
1. 개요
다양한 산업에서 컨텍스트 검색은 애플리케이션의 핵심을 이루는 중요한 기능입니다. 검색 증강 생성은 생성형 AI 기반 검색 메커니즘을 통해 오랫동안 이 중요한 기술 발전의 핵심 동인이었습니다. 생성형 모델은 큰 컨텍스트 윈도우와 인상적인 출력 품질을 바탕으로 AI를 혁신하고 있습니다. RAG는 AI 애플리케이션과 에이전트에 컨텍스트를 주입하여 구조화된 데이터베이스나 다양한 미디어의 정보를 기반으로 그라운딩하는 체계적인 방법을 제공합니다. 이러한 맥락 데이터는 사실의 명확성과 출력의 정확성에 매우 중요하지만, 결과는 얼마나 정확할까요? 비즈니스가 이러한 맥락 일치 및 관련성의 정확성에 크게 의존하나요? 그렇다면 이 프로젝트가 마음에 드실 겁니다.
벡터 검색의 숨겨진 비밀은 구축하는 것뿐만 아니라 벡터 일치가 실제로 좋은지 아는 것입니다. 결과 목록을 멍하니 바라보며'이거 제대로 작동하는 거야?'라고 생각한 적이 있을 것입니다. 벡터 일치의 품질을 실제로 평가하는 방법을 자세히 알아보겠습니다. 'RAG에서 무엇이 바뀌었나요?'라고 물으실 수 있습니다. 모든 음악 수년 동안 검색 증강 생성 (RAG)은 유망하지만 달성하기 어려운 목표처럼 여겨졌습니다. 이제 미션 크리티컬 작업에 필요한 성능과 안정성을 갖춘 RAG 애플리케이션을 빌드할 수 있는 도구가 마련되었습니다.
이제 다음 세 가지에 대한 기본적인 이해를 갖추었습니다.
- 컨텍스트 검색이 에이전트에 어떤 의미를 가지며 벡터 검색을 사용하여 이를 달성하는 방법
- 또한 데이터 범위 내, 즉 데이터베이스 자체 내에서 벡터 검색을 달성하는 방법을 자세히 살펴보았습니다 (아직 모르셨다면 모든 Google Cloud 데이터베이스에서 지원됩니다).
- Google은 ScaNN 색인으로 구동되는 AlloyDB 벡터 검색 기능을 사용하여 고성능 및 고품질의 경량 벡터 검색 RAG 기능을 달성하는 방법을 전 세계에 알리는 데 한 걸음 더 나아갔습니다.
기본, 중급, 약간 고급 RAG 실험을 아직 진행하지 않았다면 나열된 순서대로 여기, 여기, 여기에서 3가지 실험을 읽어보시기 바랍니다.
특허 검색은 사용자가 검색 텍스트와 맥락상 관련된 특허를 찾을 수 있도록 지원하며, Google은 이미 과거에 이 기능의 버전을 구축했습니다. 이제 해당 애플리케이션에 대해 품질 관리된 컨텍스트 검색을 지원하는 새롭고 고급 RAG 기능을 사용하여 빌드합니다. 그럼 자세히 살펴보죠.
아래 그림은 이 애플리케이션에서 발생하는 전체 흐름을 보여줍니다.~ 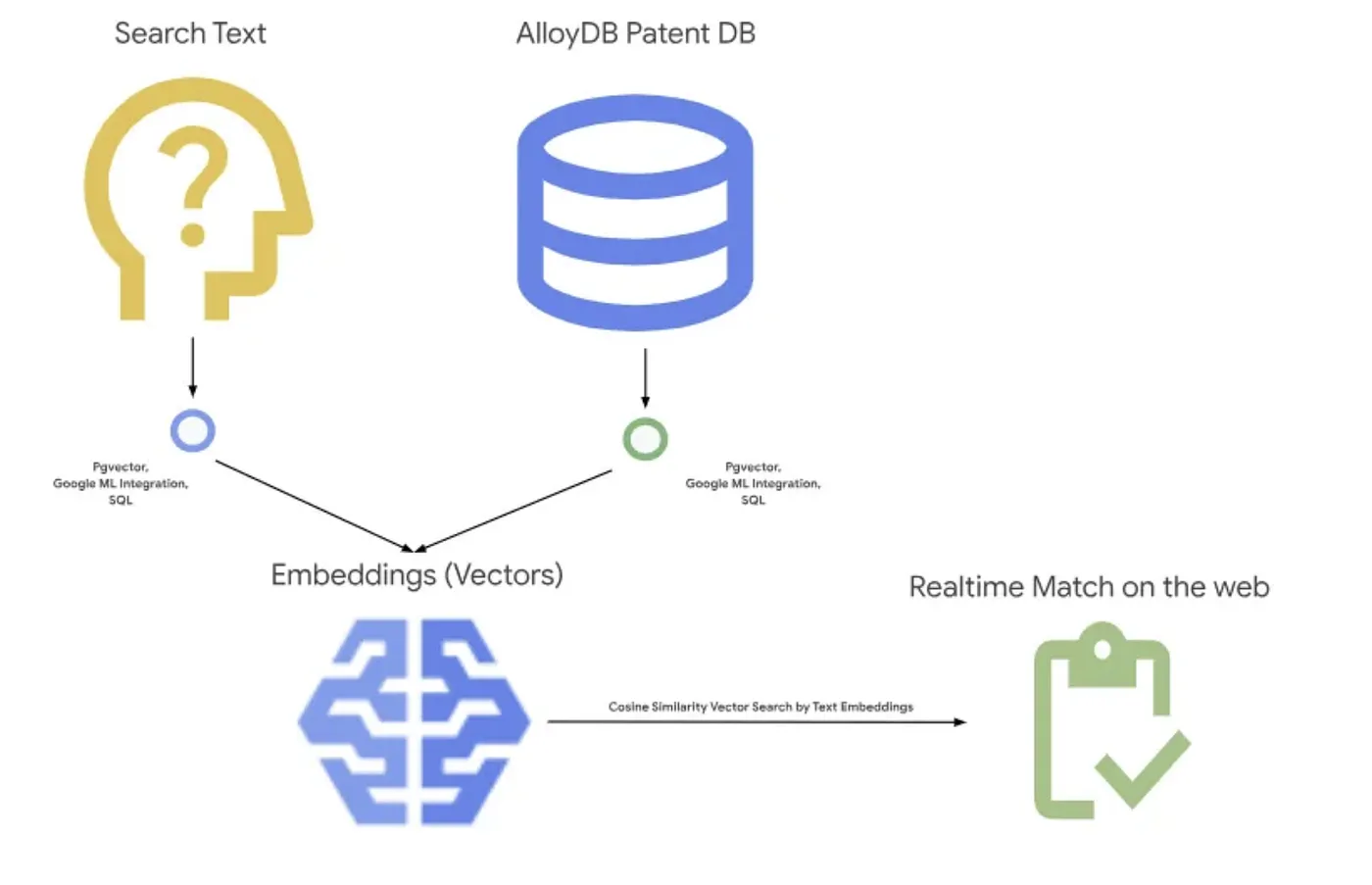
목표
사용자가 텍스트 설명을 기반으로 특허를 검색할 수 있도록 지원하며, 성능과 품질이 개선되었을 뿐만 아니라 AlloyDB의 최신 RAG 기능을 사용하여 생성된 일치 항목의 품질을 평가할 수 있습니다.
빌드할 항목
이 실습에서는 다음을 수행합니다.
- AlloyDB 인스턴스 만들기 및 특허 공개 데이터 세트 로드
- 메타데이터 색인 및 ScaNN 색인 만들기
- ScaNN의 인라인 필터링 방법을 사용하여 AlloyDB에서 고급 벡터 검색 구현
- 재현율 평가 기능 구현
- 질문에 대한 대답 평가
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요 .
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API를 사용 설정합니다. Cloud Shell 터미널에서 gcloud 명령어를 사용할 수 있습니다.
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
gcloud 명령의 대안은 콘솔을 통해 각 제품을 검색하거나 이 링크를 사용하는 것입니다.
gcloud 명령어 및 사용법은 문서를 참조하세요.
3. 데이터베이스 설정
이 실습에서는 AlloyDB를 특허 데이터의 데이터베이스로 사용합니다. 클러스터를 사용하여 데이터베이스, 로그와 같은 모든 리소스를 보유합니다. 각 클러스터에는 데이터에 대한 액세스 포인트를 제공하는 기본 인스턴스가 있습니다. 테이블에는 실제 데이터가 저장됩니다.
특허 데이터 세트가 로드될 AlloyDB 클러스터, 인스턴스, 테이블을 만들어 보겠습니다.
클러스터 및 인스턴스 만들기
- Cloud 콘솔에서 AlloyDB 페이지로 이동합니다. Cloud 콘솔에서 대부분의 페이지를 쉽게 찾으려면 콘솔의 검색창을 사용하여 검색하면 됩니다.
- 해당 페이지에서 클러스터 만들기를 선택합니다.

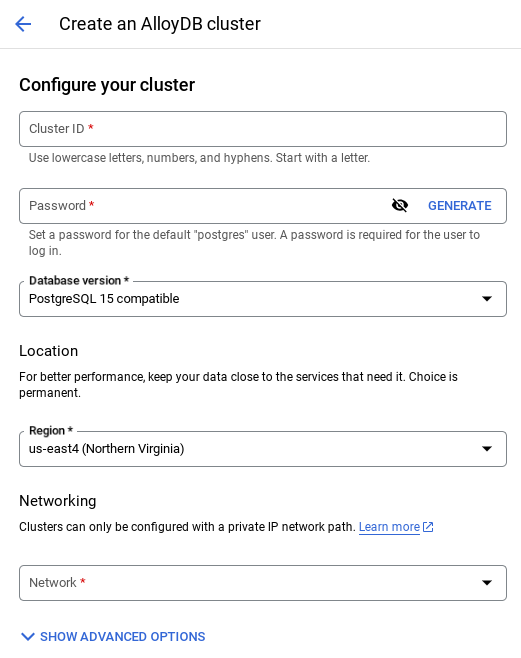
- 아래와 같은 화면이 표시됩니다. 다음 값으로 클러스터 및 인스턴스를 만듭니다 (저장소에서 애플리케이션 코드를 클론하는 경우 값이 일치하는지 확인).
- 클러스터 ID: '
vector-cluster' - password: "
alloydb" - PostgreSQL 15 / 최신 권장 버전
- 지역: "
us-central1" - 네트워킹: "
default"
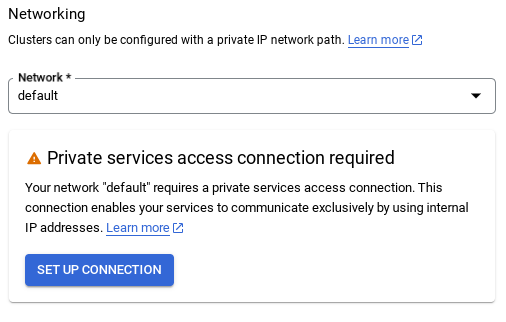
- 기본 네트워크를 선택하면 아래와 같은 화면이 표시됩니다.
연결 설정을 선택합니다.
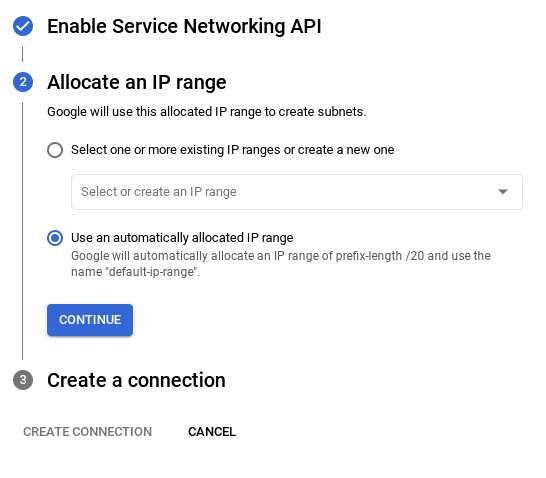
- 여기에서 '자동으로 할당된 IP 범위 사용'을 선택하고 계속을 클릭합니다. 정보를 검토한 후 연결 만들기를 선택합니다.
- 네트워크가 설정되면 클러스터를 계속 만들 수 있습니다. 클러스터 만들기를 클릭하여 아래와 같이 클러스터 설정을 완료합니다.
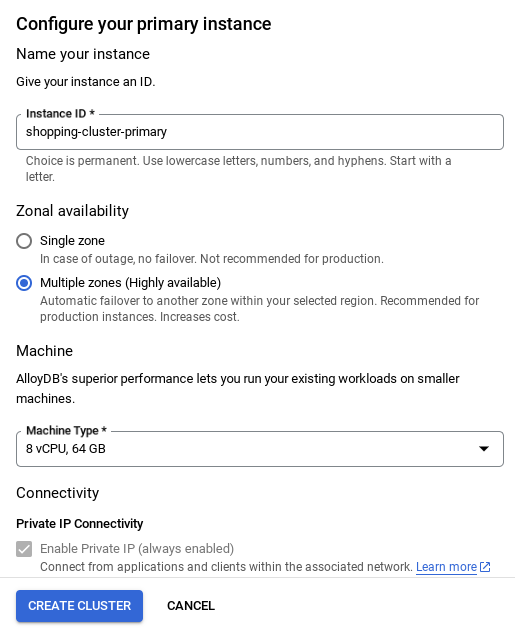
클러스터 / 인스턴스 구성 시 확인할 수 있는 인스턴스 ID를
vector-instance. 변경할 수 없는 경우 앞으로의 모든 참조에서 인스턴스 ID를 사용해야 합니다.
클러스터를 만드는 데 약 10분이 걸립니다. 성공하면 방금 만든 클러스터의 개요가 표시된 화면이 표시됩니다.
4. 데이터 수집
이제 매장에 관한 데이터가 포함된 표를 추가할 차례입니다. AlloyDB로 이동하여 기본 클러스터와 AlloyDB Studio를 선택합니다.
인스턴스 생성이 완료될 때까지 기다려야 할 수 있습니다. 완료되면 클러스터를 만들 때 만든 사용자 인증 정보를 사용하여 AlloyDB에 로그인합니다. PostgreSQL에 인증하려면 다음 데이터를 사용하세요.
- 사용자 이름 : '
postgres' - 데이터베이스 : '
postgres' - 비밀번호 : '
alloydb'
AlloyDB Studio에 인증되면 편집기에 SQL 명령어가 입력됩니다. 마지막 창 오른쪽에 있는 더하기 기호를 사용하여 여러 편집기 창을 추가할 수 있습니다.
필요에 따라 실행, 형식, 지우기 옵션을 사용하여 편집기 창에 AlloyDB 명령어를 입력합니다.
확장 프로그램 사용 설정
이 앱을 빌드하기 위해 확장 프로그램 pgvector 및 google_ml_integration를 사용합니다. pgvector 확장 프로그램을 사용하면 벡터 임베딩을 저장하고 검색할 수 있습니다. google_ml_integration 확장 프로그램은 SQL에서 예측을 수행하기 위해 Vertex AI 예측 엔드포인트에 액세스하는 데 사용하는 함수를 제공합니다. 다음 DDL을 실행하여 이러한 확장 프로그램을 사용 설정합니다.
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
데이터베이스에서 사용 설정된 확장 프로그램을 확인하려면 다음 SQL 명령어를 실행합니다.
select extname, extversion from pg_extension;
테이블 만들기
AlloyDB Studio에서 아래 DDL 문을 사용하여 테이블을 만들 수 있습니다.
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings 열을 사용하면 텍스트의 벡터 값을 저장할 수 있습니다.
권한 부여
아래 문을 실행하여 'embedding' 함수에 대한 실행 권한을 부여합니다.
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB 서비스 계정에 Vertex AI 사용자 역할 부여
Google Cloud IAM 콘솔에서 AlloyDB 서비스 계정 (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)에 'Vertex AI 사용자' 역할에 대한 액세스 권한을 부여합니다. PROJECT_NUMBER에는 프로젝트 번호가 표시됩니다.
또는 Cloud Shell 터미널에서 아래 명령어를 실행할 수 있습니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
데이터베이스에 특허 데이터 로드
BigQuery의 Google Patents 공개 데이터 세트가 데이터 세트로 사용됩니다. AlloyDB Studio를 사용하여 쿼리를 실행합니다. 데이터는 이 insert_scripts.sql 파일에 소싱되며, 이 파일을 실행하여 특허 데이터를 로드합니다.
- Google Cloud 콘솔에서 AlloyDB 페이지를 엽니다.
- 새로 만든 클러스터를 선택하고 인스턴스를 클릭합니다.
- AlloyDB 탐색 메뉴에서 AlloyDB Studio를 클릭합니다. 사용자 인증 정보로 로그인합니다.
- 오른쪽에 있는 새 탭 아이콘을 클릭하여 새 탭을 엽니다.
- 위에서 언급한
insert_scripts.sql스크립트의insert쿼리 문을 편집기에 복사합니다. 이 사용 사례를 빠르게 데모하려면 삽입 문을 10~50개 복사하면 됩니다. - 실행을 클릭합니다. 쿼리 결과가 결과 테이블에 표시됩니다.
참고: 삽입 스크립트에 많은 데이터가 포함되어 있습니다. 삽입 스크립트에 삽입이 포함되어 있기 때문입니다. GitHub에서 파일을 로드하는 데 문제가 있는 경우 'View Raw'를 클릭하세요. 이는 Google Cloud의 무료 크레딧 결제 계정을 사용하는 경우 향후 단계에서 20~25개 이상의 임베딩을 생성하는 번거로움을 덜기 위한 것입니다.
5. 특허 데이터의 임베딩 생성
먼저 다음 샘플 쿼리를 실행하여 삽입 함수를 테스트해 보겠습니다.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
그러면 쿼리의 샘플 텍스트에 대한 임베딩 벡터가 반환됩니다. 이 벡터는 부동 소수점 배열과 유사합니다. 다음과 같이 표시됩니다.
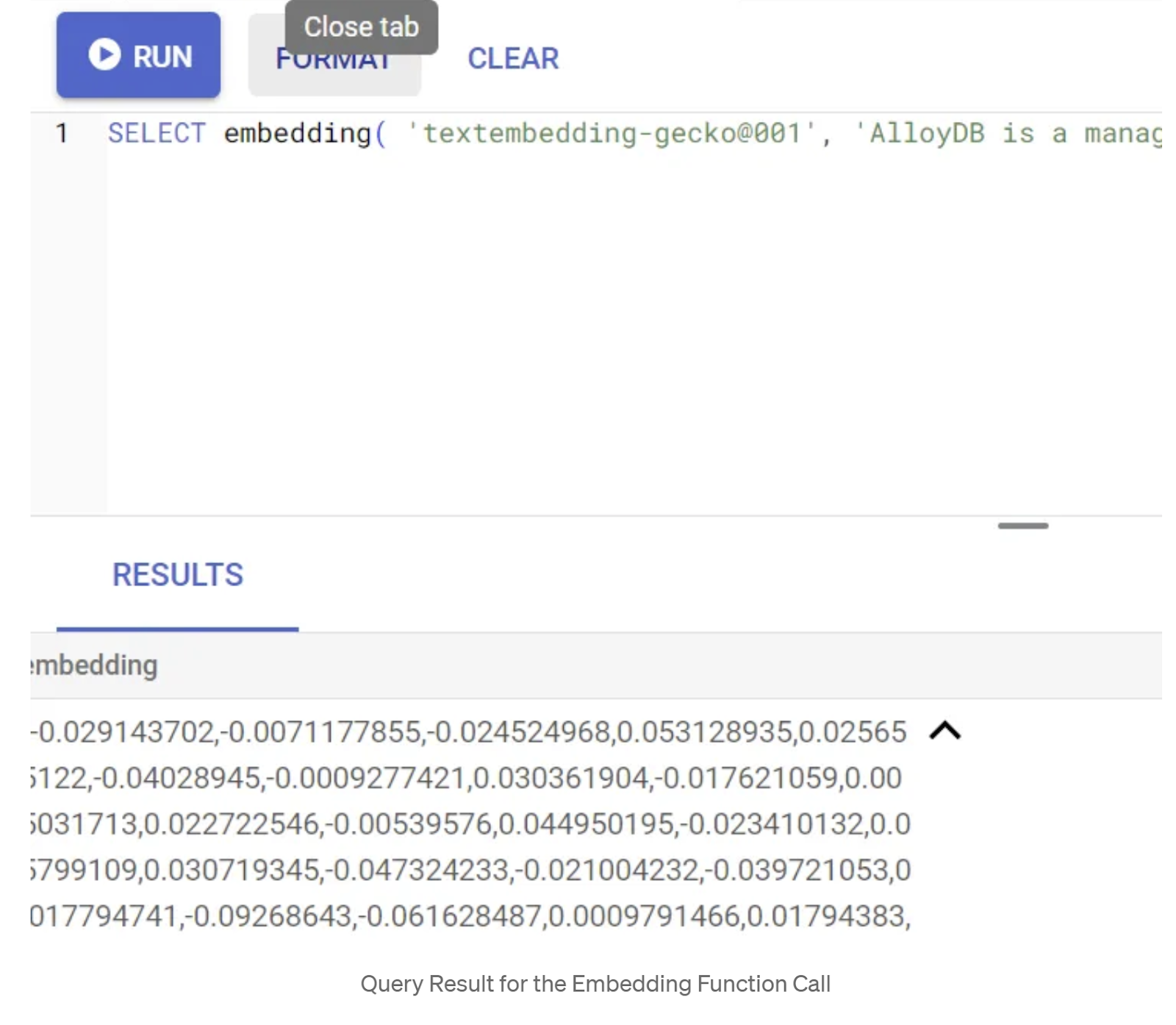
abstract_embeddings 벡터 필드 업데이트
삽입 스크립트의 일부로 abstract_embeddings 데이터를 삽입하지 않은 경우에만 아래 DML을 실행하여 테이블의 특허 초록을 해당 임베딩으로 업데이트합니다.
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Google Cloud의 무료 체험판 크레딧 결제 계정을 사용하는 경우 20~25개 이상의 임베딩을 생성하는 데 문제가 있을 수 있습니다. 따라서 삽입 스크립트에 이미 삽입을 포함했으며 '데이터베이스에 특허 데이터 로드' 단계를 완료한 경우 로드된 테이블에 삽입이 있어야 합니다.
6. AlloyDB의 새로운 기능으로 고급 RAG 실행
이제 테이블, 데이터, 임베딩이 모두 준비되었으므로 사용자 검색 텍스트에 대해 실시간 벡터 검색을 실행해 보겠습니다. 아래 쿼리를 실행하여 이를 테스트할 수 있습니다.
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
이 쿼리에서
- 사용자가 검색한 텍스트는 'Sentiment Analysis'입니다.
- text-embedding-005 모델을 사용하여 embedding() 메서드에서 임베딩으로 변환합니다.
- '<=>'는 COSINE SIMILARITY 거리 메서드의 사용을 나타냅니다.
- 데이터베이스에 저장된 벡터와 호환되도록 임베딩 메서드의 결과를 벡터 유형으로 변환하고 있습니다.
- LIMIT 10은 검색 텍스트와 가장 일치하는 10개를 선택한다는 것을 나타냅니다.
AlloyDB는 벡터 검색 RAG를 한 단계 끌어올립니다.
많은 기능이 도입되었습니다. 개발자 중심의 두 가지는 다음과 같습니다.
- 인라인 필터링
- 평가자 호출
인라인 필터링
이전에는 개발자가 벡터 검색 쿼리를 실행하고 필터링과 리콜을 처리해야 했습니다. AlloyDB 쿼리 옵티마이저는 필터가 있는 쿼리를 실행하는 방법을 선택합니다. 인라인 필터링은 AlloyDB 쿼리 옵티마이저가 메타데이터 필터링 조건과 벡터 검색을 동시에 평가하여 벡터 색인과 메타데이터 열의 색인을 모두 활용할 수 있도록 하는 새로운 쿼리 최적화 기술입니다. 이로 인해 리콜 성능이 향상되어 개발자가 AlloyDB가 기본적으로 제공하는 기능을 활용할 수 있습니다.
인라인 필터링은 선택도가 중간인 경우에 가장 적합합니다. AlloyDB는 벡터 색인을 검색할 때 메타데이터 필터링 조건 (일반적으로 WHERE 절에서 처리되는 쿼리의 기능적 필터)과 일치하는 벡터의 거리만 계산합니다. 이렇게 하면 후반 필터 또는 사전 필터의 장점을 보완하여 이러한 쿼리의 성능이 크게 향상됩니다.
- pgvector 확장 프로그램 설치 또는 업데이트
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
pgvector 확장 프로그램이 이미 설치되어 있는 경우 재현율 평가 도구 기능을 사용하기 위해 벡터 확장 프로그램을 버전 0.8.0.google-3 이상으로 업그레이드해야 합니다.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
이 단계는 벡터 확장 프로그램이 <0.8.0.google-3>인 경우에만 실행해야 합니다.
중요: 행 수가 100개 미만인 경우 행 수가 적어 ScaNN 색인이 적용되지 않으므로 ScaNN 색인을 만들 필요가 없습니다. 이 경우 다음 단계를 건너뛰세요.
- ScaNN 색인을 만들려면 alloydb_scann 확장 프로그램을 설치해야 합니다.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- 먼저 색인 없이, 인라인 필터가 사용 설정되지 않은 상태로 벡터 검색 쿼리를 실행합니다.
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
결과는 다음과 비슷해야 합니다.
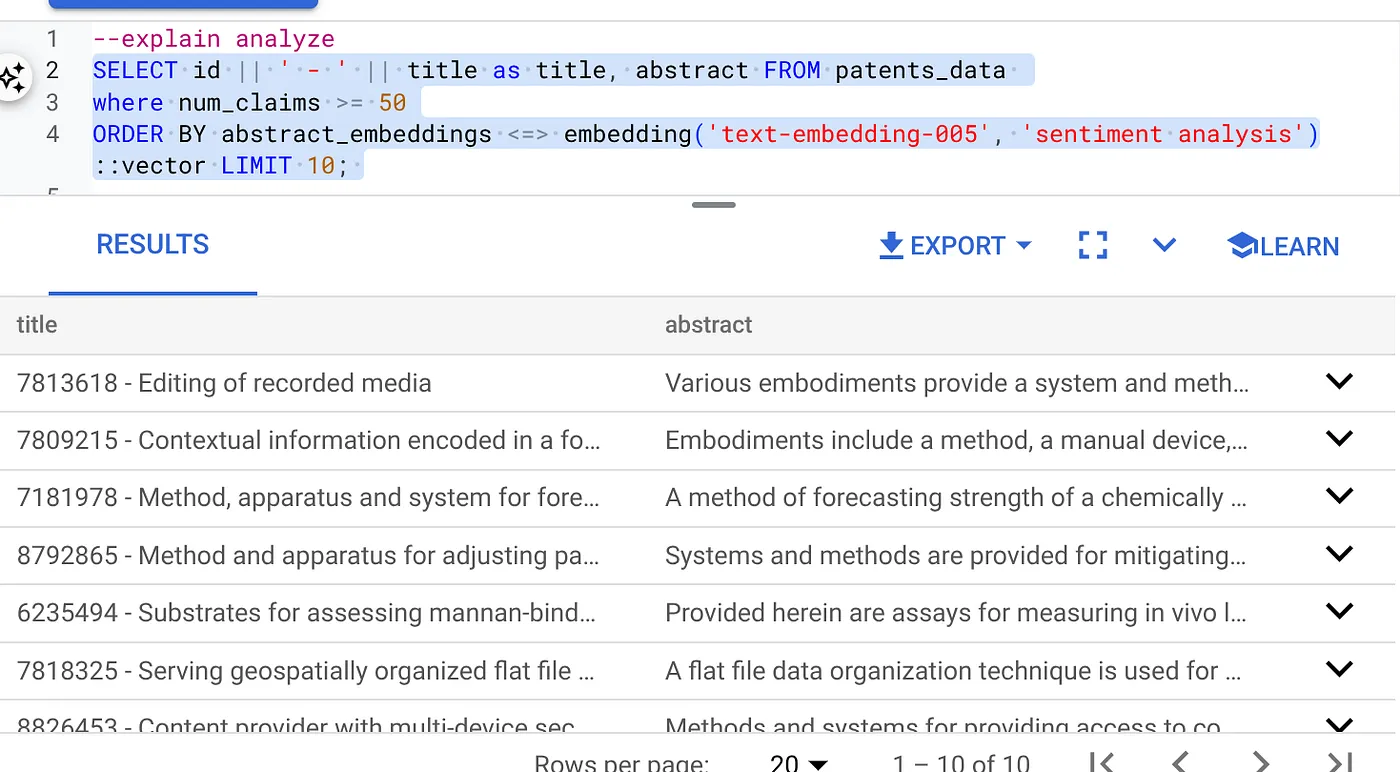
- 다음과 같이 Explain Analyze를 실행합니다(색인도 인라인 필터링도 없음).
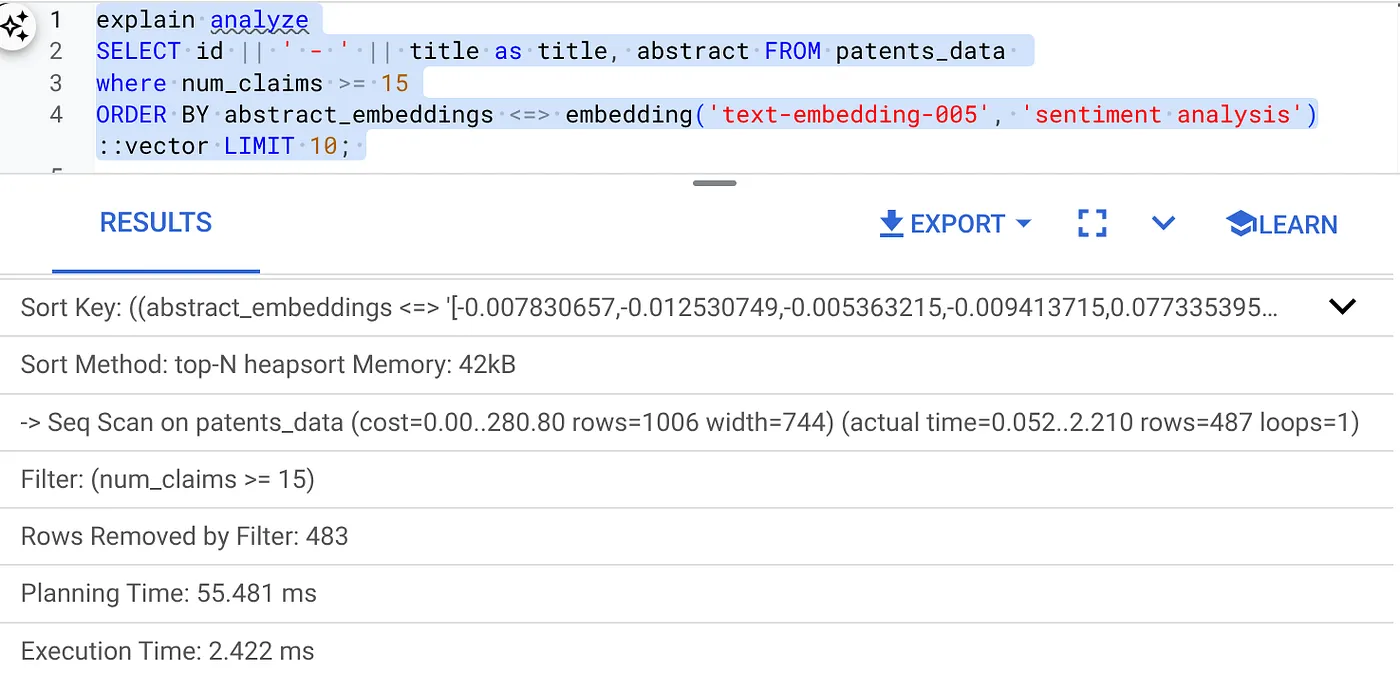
실행 시간은 2.4ms입니다.
- num_claims 필드에 일반 색인을 만들어 필터링할 수 있도록 하겠습니다.
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- 특허 검색 애플리케이션의 ScaNN 색인을 만들어 보겠습니다. AlloyDB Studio에서 다음을 실행합니다.
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
중요: (num_leaves=32)는 1,000개 이상의 행이 있는 전체 데이터 세트에 적용됩니다. 행 수가 100개 미만인 경우 행 수가 적어 적용되지 않으므로 색인을 만들 필요가 없습니다.
- ScaNN 색인에서 인라인 필터링을 사용 설정합니다.
SET scann.enable_inline_filtering = on
- 이제 필터와 벡터 검색이 포함된 동일한 쿼리를 실행해 보겠습니다.
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
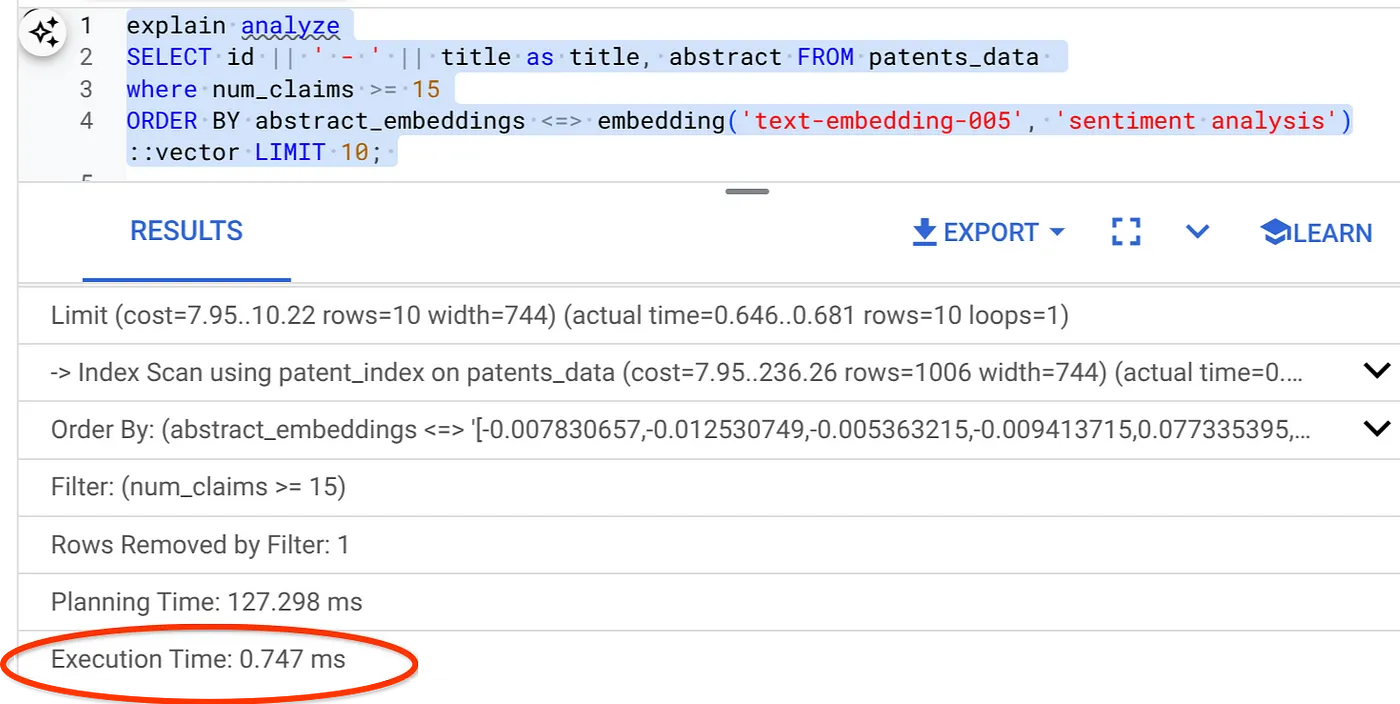
동일한 벡터 검색의 실행 시간이 크게 줄어든 것을 확인할 수 있습니다. 벡터 검색의 인라인 필터링이 적용된 ScaNN 색인 덕분에 가능해졌습니다.
다음으로 ScaNN 지원 벡터 검색의 재현율을 평가해 보겠습니다.
평가자 호출
유사성 검색의 재현율은 검색에서 검색된 관련 인스턴스의 비율, 즉 참양성 수입니다. 검색 품질을 측정하는 데 가장 일반적으로 사용되는 측정항목입니다. 재현율 손실의 한 가지 원인은 근사 최근접 이웃 검색(aNN)과 k(정확한) 최근접 이웃 검색(kNN) 간의 차이입니다. AlloyDB의 ScaNN과 같은 벡터 색인은 aNN 알고리즘을 구현하므로 재현율에서 약간의 절충을 통해 대규모 데이터 세트에서 벡터 검색 속도를 높일 수 있습니다. 이제 AlloyDB를 사용하면 개별 쿼리에 대해 데이터베이스에서 직접 이 트레이드오프를 측정하고 시간이 지나도 안정적인지 확인할 수 있습니다. 이 정보에 따라 쿼리 및 색인 매개변수를 업데이트하여 더 나은 결과와 성능을 얻을 수 있습니다.
검색 결과의 리콜 뒤에 숨겨진 논리는 무엇인가요?
벡터 검색에서 재현율은 색인이 반환하는 벡터 중 실제 최근접 이웃인 벡터의 비율을 의미합니다. 예를 들어 최근접 이웃 20개를 찾는 최근접 이웃 쿼리에서 실제 최근접 이웃 19개를 반환했다면 재현율은 19/20x100 = 95%가 됩니다. 재현율은 검색 품질에 사용되는 측정항목으로, 쿼리 벡터와 객관적으로 가장 가까운 결과 중 반환된 결과의 비율로 정의됩니다.
evaluate_query_recall 함수를 사용하면 특정 구성에 대해 벡터 색인의 벡터 쿼리에 대한 재현율을 확인할 수 있습니다. 이 함수는 원하는 벡터 쿼리 리콜 결과를 달성할 수 있도록 파라미터를 조정하는 데 유용합니다.
중요사항:
다음 단계에서 HNSW 색인에 대한 권한 거부 오류가 발생하면 지금은 리콜 평가 섹션을 모두 건너뛰세요. 이 Codelab이 문서화될 때 막 출시되었으므로 액세스 제한과 관련이 있을 수 있습니다.
- ScaNN 색인 및 HNSW 색인에서 색인 스캔 사용 설정 플래그를 설정합니다.
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio에서 다음 쿼리를 실행합니다.
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 함수는 쿼리를 매개변수로 받아 재현율을 반환합니다. 성능을 확인하는 데 사용한 쿼리를 함수 입력 쿼리로 사용하고 있습니다. SCaNN을 색인 방법으로 추가했습니다. 매개변수 옵션에 대한 자세한 내용은 문서를 참고하세요.
지금까지 사용한 이 벡터 검색 쿼리의 재현율은 다음과 같습니다.
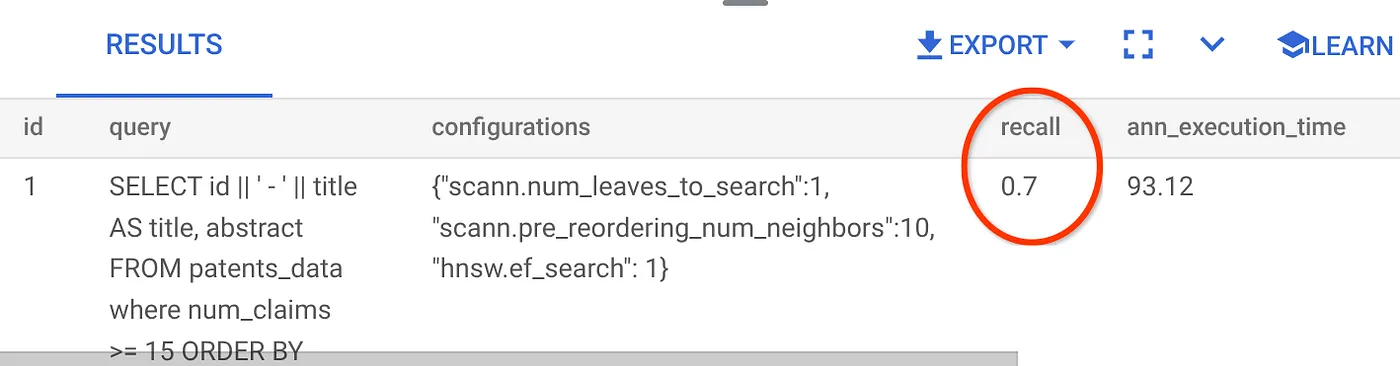
리콜이 70%인 것으로 확인됩니다. 이제 이 정보를 사용하여 색인 매개변수, 메서드, 쿼리 매개변수를 변경하고 이 벡터 검색의 재현율을 개선할 수 있습니다.
7. 수정된 쿼리 및 색인 매개변수로 테스트
이제 리콜을 기반으로 쿼리 매개변수를 수정하여 쿼리를 테스트해 보겠습니다.
- 결과 집합의 행 수를 7 (이전에는 25)로 수정했더니 재현율이 86%로 향상되었습니다.
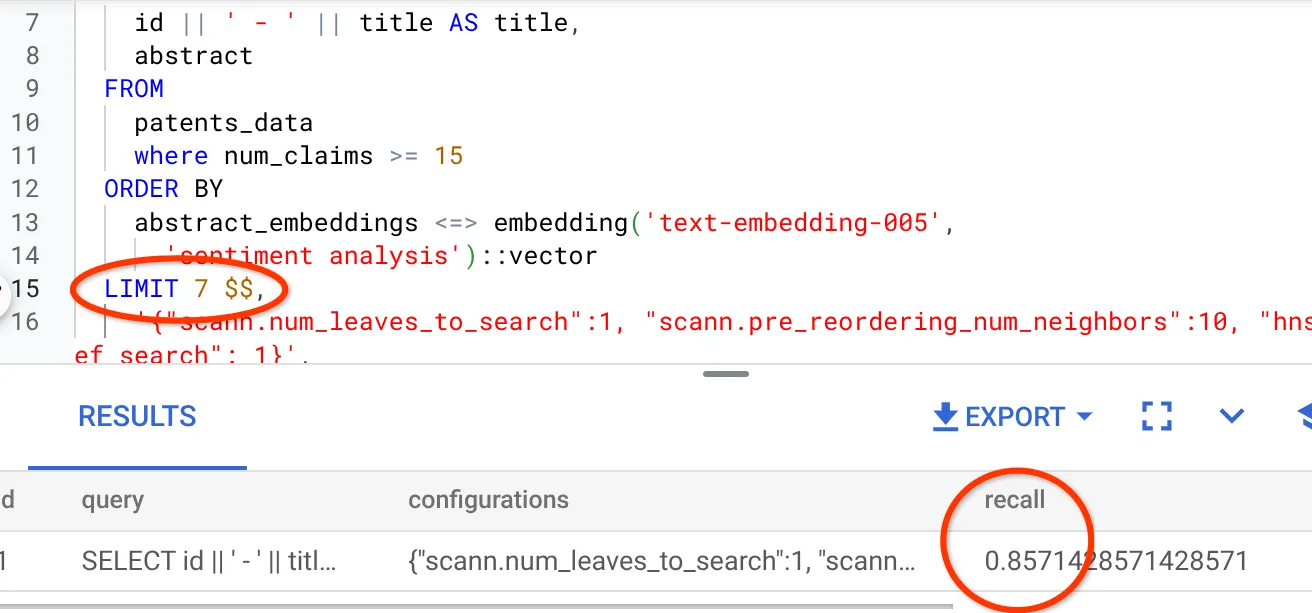
즉, 사용자의 검색 컨텍스트에 따라 일치 항목의 관련성을 개선하기 위해 사용자에게 표시되는 일치 항목 수를 실시간으로 변경할 수 있습니다.
- 색인 매개변수를 수정하여 다시 시도해 보겠습니다.
이 테스트에서는 '코사인' 유사성 거리 함수 대신 'L2 거리'를 사용합니다. 검색 결과 세트 수가 증가하더라도 검색 결과의 품질이 개선되는지 확인하기 위해 쿼리 제한을 10으로 변경하겠습니다.
[이전] 코사인 유사도 거리 함수를 사용하는 쿼리:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
매우 중요한 참고사항: '이 쿼리가 코사인 유사도를 사용하는지 어떻게 알 수 있나요?'라고 질문할 수 있습니다. 코사인 거리를 나타내는 '<=>'를 사용하여 거리 함수를 식별할 수 있습니다.
벡터 검색 거리 함수에 대한 문서 링크
위 쿼리의 결과는 다음과 같습니다.
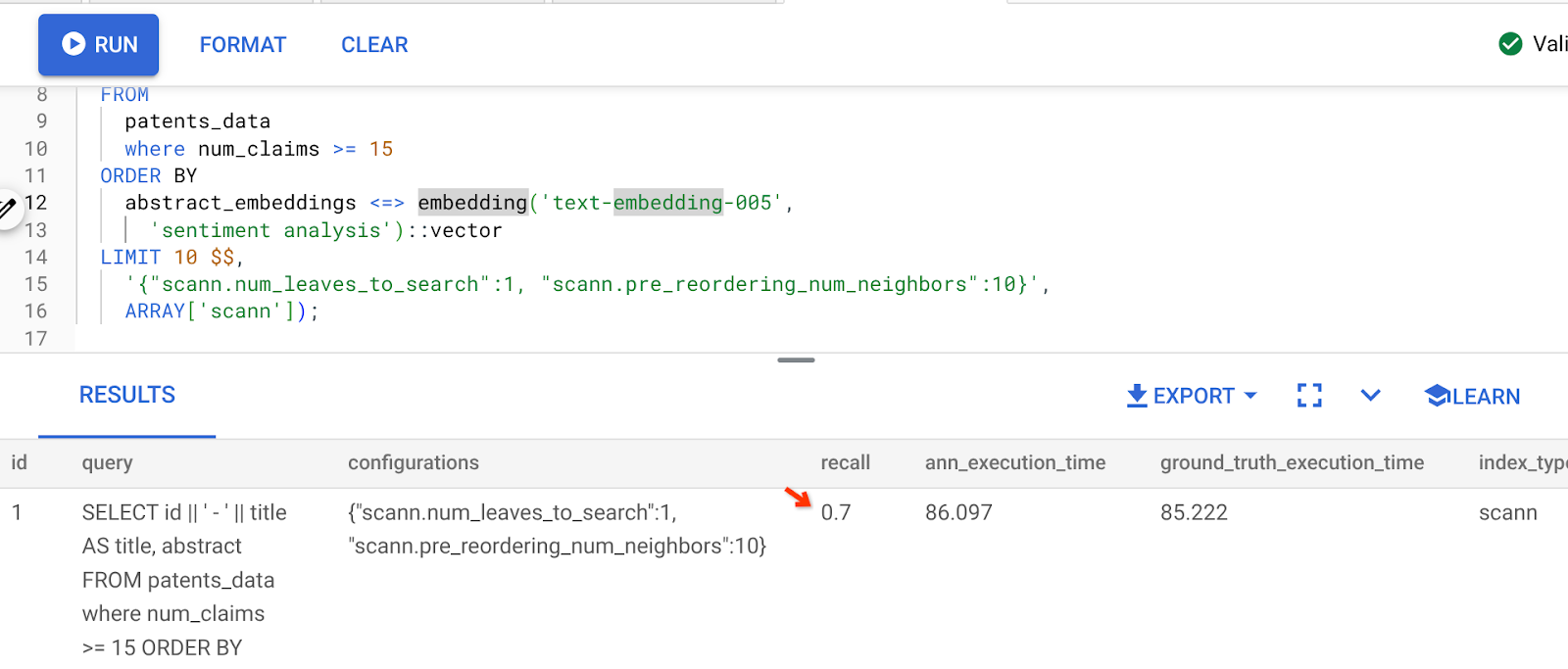
보시다시피 색인 로직을 변경하지 않아도 RECALL이 70%입니다. 인라인 필터링 섹션의 6단계에서 만든 ScaNN 색인(patent_index)을 기억하시나요? 위의 쿼리를 실행하는 동안에도 동일한 색인이 계속 유효합니다.
이제 다른 거리 함수 쿼리(L2 거리: <->)를 사용하여 색인을 만들어 보겠습니다.
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
drop index 문은 테이블에 불필요한 색인이 없도록 하기 위한 것입니다.
이제 다음 쿼리를 실행하여 벡터 검색 기능의 거리 함수를 변경한 후 재현율을 평가할 수 있습니다.
[AFTER] 코사인 유사도 거리 함수를 사용하는 쿼리:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
위 쿼리의 결과는 다음과 같습니다.
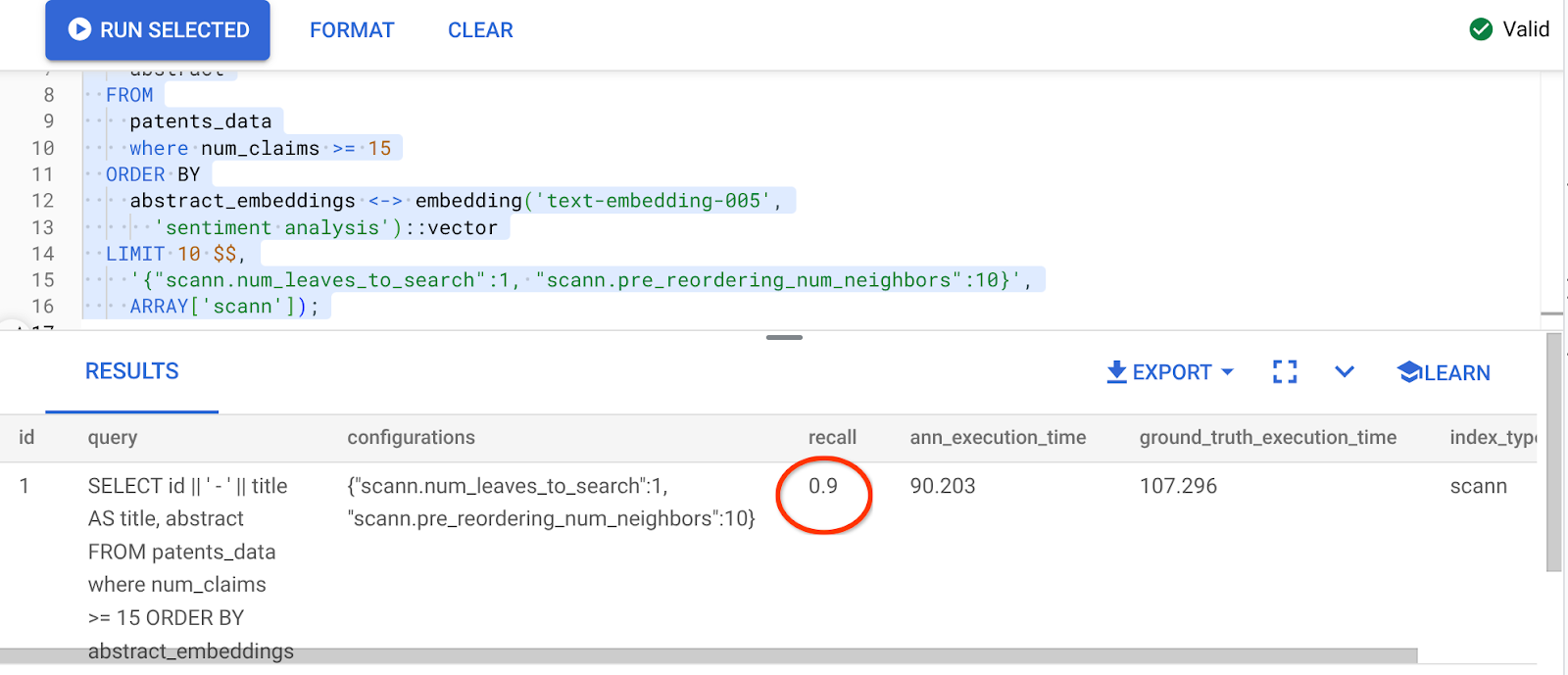
재현율이 90%로 변신했습니다!
원하는 재현율 값과 애플리케이션에서 사용하는 데이터 세트에 따라 num_leaves 등 색인에서 변경할 수 있는 다른 매개변수가 있습니다.
8. 삭제
이 게시물에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 리소스 관리자 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력하고 종료를 클릭하여 프로젝트를 삭제합니다.
- 또는 클러스터 삭제 버튼을 클릭하여 이 프로젝트를 위해 방금 만든 AlloyDB 클러스터 (구성 시 클러스터에 us-central1을 선택하지 않은 경우 이 하이퍼링크의 위치를 변경)를 삭제하면 됩니다.
9. 축하합니다
축하합니다. AlloyDB의 고급 벡터 검색을 사용하여 고성능을 지원하고 진정한 의미 기반 검색을 수행할 수 있는 컨텍스트 기반 특허 검색 쿼리를 성공적으로 빌드했습니다. ADK와 여기에서 논의한 모든 AlloyDB 기능을 사용하여 고성능의 고품질 특허 벡터 검색 및 분석기 에이전트를 만드는 품질 관리 멀티 도구 에이전트 애플리케이션을 만들었습니다. 여기에서 확인하세요. https://youtu.be/Y9fvVY0yZTY
이 에이전트를 빌드하는 방법을 알아보려면 이 Codelab을 참고하세요.