
1. Visão geral
Em diferentes setores, a pesquisa contextual é uma funcionalidade essencial que forma o coração e o centro dos aplicativos. A Geração Aumentada de Recuperação tem sido um fator importante dessa evolução tecnológica crucial há algum tempo com seus mecanismos de recuperação baseados em IA generativa. Os modelos generativos, com suas grandes janelas de contexto e qualidade de saída impressionante, estão transformando a IA. A RAG oferece uma maneira sistemática de injetar contexto em aplicativos e agentes de IA, embasando-os em bancos de dados estruturados ou informações de várias mídias. Esses dados contextuais são cruciais para fins de esclarecimento da verdade e a precisão da saída, mas qual é a acurácia desses resultados? Seu negócio depende muito da acurácia e da relevância dessas correspondências contextuais? Então este projeto vai te agradar!
O segredo sujo da pesquisa vetorial não é apenas a criação dela, mas saber se as correspondências de vetores são realmente boas. Todos nós já passamos por isso, olhando fixamente para uma lista de resultados e pensando: "Isso está funcionando?" Vamos analisar como avaliar a qualidade das correspondências de vetores. "Então, o que mudou na RAG?", você pergunta. Tudo! Por anos, a geração aumentada por recuperação (RAG) pareceu uma meta promissora, mas difícil de alcançar. Agora, finalmente, temos as ferramentas para criar aplicativos RAG com o desempenho e a confiabilidade necessários para tarefas essenciais.
Agora já temos o entendimento básico de três coisas:
- O que a pesquisa contextual significa para seu agente e como fazer isso usando a Pesquisa Vetorial.
- Também analisamos a fundo como fazer uma pesquisa vetorial no escopo dos seus dados, ou seja, no próprio banco de dados. Todos os bancos de dados do Google Cloud oferecem suporte a isso, caso você não saiba.
- Fomos um passo além do resto do mundo ao mostrar como realizar uma pesquisa vetorial RAG leve com alta performance e qualidade usando o recurso de pesquisa vetorial do AlloyDB com tecnologia do índice ScaNN.
Se você não fez esses experimentos básicos, intermediários e um pouco avançados de RAG, leia os três aqui, aqui e aqui na ordem listada.
A Pesquisa de patentes ajuda o usuário a encontrar patentes contextualmente relevantes para o texto de pesquisa. Já criamos uma versão desse recurso no passado. Agora vamos criar com recursos novos e avançados de RAG que permitem uma pesquisa contextual com controle de qualidade para esse aplicativo. Vamos lá.
A imagem abaixo mostra o fluxo geral do que está acontecendo neste aplicativo.~ 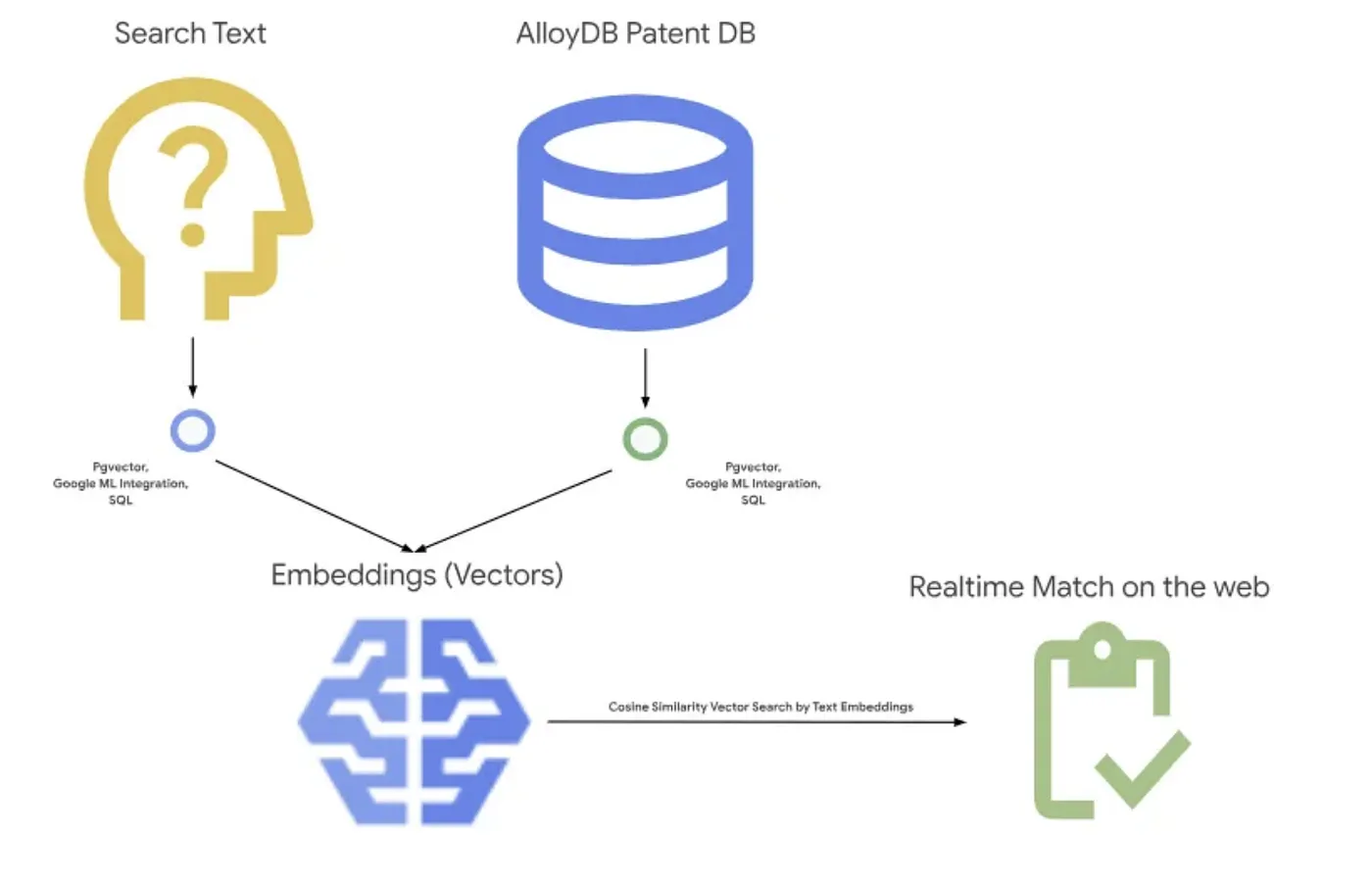
Objetivo
Permitir que um usuário pesquise patentes com base em uma descrição textual com melhor desempenho e qualidade, além de avaliar a qualidade das correspondências geradas usando os recursos mais recentes de RAG do AlloyDB.
O que você vai criar
Neste laboratório, você vai:
- Criar uma instância do AlloyDB e carregar o conjunto de dados público de patentes
- Criar índice de metadados e índice ScaNN
- Implementar a pesquisa vetorial avançada no AlloyDB usando o método de filtragem em linha do ScaNN
- Implementar o recurso de avaliação de recall
- Avaliar a resposta da consulta
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto .
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com o ID do seu projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Ativar as APIs necessárias Você pode usar um comando gcloud no terminal do Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
A alternativa ao comando gcloud é usar o console. Para isso, pesquise cada produto ou use este link.
Consulte a documentação para ver o uso e os comandos gcloud.
3. Configuração do banco de dados
Neste laboratório, vamos usar o AlloyDB como banco de dados para os dados de patentes. Ele usa clusters para armazenar todos os recursos, como bancos de dados e registros. Cada cluster tem uma instância principal que fornece um ponto de acesso aos dados. As tabelas vão conter os dados reais.
Vamos criar um cluster, uma instância e uma tabela do AlloyDB em que o conjunto de dados de patentes será carregado.
criar um cluster e uma instância
- Navegue até a página do AlloyDB no console do Cloud. Uma maneira fácil de encontrar a maioria das páginas no console do Cloud é pesquisar usando a barra de pesquisa do console.
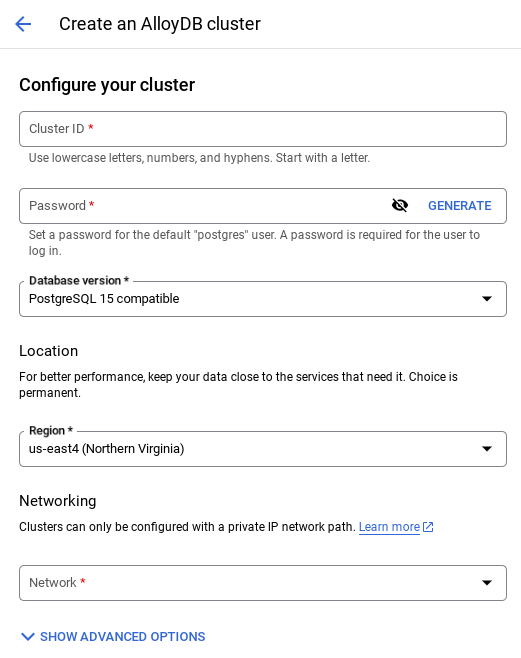
- Selecione CRIAR CLUSTER nessa página:

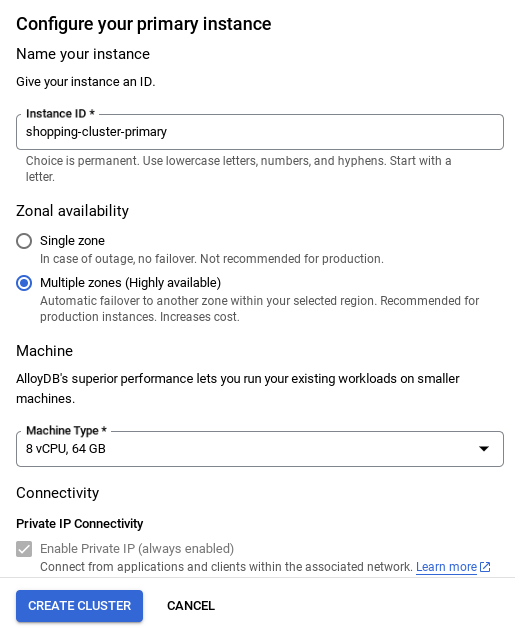
- Você vai ver uma tela como a abaixo. Crie um cluster e uma instância com os seguintes valores. Verifique se os valores correspondem caso você esteja clonando o código do aplicativo do repositório:
- ID do cluster: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / mais recente recomendado
- Região: "
us-central1" - Rede: "
default"
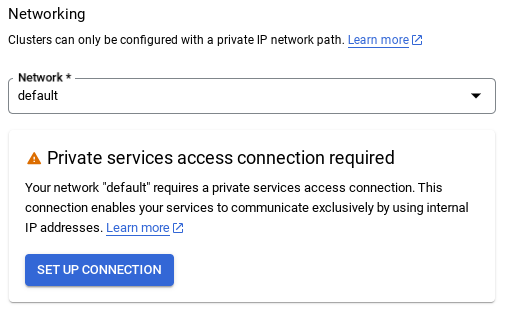
- Ao selecionar a rede padrão, uma tela como a abaixo vai aparecer.
Selecione CONFIGURAR CONEXÃO.
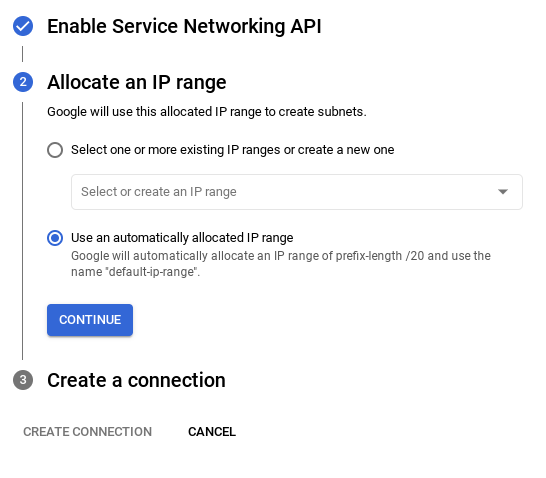
- Em seguida, selecione Usar um intervalo de IP alocado automaticamente e clique em "Continuar". Depois de revisar as informações, selecione CRIAR CONEXÃO.
- Depois que a rede for configurada, você poderá continuar criando o cluster. Clique em CRIAR CLUSTER para concluir a configuração do cluster, conforme mostrado abaixo:
Mude o ID da instância (que pode ser encontrado no momento da configuração do cluster / instância) para
vector-instance. Se não for possível mudar, use o ID da instância em todas as referências futuras.
A criação do cluster leva cerca de 10 minutos. Se tudo der certo, uma tela vai mostrar a visão geral do cluster que você acabou de criar.
4. Ingestão de dados
Agora é hora de adicionar uma tabela com os dados da loja. Acesse o AlloyDB, selecione o cluster principal e o AlloyDB Studio:
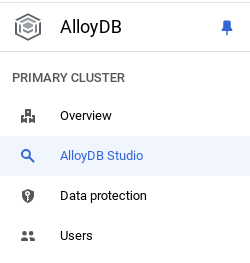
Talvez seja necessário aguardar a conclusão da criação da instância. Depois disso, faça login no AlloyDB usando as credenciais criadas ao criar o cluster. Use os seguintes dados para autenticar no PostgreSQL:
- Nome de usuário : "
postgres" - Banco de dados : "
postgres" - Senha : "
alloydb"
Depois de se autenticar no AlloyDB Studio, os comandos SQL são inseridos no editor. É possível adicionar várias janelas do Editor usando o sinal de mais à direita da última janela.
Você vai inserir comandos para o AlloyDB nas janelas do editor, usando as opções "Executar", "Formatar" e "Limpar" conforme necessário.
Ativar extensões
Para criar esse app, vamos usar as extensões pgvector e google_ml_integration. A extensão pgvector permite armazenar e pesquisar embeddings de vetores. A extensão google_ml_integration oferece funções que você usa para acessar endpoints de previsão da Vertex AI e receber previsões em SQL. Ative essas extensões executando os seguintes DDLs:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Para verificar as extensões ativadas no seu banco de dados, execute este comando SQL:
select extname, extversion from pg_extension;
Criar uma tabela
É possível criar uma tabela usando a instrução DDL abaixo no AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
A coluna "abstract_embeddings" permite armazenar os valores de vetor do texto.
Conceder permissão
Execute a instrução abaixo para conceder a execução na função "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Conceder o papel de usuário da Vertex AI à conta de serviço do AlloyDB
No console do Google Cloud IAM, conceda à conta de serviço do AlloyDB (que tem esta aparência: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acesso à função "Usuário da Vertex AI". PROJECT_NUMBER vai ter o número do seu projeto.
Como alternativa, execute o comando abaixo no terminal do Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carregar dados de patentes no banco de dados
Os conjuntos de dados públicos do Google Patentes no BigQuery serão usados como nosso conjunto de dados. Vamos usar o AlloyDB Studio para executar nossas consultas. Os dados são originados desse arquivo insert_scripts.sql, que será executado para carregar os dados de patentes.
- No console do Google Cloud, abra a página AlloyDB.
- Selecione o cluster recém-criado e clique na instância.
- No menu de navegação do AlloyDB, clique em AlloyDB Studio. Faça login com suas credenciais.
- Abra uma nova guia clicando no ícone Nova guia à direita.
- Copie a instrução de consulta
insertdo scriptinsert_scripts.sqlmencionado acima para o editor. Você pode copiar de 10 a 50 instruções de inserção para uma demonstração rápida desse caso de uso. - Clique em Executar. Os resultados da consulta aparecem na tabela Resultados.
Observação:você pode notar que o script de inserção tem muitos dados. Isso porque incluímos embeddings nos scripts de inserção. Clique em "Ver registros brutos" se tiver problemas para carregar o arquivo no GitHub. Isso é feito para evitar o trabalho (nas próximas etapas) de gerar mais do que alguns embeddings (digamos, no máximo 20 a 25) caso você esteja usando uma conta de faturamento de crédito de teste do Google Cloud.
5. Criar embeddings para dados de patentes
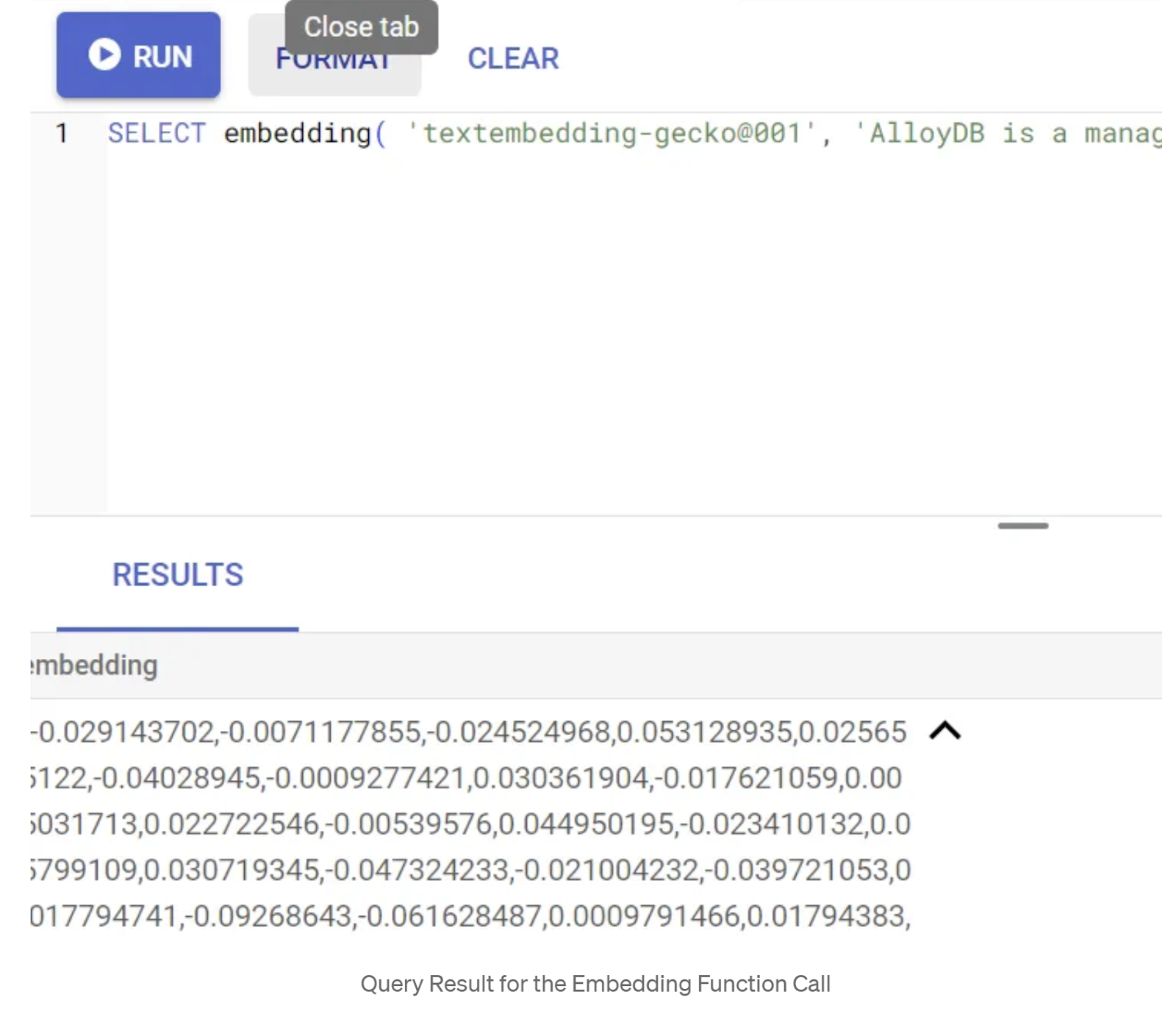
Primeiro, vamos testar a função de incorporação executando a seguinte consulta de exemplo:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Isso deve retornar o vetor de embeddings, que parece uma matriz de números de ponto flutuante, para o texto de exemplo na consulta. Ela tem esta aparência:
Atualizar o campo de vetor abstract_embeddings
Execute a DML abaixo para atualizar os resumos de patentes na tabela com os embeddings correspondentes apenas se você não tiver inserido os dados de abstract_embeddings como parte do script de inserção:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Talvez você tenha problemas para gerar mais do que alguns embeddings (digamos, no máximo 20 a 25) se estiver usando uma conta de faturamento de crédito de teste do Google Cloud. Por isso, já incluí os embeddings nos scripts de inserção. Eles devem estar na tabela carregada se você tiver concluído a etapa "Carregar dados de patentes no banco de dados".
6. Realizar RAG avançado com os novos recursos do AlloyDB
Agora que a tabela, os dados e os embeddings estão prontos, vamos realizar a pesquisa vetorial em tempo real para o texto de pesquisa do usuário. Para testar, execute a consulta abaixo:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Nesta consulta,
- O texto pesquisado pelo usuário é: "Análise de sentimento".
- Estamos convertendo em embeddings no método embedding() usando o modelo: text-embedding-005.
- "<=>" representa o uso do método de distância de similaridade de cosseno.
- Estamos convertendo o resultado do método de embedding para o tipo de vetor para torná-lo compatível com os vetores armazenados no banco de dados.
- "LIMIT 10" representa que estamos selecionando as 10 correspondências mais próximas do texto de pesquisa.
O AlloyDB leva o RAG de pesquisa vetorial a outro nível:
Há várias coisas novas. Dois deles são:
- Filtragem inline
- Avaliador de recall
Filtragem inline
Antes, como desenvolvedor, você precisava realizar a consulta de pesquisa de vetor e lidar com a filtragem e o recall. O otimizador de consultas do AlloyDB escolhe como executar uma consulta com filtros. A filtragem inline é uma nova técnica de otimização de consultas que permite que o otimizador de consultas do AlloyDB avalie as condições de filtragem de metadados e a pesquisa vetorial simultaneamente, aproveitando os índices vetoriais e os índices nas colunas de metadados. Isso aumentou o desempenho de recall, permitindo que os desenvolvedores aproveitem o que o AlloyDB tem a oferecer de imediato.
A filtragem inline é ideal para casos com seletividade média. À medida que o AlloyDB pesquisa no índice vetorial, ele só calcula distâncias para vetores que correspondem às condições de filtragem de metadados (seus filtros funcionais em uma consulta geralmente processada na cláusula WHERE). Isso melhora muito o desempenho dessas consultas, complementando as vantagens do pós-filtro ou pré-filtro.
- Instalar ou atualizar a extensão pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Se a extensão pgvector já estiver instalada, faça upgrade para a versão 0.8.0.google-3 ou mais recente para ter recursos de avaliador de recall.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Essa etapa só precisa ser executada se a extensão de vetor for <0.8.0.google-3>.
Observação importante:se a contagem de linhas for menor que 100, não será necessário criar o índice do ScaNN, já que ele não se aplica a menos linhas. Nesse caso, pule as etapas a seguir.
- Para criar índices do ScaNN, instale a extensão alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
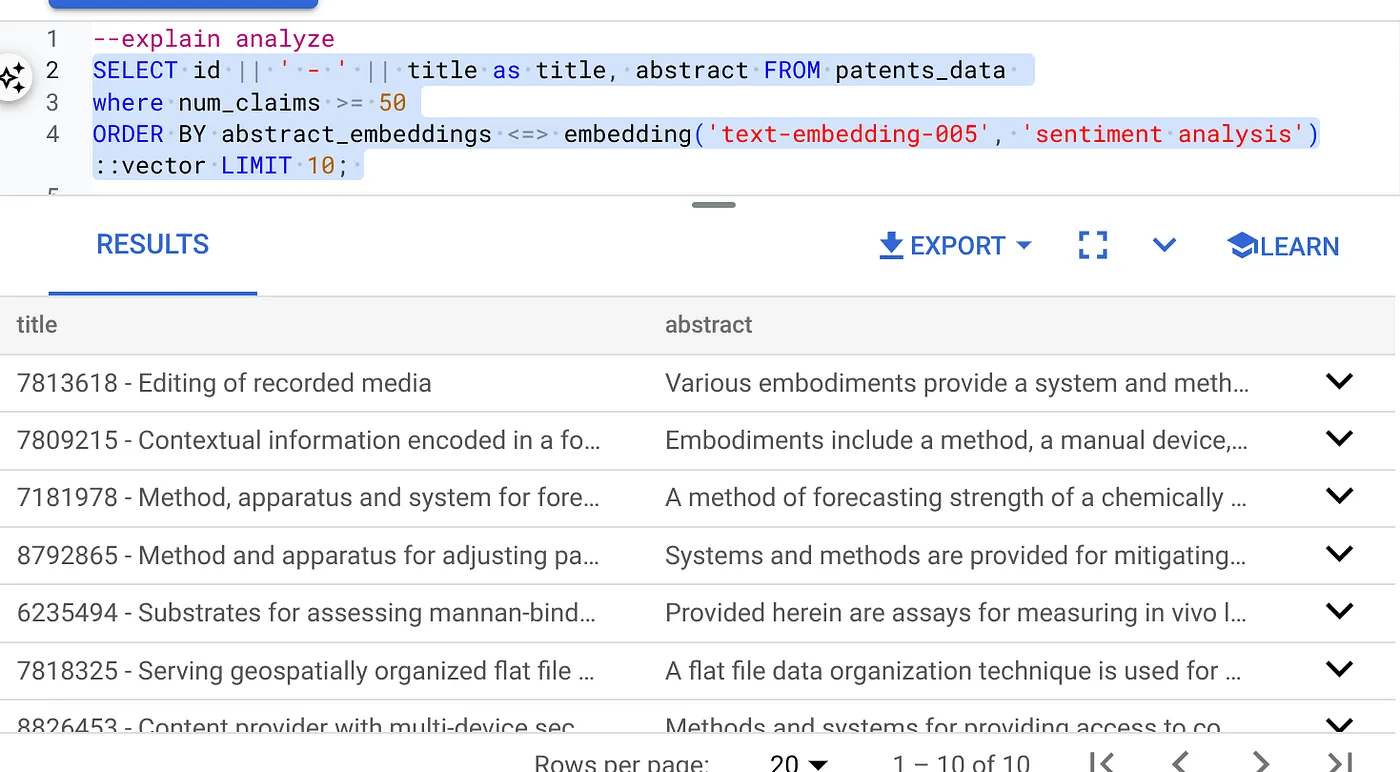
- Primeiro, execute a consulta de pesquisa vetorial sem o índice e sem o filtro inline ativado:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
O resultado será semelhante a este:
- Execute o recurso "Explicar e analisar" nele (sem índice nem filtragem inline):
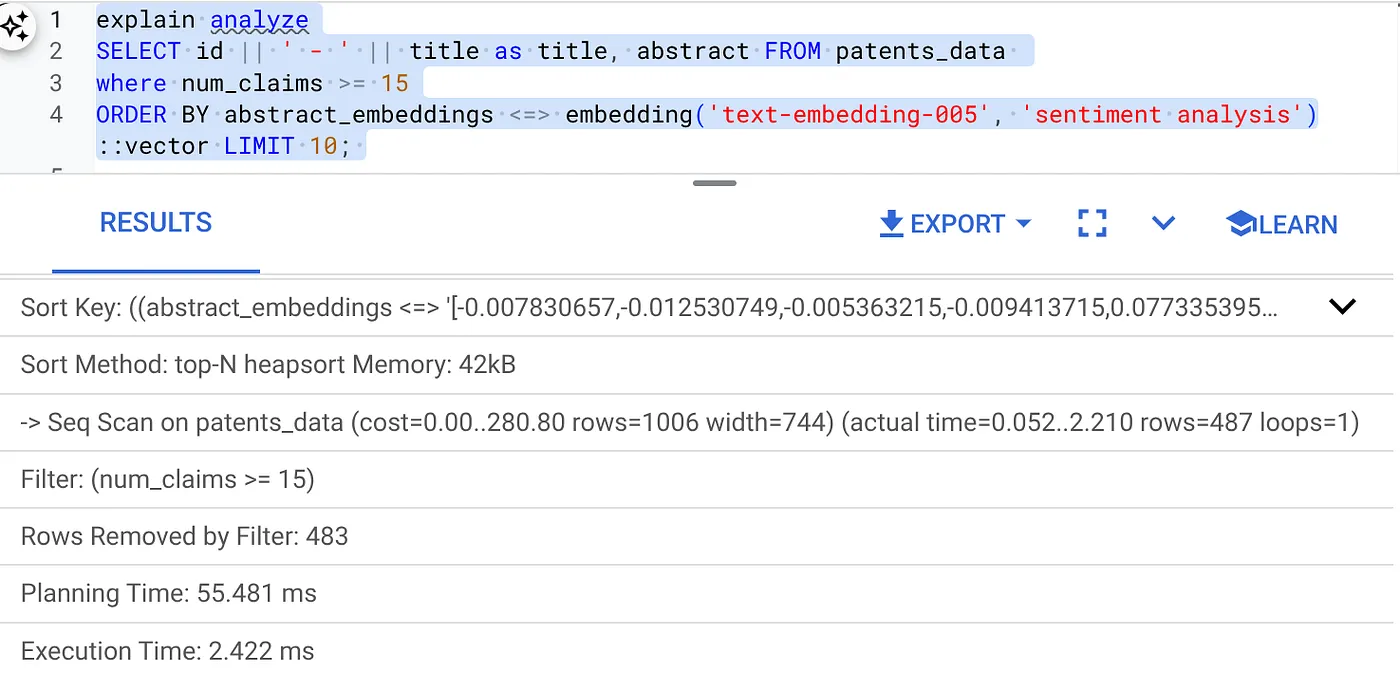
O tempo de execução é de 2,4 ms
- Vamos criar um índice regular no campo "num_claims" para que possamos filtrar por ele:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Vamos criar o índice ScaNN para nosso app de pesquisa de patentes. Execute o seguinte no AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Observação importante : (num_leaves=32) se aplica ao nosso conjunto de dados total com mais de mil linhas. Se a contagem de linhas for menor que 100, não será necessário criar um índice, já que ele não se aplica a menos linhas.
- Defina a filtragem inline ativada no índice do ScaNN:
SET scann.enable_inline_filtering = on
- Agora, vamos executar a mesma consulta com filtro e Vector Search:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
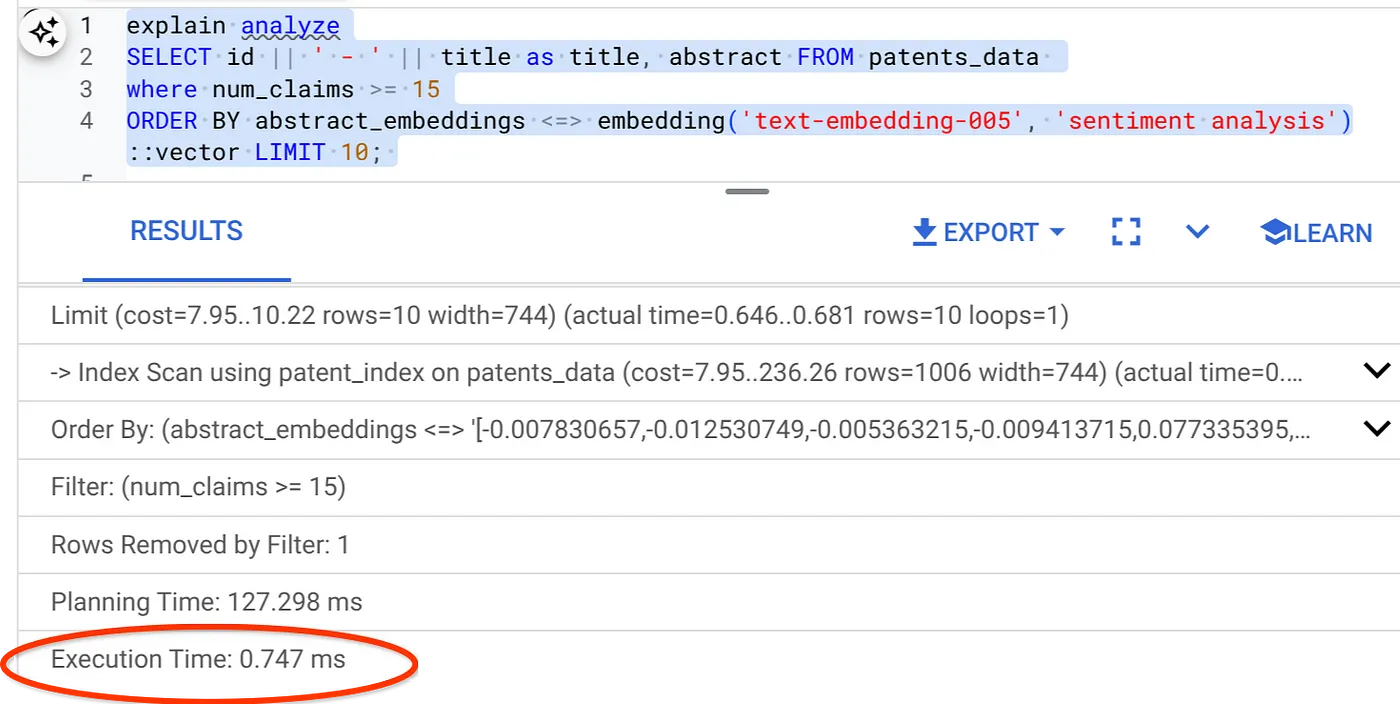
Como você pode ver, o tempo de execução é reduzido significativamente para a mesma pesquisa de vetor. O índice do ScaNN com filtragem inline na Pesquisa Vetorial tornou isso possível.
Em seguida, vamos avaliar o recall para essa Pesquisa Vetorial ativada pelo ScaNN.
Avaliador de recall
O recall na pesquisa de similaridade é a porcentagem de instâncias relevantes recuperadas de uma pesquisa, ou seja, o número de verdadeiros positivos. Essa é a métrica mais comum usada para medir a qualidade da pesquisa. Uma fonte de perda de recall vem da diferença entre a pesquisa de vizinho mais próximo aproximado (aNN) e a pesquisa de vizinho k (exato) mais próximo (kNN). Os índices vetoriais, como o ScaNN do AlloyDB, implementam algoritmos aNN, permitindo acelerar a pesquisa vetorial em grandes conjuntos de dados em troca de uma pequena compensação na recuperação. Agora, o AlloyDB permite medir essa troca diretamente no banco de dados para consultas individuais e garantir que ela seja estável ao longo do tempo. É possível atualizar os parâmetros de consulta e índice em resposta a essas informações para alcançar melhores resultados e desempenho.
Qual é a lógica por trás da recuperação de resultados da pesquisa?
No contexto da pesquisa de vetor, o recall se refere à porcentagem de vetores retornados pelo índice que são vizinhos mais próximos verdadeiros. Por exemplo, se uma consulta de vizinho mais próxima de 20 vizinhos mais próximos retornar 19 dos vizinhos mais próximos, o recall será de 19/20x100 = 95%. O recall é a métrica usada para a qualidade da pesquisa e é definida como a porcentagem dos resultados retornados que estão objetivamente mais próximos dos vetores de consulta.
É possível encontrar o recall de uma consulta vetorial em um índice vetorial para uma determinada configuração usando a função evaluate_query_recall. Com essa função, é possível ajustar os parâmetros para alcançar os resultados de recall da consulta vetorial desejados.
Observação importante:
Se você estiver enfrentando um erro de permissão negada no índice HNSW nas etapas a seguir, pule toda a seção avaliação de recall por enquanto. Isso pode estar relacionado a restrições de acesso, já que ele foi lançado recentemente quando este codelab foi documentado.
- Defina a flag "Ativar verificação de índice" no índice ScaNN e HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Execute a seguinte consulta no AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
A função "evaluate_query_recall" usa a consulta como um parâmetro e retorna a acurácia dela. Estou usando a mesma consulta que usei para verificar a performance como consulta de entrada da função. Adicionei o SCaNN como método de indexação. Para mais opções de parâmetros, consulte a documentação.
O recall para esta consulta de pesquisa vetorial que estamos usando:
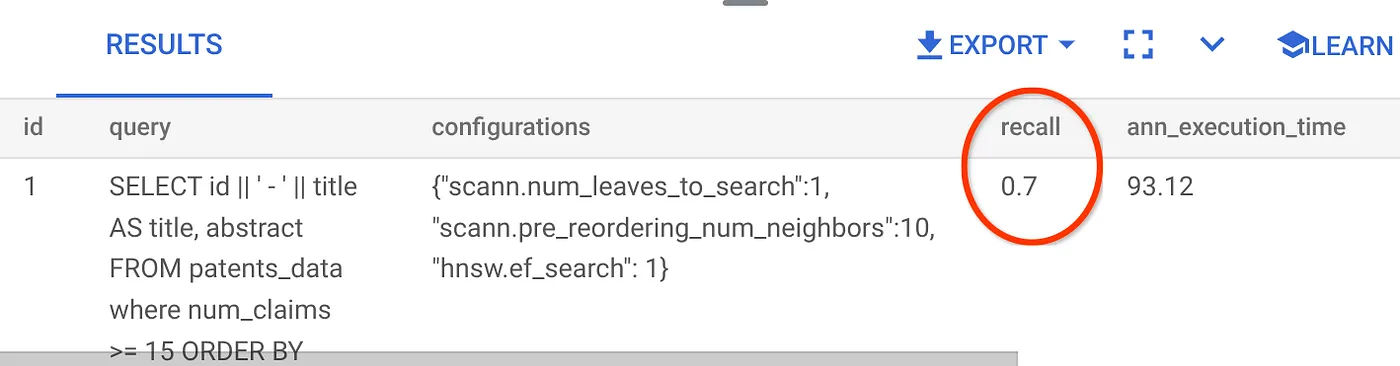
Vejo que o RECALL é de 70%. Agora posso usar essas informações para mudar os parâmetros de índice, métodos e parâmetros de consulta e melhorar o recall para essa pesquisa de vetor.
7. Teste com parâmetros de consulta e índice modificados
Agora vamos testar a consulta modificando os parâmetros de consulta com base no recall recebido.
- Modifiquei o número de linhas no conjunto de resultados para 7 (antes eram 25) e notei uma melhoria no RECALL, ou seja, 86%.
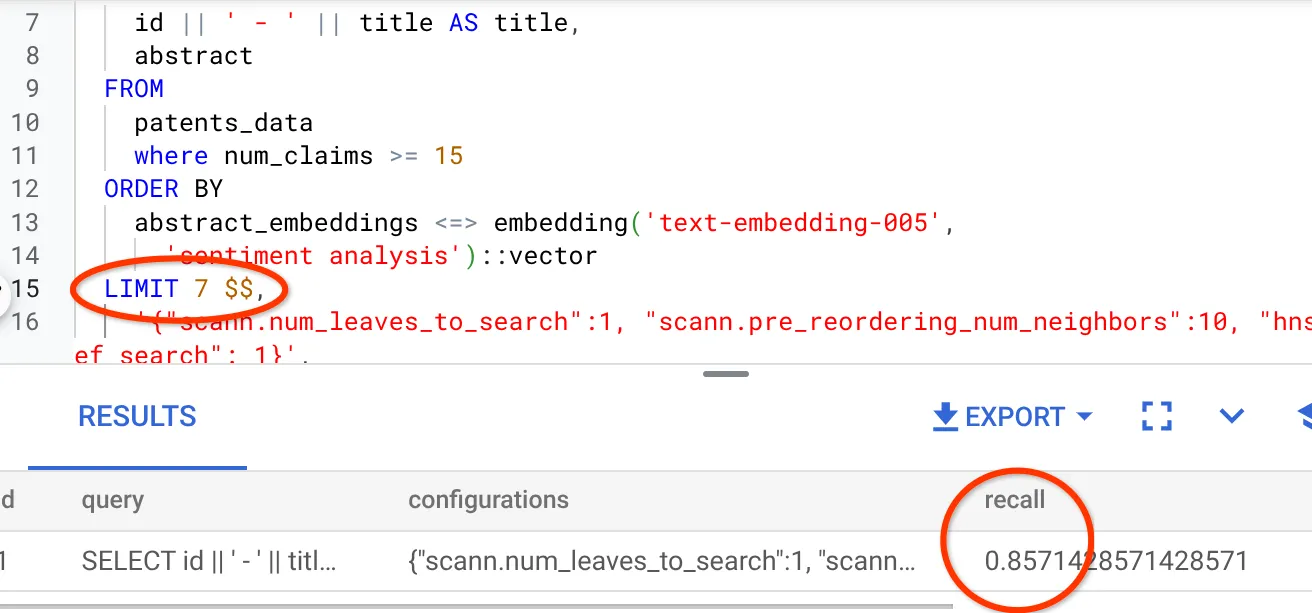
Isso significa que, em tempo real, posso variar o número de correspondências que meus usuários veem para melhorar a relevância de acordo com o contexto de pesquisa deles.
- Vamos tentar de novo modificando os parâmetros de índice:
Para este teste, vou usar "Distância L2" em vez da função de distância de similaridade "Cosseno". Também vou mudar o limite da consulta para 10 para mostrar se há uma melhoria na qualidade dos resultados da pesquisa, mesmo com um aumento na contagem do conjunto de resultados da pesquisa.
[BEFORE] Consulta que usa a função de distância de similaridade de cosseno:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Observação muito importante: "Como sabemos que essa consulta usa a similaridade de COSENO?", você pergunta. É possível identificar a função de distância pelo uso de "<=>" para representar a distância de cosseno.
Link da documentação para funções de distância da Pesquisa de vetores.
O resultado da consulta acima é:
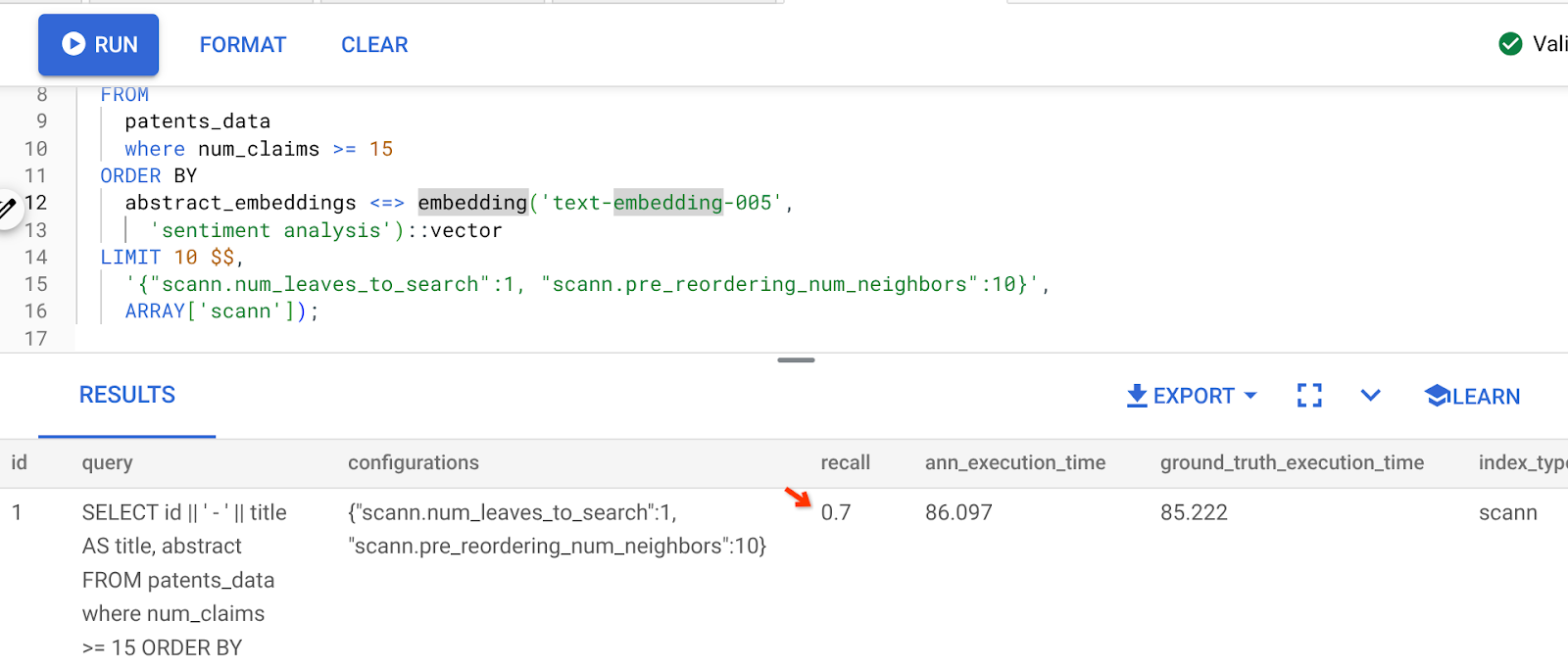
Como você pode ver, o RECALL é de 70% sem nenhuma mudança na lógica do nosso índice. Lembra do índice ScaNN que criamos na etapa 6 da seção "Filtragem inline", "patent_index"? O mesmo índice ainda é eficaz enquanto executamos a consulta acima.
Agora vamos criar um índice com uma consulta de função de distância diferente: Distância L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
A instrução "drop index" serve apenas para garantir que não haja um índice desnecessário na tabela.
Agora, posso executar a seguinte consulta para avaliar o RECALL depois de mudar a função de distância da minha funcionalidade de pesquisa vetorial.
[AFTER] Consulta que usa a função de distância de similaridade de cosseno:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
O resultado da consulta acima é:
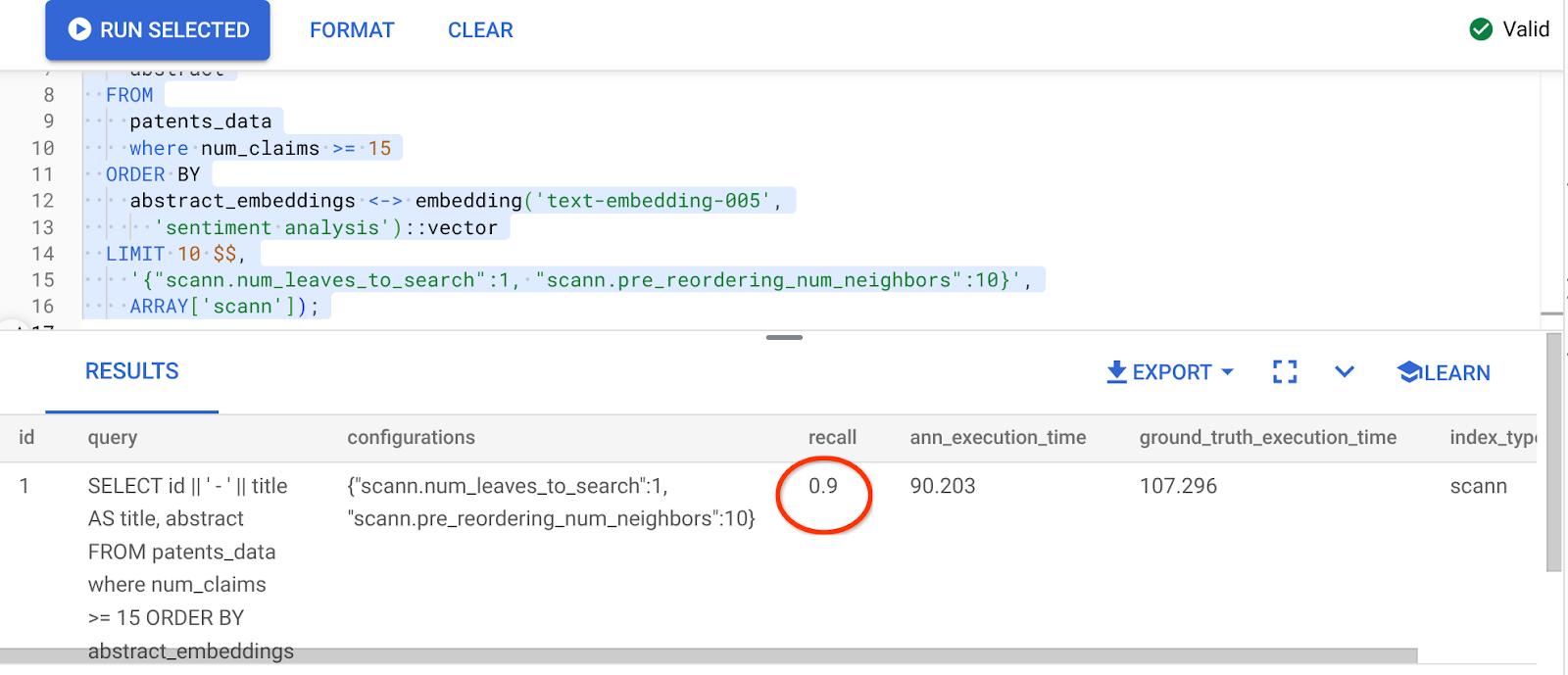
Que transformação no valor de recall, 90%!!!
Há outros parâmetros que podem ser alterados no índice, como "num_leaves" etc., com base no valor de recall desejado e no conjunto de dados usado pelo aplicativo.
8. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nesta postagem, siga estas etapas:
- No console do Google Cloud, acesse a página do Gerenciador de recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
- Como alternativa, você pode excluir o cluster do AlloyDB (mude o local neste hiperlink se não tiver escolhido us-central1 para o cluster no momento da configuração) que acabamos de criar para este projeto clicando no botão EXCLUIR CLUSTER.
9. Parabéns
Parabéns! Você criou uma consulta de pesquisa de patentes contextual com a pesquisa vetorial avançada do AlloyDB para alto desempenho e para torná-la realmente orientada por significado. Criei um aplicativo de agente multi-ferramenta com controle de qualidade que usa o ADK e todos os recursos do AlloyDB que discutimos aqui para criar um agente de pesquisa e análise de vetor de patentes de alta qualidade e desempenho que você pode conferir aqui: https://youtu.be/Y9fvVY0yZTY
Se quiser aprender a criar esse agente, consulte este codelab.