
1. Wprowadzenie
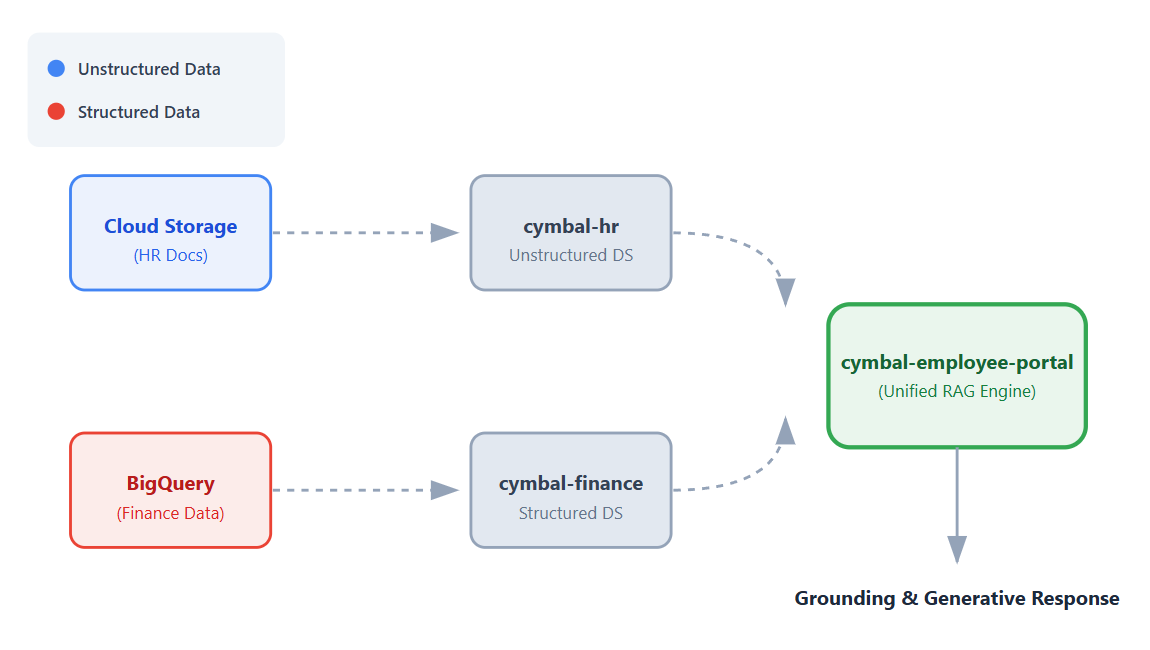
W tym ćwiczeniu utworzysz uniwersalną aplikację pomocy dla pracowników bez użycia kodu za pomocą Vertex AI Search.
Wyobraź sobie, że pracujesz w Cymbal, globalnej firmie z branży handlu detalicznego. Pracownicy często zadają pytania takie jak „Jakie są zasady rezerwowania podróży służbowych?” lub „Ile par butów sportowych mamy w magazynie?”.
Aby znaleźć te odpowiedzi, zwykle musisz zalogować się w zupełnie innych systemach. Oprócz pracy z różnymi systemami musisz też przeglądać dużą liczbę nieustrukturyzowanych danych działu kadr lub uruchamiać złożone zapytania SQL dotyczące ustrukturyzowanych danych finansowych, aby uzyskać odpowiedzi na swoje pytania.
W tym ćwiczeniu utworzysz jedną, ujednoliconą aplikację, która łączy się z tymi zbiorami danych, dzięki czemu pracownicy mogą uzyskiwać konwersacyjne, oparte na faktach odpowiedzi na swoje pytania za pomocą funkcji generowania wspomaganego wyszukiwaniem (RAG) w Vertex AI.
Jakie zadania wykonasz
W tym ćwiczeniu wykonasz te czynności:
- Skonfiguruj źródła danych. Utwórz zasobnik Cloud Storage na nieuporządkowane dokumenty HR i zbiór danych BigQuery na uporządkowane dane finansowe.
- Skonfiguruj magazyny danych. Twórz magazyny danych Vertex AI Search połączone ze źródłami danych Cloud Storage i BigQuery.
- Połącz aplikację. Utwórz aplikację Vertex AI Search i połącz z nią oba magazyny danych.
- Przetestuj aplikację. Korzystaj z ujednoliconego interfejsu wyszukiwania, aby sprawdzić odpowiedzi oparte na wiedzy, które syntetyzują informacje z obu magazynów danych.
- Poznaj kolejne kroki Poznaj opcje dostrajania modelu generatywnej AI i wdrażania aplikacji do wyszukiwania.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- Projekt Google Cloud z włączonymi płatnościami.
- Git zainstalowany na komputerze lokalnym.
To ćwiczenie jest przeznaczone dla deweloperów na wszystkich poziomach zaawansowania.
2. Zanim zaczniesz
Utwórz projekt Google Cloud i włącz wymagane interfejsy API.
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt w chmurze Google Cloud .
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Wymagane role uprawnień
W tym ćwiczeniu zakłada się, że masz rolę Właściciel projektu w projekcie Google Cloud.
Włącz interfejsy API
- W konsoli Google Cloud kliknij Aktywuj Cloud Shell. Jeśli używasz Cloud Shell po raz pierwszy, pojawi się panel z opcjami uruchomienia Cloud Shell w zaufanym środowisku z wzmocnieniem lub bez niego. Jeśli pojawi się prośba o autoryzację Cloud Shell, kliknij Autoryzuj.
- W Cloud Shell włącz wszystkie wymagane interfejsy API:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. Klonowanie repozytorium GitHub
Aby pokazać, jak działa wyszukiwanie w aplikacji pomocy dla pracowników Cymbal, potrzebujesz kilku plików testowych. W tej sekcji sklonujesz repozytorium GitHub na komputer lokalny, aby pobrać te pliki. W kolejnych krokach prześlesz te pliki do Google Cloud za pomocą interfejsu konsoli Cloud.
- W terminalu na komputerze lokalnym sklonuj repozytorium
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Przejdź do pobranego katalogu repozytorium:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - Przejrzyj pobrane pliki w tym katalogu. Zobaczysz 2 foldery:
HRiFinance.- HR. Ten folder zawiera wiele nieustrukturyzowanych plików, takich jak pliki
.doc,.txti.html. Prześlesz pliki HR do zasobnika Cloud Storage. - Finanse. Ten folder zawiera 2 pliki
.jsonl. Prześlesz te pliki do zbioru danych BigQuery.
- HR. Ten folder zawiera wiele nieustrukturyzowanych plików, takich jak pliki
4. Tworzenie zasobnika Cloud Storage na nieustrukturyzowane pliki
W tej sekcji utworzysz zasobnik Cloud Storage i prześlesz do niego dokumenty z folderu HR pobranego w sekcji Klonowanie repozytorium GitHub. Dane nieuporządkowane, takie jak dokumenty HR w tym przykładzie, nie mają zdefiniowanego formatu i mogą obejmować pliki tekstowe, dokumenty lub treści multimedialne.
- W konsoli Cloud otwórz stronę Zasobniki.
- Kliknij Utwórz.
- Na stronie Tworzenie zasobnika wpisz nazwę zasobnika. Nazwa musi być globalnie niepowtarzalna. Na przykład:
cymbal-app-hr-12. - Zachowaj opcje domyślne.
- Kliknij Utwórz.Zasobnik zostanie utworzony i wyświetli się strona Szczegóły zasobnika. Jeśli nie widzisz strony Szczegóły zasobnika, kliknij utworzony przed chwilą zasobnik.
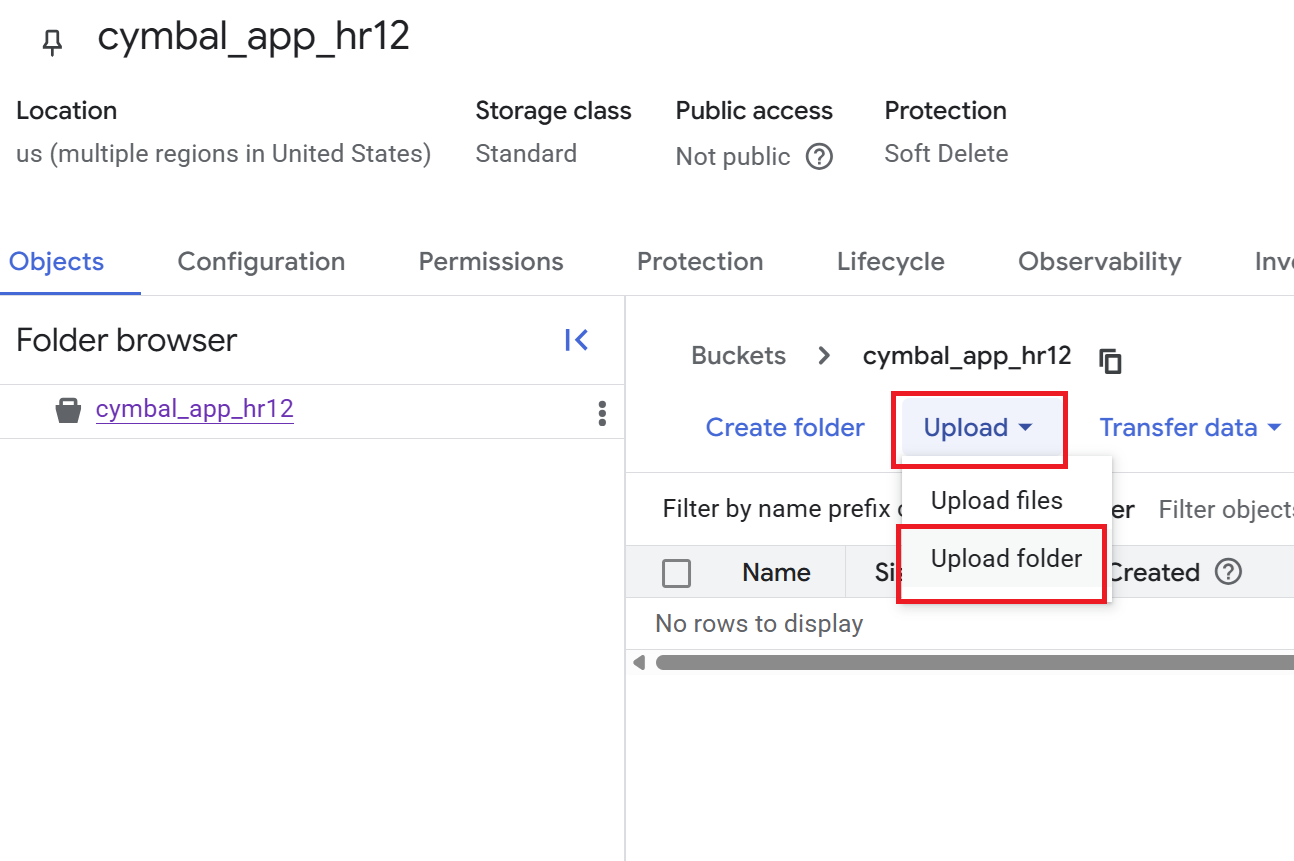
- Na stronie Szczegóły zasobnika kliknij Prześlij > Prześlij folder, a następnie wybierz folder
HRpobrany w sekcji Klonowanie repozytorium GitHub. - Potwierdź przesłanie.
- Na stronie Szczegóły zasobnika kliknij folder
HR, aby wyświetlić listę plików.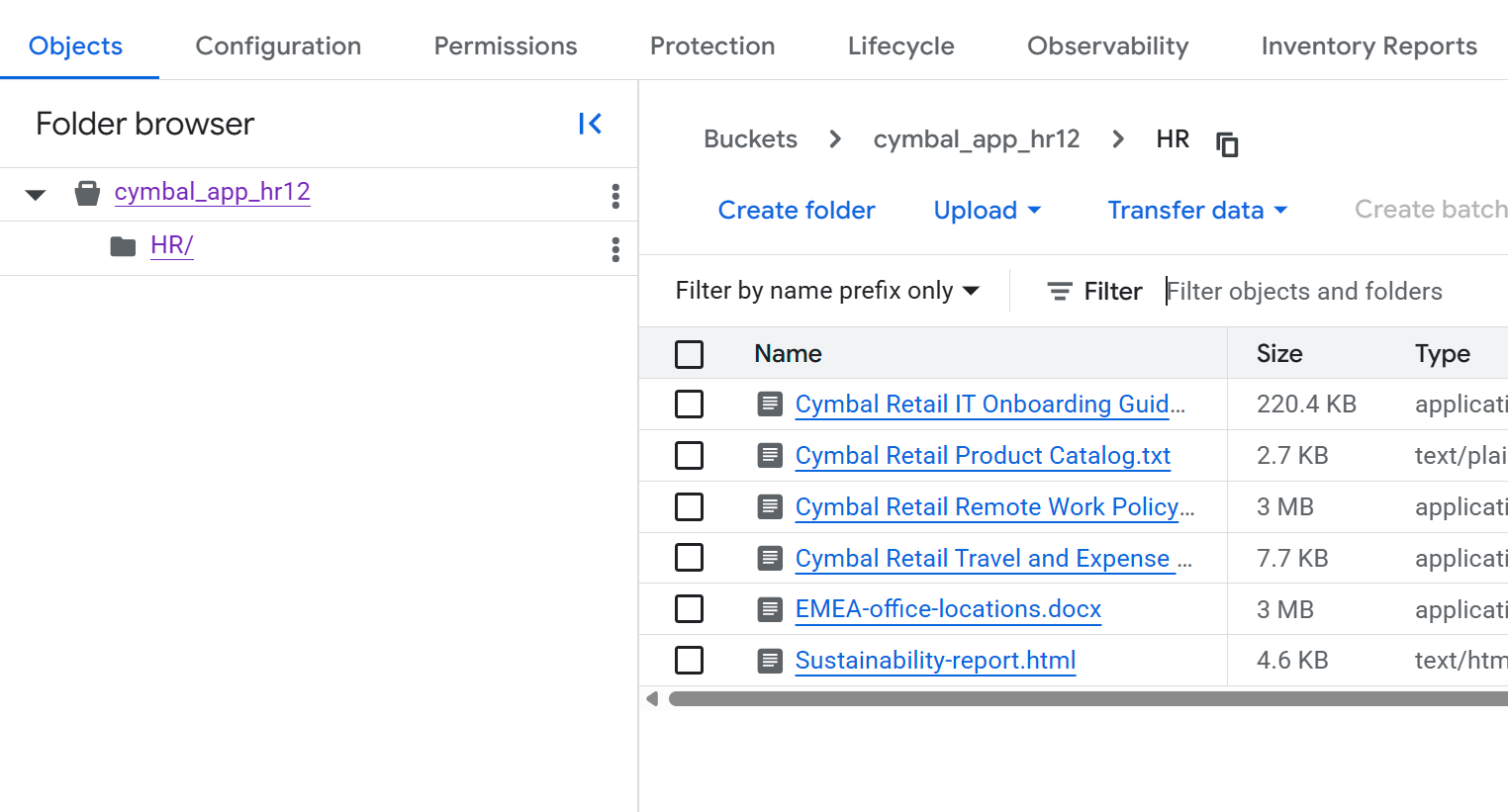
5. Tworzenie zbioru danych BigQuery na potrzeby plików strukturalnych
W tej sekcji utworzysz zbiór danych BigQuery i wczytasz dokumenty z folderu Finance pobranego w sekcji Klonowanie repozytorium GitHub do nowej tabeli. Uporządkowane dane, takie jak dokumenty finansowe w tym przykładzie, mają zdefiniowany format, np. rekordy w bazie danych.
- W konsoli Cloud otwórz stronę BigQuery.
- W panelu Eksplorator kliknij nazwę projektu, a następnie Wyświetl działania (3 pionowe kropki) > Utwórz zbiór danych.

- W panelu Utwórz zbiór danych wpisz
cymbal_financew polu Identyfikator zbioru danych. - W polu Data location (Lokalizacja danych) wybierz
US (multiple regions in United States). - Zachowaj opcje domyślne i kliknij Utwórz zbiór danych.
- W panelu Eksplorator rozwiń projekt i kliknij zbiór danych
cymbal_finance. - W panelu szczegółów zbioru danych kliknij Utwórz tabelę.
- Na stronie Utwórz tabelę w sekcji Źródło wykonaj te czynności:
- W menu Utwórz tabelę z wybierz Prześlij.
- W sekcji Wybierz plik kliknij Przeglądaj, przejdź do pobranego folderu
Financei wybierz plikcymbal_employee_finance.jsonl. - W polu Format pliku wybierz JSONL (JSON rozdzielany znakiem nowej linii).
- W sekcji Miejsce docelowe wpisz nazwę Tabela jako
employee_finance. - W sekcji Schemat zaznacz pole wyboru Automatyczne wykrywanie.
- Zachowaj pozostałe ustawienia domyślne i kliknij Utwórz tabelę.
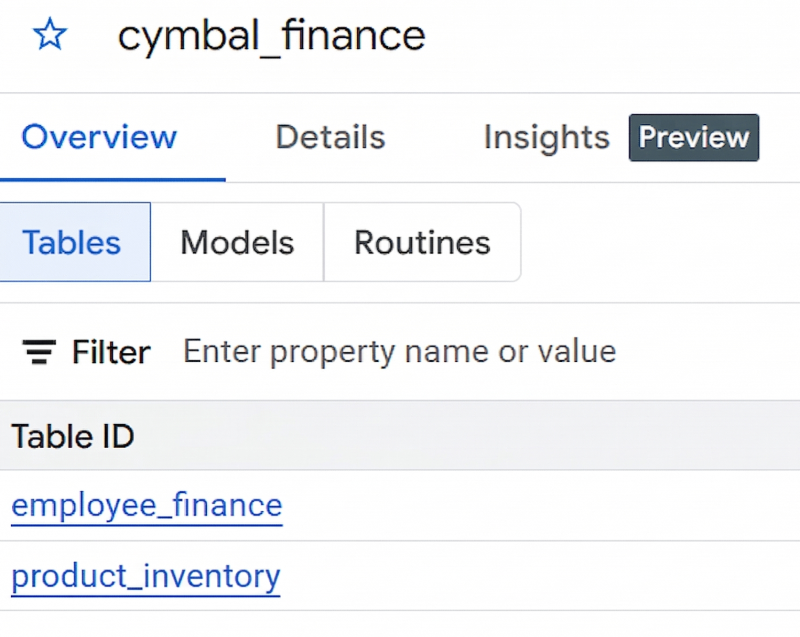
- Powtórz kroki od 7 do 11, aby wczytać dane do nowej tabeli. W kroku 8b kliknij
product_inventory.jsonl, a w kroku 9 wpiszproduct_inventoryjako nazwę tabeli.Jeśli nie widzisz tabel w panelu szczegółów zbioru danych, kliknij Odśwież. - Jeśli udało Ci się utworzyć zbiór danych i 2 tabele, powinny one wyglądać jak na tym obrazie:
6. Tworzenie aplikacji Vertex AI Search
- W konsoli Cloud otwórz stronę Vertex AI Search.
- Na kafelku Wyszukiwanie niestandardowe (ogólne) kliknij Utwórz.
- Na stronie Konfiguracja aplikacji do wyszukiwania sprawdź, czy wybrane są opcje Funkcje wersji Enterprise i Odpowiedzi generatywne.
- Nazwij aplikację
cymbal-employee-portal. - Wpisz nazwę firmy, np.
Cymbal Corp. - W polu Lokalizacja aplikacji pozostaw wartość
global. - Kliknij Dalej.
7. Tworzenie i łączenie magazynów danych
Na stronie Magazyny danych tworzysz magazyny danych, które połączysz z aplikacją. Musisz utworzyć 3 magazyny danych: 1 na nieustrukturyzowane dane HR i 2 na ustrukturyzowane dane finansowe.
Tworzenie magazynu danych dla danych nieuporządkowanych
- Na stronie Magazyny danych kliknij Utwórz magazyn danych.
- W sekcji Wybierz źródło danych kliknij Cloud Storage.
- W panelu Importuj dane z Cloud Storage kliknij Import nieuporządkowanych danych (wyszukiwanie dokumentów i RAG) i wybierz Dokumenty.
- Pozostaw opcję Częstotliwość synchronizacji ustawioną na Jednorazowo.
- W sekcji Wybierz folder lub plik, który chcesz zaimportować kliknij Folder.
- W polu
gs://...wpisz nazwę zasobnika utworzonego w sekcji Tworzenie zasobnika Cloud Storage na potrzeby plików nieustrukturyzowanych. Jeśli np. nazwa zasobnika tocymbal-app-hr-12, wpisz ją jakocymbal-app-hr-12/HR. Przetwarzanie danych z folderuHRgwarantuje, że w tym magazynie danych będą uwzględniane tylko dokumenty działu HR. - Kliknij Dalej.
- Wpisz nazwę magazynu danych w formacie
cymbal-hr. - Kliknij Dalej.
- Pozostaw opcję Ceny ogólne.
- Kliknij Utwórz.
Po kliknięciu Utwórz wrócisz na stronę Magazyny danych.
Tworzenie magazynów danych dla danych strukturalnych
Utworzysz 2 magazyny danych do przechowywania danych strukturalnych z BigQuery: jeden na potrzeby informacji finansowych o pracownikach, a drugi na potrzeby informacji o asortymencie produktów.
Tworzenie magazynu danych na potrzeby danych finansowych pracowników
- Na stronie Magazyny danych ponownie kliknij Utwórz magazyn danych.
- W sekcji Wybierz źródło danych kliknij BigQuery.
- W sekcji Importowanie danych strukturalnych wybierz Tabela BigQuery z własnym schematem.
- Pozostaw opcję Częstotliwość synchronizacji ustawioną na Jednorazowo.
- W polu Wybierz tabelę, którą chcesz zaimportować kliknij Przeglądaj. W wyświetlonym oknie Wybierz ścieżkę wybierz tabelę
employee_financeze zbioru danychcymbal_financew projekcie. Możesz zobaczyć tabele o podobnych nazwach z innych projektów, więc upewnij się, że wybierasz tabelę z Twojego projektu. - Kliknij Dalej.
- Zapoznaj się ze stroną Przejrzyj schemat i przypisz właściwości klucza.
- Kliknij Dalej.
- Wpisz nazwę magazynu danych w formacie
cymbal-finance. - Kliknij Dalej.
- Pozostaw opcję Ceny ogólne.
- Kliknij Utwórz.
Po kliknięciu Utwórz wrócisz na stronę Magazyny danych.
Tworzenie magazynu danych o asortymencie produktów
- Na stronie Magazyny danych ponownie kliknij Utwórz magazyn danych.
- W sekcji Wybierz źródło danych kliknij BigQuery.
- W sekcji Importowanie danych strukturalnych wybierz Tabela BigQuery z własnym schematem.
- Pozostaw opcję Częstotliwość synchronizacji ustawioną na Jednorazowo.
- W polu Wybierz tabelę, którą chcesz zaimportować kliknij Przeglądaj. W wyświetlonym oknie Wybierz ścieżkę wybierz tabelę
product_inventoryze zbioru danychcymbal_financew projekcie. - Kliknij Dalej.
- Zapoznaj się ze stroną Przejrzyj schemat i przypisz właściwości klucza.
- Kliknij Dalej.
- Wpisz nazwę magazynu danych w formacie
cymbal-inventory. - Kliknij Dalej.
- Pozostaw opcję Ceny ogólne.
- Kliknij Utwórz.
Po kliknięciu Utwórz wrócisz na stronę Magazyny danych.
8. Łączenie magazynów danych z aplikacją
Na liście na stronie Magazyny danych powinny być teraz widoczne 3 magazyny danych: cymbal-hr (dane nieuporządkowane), cymbal-finance (dane uporządkowane) i cymbal-inventory (dane uporządkowane). Aby połączyć te magazyny danych z aplikacją, wykonaj te czynności:
- Na stronie Magazyny danych wybierz wszystkie 3 utworzone magazyny danych:
cymbal-hr,cymbal-financeicymbal-inventory. Zanim przejdziesz dalej, wybierz wszystkie 3 magazyny danych. - Kliknij Dalej.
- Pozostaw opcję Ceny ogólne.
- Kliknij Utwórz.
9. Testowanie aplikacji portalu pracowniczego Cymbal
- W aplikacji
cymbal-employee-portalkliknij Podgląd. - W polu Wyszukaj tutaj wpisz to pytanie:
What are the stipends that I get as an employee of Cymbal located in London? - Wpisz pytanie dotyczące asortymentu produktów:
How many units of sneakers do we have in stock? - Wpisz kolejne pytanie:
What is the stipend for an executive in Cymbal?
Zwróć uwagę, jak aplikacja wyszukiwarki pobrała informacje z wielu źródeł, aby sformułować odpowiedź. Aby odpowiedzieć na te pytania, aplikacja przeszukała zarówno uporządkowane dane finansowe przechowywane w BigQuery, jak i nieuporządkowane dokumenty HR w Cloud Storage.
Pokazuje to możliwości Vertex AI Search w zakresie syntezy odpowiedzi w różnych formatach danych i rozproszonych magazynach danych w jedną, spójną całość.
Możesz też dostroić model AI, aby udzielał jeszcze dokładniejszych odpowiedzi dotyczących konkretnej dziedziny. Więcej informacji o dostosowywaniu generatywnej AI znajdziesz w dokumentacji Uzyskiwanie odpowiedzi i dalszych informacji.
10. Opcje wdrażania aplikacji
Wdrażanie aplikacji dla użytkowników nie jest objęte zakresem tego ćwiczenia, ale warto wiedzieć, jak to wygląda w rzeczywistości. Aplikację Vertex AI Search możesz zintegrować z procesami w swojej organizacji na kilka sposobów:
- Gotowy widżet internetowy. Gotowy interfejs wyszukiwania lub czatu możesz umieścić bezpośrednio w istniejącym intranecie lub na stronach internetowych firmy za pomocą tagu HTML
script. To najszybszy sposób na udostępnienie aplikacji użytkownikom. - Niestandardowa integracja interfejsu API Aby mieć pełną kontrolę nad wrażeniami użytkowników, możesz użyć interfejsów API REST Vertex AI Search lub bibliotek klienta (takich jak Python, Node.js czy Java) do utworzenia niestandardowego interfejsu od podstaw.
11. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tego ćwiczenia:
- W konsoli Cloud otwórz stronę Vertex AI Search.
- Kliknij Wyświetl istniejące aplikacje.
- W przypadku aplikacji
cymbal-employee-portalkliknij 3 kropki w pionie, aby wyświetlić Więcej, a następnie kliknij Usuń. - Postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby potwierdzić usunięcie.
- Aby usunąć magazyny danych, w panelu użytkownika po lewej stronie konsoli kliknij Magazyny danych.
- Usuń magazyny danych
cymbal-hr,cymbal-financeicymbal-inventory:- W przypadku magazynu danych
cymbal-hrkliknij 3 kropki w pionie, aby wyświetlić Więcej, a następnie kliknij Usuń. - Postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby potwierdzić usunięcie.
- W przypadku magazynu danych
cymbal-financekliknij 3 kropki w pionie, aby wyświetlić Więcej, a następnie kliknij Usuń. - Postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby potwierdzić usunięcie.
- W przypadku magazynu danych
cymbal-inventorykliknij 3 kropki w pionie, aby wyświetlić Więcej, a następnie kliknij Usuń. - Postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby potwierdzić usunięcie.
- W przypadku magazynu danych
- Otwórz stronę Zasobniki i usuń utworzony zasobnik (np.
cymbal-app-hr-12). - Otwórz stronę BigQuery i usuń zbiór danych
cymbal_finance.
12. Gratulacje
Misja ukończona! Udało Ci się utworzyć ujednoliconą wyszukiwarkę dla przedsiębiorstw za pomocą Vertex AI Search.
Dzięki połączeniu nieustrukturyzowanych danych firmowych w Cloud Storage z ustrukturyzowanymi rekordami z BigQuery udało Ci się stworzyć zaawansowane narzędzie do złożonego rozumowania biznesowego – a wszystko to bez pisania ani jednej linijki kodu uczenia maszynowego.
Czego się dowiedziałeś(-aś)
- Pozyskiwanie: jak pozyskiwać nieuporządkowane dokumenty z Cloud Storage i dane uporządkowane z BigQuery do Vertex AI Search.
- Wykonywanie zapytań w wielu sklepach danych Jak wysyłać zapytania do aplikacji do wyszukiwania w wielu magazynach danych, aby syntetyzować ujednolicone odpowiedzi zarówno z danych uporządkowanych, jak i nieuporządkowanych.
- Dostrajanie i dostosowywanie jak dostosowywać modele generatywnej AI, aby udzielały dokładniejszych odpowiedzi dotyczących konkretnych dziedzin;
- Opcje wdrażania Różne sposoby integrowania tej funkcji rozumowania z aplikacjami w rzeczywistym świecie za pomocą gotowych widżetów lub niestandardowych interfejsów API.