
1. खास जानकारी
अलग-अलग इंडस्ट्री में, कॉन्टेक्स्ट के हिसाब से खोज करने की सुविधा एक अहम फ़ंक्शन है. यह उनके ऐप्लिकेशन का मुख्य हिस्सा है. Retrieval Augmented Generation (RAG) का इस्तेमाल, इस ज़रूरी टेक्नोलॉजी को बेहतर बनाने के लिए काफ़ी समय से किया जा रहा है. इसमें जनरेटिव एआई की मदद से जानकारी पाने के तरीके शामिल हैं. जनरेटिव मॉडल, एआई की दुनिया में बदलाव ला रहे हैं. इनकी कॉन्टेक्स्ट विंडो बड़ी होती है और ये अच्छी क्वालिटी का आउटपुट देते हैं. आरएजी, एआई ऐप्लिकेशन और एजेंट में कॉन्टेक्स्ट जोड़ने का एक व्यवस्थित तरीका है. इससे उन्हें स्ट्रक्चर्ड डेटाबेस या अलग-अलग मीडिया से मिली जानकारी के आधार पर काम करने में मदद मिलती है. संदर्भ के हिसाब से मिले इस डेटा से, जवाब के सही होने और सटीक होने के बारे में पता चलता है. हालांकि, ये नतीजे कितने सटीक होते हैं? क्या आपका कारोबार, कॉन्टेक्स्ट के हिसाब से मिलते-जुलते कीवर्ड और उनकी प्रासंगिकता के सटीक होने पर निर्भर करता है? अगर हां, तो यह प्रोजेक्ट आपके लिए है!
अब कल्पना करें कि अगर हम जनरेटिव मॉडल की मदद से, ऐसे इंटरैक्टिव एजेंट बना सकें जो इस तरह की ज़रूरी जानकारी के आधार पर, अपने-आप फ़ैसले ले सकें और तथ्यों के आधार पर काम कर सकें, तो क्या होगा. आज हम ऐसा ही करने वाले हैं. हम पेटेंट का विश्लेषण करने वाले ऐप्लिकेशन के लिए, एआई एजेंट ऐप्लिकेशन बनाने जा रहे हैं. इसके लिए, हम AlloyDB में मौजूद एडवांस्ड RAG की सुविधा के साथ-साथ Agent Development Kit का इस्तेमाल करेंगे.
पेटेंट का विश्लेषण करने वाला एजेंट, उपयोगकर्ता को खोज के लिए इस्तेमाल किए गए टेक्स्ट के हिसाब से, मिलते-जुलते पेटेंट ढूंढने में मदद करता है. साथ ही, चुने गए पेटेंट के बारे में पूछने पर, साफ़ तौर पर और कम शब्दों में जानकारी देता है. अगर ज़रूरी हो, तो ज़्यादा जानकारी भी देता है. क्या आप इसे आज़माने के लिए तैयार हैं? आइए, शुरू करते हैं!
मकसद
इसका मकसद आसान है. किसी उपयोगकर्ता को टेक्स्ट के ब्यौरे के आधार पर पेटेंट खोजने की अनुमति देना. इसके बाद, उसे खोज के नतीजों में से किसी खास पेटेंट के बारे में पूरी जानकारी देना. यह सब, Java ADK, AlloyDB, वेक्टर सर्च (ऐडवांस इंडेक्स के साथ), Gemini, और Cloud Run पर सर्वरलेस तरीके से डिप्लॉय किए गए पूरे ऐप्लिकेशन का इस्तेमाल करके किया जाता है.
आपको क्या बनाना है
इस लैब में, आपको ये काम करने होंगे:
- AlloyDB इंस्टेंस बनाना और Patents Public Dataset का डेटा लोड करना
- ScaNN और रीकॉल इवैल सुविधाओं का इस्तेमाल करके, AlloyDB में बेहतर वेक्टर सर्च लागू करना
- Java ADK का इस्तेमाल करके एजेंट बनाना
- Java के बिना सर्वर वाले Cloud Functions में, डेटाबेस के सर्वर-साइड लॉजिक को लागू करना
- Cloud Run में एजेंट को डिप्लॉय और टेस्ट करना
इस डायग्राम में, डेटा के फ़्लो और इसे लागू करने के चरणों के बारे में बताया गया है.
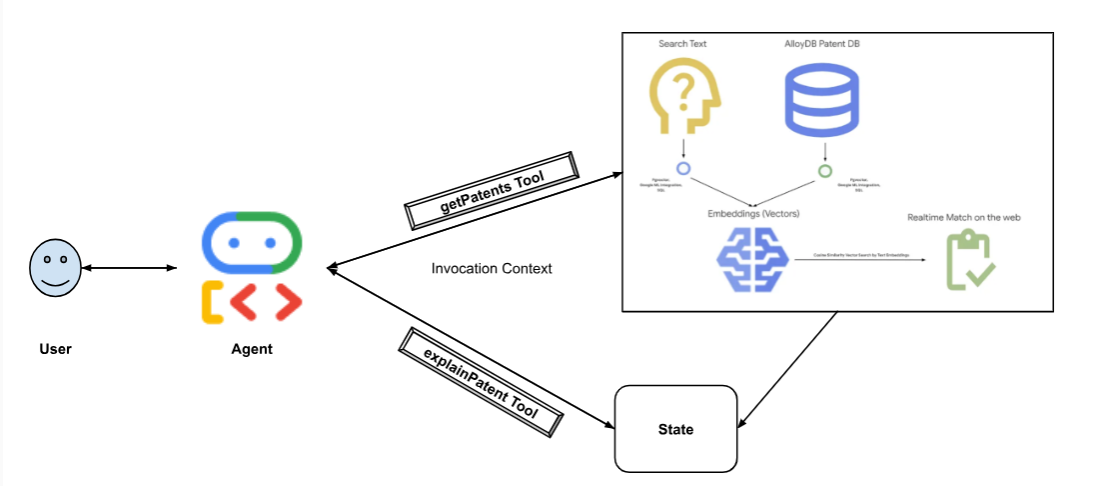
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें .
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें. Cloud Shell टर्मिनल में gcloud कमांड का इस्तेमाल किया जा सकता है:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
gcloud कमांड के बजाय, कंसोल का इस्तेमाल करके भी ऐसा किया जा सकता है. इसके लिए, हर प्रॉडक्ट को खोजें या इस लिंक का इस्तेमाल करें.
gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
3. डेटाबेस सेटअप करना
इस लैब में, हम पेटेंट के डेटा के लिए AlloyDB का इस्तेमाल करेंगे. यह सभी संसाधनों को सेव करने के लिए, क्लस्टर का इस्तेमाल करता है. जैसे, डेटाबेस और लॉग. हर क्लस्टर में एक प्राइमरी इंस्टेंस होता है, जो डेटा का ऐक्सेस पॉइंट उपलब्ध कराता है. टेबल में असल डेटा होगा.
आइए, एक AlloyDB क्लस्टर, इंस्टेंस, और टेबल बनाएं. इसमें पेटेंट का डेटासेट लोड किया जाएगा.
क्लस्टर और इंस्टेंस बनाना
- Cloud Console में AlloyDB पेज पर जाएं. Cloud Console में ज़्यादातर पेजों को आसानी से ढूंढने के लिए, कंसोल के खोज बार का इस्तेमाल करके उन्हें खोजें.
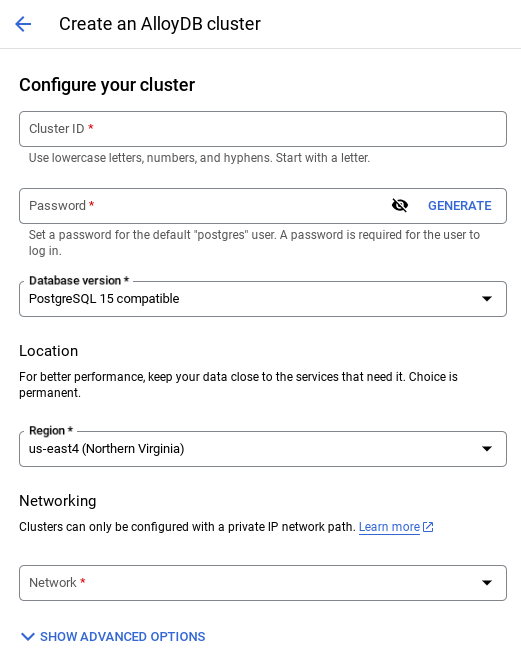
- उस पेज पर जाकर, क्लस्टर बनाएं को चुनें:

- आपको नीचे दी गई इमेज जैसी स्क्रीन दिखेगी. नीचे दी गई वैल्यू का इस्तेमाल करके, क्लस्टर और इंस्टेंस बनाएं. अगर आपको रिपॉज़िटरी से ऐप्लिकेशन कोड क्लोन करना है, तो पक्का करें कि वैल्यू मैच होती हों:
- क्लस्टर आईडी: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / सुझाया गया नया वर्शन
- इलाका: "
us-central1" - नेटवर्किंग: "
default"
- डिफ़ॉल्ट नेटवर्क चुनने पर, आपको नीचे दी गई इमेज जैसी स्क्रीन दिखेगी.
कनेक्शन सेट अप करें को चुनें.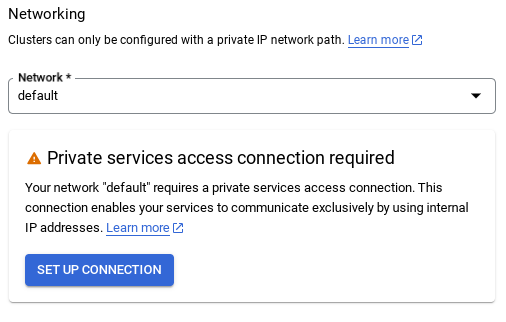
- इसके बाद, "अपने-आप असाइन की गई आईपी रेंज का इस्तेमाल करें" को चुनें और जारी रखें पर क्लिक करें. जानकारी देखने के बाद, कनेक्शन बनाएं को चुनें.
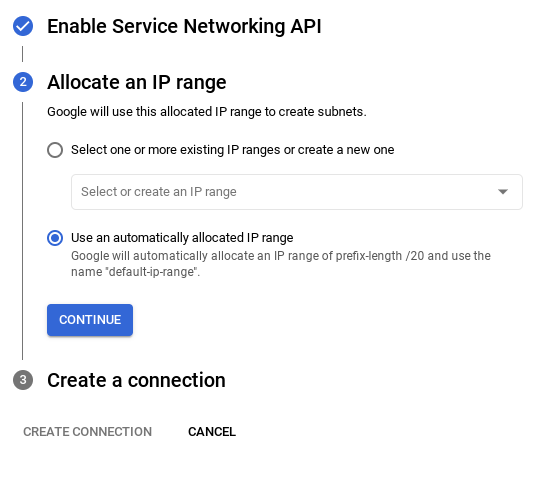
- नेटवर्क सेट अप हो जाने के बाद, क्लस्टर बनाना जारी रखा जा सकता है. नीचे दिए गए तरीके से क्लस्टर सेट अप करने के लिए, क्लस्टर बनाएं पर क्लिक करें:
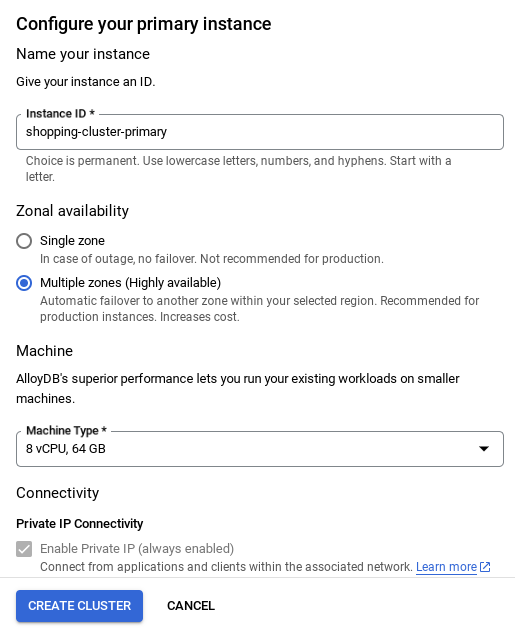
इंस्टेंस आईडी को (यह आपको क्लस्टर / इंस्टेंस को कॉन्फ़िगर करते समय दिखेगा) बदलना न भूलें
vector-instance. अगर इसे बदला नहीं जा सकता, तो आने वाले सभी रेफ़रंस में अपने इंस्टेंस आईडी का इस्तेमाल करना न भूलें.
ध्यान दें कि क्लस्टर बनने में करीब 10 मिनट लगेंगे. प्रोसेस पूरी होने के बाद, आपको एक स्क्रीन दिखेगी. इसमें, आपके बनाए गए क्लस्टर की खास जानकारी दिखेगी.
4. डेटा डालना
अब स्टोर के बारे में जानकारी देने वाली टेबल जोड़ें. AlloyDB पर जाएं. इसके बाद, प्राइमरी क्लस्टर और फिर AlloyDB Studio चुनें:
आपको इंस्टेंस बनने तक इंतज़ार करना पड़ सकता है. इसके बाद, क्लस्टर बनाते समय बनाए गए क्रेडेंशियल का इस्तेमाल करके, AlloyDB में साइन इन करें. PostgreSQL में पुष्टि करने के लिए, इस डेटा का इस्तेमाल करें:
- उपयोगकर्ता नाम : "
postgres" - डेटाबेस : "
postgres" - पासवर्ड : "
alloydb"
AlloyDB Studio में पुष्टि हो जाने के बाद, SQL कमांड को एडिटर में डाला जाता है. आखिरी विंडो के दाईं ओर मौजूद प्लस आइकॉन का इस्तेमाल करके, एक से ज़्यादा एडिटर विंडो जोड़ी जा सकती हैं.
एडिटर विंडो में, AlloyDB के लिए कमांड डाली जाती हैं. इसके लिए, ज़रूरत के हिसाब से 'चलाएं', 'फ़ॉर्मैट करें', और 'मिटाएं' विकल्पों का इस्तेमाल किया जाता है.
एक्सटेंशन चालू करना
इस ऐप्लिकेशन को बनाने के लिए, हम pgvector और google_ml_integration एक्सटेंशन का इस्तेमाल करेंगे. pgvector एक्सटेंशन की मदद से, वेक्टर एम्बेडिंग को सेव किया जा सकता है और उन्हें खोजा जा सकता है. google_ml_integration एक्सटेंशन, ऐसे फ़ंक्शन उपलब्ध कराता है जिनका इस्तेमाल करके, Vertex AI के अनुमान लगाने वाले एंडपॉइंट को ऐक्सेस किया जा सकता है. इससे एसक्यूएल में अनुमान मिलते हैं. इन एक्सटेंशन को चालू करें. इसके लिए, ये DDL चलाएं:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
अगर आपको अपने डेटाबेस पर चालू किए गए एक्सटेंशन देखने हैं, तो यह एसक्यूएल कमांड चलाएं:
select extname, extversion from pg_extension;
टेबल बनाना
AlloyDB Studio में, नीचे दिए गए डीडीएल स्टेटमेंट का इस्तेमाल करके टेबल बनाई जा सकती है:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings कॉलम में, टेक्स्ट की वेक्टर वैल्यू सेव की जा सकेंगी.
अनुमति दें
"embedding" फ़ंक्शन को लागू करने की अनुमति देने के लिए, नीचे दिए गए स्टेटमेंट को चलाएं:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB सेवा खाते को Vertex AI User की भूमिका असाइन करना
Google Cloud IAM Console में जाकर, AlloyDB सेवा खाते को "Vertex AI User" की भूमिका का ऐक्सेस दें. यह सेवा खाता इस तरह दिखता है: service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com. PROJECT_NUMBER में आपका प्रोजेक्ट नंबर होगा.
इसके अलावा, Cloud Shell टर्मिनल से नीचे दिया गया कमांड भी चलाया जा सकता है:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
डेटाबेस में पेटेंट का डेटा लोड करना
हमारा डेटासेट, BigQuery पर मौजूद Google Patents के सार्वजनिक डेटासेट का इस्तेमाल करेगा. हम क्वेरी चलाने के लिए, AlloyDB Studio का इस्तेमाल करेंगे. इस insert scripts sql फ़ाइल में डेटा, इस repo से लिया गया है. हम इसका इस्तेमाल, पेटेंट का डेटा लोड करने के लिए करेंगे.
- Google Cloud Console में, AlloyDB पेज खोलें.
- बनाया गया नया क्लस्टर चुनें और इंस्टेंस पर क्लिक करें.
- AlloyDB के नेविगेशन मेन्यू में, AlloyDB Studio पर क्लिक करें. अपने क्रेडेंशियल से साइन इन करें.
- दाईं ओर मौजूद, नया टैब आइकॉन पर क्लिक करके, एक नया टैब खोलें.
insert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlफ़ाइलों से,insertक्वेरी स्टेटमेंट को एक-एक करके कॉपी करें और चलाएं. इस इस्तेमाल के उदाहरण का तुरंत डेमो देखने के लिए, कॉपी करने के 10 से 50 इंसर्ट स्टेटमेंट चलाए जा सकते हैं.
इसे चलाने के लिए, चलाएं पर क्लिक करें. आपकी क्वेरी के नतीजे, नतीजे टेबल में दिखते हैं.
5. पेटेंट के डेटा के लिए एम्बेडिंग बनाना
सबसे पहले, एम्बेडिंग फ़ंक्शन की जांच करते हैं. इसके लिए, यहां दी गई सैंपल क्वेरी चलाएं:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
इससे क्वेरी में मौजूद सैंपल टेक्स्ट के लिए, एम्बेडिंग वेक्टर मिलना चाहिए. यह फ़्लोट की एक ऐसी कैटगरी होती है जो ऐरे की तरह दिखती है. यह इस तरह दिखता है:
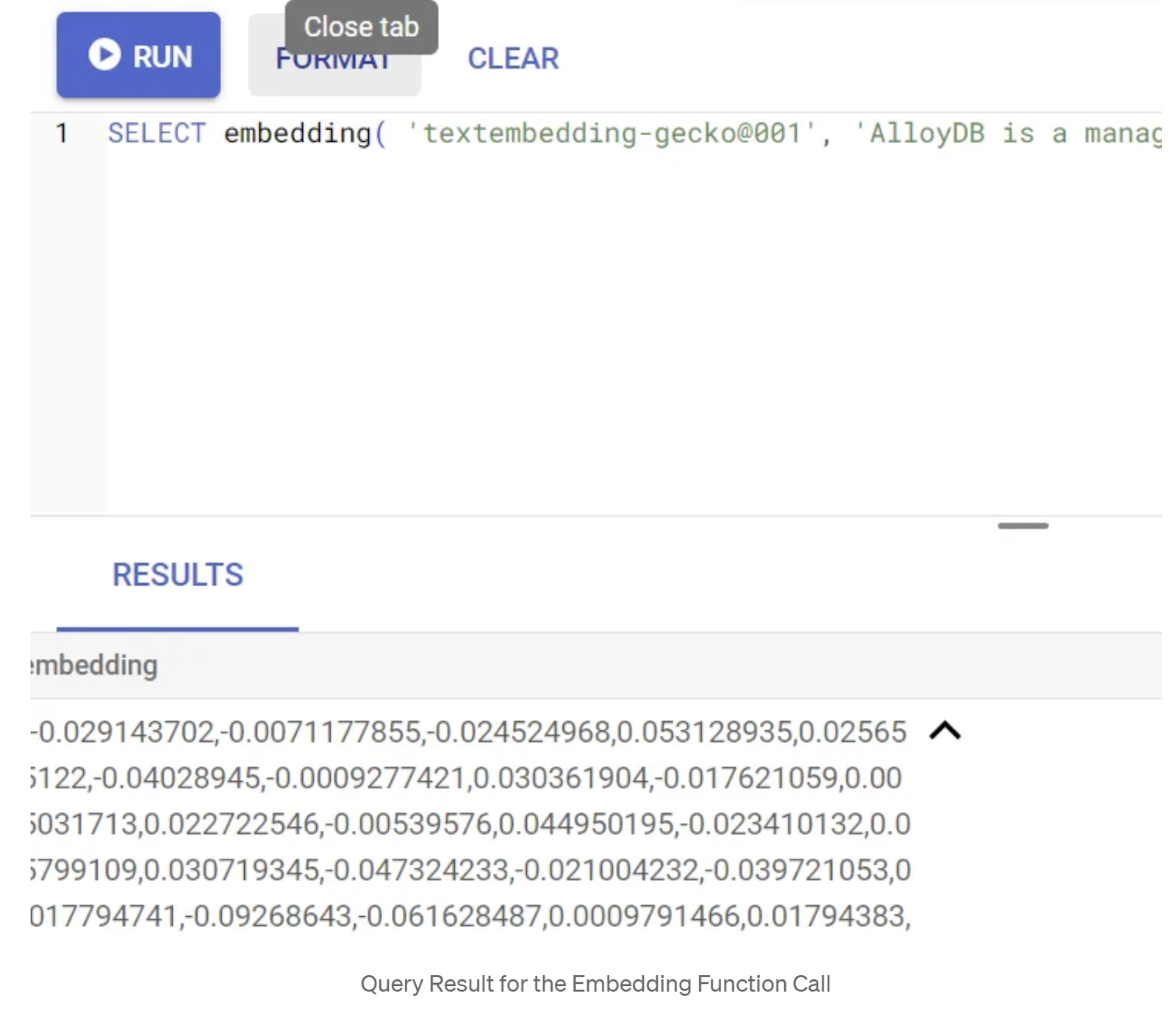
abstract_embeddings वेक्टर फ़ील्ड को अपडेट करना
अगर ऐब्स्ट्रैक्ट के लिए एम्बेडिंग जनरेट करने की ज़रूरत है, तो टेबल में पेटेंट के ऐब्स्ट्रैक्ट अपडेट करने के लिए, नीचे दिए गए डीएमएल का इस्तेमाल किया जाना चाहिए. हालांकि, हमारे मामले में, इंसर्ट स्टेटमेंट में हर ऐब्स्ट्रैक्ट के लिए ये एम्बेडिंग पहले से मौजूद हैं. इसलिए, आपको embeddings() तरीके को कॉल करने की ज़रूरत नहीं है.
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. वेक्टर सर्च करना
अब टेबल, डेटा, और एम्बेडिंग तैयार हैं. इसलिए, उपयोगकर्ता के खोज टेक्स्ट के लिए रीयल टाइम वेक्टर सर्च करते हैं. नीचे दी गई क्वेरी चलाकर, इसकी जांच की जा सकती है:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
इस क्वेरी में,
- उपयोगकर्ता ने "भावनाओं का विश्लेषण" खोजा है.
- हम इसे embedding() तरीके में एम्बेडिंग में बदल रहे हैं. इसके लिए, हम मॉडल: text-embedding-005 का इस्तेमाल कर रहे हैं.
- "<=>" का मतलब, COSINE SIMILARITY दूरी के तरीके का इस्तेमाल करना है.
- हम एम्बेड करने के तरीके के नतीजे को वेक्टर टाइप में बदल रहे हैं, ताकि यह डेटाबेस में सेव किए गए वेक्टर के साथ काम कर सके.
- LIMIT 10 का मतलब है कि हम खोजे गए टेक्स्ट से सबसे ज़्यादा मिलते-जुलते 10 नतीजे चुन रहे हैं.
AlloyDB, वेक्टर सर्च RAG को बेहतर बनाता है:
इसमें कई नई सुविधाएं जोड़ी गई हैं. डेवलपर के लिए उपलब्ध दो मुख्य टूल ये हैं:
- इनलाइन फ़िल्टरिंग
- रीकॉल का आकलन करने वाला
इनलाइन फ़िल्टरिंग
डेवलपर के तौर पर, आपको पहले वेक्टर सर्च क्वेरी करनी पड़ती थी. साथ ही, फ़िल्टर करने और वापस पाने की प्रोसेस को मैनेज करना पड़ता था. AlloyDB Query Optimizer, फ़िल्टर के साथ क्वेरी को एक्ज़ीक्यूट करने के तरीके चुनता है. इनलाइन फ़िल्टरिंग, क्वेरी ऑप्टिमाइज़ेशन की एक नई तकनीक है. इससे AlloyDB क्वेरी ऑप्टिमाइज़र, मेटाडेटा फ़िल्टर करने की शर्तों और वेक्टर सर्च, दोनों का एक साथ आकलन कर पाता है. इसके लिए, वह वेक्टर इंडेक्स और मेटाडेटा कॉलम पर मौजूद इंडेक्स, दोनों का इस्तेमाल करता है. इससे रिकॉल परफ़ॉर्मेंस बेहतर हुई है. साथ ही, डेवलपर को AlloyDB की डिफ़ॉल्ट सुविधाओं का फ़ायदा मिल रहा है.
इनलाइन फ़िल्टरिंग, ऐसे मामलों के लिए सबसे सही होती है जिनमें मध्यम स्तर की चुनिंदा जानकारी शामिल होती है. AlloyDB, वेक्टर इंडेक्स में खोज करता है. इसलिए, यह सिर्फ़ उन वेक्टर के बीच की दूरी का हिसाब लगाता है जो मेटाडेटा फ़िल्टर करने की शर्तों से मेल खाते हैं. ये शर्तें, क्वेरी में इस्तेमाल किए गए फ़ंक्शनल फ़िल्टर से मेल खाती हैं. आम तौर पर, इन्हें WHERE क्लॉज़ में हैंडल किया जाता है. इससे इन क्वेरी की परफ़ॉर्मेंस काफ़ी बेहतर हो जाती है. साथ ही, पोस्ट-फ़िल्टर या प्री-फ़िल्टर के फ़ायदे भी मिलते हैं.
- pgvector एक्सटेंशन इंस्टॉल या अपडेट करना
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
अगर pgvector एक्सटेंशन पहले से इंस्टॉल है, तो वेक्टर एक्सटेंशन को 0.8.0.google-3 या इसके बाद के वर्शन पर अपग्रेड करें. इससे आपको रीकॉल इवैल्यूएटर की सुविधाएं मिलेंगी.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
यह चरण सिर्फ़ तब पूरा करना होता है, जब आपका वेक्टर एक्सटेंशन <0.8.0.google-3 हो.
अहम जानकारी: अगर आपकी पंक्ति की संख्या 100 से कम है, तो आपको ScaNN इंडेक्स बनाने की ज़रूरत नहीं होगी. ऐसा इसलिए, क्योंकि यह कम पंक्तियों के लिए लागू नहीं होता. ऐसे में, कृपया यहां दिया गया तरीका न अपनाएं.
- ScaNN इंडेक्स बनाने के लिए, alloydb_scann एक्सटेंशन इंस्टॉल करें.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- सबसे पहले, इंडेक्स और इनलाइन फ़िल्टर को चालू किए बिना, वेक्टर सर्च क्वेरी चलाएं:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
नतीजा कुछ इस तरह का होना चाहिए:
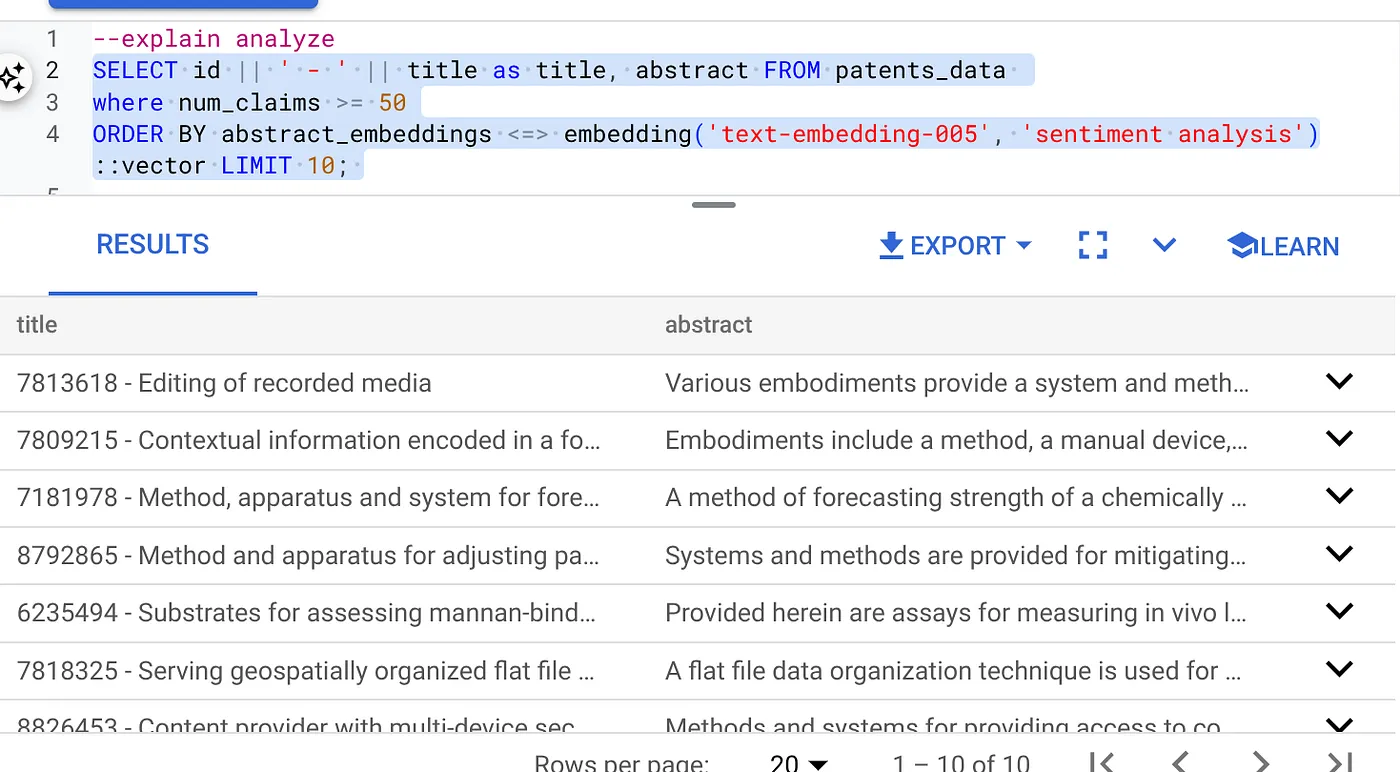
- इस पर 'विश्लेषण के बारे में ज़्यादा जानें' सुविधा का इस्तेमाल करें: (इसमें इंडेक्स या इनलाइन फ़िल्टरिंग का इस्तेमाल नहीं किया गया है)
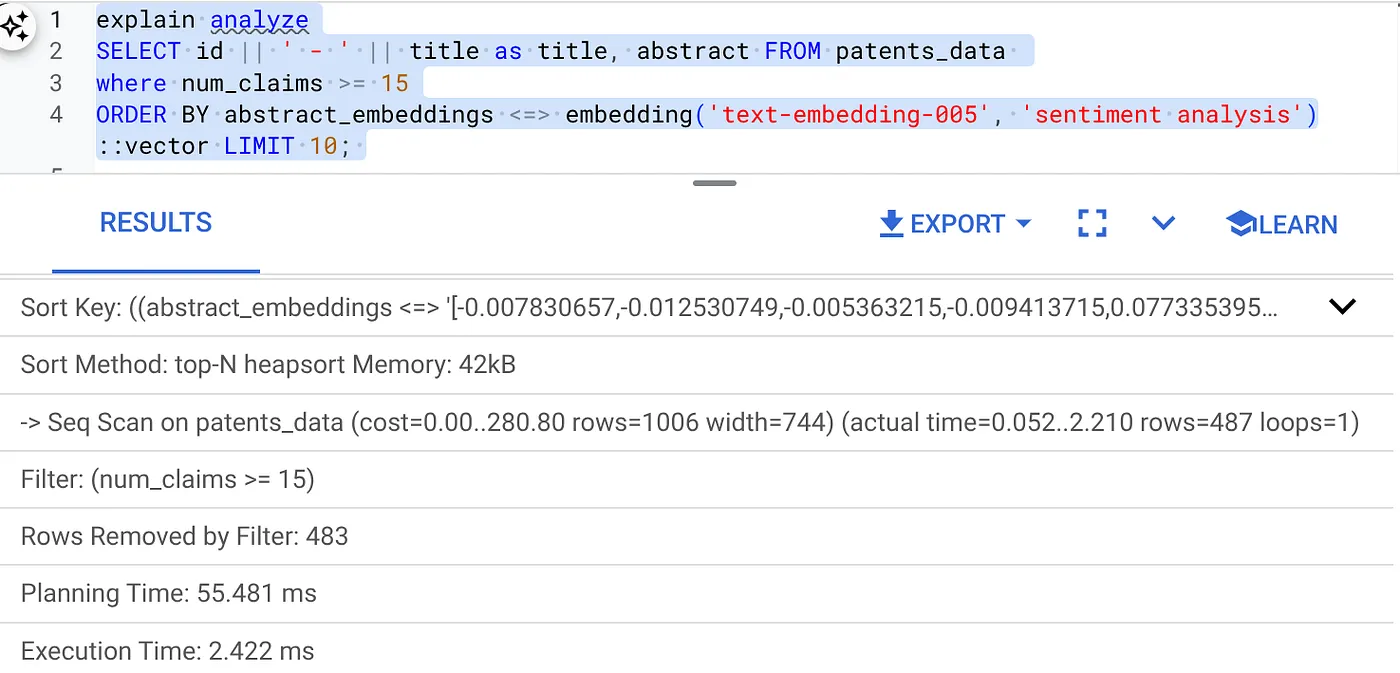
लागू करने में लगने वाला समय 2.4 मि॰से॰ है
- num_claims फ़ील्ड पर एक सामान्य इंडेक्स बनाते हैं, ताकि हम इसके हिसाब से फ़िल्टर कर सकें:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- आइए, पेटेंट खोजने वाले ऐप्लिकेशन के लिए ScaNN इंडेक्स बनाते हैं. AlloyDB Studio से यह कमांड चलाएं:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
अहम जानकारी: (num_leaves=32) यह हमारे पूरे डेटासेट पर लागू होता है, जिसमें 1,000 से ज़्यादा लाइनें हैं. अगर आपकी पंक्तियों की संख्या 100 से कम है, तो आपको इंडेक्स बनाने की ज़रूरत नहीं होगी, क्योंकि यह कम पंक्तियों पर लागू नहीं होता.
- ScaNN इंडेक्स पर इनलाइन फ़िल्टरिंग की सुविधा चालू करें:
SET scann.enable_inline_filtering = on
- अब, फ़िल्टर और वेक्टर सर्च के साथ एक ही क्वेरी चलाएं:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
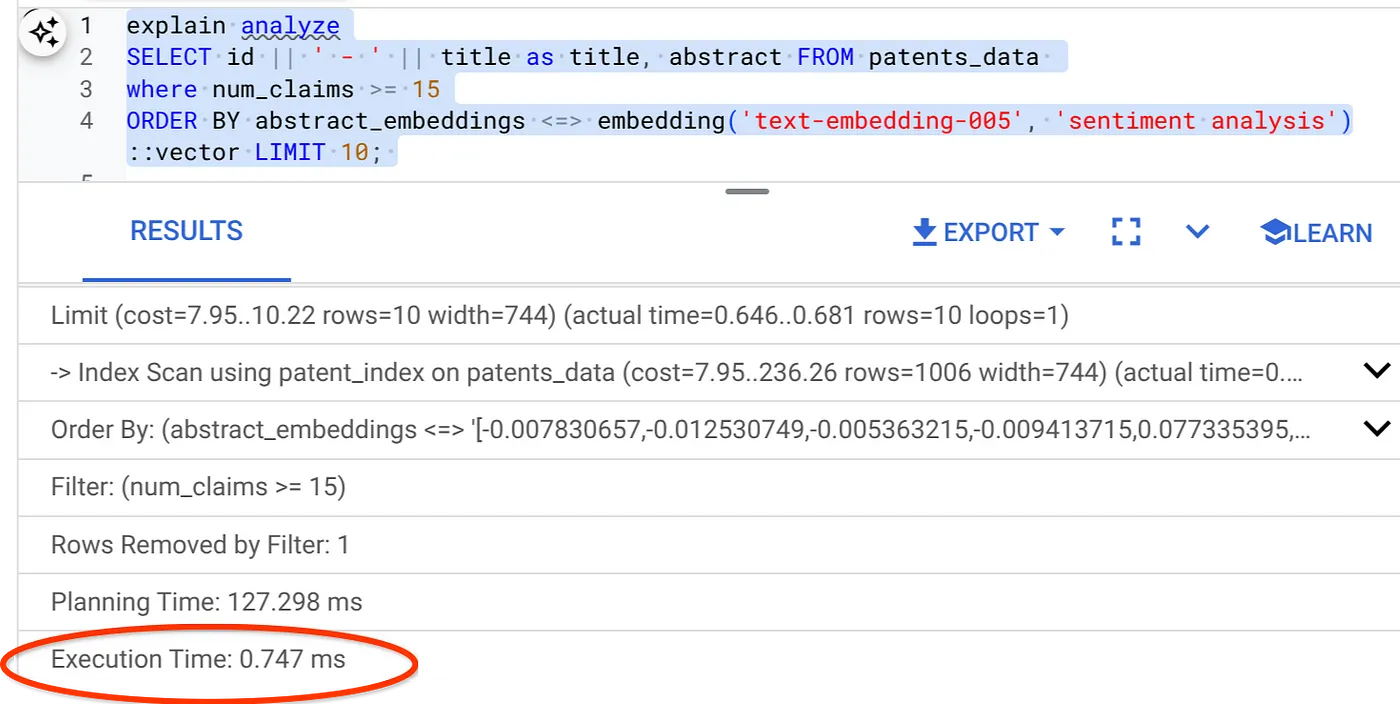
जैसा कि आप देख सकते हैं, एक ही वेक्टर सर्च के लिए एक्ज़ीक्यूशन का समय काफ़ी कम हो गया है. वेक्टर सर्च में ScaNN इंडेक्स के साथ इनलाइन फ़िल्टरिंग की सुविधा उपलब्ध होने की वजह से ऐसा हो पाया है!!!
इसके बाद, ScaNN की सुविधा के साथ काम करने वाली वेक्टर सर्च के लिए, रीकॉल का आकलन करते हैं.
रीकॉल का आकलन करने वाला
मिलती-जुलती इमेज खोजने की सुविधा में रीकॉल, खोज से वापस लाए गए काम के इंस्टेंस का प्रतिशत होता है. इसका मतलब है कि यह ट्रू पॉज़िटिव की संख्या होती है. खोज के नतीजों की क्वालिटी को मेज़र करने के लिए, इस मेट्रिक का सबसे ज़्यादा इस्तेमाल किया जाता है. मिलते-जुलते आइटम को याद न रख पाने की एक वजह, सबसे मिलते-जुलते आइटम को खोजने की अनुमानित सुविधा (एएनएन) और सबसे मिलते-जुलते आइटम को खोजने की सटीक सुविधा (केएनएन) के बीच का अंतर है. AlloyDB के ScaNN जैसे वेक्टर इंडेक्स, aNN एल्गोरिदम लागू करते हैं. इससे बड़े डेटासेट पर वेक्टर सर्च को तेज़ किया जा सकता है. हालांकि, इसके लिए रिकॉल में थोड़ा समझौता करना पड़ता है. अब AlloyDB, आपको अलग-अलग क्वेरी के लिए डेटाबेस में सीधे तौर पर इस ट्रेडऑफ़ को मेज़र करने की सुविधा देता है. साथ ही, यह पक्का करता है कि यह समय के साथ स्थिर रहे. बेहतर नतीजे और परफ़ॉर्मेंस पाने के लिए, इस जानकारी के आधार पर क्वेरी और इंडेक्स पैरामीटर अपडेट किए जा सकते हैं.
evaluate_query_recall फ़ंक्शन का इस्तेमाल करके, किसी कॉन्फ़िगरेशन के लिए वेक्टर इंडेक्स पर वेक्टर क्वेरी के लिए रीकॉल का पता लगाया जा सकता है. इस फ़ंक्शन की मदद से, अपने पैरामीटर को इस तरह से ट्यून किया जा सकता है कि आपको वेक्टर क्वेरी रिकॉल के मनमुताबिक नतीजे मिलें. रिकॉल, खोज के नतीजों की क्वालिटी को मापने के लिए इस्तेमाल की जाने वाली मेट्रिक है. इसे ऐसे नतीजों के प्रतिशत के तौर पर तय किया जाता है जो क्वेरी वेक्टर से सबसे ज़्यादा मिलते-जुलते हों. evaluate_query_recall फ़ंक्शन डिफ़ॉल्ट रूप से चालू होता है.
अहम जानकारी:
अगर आपको यहां दिए गए चरणों में, HNSW इंडेक्स पर अनुमति नहीं होने की गड़बड़ी का सामना करना पड़ रहा है, तो फ़िलहाल, इस पूरे रिकॉल के आकलन वाले सेक्शन को छोड़ दें. ऐसा हो सकता है कि इस समय ऐक्सेस से जुड़ी पाबंदियां लागू हों, क्योंकि यह सुविधा इस कोडलैब के दस्तावेज़ तैयार होने के समय ही लॉन्च हुई है.
- ScaNN इंडेक्स और HNSW इंडेक्स पर, Enable Index Scan फ़्लैग सेट करें:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio में यह क्वेरी चलाएं:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall फ़ंक्शन, क्वेरी को पैरामीटर के तौर पर लेता है और उसके रीकॉल को दिखाता है. मैंने फ़ंक्शन के इनपुट क्वेरी के तौर पर, उसी क्वेरी का इस्तेमाल किया है जिसका इस्तेमाल मैंने परफ़ॉर्मेंस की जांच करने के लिए किया था. मैंने SCaNN को इंडेक्स के तरीके के तौर पर जोड़ा है. पैरामीटर के अन्य विकल्पों के बारे में जानने के लिए, दस्तावेज़ पढ़ें.
हम इस Vector Search क्वेरी के लिए इस रिकॉल का इस्तेमाल कर रहे हैं:
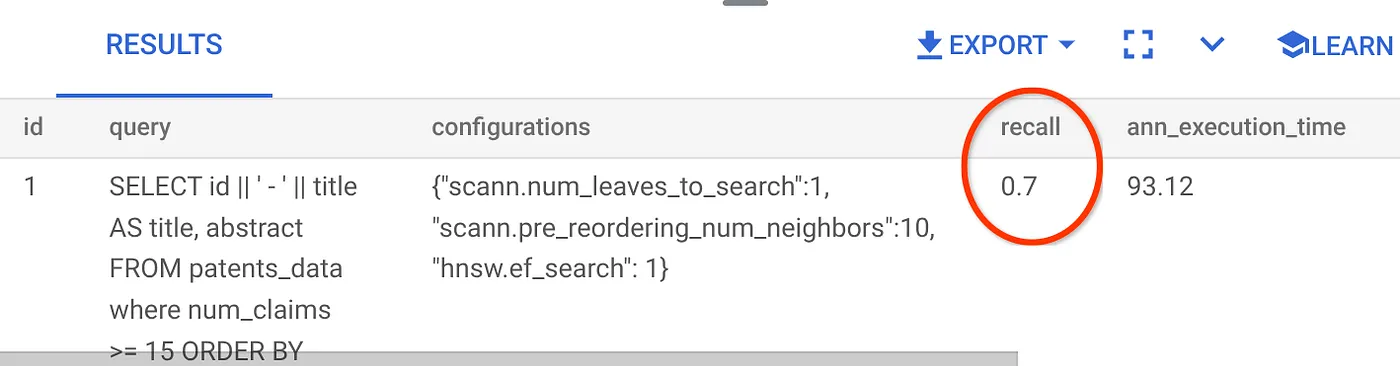
मुझे दिख रहा है कि RECALL 70% है. अब मैं इस जानकारी का इस्तेमाल करके, इंडेक्स पैरामीटर, तरीकों, और क्वेरी पैरामीटर में बदलाव कर सकता/सकती हूं. साथ ही, इस वेक्टर सर्च के लिए अपनी रीकॉल क्षमता को बेहतर बना सकता/सकती हूं!
मैंने नतीजों के सेट में लाइनों की संख्या को 10 से बदलकर 7 कर दिया है.इससे मुझे RECALL में थोड़ा सुधार देखने को मिला है. यह 86% है.
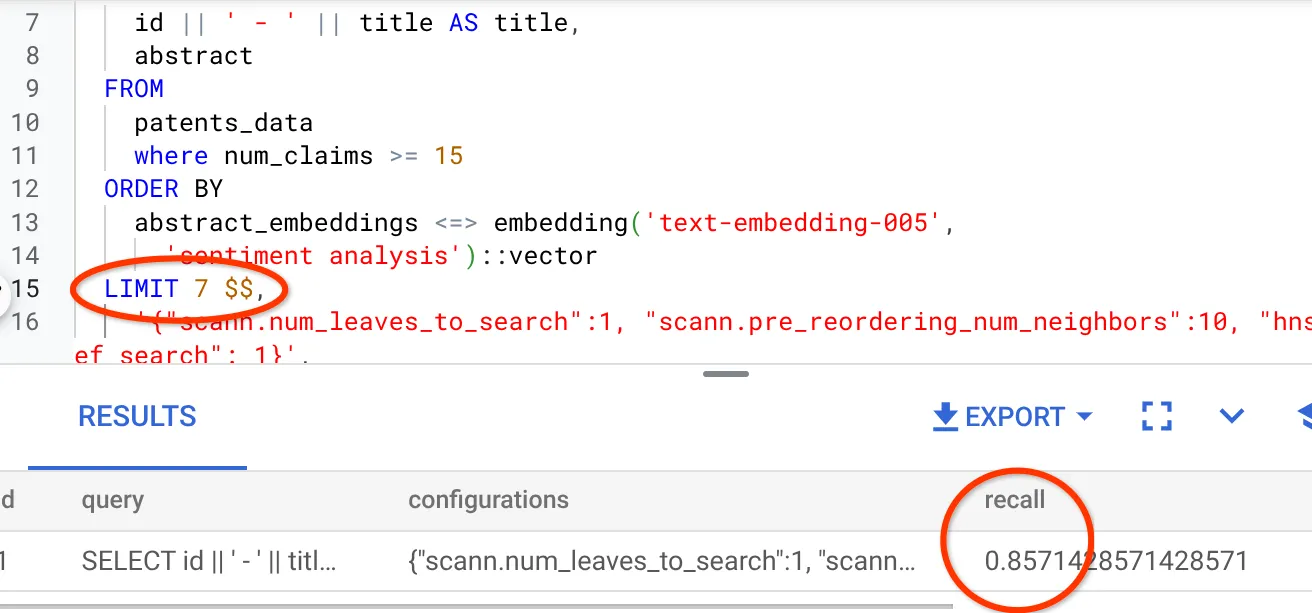
इसका मतलब है कि मैं रीयल-टाइम में, उपयोगकर्ताओं को दिखने वाले मैच की संख्या में बदलाव कर सकता/सकती हूं. इससे, उपयोगकर्ताओं की खोज के संदर्भ के हिसाब से मैच को ज़्यादा काम का बनाया जा सकता है.
ठीक है! अब डेटाबेस लॉजिक को डिप्लॉय करने और एजेंट पर स्विच करने का समय है!!!
7. डेटाबेस के लॉजिक को सर्वरलेस तरीके से वेब पर ले जाना
क्या आपको इस ऐप्लिकेशन को वेब पर उपलब्ध कराना है? नीचे दिए गए चरणों का पालन करें:
- Google Cloud Console में Cloud Run Functions पर जाएं. इसके बाद, "Write a function" पर क्लिक करके नया Cloud Run फ़ंक्शन बनाएं. इसके अलावा, इस लिंक का इस्तेमाल करें: https://console.cloud.google.com/run/create?deploymentType=function.
- "फ़ंक्शन बनाने के लिए, इनलाइन एडिटर का इस्तेमाल करें" विकल्प चुनें और कॉन्फ़िगरेशन शुरू करें. सेवा का नाम "patent-search" डालें. इसके बाद, क्षेत्र के तौर पर "us-central1" और रनटाइम के तौर पर "Java 17" चुनें. पुष्टि करने की सुविधा को "बिना पुष्टि किए गए अनुरोधों की अनुमति दें" पर सेट करें.
- "कंटेनर, वॉल्यूम, नेटवर्किंग, सुरक्षा" सेक्शन में जाकर, यहां दिया गया तरीका अपनाएं. कोई भी जानकारी न छोड़ें:
नेटवर्किंग टैब पर जाएं:
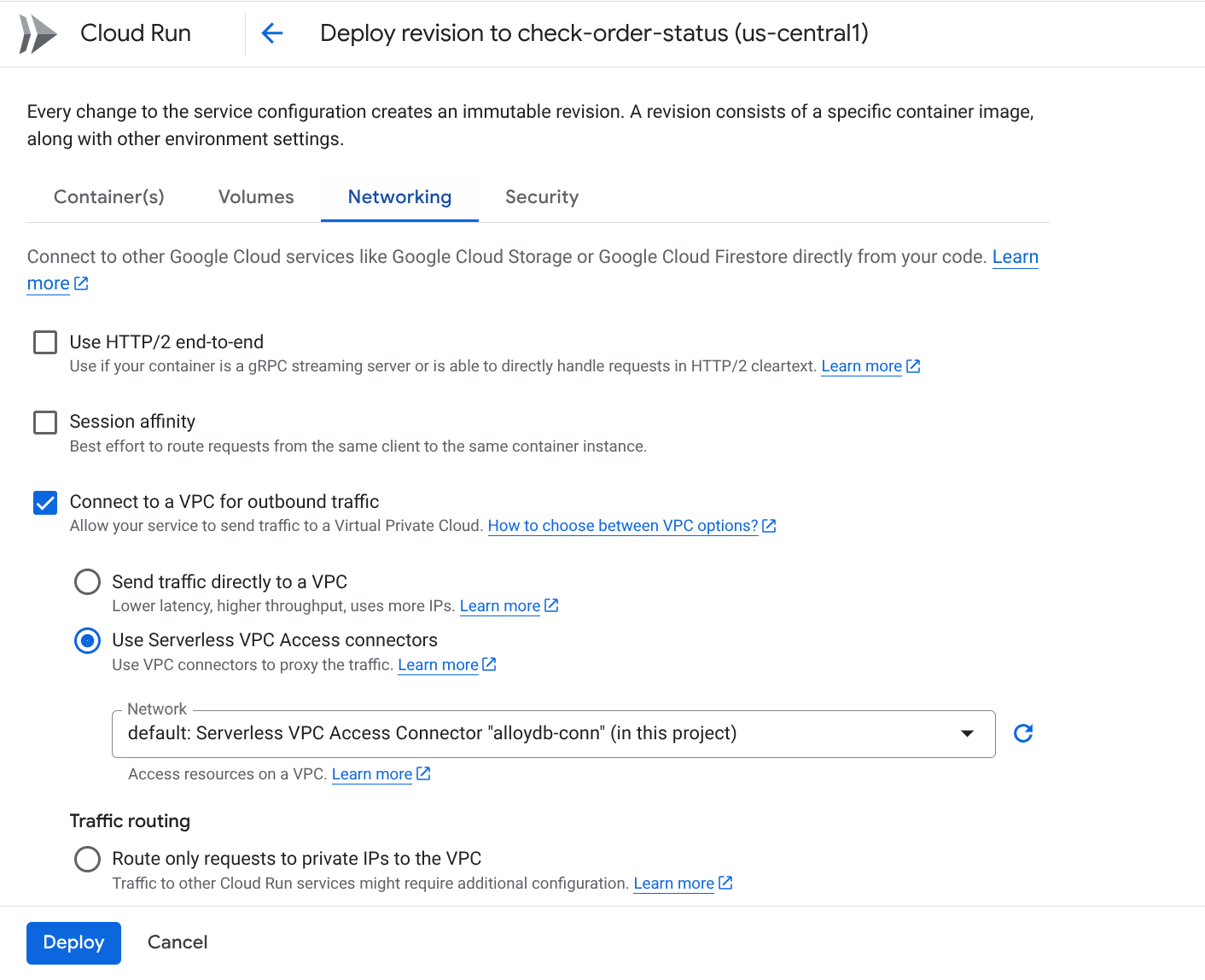
"आउटबाउंड ट्रैफ़िक के लिए वीपीसी से कनेक्ट करें" को चुनें. इसके बाद, "सर्वर के बिना वीपीसी ऐक्सेस करने की सुविधा वाले कनेक्टर का इस्तेमाल करें" को चुनें
नेटवर्क ड्रॉपडाउन में, सेटिंग पर जाएं. नेटवर्क ड्रॉपडाउन पर क्लिक करें और "नया वीपीसी कनेक्टर जोड़ें" विकल्प चुनें. ऐसा तब करें, जब आपने डिफ़ॉल्ट कनेक्टर पहले से कॉन्फ़िगर न किया हो. इसके बाद, पॉप-अप होने वाले डायलॉग बॉक्स में दिए गए निर्देशों का पालन करें:
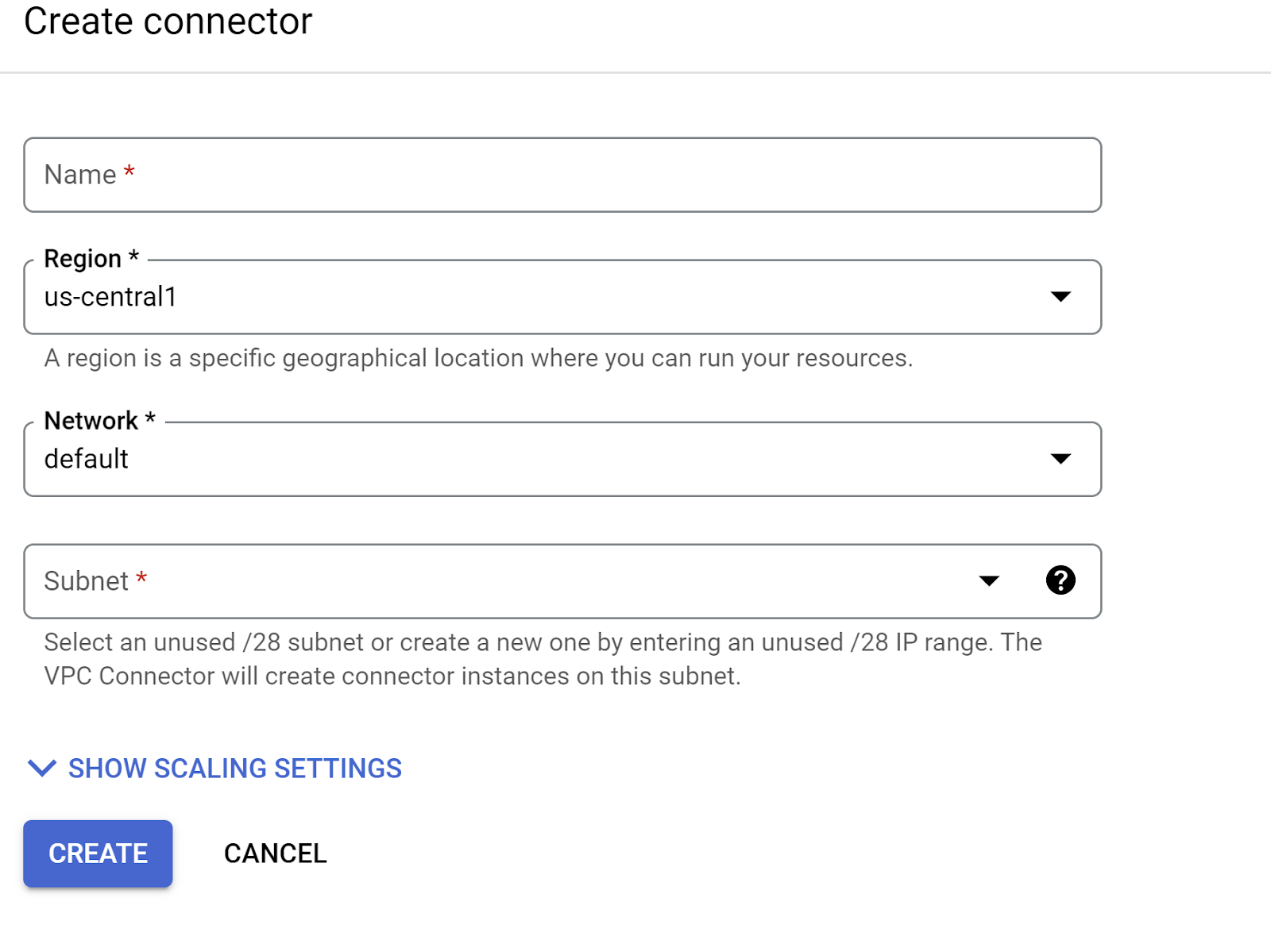
VPC कनेक्टर को कोई नाम दें. साथ ही, पक्का करें कि क्षेत्र वही हो जो आपके इंस्टेंस का है. नेटवर्क की वैल्यू को डिफ़ॉल्ट के तौर पर छोड़ दें. साथ ही, सबनेट को कस्टम आईपी रेंज के तौर पर सेट करें. इसके लिए, 10.8.0.0 या इसके जैसा कोई अन्य आईपी रेंज इस्तेमाल करें.
'स्केलिंग सेटिंग दिखाएं' को बड़ा करें और पक्का करें कि आपने कॉन्फ़िगरेशन को ठीक इस तरह सेट किया हो:
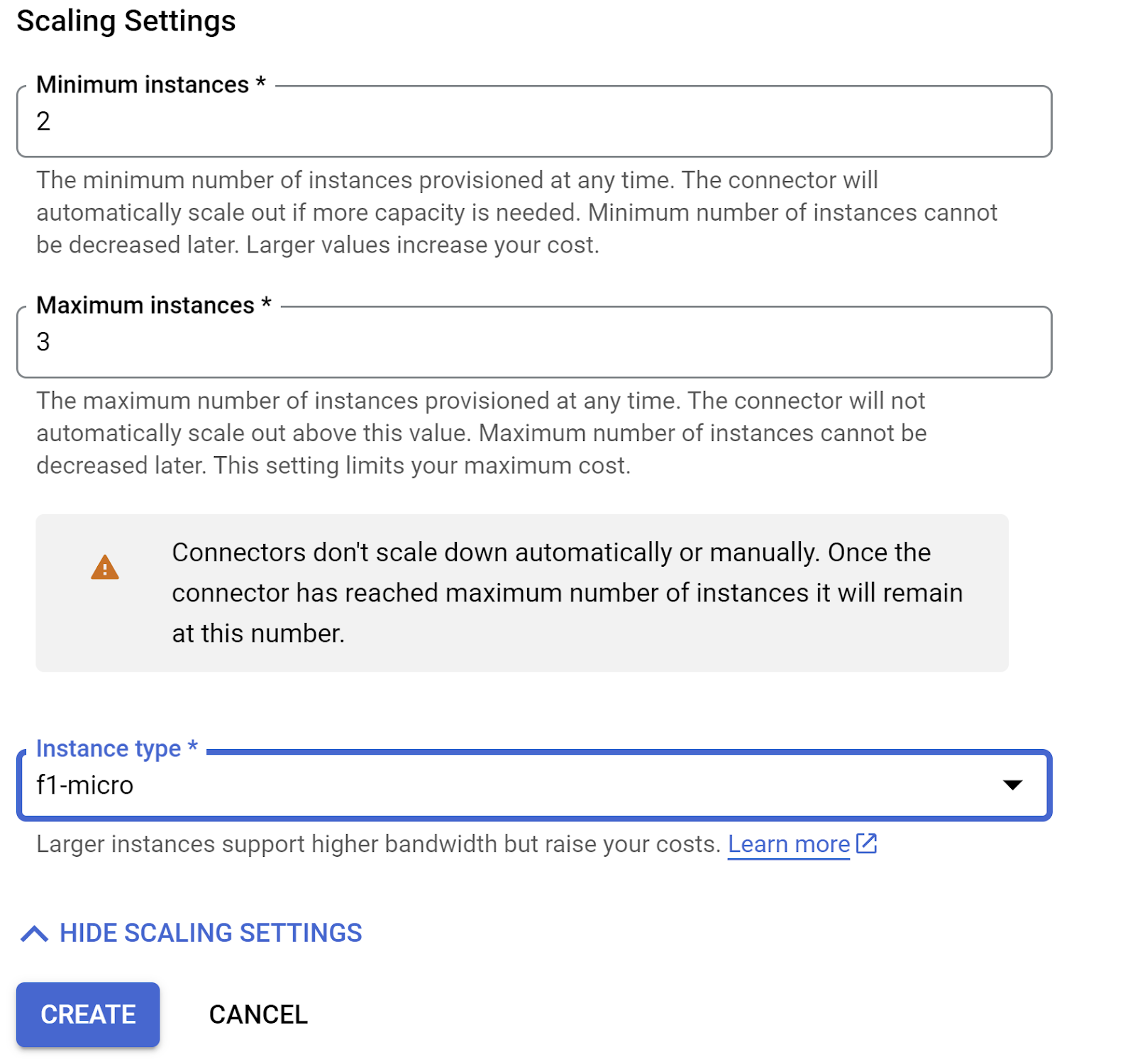
बनाएं पर क्लिक करें. अब यह कनेक्टर, डेटा बाहर भेजने की सेटिंग में दिखना चाहिए.
हाल ही में बनाया गया कनेक्टर चुनें.
इस वीपीसी कनेक्टर के ज़रिए सभी ट्रैफ़िक को रूट करने का विकल्प चुनें.
आगे बढ़ें पर क्लिक करें. इसके बाद, लागू करें पर क्लिक करें.
- डिफ़ॉल्ट रूप से, यह एंट्री पॉइंट को "gcfv2.HelloHttpFunction" पर सेट कर देगा. Cloud Run फ़ंक्शन की HelloHttpFunction.java और pom.xml में मौजूद प्लेसहोल्डर कोड को, " PatentSearch.java" और " pom.xml" से बदलें. क्लास फ़ाइल का नाम बदलकर PatentSearch.java करें.
- Java फ़ाइल में, ************* प्लेसहोल्डर और AlloyDB कनेक्शन क्रेडेंशियल को अपनी वैल्यू से बदलना न भूलें. AlloyDB के क्रेडेंशियल वही हैं जिनका इस्तेमाल हमने इस कोडलैब की शुरुआत में किया था. अगर आपने अलग-अलग वैल्यू का इस्तेमाल किया है, तो कृपया Java फ़ाइल में जाकर उनमें बदलाव करें.
- डिप्लॉय करें पर क्लिक करें.
- अपडेट किए गए Cloud Function को डिप्लॉय करने के बाद, आपको जनरेट किया गया एंडपॉइंट दिखेगा. उसे कॉपी करें और यहां दिए गए निर्देश में बदलें:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
हो गया! AlloyDB के डेटा पर Embeddings मॉडल का इस्तेमाल करके, कॉन्टेक्स्ट के हिसाब से मिलते-जुलते शब्दों को खोजने की बेहतर सुविधा का इस्तेमाल करना बहुत आसान है.
8. Java ADK की मदद से एजेंट बनाना
सबसे पहले, एडिटर में Java प्रोजेक्ट का इस्तेमाल शुरू करते हैं.
- Cloud Shell टर्मिनल पर जाएं
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- निर्देश मिलने पर अनुमति दें
- Cloud Shell कंसोल में सबसे ऊपर मौजूद एडिटर आइकॉन पर क्लिक करके, Cloud Shell Editor पर टॉगल करें

- लैंडिंग Cloud Shell Editor कंसोल में, एक नया फ़ोल्डर बनाएं और उसका नाम "adk-agents" रखें
नीचे दिए गए तरीके से, अपने Cloud Shell की रूट डायरेक्ट्री में नया फ़ोल्डर बनाएं:
इसे "adk-agents" नाम दें:
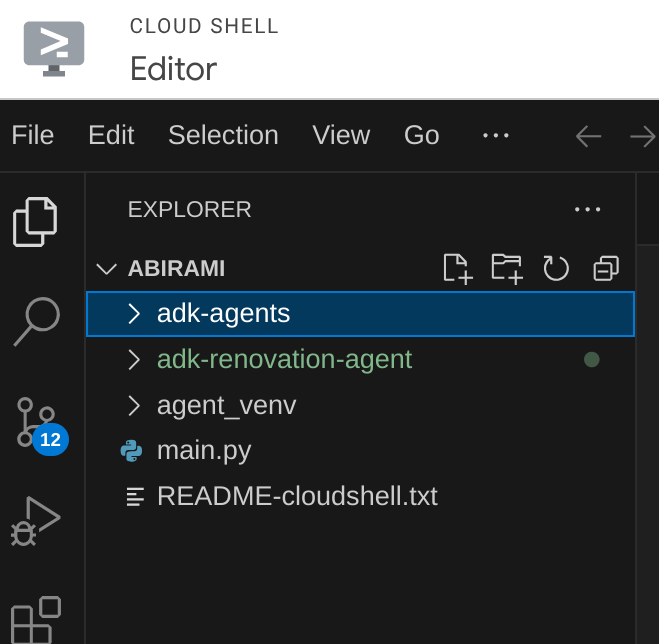
- नीचे दिए गए स्ट्रक्चर के हिसाब से फ़ोल्डर बनाएं. साथ ही, स्ट्रक्चर में दिए गए फ़ाइल नामों के हिसाब से खाली फ़ाइलें बनाएं:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- GitHub repo को किसी दूसरे टैब में खोलें. इसके बाद, App.java और pom.xml फ़ाइलों के सोर्स कोड को कॉपी करें.
- अगर आपने सबसे ऊपर दाएं कोने में मौजूद "नए टैब में खोलें" आइकॉन का इस्तेमाल करके, एडिटर को नए टैब में खोला था, तो आपके पास पेज के सबसे नीचे टर्मिनल खोलने का विकल्प होता है. एडिटर और टर्मिनल, दोनों को एक साथ खोला जा सकता है. इससे आपको काम करने में आसानी होती है.
- क्लोन करने के बाद, वापस Cloud Shell Editor कंसोल पर टॉगल करें
- हमने Cloud Run फ़ंक्शन पहले ही बना लिया है. इसलिए, आपको repo फ़ोल्डर से Cloud Run फ़ंक्शन की फ़ाइलों को कॉपी करने की ज़रूरत नहीं है.
ADK Java SDK का इस्तेमाल शुरू करना
यह काफ़ी आसान है. आपको मुख्य रूप से यह पक्का करना होगा कि क्लोन करने के चरण में ये चीज़ें शामिल हों:
- डिपेंडेंसी जोड़ें:
अपने pom.xml में google-adk और google-adk-dev (वेब यूज़र इंटरफ़ेस के लिए) आर्टफ़ैक्ट शामिल करें. अगर आपने सोर्स को रिपॉज़िटरी से कॉपी किया है, तो ये फ़ाइलों में पहले से शामिल होते हैं. आपको इन्हें शामिल करने की ज़रूरत नहीं है. आपको सिर्फ़ Cloud Run फ़ंक्शन के एंडपॉइंट में बदलाव करना होगा, ताकि डिप्लॉय किए गए एंडपॉइंट को दिखाया जा सके. इसके बारे में इस सेक्शन में आगे बताया गया है.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
सोर्स रिपॉज़िटरी से pom.xml को रेफ़रंस के तौर पर इस्तेमाल करना न भूलें. ऐसा इसलिए, क्योंकि ऐप्लिकेशन को चलाने के लिए अन्य डिपेंडेंसी और कॉन्फ़िगरेशन की ज़रूरत होती है.
- अपना प्रोजेक्ट कॉन्फ़िगर करें:
पक्का करें कि आपके pom.xml में, Java का वर्शन (17 या इससे ऊपर का वर्शन इस्तेमाल करने का सुझाव दिया जाता है) और Maven कंपाइलर की सेटिंग सही तरीके से कॉन्फ़िगर की गई हों. अपने प्रोजेक्ट को इस स्ट्रक्चर के हिसाब से कॉन्फ़िगर किया जा सकता है:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- एजेंट और उसके टूल तय करना (App.java):
ADK Java SDK का कमाल यहीं दिखता है. हम अपने एजेंट, उसकी क्षमताओं (निर्देशों), और उसके इस्तेमाल किए जा सकने वाले टूल के बारे में बताते हैं.
मुख्य एजेंट क्लास के कुछ कोड स्निपेट का आसान वर्शन यहां देखें. पूरे प्रोजेक्ट के लिए, प्रोजेक्ट रेपो यहां देखें.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
ADK के मुख्य Java कोड कॉम्पोनेंट हाइलाइट किए गए हैं:
- LlmAgent.builder(): यह फ़्लुएंट एपीआई है. इसका इस्तेमाल, अपने एजेंट को कॉन्फ़िगर करने के लिए किया जाता है.
- .instruction(...): यह LLM के लिए मुख्य प्रॉम्प्ट और दिशा-निर्देश देता है. इसमें यह भी शामिल है कि किस टूल का इस्तेमाल कब करना है.
- FunctionTool.create(App.class, "methodName"): इससे आपके Java तरीकों को टूल के तौर पर आसानी से रजिस्टर किया जा सकता है. एजेंट इन टूल को चालू कर सकता है. तरीके के नाम वाली स्ट्रिंग, किसी सार्वजनिक स्टैटिक तरीके से मेल खानी चाहिए.
- @Schema(description = ...): यह टूल के पैरामीटर को एनोटेट करता है. इससे एलएलएम को यह समझने में मदद मिलती है कि हर टूल को किस तरह के इनपुट की ज़रूरत है. टूल को सही तरीके से चुनने और पैरामीटर भरने के लिए, यह ब्यौरा देना ज़रूरी है.
- InvocationContext ctx: इसे टूल के तरीकों में अपने-आप पास कर दिया जाता है. इससे सेशन की स्थिति (ctx.session().state()), उपयोगकर्ता की जानकारी वगैरह को ऐक्सेस किया जा सकता है.
- .outputKey("patents"): जब कोई टूल डेटा दिखाता है, तो ADK इस कुंजी के तहत सेशन की स्थिति में डेटा को अपने-आप सेव कर सकता है. इस तरह explainPatent, getPatents से मिले नतीजों को ऐक्सेस कर सकता है.
- VECTOR_SEARCH_ENDPOINT: यह एक वैरिएबल है. इसमें पेटेंट की खोज के इस्तेमाल के उदाहरण में, उपयोगकर्ता के लिए कॉन्टेक्स्ट के हिसाब से सवाल-जवाब की सुविधा के लिए मुख्य फ़ंक्शनल लॉजिक होता है.
- यहां कार्रवाई करने के लिए आइटम दिया गया है: पिछले सेक्शन में दिए गए Java Cloud Run फ़ंक्शन को लागू करने के बाद, आपको डिप्लॉय किए गए अपडेट किए गए एंडपॉइंट की वैल्यू सेट करनी होगी.
- searchTool: यह टूल, उपयोगकर्ता की खोज के टेक्स्ट के लिए, पेटेंट डेटाबेस से कॉन्टेक्स्ट के हिसाब से मिलते-जुलते पेटेंट ढूंढने के लिए, उपयोगकर्ता के साथ इंटरैक्ट करता है.
- explainTool: यह टूल, उपयोगकर्ता से किसी खास पेटेंट के बारे में ज़्यादा जानकारी देने के लिए कहता है. इसके बाद, यह पेटेंट के ऐब्स्ट्रैक्ट की खास जानकारी देता है. साथ ही, यह पेटेंट की जानकारी के आधार पर, उपयोगकर्ता के ज़्यादा सवालों के जवाब दे सकता है.
अहम जानकारी: पक्का करें कि आपने VECTOR_SEARCH_ENDPOINT वैरिएबल को अपने डिप्लॉय किए गए CRF एंडपॉइंट से बदल दिया हो.
स्टेटफ़ुल इंटरैक्शन के लिए InvocationContext का इस्तेमाल करना
एजेंट को मददगार बनाने के लिए, बातचीत के कई चरणों में उसकी स्थिति को मैनेज करना ज़रूरी होता है. ADK के InvocationContext की मदद से, इसे आसानी से किया जा सकता है.
App.java में:
- जब initAgent() को तय किया जाता है, तब हम .outputKey("patents") का इस्तेमाल करते हैं. इससे ADK को यह पता चलता है कि जब कोई टूल (जैसे, getPatents) अपने रिपोर्ट फ़ील्ड में डेटा दिखाता है, तो उस डेटा को सेशन की स्थिति में "patents" कुंजी के तहत सेव किया जाना चाहिए.
- explainPatent टूल के तरीके में, हम InvocationContext ctx को इंजेक्ट करते हैं:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
इससे explainPatent टूल को, getPatents टूल से पिछली बारी में फ़ेच की गई पेटेंट की सूची को ऐक्सेस करने की अनुमति मिलती है. इससे बातचीत को स्टेटफ़ुल और सुसंगत बनाया जा सकता है.
9. सीएलआई की स्थानीय तौर पर टेस्टिंग
एनवायरमेंट वैरिएबल तय करना
आपको दो एनवायरमेंट वैरिएबल एक्सपोर्ट करने होंगे:
- Gemini का पासकोड, जिसे AI Studio से पाया जा सकता है:
इसके लिए, https://aistudio.google.com/apikey पर जाएं. इसके बाद, उस चालू Google Cloud प्रोजेक्ट के लिए एपीआई पासकोड पाएं जिसमें आपको यह ऐप्लिकेशन लागू करना है. साथ ही, उस पासकोड को कहीं सेव करें:
- कुंजी मिलने के बाद, Cloud Shell टर्मिनल खोलें और उस नई डायरेक्ट्री पर जाएं जिसे हमने अभी-अभी adk-agents नाम से बनाया है. इसके लिए, यह कमांड चलाएं:
cd adk-agents
- यह वैरिएबल यह तय करता है कि इस बार Vertex AI का इस्तेमाल नहीं किया जा रहा है.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- सीएलआई पर अपना पहला एजेंट चलाना
इस पहले एजेंट को लॉन्च करने के लिए, अपने टर्मिनल में Maven के इस निर्देश का इस्तेमाल करें:
mvn compile exec:java -DmainClass="agents.App"
आपको अपने टर्मिनल में एजेंट से मिला इंटरैक्टिव जवाब दिखेगा.
10. Cloud Run पर डिप्लॉय करना
ADK Java एजेंट को Cloud Run पर डिप्लॉय करने का तरीका, किसी अन्य Java ऐप्लिकेशन को डिप्लॉय करने के तरीके जैसा ही होता है:
- Dockerfile: अपने Java ऐप्लिकेशन को पैकेज करने के लिए, एक Dockerfile बनाएं.
- डॉकर इमेज बनाना और उसे पुश करना: Google Cloud Build और Artifact Registry का इस्तेमाल करें.
- ऊपर दिया गया चरण पूरा करने और Cloud Run में डिप्लॉय करने के लिए, सिर्फ़ एक कमांड का इस्तेमाल किया जा सकता है:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
इसी तरह, आपको अपने Java Cloud Run फ़ंक्शन (gcfv2.PatentSearch) को डिप्लॉय करना होगा. इसके अलावा, डेटाबेस लॉजिक के लिए Java Cloud Run फ़ंक्शन को सीधे Cloud Run फ़ंक्शन कंसोल से बनाया और डिप्लॉय किया जा सकता है.
11. वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके जांच करना
ADK में, एजेंट की स्थानीय तौर पर टेस्टिंग और डीबग करने के लिए, काम का वेब यूज़र इंटरफ़ेस (यूआई) होता है. App.java को स्थानीय तौर पर चलाने पर, ADK आम तौर पर एक लोकल वेब सर्वर शुरू करता है. जैसे, अगर कॉन्फ़िगर किया गया है, तो mvn exec:java -Dexec.mainClass="agents.App" या सिर्फ़ मुख्य तरीका चलाने पर.
ADK के वेब यूज़र इंटरफ़ेस (यूआई) की मदद से, ये काम किए जा सकते हैं:
- अपने एजेंट को मैसेज भेजें.
- इवेंट देखें (उपयोगकर्ता का मैसेज, टूल कॉल, टूल का जवाब, एलएलएम का जवाब).
- सेशन की स्थिति की जांच करें.
- लॉग और ट्रेस देखें.
डेवलपमेंट के दौरान, यह जानकारी बहुत काम आती है. इससे यह समझने में मदद मिलती है कि आपका एजेंट अनुरोधों को कैसे प्रोसेस करता है और अपने टूल का इस्तेमाल कैसे करता है. इससे यह माना जाता है कि pom.xml में आपका mainClass, com.google.adk.web.AdkWebServer पर सेट है और आपका एजेंट इसके साथ रजिस्टर है. इसके अलावा, यह भी माना जाता है कि आपके पास ऐसा लोकल टेस्ट रनर है जो इसे दिखाता है.
App.java को InMemoryRunner और कंसोल इनपुट के लिए Scanner के साथ चलाने पर, मुख्य एजेंट लॉजिक की जांच की जाती है. वेब यूज़र इंटरफ़ेस (यूआई), विज़ुअल डीबगिंग के लिए एक अलग कॉम्पोनेंट है. इसका इस्तेमाल अक्सर तब किया जाता है, जब एडीके आपके एजेंट को एचटीटीपी पर दिखाता है.
SpringBoot के लोकल सर्वर को लॉन्च करने के लिए, अपनी रूट डायरेक्ट्री से इस Maven कमांड का इस्तेमाल किया जा सकता है:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
इंटरफ़ेस को अक्सर उस यूआरएल पर ऐक्सेस किया जा सकता है जिसे ऊपर दिए गए कमांड से आउटपुट किया जाता है. अगर इसे Cloud Run पर डिप्लॉय किया गया है, तो इसे Cloud Run पर डिप्लॉय किए गए लिंक से ऐक्सेस किया जा सकता है.
आपको इंटरैक्टिव इंटरफ़ेस में नतीजे दिखेंगे.
हमारे पेटेंट एजेंट के बारे में जानने के लिए, यहां दिया गया वीडियो देखें:
12. व्यवस्थित करें
इस पोस्ट में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog पर जाएं
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
13. बधाई हो
बधाई हो! आपने Java में, पेटेंट का विश्लेषण करने वाला एजेंट बनाया है. इसके लिए, आपने ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI, और Vector Search की सुविधाओं का इस्तेमाल किया है. साथ ही, हमने कॉन्टेक्स्ट के हिसाब से मिलती-जुलती खोजों को ज़्यादा असरदार, बेहतर, और काम की जानकारी देने वाला बनाने के लिए, एक बड़ा कदम आगे बढ़ाया है.
आज ही शुरू करें!
ADK के दस्तावेज़: [Link to Official ADK Java Docs]
पेटेंट का विश्लेषण करने वाले एजेंट का सोर्स कोड: [Link to your (now public) GitHub Repo]
Java के सैंपल एजेंट: [link to the adk-samples repo]
ADK कम्यूनिटी में शामिल हों: https://www.reddit.com/r/agentdevelopmentkit/
एजेंट बनाने के लिए शुभकामनाएं!