
1. Przegląd
W różnych branżach wyszukiwanie kontekstowe jest kluczową funkcją, która stanowi podstawę aplikacji. Technologia Retrieval Augmented Generation od dłuższego czasu jest kluczowym czynnikiem tego ważnego rozwoju technologicznego dzięki mechanizmom wyszukiwania opartym na generatywnej AI. Modele generatywne, z ich dużymi oknami kontekstu i imponującą jakością danych wyjściowych, zmieniają AI. RAG to systematyczny sposób na wstrzykiwanie kontekstu do aplikacji i agentów AI, który opiera je na ustrukturyzowanych bazach danych lub informacjach z różnych mediów. Te dane kontekstowe mają kluczowe znaczenie w celu uniknięcia wątpliwości i dokładności wyników, ale jak dokładne są te wyniki? Czy Twoja firma w dużej mierze zależy od dokładności tych dopasowań kontekstowych i trafności? W takim razie ten projekt Cię rozbawi!
Największym problemem związanym z wyszukiwaniem wektorowym nie jest samo jego utworzenie, ale sprawdzenie, czy dopasowania wektorowe są rzeczywiście dobre. Wszyscy to znamy: patrzymy na listę wyników i zastanawiamy się, czy to w ogóle działa. Dowiedz się, jak oceniać jakość dopasowań wektorowych. „Co się zmieniło w RAG?” – zapytasz. Wszystko! Przez lata generowanie rozszerzone przez wyszukiwanie w zapisanych informacjach (RAG) wydawało się obiecującym, ale nieuchwytnym celem. Teraz wreszcie mamy narzędzia do tworzenia aplikacji RAG o wydajności i niezawodności wymaganej w przypadku zadań o krytycznym znaczeniu.
Znasz już podstawowe informacje o 3 rzeczach:
- Co oznacza wyszukiwanie kontekstowe dla Twojego agenta i jak to osiągnąć za pomocą wyszukiwania wektorowego.
- Przyjrzeliśmy się też szczegółowo uzyskiwaniu wyszukiwania wektorowego w zakresie Twoich danych, czyli w samej bazie danych (wszystkie bazy danych Google Cloud to obsługują, jeśli jeszcze o tym nie wiesz).
- Poszliśmy o krok dalej niż reszta świata i wyjaśniliśmy, jak uzyskać taką lekką funkcję RAG wyszukiwania wektorowego o wysokiej wydajności i jakości dzięki funkcji wyszukiwania wektorowego AlloyDB opartej na indeksie ScaNN.
Jeśli nie masz za sobą tych podstawowych, średnio zaawansowanych i nieco bardziej zaawansowanych eksperymentów z RAG, zachęcam Cię do przeczytania tych 3 artykułów w podanej kolejności: tutaj, tutaj i tutaj.
Patent Search pomaga użytkownikowi znaleźć patenty powiązane kontekstowo z tekstem wyszukiwania. Wersję tej funkcji stworzyliśmy już w przeszłości. Teraz stworzymy ją za pomocą nowych i zaawansowanych funkcji RAG, które umożliwiają wyszukiwanie kontekstowe z kontrolą jakości w tej aplikacji. Zaczynajmy!
Obraz poniżej przedstawia ogólny przepływ działań w tej aplikacji.~ 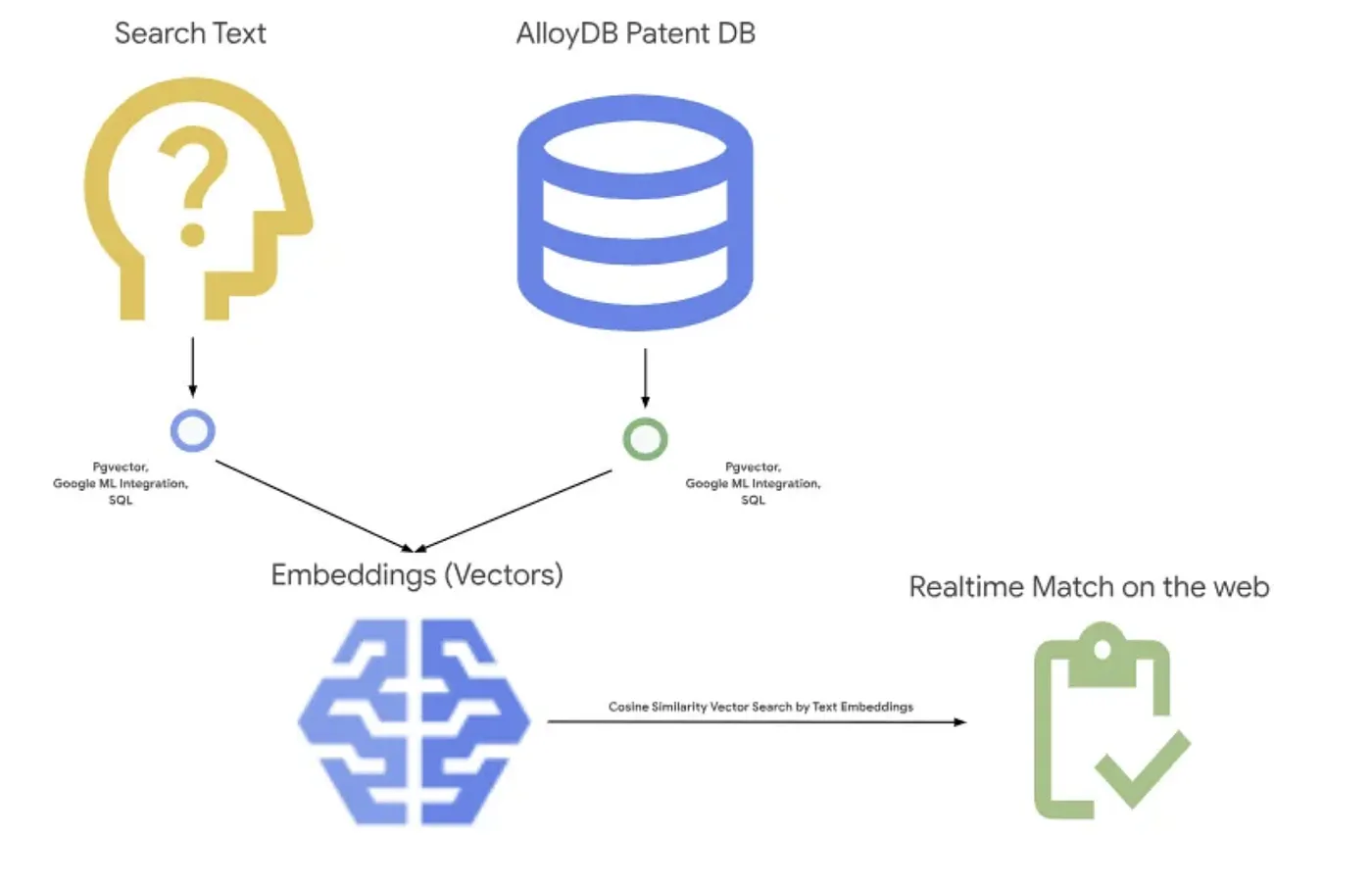
Cel
Umożliwia użytkownikowi wyszukiwanie patentów na podstawie opisu tekstowego z większą wydajnością i lepszą jakością, a także ocenianie jakości wygenerowanych wyników za pomocą najnowszych funkcji RAG w AlloyDB.
Co utworzysz
W ramach tego laboratorium:
- Tworzenie instancji AlloyDB i wczytywanie publicznego zbioru danych dotyczących patentów
- Tworzenie indeksu metadanych i indeksu ScaNN
- Wdrażanie zaawansowanego wyszukiwania wektorowego w AlloyDB za pomocą metody filtrowania wbudowanego ScaNN
- Implementowanie funkcji oceny czułości
- Ocena odpowiedzi na zapytanie
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności .
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API. W terminalu Cloud Shell możesz użyć polecenia gcloud:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Alternatywą dla polecenia gcloud jest wyszukanie poszczególnych usług w konsoli lub skorzystanie z tego linku.
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Konfiguracja bazy danych
W tym module użyjemy AlloyDB jako bazy danych do przechowywania danych o patentach. Używa klastrów do przechowywania wszystkich zasobów, takich jak bazy danych i logi. Każdy klaster ma instancję główną, która zapewnia punkt dostępu do danych. Tabele będą zawierać rzeczywiste dane.
Utwórzmy klaster, instancję i tabelę AlloyDB, do których zostanie załadowany zbiór danych patentów.
Tworzenie klastra i instancji
- Otwórz stronę AlloyDB w konsoli Cloud. Najprostszym sposobem na znalezienie większości stron w Cloud Console jest wyszukanie ich za pomocą paska wyszukiwania w konsoli.
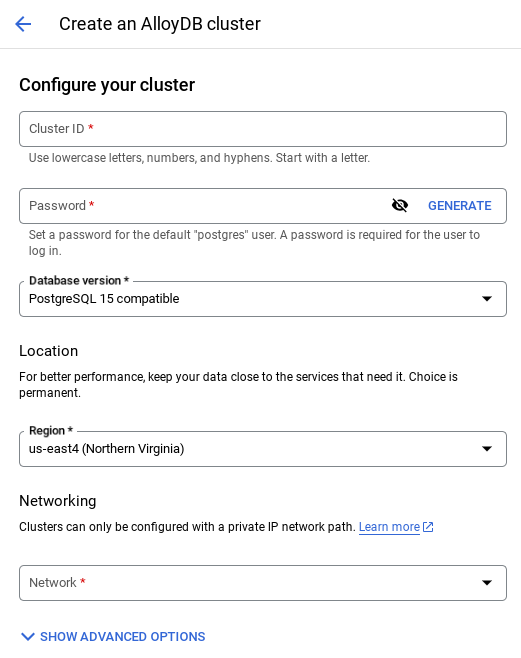
- Na tej stronie kliknij UTWÓRZ KLASTER:

- Wyświetli się ekran podobny do tego poniżej. Utwórz klaster i instancję z tymi wartościami (upewnij się, że wartości są zgodne, jeśli klonujesz kod aplikacji z repozytorium):
- id klastra: „
vector-cluster” - password: "
alloydb" - PostgreSQL 15 / najnowsza zalecana
- Region: "
us-central1" - Sieć: „
default”
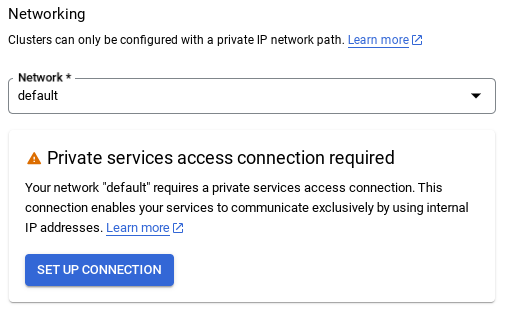
- Po wybraniu sieci domyślnej zobaczysz ekran podobny do tego poniżej.
Kliknij SKONFIGURUJ POŁĄCZENIE.
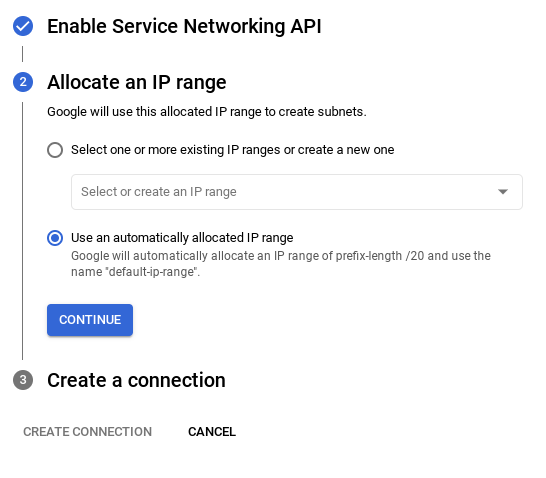
- Następnie wybierz „Użyj automatycznie przydzielonego zakresu adresów IP” i kliknij Dalej. Po sprawdzeniu informacji kliknij UTWÓRZ POŁĄCZENIE.
- Po skonfigurowaniu sieci możesz kontynuować tworzenie klastra. Kliknij UTWÓRZ KLASTER, aby dokończyć konfigurowanie klastra, jak pokazano poniżej:
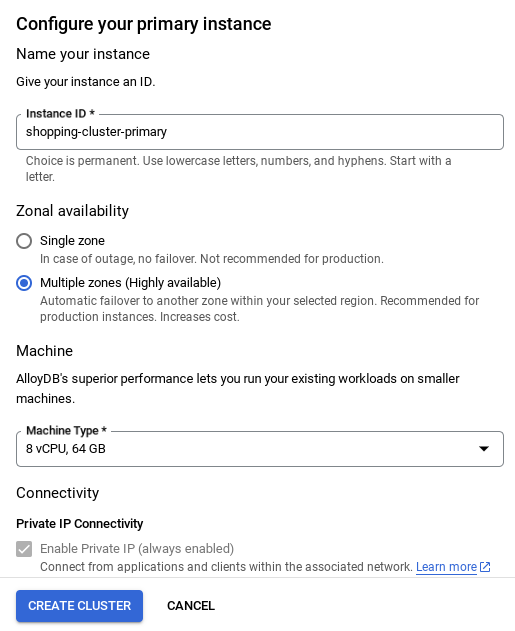
Pamiętaj, aby zmienić identyfikator instancji (który możesz znaleźć podczas konfigurowania klastra lub instancji) na
vector-instance. Jeśli nie możesz go zmienić, pamiętaj, aby we wszystkich kolejnych odwołaniach używać identyfikatora instancji.
Pamiętaj, że utworzenie klastra zajmie około 10 minut. Po zakończeniu procesu wyświetli się ekran z omówieniem utworzonego klastra.
4. Pozyskiwanie danych
Teraz dodaj tabelę z danymi o sklepie. Otwórz AlloyDB, wybierz klaster główny, a następnie AlloyDB Studio:
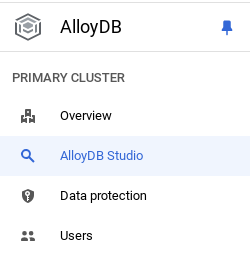
Może być konieczne poczekanie na zakończenie tworzenia instancji. Gdy to zrobisz, zaloguj się w AlloyDB przy użyciu danych logowania utworzonych podczas tworzenia klastra. Do uwierzytelniania w PostgreSQL użyj tych danych:
- Nazwa użytkownika: „
postgres” - Baza danych: „
postgres” - Hasło: „
alloydb”
Po pomyślnym uwierzytelnieniu w AlloyDB Studio polecenia SQL są wpisywane w Edytorze. Możesz dodać wiele okien Edytora, klikając znak plusa po prawej stronie ostatniego okna.
Polecenia dla AlloyDB będziesz wpisywać w oknach edytora, w razie potrzeby korzystając z opcji Uruchom, Formatuj i Wyczyść.
Włącz rozszerzenia
Do utworzenia tej aplikacji użyjemy rozszerzeń pgvector i google_ml_integration. Rozszerzenie pgvector umożliwia przechowywanie i wyszukiwanie wektorów dystrybucyjnych. Rozszerzenie google_ml_integration udostępnia funkcje, których możesz używać do uzyskiwania dostępu do punktów końcowych prognozowania Vertex AI w celu uzyskiwania prognoz w SQL. Włącz te rozszerzenia, uruchamiając te DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Jeśli chcesz sprawdzić, które rozszerzenia są włączone w bazie danych, uruchom to polecenie SQL:
select extname, extversion from pg_extension;
Tworzenie tabeli
Tabelę możesz utworzyć za pomocą instrukcji DDL poniżej w AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
Kolumna abstract_embeddings będzie umożliwiać przechowywanie wartości wektorowych tekstu.
Przyznaj uprawnienia
Uruchom poniższą instrukcję, aby przyznać uprawnienia do wykonywania funkcji „embedding”:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Przyznawanie roli Użytkownik Vertex AI kontu usługi AlloyDB
W konsoli IAM Google Cloud przyznaj kontu usługi AlloyDB (które wygląda tak: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) dostęp do roli „Użytkownik Vertex AI”. Zmienna PROJECT_NUMBER będzie zawierać numer Twojego projektu.
Możesz też uruchomić to polecenie w terminalu Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Wczytywanie danych patentowych do bazy danych
Jako zbioru danych użyjemy publicznych zbiorów danych Patenty Google w BigQuery. Do uruchamiania zapytań będziemy używać AlloyDB Studio. Dane są pobierane z tego pliku insert_scripts.sql, a my uruchomimy go, aby wczytać dane patentowe.
- W konsoli Google Cloud otwórz stronę AlloyDB.
- Wybierz nowo utworzony klaster i kliknij instancję.
- W menu nawigacyjnym AlloyDB kliknij AlloyDB Studio. Zaloguj się za pomocą swoich danych logowania.
- Otwórz nową kartę, klikając ikonę Nowa karta po prawej stronie.
- Skopiuj instrukcję zapytania
insertzeinsert_scripts.sqlskryptu wspomnianego powyżej do edytora. Możesz skopiować 10–50 instrukcji wstawiania, aby szybko zaprezentować ten przypadek użycia. - Kliknij Wykonaj. Wyniki zapytania pojawią się w tabeli Wyniki.
Uwaga: skrypt wstawiania może zawierać dużo danych. Dzieje się tak, ponieważ w skryptach wstawiania umieściliśmy komponenty do osadzania. Jeśli masz problem z wczytaniem pliku w GitHubie, kliknij „Wyświetl nieprzetworzone”. Dzięki temu w przyszłych krokach nie będziesz musiał(-a) generować więcej niż kilku wektorów dystrybucyjnych (maksymalnie 20–25), jeśli używasz konta rozliczeniowego z bezpłatnymi środkami na Google Cloud.
5. Tworzenie wektorów dystrybucyjnych na podstawie danych patentowych
Najpierw przetestujmy funkcję osadzania, uruchamiając to przykładowe zapytanie:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Powinien on zwrócić wektor dystrybucyjny, który wygląda jak tablica liczb zmiennoprzecinkowych, dla przykładowego tekstu w zapytaniu. Wygląda to tak:
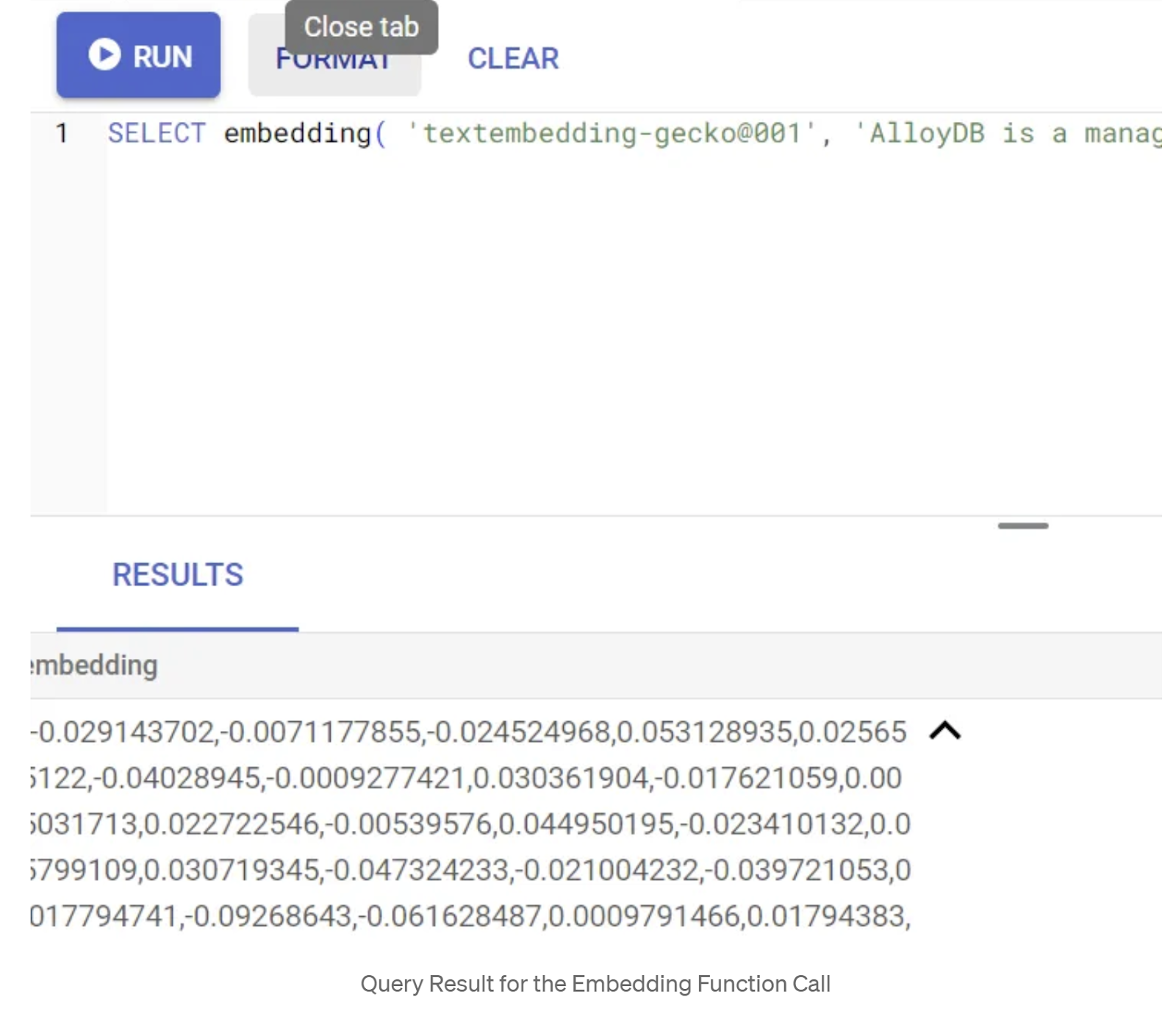
Zaktualizuj pole wektora abstract_embeddings.
Uruchom poniższy język DML, aby zaktualizować streszczenia patentów w tabeli o odpowiednie osadzanie, tylko jeśli nie zostały wstawione dane abstract_embeddings w ramach skryptu wstawiania:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Jeśli używasz konta rozliczeniowego z kredytem próbnym w Google Cloud, możesz mieć problem z wygenerowaniem więcej niż kilku osadzeń (maksymalnie 20–25). Dlatego umieściłem już wektory w skryptach wstawiania. Jeśli wykonasz krok „wczytaj dane patentowe do bazy danych”, powinny one być wczytane do tabeli.
6. Zaawansowane RAG z użyciem nowych funkcji AlloyDB
Gdy tabela, dane i wektory dystrybucyjne są gotowe, możemy przeprowadzić wyszukiwanie wektorowe w czasie rzeczywistym dla tekstu wyszukiwanego przez użytkownika. Możesz to sprawdzić, uruchamiając to zapytanie:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
W tym zapytaniu
- Tekst wyszukiwany przez użytkownika to „analiza nastawienia”.
- Konwertujemy go na wektory dystrybucyjne w metodzie embedding() za pomocą modelu text-embedding-005.
- „<=>” oznacza użycie metody odległości COSINE SIMILARITY.
- Wynik metody wektorów dystrybucyjnych przekształcamy w typ wektorowy, aby był zgodny z wektorami przechowywanymi w bazie danych.
- LIMIT 10 oznacza, że wybieramy 10 najbliższych dopasowań tekstu wyszukiwania.
AlloyDB przenosi RAG z wyszukiwaniem wektorowym na wyższy poziom:
Wprowadzono wiele nowości. Oto 2 z nich, które są przeznaczone dla deweloperów:
- Filtrowanie w tekście
- Osoba oceniająca czułość
Filtrowanie w tekście
Wcześniej jako deweloper musiałbyś wykonać zapytanie wyszukiwania wektorowego i zająć się filtrowaniem oraz przywoływaniem. Optymalizator zapytań AlloyDB wybiera sposób wykonywania zapytania z filtrami. Filtrowanie wbudowane to nowa technika optymalizacji zapytań, która umożliwia optymalizatorowi zapytań AlloyDB ocenę zarówno warunków filtrowania metadanych, jak i wyszukiwania wektorowego, z wykorzystaniem indeksów wektorowych i indeksów w kolumnach metadanych. Dzięki temu zwiększyła się skuteczność przywoływania, co pozwala deweloperom korzystać z funkcji AlloyDB od razu po wyjęciu z pudełka.
Filtrowanie wbudowane najlepiej sprawdza się w przypadku średniej selektywności. Podczas przeszukiwania indeksu wektorowego AlloyDB oblicza odległości tylko w przypadku wektorów, które spełniają warunki filtrowania metadanych (filtry funkcjonalne w zapytaniu zwykle obsługiwane w klauzuli WHERE). Znacznie zwiększa to wydajność tych zapytań, uzupełniając zalety filtrowania po lub przed.
- Instalowanie lub aktualizowanie rozszerzenia pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Jeśli rozszerzenie pgvector jest już zainstalowane, uaktualnij je do wersji 0.8.0.google-3 lub nowszej, aby uzyskać dostęp do funkcji oceny czułości.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Ten krok należy wykonać tylko wtedy, gdy rozszerzenie wektorowe ma wersję <0.8.0.google-3>.
Ważna uwaga: jeśli liczba wierszy jest mniejsza niż 100, nie musisz tworzyć indeksu ScaNN, ponieważ nie będzie on stosowany w przypadku mniejszej liczby wierszy. W takim przypadku pomiń kolejne kroki.
- Aby utworzyć indeksy ScaNN, zainstaluj rozszerzenie alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
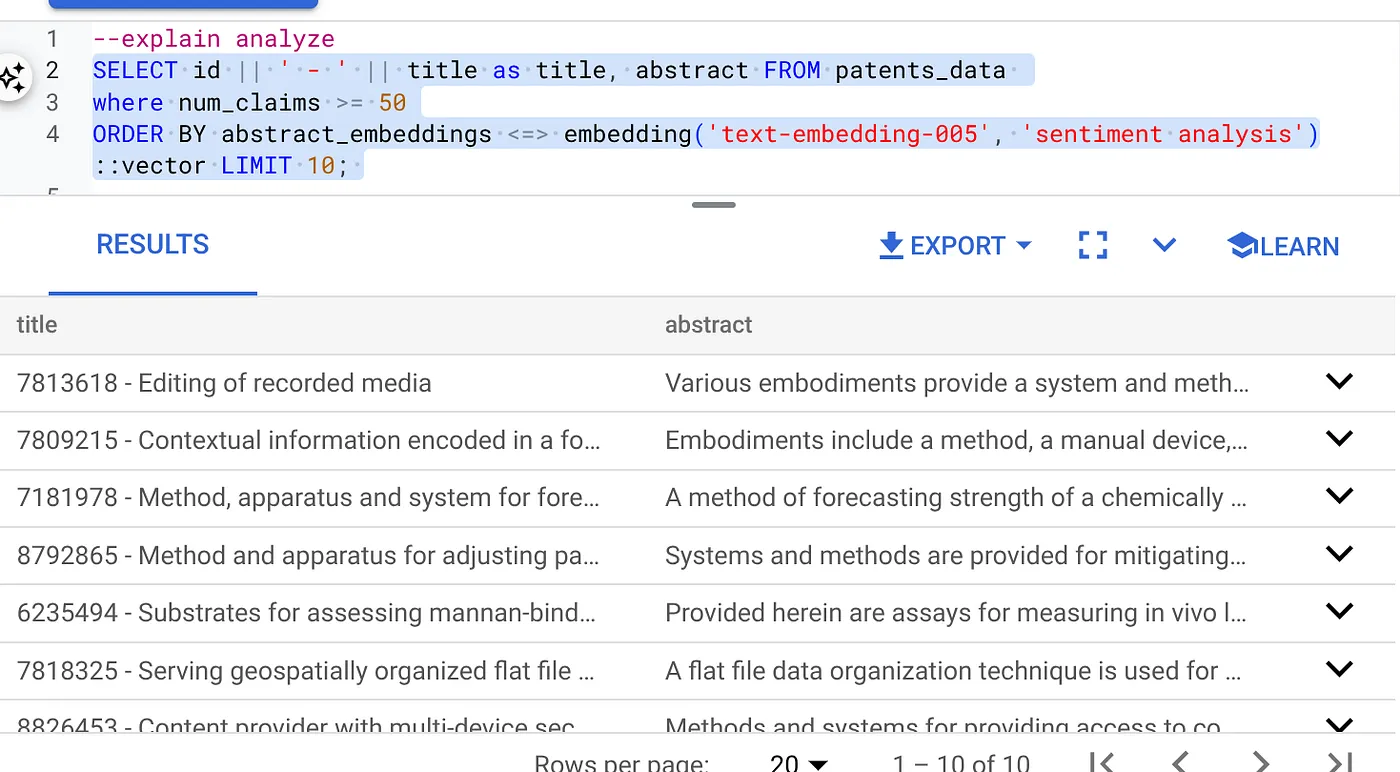
- Najpierw uruchom zapytanie w ramach wyszukiwania wektorowego bez indeksu i bez włączonego filtra wbudowanego:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Wynik powinien być podobny do tego:
- Uruchom na nim Explain Analyze (bez indeksu ani filtrowania wbudowanego):
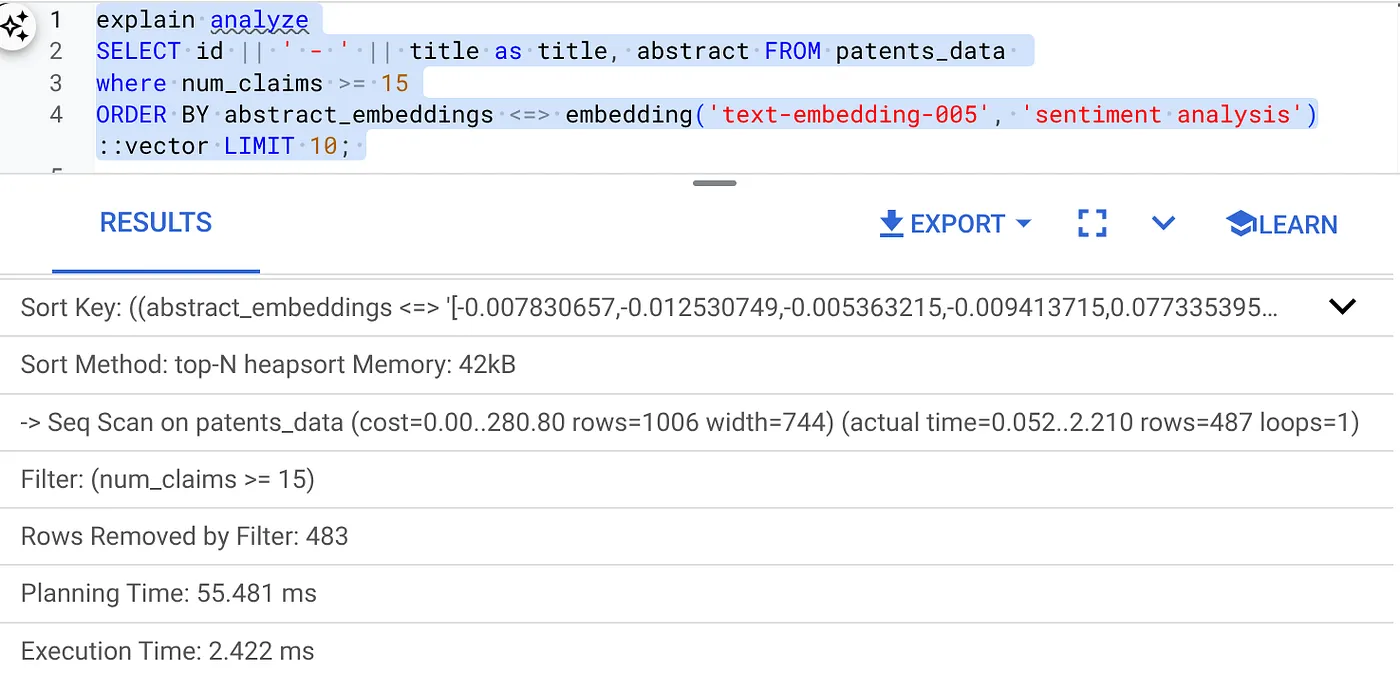
Czas wykonywania to 2,4 ms
- Utwórzmy zwykły indeks w polu num_claims, aby można było filtrować według niego:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Utwórzmy indeks ScaNN dla naszej aplikacji do wyszukiwania patentów. W AlloyDB Studio wykonaj te czynności:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Ważna uwaga: (num_leaves=32) dotyczy naszego pełnego zbioru danych zawierającego ponad 1000 wierszy. Jeśli liczba wierszy jest mniejsza niż 100, nie musisz tworzyć indeksu, ponieważ nie będzie on miał zastosowania w przypadku mniejszej liczby wierszy.
- Włącz filtrowanie wbudowane w indeksie ScaNN:
SET scann.enable_inline_filtering = on
- Teraz uruchommy to samo zapytanie z filtrem i wyszukiwaniem wektorowym:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
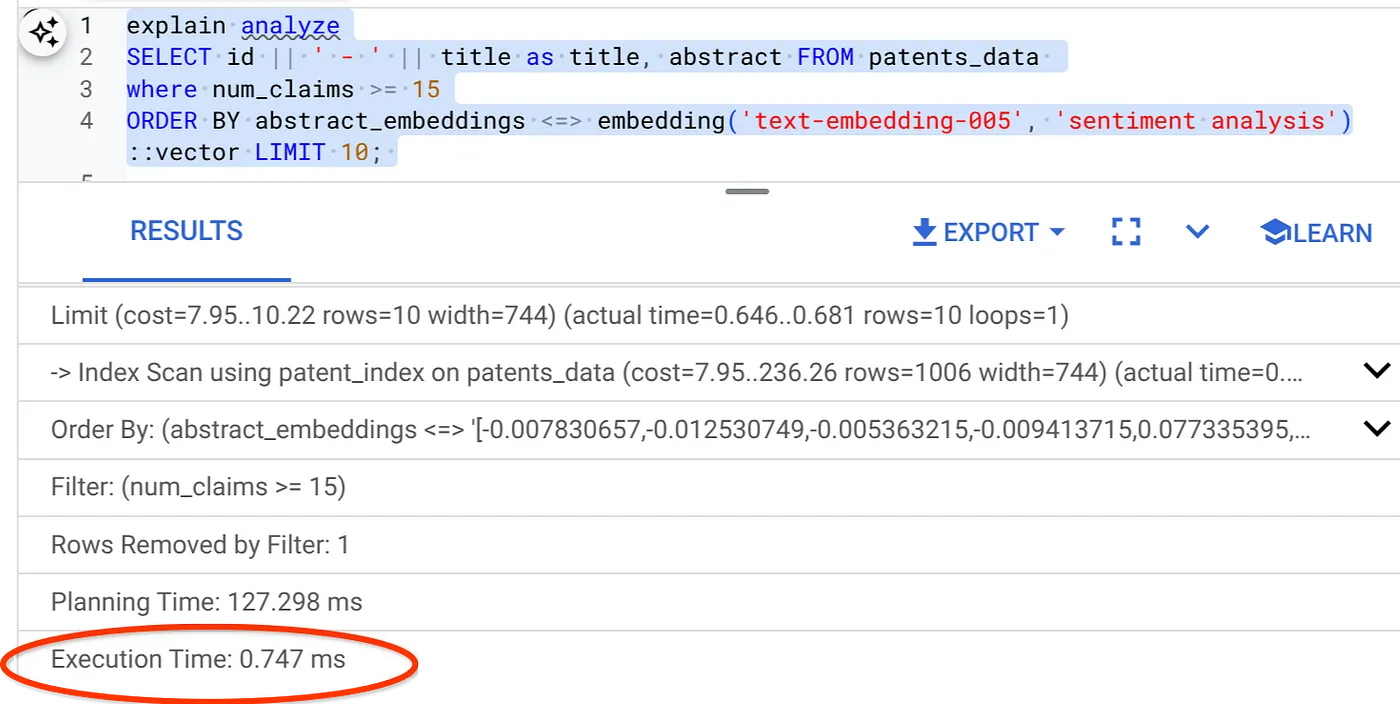
Jak widać, czas wykonania tego samego wyszukiwania wektorowego znacznie się skrócił. Umożliwia to indeks ScaNN z filtrowaniem wbudowanym w wyszukiwarce wektorowej.
Następnie sprawdźmy skuteczność wyszukiwania wektorowego z włączonym ScaNN.
Osoba oceniająca czułość
Wyszukiwanie podobieństw to odsetek trafnych wyników wyszukiwania, czyli liczba wyników prawdziwie pozytywnych. To najczęściej używane dane do pomiaru jakości wyszukiwania. Jednym ze źródeł utraty wyników jest różnica między przybliżonym wyszukiwaniem najbliższych sąsiadów (aNN) a wyszukiwaniem k najbliższych sąsiadów (kNN). Indeksy wektorowe, takie jak ScaNN w AlloyDB, implementują algorytmy aNN, co pozwala przyspieszyć wyszukiwanie wektorowe w dużych zbiorach danych w zamian za niewielkie obniżenie czułości. AlloyDB umożliwia teraz bezpośrednie mierzenie tego kompromisu w bazie danych w przypadku poszczególnych zapytań i zapewnia jego stabilność w czasie. Na podstawie tych informacji możesz aktualizować parametry zapytań i indeksów, aby osiągać lepsze wyniki i wydajność.
Jaka jest logika przywoływania wyników wyszukiwania?
W kontekście wyszukiwania wektorowego czułość odnosi się do odsetka wektorów zwracanych przez indeks, które są prawdziwymi najbliższymi sąsiadami. Jeśli na przykład zapytanie o 20 najbliższych sąsiadów zwróci 19 najbliższych sąsiadów z danych podstawowych, to czułość wynosi 19/20 x 100 = 95%. Recall to miara używana do określania jakości wyszukiwania. Jest to odsetek zwróconych wyników, które są obiektywnie najbliższe wektorom zapytania.
Wartość czułości dla zapytania wektorowego w indeksie wektorowym w przypadku danej konfiguracji możesz znaleźć za pomocą funkcji evaluate_query_recall. Ta funkcja umożliwia dostrojenie parametrów w celu uzyskania oczekiwanych wyników czułości zapytania wektorowego.
Ważna uwaga:
Jeśli podczas wykonywania poniższych czynności pojawi się błąd odmowy uprawnień w indeksie HNSW, na razie pomiń całą sekcję oceny przywoływania. Może to być związane z ograniczeniami dostępu, ponieważ w momencie tworzenia tego przewodnika usługa została dopiero udostępniona.
- Ustaw flagę Włącz skanowanie indeksu w indeksie ScaNN i indeksie HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Uruchom to zapytanie w AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Funkcja evaluate_query_recall przyjmuje zapytanie jako parametr i zwraca jego czułość. Używam tego samego zapytania, którego użyłem do sprawdzenia wydajności, jako zapytania wejściowego funkcji. Jako metodę indeksowania dodano SCaNN. Więcej opcji parametrów znajdziesz w dokumentacji.
Czułość dla używanego przez nas zapytania do wyszukiwarki wektorowej:
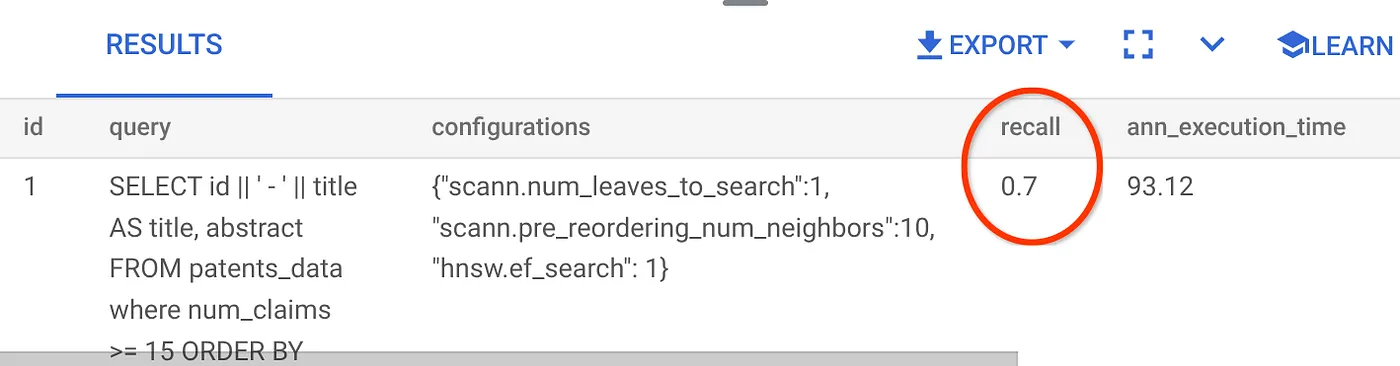
Widzę, że wartość RECALL wynosi 70%. Teraz mogę użyć tych informacji, aby zmienić parametry indeksu, metody i parametry zapytań oraz poprawić skuteczność wyszukiwania wektorowego.
7. Przetestuj go ze zmodyfikowanymi parametrami zapytania i indeksu
Teraz przetestuj zapytanie, modyfikując parametry zapytania na podstawie otrzymanej czułości.
- Zmieniłem liczbę wierszy w zbiorze wyników na 7 (wcześniej było to 25) i widzę poprawę wskaźnika RECALL, czyli 86%.
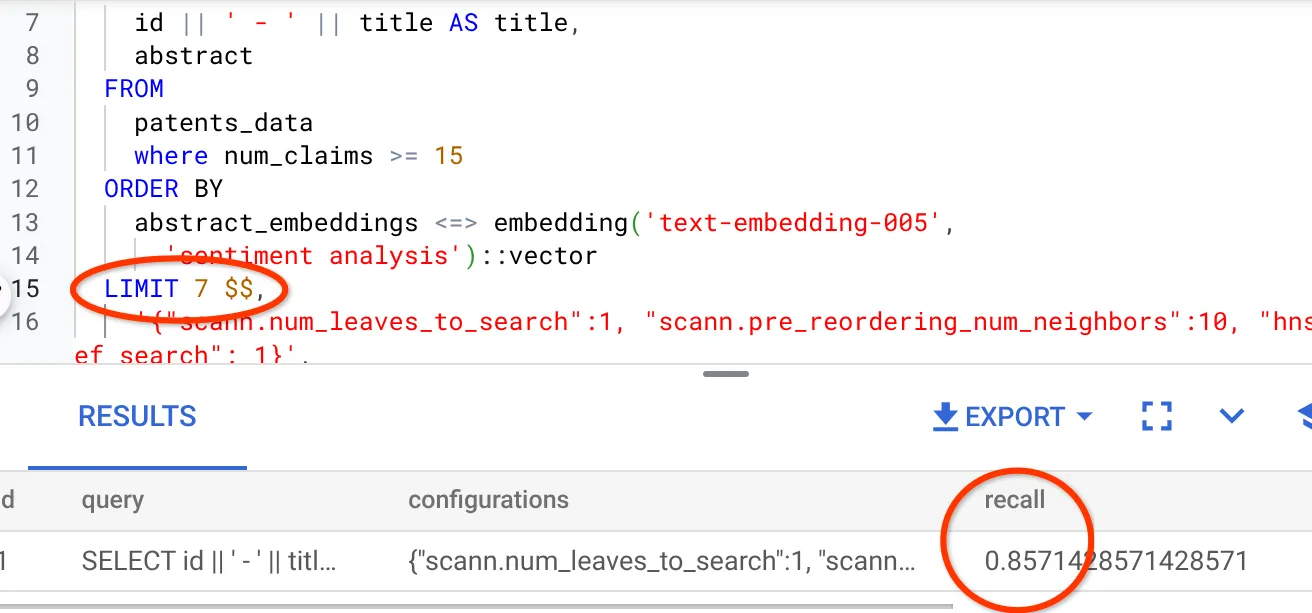
Oznacza to, że w czasie rzeczywistym mogę zmieniać liczbę wyników wyświetlanych użytkownikom, aby zwiększać ich trafność w zależności od kontekstu wyszukiwania.
- Spróbujmy jeszcze raz, modyfikując parametry indeksu:
W tym teście użyję funkcji podobieństwa „Odległość L2” zamiast „Cosinus”. Zmienię też limit zapytania na 10, aby sprawdzić, czy jakość wyników wyszukiwania poprawi się nawet przy zwiększonej liczbie wyników.
[PRZED] Zapytanie, które korzysta z funkcji odległości podobieństwa cosinusowego:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Bardzo ważna uwaga: „Skąd wiemy, że to zapytanie używa podobieństwa COSINE?” – zapytasz. Funkcję odległości możesz rozpoznać po użyciu symbolu „<=>”, który oznacza odległość kosinusową.
Link do dokumentów dotyczących funkcji odległości w Wyszukiwaniu wektorowym.
Wynik powyższego zapytania to:
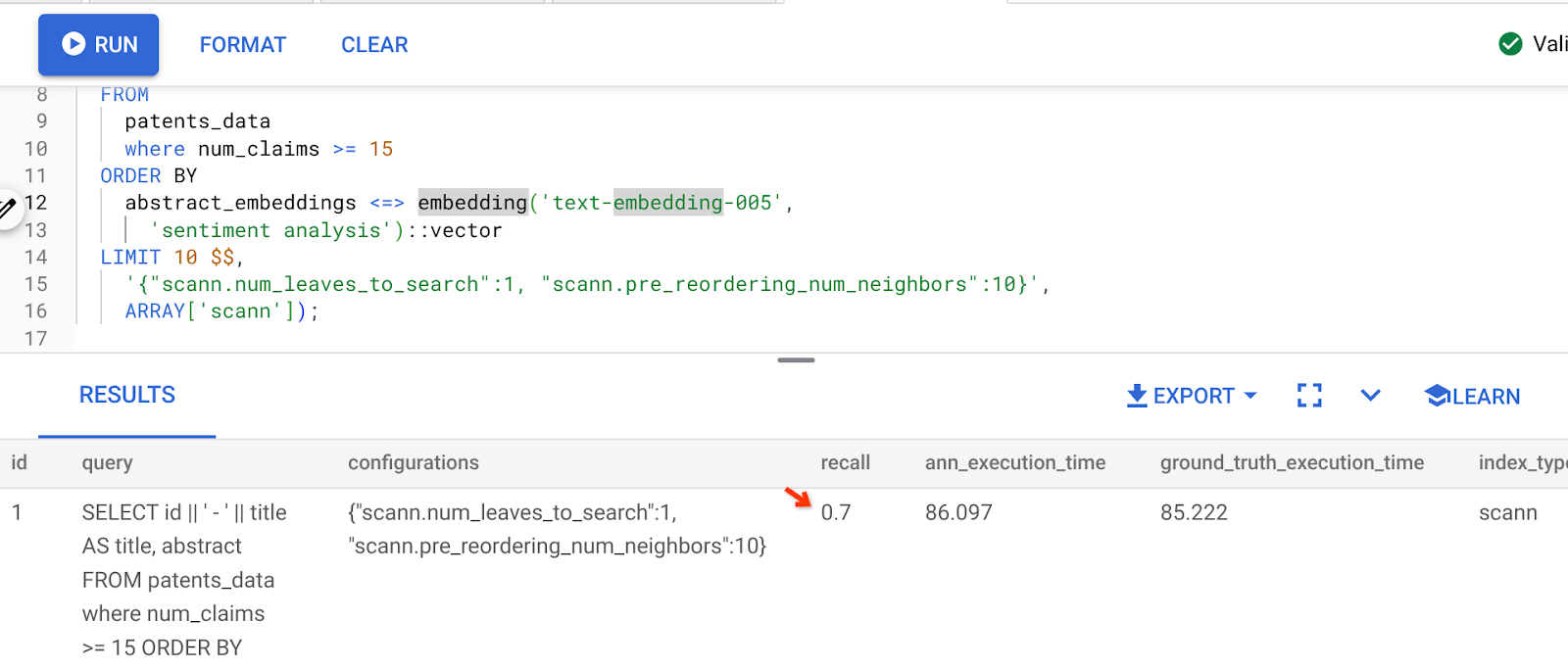
Jak widać, wartość RECALL wynosi 70% bez żadnych zmian w logice indeksu. Pamiętasz indeks ScaNN utworzony w kroku 6 sekcji Filtrowanie wbudowane „patent_index”? Ten sam indeks jest nadal skuteczny podczas wykonywania powyższego zapytania.
Teraz utwórzmy indeks z innym zapytaniem dotyczącym funkcji odległości: odległość L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
Instrukcja drop index służy tylko do zapewnienia, że w tabeli nie ma niepotrzebnego indeksu.
Teraz mogę wykonać to zapytanie, aby ocenić RECALL po zmianie funkcji odległości w funkcji wyszukiwania wektorowego.
[AFTER] Zapytanie, które korzysta z funkcji odległości podobieństwa cosinusowego:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Wynik powyższego zapytania to:
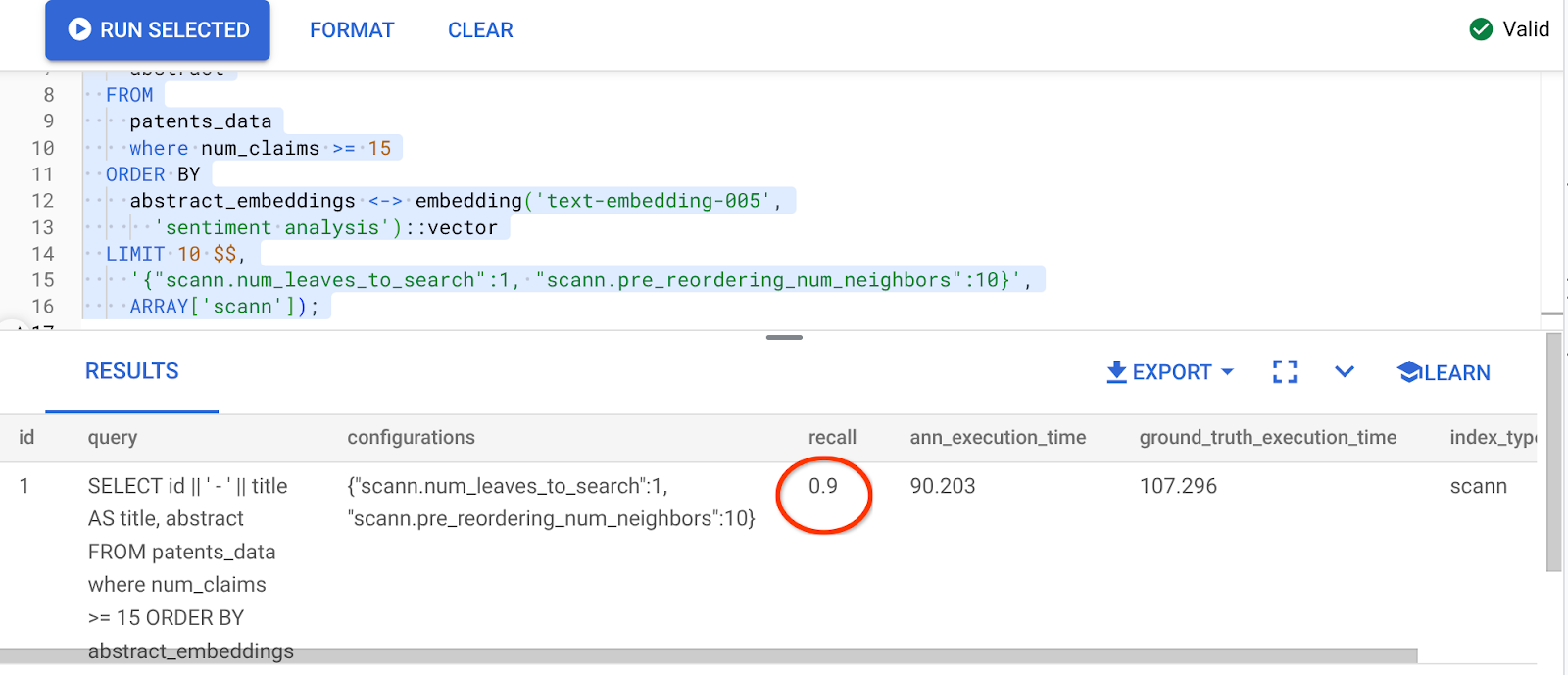
Co za zmiana rozpoznawalności, 90%!!!
W indeksie możesz zmienić inne parametry, np. num_leaves, w zależności od pożądanej wartości czułości i zbioru danych używanego przez aplikację.
8. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Menedżer zasobów.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
- Możesz też usunąć klaster AlloyDB (jeśli podczas konfiguracji nie wybrano lokalizacji us-central1, zmień ją w tym hiperlinku), który został utworzony w tym projekcie, klikając przycisk USUN KLASER.
9. Gratulacje
Gratulacje! Udało Ci się utworzyć zapytanie kontekstowe do wyszukiwania patentów za pomocą zaawansowanego wyszukiwania wektorowego AlloyDB, aby uzyskać wysoką wydajność i sprawić, że będzie ono naprawdę oparte na znaczeniu. Stworzyłem wielofunkcyjną aplikację opartą na agentach, która jest poddana kontroli jakości i wykorzystuje ADK oraz wszystkie omówione tutaj funkcje AlloyDB. Dzięki temu powstał wydajny i wysokiej jakości agent do wyszukiwania i analizowania wektorów patentów. Możesz go zobaczyć tutaj: https://youtu.be/Y9fvVY0yZTY
Jeśli chcesz się dowiedzieć, jak utworzyć takiego agenta, zapoznaj się z tym ćwiczeniem.