuật cao cấp, kỹ sư nền tảng và nhà nghiên cứu AI, những người đã quen thuộc với GKE và các khái niệm về bộ nhớ.
Tổng thời lượng ước tính: 45 đến 60 phút cộng với 2 giờ thời gian đào tạo
2. Trước khi bắt đầu
Tạo một dự án trên Google Cloud
- Trong Google Cloud Console, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud.
Khởi động Cloud Shell
Cloud Shell là một môi trường dòng lệnh chạy trong Google Cloud và được tải sẵn các công cụ cần thiết.
- Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.
- Sau khi kết nối với Cloud Shell, hãy xác minh thông tin xác thực của bạn:
gcloud auth list - Xác nhận rằng dự án của bạn đã được định cấu hình:
gcloud config get project - Nếu dự án của bạn không được thiết lập như mong đợi, hãy thiết lập dự án:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Cài đặt XPK
Lớp học lập trình này sử dụng xpk để cung cấp cụm GKE. Để biết hướng dẫn về cách cài đặt xpk, hãy xem hướng dẫn cài đặt xpk.
Trong Cloud Shell, bạn có thể cài đặt bằng cách dùng lệnh:
pip install xpk
Bật API
Chạy lệnh này trong Cloud Shell để bật tất cả các API bắt buộc:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Định cấu hình các biến môi trường
Để các lệnh trong lớp học lập trình này nhất quán, hãy thiết lập một số biến môi trường.
Tạo một tệp có tên là env.sh rồi điền cấu hình của bạn vào tệp đó. Bạn có thể sử dụng mẫu sau:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Thay thế <YOUR_PROJECT_ID> và <YOUR_HF_TOKEN> bằng các giá trị thực tế của bạn.
Nguồn tệp để tải các biến vào phiên hiện tại:
source env.sh
4. Tạo Cụm GKE bằng XPK
Trong bước này, bạn sẽ dùng xpk để cung cấp một cụm GKE có GPU Spot.
xpk là công cụ cấp phép AI Hypercomputer giúp đơn giản hoá việc tạo cụm GKE cho các khối lượng công việc tự động. Bằng cách chỉ định loại thiết bị và số lượng nút, bạn sẽ tạo được VPC, mạng con và nhóm nút cần thiết.
Chạy lệnh tạo cụm:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Đợi cho đến khi cụm được tạo. Quá trình này có thể mất vài phút.
Bật tiện ích bổ sung RayOperator
Sau khi tạo cụm, hãy bật tiện ích bổ sung RayOperator để quản lý các cụm KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Xác minh Trình điều khiển CSI Lustre
XPK sẽ tự động bật trình điều khiển Lustre CSI thông qua cờ --enable-lustre-csi-driver. Xác minh rằng tính năng này đã được bật:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Nếu lệnh này trả về false, hãy chạy lệnh dự phòng để bật:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Cấp phép phiên bản Managed Lustre
Ở bước này, bạn sẽ tạo một phiên bản Managed Service for Lustre. Lustre là một hệ thống tệp song song cung cấp thông lượng cao để kiểm tra điểm đánh dấu.
Phân bổ dải IP cho dịch vụ được quản lý
Lustre yêu cầu có một kết nối ngang hàng VPC với Dịch vụ do Google quản lý. Trước tiên, hãy phân bổ một dải IP toàn cầu:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Thiết lập kết nối ngang hàng VPC
Kết nối VPC với Dịch vụ mạng:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Tạo phiên bản Lustre
Bây giờ, hãy tạo phiên bản Lustre. Lệnh này chạy không đồng bộ.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Xác minh trạng thái Lustre
Phiên bản Lustre cần khoảng 10 đến 15 phút để sẵn sàng. Bạn có thể kiểm tra trạng thái bằng cách:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Chờ cho đến khi trạng thái là ACTIVE rồi mới tiếp tục.
6. Triển khai Cụm Ray trên GKE
Trong bước này, bạn sẽ triển khai một cụm KubeRay trên các nút GKE và gắn hệ thống tệp Lustre bằng PersistentVolume (PV) và PersistentVolumeClaim (PVC).
Tìm nạp IP Lustre
Trước khi tạo ổ đĩa, bạn cần lấy IP điểm gắn của phiên bản Lustre:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Tạo Lustre PV và PVC
Tạo một tệp có tên là rl-lustre-volume.yaml bằng cấu hình sau. Thao tác này xác định cách GKE kết nối với phiên bản Lustre của bạn.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Áp dụng cấu hình âm lượng:
kubectl apply -f rl-lustre-volume.yaml
Tạo cấu hình RayCluster
Tạo một tệp có tên là ray-cluster.yaml. Thao tác này chỉ định các nút đầu và nút tính toán của KubeRay, sử dụng loại trình tăng tốc nvidia-b200 và gắn ổ đĩa Lustre tại /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Áp dụng cấu hình cụm Ray:
kubectl apply -f ray-cluster.yaml
Xác minh trạng thái của Cụm
Theo dõi quá trình tạo nhóm:
kubectl get pods -w
Chờ cho đến khi các nhóm đầu và nhóm worker ở trạng thái Running.
7. Gửi khối lượng công việc học tăng cường
Trong bước này, bạn sẽ gửi quy trình huấn luyện NeMo-RL GRPO đến cụm Ray.
Kết nối với Trang tổng quan của Ray
Để gửi các công việc và xem chỉ số, bạn cần kết nối với Trang tổng quan của Ray. Vì trang tổng quan nằm trong GKE, hãy sử dụng tính năng chuyển tiếp cổng để truy cập vào trang tổng quan này từ Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Tạo tập lệnh thực thi
Tạo một tệp có tên là run_nemo_rl.sh. Tập lệnh này sẽ được thực thi trên các worker của cụm Ray. Chúng ta sẽ dùng cat << EOF để điền vào các biến môi trường mà bạn đã đặt trước đó.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Tạo tệp bỏ qua Ray
Tạo tệp .rayignore để ngăn Ray tải lên các thư mục lớn hoặc không cần thiết:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Tạo cấu hình môi trường thời gian chạy
Tạo một tệp JSON để truyền các biến môi trường đến công việc Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Gửi công việc
Sử dụng Ray CLI để gửi công việc đến điểm cuối trang tổng quan. Nếu không tìm thấy lệnh ray trong Cloud Shell, bạn có thể cài đặt lệnh này bằng pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
Bạn sẽ thấy nhật ký truyền trực tuyến trong thiết bị đầu cuối Cloud Shell. Tác vụ này sẽ tải mô hình, khởi động các worker Ray và bắt đầu vòng lặp huấn luyện GRPO.
8. Theo dõi hiệu suất huấn luyện
Trong bước này, bạn sẽ quan sát hiệu suất của hệ thống tệp Lustre trong quá trình huấn luyện và kiểm tra.
Kiểm tra nhật ký huấn luyện
Khi quá trình huấn luyện diễn ra, bạn sẽ thấy nhật ký cho biết các điểm kiểm tra đang được lưu vào /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. Lưu ý rằng quá trình kiểm tra điểm đánh dấu diễn ra không đồng bộ và không chặn các worker Ray trong thời gian quá dài.
Để xem tốc độ tạo điểm kiểm tra, hãy tìm các dòng nhật ký cho biết các điểm kiểm tra đã lưu.
Xem các chỉ số Lustre trong Cloud Console
Cách xem các chỉ số cho phiên bản Lustre:
- Trong Google Cloud Console, hãy tìm Managed Service for Lustre.
- Nhấp vào tên phiên bản của bạn (
rl-demo-gpu-lustre). - Nhấp vào thẻ Giám sát.
Tại đây, bạn có thể quan sát:
- Thông lượng (Byte/giây): Xem các mức tăng đột biến trong quá trình kiểm tra.
- Dung lượng: Theo dõi mức dung lượng mà các điểm kiểm tra đang sử dụng.
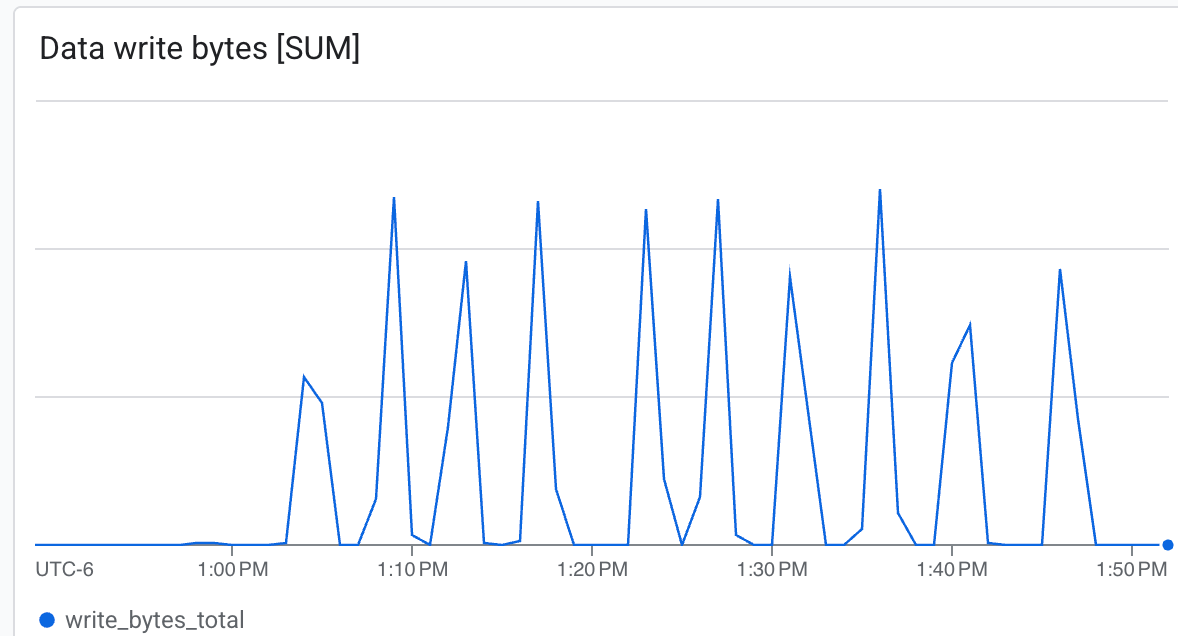 Lustre có khả năng ghi ở tốc độ rất cao, ghi các điểm kiểm tra trong thời gian tối thiểu.
Lustre có khả năng ghi ở tốc độ rất cao, ghi các điểm kiểm tra trong thời gian tối thiểu.
9. Dọn dẹp tài nguyên
Chạy các lệnh sau trong Cloud Shell để xoá các tài nguyên đã tạo trong lớp học lập trình này.
Xoá phiên bản Lustre được quản lý
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Xoá Cụm GKE bằng XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Dọn dẹp các bí danh IP (Không bắt buộc)
Nếu bạn muốn dọn dẹp hoàn toàn các dải IP được tạo cho tính năng kết nối VPC ngang hàng:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Các tài nguyên sẽ bị xoá không đồng bộ. Bạn có thể xác minh trạng thái của các yêu cầu này trong Cloud Console.
10. Xin chúc mừng
Bạn đã hoàn tất thành công lớp học lập trình Scale Reinforcement Learning with GKE and Managed Lustre (Mở rộng quy mô học tăng cường bằng GKE và Lustre được quản lý)!
Kiến thức bạn học được
- Cách sử dụng
xpkđể cung cấp một cụm GPU GKE bằng các phiên bản Spot. - Cách bật tiện ích bổ sung RayOperator và trình điều khiển CSI Lustre.
- Cách cung cấp một phiên bản Dịch vụ được quản lý của Google Cloud cho Lustre.
- Cách triển khai một cụm KubeRay và gắn bộ nhớ Lustre.
- Cách gửi khối lượng công việc huấn luyện GRPO NeMo-RL.
- Cách quan sát hiệu suất bộ nhớ trong quá trình huấn luyện.
Các bước tiếp theo
- Khám phá thêm các tính năng của NVIDIA NeMo-RL.
- Tìm hiểu thêm về Siêu máy tính AI của Google Cloud.
- Xem tài liệu về Dịch vụ được quản lý cho Lustre.