
1. 简介
如果您希望直接运行打包的脚本,而无需逐步教程,可以在 GoogleCloudPlatform/devrel-demos 代码库中找到这些脚本。
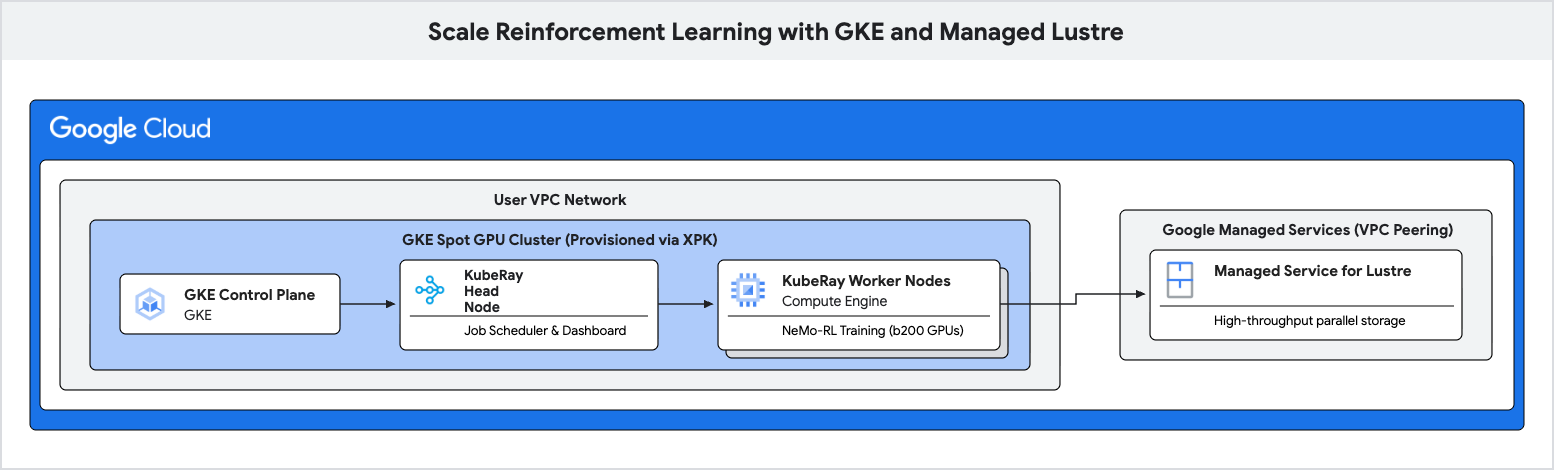
在此 Codelab 中,您将学习如何使用 Google Kubernetes Engine (GKE) 和 Managed Lustre 部署高性能强化学习 (RL) 训练流水线。
强化学习工作负载(尤其是使用组相对策略优化 [GRPO] 等算法的工作负载)在“经验生成”期间会生成大量数据,并且需要频繁进行检查点设置。标准对象存储在这些 I/O 突发期间可能会造成瓶颈,导致昂贵的加速器处于闲置状态。
您将使用并行文件系统 Managed Lustre 来消除这些瓶颈,并实现更高的训练吞吐量。
您将执行的操作
- 为基于 GPU 的 Ray 集群配置环境变量。
- 使用 XPK 工具在 GKE 上预配 Spot GPU 集群。
- 创建 Managed Lustre 实例。
- 部署 KubeRay 集群并装载 Lustre 文件系统。
- 提交 NeMo-RL 训练工作负载。
- 使用 Cloud Monitoring 观察高吞吐量和低检查点延迟时间。
所需条件
- 网络浏览器,例如 Chrome。
- 启用了结算功能的 Google Cloud 项目。
本 Codelab 适合熟悉 GKE 和存储概念的高级技术用户、平台工程师和 AI 研究人员。
预计总时长:45 到 60 分钟,外加 2 小时的培训时间
2. 准备工作
创建 Google Cloud 项目
- 在 Google Cloud 控制台中,选择或创建 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。
启动 Cloud Shell
Cloud Shell 是在 Google Cloud 中运行的命令行环境,预加载了必要的工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell。
- 连接到 Cloud Shell 后,验证您的身份验证:
gcloud auth list - 确认您的项目已配置:
gcloud config get project - 如果项目未按预期设置,请进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
安装 XPK
此 Codelab 使用 xpk 来预配 GKE 集群。如需了解如何安装 xpk,请参阅 xpk 安装指南。
在 Cloud Shell 中,您可以使用以下命令安装该工具:
pip install xpk
启用 API
在 Cloud Shell 中运行以下命令,以启用所有必需的 API:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. 配置环境变量
为了使此 Codelab 中的命令保持一致,请设置一些环境变量。
创建一个名为 env.sh 的文件,并使用您的配置填充该文件。您可以使用以下模板:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
将 <YOUR_PROJECT_ID> 和 <YOUR_HF_TOKEN> 替换为您的实际值。
获取文件以将变量加载到当前会话中:
source env.sh
4. 使用 XPK 创建 GKE 集群
在此步骤中,您将使用 xpk 预配一个具有 Spot GPU 的 GKE 集群。
xpk 是一种 AI Hypercomputer 预配工具,可简化 GKE 集群的创建,以实现工作负载自动化。通过指定设备类型和节点数量,它会创建所需的 VPC、子网和节点池。
运行集群创建命令:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
等待集群创建完成。此过程可能耗时几分钟。
启用 RayOperator 插件
创建集群后,启用 RayOperator 插件以管理 KubeRay 集群:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
验证 Lustre CSI Driver
XPK 应通过 --enable-lustre-csi-driver 标志自动启用 Lustre CSI 驱动程序。验证是否已启用:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
如果返回 false,请运行回退启用命令:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. 预配 Managed Lustre 实例
在此步骤中,您将创建一个 Managed Service for Lustre 实例。Lustre 是一种并行文件系统,可为检查点设置提供高吞吐量。
为托管式服务分配 IP 范围
Lustre 需要与 Google 代管式服务建立 VPC 对等互连连接。首先,分配一个全球 IP 范围:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
建立 VPC 对等互连
将您的 VPC 连接到 Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
创建 Lustre 实例
现在,创建 Lustre 实例。此命令以异步方式运行。
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
验证 Lustre 状态
Lustre 实例大约需要 10-15 分钟才能准备就绪。您可以使用以下命令查看状态:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
等待状态变为 ACTIVE,然后再继续。
6. 在 GKE 上部署 Ray 集群
在此步骤中,您将在 GKE 节点上部署 KubeRay 集群,并使用 PersistentVolume (PV) 和 PersistentVolumeClaim (PVC) 装载 Lustre 文件系统。
提取 Lustre IP
在创建卷之前,您需要获取 Lustre 实例的装载点 IP:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
创建 Lustre PV 和 PVC
使用以下配置创建一个名为 rl-lustre-volume.yaml 的文件。此参数用于定义 GKE 如何连接到您的 Lustre 实例。
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
应用音量配置:
kubectl apply -f rl-lustre-volume.yaml
创建 RayCluster 配置
创建一个名为 ray-cluster.yaml 的文件。这指定了 KubeRay 主节点和工作器节点,使用 nvidia-b200 加速器类型并将 Lustre 卷装载到 /lustre。
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
应用 Ray 集群配置:
kubectl apply -f ray-cluster.yaml
验证集群状态
监控 pod 的创建情况:
kubectl get pods -w
等待头 Pod 和工作器 Pod 变为 Running。
7. 提交强化学习工作负载
在此步骤中,您将向 Ray 集群提交 NeMo-RL GRPO 训练作业。
连接到 Ray 信息中心
如需提交作业和查看指标,您需要连接到 Ray 信息中心。由于信息中心位于 GKE 中,因此请使用端口转发从 Cloud Shell 访问它:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
创建执行脚本
创建一个名为 run_nemo_rl.sh 的文件。此脚本将在 Ray 集群工作器上执行。我们使用 cat << EOF 来填充您之前设置的环境变量。
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
创建 Ray 忽略文件
创建一个 .rayignore 文件,以防止 Ray 上传大型或不必要的目录:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
创建运行时环境配置
创建一个 JSON 文件,以将环境变量传递给 Ray 作业:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
提交作业
使用 Ray CLI 将作业提交到信息中心端点。如果在 Cloud Shell 中找不到 ray 命令,您可以使用 pip install ray 安装该命令:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
您会在 Cloud Shell 终端中看到流式日志。作业将加载模型、初始化 Ray 工作器,并开始 GRPO 训练循环。
8. 监控训练表现
在此步骤中,您将观察 Lustre 文件系统在训练和设置检查点期间的性能。
查看训练日志
随着训练的进行,您会看到日志表明检查点正在保存到 /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1。请注意,检查点创建是异步进行的,不会长时间阻塞 Ray worker。
如需查看检查点创建速度,请查找指示已保存检查点的日志行。
在 Cloud 控制台中查看 Lustre 指标
如需查看 Lustre 实例的指标,请执行以下操作:
- 在 Google Cloud 控制台中,搜索 Managed Service for Lustre。
- 点击您的实例名称 (
rl-demo-gpu-lustre)。 - 点击监控标签页。
您可以在此处查看:
- 吞吐量(字节/秒):查看在检查点创建期间出现的峰值。
- 容量:监控检查点正在消耗多少空间。
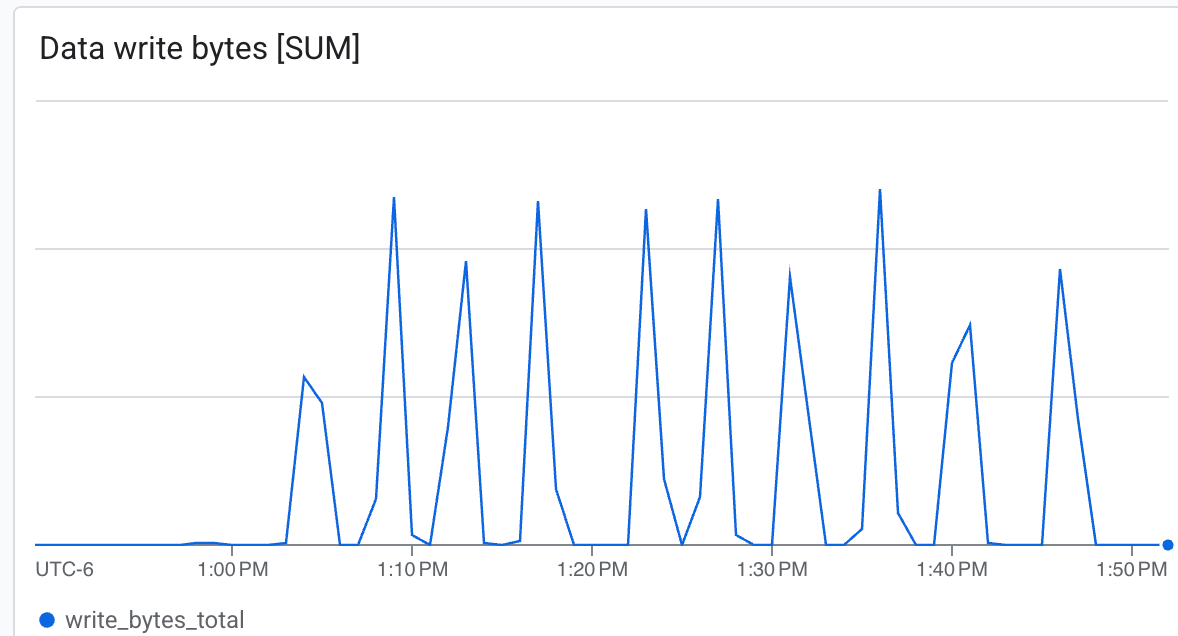 Lustre 能够以极高的速度写入,在最短的时间内写入检查点。
Lustre 能够以极高的速度写入,在最短的时间内写入检查点。
9. 清理资源
在 Cloud Shell 中运行以下命令,以删除在此 Codelab 中创建的资源。
删除 Managed Lustre 实例
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
使用 XPK 删除 GKE 集群
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
清理 IP 别名(可选)
如果您想彻底清理为 VPC 对等互连创建的 IP 范围,请执行以下操作:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
资源将被异步删除。您可以在 Cloud 控制台中验证其状态。
10. 恭喜
您已成功完成 Scale Reinforcement Learning with GKE and Managed Lustre Codelab!
您学到的内容
- 如何使用
xpk预配具有 Spot 实例的 GKE GPU 集群。 - 如何启用 Lustre CSI 驱动程序和 RayOperator 插件。
- 如何预配 Google Cloud Managed Service for Lustre 实例。
- 如何部署 KubeRay 集群并挂载 Lustre 存储空间。
- 如何提交 NeMo-RL GRPO 训练工作负载。
- 如何在训练期间观察存储性能。
后续步骤
- 探索更多 NVIDIA NeMo-RL 功能。
- 详细了解 Google Cloud AI Hypercomputer。
- 查看 Managed Service for Lustre 文档。