
1. 概要
さまざまな業界で、コンテキスト検索はアプリケーションの中核をなす重要な機能です。検索拡張生成は、生成 AI を活用した検索メカニズムにより、この重要な技術進化を長らく牽引してきました。生成モデルは、大きなコンテキスト ウィンドウと優れた出力品質により、AI を変革しています。RAG は、AI アプリケーションとエージェントにコンテキストを注入し、構造化データベースやさまざまなメディアからの情報に基づいてグラウンディングするための体系的な方法を提供します。このコンテキスト データは、真実を明確にするために記すと、出力の精度にとって重要ですが、その結果はどの程度正確ですか?ビジネスは、これらのコンテキスト マッチの精度と関連性に大きく依存していますか?このプロジェクトはあなたをくすぐるでしょう。
ベクトル検索の隠れた秘密は、構築することだけではありません。ベクトルの一致が実際に優れているかどうかを把握することです。誰もが、結果のリストをぼんやりと見つめながら、「これ、本当に機能しているの?」と疑問に思ったことがあるでしょう。ベクトル一致の品質を実際に評価する方法について説明します。「RAG で何が変わったのか?」と疑問に思われるかもしれません。すべてです。長年、検索拡張生成(RAG)は有望でありながらも実現が難しい目標のように感じられてきました。これで、ミッション クリティカルなタスクに必要なパフォーマンスと信頼性を備えた RAG アプリケーションを構築するためのツールが揃いました。
これで、次の 3 つの基礎知識が身につきました。
- コンテキスト検索がエージェントにどのような意味を持つか、ベクトル検索を使用してそれを実現する方法。
- また、データスコープ内、つまりデータベース自体内でベクトル検索を実現する方法についても詳しく説明しました(ご存じないかもしれませんが、すべての Google Cloud データベースがこれをサポートしています)。
- Google は、ScaNN インデックスを搭載した AlloyDB ベクトル検索機能を使用して、高パフォーマンスと高品質の軽量ベクトル検索 RAG 機能を実現する方法を、世界に先駆けてご紹介しました。
RAG の基本、中級、やや高度なテストをまだ実施していない場合は、こちら、こちら、こちらの 3 つを記載の順にお読みになることをおすすめします。
特許検索は、検索テキストに関連する特許をユーザーが見つけるのを支援するもので、過去にこの機能のバージョンをすでに構築しています。次に、新しい高度な RAG 機能を使用して、そのアプリケーションの品質検証(QC)されたコンテキスト検索を可能にします。それでは始めましょう。
下の図は、このアプリケーションで発生する処理の全体的な流れを示しています。~ 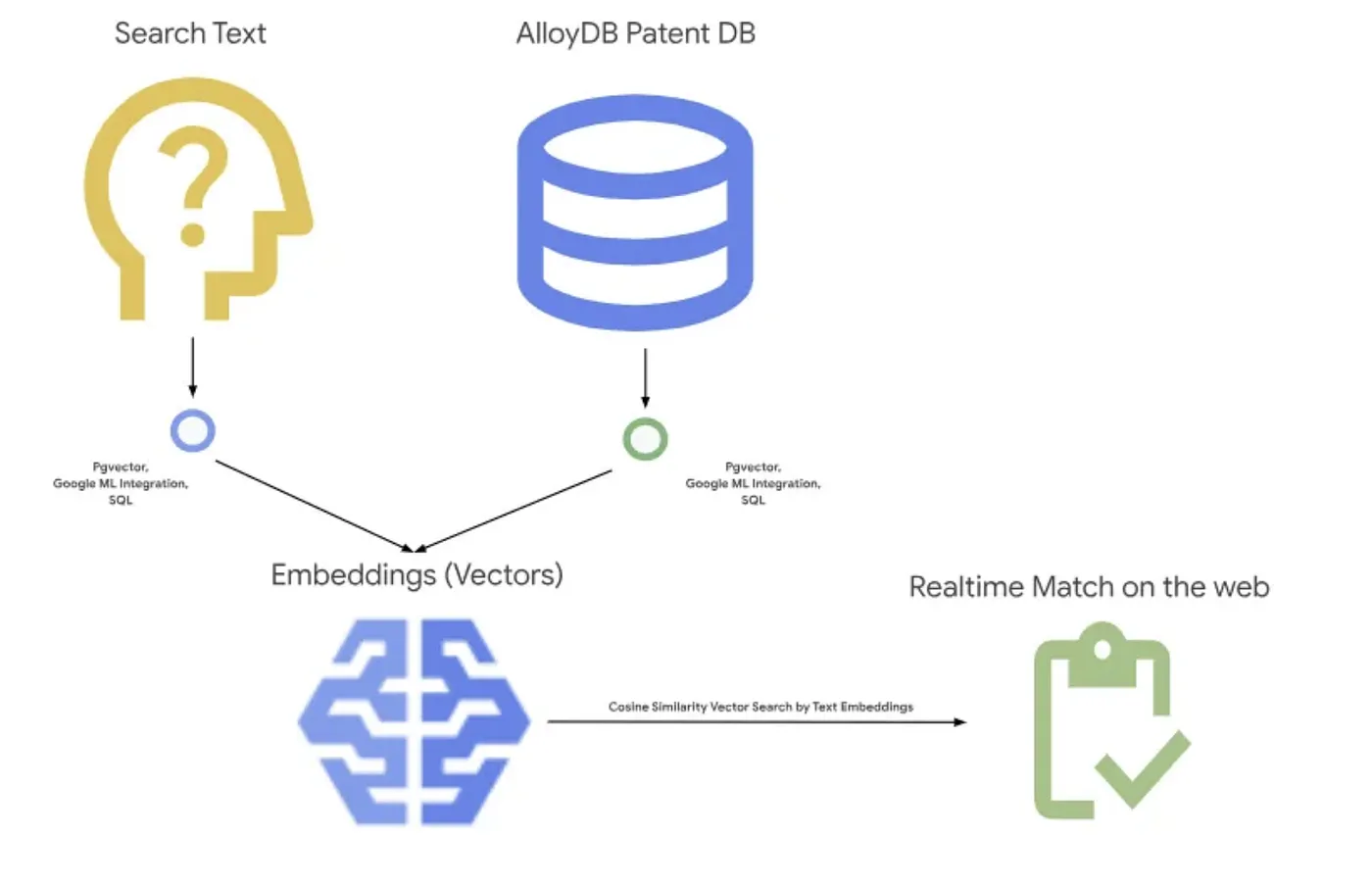
目標
ユーザーは、テキストによる説明に基づいて特許を検索できます。パフォーマンスと品質が向上し、AlloyDB の最新の RAG 機能を使用して生成された一致の品質を評価できます。
作成するアプリの概要
このラボでは、次の作業を行います。
- AlloyDB インスタンスを作成して Patents Public Dataset を読み込む
- メタデータ インデックスと ScaNN インデックスを作成する
- ScaNN のインライン フィルタリング メソッドを使用して AlloyDB で高度なベクトル検索を実装する
- 再現率評価機能を実装する
- クエリのレスポンスを評価する
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/patent-search-rag-recall/img/7875ca05ca6f7cab.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にします。Cloud Shell ターミナルで gcloud コマンドを使用できます。
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
gcloud コマンドの代わりに、コンソールで各プロダクトを検索するか、こちらのリンクを使用することもできます。
gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
3. データベースの設定
このラボでは、特許データのデータベースとして AlloyDB を使用します。クラスタを使用して、データベースやログなどのすべてのリソースを保持します。各クラスタには、データへのアクセス ポイントを提供するプライマリ インスタンスがあります。テーブルには実際のデータが格納されます。
特許データセットを読み込む AlloyDB クラスタ、インスタンス、テーブルを作成しましょう。
クラスタとインスタンスを作成する
- Cloud コンソールの AlloyDB ページに移動します。Cloud コンソールでほとんどのページを簡単に見つけるには、コンソールの検索バーを使用して検索します。
- このページで [クラスタを作成] を選択します。

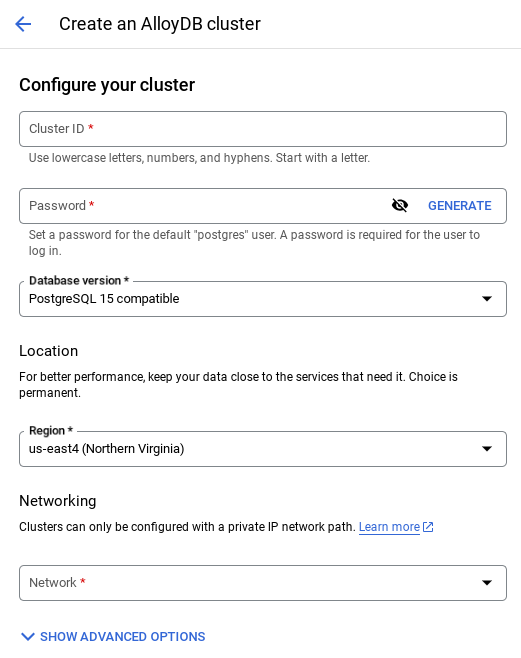
- 次のような画面が表示されます。次の値を使用してクラスタとインスタンスを作成します(リポジトリからアプリケーション コードを複製する場合は、値が一致していることを確認してください)。
- クラスタ ID: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / 最新の推奨バージョン
- Region: "
us-central1" - Networking: "
default"
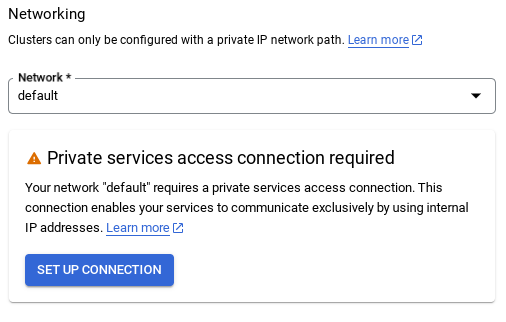
- デフォルト ネットワークを選択すると、次のような画面が表示されます。
[接続の設定] を選択します。
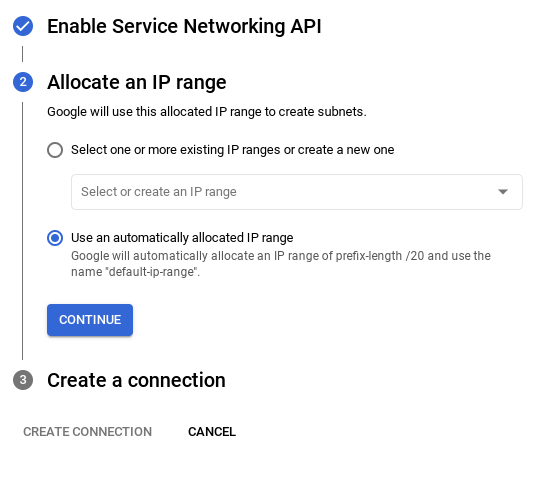
- [自動的に割り当てられた IP 範囲を使用する] を選択して、[続行] をクリックします。情報を確認したら、[接続を作成] を選択します。
- ネットワークを設定したら、クラスタの作成を続行できます。[CREATE CLUSTER] をクリックして、次のようにクラスタの設定を完了します。
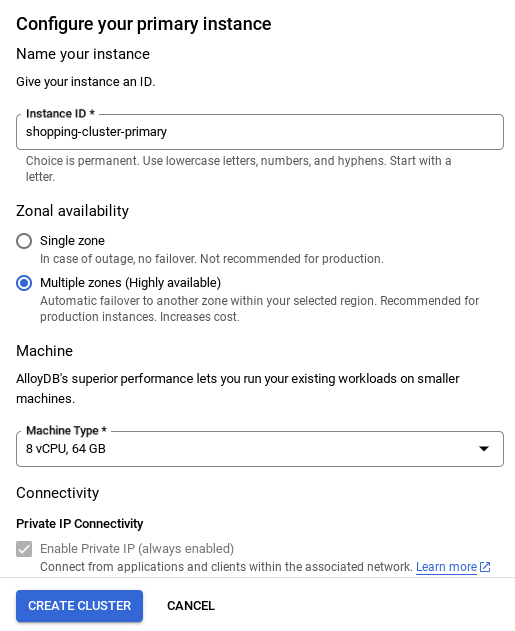
インスタンス ID を必ず変更してください(クラスタ / インスタンスの構成時に確認できます)。
vector-instance。変更できない場合は、以降のすべての参照でインスタンス ID を使用してください。
クラスタの作成には 10 分ほどかかります。成功すると、作成したクラスタの概要を示す画面が表示されます。
4. データの取り込み
次に、店舗に関するデータを含むテーブルを追加します。AlloyDB に移動し、プライマリ クラスタと AlloyDB Studio を選択します。
インスタンスの作成が完了するまで待つ必要がある場合があります。完了したら、クラスタの作成時に作成した認証情報を使用して AlloyDB にログインします。PostgreSQL の認証には次のデータを使用します。
- ユーザー名: 「
postgres」 - データベース: 「
postgres」 - パスワード: 「
alloydb」
AlloyDB Studio への認証が成功すると、エディタに SQL コマンドが入力されます。最後のウィンドウの右にあるプラス記号を使用して、複数のエディタ ウィンドウを追加できます。
必要に応じて [実行]、[形式]、[クリア] オプションを使用して、エディタ ウィンドウに AlloyDB のコマンドを入力します。
拡張機能を有効にする
このアプリのビルドには、拡張機能 pgvector と google_ml_integration を使用します。pgvector 拡張機能を使用すると、ベクトル エンベディングを保存して検索できます。google_ml_integration 拡張機能は、Vertex AI 予測エンドポイントにアクセスして SQL で予測を取得するために使用する関数を提供します。次の DDL を実行して、これらの拡張機能を有効にします。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
データベースで有効になっている拡張機能を確認するには、次の SQL コマンドを実行します。
select extname, extversion from pg_extension;
テーブルを作成する
AlloyDB Studio で次の DDL ステートメントを使用してテーブルを作成できます。
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings 列には、テキストのベクトル値を格納できます。
権限を付与
次のステートメントを実行して、「embedding」関数に対する実行権限を付与します。
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB サービス アカウントに Vertex AI ユーザーロールを付与する
Google Cloud IAM コンソールで、AlloyDB サービス アカウント(service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com のような形式)に「Vertex AI ユーザー」ロールへのアクセス権を付与します。PROJECT_NUMBER にはプロジェクト番号が設定されます。
または、Cloud Shell ターミナルから次のコマンドを実行することもできます。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
特許データをデータベースに読み込む
BigQuery の Google 特許検索 一般公開データセットをデータセットとして使用します。AlloyDB Studio を使用してクエリを実行します。データは insert_scripts.sql ファイルにソースが設定されており、このファイルを実行して特許データを読み込みます。
- Google Cloud コンソールで、[AlloyDB] ページを開きます。
- 新しく作成したクラスタを選択し、インスタンスをクリックします。
- AlloyDB のナビゲーション メニューで、[AlloyDB Studio] をクリックします。自分の認証情報でログインします。
- 右側の [新しいタブ] アイコンをクリックして、新しいタブを開きます。
- 上記の
insert_scripts.sqlスクリプトからinsertクエリ ステートメントをエディタにコピーします。このユースケースのクイック デモ用に、10 ~ 50 個の挿入ステートメントをコピーできます。 - [実行] をクリックします。クエリの結果が [結果] テーブルに表示されます。
注: 挿入スクリプトには多くのデータが含まれています。これは、挿入スクリプトにエンベディングが含まれているためです。github でファイルを読み込めない場合は、[View Raw] をクリックします。これは、Google Cloud のトライアル クレジットの請求先アカウントを使用している場合に、複数の(最大 20 ~ 25 個)エンベディングを生成する手間(次の手順)を省くためです。
5. 特許データのエンベディングを作成する
まず、次のクエリの例を実行して、エンベディング関数をテストします。
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
これにより、クエリ内のサンプル テキストのエンベディング ベクトル(浮動小数点数の配列)が返されます。次のように表示されます。
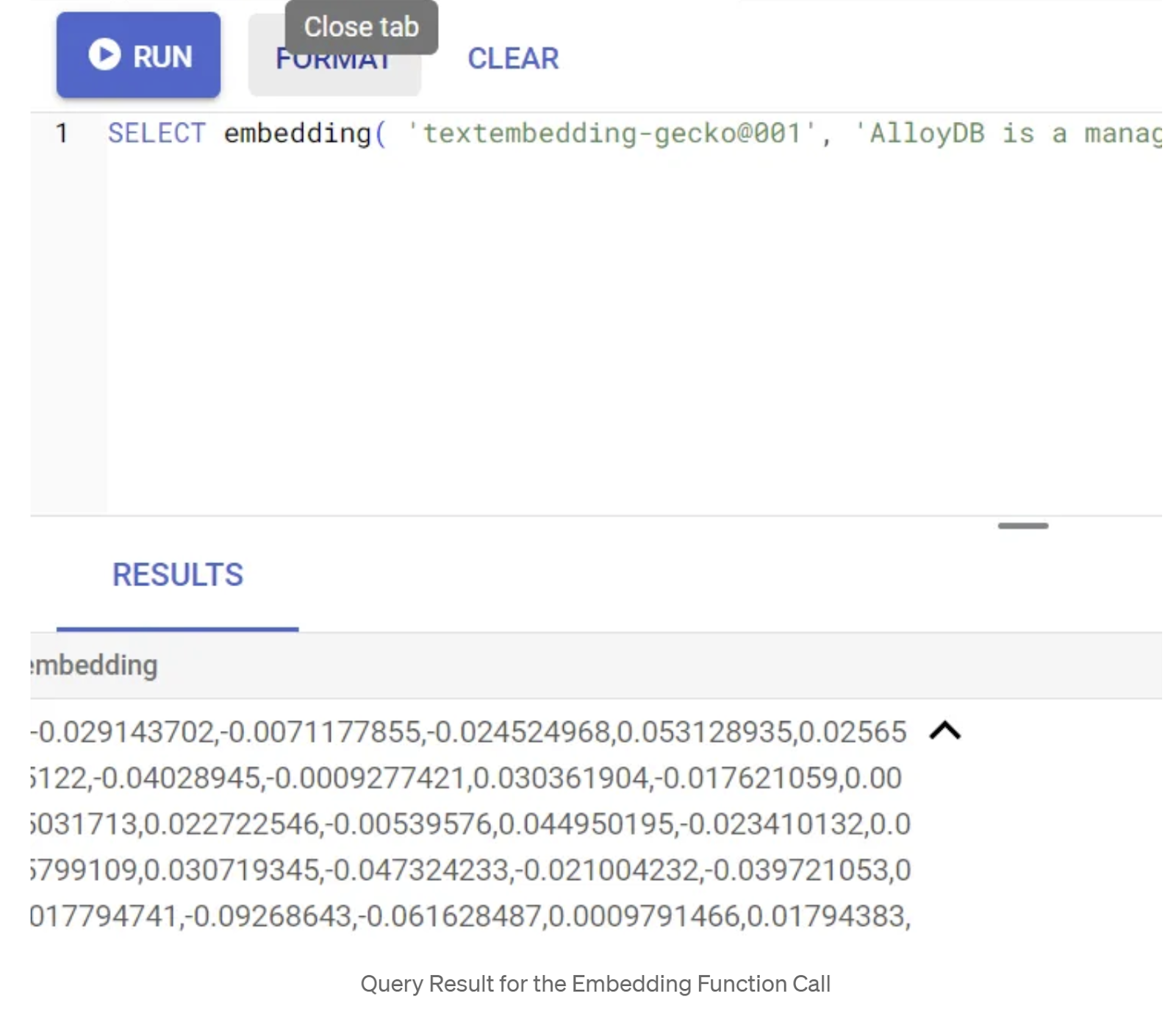
abstract_embeddings ベクトル フィールドを更新する
挿入スクリプトの一部として abstract_embeddings データを挿入していない場合にのみ、次の DML を実行して、テーブル内の特許の要約を対応するエンベディングで更新します。
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Google Cloud のトライアル クレジットの請求先アカウントを使用している場合、少数のエンベディング(最大 20 ~ 25 個)を超えるエンベディングを生成できないことがあります。そのため、挿入スクリプトにエンベディングをすでに含めています。また、「特許データをデータベースに読み込む」の手順を完了していれば、読み込まれたテーブルにエンベディングが含まれているはずです。
6. AlloyDB の新機能を使用して高度な RAG を実行する
テーブル、データ、エンベディングの準備が整ったので、ユーザーの検索テキストに対してリアルタイムのベクトル検索を実行しましょう。これをテストするには、次のクエリを実行します。
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
このクエリでは、
- ユーザーが検索したテキストは「感情分析」です。
- モデル text-embedding-005 を使用して、embedding() メソッドでエンベディングに変換しています。
- "<=>" は、COSINE SIMILARITY 距離メソッドの使用を表します。
- エンベディング メソッドの結果をベクトル型に変換して、データベースに保存されているベクトルと互換性を持たせています。
- LIMIT 10 は、検索テキストの最も近い一致を 10 個選択することを表します。
AlloyDB はベクトル検索 RAG を次のレベルに引き上げます。
多くの機能が導入されています。デベロッパー向けの 2 つの機能は次のとおりです。
- インライン フィルタリング
- 再現率エバリュエータ
インライン フィルタリング
以前は、デベロッパーがベクトル検索クエリを実行し、フィルタリングと再現率を処理する必要がありました。AlloyDB クエリ オプティマイザーは、フィルタ付きクエリの実行方法を最適化します。インライン フィルタリングは新しいクエリ最適化手法であり、これにより AlloyDB クエリ オプティマイザーは、ベクトル インデックスとメタデータ列のインデックスの両方を活用して、メタデータのフィルタ条件とベクトル検索の両方を同時に評価できます。これにより、再現率のパフォーマンスが向上し、デベロッパーは AlloyDB の機能をすぐに活用できるようになりました。
インライン フィルタリングは、選択性が中程度の場合に最適です。AlloyDB はベクトル インデックスを検索する際に、メタデータのフィルタ条件(通常はクエリの WHERE 句で処理される関数フィルタ)に一致するベクトルの距離のみを計算します。これにより、ポストフィルタやプレフィルタの利点を補完し、クエリのパフォーマンスを大幅に向上させます。
- pgvector 拡張機能をインストールまたは更新する
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
pgvector 拡張機能がすでにインストールされている場合は、ベクトル拡張機能をバージョン 0.8.0.google-3 以降にアップグレードして、再現率評価ツールを利用できるようにします。
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
この手順は、ベクトル拡張機能が <0.8.0.google-3> の場合にのみ実行する必要があります。
重要な注意事項: 行数が 100 未満の場合は、行数が少ないため ScaNN インデックスを作成する必要はありません。その場合は、以下の手順をスキップしてください。
- ScaNN インデックスを作成するには、alloydb_scann 拡張機能をインストールします。
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- まず、インデックスとインライン フィルタを有効にせずにベクトル検索クエリを実行します。
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
結果は次のようになります。
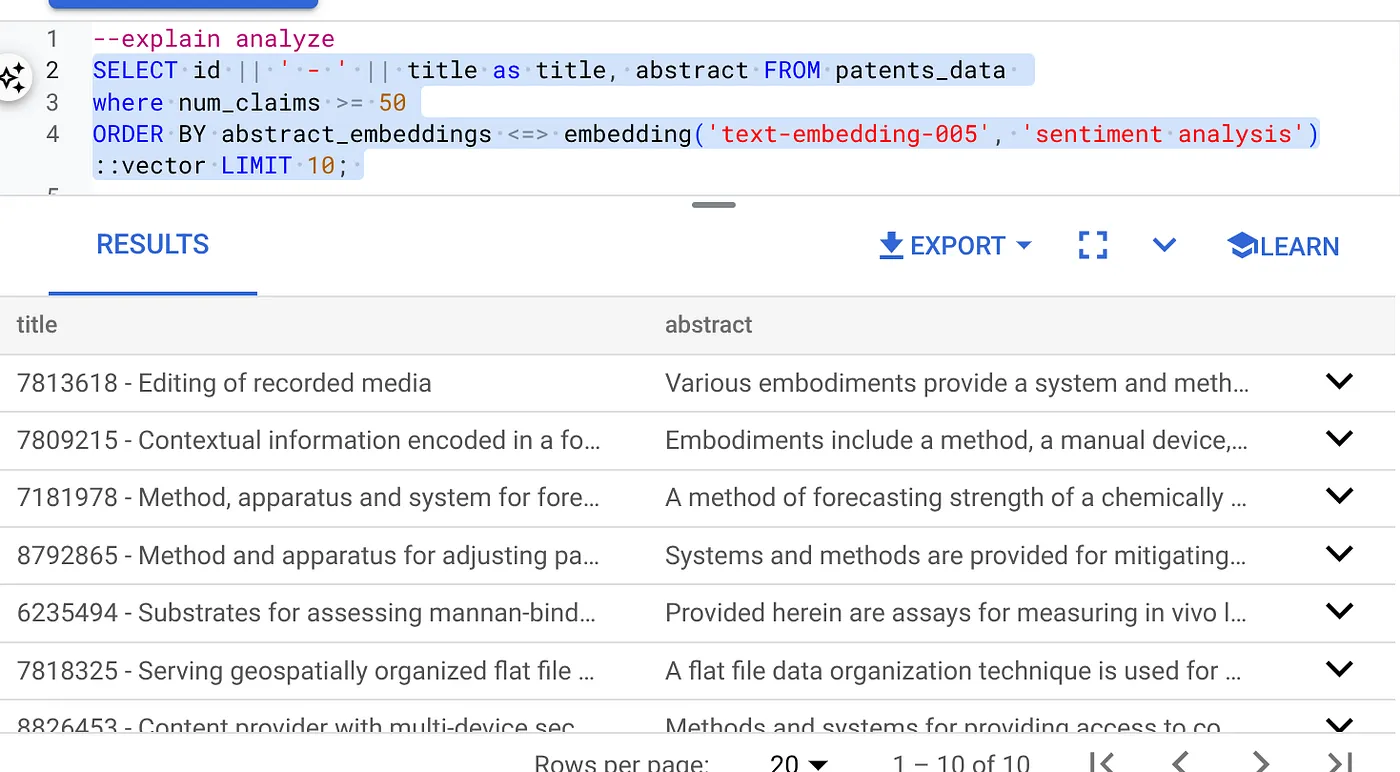
- (インデックスもインライン フィルタリングもない状態で)Explain Analyze を実行します。
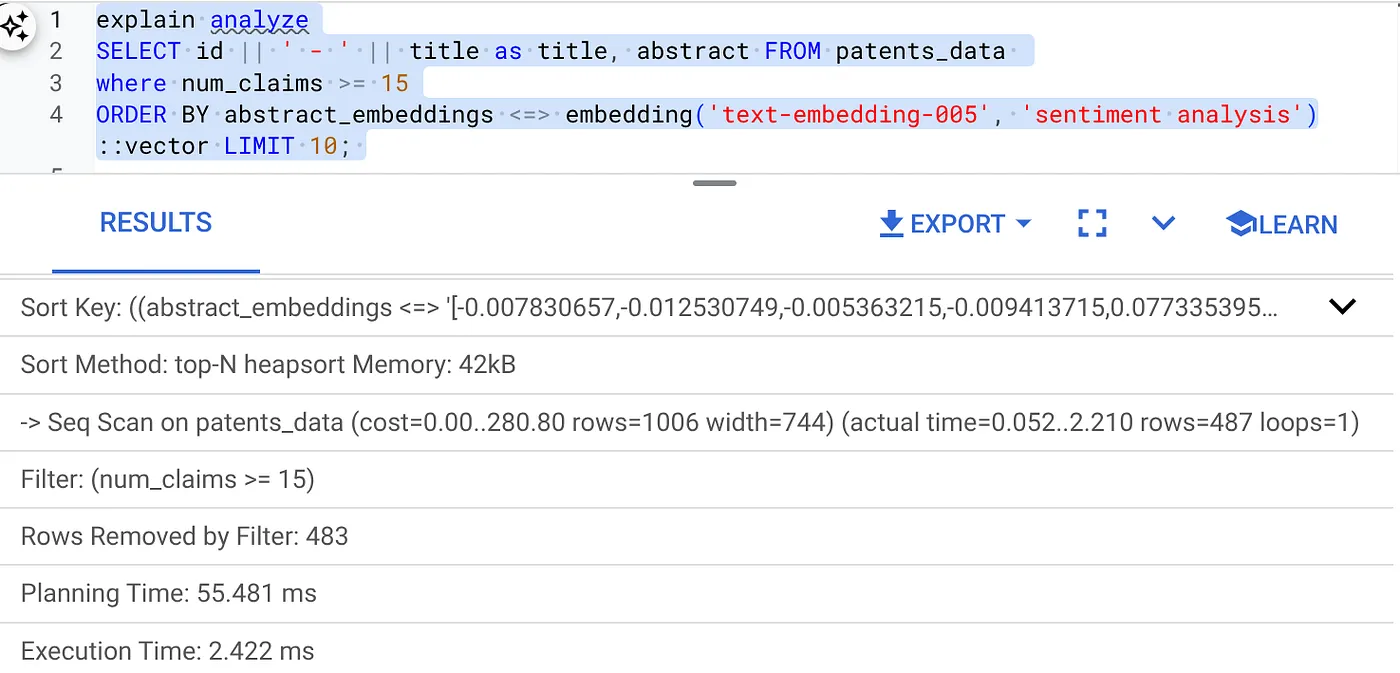
実行時間は 2.4 ミリ秒です
- num_claims フィールドに通常のインデックスを作成して、このフィールドでフィルタできるようにします。
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- 特許検索アプリケーションの ScaNN インデックスを作成しましょう。AlloyDB Studio から次のコマンドを実行します。
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
重要な注意事項: (num_leaves=32) は、1,000 行以上のデータセット全体に適用されます。行数が 100 未満の場合は、インデックスを作成する必要はありません。行数が少ない場合はインデックスが適用されないためです。
- ScaNN インデックスでインライン フィルタリングを有効にします。
SET scann.enable_inline_filtering = on
- 次に、フィルタとベクトル検索を含む同じクエリを実行します。
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
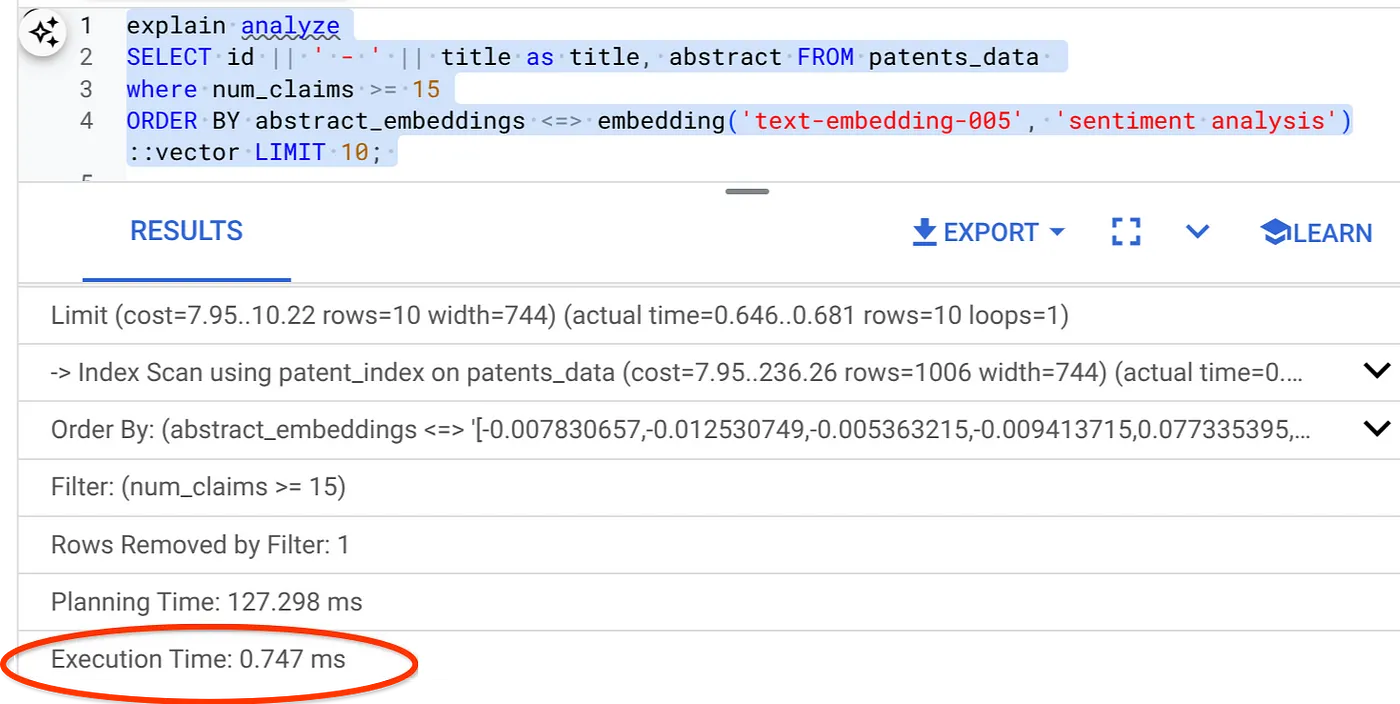
ご覧のとおり、同じベクトル検索でも実行時間が大幅に短縮されています。ベクトル検索のインライン フィルタリングが組み込まれた ScaNN インデックスにより、これが可能になりました。
次に、この ScaNN 対応のベクトル検索の再現率を評価します。
再現率エバリュエータ
類似検索における再現率とは、検索から取得された該当インスタンスの割合、つまり真陽性の数です。これは、検索品質の測定に使用される最も一般的な指標です。再現率低下の一因は、近似最近傍検索(aNN)と K 最近傍検索(kNN)の違いにあります。AlloyDB の ScaNN のようなベクトル インデックスは aNN アルゴリズムを実装しており、再現率のわずかなトレードオフと引き換えに、大規模データセットでのベクトル検索を高速化できます。AlloyDB では、個々のクエリのトレードオフをデータベース内で直接測定し、経時的な安定性を確認できるようになりました。この情報に応じてクエリやインデックスのパラメータを更新すれば、より良い検索結果とパフォーマンスを実現できます。
検索結果の再現率の背後にあるロジックは何ですか?
ベクトル検索のコンテキストにおける再現率とは、インデックスから返されたベクトルのうち、真の最近傍であるものの割合を指します。たとえば、20 個の最近傍に対する最近傍のクエリで、グラウンド トゥルースの最近傍が 19 個返された場合、再現率は 19÷20×100 = 95% となります。再現率は検索品質に使用される指標で、クエリベクトルに客観的に最も近い結果が返された割合として定義されます。
特定の構成のベクトル インデックスに対するベクトルクエリの再現率は、evaluate_query_recall 関数で確認できます。この関数を使用すると、目的のベクトルクエリの再現率を達成するようにパラメータをチューニングできます。
注意事項:
次の手順で HNSW インデックスに対する権限拒否エラーが発生した場合は、この再現率の評価セクション全体をスキップしてください。この Codelab のドキュメント作成時点ではリリースされたばかりであるため、この時点でアクセス制限が適用されている可能性があります。
- ScaNN インデックスと HNSW インデックスで Enable Index Scan フラグを設定します。
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio で次のクエリを実行します。
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 関数はクエリをパラメータとして受け取り、その再現率を返します。パフォーマンスの確認に使用したクエリと同じクエリを、関数の入力クエリとして使用しています。インデックス メソッドとして SCaNN を追加しました。その他のパラメータ オプションについては、ドキュメントをご覧ください。
これまで使用してきたこのベクトル検索クエリの再現率は次のとおりです。
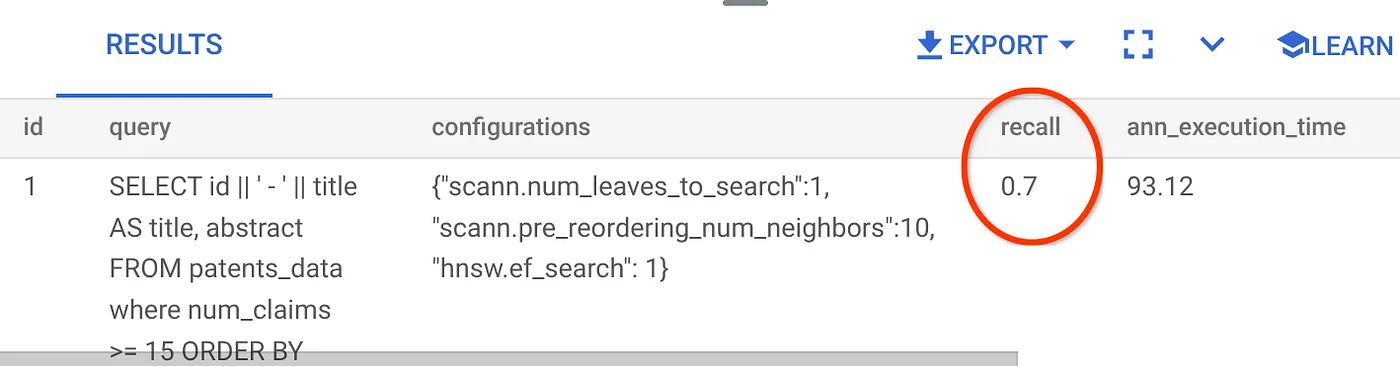
リコール率は 70% です。この情報を使用して、インデックス パラメータ、メソッド、クエリ パラメータを変更し、このベクトル検索の再現率を改善できます。
7. 変更したクエリ パラメータとインデックス パラメータでテストします。
リコールに基づいてクエリ パラメータを変更して、クエリをテストしてみましょう。
- 結果セットの行数を 7(以前は 25)に変更したところ、再現率が 86% に向上しました。
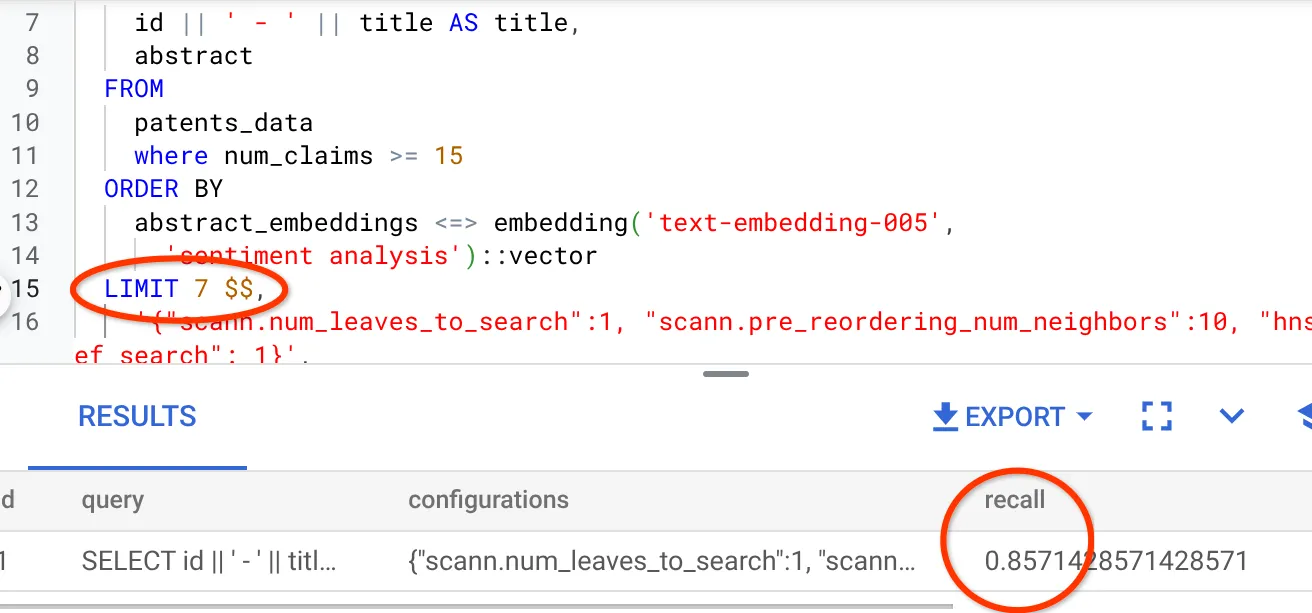
つまり、ユーザーの検索コンテキストに応じて、ユーザーに表示される一致の数をリアルタイムで調整し、一致の関連性を高めることができます。
- インデックス パラメータを変更して、もう一度試してみましょう。
このテストでは、類似性距離関数として 「コサイン」ではなく 「L2 距離」を使用します。また、検索結果セットの数が増えても検索結果の品質が向上するかどうかを確認するため、クエリの制限を 10 に変更します。
[前] コサイン類似度距離関数を使用するクエリ:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
非常に重要な注: 「このクエリでコサイン類似度が使用されていることは、どうすればわかるのですか?」という質問が寄せられることがあります。コサイン距離を表す "<=>" を使用して、距離関数を識別できます。
ベクトル検索距離関数のドキュメントへのリンク。
上記のクエリの結果は次のとおりです。
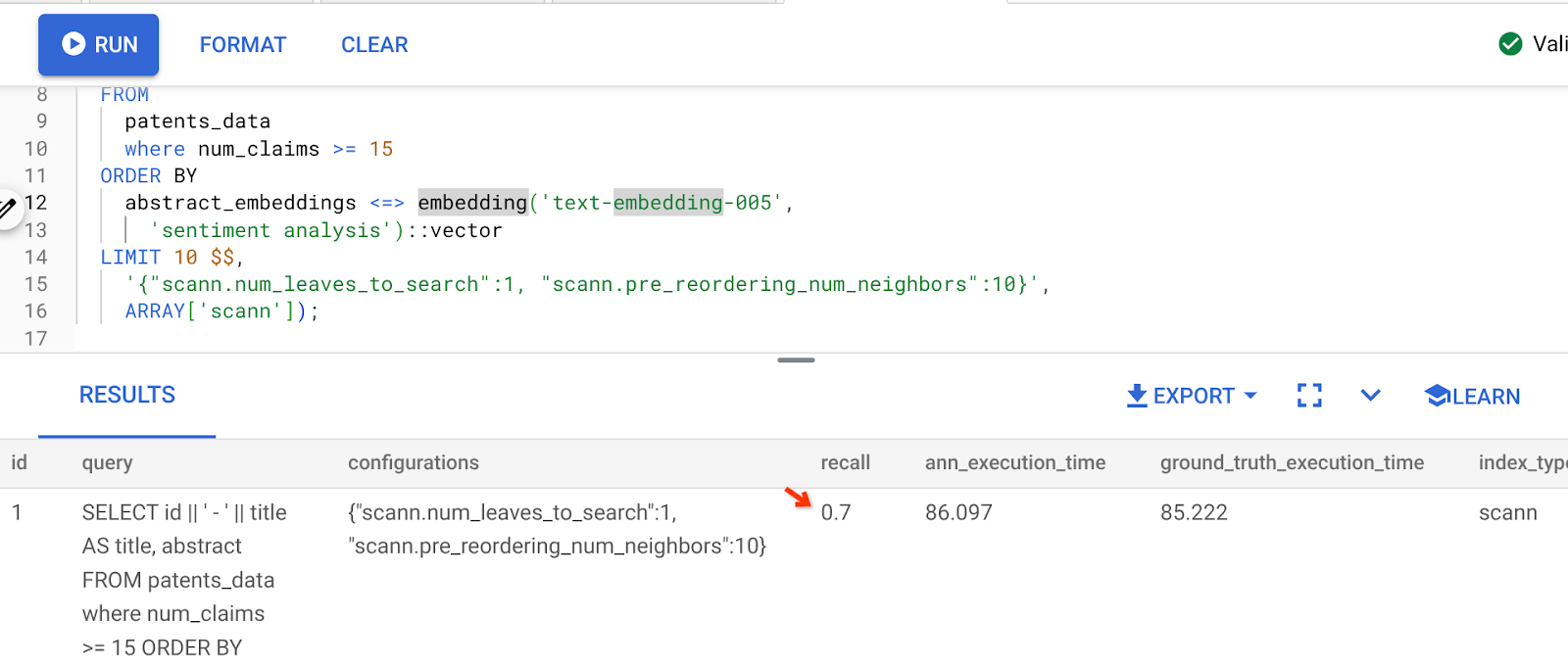
ご覧のとおり、インデックス ロジックを変更しなくても、再現率は 70% になります。インライン フィルタリング セクションのステップ 6 で作成した ScaNN インデックス「patent_index」を思い出してください。上記のクエリを実行している間も、同じインデックスが有効です。
次に、異なる距離関数クエリ(L2 距離: <->)を使用してインデックスを作成します。
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
インデックスの削除ステートメントは、テーブルに不要なインデックスがないことを確認するためのものです。
次のクエリを実行して、ベクトル検索機能の距離関数を変更した後の再現率を評価できます。
[AFTER] コサイン類似度距離関数を使用するクエリ:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
上記のクエリの結果は次のとおりです。
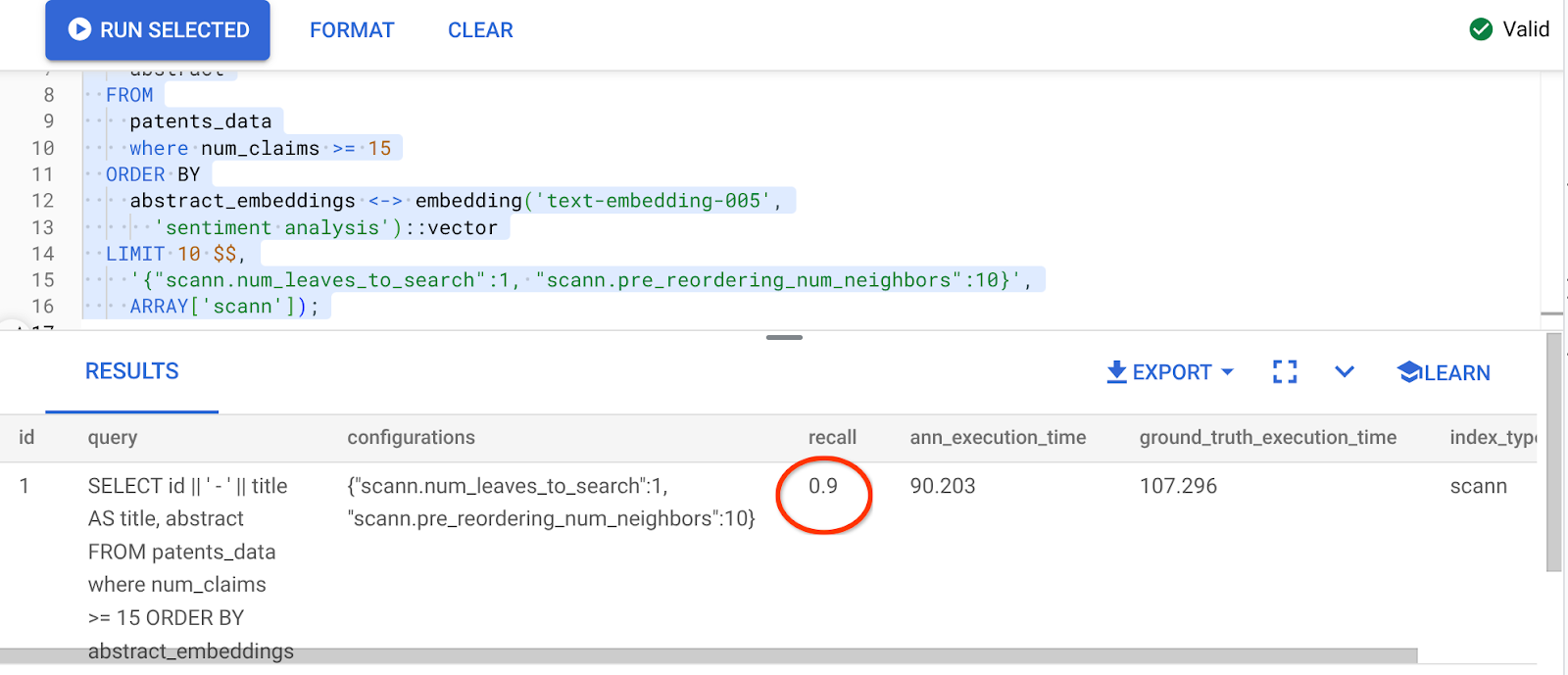
リコール値が 90% も改善されました。
インデックスでは、num_leaves など、他のパラメータも変更できます。これらのパラメータは、必要な再現率の値とアプリケーションで使用するデータセットに基づいて変更します。
8. クリーンアップ
この投稿で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順を行います。
- Google Cloud コンソールで、[リソース マネージャー] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
- または、[クラスタを削除] ボタンをクリックして、このプロジェクト用に作成した AlloyDB クラスタを削除することもできます(構成時にクラスタに us-central1 を選択しなかった場合は、このハイパーリンクのロケーションを変更してください)。
9. 完了
おめでとうございます!AlloyDB の高度なベクトル検索を使用して、コンテキストに基づく特許検索クエリを構築し、高パフォーマンスを実現して、真に意味主導型にしました。ADK とここで説明した AlloyDB のすべての機能を使用して、高品質で高性能な特許ベクトル検索と分析エージェントを作成する、品質管理されたマルチツール エージェント アプリケーションをまとめました。こちらでご覧いただけます。https://youtu.be/Y9fvVY0yZTY
このエージェントの構築方法については、こちらの Codelab をご覧ください。