
1. Présentation
Dans différents secteurs, la recherche contextuelle est une fonctionnalité essentielle qui constitue le cœur de leurs applications. La génération augmentée de récupération est un moteur clé de cette évolution technologique cruciale depuis un certain temps déjà, grâce à ses mécanismes de récupération optimisés par l'IA générative. Les modèles génératifs, avec leurs grandes fenêtres de contexte et leur impressionnante qualité de sortie, transforment l'IA. Le RAG permet d'injecter systématiquement du contexte dans les applications et agents d'IA, en les ancrant dans des bases de données structurées ou des informations provenant de différents médias. Ces données contextuelles sont essentielles pour la clarté et la précision des résultats, mais quelle est la précision de ces résultats ? Votre activité dépend-elle en grande partie de la précision et de la pertinence de ces correspondances contextuelles ? Alors, ce projet va vous plaire !
Imaginez maintenant si nous pouvions exploiter la puissance des modèles génératifs et créer des agents interactifs capables de prendre des décisions autonomes basées sur des informations aussi importantes et ancrées dans la vérité. C'est ce que nous allons faire aujourd'hui. Nous allons créer une application d'agent d'IA de bout en bout à l'aide d'Agent Development Kit, optimisée par le RAG avancé dans AlloyDB pour une application d'analyse de brevets.
L'agent d'analyse des brevets aide l'utilisateur à trouver des brevets contextuellement pertinents par rapport à son texte de recherche. Sur demande, il fournit une explication claire et concise, ainsi que des informations supplémentaires si nécessaire, pour un brevet sélectionné. Prêt à découvrir comment faire ? C'est parti !
Objectif
L'objectif est simple. Permettre à un utilisateur de rechercher des brevets à partir d'une description textuelle, puis d'obtenir une explication détaillée d'un brevet spécifique à partir des résultats de recherche. Tout cela à l'aide d'un agent d'IA conçu avec Java ADK, AlloyDB, la recherche vectorielle (avec des index avancés), Gemini et l'ensemble de l'application déployée sans serveur sur Cloud Run.
Ce que vous allez faire
Au cours de cet atelier, vous allez :
- Créer une instance AlloyDB et charger les données de l'ensemble de données public sur les brevets
- Implémenter la recherche vectorielle avancée dans AlloyDB à l'aide des fonctionnalités d'évaluation ScaNN et du rappel
- Créer un agent à l'aide de Java ADK
- Implémenter la logique côté serveur de la base de données dans des fonctions Cloud Functions Java sans serveur
- Déployer et tester l'agent dans Cloud Run
Le diagramme suivant représente le flux de données et les étapes impliquées dans l'implémentation.
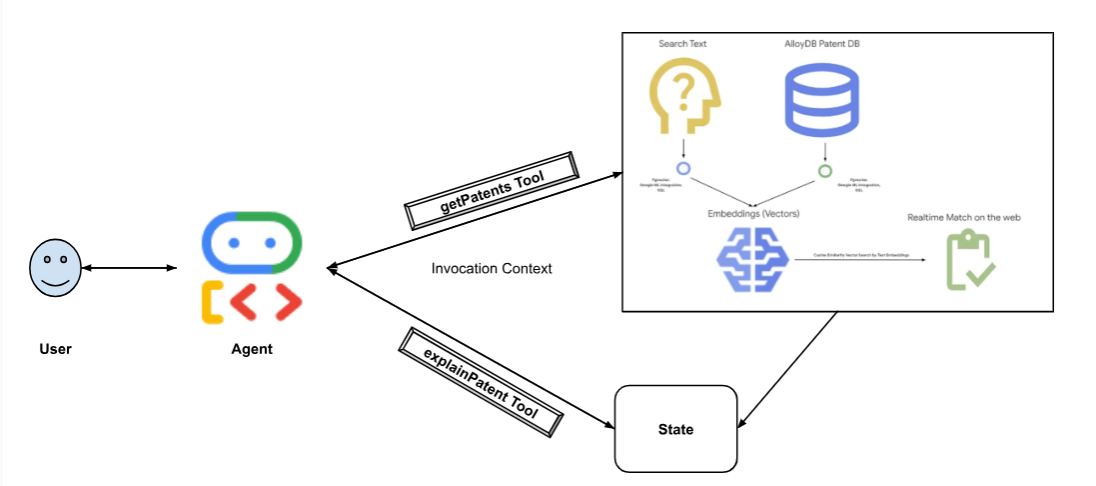
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises. Vous pouvez utiliser une commande gcloud dans le terminal Cloud Shell :
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Vous pouvez également accéder à la console en recherchant chaque produit ou en utilisant ce lien.
Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
3. Configuration de la base de données
Dans cet atelier, nous utiliserons AlloyDB comme base de données pour les données sur les brevets. Il utilise des clusters pour stocker toutes les ressources, telles que les bases de données et les journaux. Chaque cluster possède une instance principale qui fournit un point d'accès aux données. Les tables contiennent les données réelles.
Commençons par créer un cluster, une instance et une table AlloyDB dans lesquels l'ensemble de données sur les brevets sera chargé.
Créer un cluster et une instance
- Accédez à la page AlloyDB de la console Cloud. Pour trouver la plupart des pages de la console Cloud, le plus simple est de les rechercher à l'aide de la barre de recherche de la console.
- Sélectionnez CRÉER UN CLUSTER sur cette page :

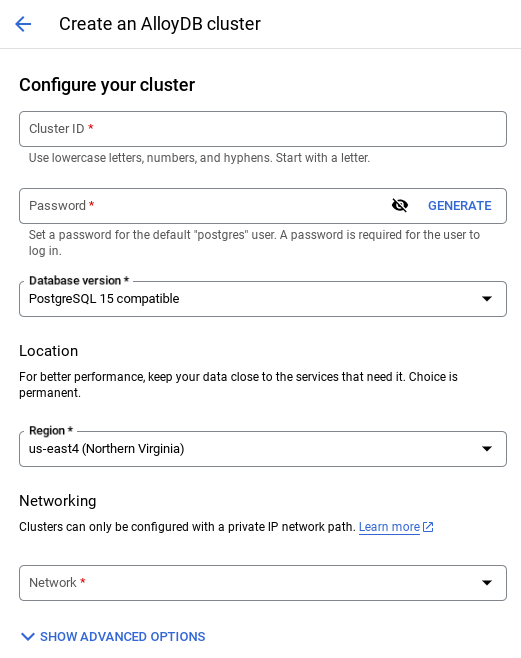
- Un écran semblable à celui ci-dessous s'affiche. Créez un cluster et une instance avec les valeurs suivantes (assurez-vous que les valeurs correspondent si vous clonez le code de l'application à partir du dépôt) :
- ID du cluster : "
vector-cluster" - password : "
alloydb" - PostgreSQL 15 / dernière version recommandée
- Région : "
us-central1" - Networking : "
default"
- Lorsque vous sélectionnez le réseau par défaut, un écran semblable à celui ci-dessous s'affiche.
Sélectionnez CONFIGURER LA CONNEXION.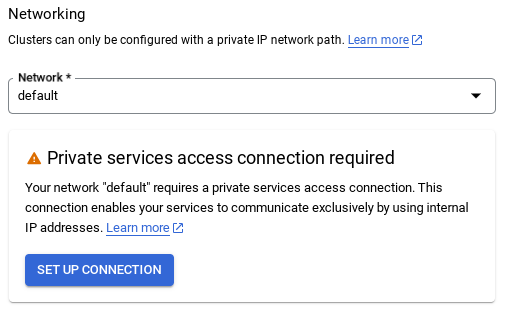
- Sélectionnez ensuite Utiliser une plage d'adresses IP automatiquement allouée, puis cliquez sur "Continuer". Après avoir vérifié les informations, sélectionnez CRÉER UNE CONNEXION.
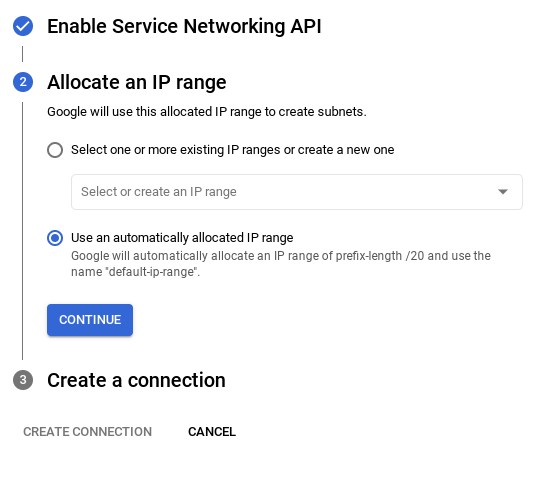
- Une fois votre réseau configuré, vous pouvez continuer à créer votre cluster. Cliquez sur CRÉER UN CLUSTER pour terminer la configuration du cluster, comme indiqué ci-dessous :
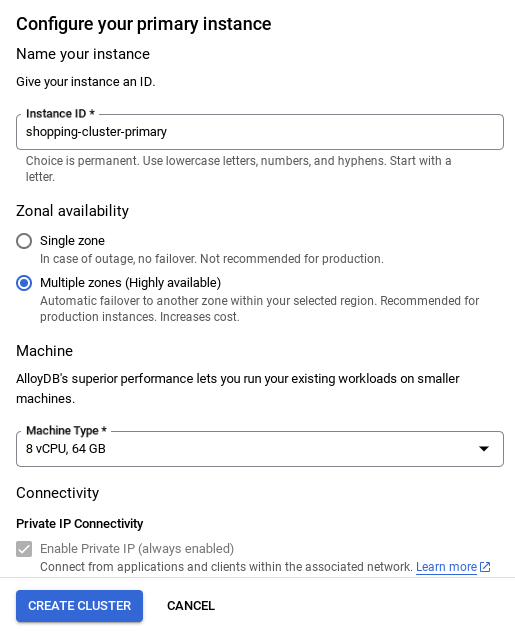
Veillez à modifier l'ID de l'instance (que vous trouverez lors de la configuration du cluster / de l'instance) par
vector-instance. Si vous ne pouvez pas le modifier, n'oubliez pas d'utiliser l'ID de votre instance dans toutes les références à venir.
Notez que la création du cluster prendra environ 10 minutes. Une fois l'opération terminée, un écran présentant le cluster que vous venez de créer devrait s'afficher.
4. Ingestion de données
Il est maintenant temps d'ajouter un tableau contenant les données sur le magasin. Accédez à AlloyDB, sélectionnez le cluster principal, puis AlloyDB Studio :
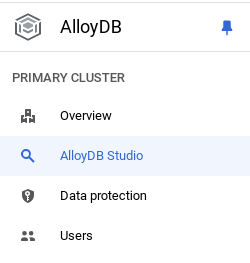
Vous devrez peut-être attendre que votre instance soit créée. Une fois le cluster créé, connectez-vous à AlloyDB à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
alloydb"
Une fois l'authentification réussie dans AlloyDB Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
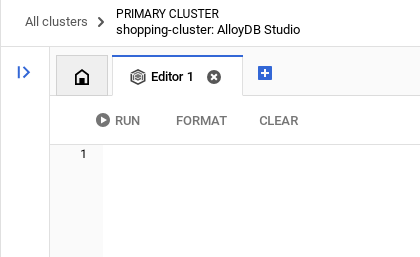
Vous saisirez des commandes pour AlloyDB dans des fenêtres d'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Activer les extensions
Pour créer cette application, nous allons utiliser les extensions pgvector et google_ml_integration. L'extension pgvector vous permet de stocker et de rechercher des embeddings vectoriels. L'extension google_ml_integration fournit les fonctions que vous utilisez pour accéder aux points de terminaison de prédiction Vertex AI afin d'obtenir des prédictions en SQL. Activez ces extensions en exécutant les LDD suivants :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Si vous souhaitez vérifier les extensions qui ont été activées dans votre base de données, exécutez la commande SQL suivante :
select extname, extversion from pg_extension;
Créer une table
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
La colonne "abstract_embeddings" permettra de stocker les valeurs vectorielles du texte.
Accorder l'autorisation
Exécutez l'instruction ci-dessous pour accorder l'exécution de la fonction "embedding" :
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Attribuer le RÔLE Utilisateur Vertex AI au compte de service AlloyDB
Dans la console Google Cloud IAM, accordez au compte de service AlloyDB (qui ressemble à ceci : service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accès au rôle "Utilisateur Vertex AI". PROJECT_NUMBER correspondra au numéro de votre projet.
Vous pouvez également exécuter la commande ci-dessous à partir du terminal Cloud Shell :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Charger les données de brevets dans la base de données
Nous utiliserons les ensembles de données publics Google Patents sur BigQuery comme ensemble de données. Nous utiliserons AlloyDB Studio pour exécuter nos requêtes. Les données sont extraites dans ce fichier insert scripts sql dans ce dépôt. Nous allons exécuter ce fichier pour charger les données sur les brevets.
- Dans la console Google Cloud, ouvrez la page AlloyDB.
- Sélectionnez le cluster que vous venez de créer, puis cliquez sur l'instance.
- Dans le menu de navigation AlloyDB, cliquez sur AlloyDB Studio. Connectez-vous avec vos identifiants.
- Ouvrez un nouvel onglet en cliquant sur l'icône Nouvel onglet à droite.
- Copiez et exécutez les instructions de requête
insertdes fichiersinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlun par un. Vous pouvez exécuter les instructions d'insertion de 10 à 50 copies pour une démonstration rapide de ce cas d'utilisation.
Pour l'exécuter, cliquez sur Exécuter. Les résultats de votre requête s'affichent dans la table Résultats.
5. Créer des embeddings pour les données de brevets
Commençons par tester la fonction d'embedding en exécutant l'exemple de requête suivant :
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Cela devrait renvoyer le vecteur d'embedding, qui ressemble à un tableau de valeurs flottantes, pour l'exemple de texte dans la requête. Voici à quoi il ressemble :
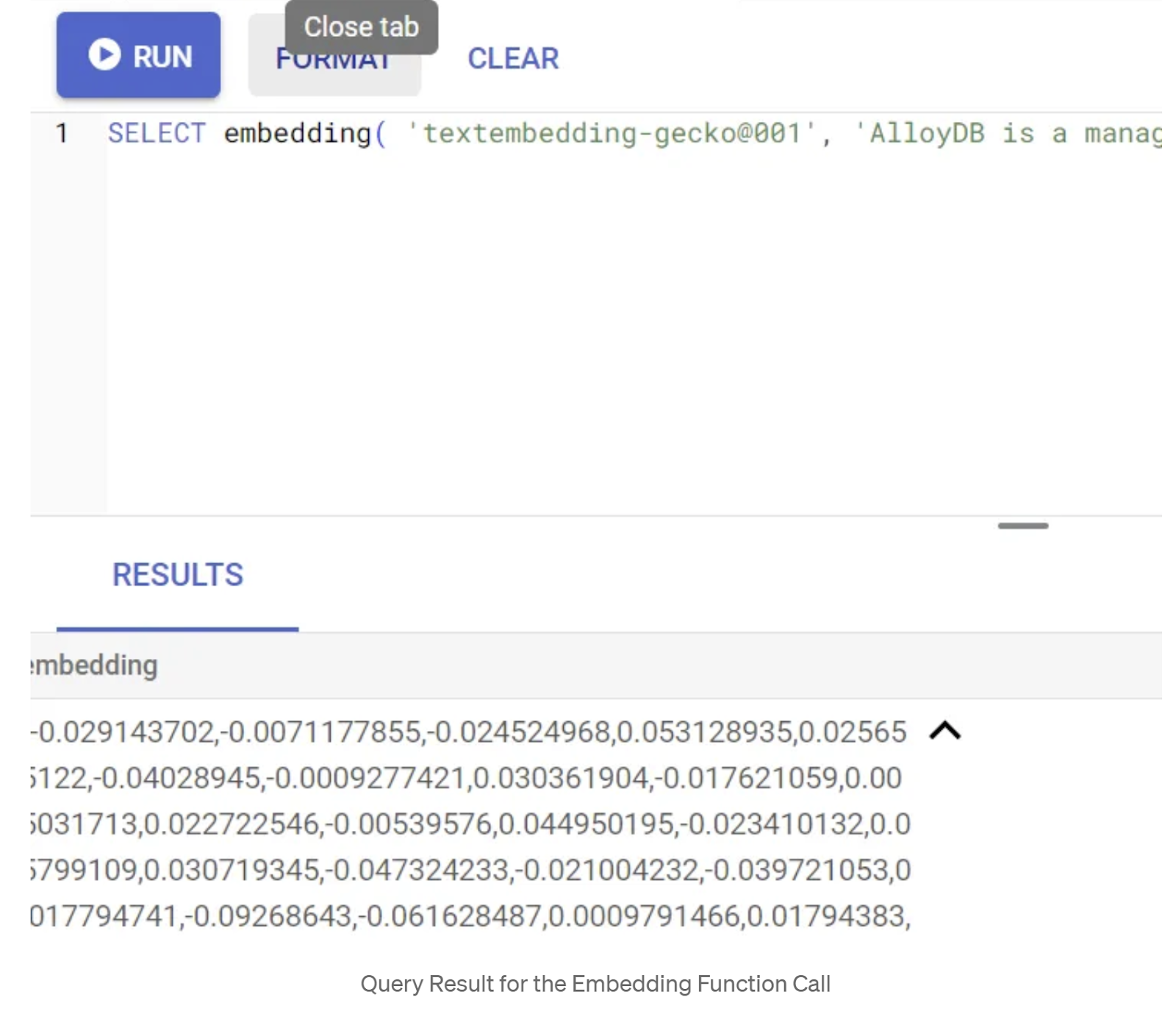
Mettre à jour le champ vectoriel "abstract_embeddings"
Le LMD ci-dessous doit être utilisé pour mettre à jour les résumés de brevets dans le tableau avec les embeddings correspondants au cas où les embeddings doivent être générés pour les résumés. Dans notre cas, les instructions d'insertion contiennent déjà ces embeddings pour chaque résumé. Vous n'avez donc pas besoin d'appeler la méthode embeddings().
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Effectuer une recherche vectorielle
Maintenant que la table, les données et les embeddings sont prêts, effectuons la recherche vectorielle en temps réel pour le texte de recherche de l'utilisateur. Pour tester cela, exécutez la requête ci-dessous :
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Dans cette requête,
- Le texte recherché par l'utilisateur est "Analyse des sentiments".
- Nous le convertissons en embeddings dans la méthode embedding() à l'aide du modèle text-embedding-005.
- "<=>" représente l'utilisation de la méthode de distance COSINE SIMILARITY.
- Nous convertissons le résultat de la méthode d'embedding en type vectoriel pour le rendre compatible avec les vecteurs stockés dans la base de données.
- LIMIT 10 signifie que nous sélectionnons les 10 correspondances les plus proches du texte de recherche.
AlloyDB booste le RAG de recherche vectorielle :
De nombreuses nouveautés ont été introduites. Voici deux d'entre elles, axées sur les développeurs :
- Filtrage intégré
- Évaluateur de rappel
Filtrage intégré
Auparavant, en tant que développeur, vous deviez effectuer la requête Vector Search et gérer le filtrage et le rappel. L'optimiseur de requêtes AlloyDB choisit la manière d'exécuter une requête avec des filtres. Le filtrage intégré est une nouvelle technique d'optimisation des requêtes qui permet à l'optimiseur de requêtes AlloyDB d'évaluer à la fois les conditions de filtrage des métadonnées et la recherche vectorielle, en tirant parti des index vectoriels et des index sur les colonnes de métadonnées. Cela a permis d'améliorer les performances de rappel, ce qui permet aux développeurs de profiter des avantages d'AlloyDB dès le départ.
Le filtrage intégré est idéal pour les cas de sélectivité moyenne. Lorsqu'AlloyDB effectue une recherche dans l'index vectoriel, il ne calcule les distances que pour les vecteurs qui correspondent aux conditions de filtrage des métadonnées (vos filtres fonctionnels dans une requête généralement gérée dans la clause WHERE). Cela améliore considérablement les performances de ces requêtes, en complément des avantages du filtrage après ou avant.
- Installer ou mettre à jour l'extension pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Si l'extension pgvector est déjà installée, mettez-la à niveau vers la version 0.8.0.google-3 ou ultérieure pour bénéficier des fonctionnalités d'évaluation du rappel.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Cette étape ne doit être exécutée que si votre extension vectorielle est antérieure à la version 0.8.0.google-3.
Important : Si votre nombre de lignes est inférieur à 100, vous n'avez pas besoin de créer l'index ScaNN, car il ne s'appliquera pas à un nombre de lignes aussi faible. Dans ce cas, veuillez ignorer les étapes suivantes.
- Pour créer des index ScaNN, installez l'extension alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
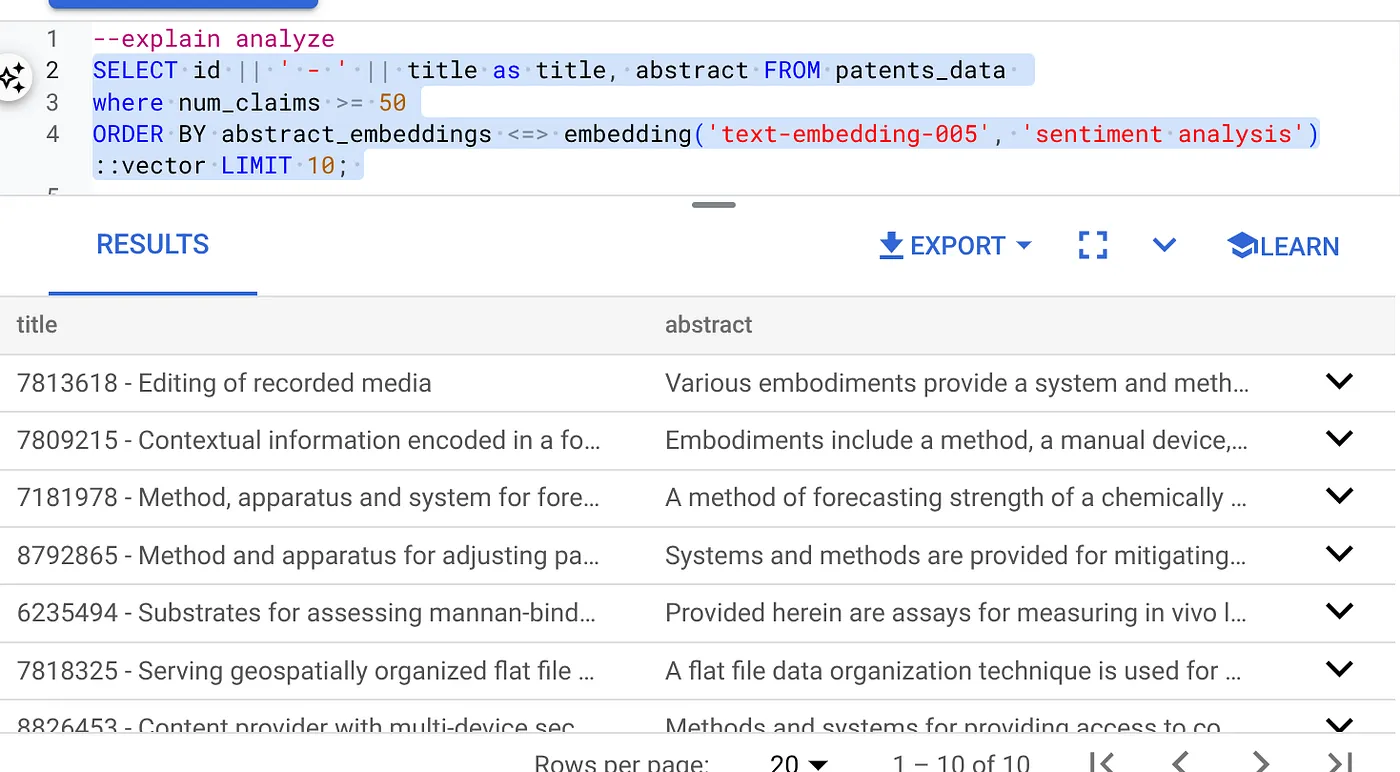
- Exécutez d'abord la requête Vector Search sans l'index et sans le filtre intégré activé :
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Le résultat doit être semblable à ceci :
- Exécutez Explain Analyze dessus (sans index ni filtrage intégré) :
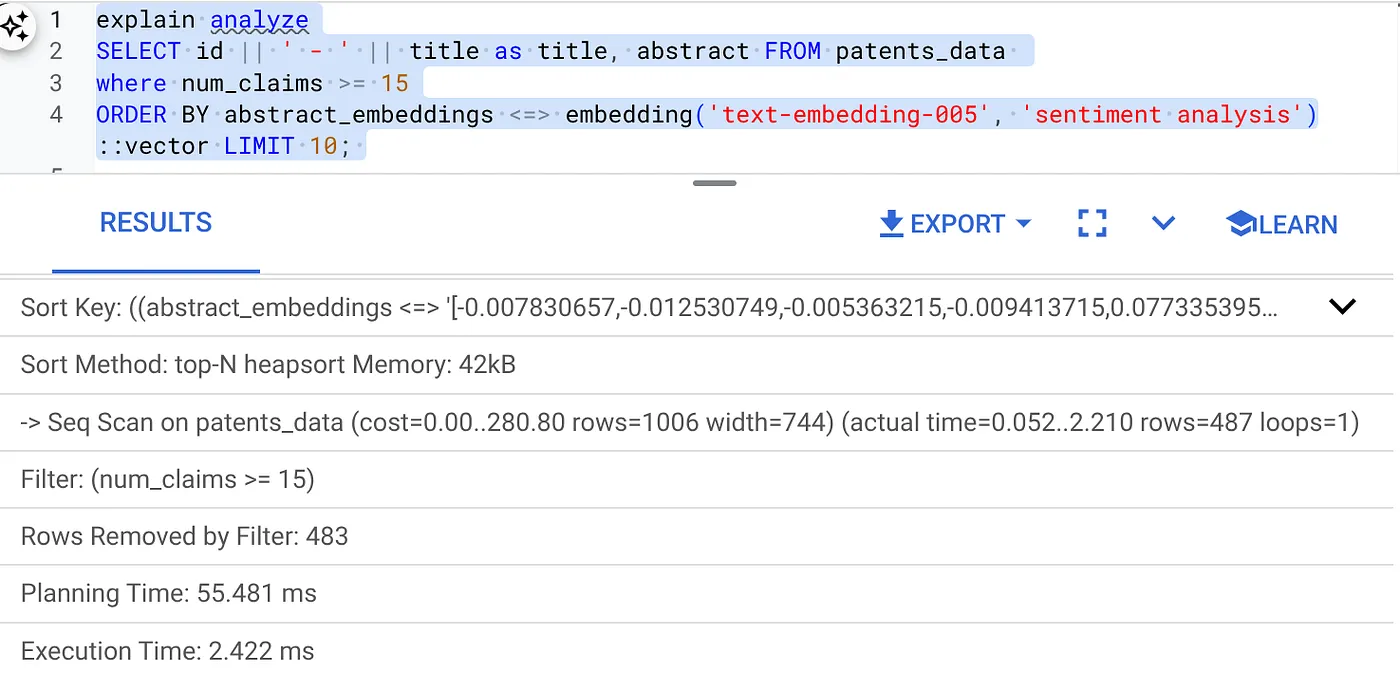
Le temps d'exécution est de 2,4 ms.
- Créons un index standard sur le champ "num_claims" afin de pouvoir le filtrer :
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Créons l'index ScaNN pour notre application de recherche de brevets. Exécutez les commandes suivantes depuis AlloyDB Studio :
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Remarque importante : (num_leaves=32) s'applique à l'ensemble de données complet comportant plus de 1 000 lignes. Si votre nombre de lignes est inférieur à 100, vous n'avez pas besoin de créer d'index, car il ne s'appliquera pas à un nombre de lignes aussi faible.
- Définissez le filtrage intégré activé sur l'index ScaNN :
SET scann.enable_inline_filtering = on
- Exécutons maintenant la même requête avec un filtre et Vector Search :
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
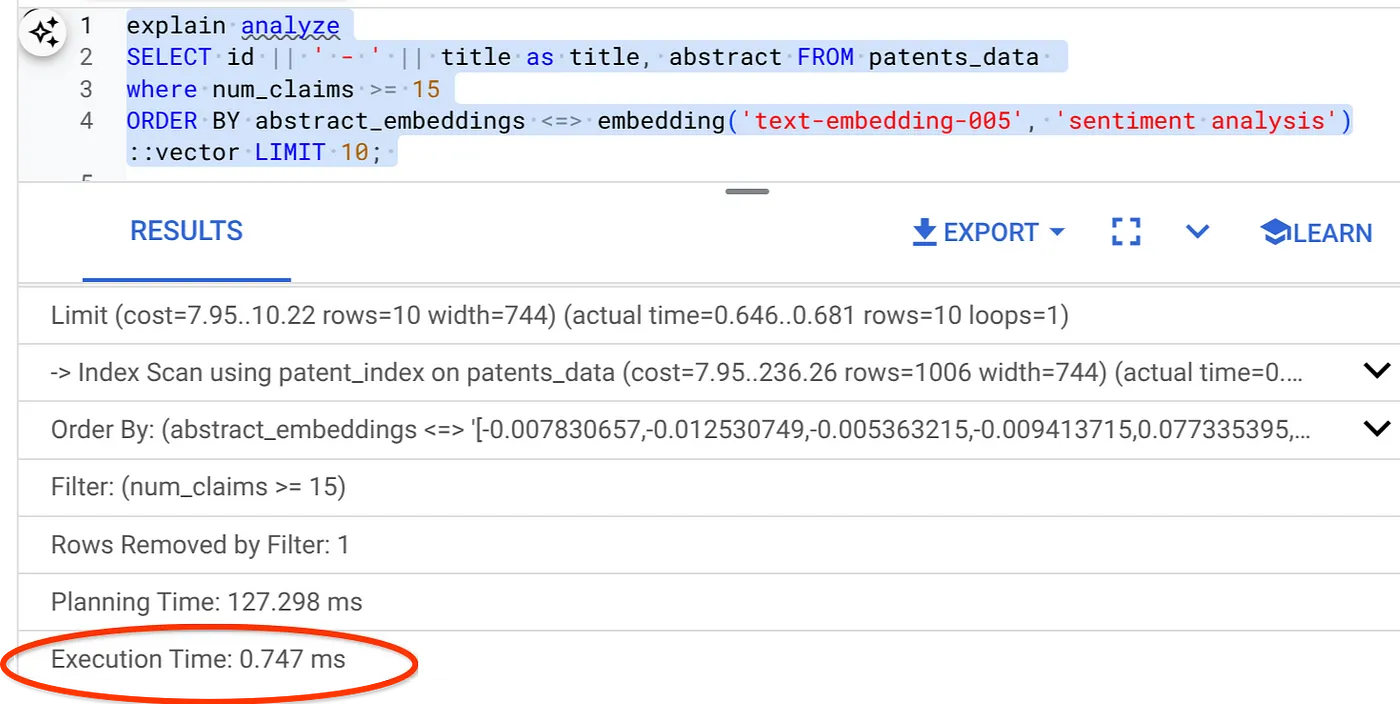
Comme vous pouvez le constater, le temps d'exécution est considérablement réduit pour la même recherche vectorielle. L'index ScaNN avec filtrage intégré dans Vector Search a rendu cela possible !!!
Ensuite, évaluons le rappel pour cette recherche vectorielle compatible avec ScaNN.
Évaluateur de rappel
Dans la recherche par similarité, le rappel correspond au pourcentage d'instances pertinentes récupérées à partir d'une recherche, c'est-à-dire le nombre de vrais positifs. Il s'agit de la métrique la plus courante pour mesurer la qualité de la recherche. Une source de perte de rappel provient de la différence entre la recherche approximative des voisins les plus proches (aNN) et la recherche des k (exacts) plus proches voisins (kNN). Les index vectoriels tels que ScaNN d'AlloyDB implémentent des algorithmes aNN, ce qui vous permet d'accélérer la recherche vectorielle sur de grands ensembles de données en échange d'un léger compromis en termes de rappel. AlloyDB vous permet désormais de mesurer ce compromis directement dans la base de données pour les requêtes individuelles et de vous assurer qu'il reste stable au fil du temps. Vous pouvez mettre à jour les paramètres de requête et d'index en fonction de ces informations pour obtenir de meilleurs résultats et performances.
Vous pouvez trouver le rappel d'une requête vectorielle sur un index vectoriel pour une configuration donnée à l'aide de la fonction evaluate_query_recall. Cette fonction vous permet d'ajuster vos paramètres pour obtenir les résultats de rappel de requête vectorielle souhaités. Le rappel est la métrique utilisée pour la qualité de la recherche. Il est défini comme le pourcentage de résultats renvoyés qui sont objectivement les plus proches des vecteurs de requête. La fonction evaluate_query_recall est activée par défaut.
Remarque importante :
Si vous rencontrez une erreur d'autorisation refusée sur l'index HNSW lors des étapes suivantes, ignorez pour l'instant toute cette section sur l'évaluation du rappel. Il peut s'agir de restrictions d'accès à ce stade, car il vient d'être publié au moment où cet atelier de programmation est documenté.
- Définissez l'indicateur "Enable Index Scan" (Activer l'analyse d'index) sur l'index ScaNN et l'index HNSW :
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Exécutez la requête suivante dans AlloyDB Studio :
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
La fonction evaluate_query_recall prend la requête comme paramètre et renvoie son rappel. J'utilise la même requête que celle que j'ai utilisée pour vérifier les performances comme requête d'entrée de la fonction. J'ai ajouté SCaNN comme méthode d'index. Pour plus d'options de paramètres, consultez la documentation.
Voici le rappel pour cette requête de recherche vectorielle que nous avons utilisée :
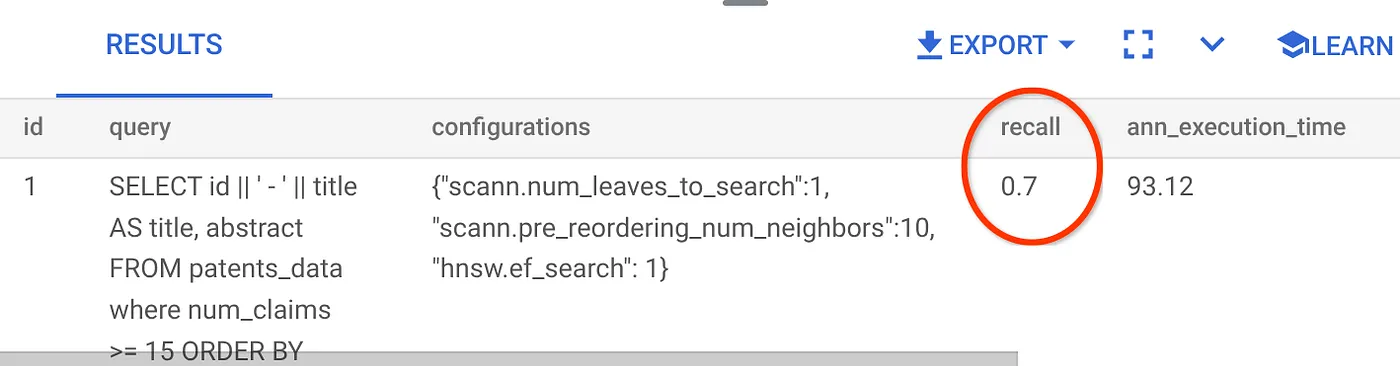
Je vois que le RECALL est de 70 %. Je peux maintenant utiliser ces informations pour modifier les paramètres, les méthodes et les paramètres de requête de l'index, et améliorer le rappel de cette recherche vectorielle.
J'ai modifié le nombre de lignes du jeu de résultats pour le ramener à 7 (au lieu de 10 auparavant). J'observe une légère amélioration du RECALL, qui passe à 86 %.
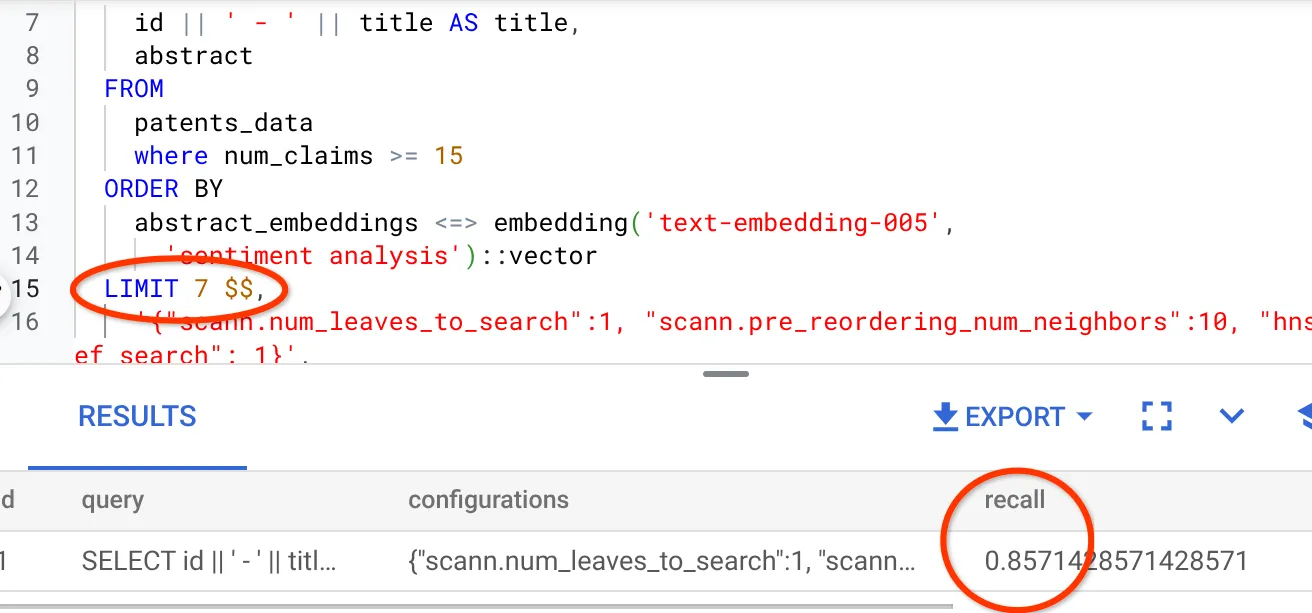
Cela signifie que je peux faire varier en temps réel le nombre de correspondances que mes utilisateurs voient pour améliorer la pertinence des correspondances en fonction du contexte de recherche des utilisateurs.
D'accord ! Il est temps de déployer la logique de la base de données et de passer à l'agent.
7. Transférer la logique de la base de données vers le serveur Web sans serveur
Prêt à déployer cette application sur le Web ? Procédez comme suit :
- Accédez à Cloud Run Functions dans la console Google Cloud pour créer une fonction Cloud Run en cliquant sur "Écrire une fonction" ou en utilisant le lien https://console.cloud.google.com/run/create?deploymentType=function.
- Sélectionnez l'option "Utiliser un éditeur intégré pour créer une fonction" et commencez la configuration. Indiquez le nom de service patent-search, sélectionnez la région us-central1 et le runtime Java 17. Définissez l'authentification sur Autoriser les appels non authentifiés.
- Dans la section "Conteneurs, volumes, mise en réseau et sécurité", suivez les étapes ci-dessous sans rien oublier :
Accédez à l'onglet "Réseau" :
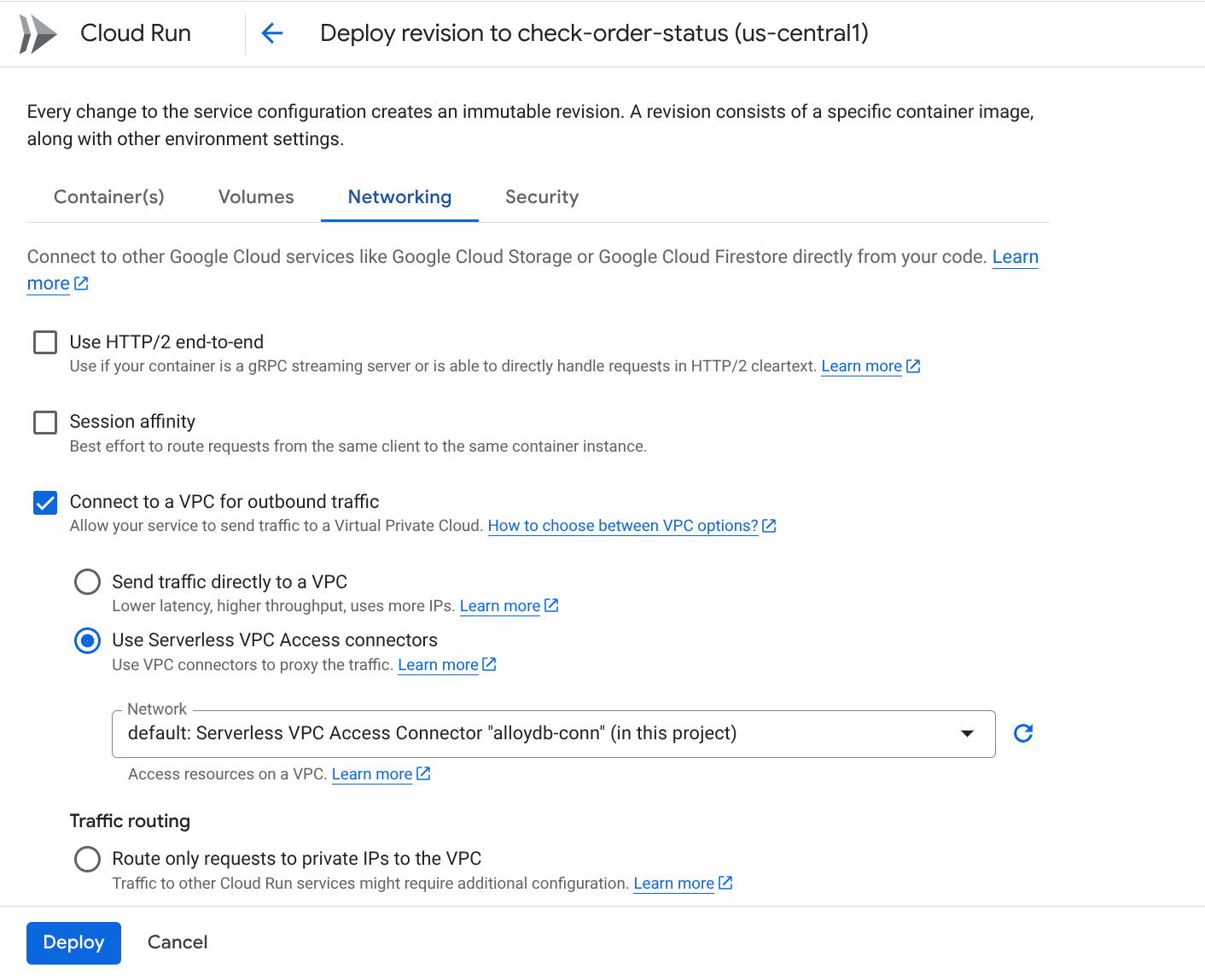
Sélectionnez Se connecter à un VPC pour le trafic sortant, puis Utiliser les connecteurs d'accès au VPC sans serveur.
Dans le menu déroulant "Réseau", cliquez sur l'option Ajouter un connecteur VPC (si vous n'avez pas encore configuré le connecteur par défaut), puis suivez les instructions qui s'affichent dans la boîte de dialogue :
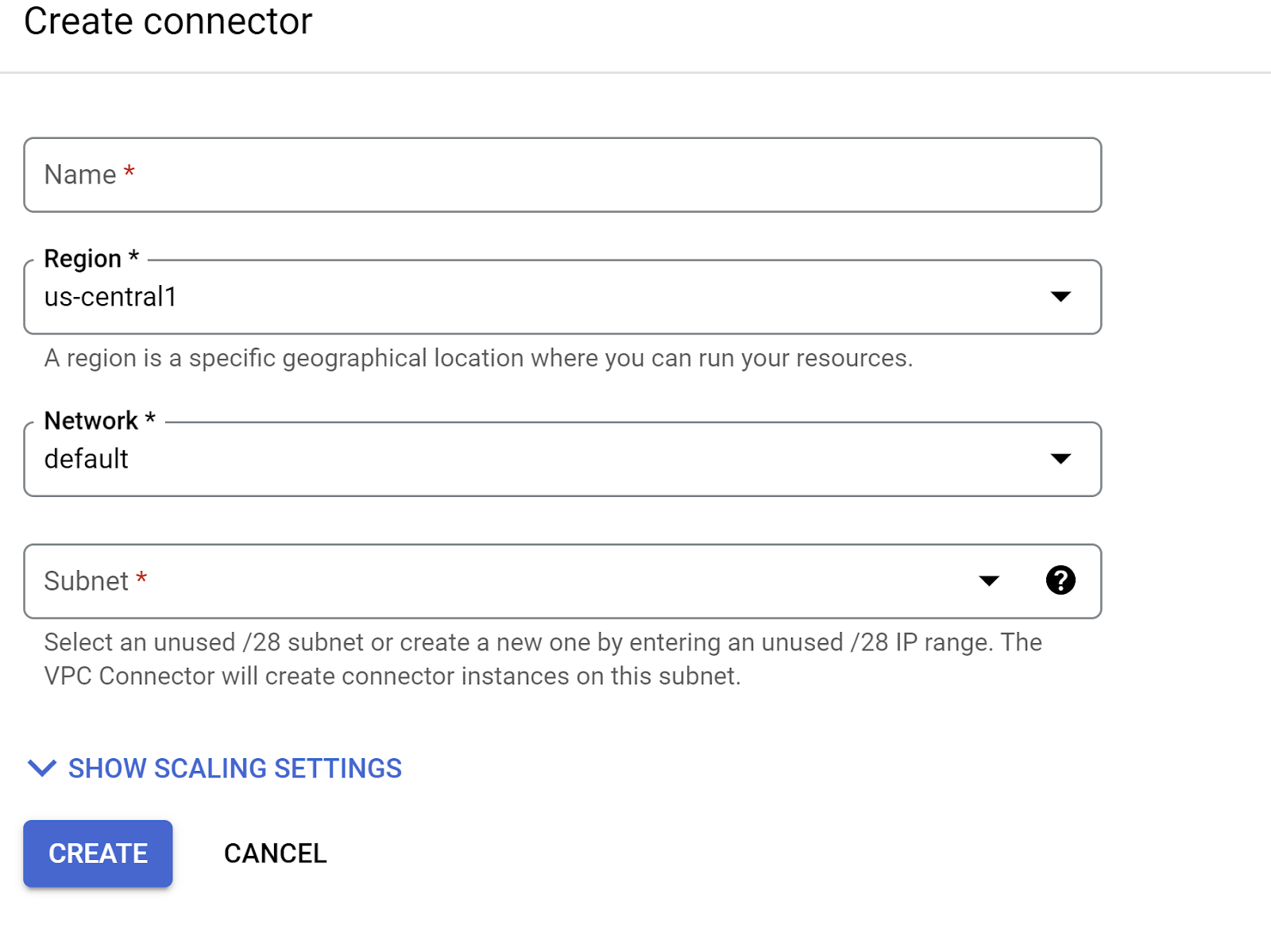
Donnez un nom au connecteur VPC et assurez-vous que la région est la même que celle de votre instance. Laissez la valeur du réseau par défaut et définissez le sous-réseau sur "Plage d'adresses IP personnalisée" avec la plage d'adresses IP 10.8.0.0 ou une plage similaire disponible.
Développez AFFICHER LES PARAMÈTRES DE SCALING et assurez-vous que la configuration est exactement la suivante :
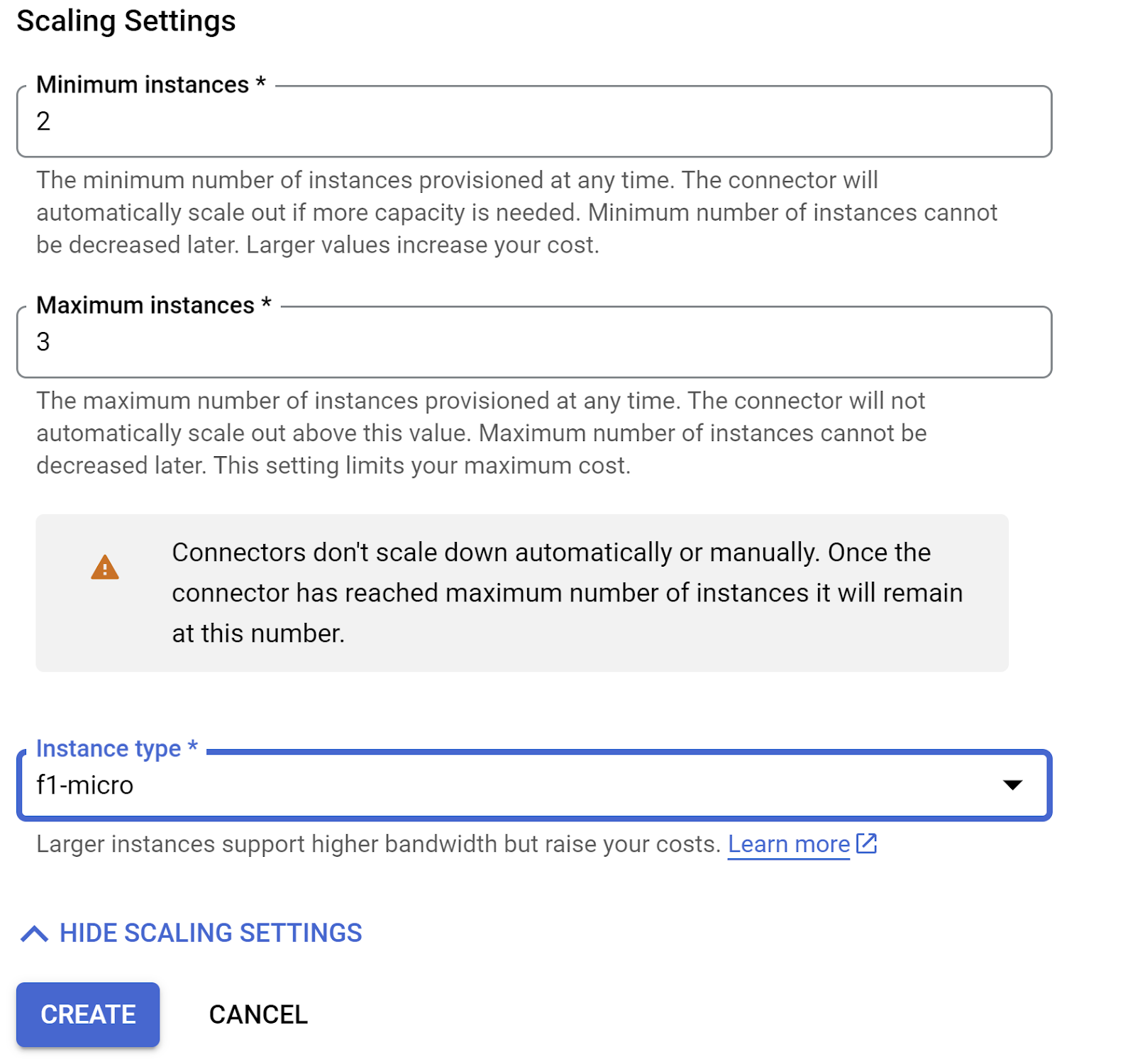
Cliquez sur CRÉER. Ce connecteur devrait maintenant figurer dans les paramètres de sortie.
Sélectionnez le connecteur que vous venez de créer.
Choisissez d'acheminer tout le trafic via ce connecteur VPC.
Cliquez sur SUIVANT, puis sur DÉPLOYER.
- Par défaut, le point d'entrée est défini sur gcfv2.HelloHttpFunction. Remplacez le code de l'espace réservé dans HelloHttpFunction.java et pom.xml de votre fonction Cloud Run par le code de PatentSearch.java et pom.xml, respectivement. Remplacez le nom du fichier de classe par PatentSearch.java.
- N'oubliez pas de remplacer l'espace réservé ************* et les identifiants de connexion AlloyDB par vos valeurs dans le fichier Java. Les identifiants AlloyDB sont ceux que nous avons utilisés au début de cet atelier de programmation. Si vous avez utilisé des valeurs différentes, veuillez les modifier dans le fichier Java.
- Cliquez sur Déployer.
- Une fois la fonction Cloud mise à jour déployée, le point de terminaison généré devrait s'afficher. Copiez-le et remplacez-le dans la commande suivante :
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
Et voilà ! Il est très simple d'effectuer une recherche vectorielle avancée par similarité contextuelle à l'aide du modèle d'embeddings sur les données AlloyDB.
8. Créons l'agent avec Java ADK
Commençons par le projet Java dans l'éditeur.
- Accéder au terminal Cloud Shell
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Autoriser lorsque vous y êtes invité
- Basculez vers l'éditeur Cloud Shell en cliquant sur l'icône de l'éditeur en haut de la console Cloud Shell.

- Dans la console Cloud Shell Editor, créez un dossier et nommez-le "adk-agents".
Cliquez sur "Créer un dossier" dans le répertoire racine de votre Cloud Shell, comme indiqué ci-dessous :
Nommez-le "adk-agents" :
- Créez la structure de dossiers suivante et les fichiers vides avec les noms de fichiers correspondants dans la structure ci-dessous :
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Ouvrez le dépôt GitHub dans un onglet distinct et copiez le code source des fichiers App.java et pom.xml.
- Si vous avez ouvert l'éditeur dans un nouvel onglet à l'aide de l'icône "Ouvrir dans un nouvel onglet" en haut à droite, vous pouvez ouvrir le terminal en bas de la page. Vous pouvez ouvrir l'éditeur et le terminal en parallèle pour travailler librement.
- Une fois le dépôt cloné, revenez à la console de l'éditeur Cloud Shell.
- Comme nous avons déjà créé la fonction Cloud Run, vous n'avez pas besoin de copier les fichiers de la fonction Cloud Run à partir du dossier du dépôt.
Premiers pas avec le SDK Java ADK
C'est assez simple. Vous devez principalement vous assurer que les éléments suivants sont couverts par votre étape de clonage :
- Ajouter des dépendances :
Incluez les artefacts google-adk et google-adk-dev (pour l'interface utilisateur Web) dans votre fichier pom.xml. Si vous avez copié la source à partir du dépôt, ces éléments sont déjà inclus dans les fichiers. Vous n'avez pas besoin de les inclure. Il vous suffit de modifier le point de terminaison Cloud Run Functions pour qu'il reflète votre point de terminaison déployé. Nous l'aborderons dans les prochaines étapes de cette section.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Veillez à référencer le fichier pom.xml du dépôt source, car d'autres dépendances et configurations sont nécessaires pour que l'application puisse s'exécuter.
- Configurer votre projet :
Assurez-vous que votre version de Java (17 ou ultérieure recommandée) et les paramètres du compilateur Maven sont correctement configurés dans votre fichier pom.xml. Vous pouvez configurer votre projet pour qu'il suive la structure ci-dessous :
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Définir l'agent et ses outils (App.java) :
C'est là que la magie du SDK Java de l'ADK opère. Nous définissons notre agent, ses capacités (instructions) et les outils qu'il peut utiliser.
Vous trouverez ici une version simplifiée de quelques extraits de code de la classe d'agent principale. Pour le projet complet, consultez le dépôt du projet ici.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Principaux composants du code Java de l'ADK mis en évidence :
- LlmAgent.builder(): : API Fluent pour configurer votre agent.
- .instruction(...) : fournit la requête principale et les consignes pour le LLM, y compris quand utiliser chaque outil.
- FunctionTool.create(App.class, "methodName") : enregistre facilement vos méthodes Java en tant qu'outils que l'agent peut appeler. La chaîne du nom de la méthode doit correspondre à une méthode statique publique réelle.
- @Schema(description = ...) : annote les paramètres de l'outil, ce qui aide le LLM à comprendre les entrées attendues par chaque outil. Cette description est essentielle pour sélectionner l'outil et renseigner les paramètres de manière précise.
- InvocationContext ctx : transmis automatiquement aux méthodes d'outil, ce qui permet d'accéder à l'état de la session (ctx.session().state()), aux informations utilisateur et plus encore.
- .outputKey("patents") : lorsqu'un outil renvoie des données, ADK peut les stocker automatiquement dans l'état de la session sous cette clé. C'est ainsi qu'explainPatent peut accéder aux résultats de getPatents.
- VECTOR_SEARCH_ENDPOINT: : il s'agit d'une variable qui contient la logique fonctionnelle de base pour les questions/réponses contextuelles pour l'utilisateur dans le cas d'utilisation de la recherche de brevets.
- Action requise : Vous devez définir une valeur de point de terminaison déployé mise à jour une fois que vous avez implémenté l'étape de la fonction Java Cloud Run de la section précédente.
- searchTool : interagit avec l'utilisateur pour trouver des brevets contextuellement pertinents dans la base de données des brevets en fonction du texte de recherche de l'utilisateur.
- explainTool : demande à l'utilisateur de choisir un brevet spécifique pour l'examiner en détail. Il résume ensuite l'abrégé du brevet et peut répondre à d'autres questions de l'utilisateur en se basant sur les informations dont il dispose sur le brevet.
Important : Veillez à remplacer la variable VECTOR_SEARCH_ENDPOINT par le point de terminaison CRF que vous avez déployé.
Exploiter InvocationContext pour les interactions avec état
L'une des fonctionnalités essentielles pour créer des agents utiles est la gestion de l'état sur plusieurs tours de conversation. Le contexte d'invocation de l'ADK facilite cette tâche.
Dans notre fichier App.java :
- Lorsque initAgent() est défini, nous utilisons .outputKey("patents"). Cela indique à ADK que lorsqu'un outil (comme getPatents) renvoie des données dans son champ de rapport, ces données doivent être stockées dans l'état de la session sous la clé "patents".
- Dans la méthode de l'outil explainPatent, nous injectons InvocationContext ctx :
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
Cela permet à l'outil explainPatent d'accéder à la liste de brevets récupérée par l'outil getPatents lors d'un tour précédent, ce qui rend la conversation cohérente et avec état.
9. Test local de l'interface de ligne de commande
Définir des variables d'environnement
Vous devez exporter deux variables d'environnement :
- Clé Gemini que vous pouvez obtenir depuis AI Studio :
Pour ce faire, accédez à https://aistudio.google.com/apikey et obtenez la clé API de votre projet Google Cloud actif dans lequel vous implémentez cette application. Enregistrez la clé quelque part :
- Une fois la clé obtenue, ouvrez le terminal Cloud Shell et accédez au nouveau répertoire adk-agents que nous venons de créer en exécutant la commande suivante :
cd adk-agents
- Variable permettant d'indiquer que nous n'utilisons pas Vertex AI cette fois-ci.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Exécuter votre premier agent sur l'interface de ligne de commande
Pour lancer ce premier agent, utilisez la commande Maven suivante dans votre terminal :
mvn compile exec:java -DmainClass="agents.App"
La réponse interactive de l'agent s'affiche dans votre terminal.
10. Déployer sur Cloud Run
Le déploiement de votre agent ADK Java sur Cloud Run est semblable à celui de n'importe quelle autre application Java :
- Dockerfile : créez un Dockerfile pour empaqueter votre application Java.
- Compiler et transmettre une image Docker : utilisez Google Cloud Build et Artifact Registry.
- Vous pouvez effectuer l'étape ci-dessus et déployer sur Cloud Run en une seule commande :
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
De même, vous déployez votre fonction Java Cloud Run (gcfv2.PatentSearch). Vous pouvez également créer et déployer la fonction Cloud Run Java pour la logique de base de données directement depuis la console Cloud Run Functions.
11. Tester avec l'UI Web
L'ADK est fourni avec une interface utilisateur Web pratique pour tester et déboguer votre agent en local. Lorsque vous exécutez votre fichier App.java en local (par exemple, mvn exec:java -Dexec.mainClass="agents.App" si configuré, ou en exécutant simplement la méthode principale), l'ADK démarre généralement un serveur Web local.
L'interface utilisateur Web de l'ADK vous permet d'effectuer les actions suivantes :
- Envoyez des messages à votre agent.
- Affichez les événements (message utilisateur, appel d'outil, réponse de l'outil, réponse du LLM).
- Inspectez l'état de la session.
- Affichez les journaux et les traces.
C'est un atout inestimable pendant le développement pour comprendre comment votre agent traite les requêtes et utilise ses outils. Cela suppose que votre mainClass dans pom.xml est définie sur com.google.adk.web.AdkWebServer et que votre agent y est enregistré, ou que vous exécutez un testeur local qui l'expose.
Lorsque vous exécutez votre App.java avec InMemoryRunner et Scanner pour la saisie dans la console, vous testez la logique de l'agent principal. L'interface utilisateur Web est un composant distinct qui permet une expérience de débogage plus visuelle. Elle est souvent utilisée lorsque l'ADK diffuse votre agent via HTTP.
Vous pouvez utiliser la commande Maven suivante à partir de votre répertoire racine pour lancer le serveur local SpringBoot :
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
L'interface est souvent accessible à l'URL générée par la commande ci-dessus. Si elle est déployée sur Cloud Run, vous devriez pouvoir y accéder à partir du lien de déploiement Cloud Run.
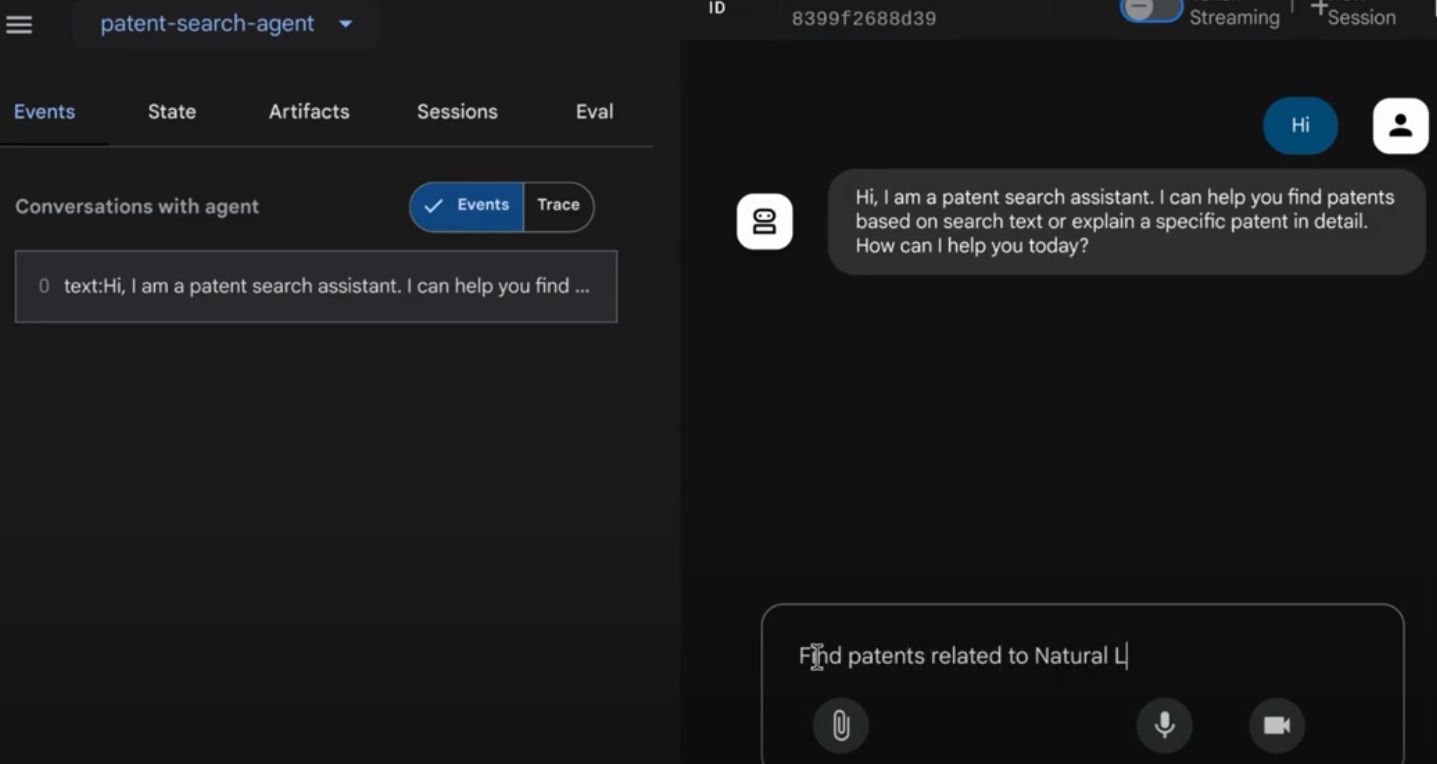
Vous devriez pouvoir voir le résultat dans une interface interactive.
Regardez la vidéo ci-dessous pour découvrir notre agent de brevets déployé :
12. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet article soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog.
- Page https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
13. Félicitations
Félicitations ! Vous avez réussi à créer votre agent d'analyse de brevets en Java en combinant les capacités d'ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI et Vector Search. Nous avons également fait un grand pas en avant pour rendre les recherches de similarité contextuelle transformatrices, efficaces et véritablement axées sur le sens.
Commencez dès aujourd'hui !
Documentation ADK : [Lien vers la documentation Java ADK officielle]
Code source de l'agent d'analyse des brevets : [lien vers votre dépôt GitHub (désormais public)]
Exemples d'agents Java : [lien vers le dépôt adk-samples]
Rejoignez la communauté ADK : https://www.reddit.com/r/agentdevelopmentkit/
Bonne création d'agents !