
۱. مقدمه
در این آزمایشگاه کد، شما با استفاده از Vertex AI Search یک اپلیکیشن پشتیبانی کارمندان بدون کدنویسی خواهید ساخت.
تصور کنید که در Cymbal، یک شرکت خرده فروشی جهانی، کار میکنید. کارمندان اغلب سوالاتی مانند «سیاست رزرو سفرهای کاری چیست؟» یا «چند واحد کفش کتانی در انبار داریم؟» دارند.
معمولاً برای یافتن این پاسخها باید وارد سیستمهای کاملاً متفاوتی شوید. علاوه بر سروکار داشتن با سیستمهای مختلف، باید تعداد زیادی از دادههای بدون ساختار منابع انسانی را نیز بخوانید یا دستورات پیچیده SQL را روی دادههای مالی ساختاریافته اجرا کنید تا به پاسخ سوالات خود برسید.
در این آزمایشگاه کد، شما یک برنامه واحد و یکپارچه خواهید ساخت که به این مجموعه دادهها متصل میشود و به کارمندان اجازه میدهد تا با استفاده از قابلیتهای بازیابی افزوده نسل (RAG) شرکت Vertex AI، پاسخهای محاورهای و مبتنی بر واقعیت برای سوالات خود دریافت کنند.
کاری که انجام خواهید داد
در این codelab، مراحل زیر را انجام خواهید داد:
- منابع داده را تنظیم کنید. یک مخزن ذخیرهسازی ابری برای اسناد منابع انسانی بدون ساختار و یک مجموعه داده BigQuery برای دادههای مالی ساختاریافته ایجاد کنید.
- پیکربندی انبارهای داده. ایجاد انبارهای داده Vertex AI Search متصل به منابع داده Cloud Storage و BigQuery شما.
- برنامه را وصل کنید. یک برنامه جستجوی هوش مصنوعی Vertex ایجاد کنید و هر دو منبع داده را به آن پیوند دهید.
- برنامه را آزمایش کنید. با رابط جستجوی یکپارچه تعامل کنید تا پاسخهای پایهای که اطلاعات را از هر دو مخزن داده ترکیب میکنند، تأیید شوند.
- مراحل بعدی را بررسی کنید. گزینههای تنظیم مدل هوش مصنوعی مولد و استقرار برنامه جستجوی خود را بررسی کنید.
آنچه نیاز دارید
- یک مرورگر وب مانند کروم .
- یک پروژه گوگل کلود با قابلیت پرداخت.
- گیت روی دستگاه محلی شما نصب شده باشد.
این آزمایشگاه کد برای توسعهدهندگان در تمام سطوح است.
۲. قبل از شروع
یک پروژه Google Cloud ایجاد کنید و API های مورد نیاز را فعال کنید.
- در کنسول گوگل کلود، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر.
نقشهای مورد نیاز IAM
این آزمایشگاه کد فرض میکند که شما نقش مالک پروژه را برای پروژه Google Cloud خود دارید.
فعال کردن APIها
- در کنسول Google Cloud، روی Activate Cloud Shell کلیک کنید: اگر قبلاً از Cloud Shell استفاده نکردهاید، پنجرهای ظاهر میشود که به شما امکان میدهد Cloud Shell را در یک محیط قابل اعتماد با یا بدون بوست شروع کنید. اگر از شما خواسته شد Cloud Shell را تأیید کنید، روی Authorize کلیک کنید.
- در Cloud Shell، تمام API های مورد نیاز را فعال کنید:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
۳. کپی کردن یک مخزن گیتهاب
برای نشان دادن نحوهی عملکرد جستجو در برنامهی پشتیبانی کارمندان Cymbal، به تعدادی فایل آزمایشی نیاز دارید. در این بخش، یک مخزن GitHub را روی دستگاه محلی خود کپی میکنید تا این فایلها را دریافت کنید. در مراحل بعدی، این فایلها را با استفاده از رابط Cloud Console در Google Cloud آپلود خواهید کرد.
- در یک ترمینال روی دستگاه محلی خود، مخزن
next-26-sessionsرا کلون کنید:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - به دایرکتوری مخزن دانلود شده بروید:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - فایلهای دانلود شده در این پوشه را بررسی کنید. متوجه خواهید شد که دو پوشه وجود دارد:
HRوFinance.- HR . این پوشه حاوی تعدادی فایل بدون ساختار مانند فایلهای
.doc،.txtو.htmlاست. شما فایلهای HR را در یک فضای ذخیرهسازی ابری آپلود خواهید کرد. - Finance . این پوشه شامل دو فایل
.jsonlاست. شما این فایلها را در مجموعه داده BigQuery آپلود خواهید کرد.
- HR . این پوشه حاوی تعدادی فایل بدون ساختار مانند فایلهای
۴. یک فضای ذخیرهسازی ابری برای فایلهای بدون ساختار ایجاد کنید
در این بخش، یک مخزن ذخیرهسازی ابری ایجاد میکنید و اسناد موجود در پوشه HR را که در بخش مخزن Clone a GitHub دانلود کردهاید، آپلود میکنید. دادههای بدون ساختار، مانند اسناد منابع انسانی در این مثال، از قالب از پیش تعریفشدهای پیروی نمیکنند و میتوانند شامل فایلهای متنی، اسناد یا محتوای چندرسانهای باشند.
- در کنسول Cloud، به صفحه Buckets بروید.
- روی ایجاد کلیک کنید.
- در صفحه ایجاد یک سطل ، نام سطل را وارد کنید. این نام باید به صورت سراسری منحصر به فرد باشد. برای مثال:
cymbal-app-hr-12. - گزینههای پیشفرض را حفظ کنید.
- روی ایجاد کلیک کنید. سطل ایجاد شده و صفحه جزئیات سطل نمایش داده میشود. اگر صفحه جزئیات سطل را نمیبینید، روی سطلی که تازه ایجاد کردهاید کلیک کنید.
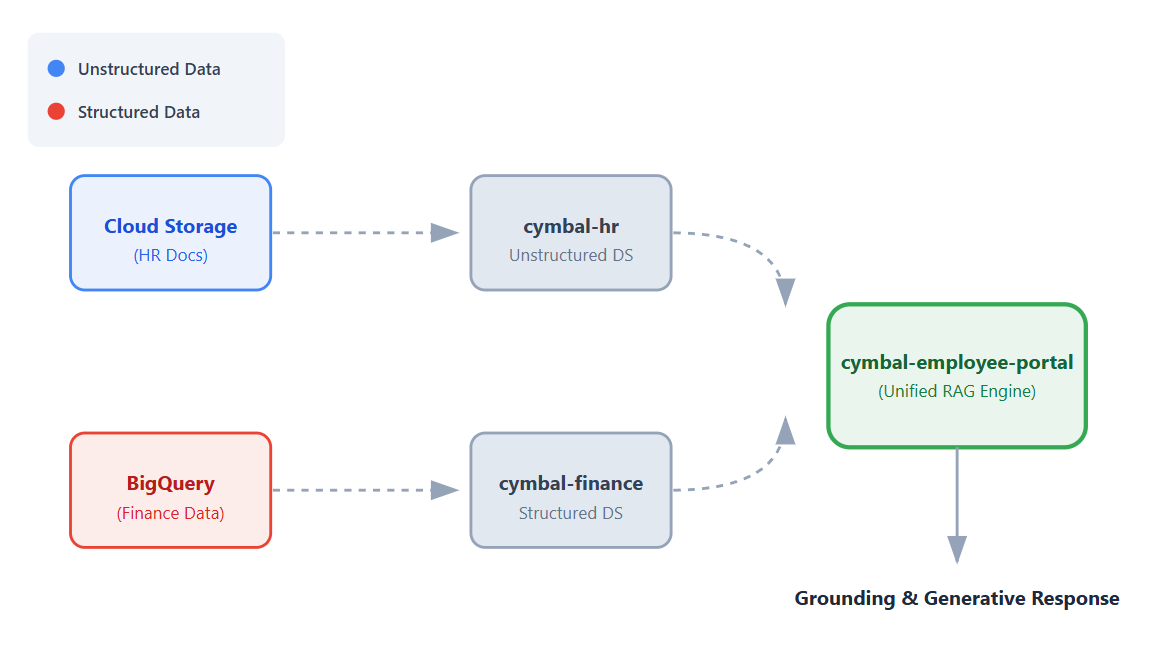
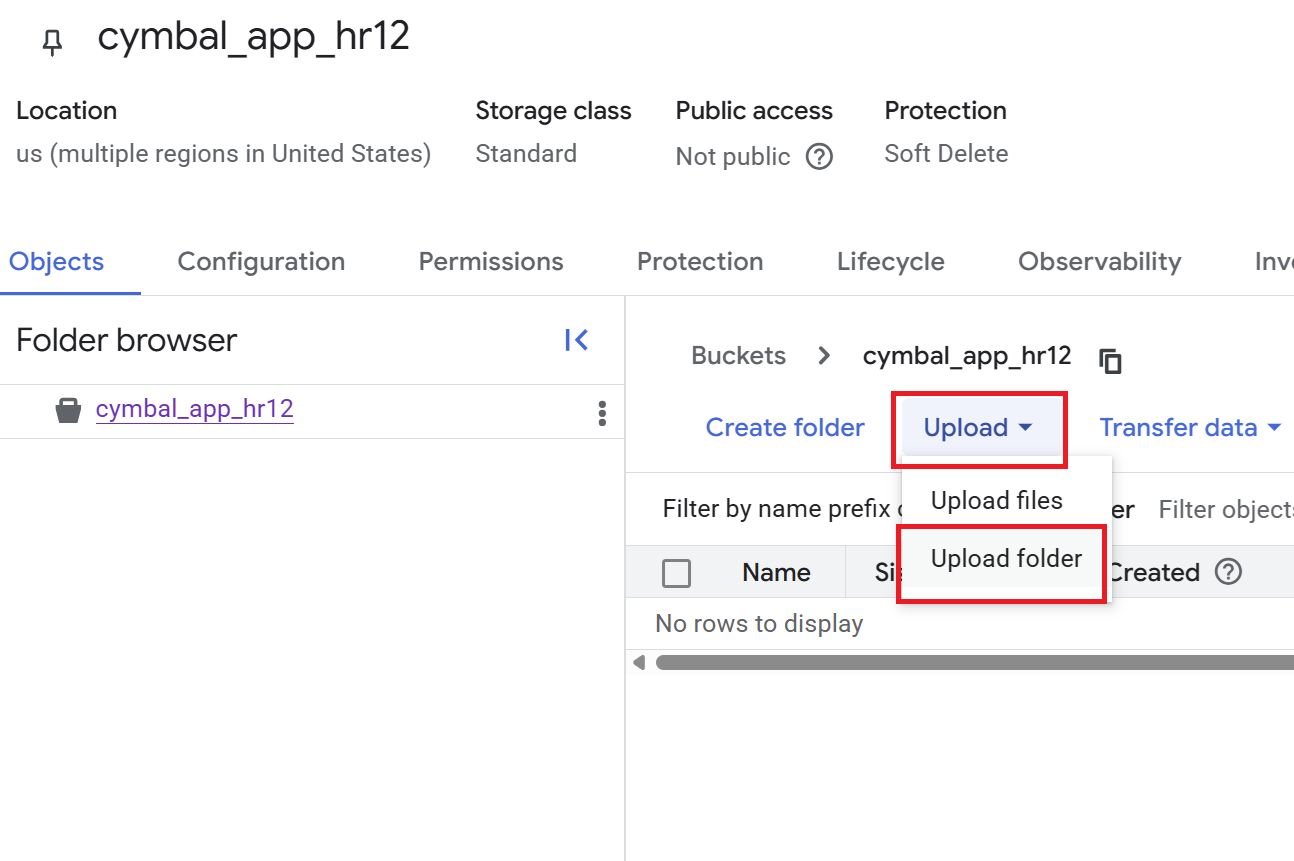
- در صفحه جزئیات Bucket ، روی Upload > Upload folder کلیک کنید و سپس پوشه
HRرا که در بخش Clone a GitHub repository دانلود کردهاید، انتخاب کنید. - آپلود را تأیید کنید.
- در صفحه جزئیات سطل ، برای مشاهده لیست فایلها، روی پوشه
HRکلیک کنید.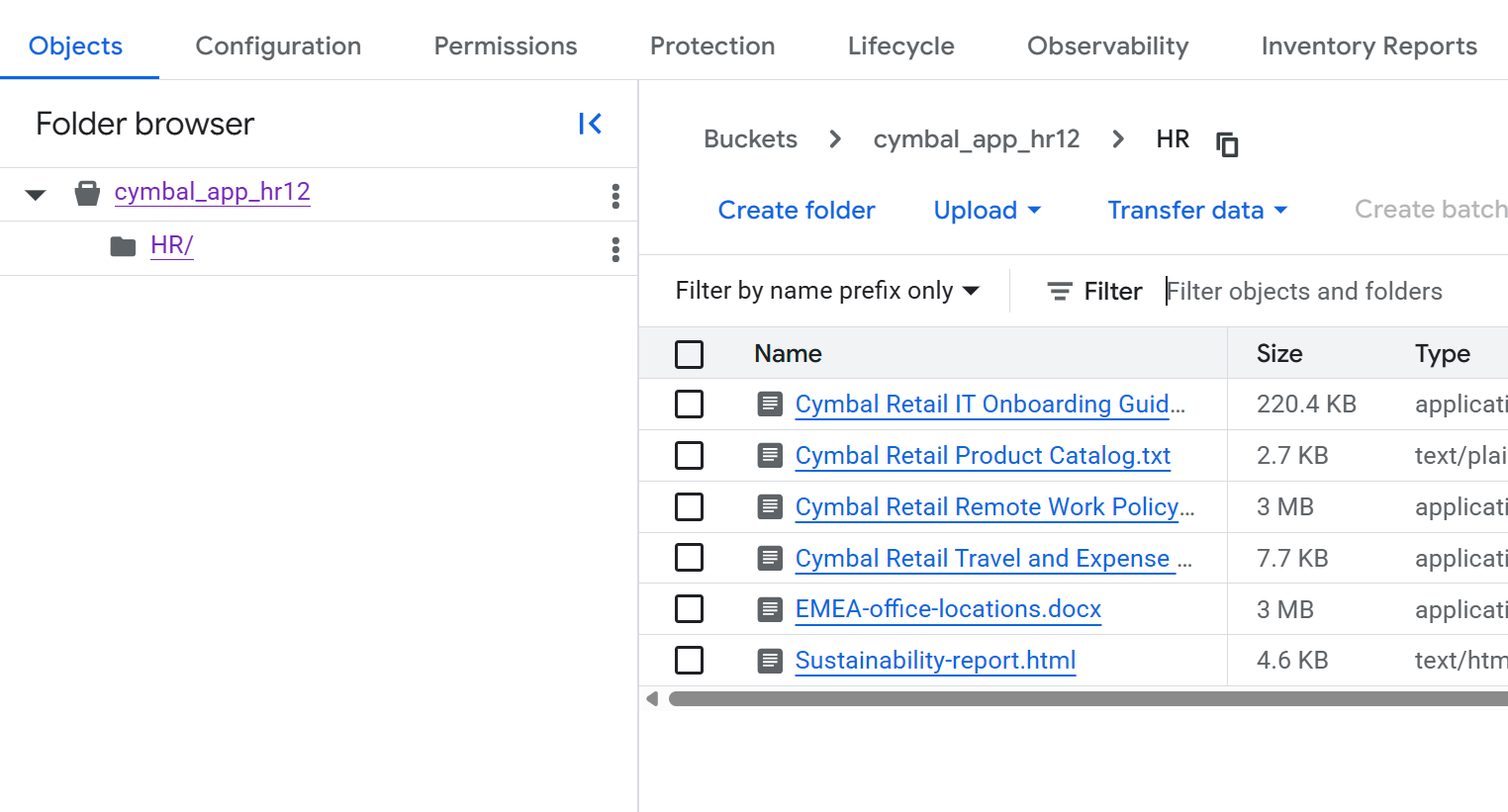
۵. یک مجموعه داده BigQuery برای فایلهای ساختاریافته ایجاد کنید
در این بخش، شما یک مجموعه داده BigQuery ایجاد میکنید و اسناد موجود در پوشه Finance را که در بخش Clone a GitHub repository دانلود کردهاید، در یک جدول جدید بارگذاری میکنید. دادههای ساختاریافته، مانند اسناد مالی در این مثال، از یک قالب از پیش تعریفشده، مانند رکوردهای موجود در یک پایگاه داده، پیروی میکنند.
- در کنسول Cloud، به صفحه BigQuery بروید.
- در پنل Explorer ، روی نام پروژه خود کلیک کنید و سپس روی View actions (سه نقطه عمودی) > Create dataset کلیک کنید.
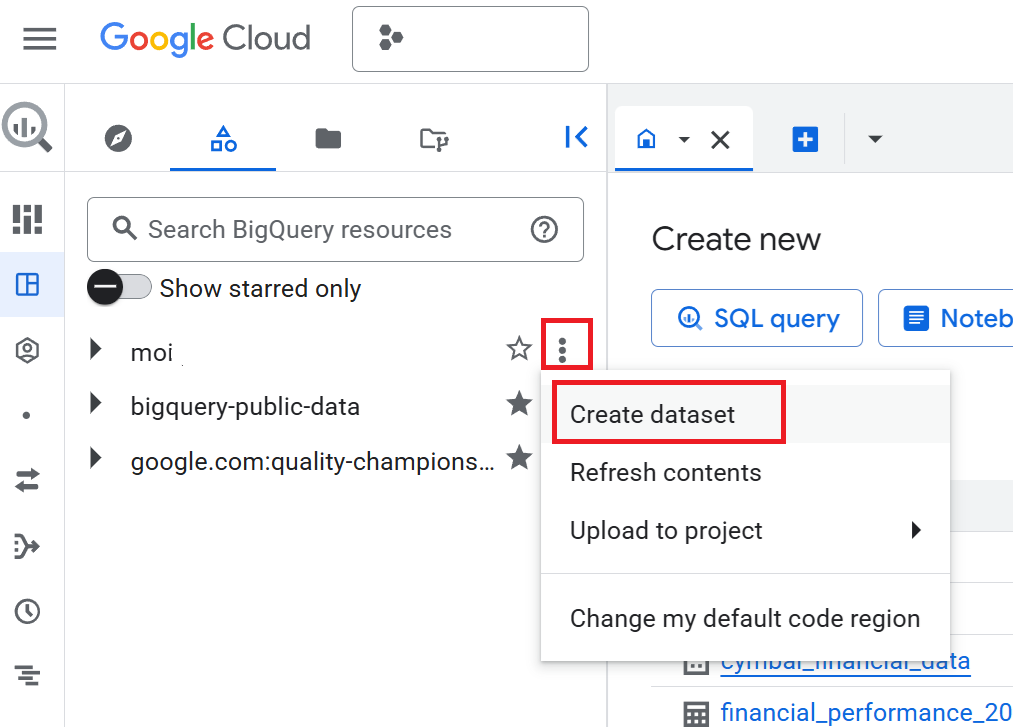
- در صفحه ایجاد مجموعه داده ، شناسه مجموعه داده را به صورت
cymbal_financeوارد کنید. - برای موقعیت مکانی داده ،
US (multiple regions in United States)را انتخاب کنید. - گزینههای پیشفرض را نگه دارید و روی ایجاد مجموعه داده کلیک کنید.
- در پنجره اکسپلورر ، پروژه خود را گسترش دهید و روی مجموعه داده
cymbal_financeکلیک کنید. - در پنجره جزئیات مجموعه دادهها، روی ایجاد جدول کلیک کنید.
- در صفحه ایجاد جدول ، در بخش منبع ، موارد زیر را انجام دهید:
- برای ایجاد جدول از ، گزینه آپلود را انتخاب کنید.
- برای انتخاب فایل ، روی مرور کلیک کنید، به پوشه
Financeکه دانلود کردهاید بروید وcymbal_employee_finance.jsonlرا انتخاب کنید. - برای قالب فایل ، JSONL (JSON با مرزبندی خط جدید) را انتخاب کنید.
- در بخش Destination ، نام جدول را
employee_financeوارد کنید. - در بخش Schema ، گزینهی Auto-detect را انتخاب کنید.
- سایر تنظیمات پیشفرض را حفظ کنید و روی ایجاد جدول کلیک کنید.
- مراحل ۷ تا ۱۱ را برای بارگذاری دادهها در یک جدول جدید تکرار کنید. در مرحله ۸ب،
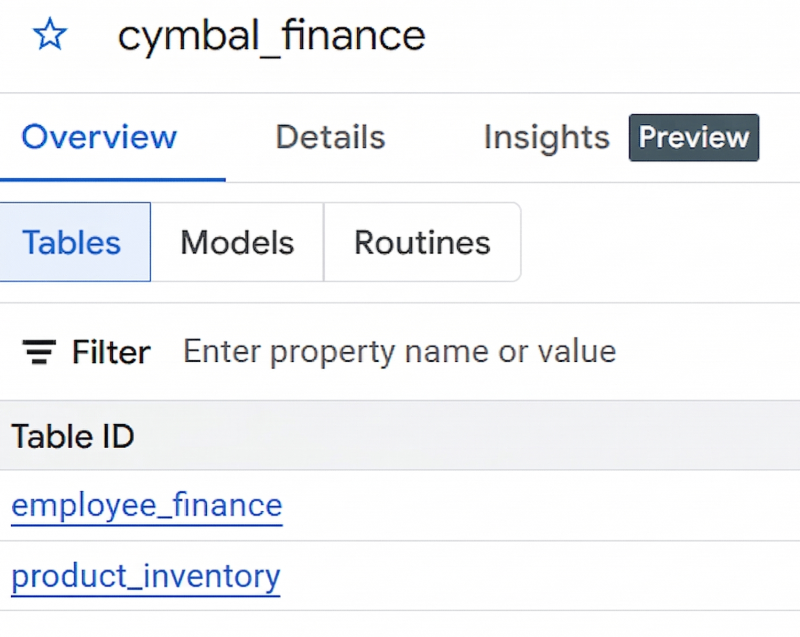
product_inventory.jsonlرا انتخاب کنید و در مرحله ۹،product_inventoryبه عنوان نام جدول وارد کنید. اگر جداول را در پنجره جزئیات مجموعه داده نمیبینید، روی Refresh کلیک کنید. - اگر مجموعه داده و دو جدول را با موفقیت ایجاد کرده باشید، باید مانند تصویر زیر باشد:
۶. یک برنامه جستجوی هوش مصنوعی Vertex ایجاد کنید
- در کنسول ابری، به صفحه جستجوی هوش مصنوعی ورتکس بروید.
- در بخش جستجوی سفارشی (عمومی) ، روی ایجاد کلیک کنید.
- در صفحه پیکربندی برنامه جستجو ، مطمئن شوید که گزینههای ویژگیهای نسخه سازمانی و پاسخهای تولیدی انتخاب شدهاند.
- نام برنامه خود را
cymbal-employee-portalبگذارید. - نام شرکت را
Cymbal Corpوارد کنید. - موقعیت مکانی برنامه خود را به صورت
globalحفظ کنید. - روی ادامه کلیک کنید.
۷. ایجاد و اتصال انبارهای داده
در صفحهی «ذخیرههای داده» ، شما باید سه مخزن داده ایجاد کنید که به برنامهی شما متصل شوند. شما باید سه مخزن داده ایجاد کنید: یکی برای دادههای منابع انسانی بدون ساختار و دو تا برای دادههای مالی ساختاریافته.
ایجاد یک مخزن داده برای دادههای بدون ساختار
- در صفحه فروشگاههای داده ، روی ایجاد فروشگاه داده کلیک کنید.
- برای انتخاب منبع داده ، فضای ذخیرهسازی ابری را انتخاب کنید.
- در صفحه «وارد کردن دادهها از فضای ذخیرهسازی ابری» ، به «وارد کردن دادههای بدون ساختار (جستجوی اسناد و RAG)» بروید و «اسناد» را انتخاب کنید.
- گزینه فرکانس همگامسازی را روی «یکباره» (One-time) نگه دارید.
- برای انتخاب پوشه یا فایلی که میخواهید وارد کنید ، روی پوشه کلیک کنید.
- در فیلد
gs://...، نام باکتی را که در بخش «ایجاد یک باکت ذخیرهسازی ابری برای فایلهای بدون ساختار» ایجاد کردهاید، وارد کنید. برای مثال، اگر نام باکتcymbal-app-hr-12است، نام آن راcymbal-app-hr-12/HRوارد کنید. دریافت از پوشهHRتضمین میکند که فقط اسناد HR در این مخزن داده گنجانده شدهاند. - روی ادامه کلیک کنید.
- نام محل ذخیرهسازی داده را
cymbal-hrوارد کنید. - روی ادامه کلیک کنید.
- گزینه قیمتگذاری عمومی را حفظ کنید.
- روی ایجاد کلیک کنید.
بعد از اینکه روی ایجاد کلیک کردید، به صفحهی ذخیرهسازی دادهها بازگردانده میشوید.
ایجاد انبارهای داده برای دادههای ساختاریافته
شما دو مخزن داده برای دادههای ساختاریافته از BigQuery ایجاد خواهید کرد: یکی برای اطلاعات مالی کارکنان و دیگری برای موجودی محصولات.
ایجاد یک مخزن داده برای دادههای مالی کارکنان
- در صفحهی «ذخیرههای داده» ، دوباره روی «ایجاد ذخیرهی داده» کلیک کنید.
- برای انتخاب منبع داده ، BigQuery را انتخاب کنید.
- برای وارد کردن دادههای ساختاریافته ، جدول BigQuery را با طرحواره خودتان انتخاب کنید.
- گزینه فرکانس همگامسازی را روی «یکباره» (One-time) نگه دارید.
- برای انتخاب جدولی که میخواهید وارد کنید ، روی مرور کلیک کنید. در کادر محاورهای انتخاب مسیر که باز میشود، جدول
employee_financeرا از مجموعه دادهcymbal_financeدر پروژه خود انتخاب کنید. ممکن است جداولی با نامهای مشابه از پروژههای دیگر ببینید، بنابراین مطمئن شوید که جدول را از پروژه خود انتخاب میکنید. - روی ادامه کلیک کنید.
- صفحه بررسی طرحواره و اختصاص ویژگیهای کلیدی را بررسی کنید.
- روی ادامه کلیک کنید.
- نام محل ذخیرهسازی داده را
cymbal-financeوارد کنید. - روی ادامه کلیک کنید.
- گزینه قیمتگذاری عمومی را حفظ کنید.
- روی ایجاد کلیک کنید.
بعد از اینکه روی ایجاد کلیک کردید، به صفحهی ذخیرهسازی دادهها بازگردانده میشوید.
ایجاد یک مخزن داده برای دادههای موجودی محصول
- در صفحهی «ذخیرههای داده» ، دوباره روی «ایجاد ذخیرهی داده» کلیک کنید.
- برای انتخاب منبع داده ، BigQuery را انتخاب کنید.
- برای وارد کردن دادههای ساختاریافته ، جدول BigQuery را با طرحواره خودتان انتخاب کنید.
- گزینه فرکانس همگامسازی را روی «یکباره» (One-time) نگه دارید.
- برای انتخاب جدولی که میخواهید وارد کنید ، روی مرور کلیک کنید. در کادر محاورهای انتخاب مسیر که باز میشود، جدول
product_inventoryرا از مجموعه دادهcymbal_financeدر پروژه خود انتخاب کنید. - روی ادامه کلیک کنید.
- صفحه بررسی طرحواره و اختصاص ویژگیهای کلیدی را بررسی کنید.
- روی ادامه کلیک کنید.
- نام محل ذخیرهسازی داده را
cymbal-inventoryوارد کنید. - روی ادامه کلیک کنید.
- گزینه قیمتگذاری عمومی را حفظ کنید.
- روی ایجاد کلیک کنید.
بعد از اینکه روی ایجاد کلیک کردید، به صفحهی ذخیرهسازی دادهها بازگردانده میشوید.
۸. اتصال فروشگاههای داده به برنامهتان
اکنون باید سه محل ذخیرهسازی داده را در لیست صفحهی محلهای ذخیرهسازی داده مشاهده کنید: cymbal-hr (بدون ساختار)، cymbal-finance (ساختاریافته) و cymbal-inventory (ساختاریافته). برای اتصال این محلهای ذخیرهسازی داده به برنامهی خود، این مراحل را دنبال کنید:
- در صفحهی Data stores ، هر سه data store که ایجاد کردهاید را انتخاب کنید:
cymbal-hr،cymbal-financeوcymbal-inventory. قبل از ادامه، مطمئن شوید که هر سه data store را انتخاب کردهاید. - روی ادامه کلیک کنید.
- گزینه قیمتگذاری عمومی را حفظ کنید.
- روی ایجاد کلیک کنید.
۹. اپلیکیشن پورتال کارمندان Cymbal را امتحان کنید
- در برنامه
cymbal-employee-portal، روی پیشنمایش کلیک کنید. - در کادر «جستجو در اینجا» ، سوال زیر را وارد کنید:
What are the stipends that I get as an employee of Cymbal located in London? - سوالی در رابطه با موجودی محصول وارد کنید:
How many units of sneakers do we have in stock? - سوال دیگری را وارد کنید:
What is the stipend for an executive in Cymbal?
توجه کنید که چگونه برنامه جستجو، اطلاعات را از منابع مختلف بازیابی میکند تا پاسخ خود را تدوین کند. برای پاسخ به این سؤالات، برنامه هم در دادههای مالی ساختاریافته ذخیرهشده در BigQuery و هم در اسناد منابع انسانی بدون ساختار در Cloud Storage جستجو کرد.
این نشان دهنده قدرت Vertex AI Search در ترکیب پاسخها در قالبهای دادهای مختلف و ذخیره دادههای پراکنده در یک تجربه واحد و منسجم است.
همچنین میتوانید مدل هوش مصنوعی را تنظیم کنید تا پاسخهای دقیقتر و مختص به حوزه مورد نظر ارائه دهد. برای اطلاعات بیشتر در مورد سفارشیسازی تجربه تولید، به مستندات «دریافت پاسخها و پیگیریها» مراجعه کنید.
۱۰. گزینههایی برای استقرار برنامه شما
اگرچه استقرار برنامه برای کاربران نهایی خارج از محدوده این آزمایشگاه کد است، اما دانستن چگونگی تبدیل آن به یک سناریوی دنیای واقعی مفید است. شما چندین گزینه برای ادغام برنامه جستجوی هوش مصنوعی Vertex خود در گردشهای کاری سازمان خود دارید:
- ویجت وب از پیش ساخته شده. شما میتوانید یک رابط جستجو یا چت آماده را مستقیماً با استفاده از یک تگ
scriptHTML در اینترانت یا صفحات وب موجود شرکت خود جاسازی کنید. این سریعترین راه برای قرار دادن برنامه شما در معرض دید کاربران است. - ادغام API سفارشی. برای کنترل کامل بر تجربه کاربری، میتوانید از APIهای Vertex AI Search REST یا کتابخانههای کلاینت (مانند پایتون، Node.js یا جاوا) برای ساخت یک رابط کاربری سفارشی از ابتدا استفاده کنید.
۱۱. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در طول این codelab را حذف کنید:
- در کنسول Cloud، به صفحه جستجوی Vertex AI بروید.
- روی «مشاهده برنامههای موجود» کلیک کنید.
- برای برنامه
cymbal-employee-portal، روی سه نقطه عمودی برای «بیشتر» کلیک کنید و سپس روی «حذف» کلیک کنید. - برای تأیید حذف، دستورالعملهای روی صفحه را دنبال کنید.
- برای حذف فروشگاههای داده، روی فروشگاههای داده در پنل ناوبری سمت چپ کنسول کلیک کنید.
- دادههای مربوط به
cymbal-hr،cymbal-financeوcymbal-inventoryرا حذف کنید:- برای ذخیره داده
cymbal-hr، روی سه نقطه عمودی برای More کلیک کنید و سپس روی Delete کلیک کنید. - برای تأیید حذف، دستورالعملهای روی صفحه را دنبال کنید.
- برای فروشگاه داده
cymbal-finance، روی سه نقطه عمودی برای «بیشتر» کلیک کنید و سپس روی «حذف» کلیک کنید. - برای تأیید حذف، دستورالعملهای روی صفحه را دنبال کنید.
- برای فروشگاه دادههای
cymbal-inventory، روی سه نقطه عمودی برای «بیشتر» کلیک کنید و سپس روی «حذف» کلیک کنید. - برای تأیید حذف، دستورالعملهای روی صفحه را دنبال کنید.
- برای ذخیره داده
- به صفحه Buckets بروید و Bucket ای که ایجاد کردهاید (برای مثال،
cymbal-app-hr-12) را حذف کنید. - به صفحه BigQuery بروید و مجموعه داده
cymbal_financeرا حذف کنید.
۱۲. تبریک
ماموریت تکمیل شد! شما با موفقیت یک تجربه جستجوی یکپارچه سازمانی با استفاده از Vertex AI Search ایجاد کردید.
با پر کردن شکاف بین دادههای سازمانی بدون ساختار شما در فضای ذخیرهسازی ابری و رکوردهای ساختاریافته از BigQuery، شما ابزاری قدرتمند ایجاد کردهاید که قادر به استدلال پیچیده تجاری است - همه اینها بدون نوشتن حتی یک خط کد یادگیری ماشین.
آنچه آموختهاید
- دریافت: نحوه دریافت اسناد بدون ساختار از فضای ذخیرهسازی ابری و دادههای ساختاریافته از BigQuery به جستجوی هوش مصنوعی Vertex.
- پرسوجوی چند دادهای . نحوه پرسوجو از یک برنامه جستجوی چند دادهای برای ترکیب پاسخهای یکپارچه از دادههای ساختاریافته و بدون ساختار.
- تنظیم و سفارشیسازی . نحوه تنظیم مدلهای هوش مصنوعی مولد برای ارائه پاسخهای دقیقتر و مختص به حوزه مورد نظر.
- گزینههای استقرار . روشهای مختلف برای ادغام این قابلیت استدلال در برنامههای دنیای واقعی با استفاده از ویجتهای از پیش ساخته شده یا APIهای سفارشی.