
১. সংক্ষিপ্ত বিবরণ
বিভিন্ন শিল্পে, প্রাসঙ্গিক অনুসন্ধান একটি অত্যন্ত গুরুত্বপূর্ণ কার্যকারিতা যা তাদের অ্যাপ্লিকেশনগুলির কেন্দ্রবিন্দু গঠন করে। রিট্রিভাল অগমেন্টেড জেনারেশন (RAG) তার জেনারেটিভ এআই চালিত পুনরুদ্ধার পদ্ধতির মাধ্যমে বেশ কিছুদিন ধরে এই গুরুত্বপূর্ণ প্রযুক্তিগত বিবর্তনের একটি প্রধান চালক হিসেবে কাজ করছে। জেনারেটিভ মডেলগুলি, তাদের বৃহৎ কনটেক্সট উইন্ডো এবং চিত্তাকর্ষক আউটপুট কোয়ালিটির মাধ্যমে, এআই-কে রূপান্তরিত করছে। RAG এআই অ্যাপ্লিকেশন এবং এজেন্টগুলিতে কনটেক্সট যুক্ত করার একটি পদ্ধতিগত উপায় প্রদান করে, যা সেগুলিকে কাঠামোগত ডেটাবেস বা বিভিন্ন মাধ্যম থেকে প্রাপ্ত তথ্যের উপর ভিত্তি করে প্রতিষ্ঠিত করে। এই প্রাসঙ্গিক ডেটা সত্যের স্বচ্ছতা এবং আউটপুটের নির্ভুলতার জন্য অত্যন্ত গুরুত্বপূর্ণ, কিন্তু সেই ফলাফলগুলি কতটা নির্ভুল? আপনার ব্যবসা কি এই প্রাসঙ্গিক মিল এবং প্রাসঙ্গিকতার নির্ভুলতার উপর অনেকাংশে নির্ভরশীল? তাহলে এই প্রকল্পটি আপনার মন জয় করে নেবে!
এখন কল্পনা করুন, যদি আমরা জেনারেটিভ মডেলের শক্তিকে কাজে লাগিয়ে এমন ইন্টারেক্টিভ এজেন্ট তৈরি করতে পারতাম, যা এই ধরনের প্রাসঙ্গিক তথ্যের ওপর ভিত্তি করে এবং সত্যের ওপর প্রতিষ্ঠিত হয়ে স্বায়ত্তশাসিত সিদ্ধান্ত নিতে সক্ষম; আজ আমরা ঠিক সেটাই তৈরি করতে যাচ্ছি। আমরা একটি পেটেন্ট বিশ্লেষণ অ্যাপ্লিকেশনের জন্য AlloyDB-তে উন্নত RAG দ্বারা চালিত এজেন্ট ডেভেলপমেন্ট কিট ব্যবহার করে একটি এন্ড-টু-এন্ড এআই এজেন্ট অ্যাপ তৈরি করব।
পেটেন্ট অ্যানালাইসিস এজেন্ট ব্যবহারকারীকে তার সার্চ টেক্সটের সাথে প্রাসঙ্গিকভাবে প্রাসঙ্গিক পেটেন্ট খুঁজে পেতে সহায়তা করে এবং অনুরোধ করলে, নির্বাচিত কোনো পেটেন্টের জন্য একটি স্পষ্ট ও সংক্ষিপ্ত ব্যাখ্যা এবং প্রয়োজনে অতিরিক্ত বিবরণ প্রদান করে। এটি কীভাবে করা হয় তা দেখতে প্রস্তুত? চলুন শুরু করা যাক!
উদ্দেশ্য
লক্ষ্যটি সহজ। একজন ব্যবহারকারীকে একটি লিখিত বিবরণের উপর ভিত্তি করে পেটেন্ট অনুসন্ধান করার সুযোগ দেওয়া এবং তারপর অনুসন্ধানের ফলাফল থেকে একটি নির্দিষ্ট পেটেন্টের বিস্তারিত ব্যাখ্যা প্রদান করা। আর এই সবকিছুই করা হয় Java ADK, AlloyDB, Vector Search (উন্নত ইনডেক্স সহ), Gemini দিয়ে নির্মিত একটি এআই এজেন্টের মাধ্যমে এবং সম্পূর্ণ অ্যাপ্লিকেশনটি Cloud Run-এ সার্ভারবিহীনভাবে স্থাপন করা হয়।
আপনি যা তৈরি করবেন
এই ল্যাবের অংশ হিসেবে, আপনি যা করবেন:
- একটি AlloyDB ইনস্ট্যান্স তৈরি করুন এবং পেটেন্ট পাবলিক ডেটাসেটের ডেটা লোড করুন।
- ScaNN ও রিকল ইভ্যাল ফিচার ব্যবহার করে AlloyDB-তে উন্নত ভেক্টর সার্চ বাস্তবায়ন করুন
- জাভা ADK ব্যবহার করে একটি এজেন্ট তৈরি করুন
- জাভা সার্ভারলেস ক্লাউড ফাংশনে ডাটাবেস সার্ভার-সাইড লজিক প্রয়োগ করুন
- ক্লাউড রানে এজেন্টটি স্থাপন ও পরীক্ষা করুন
নিম্নোক্ত চিত্রটিতে তথ্যের প্রবাহ এবং বাস্তবায়নের ধাপসমূহ দেখানো হয়েছে।
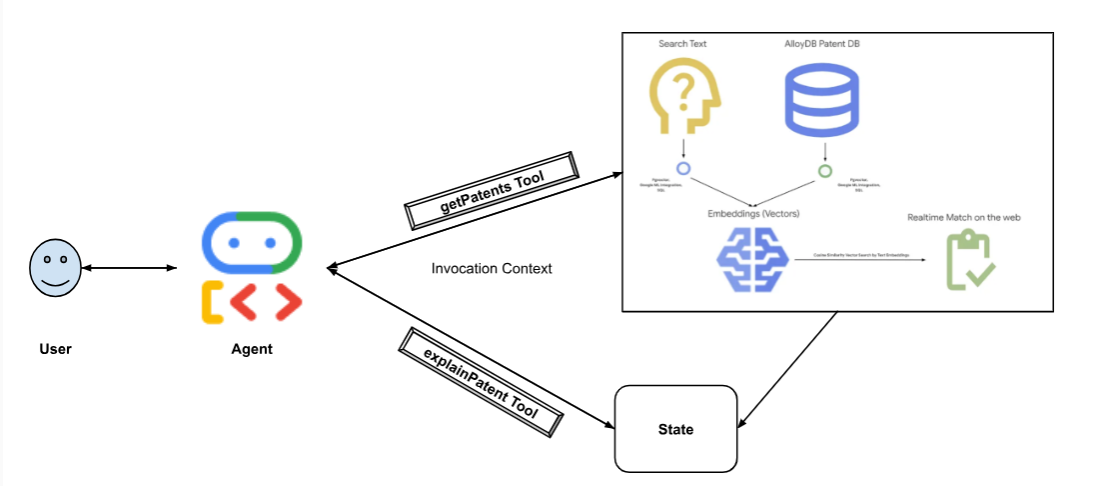
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
প্রয়োজনীয়তা
- ক্রোম বা ফায়ারফক্সের মতো একটি ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় API-গুলো সক্রিয় করুন। আপনি ক্লাউড শেল টার্মিনালে gcloud কমান্ডটি ব্যবহার করতে পারেন:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
gcloud কমান্ডের বিকল্প হলো কনসোলের মাধ্যমে প্রতিটি পণ্য অনুসন্ধান করা অথবা এই লিঙ্কটি ব্যবহার করা।
gcloud কমান্ড ও তার ব্যবহারবিধি জানতে ডকুমেন্টেশন দেখুন।
৩. ডাটাবেস সেটআপ
এই ল্যাবে আমরা পেটেন্ট ডেটার ডেটাবেস হিসেবে AlloyDB ব্যবহার করব। এটি ডেটাবেস এবং লগের মতো সমস্ত রিসোর্স ধারণ করার জন্য ক্লাস্টার ব্যবহার করে। প্রতিটি ক্লাস্টারে একটি প্রাইমারি ইনস্ট্যান্স থাকে যা ডেটাতে অ্যাক্সেস পয়েন্ট সরবরাহ করে। টেবিলগুলোতে প্রকৃত ডেটা থাকবে।
চলুন একটি AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং টেবিল তৈরি করি যেখানে পেটেন্ট ডেটাসেটটি লোড করা হবে।
একটি ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করুন
- ক্লাউড কনসোলে AlloyDB পেজটিতে যান। ক্লাউড কনসোলের বেশিরভাগ পেজ খুঁজে পাওয়ার একটি সহজ উপায় হলো কনসোলের সার্চ বার ব্যবহার করে সেগুলোর জন্য অনুসন্ধান করা।
- সেই পৃষ্ঠা থেকে CREATE CLUSTER নির্বাচন করুন:

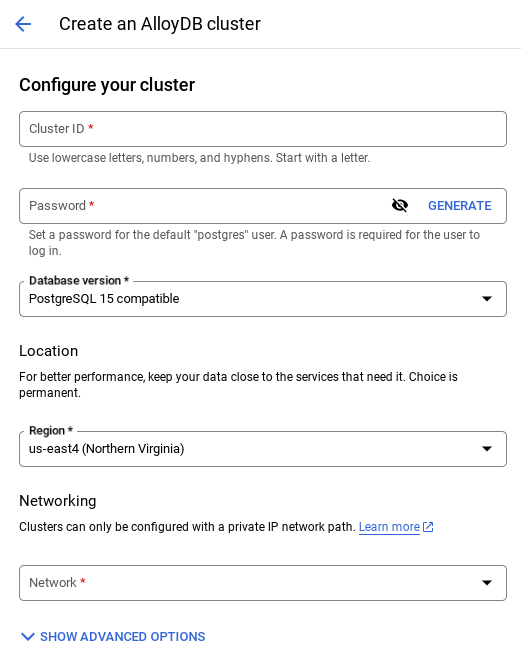
- আপনি নীচেরটির মতো একটি স্ক্রিন দেখতে পাবেন। নিম্নলিখিত মানগুলি দিয়ে একটি ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করুন (আপনি যদি রিপো থেকে অ্যাপ্লিকেশন কোড ক্লোন করেন তবে নিশ্চিত করুন যে মানগুলি মিলে যায়):
- ক্লাস্টার আইডি : "
vector-cluster" - পাসওয়ার্ড : "
alloydb" - PostgreSQL 15 / সর্বশেষ সংস্করণ সুপারিশ করা হচ্ছে
- অঞ্চল : "
us-central1" - নেটওয়ার্কিং : "
default"
- আপনি যখন ডিফল্ট নেটওয়ার্ক নির্বাচন করবেন, তখন নিচের স্ক্রিনের মতো একটি স্ক্রিন দেখতে পাবেন।
সংযোগ স্থাপন নির্বাচন করুন। 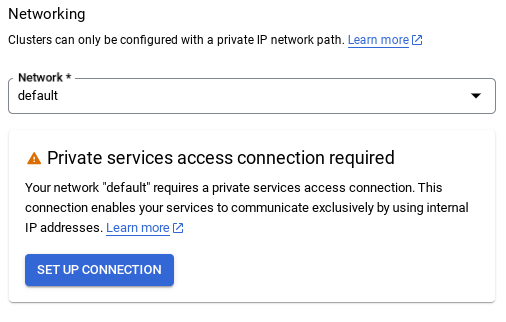
- সেখান থেকে, " Use an automatically allocated IP range " নির্বাচন করুন এবং Continue নির্বাচন করুন। তথ্য পর্যালোচনা করার পর, CREATE CONNECTION নির্বাচন করুন।
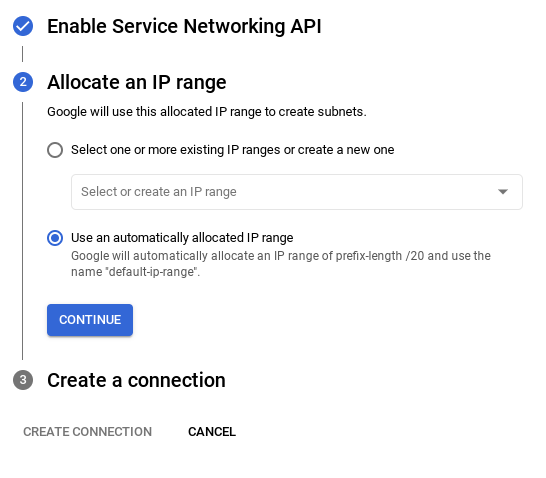
- আপনার নেটওয়ার্ক সেট আপ হয়ে গেলে, আপনি আপনার ক্লাস্টার তৈরি করা চালিয়ে যেতে পারেন। নিচে দেখানো অনুযায়ী ক্লাস্টার সেট আপ সম্পন্ন করতে CREATE CLUSTER-এ ক্লিক করুন:
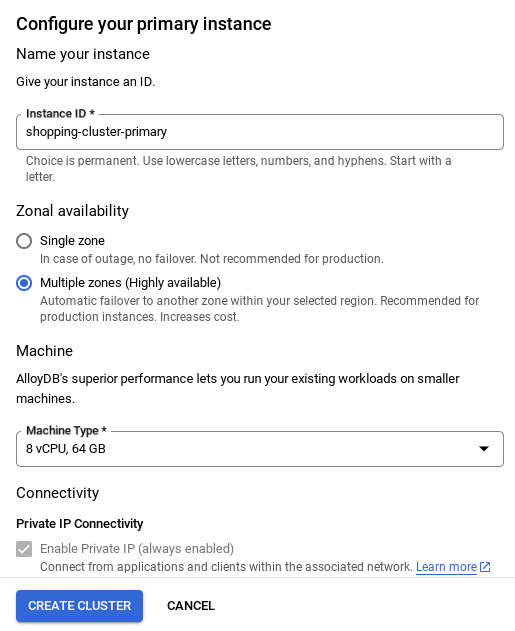
ইনস্ট্যান্স আইডিটি (যা আপনি ক্লাস্টার / ইনস্ট্যান্স কনফিগার করার সময় খুঁজে পাবেন) পরিবর্তন করে নিন ।
vector-instance । যদি আপনি এটি পরিবর্তন করতে না পারেন, তাহলে পরবর্তী সমস্ত রেফারেন্সে আপনার ইনস্ট্যান্স আইডি ব্যবহার করতে মনে রাখবেন।
মনে রাখবেন, ক্লাস্টার তৈরি হতে প্রায় ১০ মিনিট সময় লাগবে। এটি সফল হলে, আপনি আপনার তৈরি করা ক্লাস্টারের একটি সার্বিক চিত্র দেখতে পাবেন।
৪. ডেটা গ্রহণ
এখন স্টোর সম্পর্কিত ডেটা সহ একটি টেবিল যোগ করার সময় এসেছে। AlloyDB-তে যান, প্রাইমারি ক্লাস্টার নির্বাচন করুন এবং তারপর AlloyDB Studio-তে যান:
আপনার ইনস্ট্যান্সটি তৈরি হওয়া শেষ না হওয়া পর্যন্ত আপনাকে অপেক্ষা করতে হতে পারে। এটি তৈরি হয়ে গেলে, ক্লাস্টার তৈরির সময় আপনি যে ক্রেডেনশিয়ালগুলো তৈরি করেছিলেন, সেগুলো ব্যবহার করে AlloyDB-তে সাইন ইন করুন। PostgreSQL-এ প্রমাণীকরণের জন্য নিম্নলিখিত ডেটা ব্যবহার করুন:
- ব্যবহারকারীর নাম : "
postgres" - ডাটাবেস : "
postgres" - পাসওয়ার্ড : "
alloydb"
AlloyDB Studio-তে সফলভাবে প্রমাণীকরণের পর, এডিটর-এ SQL কমান্ডগুলো প্রবেশ করানো হয়। শেষ উইন্ডোটির ডানদিকে থাকা প্লাস চিহ্নটি ব্যবহার করে আপনি একাধিক এডিটর উইন্ডো যোগ করতে পারেন।
আপনি এডিটর উইন্ডোতে AlloyDB-এর জন্য কমান্ড লিখবেন এবং প্রয়োজন অনুযায়ী Run, Format ও Clear অপশনগুলো ব্যবহার করবেন।
এক্সটেনশনগুলি সক্ষম করুন
এই অ্যাপটি তৈরি করার জন্য, আমরা pgvector এবং google_ml_integration এক্সটেনশনগুলো ব্যবহার করব। pgvector এক্সটেনশনটি আপনাকে ভেক্টর এমবেডিং সংরক্ষণ এবং অনুসন্ধান করার সুযোগ দেয়। google_ml_integration এক্সটেনশনটি এমন সব ফাংশন সরবরাহ করে যা ব্যবহার করে আপনি Vertex AI প্রেডিকশন এন্ডপয়েন্টগুলো অ্যাক্সেস করে SQL-এ প্রেডিকশন পেতে পারেন। নিম্নলিখিত DDL-গুলো রান করে এই এক্সটেনশনগুলো সক্রিয় করুন :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
আপনার ডাটাবেসে কোন এক্সটেনশনগুলো সক্রিয় করা হয়েছে তা পরীক্ষা করতে চাইলে, এই SQL কমান্ডটি চালান:
select extname, extversion from pg_extension;
একটি টেবিল তৈরি করুন
আপনি AlloyDB Studio-তে নিচের DDL স্টেটমেন্টটি ব্যবহার করে একটি টেবিল তৈরি করতে পারেন:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings কলামটি টেক্সটের ভেক্টর মানগুলো সংরক্ষণের সুযোগ দেবে।
অনুমতি প্রদান করুন
'embedding' ফাংশনটিতে execute অনুমোদন দিতে নিচের স্টেটমেন্টটি চালান:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB পরিষেবা অ্যাকাউন্টে Vertex AI ব্যবহারকারীর ROLE প্রদান করুন।
Google Cloud IAM কনসোল থেকে, AlloyDB সার্ভিস অ্যাকাউন্টকে (যা দেখতে এইরকম: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) "Vertex AI User" রোলের অ্যাক্সেস দিন। PROJECT_NUMBER-এ আপনার প্রজেক্ট নম্বরটি থাকবে।
বিকল্পভাবে আপনি ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালাতে পারেন:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
ডেটাবেসে পেটেন্ট ডেটা লোড করুন
BigQuery-তে থাকা Google Patents Public Datasets আমাদের ডেটাসেট হিসেবে ব্যবহৃত হবে। আমরা আমাদের কোয়েরিগুলো চালানোর জন্য AlloyDB Studio ব্যবহার করব। এই রিপো -তে insert scripts sql ফাইলটিতে ডেটা সোর্স করা হয়েছে এবং পেটেন্ট ডেটা লোড করার জন্য আমরা এটি চালাব।
- গুগল ক্লাউড কনসোলে AlloyDB পেজটি খুলুন।
- আপনার নতুন তৈরি করা ক্লাস্টারটি নির্বাচন করুন এবং ইনস্ট্যান্সটিতে ক্লিক করুন।
- AlloyDB নেভিগেশন মেনুতে, AlloyDB Studio-তে ক্লিক করুন। আপনার ক্রেডেনশিয়াল দিয়ে সাইন ইন করুন।
- ডানদিকে থাকা নতুন ট্যাব আইকনে ক্লিক করে একটি নতুন ট্যাব খুলুন।
-
insert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlফাইলগুলো থেকেinsertকোয়েরি স্টেটমেন্টগুলো এক এক করে কপি করে রান করুন। এই ইউজ কেসটির একটি দ্রুত ডেমোর জন্য আপনি ১০-৫০টি ইনসার্ট স্টেটমেন্ট কপি করে রান করতে পারেন।
চালানোর জন্য, রান-এ ক্লিক করুন। আপনার কোয়েরির ফলাফল রেজাল্টস টেবিলে প্রদর্শিত হবে।
৫. পেটেন্ট ডেটার জন্য এমবেডিং তৈরি করুন
প্রথমে নিচের নমুনা কোয়েরিটি চালিয়ে এমবেডিং ফাংশনটি পরীক্ষা করে নেওয়া যাক:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
এটি কোয়েরিতে থাকা নমুনা টেক্সটের জন্য এমবেডিংস ভেক্টরটি রিটার্ন করবে, যা ফ্লোট সংখ্যার একটি অ্যারের মতো দেখতে। এটি দেখতে এইরকম:
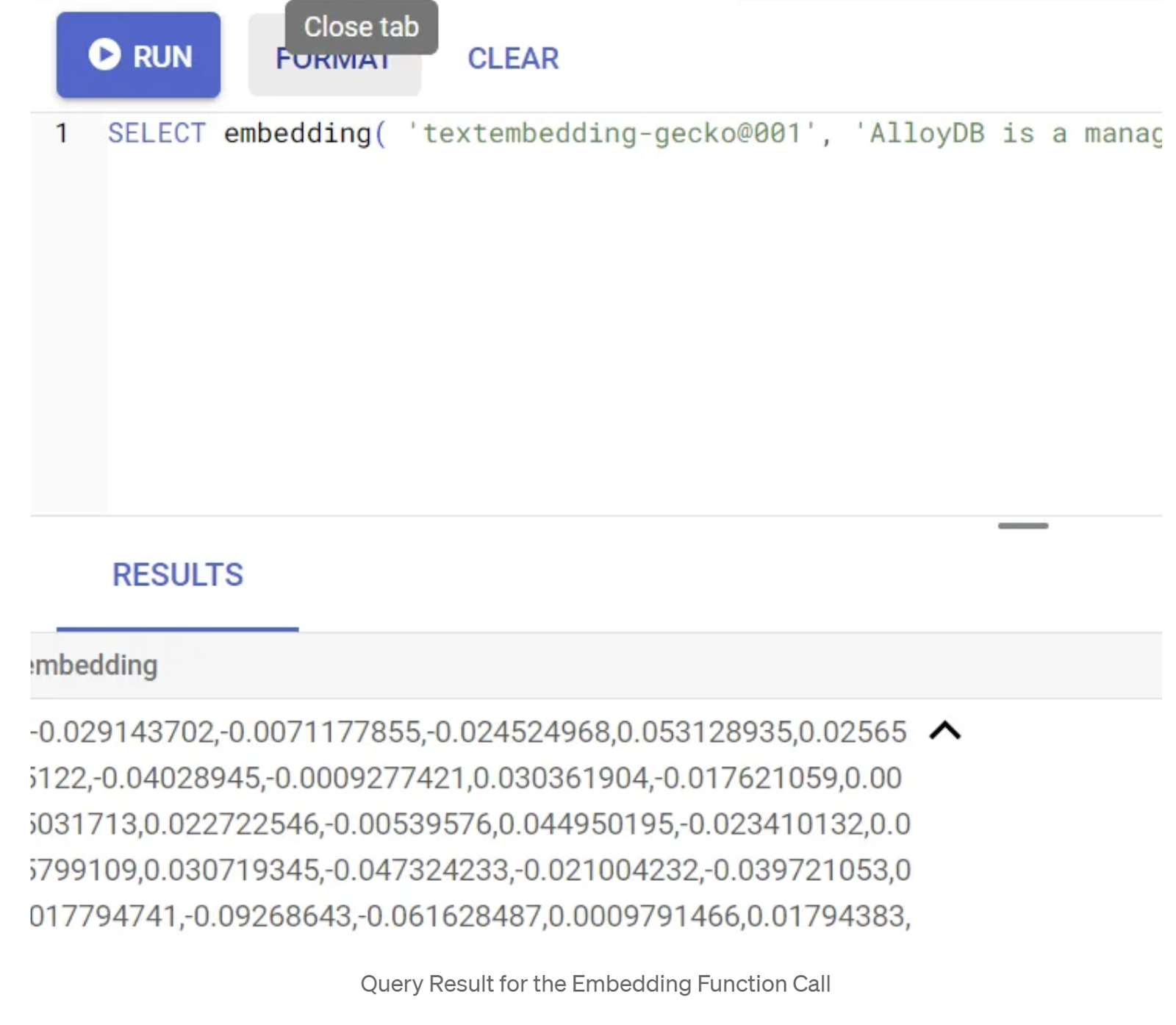
abstract_embeddings ভেক্টর ফিল্ডটি আপডেট করুন
যদি অ্যাবস্ট্র্যাক্টগুলোর জন্য এমবেডিং তৈরি করার প্রয়োজন হয়, তবে টেবিলের অ্যাবস্ট্র্যাক্টগুলোকে সংশ্লিষ্ট এমবেডিং দিয়ে আপডেট করার জন্য নিচের DML-টি ব্যবহার করতে হবে। কিন্তু আমাদের ক্ষেত্রে, ইনসার্ট স্টেটমেন্টগুলোতে প্রতিটি অ্যাবস্ট্র্যাক্টের জন্য এই এমবেডিংগুলো আগে থেকেই অন্তর্ভুক্ত থাকে, তাই আপনার embeddings() মেথডটি কল করার প্রয়োজন নেই।
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
৬. ভেক্টর অনুসন্ধান সম্পাদন করুন
এখন যেহেতু টেবিল, ডেটা, এমবেডিং সবই প্রস্তুত, চলুন ব্যবহারকারীর সার্চ টেক্সটের জন্য রিয়েল টাইম ভেক্টর সার্চটি সম্পাদন করা যাক। নিচের কোয়েরিটি চালিয়ে আপনি এটি পরীক্ষা করতে পারেন:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
এই কোয়েরিতে,
- ব্যবহারকারী যে লেখাটি অনুসন্ধান করেছেন তা হলো: "Sentiment Analysis"।
- আমরা `text-embedding-005` মডেলটি ব্যবহার করে `embedding()` মেথডে এটিকে এমবেডিং-এ রূপান্তর করছি।
- "<=>" চিহ্নটি কোসাইন সিমিলারিটি দূরত্ব পদ্ধতির ব্যবহারকে নির্দেশ করে।
- ডাটাবেসে সংরক্ষিত ভেক্টরগুলোর সাথে সামঞ্জস্যপূর্ণ করার জন্য আমরা এমবেডিং মেথডের ফলাফলকে ভেক্টর টাইপে রূপান্তর করছি।
- LIMIT 10 এর অর্থ হলো, আমরা সার্চ টেক্সটের সবচেয়ে কাছাকাছি ১০টি মিল নির্বাচন করছি।
AlloyDB ভেক্টর সার্চ RAG-কে পরবর্তী স্তরে নিয়ে যায়:
এখানে বেশ কিছু নতুন জিনিস চালু করা হয়েছে। এর মধ্যে ডেভেলপারদের জন্য দুটি হলো:
- ইনলাইন ফিল্টারিং
- প্রত্যাহার মূল্যায়নকারী
ইনলাইন ফিল্টারিং
পূর্বে একজন ডেভেলপার হিসেবে, আপনাকে ভেক্টর সার্চ কোয়েরি চালাতে হতো এবং ফিল্টারিং ও রিকল নিয়ে কাজ করতে হতো। অ্যালয়ডিবি কোয়েরি অপটিমাইজার ফিল্টারসহ একটি কোয়েরি কীভাবে কার্যকর করা হবে, সেই সিদ্ধান্ত নেয়। ইনলাইন ফিল্টারিং হলো একটি নতুন কোয়েরি অপটিমাইজেশন কৌশল, যা অ্যালয়ডিবি কোয়েরি অপটিমাইজারকে মেটাডেটা ফিল্টারিং শর্তাবলী এবং ভেক্টর সার্চ উভয়কেই একসাথে মূল্যায়ন করার সুযোগ দেয় এবং এর জন্য ভেক্টর ইনডেক্স ও মেটাডেটা কলামের ইনডেক্স উভয়কেই কাজে লাগায়। এর ফলে রিকল পারফরম্যান্স বৃদ্ধি পেয়েছে, যা ডেভেলপারদের অ্যালয়ডিবির বিল্ট-ইন সুবিধাগুলো পুরোপুরি গ্রহণ করার সুযোগ করে দিয়েছে।
মাঝারি সিলেক্টিভিটির ক্ষেত্রে ইনলাইন ফিল্টারিং সবচেয়ে ভালো। AlloyDB যখন ভেক্টর ইনডেক্সে অনুসন্ধান করে, তখন এটি শুধুমাত্র সেইসব ভেক্টরের দূরত্ব গণনা করে যা মেটাডেটা ফিল্টারিং শর্তের সাথে মেলে (একটি কোয়েরিতে আপনার ফাংশনাল ফিল্টার, যা সাধারণত WHERE ক্লজে পরিচালনা করা হয়)। এটি পোস্ট-ফিল্টার বা প্রি-ফিল্টারের সুবিধার পরিপূরক হিসেবে এই কোয়েরিগুলির পারফরম্যান্স ব্যাপকভাবে উন্নত করে।
- pgvector এক্সটেনশনটি ইনস্টল বা আপডেট করুন
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
যদি pgvector এক্সটেনশনটি আগে থেকেই ইনস্টল করা থাকে, তাহলে রিকল ইভ্যালুয়েটর সুবিধাগুলো পেতে ভেক্টর এক্সটেনশনটিকে 0.8.0.google-3 বা তার পরবর্তী সংস্করণে আপগ্রেড করুন।
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
এই ধাপটি শুধুমাত্র তখনই সম্পাদন করতে হবে, যদি আপনার ভেক্টর এক্সটেনশন <0.8.0.google-3 হয়।
গুরুত্বপূর্ণ দ্রষ্টব্য: যদি আপনার সারির সংখ্যা ১০০-এর কম হয়, তাহলে আপনাকে শুরুতেই ScaNN ইনডেক্স তৈরি করতে হবে না, কারণ এটি কম সারির ক্ষেত্রে প্রযোজ্য হবে না। সেক্ষেত্রে অনুগ্রহ করে নিম্নলিখিত ধাপগুলো এড়িয়ে যান।
- ScaNN ইনডেক্স তৈরি করতে, alloydb_scann এক্সটেনশনটি ইনস্টল করুন।
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- প্রথমে ইনডেক্স এবং ইনলাইন ফিল্টার সক্রিয় না করে ভেক্টর সার্চ কোয়েরিটি চালান:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
ফলাফলটি নিম্নরূপ হওয়া উচিত:
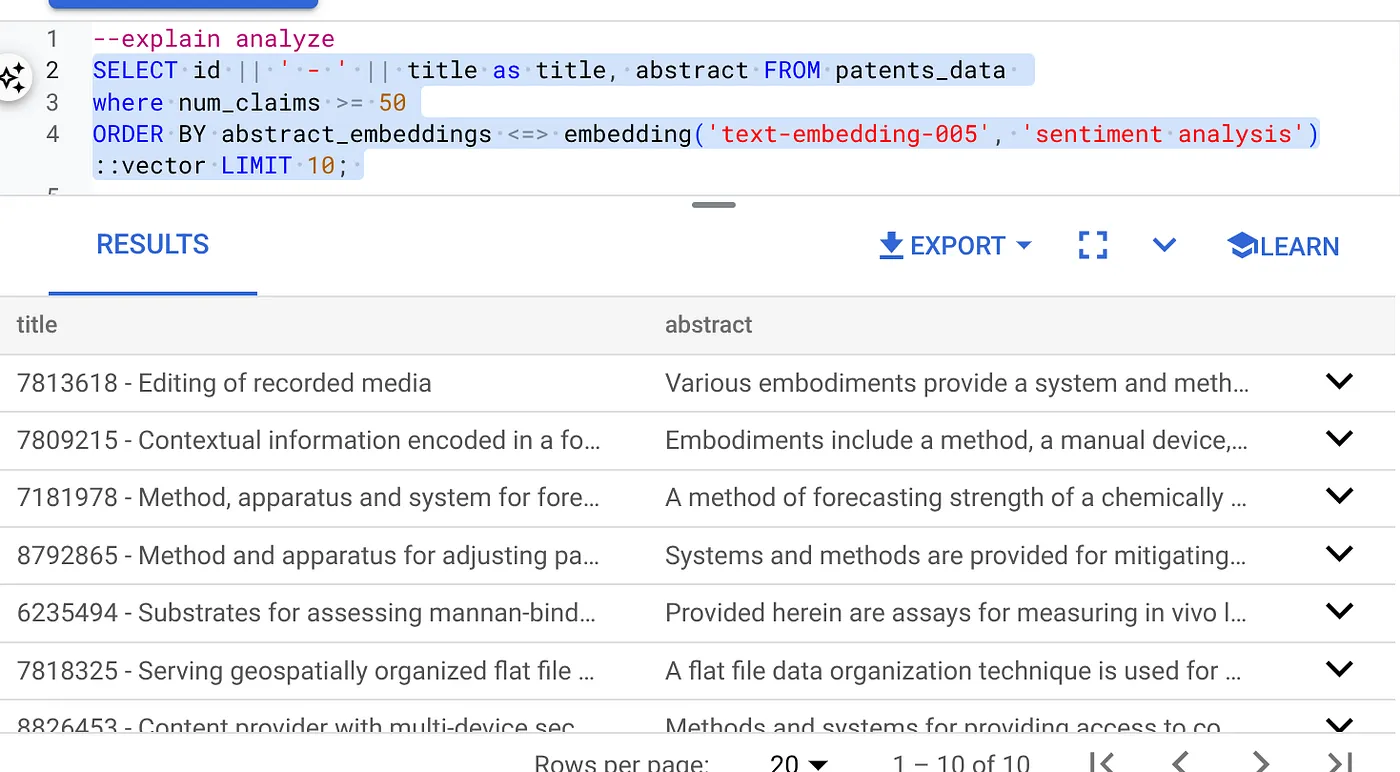
- এটির উপর এক্সপ্লেইন অ্যানালাইজ চালান: (কোনো ইনডেক্স বা ইনলাইন ফিল্টারিং ছাড়া)
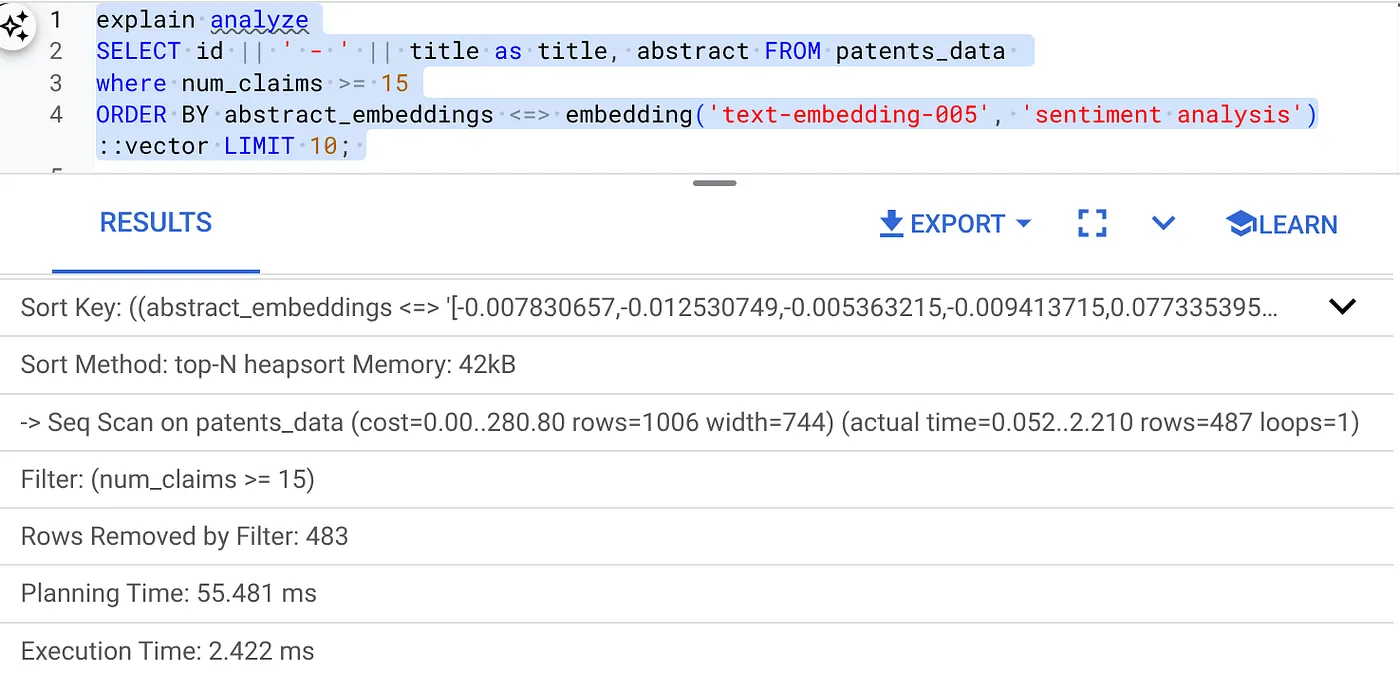
কার্য সম্পাদনের সময় ২.৪ মিলিসেকেন্ড।
- চলুন num_claims ফিল্ডটির উপর একটি সাধারণ ইনডেক্স তৈরি করি, যাতে আমরা এটি দিয়ে ফিল্টার করতে পারি:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- চলুন আমাদের পেটেন্ট সার্চ অ্যাপ্লিকেশনের জন্য ScaNN ইনডেক্স তৈরি করি। আপনার AlloyDB Studio থেকে নিম্নলিখিত কমান্ডটি চালান:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
গুরুত্বপূর্ণ দ্রষ্টব্য: (num_leaves=32) আমাদের ১০০০+ সারিযুক্ত সম্পূর্ণ ডেটাসেটের জন্য প্রযোজ্য। যদি আপনার সারির সংখ্যা ১০০-এর কম হয়, তাহলে আপনার শুরুতেই কোনো ইনডেক্স তৈরি করার প্রয়োজন হবে না, কারণ এটি কম সারির ক্ষেত্রে প্রযোজ্য হবে না।
- ScanN ইনডেক্সে ইনলাইন ফিল্টারিং সক্রিয় করুন:
SET scann.enable_inline_filtering = on
- এখন, ফিল্টার এবং ভেক্টর সার্চ সহ একই কোয়েরিটি চালানো যাক:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
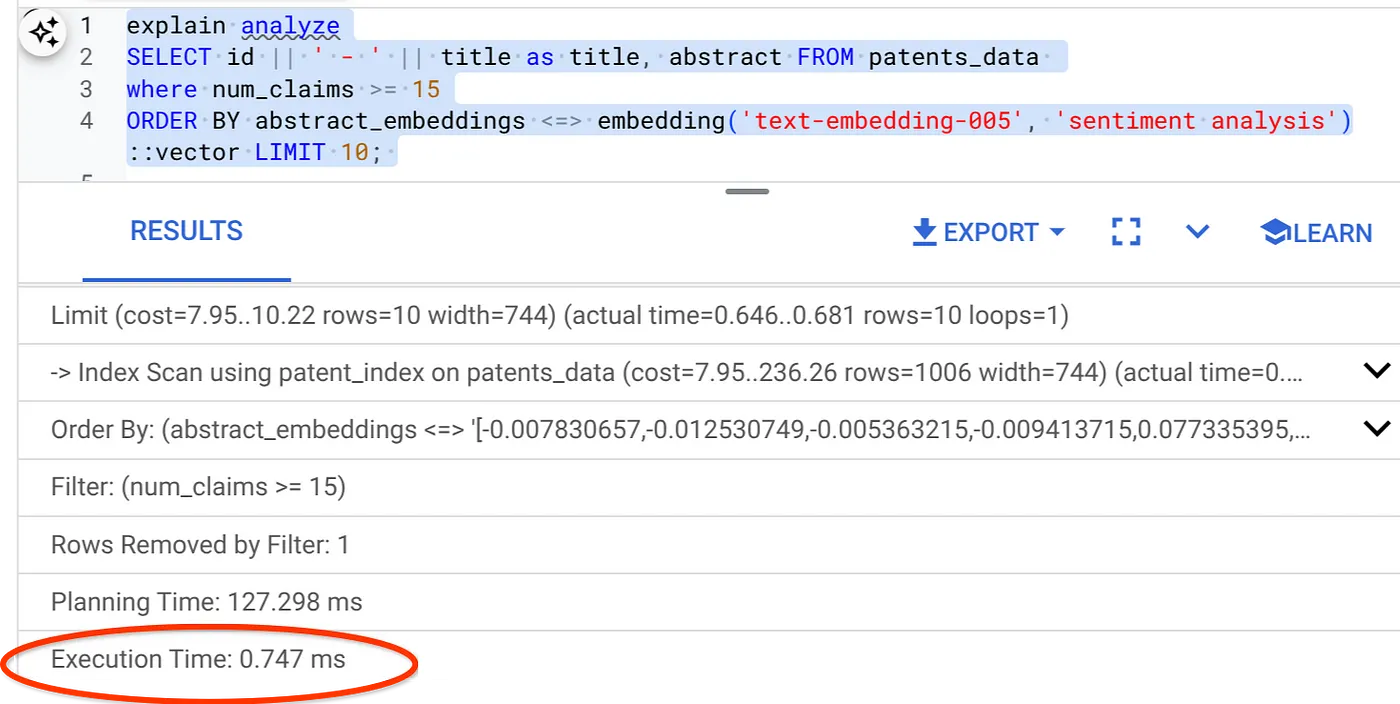
আপনি দেখতেই পাচ্ছেন, একই ভেক্টর সার্চের জন্য এক্সিকিউশন টাইম উল্লেখযোগ্যভাবে কমে গেছে। ভেক্টর সার্চে ইনলাইন ফিল্টারিং যুক্ত ScaNN ইনডেক্সই এটি সম্ভব করেছে!!!
এরপরে, এই ScaNN-সক্ষম ভেক্টর সার্চের রিকল মূল্যায়ন করা যাক।
প্রত্যাহার মূল্যায়নকারী
সিমিলারিটি সার্চে রিকল হলো একটি সার্চ থেকে প্রাপ্ত প্রাসঙ্গিক ইনস্ট্যান্সের শতাংশ, অর্থাৎ ট্রু পজিটিভের সংখ্যা। সার্চের মান পরিমাপের জন্য এটি সবচেয়ে প্রচলিত মেট্রিক। রিকল লসের একটি উৎস হলো অ্যাপ্রক্সিমেট নিয়ারেস্ট নেইবার সার্চ (aNN) এবং কে (এক্সাক্ট) নিয়ারেস্ট নেইবার সার্চ (kNN)-এর মধ্যকার পার্থক্য। AlloyDB-এর ScaNN-এর মতো ভেক্টর ইনডেক্সগুলো aNN অ্যালগরিদম প্রয়োগ করে, যা রিকলের সামান্য ঘাটতির বিনিময়ে আপনাকে বড় ডেটাসেটে ভেক্টর সার্চের গতি বাড়াতে সাহায্য করে। এখন, AlloyDB আপনাকে প্রতিটি কোয়েরির জন্য সরাসরি ডেটাবেসে এই ঘাটতি পরিমাপ করার এবং সময়ের সাথে সাথে এর স্থিতিশীলতা নিশ্চিত করার ক্ষমতা প্রদান করে। আরও ভালো ফলাফল এবং পারফরম্যান্স অর্জনের জন্য আপনি এই তথ্যের ভিত্তিতে কোয়েরি এবং ইনডেক্স প্যারামিটার আপডেট করতে পারেন।
আপনি evaluate_query_recall ফাংশনটি ব্যবহার করে একটি নির্দিষ্ট কনফিগারেশনের জন্য একটি ভেক্টর ইনডেক্সে করা ভেক্টর কোয়েরির রিকল খুঁজে পেতে পারেন। এই ফাংশনটি আপনাকে আপনার কাঙ্ক্ষিত ভেক্টর কোয়েরি রিকল ফলাফল অর্জনের জন্য প্যারামিটারগুলো টিউন করতে দেয়। রিকল হলো সার্চের গুণমান পরিমাপের জন্য ব্যবহৃত একটি মেট্রিক, এবং এটিকে কোয়েরি ভেক্টরের বস্তুনিষ্ঠভাবে সবচেয়ে কাছাকাছি থাকা ফেরত আসা ফলাফলের শতাংশ হিসাবে সংজ্ঞায়িত করা হয়। evaluate_query_recall ফাংশনটি ডিফল্টরূপে চালু থাকে।
গুরুত্বপূর্ণ দ্রষ্টব্য:
যদি আপনি নিম্নলিখিত ধাপগুলিতে HNSW ইনডেক্সে 'permission denied' ত্রুটির সম্মুখীন হন, তাহলে আপাতত এই সম্পূর্ণ রিকল ইভ্যালুয়েশন অংশটি এড়িয়ে যান। এই কোডল্যাবটি ডকুমেন্ট করার সময় এটি সদ্য প্রকাশিত হওয়ায়, এই মুহূর্তে এর কারণ অ্যাক্সেস সীমাবদ্ধতা হতে পারে।
- ScanN ইনডেক্স এবং HNSW ইনডেক্সে Enable Index Scan ফ্ল্যাগটি সেট করুন:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio-তে নিম্নলিখিত কোয়েরিটি চালান:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall ফাংশনটি প্যারামিটার হিসেবে কোয়েরি গ্রহণ করে এবং এর রিকল রিটার্ন করে। আমি পারফরম্যান্স পরীক্ষা করার জন্য যে কোয়েরিটি ব্যবহার করেছিলাম, সেটিই ফাংশনের ইনপুট কোয়েরি হিসেবে ব্যবহার করছি। আমি ইনডেক্স মেথড হিসেবে SCaNN যুক্ত করেছি। আরও প্যারামিটার অপশনের জন্য ডকুমেন্টেশন দেখুন।
আমরা যে ভেক্টর সার্চ কোয়েরিটি ব্যবহার করে আসছি তার রিকল হলো:
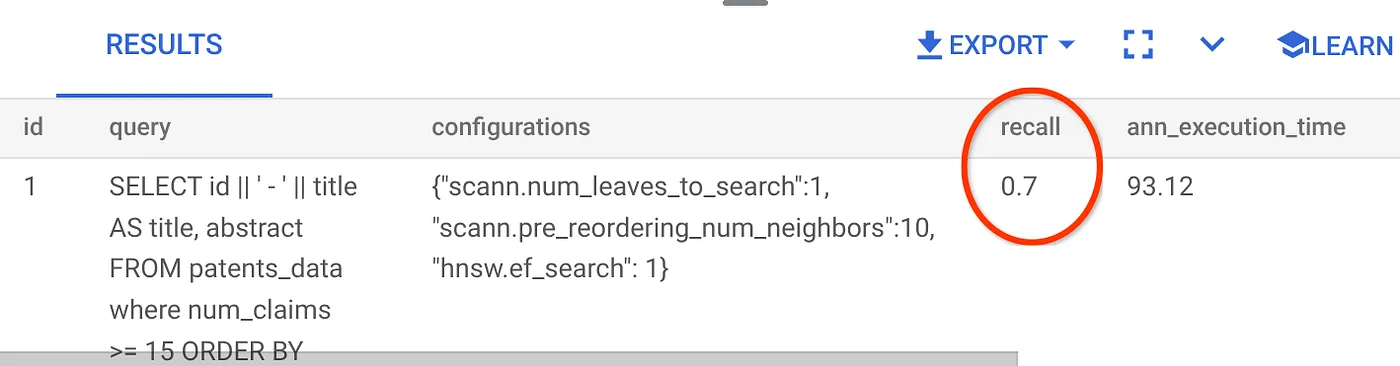
আমি দেখতে পাচ্ছি যে রিকল ৭০%। এখন আমি এই তথ্য ব্যবহার করে ইনডেক্স প্যারামিটার, মেথড এবং কোয়েরি প্যারামিটার পরিবর্তন করে এই ভেক্টর সার্চের জন্য আমার রিকল উন্নত করতে পারি!
আমি ফলাফল সেটের সারির সংখ্যা (আগের ১০ থেকে) পরিবর্তন করে ৭ করেছি এবং আমি রিকল-এর সামান্য উন্নতি দেখতে পাচ্ছি, অর্থাৎ ৮৬%।
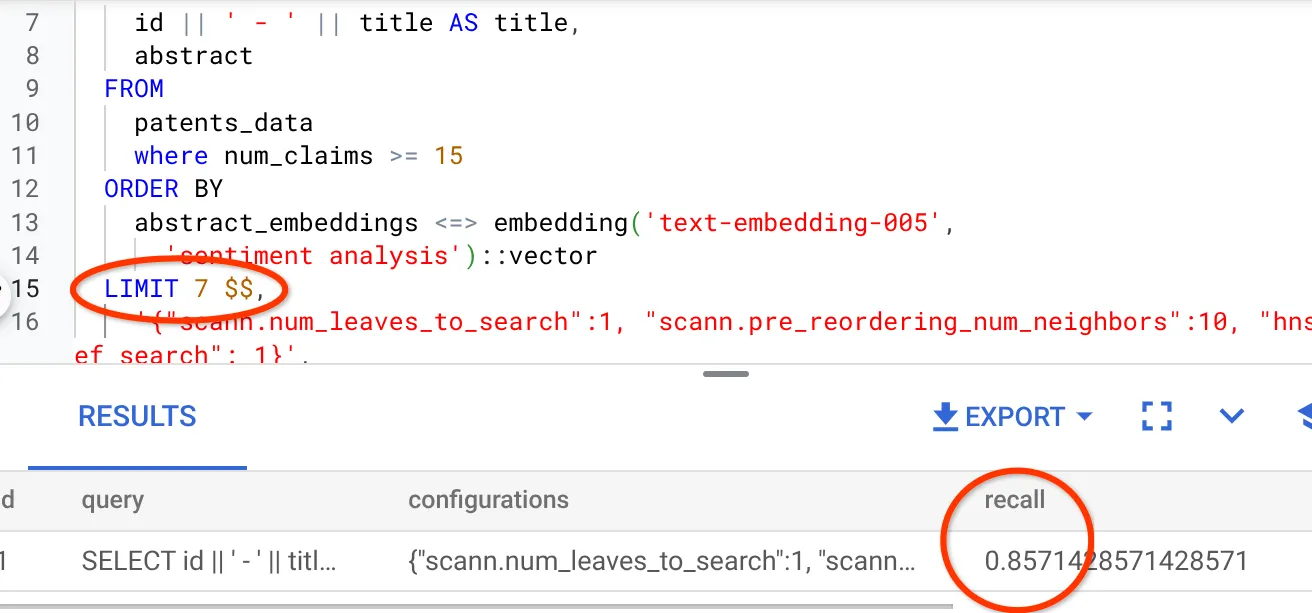
এর মানে হলো, ব্যবহারকারীর অনুসন্ধানের প্রেক্ষাপট অনুযায়ী ম্যাচগুলোর প্রাসঙ্গিকতা উন্নত করার জন্য আমি রিয়েল-টাইমে তাদের দেখানো ম্যাচের সংখ্যা পরিবর্তন করতে পারি।
ঠিক আছে, এবার ডাটাবেস লজিক ডেপ্লয় করে এজেন্টের দিকে এগিয়ে যাওয়ার পালা!!!
৭. ডাটাবেস লজিককে ওয়েব সার্ভার ছাড়াই নিয়ে যান
এই অ্যাপটি ওয়েবে নিয়ে যাওয়ার জন্য প্রস্তুত? নিচের ধাপগুলো অনুসরণ করুন:
- একটি নতুন ক্লাউড রান ফাংশন তৈরি করতে, গুগল ক্লাউড কনসোলের ক্লাউড রান ফাংশনস-এ গিয়ে "রাইট এ ফাংশন" (Write a function) -এ ক্লিক করুন অথবা এই লিঙ্কটি ব্যবহার করুন: https://console.cloud.google.com/run/create?deploymentType=function ।
- "ফাংশন তৈরি করতে একটি ইনলাইন এডিটর ব্যবহার করুন" বিকল্পটি বেছে নিন এবং কনফিগারেশন শুরু করুন। সার্ভিসের নাম " patent-search " দিন এবং অঞ্চল হিসেবে " us-central1 " ও রানটাইম হিসেবে "Java 17" বেছে নিন। প্রমাণীকরণ " অননুমোদিত আহ্বানের অনুমতি দিন "-এ সেট করুন।
- 'কন্টেইনার, ভলিউম, নেটওয়ার্কিং, সিকিউরিটি' অংশে, নিচের ধাপগুলো কোনো বিবরণ বাদ না দিয়ে অনুসরণ করুন:
নেটওয়ার্কিং ট্যাবে যান:
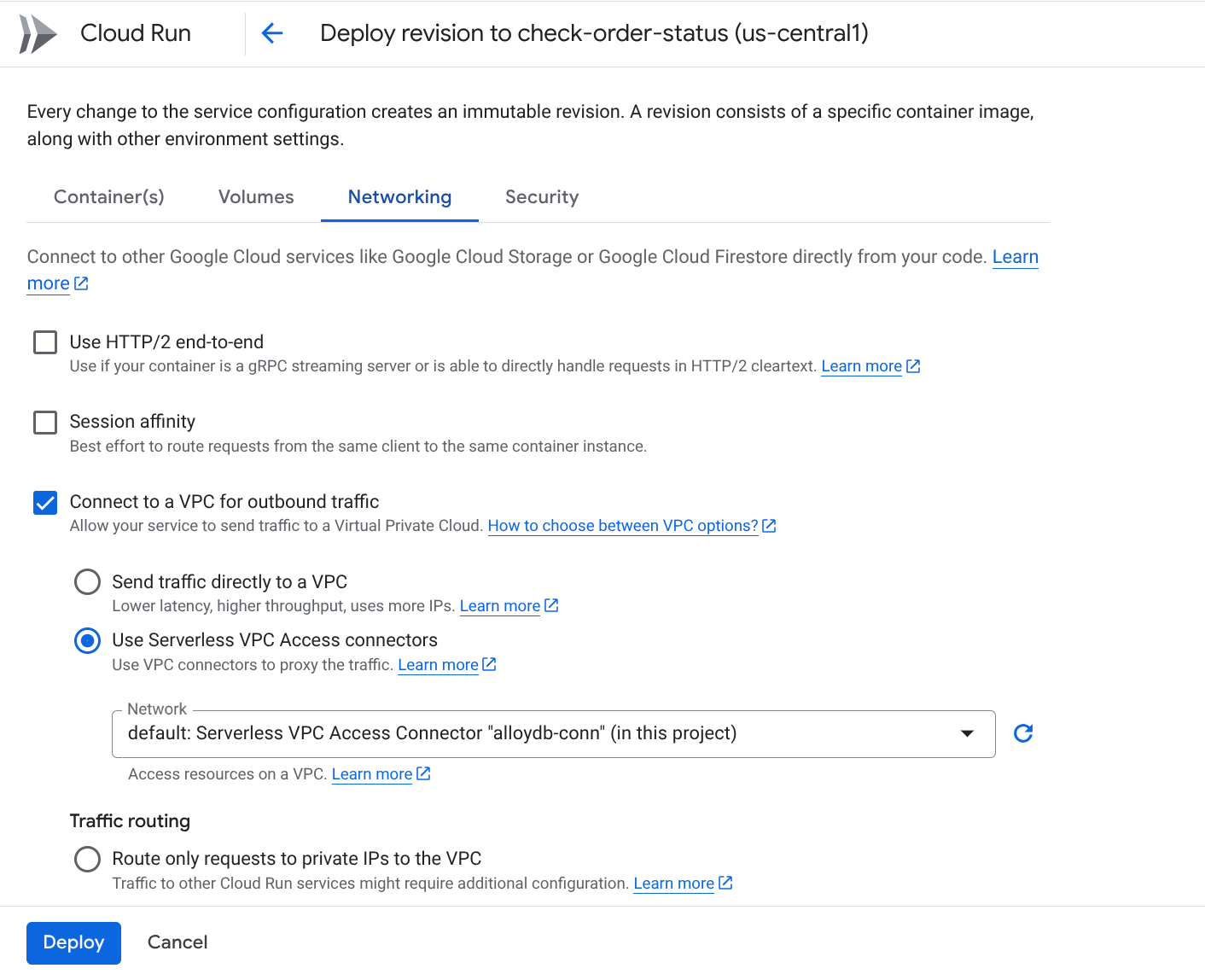
" আউটবাউন্ড ট্র্যাফিকের জন্য একটি VPC-তে সংযোগ করুন " নির্বাচন করুন এবং তারপরে " সার্ভারলেস VPC অ্যাক্সেস সংযোগকারী ব্যবহার করুন " নির্বাচন করুন।
নেটওয়ার্ক ড্রপডাউনের সেটিংসে, নেটওয়ার্ক ড্রপডাউনে ক্লিক করুন এবং " নতুন ভিপিসি কানেক্টর যোগ করুন " বিকল্পটি নির্বাচন করুন (যদি আপনি আগে থেকে ডিফল্টটি কনফিগার না করে থাকেন) এবং পপ-আপ হওয়া ডায়ালগ বক্সে প্রদর্শিত নির্দেশাবলী অনুসরণ করুন:
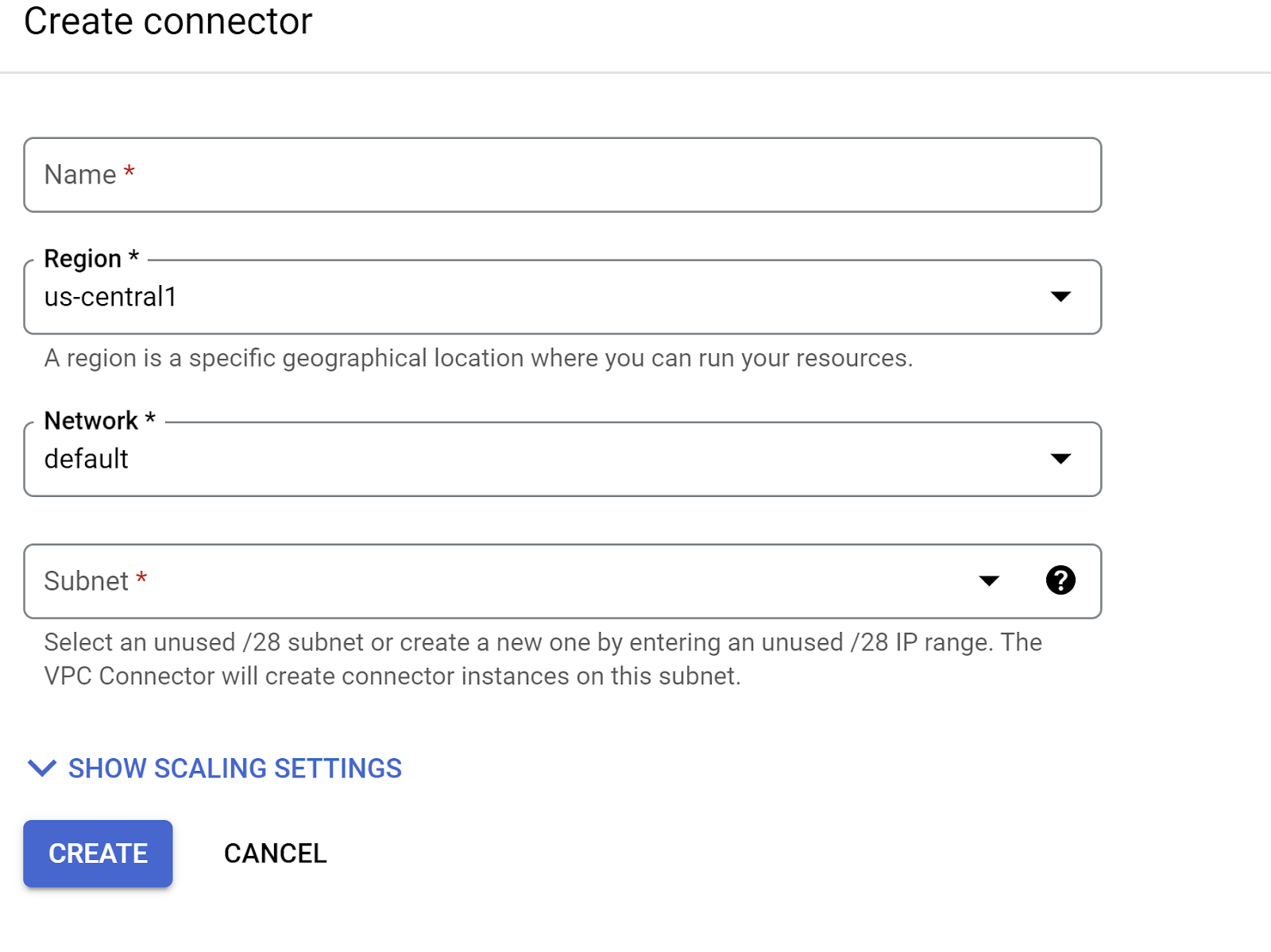
VPC কানেক্টরের জন্য একটি নাম দিন এবং নিশ্চিত করুন যে এর অঞ্চলটি আপনার ইনস্ট্যান্সের মতোই। নেটওয়ার্ক ভ্যালুটি ডিফল্ট রাখুন এবং সাবনেট হিসেবে কাস্টম আইপি রেঞ্জ সেট করুন, যেখানে আইপি রেঞ্জ হবে 10.8.0.0 অথবা এর মতো সহজলভ্য কোনো আইপি।
‘শো স্কেলিং সেটিংস’ প্রসারিত করুন এবং নিশ্চিত করুন যে আপনার কনফিগারেশনটি হুবহু নিম্নলিখিতভাবে সেট করা আছে:
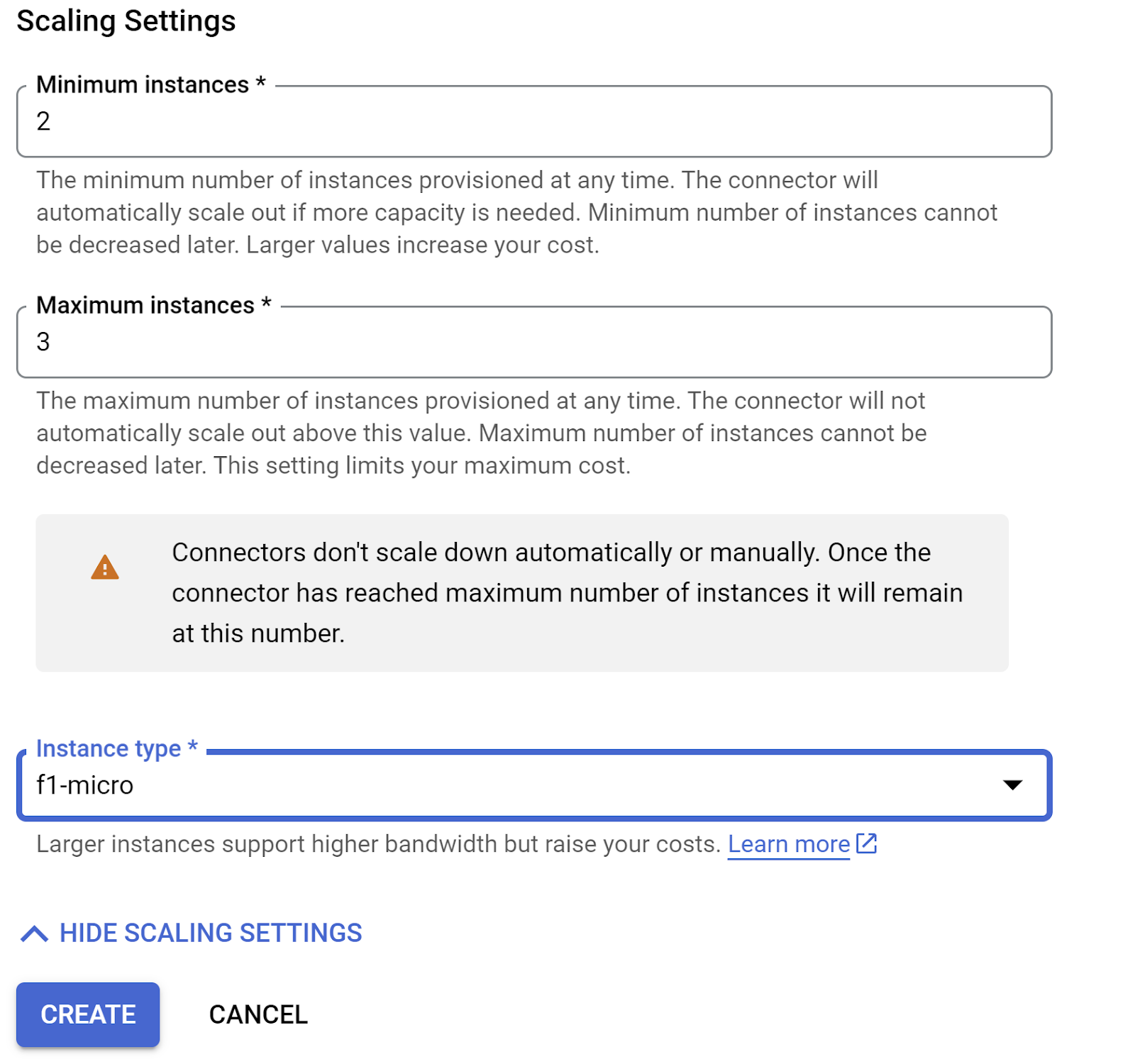
CREATE-এ ক্লিক করুন এবং এই কানেক্টরটি এখন বহির্গমন সেটিংসে তালিকাভুক্ত হওয়া উচিত।
নতুন তৈরি করা কানেক্টরটি নির্বাচন করুন।
সমস্ত ট্র্যাফিক এই VPC কানেক্টরের মাধ্যমে রাউট করার বিকল্পটি বেছে নিন।
NEXT-এ ক্লিক করুন এবং তারপর DEPLOY-তে ক্লিক করুন।
- ডিফল্টরূপে এটি এন্ট্রি পয়েন্ট ' gcfv2.HelloHttpFunction'- এ সেট করে দেবে। আপনার ক্লাউড রান ফাংশনের HelloHttpFunction.java এবং pom.xml-এ থাকা প্লেসহোল্ডার কোডটি যথাক্রমে ' PatentSearch.java ' এবং ' pom.xml ' থেকে নেওয়া কোড দিয়ে প্রতিস্থাপন করুন। ক্লাস ফাইলের নাম পরিবর্তন করে PatentSearch.java রাখুন।
- জাভা ফাইলে ************* প্লেসহোল্ডার এবং AlloyDB সংযোগের ক্রেডেনশিয়ালগুলো আপনার নিজের মান দিয়ে পরিবর্তন করতে মনে রাখবেন। AlloyDB ক্রেডেনশিয়ালগুলো হলো সেগুলোই যা আমরা এই কোডল্যাবের শুরুতে ব্যবহার করেছিলাম। আপনি যদি ভিন্ন মান ব্যবহার করে থাকেন, তবে অনুগ্রহ করে জাভা ফাইলে তা পরিবর্তন করুন।
- ডিপ্লয়-এ ক্লিক করুন।
- আপডেট করা ক্লাউড ফাংশনটি ডেপ্লয় করা হয়ে গেলে, আপনি একটি এন্ডপয়েন্ট তৈরি হতে দেখবেন। সেটি কপি করে নিচের কমান্ডে প্রতিস্থাপন করুন:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
ব্যাস! AlloyDB ডেটার উপর এমবেডিংস মডেল ব্যবহার করে একটি উন্নত কনটেক্সচুয়াল সিমিলারিটি ভেক্টর সার্চ করা এতটাই সহজ।
৮. চলুন Java ADK দিয়ে এজেন্টটি তৈরি করি।
প্রথমে, এডিটরে জাভা প্রজেক্টটি নিয়ে কাজ শুরু করা যাক।
- ক্লাউড শেল টার্মিনালে যান
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- অনুরোধ করা হলে অনুমোদন করুন।
- ক্লাউড শেল কনসোলের উপরের অংশ থেকে এডিটর আইকনে ক্লিক করে ক্লাউড শেল এডিটর চালু করুন।

- ল্যান্ডিং ক্লাউড শেল এডিটর কনসোলে, একটি নতুন ফোল্ডার তৈরি করুন এবং এর নাম দিন "adk-agents"।
নীচে দেখানো অনুযায়ী আপনার ক্লাউড শেলের রুট ডিরেক্টরিতে নতুন ফোল্ডার তৈরি করতে ক্লিক করুন:
এর নাম দিন "adk-agents":
- নিচের ফোল্ডার কাঠামো এবং সংশ্লিষ্ট ফাইলের নামসহ খালি ফাইলগুলো তৈরি করুন:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- একটি আলাদা ট্যাবে গিটহাব রিপোটি খুলুন এবং App.java ও pom.xml ফাইলগুলোর সোর্স কোড কপি করুন।
- যদি আপনি উপরের ডান কোণায় থাকা 'নতুন ট্যাবে খুলুন' আইকনটি ব্যবহার করে এডিটরটি একটি নতুন ট্যাবে খুলে থাকেন, তাহলে আপনি পেজের নীচে টার্মিনালটি খুলতে পারবেন। আপনি এডিটর এবং টার্মিনাল উভয়ই সমান্তরালভাবে খুলে রাখতে পারেন, যা আপনাকে অবাধে কাজ করার সুযোগ দেবে।
- একবার ক্লোন করা হয়ে গেলে, ক্লাউড শেল এডিটর কনসোলে ফিরে যান।
- যেহেতু আমরা ইতিমধ্যেই ক্লাউড রান ফাংশন তৈরি করে ফেলেছি, তাই আপনার রিপো ফোল্ডার থেকে ক্লাউড রান ফাংশন ফাইলগুলো কপি করার প্রয়োজন নেই ।
ADK জাভা SDK দিয়ে শুরু করা
এটি বেশ সহজ। আপনার ক্লোন ধাপে প্রাথমিকভাবে নিম্নলিখিত বিষয়গুলো নিশ্চিত করতে হবে:
- নির্ভরতা যোগ করুন:
আপনার pom.xml ফাইলে google-adk এবং google-adk-dev (ওয়েব UI-এর জন্য) আর্টিফ্যাক্টগুলো অন্তর্ভুক্ত করুন। আপনি যদি রিপো থেকে সোর্স কপি করে থাকেন, তবে এগুলো ফাইলগুলোতে আগে থেকেই অন্তর্ভুক্ত থাকে, আপনাকে আর এগুলো অন্তর্ভুক্ত করতে হবে না। আপনাকে শুধু আপনার ডেপ্লয় করা এন্ডপয়েন্টটি প্রতিফলিত করার জন্য ক্লাউড রান ফাংশন এন্ডপয়েন্টে একটি পরিবর্তন করতে হবে। এই বিভাগের পরবর্তী ধাপগুলোতে এটি আলোচনা করা হয়েছে।
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
সোর্স রিপোজিটরি থেকে pom.xml-কে রেফারেন্স করতে ভুলবেন না, কারণ অ্যাপ্লিকেশনটি চালানোর জন্য আরও অন্যান্য ডিপেন্ডেন্সি এবং কনফিগারেশনের প্রয়োজন হয়।
- আপনার প্রজেক্টটি কনফিগার করুন:
আপনার pom.xml ফাইলে জাভা ভার্সন (১৭+ প্রস্তাবিত) এবং মেভেন কম্পাইলার সেটিংস সঠিকভাবে কনফিগার করা আছে কিনা তা নিশ্চিত করুন। আপনি নিচের কাঠামো অনুসরণ করে আপনার প্রজেক্টটি কনফিগার করতে পারেন:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- এজেন্ট এবং এর সরঞ্জামসমূহ নির্ধারণ করা (App.java):
এইখানেই ADK Java SDK-এর জাদু প্রকাশ পায়। আমরা আমাদের এজেন্ট, তার সক্ষমতা (নির্দেশাবলী), এবং এটি যে টুলগুলো ব্যবহার করতে পারে, তা নির্ধারণ করি।
মূল এজেন্ট ক্লাসের কয়েকটি কোড স্নিপেটের একটি সরলীকৃত সংস্করণ এখানে খুঁজুন। সম্পূর্ণ প্রজেক্টটির জন্য এখানে প্রজেক্ট রিপোটি দেখুন।
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
ADK জাভা কোডের প্রধান উপাদানসমূহ তুলে ধরা হলো:
- LlmAgent.builder(): আপনার এজেন্ট কনফিগার করার জন্য ফ্লুয়েন্ট এপিআই।
- .instruction(...): এলএলএম-এর জন্য মূল নির্দেশনা ও নির্দেশিকা প্রদান করে, যার মধ্যে কখন কোন টুল ব্যবহার করতে হবে তাও অন্তর্ভুক্ত।
- FunctionTool.create(App.class, "methodName"): আপনার জাভা মেথডগুলোকে এজেন্টের কল করার উপযোগী টুল হিসেবে সহজেই রেজিস্টার করে। মেথডের নামের স্ট্রিংটি অবশ্যই একটি প্রকৃত পাবলিক স্ট্যাটিক মেথডের সাথে মিলতে হবে।
- @Schema(description = ...): টুলের প্যারামিটারগুলোর টীকা যোগ করে, যা LLM-কে বুঝতে সাহায্য করে যে প্রতিটি টুল কী ধরনের ইনপুট আশা করে। সঠিক টুল নির্বাচন এবং প্যারামিটার পূরণের জন্য এই বিবরণটি অত্যন্ত গুরুত্বপূর্ণ।
- InvocationContext ctx: টুল মেথডগুলিতে স্বয়ংক্রিয়ভাবে পাস করা হয়, যা সেশন স্টেট (ctx.session().state()), ব্যবহারকারীর তথ্য এবং আরও অনেক কিছুতে অ্যাক্সেস দেয়।
- .outputKey("patents"): যখন কোনো টুল ডেটা ফেরত দেয়, ADK স্বয়ংক্রিয়ভাবে এই কী-এর অধীনে সেশন স্টেটে তা সংরক্ষণ করতে পারে। এভাবেই explainPatent, getPatents থেকে প্রাপ্ত ফলাফল অ্যাক্সেস করতে পারে।
- VECTOR_SEARCH_ENDPOINT: এটি এমন একটি ভেরিয়েবল যা পেটেন্ট অনুসন্ধান ব্যবহারের ক্ষেত্রে ব্যবহারকারীর জন্য প্রাসঙ্গিক প্রশ্নোত্তরের মূল কার্যকরী লজিক ধারণ করে।
- করণীয়: পূর্ববর্তী বিভাগের জাভা ক্লাউড রান ফাংশন ধাপটি বাস্তবায়ন করার পর আপনাকে একটি আপডেট করা ডেপ্লয়েড এন্ডপয়েন্ট ভ্যালু সেট করতে হবে।
- সার্চটুল : এটি ব্যবহারকারীর সার্চ টেক্সটের জন্য পেটেন্ট ডেটাবেস থেকে প্রাসঙ্গিকভাবে প্রাসঙ্গিক পেটেন্ট ম্যাচ খুঁজে বের করতে ব্যবহারকারীকে সহায়তা করে।
- explainTool : এটি ব্যবহারকারীর কাছে একটি নির্দিষ্ট পেটেন্ট সম্পর্কে গভীরভাবে জানার জন্য অনুরোধ করে। তারপর এটি পেটেন্টের সারসংক্ষেপটি সংক্ষিপ্ত করে এবং এর কাছে থাকা পেটেন্টের বিবরণের উপর ভিত্তি করে ব্যবহারকারীর আরও প্রশ্নের উত্তর দিতে সক্ষম হয়।
গুরুত্বপূর্ণ দ্রষ্টব্য: VECTOR_SEARCH_ENDPOINT ভেরিয়েবলটি আপনার ডেপ্লয় করা CRF এন্ডপয়েন্ট দিয়ে প্রতিস্থাপন করতে ভুলবেন না।
স্টেটফুল ইন্টারঅ্যাকশনের জন্য ইনভোকেশনকনটেক্সট ব্যবহার করা
কার্যকরী এজেন্ট তৈরির জন্য অন্যতম গুরুত্বপূর্ণ বৈশিষ্ট্য হলো একটি কথোপকথনের একাধিক পর্যায় জুড়ে স্টেট পরিচালনা করা। ADK-এর InvocationContext এই কাজটি সহজ করে তোলে।
আমাদের App.java-তে:
- যখন initAgent() সংজ্ঞায়িত করা হয়, তখন আমরা .outputKey("patents") ব্যবহার করি। এটি ADK-কে বলে যে, যখন কোনো টুল (যেমন getPatents) তার রিপোর্ট ফিল্ডে ডেটা ফেরত দেয়, তখন সেই ডেটা সেশন স্টেটে "patents" কী-এর অধীনে সংরক্ষণ করা উচিত।
- explainPatent টুল মেথডে, আমরা InvocationContext ctx ইনজেক্ট করি:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
এর ফলে explainPatent টুলটি পূর্ববর্তী ধাপে getPatents টুল দ্বারা সংগৃহীত পেটেন্ট তালিকাটি অ্যাক্সেস করতে পারে, যা আলোচনাটিকে অবস্থা-নির্ভর এবং সুসংগত করে তোলে।
৯. স্থানীয় CLI পরীক্ষা
পরিবেশ ভেরিয়েবল সংজ্ঞায়িত করুন
আপনাকে দুটি এনভায়রনমেন্ট ভেরিয়েবল এক্সপোর্ট করতে হবে:
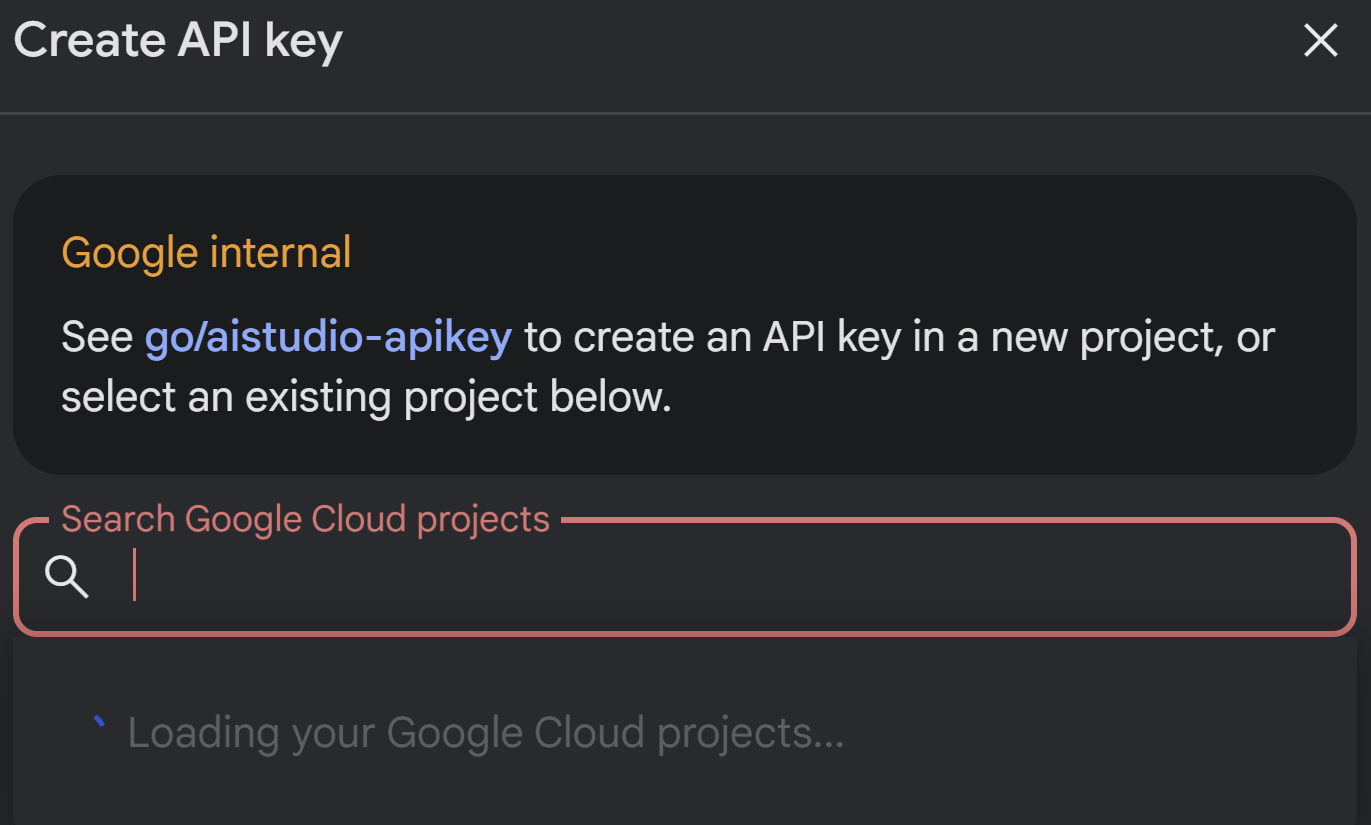
- একটি জেমিনি কী যা আপনি এআই স্টুডিও থেকে পেতে পারেন:
এটি করার জন্য, https://aistudio.google.com/apikey-এ যান এবং আপনার সক্রিয় গুগল ক্লাউড প্রজেক্টের (যেটিতে আপনি এই অ্যাপ্লিকেশনটি তৈরি করছেন) জন্য আপনার এপিআই কী (API Key) সংগ্রহ করুন এবং কী-টি কোথাও সংরক্ষণ করুন:
- একবার আপনি কী-টি পেয়ে গেলে, ক্লাউড শেল টার্মিনাল খুলুন এবং নিম্নলিখিত কমান্ডটি চালিয়ে আমাদের তৈরি করা নতুন ডিরেক্টরি adk-agents-এ যান:
cd adk-agents
- এইবার আমরা ভার্টেক্স এআই ব্যবহার করছি না, তা বোঝানোর জন্য একটি ভ্যারিয়েবল।
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- CLI-তে আপনার প্রথম এজেন্ট চালান।
এই প্রথম এজেন্টটি চালু করতে, আপনার টার্মিনালে নিম্নলিখিত Maven কমান্ডটি ব্যবহার করুন:
mvn compile exec:java -DmainClass="agents.App"
আপনি আপনার টার্মিনালে এজেন্টের কাছ থেকে ইন্টারেক্টিভ প্রতিক্রিয়া দেখতে পাবেন।
১০. ক্লাউড রানে ডেপ্লয় করা
ক্লাউড রানে আপনার ADK জাভা এজেন্ট স্থাপন করা অন্য যেকোনো জাভা অ্যাপ্লিকেশন স্থাপন করার মতোই:
- ডকারফাইল: আপনার জাভা অ্যাপ্লিকেশন প্যাকেজ করার জন্য একটি ডকারফাইল তৈরি করুন।
- ডকার ইমেজ তৈরি ও পুশ করুন: গুগল ক্লাউড বিল্ড এবং আর্টিফ্যাক্ট রেজিস্ট্রি ব্যবহার করুন।
- আপনি উপরের ধাপটি সম্পন্ন করে মাত্র একটি কমান্ডেই ক্লাউড রান-এ ডেপ্লয় করতে পারেন:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
একইভাবে, আপনি আপনার জাভা ক্লাউড রান ফাংশন (gcfv2.PatentSearch) ডিপ্লয় করবেন। বিকল্পভাবে, আপনি সরাসরি ক্লাউড রান ফাংশন কনসোল থেকে ডাটাবেস লজিকের জন্য জাভা ক্লাউড রান ফাংশনটি তৈরি এবং ডিপ্লয় করতে পারেন।
১১. ওয়েব UI দিয়ে পরীক্ষা করা
আপনার এজেন্টের স্থানীয় পরীক্ষা এবং ডিবাগিংয়ের জন্য ADK-এর সাথে একটি সুবিধাজনক ওয়েব UI থাকে। যখন আপনি আপনার App.java স্থানীয়ভাবে চালান (যেমন, কনফিগার করা থাকলে mvn exec:java -Dexec.mainClass="agents.App" কমান্ড দিয়ে, অথবা শুধু main মেথডটি চালিয়ে), তখন ADK সাধারণত একটি স্থানীয় ওয়েব সার্ভার চালু করে।
ADK ওয়েব UI আপনাকে নিম্নলিখিত কাজগুলো করার সুযোগ দেয়:
- আপনার এজেন্টকে বার্তা পাঠান।
- ইভেন্টগুলো দেখুন (ব্যবহারকারীর বার্তা, টুল কল, টুলের প্রতিক্রিয়া, এলএলএম প্রতিক্রিয়া)।
- সেশনের অবস্থা পরিদর্শন করুন।
- লগ এবং ট্রেস দেখুন।
আপনার এজেন্ট কীভাবে অনুরোধগুলি প্রক্রিয়া করে এবং এর সরঞ্জামগুলি ব্যবহার করে, তা বোঝার জন্য ডেভেলপমেন্টের সময় এটি অমূল্য। এর জন্য ধরে নেওয়া হচ্ছে যে, আপনার pom.xml-এর mainClass-টি com.google.adk.web.AdkWebServer- এ সেট করা আছে এবং আপনার এজেন্টটি এর সাথে নিবন্ধিত, অথবা আপনি এমন একটি স্থানীয় টেস্ট রানার চালাচ্ছেন যা এটিকে উন্মুক্ত করে।
যখন আপনি কনসোল ইনপুটের জন্য আপনার App.java-কে এর InMemoryRunner এবং Scanner সহ রান করেন, তখন আপনি মূল এজেন্ট লজিকটি পরীক্ষা করছেন। ওয়েব UI হলো আরও ভিজ্যুয়াল ডিবাগিং অভিজ্ঞতার জন্য একটি আলাদা কম্পোনেন্ট, যা প্রায়শই তখন ব্যবহৃত হয় যখন ADK আপনার এজেন্টকে HTTP-এর মাধ্যমে সার্ভ করে।
আপনার রুট ডিরেক্টরি থেকে SpringBoot লোকাল সার্ভার চালু করতে আপনি নিম্নলিখিত Maven কমান্ডটি ব্যবহার করতে পারেন:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
উপরের কমান্ডটি যে URL আউটপুট করে, প্রায়শই সেই URL-এ ইন্টারফেসটি অ্যাক্সেস করা যায়। যদি এটি ক্লাউড রান-এ ডেপ্লয় করা হয়ে থাকে , তাহলে আপনি ক্লাউড রান ডেপ্লয়েড লিঙ্কটি থেকে এটি অ্যাক্সেস করতে পারবেন।
আপনি একটি ইন্টারেক্টিভ ইন্টারফেসে ফলাফলটি দেখতে পাবেন।
আমাদের নিযুক্ত পেটেন্ট এজেন্টের জন্য নিচের ভিডিওটি দেখুন:
AlloyDB ইনলাইন সার্চ ও রিকল ইভ্যালুয়েশন সহ একটি মান নিয়ন্ত্রিত পেটেন্ট এজেন্টের ডেমো!
১২. পরিষ্কার করুন
এই পোস্টে ব্যবহৃত রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, এই ধাপগুলো অনুসরণ করুন:
- Google Cloud কনসোলে, https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog -এ যান।
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog page.
- প্রজেক্ট তালিকা থেকে, আপনি যে প্রজেক্টটি মুছতে চান সেটি নির্বাচন করুন এবং তারপর ডিলিট বোতামে ক্লিক করুন।
- ডায়ালগ বক্সে প্রজেক্ট আইডি টাইপ করুন এবং তারপর প্রজেক্টটি মুছে ফেলার জন্য 'শাট ডাউন'-এ ক্লিক করুন।
১৩. অভিনন্দন
অভিনন্দন! আপনি ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog , Vertex AI, এবং Vector Search-এর সক্ষমতাগুলোকে একত্রিত করে জাভাতে সফলভাবে আপনার পেটেন্ট অ্যানালাইসিস এজেন্ট তৈরি করেছেন। এছাড়াও, আমরা প্রাসঙ্গিক সাদৃশ্য অনুসন্ধানকে অত্যন্ত রূপান্তরকারী, কার্যকর এবং সত্যিকারের অর্থ-চালিত করে তোলার ক্ষেত্রে এক বিশাল অগ্রগতি সাধন করেছি।
আজই শুরু করুন!
ADK ডকুমেন্টেশন: [অফিসিয়াল ADK জাভা ডক্সের লিঙ্ক]
পেটেন্ট বিশ্লেষণ এজেন্টের সোর্স কোড: [আপনার (এখন সর্বজনীন) গিটহাব রিপোর লিঙ্ক]
জাভা স্যাম্পল এজেন্ট: [adk-samples রিপো-এর লিঙ্ক]
ADK কমিউনিটিতে যোগ দিন: https://www.reddit.com/r/agentdevelopmentkit/
এজেন্ট নির্মাণ শুভ হোক!