
1. Introduzione
In questo codelab creerai un'app di helpdesk universale per i dipendenti senza codice utilizzando Vertex AI Search.
Immagina di lavorare in Cymbal, un'azienda di vendita al dettaglio globale. I dipendenti spesso hanno domande come "Qual è la policy per la prenotazione di viaggi di lavoro?" o "Quante unità di sneaker abbiamo disponibili?".
In genere, devi accedere a sistemi completamente diversi per trovare queste risposte. Oltre a dover gestire sistemi diversi, devi anche leggere un gran numero di dati HR non strutturati o eseguire prompt SQL complessi su dati finanziari strutturati per ottenere risposte alle tue domande.
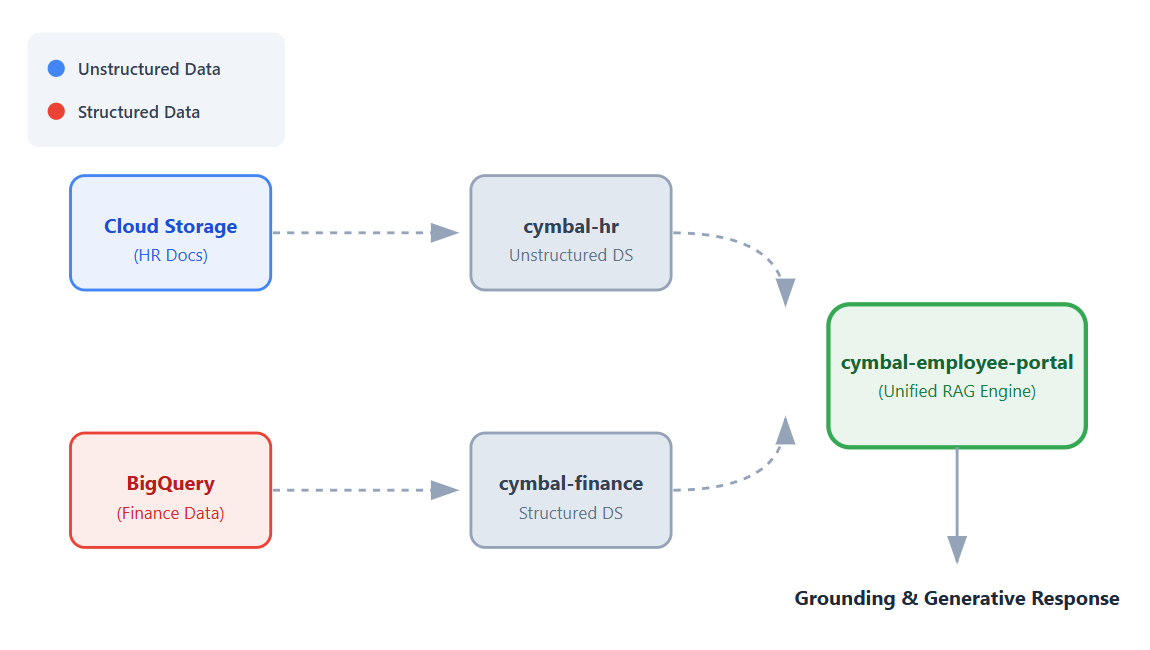
In questo codelab creerai un'unica app unificata che si connette a questi set di dati, consentendo ai dipendenti di ottenere risposte conversazionali e basate sui dati alle loro domande utilizzando le funzionalità di Retrieval Augmented Generation (RAG) di Vertex AI.
In questo lab proverai a:
In questo codelab completerai i seguenti passaggi:
- Configurare le origini dati. Crea un bucket Cloud Storage per i documenti HR non strutturati e un set di dati BigQuery per i dati finanziari strutturati.
- Configurare i datastore. Crea datastore Vertex AI Search connessi alle origini dati Cloud Storage e BigQuery.
- Connettere l'app. Crea un'app Vertex AI Search e collega entrambi i datastore.
- Testare l'app. Interagisci con l'interfaccia di ricerca unificata per verificare le risposte basate sui dati che sintetizzano le informazioni di entrambi i datastore.
- Scoprire i passaggi successivi. Esamina le opzioni per ottimizzare il modello di AI generativa ed eseguire il deployment dell'app di ricerca.
Che cosa ti serve
- Un browser web come Chrome.
- Un progetto Google Cloud con la fatturazione abilitata.
- Git installato sulla tua macchina locale.
Questo codelab è rivolto a sviluppatori di tutti i livelli.
2. Prima di iniziare
Crea un progetto Google Cloud e abilita le API richieste.
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud .
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Ruoli IAM richiesti
Questo codelab presuppone che tu abbia il ruolo di Proprietario del progetto per il tuo progetto Google Cloud.
Abilita API
- Nella console Google Cloud, fai clic su Attiva Cloud Shell: se non hai mai utilizzato Cloud Shell, viene visualizzato un riquadro che ti consente di avviare Cloud Shell in un ambiente attendibile con o senza boost. Se ti viene chiesto di autorizzare Cloud Shell, fai clic su Autorizza.
- In Cloud Shell, abilita tutte le API richieste:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. Clona un repository GitHub
Per mostrare come funziona la ricerca nell'app di helpdesk per i dipendenti di Cymbal, sono necessari alcuni file di test. In questa sezione clonerai un repository GitHub sulla tua macchina locale per ottenere questi file. Caricherai questi file in Google Cloud nei passaggi successivi utilizzando l'interfaccia della console Cloud.
- In un terminale sulla tua macchina locale, clona il repository
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Vai alla directory del repository scaricato:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - Esplora i file scaricati in questa directory. Noterai che sono presenti due cartelle:
HReFinance.- HR. Questa cartella contiene una serie di file non strutturati, come file
.doc,.txte.html. Caricherai i file HR in un bucket Cloud Storage. - Finance. Questa cartella contiene due file
.jsonl. Caricherai questi file in un set di dati BigQuery.
- HR. Questa cartella contiene una serie di file non strutturati, come file
4. Crea un bucket Cloud Storage per i file non strutturati
In questa sezione creerai un bucket Cloud Storage e caricherai i documenti nella cartella HR che hai scaricato nella sezione Clona un repository GitHub. I dati non strutturati, come i documenti HR in questo esempio, non seguono un formato predefinito e possono includere file di testo, documenti o contenuti multimediali.
- Nella console Cloud, vai alla pagina Bucket.
- Fai clic su Crea.
- Nella pagina Crea un bucket, inserisci il nome di un bucket. Il nome deve essere univoco a livello globale. Ad esempio:
cymbal-app-hr-12. - Mantieni le opzioni predefinite.
- Fai clic su Crea.Il bucket viene creato e viene visualizzata la pagina Dettagli bucket. Se non vedi la pagina Dettagli bucket, fai clic sul bucket che hai appena creato.
- Nella pagina Dettagli bucket, fai clic su Carica > Carica cartella, quindi seleziona la cartella
HRche hai scaricato nella sezione Clona un repository GitHub. - Conferma il caricamento.
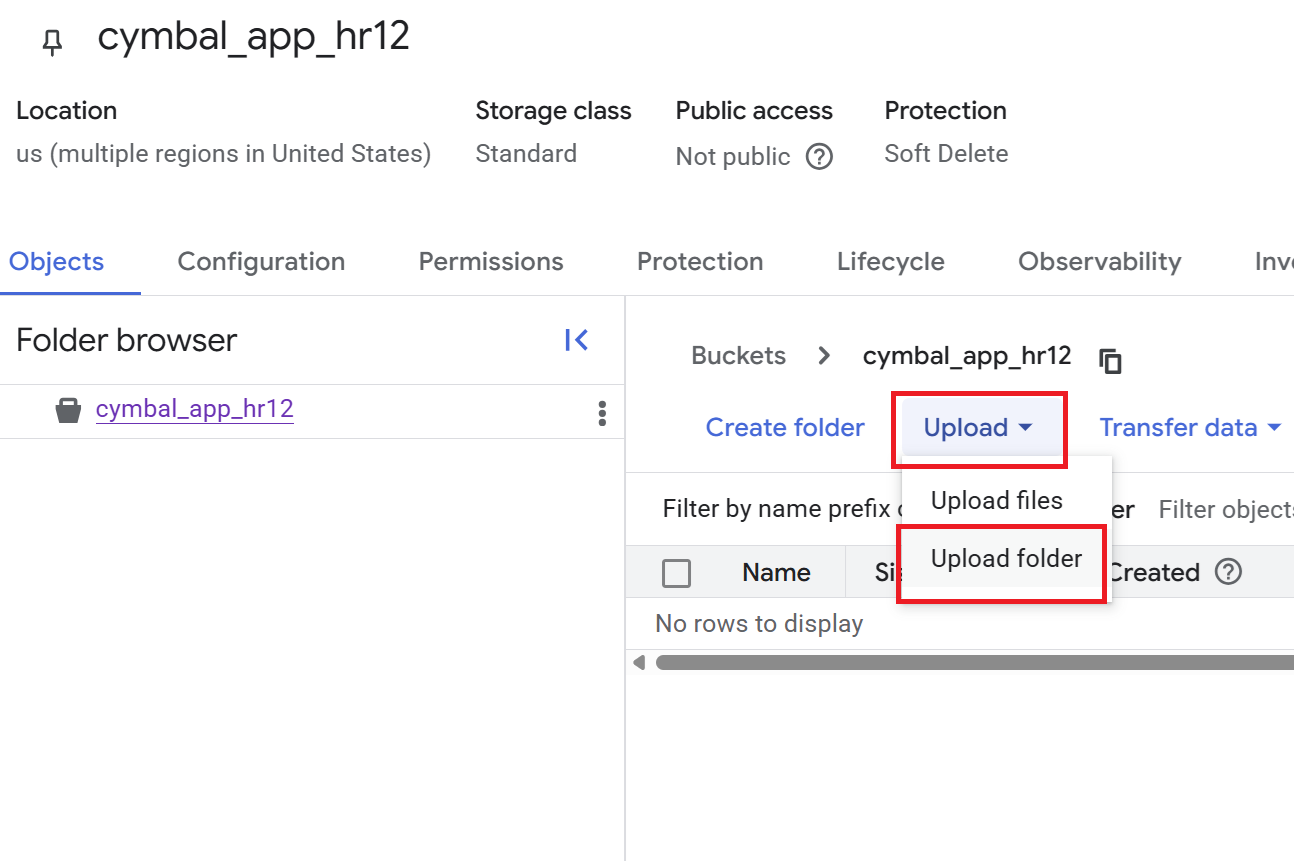
- Nella pagina Dettagli bucket, fai clic sulla cartella
HRper visualizzare l'elenco dei file.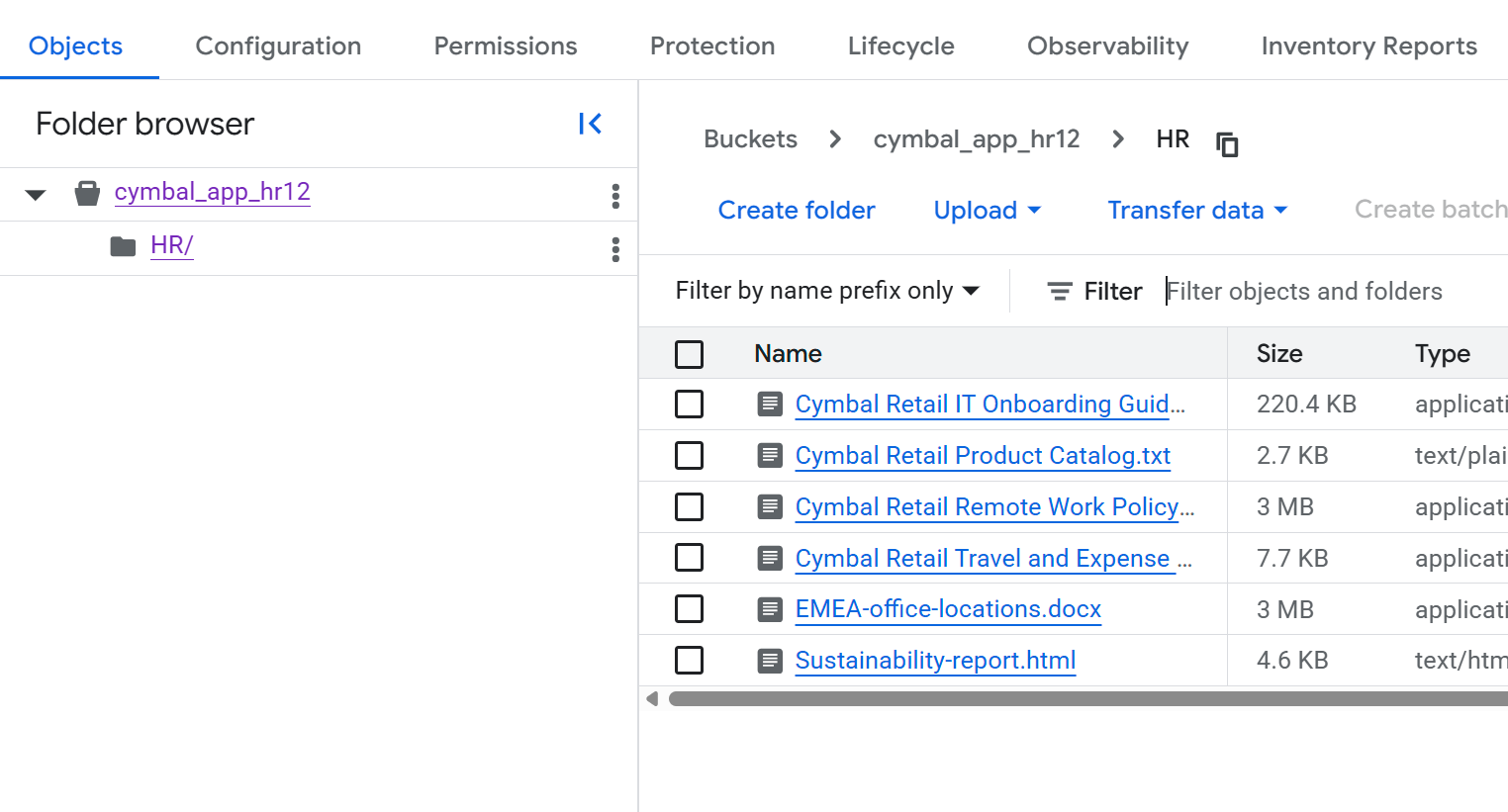
5. Crea un set di dati BigQuery per i file strutturati
In questa sezione creerai un set di dati BigQuery e caricherai i documenti nella cartella Finance che hai scaricato nella sezione Clona un repository GitHub in una nuova tabella. I dati strutturati, come i documenti finanziari in questo esempio, seguono un formato predefinito, ad esempio i record in un database.
- Nella console Cloud, vai alla pagina BigQuery.
- Nel riquadro Explorer, fai clic sul nome del progetto, quindi su Visualizza azioni (i tre puntini verticali) > Crea set di dati.
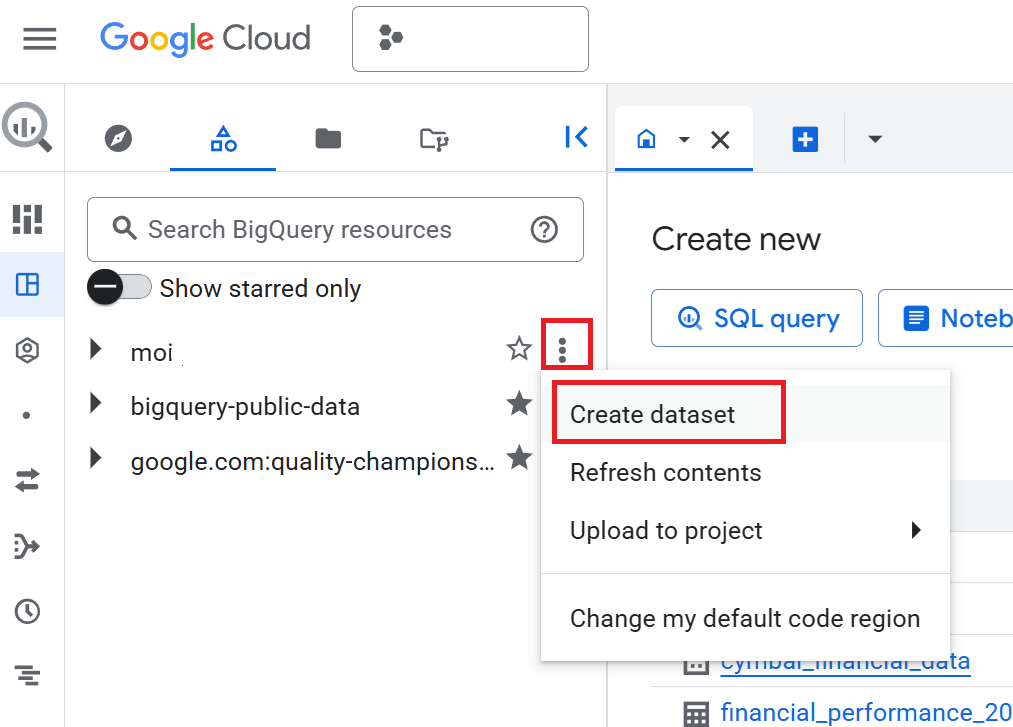
- Nel riquadro Crea set di dati, inserisci
cymbal_financecome ID set di dati. - Per Località dei dati, seleziona
US (multiple regions in United States). - Mantieni le opzioni predefinite e fai clic su Crea set di dati.
- Nel riquadro Explorer , espandi il progetto e fai clic sul set di dati
cymbal_finance. - Nel riquadro dei dettagli del set di dati, fai clic su Crea tabella.
- Nella sezione Origine della pagina Crea tabella , procedi nel seguente modo:
- In Crea tabella da, seleziona Carica.
- In Seleziona file, fai clic su Sfoglia, vai alla cartella
Financeche hai scaricato e selezionacymbal_employee_finance.jsonl. - In Formato file, seleziona JSONL (JSON delimitato da nuova riga).
- Nella sezione Destinazione, inserisci
employee_financecome Nome tabella. - Nella sezione Schema, seleziona la casella di controllo Rilevamento automatico.
- Mantieni le altre impostazioni predefinite e fai clic su Crea tabella.
- Ripeti i passaggi da 7 a 11 per caricare i dati in una nuova tabella. Nel passaggio 8b, seleziona
product_inventory.jsonle, nel passaggio 9, inserisciproduct_inventorycome Nome tabella.Se non vedi le tabelle nel riquadro dei dettagli del set di dati, fai clic su Aggiorna. - Se hai creato correttamente il set di dati e le due tabelle, dovresti vedere un'immagine simile alla seguente:
6. Crea un'app Vertex AI Search
- Nella console Cloud, vai alla pagina Vertex AI Search.
- Nel riquadro Ricerca personalizzata (generale), fai clic su Crea.
- Nella pagina Configurazione dell'app di ricerca, assicurati che le opzioni Funzionalità dell'edizione Enterprise e Risposte generative siano selezionate.
- Assegna all'app il nome
cymbal-employee-portal. - Inserisci nome dell'azienda come
Cymbal Corp. - Mantieni Località dell'app come
global. - Fai clic su Continua.
7. Crea e collega i datastore
Nella pagina Datastore , crea i datastore che collegherai all'app. Devi creare tre datastore: uno per i dati HR non strutturati e due per i dati finanziari strutturati.
Crea un datastore per i dati non strutturati
- Nella pagina Datastore, fai clic su Crea datastore.
- In Seleziona un'origine dati, seleziona Cloud Storage.
- Nel riquadro Importa dati da Cloud Storage , vai a Importazione di dati non strutturati (ricerca di documenti e RAG) e seleziona Documenti.
- Mantieni l'opzione Frequenza della sincronizzazione come Una volta.
- In Seleziona una cartella o un file da importare, fai clic su Cartella.
- Nel campo
gs://..., inserisci il nome del bucket che hai creato nella sezione Crea un bucket Cloud Storage per i file non strutturati. Ad esempio, se il nome del bucket ècymbal-app-hr-12, inserisci il nome comecymbal-app-hr-12/HR.L'importazione dalla cartellaHRgarantisce che in questo datastore siano inclusi solo i documenti HR. - Fai clic su Continua.
- Inserisci
cymbal-hrcome nome del datastore. - Fai clic su Continua.
- Mantieni l'opzione per i prezzi generali.
- Fai clic su Crea.
Dopo aver fatto clic su Crea, tornerai alla pagina Datastore.
Crea datastore per i dati strutturati
Creerai due datastore per i dati strutturati di BigQuery: uno per le informazioni finanziarie dei dipendenti e un altro per l'inventario dei prodotti.
Crea un datastore per i dati finanziari dei dipendenti
- Nella pagina Datastore, fai di nuovo clic su Crea datastore.
- In Seleziona un'origine dati, seleziona BigQuery.
- In Importazione di dati strutturati, seleziona Tabella BigQuery con il tuo schema.
- Mantieni l'opzione Frequenza della sincronizzazione come Una volta.
- In Seleziona una tabella da importare, fai clic su Sfoglia. Nella finestra di dialogo Seleziona percorso che si apre, seleziona la tabella
employee_financedal set di daticymbal_financenel tuo progetto. Potresti visualizzare tabelle con nomi simili di altri progetti, quindi assicurati di selezionare la tabella del tuo progetto. - Fai clic su Continua.
- Esamina la pagina Esamina lo schema e assegna le proprietà chiave.
- Fai clic su Continua.
- Inserisci
cymbal-financecome nome del datastore. - Fai clic su Continua.
- Mantieni l'opzione per i prezzi generali.
- Fai clic su Crea.
Dopo aver fatto clic su Crea, tornerai alla pagina Datastore.
Crea un datastore per i dati dell'inventario dei prodotti
- Nella pagina Datastore, fai di nuovo clic su Crea datastore.
- In Seleziona un'origine dati, seleziona BigQuery.
- In Importazione di dati strutturati, seleziona Tabella BigQuery con il tuo schema.
- Mantieni l'opzione Frequenza della sincronizzazione come Una volta.
- In Seleziona una tabella da importare, fai clic su Sfoglia. Nella finestra di dialogo Seleziona percorso che si apre, seleziona la tabella
product_inventorydal set di daticymbal_financenel tuo progetto. - Fai clic su Continua.
- Esamina la pagina Esamina lo schema e assegna le proprietà chiave.
- Fai clic su Continua.
- Inserisci
cymbal-inventorycome nome del datastore. - Fai clic su Continua.
- Mantieni l'opzione per i prezzi generali.
- Fai clic su Crea.
Dopo aver fatto clic su Crea, tornerai alla pagina Datastore.
8. Collega i datastore all'app
Ora dovresti visualizzare tre datastore nell'elenco della pagina Datastore: cymbal-hr (non strutturato), cymbal-finance (strutturato) e cymbal-inventory (strutturato). Per collegare questi datastore all'app:
- Nella pagina Datastore , seleziona tutti e tre i datastore che hai appena creato:
cymbal-hr,cymbal-financeecymbal-inventory. Assicurati di selezionare tutti e tre i datastore prima di procedere. - Fai clic su Continua.
- Mantieni l'opzione per i prezzi generali.
- Fai clic su Crea.
9. Testa l'app del portale per i dipendenti di Cymbal
- Nell'app
cymbal-employee-portal, fai clic su Anteprima. - Nella casella Cerca qui, inserisci la seguente domanda:
What are the stipends that I get as an employee of Cymbal located in London? - Inserisci una domanda relativa all'inventario dei prodotti:
How many units of sneakers do we have in stock? - Inserisci un'altra domanda:
What is the stipend for an executive in Cymbal?
Nota come l'app di ricerca abbia recuperato informazioni da più origini per formulare la risposta. Per rispondere a queste domande, l'app ha eseguito ricerche sia nei dati finanziari strutturati archiviati in BigQuery sia nei documenti HR non strutturati in Cloud Storage.
Questo dimostra la potenza di Vertex AI Search nel sintetizzare le risposte in vari formati di dati e datastore disparati in un'unica esperienza coerente.
Puoi anche ottimizzare il modello di AI per fornire risposte ancora più accurate e specifiche per il dominio. Per ulteriori informazioni sulla personalizzazione dell'esperienza generativa, consulta la documentazione Ottieni risposte e follow-up.
10. Opzioni per il deployment dell'app
Sebbene il deployment dell'applicazione per gli utenti finali non rientri nell'ambito di questo codelab, è utile sapere come si traduce in uno scenario reale. Sono disponibili diverse opzioni per integrare l'app Vertex AI Search nei flussi di lavoro della tua organizzazione:
- Widget web predefinito. Puoi incorporare un'interfaccia di ricerca o chat pronta all'uso direttamente nelle pagine web o intranet esistenti della tua azienda utilizzando un tag
scriptHTML. Questo è il modo più rapido per rendere disponibile l'app agli utenti. - Integrazione API personalizzata. Per un controllo completo dell'esperienza utente, puoi utilizzare le API REST di Vertex AI Search o le librerie client (come Python, Node.js o Java) per creare un frontend personalizzato da zero.
11. Libera spazio
Per evitare addebiti continui sul tuo account Google Cloud, elimina le risorse create durante questo codelab:
- Nella console Cloud, vai alla pagina Vertex AI Search.
- Fai clic su Visualizza le app esistenti.
- Per l'app
cymbal-employee-portal, fai clic sui tre puntini verticali per Altro, quindi su Elimina. - Segui le istruzioni sullo schermo per confermare l'eliminazione.
- Per eliminare i datastore, fai clic su Datastore nel pannello di navigazione a sinistra della console.
- Elimina i datastore
cymbal-hr,cymbal-financeecymbal-inventory:- Per il datastore
cymbal-hr, fai clic sui tre puntini verticali per Altro, quindi su Elimina. - Segui le istruzioni sullo schermo per confermare l'eliminazione.
- Per il datastore
cymbal-finance, fai clic sui tre puntini verticali per Altro, quindi su Elimina. - Segui le istruzioni sullo schermo per confermare l'eliminazione.
- Per il datastore
cymbal-inventory, fai clic sui tre puntini verticali per Altro, quindi su Elimina. - Segui le istruzioni sullo schermo per confermare l'eliminazione.
- Per il datastore
- Vai alla pagina Bucket ed elimina il bucket che hai creato (ad esempio
cymbal-app-hr-12). - Vai alla pagina BigQuery ed elimina il set di dati
cymbal_finance.
12. Complimenti
Missione compiuta! Hai creato correttamente un'esperienza di ricerca aziendale unificata utilizzando Vertex AI Search.
Colmando il divario tra i dati aziendali non strutturati in Cloud Storage e i record strutturati di BigQuery, hai creato un potente strumento in grado di eseguire ragionamenti aziendali complessi, il tutto senza scrivere una sola riga di codice di machine learning.
Che cosa hai imparato
- Importazione: come importare documenti non strutturati da Cloud Storage e dati strutturati da BigQuery in Vertex AI Search.
- Esecuzione di query su più datastore. Come eseguire query su un'app di ricerca con più datastore per sintetizzare risposte unificate da dati strutturati e non strutturati.
- Ottimizzazione e personalizzazione. Come ottimizzare i modelli di AI generativa per fornire risposte più accurate e specifiche per il dominio.
- Opzioni di deployment. I vari modi per integrare questa funzionalità di ragionamento nelle applicazioni reali utilizzando widget predefiniti o API personalizzate.