
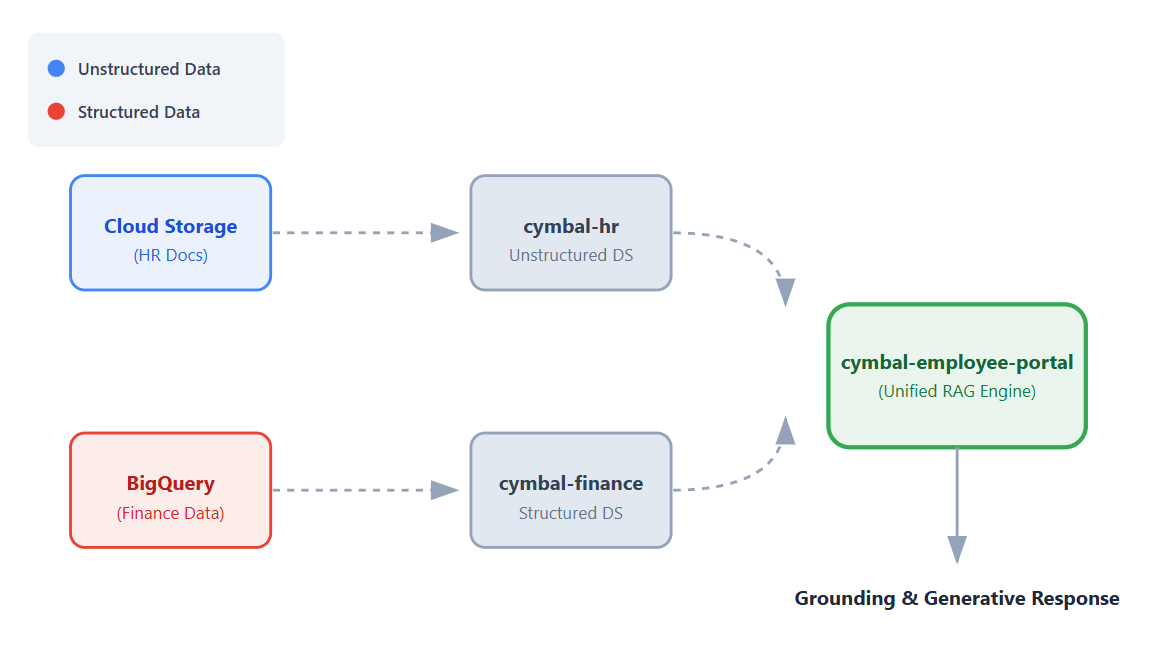
1. 소개
이 Codelab에서는 Vertex AI Search를 사용하여 코드가 없는 범용 직원 헬프데스크 앱을 빌드합니다.
글로벌 소매업체인 Cymbal에서 일하고 있다고 가정해 보겠습니다. 직원들은 '출장 예약 정책은 무엇인가요?' 또는 '스니커즈 재고 있음은 몇 개나 있나요?'와 같은 질문을 자주 합니다.
일반적으로 이러한 답변을 찾으려면 완전히 다른 시스템에 로그인해야 합니다. 다양한 시스템을 처리하는 것 외에도 질문에 대한 답변을 얻으려면 많은 수의 비정형 HR 데이터를 읽거나 정형 재무 데이터에 복잡한 SQL 프롬프트를 실행해야 합니다.
이 Codelab에서는 이러한 데이터 세트에 연결되는 단일 통합 앱을 빌드하여 직원이 Vertex AI의 검색 증강 생성 (RAG) 기능을 사용하여 질문에 대한 대화형 그라운딩된 답변을 얻을 수 있도록 합니다.
실습할 내용
이 Codelab에서는 다음 단계를 완료합니다.
- 데이터 소스 설정. 비정형 HR 문서를 위한 Cloud Storage 버킷과 정형 재무 데이터를 위한 BigQuery 데이터 세트를 만듭니다.
- 데이터 스토어 구성. Cloud Storage 및 BigQuery 데이터 소스에 연결된 Vertex AI Search 데이터 스토어를 만듭니다.
- 앱 연결. Vertex AI Search 앱을 만들고 두 데이터 스토어를 모두 연결합니다.
- 앱 테스트. 통합 검색 인터페이스와 상호작용하여 두 데이터 스토어의 정보를 종합하는 그라운딩된 답변을 확인합니다.
- 다음 단계 살펴보기. 생성형 AI 모델을 조정하고 검색 앱을 배포하는 옵션을 검토합니다.
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트.
- 로컬 머신에 설치된 Git
이 Codelab은 모든 수준의 개발자를 대상으로 합니다.
2. 시작하기 전에
Google Cloud 프로젝트를 만들고 필요한 API를 사용 설정합니다.
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트 를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에서 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
필요한 IAM 역할
이 Codelab에서는 Google Cloud 프로젝트에 대해 프로젝트 소유자 역할이 있다고 가정합니다.
API 사용 설정
- Google Cloud 콘솔에서 Cloud Shell 활성화를 클릭합니다. Cloud Shell을 이전에 사용한 적이 없는 경우 부스트가 있거나 없는 신뢰할 수 있는 환경에서 Cloud Shell을 시작할 수 있는 선택사항을 제공하는 창이 표시됩니다. Cloud Shell을 승인하라는 메시지가 표시되면 승인 을 클릭합니다.
- Cloud Shell에서 필요한 API를 모두 사용 설정합니다.
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. GitHub 저장소 클론
Cymbal 직원 헬프데스크 앱에서 검색이 작동하는 방식을 보여주려면 일부 모의 파일이 필요합니다. 이 섹션에서는 GitHub 저장소를 로컬 머신에 클론하여 이러한 파일을 가져옵니다. 이러한 파일은 이후 단계에서 Cloud Console 인터페이스를 사용하여 Google Cloud에 업로드합니다.
- 로컬 머신의 터미널에서
next-26-sessions저장소를 클론합니다.git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - 다운로드한 저장소 디렉터리로 이동합니다.
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - 이 디렉터리에서 다운로드한 파일을 살펴봅니다.
HR및Finance라는 두 개의 폴더가 있습니다.- HR. 이 폴더에는
.doc,.txt,.html파일과 같은 여러 비정형 파일이 포함되어 있습니다. HR 파일을 Cloud Storage 버킷에 업로드합니다. - 금융. 이 폴더에는
.jsonl파일 두 개가 포함되어 있습니다. 이러한 파일은 BigQuery 데이터 세트에 업로드합니다.
- HR. 이 폴더에는
4. 비정형 파일을 위한 Cloud Storage 버킷 만들기
이 섹션에서는 Cloud Storage 버킷을 만들고 GitHub 저장소 클론 섹션에서 다운로드한 HR 폴더의 문서를 업로드합니다. 이 예의 HR 문서와 같은 비정형 데이터는 사전 정의된 형식을 따르지 않으며 텍스트 파일, 문서 또는 멀티미디어 콘텐츠를 포함할 수 있습니다.
- Cloud 콘솔에서 버킷 페이지로 이동합니다.
- 만들기 를 클릭합니다.
- 버킷 만들기 페이지에서 버킷 이름을 입력합니다. 이름은 전역적으로 고유해야 합니다. 예를 들면
cymbal-app-hr-12입니다. - 기본 옵션을 유지합니다.
- 만들기 를 클릭합니다.버킷이 생성되고 버킷 세부정보 페이지가 표시됩니다. 버킷 세부정보 페이지가 표시되지 않으면 방금 만든 버킷을 클릭합니다.
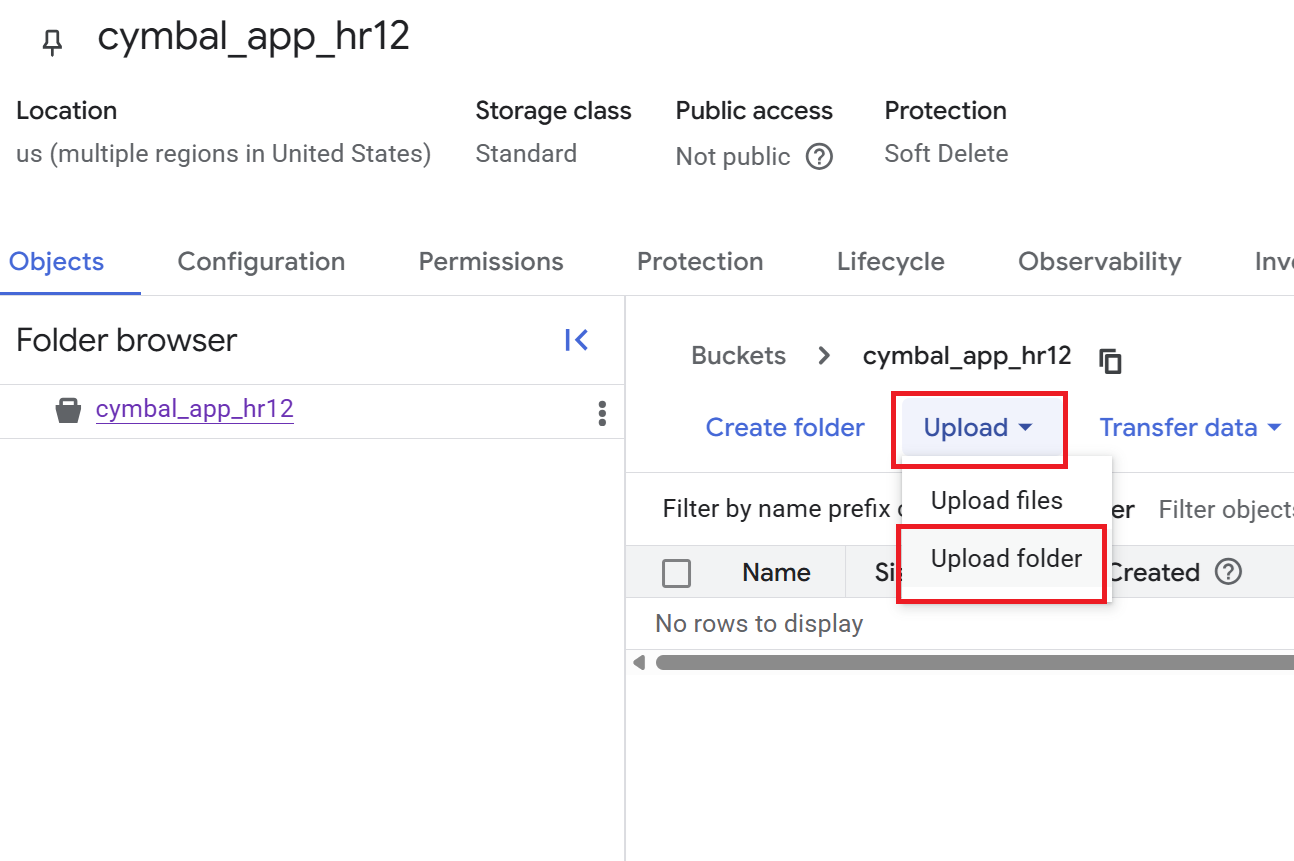
- 버킷 세부정보 페이지에서 업로드 > 폴더 업로드를 클릭한 후
HR폴더를 선택합니다. - 업로드를 확인합니다.
- 버킷 세부정보 페이지에서
HR폴더를 클릭하여 파일 목록을 확인합니다.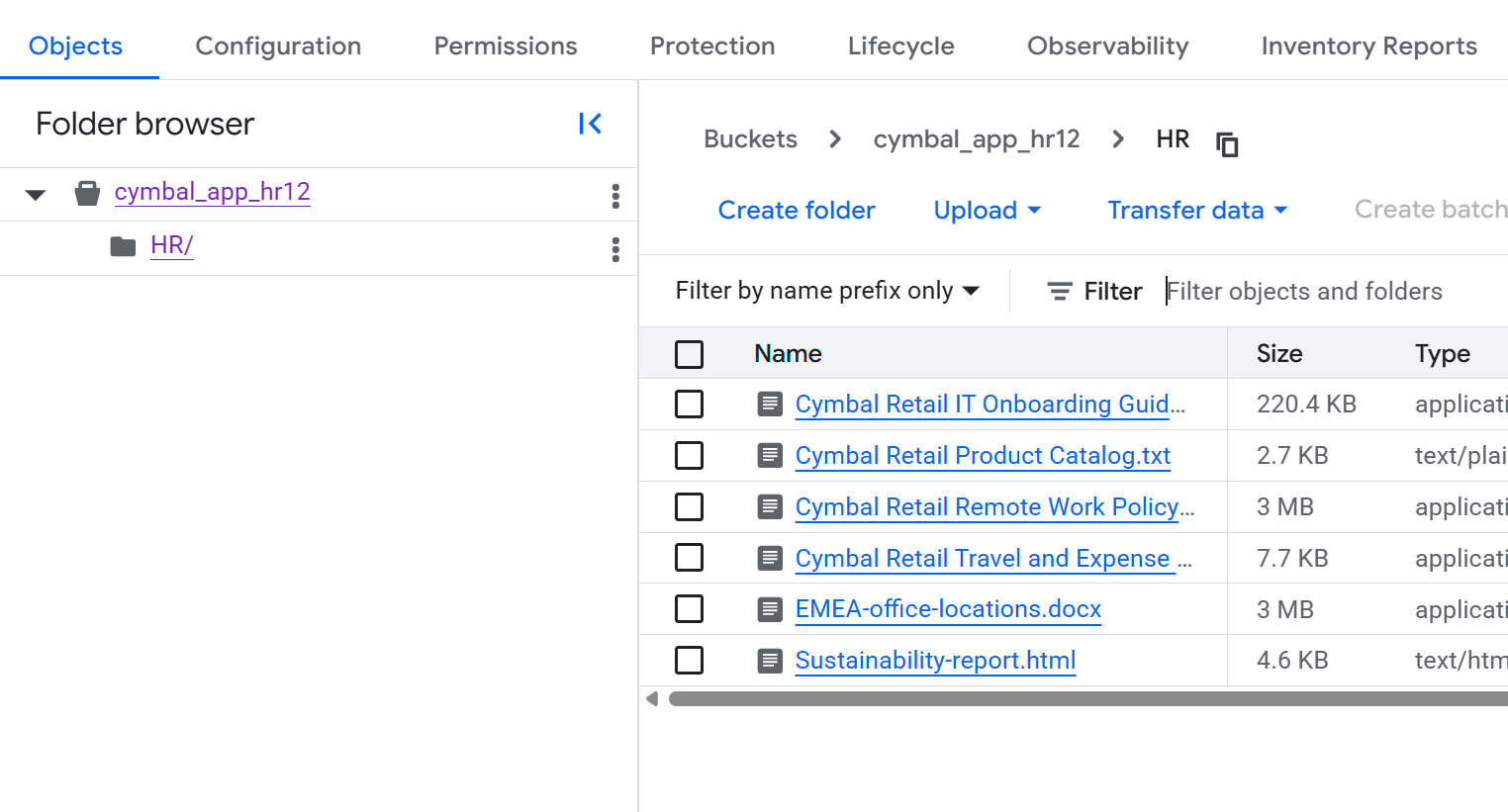
5. 정형 파일을 위한 BigQuery 데이터 세트 만들기
이 섹션에서는 BigQuery 데이터 세트를 만들고 GitHub 저장소 클론 섹션에서 다운로드한 Finance 폴더의 문서를 새 테이블에 로드합니다. 이 예의 재무 문서와 같은 구조화된 데이터는 데이터베이스의 레코드와 같은 사전 정의된 형식을 따릅니다.
- Cloud Console에서 BigQuery 페이지로 이동합니다.
- 탐색기 창에서 프로젝트 이름을 클릭한 다음 작업 보기 (세로로 나열된 세 개의 점) > 데이터 세트 만들기를 클릭합니다.
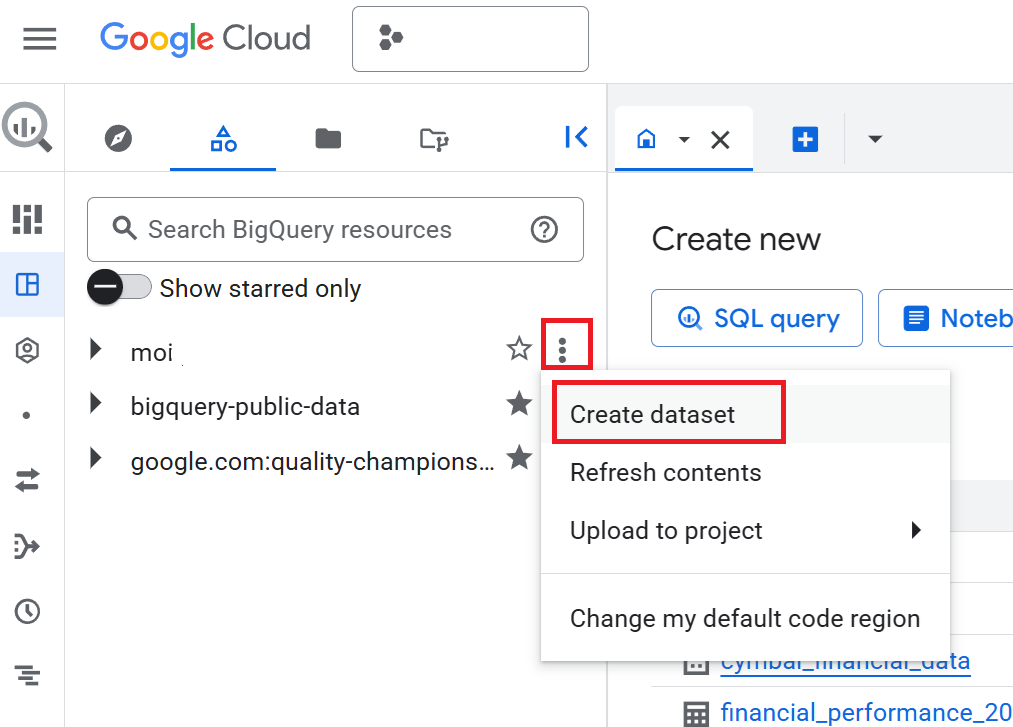
- 데이터 세트 만들기 창에서 데이터 세트 ID 를
cymbal_finance로 입력합니다. - 데이터 위치로
US (multiple regions in United States)를 선택합니다. - 기본 옵션을 유지하고 데이터 세트 만들기 를 클릭합니다.
- 탐색기 창에서 프로젝트를 펼치고
cymbal_finance데이터 세트를 클릭합니다. - 데이터 세트 세부정보 창에서 테이블 만들기 를 클릭합니다.
- 테이블 만들기 페이지의 소스 섹션에서 다음을 수행합니다.
- **다음 항목으로 테이블 만들기** 에서 **업로드** 를 선택합니다.
- 파일 선택에서 찾아보기를 클릭하고 다운로드한
Finance폴더로 이동한 후cymbal_employee_finance.jsonl을 선택합니다. - 파일 형식에서 JSONL (줄바꿈으로 구분된 JSON)을 선택합니다.
- 대상 섹션에서 테이블 이름을
employee_finance로 입력합니다. - 스키마 섹션에서 자동 감지 체크박스를 선택합니다.
- 다른 기본 설정은 그대로 두고 테이블 만들기 를 클릭합니다.
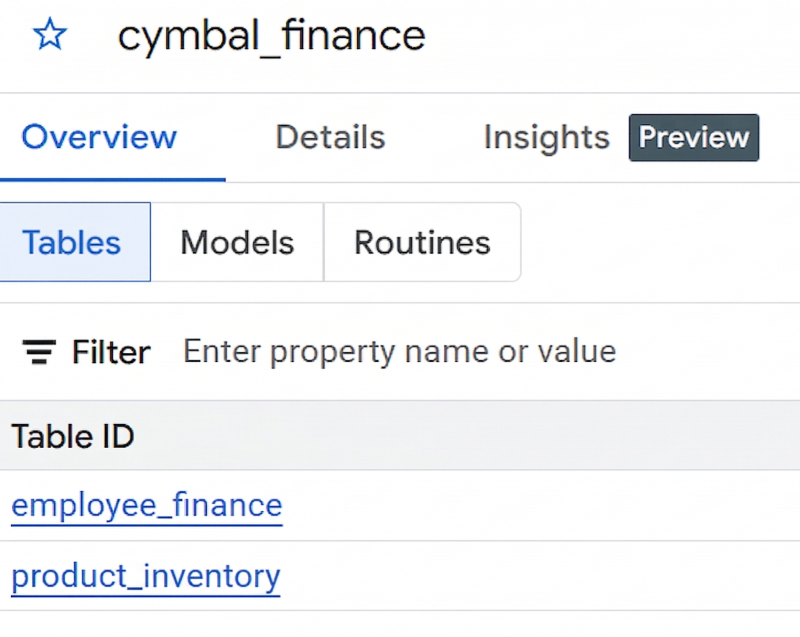
- 7~11단계를 반복하여 새 테이블에 데이터를 로드합니다. 8b단계에서
product_inventory.jsonl을 선택하고 9단계에서product_inventory을 테이블 이름으로 입력합니다.데이터 세트 세부정보 창에 테이블이 표시되지 않으면 새로고침을 클릭합니다. - 데이터 세트와 두 테이블을 만들었다면 다음 이미지와 같이 표시됩니다.
6. Vertex AI Search 앱 만들기
- Cloud Console에서 Vertex AI Search 페이지로 이동합니다.
- 커스텀 검색 (일반) 타일에서 만들기 를 클릭합니다.
- 검색 앱 구성 페이지에서 Enterprise 버전 기능 및 생성형 응답 옵션이 선택되어 있는지 확인합니다.
- 앱 이름을
cymbal-employee-portal로 지정합니다. - 회사 이름 을
Cymbal Corp로 입력합니다. - 앱 위치 를
global로 유지합니다. - 계속 을 클릭합니다.
7. 데이터 스토어 만들기 및 연결
데이터 스토어 페이지에서 앱에 연결할 데이터 스토어를 만듭니다. 비정형 HR 데이터용 데이터 스토어 1개와 정형 재무 데이터용 데이터 스토어 2개 등 총 3개의 데이터 스토어를 만들어야 합니다.
비정형 데이터용 데이터 스토어 만들기
- 데이터 스토어 페이지에서 데이터 스토어 만들기 를 클릭합니다.
- 데이터 소스 선택에서 Cloud Storage를 선택합니다.
- Cloud Storage에서 데이터 가져오기 창에서 비정형 데이터 가져오기 (문서 검색 및 RAG)로 이동하여 문서를 선택합니다.
- 동기화 빈도 옵션을 일회성 으로 유지합니다.
- 가져올 폴더 또는 파일 선택에서 폴더를 클릭합니다.
gs://...필드에 비정형 파일을 위한 Cloud Storage 버킷 만들기 섹션에서 만든 버킷의 이름을 입력합니다. 예를 들어 버킷 이름이cymbal-app-hr-12이면 이름을cymbal-app-hr-12/HR로 입력합니다.HR폴더에서 수집하면 이 데이터 스토어에 HR 문서만 포함됩니다.- 계속 을 클릭합니다.
- 데이터 스토어 이름을
cymbal-hr로 입력합니다. - 계속 을 클릭합니다.
- 일반 가격 옵션을 유지합니다.
- 만들기 를 클릭합니다.
만들기를 클릭하면 데이터 스토어 페이지로 돌아갑니다.
구조화된 데이터용 데이터 스토어 만들기
BigQuery의 구조화된 데이터용 데이터 스토어 2개를 만듭니다. 하나는 직원 재무 정보용이고 다른 하나는 제품 인벤토리용입니다.
직원 재무 데이터용 데이터 스토어 만들기
- 데이터 스토어 페이지에서 데이터 스토어 만들기 를 다시 클릭합니다.
- 데이터 소스 선택에서 BigQuery를 선택합니다.
- 구조화된 데이터 가져오기에서 자체 스키마가 있는 BigQuery 테이블을 선택합니다.
- 동기화 빈도 옵션을 일회성 으로 유지합니다.
- 가져올 테이블 선택에서 찾아보기를 클릭합니다. 열리는 경로 선택 대화상자에서 프로젝트의
cymbal_finance데이터 세트에서employee_finance테이블을 선택합니다. 다른 프로젝트의 이름이 비슷한 테이블이 표시될 수 있으므로 프로젝트의 테이블을 선택해야 합니다. - 계속 을 클릭합니다.
- 스키마 검토 및 키 속성 할당 페이지를 검토합니다.
- 계속 을 클릭합니다.
- 데이터 스토어 이름을
cymbal-finance로 입력합니다. - 계속 을 클릭합니다.
- 일반 가격 옵션을 유지합니다.
- 만들기 를 클릭합니다.
만들기를 클릭하면 데이터 스토어 페이지로 돌아갑니다.
제품 인벤토리 데이터용 데이터 스토어 만들기
- 데이터 스토어 페이지에서 데이터 스토어 만들기 를 다시 클릭합니다.
- 데이터 소스 선택에서 BigQuery를 선택합니다.
- 구조화된 데이터 가져오기에서 자체 스키마가 있는 BigQuery 테이블을 선택합니다.
- 동기화 빈도 옵션을 일회성 으로 유지합니다.
- 가져올 테이블 선택에서 찾아보기를 클릭합니다. 열리는 경로 선택 대화상자에서 프로젝트의
cymbal_finance데이터 세트에서product_inventory테이블을 선택합니다. - 계속 을 클릭합니다.
- 스키마 검토 및 키 속성 할당 페이지를 검토합니다.
- 계속 을 클릭합니다.
- 데이터 스토어 이름을
cymbal-inventory로 입력합니다. - 계속 을 클릭합니다.
- 일반 가격 옵션을 유지합니다.
- 만들기 를 클릭합니다.
만들기를 클릭하면 데이터 스토어 페이지로 돌아갑니다.
8. 데이터 스토어를 앱에 연결
이제 데이터 스토어 페이지의 목록에 cymbal-hr (비정형), cymbal-finance (정형), cymbal-inventory (정형)의 세 데이터 스토어가 표시됩니다. 이러한 데이터 스토어를 앱에 연결하려면 다음 단계를 따르세요.
- 데이터 스토어 페이지에서 방금 만든 데이터 스토어 3개(
cymbal-hr,cymbal-finance,cymbal-inventory)를 모두 선택합니다. 계속하기 전에 데이터 스토어 3개를 모두 선택해야 합니다. - 계속 을 클릭합니다.
- 일반 가격 옵션을 유지합니다.
- 만들기 를 클릭합니다.
9. Cymbal 직원 포털 앱 테스트
cymbal-employee-portal앱에서 미리보기 를 클릭합니다.- 여기에서 검색 상자에 다음 질문을 입력합니다.
What are the stipends that I get as an employee of Cymbal located in London? - 제품 인벤토리와 관련된 질문을 입력합니다.
How many units of sneakers do we have in stock? - 다른 질문을 입력합니다.
What is the stipend for an executive in Cymbal?
검색 앱이 여러 소스에서 정보를 가져와 응답을 구성하는 방식을 확인합니다. 이러한 질문에 답변하기 위해 앱은 BigQuery에 저장된 정형 재무 데이터와 Cloud Storage의 비정형 HR 문서를 모두 검색했습니다.
이는 다양한 데이터 형식과 이기종 데이터 스토어에서 답변을 종합하여 단일의 일관된 환경을 제공하는 Vertex AI Search의 기능을 보여줍니다.
AI 모델을 조정하여 더 정확하고 도메인별 답변을 제공할 수도 있습니다. 생성형 환경 맞춤설정에 관한 자세한 내용은 답변 및 후속 조치 가져오기 문서를 참고하세요.
10. 앱 배포 옵션
최종 사용자에게 애플리케이션을 배포하는 것은 이 Codelab의 범위를 벗어나지만, 이것이 실제 시나리오로 어떻게 전환되는지 알아두면 유용합니다. Vertex AI Search 앱을 조직의 워크플로에 통합하는 방법에는 여러 가지가 있습니다.
- 사전 빌드된 웹 위젯. HTML
script태그를 사용하여 즉시 사용 가능한 검색 또는 채팅 인터페이스를 회사 기존 인트라넷 또는 웹페이지에 직접 삽입할 수 있습니다. 이는 앱을 사용자에게 가장 빠르게 제공하는 방법입니다. - 커스텀 API 통합. 사용자 환경을 완전히 제어하려면 Vertex AI Search REST API 또는 클라이언트 라이브러리 (예: Python, Node.js, Java)를 사용하여 커스텀 프런트엔드를 처음부터 빌드할 수 있습니다.
11. 정리
Google Cloud 계정에 지속적으로 비용이 청구되지 않도록 하려면 이 Codelab 중에 만든 리소스를 삭제합니다.
- Cloud 콘솔에서 Vertex AI Search 페이지로 이동합니다.
- 기존 앱 보기 를 클릭합니다.
cymbal-employee-portal앱에서 더보기 의 세로로 나열된 세 개의 점을 클릭한 다음 삭제 를 클릭합니다.- 화면에 표시된 메시지에 따라 삭제를 확인합니다.
- 데이터 스토어를 삭제하려면 콘솔의 왼쪽 탐색 패널에서 데이터 스토어 를 클릭합니다.
cymbal-hr,cymbal-finance,cymbal-inventory데이터 스토어를 삭제합니다.cymbal-hr데이터 스토어에서 더보기 의 세로로 나열된 세 개의 점을 클릭한 다음 삭제 를 클릭합니다.- 화면에 표시된 메시지에 따라 삭제를 확인합니다.
cymbal-finance데이터 스토어에서 더보기 의 세로로 나열된 세 개의 점을 클릭한 다음 삭제 를 클릭합니다.- 화면에 표시된 메시지에 따라 삭제를 확인합니다.
cymbal-inventory데이터 스토어에서 더보기 의 세로로 나열된 세 개의 점을 클릭한 다음 삭제 를 클릭합니다.- 화면에 표시된 메시지에 따라 삭제를 확인합니다.
- **버킷** 페이지로 이동하여 만든 버킷 (예:
cymbal-app-hr-12)을 삭제합니다. - BigQuery 페이지로 이동하여
cymbal_finance데이터 세트를 삭제합니다.
12. 축하합니다
미션 완료! Vertex AI Search를 사용하여 통합 엔터프라이즈 검색 환경을 빌드했습니다.
Cloud Storage의 비정형 엔터프라이즈 데이터와 BigQuery의 정형 레코드 간의 격차를 해소하여 머신러닝 코드를 한 줄도 작성하지 않고도 복잡한 비즈니스 추론을 수행할 수 있는 강력한 도구를 만들었습니다.
학습한 내용
- 수집: Cloud Storage의 비정형 문서와 BigQuery의 구조화된 데이터를 Vertex AI Search로 수집하는 방법.
- 다중 데이터 스토어 쿼리. 다중 데이터 스토어 검색 앱을 쿼리하여 정형 데이터와 비정형 데이터 모두에서 통합된 답변을 종합하는 방법.
- 조정 및 맞춤설정. 생성형 AI 모델을 조정하여 더 정확하고 도메인별 답변을 제공하는 방법.
- 배포 옵션. 사전 빌드된 위젯 또는 커스텀 API를 사용하여 이 추론 기능을 실제 애플리케이션에 통합하는 다양한 방법.