
1. ภาพรวม
การค้นหาตามบริบทเป็นฟังก์ชันที่สำคัญซึ่งเป็นหัวใจหลักของแอปพลิเคชันในอุตสาหกรรมต่างๆ การสร้างแบบดึงข้อมูลเสริมเป็นตัวขับเคลื่อนหลักของการพัฒนาเทคโนโลยีที่สำคัญนี้มาสักระยะแล้วด้วยกลไกการดึงข้อมูลที่ทำงานด้วยระบบ Generative AI โมเดล Generative ที่มีหน้าต่างบริบทขนาดใหญ่และคุณภาพเอาต์พุตที่น่าประทับใจกำลังเปลี่ยนโฉมหน้า AI RAG เป็นวิธีที่เป็นระบบในการแทรกบริบทลงในแอปพลิเคชันและเอเจนต์ AI โดยอิงตามฐานข้อมูลที่มีโครงสร้างหรือข้อมูลจากสื่อต่างๆ ข้อมูลตามบริบทนี้มีความสำคัญอย่างยิ่งต่อความชัดเจนของความจริงและความถูกต้องของเอาต์พุต แต่ผลลัพธ์เหล่านั้นมีความถูกต้องเพียงใด ธุรกิจของคุณขึ้นอยู่กับความแม่นยำและความเกี่ยวข้องของการจับคู่ตามบริบทเหล่านี้เป็นส่วนใหญ่ใช่ไหม โปรเจ็กต์นี้จะทำให้คุณหัวเราะได้แน่นอน
ลองนึกภาพว่าหากเราใช้ความสามารถของโมเดล Generative และสร้างเอเจนต์แบบอินเทอร์แอกทีฟที่สามารถตัดสินใจด้วยตนเองโดยอิงตามข้อมูลที่สำคัญต่อบริบทดังกล่าวและอิงตามข้อเท็จจริงได้ นั่นคือสิ่งที่เราจะสร้างในวันนี้ เราจะสร้างแอป AI Agent แบบครบวงจรโดยใช้ Agent Development Kit ที่ขับเคลื่อนโดย RAG ขั้นสูงใน AlloyDB สำหรับแอปพลิเคชันวิเคราะห์สิทธิบัตร
เอเจนต์วิเคราะห์สิทธิบัตรจะช่วยผู้ใช้ค้นหาสิทธิบัตรที่เกี่ยวข้องตามบริบทกับข้อความค้นหา และเมื่อมีการขอ เอเจนต์จะให้คำอธิบายที่ชัดเจนและกระชับ รวมถึงรายละเอียดเพิ่มเติมหากจำเป็นสำหรับสิทธิบัตรที่เลือก พร้อมดูวิธีการแล้วใช่ไหม มาดูกันเลย
วัตถุประสงค์
เป้าหมายนั้นง่ายมาก อนุญาตให้ผู้ใช้ค้นหาสิทธิบัตรตามคำอธิบายที่เป็นข้อความ แล้วรับคำอธิบายโดยละเอียดของสิทธิบัตรที่เฉพาะเจาะจงจากผลการค้นหา ทั้งหมดนี้ใช้ AI Agent ที่สร้างด้วย Java ADK, AlloyDB, Vector Search (พร้อมดัชนีขั้นสูง), Gemini และแอปพลิเคชันทั้งหมดที่ติดตั้งใช้งานแบบไร้เซิร์ฟเวอร์ใน Cloud Run
สิ่งที่คุณจะสร้าง
ในห้องทดลองนี้ คุณจะทำสิ่งต่อไปนี้
- สร้างอินสแตนซ์ AlloyDB และโหลดข้อมูลชุดข้อมูลสาธารณะเกี่ยวกับสิทธิบัตร
- ใช้ Vector Search ขั้นสูงใน AlloyDB โดยใช้ฟีเจอร์ ScaNN และการประเมินการเรียกคืน
- สร้าง Agent โดยใช้ Java ADK
- ใช้ตรรกะฝั่งเซิร์ฟเวอร์ของฐานข้อมูลใน Cloud Functions แบบ Serverless ของ Java
- ติดตั้งใช้งานและทดสอบ Agent ใน Cloud Run
แผนภาพต่อไปนี้แสดงขั้นตอนและโฟลว์ของข้อมูลที่เกี่ยวข้องในการติดตั้งใช้งาน
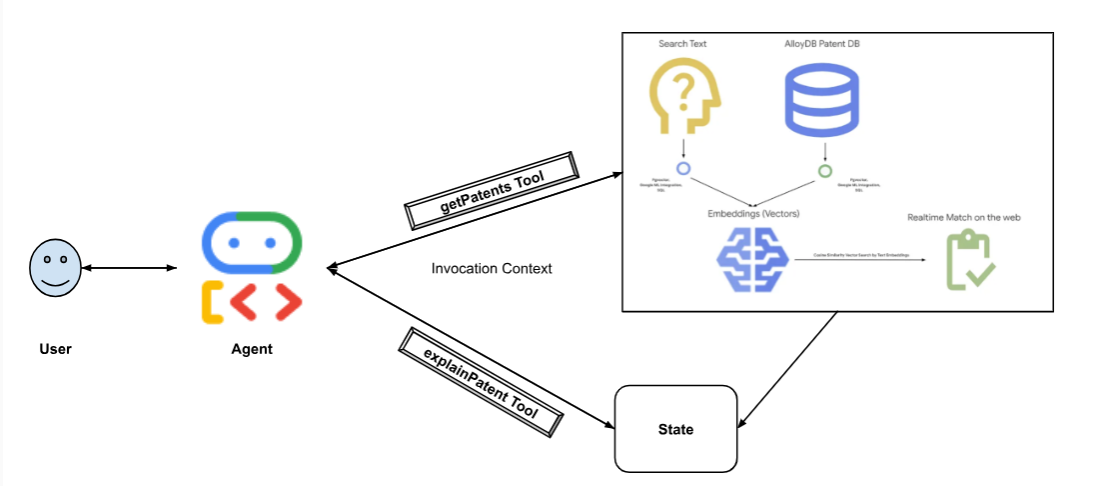
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น คุณใช้คำสั่ง gcloud ในเทอร์มินัล Cloud Shell ได้โดยทำดังนี้
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
คุณสามารถใช้คอนโซลแทนคำสั่ง gcloud ได้โดยค้นหาแต่ละผลิตภัณฑ์หรือใช้ลิงก์นี้
โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
3. การตั้งค่าฐานข้อมูล
ในแล็บนี้ เราจะใช้ AlloyDB เป็นฐานข้อมูลสำหรับข้อมูลสิทธิบัตร โดยจะใช้คลัสเตอร์เพื่อจัดเก็บทรัพยากรทั้งหมด เช่น ฐานข้อมูลและบันทึก แต่ละคลัสเตอร์มีอินสแตนซ์หลักที่ให้จุดเข้าใช้งานข้อมูล ตารางจะเก็บข้อมูลจริง
มาสร้างคลัสเตอร์ อินสแตนซ์ และตาราง AlloyDB ที่จะโหลดชุดข้อมูลสิทธิบัตรกัน
สร้างคลัสเตอร์และอินสแตนซ์
- ไปที่หน้า AlloyDB ใน Cloud Console วิธีง่ายๆ ในการค้นหาหน้าส่วนใหญ่ใน Cloud Console คือการค้นหาโดยใช้แถบค้นหาของคอนโซล
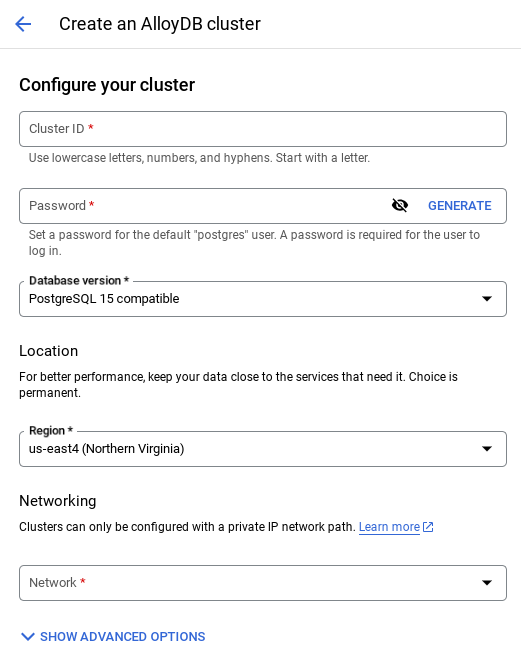
- เลือกสร้างคลัสเตอร์จากหน้านั้น

- คุณจะเห็นหน้าจอคล้ายกับหน้าจอด้านล่าง สร้างคลัสเตอร์และอินสแตนซ์ด้วยค่าต่อไปนี้ (ตรวจสอบว่าค่าตรงกันในกรณีที่คุณโคลนโค้ดของแอปพลิเคชันจากที่เก็บ)
- รหัสคลัสเตอร์: "
vector-cluster" - รหัสผ่าน: "
alloydb" - PostgreSQL 15 / ล่าสุดที่แนะนำ
- ภูมิภาค: "
us-central1" - เครือข่าย: "
default"
- เมื่อเลือกเครือข่ายเริ่มต้น คุณจะเห็นหน้าจอคล้ายกับหน้าจอด้านล่าง
เลือกตั้งค่าการเชื่อมต่อ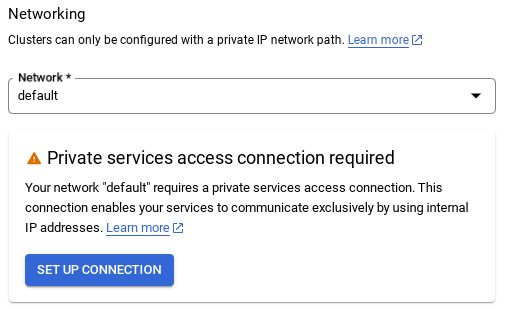
- จากนั้นเลือก "ใช้ช่วง IP ที่มีการจัดสรรโดยอัตโนมัติ" แล้วคลิก "ต่อไป" หลังจากตรวจสอบข้อมูลแล้ว ให้เลือกสร้างการเชื่อมต่อ
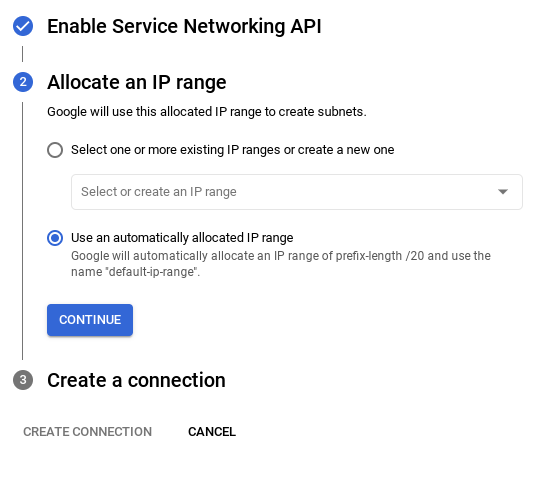
- เมื่อตั้งค่าเครือข่ายแล้ว คุณจะสร้างคลัสเตอร์ต่อไปได้ คลิกสร้างคลัสเตอร์เพื่อตั้งค่าคลัสเตอร์ให้เสร็จสมบูรณ์ตามที่แสดงด้านล่าง
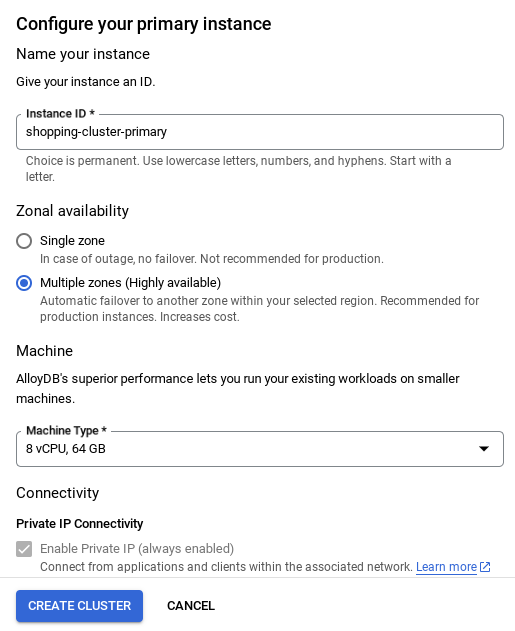
อย่าลืมเปลี่ยนรหัสอินสแตนซ์ (ซึ่งคุณดูได้ในขณะที่กำหนดค่าคลัสเตอร์ / อินสแตนซ์) เป็น
vector-instance หากเปลี่ยนไม่ได้ โปรดใช้รหัสอินสแตนซ์ในการอ้างอิงที่จะเกิดขึ้นทั้งหมด
โปรดทราบว่าการสร้างคลัสเตอร์จะใช้เวลาประมาณ 10 นาที เมื่อดำเนินการสำเร็จแล้ว คุณควรเห็นหน้าจอที่แสดงภาพรวมของคลัสเตอร์ที่เพิ่งสร้าง
4. การนำเข้าข้อมูล
ตอนนี้ได้เวลาเพิ่มตารางที่มีข้อมูลเกี่ยวกับร้านค้าแล้ว ไปที่ AlloyDB เลือกคลัสเตอร์หลัก แล้วเลือก AlloyDB Studio โดยทำดังนี้
คุณอาจต้องรอให้อินสแตนซ์สร้างเสร็จ เมื่อพร้อมแล้ว ให้ลงชื่อเข้าใช้ AlloyDB โดยใช้ข้อมูลเข้าสู่ระบบที่คุณสร้างขึ้นเมื่อสร้างคลัสเตอร์ ใช้ข้อมูลต่อไปนี้เพื่อตรวจสอบสิทธิ์ใน PostgreSQL
- ชื่อผู้ใช้ : "
postgres" - ฐานข้อมูล : "
postgres" - รหัสผ่าน : "
alloydb"
เมื่อตรวจสอบสิทธิ์ใน AlloyDB Studio สำเร็จแล้ว ให้ป้อนคำสั่ง SQL ในเอดิเตอร์ คุณเพิ่มหน้าต่างเอดิเตอร์หลายหน้าต่างได้โดยใช้เครื่องหมายบวกทางด้านขวาของหน้าต่างสุดท้าย
คุณจะป้อนคำสั่งสำหรับ AlloyDB ในหน้าต่างเอดิเตอร์ โดยใช้ตัวเลือกเรียกใช้ จัดรูปแบบ และล้างตามที่จำเป็น
เปิดใช้ส่วนขยาย
ในการสร้างแอปนี้ เราจะใช้ส่วนขยาย pgvector และ google_ml_integration ส่วนขยาย pgvector ช่วยให้คุณจัดเก็บและค้นหาการฝังเวกเตอร์ได้ ส่วนขยาย google_ml_integration มีฟังก์ชันที่คุณใช้เพื่อเข้าถึงปลายทางการคาดการณ์ของ Vertex AI เพื่อรับการคาดการณ์ใน SQL เปิดใช้ส่วนขยายเหล่านี้โดยเรียกใช้ DDL ต่อไปนี้
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
หากต้องการตรวจสอบส่วนขยายที่เปิดใช้ในฐานข้อมูล ให้เรียกใช้คำสั่ง SQL นี้
select extname, extversion from pg_extension;
สร้างตาราง
คุณสร้างตารางได้โดยใช้คำสั่ง DDL ด้านล่างใน AlloyDB Studio
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
คอลัมน์ abstract_embeddings จะอนุญาตให้จัดเก็บค่าเวกเตอร์ของข้อความ
ให้สิทธิ์
เรียกใช้คำสั่งด้านล่างเพื่อให้สิทธิ์ดำเนินการในฟังก์ชัน "ฝัง"
GRANT EXECUTE ON FUNCTION embedding TO postgres;
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ AlloyDB
จากคอนโซล Google Cloud IAM ให้สิทธิ์เข้าถึงบทบาท "ผู้ใช้ Vertex AI" แก่บัญชีบริการ AlloyDB (ซึ่งมีลักษณะดังนี้ service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com) PROJECT_NUMBER จะมีหมายเลขโปรเจ็กต์ของคุณ
หรือคุณอาจเรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell ก็ได้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
โหลดข้อมูลสิทธิบัตรลงในฐานข้อมูล
เราจะใช้ชุดข้อมูลสาธารณะของ Google Patents ใน BigQuery เป็นชุดข้อมูล เราจะใช้ AlloyDB Studio เพื่อเรียกใช้การค้นหา เราจะดึงข้อมูลลงในinsert scripts sqlไฟล์นี้ในที่เก็บนี้ และจะเรียกใช้ไฟล์นี้เพื่อโหลดข้อมูลสิทธิบัตร
- เปิดหน้า AlloyDB ในคอนโซล Google Cloud
- เลือกคลัสเตอร์ที่สร้างขึ้นใหม่ แล้วคลิกอินสแตนซ์
- ในเมนูการนำทางของ AlloyDB ให้คลิก AlloyDB Studio ลงชื่อเข้าใช้ด้วยข้อมูลเข้าสู่ระบบ
- เปิดแท็บใหม่โดยคลิกไอคอนแท็บใหม่ทางด้านขวา
- คัดลอกและเรียกใช้คำสั่งการค้นหา
insertจากไฟล์insert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlทีละไฟล์ คุณเรียกใช้คำสั่งแทรกสำเนา 10-50 รายการเพื่อดูการสาธิตกรณีการใช้งานนี้อย่างรวดเร็วได้
หากต้องการเรียกใช้ ให้คลิกเรียกใช้ ผลลัพธ์ของคำค้นหาจะปรากฏในตารางผลลัพธ์
5. สร้างการฝังสำหรับข้อมูลสิทธิบัตร
ก่อนอื่น มาทดสอบฟังก์ชันการฝังโดยเรียกใช้การสืบค้นตัวอย่างต่อไปนี้
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
ซึ่งควรแสดงผลเวกเตอร์การฝังที่มีลักษณะคล้ายอาร์เรย์ของจำนวนทศนิยมสำหรับข้อความตัวอย่างในการค้นหา มีลักษณะดังนี้
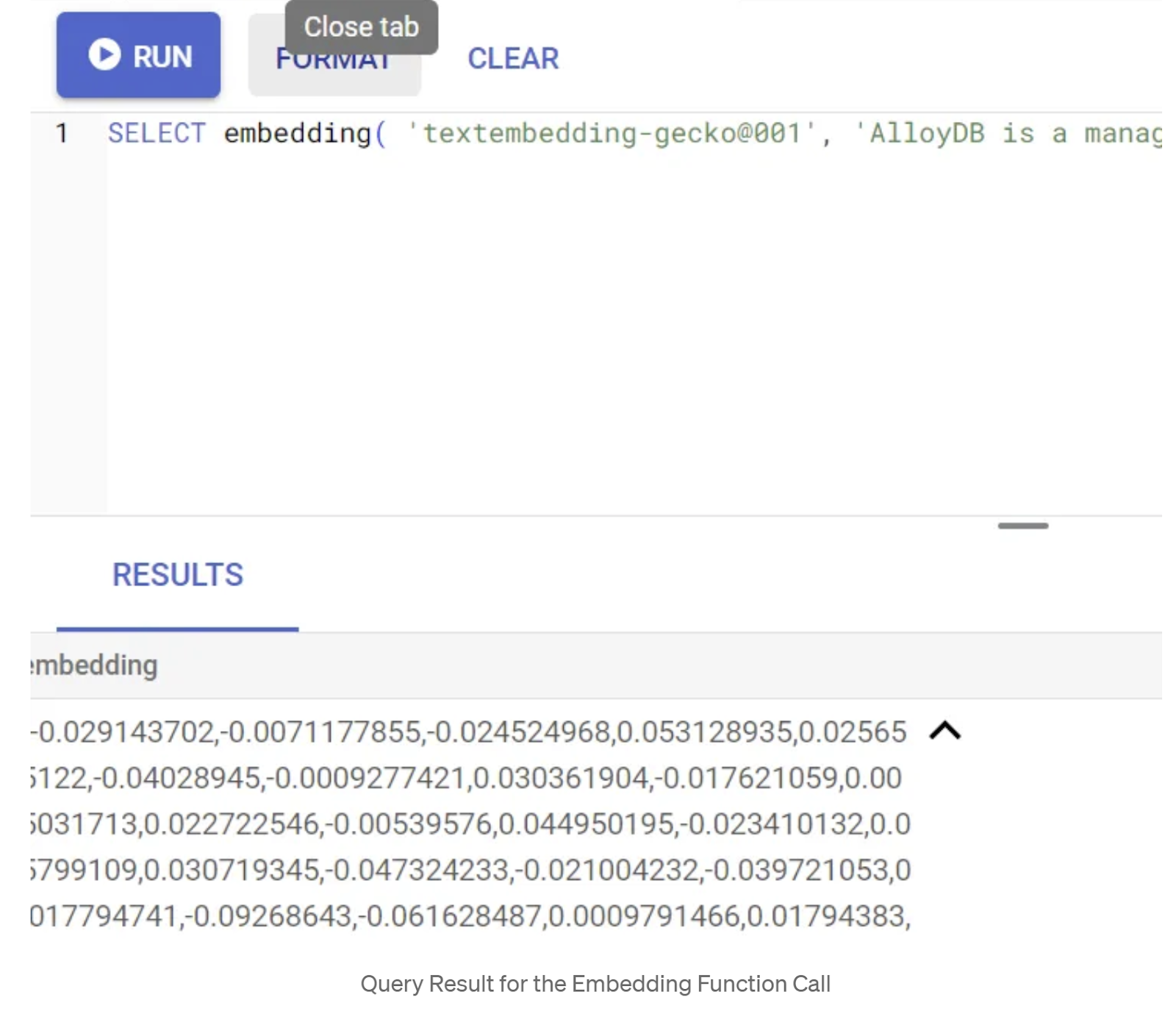
อัปเดตฟิลด์เวกเตอร์ abstract_embeddings
ควรใช้ DML ด้านล่างเพื่ออัปเดตบทคัดย่อสิทธิบัตรในตารางด้วยการฝังที่เกี่ยวข้องในกรณีที่ต้องสร้างการฝังสำหรับบทคัดย่อ แต่ในกรณีของเรา คำสั่งแทรกมี Embedding เหล่านี้สำหรับแต่ละบทคัดย่ออยู่แล้ว คุณจึงไม่จำเป็นต้องเรียกใช้เมธอด embeddings()
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. ทำการค้นหาเวกเตอร์
ตอนนี้ตาราง ข้อมูล และการฝังพร้อมใช้งานแล้ว มาทำการค้นหาเวกเตอร์แบบเรียลไทม์สำหรับข้อความค้นหาของผู้ใช้กัน คุณทดสอบได้โดยเรียกใช้คำค้นหาด้านล่าง
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
ในคำค้นหานี้
- ข้อความที่ผู้ใช้ค้นหาคือ "การวิเคราะห์ความเห็น"
- เราจะแปลงเป็น Embedding ในเมธอด embedding() โดยใช้โมเดล text-embedding-005
- "<=>" แสดงถึงการใช้วิธีการวัดระยะทาง COSINE SIMILARITY
- เราจะแปลงผลลัพธ์ของวิธีการฝังเป็นประเภทเวกเตอร์เพื่อให้เข้ากันได้กับเวกเตอร์ที่จัดเก็บไว้ในฐานข้อมูล
- LIMIT 10 หมายความว่าเราจะเลือกข้อความค้นหาที่ตรงกันมากที่สุด 10 รายการ
AlloyDB ยกระดับ RAG ของ Vector Search ไปอีกขั้น
เราได้เปิดตัวฟีเจอร์ใหม่ๆ มากมาย โดยมี 2 รายการที่มุ่งเน้นนักพัฒนาแอปโดยเฉพาะ ดังนี้
- การกรองแบบอินไลน์
- ผู้ประเมินฟีเจอร์ความทรงจำ
การกรองแบบอินไลน์
ก่อนหน้านี้ในฐานะนักพัฒนาซอฟต์แวร์ คุณจะต้องทำการค้นหาเวกเตอร์และต้องจัดการกับการกรองและการเรียกคืน ตัวเพิ่มประสิทธิภาพการค้นหาของ AlloyDB จะเลือกวิธีดำเนินการค้นหาด้วยตัวกรอง การกรองในบรรทัดเป็นเทคนิคการเพิ่มประสิทธิภาพการค้นหาแบบใหม่ที่ช่วยให้เครื่องมือเพิ่มประสิทธิภาพการค้นหาของ AlloyDB ประเมินทั้งเงื่อนไขการกรองข้อมูลเมตาและการค้นหาเวกเตอร์ควบคู่กันไป โดยใช้ทั้งดัชนีเวกเตอร์และดัชนีในคอลัมน์ข้อมูลเมตา ซึ่งช่วยเพิ่มประสิทธิภาพการเรียกคืนข้อมูล ทำให้นักพัฒนาแอปใช้ประโยชน์จากสิ่งที่ AlloyDB มีให้ได้ทันที
การกรองในบรรทัดเหมาะที่สุดสำหรับกรณีที่มีการเลือกปานกลาง ขณะที่ AlloyDB ค้นหาผ่านดัชนีเวกเตอร์ ระบบจะคำนวณระยะทางสำหรับเวกเตอร์ที่ตรงกับเงื่อนไขการกรองข้อมูลเมตาเท่านั้น (ตัวกรองฟังก์ชันการทำงานในคำค้นหาซึ่งมักจะจัดการในอนุประโยค WHERE) ซึ่งจะช่วยปรับปรุงประสิทธิภาพการค้นหาเหล่านี้ได้อย่างมาก โดยเสริมข้อดีของการกรองหลังการค้นหาหรือการกรองก่อนการค้นหา
- ติดตั้งหรืออัปเดตส่วนขยาย pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
หากติดตั้งส่วนขยาย pgvector ไว้แล้ว ให้อัปเกรดส่วนขยายเวกเตอร์เป็นเวอร์ชัน 0.8.0.google-3 ขึ้นไปเพื่อรับความสามารถของเครื่องมือประเมินการเรียกคืน
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
คุณต้องทำตามขั้นตอนนี้เฉพาะในกรณีที่ส่วนขยายเวกเตอร์เป็น <0.8.0.google-3
หมายเหตุสำคัญ: หากจำนวนแถวน้อยกว่า 100 คุณไม่จำเป็นต้องสร้างดัชนี ScaNN ตั้งแต่แรก เนื่องจากดัชนีนี้จะใช้ไม่ได้กับแถวที่น้อยกว่า ในกรณีนี้ โปรดข้ามขั้นตอนต่อไปนี้
- หากต้องการสร้างดัชนี ScaNN ให้ติดตั้งส่วนขยาย alloydb_scann
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- ก่อนอื่น ให้เรียกใช้คำค้นหาการค้นหาเวกเตอร์โดยไม่มีดัชนีและไม่ได้เปิดใช้ตัวกรองแบบอินไลน์
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
ผลลัพธ์ควรมีลักษณะดังนี้
- เรียกใช้ Explain Analyze ในตาราง (ไม่มีดัชนีหรือการกรองในบรรทัด)
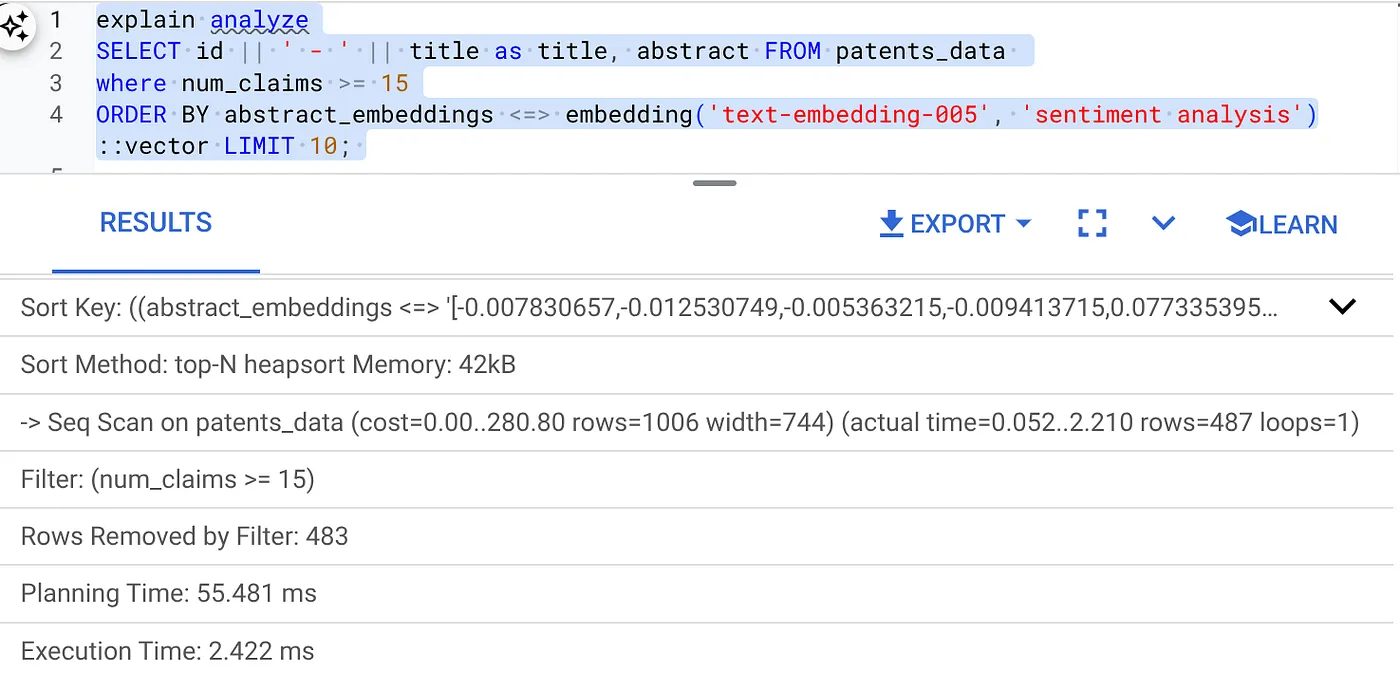
เวลาดำเนินการคือ 2.4 มิลลิวินาที
- มาสร้างดัชนีปกติในฟิลด์ num_claims เพื่อให้เรากรองตามฟิลด์นี้ได้
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- มาสร้างดัชนี ScaNN สำหรับแอปพลิเคชันการค้นหาสิทธิบัตรกัน เรียกใช้คำสั่งต่อไปนี้จาก AlloyDB Studio
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
หมายเหตุสำคัญ: (num_leaves=32) ใช้กับชุดข้อมูลทั้งหมดของเราที่มีมากกว่า 1,000 แถว หากจำนวนแถวน้อยกว่า 100 คุณไม่จำเป็นต้องสร้างดัชนีตั้งแต่แรกเนื่องจากดัชนีจะไม่มีผลกับแถวที่น้อยกว่า
- ตั้งค่าการกรองในบรรทัดที่เปิดใช้ในดัชนี ScaNN ดังนี้
SET scann.enable_inline_filtering = on
- ตอนนี้มาเรียกใช้การค้นหาเดียวกันโดยมีตัวกรองและการค้นหาเวกเตอร์กัน
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
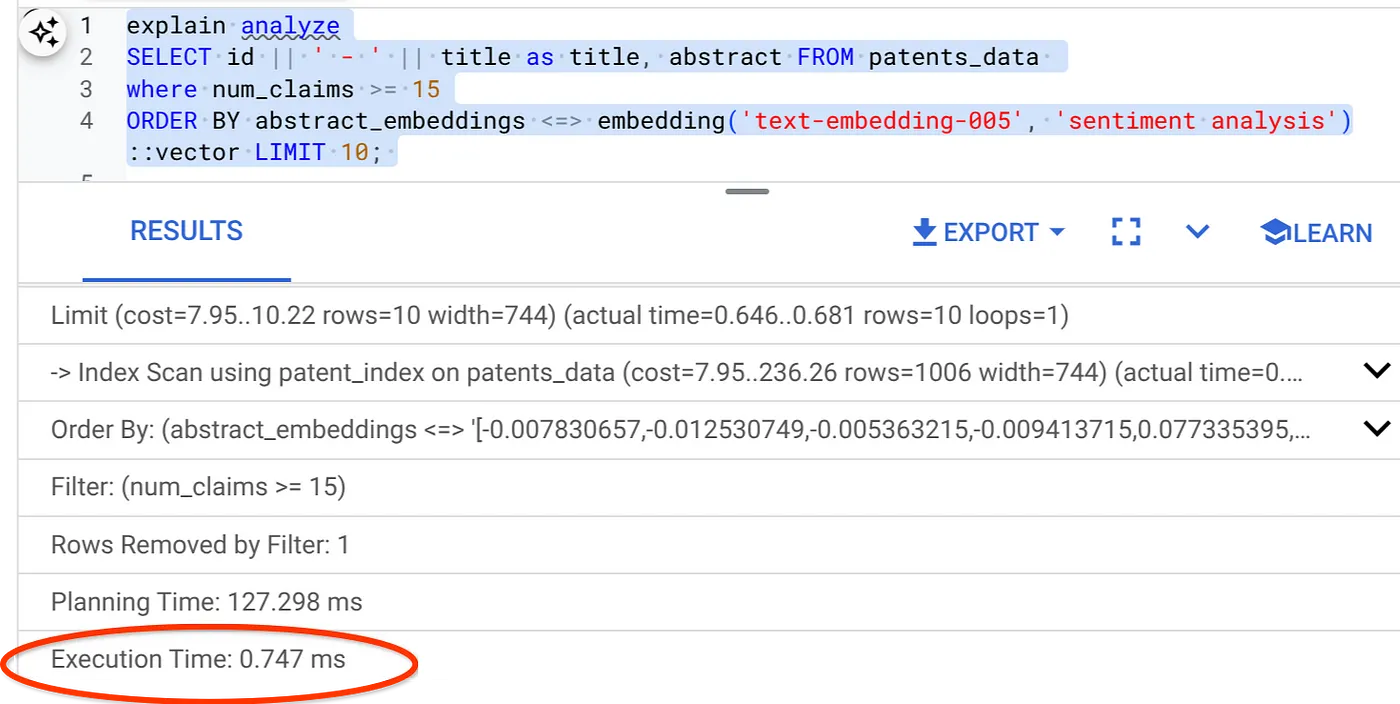
ดังที่เห็นได้ว่าเวลาในการดำเนินการลดลงอย่างมากสำหรับการค้นหาเวกเตอร์เดียวกัน ดัชนี ScaNN ที่มีการกรองในบรรทัดใน Vector Search ช่วยให้ทำเช่นนี้ได้!!!
ต่อไป เราจะประเมินการเรียกคืนสำหรับการค้นหาเวกเตอร์ที่เปิดใช้ ScaNN นี้
ผู้ประเมินฟีเจอร์ความทรงจำ
การเรียกคืนในการค้นหาที่คล้ายกันคือเปอร์เซ็นต์ของอินสแตนซ์ที่เกี่ยวข้องซึ่งดึงมาจากการค้นหา นั่นคือจำนวนผลบวกจริง นี่คือเมตริกที่ใช้กันโดยทั่วไปในการวัดคุณภาพการค้นหา แหล่งที่มาหนึ่งของการสูญเสียการเรียกคืนเกิดจากความแตกต่างระหว่างการค้นหาเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ หรือ aNN กับการค้นหาเพื่อนบ้านที่ใกล้ที่สุด k (แน่นอน) หรือ kNN ดัชนีเวกเตอร์ เช่น ScaNN ของ AlloyDB จะใช้อัลกอริทึม aNN ซึ่งช่วยให้คุณค้นหาเวกเตอร์ในชุดข้อมูลขนาดใหญ่ได้เร็วขึ้นโดยแลกกับการลดความสามารถในการเรียกคืนลงเล็กน้อย ตอนนี้ AlloyDB ช่วยให้คุณวัดการแลกเปลี่ยนนี้ได้โดยตรงในฐานข้อมูลสำหรับคำค้นหาแต่ละรายการ และมั่นใจได้ว่าการแลกเปลี่ยนนี้จะคงที่เมื่อเวลาผ่านไป คุณสามารถอัปเดตพารามิเตอร์การค้นหาและดัชนีเพื่อตอบสนองต่อข้อมูลนี้เพื่อให้ได้ผลลัพธ์และประสิทธิภาพที่ดีขึ้น
คุณดูการเรียกคืนสำหรับการค้นหาเวกเตอร์ในดัชนีเวกเตอร์สำหรับการกำหนดค่าที่ระบุได้โดยใช้ฟังก์ชัน evaluate_query_recall ฟังก์ชันนี้ช่วยให้คุณปรับแต่งพารามิเตอร์เพื่อให้ได้ผลลัพธ์การเรียกคืนการค้นหาเวกเตอร์ที่ต้องการ การเรียกคืนคือเมตริกที่ใช้สําหรับคุณภาพการค้นหา และกําหนดเป็นเปอร์เซ็นต์ของผลลัพธ์ที่แสดงซึ่งใกล้เคียงกับเวกเตอร์การค้นหามากที่สุดตามวัตถุประสงค์ ฟังก์ชัน evaluate_query_recall จะเปิดอยู่โดยค่าเริ่มต้น
หมายเหตุสำคัญ:
หากคุณพบข้อผิดพลาด "ปฏิเสธการเข้าถึง" ในดัชนี HNSW ในขั้นตอนต่อไปนี้ ให้ข้ามส่วนการประเมินการเรียกคืนทั้งหมดนี้ไปก่อน อาจเกี่ยวข้องกับข้อจำกัดในการเข้าถึงในตอนนี้ เนื่องจากเพิ่งเปิดตัวในขณะที่บันทึก Codelab นี้
- ตั้งค่าสถานะเปิดใช้การสแกนดัชนีในดัชนี ScaNN และดัชนี HNSW
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- เรียกใช้การค้นหาต่อไปนี้ใน AlloyDB Studio
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
ฟังก์ชัน evaluate_query_recall จะรับการค้นหาเป็นพารามิเตอร์และแสดงผลการเรียกคืน ฉันใช้การค้นหาเดียวกันกับที่ใช้ตรวจสอบประสิทธิภาพเป็นการค้นหาอินพุตของฟังก์ชัน ฉันได้เพิ่ม SCaNN เป็นวิธีการจัดทำดัชนี ดูตัวเลือกพารามิเตอร์เพิ่มเติมได้ในเอกสารประกอบ
การเรียกคืนสำหรับคำค้นหา Vector Search ที่เราใช้มีดังนี้
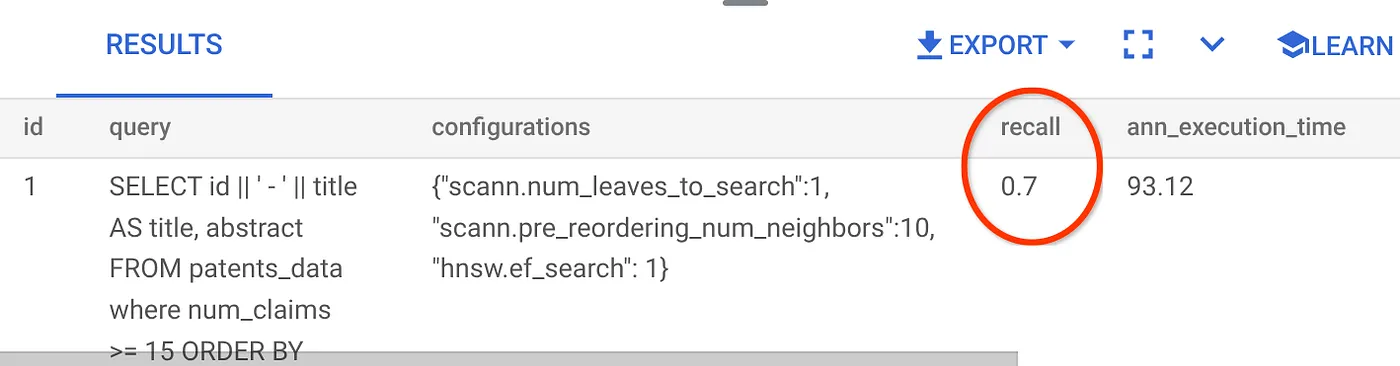
เราเห็นว่าการเรียกคืนอยู่ที่ 70% ตอนนี้ฉันสามารถใช้ข้อมูลนี้เพื่อเปลี่ยนพารามิเตอร์ดัชนี วิธีการ และพารามิเตอร์การค้นหา รวมถึงปรับปรุงการเรียกคืนสำหรับการค้นหาเวกเตอร์นี้ได้แล้ว
เราได้แก้ไขจำนวนแถวในชุดผลลัพธ์เป็น 7 (จากเดิม 10) และเห็นว่า RECALL ดีขึ้นเล็กน้อย นั่นคือ 86%
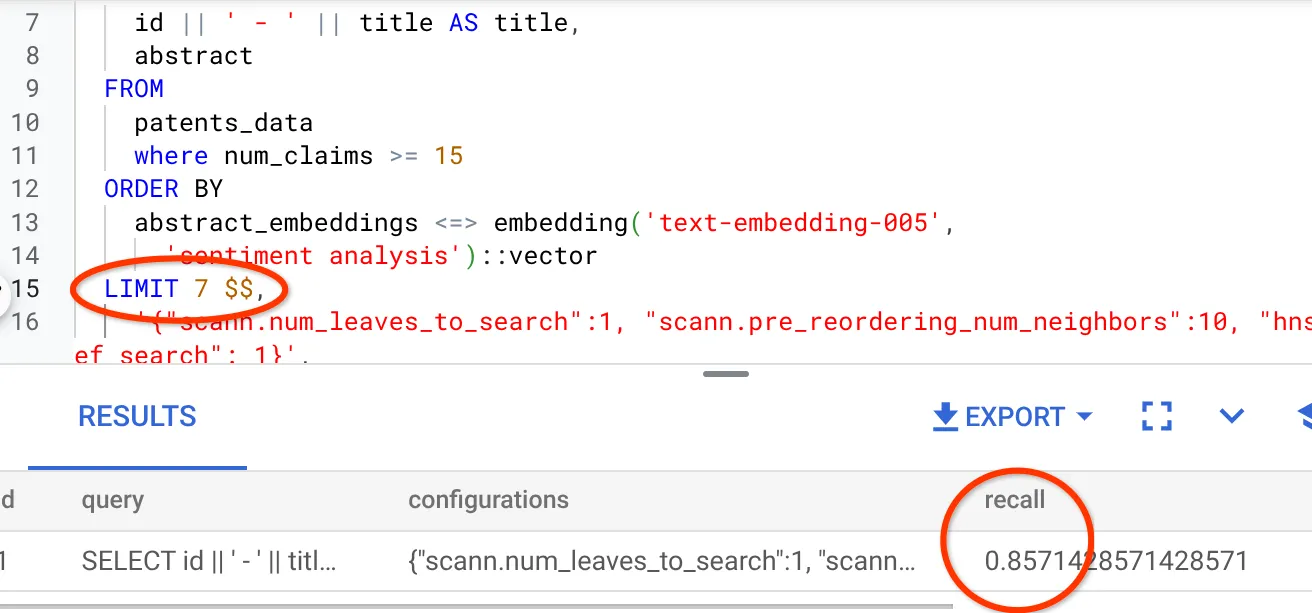
ซึ่งหมายความว่าฉันสามารถปรับเปลี่ยนจำนวนการจับคู่ที่ผู้ใช้เห็นได้แบบเรียลไทม์เพื่อปรับปรุงความเกี่ยวข้องของการจับคู่ให้สอดคล้องกับบริบทการค้นหาของผู้ใช้
เอาล่ะ ถึงเวลาทำให้ตรรกะของฐานข้อมูลใช้งานได้และไปที่ Agent แล้ว!!!
7. นำตรรกะของฐานข้อมูลไปยังเว็บแบบไร้เซิร์ฟเวอร์
พร้อมที่จะนำแอปนี้ไปใช้บนเว็บแล้วหรือยัง โดยทำตามขั้นตอนต่อไปนี้
- ไปที่ฟังก์ชัน Cloud Run ในคอนโซล Google Cloud เพื่อสร้างฟังก์ชัน Cloud Run ใหม่โดยคลิก "เขียนฟังก์ชัน" หรือใช้ลิงก์ https://console.cloud.google.com/run/create?deploymentType=function
- เลือกตัวเลือก "ใช้เครื่องมือแก้ไขในบรรทัดเพื่อสร้างฟังก์ชัน" แล้วเริ่มการกำหนดค่า ระบุชื่อบริการ "patent-search" และเลือกภูมิภาคเป็น "us-central1" และรันไทม์เป็น "Java 17" ตั้งค่าการตรวจสอบสิทธิ์เป็น "อนุญาตการเรียกใช้ที่ไม่ผ่านการตรวจสอบสิทธิ์"
- ในส่วน "คอนเทนเนอร์, ปริมาณข้อมูล, เครือข่าย, ความปลอดภัย" ให้ทำตามขั้นตอนด้านล่างโดยไม่พลาดรายละเอียดใดๆ
ไปที่แท็บการสร้างเครือข่าย
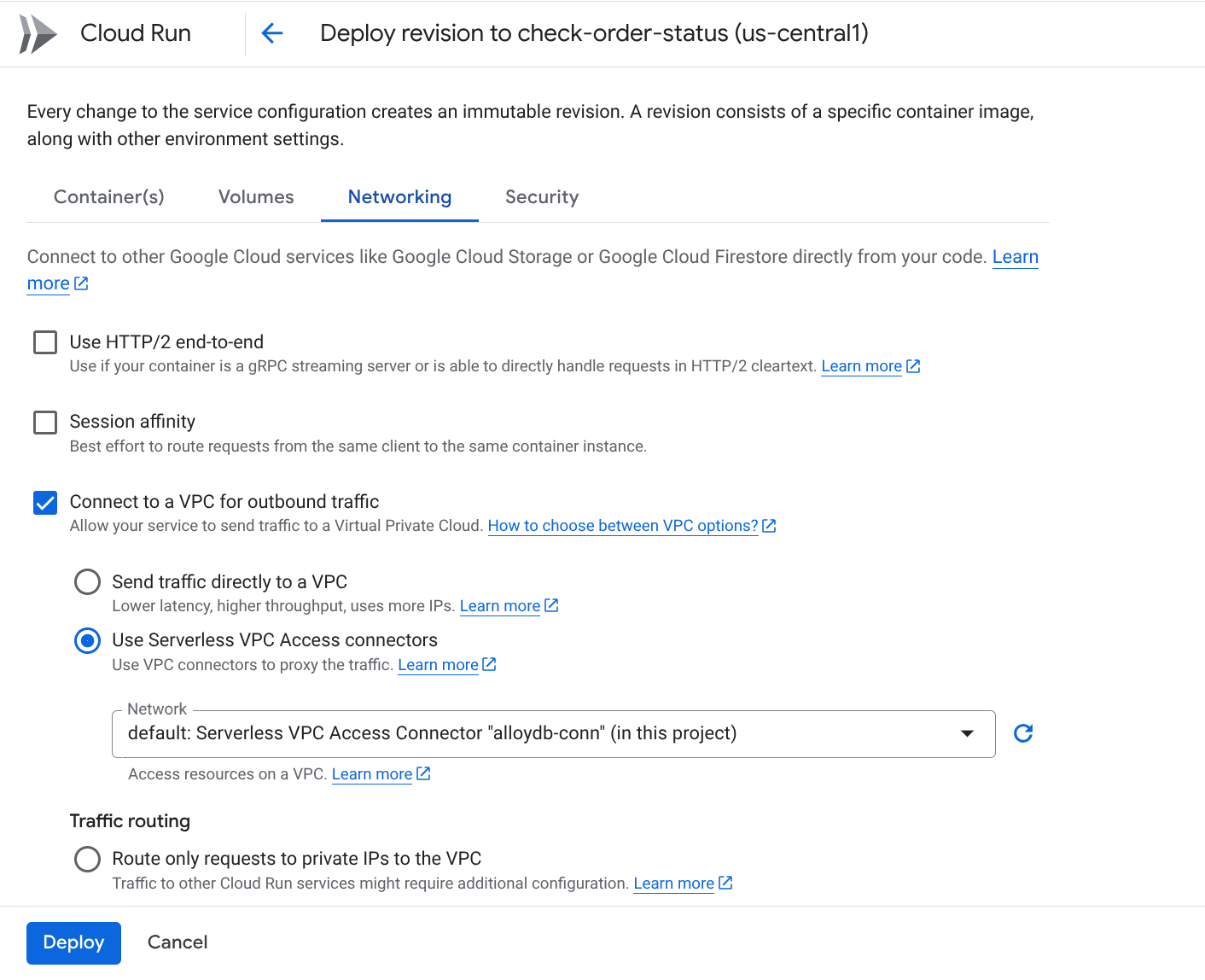
เลือก "เชื่อมต่อกับ VPC สำหรับการรับส่งข้อมูลขาออก" แล้วเลือก "ใช้เครื่องมือเชื่อมต่อการเข้าถึง VPC แบบ Serverless"
ในการตั้งค่าเมนูแบบเลื่อนลงของเครือข่าย ให้คลิกเมนูแบบเลื่อนลงของเครือข่าย แล้วเลือกตัวเลือก "เพิ่มตัวเชื่อมต่อ VPC ใหม่" (หากยังไม่ได้กำหนดค่าตัวเชื่อมต่อ default) แล้วทำตามวิธีการที่แสดงในกล่องโต้ตอบที่ปรากฏขึ้น
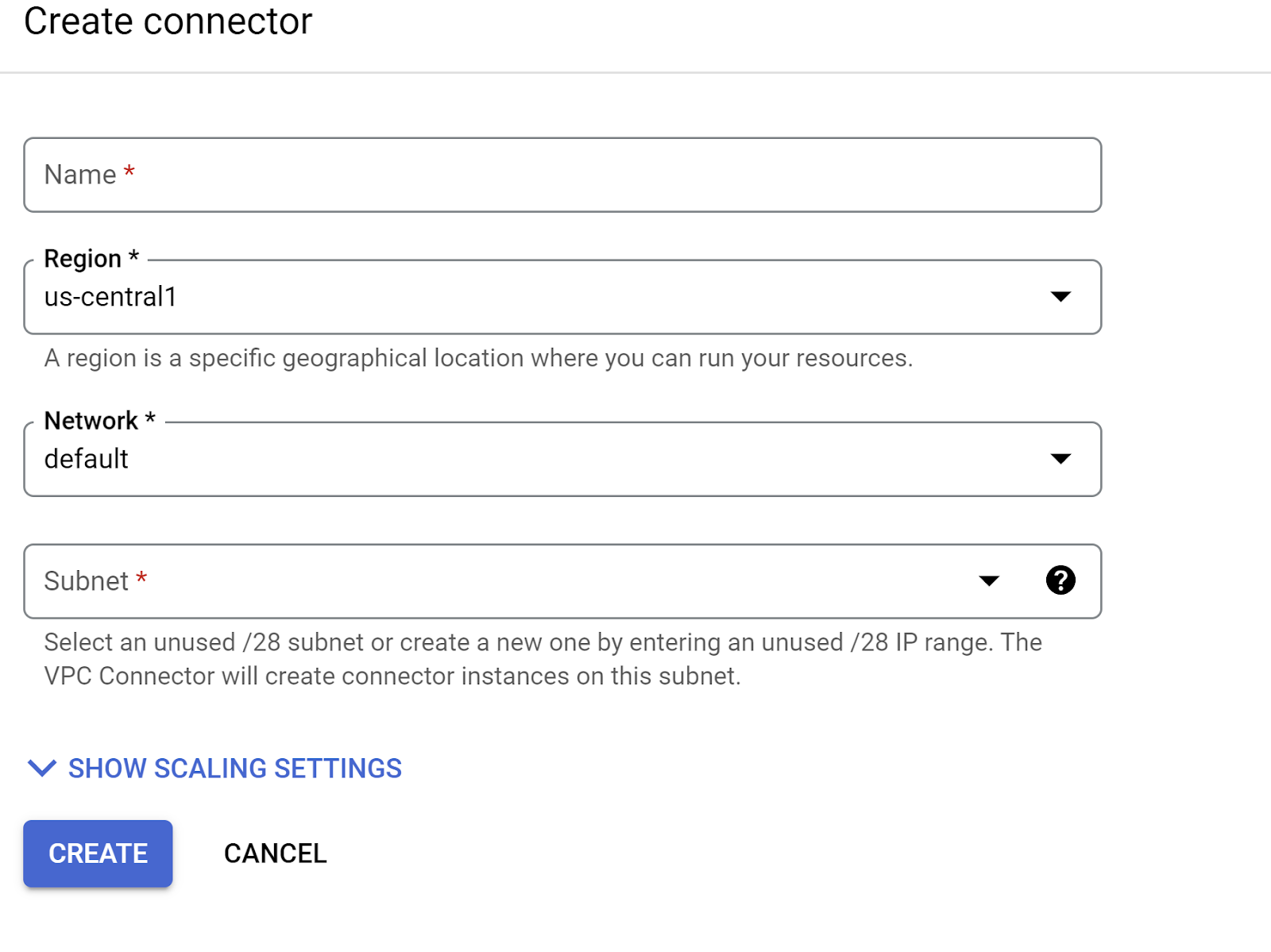
ระบุชื่อเครื่องมือเชื่อมต่อ VPC และตรวจสอบว่าภูมิภาคตรงกับอินสแตนซ์ ปล่อยให้ค่าเครือข่ายเป็นค่าเริ่มต้น และตั้งค่าซับเน็ตเป็นช่วง IP ที่กำหนดเองโดยมีช่วง IP เป็น 10.8.0.0 หรือค่าที่คล้ายกันที่ใช้ได้
ขยาย "แสดงการตั้งค่าการปรับขนาด" และตรวจสอบว่าคุณได้ตั้งค่าการกำหนดค่าเป็นดังนี้
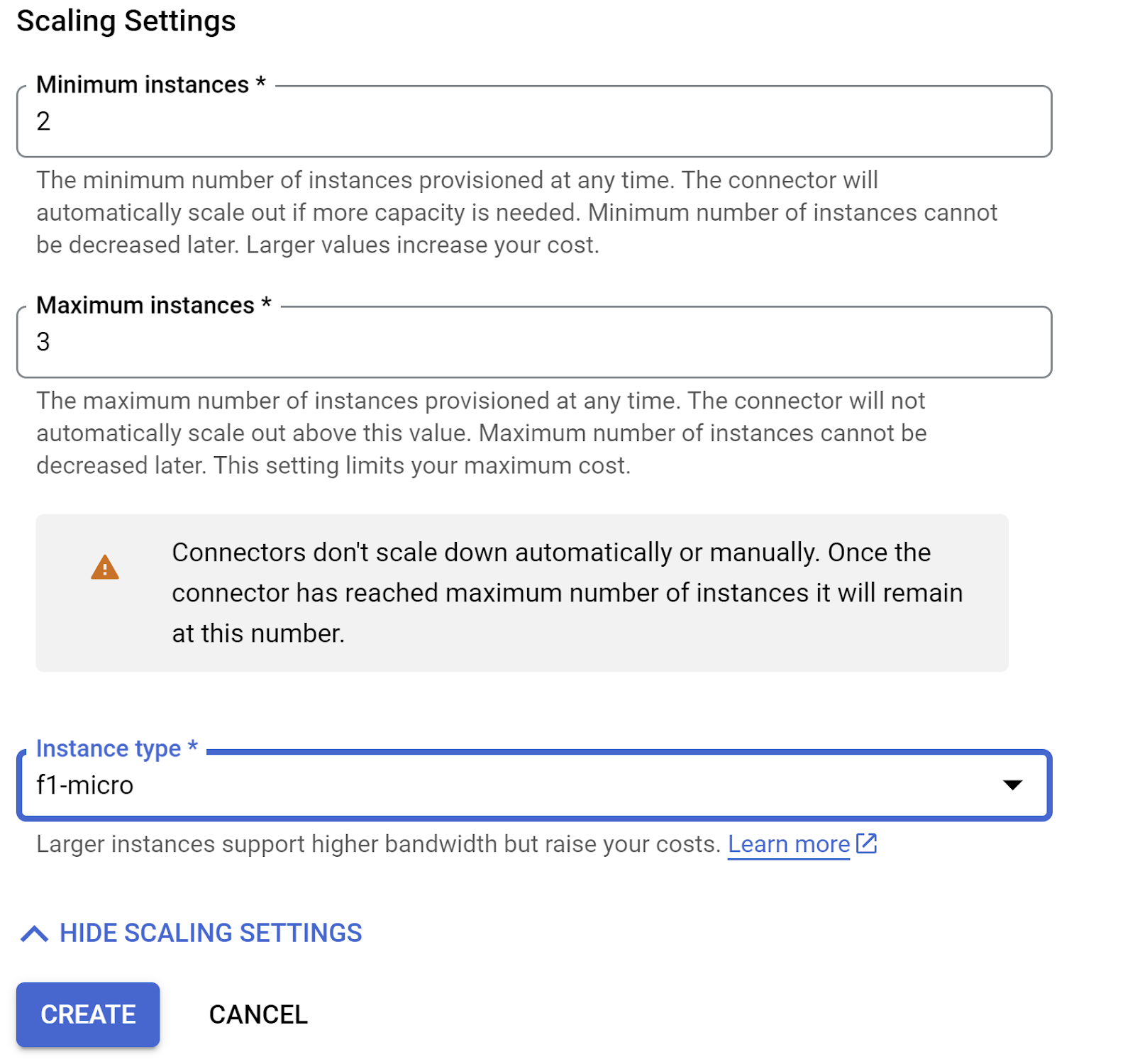
คลิกสร้าง แล้วตัวเชื่อมต่อนี้ควรแสดงในการตั้งค่าขาออกแล้ว
เลือกเครื่องมือเชื่อมต่อที่สร้างขึ้นใหม่
เลือกให้กำหนดเส้นทางการรับส่งข้อมูลทั้งหมดผ่านเครื่องมือเชื่อมต่อ VPC นี้
คลิกถัดไป แล้วคลิกติดตั้งใช้งาน
- โดยค่าเริ่มต้น ระบบจะตั้งค่าจุดแรกเข้าเป็น "gcfv2.HelloHttpFunction" แทนที่โค้ดตัวยึดตำแหน่งใน HelloHttpFunction.java และ pom.xml ของฟังก์ชัน Cloud Run ด้วยโค้ดจาก " PatentSearch.java" และ " pom.xml" ตามลำดับ เปลี่ยนชื่อไฟล์คลาสเป็น PatentSearch.java
- อย่าลืมเปลี่ยนตัวยึดตำแหน่ง ************* และข้อมูลเข้าสู่ระบบการเชื่อมต่อ AlloyDB ด้วยค่าของคุณในไฟล์ Java ข้อมูลเข้าสู่ระบบ AlloyDB คือข้อมูลที่เราใช้ตอนเริ่ม Codelab นี้ หากคุณใช้ค่าอื่น โปรดแก้ไขค่าดังกล่าวในไฟล์ Java
- คลิกทำให้ใช้งานได้
- เมื่อติดตั้งใช้งาน Cloud Function ที่อัปเดตแล้ว คุณจะเห็นปลายทางที่สร้างขึ้น คัดลอกและแทนที่ในคำสั่งต่อไปนี้
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
เท่านี้ก็เรียบร้อย การค้นหาเวกเตอร์ความคล้ายตามบริบทขั้นสูงโดยใช้โมเดลการฝังในข้อมูล AlloyDB นั้นทำได้ง่ายๆ เพียงเท่านี้
8. มาสร้าง Agent ด้วย Java ADK กัน
ก่อนอื่น มาเริ่มต้นใช้งานโปรเจ็กต์ Java ในเอดิเตอร์กัน
- ไปที่เทอร์มินัล Cloud Shell
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- ให้สิทธิ์เมื่อได้รับข้อความแจ้ง
- สลับไปที่ Cloud Shell Editor โดยคลิกไอคอนเอดิเตอร์จากด้านบนของคอนโซล Cloud Shell

- ในคอนโซล Cloud Shell Editor ที่หน้า Landing Page ให้สร้างโฟลเดอร์ใหม่และตั้งชื่อว่า "adk-agents"
คลิกสร้างโฟลเดอร์ใหม่ในไดเรกทอรีรากของ Cloud Shell ดังที่แสดงด้านล่าง
ตั้งชื่อว่า "adk-agents" ดังนี้
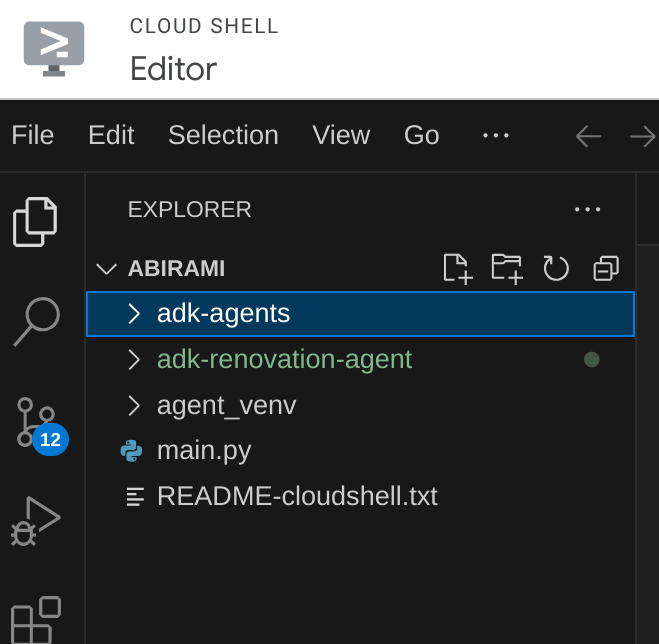
- สร้างโครงสร้างโฟลเดอร์ต่อไปนี้และไฟล์เปล่าที่มีชื่อไฟล์ที่เกี่ยวข้องในโครงสร้างด้านล่าง
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- เปิด github repo ในแท็บแยกต่างหาก แล้วคัดลอกซอร์สโค้ดสำหรับไฟล์ App.java และ pom.xml
- หากเปิดเครื่องมือแก้ไขในแท็บใหม่โดยใช้ไอคอน "เปิดในแท็บใหม่" ที่มุมขวาบน คุณจะเปิดเทอร์มินัลที่ด้านล่างของหน้าได้ คุณสามารถเปิดทั้งเครื่องมือแก้ไขและเทอร์มินัลควบคู่กันไปได้ ซึ่งจะช่วยให้คุณดำเนินการได้อย่างอิสระ
- เมื่อโคลนแล้ว ให้สลับกลับไปที่คอนโซล Cloud Shell Editor
- เนื่องจากเราได้สร้างฟังก์ชัน Cloud Run ไว้แล้ว คุณไม่จำเป็นต้องคัดลอกไฟล์ฟังก์ชัน Cloud Run จากโฟลเดอร์ Repo
เริ่มต้นใช้งาน ADK Java SDK
ซึ่งค่อนข้างตรงไปตรงมา คุณต้องตรวจสอบว่าขั้นตอนการโคลนครอบคลุมสิ่งต่อไปนี้เป็นหลัก
- เพิ่มทรัพยากร Dependency
รวมอาร์ติแฟกต์ google-adk และ google-adk-dev (สำหรับ UI บนเว็บ) ไว้ใน pom.xml หากคุณคัดลอกแหล่งที่มาจากที่เก็บ ข้อมูลเหล่านี้จะรวมอยู่ในไฟล์อยู่แล้ว คุณจึงไม่ต้องใส่ข้อมูลดังกล่าว คุณเพียงต้องทำการเปลี่ยนแปลงในปลายทางของฟังก์ชัน Cloud Run เพื่อให้สอดคล้องกับปลายทางที่ทำให้ใช้งานได้ ซึ่งจะอธิบายในขั้นตอนถัดไปในส่วนนี้
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
อย่าลืมอ้างอิง pom.xml จากที่เก็บแหล่งที่มา เนื่องจากมีทรัพยากร Dependency และการกำหนดค่าอื่นๆ ที่จำเป็นเพื่อให้แอปพลิเคชันทำงานได้
- กำหนดค่าโปรเจ็กต์:
ตรวจสอบว่าได้กำหนดค่าเวอร์ชัน Java (แนะนำ 17 ขึ้นไป) และการตั้งค่าคอมไพเลอร์ Maven อย่างถูกต้องใน pom.xml คุณกำหนดค่าโปรเจ็กต์ให้เป็นไปตามโครงสร้างด้านล่างได้
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- การกำหนดตัวแทนและเครื่องมือ (App.java):
ซึ่งเป็นจุดที่ ADK Java SDK แสดงให้เห็นถึงความมหัศจรรย์ เรากำหนด Agent ความสามารถ (คำสั่ง) และเครื่องมือที่ Agent ใช้ได้
ดูเวอร์ชันแบบง่ายของข้อมูลโค้ดบางส่วนของคลาส Agent หลักได้ที่นี่ ดูโปรเจ็กต์ทั้งหมดได้ที่ที่เก็บโปรเจ็กต์ที่นี่
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
ส่วนประกอบโค้ด Java ของ ADK ที่สำคัญมีดังนี้
- LlmAgent.builder(): Fluent API สำหรับกำหนดค่าเอเจนต์
- .instruction(...): ระบุพรอมต์และหลักเกณฑ์หลักสำหรับ LLM รวมถึงเวลาที่ควรใช้เครื่องมือใด
- FunctionTool.create(App.class, "methodName"): ลงทะเบียนเมธอด Java เป็นเครื่องมือที่ตัวแทนเรียกใช้ได้ง่ายๆ สตริงชื่อเมธอดต้องตรงกับเมธอดแบบคงที่สาธารณะที่มีอยู่จริง
- @Schema(description = ...): ใส่คำอธิบายประกอบพารามิเตอร์ของเครื่องมือ ซึ่งจะช่วยให้ LLM เข้าใจว่าเครื่องมือแต่ละอย่างคาดหวังอินพุตแบบใด คำอธิบายนี้มีความสำคัญอย่างยิ่งต่อการเลือกเครื่องมือและการกรอกพารามิเตอร์ที่ถูกต้อง
- InvocationContext ctx: ส่งไปยังเมธอดเครื่องมือโดยอัตโนมัติ ซึ่งให้สิทธิ์เข้าถึงสถานะเซสชัน (ctx.session().state()) ข้อมูลผู้ใช้ และอื่นๆ
- .outputKey("patents"): เมื่อเครื่องมือแสดงข้อมูล ADK จะจัดเก็บข้อมูลนั้นไว้ในสถานะเซสชันโดยอัตโนมัติภายใต้คีย์นี้ นี่คือวิธีที่ explainPatent เข้าถึงผลลัพธ์จาก getPatents ได้
- VECTOR_SEARCH_ENDPOINT: ตัวแปรนี้มีตรรกะการทำงานหลักสำหรับคำถามและคำตอบตามบริบทสำหรับผู้ใช้ในกรณีการค้นหาสิทธิบัตร
- รายการการดำเนินการที่นี่: คุณต้องตั้งค่าปลายทางที่อัปเดตแล้วเมื่อติดตั้งใช้งานขั้นตอนฟังก์ชัน Java Cloud Run จากส่วนก่อนหน้า
- searchTool: เครื่องมือนี้จะโต้ตอบกับผู้ใช้เพื่อค้นหาการจับคู่สิทธิบัตรที่เกี่ยวข้องตามบริบทจากฐานข้อมูลสิทธิบัตรสำหรับข้อความค้นหาของผู้ใช้
- explainTool: ถามผู้ใช้เกี่ยวกับสิทธิบัตรที่เฉพาะเจาะจงเพื่อเจาะลึก จากนั้นจะสรุปบทคัดย่อสิทธิบัตรและตอบคำถามเพิ่มเติมจากผู้ใช้ได้โดยอิงตามรายละเอียดสิทธิบัตรที่มี
หมายเหตุสำคัญ: โปรดตรวจสอบว่าได้แทนที่ตัวแปร VECTOR_SEARCH_ENDPOINT ด้วยปลายทาง CRF ที่คุณทำให้ใช้งานได้แล้ว
ใช้ประโยชน์จาก InvocationContext สำหรับการโต้ตอบแบบเก็บสถานะ
ฟีเจอร์ที่สำคัญอย่างหนึ่งในการสร้างเอเจนต์ที่มีประโยชน์คือการจัดการสถานะในการสนทนาหลายรอบ InvocationContext ของ ADK ช่วยให้การดำเนินการนี้ตรงไปตรงมายิ่งขึ้น
ใน App.java
- เมื่อกำหนด initAgent() เราจะใช้ .outputKey("patents") ซึ่งจะบอก ADK ว่าเมื่อเครื่องมือ (เช่น getPatents) แสดงข้อมูลในฟิลด์รายงาน ควรจัดเก็บข้อมูลนั้นไว้ในสถานะเซสชันภายใต้คีย์ "patents"
- ในเมธอดเครื่องมือ explainPatent เราจะแทรก InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
ซึ่งจะช่วยให้เครื่องมือ explainPatent เข้าถึงรายการสิทธิบัตรที่เครื่องมือ getPatents ดึงมาได้ในรอบก่อนหน้า ทำให้การสนทนามีสถานะและสอดคล้องกัน
9. การทดสอบ CLI ในเครื่อง
กำหนดตัวแปรสภาพแวดล้อม
คุณจะต้องส่งออกตัวแปรสภาพแวดล้อม 2 รายการ ดังนี้
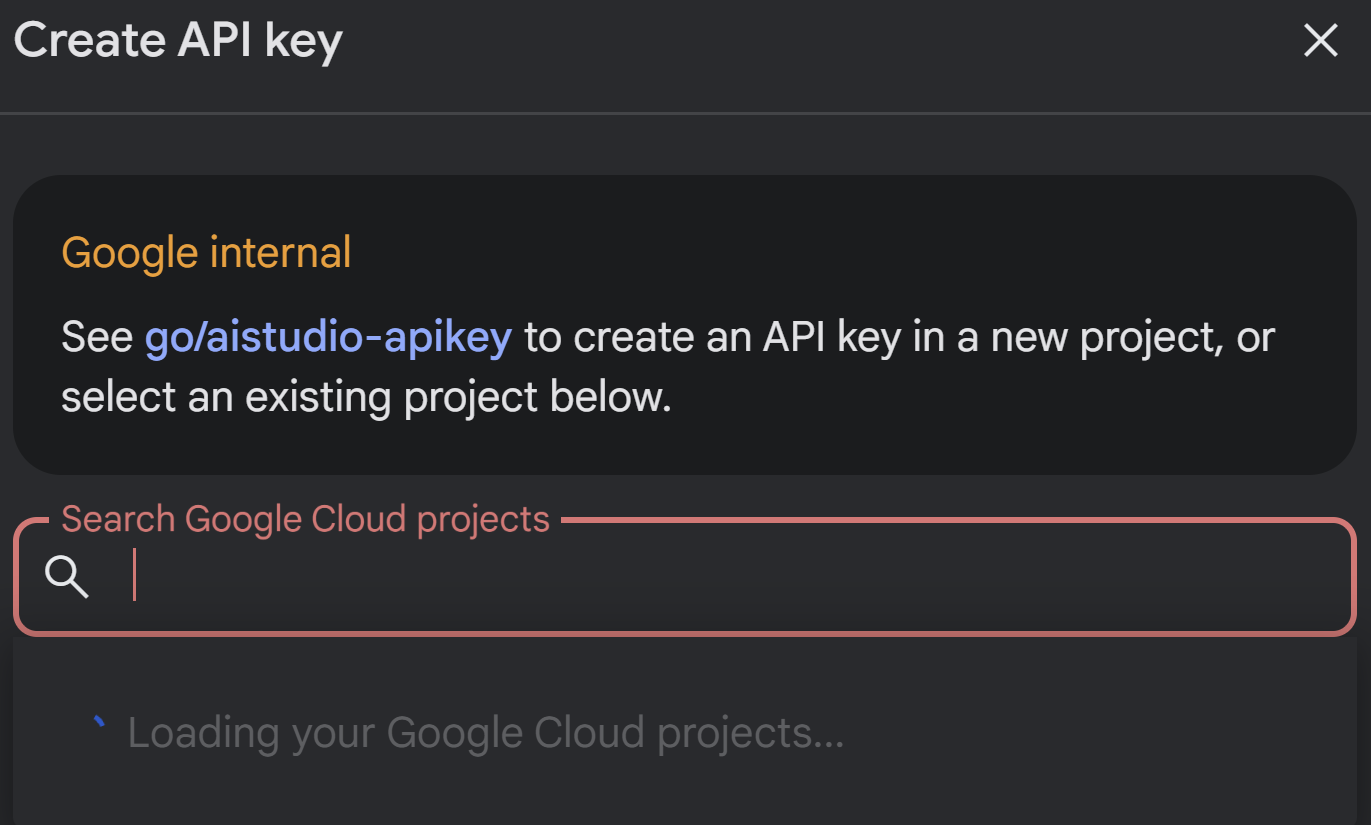
- คีย์ Gemini ที่คุณรับได้จาก AI Studio
โดยไปที่ https://aistudio.google.com/apikey แล้วรับคีย์ API สำหรับโปรเจ็กต์ Google Cloud ที่ใช้งานอยู่ซึ่งคุณกำลังใช้แอปพลิเคชันนี้ และบันทึกคีย์ไว้ที่ใดที่หนึ่ง
- เมื่อได้คีย์แล้ว ให้เปิดเทอร์มินัล Cloud Shell แล้วย้ายไปที่ไดเรกทอรีใหม่ที่เราเพิ่งสร้างขึ้น adk-agents โดยเรียกใช้คำสั่งต่อไปนี้
cd adk-agents
- ตัวแปรที่ระบุว่าเราไม่ได้ใช้ Vertex AI ในครั้งนี้
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- เรียกใช้ Agent ตัวแรกใน CLI
หากต้องการเปิดใช้เอเจนต์ตัวแรกนี้ ให้ใช้คำสั่ง Maven ต่อไปนี้ในเทอร์มินัล
mvn compile exec:java -DmainClass="agents.App"
คุณจะเห็นคำตอบแบบอินเทอร์แอกทีฟจากตัวแทนในเทอร์มินัล
10. การติดตั้งใช้งานกับ Cloud Run
การติดตั้งใช้งาน ADK Java Agent ใน Cloud Run จะคล้ายกับการติดตั้งใช้งานแอปพลิเคชัน Java อื่นๆ ดังนี้
- Dockerfile: สร้าง Dockerfile เพื่อแพ็กเกจแอปพลิเคชัน Java
- สร้างและพุชอิมเมจ Docker: ใช้ Google Cloud Build และ Artifact Registry
- คุณสามารถทำขั้นตอนข้างต้นและทำให้ใช้งานได้กับ Cloud Run ได้ในคำสั่งเดียว ดังนี้
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
ในทำนองเดียวกัน คุณจะทำให้ฟังก์ชัน Cloud Run ของ Java (gcfv2.PatentSearch) ใช้งานได้ หรือจะสร้างและทำให้ฟังก์ชัน Java Cloud Run ใช้งานได้สำหรับตรรกะของฐานข้อมูลโดยตรงจากคอนโซลฟังก์ชัน Cloud Run ก็ได้
11. การทดสอบด้วย UI บนเว็บ
ADK มาพร้อมกับ Web UI ที่สะดวกสำหรับการทดสอบในเครื่องและการแก้ไขข้อบกพร่องของ Agent เมื่อคุณเรียกใช้ App.java ในเครื่อง (เช่น mvn exec:java -Dexec.mainClass="agents.App" หากกำหนดค่าไว้ หรือเพียงแค่เรียกใช้เมธอดหลัก) โดยปกติแล้ว ADK จะเริ่มเว็บเซิร์ฟเวอร์ในเครื่อง
UI เว็บของ ADK ช่วยให้คุณทำสิ่งต่อไปนี้ได้
- ส่งข้อความถึงตัวแทน
- ดูเหตุการณ์ (ข้อความของผู้ใช้ การเรียกใช้เครื่องมือ การตอบกลับของเครื่องมือ การตอบกลับของ LLM)
- ตรวจสอบสถานะเซสชัน
- ดูบันทึกและร่องรอย
ซึ่งมีประโยชน์อย่างมากในระหว่างการพัฒนาเพื่อทำความเข้าใจวิธีที่เอเจนต์ประมวลผลคำขอและใช้เครื่องมือ ซึ่งถือว่าคุณตั้งค่า mainClass ใน pom.xml เป็น com.google.adk.web.AdkWebServer และลงทะเบียนเอเจนต์กับ mainClass หรือคุณกำลังเรียกใช้โปรแกรมทดสอบในเครื่องที่เปิดเผย mainClass นี้
เมื่อเรียกใช้ App.java ด้วย InMemoryRunner และ Scanner สำหรับอินพุตคอนโซล คุณจะทดสอบตรรกะหลักของเอเจนต์ UI บนเว็บเป็นคอมโพเนนต์แยกต่างหากเพื่อให้ประสบการณ์การแก้ไขข้อบกพร่องเป็นภาพมากขึ้น ซึ่งมักใช้เมื่อ ADK แสดงผล Agent ผ่าน HTTP
คุณใช้คำสั่ง Maven ต่อไปนี้จากไดเรกทอรีรากเพื่อเปิดใช้เซิร์ฟเวอร์ภายในของ SpringBoot ได้
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
โดยปกติแล้ว คุณจะเข้าถึงอินเทอร์เฟซได้ที่ URL ที่คำสั่งด้านบนแสดง หากเป็น Cloud Run ที่ติดตั้งใช้งาน คุณควรเข้าถึงได้จากลิงก์ Cloud Run ที่ติดตั้งใช้งาน
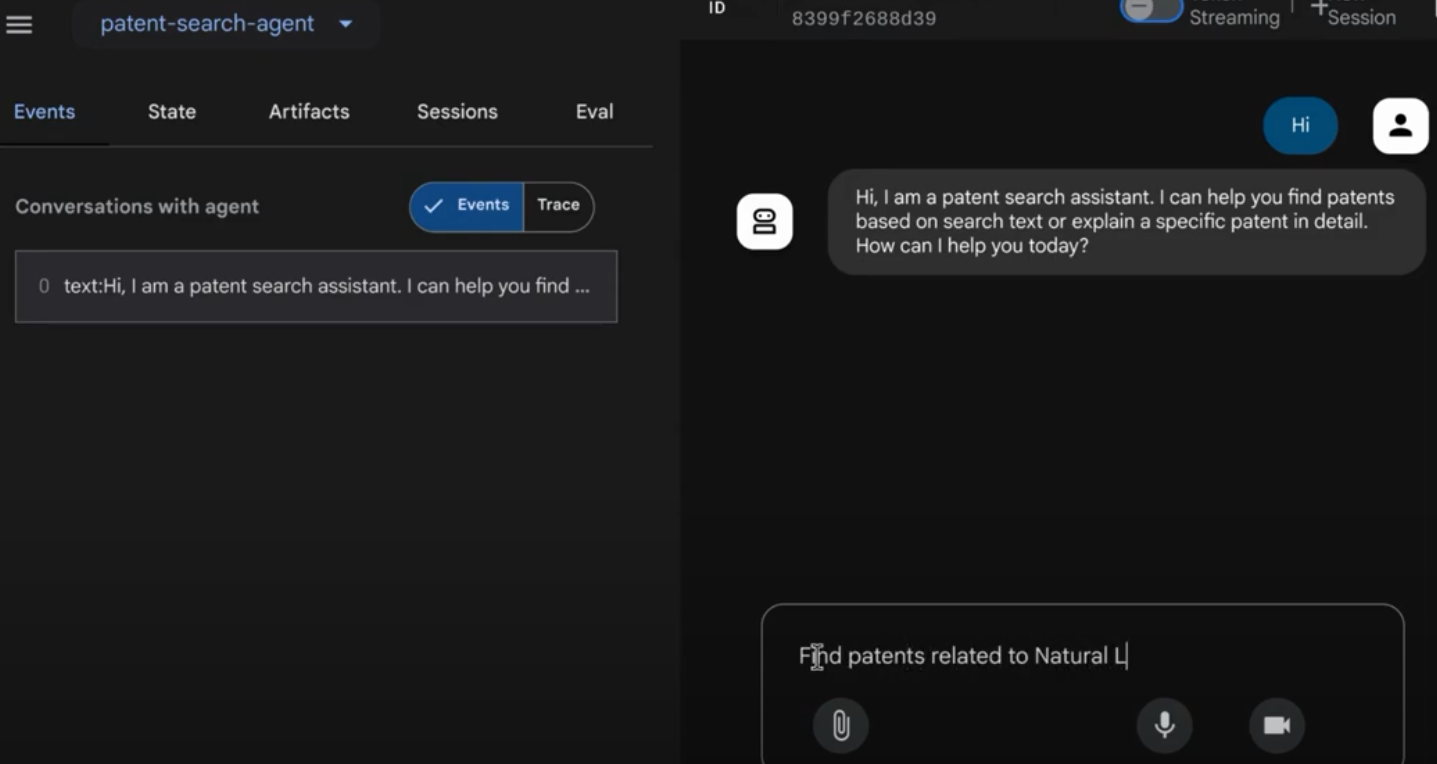
คุณควรจะเห็นผลลัพธ์ในอินเทอร์เฟซแบบอินเทอร์แอกทีฟ
ดูวิดีโอด้านล่างเพื่อดูตัวแทนสิทธิบัตรที่ใช้งานจริง
การสาธิตตัวแทนสิทธิบัตรที่มีการควบคุมคุณภาพด้วยการค้นหาในบรรทัดของ AlloyDB และการประเมินการเรียกคืน
12. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่ https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
13. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างเอเจนต์วิเคราะห์สิทธิบัตรใน Java ได้สำเร็จโดยการรวมความสามารถของ ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI และ Vector Search นอกจากนี้ เรายังก้าวกระโดดไปข้างหน้าในการทําให้การค้นหาความคล้ายคลึงตามบริบทเป็นการเปลี่ยนแปลงที่มีประสิทธิภาพและขับเคลื่อนด้วยความหมายอย่างแท้จริง
เริ่มใช้งานวันนี้เลย
เอกสารประกอบ ADK: [ลิงก์ไปยังเอกสารประกอบ Java อย่างเป็นทางการของ ADK]
ซอร์สโค้ดของ Agent วิเคราะห์สิทธิบัตร: [ลิงก์ไปยังที่เก็บ GitHub (ตอนนี้เป็นแบบสาธารณะ)]
ตัวอย่าง Agent ใน Java: [ลิงก์ไปยังที่เก็บ adk-samples]
เข้าร่วมชุมชน ADK: https://www.reddit.com/r/agentdevelopmentkit/
ขอให้สนุกกับการสร้าง Agent