
1. Panoramica
In diversi settori, la ricerca contestuale è una funzionalità fondamentale che costituisce il cuore e il centro delle applicazioni. La generazione aumentata dal recupero è da tempo un fattore chiave di questa evoluzione tecnologica cruciale, grazie ai suoi meccanismi di recupero basati sull'AI generativa. I modelli generativi, con le loro grandi finestre contestuali e l'impressionante qualità dell'output, stanno trasformando l'AI. La RAG fornisce un modo sistematico per inserire il contesto nelle applicazioni e negli agenti di AI, basandoli su database strutturati o informazioni provenienti da vari media. Questi dati contestuali sono fondamentali per chiarezza della verità e accuratezza dell'output, ma quanto sono precisi i risultati? La tua attività dipende in gran parte dall'accuratezza di queste corrispondenze contestuali e dalla pertinenza? Allora questo progetto ti farà ridere!
Il segreto della ricerca vettoriale non è solo la sua creazione, ma anche la verifica della qualità delle corrispondenze vettoriali. Capita a tutti di fissare un elenco di risultati, chiedendosi: "Ma funziona davvero?". Vediamo come valutare la qualità delle corrispondenze vettoriali. "Quindi cosa è cambiato in RAG?", ti chiederai. Tutto! Per anni, la Retrieval Augmented Generation (RAG) è sembrata un obiettivo promettente ma sfuggente. Ora, finalmente, abbiamo gli strumenti per creare applicazioni RAG con le prestazioni e l'affidabilità necessarie per le attività di importanza cruciale.
Ora abbiamo già una comprensione di base di tre cose:
- Che cosa significa ricerca contestuale per il tuo agente e come realizzarla utilizzando Vector Search.
- Abbiamo anche approfondito l'argomento della ricerca vettoriale nell'ambito dei tuoi dati, ovvero all'interno del database stesso (tutti i database Google Cloud lo supportano, se non lo sapevi già).
- Abbiamo fatto un passo avanti rispetto al resto del mondo, spiegandoti come ottenere una funzionalità RAG di ricerca vettoriale leggera con prestazioni e qualità elevate grazie alla funzionalità di ricerca vettoriale di AlloyDB basata sull'indice ScaNN.
Se non hai eseguito gli esperimenti di base, intermedi e leggermente avanzati di RAG, ti consiglio di leggere questi tre articoli qui, qui e qui nell'ordine elencato.
La ricerca di brevetti aiuta l'utente a trovare brevetti contestualmente pertinenti al testo di ricerca e ne abbiamo già creato una versione in passato. Ora lo creeremo con nuove funzionalità RAG avanzate che consentono una ricerca contestuale controllata per la qualità per questa applicazione. Iniziamo.
L'immagine seguente mostra il flusso complessivo di ciò che accade in questa applicazione.~ 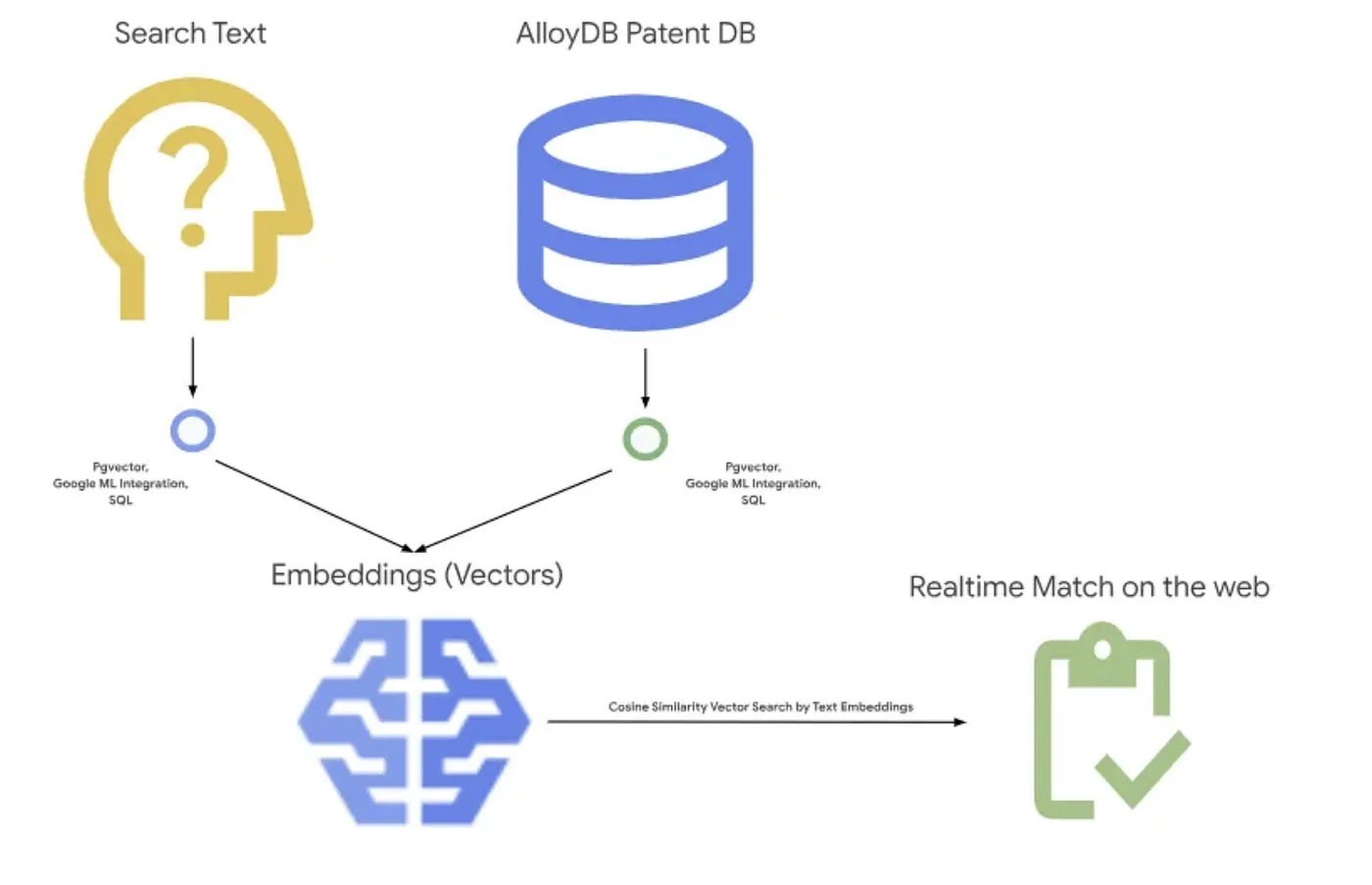
Obiettivo
Consenti a un utente di cercare brevetti in base a una descrizione testuale con prestazioni migliorate e una qualità superiore, consentendo al contempo di valutare la qualità delle corrispondenze generate utilizzando le ultime funzionalità RAG di AlloyDB.
Cosa creerai
Nell'ambito di questo lab, imparerai a:
- Crea un'istanza AlloyDB e carica il set di dati pubblico sui brevetti
- Crea l'indice dei metadati e l'indice ScaNN
- Implementa la ricerca vettoriale avanzata in AlloyDB utilizzando il metodo di filtraggio incorporato di ScaNN
- Implementare la funzionalità di valutazione del ritiro
- Valuta la risposta alla query
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto .
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste. Puoi utilizzare un comando gcloud nel terminale Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
L'alternativa al comando gcloud è tramite la console, cercando ogni prodotto o utilizzando questo link.
Consulta la documentazione per i comandi e l'utilizzo di gcloud.
3. Configurazione del database
In questo lab utilizzeremo AlloyDB come database per i dati sui brevetti. Utilizza i cluster per contenere tutte le risorse, come database e log. Ogni cluster ha un'istanza primaria che fornisce un punto di accesso ai dati. Le tabelle conterranno i dati effettivi.
Creiamo un cluster, un'istanza e una tabella AlloyDB in cui verrà caricato il set di dati sui brevetti.
Crea un cluster e un'istanza
- Vai alla pagina AlloyDB nella console Cloud. Un modo semplice per trovare la maggior parte delle pagine in Cloud Console è cercarle utilizzando la barra di ricerca della console.
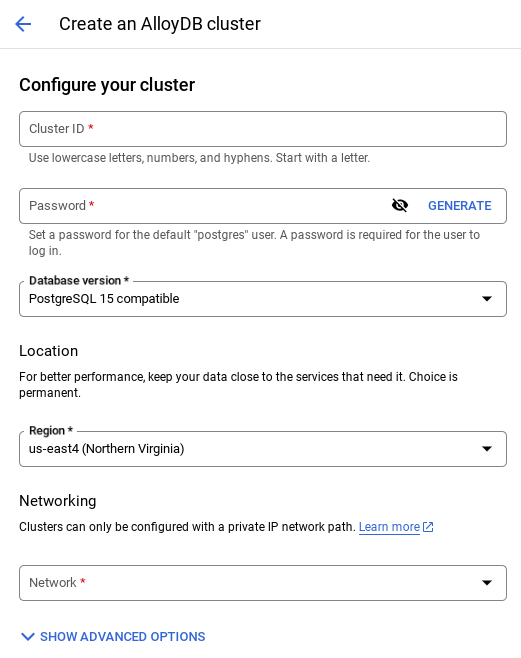
- Seleziona CREA CLUSTER da questa pagina:

- Vedrai una schermata come quella riportata di seguito. Crea un cluster e un'istanza con i seguenti valori (assicurati che i valori corrispondano se cloni il codice dell'applicazione dal repository):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / ultima versione consigliata
- Region: "
us-central1" - Networking: "
default"
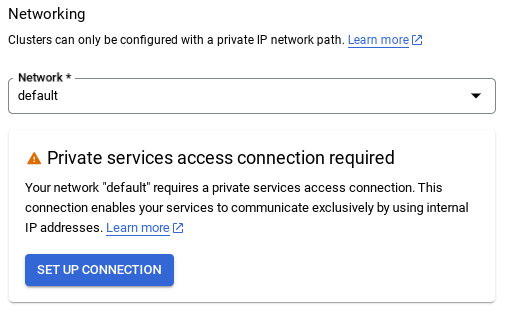
- Quando selezioni la rete predefinita, viene visualizzata una schermata come quella riportata di seguito.
Seleziona CONFIGURA CONNESSIONE.
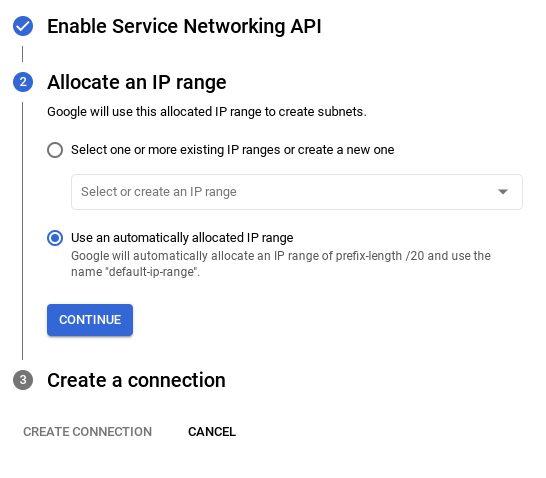
- Da qui, seleziona "Utilizza un intervallo IP allocato automaticamente" e fai clic su Continua. Dopo aver esaminato le informazioni, seleziona CREA CONNESSIONE.
- Una volta configurata la rete, puoi continuare a creare il cluster. Fai clic su CREA CLUSTER per completare la configurazione del cluster come mostrato di seguito:
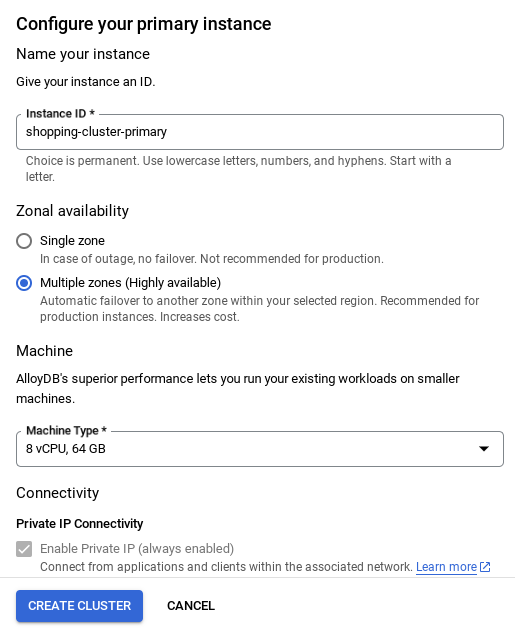
Assicurati di modificare l'ID istanza (che puoi trovare al momento della configurazione del cluster / dell'istanza) in
vector-instance. Se non riesci a modificarlo, ricorda di utilizzare l'ID istanza in tutti i riferimenti futuri.
Tieni presente che la creazione del cluster richiederà circa 10 minuti. Una volta completata l'operazione, dovresti visualizzare una schermata che mostra la panoramica del cluster che hai appena creato.
4. Importazione dati
Ora è il momento di aggiungere una tabella con i dati del negozio. Vai ad AlloyDB, seleziona il cluster principale e poi AlloyDB Studio:
Potrebbe essere necessario attendere il completamento della creazione dell'istanza. Una volta creato, accedi ad AlloyDB utilizzando le credenziali che hai creato durante la creazione del cluster. Utilizza i seguenti dati per l'autenticazione a PostgreSQL:
- Nome utente : "
postgres" - Database : "
postgres" - Password : "
alloydb"
Una volta eseguita l'autenticazione in AlloyDB Studio, i comandi SQL vengono inseriti nell'editor. Puoi aggiungere più finestre dell'editor utilizzando il segno più a destra dell'ultima finestra.
Inserirai i comandi per AlloyDB nelle finestre dell'editor, utilizzando le opzioni Esegui, Formatta e Cancella in base alle esigenze.
Attivare le estensioni
Per creare questa app, utilizzeremo le estensioni pgvector e google_ml_integration. L'estensione pgvector consente di archiviare ed eseguire ricerche di vector embedding. L'estensione google_ml_integration fornisce funzioni che utilizzi per accedere agli endpoint di previsione Vertex AI per ottenere previsioni in SQL. Attiva queste estensioni eseguendo i seguenti DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Se vuoi controllare le estensioni abilitate sul tuo database, esegui questo comando SQL:
select extname, extversion from pg_extension;
Creare una tabella
Puoi creare una tabella utilizzando l'istruzione DDL riportata di seguito in AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
La colonna abstract_embeddings consentirà l'archiviazione dei valori vettoriali del testo.
Concedi autorizzazione
Esegui l'istruzione riportata di seguito per concedere l'esecuzione della funzione "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Concedi il ruolo Utente Vertex AI al service account AlloyDB
Dalla console Google Cloud IAM, concedi al service account AlloyDB (simile a service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accesso al ruolo "Utente Vertex AI". PROJECT_NUMBER conterrà il numero del tuo progetto.
In alternativa, puoi eseguire il comando riportato di seguito dal terminale Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Caricare i dati dei brevetti nel database
Come set di dati utilizzeremo i set di dati pubblici di Google Brevetti su BigQuery. Utilizzeremo AlloyDB Studio per eseguire le query. I dati vengono inseriti in questo file insert_scripts.sql e lo eseguiamo per caricare i dati dei brevetti.
- Nella console Google Cloud, apri la pagina AlloyDB.
- Seleziona il cluster appena creato e fai clic sull'istanza.
- Nel menu di navigazione di AlloyDB, fai clic su AlloyDB Studio. Accedi con le tue credenziali.
- Apri una nuova scheda facendo clic sull'icona Nuova scheda a destra.
- Copia l'istruzione della query
insertdallo scriptinsert_scripts.sqlmenzionato sopra nell'editor. Puoi copiare da 10 a 50 istruzioni di inserimento per una rapida demo di questo caso d'uso. - Fai clic su Esegui. I risultati della query vengono visualizzati nella tabella Risultati.
Nota:potresti notare che lo script di inserimento contiene molti dati. Questo perché abbiamo incluso gli incorporamenti negli script di inserimento. Fai clic su "Visualizza non elaborati" se hai difficoltà a caricare il file su GitHub. Questa operazione viene eseguita per evitarti la difficoltà (nei passaggi successivi) di generare più di alcuni embedding (diciamo 20-25 al massimo) nel caso in cui utilizzi un account di fatturazione con credito di prova per Google Cloud.
5. Crea incorporamenti per i dati dei brevetti
Innanzitutto, testiamo la funzione di incorporamento eseguendo la seguente query di esempio:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dovrebbe restituire il vettore di embedding, che ha l'aspetto di un array di numeri in virgola mobile, per il testo di esempio nella query. Ecco come appare:
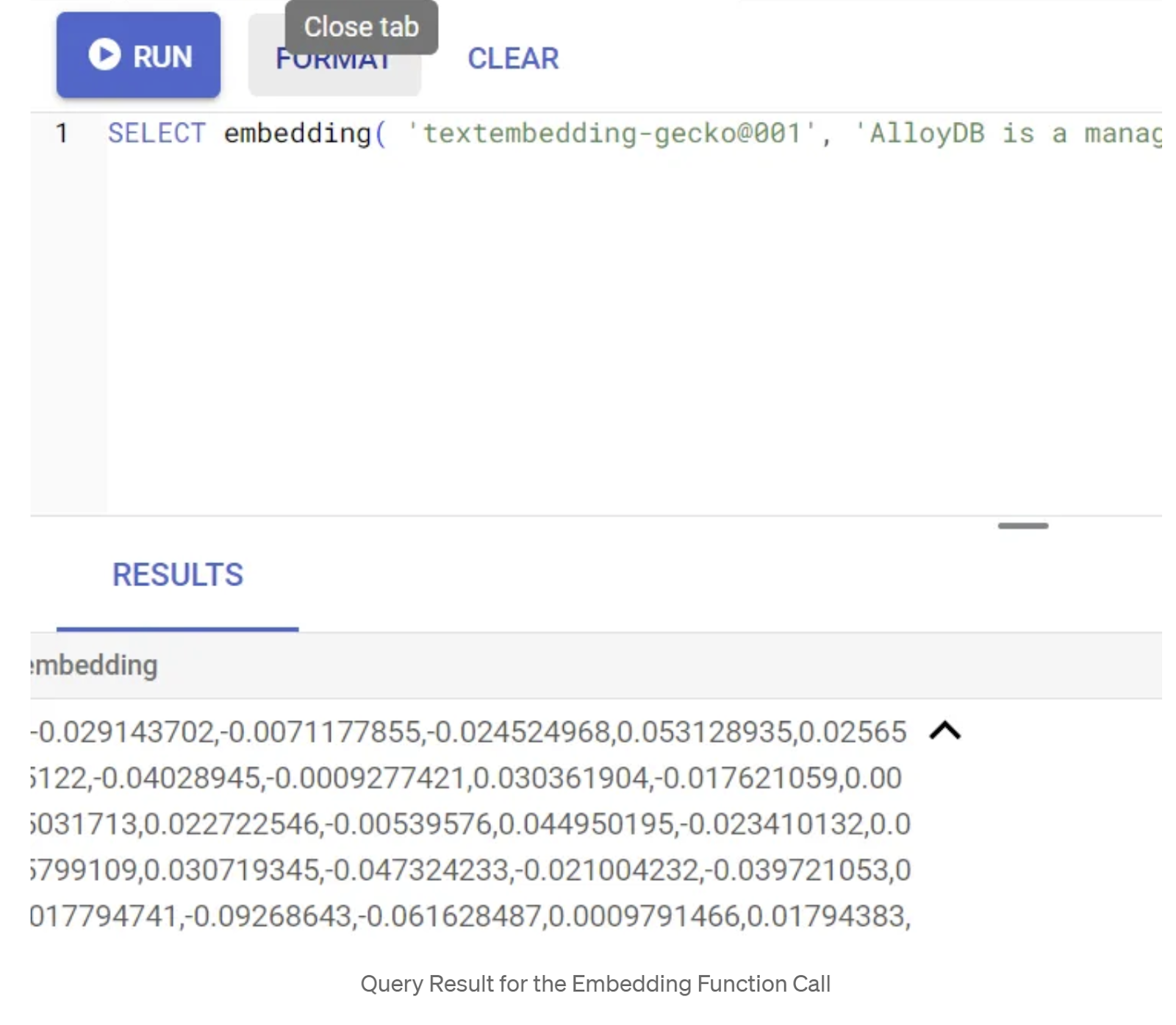
Aggiorna il campo vettoriale abstract_embeddings
Esegui il seguente DML per aggiornare i riassunti dei brevetti nella tabella con gli incorporamenti corrispondenti solo se non hai inserito i dati abstract_embeddings come parte dello script di inserimento:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Se utilizzi un account di fatturazione con credito di prova per Google Cloud, potresti avere difficoltà a generare più di pochi incorporamenti (ad esempio 20-25 al massimo). Per questo motivo, ho già incluso gli incorporamenti negli script di inserimento e dovresti averli caricati nella tabella se hai completato il passaggio "Carica i dati dei brevetti nel database".
6. Eseguire RAG avanzato con le nuove funzionalità di AlloyDB
Ora che la tabella, i dati e gli embedding sono pronti, eseguiamo la ricerca vettoriale in tempo reale per il testo di ricerca dell'utente. Puoi testarlo eseguendo la query riportata di seguito:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
In questa query,
- Il testo cercato dall'utente è: "Analisi del sentiment".
- Lo convertiamo in incorporamenti nel metodo embedding() utilizzando il modello text-embedding-005.
- "<=>" rappresenta l'utilizzo del metodo di distanza COSINE SIMILARITY.
- Stiamo convertendo il risultato del metodo di embedding in tipo vettoriale per renderlo compatibile con i vettori archiviati nel database.
- LIMIT 10 indica che stiamo selezionando le 10 corrispondenze più vicine al testo di ricerca.
AlloyDB porta la RAG di ricerca vettoriale a un livello superiore:
Sono state introdotte diverse novità. Due di queste, incentrate sugli sviluppatori, sono:
- Filtro in linea
- Richiama valutatore
Filtro in linea
In precedenza, in qualità di sviluppatore, dovevi eseguire la query Vector Search e occuparti del filtraggio e del recupero. Lo strumento di ottimizzazione delle query di AlloyDB sceglie come eseguire una query con filtri. Il filtraggio in linea è una nuova tecnica di ottimizzazione delle query che consente all'ottimizzatore delle query AlloyDB di valutare contemporaneamente le condizioni di filtraggio dei metadati e la ricerca vettoriale, sfruttando sia gli indici vettoriali sia gli indici sulle colonne dei metadati. Ciò ha aumentato le prestazioni di richiamo, consentendo agli sviluppatori di sfruttare al meglio le funzionalità di AlloyDB.
Il filtro in linea è ideale per i casi con selettività media. Man mano che AlloyDB esegue ricerche nell'indice vettoriale, calcola le distanze solo per i vettori che corrispondono alle condizioni di filtro dei metadati (i filtri funzionali in una query gestiti di solito nella clausola WHERE). In questo modo, le prestazioni di queste query migliorano notevolmente, integrando i vantaggi del pre-filtraggio o del post-filtraggio.
- Installa o aggiorna l'estensione pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Se l'estensione pgvector è già installata, esegui l'upgrade all'estensione vettoriale alla versione 0.8.0.google-3 o successive per ottenere le funzionalità di valutazione del richiamo.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Questo passaggio deve essere eseguito solo se l'estensione vettoriale è <0.8.0.google-3>.
Nota importante:se il conteggio delle righe è inferiore a 100, non dovrai creare l'indice ScaNN, in quanto non verrà applicato a un numero inferiore di righe. In questo caso, ignora i passaggi che seguono.
- Per creare indici ScaNN, installa l'estensione alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Per prima cosa, esegui la query di ricerca vettoriale senza l'indice e senza il filtro in linea abilitato:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Il risultato dovrebbe essere simile a questo:
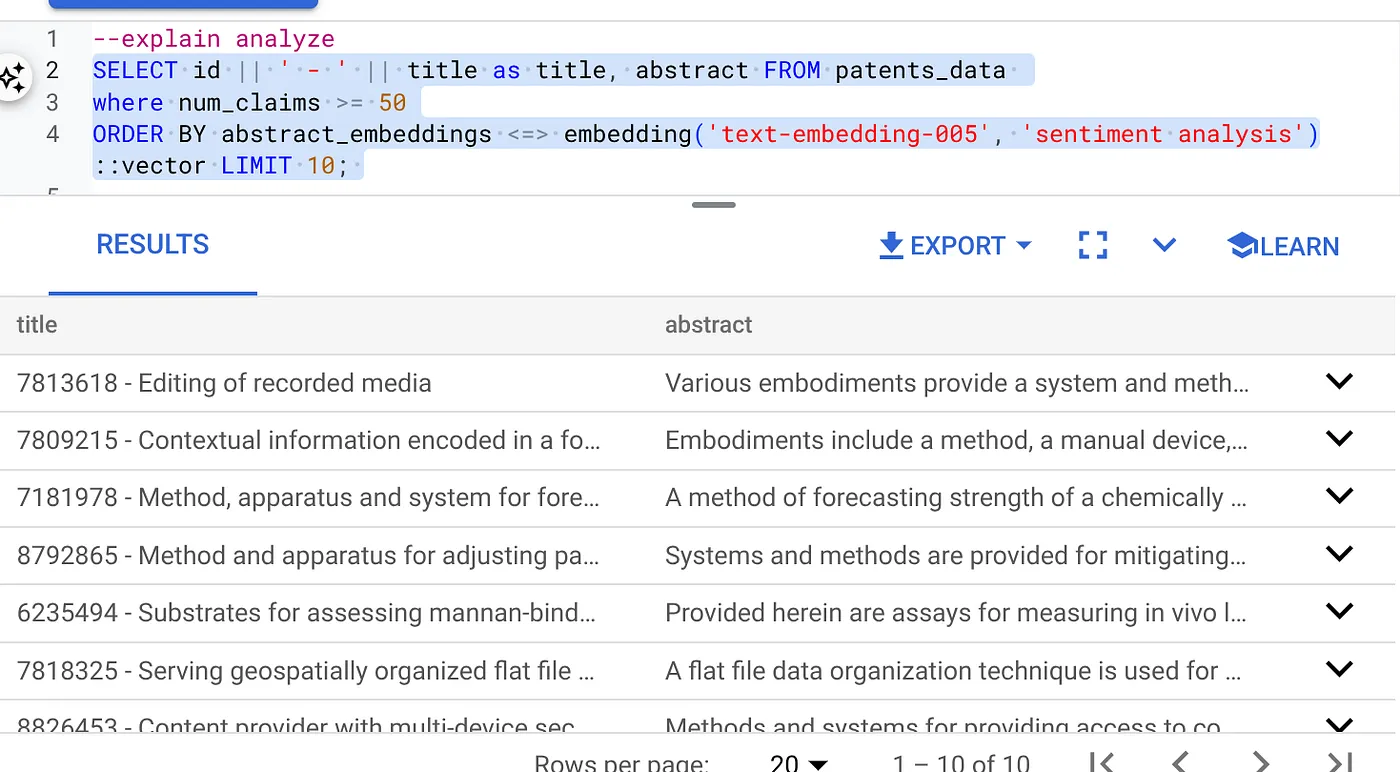
- Esegui Explain Analyze: (senza indice né filtro in linea)
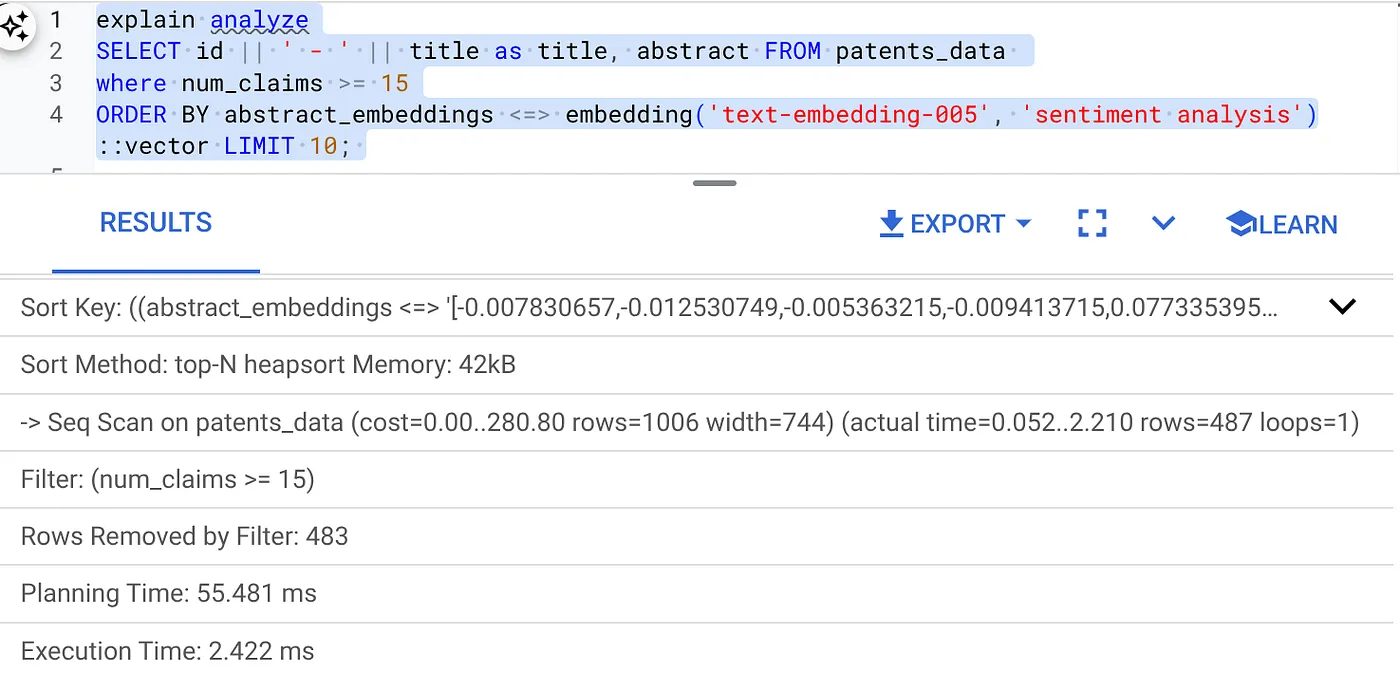
Il tempo di esecuzione è 2,4 ms
- Creiamo un indice normale sul campo num_claims in modo da poterlo filtrare:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Creiamo l'indice ScaNN per la nostra applicazione di ricerca di brevetti. Esegui questo codice da AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Nota importante: (num_leaves=32) si applica al nostro set di dati totale con più di 1000 righe. Se il conteggio delle righe è inferiore a 100, non è necessario creare un indice, in quanto non si applica a un numero inferiore di righe.
- Imposta il filtro in linea abilitato sull'indice ScaNN:
SET scann.enable_inline_filtering = on
- Ora eseguiamo la stessa query con il filtro e la ricerca vettoriale:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
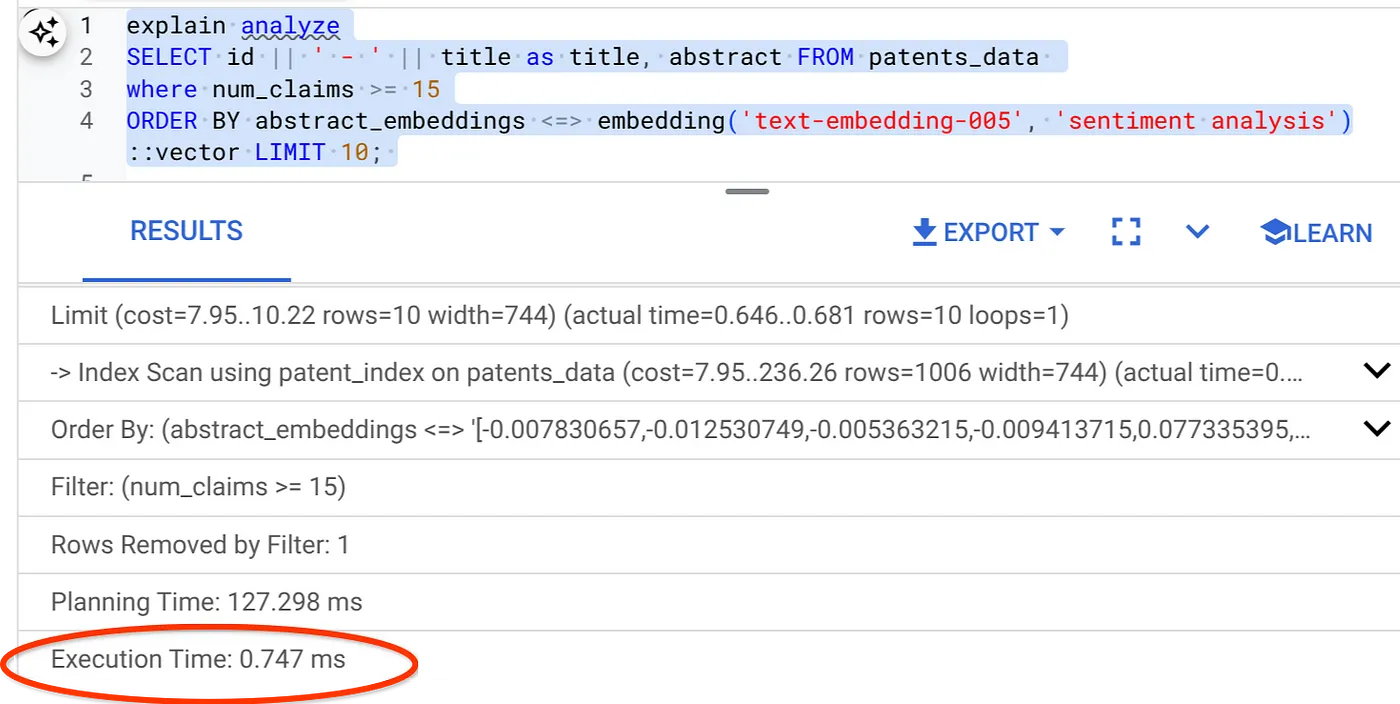
Come puoi vedere, il tempo di esecuzione è ridotto in modo significativo per la stessa ricerca vettoriale. L'indice ScaNN con filtro incorporato in Vector Search ha reso possibile tutto questo.
Successivamente, valutiamo il richiamo per questa ricerca vettoriale abilitata per ScaNN.
Richiama valutatore
Il richiamo nella ricerca per similarità è la percentuale di istanze pertinenti recuperate da una ricerca, ovvero il numero di veri positivi. Si tratta della metrica più comune utilizzata per misurare la qualità della ricerca. Una fonte di perdita di richiamo deriva dalla differenza tra la ricerca approssimativa del vicino più prossimo (ANN) e la ricerca esatta del vicino più prossimo (KNN). Gli indici vettoriali come ScaNN di AlloyDB implementano algoritmi ANN, consentendoti di velocizzare la ricerca vettoriale su set di dati di grandi dimensioni in cambio di un piccolo compromesso nel richiamo. Ora AlloyDB ti offre la possibilità di misurare questo compromesso direttamente nel database per le singole query e garantire che sia stabile nel tempo. Puoi aggiornare i parametri di query e indice in risposta a queste informazioni per ottenere risultati e prestazioni migliori.
Qual è la logica alla base del richiamo dei risultati di ricerca?
Nel contesto della ricerca vettoriale, il richiamo si riferisce alla percentuale di vettori restituiti dall'indice che sono i vicini più prossimi effettivi. Ad esempio, se una query per i 20 vicini più prossimi restituisce 19 dei vicini più prossimi della verità di base, il richiamo è 19/20 x 100 = 95%. Il richiamo è la metrica utilizzata per la qualità della ricerca ed è definito come la percentuale dei risultati restituiti che sono oggettivamente più vicini ai vettori di query.
Puoi trovare il richiamo per una query vettoriale su un indice vettoriale per una determinata configurazione utilizzando la funzione evaluate_query_recall. Questa funzione ti consente di ottimizzare i parametri per ottenere i risultati di richiamo della query vettoriale che desideri.
Nota importante:
Se riscontri l'errore Autorizzazione negata nell'indice HNSW nei passaggi seguenti, salta per il momento l'intera sezione Valutazione del richiamo. A questo punto, potrebbe trattarsi di restrizioni di accesso, in quanto è stato rilasciato al momento della documentazione di questo codelab.
- Imposta il flag Enable Index Scan (Attiva scansione indice) sull'indice ScaNN e sull'indice HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Esegui la seguente query in AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
La funzione evaluate_query_recall accetta la query come parametro e ne restituisce il richiamo. Utilizzo la stessa query che ho utilizzato per controllare il rendimento come query di input della funzione. Ho aggiunto SCaNN come metodo di indice. Per altre opzioni di parametri, consulta la documentazione.
Il richiamo per questa query di Vector Search che abbiamo utilizzato:
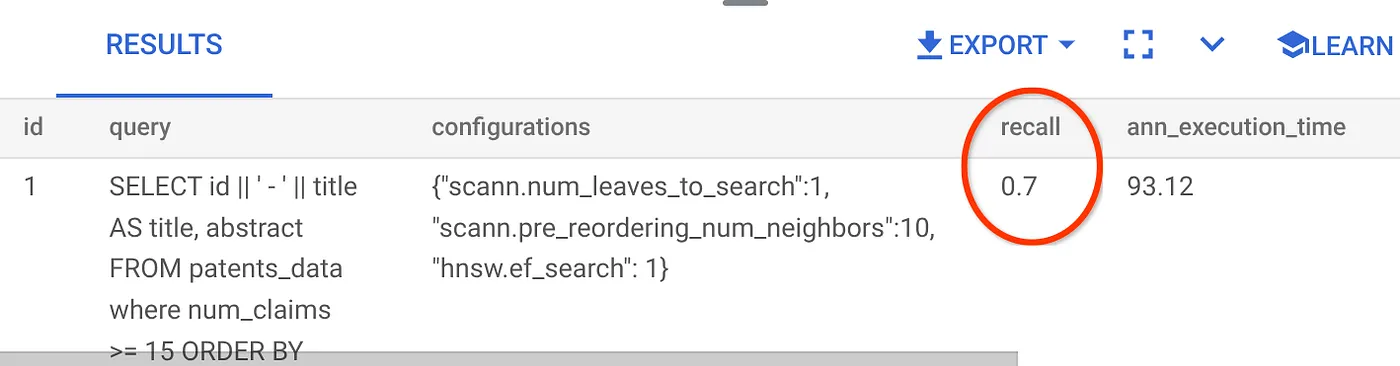
Vedo che il RECALL è del 70%. Ora posso utilizzare queste informazioni per modificare i parametri, i metodi e i parametri di query dell'indice e migliorare il recupero per questa ricerca vettoriale.
7. Testalo con parametri di query e indice modificati
Ora testiamo la query modificando i parametri di query in base al richiamo ricevuto.
- Ho modificato il numero di righe nel set di risultati portandolo a 7 (in precedenza era 25) e ho notato un RECALL migliorato, ovvero dell'86%.
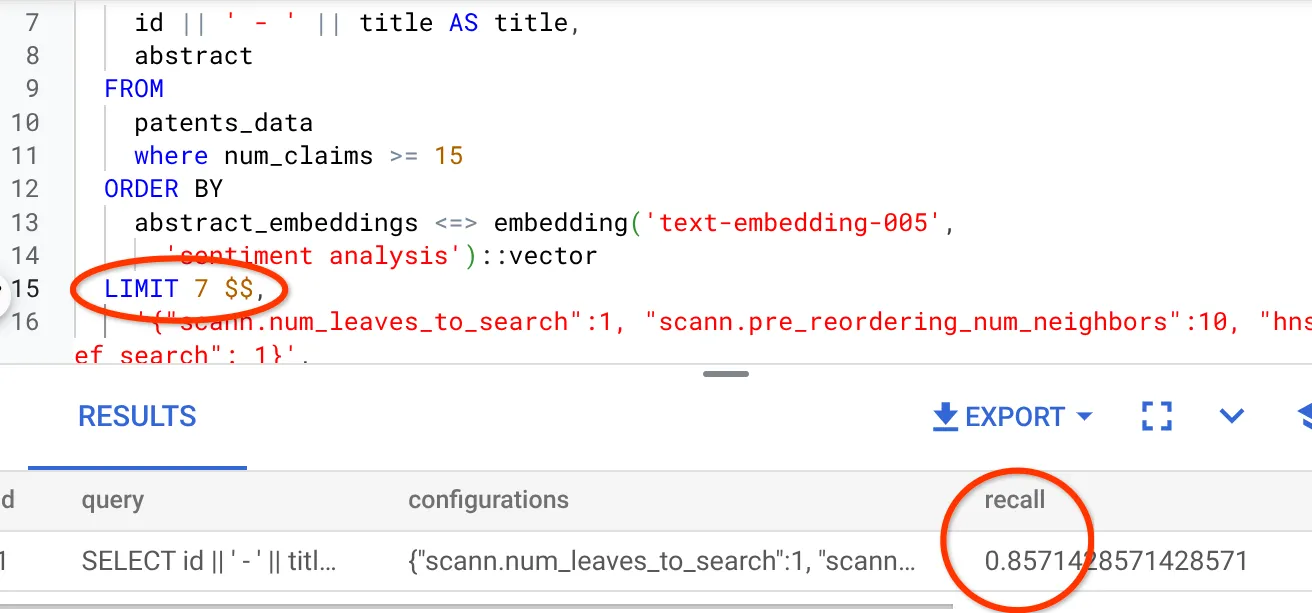
Ciò significa che in tempo reale posso variare il numero di corrispondenze che i miei utenti vedono per migliorare la pertinenza delle corrispondenze in base al contesto di ricerca degli utenti.
- Proviamo di nuovo modificando i parametri dell'indice:
Per questo test, utilizzerò la "Distanza L2" anziché la funzione di distanza di similarità "Coseno". Modificherò anche il limite della query a 10 per mostrare se c'è un miglioramento della qualità dei risultati di ricerca anche con un numero maggiore di risultati di ricerca.
[PRIMA] Query che utilizza la funzione di distanza di similarità del coseno:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Nota molto importante: ti starai chiedendo: "Come facciamo a sapere che questa query utilizza la similarità del coseno?". Puoi identificare la funzione di distanza dall'utilizzo di "<=>" per rappresentare la distanza del coseno.
Link alla documentazione per le funzioni di distanza di Ricerca vettoriale.
Il risultato della query precedente è:
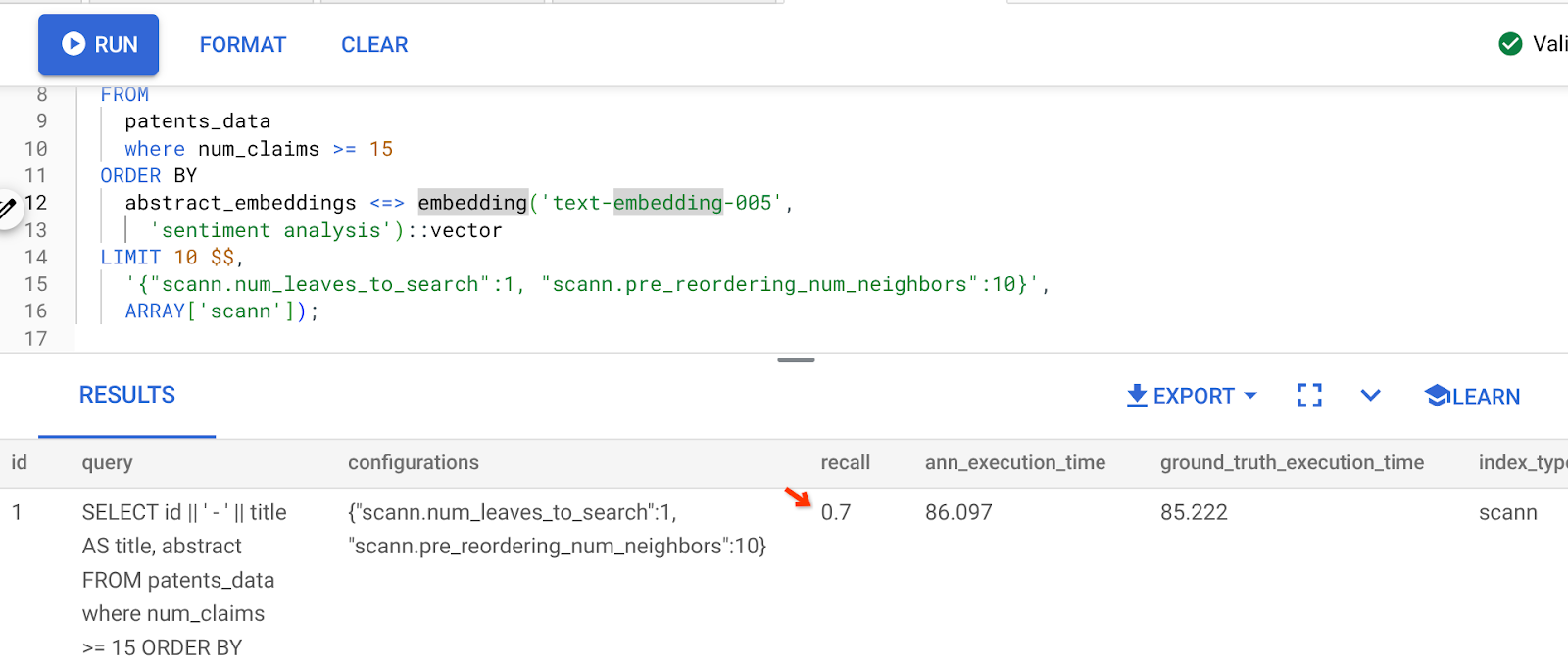
Come puoi vedere, il RECALL è del 70% senza alcuna modifica alla logica dell'indice. Ricordi l'indice ScaNN che abbiamo creato nel passaggio 6 della sezione Filtro in linea, "patent_index "? Lo stesso indice è ancora efficace mentre abbiamo eseguito la query precedente.
Ora creiamo un indice con una query di funzione di distanza diversa: Distanza L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
L'istruzione di eliminazione dell'indice serve solo a garantire che non ci siano indici non necessari nella tabella.
Ora posso eseguire la seguente query per valutare il RECALL dopo aver modificato la funzione di distanza della funzionalità di ricerca vettoriale.
[AFTER] Query che utilizza la funzione di distanza di similarità del coseno:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Il risultato della query precedente è:
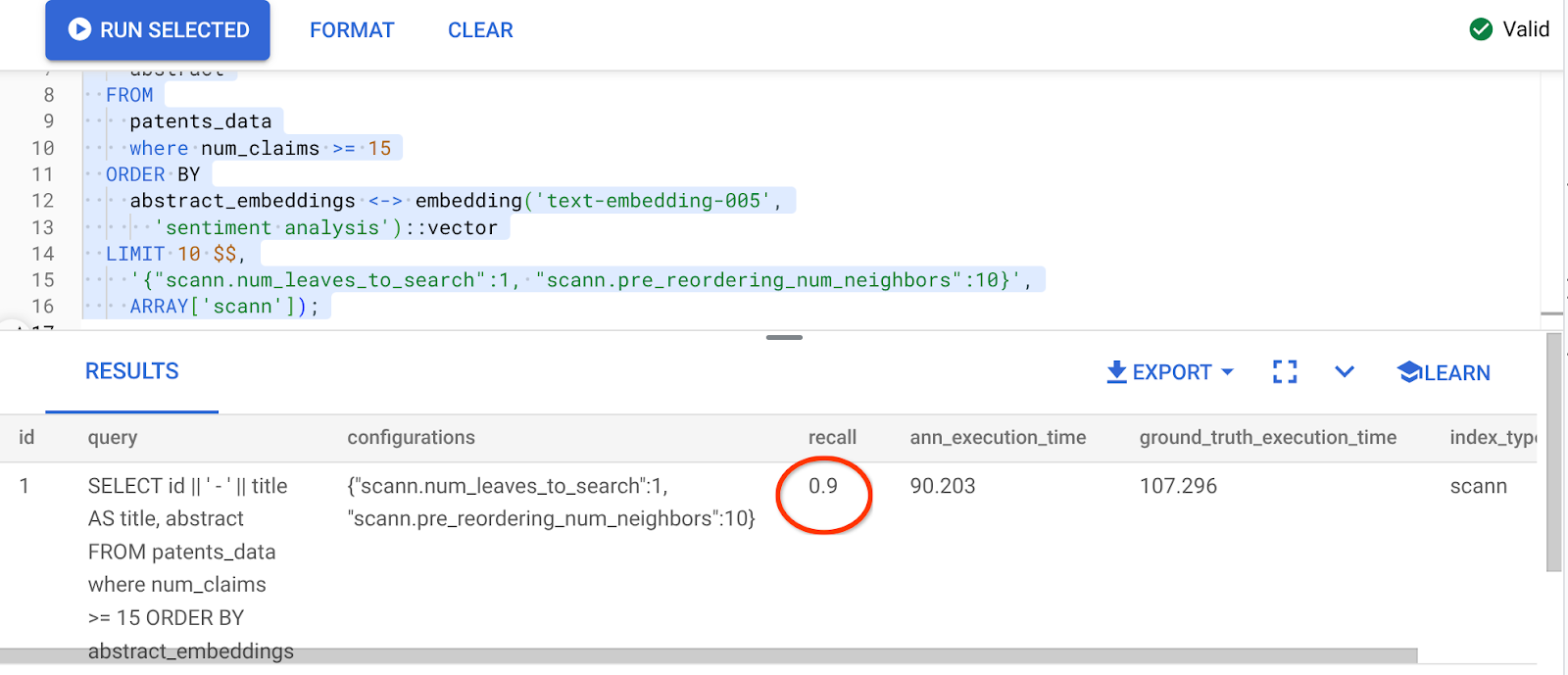
Che trasformazione nel valore di recall, 90%!!!
Nell'indice puoi modificare altri parametri, ad esempio num_leaves, in base al valore di richiamo desiderato e al set di dati utilizzato dall'applicazione.
8. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo post, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Resource Manager.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
- In alternativa, puoi eliminare il cluster AlloyDB (modifica la posizione in questo collegamento ipertestuale se non hai scelto us-central1 per il cluster al momento della configurazione) che abbiamo appena creato per questo progetto facendo clic sul pulsante ELIMINA CLUSTER.
9. Complimenti
Complimenti! Hai creato correttamente la query di ricerca di brevetti contestuale con la ricerca vettoriale avanzata di AlloyDB per ottenere prestazioni elevate e renderla davvero basata sul significato. Ho creato un'applicazione multi-strumento controllata per la qualità che utilizza ADK e tutti gli elementi di AlloyDB di cui abbiamo parlato qui per creare un agente di ricerca e analisi di brevetti vettoriali di alta qualità e ad alto rendimento che puoi visualizzare qui: https://youtu.be/Y9fvVY0yZTY
Se vuoi imparare a creare questo agente, consulta questo codelab.