
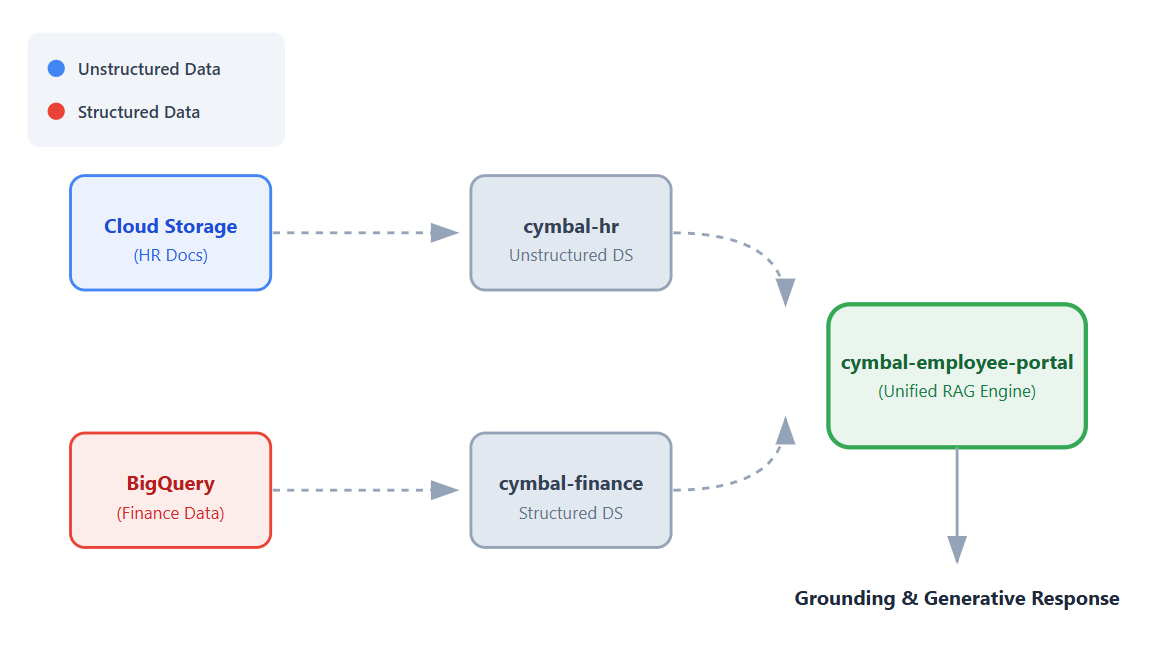
1. 简介
在此 Codelab 中,您将使用 Vertex AI Search 构建一个无需编码的通用员工帮助台应用。
假设您在一家全球零售公司 Cymbal 工作。员工经常会问一些问题,例如“预订商务旅行的政策是什么?”或“我们有多少双运动鞋有货?”
通常,您必须登录完全不同的系统才能找到这些答案。除了处理不同的系统外,您还必须浏览大量非结构化 HR 数据,或对结构化财务数据运行复杂的 SQL 提示,才能获得问题的答案。
在此 Codelab 中,您将构建一个连接到这些数据集的统一应用,让员工能够使用 Vertex AI 的检索增强生成 (RAG) 功能,以对话方式获得基于自有数据的回答。
您将执行的操作
在此 Codelab 中,您将完成以下步骤:
- 设置数据源。为非结构化的人力资源文档创建一个 Cloud Storage 存储分区,并为结构化财务数据创建一个 BigQuery 数据集。
- 配置数据存储区。创建与 Cloud Storage 和 BigQuery 数据源相关联的 Vertex AI Search 数据存储区。
- 关联应用。创建 Vertex AI Search 应用,并将这两个数据存储区都关联到该应用。
- 测试应用。与统一搜索界面互动,验证接地回答是否能综合来自两个数据存储区的信息。
- 探索后续步骤。查看用于调优生成式 AI 模型和部署搜索应用的选项。
所需条件
- 网络浏览器,例如 Chrome。
- 启用了结算功能的 Google Cloud 项目。
- 本地机器上已安装 Git。
本 Codelab 适用于各种水平的开发者。
2. 准备工作
创建 Google Cloud 云项目并启用所需的 API。
- 在 Google Cloud 控制台的“项目选择器”页面上,选择或创建 Google Cloud 项目 。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
所需 IAM 角色
此 Codelab 假定您具有 Google Cloud 项目的Project Owner角色。
启用 API
- 在 Google Cloud 控制台中,点击激活 Cloud Shell:如果您之前从未使用过 Cloud Shell,系统会显示一个窗格,让您选择在可信环境中启动 Cloud Shell,并可选择是否启用加速功能。如果系统要求您授权 Cloud Shell,请点击授权。
- 在 Cloud Shell 中,启用所有必需的 API:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. 克隆 GitHub 代码库
为了展示搜索功能在 Cymbal 员工帮助台应用中的运作方式,您需要一些模拟文件。在本部分中,您将 GitHub 代码库克隆到本地机器,以获取这些文件。您将在后续步骤中使用 Cloud 控制台界面将这些文件上传到 Google Cloud。
- 在本地机器的终端中,克隆
next-26-sessions代码库:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - 前往下载的代码库目录:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - 探索此目录中的下载文件。您会看到有两个文件夹:
HR和Finance。- HR。此文件夹包含许多非结构化文件,例如
.doc、.txt和.html文件。您需要将 HR 文件上传到 Cloud Storage 存储分区。 - 金融。此文件夹包含两个
.jsonl文件。您需要将这些文件上传到 BigQuery 数据集。
- HR。此文件夹包含许多非结构化文件,例如
4. 为非结构化文件创建 Cloud Storage 存储分区
在本部分中,您将创建一个 Cloud Storage 存储分区,并上传在克隆 GitHub 代码库部分下载的 HR 文件夹中的文档。非结构化数据(例如本例中的 HR 文档)不遵循预定义的格式,可以包括文本文件、文档或多媒体内容。
- 在 Cloud 控制台中,前往存储分区页面。
- 点击创建。
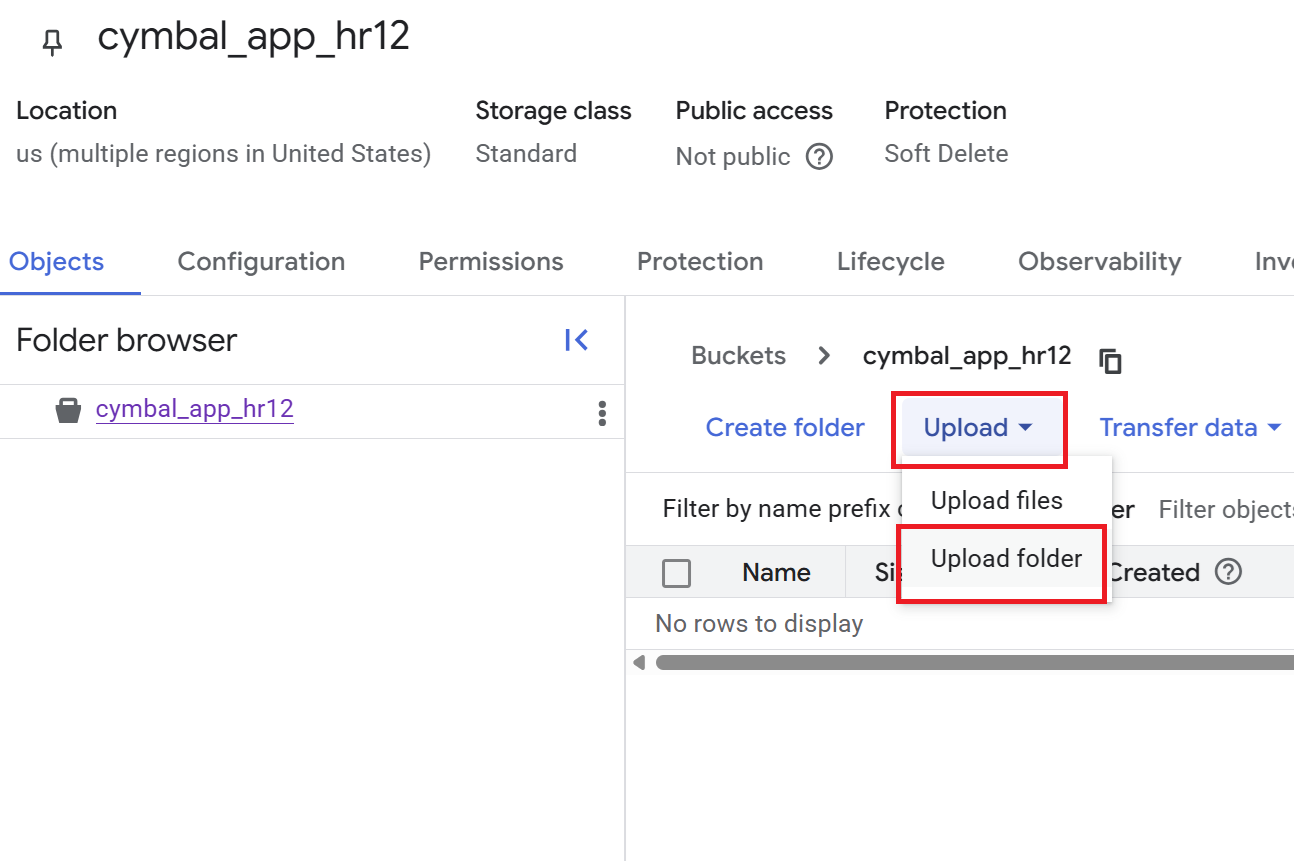
- 在创建存储分区页面上,输入存储分区的名称。该名称必须是全局唯一的。例如:
cymbal-app-hr-12。 - 保留默认选项。
- 点击创建。系统会创建存储分区并显示存储分区详情页面。如果您没有看到存储分区详情页面,请点击您刚刚创建的存储分区。
- 在存储分区详情页面上,依次点击上传 > 上传文件夹,然后选择您在克隆 GitHub 代码库部分下载的
HR文件夹。 - 确认上传。
- 在存储分区详情页面上,点击
HR文件夹以查看文件列表。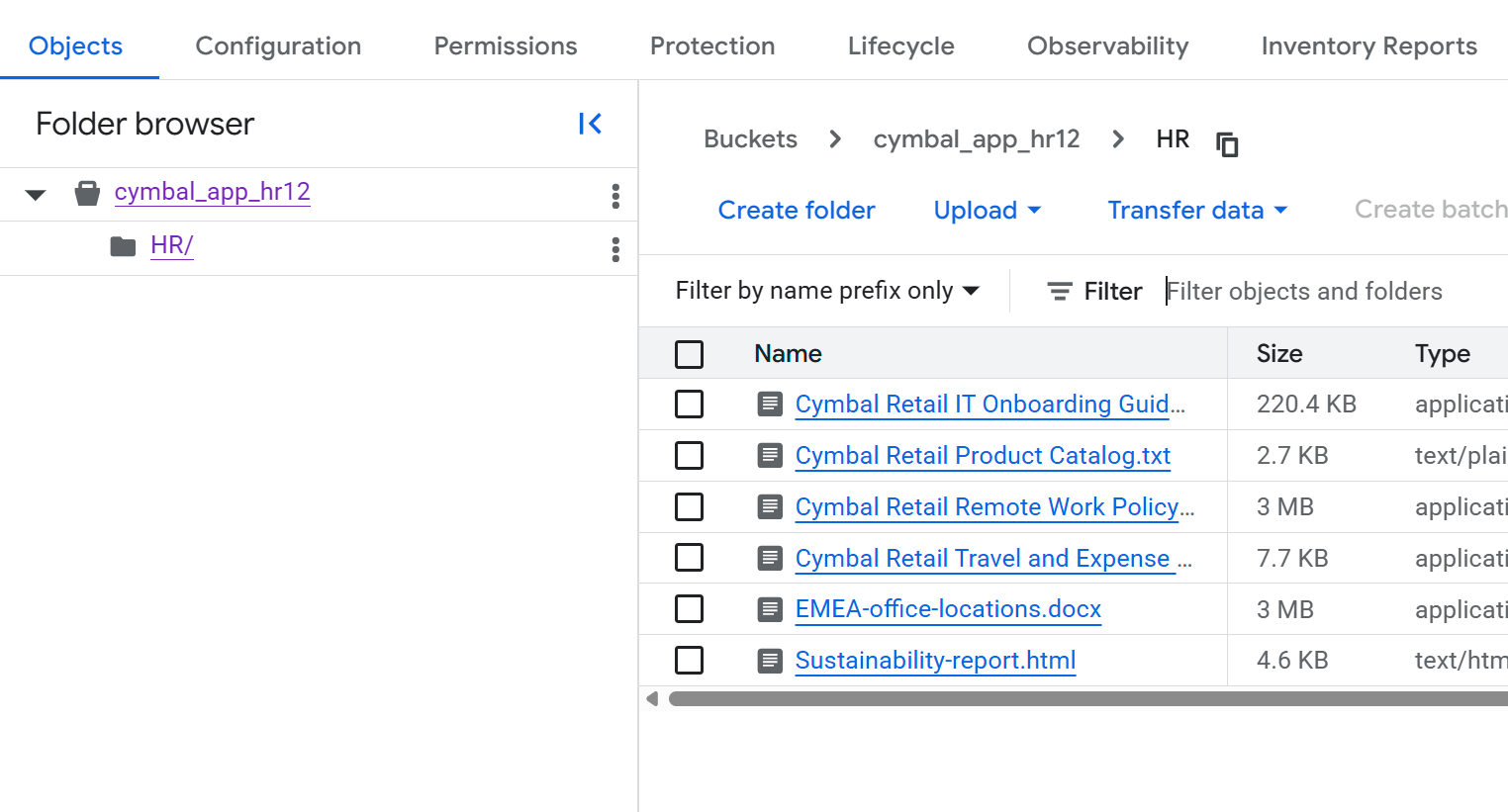
5. 为结构化文件创建 BigQuery 数据集
在本部分中,您将创建一个 BigQuery 数据集,并将您在克隆 GitHub 代码库部分中下载的 Finance 文件夹中的文档加载到新表中。结构化数据(例如本例中的财务文件)遵循预定义的格式,例如数据库中的记录。
- 在 Cloud 控制台中,前往 BigQuery 页面。
- 在探索器窗格中,点击项目名称,然后依次点击查看操作(三个竖点)> 创建数据集。
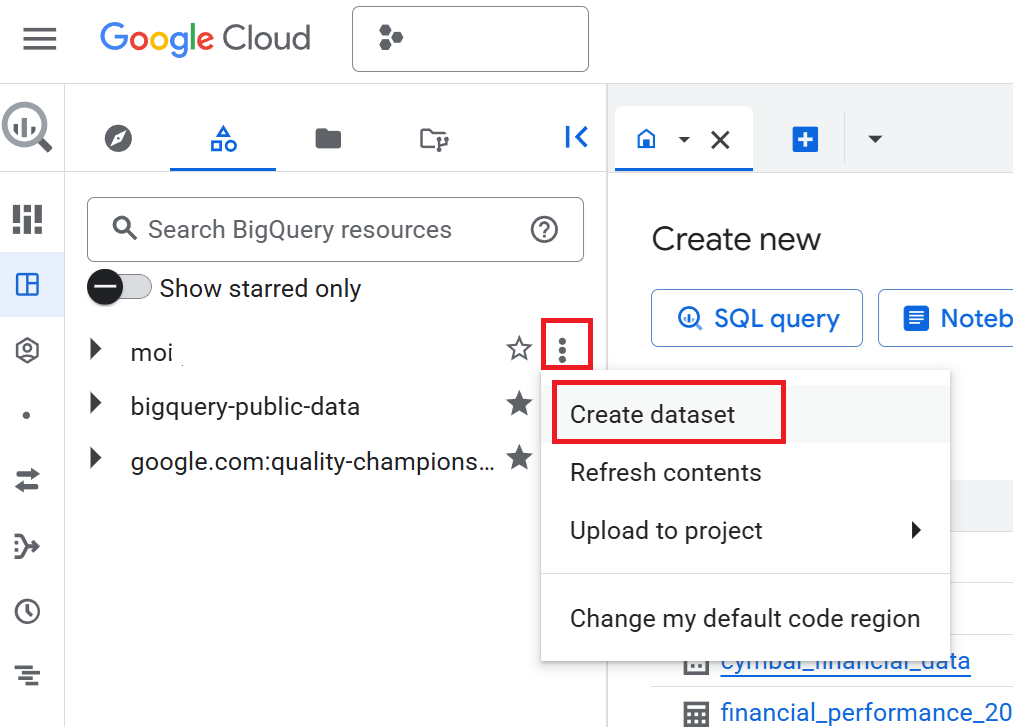
- 在创建数据集窗格中,将数据集 ID 输入为
cymbal_finance。 - 在数据位置中选择
US (multiple regions in United States)。 - 保留默认选项,然后点击创建数据集。
- 在探索器窗格中,展开您的项目,然后点击
cymbal_finance数据集。 - 在数据集详情窗格中,点击创建表。
- 在创建表页面的来源部分,执行以下操作:
- 在基于以下数据创建表部分,选择上传。
- 在选择文件部分,点击浏览,导航到您下载的
Finance文件夹,然后选择cymbal_employee_finance.jsonl。 - 在文件格式部分,选择 JSONL(以换行符分隔的 JSON)。
- 在目标部分,输入表名称
employee_finance。 - 在架构部分,选中自动检测复选框。
- 保留其他默认设置,然后点击创建表。
- 重复第 7 步到第 11 步,将数据加载到新表中。在第 8b 步中,选择
product_inventory.jsonl,然后在第 9 步中,输入product_inventory作为表名称。如果您在数据集详情窗格中看不到表,请点击刷新。 - 如果您已成功创建数据集和这两个表,则应看到如下所示的界面:
6. 创建 Vertex AI Search 应用
- 在 Cloud 控制台中,前往 Vertex AI Search 页面。
- 在自定义搜索(常规)图块中,点击创建。
- 在搜索应用配置页面上,确保已选择企业版功能和生成式回答选项。
- 为应用命名
cymbal-employee-portal。 - 输入公司名称作为
Cymbal Corp。 - 将应用的位置保留为
global。 - 点击继续。
7. 创建和连接数据存储区
在数据存储区页面上,您可以创建将与应用相关联的数据存储区。您必须创建三个数据存储区:一个用于非结构化人力资源数据,另外两个用于结构化财务数据。
为非结构化数据创建数据存储区
- 在数据存储区页面上,点击创建数据存储区。
- 在选择数据源部分,选择 Cloud Storage。
- 在从 Cloud Storage 导入数据窗格中,前往非结构化数据导入(文档搜索和 RAG),然后选择文档。
- 将同步频率选项保留为一次。
- 对于选择您要导入的文件夹或文件,请点击文件夹。
- 在
gs://...字段中,输入您在为非结构化文件创建 Cloud Storage 存储分区部分中创建的存储分区的名称。例如,如果存储分区的名称为cymbal-app-hr-12,请输入名称cymbal-app-hr-12/HR。从HR文件夹中提取数据可确保此数据存储区中仅包含 HR 文档。 - 点击继续。
- 输入数据存储区的名称,即
cymbal-hr。 - 点击继续。
- 保留一般定价选项。
- 点击创建。
点击创建后,系统会返回到数据存储区页面。
为结构化数据创建数据存储区
您将从 BigQuery 为结构化数据创建两个数据存储区:一个用于员工财务信息,另一个用于商品目录。
为员工财务数据创建数据存储区
- 在数据存储区页面上,再次点击创建数据存储区。
- 在选择数据源部分,选择 BigQuery。
- 对于结构化数据导入,选择采用您自己的架构的 BigQuery 表。
- 将同步频率选项保留为一次。
- 在选择要导入的表格部分,点击浏览。在打开的选择路径对话框中,从项目中的
cymbal_finance数据集中选择employee_finance表。您可能会看到其他项目中具有类似名称的表格,因此请务必选择您项目中的表格。 - 点击继续。
- 查看检查架构并分配关键属性页面。
- 点击继续。
- 输入数据存储区的名称,即
cymbal-finance。 - 点击继续。
- 保留一般定价选项。
- 点击创建。
点击创建后,系统会返回到数据存储区页面。
为商品目录数据创建数据存储区
- 在数据存储区页面上,再次点击创建数据存储区。
- 在选择数据源部分,选择 BigQuery。
- 对于结构化数据导入,选择采用您自己的架构的 BigQuery 表。
- 将同步频率选项保留为一次。
- 在选择要导入的表格部分,点击浏览。在打开的选择路径对话框中,从项目中的
cymbal_finance数据集中选择product_inventory表。 - 点击继续。
- 查看检查架构并分配关键属性页面。
- 点击继续。
- 输入数据存储区的名称,即
cymbal-inventory。 - 点击继续。
- 保留一般定价选项。
- 点击创建。
点击创建后,系统会返回到数据存储区页面。
8. 将数据存储区连接到应用
现在,您应该会在数据存储区页面上的列表中看到三个数据存储区:cymbal-hr(非结构化)、cymbal-finance(结构化)和 cymbal-inventory(结构化)。如需将这些数据存储区关联到您的应用,请按以下步骤操作:
- 在数据存储区页面上,选择您刚刚创建的全部三个数据存储区:
cymbal-hr、cymbal-finance和cymbal-inventory。请确保您已选择所有三个数据存储区,然后再继续。 - 点击继续。
- 保留一般定价选项。
- 点击创建。
9. 测试 Cymbal 员工门户应用
- 在
cymbal-employee-portal应用中,点击预览。 - 在在此处搜索框中,输入以下问题:
What are the stipends that I get as an employee of Cymbal located in London? - 输入与商品目录相关的问题:
How many units of sneakers do we have in stock? - 输入其他问题:
What is the stipend for an executive in Cymbal?
请注意,搜索应用如何从多个来源检索信息以生成回答。为了回答这些问题,该应用同时搜索了 BigQuery 中存储的结构化财务数据和 Cloud Storage 中的非结构化人力资源文档。
这充分展示了 Vertex AI Search 的强大功能,它可以将各种数据格式和不同的数据存储区中的信息整合到一起,提供流畅的体验。
您还可以对 AI 模型进行调优,使其提供更准确、更专业的回答。如需详细了解如何自定义生成式体验,请参阅获取回答和后续问题文档。
10. 部署应用的选项
虽然将应用部署到最终用户不在本 Codelab 的讨论范围内,但了解这如何转化为实际应用场景很有帮助。您可以通过多种方式将 Vertex AI Search 应用集成到组织的工作流中:
- 预构建的 Web widget。您可以使用 HTML
script标记将现成的搜索或聊天界面直接嵌入到公司的现有内部网或网页中。这是让用户了解您的应用的最快方式。 - 自定义 API 集成。为了完全掌控用户体验,您可以使用 Vertex AI Search REST API 或客户端库(例如 Python、Node.js 或 Java)从头开始构建自定义前端。
11. 清理
为避免系统向您的 Google Cloud 账号持续收取费用,请删除在此 Codelab 中创建的资源:
- 在 Cloud 控制台中,前往 Vertex AI Search 页面。
- 点击查看现有应用。
- 对于
cymbal-employee-portal应用,点击 更多对应的三个垂直点,然后点击删除。 - 按照屏幕上的提示确认删除。
- 如需删除数据存储区,请点击控制台左侧导航面板中的数据存储区。
- 删除
cymbal-hr、cymbal-finance和cymbal-inventory数据存储区:- 对于
cymbal-hr数据存储区,请点击三个垂直点以显示更多选项,然后点击删除。 - 按照屏幕上的提示确认删除。
- 对于
cymbal-finance数据存储区,请点击三个垂直点以显示更多选项,然后点击删除。 - 按照屏幕上的提示确认删除。
- 对于
cymbal-inventory数据存储区,请点击三个垂直点以显示更多选项,然后点击删除。 - 按照屏幕上的提示确认删除。
- 对于
- 前往存储分区页面,然后删除您创建的存储分区(例如
cymbal-app-hr-12)。 - 前往 BigQuery 页面,然后删除
cymbal_finance数据集。
12. 恭喜
任务完成!您已成功使用 Vertex AI Search 构建统一的企业搜索体验。
通过弥合 Cloud Storage 中的非结构化企业数据与 BigQuery 中的结构化记录之间的差距,您创建了一个能够进行复杂业务推理的强大工具,而无需编写任何机器学习代码。
您学到的内容
- 提取:如何将 Cloud Storage 中的非结构化文档和 BigQuery 中的结构化数据提取到 Vertex AI Search 中。
- 多数据存储区查询。如何查询多数据存储区搜索应用,以从结构化数据和非结构化数据中合成统一的答案。
- 调整和自定义。如何调整生成式 AI 模型,使其提供更准确、更专业的回答。
- 部署选项。使用预建 widget 或自定义 API 将此推理功能集成到实际应用中的各种方法。