
1. סקירה כללית
בתעשיות שונות, חיפוש הקשרי הוא פונקציונליות קריטית שמהווה את הליבה של האפליקציות שלהן. מנגנוני השליפה שמבוססים על AI גנרטיבי ב-RAG (שליפה משופרת של מידע) הם גורם מרכזי בהתפתחות הטכנולוגית החשובה הזו כבר זמן רב. מודלים גנרטיביים, עם חלונות הקשר גדולים ואיכות פלט מרשימה, משנים את תחום ה-AI. טכנולוגיית RAG מספקת דרך שיטתית להוספת הקשר לאפליקציות ולסוכני AI, ומבססת אותם על מסדי נתונים מובְנים או על מידע ממדיה שונה. הנתונים ההקשריים האלה חשובים מאוד כדי להבהיר את האמת ולשפר את הדיוק של הפלט, אבל עד כמה התוצאות האלה מדויקות? האם העסק שלך תלוי במידה רבה בדיוק של ההתאמות ההקשריות והרלוונטיות האלה? אז הפרויקט הזה יתאים לכם בול!
עכשיו דמיינו שאפשר לקחת את העוצמה של מודלים גנרטיביים ולבנות סוכנים אינטראקטיביים שמסוגלים לקבל החלטות אוטונומיות שמבוססות על מידע חיוני כזה ומעוגנות במציאות. זה מה שאנחנו הולכים לבנות היום. אנחנו הולכים ליצור אפליקציית סוכן AI מקצה לקצה באמצעות Agent Development Kit (ערכת כלים לפיתוח סוכנים) שמבוססת על RAG מתקדם ב-AlloyDB, עבור אפליקציה לניתוח פטנטים.
הסוכן לניתוח פטנטים עוזר למשתמשים למצוא פטנטים שרלוונטיים להקשר של הטקסט שהם מחפשים, ומספק הסבר ברור ותמציתי ופרטים נוספים על פטנט נבחר, אם המשתמש מבקש זאת. רוצים לראות איך עושים את זה? קדימה, מתחילים!
מטרה
המטרה פשוטה. לאפשר למשתמש לחפש פטנטים על סמך תיאור טקסטואלי, ואז לקבל הסבר מפורט על פטנט ספציפי מתוצאות החיפוש. כל זה באמצעות סוכן AI שנבנה באמצעות Java ADK, AlloyDB, Vector Search (עם אינדקסים מתקדמים), Gemini וכל האפליקציה שנפרסה ללא שרת ב-Cloud Run.
מה תפַתחו
במסגרת ה-Lab הזה:
- יצירה של מכונת AlloyDB וטעינה של נתונים ממערך נתונים ציבורי של פטנטים
- הטמעה של חיפוש וקטורים מתקדם ב-AlloyDB באמצעות תכונות של ScaNN ושל Recall eval
- יצירת סוכן באמצעות Java ADK
- הטמעה של לוגיקה בצד השרת של מסד הנתונים ב-Cloud Functions ללא שרת ב-Java
- פריסה ובדיקה של הסוכן ב-Cloud Run
הדיאגרמה הבאה מייצגת את רצף הפעולות של הנתונים והשלבים שנדרשים להטמעה.
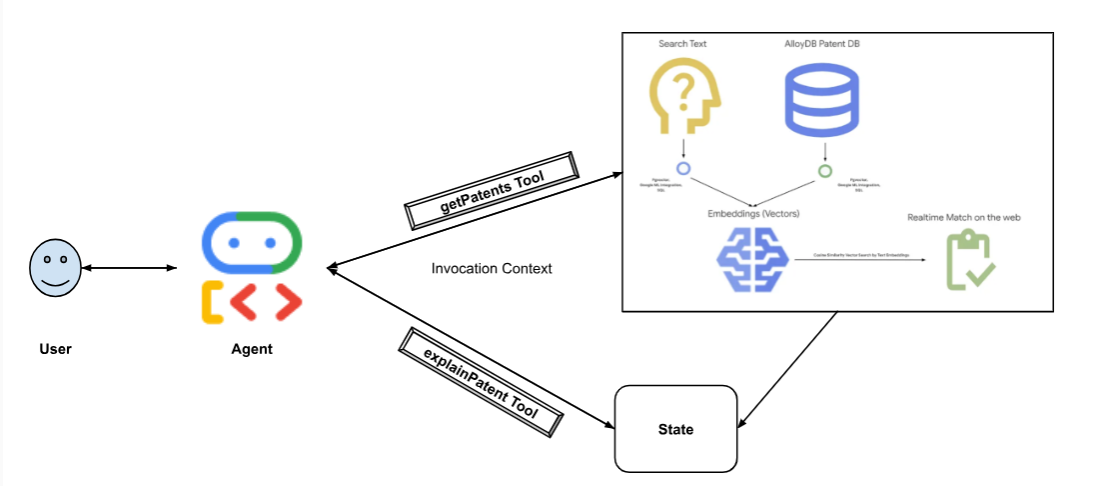
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, בודקים שכבר בוצע אימות ושהפרויקט מוגדר למזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים. אפשר להשתמש בפקודת gcloud בטרמינל של Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
אפשר גם לחפש כל מוצר במסוף או להשתמש בקישור הזה במקום בפקודת gcloud.
אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
3. הגדרת מסד נתונים
בשיעור ה-Lab הזה נשתמש ב-AlloyDB כמסד הנתונים של נתוני הפטנטים. הוא משתמש באשכולות כדי להכיל את כל המשאבים, כמו מסדי נתונים ויומנים. לכל אשכול יש מופע ראשי שמספק נקודת גישה לנתונים. הטבלאות יכילו את הנתונים בפועל.
ניצור אשכול, מופע וטבלה של AlloyDB שבהם ייטען מערך הנתונים של הפטנטים.
יצירת אשכול ומופע
- עוברים לדף AlloyDB במסוף Cloud. דרך קלה למצוא את רוב הדפים ב-Cloud Console היא לחפש אותם באמצעות סרגל החיפוש של המסוף.
- בדף הזה, לוחצים על יצירת אשכול:

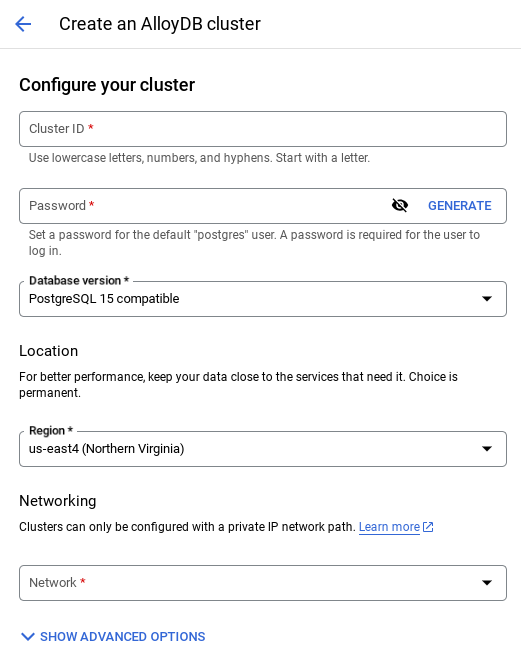
- יוצג מסך כמו זה שבהמשך. יוצרים אשכול ומופע עם הערכים הבאים (אם משכפלים את קוד האפליקציה מהמאגר, חשוב לוודא שהערכים זהים):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / הגרסה המומלצת האחרונה
- אזור: "
us-central1" - רשת: "
default"
- כשבוחרים את רשת ברירת המחדל, מוצג מסך כמו זה שבהמשך.
לוחצים על הגדרת חיבור.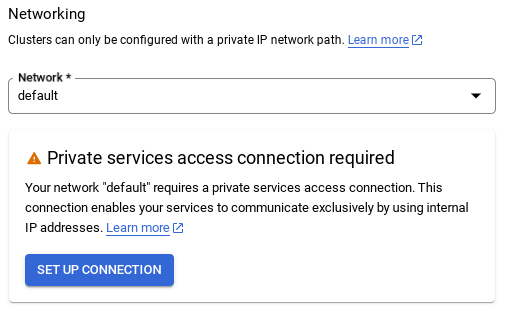
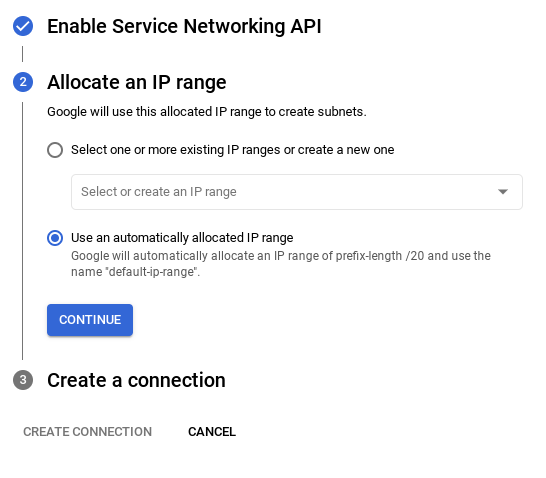
- משם, בוחרים באפשרות שימוש בטווח כתובות IP שהוקצה באופן אוטומטי ולוחצים על 'המשך'. אחרי שבודקים את המידע, לוחצים על CREATE CONNECTION (יצירת חיבור).
- אחרי שמגדירים את הרשת, אפשר להמשיך ליצור את האשכול. לוחצים על CREATE CLUSTER (יצירת אשכול) כדי להשלים את הגדרת האשכול, כמו שמוצג בהמשך:
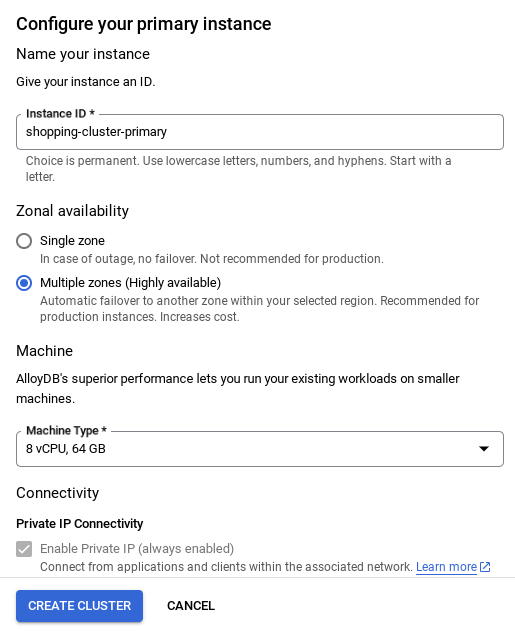
חשוב לשנות את מזהה המופע (שאפשר למצוא בזמן ההגדרה של האשכול או המופע) ל
vector-instance. אם אי אפשר לשנות אותו, חשוב להשתמש במזהה המכונה בכל ההפניות הבאות.
שימו לב: תהליך יצירת האשכול יימשך כ-10 דקות. אחרי שהפעולה תסתיים בהצלחה, יוצג מסך עם סקירה כללית של האשכול שיצרתם.
4. הטמעת נתונים
עכשיו צריך להוסיף טבלה עם הנתונים על החנות. עוברים אל AlloyDB, בוחרים את האשכול הראשי ואז את AlloyDB Studio:
יכול להיות שתצטרכו להמתין עד שהמופע שלכם ייווצר. אחרי שזה קורה, נכנסים ל-AlloyDB באמצעות פרטי הכניסה שיצרתם כשנוצר האשכול. משתמשים בנתונים הבאים כדי לבצע אימות ב-PostgreSQL:
- שם משתמש : "
postgres" - מסד נתונים : "
postgres" - סיסמה : "
alloydb"
אחרי שתעברו בהצלחה את תהליך האימות ב-AlloyDB Studio, תוכלו להזין פקודות SQL בכלי העריכה. אפשר להוסיף כמה חלונות של Editor באמצעות סימן הפלוס שמימין לחלון האחרון.
מזינים פקודות ל-AlloyDB בחלונות של כלי העריכה, ומשתמשים באפשרויות Run (הפעלה), Format (עיצוב) ו-Clear (ניקוי) לפי הצורך.
הפעלת תוספים
כדי ליצור את האפליקציה הזו, נשתמש בתוספים pgvector ו-google_ml_integration. התוסף pgvector מאפשר לכם לאחסן ולחפש הטמעות של וקטורים. התוסף google_ml_integration מספק פונקציות שמשמשות לגישה לנקודות קצה של חיזוי ב-Vertex AI כדי לקבל חיזויים ב-SQL. מפעילים את התוספים האלה על ידי הפעלת פקודות ה-DDL הבאות:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
כדי לבדוק אילו תוספים הופעלו במסד הנתונים, מריצים את פקודת ה-SQL הבאה:
select extname, extversion from pg_extension;
צור טבלה
אתם יכולים ליצור טבלה באמצעות הצהרת ה-DDL שבהמשך ב-AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
בעמודה abstract_embeddings אפשר לאחסן את ערכי הווקטור של הטקסט.
מתן הרשאה
מריצים את ההצהרה הבאה כדי להעניק הרשאת הפעלה לפונקציה embedding:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
נותנים לחשבון השירות של AlloyDB את התפקיד Vertex AI User
במסוף IAM של Google Cloud, מעניקים לחשבון השירות של AlloyDB (שנראה כך: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) גישה לתפקיד Vertex AI User. PROJECT_NUMBER יכיל את מספר הפרויקט.
אפשר גם להריץ את הפקודה הבאה מ-Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
טעינת נתוני פטנטים למסד הנתונים
נשתמש ב-Google Patents Public Datasets ב-BigQuery כמערך הנתונים שלנו. נשתמש ב-AlloyDB Studio כדי להריץ את השאילתות. הנתונים מגיעים לקובץ insert scripts sql הזה במאגר הזה, ואנחנו נריץ אותו כדי לטעון את נתוני הפטנטים.
- במסוף Google Cloud, פותחים את הדף AlloyDB.
- בוחרים את האשכול החדש שנוצר ולוחצים על המופע.
- בתפריט הניווט של AlloyDB, לוחצים על AlloyDB Studio. נכנסים באמצעות פרטי הכניסה.
- לוחצים על סמל הכרטיסייה החדשה בצד שמאל כדי לפתוח כרטיסייה חדשה.
- מעתיקים ומריצים את הצהרות השאילתה
insertמהקבציםinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlאחד אחרי השני. כדי לראות הדגמה מהירה של תרחיש השימוש הזה, אפשר להריץ 10-50 הצהרות של הכנסת עותק.
כדי להריץ את הדוח, לוחצים על הפעלה. התוצאות של השאילתה יופיעו בטבלה Results.
5. יצירת הטמעות לנתוני פטנטים
קודם נבדוק את פונקציית ההטמעה על ידי הרצת שאילתת הדוגמה הבאה:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
הפונקציה אמורה להחזיר את וקטור ההטמעה, שנראה כמו מערך של מספרים ממשיים, עבור טקסט הדוגמה בשאילתה. כך זה נראה:
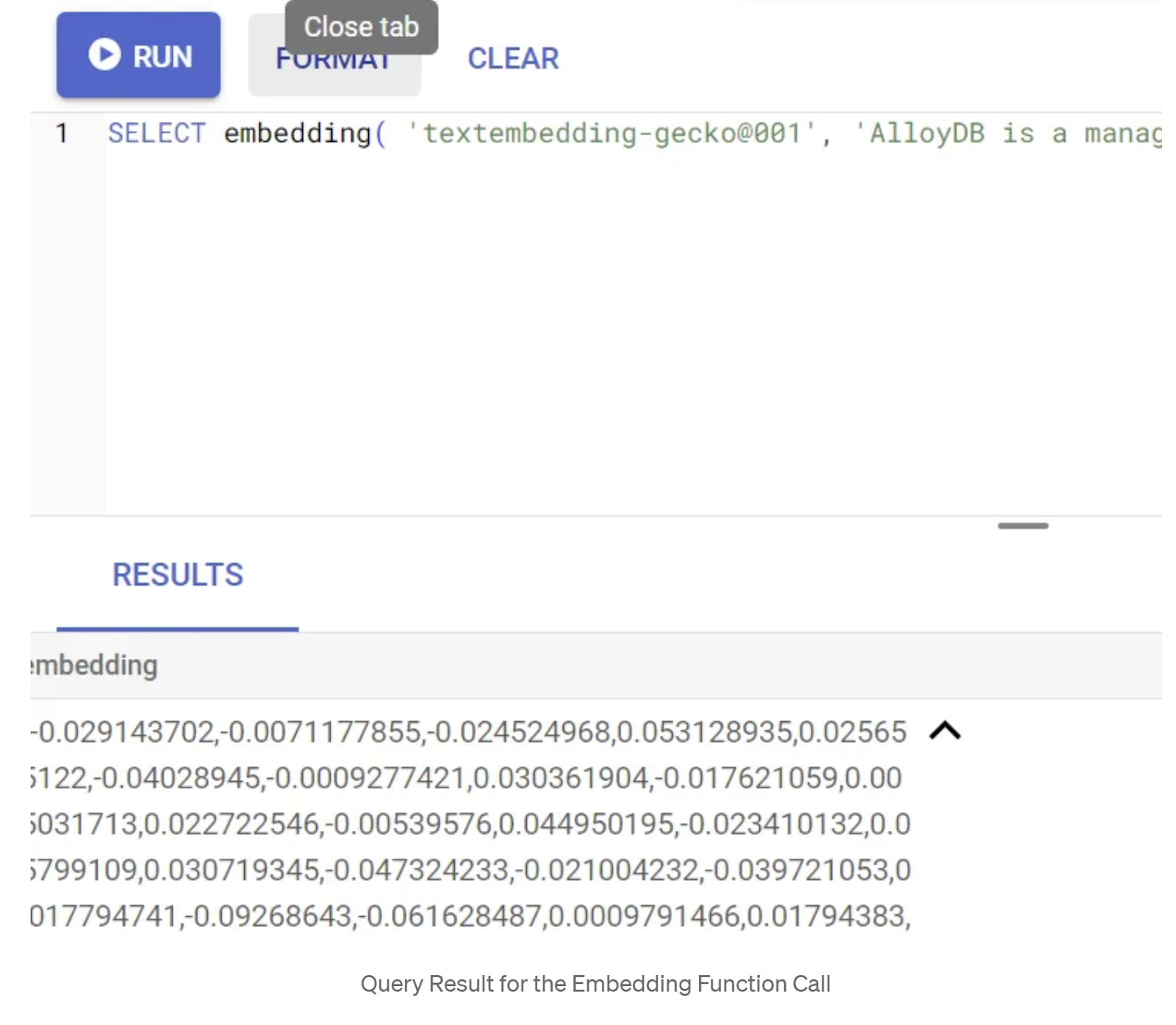
עדכון שדה הווקטור abstract_embeddings
אם צריך ליצור הטמעות לתקצירי הפטנטים, צריך להשתמש בפקודות DML הבאות כדי לעדכן את ההטמעות התואמות בטבלה. אבל במקרה שלנו, משפטי ה-insert כבר מכילים את ההטמעות האלה לכל תקציר, כך שלא צריך להפעיל את השיטה embeddings().
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. ביצוע חיפוש וקטור
עכשיו, כשהטבלה, הנתונים וההטמעות מוכנים, אפשר לבצע חיפוש וקטורי בזמן אמת של טקסט החיפוש של המשתמש. כדי לבדוק את זה, מריצים את השאילתה הבאה:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
בשאילתה הזו,
- הטקסט שחיפש המשתמש הוא: "ניתוח סנטימנטים".
- אנחנו ממירים אותו להטמעות באמצעות השיטה embedding() באמצעות המודל: text-embedding-005.
- "<=>" מייצג את השימוש בשיטת המרחק COSINE SIMILARITY.
- אנחנו ממירים את התוצאה של שיטת ההטמעה לסוג וקטור כדי שתהיה תואמת לווקטורים שמאוחסנים במסד הנתונים.
- הערך LIMIT 10 מייצג את 10 ההתאמות הכי קרובות לטקסט החיפוש.
AlloyDB מעלה את RAG של Vector Search לרמה הבאה:
יש הרבה דברים חדשים. שני תגים שמתמקדים במפתחים הם:
- סינון בתוך השורה
- כלי להערכת זכירת המודעה
סינון בתוך השורה
בעבר, מפתחים היו צריכים להריץ את השאילתה של חיפוש וקטורי ולטפל בסינון ובאחזור. הכלי AlloyDB Query Optimizer בוחר איך להריץ שאילתה עם מסננים. סינון מוטבע הוא טכניקה חדשה לאופטימיזציה של שאילתות, שמאפשרת לאופטימיזטור של שאילתות ב-AlloyDB להעריך את תנאי הסינון של המטא-נתונים ואת החיפוש הווקטורי במקביל, תוך שימוש באינדקסים וקטוריים ובאינדקסים בעמודות המטא-נתונים. כך משתפרים ביצועי ההחזרה, ומפתחים יכולים ליהנות ממה ש-AlloyDB מציע כבר מההתחלה.
סינון מוטבע מתאים במיוחד למקרים עם סלקטיביות בינונית. במהלך החיפוש במדד הווקטורים, AlloyDB מחשב מרחקים רק לווקטורים שתואמים לתנאי הסינון של המטא-נתונים (המסננים הפונקציונליים בשאילתה, שמטופלים בדרך כלל בסעיף WHERE). השיפור הזה משפר משמעותית את הביצועים של השאילתות האלה, ומשלים את היתרונות של סינון אחרי או לפני.
- התקנה או עדכון של התוסף pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
אם התוסף pgvector כבר מותקן, צריך לשדרג את התוסף vector לגרסה 0.8.0.google-3 ואילך כדי לקבל יכולות של הערכת היזכרות.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
צריך לבצע את השלב הזה רק אם התוסף של הווקטור הוא בגרסה <0.8.0.google-3.
הערה חשובה: אם מספר השורות קטן מ-100, לא צריך ליצור את אינדקס ScaNN כי הוא לא רלוונטי למספר קטן יותר של שורות. במקרה כזה, אפשר לדלג על השלבים הבאים.
- כדי ליצור אינדקסים של ScaNN, צריך להתקין את התוסף alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- קודם מריצים את שאילתת החיפוש הווקטורי בלי האינדקס ובלי שהמסנן המוטבע מופעל:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
התוצאה צריכה להיות דומה לתוצאה הבאה:
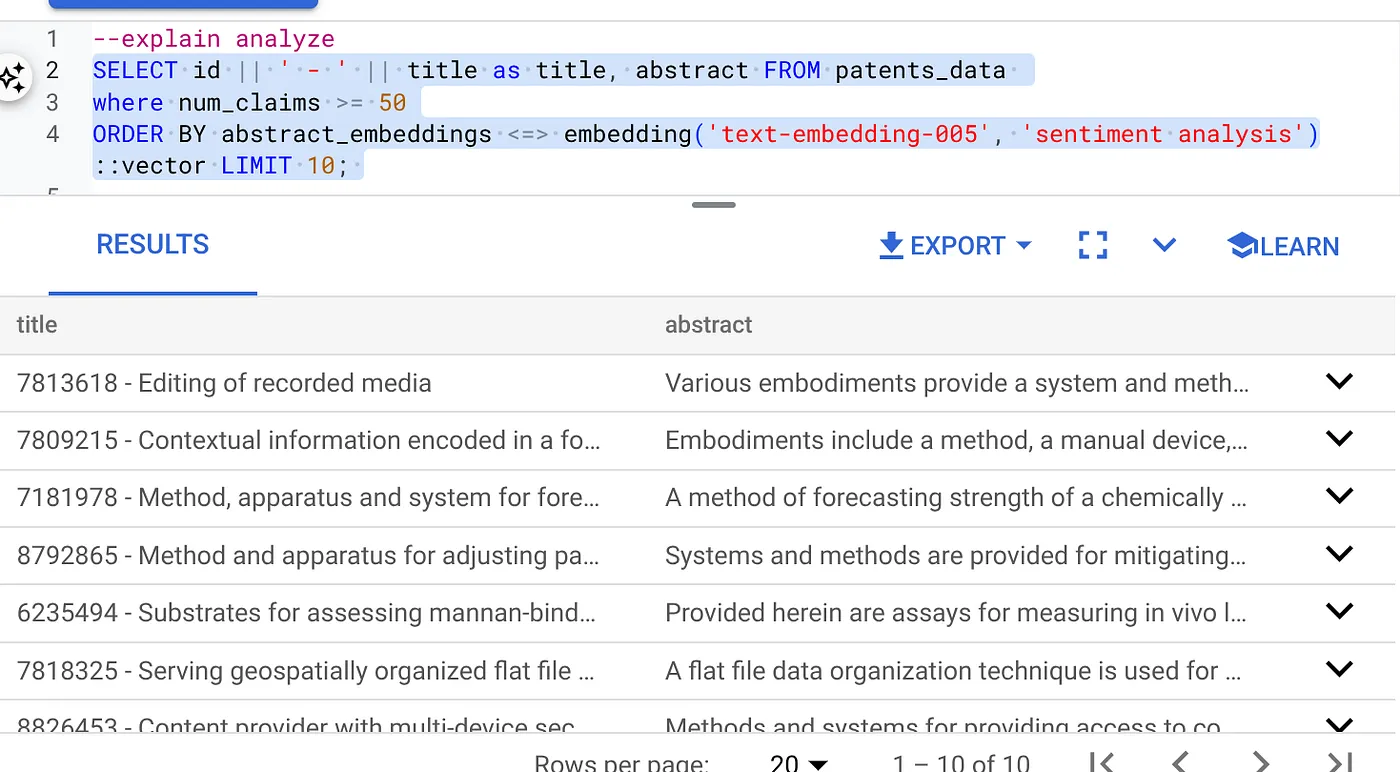
- מריצים עליו את Explain Analyze: (ללא אינדקס וללא סינון מוטבע)
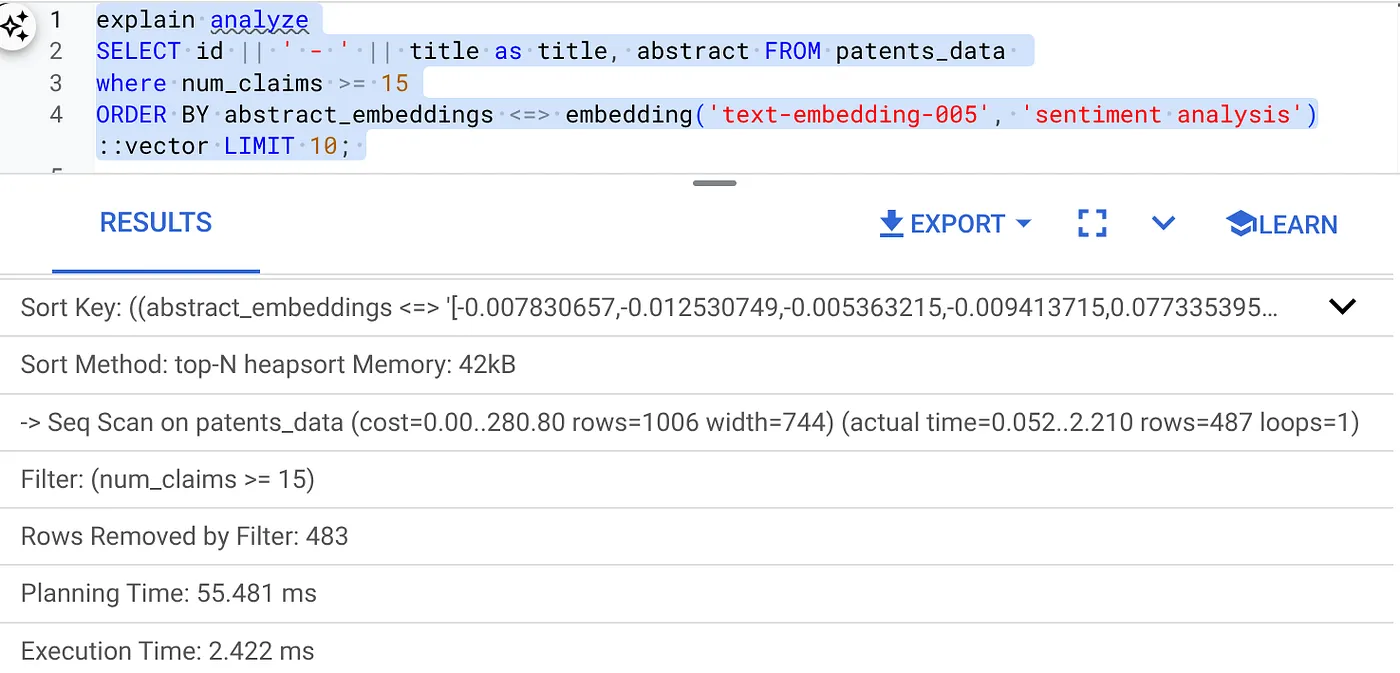
זמן הביצוע הוא 2.4 אלפיות השנייה
- ניצור אינדקס רגיל בשדה num_claims כדי שנוכל לסנן לפי השדה הזה:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- ניצור את אינדקס ScaNN לאפליקציית חיפוש הפטנטים שלנו. מריצים את הפקודה הבאה מ-AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
הערה חשובה: (num_leaves=32) תקף למערך הנתונים הכולל שלנו עם יותר מ-1,000 שורות. אם מספר השורות קטן מ-100, לא צריך ליצור אינדקס כי הוא לא רלוונטי למספר קטן יותר של שורות.
- מגדירים את הסינון המוכלל שמופעל באינדקס ScaNN:
SET scann.enable_inline_filtering = on
- עכשיו נריץ את אותה שאילתה עם מסנן וחיפוש וקטורי:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
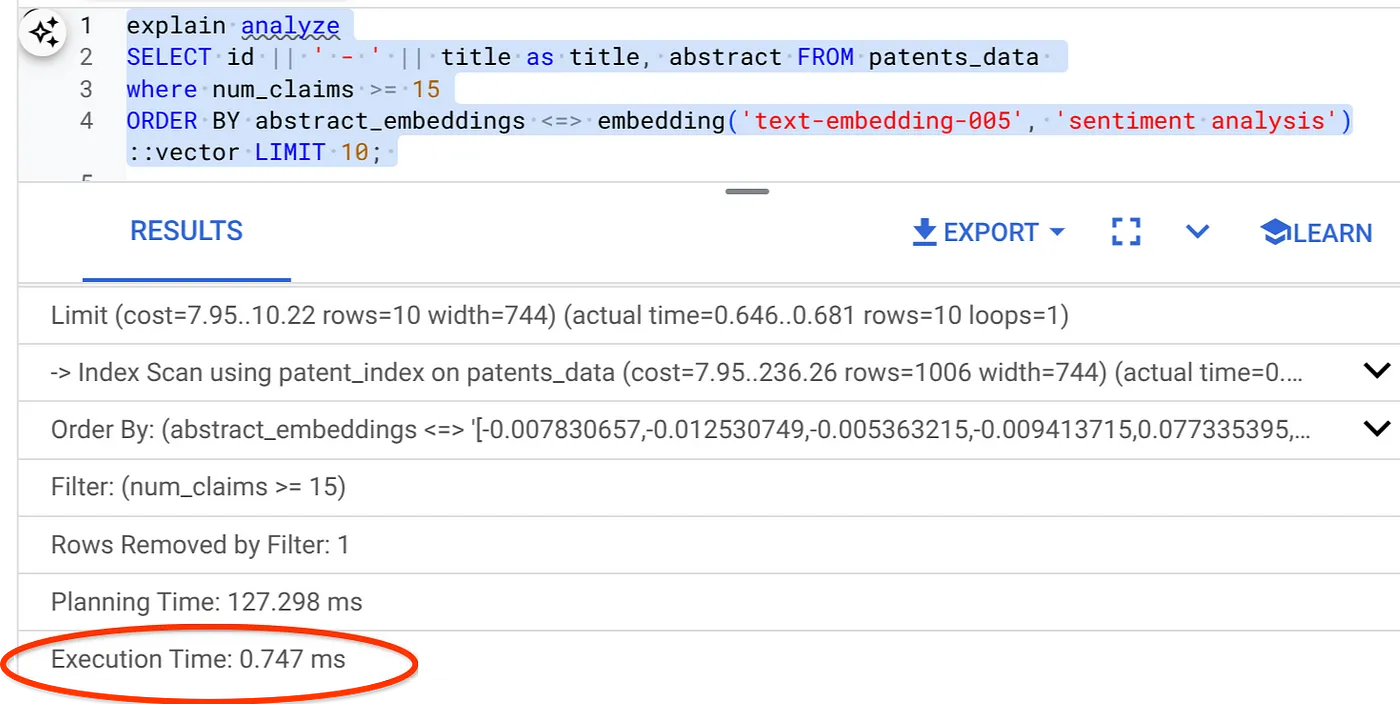
כפי שאפשר לראות, זמן הביצוע של אותו חיפוש וקטורי קוצר באופן משמעותי. האינדקס של ScaNN עם סינון מוטבע ב-Vector Search מאפשר זאת!!!
עכשיו נבדוק את ההחזרה של חיפוש וקטורי שמופעל בו ScaNN.
כלי להערכת זכירת המודעה
ההחזרה בחיפוש לפי דמיון היא אחוז המקרים הרלוונטיים שאותרו בחיפוש, כלומר מספר התוצאות החיוביות האמיתיות. זהו המדד הנפוץ ביותר למדידת איכות החיפוש. אחד הגורמים לאובדן של recall הוא ההבדל בין חיפוש של השכן הקרוב המשוער (aNN) לבין חיפוש של k (מדויק) של השכן הקרוב (kNN). אינדקסים וקטוריים כמו ScaNN של AlloyDB מיישמים אלגוריתמים של חיפוש שכנים קרובים (aNN), ומאפשרים לכם להאיץ את החיפוש הווקטורי במערכי נתונים גדולים בתמורה לפשרה קטנה ב-recall. מעכשיו, AlloyDB מאפשר לכם למדוד את האיזון הזה ישירות במסד הנתונים עבור שאילתות ספציפיות, ולוודא שהוא נשאר יציב לאורך זמן. אפשר לעדכן את הפרמטרים של השאילתה והאינדקס בתגובה למידע הזה כדי לשפר את התוצאות והביצועים.
אפשר למצוא את הזיכרון של שאילתת וקטור באינדקס וקטור עבור הגדרה נתונה באמצעות הפונקציה evaluate_query_recall. הפונקציה הזו מאפשרת לכם לכוונן את הפרמטרים כדי להשיג את תוצאות ההחזרה של שאילתת הווקטור שאתם רוצים. המדד שמשמש לאיכות החיפוש הוא Recall, והוא מוגדר כאחוז התוצאות שהוחזרו שהכי קרובות באופן אובייקטיבי לווקטורים של השאילתה. הפונקציה evaluate_query_recall מופעלת כברירת מחדל.
הערה חשובה:
אם נתקלתם בשגיאה 'ההרשאה נדחתה' באינדקס HNSW בשלבים הבאים, דלגו על כל הקטע הזה של הערכת ההחזרה לעת עתה. יכול להיות שזה קשור להגבלות גישה בשלב הזה, כי הוא רק הושק בזמן שבו נכתב ה-codelab הזה.
- מגדירים את הדגל Enable Index Scan באינדקס ScaNN ובאינדקס HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- מריצים את השאילתה הבאה ב-AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
הפונקציה evaluate_query_recall מקבלת את השאילתה כפרמטר ומחזירה את הזיכרון שלה. אני משתמש באותה שאילתה שבה השתמשתי כדי לבדוק את הביצועים כשאילתת הקלט של הפונקציה. הוספתי את SCaNN כשיטת האינדקס. אפשרויות נוספות של פרמטרים מפורטות במאמרי העזרה.
ההחזרה של שאילתת חיפוש וקטורי שבה השתמשנו:
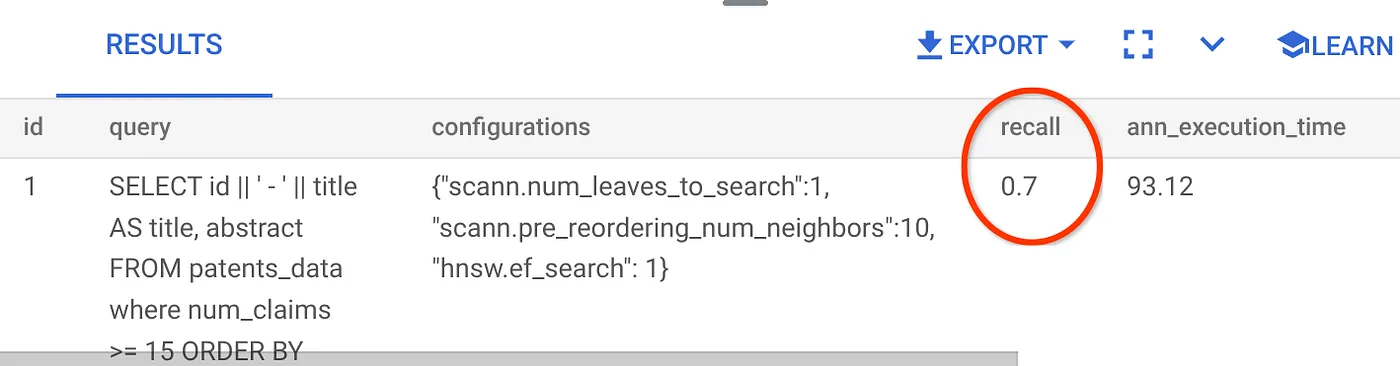
אני רואה שהערך של RECALL הוא 70%. עכשיו אוכל להשתמש במידע הזה כדי לשנות את פרמטרים האינדקס, השיטות והפרמטרים של השאילתה, ולשפר את ההחזרה של התוצאות בחיפוש הווקטורי הזה.
שיניתי את מספר השורות בערכת התוצאות ל-7 (לעומת 10 קודם) ואני רואה שיפור קל בזיכרון, כלומר 86%.
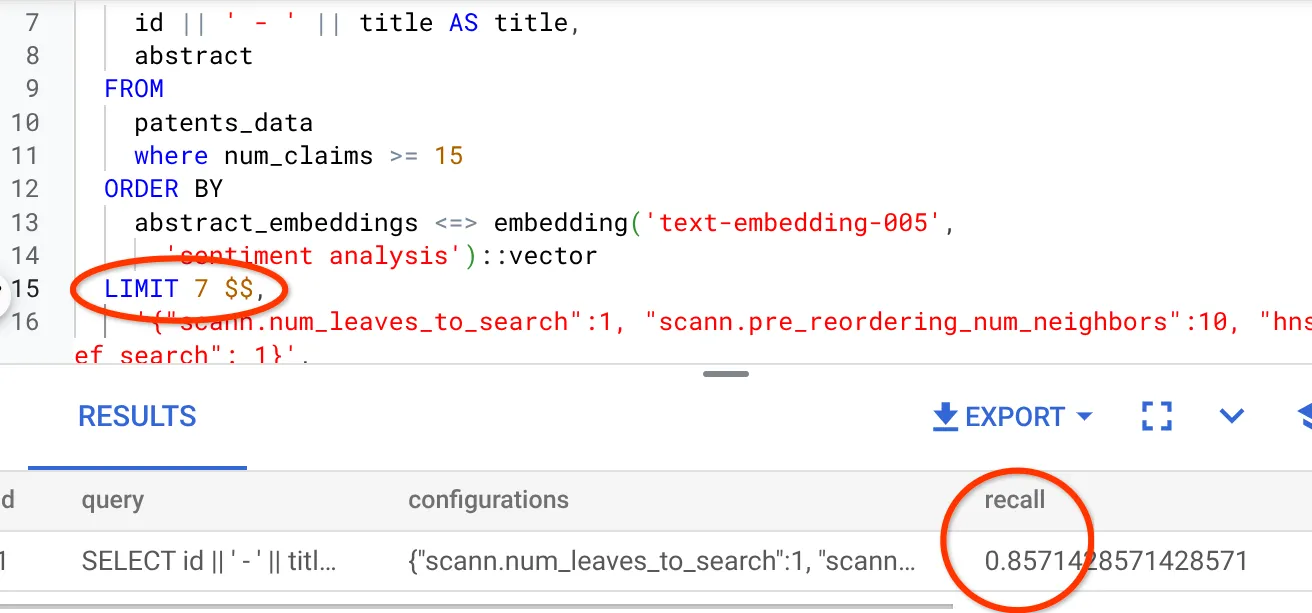
המשמעות היא שאני יכול לשנות בזמן אמת את מספר ההתאמות שמוצגות למשתמשים כדי לשפר את הרלוונטיות של ההתאמות בהתאם להקשר החיפוש של המשתמשים.
יופי! הגיע הזמן לפרוס את הלוגיקה של מסד הנתונים ולעבור לסוכן!!!
7. העברת הלוגיקה של מסד הנתונים לשרת האינטרנט ללא שרת
רוצה להעביר את האפליקציה הזו לאינטרנט? כך עושים זאת:
- כדי ליצור פונקציית Cloud Run חדשה, נכנסים אל פונקציות Cloud Run ב-מסוף Google Cloud ולוחצים על Write a function (כתיבת פונקציה) או משתמשים בקישור: https://console.cloud.google.com/run/create?deploymentType=function.
- בוחרים באפשרות 'שימוש בכלי לעריכה מוטבעת כדי ליצור פונקציה' ומתחילים בהגדרה. מזינים את שם השירות patent-search, בוחרים באזור us-central1 ובזמן הריצה Java 17. מגדירים את האימות לאפשר הפעלות לא מאומתות.
- בקטע Containers, Volumes, Networking, Security (מאגרי תגים, נפחים, רשתות, אבטחה), פועלים לפי השלבים הבאים בלי לפספס אף פרט:
עוברים לכרטיסייה 'רשת':
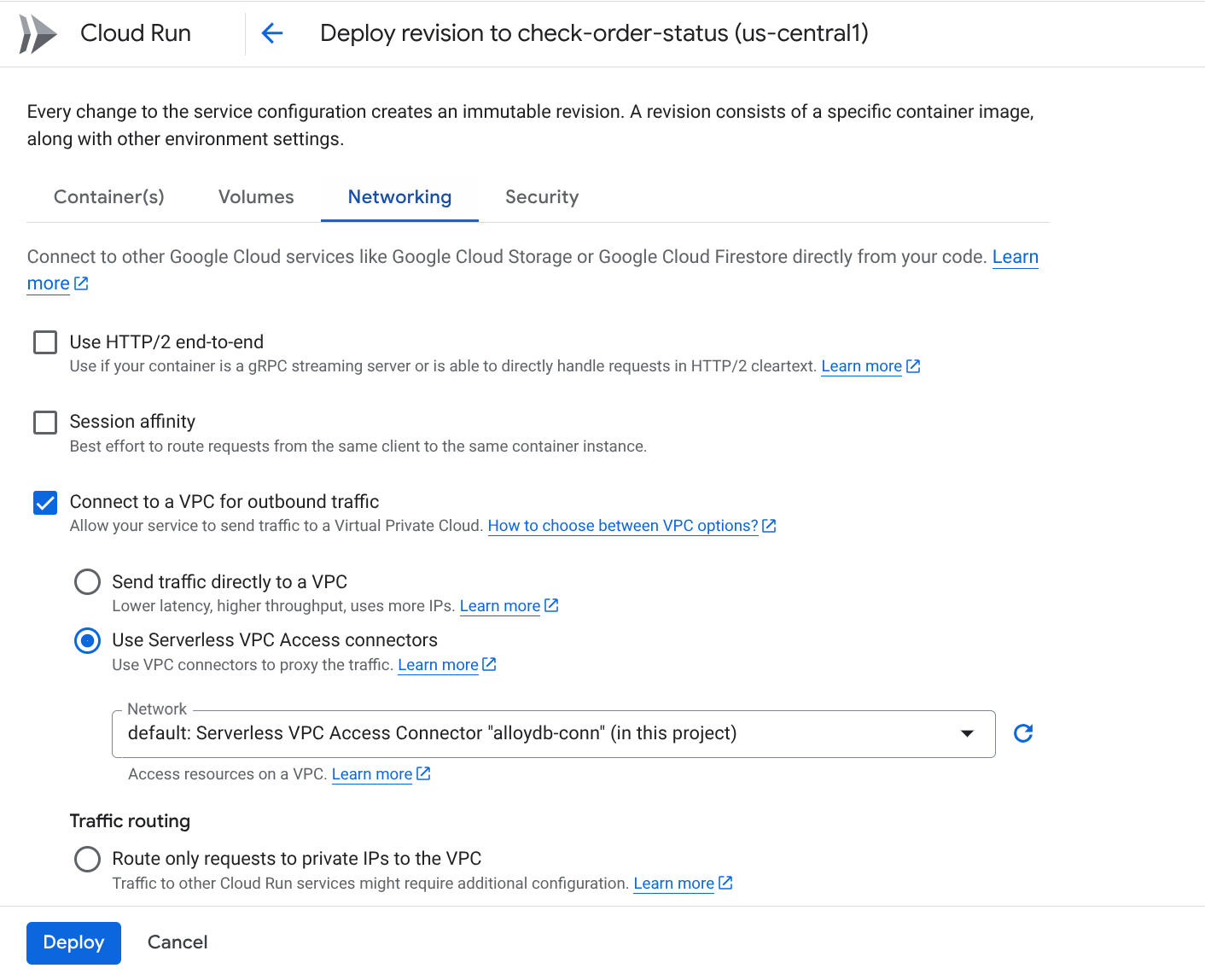
בוחרים באפשרות Connect to a VPC for outbound traffic (חיבור לרשת (VPC) לתנועה יוצאת) ואז באפשרות Use Serverless VPC Access connectors (שימוש במחברי חיבור לרשת (VPC) מאפליקציית serverless)
בתפריט הנפתח 'רשת', לוחצים על האפשרות הוספת מחבר VPC חדש (אם עדיין לא הגדרתם את ברירת המחדל) ופועלים לפי ההוראות שמופיעות בתיבת הדו-שיח שקופצת:
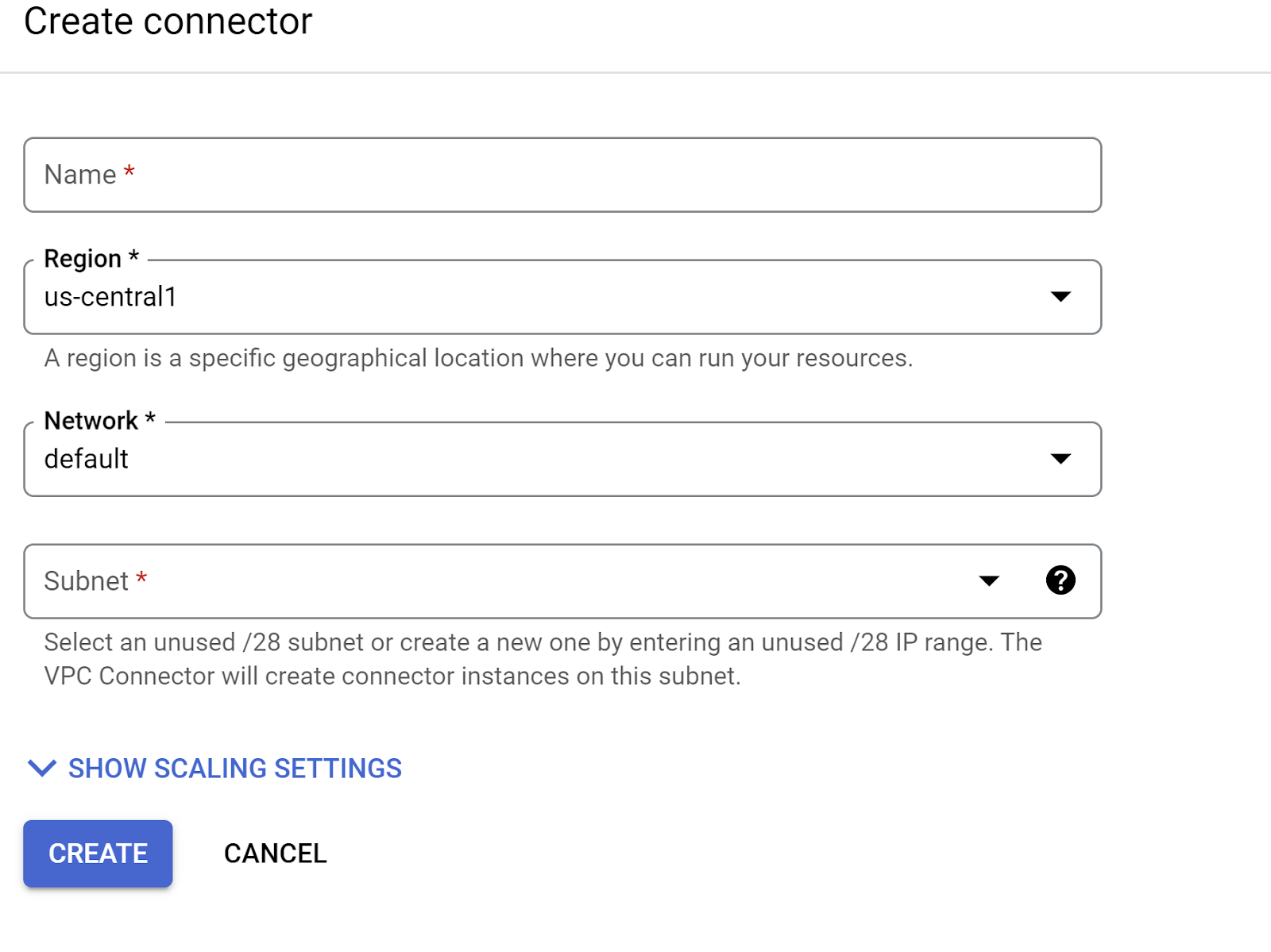
נותנים שם למחבר ה-VPC ומוודאים שהאזור זהה לאזור של המכונה. משאירים את ערך הרשת כברירת מחדל ומגדירים את רשת המשנה כטווח IP מותאם אישית עם טווח ה-IP 10.8.0.0 או ערך דומה אחר שזמין.
מרחיבים את האפשרות SHOW SCALING SETTINGS (הצגת הגדרות שינוי הגודל) ומוודאים שההגדרה מוגדרת בדיוק כמו שמופיע כאן:
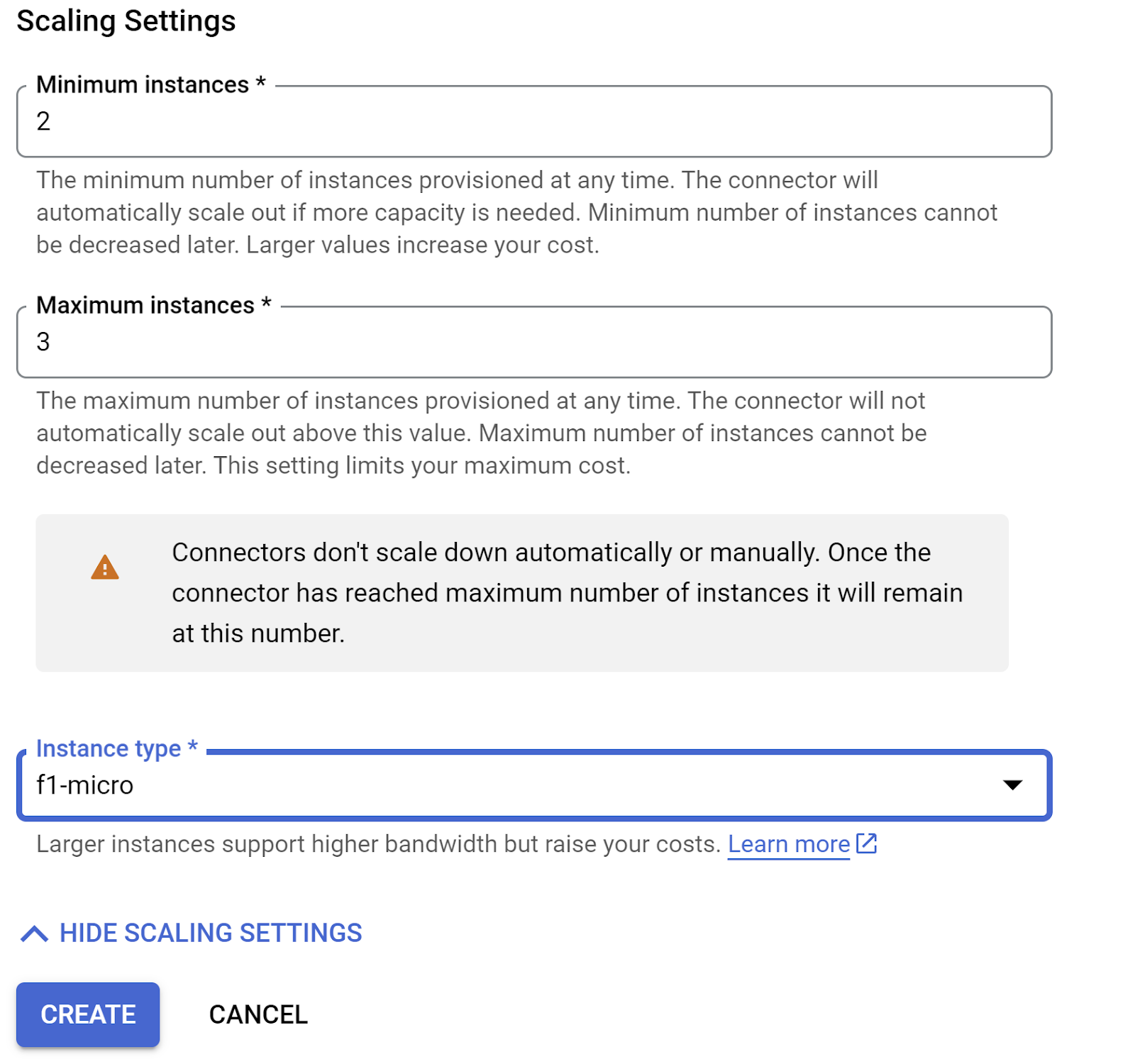
לוחצים על יצירה. המחבר הזה אמור להופיע עכשיו בהגדרות היציאה.
בוחרים את המחבר החדש שנוצר.
בוחרים שכל התנועה תנותב דרך מחבר ה-VPC הזה.
לוחצים על הבא ואז על פריסה.
- כברירת מחדל, נקודת הכניסה תוגדר כ-gcfv2.HelloHttpFunction. מחליפים את קוד ה-placeholder בקובץ HelloHttpFunction.java ובקובץ pom.xml של פונקציית Cloud Run בקוד מהקובץ PatentSearch.java ומהקובץ pom.xml, בהתאמה. משנים את השם של קובץ הכיתה ל-PatentSearch.java.
- חשוב לזכור להחליף את ה-placeholder ************* ואת פרטי החיבור ל-AlloyDB בערכים שלכם בקובץ Java. פרטי הכניסה ל-AlloyDB הם אותם פרטי כניסה שבהם השתמשנו בתחילת ה-codelab הזה. אם השתמשתם בערכים שונים, עליכם לשנות אותם בקובץ Java.
- לוחצים על פריסה.
- אחרי שפורסים את הפונקציה המעודכנת ב-Cloud Functions, אמורה להופיע נקודת הקצה שנוצרה. מעתיקים את הערך הזה ומחליפים אותו בפקודה הבאה:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
זהו! זה כל מה שצריך כדי לבצע חיפוש מתקדם של וקטורים של דמיון הקשרי באמצעות מודל ההטמעות בנתוני AlloyDB.
8. יצירת סוכן באמצעות Java ADK
קודם כל, נתחיל עם פרויקט Java בעורך.
- מעבר לטרמינל Cloud Shell
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- אישור כשמוצגת בקשה לעשות זאת
- כדי לעבור ל-Cloud Shell Editor, לוחצים על סמל העורך בחלק העליון של מסוף Cloud Shell.

- במסוף של Cloud Shell Editor, יוצרים תיקייה חדשה ונותנים לה את השם adk-agents.
לוחצים על 'יצירת תיקייה חדשה' בספריית השורש של Cloud Shell, כמו שמוצג בהמשך:
נותנים לו את השם adk-agents:
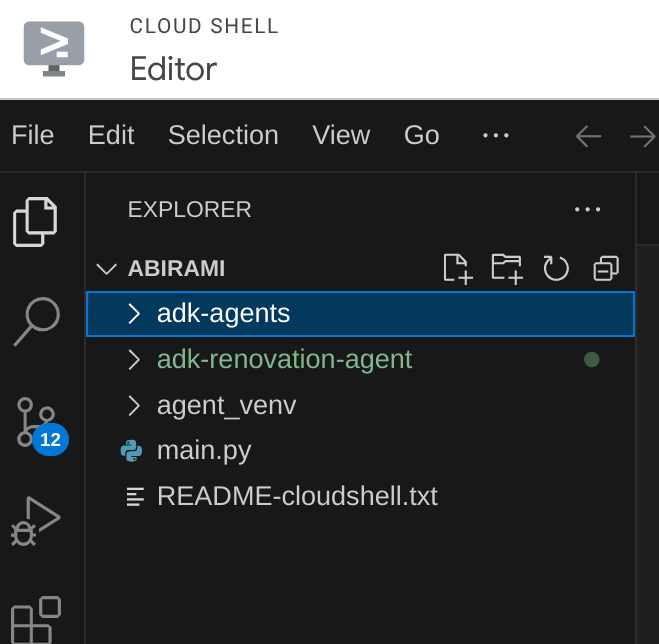
- יוצרים את מבנה התיקיות הבא ואת הקבצים הריקים עם שמות הקבצים המתאימים במבנה שבהמשך:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- פותחים את מאגר github בכרטיסייה נפרדת ומעתיקים את קוד המקור של הקבצים App.java ו-pom.xml.
- אם פתחתם את הכלי לעריכה בכרטיסייה חדשה באמצעות הסמל 'פתיחה בכרטיסייה חדשה' בפינה השמאלית העליונה, תוכלו לפתוח את הטרמינל בתחתית הדף. אתם יכולים לפתוח את העורך ואת הטרמינל במקביל כדי שתוכלו לפעול בחופשיות.
- אחרי השיבוט, חוזרים למסוף Cloud Shell Editor.
- מכיוון שכבר יצרנו את פונקציית Cloud Run, אין צורך להעתיק את קובצי פונקציית Cloud Run מתיקיית המאגר.
תחילת העבודה עם ADK Java SDK
התהליך די פשוט. בעיקר צריך לוודא שהפעולות הבאות כלולות בשלב השכפול:
- הוספת יחסי תלות:
כוללים את הארטיפקטים google-adk ו-google-adk-dev (לממשק המשתמש באינטרנט) בקובץ pom.xml. אם העתקתם את המקור ממאגר, הם כבר כלולים בקבצים, ואתם לא צריכים לכלול אותם. צריך רק לבצע שינוי בנקודת הקצה של פונקציית Cloud Run כדי לשקף את נקודת הקצה שנפרסה. ההסבר מופיע בשלבים הבאים בקטע הזה.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
חשוב להפנות אל pom.xml ממאגר המקור, כי יש תלויות והגדרות אחרות שנדרשות כדי שהאפליקציה תוכל לפעול.
- הגדרת הפרויקט:
מוודאים שגרסת Java (מומלצת גרסה 17 ומעלה) והגדרות הקומפיילר של Maven מוגדרות בצורה נכונה בקובץ pom.xml. אתם יכולים להגדיר את הפרויקט כך שיתאים למבנה הבא:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- הגדרת הסוכן והכלים שלו (App.java):
כאן נכנס לתמונה הקסם של ADK Java SDK. אנחנו מגדירים את הסוכן, את היכולות שלו (הוראות) ואת הכלים שהוא יכול להשתמש בהם.
כאן אפשר למצוא גרסה פשוטה של כמה קטעי קוד של מחלקת הסוכן הראשית. הפרויקט המלא זמין במאגר הפרויקט כאן.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
הדגשה של רכיבי קוד Java עיקריים ב-ADK:
- LlmAgent.builder(): Fluent API להגדרת הסוכן.
- .instruction(...): מספק את ההנחיה העיקרית וההנחיות ל-LLM, כולל מתי להשתמש באיזה כלי.
- FunctionTool.create(App.class, "methodName"): מאפשר לרשום בקלות שיטות Java ככלים שהסוכן יכול להפעיל. מחרוזת שם השיטה חייבת להתאים לשיטה סטטית ציבורית בפועל.
- @Schema(description = ...): מוסיף הערות לפרמטרים של כלי, ועוזר ל-LLM להבין איזה קלט כל כלי מצפה לקבל. התיאור הזה חשוב מאוד לבחירה מדויקת של כלי ולמילוי הפרמטרים.
- InvocationContext ctx: מועבר אוטומטית לשיטות של כלי, ומעניק גישה למצב הסשן (ctx.session().state()), לפרטי המשתמש ועוד.
- .outputKey("patents"): כשכלי מחזיר נתונים, ADK יכול לאחסן אותם באופן אוטומטי במצב הסשן תחת המפתח הזה. כך explainPatent יכול לגשת לתוצאות מ-getPatents.
- VECTOR_SEARCH_ENDPOINT: זהו משתנה שמכיל את הלוגיקה הפונקציונלית העיקרית של שאלות ותשובות בהקשר של המשתמש בתרחיש השימוש של חיפוש פטנטים.
- פעולה נדרשת: צריך להגדיר ערך מעודכן של נקודת קצה שנפרסה אחרי שמטמיעים את השלב של פונקציית Java Cloud Run מהקטע הקודם.
- searchTool: הכלי הזה מתקשר עם המשתמש כדי למצוא התאמות רלוונטיות מבחינה הקשרית לפטנטים מתוך מסד הנתונים של הפטנטים, על סמך טקסט החיפוש של המשתמש.
- explainTool: המשתמש מתבקש לבחור פטנט ספציפי כדי לקבל עליו מידע מפורט. לאחר מכן, הוא מסכם את תקציר הפטנט ויכול לענות על שאלות נוספות של המשתמש על סמך פרטי הפטנט שברשותו.
הערה חשובה: הקפידו להחליף את המשתנה VECTOR_SEARCH_ENDPOINT בנקודת הקצה של ה-CRF שפרסתם.
שימוש ב-InvocationContext לאינטראקציות עם שמירת מצב
אחד מהמאפיינים החשובים ליצירת סוכנים שימושיים הוא ניהול מצב בכמה תורות של שיחה. ה-ADK כולל את InvocationContext, שמפשט את התהליך.
ב-App.java:
- כשמגדירים את initAgent(), משתמשים ב- .outputKey("patents"). ההגדרה הזו אומרת ל-ADK שכאשר כלי (כמו getPatents) מחזיר נתונים בשדה הדוח שלו, הנתונים האלה צריכים להישמר במצב הסשן תחת המפתח patents.
- בשיטה של הכלי explainPatent, אנחנו מחדירים InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
כך הכלי explainPatent יכול לגשת לרשימת הפטנטים שאוחזרה על ידי הכלי getPatents בתור הקודם, והשיחה היא בעלת מצב ועקבית.
9. בדיקה מקומית של CLI
הגדרת משתני סביבה
צריך לייצא שני משתני סביבה:
- מפתח Gemini שאפשר לקבל מ-AI Studio:
כדי לעשות את זה, עוברים אל https://aistudio.google.com/apikey ומקבלים את מפתח ה-API של פרויקט Google Cloud הפעיל שבו אתם מטמיעים את האפליקציה הזו, ושומרים את המפתח במקום כלשהו:
- אחרי שמקבלים את המפתח, פותחים את הטרמינל של Cloud Shell ועוברים לספרייה החדשה שיצרנו adk-agents באמצעות הפקודה הבאה:
cd adk-agents
- משתנה שמציין שלא משתמשים ב-Vertex AI הפעם.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- הפעלת סוכן ראשון ב-CLI
כדי להפעיל את הסוכן הראשון, משתמשים בפקודת Maven הבאה בטרמינל:
mvn compile exec:java -DmainClass="agents.App"
התשובה האינטראקטיבית מהסוכן תופיע בטרמינל.
10. פריסה ב-Cloud Run
פריסת סוכן ADK Java ב-Cloud Run דומה לפריסה של כל אפליקציית Java אחרת:
- Dockerfile: יוצרים קובץ Dockerfile כדי לארוז את אפליקציית Java.
- יצירה והעברה בדחיפה של קובץ אימג' של Docker: שימוש ב-Google Cloud Build וב-Artifact Registry.
- אפשר לבצע את השלב שלמעלה ולפרוס ל-Cloud Run באמצעות פקודה אחת בלבד:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
באופן דומה, פורסים את פונקציית Java Cloud Run (gcfv2.PatentSearch). לחלופין, אפשר ליצור ולפרוס את פונקציית Java Cloud Run ללוגיקת מסד הנתונים ישירות ממסוף Cloud Run Function.
11. בדיקה באמצעות ממשק המשתמש באינטרנט
חבילת ה-ADK כוללת ממשק משתמש נוח באינטרנט לבדיקה ולניפוי באגים של הסוכן באופן מקומי. כשמריצים את App.java באופן מקומי (למשל, mvn exec:java -Dexec.mainClass="agents.App" אם הוגדר, או פשוט מריצים את השיטה הראשית), בדרך כלל ה-ADK מפעיל שרת אינטרנט מקומי.
ממשק המשתמש האינטרנטי של ADK מאפשר לכם:
- שליחת הודעות לסוכן.
- לראות את האירועים (הודעת משתמש, קריאה לכלי, תגובה של הכלי, תגובה של LLM).
- בדיקת מצב ההפעלה.
- צפייה ביומנים ובמעקב.
המידע הזה חשוב מאוד במהלך הפיתוח, כי הוא מאפשר להבין איך הסוכן מעבד בקשות ומשתמש בכלים שלו. ההנחה היא שהערך של mainClass בקובץ pom.xml מוגדר ל-com.google.adk.web.AdkWebServer והסוכן רשום בו, או שאתם מריצים כלי מקומי להרצת בדיקות שחושף את הערך הזה.
כשמריצים את App.java עם InMemoryRunner ו-Scanner לקלט של המסוף, בודקים את לוגיקת הסוכן המרכזית. ממשק המשתמש האינטרנטי הוא רכיב נפרד שמאפשר חוויית ניפוי באגים ויזואלית יותר, ולרוב משתמשים בו כש-ADK מפעיל את הסוכן שלכם באמצעות HTTP.
כדי להפעיל את השרת המקומי של SpringBoot, מריצים את פקודת Maven הבאה מספריית הבסיס:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
לרוב אפשר לגשת לממשק בכתובת ה-URL שהפקודה שלמעלה מוציאה. אם הוא נפרס ב-Cloud Run, אמורה להיות לכם גישה אליו דרך הקישור לפריסה ב-Cloud Run.
התוצאה אמורה להופיע בממשק אינטראקטיבי.
בסרטון הבא אפשר לראות את סוכן הפטנטים שפרסנו:
הדגמה של סוכן פטנטים עם בקרת איכות באמצעות AlloyDB Inline Search ו-Recall Evaluation!
12. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם במאמר הזה:
- במסוף Google Cloud, עוברים אל https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- בדף https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
13. מזל טוב
מעולה! הצלחת ליצור סוכן לניתוח פטנטים ב-Java באמצעות שילוב היכולות של ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI ו-Vector Search. בנוסף, עשינו קפיצת מדרגה משמעותית ביצירת חיפושים של דמיון הקשרי שהם יעילים, משמעותיים ומשנים את פני השוק.
מתחילים עוד היום!
מסמכי תיעוד בנושא ADK: [Link to Official ADK Java Docs]
קוד המקור של סוכן ניתוח הפטנטים: [קישור למאגר שלך ב-GitHub (עכשיו ציבורי)]
סוכנים לדוגמה ב-Java: [link to the adk-samples repo]
הצטרפות לקהילת ADK: https://www.reddit.com/r/agentdevelopmentkit/
תהנו מיצירת הסוכן!