
1. Введение
В этом практическом занятии вы создадите универсальное приложение для службы поддержки сотрудников без использования кода, применяя Vertex AI Search.
Представьте, что вы работаете в компании Cymbal, глобальной розничной сети. Сотрудники часто задают вопросы типа: «Какова политика бронирования деловых поездок?» или «Сколько кроссовок у нас есть в наличии?».
Как правило, для получения ответов на эти вопросы необходимо войти в совершенно разные системы. Помимо работы с различными системами, вам также придётся просмотреть большое количество неструктурированных данных по персоналу или выполнить сложные SQL-запросы к структурированным финансовым данным, чтобы получить ответы на свои вопросы.
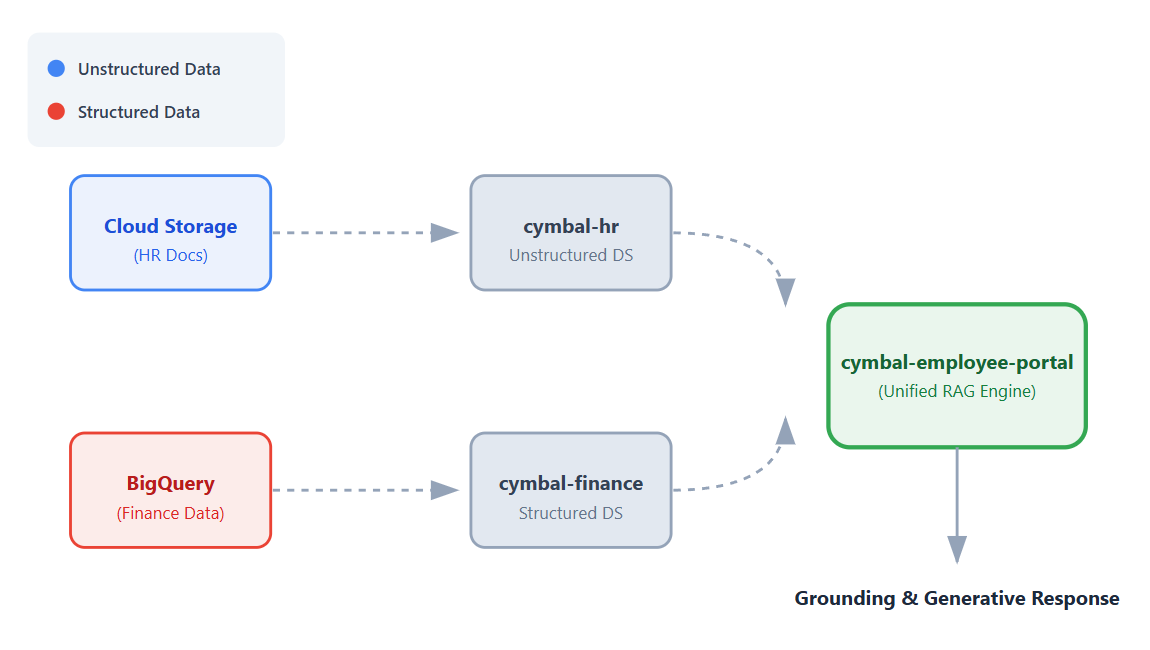
В этом практическом занятии вы создадите единое, унифицированное приложение, которое будет подключаться к этим наборам данных, позволяя сотрудникам получать ответы на свои вопросы в разговорном формате, используя возможности дополненной генерации данных (Retrieval Augmented Generation, RAG) от Vertex AI.
Что вы будете делать
В этом практическом задании вы выполните следующие шаги:
- Настройте источники данных. Создайте хранилище Cloud Storage для неструктурированных документов отдела кадров и набор данных BigQuery для структурированных финансовых данных.
- Настройте хранилища данных. Создайте хранилища данных Vertex AI Search, подключенные к вашим источникам данных Cloud Storage и BigQuery.
- Подключите приложение. Создайте приложение Vertex AI Search и свяжите с ним оба хранилища данных.
- Протестируйте приложение. Взаимодействуйте с единым интерфейсом поиска, чтобы проверить обоснованные ответы, которые объединяют информацию из обоих хранилищ данных.
- Изучите дальнейшие шаги. Ознакомьтесь с вариантами настройки модели генеративного ИИ и развертывания вашего поискового приложения.
Что вам понадобится
- Веб-браузер, например Chrome .
- Проект Google Cloud с включенной функцией выставления счетов.
- Установите Git на свой локальный компьютер.
Этот практический семинар предназначен для разработчиков всех уровней.
2. Прежде чем начать
Создайте проект в Google Cloud и включите необходимые API.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить , включена ли функция выставления счетов для проекта .
Необходимые роли IAM
В этом практическом занятии предполагается, что у вас есть роль « Владелец проекта» для вашего проекта в Google Cloud.
Включить API
- В консоли Google Cloud нажмите «Активировать Cloud Shell» : если вы никогда раньше не использовали Cloud Shell, появится панель, позволяющая запустить Cloud Shell в доверенной среде с ускорением или без него. Если вас попросят авторизовать Cloud Shell, нажмите «Авторизовать» .
- В Cloud Shell включите все необходимые API:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. Клонируйте репозиторий GitHub.
Чтобы продемонстрировать работу поиска в приложении Cymbal для службы поддержки сотрудников, вам потребуются несколько фиктивных файлов. В этом разделе вы клонируете репозиторий GitHub на свой локальный компьютер, чтобы получить эти файлы. На последующих этапах вы загрузите эти файлы в Google Cloud, используя интерфейс Cloud Console.
- В терминале на вашем локальном компьютере клонируйте репозиторий
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Перейдите в каталог загруженного репозитория:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - Изучите загруженные файлы в этой директории. Вы заметите, что там есть две папки:
HRиFinance.- Папка HR содержит ряд неструктурированных файлов, таких как файлы
.doc,.txtи.html. Вам необходимо загрузить файлы HR в хранилище Cloud Storage. - Финансы . Эта папка содержит два файла
.jsonl. Вам нужно будет загрузить эти файлы в набор данных BigQuery.
- Папка HR содержит ряд неструктурированных файлов, таких как файлы
4. Создайте сегмент облачного хранилища для неструктурированных файлов.
В этом разделе вы создаете хранилище Cloud Storage и загружаете документы в папку HR , которую вы скачали в разделе «Клонирование репозитория GitHub» . Неструктурированные данные, такие как документы HR в этом примере, не имеют предопределенного формата и могут включать текстовые файлы, документы или мультимедийный контент.
- В консоли Cloud перейдите на страницу «Корзины» .
- Нажмите «Создать» .
- На странице «Создать корзину» введите имя корзины. Имя должно быть уникальным во всем мире. Например:
cymbal-app-hr-12. - Сохраните параметры по умолчанию.
- Нажмите «Создать» . Корзина будет создана, и отобразится страница с подробными сведениями о корзине . Если вы не видите страницу с подробными сведениями о корзине , щелкните по только что созданной корзине.
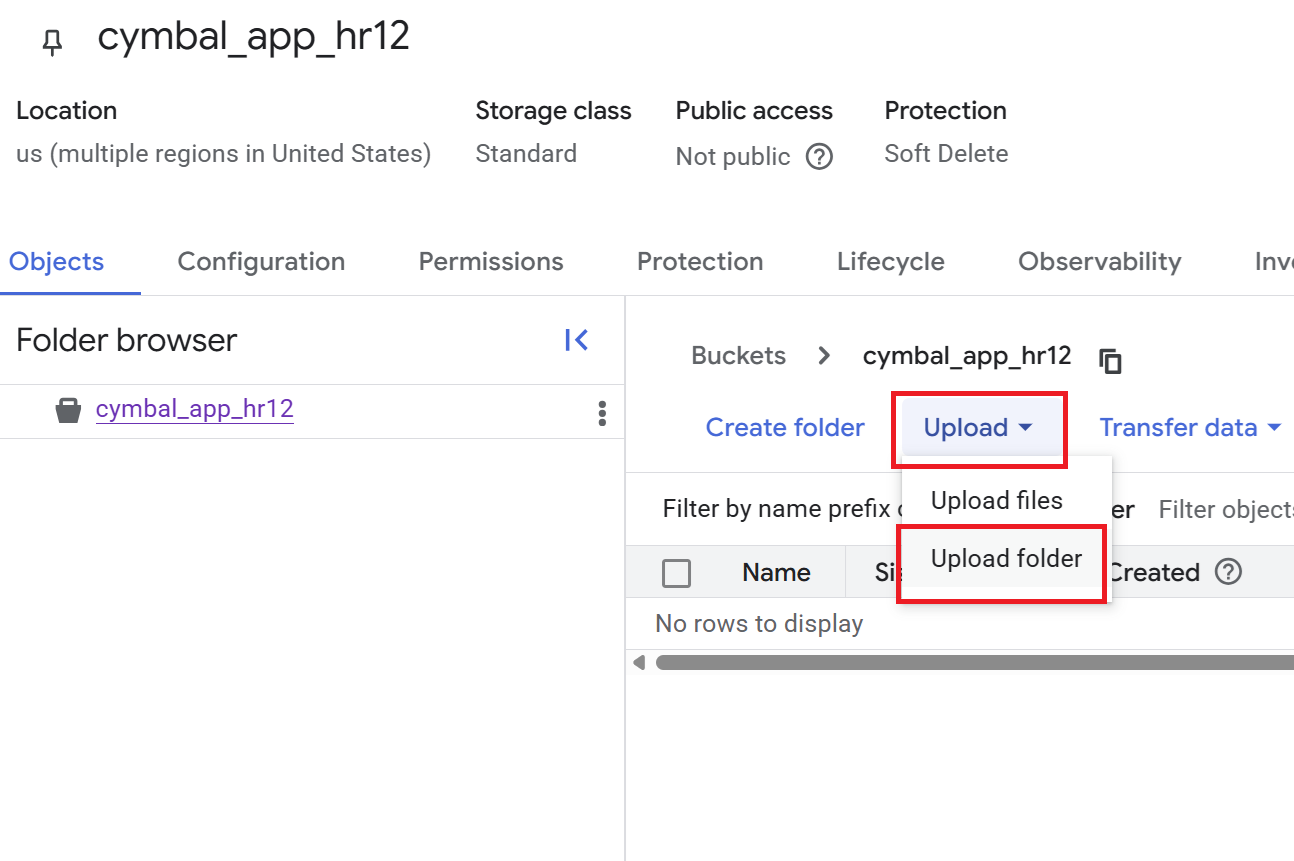
- На странице сведений о хранилище нажмите «Загрузка» > «Загрузить папку» , а затем выберите папку
HR, которую вы загрузили в разделе «Клонировать репозиторий GitHub» . - Подтвердите загрузку.
- На странице с подробными сведениями о папке нажмите на папку
HR, чтобы просмотреть список файлов.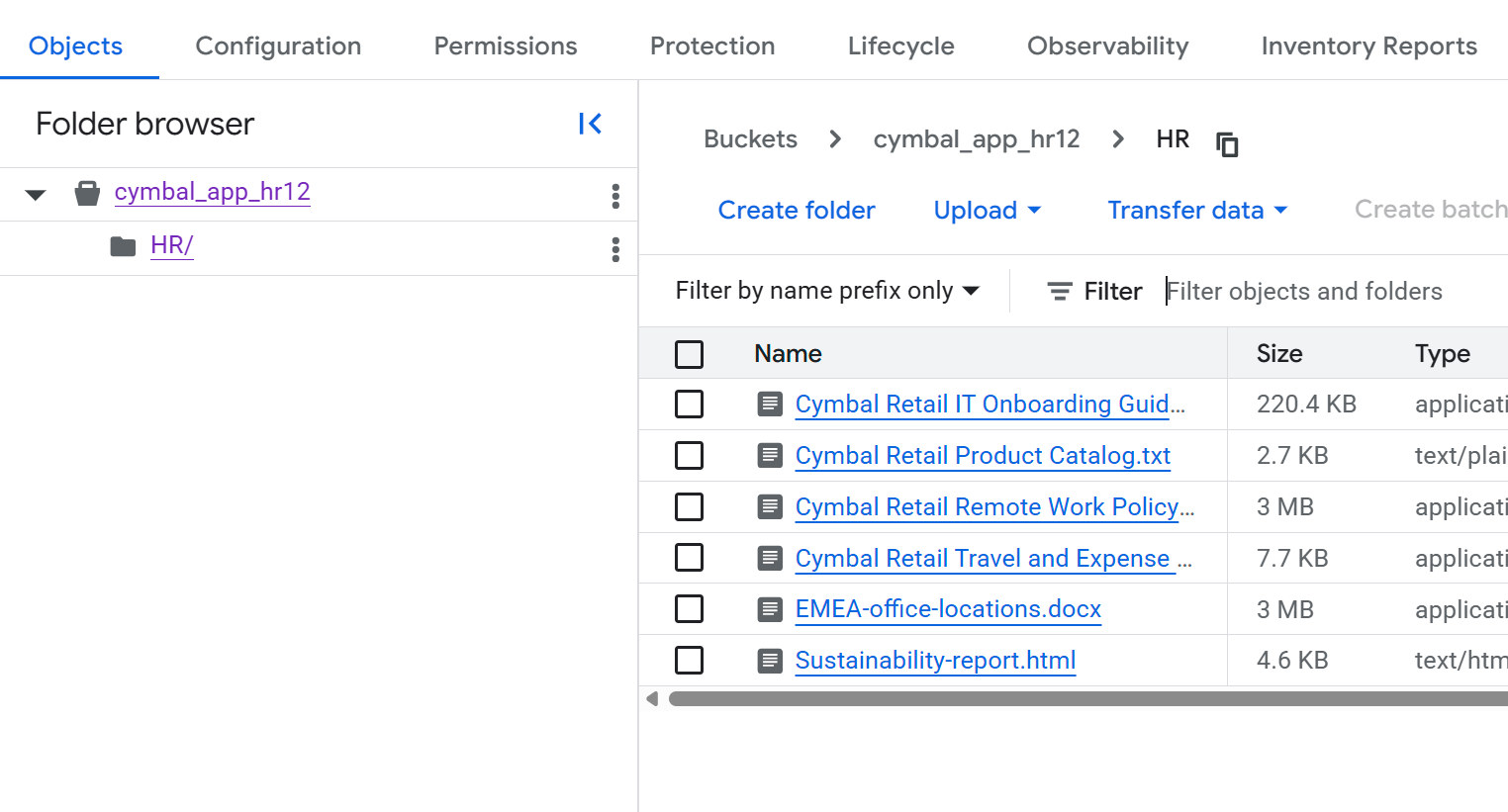
5. Создайте набор данных BigQuery для структурированных файлов.
В этом разделе вы создадите набор данных BigQuery и загрузите документы из папки Finance , которую вы скачали в разделе «Клонирование репозитория GitHub», в новую таблицу. Структурированные данные, такие как финансовые документы в этом примере, соответствуют предопределенному формату, например, записям в базе данных.
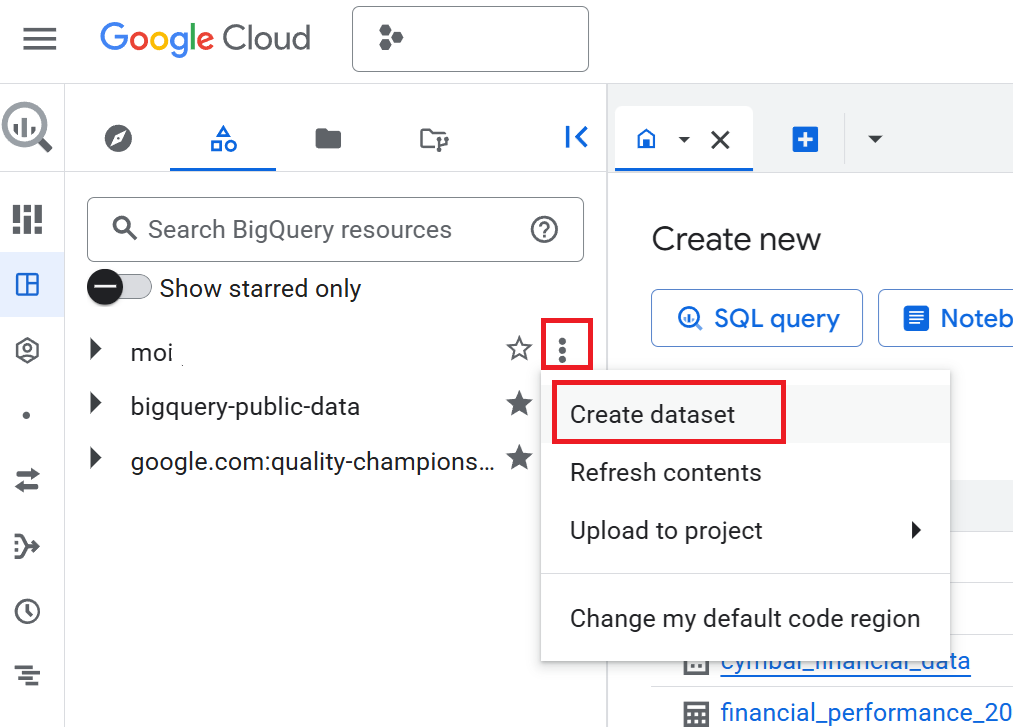
- В консоли Cloud перейдите на страницу BigQuery .
- В панели «Проводник» щелкните имя своего проекта, а затем выберите «Действия просмотра» (три вертикальные точки) > «Создать набор данных» .
- На панели «Создать набор данных» введите идентификатор набора данных как
cymbal_finance. - В поле «Местоположение данных» выберите
US (multiple regions in United States). - Сохраните параметры по умолчанию и нажмите «Создать набор данных» .
- В панели «Проводник» разверните свой проект и щелкните набор данных
cymbal_finance. - В панели сведений о наборе данных нажмите «Создать таблицу» .
- На странице «Создать таблицу» в разделе «Источник» выполните следующие действия:
- Для создания таблицы из выберите «Загрузить» .
- Для выбора файла нажмите «Обзор» , перейдите в папку
Financeкоторую вы скачали, и выберите файлcymbal_employee_finance.jsonl. - В поле «Формат файла» выберите JSONL (JSON с разделителями-переносчиками) .
- В разделе «Назначение» введите имя таблицы как
employee_finance. - В разделе «Схема» установите флажок «Автоматическое определение» .
- Сохраните остальные настройки по умолчанию и нажмите «Создать таблицу» .
- Повторите шаги с 7 по 11, чтобы загрузить данные в новую таблицу. На шаге 8b выберите
product_inventory.jsonl, а на шаге 9 введитеproduct_inventoryв качестве имени таблицы . Если вы не видите таблицы в панели сведений о наборе данных, нажмите «Обновить» . - Если вы успешно создали набор данных и две таблицы, то результат должен выглядеть примерно так:
6. Создайте приложение Vertex AI Search.
- В облачной консоли перейдите на страницу поиска Vertex AI .
- В разделе «Пользовательский поиск (общий)» нажмите «Создать» .
- На странице настроек приложения «Поиск» убедитесь, что выбраны параметры «Функции корпоративной версии» и «Генеративные ответы» .
- Назовите свое приложение
cymbal-employee-portal. - Введите название компании как
Cymbal Corp - Сохраните местоположение вашего приложения как
global. - Нажмите «Продолжить» .
7. Создайте и подключите хранилища данных.
На странице «Хранилища данных» вы создаете хранилища данных, которые будете подключать к своему приложению. Вам необходимо создать три хранилища данных: одно для неструктурированных данных отдела кадров и два для структурированных финансовых данных.
Создайте хранилище данных для неструктурированных данных.
- На странице «Хранилища данных» нажмите «Создать хранилище данных» .
- В разделе «Выберите источник данных» выберите «Облачное хранилище» .
- На панели «Импорт данных из облачного хранилища» перейдите в раздел «Импорт неструктурированных данных (поиск документов и RAG)» и выберите «Документы» .
- Оставьте параметр « Частота синхронизации» в значении «Одноразовая» .
- Чтобы выбрать папку или файл для импорта , нажмите «Папка» .
- В поле
gs://...введите имя корзины, созданной вами в разделе «Создание корзины Cloud Storage для неструктурированных файлов» . Например, если имя корзины —cymbal-app-hr-12, введите имя какcymbal-app-hr-12/HR. Загрузка данных из папкиHRгарантирует, что в это хранилище данных будут включены только документы HR. - Нажмите «Продолжить» .
- Введите имя хранилища данных как
cymbal-hr. - Нажмите «Продолжить» .
- Сохраните опцию "Общие цены" .
- Нажмите «Создать» .
После нажатия кнопки «Создать » вы вернетесь на страницу хранилищ данных .
Создайте хранилища данных для структурированных данных.
Вам предстоит создать два хранилища данных для структурированных данных из BigQuery: одно для финансовой информации о сотрудниках, а другое для товарных запасов.
Создайте хранилище данных для финансовой информации о сотрудниках.
- На странице «Хранилища данных» снова нажмите «Создать хранилище данных» .
- В поле «Выберите источник данных» выберите BigQuery .
- Для импорта структурированных данных выберите таблицу BigQuery с собственной схемой .
- Оставьте параметр « Частота синхронизации» в значении «Одноразовая» .
- Для выбора таблицы, которую вы хотите импортировать , нажмите кнопку «Обзор» . В открывшемся диалоговом окне «Выбор пути» выберите таблицу
employee_financeиз набора данныхcymbal_financeв вашем проекте. Вы можете увидеть таблицы с похожими именами из других проектов, поэтому убедитесь, что вы выбрали таблицу из своего проекта. - Нажмите «Продолжить» .
- Просмотрите страницу «Проверка схемы и назначение ключевых свойств» .
- Нажмите «Продолжить» .
- Введите название хранилища данных как
cymbal-finance. - Нажмите «Продолжить» .
- Сохраните опцию "Общие цены" .
- Нажмите «Создать» .
После нажатия кнопки «Создать » вы вернетесь на страницу хранилищ данных .
Создайте хранилище данных для информации о товарных запасах.
- На странице «Хранилища данных» снова нажмите «Создать хранилище данных» .
- В поле «Выберите источник данных» выберите BigQuery .
- Для импорта структурированных данных выберите таблицу BigQuery с собственной схемой .
- Оставьте параметр « Частота синхронизации» в значении «Одноразовая» .
- Чтобы выбрать таблицу для импорта , нажмите кнопку «Обзор» . В открывшемся диалоговом окне «Выбор пути» выберите таблицу
product_inventoryиз набора данныхcymbal_financeв вашем проекте. - Нажмите «Продолжить» .
- Просмотрите страницу «Проверка схемы и назначение ключевых свойств» .
- Нажмите «Продолжить» .
- Введите название хранилища данных как
cymbal-inventory. - Нажмите «Продолжить» .
- Сохраните опцию "Общие цены" .
- Нажмите «Создать» .
После нажатия кнопки «Создать » вы вернетесь на страницу хранилищ данных .
8. Подключите хранилища данных к вашему приложению.
Теперь на странице «Хранилища данных» вы должны увидеть три хранилища данных: cymbal-hr (неструктурированные), cymbal-finance (структурированные) и cymbal-inventory (структурированные). Чтобы подключить эти хранилища данных к вашему приложению, выполните следующие действия:
- На странице «Хранилища данных» выберите все три только что созданных хранилища данных:
cymbal-hr,cymbal-financeиcymbal-inventory. Убедитесь, что вы выбрали все три хранилища данных, прежде чем продолжить. - Нажмите «Продолжить» .
- Сохраните опцию "Общие цены" .
- Нажмите «Создать» .
9. Протестируйте приложение корпоративного портала Cymbal для сотрудников.
- В приложении
cymbal-employee-portalнажмите «Предварительный просмотр» . - В поле «Поиск здесь» введите следующий вопрос:
What are the stipends that I get as an employee of Cymbal located in London? - Введите вопрос, связанный с товарными запасами:
How many units of sneakers do we have in stock? - Введите еще один вопрос:
What is the stipend for an executive in Cymbal?
Обратите внимание, как поисковое приложение извлекало информацию из нескольких источников для формирования своего ответа. Чтобы ответить на эти вопросы, приложение осуществляло поиск как по структурированным финансовым данным, хранящимся в BigQuery, так и по неструктурированным документам отдела кадров в Cloud Storage.
Это демонстрирует возможности Vertex AI Search по объединению ответов из различных форматов данных и разрозненных хранилищ данных в единый, целостный результат.
Вы также можете настроить модель ИИ для получения еще более точных и специализированных ответов. Для получения дополнительной информации о настройке генеративного интерфейса обратитесь к документации « Получение ответов и последующих действий» .
10. Варианты развертывания вашего приложения
Хотя развертывание приложения для конечных пользователей выходит за рамки данного практического занятия, полезно знать, как это применимо в реальных условиях. У вас есть несколько вариантов интеграции вашего приложения Vertex AI Search в рабочие процессы вашей организации:
- Готовый веб-виджет. Вы можете встроить готовый к использованию интерфейс поиска или чата непосредственно в существующие страницы интранета или веб-сайта вашей компании, используя HTML-тег
script. Это самый быстрый способ представить ваше приложение пользователям. - Интеграция пользовательских API. Для полного контроля над пользовательским интерфейсом вы можете использовать REST API Vertex AI Search или клиентские библиотеки (например, Python, Node.js или Java) для создания пользовательского интерфейса с нуля.
11. Уборка
Чтобы избежать дальнейших списаний средств с вашего аккаунта Google Cloud, удалите ресурсы, созданные в ходе этого практического занятия:
- В консоли Cloud перейдите на страницу поиска Vertex AI .
- Нажмите « Посмотреть существующие приложения» .
- Чтобы открыть приложение
cymbal-employee-portal, нажмите на три вертикальные точки, чтобы выбрать «Ещё» , а затем нажмите «Удалить» . - Следуйте инструкциям на экране, чтобы подтвердить удаление.
- Чтобы удалить хранилища данных, нажмите «Хранилища данных» на левой панели навигации консоли.
- Удалите хранилища данных
cymbal-hr,cymbal-financeиcymbal-inventory:- Чтобы открыть хранилище данных
cymbal-hr, нажмите на три вертикальные точки, чтобы выбрать «Дополнительно» , а затем нажмите «Удалить» . - Следуйте инструкциям на экране, чтобы подтвердить удаление.
- Чтобы открыть хранилище данных
cymbal-finance, нажмите на три вертикальные точки «Подробнее» , а затем нажмите «Удалить» . - Следуйте инструкциям на экране, чтобы подтвердить удаление.
- Чтобы открыть хранилище данных
cymbal-inventory, нажмите на три вертикальные точки «Дополнительно» , а затем нажмите «Удалить» . - Следуйте инструкциям на экране, чтобы подтвердить удаление.
- Чтобы открыть хранилище данных
- Перейдите на страницу «Корзины» и удалите созданную вами корзину (например,
cymbal-app-hr-12). - Перейдите на страницу BigQuery и удалите набор данных
cymbal_finance.
12. Поздравляем!
Миссия выполнена! Вы успешно создали единую систему корпоративного поиска с помощью Vertex AI Search.
Преодолев разрыв между неструктурированными корпоративными данными в облачном хранилище и структурированными записями из BigQuery, вы создали мощный инструмент, способный к сложному бизнес-анализу — и все это без написания единой строки кода машинного обучения.
Что вы узнали
- Загрузка данных: Как загрузить неструктурированные документы из облачного хранилища и структурированные данные из BigQuery в Vertex AI Search.
- Запросы к нескольким хранилищам данных . Как выполнить запрос к приложению поиска, использующему несколько хранилищ данных, чтобы получить единые ответы как из структурированных, так и из неструктурированных данных.
- Настройка и персонализация . Как настроить модели генеративного ИИ для получения более точных, специализированных ответов.
- Варианты развертывания . Различные способы интеграции этой функции логического мышления в реальные приложения с использованием готовых виджетов или пользовательских API.