
1. Introdução
Neste codelab, você vai criar um app universal de help desk para funcionários sem código usando a Vertex AI para Pesquisa.
Imagine que você trabalha na Cymbal, uma empresa global de varejo. Os funcionários costumam ter dúvidas como "Qual é a política para reservar viagens de negócios?" ou "Quantas unidades de tênis temos em estoque?".
Normalmente, é necessário fazer login em sistemas completamente diferentes para encontrar essas respostas. Além de lidar com sistemas diferentes, você também precisa ler um grande número de dados de RH não estruturados ou executar comandos SQL complexos em dados financeiros estruturados para obter respostas às suas perguntas.
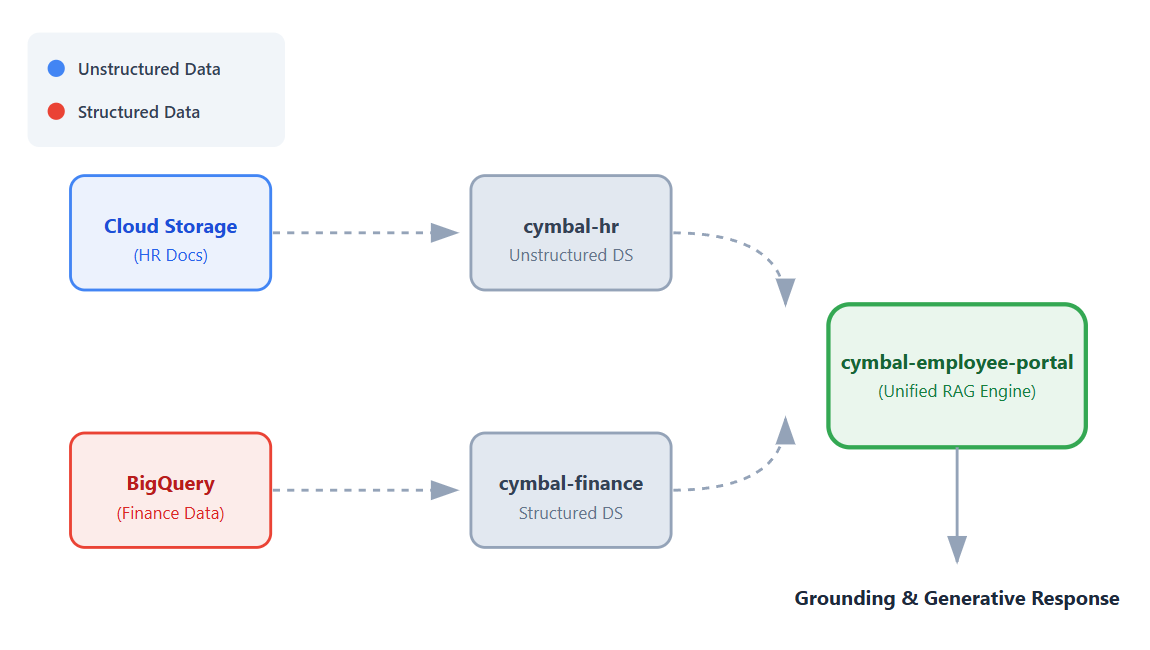
Neste codelab, você vai criar um app único e unificado que se conecta a esses conjuntos de dados, permitindo que os funcionários recebam respostas conversacionais e fundamentadas às perguntas usando os recursos de geração aumentada por recuperação (RAG, na sigla em inglês) da Vertex AI.
Atividades deste laboratório
Neste codelab, você vai concluir as seguintes etapas:
- Configurar fontes de dados. Crie um bucket do Cloud Storage para documentos de RH não estruturados e um conjunto de dados do BigQuery para dados financeiros estruturados.
- Configurar repositórios de dados. Crie repositórios de dados da Vertex AI para Pesquisa conectados às fontes de dados do Cloud Storage e do BigQuery.
- Conectar o app : crie um app da Vertex AI para Pesquisa e vincule os dois repositórios de dados a ele.
- Testar o app : interaja com a interface de pesquisa unificada para verificar respostas fundamentadas que sintetizam informações de ambos os repositórios de dados.
- Confira as próximas etapas. Analise as opções para ajustar o modelo de IA generativa e implantar o app de pesquisa.
O que é necessário
- Um navegador da Web, como o Chrome.
- Ter um projeto do Google Cloud com o faturamento ativado.
- Git instalado na sua máquina local.
Este codelab é destinado a desenvolvedores de todos os níveis.
2. Antes de começar
Crie um projeto na nuvem do Google Cloud e ative as APIs necessárias.
- No Console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem .
- Verifique se o faturamento está ativado para seu projeto na nuvem. Saiba como verificar se o faturamento está ativado em um projeto.
Papéis do IAM obrigatórios
Este codelab pressupõe que você tenha o papel de Proprietário do projeto no seu projeto na nuvem do Google Cloud.
Ativar APIs
- No console do Google Cloud, clique em Ativar o Cloud Shell: se você nunca usou o Cloud Shell antes, um painel vai aparecer oferecendo a opção de iniciar o Cloud Shell em um ambiente confiável com ou sem um aumento. Se for preciso autorizar o Cloud Shell, clique em Autorizar.
- No Cloud Shell, ative todas as APIs necessárias:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. Clonar um repositório do GitHub
Para mostrar como a pesquisa funciona no app de help desk para funcionários da Cymbal, você precisa de alguns arquivos de simulação. Nesta seção, você vai clonar um repositório do GitHub na sua máquina local para receber esses arquivos. Você vai fazer upload desses arquivos para o Google Cloud nas etapas posteriores usando a interface do console do Cloud.
- Em um terminal na sua máquina local, clone o repositório
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Navegue até o diretório do repositório transferido por download:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - Explore os arquivos transferidos por download nesse diretório. Você vai notar que há duas pastas:
HReFinance.- HR. Essa pasta contém vários arquivos não estruturados, como arquivos
.doc,.txte.html. Você vai fazer upload dos arquivos de RH para um bucket do Cloud Storage. - Finance. Essa pasta contém dois arquivos
.jsonl. Você vai fazer upload desses arquivos para um conjunto de dados do BigQuery.
- HR. Essa pasta contém vários arquivos não estruturados, como arquivos
4. Criar um bucket do Cloud Storage para arquivos não estruturados
Nesta seção, você vai criar um bucket do Cloud Storage e fazer upload dos documentos na pasta HR que você transferiu por download na seção Clonar um repositório do GitHub. Dados não estruturados, como os documentos de RH neste exemplo, não seguem um formato predefinido e podem incluir arquivos de texto, documentos ou conteúdo multimídia.
- No console do Cloud, acesse a página Buckets.
- Clique em Criar.
- Na página Criar um bucket, insira o nome de um bucket. O nome precisa ser globalmente exclusivo. Por exemplo,
cymbal-app-hr-12. - Mantenha as opções padrão.
- Clique em Criar.O bucket é criado e a página Detalhes do bucket é exibida. Se a página Detalhes do bucket não aparecer, clique no bucket que você acabou de criar.
- Na página Detalhes do bucket , clique em Fazer upload > Fazer upload da pasta e selecione a pasta
HRque você transferiu por download na seção Clonar um repositório do GitHub. - Confirme o upload.
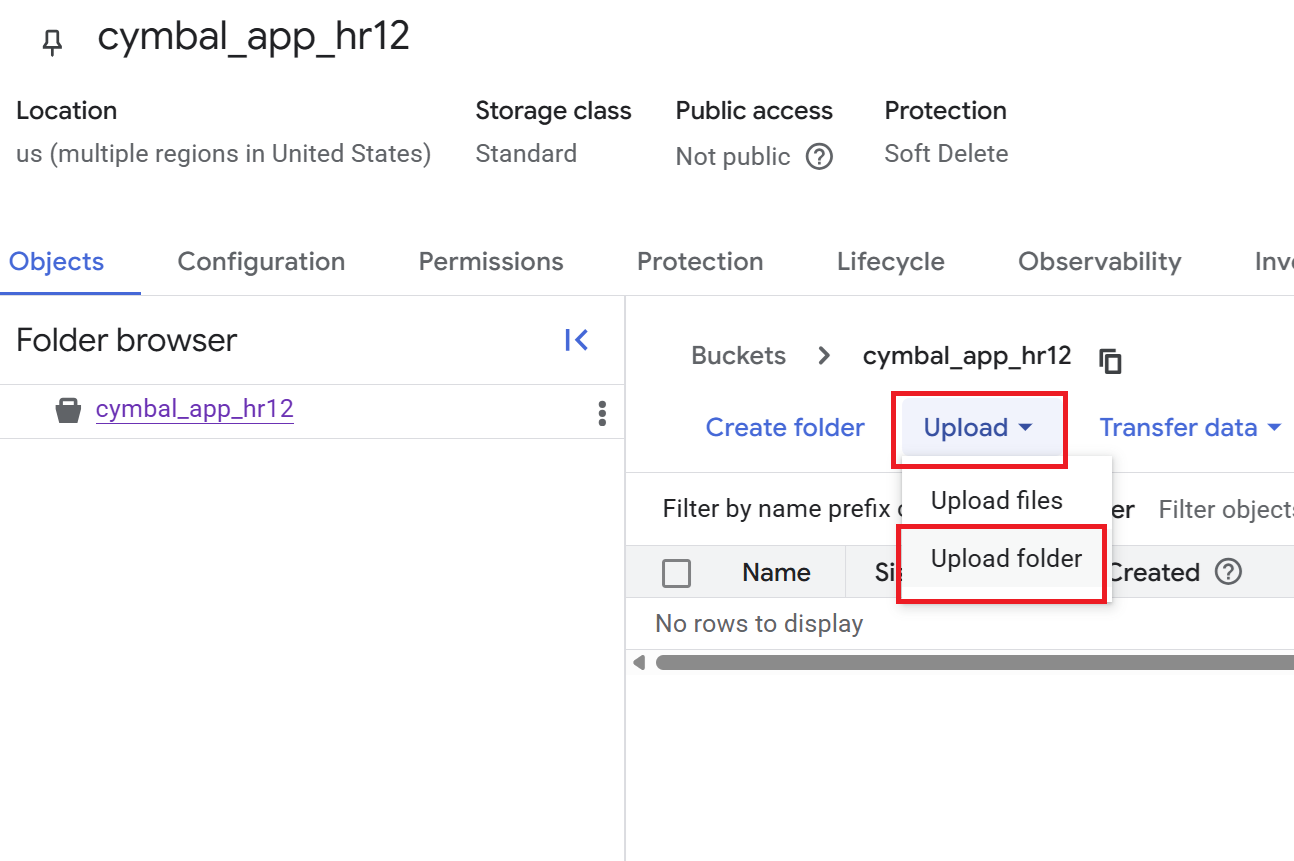
- Na página Detalhes do bucket, clique na pasta
HRpara conferir a lista de arquivos.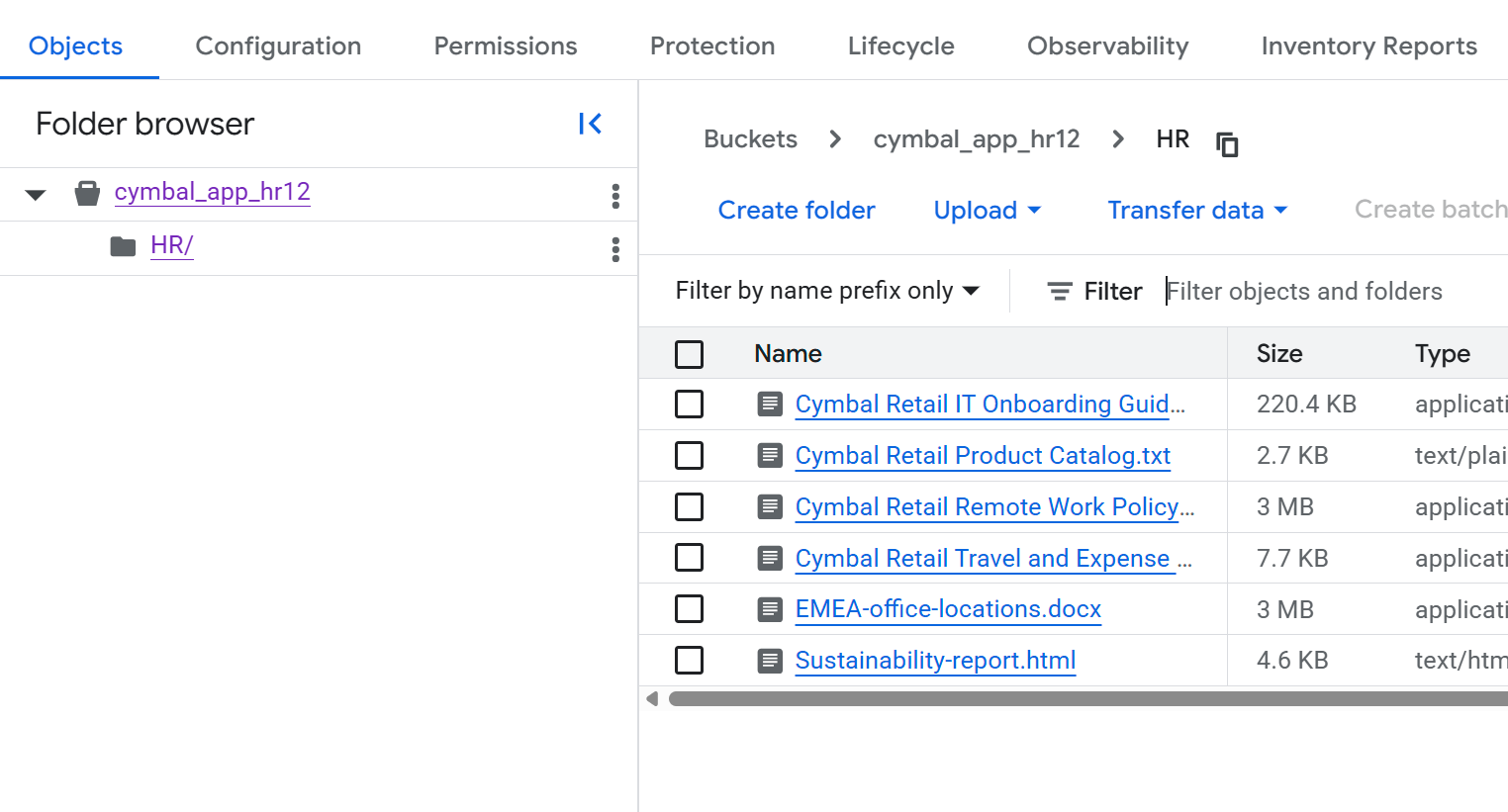
5. Criar um conjunto de dados do BigQuery para arquivos estruturados
Nesta seção, você vai criar um conjunto de dados do BigQuery e carregar os documentos na pasta Finance que você transferiu por download na seção Clonar um repositório do GitHub em uma nova tabela. Dados estruturados, como os documentos financeiros neste exemplo, seguem um formato predefinido, como registros em um banco de dados.
- No console do Cloud, acesse a página do BigQuery.
- No painel Explorer, clique no nome do projeto e em Ver ações (os três pontos verticais) > Criar conjunto de dados.
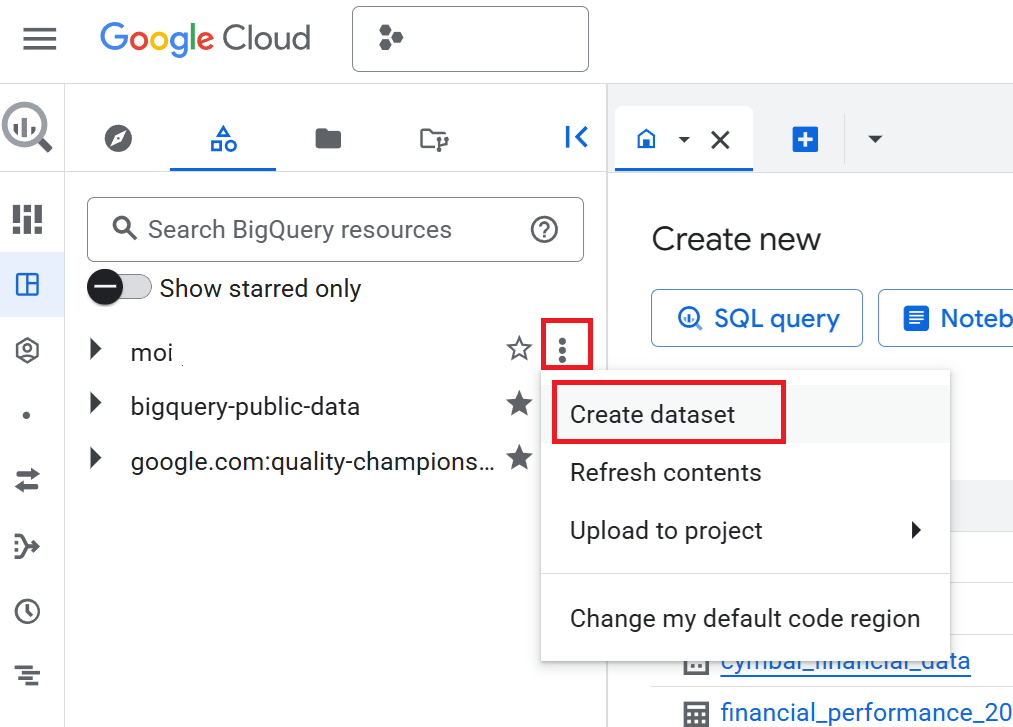
- No painel Criar conjunto de dados, insira o ID do conjunto de dados como
cymbal_finance. - Em Local dos dados, selecione
US (multiple regions in United States). - Mantenha as opções padrão e clique em Criar conjunto de dados.
- No painel Explorer , expanda o projeto e clique no conjunto de dados
cymbal_finance. - No painel de detalhes do conjunto de dados, clique em Criar tabela.
- Na página Criar tabela, na seção Origem, faça o seguinte:
- Em Criar tabela de, selecione Fazer upload.
- Para Selecionar arquivo, clique em Procurar, navegue até a pasta
Financeque você transferiu por download e selecionecymbal_employee_finance.jsonl. - Em Formato do arquivo, selecione JSONL (JSON delimitado por nova linha).
- Na seção Destino, insira o nome da Tabela como
employee_finance. - Na seção Esquema, selecione a caixa de seleção Detecção automática.
- Mantenha as outras configurações padrão e clique em Criar tabela.
- Repita as etapas de 7 a 11 para carregar dados em uma nova tabela. Na etapa 8b, selecione
product_inventory.jsonle, na etapa 9, insiraproduct_inventorycomo o nome da Tabela.Se as tabelas não aparecerem no painel de detalhes do conjunto de dados, clique em Atualizar. - Se você criou o conjunto de dados e as duas tabelas, ele vai aparecer como na imagem a seguir:
6. Criar um app da Vertex AI para Pesquisa
- No console do Cloud, acesse a página da Vertex AI para Pesquisa.
- No bloco Pesquisa personalizada (geral), clique em Criar.
- Na página Configuração do app de pesquisa, verifique se as opções Recursos da edição Enterprise e Respostas generativas estão selecionadas.
- Nomeie o app
cymbal-employee-portal. - Insira o Nome da empresa como
Cymbal Corp. - Mantenha o Local do app como
global. - Clique em Continuar.
7. Criar e conectar repositórios de dados
Na página Repositórios de dados , crie repositórios de dados que serão conectados ao seu app. É necessário criar três repositórios de dados: um para dados de RH não estruturados e dois para dados financeiros estruturados.
Criar um repositório de dados para dados não estruturados
- Na página Repositórios de dados, clique em Criar repositório de dados.
- Em Selecionar uma fonte de dados, selecione Cloud Storage.
- No painel Importar dados do Cloud Storage , acesse Importação de dados não estruturados (pesquisa de documentos e RAG) e selecione Documentos.
- Mantenha a opção Frequência de sincronização como Uma vez.
- Em Selecionar uma pasta ou um arquivo para importar, clique em Pasta.
- No campo
gs://..., insira o nome do bucket que você criou na seção Criar um bucket do Cloud Storage para arquivos não estruturados. Por exemplo, se o nome do bucket forcymbal-app-hr-12, insira o nome comocymbal-app-hr-12/HR.A ingestão da pastaHRgarante que apenas os documentos de RH sejam incluídos nesse repositório de dados. - Clique em Continuar.
- Insira o nome do repositório de dados como
cymbal-hr. - Clique em Continuar.
- Mantenha a opção de Preços gerais.
- Clique em Criar.
Depois de clicar em Criar, você vai voltar para a página Repositórios de dados.
Criar repositórios de dados para dados estruturados
Você vai criar dois repositórios de dados para dados estruturados do BigQuery: um para informações financeiras dos funcionários e outro para o inventário de produtos.
Criar um repositório de dados para dados financeiros dos funcionários
- Na página Repositórios de dados, clique em Criar repositório de dados novamente.
- Em Selecionar uma fonte de dados, selecione BigQuery.
- Em Importação de dados estruturados, selecione Tabela do BigQuery com seu próprio esquema.
- Mantenha a opção Frequência de sincronização como Uma vez.
- Em Selecionar uma tabela para importar, clique em Procurar. Na caixa de diálogo Selecionar caminho que é aberta, selecione a tabela
employee_financedo conjunto de dadoscymbal_financeno seu projeto. É possível que tabelas com nomes semelhantes de outros projetos apareçam. Por isso, selecione a tabela do seu projeto. - Clique em Continuar.
- Analise a página Analisar esquema e atribuir propriedades principais.
- Clique em Continuar.
- Insira o nome do repositório de dados como
cymbal-finance. - Clique em Continuar.
- Mantenha a opção de Preços gerais.
- Clique em Criar.
Depois de clicar em Criar, você vai voltar para a página Repositórios de dados.
Criar um repositório de dados para dados de inventário de produtos
- Na página Repositórios de dados, clique em Criar repositório de dados novamente.
- Em Selecionar uma fonte de dados, selecione BigQuery.
- Em Importação de dados estruturados, selecione Tabela do BigQuery com seu próprio esquema.
- Mantenha a opção Frequência de sincronização como Uma vez.
- Em Selecionar uma tabela para importar, clique em Procurar. Na caixa de diálogo Selecionar caminho que é aberta, selecione a tabela
product_inventorydo conjunto de dadoscymbal_financeno seu projeto. - Clique em Continuar.
- Analise a página Analisar esquema e atribuir propriedades principais.
- Clique em Continuar.
- Insira o nome do repositório de dados como
cymbal-inventory. - Clique em Continuar.
- Mantenha a opção de Preços gerais.
- Clique em Criar.
Depois de clicar em Criar, você vai voltar para a página Repositórios de dados.
8. Conectar repositórios de dados ao seu app
Agora você vai encontrar três repositórios de dados na lista da página Repositórios de dados: cymbal-hr (não estruturado), cymbal-finance (estruturado) e cymbal-inventory (estruturado). Para conectar esses repositórios de dados ao seu app, siga estas etapas:
- Na página Repositórios de dados , selecione os três repositórios de dados que você acabou de criar:
cymbal-hr,cymbal-financeecymbal-inventory. Selecione todos os três repositórios de dados antes de continuar. - Clique em Continuar.
- Mantenha a opção de Preços gerais.
- Clique em Criar.
9. Testar o app do portal de funcionários da Cymbal
- No app
cymbal-employee-portal, clique em Visualizar. - Na caixa Pesquisar aqui, insira a seguinte pergunta:
What are the stipends that I get as an employee of Cymbal located in London? - Insira uma pergunta relacionada ao inventário de produtos:
How many units of sneakers do we have in stock? - Insira outra pergunta:
What is the stipend for an executive in Cymbal?
Observe como o app de pesquisa recuperou informações de várias fontes para formular a resposta. Para responder a essas perguntas, o app pesquisou os dados financeiros estruturados armazenados no BigQuery e os documentos de RH não estruturados no Cloud Storage.
Isso demonstra o poder da Vertex AI para Pesquisa de sintetizar respostas em vários formatos de dados e repositórios de dados diferentes em uma única experiência coesa.
Você também pode ajustar o modelo de IA para fornecer respostas ainda mais precisas e específicas do domínio. Para mais informações sobre como personalizar a experiência generativa, consulte a documentação Receber respostas e acompanhamentos.
10. Opções para implantar seu app
Embora a implantação do aplicativo para usuários finais esteja fora do escopo deste codelab, é útil saber como isso se traduz em um cenário real. Você tem várias opções para integrar o app da Vertex AI para Pesquisa aos fluxos de trabalho da sua organização:
- Widget da Web pré-criado. É possível incorporar uma interface de pesquisa ou chat pronta para uso diretamente na intranet ou nas páginas da Web da sua empresa usando uma tag
scriptHTML. Essa é a maneira mais rápida de disponibilizar seu app para os usuários. - Integração de API personalizada. Para ter controle total sobre a experiência do usuário, use as APIs REST da Vertex AI para Pesquisa ou bibliotecas de cliente (como Python, Node.js ou Java) para criar um front-end personalizado do zero.
11. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados durante este codelab:
- No console do Cloud, acesse a página da Vertex AI para Pesquisa.
- Clique em Acessar apps atuais.
- No app
cymbal-employee-portal, clique nos três pontos verticais em Mais e em Excluir. - Siga as instruções na tela para confirmar a exclusão.
- Para excluir os repositórios de dados, clique em Repositórios de dados no painel de navegação à esquerda do console.
- Exclua os repositórios de dados
cymbal-hr,cymbal-financeecymbal-inventory:- No repositório de dados
cymbal-hr, clique nos três pontos verticais em Mais e em Excluir. - Siga as instruções na tela para confirmar a exclusão.
- No repositório de dados
cymbal-finance, clique nos três pontos verticais em Mais e em Excluir. - Siga as instruções na tela para confirmar a exclusão.
- No repositório de dados
cymbal-inventory, clique nos três pontos verticais em Mais e em Excluir. - Siga as instruções na tela para confirmar a exclusão.
- No repositório de dados
- Acesse a página Buckets e exclua o bucket que você criou (por exemplo,
cymbal-app-hr-12). - Acesse a página do BigQuery e exclua o conjunto de dados
cymbal_finance.
12. Parabéns
Missão concluída! Você criou uma experiência de pesquisa empresarial unificada usando a Vertex AI para Pesquisa.
Ao preencher a lacuna entre os dados empresariais não estruturados no Cloud Storage e os registros estruturados do BigQuery, você criou uma ferramenta poderosa capaz de raciocínio empresarial complexo, tudo sem escrever uma única linha de código de aprendizado de máquina.
O que você aprendeu
- Ingestão:como ingerir documentos não estruturados do Cloud Storage e dados estruturados do BigQuery na Vertex AI para Pesquisa.
- Consulta de vários repositórios de dados. Como consultar um app de pesquisa de vários repositórios de dados para sintetizar respostas unificadas de dados estruturados e não estruturados.
- Ajuste e personalização. Como ajustar os modelos de IA generativa para fornecer respostas mais precisas e específicas do domínio.
- Opções de implantação. As várias maneiras de integrar esse recurso de raciocínio em aplicativos do mundo real usando widgets pré-criados ou APIs personalizadas.