
۱. مرور کلی
در صنایع مختلف، جستجوی متنی یک قابلیت حیاتی است که قلب و مرکز برنامههای کاربردی آنها را تشکیل میدهد. بازیابی نسل افزوده مدتی است که با مکانیسمهای بازیابی مبتنی بر هوش مصنوعی مولد خود، محرک اصلی این تکامل حیاتی فناوری بوده است. مدلهای مولد، با پنجرههای متنی بزرگ و کیفیت خروجی چشمگیر، در حال تغییر هوش مصنوعی هستند. RAG روشی سیستماتیک برای تزریق متن به برنامهها و عاملهای هوش مصنوعی فراهم میکند و آنها را در پایگاههای داده ساختار یافته یا اطلاعات از رسانههای مختلف قرار میدهد. این دادههای متنی برای وضوح حقیقت و دقت خروجی بسیار مهم هستند، اما این نتایج چقدر دقیق هستند؟ آیا کسب و کار شما تا حد زیادی به دقت این تطابقها و ارتباط متنی بستگی دارد؟ پس این پروژه شما را شگفتزده خواهد کرد!
حال تصور کنید که اگر میتوانستیم از قدرت مدلهای مولد استفاده کنیم و عاملهای تعاملی بسازیم که قادر به تصمیمگیریهای مستقل با پشتیبانی چنین اطلاعات حساس و مبتنی بر حقیقت باشند؛ این چیزی است که امروز قرار است بسازیم. ما قرار است یک برنامه عامل هوش مصنوعی سرتاسری با استفاده از کیت توسعه عامل که توسط RAG پیشرفته در AlloyDB پشتیبانی میشود، برای یک برنامه تحلیل اختراع بسازیم.
عامل تحلیل پتنت به کاربر در یافتن پتنتهای مرتبط با متن جستجویش کمک میکند و پس از درخواست، توضیحی واضح و مختصر و در صورت لزوم جزئیات بیشتری را برای یک پتنت انتخاب شده ارائه میدهد. آمادهاید تا ببینید چگونه این کار انجام میشود؟ بیایید شروع کنیم!
هدف
هدف ساده است. به کاربر اجازه دهید بر اساس توضیحات متنی، اختراعات را جستجو کند و سپس توضیح مفصلی از یک اختراع خاص را از نتایج جستجو دریافت کند و همه اینها با استفاده از یک عامل هوش مصنوعی ساخته شده با Java ADK، AlloyDB، Vector Search (با شاخصهای پیشرفته)، Gemini و کل برنامه که به صورت بدون سرور در Cloud Run مستقر است، انجام میشود.
آنچه خواهید ساخت
به عنوان بخشی از این آزمایشگاه، شما:
- یک نمونه AlloyDB ایجاد کنید و دادههای مجموعه دادههای عمومی ثبت اختراعات را بارگذاری کنید
- پیادهسازی جستجوی برداری پیشرفته در AlloyDB با استفاده از ScaNN و ویژگیهای ارزیابی Recall
- ایجاد یک عامل با استفاده از Java ADK
- منطق سمت سرور پایگاه داده را در توابع ابری بدون سرور جاوا پیاده سازی کنید
- استقرار و آزمایش عامل در Cloud Run
نمودار زیر جریان دادهها و مراحل پیادهسازی را نشان میدهد.
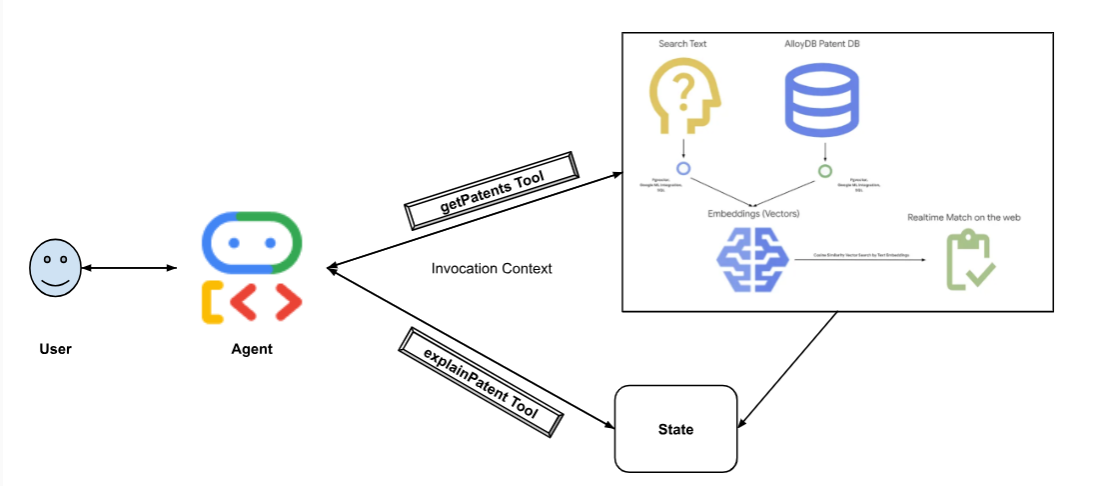
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
- API های مورد نیاز را فعال کنید. میتوانید از دستور gcloud در ترمینال Cloud Shell استفاده کنید:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
جایگزین دستور gcloud از طریق کنسول با جستجوی هر محصول یا استفاده از این لینک است.
برای دستورات و نحوهی استفاده از gcloud به مستندات مراجعه کنید.
۳. راهاندازی پایگاه داده
در این آزمایش، ما از AlloyDB به عنوان پایگاه داده برای دادههای ثبت اختراع استفاده خواهیم کرد. این پایگاه داده از خوشهها برای نگهداری تمام منابع، مانند پایگاههای داده و گزارشها، استفاده میکند. هر خوشه یک نمونه اصلی دارد که یک نقطه دسترسی به دادهها را فراهم میکند. جداول، دادههای واقعی را نگهداری میکنند.
بیایید یک کلاستر، نمونه و جدول AlloyDB ایجاد کنیم که مجموعه دادههای ثبت اختراع در آن بارگذاری شود.
ایجاد یک کلاستر و نمونه
- در کنسول ابری، صفحه AlloyDB را پیمایش کنید. یک راه آسان برای یافتن اکثر صفحات در کنسول ابری، جستجوی آنها با استفاده از نوار جستجوی کنسول است.
- از آن صفحه، گزینه CREATE CLUSTER را انتخاب کنید:

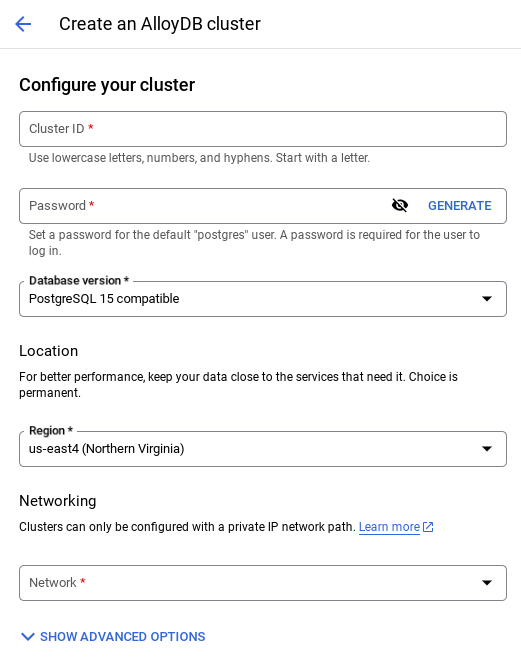
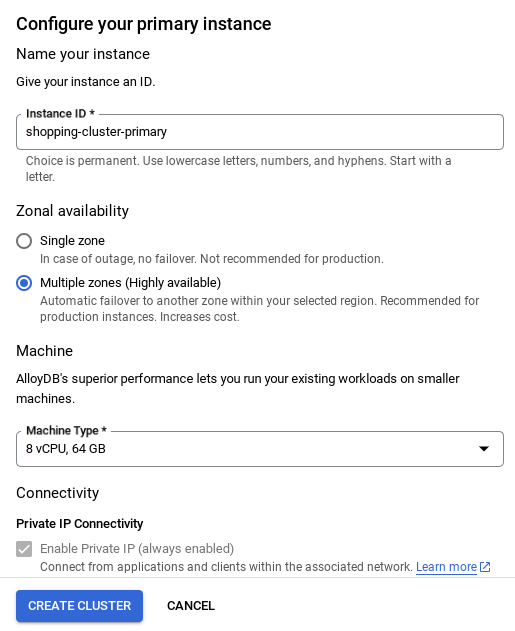
- صفحهای مانند تصویر زیر خواهید دید. یک کلاستر و نمونه با مقادیر زیر ایجاد کنید (مطمئن شوید که مقادیر مطابقت دارند، در صورتی که کد برنامه را از مخزن کپی میکنید):
- شناسه خوشه : "
vector-cluster" - رمز عبور : "
alloydb" - PostgreSQL 15 / آخرین نسخه توصیه شده
- منطقه : "
us-central1" - شبکه : "
default"
- وقتی شبکه پیشفرض را انتخاب میکنید، صفحهای مانند تصویر زیر مشاهده خواهید کرد.
تنظیم اتصال را انتخاب کنید. 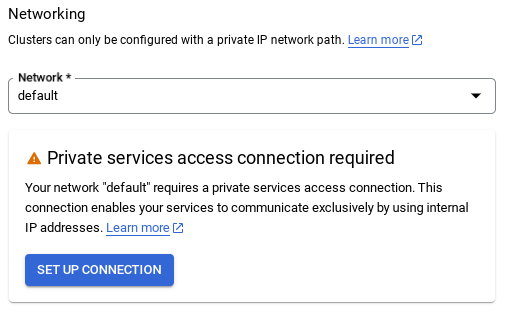
- از آنجا، « استفاده از یک محدوده IP اختصاص داده شده خودکار » را انتخاب کرده و ادامه دهید. پس از بررسی اطلاعات، «ایجاد اتصال» را انتخاب کنید.
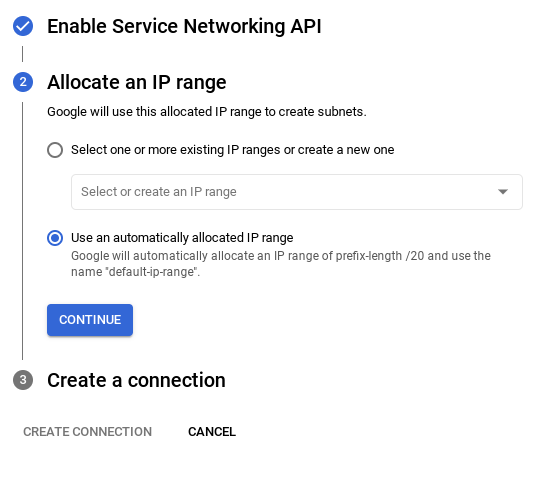
- پس از راهاندازی شبکه، میتوانید به ایجاد خوشه خود ادامه دهید. برای تکمیل راهاندازی خوشه، مطابق شکل زیر، روی CREATE CLUSTER کلیک کنید:
مطمئن شوید که شناسه نمونه (که میتوانید در زمان پیکربندی خوشه/نمونه پیدا کنید) را به ... تغییر دهید.
اگر نمیتوانید آن را تغییر دهید، به یاد داشته باشید که در تمام ارجاعات بعدی از vector-instance نمونه خود استفاده کنید .
توجه داشته باشید که ایجاد خوشه حدود ۱۰ دقیقه طول خواهد کشید. پس از موفقیتآمیز بودن، باید صفحهای را مشاهده کنید که نمای کلی خوشه ایجاد شده شما را نشان میدهد.
۴. دریافت دادهها
حالا وقت آن رسیده که یک جدول با دادههای مربوط به فروشگاه اضافه کنیم. به AlloyDB بروید، خوشه اصلی و سپس AlloyDB Studio را انتخاب کنید:
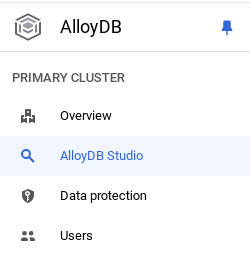
ممکن است لازم باشد منتظر بمانید تا نمونه شما به طور کامل ایجاد شود. پس از اتمام این کار، با استفاده از اعتبارنامههایی که هنگام ایجاد خوشه ایجاد کردهاید، وارد AlloyDB شوید. از دادههای زیر برای تأیید اعتبار در PostgreSQL استفاده کنید:
- نام کاربری: "
postgres" - پایگاه داده: "
postgres" - رمز عبور: "
alloydb"
پس از اینکه با موفقیت در AlloyDB Studio احراز هویت شدید، دستورات SQL در ویرایشگر وارد میشوند. میتوانید با استفاده از علامت + در سمت راست آخرین پنجره، چندین پنجره ویرایشگر اضافه کنید.
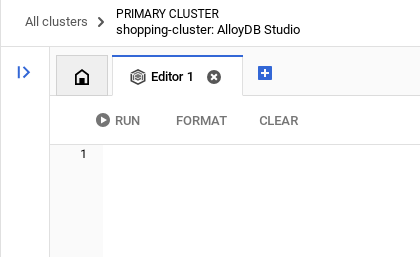
شما میتوانید دستورات AlloyDB را در پنجرههای ویرایشگر وارد کنید و در صورت لزوم از گزینههای Run، Format و Clear استفاده کنید.
فعال کردن افزونهها
برای ساخت این برنامه، از افزونههای pgvector و google_ml_integration استفاده خواهیم کرد. افزونه pgvector به شما امکان ذخیره و جستجوی جاسازیهای برداری را میدهد. افزونه google_ml_integration توابعی را ارائه میدهد که برای دسترسی به نقاط پایانی پیشبینی هوش مصنوعی Vertex برای دریافت پیشبینیها در SQL استفاده میکنید. این افزونهها را با اجرای DDL های زیر فعال کنید :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
اگر میخواهید افزونههایی که در پایگاه داده شما فعال شدهاند را بررسی کنید، این دستور SQL را اجرا کنید:
select extname, extversion from pg_extension;
ایجاد یک جدول
شما میتوانید با استفاده از دستور DDL زیر در AlloyDB Studio یک جدول ایجاد کنید:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
ستون abstract_embeddings امکان ذخیرهسازی مقادیر برداری متن را فراهم میکند.
اعطای مجوز
برای اعطای مجوز اجرا به تابع "embedding"، دستور زیر را اجرا کنید:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
اعطای نقش کاربری Vertex AI به حساب سرویس AlloyDB
از کنسول Google Cloud IAM ، به حساب سرویس AlloyDB (که به این شکل است: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) دسترسی به نقش "Vertex AI User" را بدهید. PROJECT_NUMBER شماره پروژه شما را خواهد داشت.
همچنین میتوانید دستور زیر را از ترمینال Cloud Shell اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
بارگذاری دادههای ثبت اختراع در پایگاه داده
مجموعه دادههای عمومی ثبت اختراعات گوگل در BigQuery به عنوان مجموعه داده ما استفاده خواهد شد. ما از AlloyDB Studio برای اجرای کوئریهای خود استفاده خواهیم کرد. دادهها در این فایل insert scripts sql در این مخزن قرار داده شدهاند و ما آن را برای بارگذاری دادههای ثبت اختراع اجرا خواهیم کرد.
- در کنسول Google Cloud، صفحه AlloyDB را باز کنید.
- کلاستر تازه ایجاد شده خود را انتخاب کنید و روی نمونه کلیک کنید.
- در منوی ناوبری AlloyDB، روی AlloyDB Studio کلیک کنید. با اطلاعات کاربری خود وارد شوید.
- با کلیک روی نماد برگه جدید در سمت راست، یک برگه جدید باز کنید.
- دستورات کوئری
insertرا از فایلهایinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlیکی یکی کپی و اجرا کنید. میتوانید دستورات درج کپی ۱۰ تا ۵۰ را برای نمایش سریع این مورد استفاده اجرا کنید.
برای اجرا، روی Run کلیک کنید. نتایج پرسوجوی شما در جدول نتایج ظاهر میشود.
۵. ایجاد جاسازیها برای دادههای ثبت اختراع
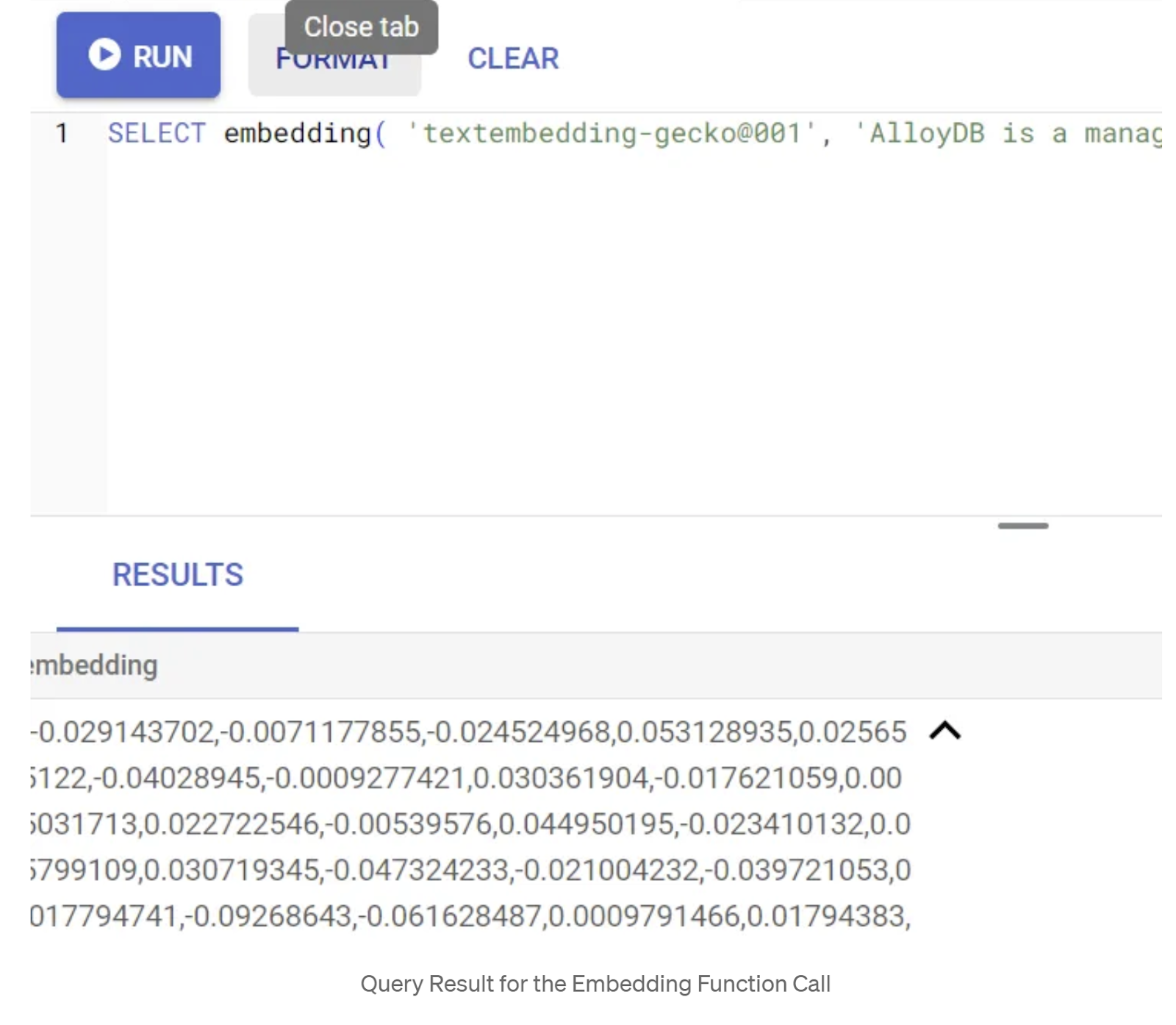
ابتدا بیایید تابع جاسازی را با اجرای کوئری نمونه زیر آزمایش کنیم:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
این باید بردار جاسازیها را که شبیه آرایهای از اعداد اعشاری است، برای متن نمونه در پرسوجو برگرداند. به این شکل است:
فیلد بردار abstract_embeddings را بهروزرسانی کنید
در صورتی که نیاز به ایجاد جاسازی برای چکیدهها باشد، باید از DML زیر برای بهروزرسانی چکیدههای ثبت اختراع در جدول با جاسازیهای مربوطه استفاده شود. اما در مورد ما، دستورات درج از قبل حاوی این جاسازیها برای هر چکیده هستند، بنابراین نیازی به فراخوانی متد embeddings() نیست.
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
۶. جستجوی برداری انجام دهید
حالا که جدول، دادهها و جاسازیها آماده هستند، بیایید جستجوی برداری بلادرنگ (real-time Vector Search) را برای متن جستجوی کاربر انجام دهیم. میتوانید این را با اجرای کوئری زیر آزمایش کنید:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
در این پرس و جو،
- متن جستجو شده توسط کاربر عبارت است از: «تحلیل احساسات».
- ما آن را در متد embedding() با استفاده از مدل text-embedding-005 به embedding تبدیل میکنیم.
- «<=>» نشان دهنده استفاده از روش فاصله تشابه کسینوس است.
- ما در حال تبدیل نتیجه روش جاسازی به نوع بردار هستیم تا آن را با بردارهای ذخیره شده در پایگاه داده سازگار کنیم.
- LIMIT 10 نشان میدهد که ما 10 مورد از نزدیکترین تطابقها را با متن جستجو انتخاب میکنیم.
AlloyDB، جستجوی برداری RAG را به سطح بالاتری میبرد:
تعداد زیادی مورد معرفی شده است. دو مورد از موارد متمرکز بر توسعهدهندگان عبارتند از:
- فیلتر درون خطی
- ارزیاب یادآوری
فیلتر درون خطی
پیش از این، به عنوان یک توسعهدهنده، شما مجبور بودید کوئری Vector Search را انجام دهید و با فیلتر کردن و فراخوانی آن سر و کار داشته باشید. AlloyDB Query Optimizer در مورد نحوه اجرای یک کوئری با فیلترها تصمیم میگیرد. فیلتر درونخطی، یک تکنیک جدید بهینهسازی کوئری است که به بهینهساز کوئری AlloyDB اجازه میدهد تا هم شرایط فیلتر کردن فراداده و هم جستجوی برداری را در کنار آن ارزیابی کند و از شاخصهای برداری و شاخصهای ستونهای فراداده بهره ببرد. این امر باعث افزایش عملکرد فراخوانی شده است و به توسعهدهندگان اجازه میدهد تا از آنچه AlloyDB به صورت پیشفرض ارائه میدهد، بهرهمند شوند.
فیلترینگ درونخطی برای مواردی با گزینشپذیری متوسط بهترین گزینه است. از آنجایی که AlloyDB در شاخص بردار جستجو میکند، فقط فواصل بردارهایی را محاسبه میکند که با شرایط فیلترینگ فراداده مطابقت دارند (فیلترهای عملکردی شما در یک پرسوجو که معمولاً در بند WHERE مدیریت میشوند). این امر عملکرد این پرسوجوها را به طور چشمگیری بهبود میبخشد و مزایای پس از فیلتر یا پیش از فیلتر را تکمیل میکند.
- افزونه pgvector را نصب یا بهروزرسانی کنید
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
اگر افزونهی pgvector از قبل نصب شده است، افزونهی vector را به نسخه 0.8.0.google-3 یا بالاتر ارتقا دهید تا از قابلیتهای ارزیابی فراخوان (recall evaluator) بهرهمند شوید.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
این مرحله فقط در صورتی باید اجرا شود که پسوند بردار شما <0.8.0.google-3 باشد.
نکته مهم: اگر تعداد ردیفهای شما کمتر از ۱۰۰ باشد، نیازی به ایجاد شاخص ScaNN در وهله اول نخواهید داشت زیرا برای ردیفهای کمتر اعمال نمیشود. لطفاً در این صورت از مراحل زیر صرف نظر کنید.
- برای ایجاد اندیسهای ScaNN، افزونه alloydb_scann را نصب کنید.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- ابتدا جستجوی برداری (Vector Search Query) را بدون اندیس و بدون فعال بودن فیلتر درونخطی (Inline Filter) اجرا کنید:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
نتیجه باید مشابه زیر باشد:
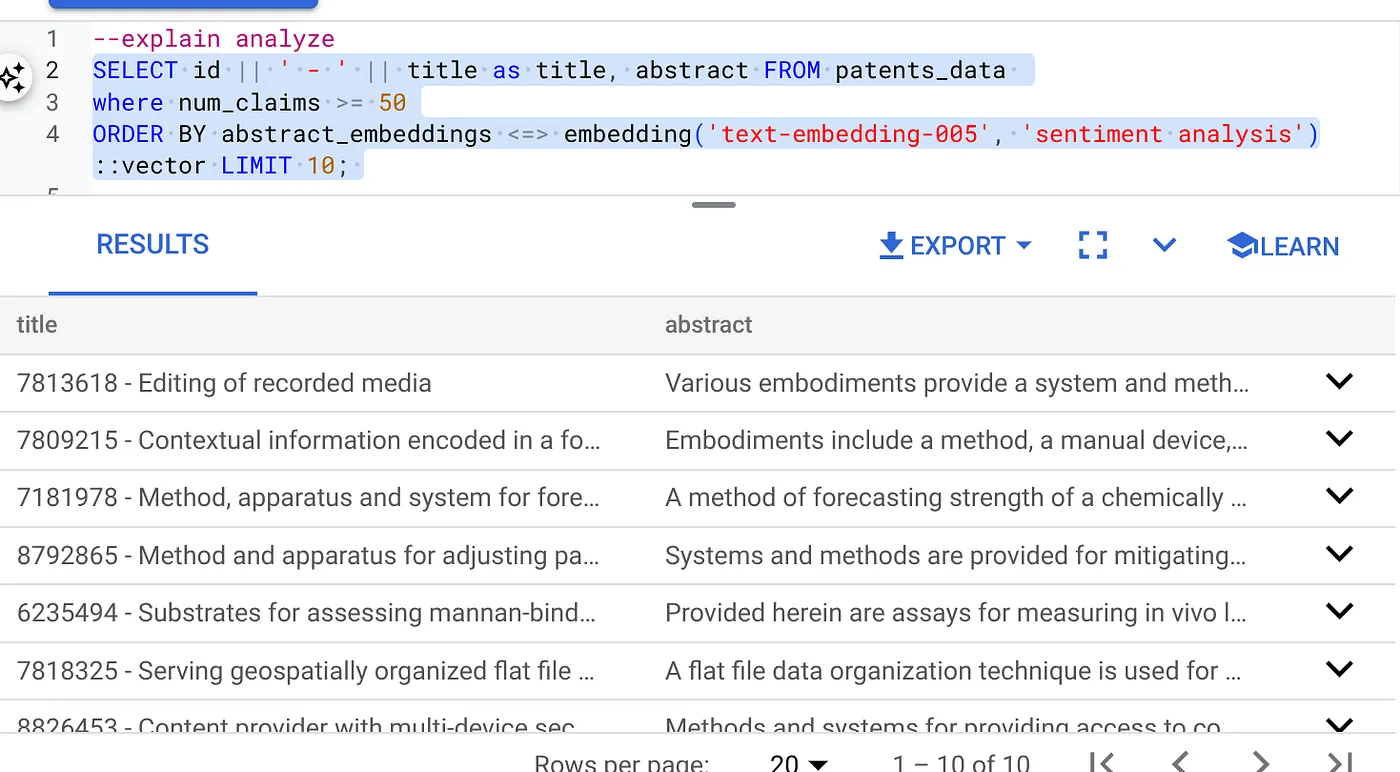
- دستور Explain Analyze را روی آن اجرا کنید: (بدون اندیس و فیلتر درونخطی)
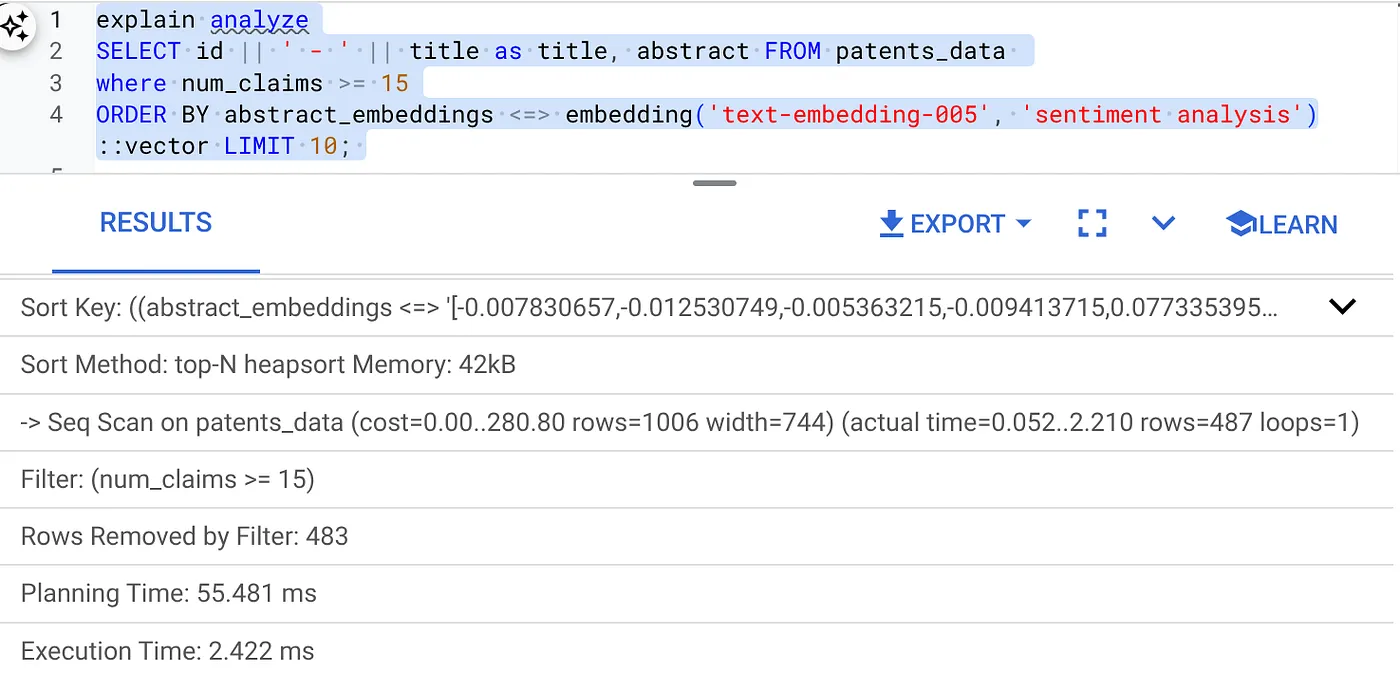
زمان اجرا ۲.۴ میلیثانیه
- بیایید یک اندیس معمولی روی فیلد num_claims ایجاد کنیم تا بتوانیم بر اساس آن فیلتر کنیم:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- بیایید شاخص ScaNN را برای برنامه جستجوی اختراع خود ایجاد کنیم. دستور زیر را از AlloyDB Studio خود اجرا کنید:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
نکته مهم: (num_leaves=32) برای کل مجموعه دادههای ما با بیش از ۱۰۰۰ ردیف اعمال میشود. اگر تعداد ردیفهای شما کمتر از ۱۰۰ باشد، نیازی به ایجاد شاخص در وهله اول نخواهید داشت زیرا برای ردیفهای کمتر اعمال نمیشود.
- فیلترینگ درونخطی را روی شاخص ScaNN فعال کنید:
SET scann.enable_inline_filtering = on
- حالا، بیایید همان کوئری را با فیلتر و جستجوی برداری در آن اجرا کنیم:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
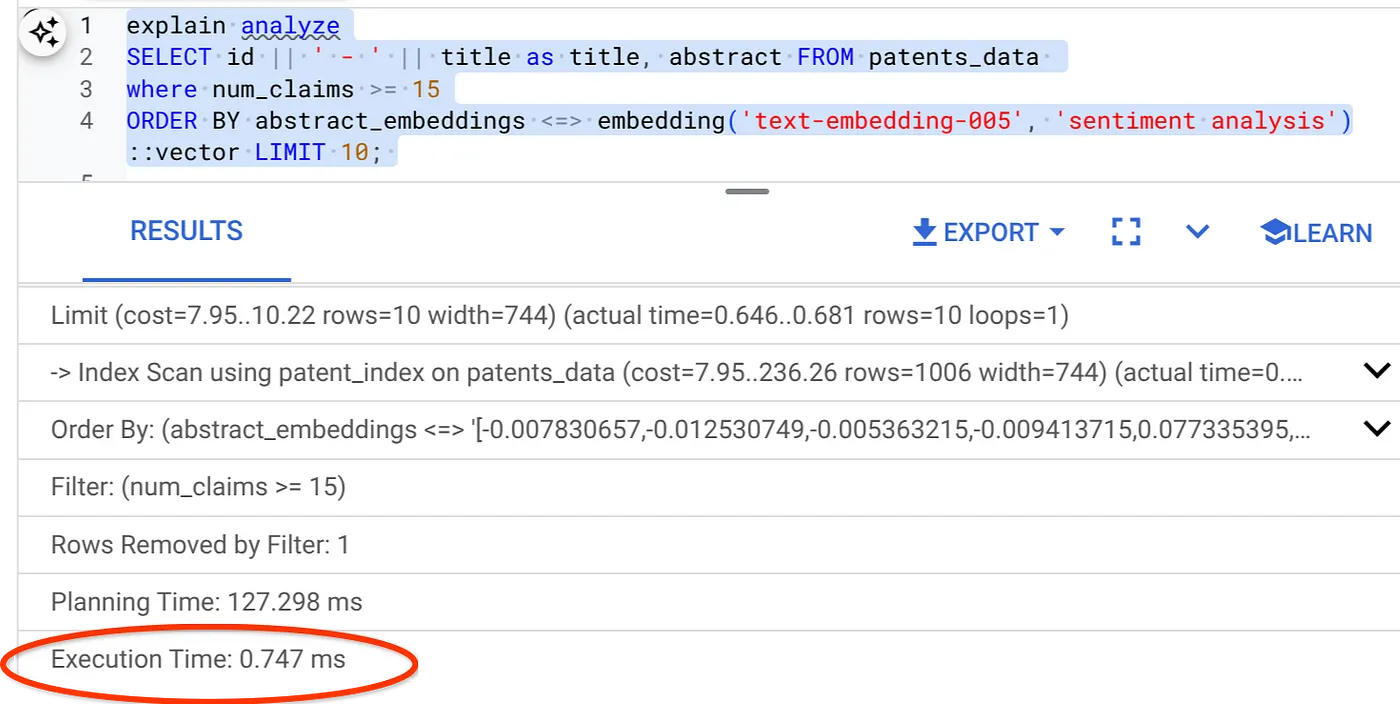
همانطور که میبینید، زمان اجرا برای همان جستجوی برداری به طور قابل توجهی کاهش یافته است. فیلتر درونخطی و تزریق شاخص ScaNN روی جستجوی برداری، این امر را ممکن ساخته است!!!
در مرحله بعد، بیایید میزان فراخوانی را برای این جستجوی برداری فعالشده توسط ScaNN ارزیابی کنیم.
ارزیاب یادآوری
فراخوانی در جستجوی شباهت، درصد نمونههای مرتبطی است که از یک جستجو بازیابی شدهاند، یعنی تعداد موارد مثبت واقعی. این رایجترین معیار مورد استفاده برای اندازهگیری کیفیت جستجو است. یکی از منابع از دست دادن فراخوانی، تفاوت بین جستجوی تقریبی نزدیکترین همسایه یا aNN و جستجوی k (دقیق) نزدیکترین همسایه یا kNN است. شاخصهای برداری مانند ScaNN از AlloyDB الگوریتمهای aNN را پیادهسازی میکنند و به شما این امکان را میدهند که در ازای یک بدهبستان کوچک در فراخوانی، جستجوی برداری را در مجموعه دادههای بزرگ سرعت بخشید. اکنون، AlloyDB این امکان را برای شما فراهم میکند که این بدهبستان را مستقیماً در پایگاه داده برای پرسوجوهای فردی اندازهگیری کنید و از پایداری آن در طول زمان اطمینان حاصل کنید. میتوانید پارامترهای پرسوجو و شاخص را در پاسخ به این اطلاعات بهروزرسانی کنید تا به نتایج و عملکرد بهتری دست یابید.
شما میتوانید با استفاده از تابع evaluate_query_recall، فراخوانی یک پرسوجوی برداری را روی یک شاخص برداری برای یک پیکربندی مشخص پیدا کنید. این تابع به شما امکان میدهد پارامترهای خود را تنظیم کنید تا به نتایج فراخوانی پرسوجوی برداری مورد نظر خود برسید. فراخوانی معیاری است که برای کیفیت جستجو استفاده میشود و به عنوان درصد نتایج برگشتی که به طور عینی به بردارهای پرسوجو نزدیکتر هستند تعریف میشود. تابع evaluate_query_recall به طور پیشفرض فعال است.
نکته مهم:
اگر در مراحل بعدی با خطای عدم اجازه دسترسی در شاخص HNSW مواجه شدید، فعلاً از کل این بخش ارزیابی فراخوان صرف نظر کنید. ممکن است در حال حاضر مربوط به محدودیتهای دسترسی باشد، زیرا این خطا در زمان انتشار این کد منتشر شده است.
- پرچم Enable Index Scan را روی شاخص ScaNN و شاخص HNSW تنظیم کنید:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- کوئری زیر را در AlloyDB Studio اجرا کنید:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
تابع evaluate_query_recall پرسوجو را به عنوان پارامتر دریافت میکند و فراخوانی آن را برمیگرداند. من از همان پرسوجویی که برای بررسی عملکرد به عنوان پرسوجوی ورودی تابع استفاده کردم، استفاده میکنم. من SCaNN را به عنوان متد شاخص اضافه کردهام. برای گزینههای پارامتر بیشتر به مستندات مراجعه کنید.
فراخوانی برای این کوئری جستجوی برداری که ما استفاده کردهایم:
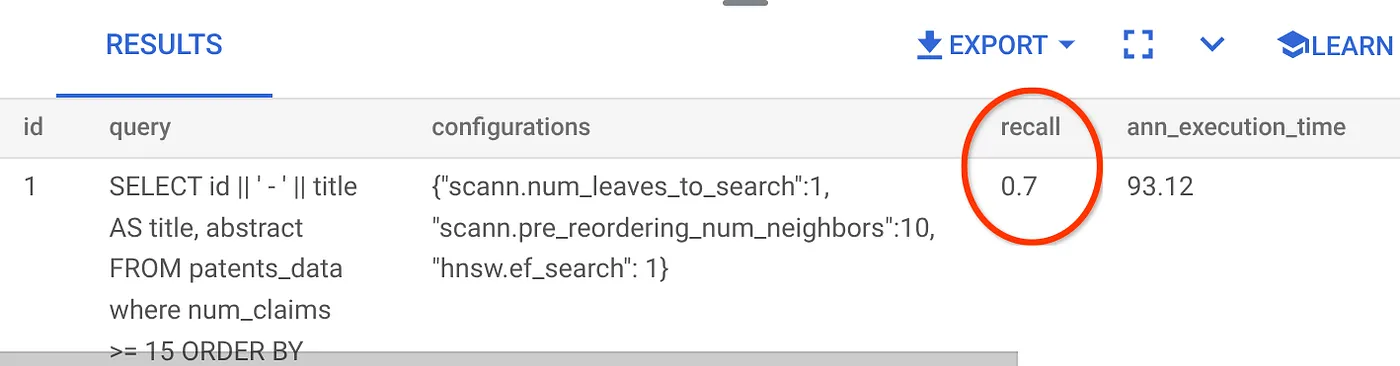
میبینم که میزان فراخوانی (RECALL) برابر با ۷۰٪ است. حالا میتوانم از این اطلاعات برای تغییر پارامترهای اندیس، متدها و پارامترهای پرسوجو استفاده کنم و فراخوانی خود را برای این جستجوی برداری بهبود بخشم!
من تعداد ردیفهای مجموعه نتایج را به ۷ تغییر دادهام (از ۱۰ ردیف قبلی) و میزان RECALL کمی بهبود یافته، یعنی ۸۶٪، را میبینم.
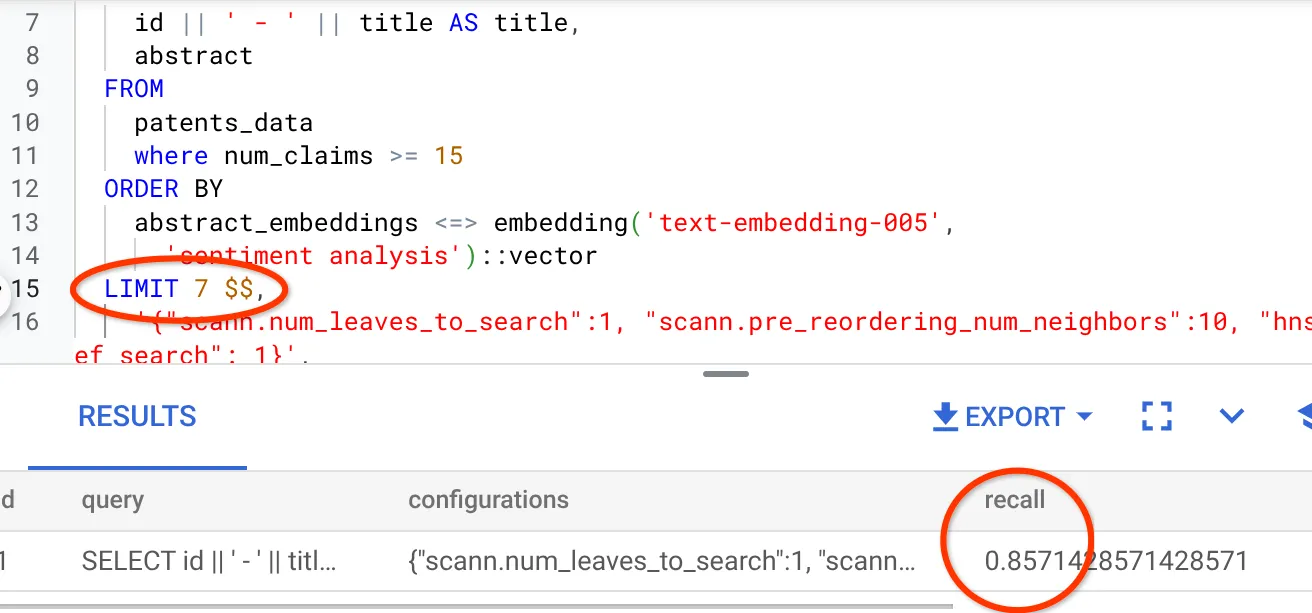
این یعنی میتوانم در لحظه تعداد تطابقهایی که کاربرانم میبینند را تغییر دهم تا ارتباط تطابقها را مطابق با زمینه جستجوی کاربران بهبود بخشم.
بسیار خب، حالا وقت آن رسیده که منطق پایگاه داده را مستقر کنیم و به سراغ عامل برویم!!!
۷. منطق پایگاه داده را بدون سرور به وب ببرید
آمادهاید که این برنامه را به وب ببرید؟ مراحل زیر را دنبال کنید:
- برای ایجاد یک تابع Cloud Run جدید، روی «نوشتن یک تابع» کلیک کنید یا از لینک https://console.cloud.google.com/run/create?deploymentType=function استفاده کنید. در کنسول Google Cloud به Cloud Run Functions بروید.
- گزینه "استفاده از یک ویرایشگر درونخطی برای ایجاد یک تابع" را انتخاب کرده و پیکربندی را شروع کنید. نام سرویس را " patent-search " وارد کنید و منطقه را " us-central1 " و زمان اجرا را "Java 17" انتخاب کنید. Authentication را روی " Allow unauthenticated invocations " تنظیم کنید.
- در بخش «کانتینرها، ولومها، شبکه، امنیت»، مراحل زیر را بدون از دست دادن هیچ جزئیاتی دنبال کنید:
به برگه شبکه بروید:
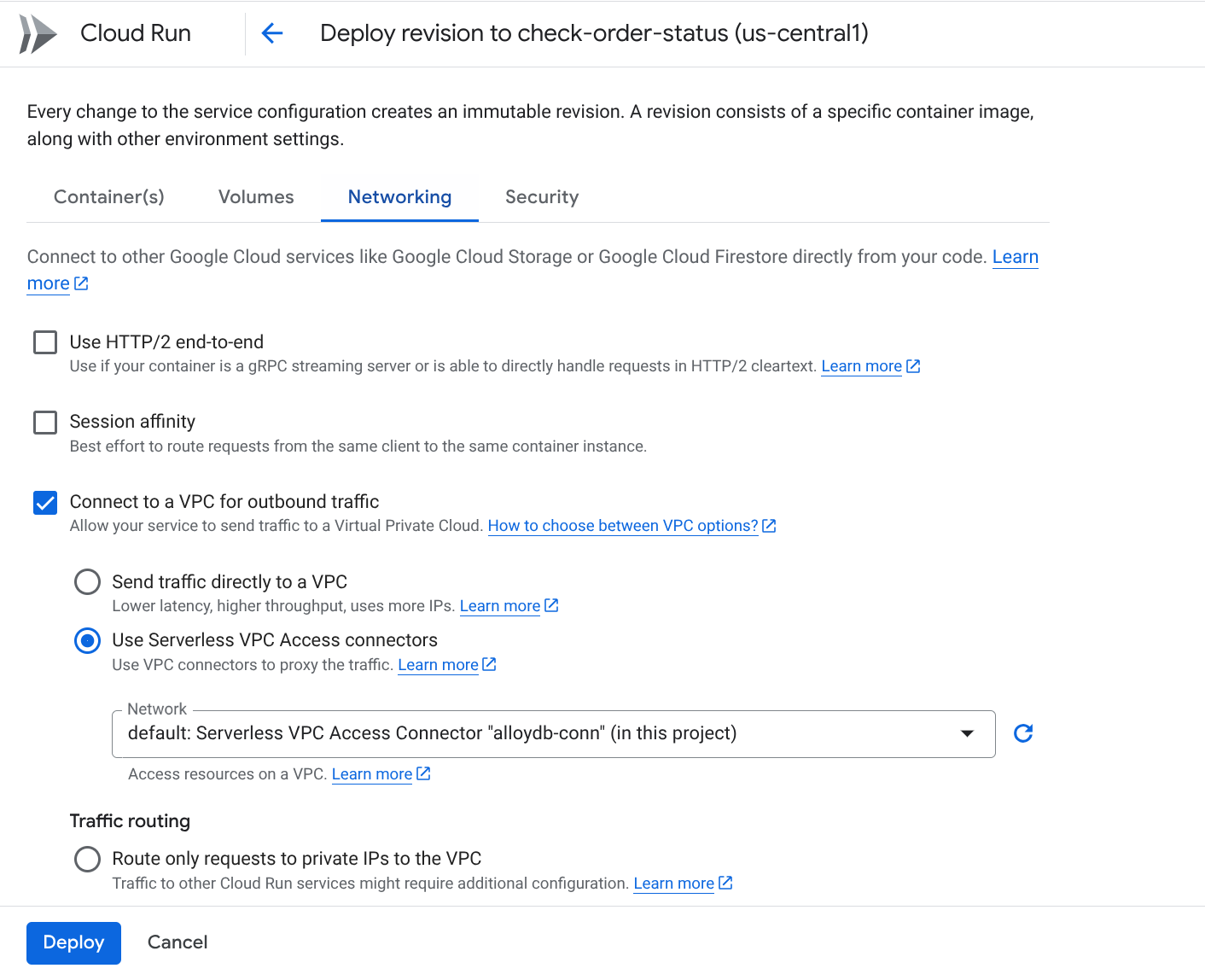
گزینه « اتصال به یک VPC برای ترافیک خروجی » و سپس « استفاده از کانکتورهای دسترسی VPC بدون سرور » را انتخاب کنید.
در منوی کشویی Network، تنظیمات، روی منوی کشویی Network کلیک کنید و گزینه " Add New VPC Connector " را انتخاب کنید (اگر قبلاً گزینه پیشفرض را پیکربندی نکردهاید) و دستورالعملهای نمایش داده شده در کادر محاورهای را دنبال کنید:
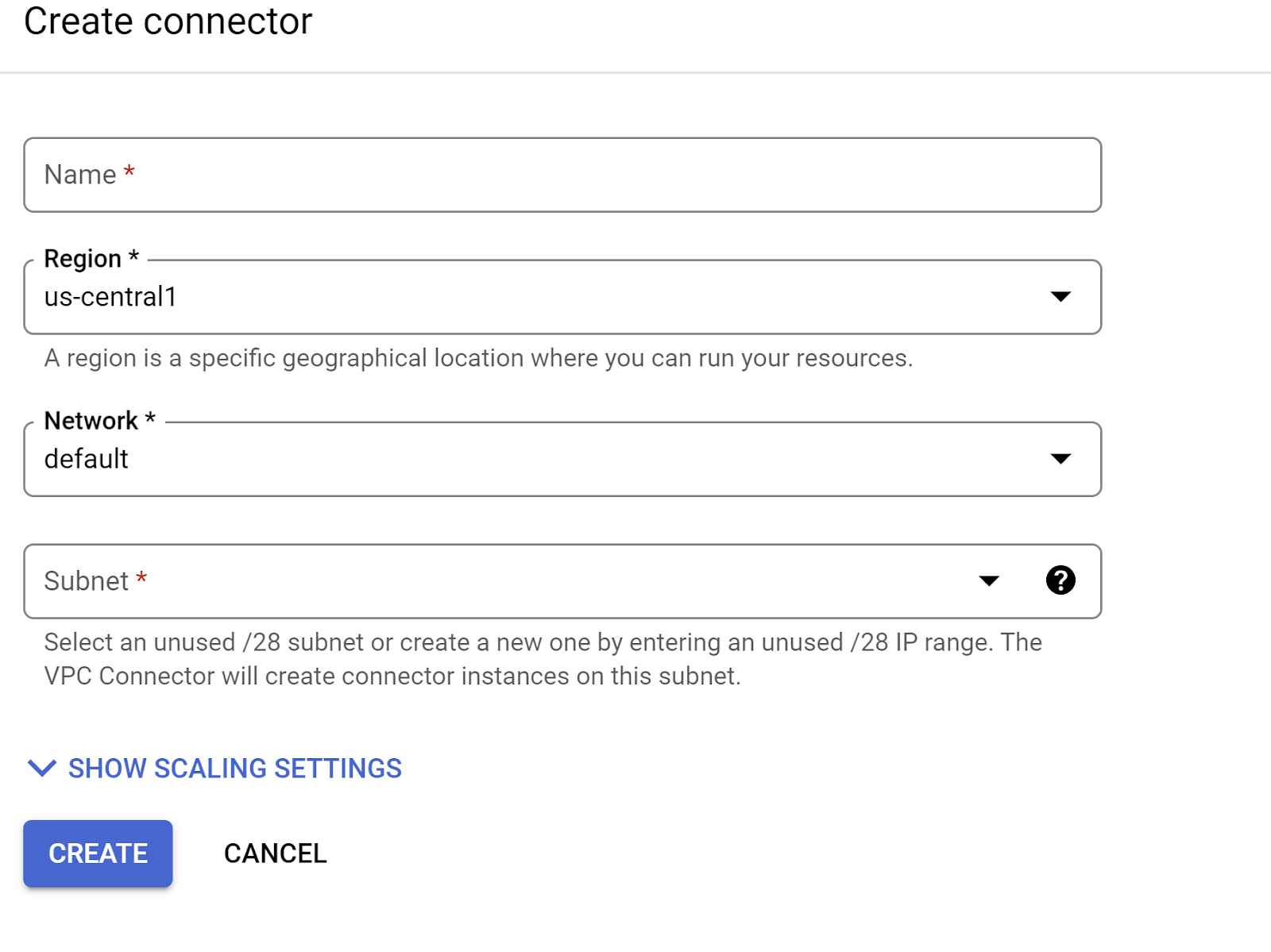
یک نام برای رابط VPC انتخاب کنید و مطمئن شوید که منطقه آن با منطقه شما یکسان است. مقدار Network را به صورت پیشفرض رها کنید و Subnet را روی Custom IP Range با محدوده IP 10.8.0.0 یا چیزی مشابه آن که در دسترس است، تنظیم کنید.
SHOW SCALINING SETTINGS را باز کنید و مطمئن شوید که پیکربندی دقیقاً روی موارد زیر تنظیم شده است:
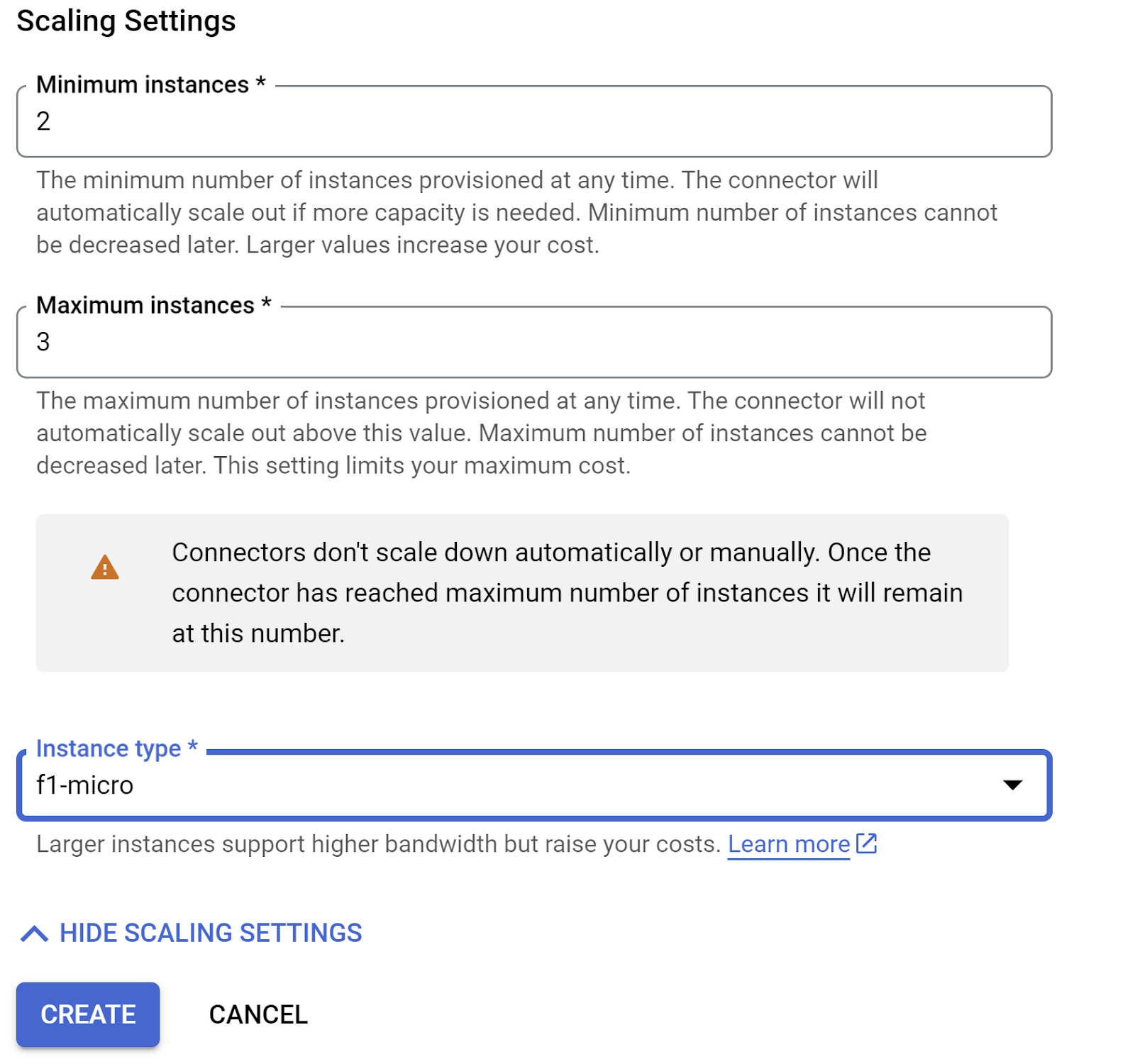
روی CREATE کلیک کنید و این کانکتور اکنون باید در تنظیمات خروجی فهرست شده باشد.
کانکتور تازه ایجاد شده را انتخاب کنید.
انتخاب کنید که تمام ترافیک از طریق این کانکتور VPC هدایت شود.
روی NEXT و سپس DEPLOY کلیک کنید.
- به طور پیشفرض، نقطه ورود (Entry Point) را روی " gcfv2.HelloHttpFunction " تنظیم میکند. کد جاینگهدار (placeholder) در HelloHttpFunction.java و pom.xml از تابع Cloud Run خود را به ترتیب با کد " PatentSearch.java " و " pom.xml " جایگزین کنید. نام فایل کلاس را به PatentSearch.java تغییر دهید.
- به یاد داشته باشید که محل قرارگیری ************* و اعتبارنامههای اتصال AlloyDB را با مقادیر خود در فایل جاوا تغییر دهید. اعتبارنامههای AlloyDB همانهایی هستند که در ابتدای این آزمایشگاه کد استفاده کردهایم. اگر از مقادیر متفاوتی استفاده کردهاید، لطفاً همانها را در فایل جاوا تغییر دهید.
- روی استقرار کلیک کنید.
- پس از استقرار تابع ابری بهروزرسانیشده، باید نقطه پایانی ایجاد شده را مشاهده کنید. آن را کپی کرده و در دستور زیر جایگزین کنید:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
همین! انجام یک جستجوی برداری شباهت زمینهای پیشرفته با استفاده از مدل Embeddings روی دادههای AlloyDB به همین سادگی است.
۸. بیایید عامل را با Java ADK بسازیم
ابتدا، بیایید با پروژه جاوا در ویرایشگر شروع کنیم.
- به ترمینال Cloud Shell بروید
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- در صورت درخواست، مجوز دهید
- با کلیک روی آیکون ویرایشگر از بالای کنسول Cloud Shell، به ویرایشگر Cloud Shell بروید.

- در کنسول Cloud Shell Editor که در حال اجرا است، یک پوشه جدید ایجاد کنید و نام آن را "adk-agents" بگذارید.
مطابق شکل زیر، روی ایجاد پوشه جدید در دایرکتوری ریشه پوسته ابری خود کلیک کنید:
نام آن را «adk-agents» بگذارید:
- ساختار پوشه زیر و فایلهای خالی با نامهای متناظر را در ساختار زیر ایجاد کنید:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- مخزن گیتهاب را در یک تب جداگانه باز کنید و کد منبع فایلهای App.java و pom.xml را کپی کنید.
- اگر ویرایشگر را در یک تب جدید با استفاده از آیکون «باز کردن در تب جدید» در گوشه بالا سمت راست باز کرده باشید، میتوانید ترمینال را در پایین صفحه باز کنید. میتوانید هم ویرایشگر و هم ترمینال را به صورت موازی باز نگه دارید تا بتوانید آزادانه کار کنید.
- پس از کلون کردن، به کنسول ویرایشگر Cloud Shell برگردید
- از آنجایی که ما قبلاً تابع Cloud Run را ایجاد کردهایم، نیازی به کپی کردن فایلهای تابع Cloud Run از پوشه repo ندارید.
شروع کار با ADK Java SDK
این کار نسبتاً سرراست است. در درجه اول باید مطمئن شوید که موارد زیر در مرحله کلون شما پوشش داده شده است:
- اضافه کردن وابستگیها:
فایلهای google-adk و google-adk-dev (برای رابط کاربری وب) را در pom.xml خود وارد کنید. اگر منبع را از مخزن کپی کردهاید، این فایلها از قبل در فایلها گنجانده شدهاند و نیازی به وارد کردن آنها نیست. فقط باید در نقطه پایانی Cloud Run Function تغییری ایجاد کنید تا نقطه پایانی پیادهسازی شده شما را منعکس کند. این موضوع در مراحل بعدی این بخش پوشش داده شده است.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
مطمئن شوید که pom.xml را از مخزن منبع ارجاع میدهید، زیرا وابستگیها و پیکربندیهای دیگری نیز وجود دارد که برای اجرای برنامه مورد نیاز است.
- پروژه خود را پیکربندی کنید:
مطمئن شوید که نسخه جاوا (۱۷+ توصیه میشود) و تنظیمات کامپایلر Maven به درستی در pom.xml شما پیکربندی شدهاند. میتوانید پروژه خود را طوری پیکربندی کنید که از ساختار زیر پیروی کند:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- تعریف عامل و ابزارهای آن (App.java):
اینجاست که جادوی ADK Java SDK میدرخشد. ما عامل خود، قابلیتها (دستورالعملها) و ابزارهایی که میتواند استفاده کند را تعریف میکنیم.
نسخه سادهشدهای از چند قطعه کد کلاس عامل اصلی را اینجا بیابید. برای پروژه کامل به مخزن پروژه اینجا مراجعه کنید.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
اجزای کلیدی کد جاوا ADK برجسته شده:
- LlmAgent.builder(): رابط برنامهنویسی کاربردی (API) روان برای پیکربندی عامل شما.
- .instruction(...): دستورالعمل اصلی و دستورالعملهای LLM، از جمله زمان استفاده از ابزار را ارائه میدهد.
- FunctionTool.create(App.class, "methodName"): به راحتی متدهای جاوای شما را به عنوان ابزارهایی که عامل میتواند فراخوانی کند، ثبت میکند. رشته نام متد باید با یک متد استاتیک عمومی واقعی مطابقت داشته باشد.
- @Schema(description = ...): پارامترهای ابزار را حاشیهنویسی میکند و به LLM کمک میکند تا بفهمد هر ابزار چه ورودیهایی را انتظار دارد. این توضیحات برای انتخاب دقیق ابزار و پر کردن پارامترها بسیار مهم است.
- InvocationContext ctx: به طور خودکار به متدهای ابزار ارسال میشود و به وضعیت جلسه (ctx.session().state())، اطلاعات کاربر و موارد دیگر دسترسی میدهد.
- .outputKey("patents"): وقتی ابزاری دادهها را برمیگرداند، ADK میتواند بهطور خودکار آن را در session state تحت این کلید ذخیره کند. اینگونه است که explainPatent میتواند به نتایج getPatents دسترسی پیدا کند.
- VECTOR_SEARCH_ENDPOINT: این متغیری است که منطق عملکردی اصلی را برای پرسش و پاسخ زمینهای برای کاربر در مورد جستجوی پتنت نگه میدارد.
- مورد اقدام در اینجا: شما باید پس از پیادهسازی مرحله Java Cloud Run Function از بخش قبل، مقدار نقطه پایانی مستقر شده را بهروزرسانی کنید.
- ابزار جستجو (searchTool) : این ابزار با کاربر تعامل میکند تا تطابقهای مرتبط با متن جستجوی کاربر را از پایگاه داده ثبت اختراع پیدا کند.
- ابزار توضیح (describeTool) : این ابزار از کاربر درخواست میکند تا یک پتنت خاص را به طور کامل بررسی کند. سپس خلاصهای از چکیده پتنت را ارائه میدهد و بر اساس جزئیات پتنت موجود، به سوالات بیشتر کاربر پاسخ میدهد.
نکته مهم: مطمئن شوید که متغیر VECTOR_SEARCH_ENDPOINT را با نقطه پایانی CRF مستقر شده خود جایگزین کنید.
استفاده از InvocationContext برای تعاملات Stateful
یکی از ویژگیهای حیاتی برای ساخت عاملهای مفید، مدیریت وضعیت در چندین نوبت مکالمه است. InvocationContext در ADK این کار را ساده میکند.
در App.java ما:
- وقتی initAgent() تعریف میشود، از .outputKey("patents") استفاده میکنیم. این به ADK میگوید که وقتی ابزاری (مانند getPatents) دادهها را در فیلد گزارش خود برمیگرداند، آن دادهها باید در session state تحت کلید "patents" ذخیره شوند.
- در متد ابزار explainPatent، ما ctx مربوط به InvocationContext را تزریق میکنیم:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
این به ابزار explainPatent اجازه میدهد تا به لیست پتنتهای دریافت شده توسط ابزار getPatents در نوبت قبلی دسترسی پیدا کند و مکالمه را منسجم و باوضوح کند.
۹. تست رابط خط فرمان محلی
تعریف متغیرهای محیطی
شما باید دو متغیر محیطی را export کنید:
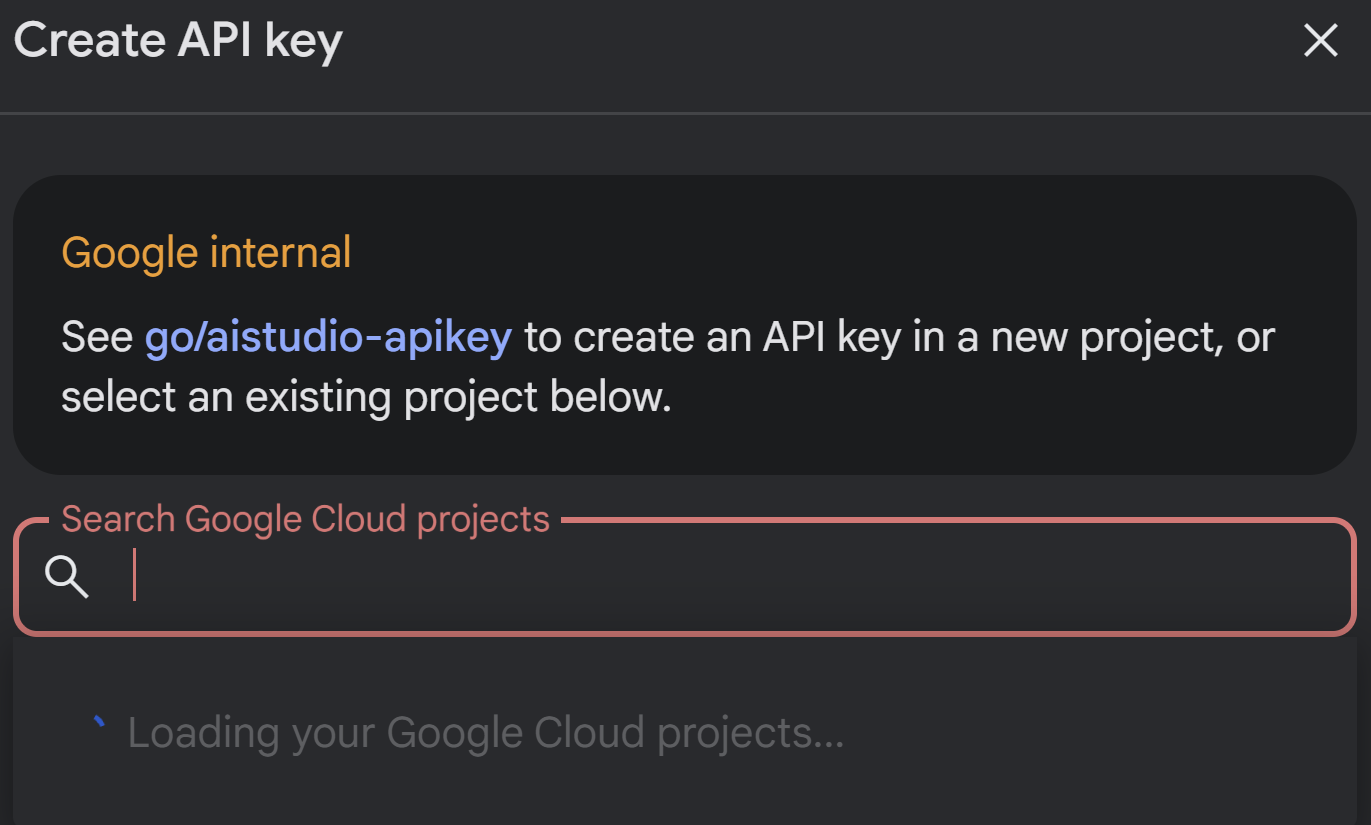
- یک کلید Gemini که میتوانید از AI Studio دریافت کنید:
برای انجام این کار، به https://aistudio.google.com/apikey بروید و کلید API خود را برای پروژه فعال Google Cloud خود که این برنامه را در آن پیادهسازی میکنید، دریافت کنید و کلید را در جایی ذخیره کنید:
- پس از دریافت کلید، ترمینال Cloud Shell را باز کنید و با اجرای دستور زیر به دایرکتوری جدیدی که adk-agents در آن ایجاد کردهایم، بروید:
cd adk-agents
- یک متغیر برای مشخص کردن اینکه این بار از Vertex AI استفاده نمیکنیم.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- اولین عامل خود را روی CLI اجرا کنید
برای راهاندازی این اولین عامل، از دستور Maven زیر در ترمینال خود استفاده کنید:
mvn compile exec:java -DmainClass="agents.App"
شما پاسخ تعاملی از عامل را در ترمینال خود مشاهده خواهید کرد.
۱۰. استقرار در Cloud Run
استقرار عامل جاوا ADK شما در Cloud Run مشابه استقرار هر برنامه جاوای دیگری است:
- Dockerfile: یک Dockerfile برای بستهبندی برنامه جاوای خود ایجاد کنید.
- ساخت و ارسال تصویر داکر: از Google Cloud Build و Artifact Registry استفاده کنید.
- شما میتوانید مرحله بالا را انجام دهید و تنها با یک دستور، Cloud Run را مستقر کنید:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
به طور مشابه، شما میتوانید تابع Java Cloud Run خود (gcfv2.PatentSearch) را مستقر کنید. به طور جایگزین، میتوانید تابع Java Cloud Run را برای منطق پایگاه داده مستقیماً از کنسول Cloud Run Function ایجاد و مستقر کنید.
۱۱. تست با رابط کاربری وب
ADK با یک رابط کاربری وب مفید برای آزمایش و اشکالزدایی محلی عامل شما ارائه میشود. وقتی App.java خود را به صورت محلی اجرا میکنید (مثلاً mvn exec:java -Dexec.mainClass="agents.App" در صورت پیکربندی، یا فقط اجرای متد main)، ADK معمولاً یک سرور وب محلی را راهاندازی میکند.
رابط کاربری وب ADK به شما امکان میدهد:
- برای نماینده خود پیام ارسال کنید.
- رویدادها (پیام کاربر، فراخوانی ابزار، پاسخ ابزار، پاسخ LLM) را مشاهده کنید.
- وضعیت جلسه را بررسی کنید.
- مشاهده لاگها و ردپاها.
این در طول توسعه برای درک نحوه پردازش درخواستها توسط عامل شما و استفاده از ابزارهایش بسیار ارزشمند است. این فرض را در نظر میگیرد که mainClass شما در pom.xml روی com.google.adk.web.AdkWebServer تنظیم شده است و عامل شما در آن ثبت شده است، یا شما در حال اجرای یک اجراکننده تست محلی هستید که این را نشان میدهد.
هنگام اجرای App.java با InMemoryRunner و Scanner برای ورودی کنسول، شما در حال آزمایش منطق عامل اصلی هستید. رابط کاربری وب یک جزء جداگانه برای یک تجربه اشکالزدایی بصریتر است که اغلب زمانی استفاده میشود که ADK عامل شما را از طریق HTTP ارائه میدهد.
شما میتوانید از دستور Maven زیر در دایرکتوری ریشه خود برای راهاندازی سرور محلی SpringBoot استفاده کنید:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
این رابط اغلب از طریق URL که دستور بالا با آن خروجی میدهد قابل دسترسی است. اگر Cloud Run deploy شده باشد، باید بتوانید از طریق لینک Cloud Run deploy شده به آن دسترسی پیدا کنید.
شما باید بتوانید نتیجه را در یک رابط کاربری تعاملی مشاهده کنید.
ویدیوی زیر را برای نماینده ثبت اختراع مستقر ما ببینید:
نسخه آزمایشی یک نماینده ثبت اختراع با کنترل کیفیت به همراه ارزیابی جستجو و فراخوان درون خطی AlloyDB!
۱۲. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این پست، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به آدرس https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog بروید.
- صفحه وبلاگ https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog .
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
۱۳. تبریک
تبریک! شما با موفقیت عامل تحلیل پتنت خود را در جاوا با ترکیب قابلیتهای ADK، https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog ، Vertex AI و Vector Search ساختید، همچنین ما جهش بزرگی در متحول کردن، کارآمد کردن و واقعاً معنامحور کردن جستجوهای شباهت زمینهای برداشتهایم.
همین امروز شروع کنید!
مستندات ADK: [لینک به مستندات رسمی جاوا ADK]
کد منبع عامل تحلیل پتنت: [لینک به مخزن گیتهاب شما (که اکنون عمومی است)]
عاملهای نمونه جاوا: [لینک به مخزن adk-samples]
به انجمن ADK بپیوندید: https://www.reddit.com/r/agentdevelopmentkit/
ساختمان کارگزاری مبارک!