
1. 簡介
在本程式碼研究室中,您將使用 Vertex AI Search 建構無程式碼的通用員工服務台應用程式。
假設您在跨國零售公司 Cymbal 工作。員工經常會問「預訂商務旅行的政策是什麼?」或「我們有多少雙運動鞋的庫存?」等問題。
通常您必須登入完全不同的系統,才能找到這些答案。除了處理不同的系統,您還必須讀取大量非結構化的人資資料,或對結構化財務資料執行複雜的 SQL 提示,才能取得問題的解答。
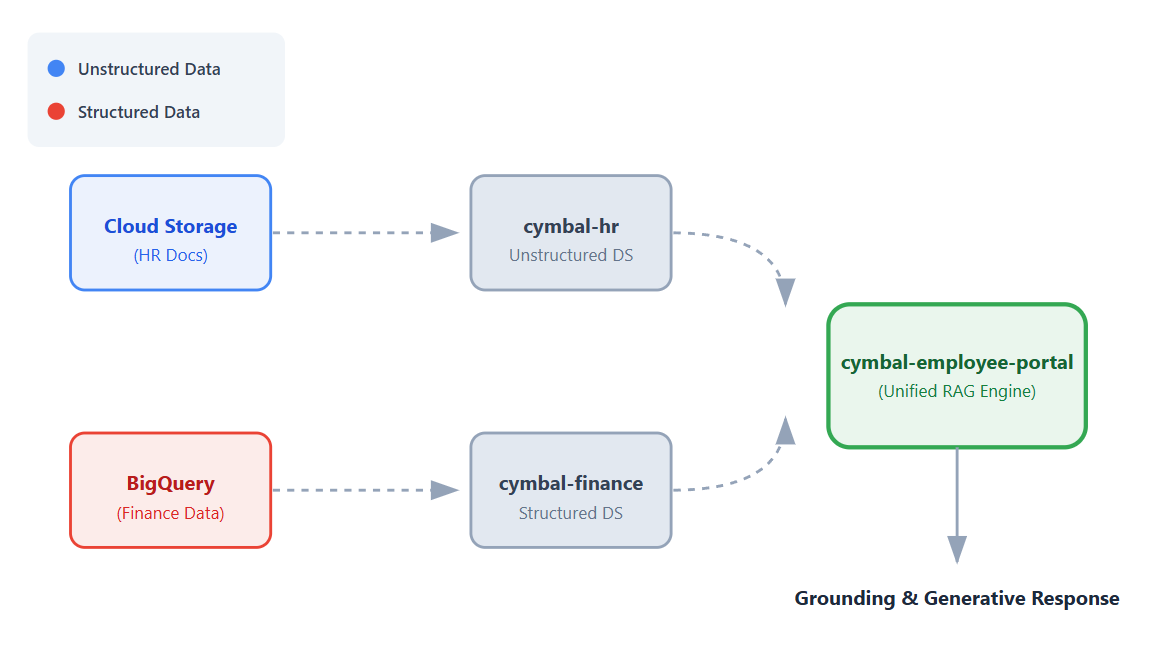
在本程式碼研究室中,您將建構單一整合式應用程式,連結至這些資料集,讓員工使用 Vertex AI 的檢索增強生成 (RAG) 功能,以對話方式取得問題的基準答案。
學習內容
在本程式碼研究室中,您將完成下列步驟:
- 設定資料來源。為非結構化的人資文件建立 Cloud Storage bucket,並為結構化財務資料建立 BigQuery 資料集。
- 設定資料儲存庫。建立連結至 Cloud Storage 和 BigQuery 資料來源的 Vertex AI Search 資料儲存庫。
- 連結應用程式。建立 Vertex AI Search 應用程式,並將兩個資料儲存庫連結至該應用程式。
- 測試應用程式。與整合式搜尋介面互動,確認系統是否會根據兩個資料儲存庫的資訊,提供有根據的答案。
- 瞭解後續步驟。查看調整生成式 AI 模型和部署搜尋應用程式的選項。
軟硬體需求
- 網路瀏覽器,例如 Chrome。
- 已啟用計費功能的 Google Cloud 專案。
- 本機電腦上已安裝 Git。
本程式碼研究室適合各種程度的開發人員。
2. 事前準備
建立 Google Cloud 專案並啟用必要 API。
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案 。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
必要的 IAM 角色
本程式碼研究室假設您已具備 Google Cloud 雲端專案的「專案擁有者」角色。
啟用 API
- 在 Google Cloud 控制台中,按一下「啟用 Cloud Shell」:如果您從未使用過 Cloud Shell,系統會顯示窗格,讓您選擇是否要在受信任的環境中啟動 Cloud Shell,以及是否要啟用加速功能。如果系統要求您授權 Cloud Shell,請點選「授權」。
- 在 Cloud Shell 中,啟用所有必要的 API:
gcloud services enable \ discoveryengine.googleapis.com \ aiplatform.googleapis.com \ bigquery.googleapis.com \ storage.googleapis.com
3. 複製 GitHub 存放區
如要展示在 Cymbal 員工服務台應用程式中搜尋的運作方式,您需要一些模擬檔案。在本節中,您會將 GitHub 存放區複製到本機電腦,以取得這些檔案。您會在後續步驟中使用 Cloud 控制台介面,將這些檔案上傳至 Google Cloud。
- 在本機電腦的終端機中,複製
next-26-sessions存放區:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - 前往下載的存放區目錄:
cd next-26-sessions/BRK1-063-the-knowledge-source/cymbal-employee-helpdesk - 在這個目錄中探索下載的檔案。你會發現有兩個資料夾:
HR和Finance。- HR。這個資料夾包含許多非結構化檔案,例如
.doc、.txt和.html檔案。您會將人資檔案上傳至 Cloud Storage bucket。 - 金融。這個資料夾包含兩個
.jsonl檔案。您會將這些檔案上傳至 BigQuery 資料集。
- HR。這個資料夾包含許多非結構化檔案,例如
4. 建立非結構化檔案的 Cloud Storage bucket
在本節中,您將建立 Cloud Storage bucket,並上傳在「複製 GitHub 存放區」一節中下載的 HR 資料夾中的文件。非結構化資料 (例如本例中的人資文件) 沒有預先定義的格式,可能包含文字檔、文件或多媒體內容。
- 前往 Cloud 控制台的「Bucket」頁面。
- 點選「建立」。
- 在「建立 bucket」頁面中,輸入 bucket 名稱。名稱不得重複。例如:
cymbal-app-hr-12。 - 保留預設選項。
- 按一下「建立」。系統會建立 bucket,並顯示「Bucket details」(bucket 詳細資料) 頁面。如果沒有看到「Bucket details」頁面,請按一下剛才建立的 bucket。
- 在「Bucket details」(值區詳細資料) 頁面中,依序點選「Upload」(上傳) >「Upload folder」(上傳資料夾),然後選取您在「複製 GitHub 存放區」一節中下載的
HR資料夾。 - 確認上傳。
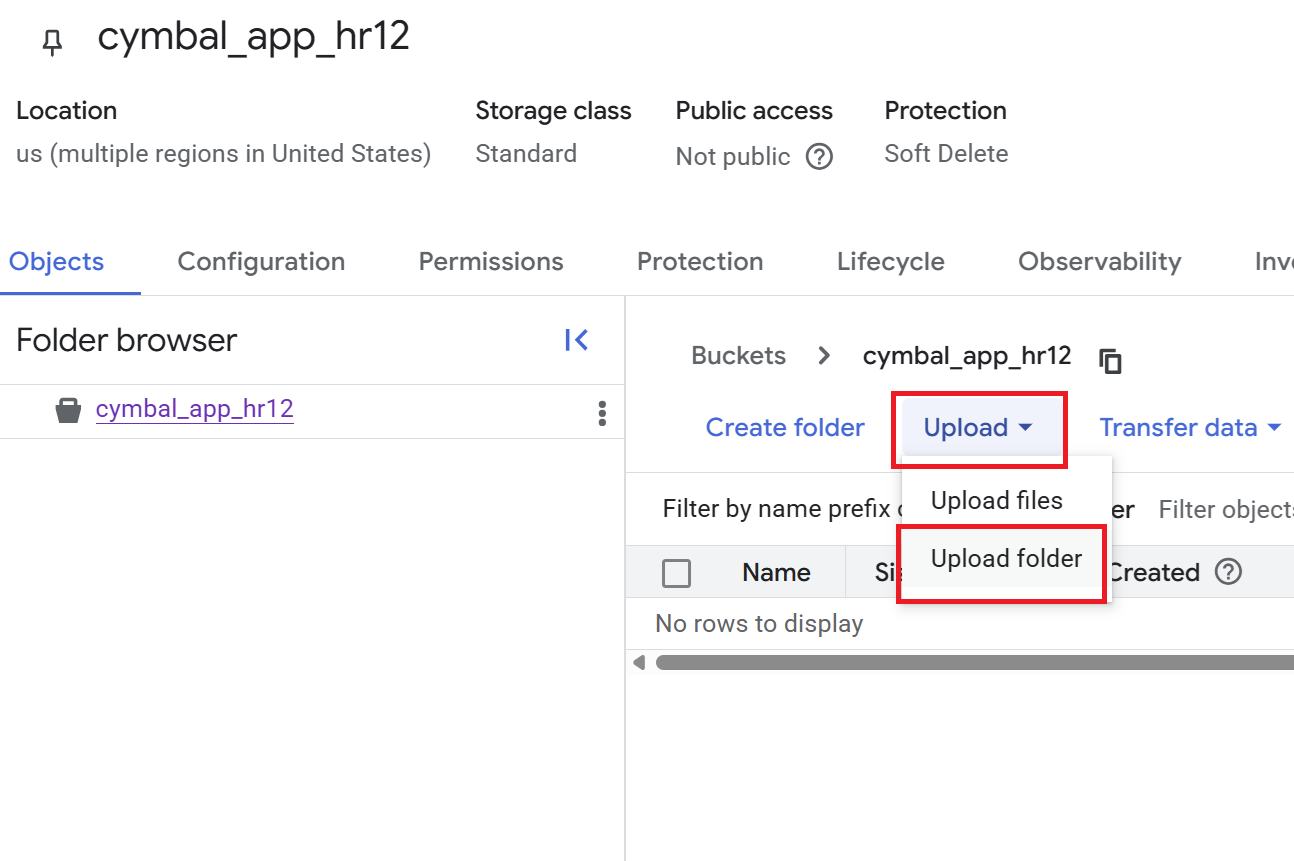
- 在「Bucket details」(值區詳細資料) 頁面中,按一下
HR資料夾即可查看檔案清單。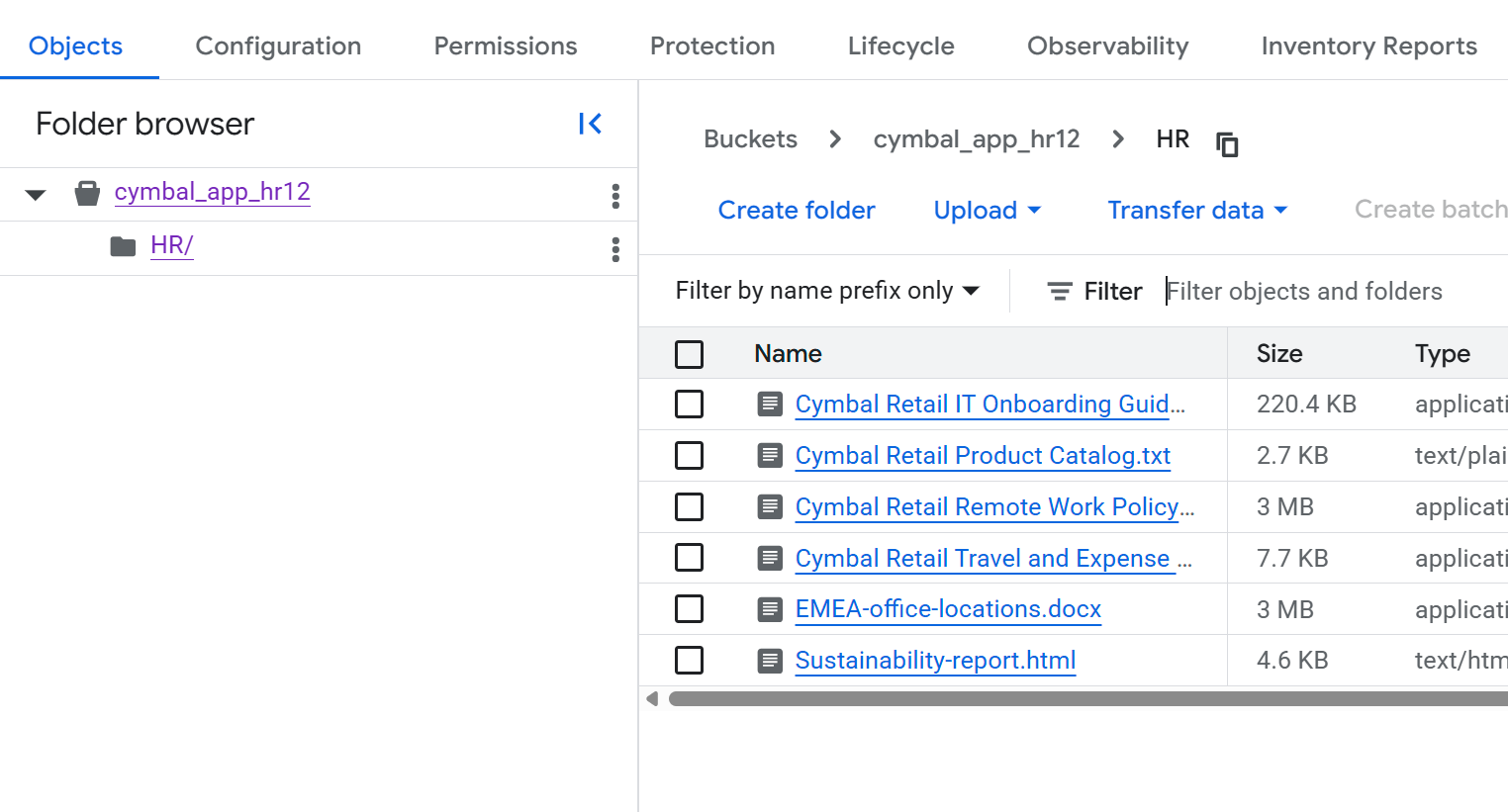
5. 為結構化檔案建立 BigQuery 資料集
在本節中,您將建立 BigQuery 資料集,並將在「複製 GitHub 存放區」一節下載的 Finance 資料夾中的文件載入新資料表。結構化資料 (例如本例中的財務文件) 遵循預先定義的格式,例如資料庫中的記錄。
- 前往 Cloud 控制台的「BigQuery」頁面。
- 在「Explorer」窗格中,依序點選專案名稱 >「查看動作」 (直向三點) >「建立資料集」。
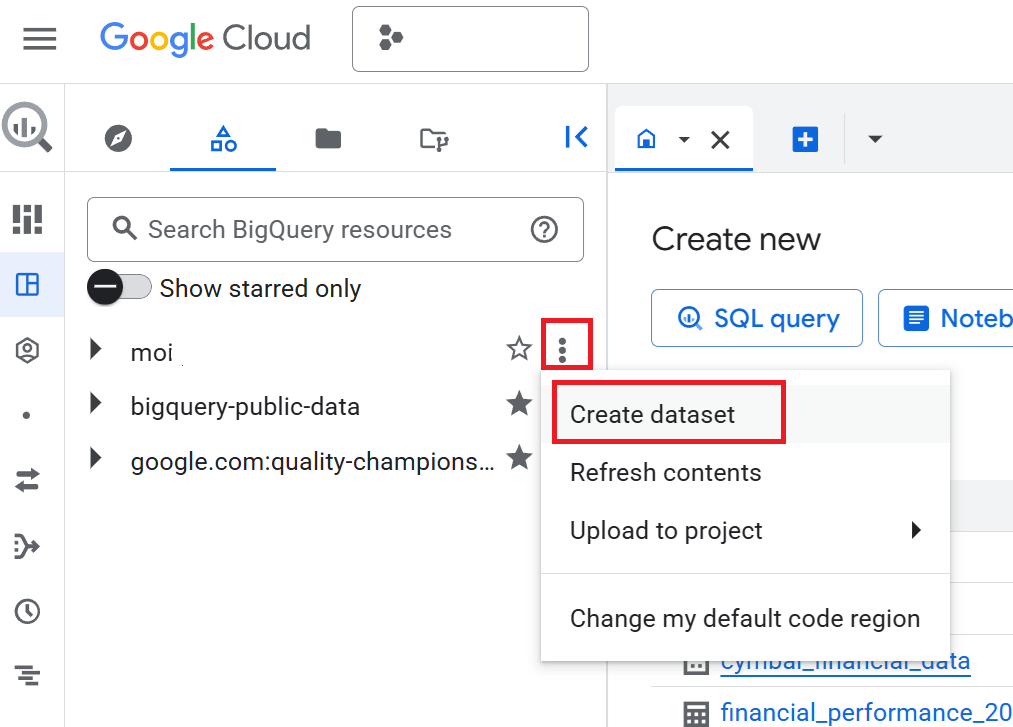
- 在「建立資料集」窗格中,輸入「資料集 ID」,設為
cymbal_finance。 - 選取「資料位置」的
US (multiple regions in United States)。 - 保留預設選項,然後點選「建立資料集」。
- 在「Explorer」窗格中展開專案,然後按一下
cymbal_finance資料集。 - 在資料集詳細資料窗格中,按一下「建立資料表」。
- 在「Create table」(建立資料表) 頁面的「Source」(來源) 區段中,執行下列操作:
- 針對「Create table from」(使用下列資料建立資料表),選取 [Upload] (上傳)。
- 在「Select file」(選取檔案) 部分,按一下「Browse」(瀏覽) 前往下載的
Finance資料夾,然後選取cymbal_employee_finance.jsonl。 - 針對「File format」(檔案格式) 選取「JSONL (Newline delimited JSON)」(JSONL (以換行符號分隔的 JSON))。
- 在「Destination」(目的地) 部分,輸入「Table」(資料表) 名稱
employee_finance。 - 在「Schema」(結構定義) 區段中,勾選「Auto-detect」(自動偵測) 核取方塊。
- 保留其他預設設定,然後按一下「建立資料表」。
- 重複步驟 7 到 11,將資料載入新資料表。在步驟 8b 中選取
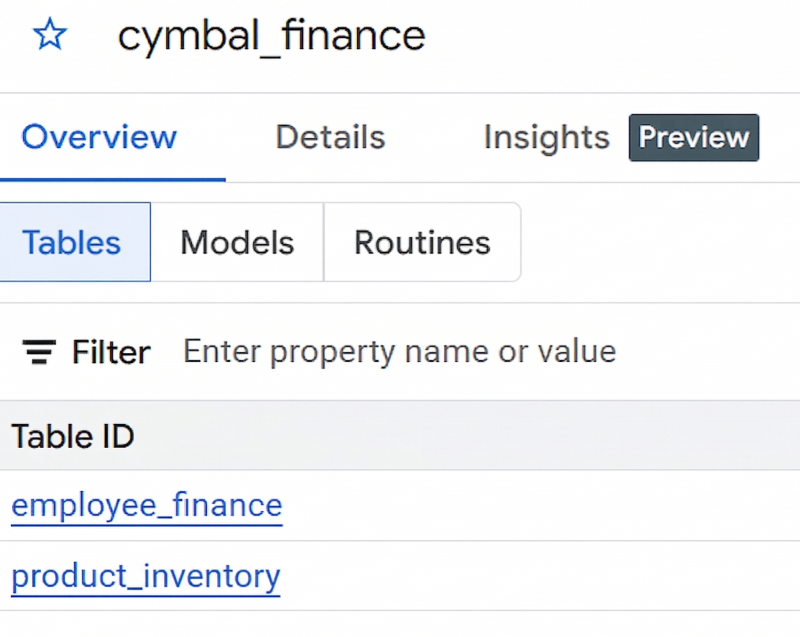
product_inventory.jsonl,然後在步驟 9 中輸入product_inventory做為「資料表」名稱。如果資料集詳細資料窗格中未顯示資料表,請按一下「重新整理」。 - 如果已成功建立資料集和兩個資料表,畫面應會顯示如下圖:
6. 建立 Vertex AI Search 應用程式
7. 建立及連結資料儲存庫
在「Data stores」(資料儲存庫) 頁面中,建立要連結至應用程式的資料儲存庫。您必須建立三個資料儲存庫:一個用於非結構化的人資資料,另外兩個用於結構化財務資料。
建立非結構化資料的資料儲存庫
- 在「Data stores」(資料儲存庫) 頁面,點選「Create data store」(建立資料儲存庫)。
- 在「選取資料來源」部分,選取「Cloud Storage」。
- 在「從 Cloud Storage 匯入資料」窗格中,前往「匯入非結構化資料 (文件搜尋和 RAG)」,然後選取「文件」。
- 將「同步處理頻率」選項保留為「單次」。
- 在「選取要匯入的資料夾或檔案」下方,按一下「資料夾」。
- 在「
gs://...」欄位中,輸入您在「為非結構化檔案建立 Cloud Storage bucket」一節中建立的 bucket 名稱。舉例來說,如果值區名稱為cymbal-app-hr-12,請輸入cymbal-app-hr-12/HR。從HR資料夾擷取資料,可確保這個資料儲存庫只包含人資文件。 - 按一下「繼續」。
- 輸入資料儲存庫名稱
cymbal-hr。 - 按一下「繼續」。
- 保留「一般定價」選項。
- 點選「建立」。
按一下「建立」後,系統會將您帶回「資料儲存庫」頁面。
為結構化資料建立資料儲存庫
您將為 BigQuery 中的結構化資料建立兩個資料儲存庫:一個用於員工財務資訊,另一個用於商品目錄。
為員工財務資料建立資料儲存庫
- 在「Data stores」(資料儲存庫) 頁面,再次點選「Create data store」(建立資料儲存庫)。
- 在「選取資料來源」部分,選取「BigQuery」。
- 如要匯入結構化資料,請選取「BigQuery table with your own schema」(具有自有結構定義的 BigQuery 資料表)。
- 將「同步處理頻率」選項保留為「單次」。
- 在「選取要匯入的資料表」下方,按一下「瀏覽」。在隨即開啟的「選取路徑」對話方塊中,選取專案中
cymbal_finance資料集的employee_finance表格。您可能會看到其他專案中名稱類似的資料表,因此請務必選取專案中的資料表。 - 按一下「繼續」。
- 查看「查看結構定義並指派重要屬性」頁面。
- 按一下「繼續」。
- 輸入資料儲存庫名稱
cymbal-finance。 - 按一下「繼續」。
- 保留「一般定價」選項。
- 點選「建立」。
按一下「建立」後,系統會將您帶回「資料儲存庫」頁面。
建立商品目錄資料的資料儲存庫
- 在「Data stores」(資料儲存庫) 頁面,再次點選「Create data store」(建立資料儲存庫)。
- 在「選取資料來源」部分,選取「BigQuery」。
- 如要匯入結構化資料,請選取「BigQuery table with your own schema」(具有自有結構定義的 BigQuery 資料表)。
- 將「同步處理頻率」選項保留為「單次」。
- 在「選取要匯入的資料表」下方,按一下「瀏覽」。在隨即開啟的「選取路徑」對話方塊中,選取專案中
cymbal_finance資料集的product_inventory表格。 - 按一下「繼續」。
- 查看「查看結構定義並指派重要屬性」頁面。
- 按一下「繼續」。
- 輸入資料儲存庫名稱
cymbal-inventory。 - 按一下「繼續」。
- 保留「一般定價」選項。
- 點選「建立」。
按一下「建立」後,系統會將您帶回「資料儲存庫」頁面。
8. 將資料儲存庫連結至應用程式
現在您應該會在「資料儲存庫」頁面的清單中看到三個資料儲存庫:cymbal-hr (非結構化)、cymbal-finance (結構化) 和 cymbal-inventory (結構化)。如要將這些資料儲存庫連結至應用程式,請按照下列步驟操作:
- 在「資料儲存庫」頁面,選取剛建立的三個資料儲存庫:
cymbal-hr、cymbal-finance和cymbal-inventory。請務必選取所有三個資料儲存庫,再繼續操作。 - 按一下「繼續」。
- 保留「一般定價」選項。
- 點選「建立」。
9. 測試 Cymbal 員工入口網站應用程式
- 在
cymbal-employee-portal應用程式中,按一下「預覽」。 - 在「在這裡搜尋」方塊中,輸入下列問題:
What are the stipends that I get as an employee of Cymbal located in London? - 輸入與商品目錄相關的問題:
How many units of sneakers do we have in stock? - 輸入其他問題:
What is the stipend for an executive in Cymbal?
請注意,搜尋應用程式會從多個來源擷取資訊,然後生成回覆。為回答這些問題,應用程式同時搜尋 BigQuery 中儲存的結構化財務資料,以及 Cloud Storage 中的非結構化人資文件。
這項功能展現了 Vertex AI Search 的強大能力,可將各種資料格式和不同資料儲存庫中的答案整合為單一連貫的體驗。
你也可以調整 AI 模型,讓模型提供更準確的特定領域答案。如要進一步瞭解如何自訂生成式體驗,請參閱「取得解答和後續追蹤」說明文件。
10. 部署應用程式的選項
雖然本程式碼研究室不包含向使用者部署應用程式的內容,但瞭解這項操作在實際情況中如何運作,仍有助於您掌握相關知識。您可以透過下列幾種方式,將 Vertex AI Search 應用程式整合到機構的工作流程:
- 預先建構的網頁小工具。您可以使用 HTML
script標記,將現成的搜尋或即時通訊介面直接嵌入公司現有的內部網路或網頁。這是最快速的宣傳應用程式方式。 - 整合自訂 API。如要全面掌控使用者體驗,您可以從頭開始建構自訂前端,並使用 Vertex AI Search REST API 或用戶端程式庫 (例如 Python、Node.js 或 Java)。
11. 清理
如要避免系統持續向您的 Google Cloud 帳戶收取費用,請刪除本程式碼研究室中建立的資源:
- 前往 Cloud 控制台的「Vertex AI Search」頁面。
- 按一下「查看現有的應用程式」。
- 如果是
cymbal-employee-portal應用程式,請按一下「更多」的三個垂直圓點,然後按一下「刪除」。 - 按照畫面上的提示確認刪除。
- 如要刪除資料儲存庫,請點選主控台左側導覽面板中的「資料儲存庫」。
- 刪除
cymbal-hr、cymbal-finance和cymbal-inventory資料儲存庫:- 如果是
cymbal-hr資料儲存庫,請按一下 更多 的三個垂直點,然後按一下 刪除。 - 按照畫面上的提示確認刪除。
- 如果是
cymbal-finance資料儲存庫,請按一下 更多 的三個垂直點,然後按一下 刪除。 - 按照畫面上的提示確認刪除。
- 如果是
cymbal-inventory資料儲存庫,請按一下 更多 的三個垂直點,然後按一下 刪除。 - 按照畫面上的提示確認刪除。
- 如果是
- 前往「Buckets」頁面,然後刪除您建立的 bucket (例如
cymbal-app-hr-12)。 - 前往「BigQuery」頁面,然後刪除
cymbal_finance資料集。
12. 恭喜
任務完成!您已使用 Vertex AI Search 成功建構統一的企業搜尋體驗。
您已彌合 Cloud Storage 中非結構化企業資料與 BigQuery 結構化記錄之間的差距,建立強大的工具,能夠進行複雜的業務推論,而且完全不必編寫任何一行機器學習程式碼。
目前所學內容
- 擷取:如何將 Cloud Storage 中的非結構化文件和 BigQuery 中的結構化資料擷取至 Vertex AI Search。
- 查詢多個資料存放區。如何查詢多資料儲存空間搜尋應用程式,從結構化和非結構化資料中統整出一致的答案。
- 微調與自訂:如何調整生成式 AI 模型,提供更準確的特定領域答案。
- 部署選項。使用預先建構的小工具或自訂 API,將這項推論功能整合至實際應用程式的各種方式。