
1. نظرة عامة
في مختلف المجالات، يشكّل البحث السياقي وظيفة أساسية في صميم تطبيقاتها. لقد كانت عملية الاسترجاع المعزّز بالإنشاء عاملاً رئيسيًا في هذا التطور التكنولوجي المهم منذ فترة طويلة، وذلك بفضل آليات الاسترجاع المستندة إلى الذكاء الاصطناعي التوليدي. تساهم النماذج التوليدية في إحداث تحوّل في الذكاء الاصطناعي، وذلك بفضل قدرتها على استيعاب سياقات كبيرة وجودة مخرجاتها الرائعة. يوفّر التوليد المعزّز بالاسترجاع طريقة منهجية لإدخال السياق في تطبيقات الذكاء الاصطناعي والوكلاء، ما يتيح لهم الاستناد إلى قواعد بيانات منظَّمة أو معلومات من وسائط مختلفة. تُعدّ هذه البيانات السياقية ضرورية لتوضيح صحة المعلومات ودقة النتائج، ولكن ما مدى دقة هذه النتائج؟ هل يعتمد نشاطك التجاري بشكل كبير على دقة هذه المطابقات السياقية ومدى صلتها بالموضوع؟ إذًا هذا المشروع سيثير اهتمامك.
إنّ السرّ الخفي للبحث المتّجه ليس مجرد إنشائه، بل معرفة ما إذا كانت نتائج المطابقة المتّجهة جيدة بالفعل. لقد مررنا كلّنا بهذه التجربة، حيث نحدّق في قائمة النتائج ونتساءل: "هل هذا التطبيق يعمل أصلاً؟" لنطّلِع على كيفية تقييم جودة تطابقات الموجّه. قد تتساءل: "ما هي التغييرات التي طرأت على RAG؟" كل شيء لسنوات، بدا التوليد المعزّز بالاسترجاع (RAG) هدفًا واعدًا ولكن يصعب تحقيقه. أخيرًا، لدينا الآن الأدوات اللازمة لإنشاء تطبيقات RAG ذات الأداء والموثوقية المطلوبَين للمهام البالغة الأهمية.
لدينا الآن فهم أساسي لثلاثة أمور:
- ماذا يعني البحث السياقي بالنسبة إلى الوكيل وكيفية إنجازه باستخدام "البحث المتّجه"
- تحدّثنا أيضًا بالتفصيل عن إمكانية استخدام Vector Search ضمن نطاق بياناتك، أي داخل قاعدة البيانات نفسها (تتيح جميع قواعد بيانات Google Cloud هذه الإمكانية، إذا لم تكن على علم بذلك).
- لقد ذهبنا إلى أبعد من ذلك في إطلاعك على كيفية إنجاز إمكانية RAG خفيفة الوزن للبحث المتّجه بأداء وجودة عاليتَين باستخدام إمكانية البحث المتّجه في AlloyDB المستندة إلى فهرس ScaNN.
إذا لم تكن قد اطّلعت على تجارب RAG الأساسية والمتوسطة والمتقدّمة قليلاً، أنصحك بقراءة هذه التجارب الثلاث هنا وهنا وهنا بالترتيب المذكور.
تساعد أداة البحث عن براءات الاختراع المستخدم في العثور على براءات اختراع ذات صلة سياقيًا بنص البحث، وقد أنشأنا بالفعل إصدارًا من هذه الأداة في الماضي. سننشئ الآن تطبيقًا باستخدام ميزات جديدة ومتقدّمة للتوليد المعزّز بالاسترجاع (RAG) تتيح إجراء بحث سياقي يتم التحكّم في جودته لهذا التطبيق. لنبدأ!
تعرض الصورة أدناه التدفق العام لما يحدث في هذا التطبيق.~ 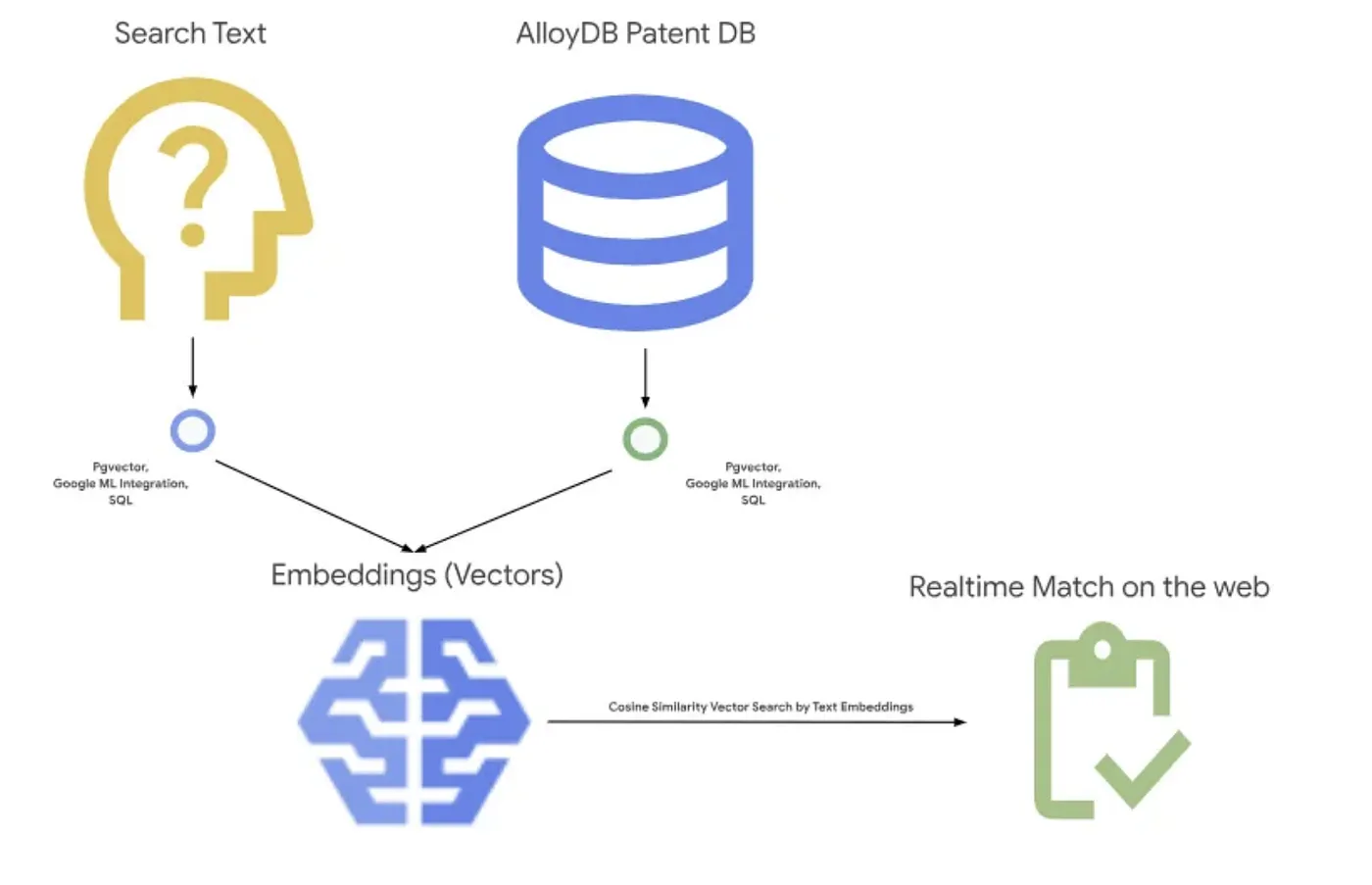
الهدف
السماح للمستخدم بالبحث عن براءات الاختراع استنادًا إلى وصف نصي مع تحسين الأداء والجودة، مع إمكانية تقييم جودة النتائج المطابقة التي تم إنشاؤها باستخدام أحدث ميزات التوليد المعزّز بالاسترجاع (RAG) في AlloyDB
ما ستنشئه
في هذا الدرس التطبيقي، ستنفّذ ما يلي:
- إنشاء مثيل AlloyDB وتحميل مجموعة بيانات Patents Public Dataset
- إنشاء فهرس البيانات الوصفية وفهرس ScaNN
- تنفيذ ميزة "البحث المتّجه" المتقدّمة في AlloyDB باستخدام طريقة الفلترة المضمّنة في ScaNN
- تنفيذ ميزة تقييم Recall
- تقييم الردّ على طلب البحث
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئه.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. تعرَّف على كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع .
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة. يمكنك استخدام أمر gcloud في وحدة Cloud Shell الطرفية:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
يمكنك بدلاً من استخدام أمر gcloud، البحث عن كل منتج في وحدة التحكّم أو استخدام هذا الرابط.
راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
3- إعداد قاعدة البيانات
في هذا التمرين المعملي، سنستخدم AlloyDB كقاعدة بيانات لبيانات براءات الاختراع. يستخدم المجموعات للاحتفاظ بجميع الموارد، مثل قواعد البيانات والسجلات. تحتوي كل مجموعة على مثيل أساسي يوفّر نقطة وصول إلى البيانات. ستحتوي الجداول على البيانات الفعلية.
لننشئ مجموعة ومثيل وجدول AlloyDB سيتم تحميل مجموعة بيانات براءات الاختراع فيها.
إنشاء مجموعة ومثيل
- انتقِل إلى صفحة AlloyDB في Cloud Console. تتمثّل إحدى الطرق السهلة للعثور على معظم الصفحات في Cloud Console في البحث عنها باستخدام شريط البحث في وحدة التحكّم.
- اختَر إنشاء مجموعة من تلك الصفحة:

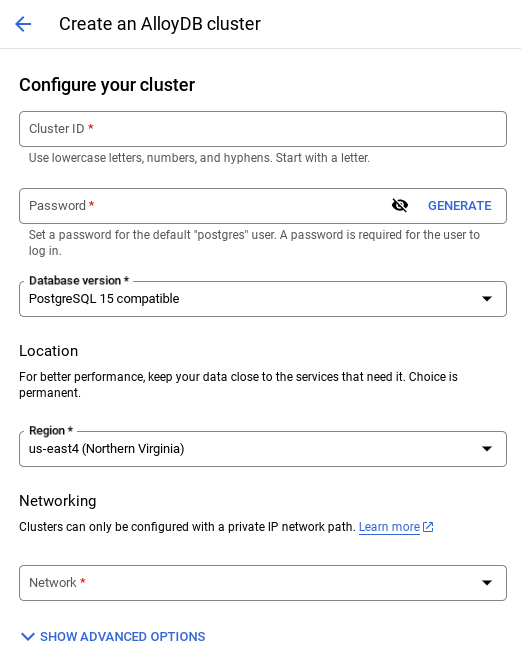
- ستظهر لك شاشة مشابهة للشاشة أدناه. أنشئ مجموعة ومثيل بالقيم التالية (تأكَّد من تطابق القيم في حال استنساخ الرمز البرمجي للتطبيق من المستودع):
- معرّف المجموعة: "
vector-cluster" - كلمة المرور: "
alloydb" - PostgreSQL 15 / أحدث إصدار يُنصح به
- المنطقة: "
us-central1" - الشبكات: "
default"
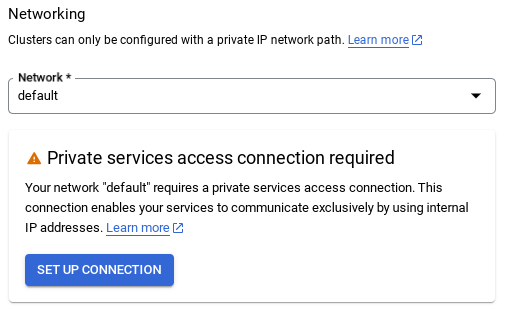
- عند اختيار الشبكة الافتراضية، ستظهر لك شاشة مثل الشاشة أدناه.
انقر على إعداد الاتصال.
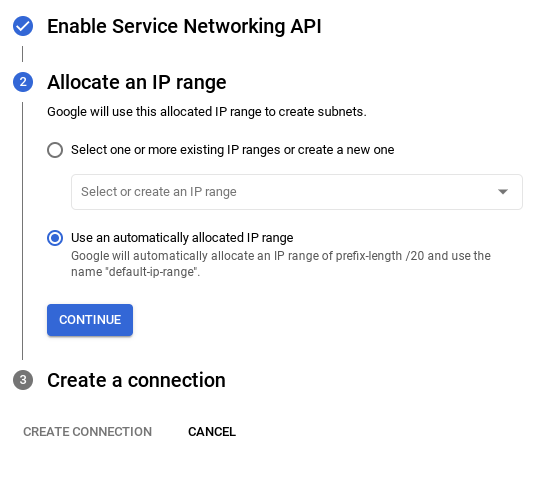
- من هناك، اختَر استخدام نطاق عناوين IP تم تخصيصه تلقائيًا وانقر على "متابعة". بعد مراجعة المعلومات، انقر على "إنشاء ربط".
- بعد إعداد شبكتك، يمكنك مواصلة إنشاء مجموعتك. انقر على إنشاء مجموعة لإكمال عملية إعداد المجموعة كما هو موضّح أدناه:
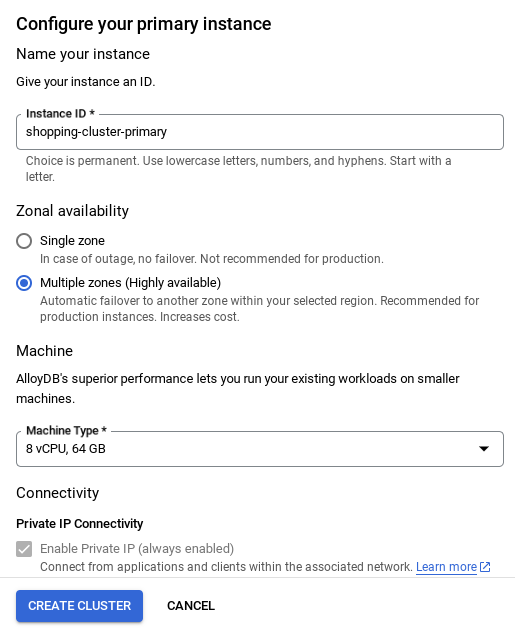
احرص على تغيير رقم تعريف المثيل (الذي يمكنك العثور عليه عند إعداد المجموعة أو المثيل) إلى
vector-instance: إذا لم تتمكّن من تغييره، تذكَّر استخدام معرّف مثيلك في جميع المراجع القادمة.
يُرجى العِلم أنّ إنشاء المجموعة سيستغرق حوالي 10 دقائق. بعد إتمام العملية بنجاح، من المفترض أن تظهر لك شاشة تعرض نظرة عامة على المجموعة التي أنشأتها للتو.
4. نقل البيانات
حان الوقت الآن لإضافة جدول يتضمّن بيانات حول المتجر. انتقِل إلى AlloyDB، واختَر المجموعة الأساسية، ثم AlloyDB Studio:
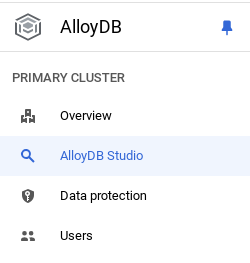
قد تحتاج إلى الانتظار إلى أن يكتمل إنشاء مثيلك. بعد ذلك، سجِّل الدخول إلى AlloyDB باستخدام بيانات الاعتماد التي أنشأتها عند إنشاء المجموعة. استخدِم البيانات التالية للمصادقة على PostgreSQL:
- اسم المستخدم : "
postgres" - قاعدة البيانات : "
postgres" - كلمة المرور : "
alloydb"
بعد إكمال عملية المصادقة بنجاح في AlloyDB Studio، يتم إدخال أوامر SQL في "المحرّر". يمكنك إضافة نوافذ "المحرّر" متعددة باستخدام علامة الجمع على يسار النافذة الأخيرة.
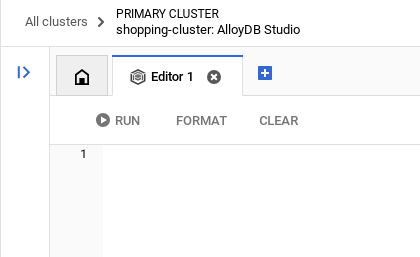
ستُدخل أوامر AlloyDB في نوافذ المحرّر، باستخدام الخيارات "تشغيل" و"تنسيق" و"محو" حسب الحاجة.
تفعيل الإضافات
لإنشاء هذا التطبيق، سنستخدم الإضافتين pgvector وgoogle_ml_integration. تتيح لك إضافة pgvector تخزين عمليات التضمين المتجهة والبحث عنها. توفّر إضافة google_ml_integration دوال يمكنك استخدامها للوصول إلى نقاط نهاية التوقّعات في Vertex AI من أجل الحصول على توقّعات في SQL. فعِّل هذه الإضافات من خلال تنفيذ تعريفات البيانات التالية:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
إذا أردت التحقّق من الإضافات التي تم تفعيلها في قاعدة البيانات، نفِّذ أمر SQL التالي:
select extname, extversion from pg_extension;
إنشاء جدول
يمكنك إنشاء جدول باستخدام عبارة DDL أدناه في AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
سيسمح عمود abstract_embeddings بتخزين قيم المتجهات للنص.
منح الإذن
نفِّذ العبارة أدناه لمنح إذن التنفيذ على الدالة "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
منح دور "مستخدم Vertex AI" لحساب خدمة AlloyDB
من وحدة تحكّم Google Cloud IAM، امنح حساب خدمة AlloyDB (الذي يبدو على النحو التالي: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) إذن الوصول إلى الدور "مستخدم Vertex AI". سيحتوي PROJECT_NUMBER على رقم مشروعك.
بدلاً من ذلك، يمكنك تنفيذ الأمر أدناه من "وحدة Cloud Shell الطرفية":
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
تحميل بيانات براءات الاختراع إلى قاعدة البيانات
سيتم استخدام مجموعات البيانات العامة لبراءات الاختراع من Google على BigQuery كمجموعة البيانات الخاصة بنا. سنستخدم AlloyDB Studio لتنفيذ استعلاماتنا. يتم استيراد البيانات إلى ملف insert_scripts.sql هذا، وسننفّذ هذا الملف لتحميل بيانات براءات الاختراع.
- في وحدة تحكّم Google Cloud، افتح صفحة AlloyDB.
- اختَر المجموعة التي تم إنشاؤها حديثًا وانقر على الجهاز الظاهري.
- في قائمة التنقّل في AlloyDB، انقر على AlloyDB Studio. سجِّل الدخول باستخدام بيانات اعتمادك.
- افتح علامة تبويب جديدة من خلال النقر على رمز علامة تبويب جديدة على يسار الشاشة.
- انسخ عبارة طلب البحث
insertمن النص البرمجيinsert_scripts.sqlالمذكور أعلاه إلى المحرّر. يمكنك نسخ 10 إلى 50 عبارة إدراج للحصول على عرض توضيحي سريع لحالة الاستخدام هذه. - انقر على تشغيل. تظهر نتائج طلب البحث في جدول النتائج.
ملاحظة: قد تلاحظ أنّ نص الإدراج يحتوي على الكثير من البيانات. ويرجع ذلك إلى أنّنا أدرجنا عمليات تضمين في نصوص الإدراج. انقر على "عرض البيانات الأولية" (View Raw) في حال واجهت مشكلة في تحميل الملف على GitHub. يتم ذلك لتوفير عناء إنشاء أكثر من بضع تضمينات (20 إلى 25 كحد أقصى مثلاً) في الخطوات القادمة، وذلك في حال استخدام حساب فوترة برصيد تجريبي في Google Cloud.
5- إنشاء تضمينات لبيانات براءات الاختراع
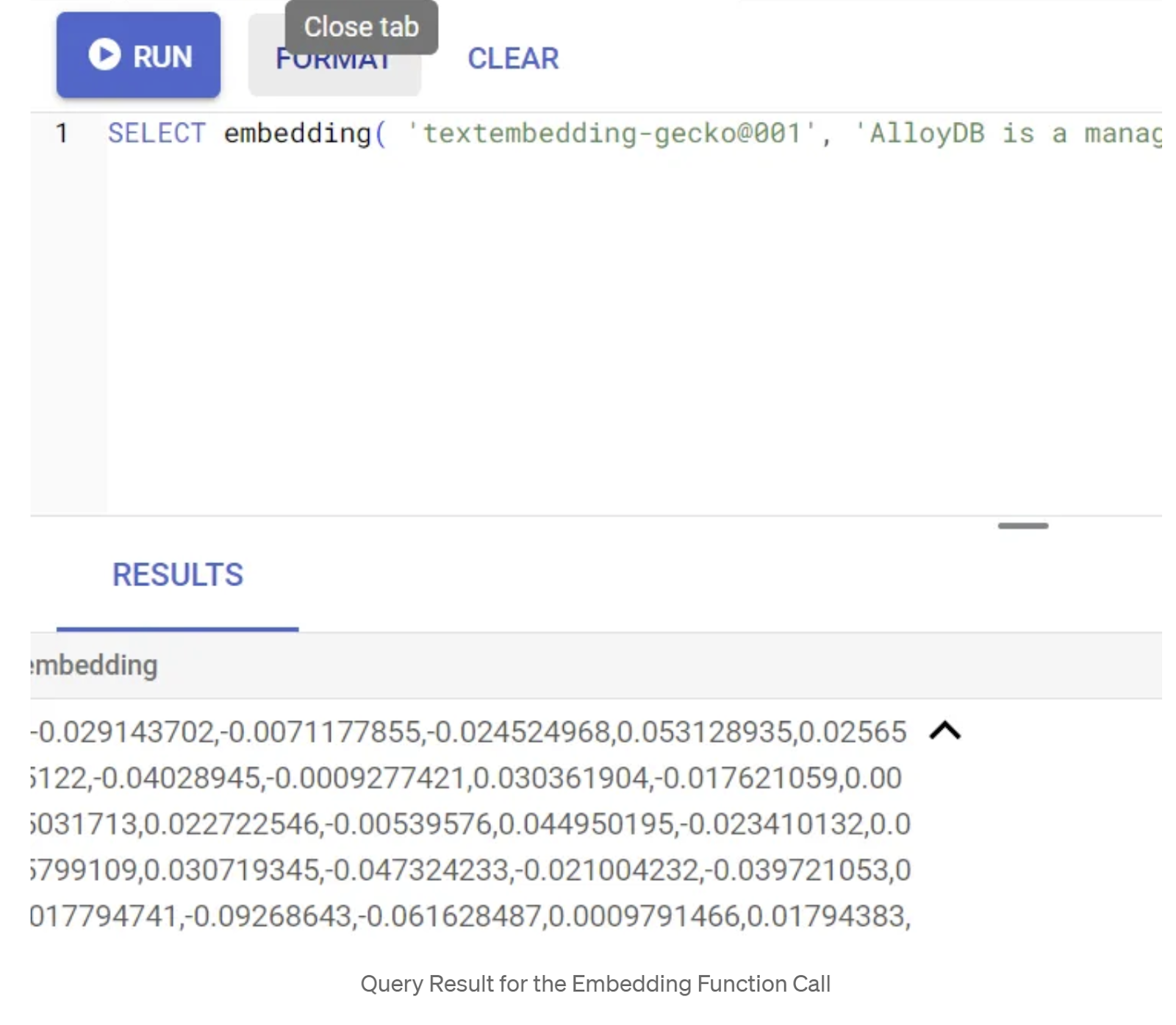
لنختبر أولاً دالة التضمين من خلال تنفيذ طلب البحث النموذجي التالي:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
من المفترض أن يعرض هذا الطلب متجه التضمينات، الذي يبدو كصفيف من الأرقام العشرية، للنص النموذجي في الطلب. يبدو على النحو التالي:
تعديل حقل المتّجه abstract_embeddings
نفِّذ لغة معالجة البيانات (DML) أدناه لتعديل ملخّصات براءات الاختراع في الجدول باستخدام عمليات التضمين المقابلة فقط في حال عدم إدراج بيانات abstract_embeddings كجزء من نص الإدراج:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
قد تواجه مشكلة في إنشاء أكثر من عدد قليل من التضمينات (20 إلى 25 كحد أقصى) إذا كنت تستخدم حساب فوترة برصيد تجريبي على Google Cloud. لهذا السبب، أدرجتُ عمليات التضمين في نصوص البرامج الخاصة بالإدراج، ويجب أن تكون متوفّرة في الجدول الذي تم تحميله إذا كنت قد أكملت خطوة "تحميل بيانات براءات الاختراع إلى قاعدة البيانات".
6. إجراء عملية توليد معزّز بالاسترجاع (RAG) متقدّمة باستخدام ميزات AlloyDB الجديدة
بعد أن أصبح الجدول والبيانات والتضمينات جاهزة، لننفّذ الآن عملية البحث المتّجه في الوقت الفعلي عن نص بحث المستخدم. يمكنك اختبار ذلك من خلال تنفيذ طلب البحث أدناه:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
في هذا الاستعلام،
- نص البحث الذي أدخله المستخدم هو: "تحليل المشاعر".
- نحوّل النص إلى تضمينات في الدالة embedding() باستخدام النموذج: text-embedding-005.
- يمثّل "<=>" استخدام طريقة قياس المسافة COSINE SIMILARITY.
- نحوّل نتيجة طريقة التضمين إلى نوع متّجه لجعلها متوافقة مع المتّجهات المخزّنة في قاعدة البيانات.
- يشير LIMIT 10 إلى أنّنا نختار 10 نتائج مطابقة لنص البحث.
ترتقي AlloyDB بميزة "التوليد المعزّز بالاسترجاع" (RAG) في "البحث المتّجه" إلى المستوى التالي:
تم تقديم عدد كبير من الميزات. في ما يلي اثنان من هذه المؤشرات التي تركّز على المطوّرين:
- التصفية المضمّنة
- Recall Evaluator
التصفية المضمّنة
في السابق، كان على المطوّر إجراء طلب بحث عن تطابق الأوصاف المتّجهة والتعامل مع الفلترة والاسترجاع. يتّخذ "محسِّن طلبات البحث" في AlloyDB قرارات بشأن كيفية تنفيذ طلب بحث باستخدام الفلاتر. الفلترة المضمّنة هي تقنية جديدة لتحسين طلبات البحث تتيح لمُحسِّن طلبات البحث في AlloyDB تقييم كلّ من شروط فلترة البيانات الوصفية والبحث المتّجه في الوقت نفسه، والاستفادة من كلّ من فهارس المتّجهات والفهارس في أعمدة البيانات الوصفية. وقد أدّى ذلك إلى تحسين أداء الاسترجاع، ما يتيح للمطوّرين الاستفادة من مزايا AlloyDB الجاهزة للاستخدام.
تكون الفلترة المضمّنة هي الأفضل في الحالات التي تتضمّن انتقائية متوسطة. أثناء بحث AlloyDB في فهرس المتجهات، لا يحتسب المسافات إلا للمتجهات التي تتطابق مع شروط فلترة البيانات الوصفية (الفلاتر الوظيفية في الاستعلام التي يتم التعامل معها عادةً في عبارة WHERE). يؤدي ذلك إلى تحسين الأداء بشكل كبير لهذه الطلبات، ما يكمّل مزايا الفلترة اللاحقة أو الفلترة المسبقة.
- تثبيت إضافة pgvector أو تحديثها
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
إذا كانت إضافة pgvector مثبَّتة من قبل، عليك ترقية إضافة المتّجه إلى الإصدار 0.8.0.google-3 أو إصدار أحدث للاستفادة من إمكانات أداة تقييم الاسترجاع.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
يجب تنفيذ هذه الخطوة فقط إذا كان إصدار إضافة المتجهات لديك <0.8.0.google-3>.
ملاحظة مهمة: إذا كان عدد الصفوف أقل من 100، لن تحتاج إلى إنشاء فهرس ScaNN في المقام الأول لأنّه لن ينطبق على عدد أقل من الصفوف. في هذه الحالة، يُرجى تخطّي الخطوات التالية.
- لإنشاء فهارس ScaNN، ثبِّت إضافة alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- أولاً، نفِّذ طلب بحث "البحث المتّجه" بدون الفهرس وبدون تفعيل "الفلتر المضمّن":
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
يجب أن تكون النتيجة مشابهة لما يلي:
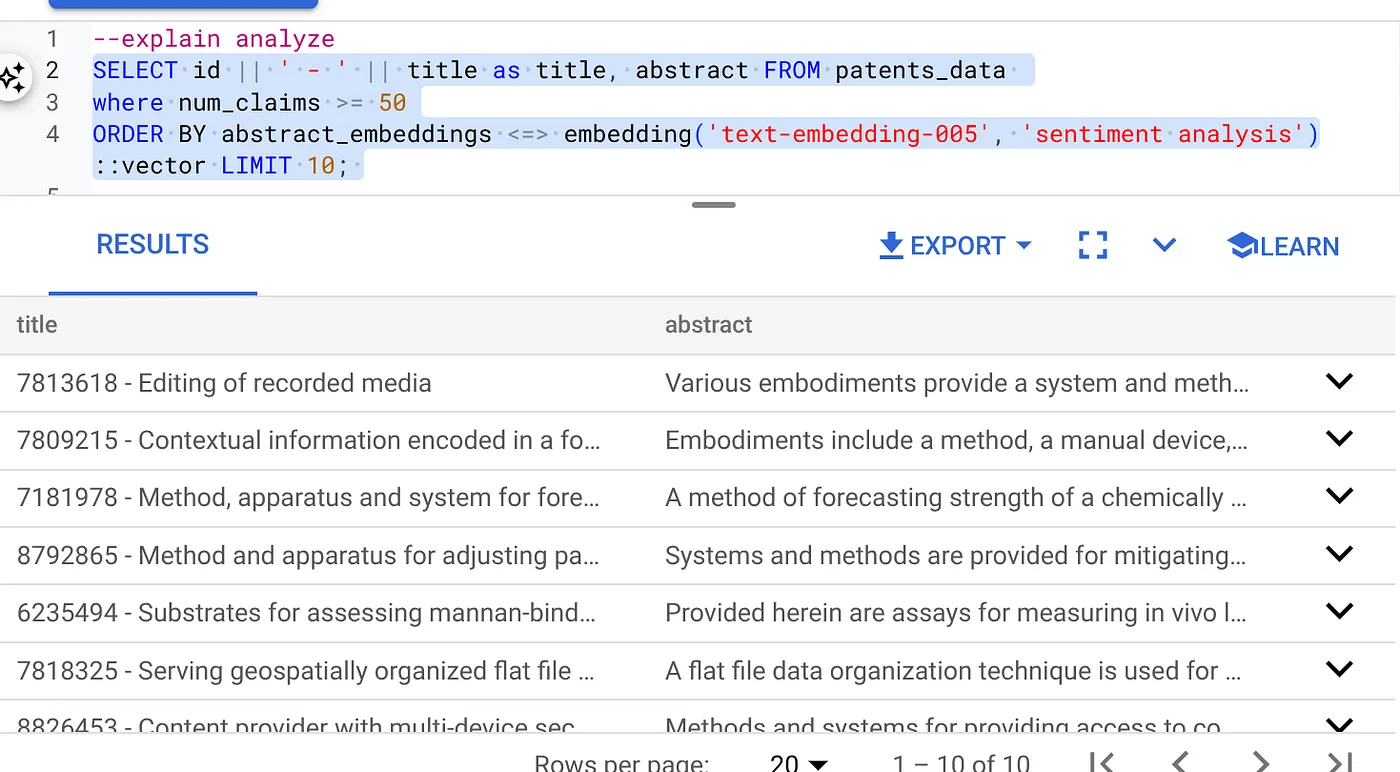
- تشغيل Explain Analyze عليه: (بدون فهرس أو "فلترة مضمّنة")
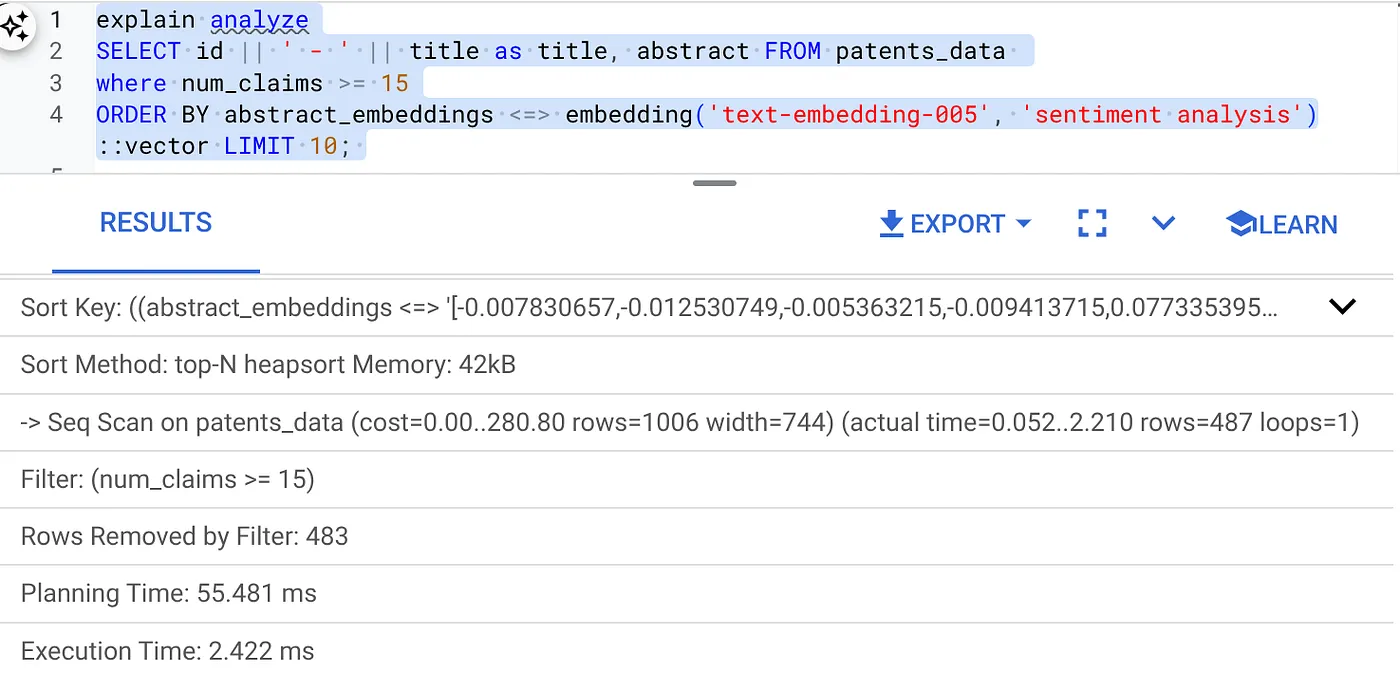
يستغرق التنفيذ 2.4 ملي ثانية
- لننشئ فهرسًا عاديًا في الحقل num_claims حتى نتمكّن من الفلترة حسبه:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- لننشئ فهرس ScaNN لتطبيق "بحث براءات الاختراع". نفِّذ ما يلي من AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
ملاحظة مهمة: تنطبق (num_leaves=32) على مجموعة البيانات الكاملة التي تتضمّن أكثر من 1,000 صف. إذا كان عدد الصفوف أقل من 100، لن تحتاج إلى إنشاء فهرس في المقام الأول لأنّه لن ينطبق على عدد الصفوف الأقل.
- اضبط ميزة "الفلترة المضمّنة" على "مفعّلة" في فهرس ScaNN:
SET scann.enable_inline_filtering = on
- الآن، لننفّذ طلب البحث نفسه مع تضمين فلتر و"البحث الدلالي":
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
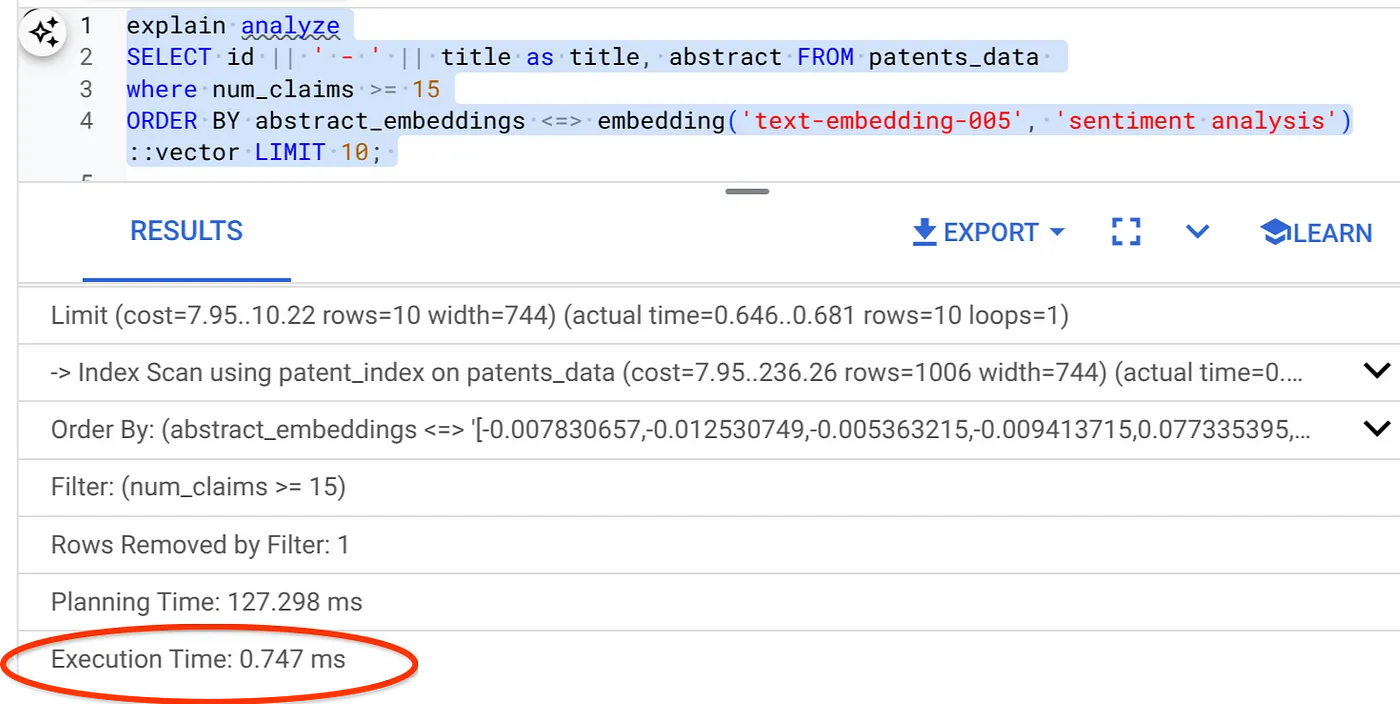
كما تلاحظ، تم تقليل وقت التنفيذ بشكلٍ كبير لعملية "البحث المتّجه" نفسها. أتاحت ميزة "الفلترة المضمّنة" المدمجة في فهرس ScaNN على "البحث المتّجه" إمكانية إجراء ذلك.
بعد ذلك، لنقيّم معدّل الاسترجاع لعملية "البحث المتّجه" المفعَّلة باستخدام ScaNN.
Recall Evaluator
في البحث المشابه، يشير التذكّر إلى النسبة المئوية للحالات ذات الصلة التي تم استرجاعها من عملية بحث، أي عدد النتائج الموجبة الصحيحة. هذا هو المقياس الأكثر شيوعًا المستخدَم لقياس جودة البحث. أحد أسباب فقدان الاسترجاع هو الفرق بين البحث عن الجيران الأقرب التقريبي، أو aNN، والبحث عن الجيران الأقرب k (التام)، أو kNN. تنفّذ فهارس المتجهات، مثل ScaNN في AlloyDB، خوارزميات aNN، ما يتيح لك تسريع البحث المتّجه في مجموعات البيانات الكبيرة مقابل تنازل بسيط عن الدقة. تتيح لك AlloyDB الآن إمكانية قياس هذا التوازن مباشرةً في قاعدة البيانات للاستعلامات الفردية والتأكّد من ثباته بمرور الوقت. يمكنك تعديل مَعلمات الطلب والفهرس استجابةً لهذه المعلومات لتحقيق نتائج وأداء أفضل.
ما هو المنطق الذي يستند إليه استرجاع نتائج البحث؟
في سياق البحث المتّجهي، يشير الاسترجاع إلى النسبة المئوية للمتّجهات التي يعرضها الفهرس والتي تمثّل أقرب الجيران الحقيقيين. على سبيل المثال، إذا كان طلب البحث عن الجيران الأقرب لـ 20 جارًا أقرب يعرض 19 من الجيران الأقرب المطابقين للواقع، تكون نسبة الاسترجاع 19/20x100 = %95. الاسترجاع هو المقياس المستخدَم لجودة البحث، ويتم تعريفه على أنّه النسبة المئوية للنتائج التي تم عرضها والتي تكون الأقرب موضوعيًا إلى متجهات طلب البحث.
يمكنك العثور على مقياس الاسترجاع لاستعلام متّجه في فهرس متّجه لإعدادات معيّنة باستخدام الدالة evaluate_query_recall. تتيح لك هذه الدالة ضبط المَعلمات للحصول على نتائج استرجاع طلب البحث المتّجه التي تريدها.
ملاحظة مهمة:
إذا واجهت خطأ "تم رفض الإذن" في فهرس HNSW في الخطوات التالية، يمكنك تخطّي قسم تقييم الاسترجاع بالكامل في الوقت الحالي. قد يكون ذلك مرتبطًا بقيود الوصول في هذه المرحلة، لأنّ هذه الميزة تم إطلاقها للتوّ في وقت إعداد مستندات هذا الدرس العملي.
- اضبط العلامة Enable Index Scan على فهرس ScaNN وفهرس HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- نفِّذ طلب البحث التالي في AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
تتلقّى الدالة evaluate_query_recall طلب البحث كمَعلمة وتعرض مدى استرجاعه. أستخدم طلب البحث نفسه الذي استخدمته للتحقّق من الأداء كطلب بحث إدخال للدالة. لقد أضفتُ SCaNN كطريقة فهرسة. لمزيد من خيارات المَعلمات، يُرجى الرجوع إلى المستندات.
معدّل الاسترجاع لطلب البحث في "البحث المتّجه" الذي استخدمناه:
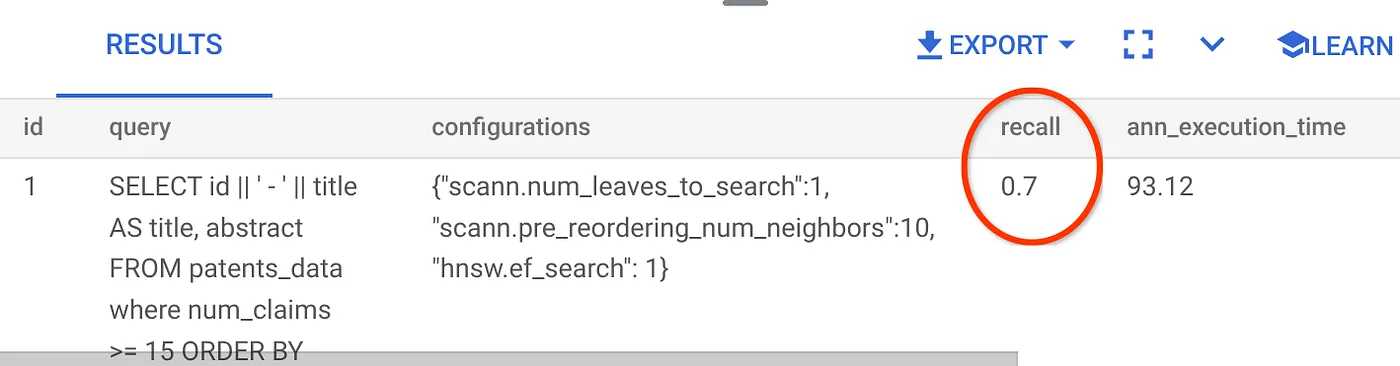
أرى أنّ معدّل الاسترجاع هو %70. يمكنني الآن استخدام هذه المعلومات لتغيير مَعلمات الفهرس والطرق ومَعلمات طلب البحث وتحسين استرجاع البيانات في "البحث المتّجه".
7. اختبارها باستخدام مَعلمات طلب البحث والفهرس المعدَّلة
لنختبر الآن طلب البحث من خلال تعديل مَعلمات طلب البحث استنادًا إلى الاستدعاء الذي تم تلقّيه.
- لقد عدّلتُ عدد الصفوف في مجموعة النتائج إلى 7 (بدلاً من 25 سابقًا)، ولاحظتُ تحسّنًا في مقياس RECALL، أي بنسبة %86.
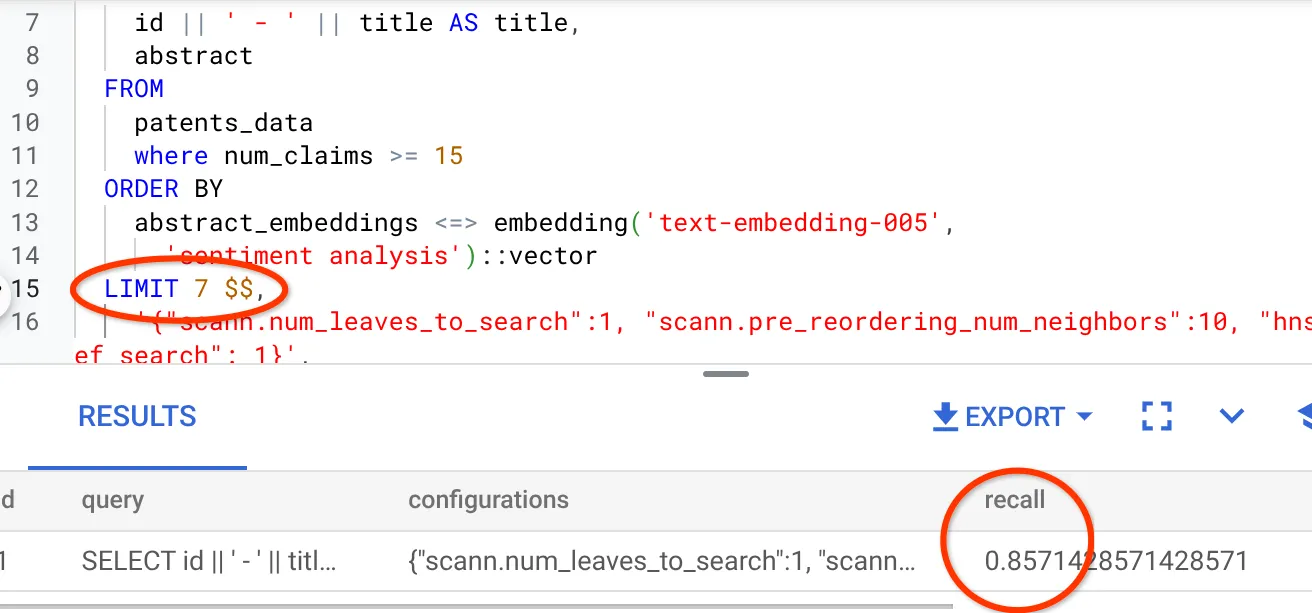
وهذا يعني أنّه يمكنني في الوقت الفعلي تغيير عدد النتائج التي تظهر للمستخدمين لتحسين مدى ملاءمتها لسياق بحثهم.
- لنحاول مرة أخرى عن طريق تعديل مَعلمات الفهرس:
في هذا الاختبار، سأستخدم "مسافة L2" بدلاً من دالة مسافة التشابه "جيب التمام". سأغيّر أيضًا الحد الأقصى لطلب البحث إلى 10 نتائج لعرض ما إذا كان هناك تحسّن في جودة نتائج البحث حتى مع زيادة عدد مجموعة نتائج البحث.
[BEFORE] طلب البحث الذي يستخدم دالة المسافة "تشابه جيب التمام":
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
ملاحظة مهمة جدًا: قد تسأل "كيف نعرف أنّ طلب البحث هذا يستخدم التشابه الجيب التمامي؟". يمكنك تحديد دالة المسافة من خلال استخدام "<=>" لتمثيل مسافة جيب التمام.
رابط مستندات حول دوال المسافة في "البحث المتّجه"
نتيجة طلب البحث أعلاه هي:
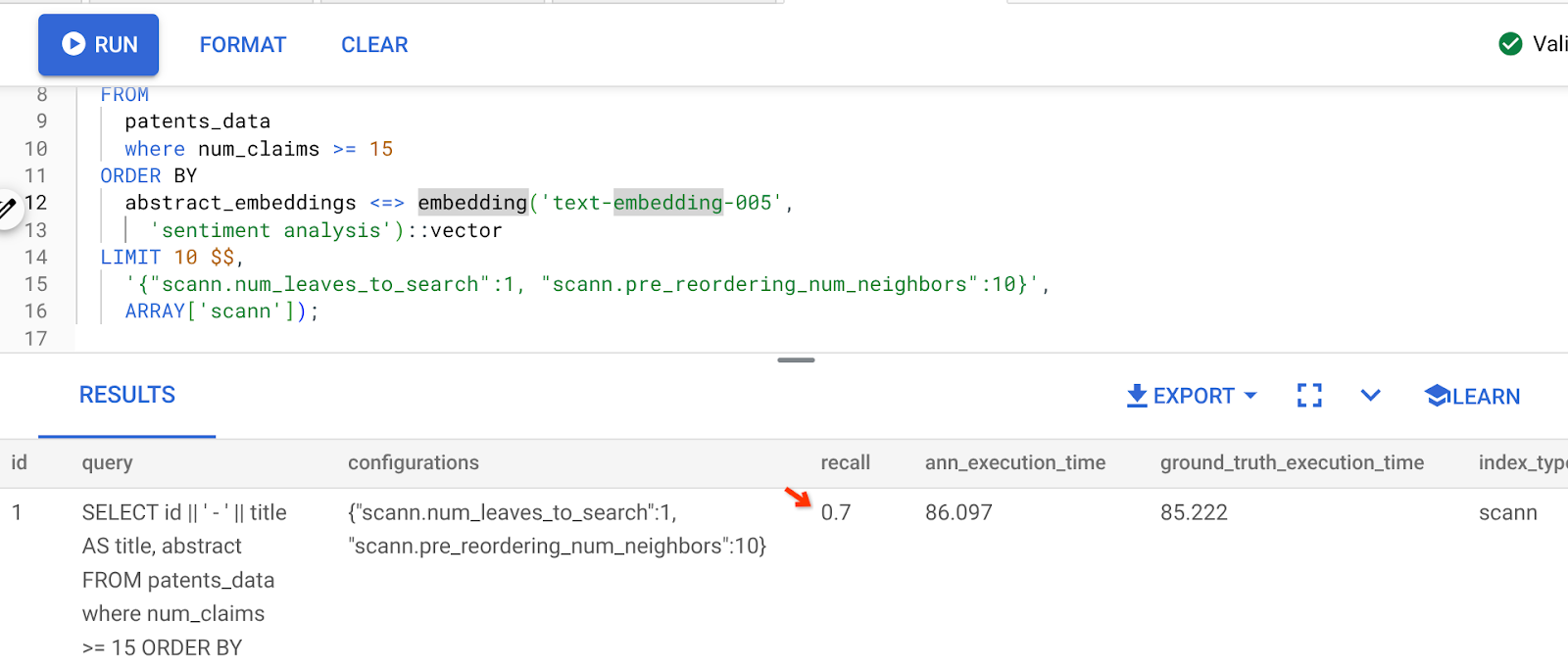
كما ترى، تبلغ قيمة RECALL 70% بدون أي تغيير في منطق الفهرس. تذكَّر فهرس ScaNN الذي أنشأناه في الخطوة 6 من قسم "الفلترة المضمّنة"، "patent_index"؟ لا يزال الفهرس نفسه ساريًا أثناء تنفيذ طلب البحث أعلاه.
لننشئ الآن فهرسًا باستخدام طلب بحث مختلف لدالة المسافة: مسافة L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
عبارة حذف الفهرس هي فقط لضمان عدم وجود فهرس غير ضروري في الجدول.
يمكنني الآن تنفيذ الاستعلام التالي لتقييم RECALL بعد تغيير دالة المسافة في وظيفة "البحث المتّجه".
طلب البحث [AFTER] الذي يستخدم دالة مسافة "تشابه جيب التمام":
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
نتيجة طلب البحث أعلاه هي:
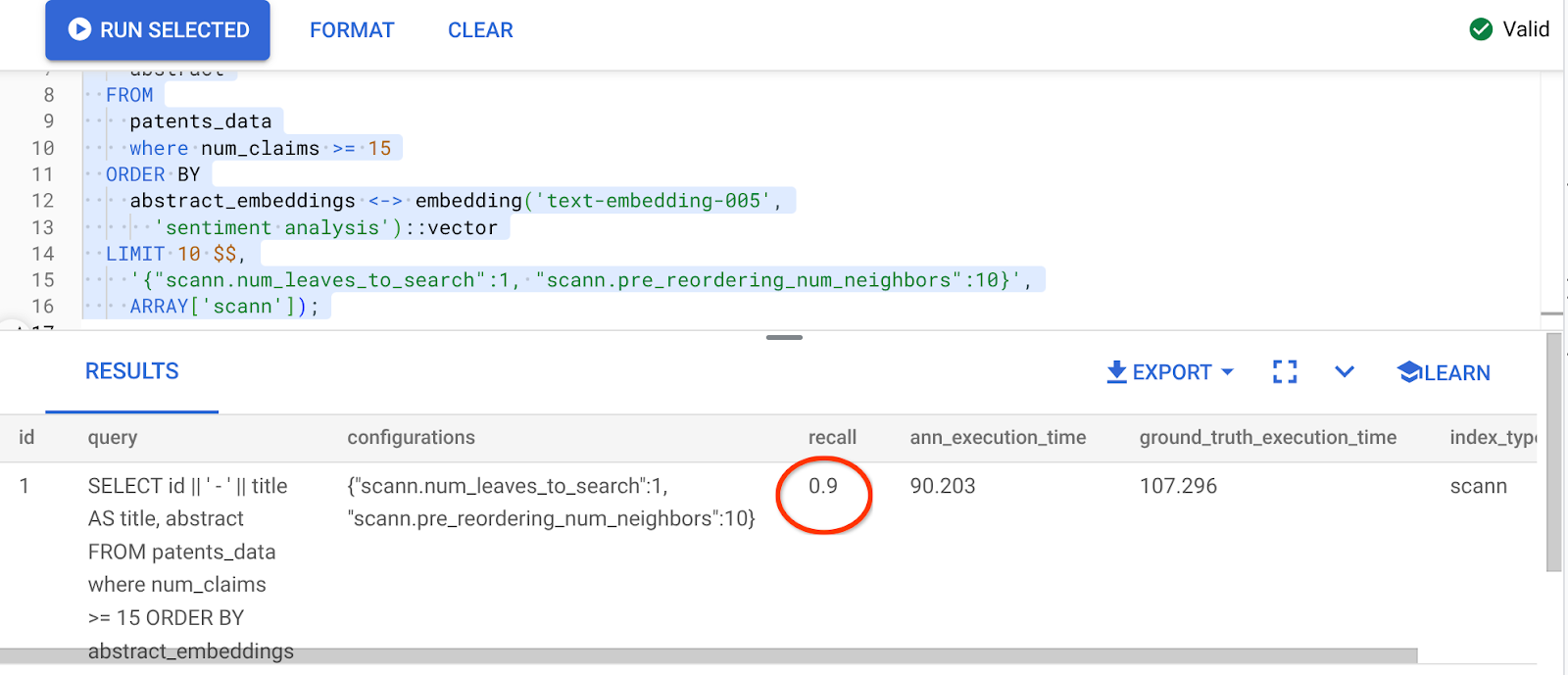
يا له من تحسّن في قيمة التذكّر، 90%!!!
هناك مَعلمات أخرى يمكنك تغييرها في الفهرس، مثل num_leaves وما إلى ذلك، استنادًا إلى قيمة الاسترجاع المطلوبة ومجموعة البيانات التي يستخدمها تطبيقك.
8. تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذه المشاركة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة Resource Manager.
- في قائمة المشاريع، اختَر المشروع الذي تريد حذفه، ثم انقر على حذف.
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على إيقاف لحذف المشروع.
- بدلاً من ذلك، يمكنك حذف مجموعة AlloyDB التي أنشأناها للتو لهذا المشروع (غيِّر الموقع الجغرافي في هذا الارتباط التشعّبي إذا لم تختر us-central1 للمجموعة في وقت الإعداد) من خلال النقر على الزر DELETE CLUSTER (حذف المجموعة).
9- تهانينا
تهانينا! لقد أنشأت بنجاح طلب البحث السياقي عن براءات الاختراع باستخدام ميزة "البحث المتّجه" المتقدّمة في AlloyDB لتحقيق أداء عالٍ وجعل البحث يستند إلى المعنى. لقد أنشأتُ تطبيقًا متعدد الأدوات يعتمد على الوكلاء ويخضع لمراقبة الجودة، ويستخدم حزمة تطوير البرامج (ADK) وجميع ميزات AlloyDB التي ناقشناها هنا لإنشاء وكيل عالي الأداء والجودة للبحث عن براءات الاختراع وتحليلها، ويمكنك الاطّلاع عليه هنا: https://youtu.be/Y9fvVY0yZTY
إذا أردت تعلُّم كيفية إنشاء هذا الوكيل، يُرجى الرجوع إلى الدرس التطبيقي حول الترميز.