
1. 總覽
在各行各業中,專利研究都是瞭解競爭環境、發掘潛在授權或收購機會,以及避免侵犯現有專利的重要工具。
專利研究範圍廣泛且複雜,從無數技術摘要中篩選出相關創新內容,是一項艱鉅的任務。傳統的關鍵字搜尋往往不準確且耗時。摘要冗長且技術性高,難以快速掌握核心概念。這可能會導致研究人員錯過重要專利,或在不相關的結果上浪費時間。
這項革命背後的祕密武器就是 Vector Search。向量搜尋不會比對關鍵字,而是將文字轉換為數值表示法 (嵌入),這項技術可讓我們根據查詢的意義進行搜尋,而不只是查詢中使用的特定字詞。在文獻搜尋領域,這是一項重大突破。舉例來說,即使文件中沒有使用「穿戴式心率監測器」這個確切詞組,您也能找到相關專利。
目標
在本程式碼研究室中,我們將運用 AlloyDB、pgvector 擴充功能、Gemini 1.5 Pro、Embeddings 和 Vector Search,讓專利搜尋程序更快、更直覺,且精確度極高。
建構項目
本實驗室的學習內容包括:
- 建立 AlloyDB 執行個體並載入專利公開資料集資料
- 在 AlloyDB 中啟用 pgvector 和生成式 AI 模型擴充功能
- 從洞察資料生成嵌入
- 針對使用者搜尋文字執行即時餘弦相似度搜尋
- 在無伺服器 Cloud Functions 中部署解決方案
下圖說明實作時的資料流和步驟。

High level diagram representing the flow of the Patent Search Application with AlloyDB
需求條件
2. 事前準備
建立專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
- 您將使用 Cloud Shell,這是 Google Cloud 中執行的指令列環境,預先載入了 bq。點選 Google Cloud 控制台頂端的「啟用 Cloud Shell」。

- 連至 Cloud Shell 後,請使用下列指令確認驗證已完成,專案也已設為獲派的專案 ID:
gcloud auth list
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令已瞭解您的專案。
gcloud config list project
- 如果未設定專案,請使用下列指令來設定:
gcloud config set project <YOUR_PROJECT_ID>
- 啟用必要的 API。您可以在 Cloud Shell 終端機中使用 gcloud 指令:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
除了使用 gcloud 指令,您也可以透過控制台搜尋各項產品,或使用這個連結。
如要瞭解 gcloud 指令和用法,請參閱說明文件。
3. 準備 AlloyDB 資料庫
我們來建立 AlloyDB 叢集、執行個體和資料表,以便載入專利資料集。
建立 AlloyDB 物件
使用叢集 ID「patent-cluster」、密碼「alloydb」、PostgreSQL 15 相容性,以及「us-central1」區域,建立叢集和執行個體,並將網路設為「default」。將執行個體 ID 設為「patent-instance」。按一下「建立叢集」。如需建立叢集的詳細資料,請參閱:https://cloud.google.com/alloydb/docs/cluster-create。
建立資料表
您可以在 AlloyDB Studio 中使用下列 DDL 陳述式建立資料表:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT) ;
啟用擴充功能
建構專利搜尋應用程式時,我們會使用 pgvector 和 google_ml_integration 擴充功能。pgvector 擴充功能可讓您儲存及搜尋向量嵌入。google_ml_integration 擴充功能提供多種函式,可存取 Vertex AI 預測端點,並在 SQL 中取得預測結果。執行下列 DDL,啟用這些擴充功能:
CREATE EXTENSION vector;
CREATE EXTENSION google_ml_integration;
授予權限
執行下列陳述式,授予「embedding」函式的執行權:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
為 AlloyDB 服務帳戶授予 Vertex AI 使用者角色
在 Google Cloud IAM 控制台,將「Vertex AI 使用者」角色授予 AlloyDB 服務帳戶 (格式為 service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)。PROJECT_NUMBER 會顯示您的專案編號。
或者,您也可以使用 gcloud 指令授予存取權:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
修改資料表,新增用來儲存嵌入的向量資料欄
執行下列 DDL,將 abstract_embeddings 欄位新增至剛建立的資料表。這個資料欄可儲存文字的向量值:
ALTER TABLE patents_data ADD column abstract_embeddings vector(3072);
4. 將專利資料載入資料庫
我們將使用 BigQuery 上的 Google 專利公開資料集做為資料集。我們將使用 AlloyDB Studio 執行查詢。alloydb-pgvector 存放區包含 insert_into_patents_data.sql 指令碼,我們將執行該指令碼來載入專利資料。
- 在 Google Cloud 控制台中,開啟「AlloyDB」AlloyDB頁面。
- 選取新建立的叢集,然後按一下執行個體。
- 在 AlloyDB 導覽選單中,按一下「AlloyDB Studio」。使用憑證登入。
- 按一下右側的「新增分頁」圖示,開啟新分頁。
- 從上述
insert_into_patents_data.sql指令碼複製insert查詢陳述式,並貼到編輯器。您可以複製 50 到 100 個插入陳述式,快速展示這個用途。 - 按一下「執行」。查詢結果會顯示在「結果」表格中。
5. 為專利資料建立嵌入
首先,請執行下列範例查詢,測試嵌入函式:
SELECT embedding( 'gemini-embedding-001', 'AlloyDB is a managed, cloud-hosted SQL database service.');
這應該會傳回查詢中範例文字的嵌入向量,看起來像是浮點數陣列。如下所示:

更新 abstract_embeddings 向量欄位
執行下列 DML,更新資料表中的專利摘要,並加入對應的嵌入內容:
UPDATE patents_data set abstract_embeddings = embedding( 'gemini-embedding-001', abstract);
6. 執行向量搜尋
現在資料表、資料和嵌入都已準備就緒,讓我們對使用者搜尋文字執行即時向量搜尋。您可以執行下列查詢來測試這項功能:
SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('gemini-embedding-001', 'A new Natural Language Processing related Machine Learning Model')::vector LIMIT 10;
在這項查詢中,
- 使用者搜尋文字:「新的自然語言處理相關機器學習模型」。
- 我們使用模型:gemini-embedding-001,在 embedding() 方法中將其轉換為嵌入。
- 「<=>」代表使用餘弦相似度距離法。
- 我們會將嵌入方法的結果轉換為向量型別,使其與資料庫中儲存的向量相容。
- LIMIT 10 代表我們選取與搜尋文字最接近的 10 個相符項目。
結果如下:

如搜尋結果所示,相符項目與搜尋文字相當接近。
7. 將應用程式帶到網頁
準備好將這個應用程式帶到網路上嗎?步驟如下:
- 前往 Cloud Shell 編輯器,然後按一下編輯器左下角 (狀態列) 的「Cloud Code - Sign in」圖示。選取已啟用帳單的現有 Google Cloud 專案,並確認您也從 Gemini 登入同一個專案 (狀態列的右下角)。
- 按一下 Cloud Code 圖示,然後等待 Cloud Code 對話方塊彈出。選取「New Application」(新增應用程式),然後在「Create New Application」(建立新應用程式) 快顯視窗中,選取「Cloud Functions application」(Cloud Functions 應用程式):

在「Create New Application」(建立新的應用程式) 快顯視窗的第 2/2 頁面中,選取「Java: Hello World」,並在偏好的位置輸入專案名稱「alloydb-pgvector」,然後按一下「OK」:

- 在產生的專案結構中,搜尋 pom.xml,然後將其內容替換為存放區檔案的內容。除了其他幾個依附元件外,還應包含下列依附元件:

- 將 HelloWorld.java 檔案替換為 repo 檔案的內容。
請注意,您必須將下列值替換為實際值:
String ALLOYDB_DB = "postgres";
String ALLOYDB_USER = "postgres";
String ALLOYDB_PASS = "*****";
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
//Replace YOUR_PROJECT_ID, YOUR_CLUSTER, YOUR_INSTANCE with your actual values
請注意,函式會將搜尋文字做為輸入內容參數,並以「search」做為鍵。在這個實作中,我們只會從資料庫傳回最接近的相符項目:
// Get the request body as a JSON object.
JsonObject requestJson = new Gson().fromJson(request.getReader(), JsonObject.class);
String searchText = requestJson.get("search").getAsString();
//Sample searchText: "A new Natural Language Processing related Machine Learning Model";
BufferedWriter writer = response.getWriter();
String result = "";
HikariDataSource dataSource = AlloyDbJdbcConnector();
try (Connection connection = dataSource.getConnection()) {
//Retrieve Vector Search by text (converted to embeddings) using "Cosine Similarity" method
try (PreparedStatement statement = connection.prepareStatement("SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('tgemini-embedding-001', '" + searchText + "' )::vector LIMIT 1")) {
ResultSet resultSet = statement.executeQuery();
resultSet.next();
String lit = resultSet.getString("literature");
result = result + lit + "\n";
System.out.println("Matching Literature: " + lit);
}
writer.write("Here is the closest match: " + result);
}
- 如要部署剛建立的 Cloud 函式,請從 Cloud Shell 終端機執行下列指令。請務必先使用下列指令,前往對應的專案資料夾:
cd alloydb-pgvector
然後執行下列指令:
gcloud functions deploy patent-search --gen2 --region=us-central1 --runtime=java11 --source=. --entry-point=cloudcode.helloworld.HelloWorld --trigger-http
重要步驟:
設定部署作業後,您應該就能在 Google Cloud Run Functions 控制台中看到函式。搜尋並開啟新建立的函式,編輯設定並變更下列項目:
- 前往「執行階段、建構作業、連線和安全性設定」
- 將逾時時間增加至 180 秒
- 前往「連線」分頁:
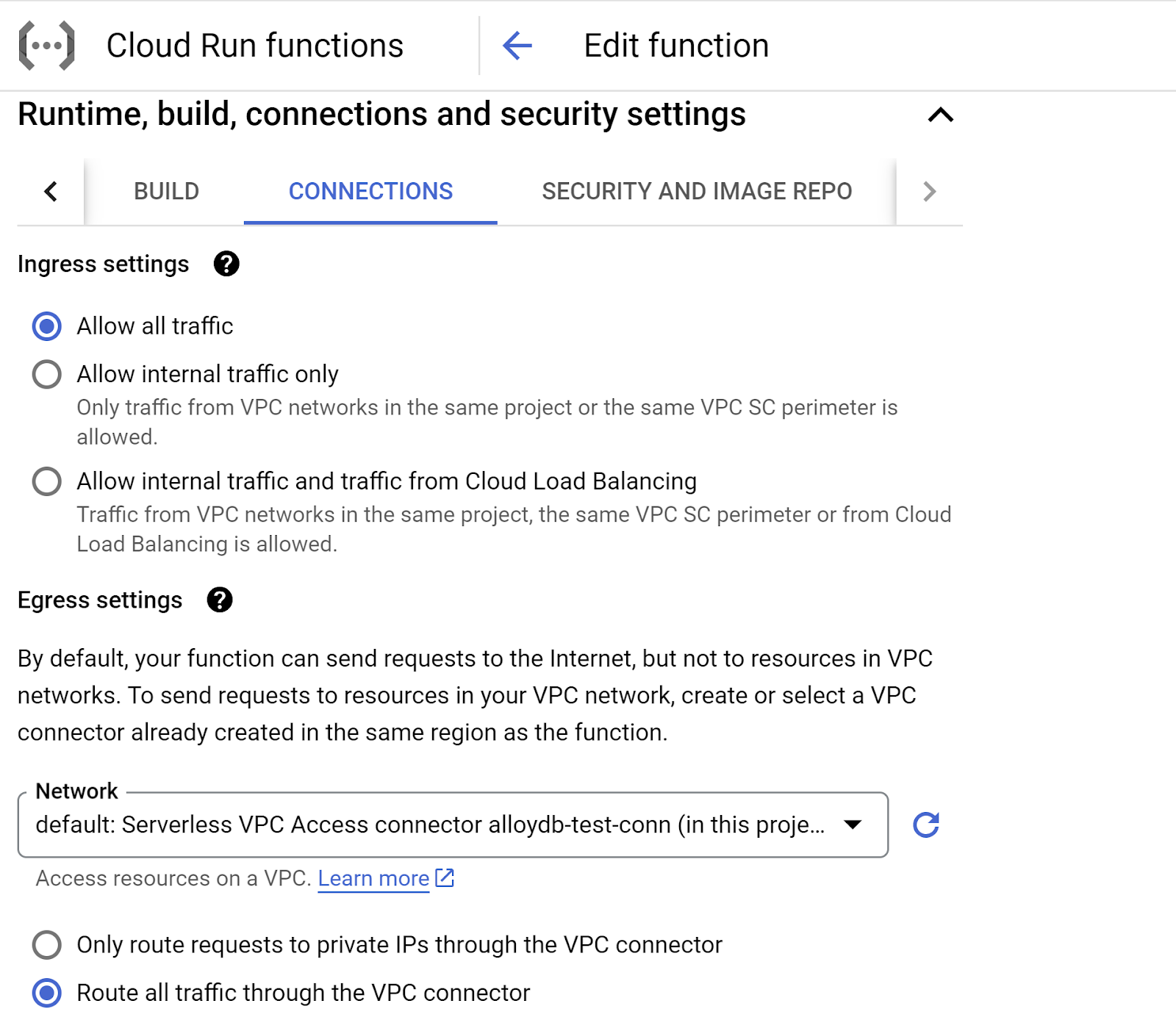
- 在 Ingress 設定下方,確認已選取「允許所有流量」。
- 在「輸出設定」下方,按一下「網路」下拉式選單,然後選取「新增虛擬私有雲連接器」選項,並按照彈出式對話方塊中顯示的操作說明進行操作:

- 提供 VPC 連接器的名稱,並確認區域與執行個體相同。將「網路」值保留為預設值,並將「子網路」設為「自訂 IP 範圍」,IP 範圍為 10.8.0.0 或類似的可用範圍。
- 展開「顯示縮放設定」,確認設定完全符合下列條件:

- 按一下「CREATE」,這個連接器現在應該會列在輸出設定中。
- 選取新建立的連接器
- 選擇透過這個虛擬私有雲連接器轉送所有流量。
8. 測試應用程式
部署完成後,您應該會看到下列格式的端點:
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/patent-search
您可以在 Cloud Shell 終端機中執行下列指令進行測試:
gcloud functions call patent-search --region=us-central1 --gen2 --data '{"search": "A new Natural Language Processing related Machine Learning Model"}'
結果:

您也可以從 Cloud Functions 清單進行測試。選取已部署的函式,然後前往「測試」分頁標籤。在「Configure triggering event」(設定觸發事件) 區段的「request json」(要求 JSON) 文字方塊中,輸入下列內容:
{"search": "A new Natural Language Processing related Machine Learning Model"}
按一下「測試函式」按鈕,即可在頁面右側查看結果:

大功告成!在 AlloyDB 資料上使用 Embeddings 模型執行相似度向量搜尋,就是這麼簡單。
9. 清理
如要避免系統向您的 Google Cloud 帳戶收取本文章所用資源的費用,請按照下列步驟操作:
- 前往 Google Cloud 控制台的「管理」
- 資源頁面。
- 在專案清單中選取要刪除的專案,然後點按「刪除」。
- 在對話方塊中輸入專案 ID,然後按一下「Shut down」(關機) 即可刪除專案。
10. 恭喜
恭喜!您已使用 AlloyDB、pgvector 和向量搜尋功能,成功執行相似度搜尋。結合 AlloyDB、Vertex AI 和 Vector Search 的功能,我們在文學搜尋領域取得重大進展,讓搜尋作業更易於存取、效率更高,且真正以意義為導向。