
1. Introduction
Dans cet atelier de programmation, vous allez créer une application d'assistance universelle pour les employés sans code à l'aide de Vertex AI Search.
Imaginez que vous travaillez chez Cymbal, une entreprise mondiale de vente au détail. Les employés posent souvent des questions telles que "Quelle est la politique de réservation des voyages d'affaires ?" ou "Combien d'unités de baskets avons-nous en stock ?".
En règle générale, vous devez vous connecter à des systèmes complètement différents pour trouver ces réponses. En plus de gérer différents systèmes, vous devez également lire un grand nombre de données RH non structurées ou exécuter des invites SQL complexes sur des données financières structurées pour obtenir des réponses à vos questions.
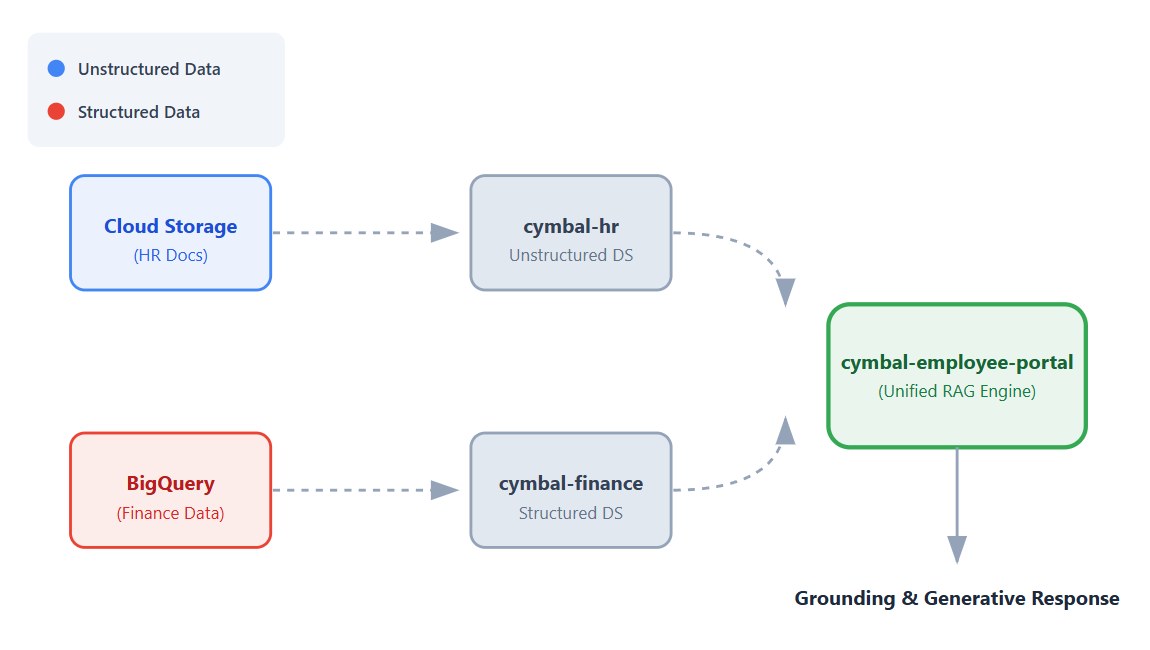
Dans cet atelier de programmation, vous allez créer une application unique et unifiée qui se connecte à ces ensembles de données, permettant aux employés d'obtenir des réponses conversationnelles et fondées à leurs questions à l'aide des fonctionnalités de génération augmentée par récupération (RAG) de Vertex AI.
Objectifs de l'atelier
Dans cet atelier de programmation, vous allez effectuer les étapes suivantes :
- Configurer des sources de données. Créez un bucket Cloud Storage pour les documents RH non structurés et un ensemble de données BigQuery pour les données financières structurées.
- Configurer des datastores. Créez des datastores Vertex AI Search connectés à vos sources de données Cloud Storage et BigQuery.
- Connecter l'application. Créez une application Vertex AI Search et associez-y les deux datastores.
- Tester l'application. Interagissez avec l'interface de recherche unifiée pour vérifier les réponses fondées qui synthétisent les informations des deux datastores.
- Découvrir les étapes suivantes. Passez en revue les options permettant d'ajuster le modèle d'IA générative et de déployer votre application de recherche.
Ce dont vous avez besoin
- Un navigateur Web tel que Chrome.
- Un projet Google Cloud avec facturation activée.
- Git installé sur votre machine locale.
Cet atelier de programmation s'adresse aux développeurs de tous niveaux.
2. Avant de commencer
Créez un projet Google Cloud et activez les API requises.
- Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud .
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Rôles IAM requis
Cet atelier de programmation suppose que vous disposez du rôle Propriétaire du projet pour votre projet Google Cloud.
Activer les API
- Dans la console Google Cloud, cliquez sur Activer Cloud Shell. Si vous n'avez jamais utilisé Cloud Shell auparavant, un volet s'affiche et vous permet de démarrer Cloud Shell dans un environnement de confiance avec ou sans boost. Si vous êtes invité à autoriser Cloud Shell, cliquez sur Autoriser.
- Dans Cloud Shell, activez toutes les API requises :
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. Cloner un dépôt GitHub
Pour montrer comment la recherche fonctionne dans l'application d'assistance aux employés Cymbal, vous avez besoin de quelques fichiers factices. Dans cette section, vous allez cloner un dépôt GitHub sur votre machine locale pour obtenir ces fichiers. Vous les importerez dans Google Cloud lors d'étapes ultérieures à l'aide de l'interface Cloud Console.
- Dans un terminal de votre machine locale, clonez le dépôt
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Accédez au répertoire du dépôt téléchargé :
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - Explorez les fichiers téléchargés dans ce répertoire. Vous remarquerez qu'il existe deux dossiers :
HRetFinance.- HR. Ce dossier contient un certain nombre de fichiers non structurés, tels que des fichiers
.doc,.txtet.html. Vous importerez les fichiers RH dans un bucket Cloud Storage. - Finance. Ce dossier contient deux fichiers
.jsonl. Vous les importerez dans un ensemble de données BigQuery.
- HR. Ce dossier contient un certain nombre de fichiers non structurés, tels que des fichiers
4. Créer un bucket Cloud Storage pour les fichiers non structurés
Dans cette section, vous allez créer un bucket Cloud Storage et importer les documents du dossier HR que vous avez téléchargés dans la section Cloner un dépôt GitHub. Les données non structurées, comme les documents RH de cet exemple, ne suivent pas un format prédéfini et peuvent inclure des fichiers texte, des documents ou du contenu multimédia.
- Dans Cloud Console, accédez à la page Buckets.
- Cliquez sur Créer.
- Sur la page Créer un bucket, saisissez le nom d'un bucket. Le nom doit être unique. Exemple :
cymbal-app-hr-12. - Conservez les options par défaut.
- Cliquez sur Créer.Le bucket est créé et la page Informations sur le bucket s'affiche. Si la page Informations sur le bucket ne s'affiche pas, cliquez sur le bucket que vous venez de créer.
- Sur la page Informations sur le bucket, cliquez sur Importer > Importer un dossier, puis sélectionnez le dossier
HRque vous avez téléchargé dans la section Cloner un dépôt GitHub. - Confirmez l'importation.
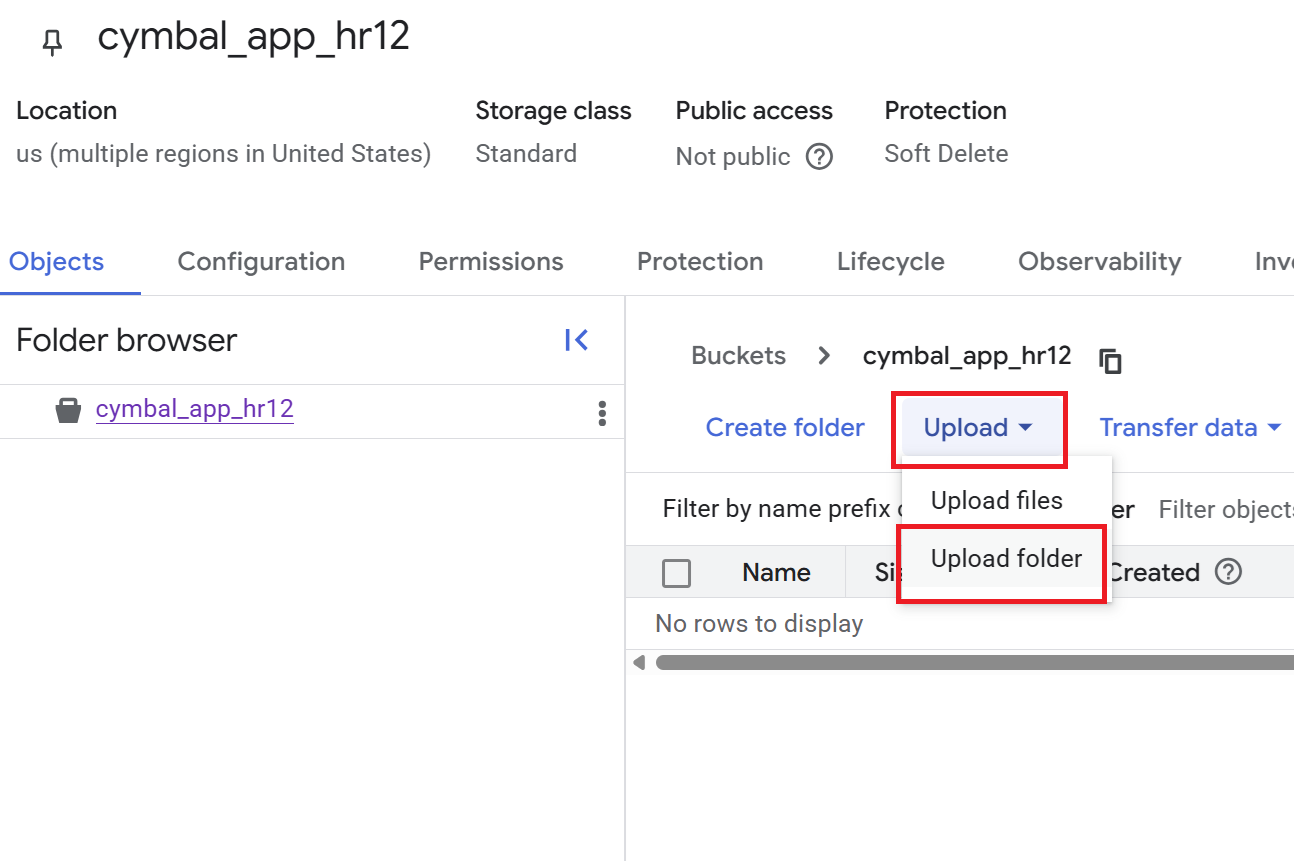
- Sur la page Informations sur le bucket, cliquez sur le dossier
HRpour afficher la liste des fichiers.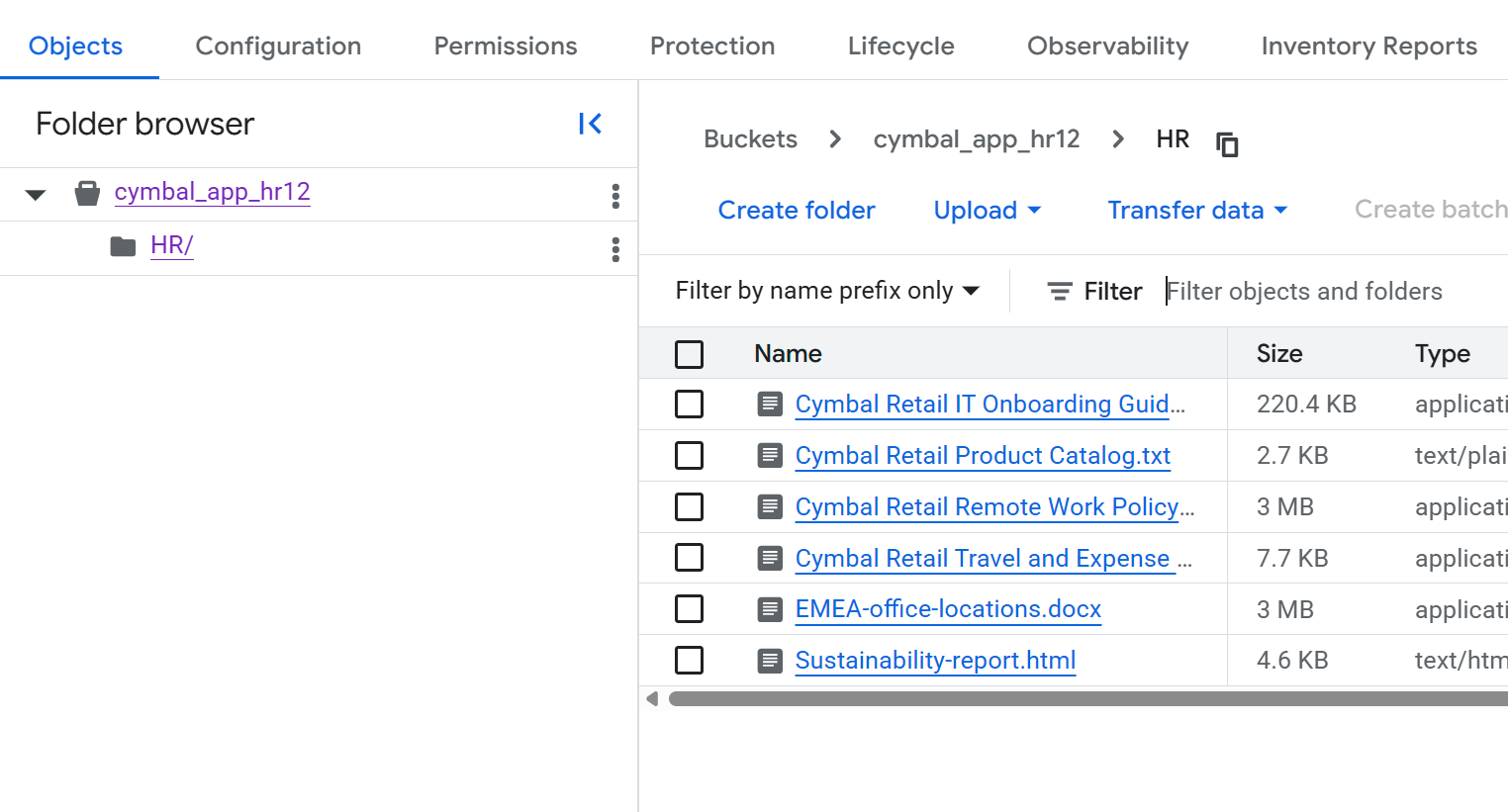
5. Créer un ensemble de données BigQuery pour les fichiers structurés
Dans cette section, vous allez créer un ensemble de données BigQuery et charger les documents du dossier Finance que vous avez téléchargés dans la section Cloner un dépôt GitHub dans une nouvelle table. Les données structurées, comme les documents financiers de cet exemple, suivent un format prédéfini, tel que des enregistrements dans une base de données.
- Dans la console Cloud, accédez à la page BigQuery.
- Dans le volet Explorateur, cliquez sur le nom de votre projet, puis sur Afficher les actions (les trois points verticaux) > Créer un ensemble de données.
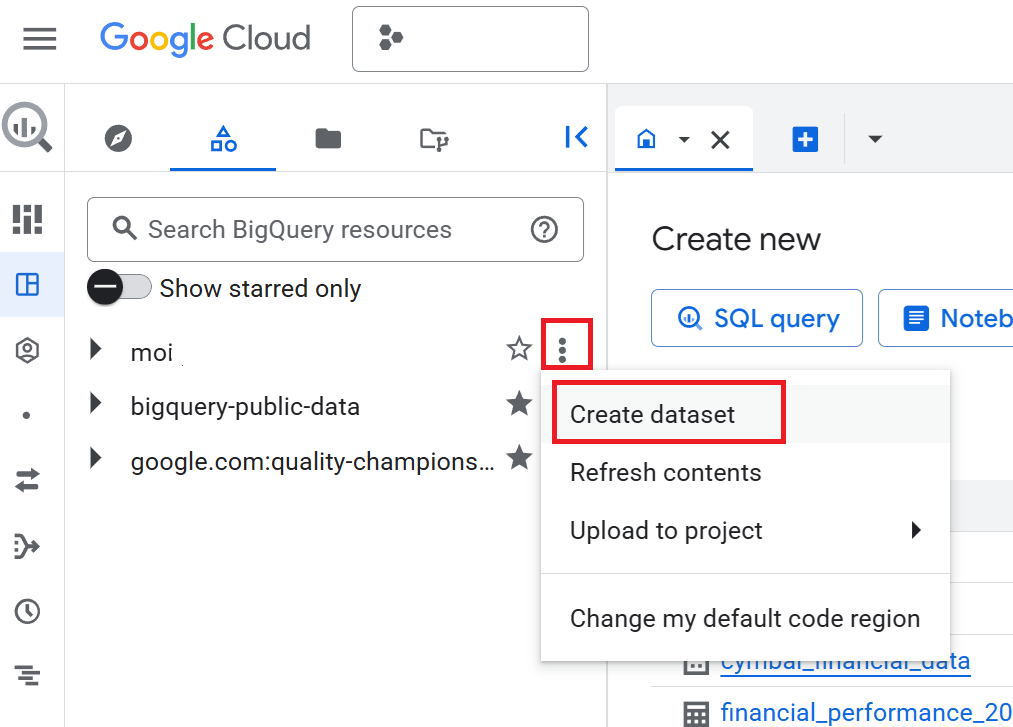
- Dans le volet Créer un ensemble de données, saisissez
cymbal_financecomme ID de l'ensemble de données. - Pour Emplacement des données, sélectionnez
US (multiple regions in United States). - Conservez les options par défaut et cliquez sur Créer un ensemble de données.
- Dans le volet Explorateur, développez votre projet, puis cliquez sur l'ensemble de données
cymbal_finance. - Dans le volet des détails de l'ensemble de données, cliquez sur Créer une table.
- Dans la section Source de la page Créer une table , procédez comme suit :
- Dans le champ Créer une table à partir de, sélectionnez Importer.
- Sous Sélectionner un fichier, cliquez sur Parcourir, accédez au dossier
Financeque vous avez téléchargé, puis sélectionnezcymbal_employee_finance.jsonl. - Pour le champ Format de fichier, sélectionnez JSONL (JSON délimité par un retour à la ligne).
- Dans la section Destination, saisissez
employee_financecomme Nom de la table. - Dans la section Schéma, cochez la case Détection automatique.
- Conservez les autres paramètres par défaut, puis cliquez sur Créer une table.
- Répétez les étapes 7 à 11 pour charger les données dans une nouvelle table. À l'étape 8b, sélectionnez
product_inventory.jsonl, et à l'étape 9, saisissezproduct_inventorycomme Nom de la table.Si les tables ne s'affichent pas dans le volet des détails de l'ensemble de données, cliquez sur Actualiser. - Si vous avez créé l'ensemble de données et les deux tables, l'image suivante devrait s'afficher :
6. Créer une application Vertex AI Search
- Dans Cloud Console, accédez à la page Vertex AI Search.
- Dans la tuile Recherche personnalisée (général), cliquez sur Créer.
- Sur la page Configuration de l'application de recherche, assurez-vous que les options Fonctionnalités de l'édition Enterprise et Réponses génératives sont sélectionnées.
- Nommez votre application
cymbal-employee-portal. - Saisissez
Cymbal Corpcomme Nom de l'entreprise. - Conservez
globalcomme Emplacement de votre application. - Cliquez sur Continuer.
7. Créer et connecter des datastores
Sur la page Datastores , vous allez créer des datastores que vous connecterez à votre application. Vous devez créer trois datastores : un pour les données RH non structurées et deux pour les données financières structurées.
Créer un datastore pour les données non structurées
- Sur la page Datastores, cliquez sur Créer un datastore.
- Pour Sélectionner une source de données, sélectionnez Cloud Storage.
- Dans le volet Importer des données depuis Cloud Storage, accédez à Importation de données non structurées (recherche de documents et RAG), puis sélectionnez Documents.
- Conservez l'option Fréquence de synchronisation sur Une seule fois.
- Pour Sélectionner un dossier ou un fichier à importer, cliquez sur Dossier.
- Dans le champ
gs://..., saisissez le nom du bucket que vous avez créé dans la section Créer un bucket Cloud Storage pour les fichiers non structurés. Par exemple, si le nom du bucket estcymbal-app-hr-12, saisissezcymbal-app-hr-12/HR.L'ingestion à partir du dossierHRgarantit que seuls les documents RH sont inclus dans ce datastore. - Cliquez sur Continuer.
- Saisissez
cymbal-hrcomme nom du datastore. - Cliquez sur Continuer.
- Conservez l'option Tarification générale.
- Cliquez sur Créer.
Après avoir cliqué sur Créer, vous revenez à la page Datastores.
Créer des datastores pour les données structurées
Vous allez créer deux datastores pour les données structurées de BigQuery : un pour les informations financières des employés et un autre pour l'inventaire des produits.
Créer un datastore pour les données financières des employés
- Sur la page Datastores, cliquez à nouveau sur Créer un datastore.
- Pour Sélectionner une source de données, sélectionnez BigQuery.
- Pour Importation de données structurées, sélectionnez Table BigQuery avec votre propre schéma.
- Conservez l'option Fréquence de synchronisation sur Une seule fois.
- Pour Sélectionner une table à importer, cliquez sur Parcourir. Dans la boîte de dialogue Sélectionner un chemin d'accès qui s'ouvre, sélectionnez la table
employee_financede l'ensemble de donnéescymbal_financedans votre projet. Vous pouvez voir des tables portant des noms semblables provenant d'autres projets. Assurez-vous donc de sélectionner la table de votre projet. - Cliquez sur Continuer.
- Consultez la page Vérifier le schéma et attribuer des propriétés clés.
- Cliquez sur Continuer.
- Saisissez
cymbal-financecomme nom du datastore. - Cliquez sur Continuer.
- Conservez l'option Tarification générale.
- Cliquez sur Créer.
Après avoir cliqué sur Créer, vous revenez à la page Datastores.
Créer un datastore pour les données d'inventaire des produits
- Sur la page Datastores, cliquez à nouveau sur Créer un datastore.
- Pour Sélectionner une source de données, sélectionnez BigQuery.
- Pour Importation de données structurées, sélectionnez Table BigQuery avec votre propre schéma.
- Conservez l'option Fréquence de synchronisation sur Une seule fois.
- Pour Sélectionner une table à importer, cliquez sur Parcourir. Dans la boîte de dialogue Sélectionner un chemin d'accès qui s'ouvre, sélectionnez la table
product_inventoryde l'ensemble de donnéescymbal_financedans votre projet. - Cliquez sur Continuer.
- Consultez la page Vérifier le schéma et attribuer des propriétés clés.
- Cliquez sur Continuer.
- Saisissez
cymbal-inventorycomme nom du datastore. - Cliquez sur Continuer.
- Conservez l'option Tarification générale.
- Cliquez sur Créer.
Après avoir cliqué sur Créer, vous revenez à la page Datastores.
8. Connecter des datastores à votre application
Vous devriez maintenant voir trois datastores dans la liste de la page Datastores : cymbal-hr (non structuré), cymbal-finance (structuré) et cymbal-inventory (structuré). Pour connecter ces datastores à votre application, procédez comme suit :
- Sur la page Datastores , sélectionnez les trois datastores que vous venez de créer :
cymbal-hr,cymbal-financeetcymbal-inventory. Assurez-vous de sélectionner les trois datastores avant de continuer. - Cliquez sur Continuer.
- Conservez l'option Tarification générale.
- Cliquez sur Créer.
9. Tester l'application du portail des employés Cymbal
- Dans l'application
cymbal-employee-portal, cliquez sur Aperçu. - Dans le champ Rechercher ici, saisissez la question suivante :
What are the stipends that I get as an employee of Cymbal located in London? - Saisissez une question concernant l'inventaire des produits :
How many units of sneakers do we have in stock? - Saisissez une autre question :
What is the stipend for an executive in Cymbal?
Notez comment l'application de recherche a récupéré des informations provenant de plusieurs sources pour formuler sa réponse. Pour répondre à ces questions, l'application a effectué une recherche dans les données financières structurées stockées dans BigQuery et dans les documents RH non structurés dans Cloud Storage.
Cela illustre la puissance de Vertex AI Search pour synthétiser des réponses dans différents formats de données et des datastores disparates en une expérience unique et cohérente.
Vous pouvez également ajuster le modèle d'IA pour fournir des réponses encore plus précises et spécifiques au domaine. Pour en savoir plus sur la personnalisation de l'expérience générative, consultez la documentation Obtenir des réponses et des suivis.
10. Options de déploiement de votre application
Bien que le déploiement de l'application auprès des utilisateurs finaux ne soit pas abordé dans cet atelier de programmation, il est utile de savoir comment cela se traduit dans un scénario réel. Vous disposez de plusieurs options pour intégrer votre application Vertex AI Search dans les workflows de votre organisation :
- Widget Web prédéfini. Vous pouvez intégrer une interface de recherche ou de chat prête à l'emploi directement dans l'intranet ou les pages Web existants de votre entreprise à l'aide d'une balise
scriptHTML. Il s'agit du moyen le plus rapide de présenter votre application aux utilisateurs. - Intégration d'API personnalisée. Pour un contrôle total de l'expérience utilisateur, vous pouvez utiliser les API REST Vertex AI Search ou des bibliothèques clientes (telles que Python, Node.js ou Java) pour créer une interface personnalisée de A à Z.
11. Effectuer un nettoyage
Pour éviter que votre compte Google Cloud ne soit facturé en permanence, supprimez les ressources créées lors de cet atelier de programmation :
- Dans Cloud Console, accédez à la page Vertex AI Search.
- Cliquez sur Voir les applications existantes.
- Pour l'application
cymbal-employee-portal, cliquez sur les trois points verticaux de Plus, puis sur Supprimer. - Suivez les invites à l'écran pour confirmer la suppression.
- Pour supprimer les datastores, cliquez sur Datastores dans le panneau de navigation de gauche de la console.
- Supprimez les datastores
cymbal-hr,cymbal-financeetcymbal-inventory:- Pour le datastore
cymbal-hr, cliquez sur les trois points verticaux de Plus, puis sur Supprimer. - Suivez les invites à l'écran pour confirmer la suppression.
- Pour le datastore
cymbal-finance, cliquez sur les trois points verticaux de Plus, puis sur Supprimer. - Suivez les invites à l'écran pour confirmer la suppression.
- Pour le datastore
cymbal-inventory, cliquez sur les trois points verticaux de Plus, puis sur Supprimer. - Suivez les invites à l'écran pour confirmer la suppression.
- Pour le datastore
- Accédez à la page Buckets et supprimez le bucket que vous avez créé (par exemple,
cymbal-app-hr-12). - Accédez à la page BigQuery et supprimez l'ensemble de données
cymbal_finance.
12. Félicitations
Mission accomplie ! Vous avez créé une expérience de recherche d'entreprise unifiée à l'aide de Vertex AI Search.
En comblant le fossé entre vos données d'entreprise non structurées dans Cloud Storage et les enregistrements structurés de BigQuery, vous avez créé un outil puissant capable de raisonnement commercial complexe, le tout sans écrire une seule ligne de code de machine learning.
Connaissances acquises
- Ingestion : comment ingérer des documents non structurés depuis Cloud Storage et des données structurées depuis BigQuery dans Vertex AI Search.
- Interrogation de plusieurs datastores. Comment interroger une application de recherche multi-datastores pour synthétiser des réponses unifiées à partir de données structurées et non structurées.
- Ajustement et personnalisation. Comment ajuster les modèles d'IA générative pour fournir des réponses plus précises et spécifiques au domaine.
- Options de déploiement. Les différentes façons d'intégrer cette fonctionnalité de raisonnement dans des applications réelles à l'aide de widgets prédéfinis ou d'API personnalisées.