
1. はじめに
この Codelab では、Vertex AI Search を使用して、コード不要のユニバーサル従業員向けヘルプデスク アプリを構築します。
たとえば、グローバルな小売企業である Cymbal で働いているとします。従業員は、「出張の予約に関するポリシーは何ですか?」や「スニーカーの在庫は何足ありますか?」といった質問をよくします。
通常、これらの回答を見つけるには、まったく異なるシステムにログインする必要があります。さまざまなシステムに対応するだけでなく、質問への回答を得るには、大量の非構造化 HR データを読み込んだり、構造化された財務データに対して複雑な SQL プロンプトを実行したりする必要があります。
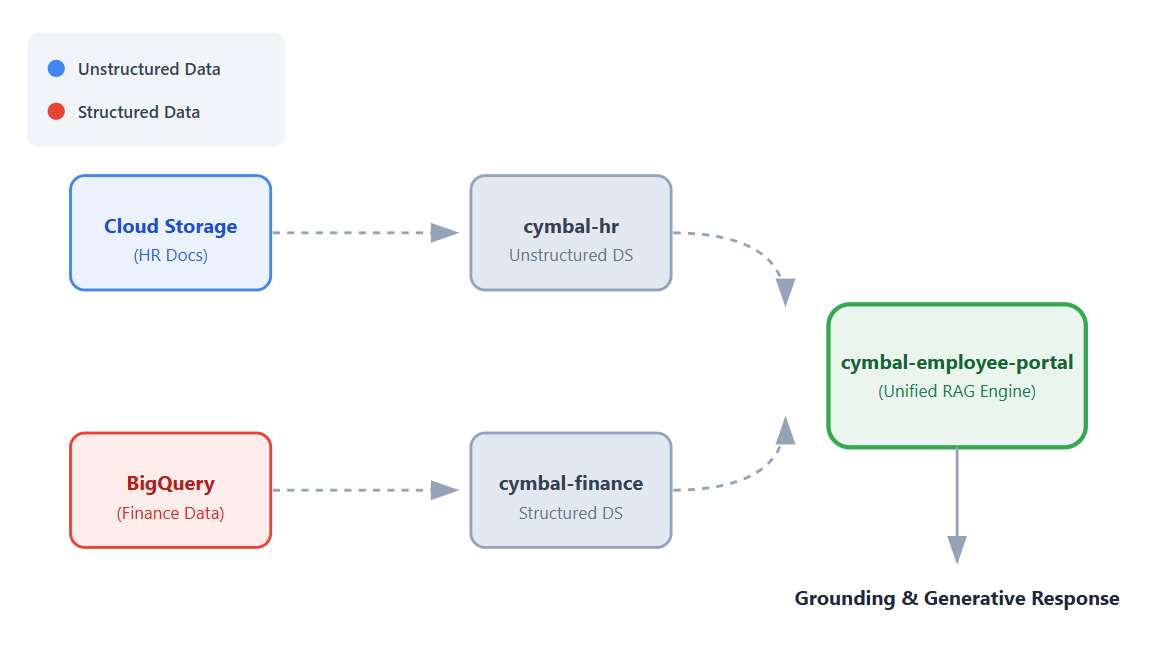
この Codelab では、これらのデータセットに接続する単一の統合アプリを構築します。これにより、従業員は Vertex AI の検索拡張生成(RAG)機能を使用して、質問に対する会話形式のグラウンディングされた回答を得ることができます。
演習内容
この Codelab では、次の手順を完了します。
- データソースを設定する。非構造化 HR ドキュメント用の Cloud Storage バケットと、構造化された財務データ用の BigQuery データセットを作成します。
- データストアを構成する。Cloud Storage と BigQuery のデータソースに接続された Vertex AI Search データストアを作成します。
- アプリを接続する。 Vertex AI Search アプリを作成し、両方のデータストアをリンクします。
- アプリをテストする。 統合された検索インターフェースを操作して、両方のデータストアの情報を合成したグラウンディングされた回答を確認します。
- 次のステップを確認する。生成 AI モデルをチューニングして検索アプリをデプロイするためのオプションを確認します。
必要なもの
- ウェブブラウザ(Chrome など)。
- 課金を有効にした Google Cloud プロジェクト。
- ローカルマシンにインストールされた Git。
この Codelab は、あらゆるレベルのデベロッパーを対象としています。
2. 始める前に
Google Cloud プロジェクトを作成し、必要な API を有効にします。
- Google Cloud コンソールの [プロジェクト セレクタ] ページで、Google Cloud プロジェクト を選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
必要な IAM のロール
この Codelab では、Google Cloud プロジェクトのプロジェクト オーナー ロールがあることを前提としています。
API を有効にする
- Google Cloud コンソールで、[Cloud Shell をアクティブにする] をクリックします。Cloud Shell を使用したことがない場合は、信頼できる環境で Cloud Shell を起動するかどうかを選択できるペインが表示されます。Cloud Shell を承認するよう求められたら、[承認] をクリックします。
- Cloud Shell で、必要な API をすべて有効にします。
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. GitHub リポジトリのクローンを作成する
Cymbal 従業員向けヘルプデスク アプリで検索がどのように機能するかを示すには、モックファイルが必要です。このセクションでは、これらのファイルを取得するために、GitHub リポジトリのクローンをローカルマシンに作成します。これらのファイルは、後の手順で Cloud コンソール インターフェースを使用して Google Cloud にアップロードします。
- ローカルマシンのターミナルで、
next-26-sessionsリポジトリのクローンを作成します。git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - ダウンロードしたリポジトリ ディレクトリに移動します。
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - このディレクトリでダウンロードしたファイルを確認します。
HRとFinanceの 2 つのフォルダがあります。- HR 。このフォルダには、
.doc、.txt、.htmlファイルなど、多数の非構造化ファイルが含まれています。HR ファイルを Cloud Storage バケットにアップロードします。 - Finance 。このフォルダには、2 つの
.jsonlファイルが含まれています。これらのファイルを BigQuery データセットにアップロードします。
- HR 。このフォルダには、
4. 非構造化ファイル用の Cloud Storage バケットを作成する
このセクションでは、Cloud Storage バケットを作成し、GitHub リポジトリのクローンを作成する セクションでダウンロードした HR フォルダ内のドキュメントをアップロードします。この例の HR ドキュメントのような非構造化データは、事前定義された形式に従っておらず、テキスト ファイル、ドキュメント、マルチメディア コンテンツなどを含めることができます。
- Cloud コンソールで、[**バケット**] ページに移動します。
- [作成] をクリックします。
- [バケットの作成] ページで、バケットの名前を入力します。名前はグローバルに一意である必要があります。例:
cymbal-app-hr-12。 - デフォルトのオプションをそのまま使用します。
- [作成] をクリックします。バケットが作成され、[バケットの詳細] ページが表示されます。[バケットの詳細] ページが表示されない場合は、作成したバケットをクリックします。
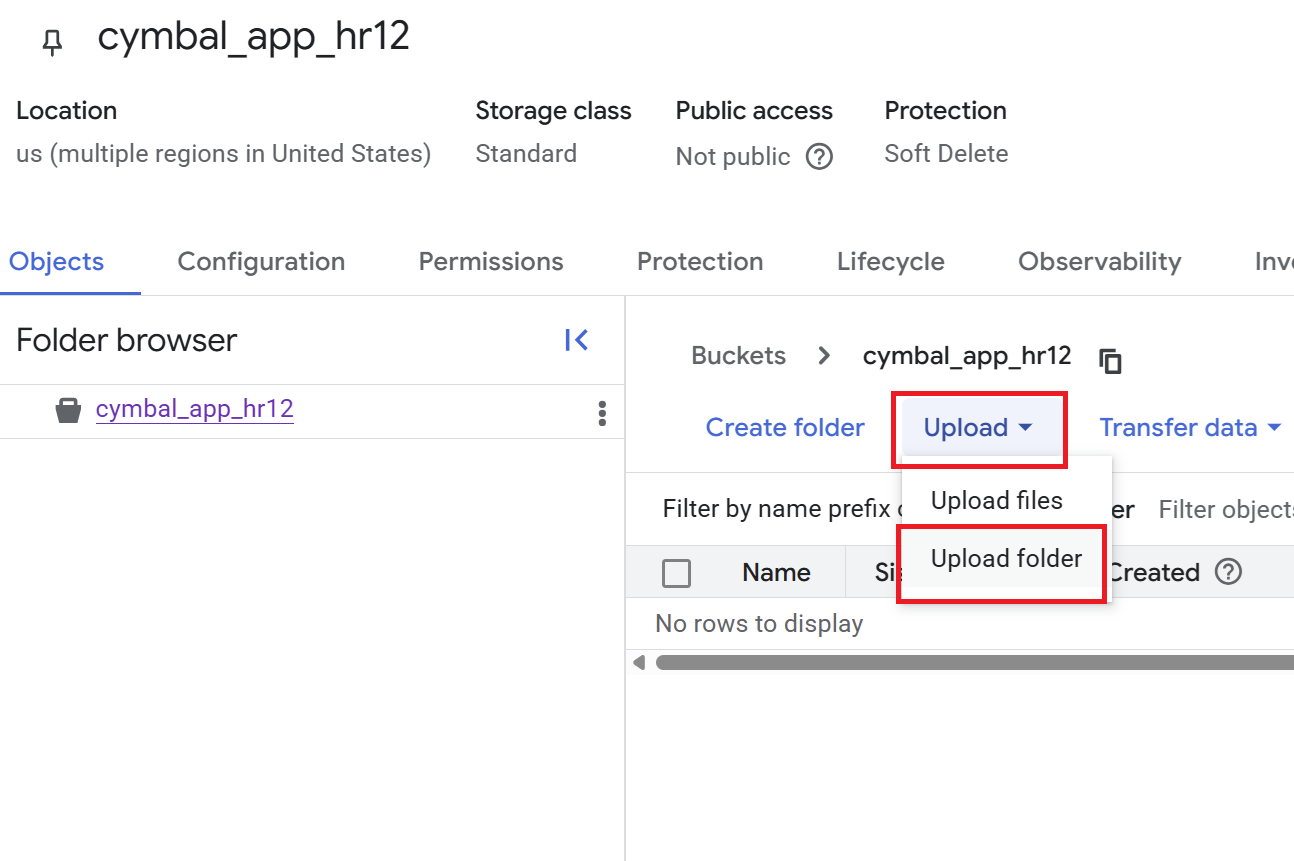
- [**バケットの詳細**] ページで、[**アップロード**] > [**フォルダをアップロード**] をクリックし、
HRフォルダを [**GitHub リポジトリのクローンを作成する**] セクションでダウンロードします。 - アップロードを確認します。
- [バケットの詳細] ページで、
HRフォルダをクリックしてファイルの一覧を表示します。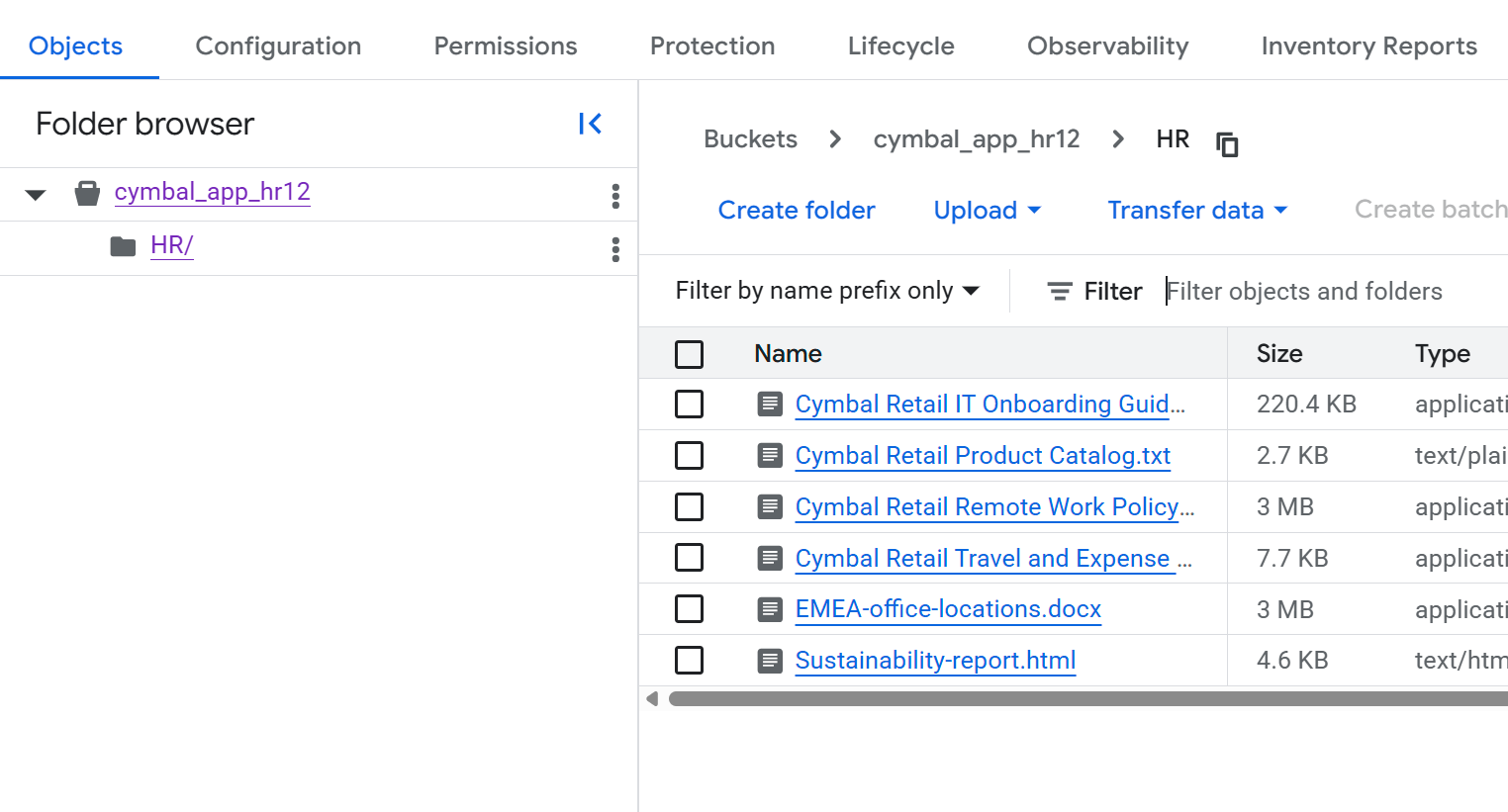
5. 構造化ファイル用の BigQuery データセットを作成する
このセクションでは、BigQuery データセットを作成し、GitHub リポジトリのクローンを作成する セクションでダウンロードした Finance フォルダ内のドキュメントを新しいテーブルに読み込みます。この例の財務ドキュメントのような構造化データは、データベース内のレコードなど、事前定義された形式に従います。
- Cloud コンソールで、[BigQuery] ページに移動します。
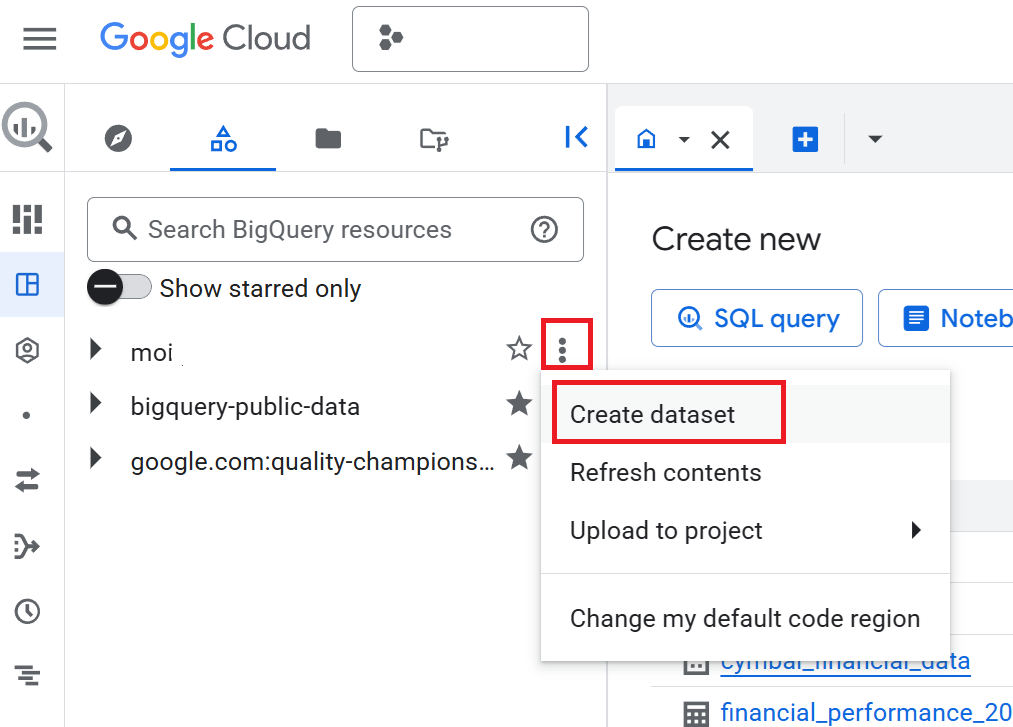
- [エクスプローラ] ペインで、プロジェクト名をクリックし、[アクションを表示](縦に 3 つ並んだ点)> [データセットを作成] をクリックします。
- [データセットを作成] ペインで、データセット ID に「
cymbal_finance」と入力します。 - [データのロケーション] で、
US (multiple regions in United States)を選択します。 - デフォルトのオプションをそのまま使用して、[データセットを作成] をクリックします。
- [エクスプローラ] ペインで、プロジェクトを開き、
cymbal_financeデータセットをクリックします。 - データセットの詳細ペインで、[テーブルを作成] をクリックします。
- [テーブルの作成] ページの [ソース] セクションで、次の操作を行います。
- [**テーブルの作成元**] で [**アップロード**] を選択します。
- [ファイルを選択] で [参照] をクリックし、ダウンロードした
Financeフォルダに移動して、cymbal_employee_finance.jsonlを選択します。 - [**ファイル形式**] で [**JSONL(改行区切り JSON)**] を選択します。
- [宛先] セクションで、テーブル 名に「
employee_finance」と入力します。 - [スキーマ] セクションで、[自動検出] チェックボックスをオンにします。
- その他のデフォルト設定はそのままにして、[テーブルを作成] をクリックします。
- 手順 7 ~ 11 を繰り返して、新しいテーブルにデータを読み込みます。手順 8b で
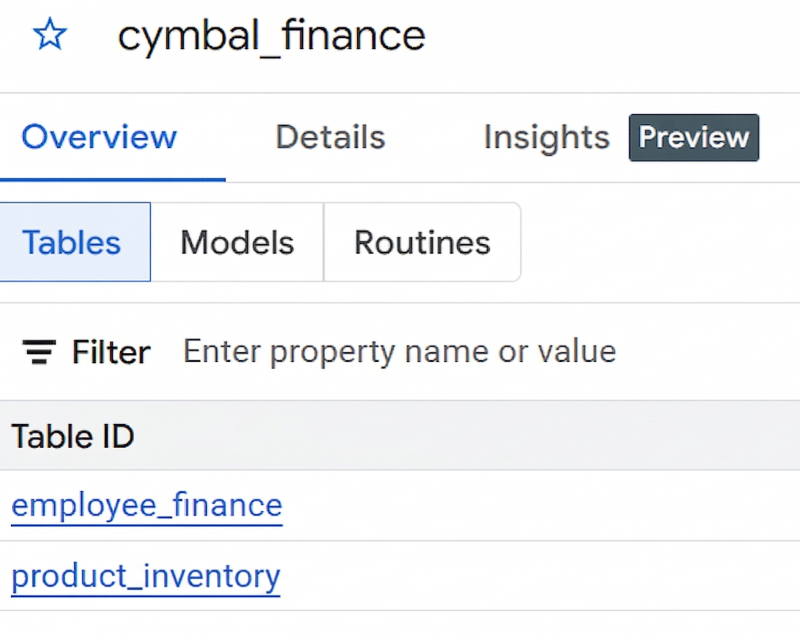
product_inventory.jsonlを選択し、手順 9 でproduct_inventoryを テーブル名として入力します。データセットの詳細ペインにテーブルが表示されない場合は、[更新] をクリックします。 - データセットと 2 つのテーブルが正常に作成されると、次の画像のようになります。
6. Vertex AI Search アプリを作成する
- Cloud Console で、Vertex AI Search のページに移動します。
- [カスタム検索(一般)] タイルで、[作成] をクリックします。
- [検索アプリの構成] ページで、[Enterprise Edition の機能] オプションと [生成レスポンス] オプションが選択されていることを確認します。
- アプリに「
cymbal-employee-portal」という名前を付けます。 - 会社名 に「
Cymbal Corp」と入力します。 - アプリのロケーション は
globalのままにします。 - [続行] をクリックします。
7. データストアを作成して接続する
[データストア] ページで、アプリに接続するデータストアを作成します。非構造化 HR データ用に 1 つ、構造化された財務データ用に 2 つのデータストアを作成する必要があります。
非構造化データのデータストアを作成する
- [データストア] ページで、[データストアを作成] をクリックします。
- [データソースを選択] で [Cloud Storage] を選択します。
- [**Cloud Storage からデータをインポート**] ペインで、[**非構造化データのインポート(ドキュメント検索と RAG)**] に移動し、[**ドキュメント**] を選択します。
- [同期の頻度] オプションは [1 回限り] のままにします。
- [インポートするフォルダまたはファイルを選択] で、[フォルダ] をクリックします。
gs://...フィールドに、非構造化ファイル用の Cloud Storage バケットを作成する セクションで作成したバケットの名前を入力します。たとえば、バケットの名前がcymbal-app-hr-12の場合は、「cymbal-app-hr-12/HR」と入力します。HRフォルダから取り込むことで、このデータストアには HR ドキュメントのみが含まれるようになります。- [続行] をクリックします。
- データストアの名前として「
cymbal-hr」と入力します。 - [続行] をクリックします。
- [一般的な料金] のオプションはそのままにします。
- [作成] をクリックします。
[作成] をクリックすると、[データストア] ページに戻ります。
構造化データのデータストアを作成する
BigQuery の構造化データ用に 2 つのデータストアを作成します。1 つは従業員の財務情報用、もう 1 つは商品在庫用です。
従業員の財務データ用のデータストアを作成する
- [データストア] ページで、[データストアを作成] をもう一度クリックします。
- [**データソースを選択**] で [**BigQuery**] を選択します。
- [構造化データのインポート] で、[独自のスキーマを持つ BigQuery テーブル] を選択します。
- [同期の頻度] オプションは [1 回限り] のままにします。
- [**インポートするテーブルを選択**] で、[**参照**] をクリックします。表示された [パスを選択] ダイアログで、プロジェクトの
cymbal_financeデータセットからemployee_financeテーブルを選択します。他のプロジェクトから同様の名前のテーブルが表示されることがあるため、プロジェクトのテーブルを選択してください。 - [続行] をクリックします。
- [スキーマを確認してキー プロパティを割り当てる] ページを確認します。
- [続行] をクリックします。
- データストアの名前として「
cymbal-finance」と入力します。 - [続行] をクリックします。
- [一般的な料金] のオプションはそのままにします。
- [作成] をクリックします。
[作成] をクリックすると、[データストア] ページに戻ります。
商品在庫データ用のデータストアを作成する
- [データストア] ページで、[データストアを作成] をもう一度クリックします。
- [**データソースを選択**] で [**BigQuery**] を選択します。
- [構造化データのインポート] で、[独自のスキーマを持つ BigQuery テーブル] を選択します。
- [同期の頻度] オプションは [1 回限り] のままにします。
- [**インポートするテーブルを選択**] で、[**参照**] をクリックします。表示された [パスを選択] ダイアログで、プロジェクトの
cymbal_financeデータセットからproduct_inventoryテーブルを選択します。 - [続行] をクリックします。
- [スキーマを確認してキー プロパティを割り当てる] ページを確認します。
- [続行] をクリックします。
- データストアの名前として「
cymbal-inventory」と入力します。 - [続行] をクリックします。
- [一般的な料金] のオプションはそのままにします。
- [作成] をクリックします。
[作成] をクリックすると、[データストア] ページに戻ります。
8. データストアをアプリに接続する
[データストア] ページのリストに、cymbal-hr(非構造化)、cymbal-finance(構造化)、cymbal-inventory(構造化)の 3 つのデータストアが表示されます。これらのデータストアをアプリに接続する手順は次のとおりです。
- [データストア] ページで、作成した 3 つのデータストア(
cymbal-hr、cymbal-finance、cymbal-inventory)をすべて選択します。続行する前に、3 つのデータストアをすべて選択してください。 - [続行] をクリックします。
- [一般的な料金] のオプションはそのままにします。
- [作成] をクリックします。
9. Cymbal 従業員ポータル アプリをテストする
cymbal-employee-portalアプリで、[プレビュー] をクリックします。- [検索] ボックスに次の質問を入力します。
What are the stipends that I get as an employee of Cymbal located in London? - 商品在庫に関する質問を入力します。
How many units of sneakers do we have in stock? - 別の質問を入力します。
What is the stipend for an executive in Cymbal?
検索アプリが複数のソースから情報を取得してレスポンスを作成していることに注目してください。これらの質問に回答するために、アプリは BigQuery に保存されている構造化された財務データと、Cloud Storage 内の非構造化 HR ドキュメントの両方を検索しました。
これは、Vertex AI Search の強力な機能を示しています。さまざまなデータ形式と異なるデータストアの回答を 1 つのまとまりのあるエクスペリエンスに統合できます。
AI モデルをチューニングして、より正確でドメイン固有の回答を提供することもできます。生成エクスペリエンスのカスタマイズについて詳しくは、回答とフォローアップのドキュメントをご覧ください。
10. アプリをデプロイするためのオプション
エンドユーザーにアプリケーションをデプロイすることは、この Codelab の範囲外ですが、これが実際のシナリオにどのように変換されるかを知っておくと便利です。Vertex AI Search アプリを組織のワークフローに統合するには、次のようないくつかの方法があります。
- 事前構築済みのウェブ ウィジェット。HTML の
scriptタグを使用して、すぐに使用できる検索またはチャット インターフェースを、会社の既存のイントラネットまたはウェブページに直接埋め込むことができます。これは、アプリをユーザーに公開する最も簡単な方法です。 - カスタム API との連携。ユーザー エクスペリエンスを完全に制御するには、Vertex AI Search REST API またはクライアント ライブラリ(Python、Node.js、Java など)を使用して、カスタム フロントエンドをゼロから構築します。
11. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
- Cloud コンソールで、Vertex AI Search のページに移動します。
- [既存のアプリを表示] をクリックします。
cymbal-employee-portalアプリで、[**その他**] の縦に 3 つ並んだ点をクリックし、[**削除**] をクリックします。- 画面上のプロンプトに沿って削除を確認します。
- データストアを削除するには、コンソールの左側のナビゲーション パネルで [データストア] をクリックします。
cymbal-hr、cymbal-finance、cymbal-inventoryデータストアを削除します。cymbal-hrデータストアで、[**その他**] の縦に 3 つ並んだ点をクリックし、[**削除**] をクリックします。- 画面上のプロンプトに沿って削除を確認します。
cymbal-financeデータストアで、[**その他**] の縦に 3 つ並んだ点をクリックし、[**削除**] をクリックします。- 画面上のプロンプトに沿って削除を確認します。
cymbal-inventoryデータストアで、[**その他**] の縦に 3 つ並んだ点をクリックし、[**削除**] をクリックします。- 画面上のプロンプトに沿って削除を確認します。
- [**バケット**] ページに移動し、作成したバケット(
cymbal-app-hr-12など)を削除します。 - [BigQuery] ページに移動し、
cymbal_financeデータセットを削除します。
12. 完了
ミッション完了!Vertex AI Search を使用して、統合されたエンタープライズ検索エクスペリエンスを構築できました。
Cloud Storage 内の非構造化エンタープライズ データと BigQuery の構造化レコードのギャップを埋めることで、複雑なビジネス推論が可能な強力なツールを作成しました。ML コードを 1 行も記述せずに実現できます。
学習した内容
- 取り込み: Cloud Storage から非構造化ドキュメントを取り込み、BigQuery から構造化データを Vertex AI Search に取り込む方法。
- マルチデータストアのクエリ 。マルチデータストア検索アプリにクエリを実行して、構造化データと非構造化データの両方から統合された回答を合成する方法。
- チューニングとカスタマイズ 。生成 AI モデルをチューニングして、より正確でドメイン固有の回答を提供する方法。
- デプロイのオプション 。事前構築済みのウィジェットまたはカスタム API を使用して、この推論機能を実際のアプリケーションに統合するさまざまな方法。