
1. परिचय
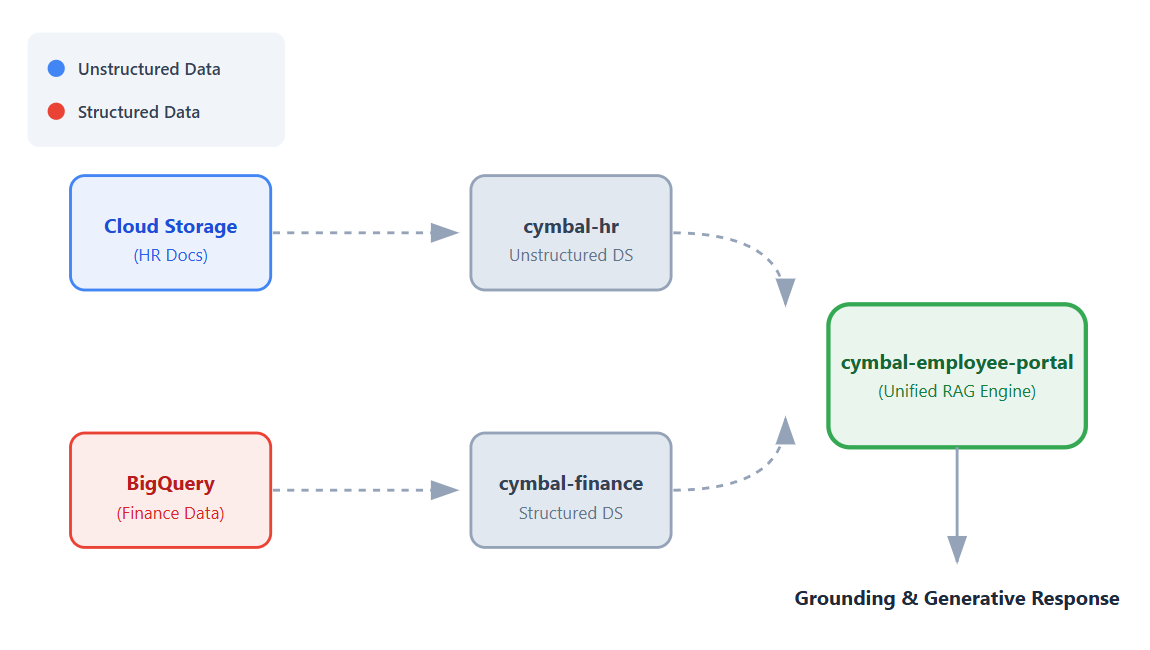
इस कोडलैब में, Vertex AI Search का इस्तेमाल करके, बिना कोड लिखे कर्मचारियों के लिए एक यूनिवर्सल हेल्पडेस्क ऐप्लिकेशन बनाया जाएगा.
मान लें कि आप Cymbal में काम करते/करती हैं. यह खुदरा कारोबार करने वाली एक ग्लोबल कंपनी है. कर्मचारियों के अक्सर ये सवाल होते हैं, जैसे "कारोबारी यात्रा बुक करने की नीति क्या है?" या "हमारे पास स्नीकर की कितनी यूनिट स्टॉक में हैं?".
आम तौर पर, इन सवालों के जवाब पाने के लिए, आपको पूरी तरह से अलग-अलग सिस्टम में साइन इन करना पड़ता है. अलग-अलग सिस्टम को मैनेज करने के अलावा, आपको एचआर के अनस्ट्रक्चर्ड डेटा को भी पढ़ना पड़ता है. साथ ही, अपने सवालों के जवाब पाने के लिए, फ़ाइनेंशियल डेटा पर जटिल एसक्यूएल प्रॉम्प्ट चलाने पड़ते हैं.
इस कोडलैब में, एक ऐसा यूनिफ़ाइड ऐप्लिकेशन बनाया जाएगा जो इन डेटासेट से कनेक्ट होता है. इससे कर्मचारियों को Vertex AI की Retrieval Augmented Generation (RAG) की सुविधाओं का इस्तेमाल करके, बातचीत के फ़ॉर्मैट में सटीक जवाब मिल पाएंगे.
आपको क्या करना होगा
इस कोडलैब में, आपको यह तरीका अपनाना होगा:
- डेटा सोर्स सेट अप करना. एचआर के अनस्ट्रक्चर्ड दस्तावेज़ों के लिए Cloud Storage बकेट और फ़ाइनेंशियल डेटा के लिए BigQuery डेटासेट बनाना.
- डेटा स्टोर कॉन्फ़िगर करना. Vertex AI Search के डेटा स्टोर बनाना. ये डेटा स्टोर, Cloud Storage और BigQuery के डेटा सोर्स से कनेक्ट होते हैं.
- ऐप्लिकेशन को कनेक्ट करना. Vertex AI Search का ऐप्लिकेशन बनाना और दोनों डेटा स्टोर को उससे लिंक करना.
- ऐप्लिकेशन की जांच करना. यूनिफ़ाइड सर्च इंटरफ़ेस के साथ इंटरैक्ट करके, सटीक जवाबों की पुष्टि करना. ये जवाब, दोनों डेटा स्टोर से जानकारी को मिलाकर तैयार किए जाते हैं.
- अगले चरण देखना. जनरेटिव एआई मॉडल को ट्यून करने और अपने सर्च ऐप्लिकेशन को डिप्लॉय करने के विकल्प देखना.
आपको किन चीज़ों की ज़रूरत होगी
- Chrome जैसे वेब ब्राउज़र.
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
- आपके कंप्यूटर पर Git इंस्टॉल होना चाहिए.
यह कोडलैब, सभी लेवल के डेवलपर के लिए है.
2. शुरू करने से पहले
एक Google Cloud प्रोजेक्ट बनाएं और ज़रूरी एपीआई चालू करें.
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, कोई Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट पर बिलिंग की सुविधा चालू है या नहीं, यह देखने का तरीका जानें.
ज़रूरी IAM भूमिकाएं
इस कोडलैब में यह माना जाता है कि आपके पास Google Cloud प्रोजेक्ट के लिए प्रोजेक्ट के मालिक की भूमिका है.
एपीआई चालू करें
- Google Cloud Console में, Cloud Shell चालू करें पर क्लिक करें: अगर आपने पहले कभी Cloud Shell का इस्तेमाल नहीं किया है, तो एक पैनल दिखता है. इसमें आपको भरोसेमंद एनवायरमेंट में, Cloud Shell को बूस्ट के साथ या बिना बूस्ट के शुरू करने का विकल्प मिलता है. अगर आपसे Cloud Shell को अनुमति देने के लिए कहा जाता है, तो अनुमति दें पर क्लिक करें.
- Cloud Shell में, सभी ज़रूरी एपीआई चालू करें:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. GitHub रिपॉज़िटरी को क्लोन करना
Cymbal के कर्मचारियों के लिए बने हेल्पडेस्क ऐप्लिकेशन में, खोज की सुविधा कैसे काम करती है, यह दिखाने के लिए आपको कुछ मॉक फ़ाइलों की ज़रूरत होगी. इस सेक्शन में, इन फ़ाइलों को पाने के लिए, GitHub रिपॉज़िटरी को अपने कंप्यूटर पर क्लोन करें. इन फ़ाइलों को बाद के चरणों में, Cloud Console इंटरफ़ेस का इस्तेमाल करके Google Cloud पर अपलोड किया जाएगा.
- अपने कंप्यूटर पर मौजूद किसी टर्मिनल में,
next-26-sessionsरिपॉज़िटरी को क्लोन करें:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - डाउनलोड की गई रिपॉज़िटरी की डायरेक्ट्री पर जाएं:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - इस डायरेक्ट्री में डाउनलोड की गई फ़ाइलें देखें. आपको दिखेगा कि यहां दो फ़ोल्डर हैं:
HRऔरFinance.- HR. इस फ़ोल्डर में, अनस्ट्रक्चर्ड फ़ाइलें हैं. जैसे,
.doc,.txt, और.htmlफ़ाइलें. एचआर की फ़ाइलों को Cloud Storage बकेट में अपलोड किया जाएगा. - फ़ाइनेंस. इस फ़ोल्डर में, दो
.jsonlफ़ाइलें हैं. इन फ़ाइलों को BigQuery डेटासेट में अपलोड किया जाएगा.
- HR. इस फ़ोल्डर में, अनस्ट्रक्चर्ड फ़ाइलें हैं. जैसे,
4. अनस्ट्रक्चर्ड फ़ाइलों के लिए Cloud Storage बकेट बनाना
इस सेक्शन में, Cloud Storage बकेट बनाएं और GitHub रिपॉज़िटरी को क्लोन करना सेक्शन में डाउनलोड किए गए HR फ़ोल्डर में मौजूद दस्तावेज़ अपलोड करें. अनस्ट्रक्चर्ड डेटा, जैसे कि इस उदाहरण में एचआर के दस्तावेज़, पहले से तय किए गए फ़ॉर्मैट में नहीं होते. इनमें टेक्स्ट फ़ाइलें, दस्तावेज़ या मल्टीमीडिया कॉन्टेंट शामिल हो सकता है.
- Cloud Console में, बकेट पेज पर जाएं.
- बनाएं पर क्लिक करें.
- बकेट बनाएं पेज पर, किसी बकेट का नाम डालें. नाम, दुनिया भर में यूनीक होना चाहिए. उदाहरण के लिए:
cymbal-app-hr-12. - डिफ़ॉल्ट विकल्प चुने रहने दें.
- बनाएं पर क्लिक करें.बकेट बन जाती है और बकेट की जानकारी पेज दिखता है. अगर आपको बकेट की जानकारी पेज नहीं दिखता है, तो अभी बनाई गई बकेट पर क्लिक करें.
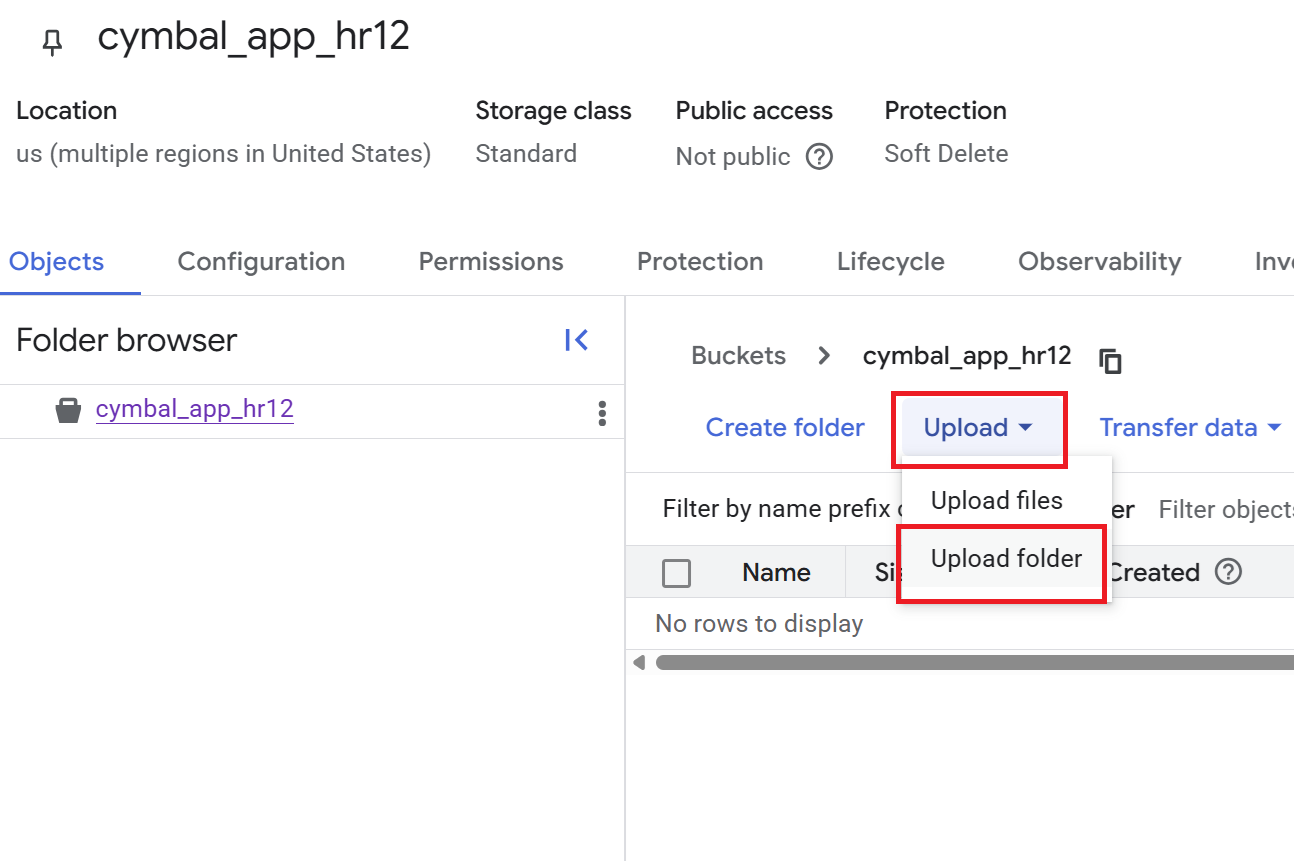
- बकेट की जानकारी पेज पर, अपलोड करें > फ़ोल्डर अपलोड करें पर क्लिक करें. इसके बाद,
HRफ़ोल्डर चुनें जिसे आपने GitHub रिपॉज़िटरी को क्लोन करना सेक्शन में डाउनलोड किया था. - अपलोड की पुष्टि करें.
- फ़ाइलों की सूची देखने के लिए, बकेट की जानकारी पेज पर,
HRफ़ोल्डर पर क्लिक करें.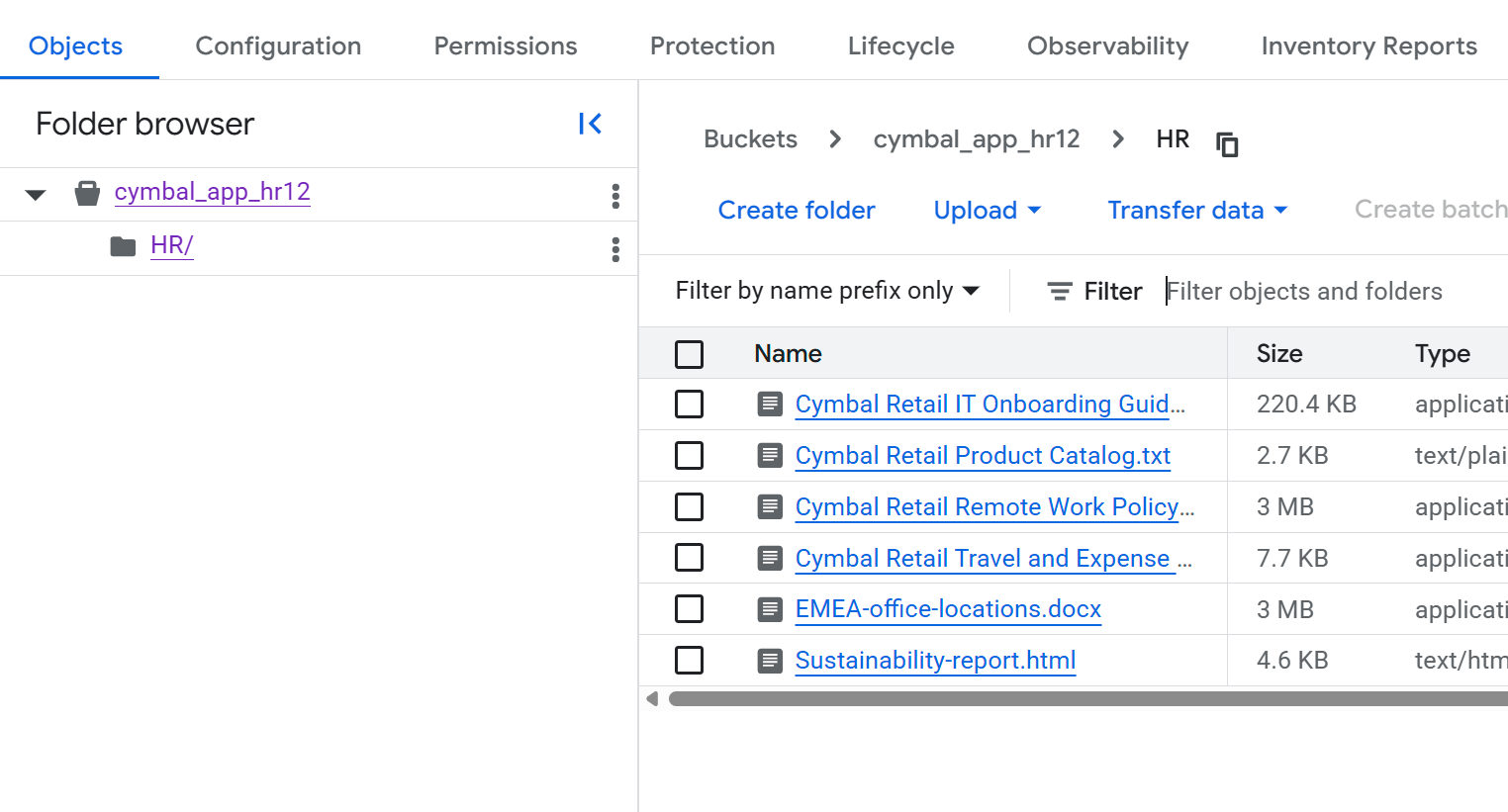
5. स्ट्रक्चर्ड फ़ाइलों के लिए BigQuery डेटासेट बनाना
इस सेक्शन में, BigQuery डेटासेट बनाएं और GitHub रिपॉज़िटरी को क्लोन करना सेक्शन में डाउनलोड किए गए Finance फ़ोल्डर में मौजूद दस्तावेज़ों को नई टेबल में लोड करें. स्ट्रक्चर्ड डेटा, जैसे कि इस उदाहरण में फ़ाइनेंशियल दस्तावेज़, पहले से तय किए गए फ़ॉर्मैट में होते हैं. जैसे, डेटाबेस में रिकॉर्ड.
- Cloud Console में, BigQuery पेज पर जाएं.
- एक्सप्लोरर पैनल में, अपने प्रोजेक्ट के नाम पर क्लिक करें. इसके बाद, कार्रवाइयां देखें (तीन वर्टिकल बिंदु) > डेटासेट बनाएं पर क्लिक करें.
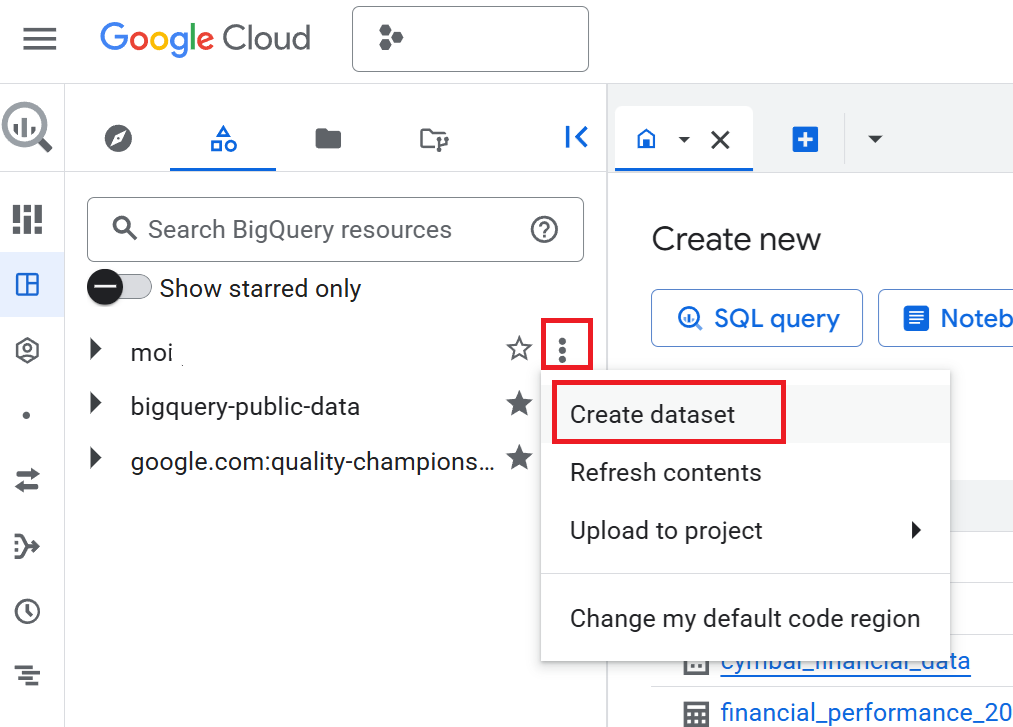
- डेटासेट बनाएं पैनल में, डेटासेट आईडी के तौर पर
cymbal_financeडालें. - डेटा की लोकेशन के लिए,
US (multiple regions in United States)चुनें. - डिफ़ॉल्ट विकल्प चुने रहने दें और डेटासेट बनाएं पर क्लिक करें.
- एक्सप्लोरर पैनल में, अपना प्रोजेक्ट बड़ा करें और
cymbal_financeडेटासेट पर क्लिक करें. - डेटासेट की जानकारी वाले पैनल में, टेबल बनाएं पर क्लिक करें.
- टेबल बनाएं पेज पर, सोर्स सेक्शन में यह तरीका अपनाएं:
- **इससे टेबल बनाएं** के लिए, **अपलोड करें** चुनें.
- **फ़ाइल चुनें** के लिए, **ब्राउज़ करें** पर क्लिक करें. इसके बाद, डाउनलोड किए गए
Financeफ़ोल्डर पर जाएं औरcymbal_employee_finance.jsonlचुनें. - फ़ाइल फ़ॉर्मैट के लिए, JSONL (Newline delimited JSON) चुनें.
- डेस्टिनेशन सेक्शन में, टेबल के नाम के तौर पर
employee_financeडालें. - स्कीमा सेक्शन में, अपने-आप पता लगाएं चेकबॉक्स चुनें.
- अन्य डिफ़ॉल्ट सेटिंग चुने रहने दें और टेबल बनाएं पर क्लिक करें.
- नया डेटा लोड करने के लिए, सात से 11 तक के चरण दोहराएं. आठवें चरण में,
product_inventory.jsonlचुनें. इसके बाद, नौवें चरण में,product_inventoryको टेबल के नाम के तौर पर डालें.अगर आपको डेटासेट की जानकारी वाले पैनल में टेबल नहीं दिखती हैं, तो रीफ़्रेश करें पर क्लिक करें. - अगर आपने डेटासेट और दोनों टेबल बना ली हैं, तो यह इमेज की तरह दिखना चाहिए:
6. Vertex AI Search का ऐप्लिकेशन बनाना
- Cloud Console में, Vertex AI Search पेज पर जाएं.
- पसंद के मुताबिक सर्च (सामान्य) टाइल में, बनाएं पर क्लिक करें.
- सर्च ऐप्लिकेशन का कॉन्फ़िगरेशन पेज पर, पक्का करें कि Enterprise Edition की सुविधाएं और जनरेटिव जवाब विकल्प चुने गए हों.
- अपने ऐप्लिकेशन का नाम
cymbal-employee-portalरखें. - कंपनी का नाम के तौर पर
Cymbal Corpडालें. - आपके ऐप्लिकेशन की लोकेशन के तौर पर
globalको चुने रहने दें. - जारी रखें पर क्लिक करें.
7. डेटा स्टोर बनाना और उन्हें कनेक्ट करना
डेटा स्टोर पेज पर, ऐसे डेटा स्टोर बनाएं जिन्हें अपने ऐप्लिकेशन से कनेक्ट किया जाएगा. आपको तीन डेटा स्टोर बनाने होंगे: एचआर के अनस्ट्रक्चर्ड डेटा के लिए एक और फ़ाइनेंशियल डेटा के लिए दो.
अनस्ट्रक्चर्ड डेटा के लिए डेटा स्टोर बनाना
- डेटा स्टोर पेज पर, डेटा स्टोर बनाएं पर क्लिक करें.
- कोई डेटा सोर्स चुनें के लिए, Cloud Storage चुनें.
- Cloud Storage से डेटा इंपोर्ट करें पैनल में, अनस्ट्रक्चर्ड डेटा इंपोर्ट करें (दस्तावेज़ खोजें और RAG) पर जाएं और दस्तावेज़ चुनें.
- सिंक्रनाइज़ेशन की फ़्रीक्वेंसी विकल्प को एक बार पर सेट रहने दें.
- इंपोर्ट करने के लिए कोई फ़ोल्डर या फ़ाइल चुनें के लिए, फ़ोल्डर पर क्लिक करें.
gs://...फ़ील्ड में, अनस्ट्रक्चर्ड फ़ाइलों के लिए Cloud Storage बकेट बनाना सेक्शन में बनाई गई बकेट का नाम डालें. उदाहरण के लिए, अगर बकेट का नामcymbal-app-hr-12है, तो नाम के तौर परcymbal-app-hr-12/HRडालें.HRफ़ोल्डर से डेटा इनजेस्ट करने पर, यह पक्का होता है कि इस डेटा स्टोर में सिर्फ़ एचआर के दस्तावेज़ शामिल हों.- जारी रखें पर क्लिक करें.
- डेटा स्टोर का नाम
cymbal-hrडालें. - जारी रखें पर क्लिक करें.
- सामान्य कीमत का विकल्प चुने रहने दें.
- बनाएं पर क्लिक करें.
बनाएं पर क्लिक करने के बाद, आपको डेटा स्टोर पेज पर वापस ले जाया जाता है.
स्ट्रक्चर्ड डेटा के लिए डेटा स्टोर बनाना
BigQuery से स्ट्रक्चर्ड डेटा के लिए दो डेटा स्टोर बनाए जाएंगे: कर्मचारियों के फ़ाइनेंशियल डेटा के लिए एक और प्रॉडक्ट इन्वेंट्री के लिए दूसरा.
कर्मचारियों के फ़ाइनेंशियल डेटा के लिए डेटा स्टोर बनाना
- डेटा स्टोर पेज पर, डेटा स्टोर बनाएं पर फिर से क्लिक करें.
- **कोई डेटा सोर्स चुनें** के लिए, **BigQuery** चुनें.
- स्ट्रक्चर्ड डेटा इंपोर्ट करें के लिए, अपने स्कीमा वाली BigQuery टेबल चुनें.
- सिंक्रनाइज़ेशन की फ़्रीक्वेंसी विकल्प को एक बार पर सेट रहने दें.
- इंपोर्ट करने के लिए कोई टेबल चुनें के लिए, ब्राउज़ करें पर क्लिक करें. आपको पाथ चुनें डायलॉग दिखेगा. इसमें, अपने प्रोजेक्ट में मौजूद
cymbal_financeडेटासेट सेemployee_financeटेबल चुनें. आपको दूसरे प्रोजेक्ट की टेबल भी दिख सकती हैं जिनके नाम मिलते-जुलते हों. इसलिए, पक्का करें कि आपने अपने प्रोजेक्ट की टेबल चुनी हो. - जारी रखें पर क्लिक करें.
- स्कीमा की समीक्षा करें और मुख्य प्रॉपर्टी असाइन करें पेज देखें.
- जारी रखें पर क्लिक करें.
- डेटा स्टोर का नाम
cymbal-financeडालें. - जारी रखें पर क्लिक करें.
- सामान्य कीमत का विकल्प चुने रहने दें.
- बनाएं पर क्लिक करें.
बनाएं पर क्लिक करने के बाद, आपको डेटा स्टोर पेज पर वापस ले जाया जाता है.
प्रॉडक्ट इन्वेंट्री डेटा के लिए डेटा स्टोर बनाना
- डेटा स्टोर पेज पर, डेटा स्टोर बनाएं पर फिर से क्लिक करें.
- **कोई डेटा सोर्स चुनें** के लिए, **BigQuery** चुनें.
- स्ट्रक्चर्ड डेटा इंपोर्ट करें के लिए, अपने स्कीमा वाली BigQuery टेबल चुनें.
- सिंक्रनाइज़ेशन की फ़्रीक्वेंसी विकल्प को एक बार पर सेट रहने दें.
- इंपोर्ट करने के लिए कोई टेबल चुनें के लिए, ब्राउज़ करें पर क्लिक करें. आपको पाथ चुनें डायलॉग दिखेगा. इसमें, अपने प्रोजेक्ट में मौजूद
cymbal_financeडेटासेट सेproduct_inventoryटेबल चुनें. - जारी रखें पर क्लिक करें.
- स्कीमा की समीक्षा करें और मुख्य प्रॉपर्टी असाइन करें पेज देखें.
- जारी रखें पर क्लिक करें.
- डेटा स्टोर का नाम
cymbal-inventoryडालें. - जारी रखें पर क्लिक करें.
- सामान्य कीमत का विकल्प चुने रहने दें.
- बनाएं पर क्लिक करें.
बनाएं पर क्लिक करने के बाद, आपको डेटा स्टोर पेज पर वापस ले जाया जाता है.
8. अपने ऐप्लिकेशन से डेटा स्टोर कनेक्ट करना
अब आपको डेटा स्टोर पेज पर, सूची में तीन डेटा स्टोर दिखने चाहिए: cymbal-hr (अनस्ट्रक्चर्ड), cymbal-finance (स्ट्रक्चर्ड), और cymbal-inventory (स्ट्रक्चर्ड). इन डेटा स्टोर को अपने ऐप्लिकेशन से कनेक्ट करने के लिए, यह तरीका अपनाएं:
- डेटा स्टोर पेज पर, अभी बनाए गए तीनों डेटा स्टोर चुनें:
cymbal-hr,cymbal-finance, औरcymbal-inventory. आगे बढ़ने से पहले, पक्का करें कि आपने तीनों डेटा स्टोर चुने हों. - जारी रखें पर क्लिक करें.
- सामान्य कीमत का विकल्प चुने रहने दें.
- बनाएं पर क्लिक करें.
9. Cymbal के कर्मचारियों के लिए बने पोर्टल ऐप्लिकेशन की जांच करना
cymbal-employee-portalऐप्लिकेशन में, झलक देखें पर क्लिक करें.- यहां खोजें बॉक्स में, यह सवाल डालें:
What are the stipends that I get as an employee of Cymbal located in London? - प्रॉडक्ट इन्वेंट्री से जुड़ा कोई सवाल डालें:
How many units of sneakers do we have in stock? - कोई दूसरा सवाल डालें:
What is the stipend for an executive in Cymbal?
ध्यान दें कि सर्च ऐप्लिकेशन ने जवाब तैयार करने के लिए, कई सोर्स से जानकारी कैसे ली. इन सवालों के जवाब देने के लिए, ऐप्लिकेशन ने BigQuery में सेव किए गए फ़ाइनेंशियल डेटा और Cloud Storage में मौजूद एचआर के अनस्ट्रक्चर्ड दस्तावेज़ों, दोनों में खोज की.
इससे पता चलता है कि Vertex AI Search में, अलग-अलग फ़ॉर्मैट के डेटा और अलग-अलग डेटा स्टोर से जवाब तैयार करने की कितनी क्षमता है. साथ ही, यह भी पता चलता है कि यह एक ही जगह पर सटीक जवाब कैसे दे सकता है.
एआई मॉडल को ट्यून करके, ज़्यादा सटीक और डोमेन के हिसाब से जवाब भी पाए जा सकते हैं. जनरेटिव अनुभव को पसंद के मुताबिक बनाने के बारे में ज़्यादा जानकारी के लिए, जवाब पाना और फ़ॉलो-अप करना दस्तावेज़ देखें.
10. अपने ऐप्लिकेशन को डिप्लॉय करने के विकल्प
इस कोडलैब में, ऐप्लिकेशन को उपयोगकर्ताओं के लिए डिप्लॉय करने के बारे में नहीं बताया गया है. हालांकि, यह जानना ज़रूरी है कि असल में यह कैसे काम करता है. Vertex AI Search के ऐप्लिकेशन को अपनी कंपनी के वर्कफ़्लो में इंटिग्रेट करने के कई विकल्प हैं:
- पहले से बना वेब विजेट. एचटीएमएल
scriptटैग का इस्तेमाल करके, इस्तेमाल के लिए तैयार सर्च या चैट इंटरफ़ेस को सीधे अपनी कंपनी के मौजूदा इंट्रनेट या वेब पेजों में एम्बेड किया जा सकता है. यह अपने ऐप्लिकेशन को उपयोगकर्ताओं तक पहुंचाने का सबसे तेज़ तरीका है. - कस्टम एपीआई इंटिग्रेशन. उपयोगकर्ता अनुभव पर पूरी तरह से कंट्रोल पाने के लिए, Vertex AI Search के REST API या क्लाइंट लाइब्रेरी (जैसे, Python, Node.js या Java) का इस्तेमाल करके, कस्टम फ़्रंटएंड बनाया जा सकता है.
11. व्यवस्थित करें
Google Cloud खाते पर लगातार शुल्क लगने से बचने के लिए, इस कोडलैब के दौरान बनाए गए संसाधन मिटाएं:
- Cloud Console में, Vertex AI Search पेज पर जाएं.
- मौजूदा ऐप्लिकेशन देखें पर क्लिक करें.
cymbal-employee-portalऐप्लिकेशन के लिए, ज़्यादा के लिए तीन वर्टिकल बिंदुओं पर क्लिक करें. इसके बाद, मिटाएं पर क्लिक करें.- मिटाने की पुष्टि करने के लिए, स्क्रीन पर दिखने वाले निर्देशों का पालन करें.
- डेटा स्टोर मिटाने के लिए, कंसोल के बाएं नेविगेशन पैनल में डेटा स्टोर पर क्लिक करें.
cymbal-hr,cymbal-finance, औरcymbal-inventoryडेटा स्टोर मिटाएं:cymbal-hrडेटा स्टोर के लिए, ज़्यादा के लिए तीन वर्टिकल बिंदुओं पर क्लिक करें. इसके बाद, मिटाएं पर क्लिक करें.- मिटाने की पुष्टि करने के लिए, स्क्रीन पर दिखने वाले निर्देशों का पालन करें.
cymbal-financeडेटा स्टोर के लिए, ज़्यादा के लिए तीन वर्टिकल बिंदुओं पर क्लिक करें. इसके बाद, मिटाएं पर क्लिक करें.- मिटाने की पुष्टि करने के लिए, स्क्रीन पर दिखने वाले निर्देशों का पालन करें.
cymbal-inventoryडेटा स्टोर के लिए, ज़्यादा के लिए तीन वर्टिकल बिंदुओं पर क्लिक करें. इसके बाद, मिटाएं पर क्लिक करें.- मिटाने की पुष्टि करने के लिए, स्क्रीन पर दिखने वाले निर्देशों का पालन करें.
- बकेट पेज पर जाएं और बनाई गई बकेट मिटाएं. उदाहरण के लिए,
cymbal-app-hr-12. - BigQuery पेज पर जाएं और
cymbal_financeडेटासेट मिटाएं.
12. बधाई हो
मिशन पूरा हुआ! आपने Vertex AI Search का इस्तेमाल करके, एंटरप्राइज़ के लिए यूनिफ़ाइड सर्च की सुविधा वाला ऐप्लिकेशन बना लिया है.
Cloud Storage में मौजूद एंटरप्राइज़ के अनस्ट्रक्चर्ड डेटा और BigQuery में मौजूद स्ट्रक्चर्ड रिकॉर्ड के बीच का अंतर खत्म करके, आपने एक ऐसा टूल बनाया है जो कारोबार से जुड़े जटिल तर्क दे सकता है. इसके लिए, मशीन लर्निंग का एक भी कोड लिखने की ज़रूरत नहीं पड़ी.
आपको क्या सीखने को मिला
- डेटा इनजेस्ट करना: Vertex AI Search में, Cloud Storage से अनस्ट्रक्चर्ड दस्तावेज़ और BigQuery से स्ट्रक्चर्ड डेटा इनजेस्ट करने का तरीका.
- एक से ज़्यादा डेटा स्टोर के लिए क्वेरी करना. स्ट्रक्चर्ड और अनस्ट्रक्चर्ड, दोनों तरह के डेटा से यूनिफ़ाइड जवाब तैयार करने के लिए, एक से ज़्यादा डेटा स्टोर वाले सर्च ऐप्लिकेशन के लिए क्वेरी करने का तरीका.
- ट्यून करना और पसंद के मुताबिक बनाना. जनरेटिव एआई मॉडल को ट्यून करके, ज़्यादा सटीक और डोमेन के हिसाब से जवाब पाने का तरीका.
- डिप्लॉयमेंट के विकल्प. पहले से बने विजेट या कस्टम एपीआई का इस्तेमाल करके, इस तर्क की सुविधा को असल दुनिया के ऐप्लिकेशन में इंटिग्रेट करने के अलग-अलग तरीके.