
1. מבוא
בשיעור Codelab הזה נסביר איך ליצור אפליקציה אוניברסלית למוקד תמיכה לעובדים בלי צורך בתכנות באמצעות חיפוש מבוסס-Vertex AI.
נניח שאתם עובדים ב-Cymbal, חברה קמעונאית גלובלית. לעתים קרובות לעובדים יש שאלות כמו "מה המדיניות לגבי הזמנת נסיעות עסקיות?" או "כמה יחידות של נעלי ספורט יש לנו במלאי?".
בדרך כלל, כדי למצוא את התשובות האלה צריך להיכנס למערכות שונות לחלוטין. בנוסף להתמודדות עם מערכות שונות, כדי לקבל תשובות לשאלות, צריך גם לעיין במספר גדול של נתוני משאבי אנוש לא מובְנים או להריץ הנחיות SQL מורכבות על נתונים פיננסיים מובְנים.
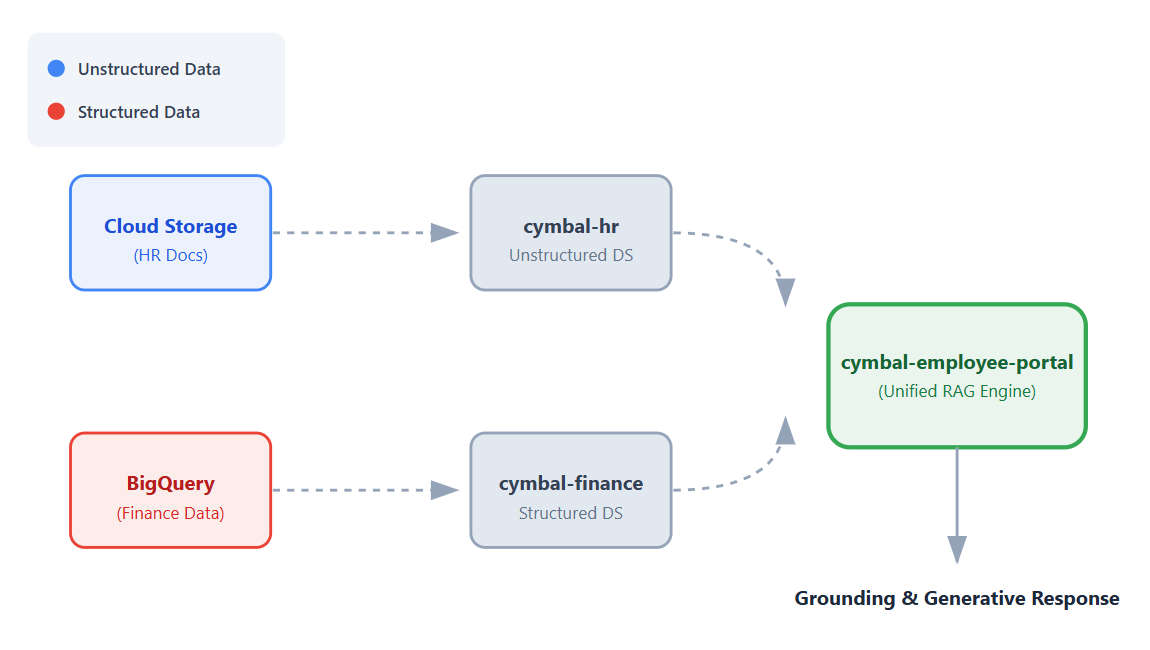
ב-Codelab הזה תלמדו איך ליצור אפליקציה אחת מאוחדת שמתחברת למערכי הנתונים האלה, כדי שהעובדים יוכלו לקבל תשובות מבוססות-נתונים לשאלות שלהם באמצעות יכולות ה-Retrieval Augmented Generation (יצירה משולבת-אחזור, RAG) של Vertex AI.
הפעולות שתבצעו:
ב-Codelab הזה תבצעו את השלבים הבאים:
- מגדירים מקורות נתונים. יוצרים קטגוריה של Cloud Storage למסמכי משאבי אנוש לא מובְנים ומערך נתונים ב-BigQuery לנתונים פיננסיים מובְנים.
- מגדירים מאגרי נתונים. יוצרים מאגרי נתונים של חיפוש מבוסס-Vertex AI שמחוברים למקורות הנתונים של Cloud Storage ו-BigQuery.
- מקשרים את האפליקציה. יוצרים אפליקציה של חיפוש מבוסס-Vertex AI ומקשרים אליה את שני מאגרי הנתונים.
- בודקים את האפליקציה. כדי לוודא שהתשובות מבוססות על מידע משני מאגרי הנתונים, מנסים להשתמש בממשק החיפוש המאוחד.
- לשלבים הבאים אפשר לעיין באפשרויות לכוונון המודל של ה-AI הגנרטיבי ולפריסת אפליקציית החיפוש.
הדרישות
- דפדפן אינטרנט כמו Chrome.
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- Git מותקן במחשב המקומי.
שיעור ה-Codelab הזה מיועד למפתחים בכל הרמות.
2. לפני שמתחילים
יוצרים פרויקט בענן ב-Google Cloud ומפעילים את ממשקי ה-API הנדרשים.
- במסוף Google Cloud, בדף לבחירת הפרויקט בוחרים פרויקט בענן או לוחצים על Create a Google Cloud project .
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט.
התפקידים שצריך ב-IAM
ב-Codelab הזה אנחנו מניחים שיש לכם את התפקיד בעלי הפרויקט בפרויקט שלכם ב-Google Cloud.
הפעלת ממשקי ה-API
- במסוף Google Cloud, לוחצים על Activate Cloud Shell: אם זו הפעם הראשונה שאתם משתמשים ב-Cloud Shell, יופיע חלונית עם אפשרות להפעיל את Cloud Shell בסביבה מהימנה עם או בלי שיפור ביצועים. אם מתבקשים לאשר את Cloud Shell, לוחצים על Authorize.
- ב-Cloud Shell, מפעילים את כל ממשקי ה-API הנדרשים:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. שיבוט מאגר GitHub
כדי להדגים איך החיפוש פועל באפליקציית מוקד התמיכה לעובדים של Cymbal, צריך כמה קבצים לדוגמה. בקטע הזה, משכפלים מאגר GitHub למחשב המקומי כדי לקבל את הקבצים האלה. תעלו את הקבצים האלה ל-Google Cloud בשלבים הבאים באמצעות ממשק Cloud Console.
- בטרמינל במחשב המקומי, משכפלים את מאגר
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - עוברים לספרייה של המאגר שהורדתם:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - בודקים את הקבצים שהורדו בספרייה הזו. תראו שיש שתי תיקיות:
HRו-Finance.- HR. התיקייה הזו מכילה מספר קבצים לא מובְנים, כמו קבצים מסוג
.doc,.txtו-.html. תעלו את קובצי משאבי האנוש לקטגוריה של Cloud Storage. - Finance. התיקייה הזו מכילה שני קובצי
.jsonl. תעלו את הקבצים האלה למערך נתונים ב-BigQuery.
- HR. התיקייה הזו מכילה מספר קבצים לא מובְנים, כמו קבצים מסוג
4. יצירת קטגוריה של Cloud Storage לקבצים לא מובנים
בקטע הזה, יוצרים קטגוריה של Cloud Storage ומעלים אליה את המסמכים בתיקייה HR שהורדתם בקטע שכפול מאגר GitHub. נתונים לא מובְנים, כמו מסמכי משאבי האנוש בדוגמה הזו, לא עומדים בפורמט מוגדר מראש ויכולים לכלול קובצי טקסט, מסמכים או תוכן מולטימדיה.
- נכנסים לדף Buckets במסוף Cloud.
- לוחצים על יצירה.
- בדף Create a bucket מזינים את שם הקטגוריה. השם חייב להיות ייחודי באופן גלובלי. לדוגמה:
cymbal-app-hr-12. - משאירים את אפשרויות ברירת המחדל.
- לוחצים על Create.הקטגוריה נוצרת ומוצג הדף Bucket details. אם הדף Bucket details לא מופיע, לוחצים על קטגוריית ה-bucket שיצרתם.
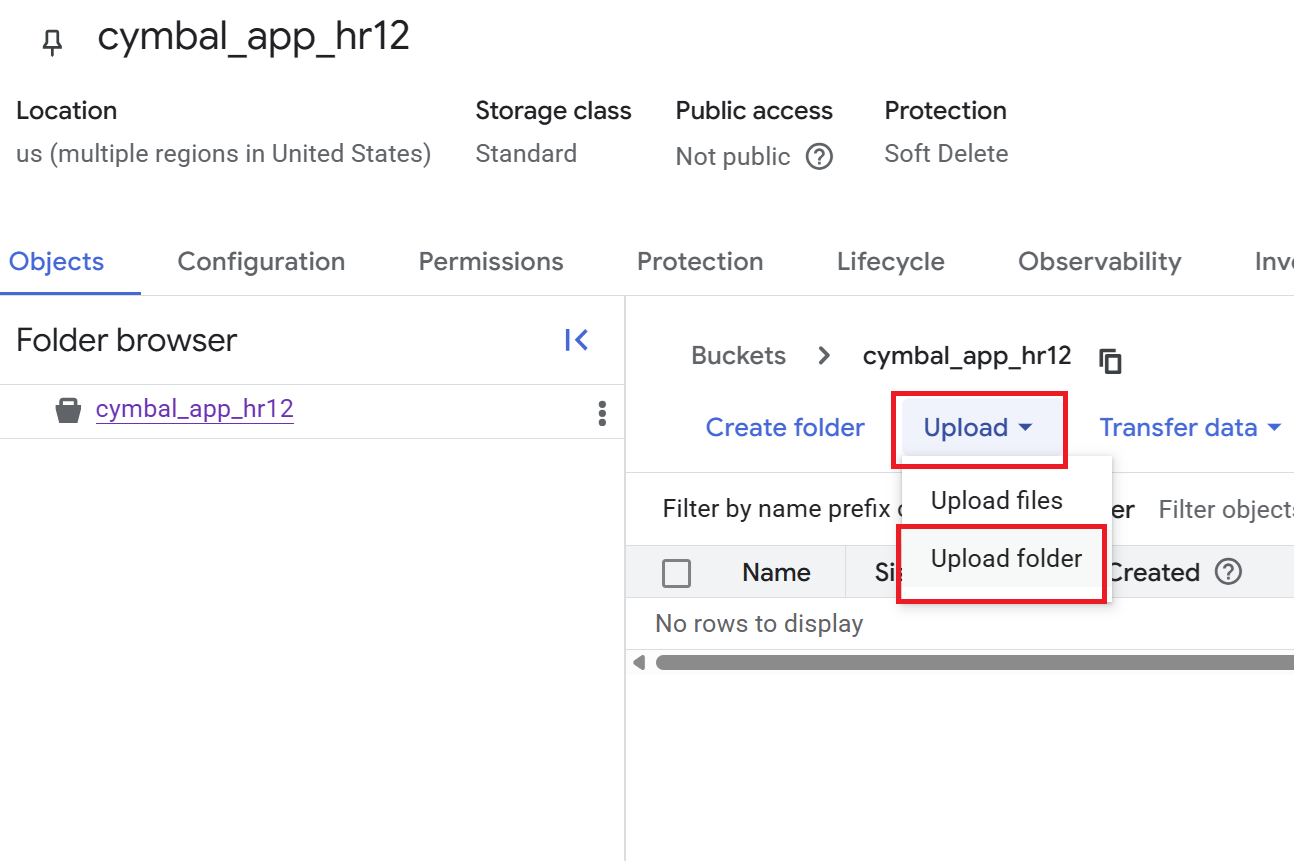
- בדף Bucket details, לוחצים על Upload > Upload folder, ואז בוחרים את התיקייה
HRשהורדתם בקטע Clone a GitHub repository. - מאשרים את ההעלאה.
- בדף Bucket details, לוחצים על התיקייה
HRכדי להציג את רשימת הקבצים.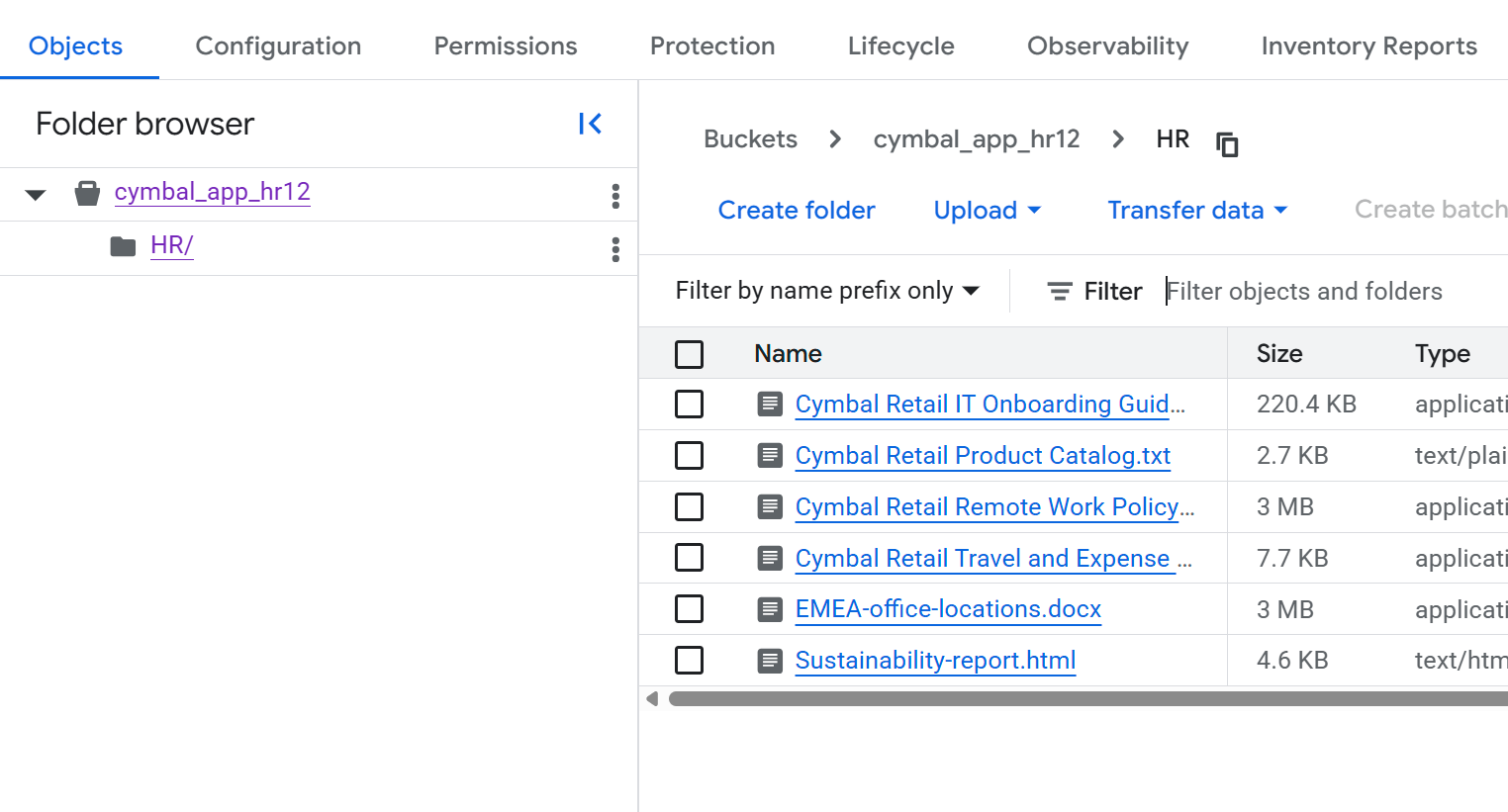
5. יצירת מערך נתונים ב-BigQuery לקבצים מובנים
בקטע הזה, תיצרו מערך נתונים ב-BigQuery ותטענו את המסמכים בתיקייה Finance שהורדתם בקטע שיבוט מאגר GitHub לטבלה חדשה. נתונים מובְנים, כמו המסמכים הפיננסיים בדוגמה הזו, עומדים בפורמט מוגדר מראש, כמו רשומות במסד נתונים.
- במסוף Cloud, עוברים לדף BigQuery.
- בחלונית Explorer, לוחצים על שם הפרויקט ואז על View actions (הסמל של שלוש הנקודות האנכיות) > Create dataset.
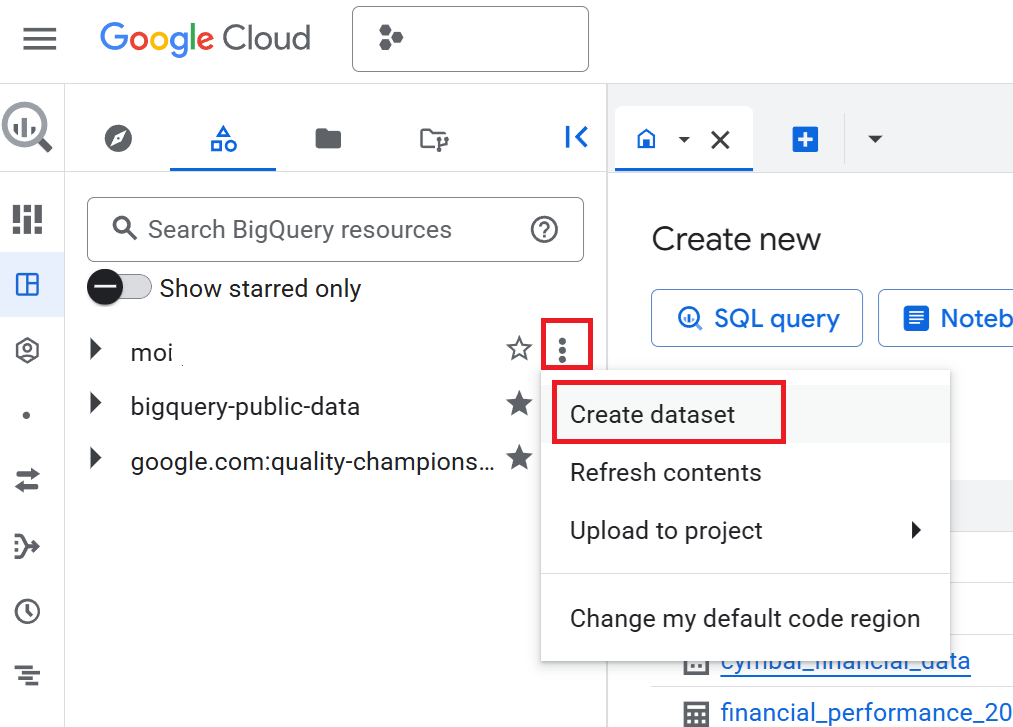
- בחלונית Create dataset (יצירת מערך נתונים), מזינים את מזהה מערך הנתונים בתור
cymbal_finance. - בקטע Data location (מיקום הנתונים), בוחרים באפשרות
US (multiple regions in United States). - משאירים את אפשרויות ברירת המחדל ולוחצים על יצירת מערך נתונים.
- בחלונית Explorer, מרחיבים את הפרויקט ולוחצים על מערך הנתונים
cymbal_finance. - בחלונית הפרטים של מערך הנתונים, לוחצים על יצירת טבלה.
- בדף Create table, בקטע Source, מבצעים את הפעולות הבאות:
- בקטע יצירת טבלה מ, בוחרים באפשרות העלאה.
- בקטע בחירת קובץ, לוחצים על עיון, עוברים לתיקייה
Financeשהורדתם ובוחרים באפשרותcymbal_employee_finance.jsonl. - בקטע File format (פורמט קובץ), בוחרים באפשרות JSONL (Newline delimited JSON) (פורמט JSON שמופרד בתו שורה חדשה).
- בקטע Destination (יעד), מזינים את שם הטבלה בתור
employee_finance. - בקטע סכימה, מסמנים את תיבת הסימון זיהוי אוטומטי.
- משאירים את שאר הגדרות ברירת המחדל ולוחצים על יצירת טבלה.
- חוזרים על שלבים 7 עד 11 כדי לטעון נתונים לטבלה חדשה. בשלב 8ב, בוחרים באפשרות
product_inventory.jsonl, ובשלב 9 מזיניםproduct_inventoryבתור שם הטבלה.אם הטבלאות לא מופיעות בחלונית הפרטים של מערך הנתונים, לוחצים על רענון. - אם יצרתם את מערך הנתונים ואת שני הטבלאות בהצלחה, הם אמורים להיראות כמו בתמונה הבאה:
6. יצירת אפליקציית חיפוש מבוססת-Vertex AI
- במסוף Cloud, עוברים לדף חיפוש מבוסס-Vertex AI.
- בכרטיס חיפוש מותאם אישית (כללי), לוחצים על יצירה.
- בדף הגדרת אפליקציית החיפוש, מוודאים שהאפשרויות תכונות של מהדורת Enterprise ותשובות גנרטיביות מסומנות.
- נותנים לאפליקציה שם
cymbal-employee-portal. - מזינים את שם החברה בתור
Cymbal Corp. - שומרים את המיקום של האפליקציה כ-
global. - לוחצים על המשך.
7. יצירה וקישור של מאגרי נתונים
בדף מאגרי נתונים יוצרים מאגרי נתונים שמתחברים לאפליקציה. צריך ליצור שלושה מאגרי נתונים: אחד לנתוני משאבי אנוש לא מובְנים ושניים לנתונים פיננסיים מובְנים.
יצירת מאגר נתונים לנתונים לא מובנים
- בדף מאגרי נתונים, לוחצים על יצירת מאגר נתונים.
- בקטע בחירת מקור נתונים, בוחרים באפשרות אחסון בענן.
- בחלונית ייבוא נתונים מ-Cloud Storage, עוברים אל ייבוא נתונים לא מובְנים (חיפוש מסמכים ו-RAG) ובוחרים באפשרות מסמכים.
- משאירים את האפשרות תדירות הסנכרון כפעם אחת.
- בקטע בחירת תיקייה או קובץ לייבוא, לוחצים על תיקייה.
- בשדה
gs://..., מזינים את שם הקטגוריה שיצרתם בקטע יצירת קטגוריה של Cloud Storage לקבצים לא מובנים. לדוגמה, אם שם הקטגוריה הואcymbal-app-hr-12, מזינים את השם בתורcymbal-app-hr-12/HR.הטמעה מהתיקייהHRמבטיחה שרק מסמכי משאבי האנוש ייכללו במאגר הנתונים הזה. - לוחצים על המשך.
- מזינים את השם של מאגר הנתונים בתור
cymbal-hr. - לוחצים על המשך.
- משאירים את האפשרות תמחור כללי.
- לוחצים על יצירה.
אחרי שלוחצים על יצירה, חוזרים לדף מאגרי נתונים.
יצירת מאגרי נתונים לנתונים מובְנים
תיצרו שני מאגרי נתונים לנתונים מובנים מ-BigQuery: אחד למידע פיננסי על עובדים ואחד למלאי מוצרים.
יצירת מאגר נתונים של נתונים פיננסיים של עובדים
- בדף מאגרי נתונים, לוחצים שוב על יצירת מאגר נתונים.
- בקטע בחירת מקור נתונים, בוחרים באפשרות BigQuery.
- בקטע ייבוא נתונים מובנים, בוחרים באפשרות טבלה ב-BigQuery עם סכימה משלכם.
- משאירים את האפשרות תדירות הסנכרון כפעם אחת.
- בקטע בחירת טבלה לייבוא, לוחצים על עיון. בתיבת הדו-שיח Select path (בחירת נתיב) שנפתחת, בוחרים את הטבלה
employee_financeממערך הנתוניםcymbal_financeבפרויקט. יכול להיות שיוצגו טבלאות עם שמות דומים מפרויקטים אחרים, לכן חשוב לוודא שבוחרים את הטבלה מהפרויקט שלכם. - לוחצים על המשך.
- כדאי לעיין בדף בדיקת סכימה והקצאת מאפיינים מרכזיים.
- לוחצים על המשך.
- מזינים את השם של מאגר הנתונים בתור
cymbal-finance. - לוחצים על המשך.
- משאירים את האפשרות תמחור כללי.
- לוחצים על יצירה.
אחרי שלוחצים על יצירה, חוזרים לדף מאגרי נתונים.
יצירת מאגר נתונים של נתוני מלאי מוצרים
- בדף מאגרי נתונים, לוחצים שוב על יצירת מאגר נתונים.
- בקטע בחירת מקור נתונים, בוחרים באפשרות BigQuery.
- בקטע ייבוא נתונים מובנים, בוחרים באפשרות טבלה ב-BigQuery עם סכימה משלכם.
- משאירים את האפשרות תדירות הסנכרון כפעם אחת.
- בקטע בחירת טבלה לייבוא, לוחצים על עיון. בתיבת הדו-שיח Select path (בחירת נתיב) שנפתחת, בוחרים את הטבלה
product_inventoryממערך הנתוניםcymbal_financeבפרויקט. - לוחצים על המשך.
- כדאי לעיין בדף בדיקת סכימה והקצאת מאפיינים מרכזיים.
- לוחצים על המשך.
- מזינים את השם של מאגר הנתונים בתור
cymbal-inventory. - לוחצים על המשך.
- משאירים את האפשרות תמחור כללי.
- לוחצים על יצירה.
אחרי שלוחצים על יצירה, חוזרים לדף מאגרי נתונים.
8. קישור מאגרי נתונים לאפליקציה
עכשיו אמורים להופיע שלושה מאגרי נתונים ברשימה בדף מאגרי נתונים: cymbal-hr (לא מובנה), cymbal-finance (מובנה) ו-cymbal-inventory (מובנה). כדי לקשר את מאגרי הנתונים האלה לאפליקציה, פועלים לפי השלבים הבאים:
- בדף Data stores (מאגרי נתונים), בוחרים את שלושת מאגרי הנתונים שיצרתם:
cymbal-hr,cymbal-financeו-cymbal-inventory. חשוב לבחור את כל שלושת מאגרי הנתונים לפני שממשיכים. - לוחצים על המשך.
- משאירים את האפשרות תמחור כללי.
- לוחצים על יצירה.
9. בדיקת אפליקציית הפורטל לעובדים של Cymbal
- באפליקציית
cymbal-employee-portal, לוחצים על תצוגה מקדימה. - בתיבה חיפוש כאן, מזינים את השאלה הבאה:
What are the stipends that I get as an employee of Cymbal located in London? - מזינים שאלה שקשורה למלאי המוצרים:
How many units of sneakers do we have in stock? - צריך להזין עוד שאלה:
What is the stipend for an executive in Cymbal?
שימו לב איך אפליקציית החיפוש אחזרה מידע מכמה מקורות כדי לגבש את התשובה. כדי לענות על השאלות האלה, האפליקציה חיפשה גם בנתונים הפיננסיים המובְנים שמאוחסנים ב-BigQuery וגם במסמכי משאבי האנוש הלא מובְנים ב-Cloud Storage.
הדוגמה הזו ממחישה את היכולת של חיפוש מבוסס-Vertex AI לסנתז תשובות מנתונים בפורמטים שונים וממאגרי נתונים שונים, וליצור חוויה אחת מגובשת.
אפשר גם לכוון את מודל ה-AI כדי לקבל תשובות מדויקות יותר שמתאימות לתחום מסוים. מידע נוסף על התאמה אישית של חוויית השימוש ב-AI גנרטיבי זמין במאמר בנושא קבלת תשובות ושאלות המשך.
10. אפשרויות לפריסת האפליקציה
הפריסה של האפליקציה למשתמשי קצה היא לא חלק מה-Codelab הזה, אבל כדאי לדעת איך זה מתבצע בתרחיש מהעולם האמיתי. יש כמה אפשרויות לשילוב אפליקציית חיפוש מבוסס-Vertex AI בתהליכי העבודה של הארגון:
- ווידג'ט מוכן מראש לאתרים. אתם יכולים להטמיע ממשק חיפוש או צ'אט מוכן לשימוש ישירות באינטראנט הקיים של החברה או בדפי האינטרנט שלה באמצעות תג HTML
script. זו הדרך המהירה ביותר לחשוף את האפליקציה למשתמשים. - שילוב API בהתאמה אישית כדי לקבל שליטה מלאה בחוויית המשתמש, אתם יכולים להשתמש ב-API בארכיטקטורת REST או בספריות לקוח (כמו Python, Node.js או Java) של חיפוש מבוסס-Vertex AI כדי לבנות ממשק קצה מותאם אישית מאפס.
11. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud, מוחקים את המשאבים שנוצרו במהלך ה-codelab הזה:
- במסוף Cloud, עוברים לדף חיפוש מבוסס-Vertex AI.
- לוחצים על הצגת אפליקציות קיימות.
- באפליקציית
cymbal-employee-portal, לוחצים על סמל האפשרויות הנוספות (שלוש נקודות אנכיות) ואז על מחיקה. - פועלים לפי ההנחיות שעל המסך כדי לאשר את המחיקה.
- כדי למחוק את מאגרי הנתונים, לוחצים על Data stores (מאגרי נתונים) בחלונית הניווט הימנית של המסוף.
- מחיקת מאגרי הנתונים
cymbal-hr,cymbal-financeו-cymbal-inventory:- במאגר הנתונים
cymbal-hr, לוחצים על סמל האפשרויות הנוספות (שלוש נקודות אנכיות) ואז על מחיקה. - פועלים לפי ההנחיות שעל המסך כדי לאשר את המחיקה.
- במאגר הנתונים
cymbal-finance, לוחצים על סמל האפשרויות הנוספות (שלוש נקודות אנכיות) ואז על מחיקה. - פועלים לפי ההנחיות שעל המסך כדי לאשר את המחיקה.
- במאגר הנתונים
cymbal-inventory, לוחצים על סמל האפשרויות הנוספות (שלוש נקודות אנכיות) ואז על מחיקה. - פועלים לפי ההנחיות שעל המסך כדי לאשר את המחיקה.
- במאגר הנתונים
- עוברים לדף Buckets ומוחקים את הקטגוריה שיצרתם (לדוגמה,
cymbal-app-hr-12). - עוברים לדף BigQuery ומוחקים את מערך הנתונים
cymbal_finance.
12. מזל טוב
המשימה הושלמה! יצרתם בהצלחה חוויית חיפוש ארגונית מאוחדת באמצעות חיפוש מבוסס-Vertex AI.
הגשרתם את הפער בין נתונים לא מובנים של הארגון ב-Cloud Storage לבין רשומות מובנות מ-BigQuery, ויצרתם כלי רב עוצמה שיכול לבצע ניתוח עסקי מורכב – בלי לכתוב שורת קוד אחת של למידת מכונה.
מה למדתם
- הטמעה: איך להטמיע מסמכים לא מובְנים מ-Cloud Storage ונתונים מובְנים מ-BigQuery בחיפוש מבוסס-Vertex AI.
- שאילתות בכמה מאגרי נתונים. איך לשלוח שאילתה לאפליקציית חיפוש עם כמה מאגרי נתונים כדי ליצור תשובות מאוחדות מנתונים מובנים ולא מובנים.
- התאמה ושינוי. איך מכווננים את המודלים של ה-AI הגנרטיבי כדי לקבל תשובות מדויקות יותר שמתאימות לתחום מסוים.
- אפשרויות פריסה. הדרכים השונות לשלב את יכולת ההסקה הזו באפליקציות בעולם האמיתי באמצעות ווידג'טים מוכנים מראש או ממשקי API מותאמים אישית.