
1. Einführung
In diesem Codelab erstellen Sie mit Vertex AI Search eine universelle No-Code-Helpdesk-App für Mitarbeiter.
Stellen Sie sich vor, Sie arbeiten bei Cymbal, einem globalen Einzelhandelsunternehmen. Mitarbeiter haben oft Fragen wie „Welche Richtlinien gelten für die Buchung von Geschäftsreisen?“ oder „Wie viele Sneaker haben wir auf Lager?“.
Normalerweise müssen Sie sich in völlig unterschiedlichen Systemen anmelden, um diese Antworten zu finden. Sie müssen nicht nur mit verschiedenen Systemen arbeiten, sondern auch eine große Menge unstrukturierter HR-Daten durchlesen oder komplexe SQL-Prompts für strukturierte Finanzdaten ausführen, um Antworten auf Ihre Fragen zu erhalten.
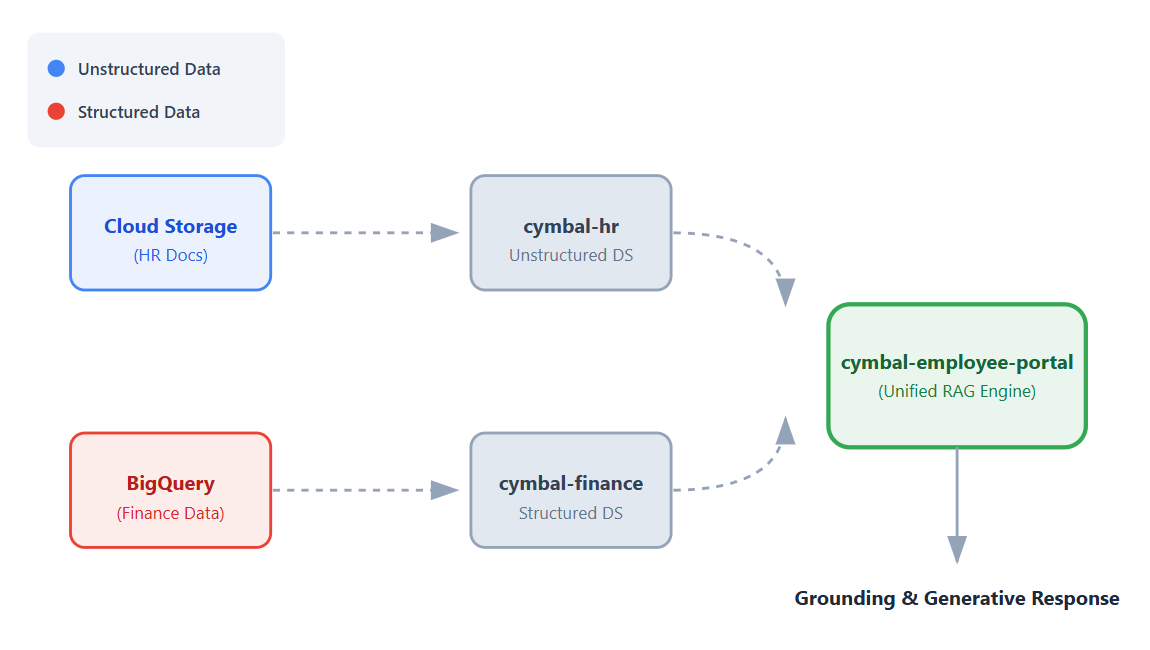
In diesem Codelab erstellen Sie eine einzelne, einheitliche App, die eine Verbindung zu diesen Datasets herstellt. So können Mitarbeiter mithilfe der RAG-Funktionen (Retrieval Augmented Generation) von Vertex AI konversationelle, fundierte Antworten auf ihre Fragen erhalten.
Aufgaben
In diesem Codelab führen Sie die folgenden Schritte aus:
- Datenquellen einrichten Erstellen Sie einen Cloud Storage-Bucket für unstrukturierte HR-Dokumente und ein BigQuery-Dataset für strukturierte Finanzdaten.
- Datenspeicher konfigurieren: Vertex AI Search-Datenspeicher erstellen, die mit Ihren Cloud Storage- und BigQuery-Datenquellen verbunden sind.
- App verbinden: Erstellen Sie eine Vertex AI Search-App und verknüpfen Sie beide Datenspeicher damit.
- App testen: Interagieren Sie mit der einheitlichen Suchoberfläche, um fundierte Antworten zu erhalten, die Informationen aus beiden Datenspeichern zusammenfassen.
- Nächste Schritte Hier finden Sie Optionen zum Optimieren des generativen KI-Modells und zum Bereitstellen Ihrer Suchanwendung.
Voraussetzungen
- Ein Webbrowser wie Chrome.
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Git ist auf Ihrem lokalen Computer installiert.
Dieses Codelab richtet sich an Entwickler aller Erfahrungsstufen.
2. Hinweis
Erstellen Sie ein Google Cloud-Projekt und aktivieren Sie die erforderlichen APIs.
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Erforderliche IAM-Rollen
In diesem Codelab wird davon ausgegangen, dass Sie die Rolle Projektinhaber für Ihr Google Cloud-Projekt haben.
APIs aktivieren
- Klicken Sie in der Google Cloud Console auf Cloud Shell aktivieren: Wenn Sie Cloud Shell noch nie verwendet haben, wird ein Bereich angezeigt, in dem Sie auswählen können, ob Sie Cloud Shell in einer vertrauenswürdigen Umgebung mit oder ohne Boost starten möchten. Wenn Sie zur Autorisierung von Cloud Shell aufgefordert werden, klicken Sie auf Autorisieren.
- Aktivieren Sie in Cloud Shell alle erforderlichen APIs:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. GitHub-Repository klonen
Um zu zeigen, wie die Suche in der Mitarbeiter-Helpdesk-App von Cymbal funktioniert, benötigen Sie einige Mock-Dateien. In diesem Abschnitt klonen Sie ein GitHub-Repository auf Ihren lokalen Computer, um diese Dateien abzurufen. Sie laden diese Dateien in späteren Schritten über die Cloud Console in Google Cloud hoch.
- Klonen Sie das
next-26-sessions-Repository in einem Terminal auf Ihrem lokalen Computer:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Wechseln Sie zum heruntergeladenen Repository-Verzeichnis:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - Sehen Sie sich die heruntergeladenen Dateien in diesem Verzeichnis an. Sie werden feststellen, dass es zwei Ordner gibt:
HRundFinance.- HR. Dieser Ordner enthält eine Reihe unstrukturierter Dateien, z. B.
.doc-,.txt- und.html-Dateien. Sie laden die HR-Dateien in einen Cloud Storage-Bucket hoch. - Finanzen Dieser Ordner enthält zwei
.jsonl-Dateien. Sie laden diese Dateien in ein BigQuery-Dataset hoch.
- HR. Dieser Ordner enthält eine Reihe unstrukturierter Dateien, z. B.
4. Cloud Storage-Bucket für unstrukturierte Dateien erstellen
In diesem Abschnitt erstellen Sie einen Cloud Storage-Bucket und laden die Dokumente im Ordner HR hoch, die Sie im Abschnitt GitHub-Repository klonen heruntergeladen haben. Unstrukturierte Daten, wie die HR-Dokumente in diesem Beispiel, folgen keinem vordefinierten Format und können Textdateien, Dokumente oder Multimedia-Inhalte umfassen.
- Rufen Sie in der Cloud Console die Seite Buckets auf.
- Klicken Sie auf Erstellen.
- Geben Sie auf der Seite Bucket erstellen den Namen eines Buckets ein. Der Name muss global eindeutig sein. Beispiel:
cymbal-app-hr-12 - Behalten Sie die Standardoptionen bei.
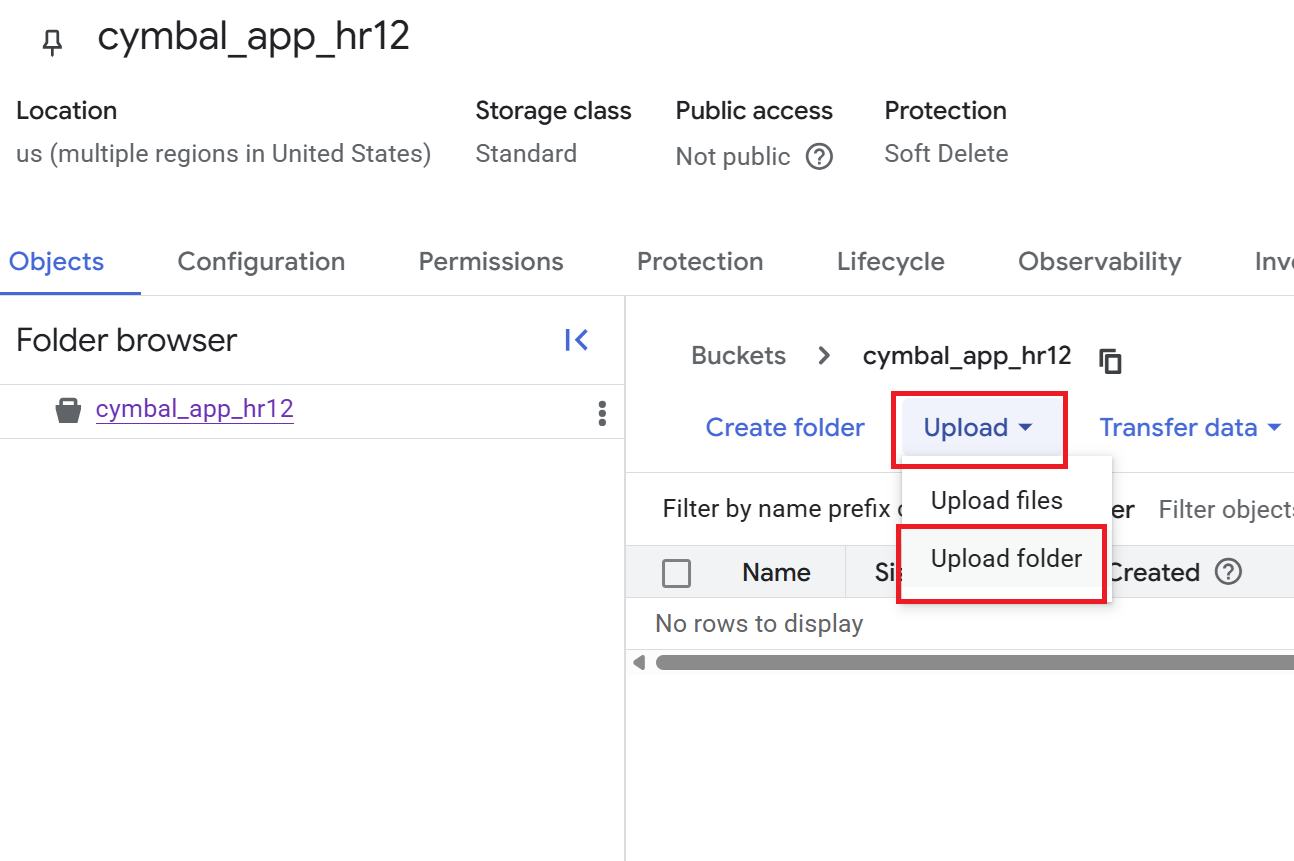
- Klicken Sie auf Erstellen.Der Bucket wird erstellt und die Seite Bucket-Details wird angezeigt. Wenn die Seite Bucket-Details nicht angezeigt wird, klicken Sie auf den Bucket, den Sie gerade erstellt haben.
- Klicken Sie auf der Seite Bucket-Details auf Hochladen > Ordner hochladen und wählen Sie dann den Ordner
HRaus, den Sie im Abschnitt GitHub-Repository klonen heruntergeladen haben. - Bestätigen Sie den Upload.
- Klicken Sie auf der Seite Bucket-Details auf den Ordner
HR, um die Liste der Dateien aufzurufen.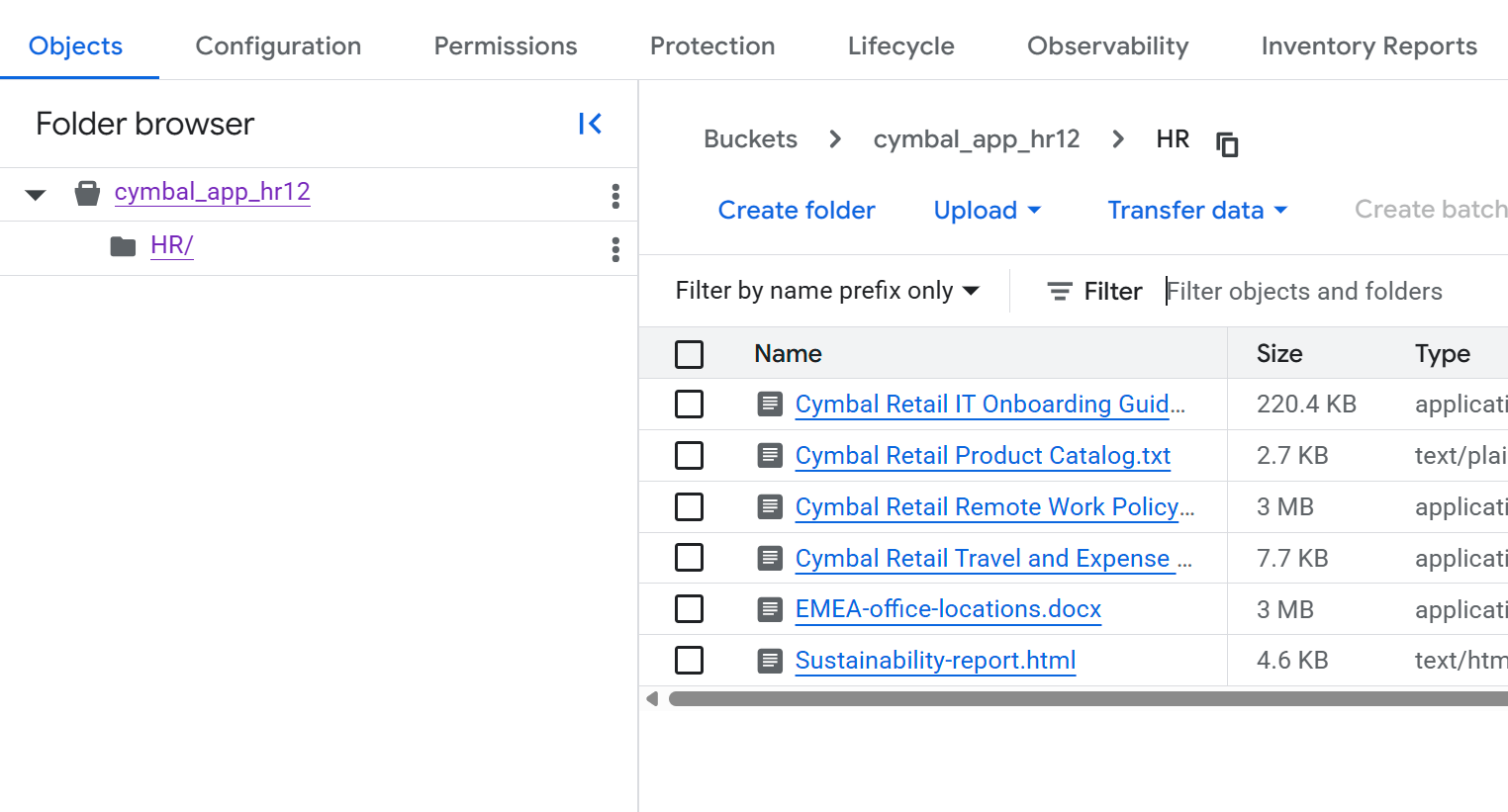
5. BigQuery-Dataset für strukturierte Dateien erstellen
In diesem Abschnitt erstellen Sie ein BigQuery-Dataset und laden die Dokumente im Ordner Finance, die Sie im Abschnitt GitHub-Repository klonen heruntergeladen haben, in eine neue Tabelle. Strukturierte Daten, wie die Finanzdokumente in diesem Beispiel, folgen einem vordefinierten Format, z. B. Datensätzen in einer Datenbank.
- Rufen Sie in der Cloud Console die Seite BigQuery auf.
- Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts und dann auf Aktionen ansehen (die drei vertikalen Punkte) > Dataset erstellen.
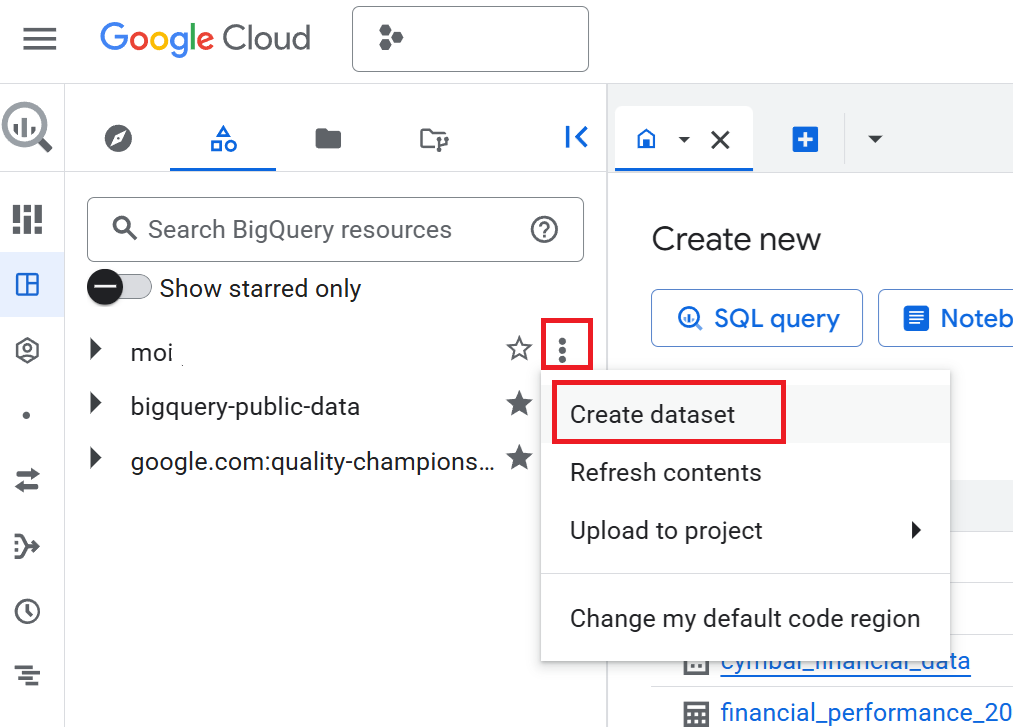
- Geben Sie im Bereich Dataset erstellen
cymbal_financeals Dataset-ID ein. - Wählen Sie als Speicherort der Daten die Option
US (multiple regions in United States)aus. - Übernehmen Sie die Standardoptionen und klicken Sie auf Dataset erstellen.
- Maximieren Sie im Bereich Explorer Ihr Projekt und klicken Sie auf das Dataset
cymbal_finance. - Klicken Sie im Detailbereich des Datasets auf Tabelle erstellen.
- Gehen Sie auf der Seite Tabelle erstellen im Abschnitt Quelle so vor:
- Wählen Sie unter Tabelle erstellen aus die Option Hochladen aus.
- Klicken Sie unter Datei auswählen auf Durchsuchen, wechseln Sie zum heruntergeladenen Ordner
Financeund wählen Siecymbal_employee_finance.jsonlaus. - Wählen Sie für Dateiformat den Eintrag JSONL (durch Zeilenumbruch getrenntes JSON) aus.
- Geben Sie im Abschnitt Ziel den Tabellennamen als
employee_financeein. - Klicken Sie im Bereich Schema das Kästchen Automatisch erkennen an.
- Behalten Sie die anderen Standardeinstellungen bei und klicken Sie auf Tabelle erstellen.
- Wiederholen Sie die Schritte 7 bis 11, um Daten in eine neue Tabelle zu laden. Wählen Sie in Schritt 8b
product_inventory.jsonlaus und geben Sie in Schritt 9product_inventoryals Tabellenname ein.Wenn die Tabellen nicht im Detailbereich des Datasets angezeigt werden, klicken Sie auf Aktualisieren. - Wenn Sie das Dataset und die beiden Tabellen erfolgreich erstellt haben, sollte es so aussehen:
6. Vertex AI Search-Anwendung erstellen
- Rufen Sie in der Cloud Console die Seite Vertex AI Search auf.
- Klicken Sie auf der Kachel Benutzerdefinierte Suche (allgemein) auf Erstellen.
- Achten Sie darauf, dass auf der Seite Such-App-Konfiguration die Optionen Features der Enterprise-Version und Generative Antworten ausgewählt sind.
- Benennen Sie Ihre App mit
cymbal-employee-portal. - Geben Sie als Name des Unternehmens
Cymbal Corpein. - Behalten Sie den Standort Ihrer App als
globalbei. - Klicken Sie auf Weiter.
7. Datenspeicher erstellen und verbinden
Auf der Seite Datenspeicher erstellen Sie Datenspeicher, die Sie mit Ihrer App verbinden. Sie müssen drei Datenspeicher erstellen: einen für unstrukturierte HR-Daten und zwei für strukturierte Finanzdaten.
Datenspeicher für unstrukturierte Daten erstellen
- Klicken Sie auf der Seite Datenspeicher auf Datenspeicher erstellen.
- Wählen Sie für Datenquelle auswählen die Option Cloud Storage aus.
- Gehen Sie im Bereich Daten aus Cloud Storage importieren zu Import unstrukturierter Daten (Dokumentsuche und RAG) und wählen Sie Dokumente aus.
- Behalten Sie die Option Häufigkeit der Synchronisierung als Einmal bei.
- Klicken Sie unter Ordner oder Datei für Import auswählen auf Ordner.
- Geben Sie im Feld
gs://...den Namen des Buckets ein, den Sie im Abschnitt Cloud Storage-Bucket für unstrukturierte Dateien erstellen erstellt haben. Wenn der Name des Buckets beispielsweisecymbal-app-hr-12lautet, geben Sie den Namen alscymbal-app-hr-12/HRein.Durch die Aufnahme aus dem OrdnerHRwird sichergestellt, dass nur die HR-Dokumente in diesem Datenspeicher enthalten sind. - Klicken Sie auf Weiter.
- Geben Sie den Namen des Datenspeichers als
cymbal-hrein. - Klicken Sie auf Weiter.
- Behalten Sie die Option Allgemeine Preise bei.
- Klicken Sie auf Erstellen.
Nachdem Sie auf Erstellen geklickt haben, werden Sie zur Seite Datenspeicher zurückgeleitet.
Datenspeicher für strukturierte Daten erstellen
Sie erstellen zwei Datenspeicher für strukturierte Daten aus BigQuery: einen für Finanzinformationen von Mitarbeitern und einen für das Produktinventar.
Datenspeicher für Mitarbeiterfinanzdaten erstellen
- Klicken Sie auf der Seite Datenspeicher noch einmal auf Datenspeicher erstellen.
- Wählen Sie unter Datenquelle auswählen die Option BigQuery aus.
- Wählen Sie für Import strukturierter Daten die Option BigQuery-Tabelle mit eigenem Schema aus.
- Behalten Sie die Option Häufigkeit der Synchronisierung als Einmal bei.
- Klicken Sie unter Zu importierende Tabelle auswählen auf Durchsuchen. Wählen Sie im Dialogfeld Pfad auswählen, das sich öffnet, die Tabelle
employee_financeaus dem Datasetcymbal_financein Ihrem Projekt aus. Möglicherweise werden Tabellen mit ähnlichen Namen aus anderen Projekten angezeigt. Achten Sie darauf, dass Sie die Tabelle aus Ihrem Projekt auswählen. - Klicken Sie auf Weiter.
- Informationen zum Überprüfen des Schemas und Zuweisen von Schlüsselattributen
- Klicken Sie auf Weiter.
- Geben Sie den Namen des Datenspeichers als
cymbal-financeein. - Klicken Sie auf Weiter.
- Behalten Sie die Option Allgemeine Preise bei.
- Klicken Sie auf Erstellen.
Nachdem Sie auf Erstellen geklickt haben, werden Sie zur Seite Datenspeicher zurückgeleitet.
Datenspeicher für Produktinventardaten erstellen
- Klicken Sie auf der Seite Datenspeicher noch einmal auf Datenspeicher erstellen.
- Wählen Sie unter Datenquelle auswählen die Option BigQuery aus.
- Wählen Sie für Import strukturierter Daten die Option BigQuery-Tabelle mit eigenem Schema aus.
- Behalten Sie die Option Häufigkeit der Synchronisierung als Einmal bei.
- Klicken Sie unter Zu importierende Tabelle auswählen auf Durchsuchen. Wählen Sie im Dialogfeld Pfad auswählen, das sich öffnet, die Tabelle
product_inventoryaus dem Datasetcymbal_financein Ihrem Projekt aus. - Klicken Sie auf Weiter.
- Informationen zum Überprüfen des Schemas und Zuweisen von Schlüsselattributen
- Klicken Sie auf Weiter.
- Geben Sie den Namen des Datenspeichers als
cymbal-inventoryein. - Klicken Sie auf Weiter.
- Behalten Sie die Option Allgemeine Preise bei.
- Klicken Sie auf Erstellen.
Nachdem Sie auf Erstellen geklickt haben, werden Sie zur Seite Datenspeicher zurückgeleitet.
8. Datenspeicher mit Ihrer App verbinden
In der Liste auf der Seite Datenspeicher sollten jetzt drei Datenspeicher zu sehen sein: cymbal-hr (unstrukturiert), cymbal-finance (strukturiert) und cymbal-inventory (strukturiert). So verbinden Sie diese Datenspeicher mit Ihrer App:
- Wählen Sie auf der Seite Datenspeicher alle drei Datenspeicher aus, die Sie gerade erstellt haben:
cymbal-hr,cymbal-financeundcymbal-inventory. Achten Sie darauf, dass Sie alle drei Datenspeicher auswählen, bevor Sie fortfahren. - Klicken Sie auf Weiter.
- Behalten Sie die Option Allgemeine Preise bei.
- Klicken Sie auf Erstellen.
9. Cymbal-Mitarbeiterportal-App testen
- Klicken Sie in der
cymbal-employee-portalApp auf Vorschau. - Geben Sie im Feld Hier suchen die folgende Frage ein:
What are the stipends that I get as an employee of Cymbal located in London? - Geben Sie eine Frage zum Produktinventar ein:
How many units of sneakers do we have in stock? - Geben Sie eine weitere Frage ein:
What is the stipend for an executive in Cymbal?
Beachten Sie, dass die Such-App Informationen aus mehreren Quellen abgerufen hat, um die Antwort zu formulieren. Um diese Fragen zu beantworten, hat die App sowohl die strukturierten Finanzdaten in BigQuery als auch die unstrukturierten HR-Dokumente in Cloud Storage durchsucht.
Dies zeigt, wie leistungsstark Vertex AI Search ist, um Antworten aus verschiedenen Datenformaten und unterschiedlichen Datenspeichern in einer einzigen, zusammenhängenden Lösung zu synthetisieren.
Sie können das KI-Modell auch so abstimmen, dass es noch genauere und domänenspezifische Antworten liefert. Weitere Informationen zum Anpassen der generativen KI finden Sie in der Dokumentation Antworten und Follow-ups erhalten.
10. Optionen zum Bereitstellen Ihrer App
Die Bereitstellung der Anwendung für Endnutzer geht über den Rahmen dieses Codelabs hinaus. Es ist jedoch hilfreich zu wissen, wie sich das auf ein reales Szenario auswirkt. Sie haben mehrere Möglichkeiten, Ihre Vertex AI Search-Anwendung in die Workflows Ihrer Organisation einzubinden:
- Vordefiniertes Web-Widget Sie können eine sofort einsatzbereite Such- oder Chatoberfläche direkt in das bestehende Intranet oder die Webseiten Ihres Unternehmens einbetten. Verwenden Sie dazu das HTML-Tag
script. So können Sie Ihre App am schnellsten Nutzern präsentieren. - Benutzerdefinierte API-Integration Wenn Sie die Nutzerfreundlichkeit vollständig selbst bestimmen möchten, können Sie mit den Vertex AI Search REST APIs oder Clientbibliotheken (z. B. Python, Node.js oder Java) ein benutzerdefiniertes Frontend von Grund auf neu erstellen.
11. Bereinigen
Damit Ihrem Google Cloud-Konto keine laufenden Gebühren in Rechnung gestellt werden, löschen Sie die in diesem Codelab erstellten Ressourcen:
- Rufen Sie in der Cloud Console die Seite Vertex AI Search auf.
- Klicken Sie auf Vorhandene Apps ansehen.
- Klicken Sie für die
cymbal-employee-portalApp auf das Dreipunkt-Menü für Mehr und dann auf Löschen. - Folgen Sie der Anleitung auf dem Bildschirm, um das Löschen zu bestätigen.
- Wenn Sie die Datenspeicher löschen möchten, klicken Sie im linken Navigationsbereich der Konsole auf Datenspeicher.
- Löschen Sie die Datenspeicher
cymbal-hr,cymbal-financeundcymbal-inventory:- Klicken Sie für den Datenspeicher
cymbal-hrauf das Dreipunkt-Menü Mehr und dann auf Löschen. - Folgen Sie der Anleitung auf dem Bildschirm, um das Löschen zu bestätigen.
- Klicken Sie für den Datenspeicher
cymbal-financeauf das Dreipunkt-Menü Mehr und dann auf Löschen. - Folgen Sie der Anleitung auf dem Bildschirm, um das Löschen zu bestätigen.
- Klicken Sie für den Datenspeicher
cymbal-inventoryauf das Dreipunkt-Menü Mehr und dann auf Löschen. - Folgen Sie der Anleitung auf dem Bildschirm, um das Löschen zu bestätigen.
- Klicken Sie für den Datenspeicher
- Rufen Sie die Seite Buckets auf und löschen Sie den Bucket, den Sie erstellt haben (z. B.
cymbal-app-hr-12). - Rufen Sie die Seite BigQuery auf und löschen Sie das Dataset
cymbal_finance.
12. Glückwunsch
Mission abgeschlossen! Sie haben mit Vertex AI Search eine einheitliche Unternehmenssuche erstellt.
Indem Sie die Lücke zwischen Ihren unstrukturierten Unternehmensdaten in Cloud Storage und strukturierten Datensätzen aus BigQuery schließen, haben Sie ein leistungsstarkes Tool für komplexe geschäftliche Entscheidungen geschaffen – und das alles, ohne eine einzige Zeile Code für maschinelles Lernen zu schreiben.
Das haben Sie gelernt
- Aufnahme:Hier erfahren Sie, wie Sie unstrukturierte Dokumente aus Cloud Storage und strukturierte Daten aus BigQuery in Vertex AI Search aufnehmen.
- Abfragen mehrerer Datenspeicher: So fragen Sie eine Such-App mit mehreren Datenspeichern ab, um einheitliche Antworten aus strukturierten und unstrukturierten Daten zu generieren.
- Abstimmung und Anpassung: Wie Sie die generativen KI-Modelle so abstimmen, dass sie genauere, domänenspezifische Antworten liefern.
- Bereitstellungsoptionen Die verschiedenen Möglichkeiten, diese Funktion in realen Anwendungen zu integrieren, indem Sie vorgefertigte Widgets oder benutzerdefinierte APIs verwenden.