
1. Genel Bakış
Bağlamsal arama, farklı sektörlerde uygulamaların kalbini ve merkezini oluşturan kritik bir işlevdir. Retrieval Augmented Generation, üretken yapay zeka destekli alma mekanizmalarıyla bir süredir bu önemli teknolojik evrimin temel itici gücü olmuştur. Geniş bağlam pencereleri ve etkileyici çıkış kalitesiyle üretken modeller, yapay zekayı dönüştürüyor. RAG, bağlamı yapay zeka uygulamalarına ve aracılarına yerleştirmenin sistematik bir yolunu sunar. Bu sayede, yapılandırılmış veritabanlarında veya çeşitli medyaların bilgilerinde temellendirme yapılır. Bu bağlamsal veriler, doğrunun netliği ve çıktının doğruluğu açısından çok önemlidir. Ancak bu sonuçlar ne kadar doğrudur? İşletmeniz büyük ölçüde bu bağlamsal eşleşmelerin doğruluğuna ve alaka düzeyine mi bağlı? O zaman bu proje sizi çok eğlendirecek!
Vektör aramanın kirli sırrı yalnızca oluşturmak değil, vektör eşleşmelerinizin gerçekten iyi olup olmadığını bilmektir. Hepimiz sonuç listesine boş boş bakıp "Bu şey çalışıyor mu acaba?" diye düşünmüşüzdür. Vektör eşleşmelerinizin kalitesini nasıl değerlendireceğinizi ayrıntılı olarak inceleyelim. "Peki RAG'de ne değişti?" diye sorabilirsiniz. Her şey! Veriyle Artırılmış Üretim (RAG), yıllardır umut verici ancak ulaşılması zor bir hedef gibiydi. Artık nihayet iş açısından kritik görevler için gereken performans ve güvenilirliğe sahip RAG uygulamaları oluşturma araçlarına sahibiz.
Şimdiye kadar 3 temel kavramı öğrendik:
- Bağlamsal aramanın temsilciniz için ne anlama geldiği ve Vector Search'ü kullanarak bunu nasıl başaracağınız.
- Ayrıca, verileriniz kapsamında, yani veritabanınızın kendisinde Vector Search'ü kullanma konusunu da ayrıntılı olarak ele aldık (Google Cloud Veritabanlarının tümü bunu destekler).
- ScaNN dizini tarafından desteklenen AlloyDB vektör arama özelliğiyle yüksek performans ve kaliteye sahip bu tür hafif bir vektör arama RAG özelliğini nasıl kullanacağınızı anlatarak dünyanın geri kalanından bir adım öteye gittik.
Temel, orta ve biraz gelişmiş RAG denemelerini yapmadıysanız listelenen sırayla buradaki, buradaki ve buradaki 3 denemeyi okumanızı öneririz.
Patent Arama, kullanıcının arama metniyle bağlamsal olarak alakalı patentleri bulmasına yardımcı olur. Bu özelliğin bir sürümünü geçmişte oluşturmuştuk. Şimdi bu uygulamayı, kalite kontrollü bağlamsal arama sağlayan yeni ve gelişmiş RAG özellikleriyle oluşturacağız. Haydi başlayalım.
Aşağıdaki resimde, bu uygulamada olan bitenin genel akışı gösterilmektedir.~ 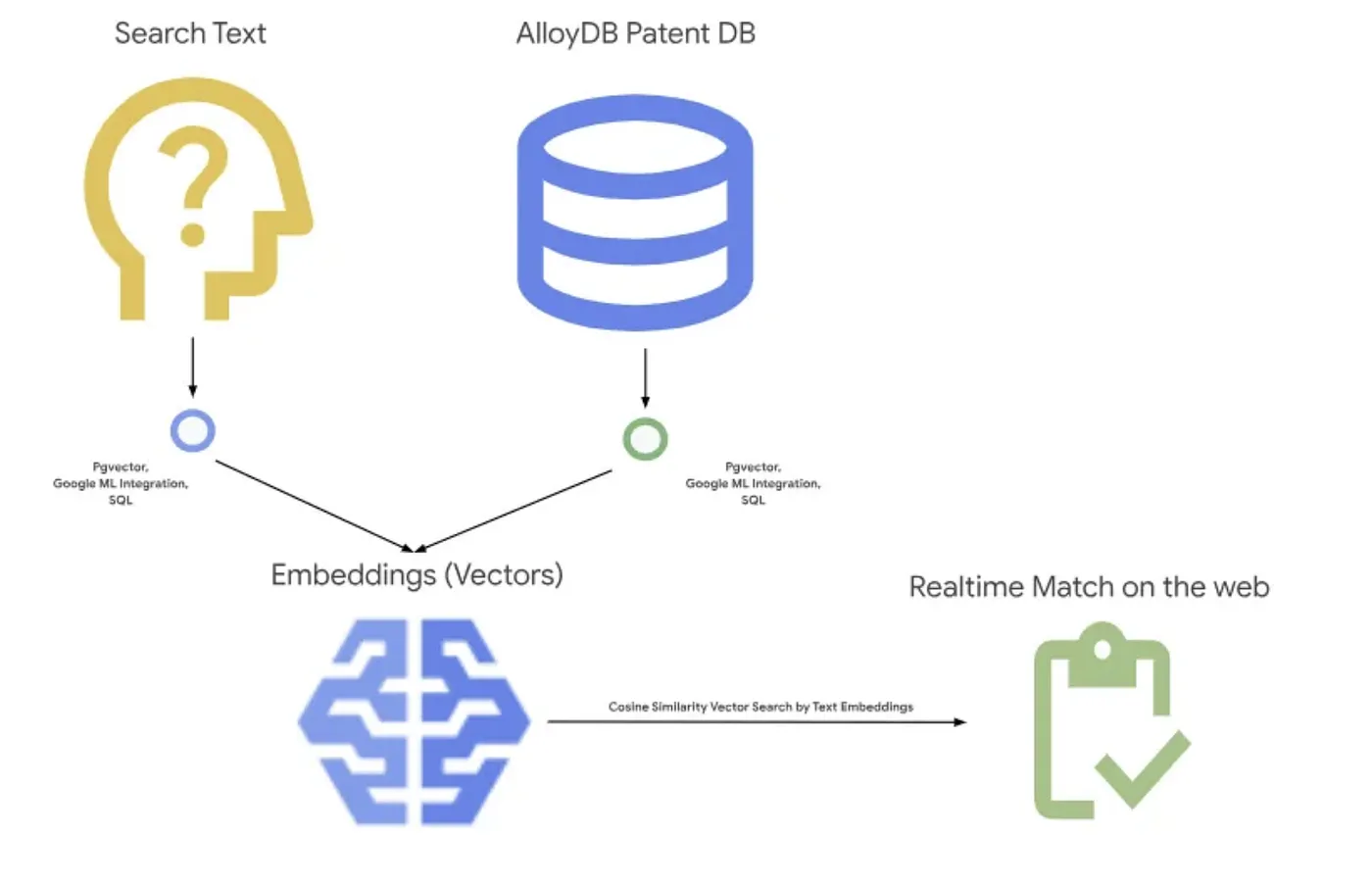
Hedef
AlloyDB'nin en yeni RAG özelliklerini kullanarak oluşturulan eşleşmelerin kalitesini değerlendirirken kullanıcının, geliştirilmiş performans ve daha iyi kaliteyle metin açıklamasına dayalı olarak patent aramasını sağlayın.
Ne oluşturacaksınız?
Bu laboratuvar kapsamında şunları yapacaksınız:
- AlloyDB örneği oluşturma ve Patents Public Dataset'i yükleme
- Meta veri dizini ve ScaNN dizini oluşturma
- ScaNN'nin satır içi filtreleme yöntemini kullanarak AlloyDB'de gelişmiş vektör araması uygulama
- Geri Çağırma değerlendirme özelliğini uygulama
- Sorgu yanıtını değerlendirme
Şartlar
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin .
- Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
gcloud config set project <YOUR_PROJECT_ID>
- Gerekli API'leri etkinleştirin. Cloud Shell terminalinde bir gcloud komutu kullanabilirsiniz:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Gcloud komutuna alternatif olarak, her ürünü arayarak veya bu bağlantıyı kullanarak konsolu kullanabilirsiniz.
gcloud komutları ve kullanımı için belgelere bakın.
3. Veritabanı kurulumu
Bu laboratuvarda patent verileri için veritabanı olarak AlloyDB'yi kullanacağız. Veritabanları ve günlükler gibi tüm kaynakları tutmak için kümeler kullanılır. Her kümede, verilere erişim noktası sağlayan bir birincil örnek bulunur. Tablolar gerçek verileri içerir.
Patent veri kümesinin yükleneceği bir AlloyDB kümesi, örneği ve tablosu oluşturalım.
Küme ve örnek oluşturma
- Cloud Console'da AlloyDB sayfasına gidin. Cloud Console'daki çoğu sayfayı bulmanın kolay bir yolu, konsolun arama çubuğunu kullanarak arama yapmaktır.
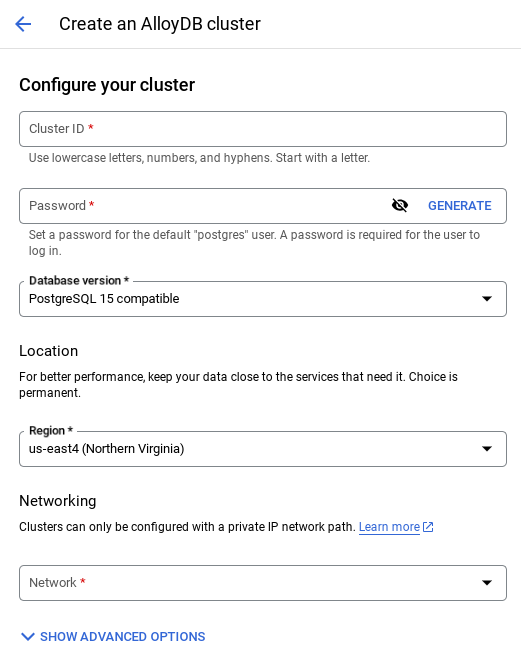
- Bu sayfada KÜME OLUŞTUR'u seçin:

- Aşağıdaki gibi bir ekran görürsünüz. Aşağıdaki değerlerle bir küme ve örnek oluşturun (Uygulama kodunu depodan klonluyorsanız değerlerin eşleştiğinden emin olun):
- küme kimliği: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / en son önerilen
- Bölge: "
us-central1" - Ağ: "
default"
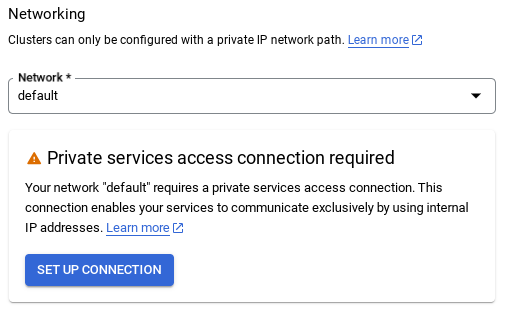
- Varsayılan ağı seçtiğinizde aşağıdaki gibi bir ekran görürsünüz.
BAĞLANTIYI AYARLA'yı seçin.
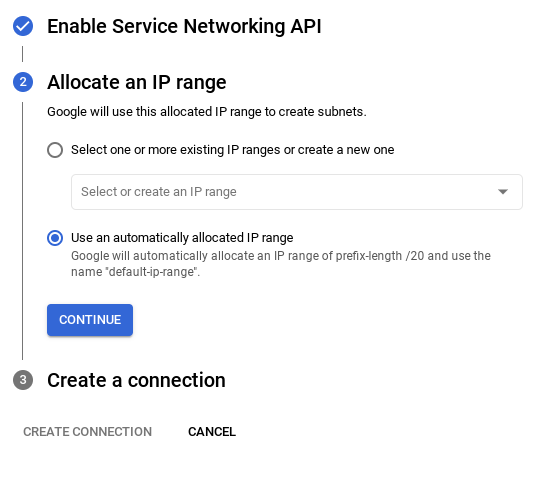
- Buradan "Otomatik olarak atanmış bir IP aralığı kullan"ı seçip Devam'ı tıklayın. Bilgileri inceledikten sonra BAĞLANTI OLUŞTUR'u seçin.
- Ağınız kurulduktan sonra kümenizi oluşturmaya devam edebilirsiniz. Aşağıda gösterildiği gibi küme kurulumunu tamamlamak için CREATE CLUSTER'ı (KÜME OLUŞTUR) tıklayın:
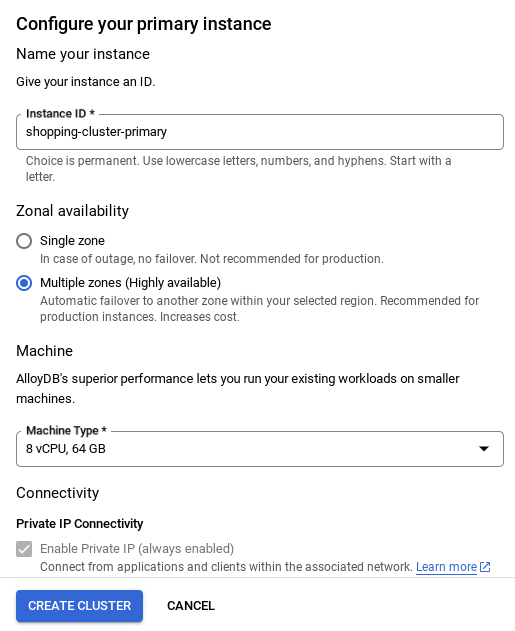
Örnek kimliğini değiştirdiğinizden emin olun (küme / örnek yapılandırılırken bulabilirsiniz) ile
vector-instance. Değiştiremiyorsanız gelecekteki tüm referanslarda örnek kimliğinizi kullanmayı unutmayın.
Küme oluşturma işleminin yaklaşık 10 dakika süreceğini unutmayın. İşlem başarılı olduğunda, yeni oluşturduğunuz kümenizin genel görünümünü gösteren bir ekran görürsünüz.
4. Veri kullanımı
Şimdi de mağazayla ilgili verilerin bulunduğu bir tablo ekleme zamanı. AlloyDB'ye gidin, birincil kümeyi ve ardından AlloyDB Studio'yu seçin:
Örneğinizin oluşturulmasının tamamlanmasını beklemeniz gerekebilir. Bu işlem tamamlandıktan sonra, kümeyi oluştururken oluşturduğunuz kimlik bilgilerini kullanarak AlloyDB'de oturum açın. PostgreSQL'de kimlik doğrulaması yapmak için aşağıdaki verileri kullanın:
- Kullanıcı adı : "
postgres" - Veritabanı : "
postgres" - Şifre : "
alloydb"
AlloyDB Studio'da kimliğinizi başarıyla doğruladıktan sonra SQL komutları Düzenleyici'ye girilir. Son pencerenin sağındaki artı işaretini kullanarak birden fazla Düzenleyici penceresi ekleyebilirsiniz.
AlloyDB için komutları düzenleyici pencerelerine girerken gerektiğinde Çalıştır, Biçimlendir ve Temizle seçeneklerini kullanacaksınız.
Uzantıları etkinleştirme
Bu uygulamayı oluşturmak için pgvector ve google_ml_integration uzantılarını kullanacağız. pgvector uzantısı, vektör yerleştirmelerini depolamanıza ve aramanıza olanak tanır. google_ml_integration uzantısı, SQL'de tahmin almak için Vertex AI tahmin uç noktalarına erişmek üzere kullandığınız işlevleri sağlar. Aşağıdaki DDL'leri çalıştırarak bu uzantıları etkinleştirin:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Veritabanınızda etkinleştirilen uzantıları kontrol etmek istiyorsanız şu SQL komutunu çalıştırın:
select extname, extversion from pg_extension;
Tablo oluşturma
AlloyDB Studio'da aşağıdaki DDL ifadesini kullanarak bir tablo oluşturabilirsiniz:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings sütunu, metnin vektör değerlerinin depolanmasına olanak tanır.
İzin Ver
"embedding" işlevinde yürütme izni vermek için aşağıdaki ifadeyi çalıştırın:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB hizmet hesabına Vertex AI Kullanıcısı ROLÜ'nü verme
Google Cloud IAM Console'dan AlloyDB hizmet hesabına (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com şeklinde görünür) "Vertex AI Kullanıcısı" rolüne erişim izni verin. PROJECT_NUMBER, proje numaranızı içerir.
Alternatif olarak, aşağıdaki komutu Cloud Shell Terminali'nden çalıştırabilirsiniz:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Veritabanına patent verileri yükleme
Veri kümemiz olarak BigQuery'deki Google Patents Public Datasets (Google Patentleri Herkese Açık Veri Kümeleri) kullanılacaktır. Sorgularımızı çalıştırmak için AlloyDB Studio'yu kullanacağız. Veriler bu insert_scripts.sql dosyasından alınır ve patent verilerini yüklemek için bu dosyayı çalıştırırız.
- Google Cloud Console'da AlloyDB sayfasını açın.
- Yeni oluşturduğunuz kümeyi seçin ve örneği tıklayın.
- AlloyDB gezinme menüsünde AlloyDB Studio'yu tıklayın. Kimlik bilgilerinizle oturum açın.
- Sağdaki Yeni sekme simgesini tıklayarak yeni bir sekme açın.
- Yukarıda belirtilen
insert_scripts.sqlkomut dosyasındaninsertsorgu ifadesini kopyalayıp düzenleyiciye yapıştırın. Bu kullanım alanının hızlı bir demosunu yapmak için 10-50 ekleme ifadesini kopyalayabilirsiniz. - Çalıştır'ı tıklayın. Sorgunuzun sonuçları Sonuçlar tablosunda görünür.
Not: Ekleme komut dosyasında çok fazla veri olduğunu fark edebilirsiniz. Bunun nedeni, ekleme komut dosyalarına yerleştirmeler eklememizdir. Dosyayı GitHub'da yüklemekte sorun yaşıyorsanız "View Raw" (Ham Olarak Görüntüle) seçeneğini tıklayın. Bu, Google Cloud için deneme kredisi faturalandırma hesabı kullanıyorsanız (sonraki adımlarda) birkaç yerleştirme (ör. en fazla 20-25) oluşturma zahmetinden kurtulmanızı sağlamak için yapılır.
5. Patent verileri için yerleştirilmiş öğeler oluşturma
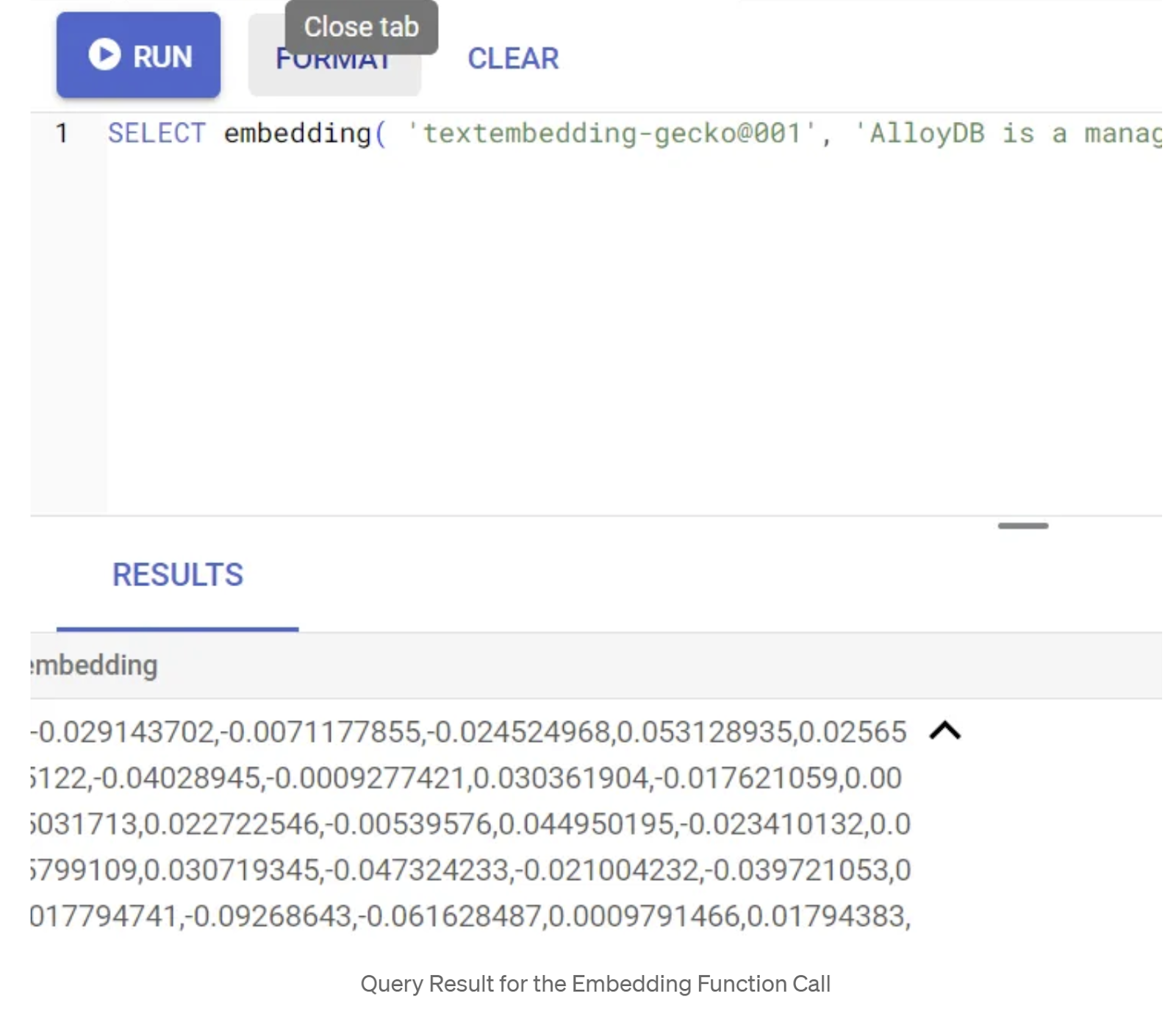
Öncelikle aşağıdaki örnek sorguyu çalıştırarak yerleştirme işlevini test edelim:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Bu işlem, sorgudaki örnek metin için kayan nokta dizisi gibi görünen yerleştirme vektörünü döndürmelidir. Şöyle görünür:
abstract_embeddings Vector alanını güncelleme
abstract_embeddings verilerini ekleme komut dosyasının bir parçası olarak eklemediyseniz tablodaki patent özetlerini yalnızca karşılık gelen yerleştirmelerle güncellemek için aşağıdaki DML'yi çalıştırın:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Google Cloud için deneme kredisi faturalandırma hesabı kullanıyorsanız birkaç yerleştirme (ör. en fazla 20-25) oluşturmakta sorun yaşayabilirsiniz. Bu nedenle, yerleştirmeleri ekleme komut dosyalarına ekledim. "Patent verilerini veritabanına yükleme" adımını tamamladıysanız bu yerleştirmeler yüklenen tablonuzda da yer almalıdır.
6. AlloyDB'nin yeni özellikleriyle gelişmiş RAG gerçekleştirme
Tablo, veriler ve yerleştirmeler hazır olduğuna göre artık kullanıcı arama metni için gerçek zamanlı vektör araması yapabiliriz. Aşağıdaki sorguyu çalıştırarak bunu test edebilirsiniz:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Bu sorguda,
- Kullanıcının aradığı metin: "Duygu Analizi".
- Bu metni, model: text-embedding-005 kullanarak embedding() yönteminde yerleştirmelere dönüştürüyoruz.
- "<=>", KOSİNÜS BENZERLİĞİ uzaklık yönteminin kullanımını gösterir.
- Yerleştirme yönteminin sonucunu, veritabanında depolanan vektörlerle uyumlu hale getirmek için vektör türüne dönüştürüyoruz.
- LIMIT 10, arama metninin en yakın 10 eşleşmesini seçtiğimizi gösterir.
AlloyDB, vektör arama RAG'i bir üst seviyeye taşıyor:
Birçok yeni özellik kullanıma sunuldu. Geliştiricilere yönelik iki önemli özellik şunlardır:
- Satır İçi Filtreleme
- Geri Çağırma Değerlendiricisi
Satır İçi Filtreleme
Daha önce bir geliştirici olarak Vector Search sorgusunu çalıştırmanız, filtreleme ve geri çağırma işlemlerini yapmanız gerekiyordu. AlloyDB Query Optimizer, filtre içeren bir sorgunun nasıl yürütüleceği konusunda seçimler yapar. Satır içi filtreleme, AlloyDB sorgu optimizasyon aracının hem meta veri filtreleme koşullarını hem de vektör aramasını birlikte değerlendirmesine olanak tanıyan yeni bir sorgu optimizasyonu tekniğidir. Bu teknik, hem vektör dizinlerinden hem de meta veri sütunlarındaki dizinlerden yararlanır. Bu sayede hatırlama performansı artmış ve geliştiriciler, AlloyDB'nin kullanıma hazır sunduğu özelliklerden yararlanabilmiştir.
Satır içi filtreleme, orta seçiciliğe sahip durumlar için en iyisidir. AlloyDB, vektör dizininde arama yaparken yalnızca meta veri filtreleme koşullarıyla eşleşen vektörlerin mesafelerini hesaplar (bir sorguda genellikle WHERE ifadesinde işlenen işlevsel filtreleriniz). Bu, filtre sonrası veya filtre öncesi avantajlarını tamamlayarak bu sorguların performansını büyük ölçüde artırır.
- pgvector uzantısını yükleme veya güncelleme
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
pgvector uzantısı zaten yüklüyse geri çağırma değerlendirici özelliklerini kullanmak için vektör uzantısını 0.8.0.google-3 veya sonraki bir sürüme yükseltin.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Bu adım yalnızca vektör uzantınız <0.8.0.google-3> ise uygulanmalıdır.
Önemli not: Satır sayınız 100'den azsa daha az satır için geçerli olmayacağından ScaNN dizini oluşturmanız gerekmez. Bu durumda lütfen aşağıdaki adımları atlayın.
- ScaNN dizinleri oluşturmak için alloydb_scann uzantısını yükleyin.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Öncelikle Vector Search sorgusunu dizin olmadan ve satır içi filtre etkinleştirilmeden çalıştırın:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Sonuç şuna benzer olmalıdır:
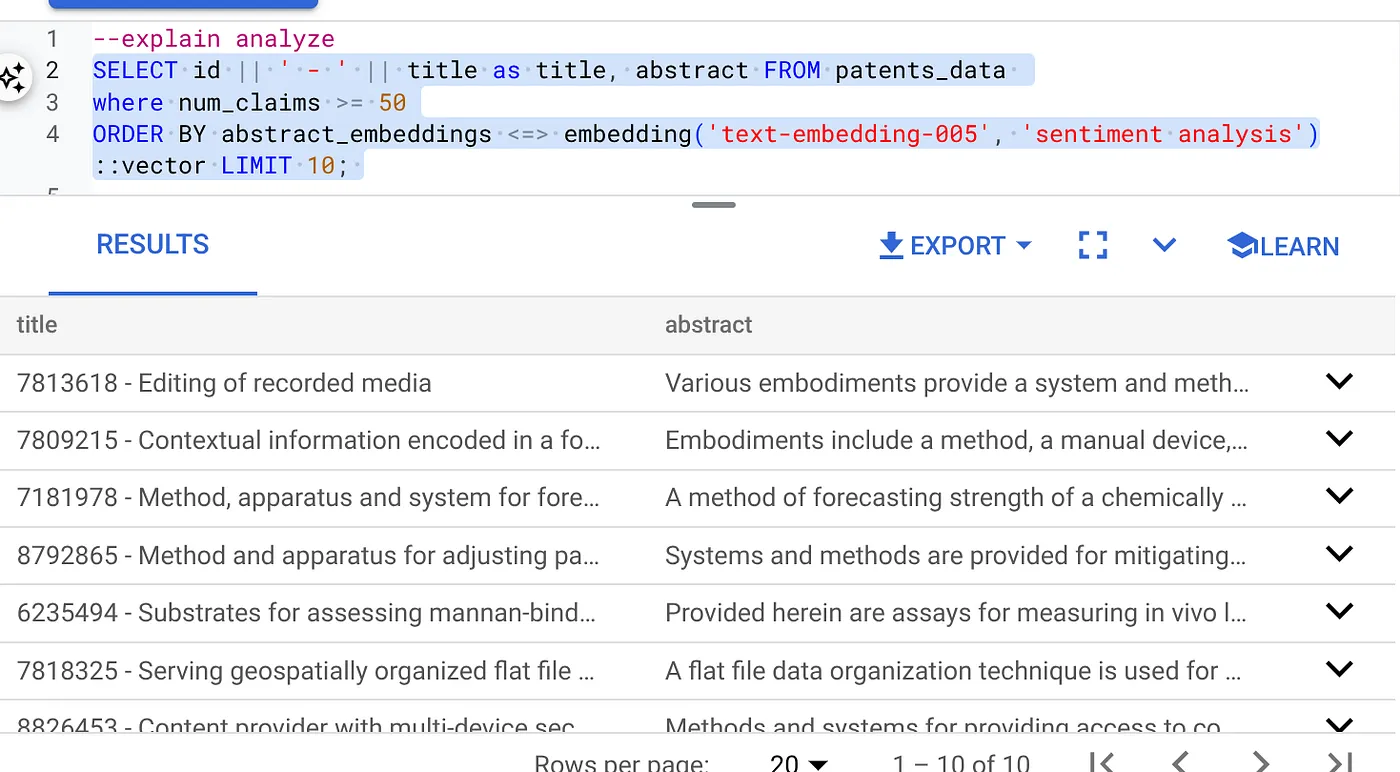
- Üzerinde Analizi Açıklama'yı çalıştırın: (Dizin veya satır içi filtreleme olmadan)
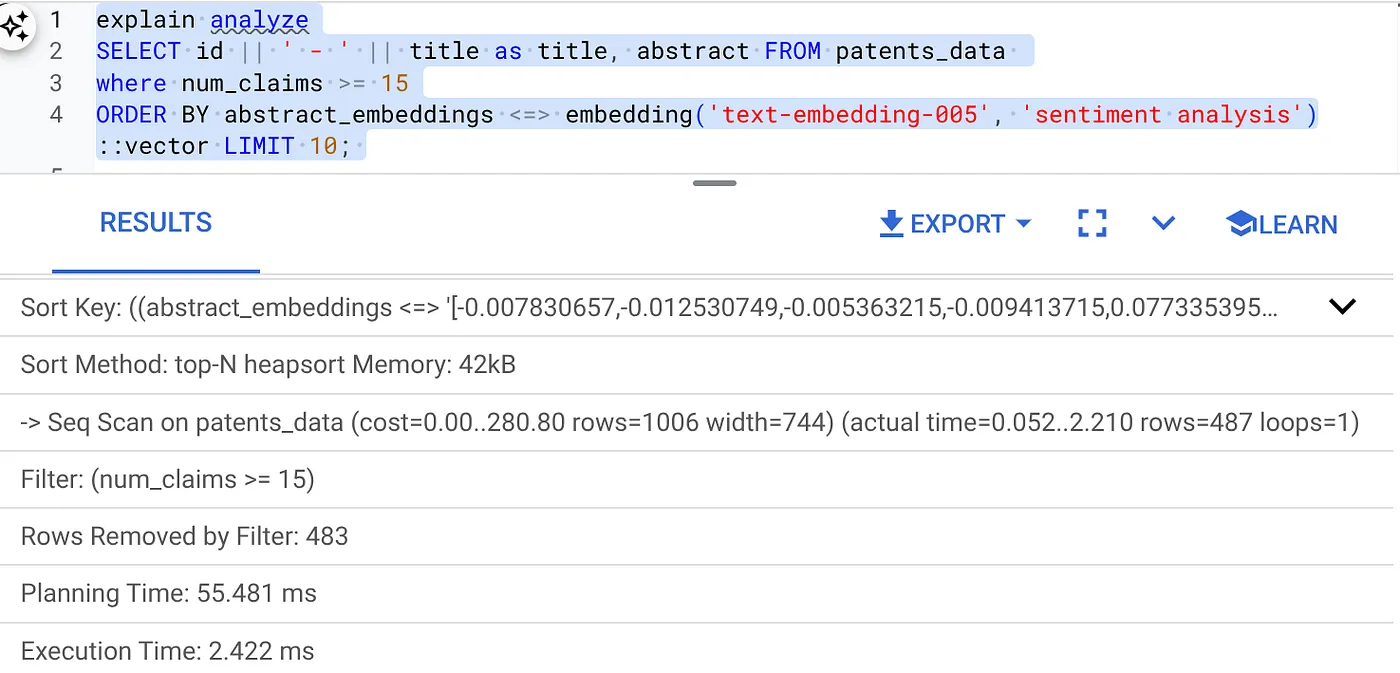
Yürütme süresi 2,4 ms
- num_claims alanında normal bir dizin oluşturalım, böylece bu alana göre filtreleme yapabiliriz:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Patent Arama uygulamamız için ScaNN dizinini oluşturalım. AlloyDB Studio'nuzda aşağıdakileri çalıştırın:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Önemli not: (num_leaves=32), 1.000'den fazla satır içeren toplam veri setimiz için geçerlidir. Satır sayınız 100'den azsa daha az satır için geçerli olmayacağından dizin oluşturmanız gerekmez.
- ScaNN dizininde satır içi filtrelemeyi etkinleştirin:
SET scann.enable_inline_filtering = on
- Şimdi aynı sorguyu filtre ve vektör aramasıyla birlikte çalıştıralım:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
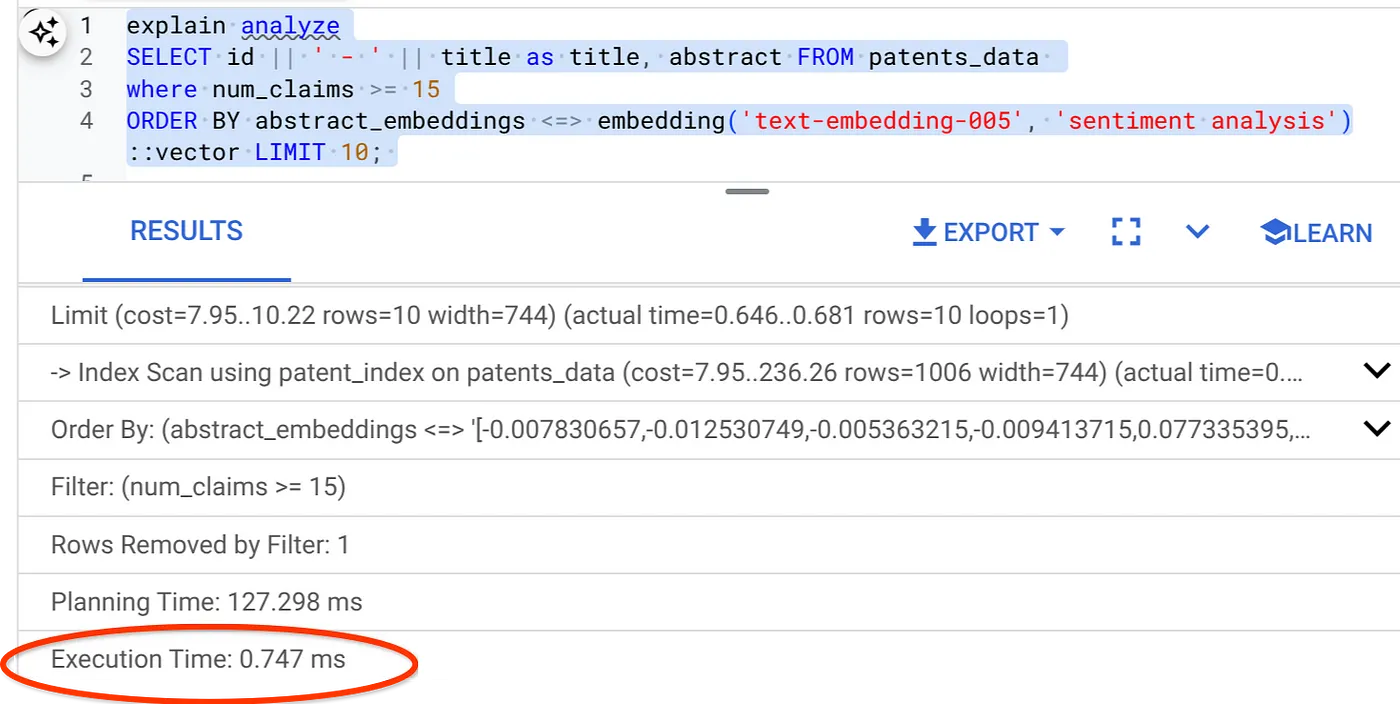
Aynı vektör araması için yürütme süresinin önemli ölçüde kısaldığını görebilirsiniz. Vector Search'teki satır içi filtreleme özellikli ScaNN dizini bunu mümkün kıldı.
Ardından, ScaNN'nin etkinleştirildiği bu vektör aramasının hatırlama oranını değerlendirelim.
Geri Çağırma Değerlendiricisi
Benzerlik aramasında hatırlama, bir aramadan alınan alakalı örneklerin yüzdesidir. Diğer bir deyişle, doğru pozitiflerin sayısıdır. Bu metrik, arama kalitesini ölçmek için kullanılan en yaygın metriktir. Geri çağırma kaybının bir nedeni, yaklaşık en yakın komşu araması (aNN) ile k (tam) en yakın komşu araması (kNN) arasındaki farktır. AlloyDB'nin ScaNN'si gibi vektör dizinleri, aNN algoritmalarını uygular. Bu sayede, hatırlama konusunda küçük bir ödün vererek büyük veri kümelerinde vektör aramasını hızlandırabilirsiniz. AlloyDB artık bu dengeyi doğrudan veritabanında tek tek sorgular için ölçmenize ve zaman içinde istikrarlı olmasını sağlamanıza olanak tanır. Daha iyi sonuçlar ve performans elde etmek için bu bilgilere yanıt olarak sorgu ve dizin parametrelerini güncelleyebilirsiniz.
Arama sonuçlarının geri çağrılmasının arkasındaki mantık nedir?
Vektör arama bağlamında hatırlama, dizinin döndürdüğü ve gerçek en yakın komşular olan vektörlerin yüzdesini ifade eder. Örneğin, en yakın 20 komşuya yönelik bir en yakın komşu sorgusu, gerçek en yakın komşulardan 19'unu döndürürse geri çağırma oranı 19/20x100 = %95 olur. Arama kalitesi için kullanılan metrik hatırlama'dır ve sorgu vektörlerine nesnel olarak en yakın olan döndürülen sonuçların yüzdesi olarak tanımlanır.
evaluate_query_recall işlevini kullanarak belirli bir yapılandırma için vektör dizinindeki vektör sorgusunun geri çağırmasını bulabilirsiniz. Bu işlev, istediğiniz vektör sorgusu hatırlama sonuçlarını elde etmek için parametrelerinizi ayarlamanıza olanak tanır.
Önemli Not:
Aşağıdaki adımlarda HNSW dizininde "izin reddedildi" hatasıyla karşılaşırsanız şimdilik bu geri çağırma değerlendirmesi bölümünün tamamını atlayın. Bu durum, codelab'in belgelendiği sırada yeni yayınlandığı için erişim kısıtlamalarıyla ilgili olabilir.
- ScaNN dizininde ve HNSW dizininde dizin taramayı etkinleştirme işaretini ayarlayın:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio'da aşağıdaki sorguyu çalıştırın:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall işlevi, sorguyu parametre olarak alır ve geri çağırmasını döndürür. İşlev giriş sorgusu olarak performansı kontrol etmek için kullandığım sorguyu kullanıyorum. SCaNN'yi dizin yöntemi olarak ekledim. Daha fazla parametre seçeneği için belgelere bakın.
Kullandığımız bu vektör arama sorgusunun hatırlama özelliği:
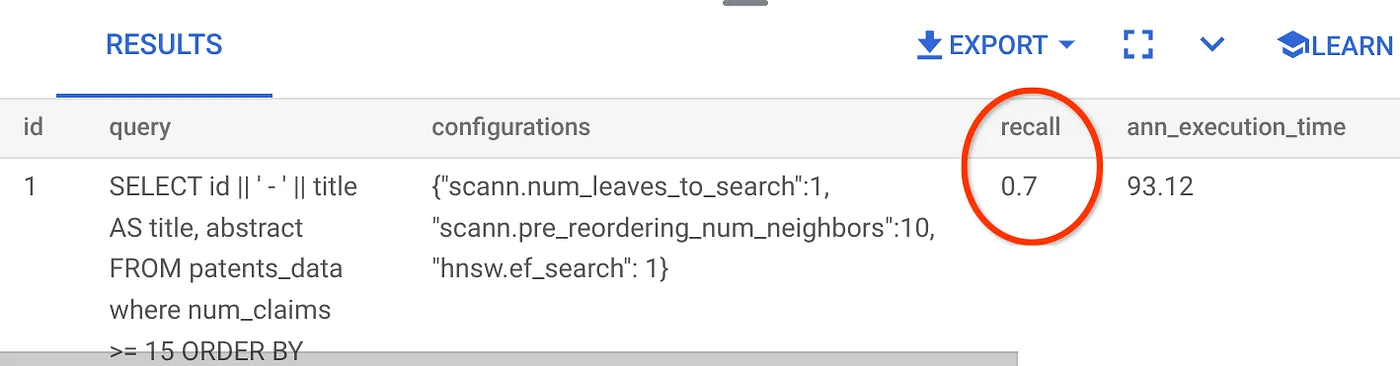
Geri çağırma oranının %70 olduğunu görüyorum. Artık bu bilgileri kullanarak dizin parametrelerini, yöntemleri ve sorgu parametrelerini değiştirebilir ve bu vektör aramasındaki hatırlama oranımı artırabilirim.
7. Değiştirilmiş sorgu ve dizin parametreleriyle test etme
Şimdi, alınan geri çağırmaya göre sorgu parametrelerini değiştirerek sorguyu test edelim.
- Sonuç kümesindeki satır sayısını 7 olarak değiştirdim (önceki değer 25'ti) ve daha iyi bir geri çağırma oranı (%86) elde ettim.
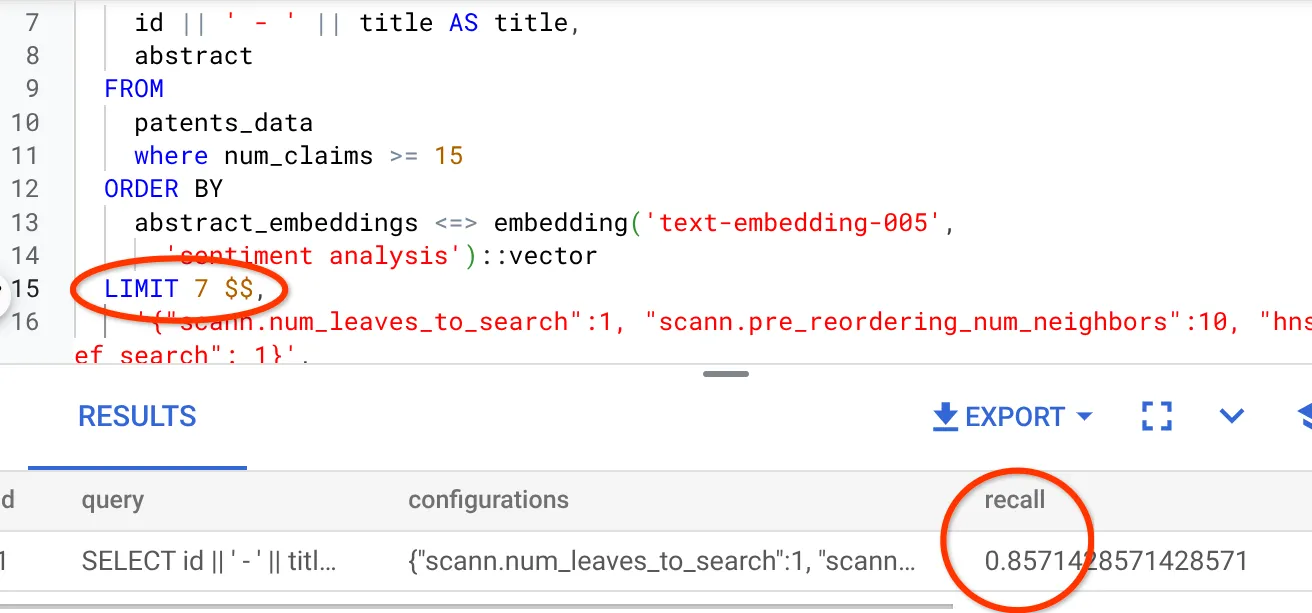
Bu sayede, kullanıcılarımın gördüğü eşleşme sayısını anlık olarak değiştirebiliyorum. Böylece, eşleşmelerin alaka düzeyini kullanıcıların arama bağlamına göre iyileştirebiliyorum.
- Dizin parametrelerini değiştirerek tekrar deneyelim:
Bu test için "Kosinüs" benzerlik mesafesi işlevi yerine "L2 Mesafesi"ni kullanacağım. Arama sonucu kümesi sayısı artmış olsa bile arama sonuçlarının kalitesinde iyileşme olup olmadığını göstermek için sorgu sınırını da 10 olarak değiştireceğim.
[ÖNCE] Kosinüs benzerliği uzaklık işlevini kullanan sorgu:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Çok Önemli Not: "Bu sorgunun COSINE benzerliğini kullandığını nereden biliyoruz?" diye sorabilirsiniz. Kosinüs uzaklığını temsil etmek için "<=>" kullanılarak uzaklık işlevi tanımlanabilir.
Vektör Arama uzaklık işlevleriyle ilgili doküman bağlantısı.
Yukarıdaki sorgunun sonucu şudur:
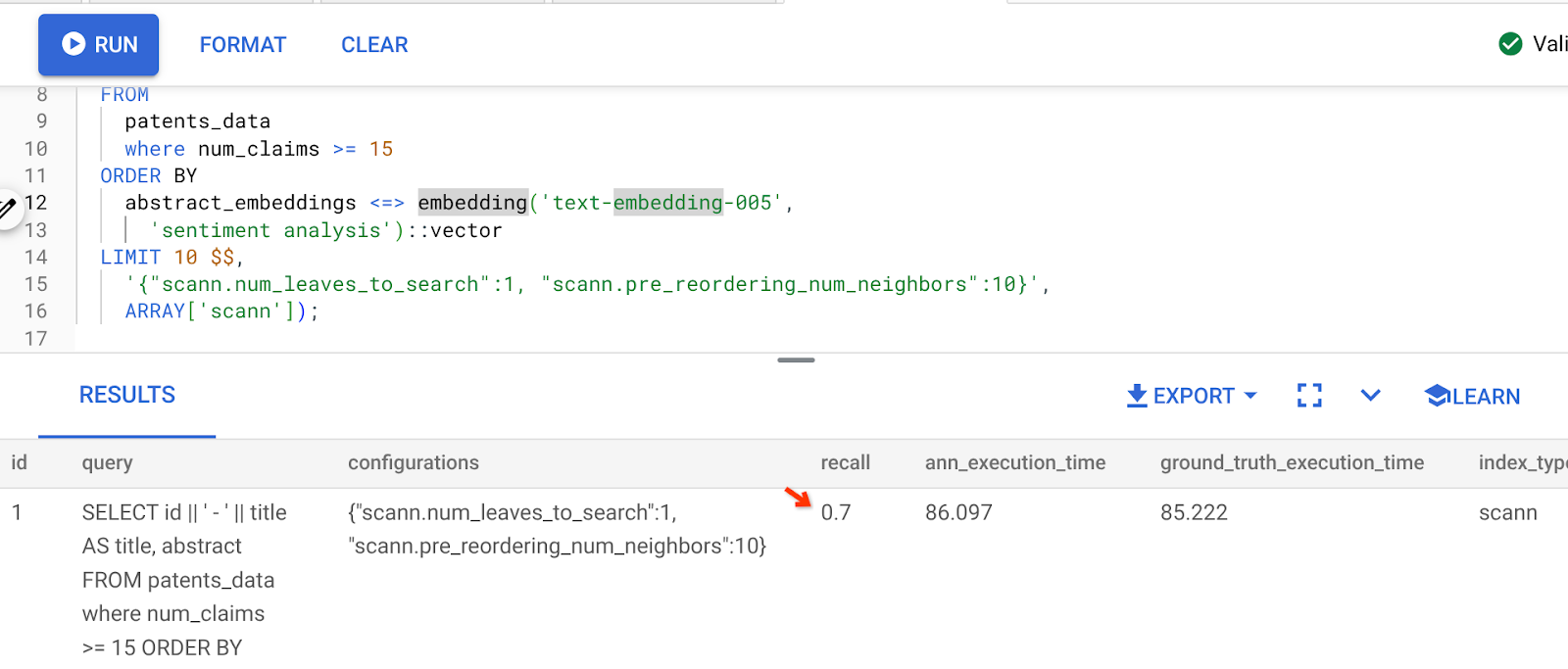
Gördüğünüz gibi, dizin mantığımızda herhangi bir değişiklik yapmadan RECALL değeri %70'tir. Satır İçi Filtreleme bölümünün 6. adımında oluşturduğumuz ScaNN dizinini ("patent_index ") hatırlıyor musunuz? Yukarıdaki sorguyu çalıştırırken aynı dizin geçerliliğini korur.
Şimdi farklı bir mesafe fonksiyonu sorgusuyla dizin oluşturalım: L2 mesafesi: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
DROP INDEX ifadesi, tabloda gereksiz dizin olmamasını sağlamak için kullanılır.
Artık Vector Search işlevimin mesafe işlevini değiştirdikten sonra RECALL'u değerlendirmek için aşağıdaki sorguyu yürütebiliyorum.
[SONRA] Kosinüs benzerliği uzaklık işlevini kullanan sorgu:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Yukarıdaki sorgunun sonucu şudur:
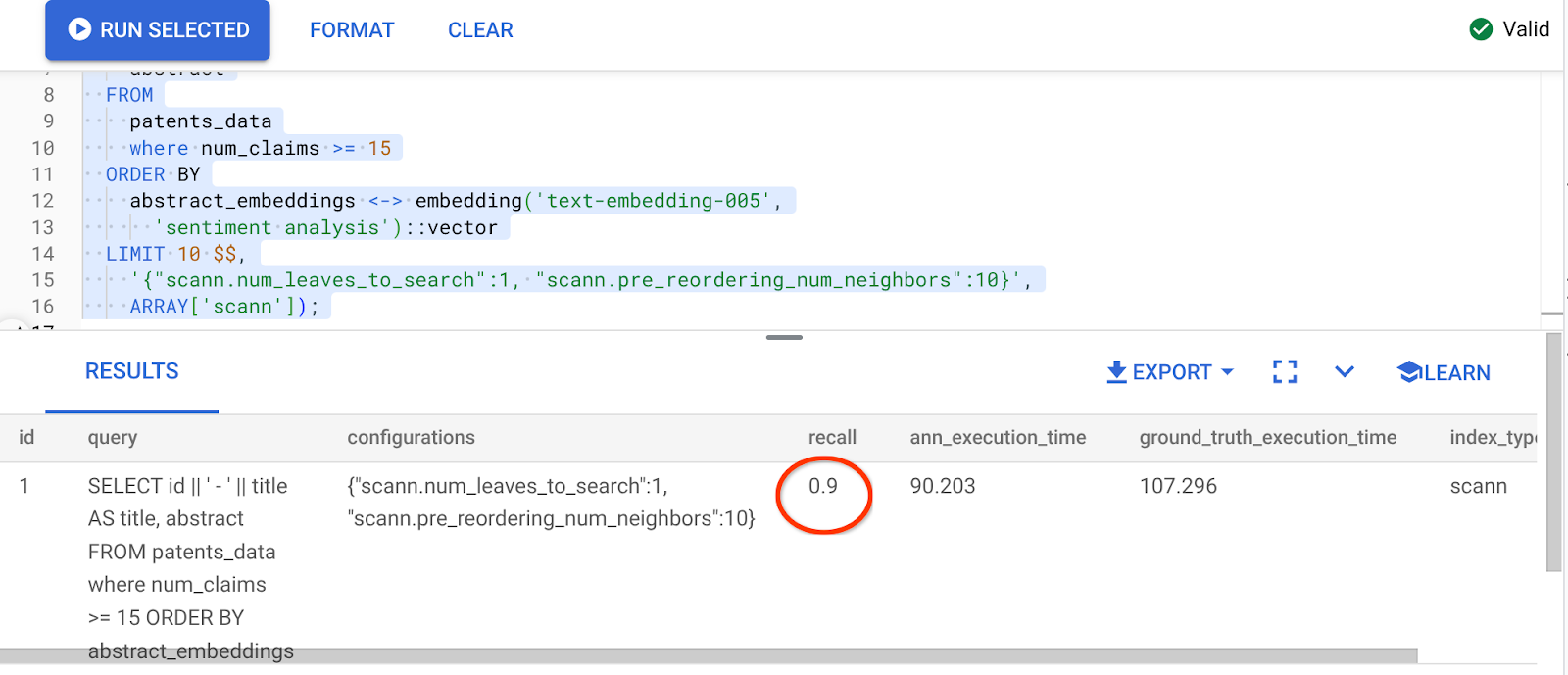
Hatırlanabilirlik değerinde %90'lık bir dönüşüm!
İstenen geri çağırma değerine ve uygulamanızın kullandığı veri kümesine bağlı olarak dizinde değiştirebileceğiniz başka parametreler de vardır (ör. num_leaves).
8. Temizleme
Bu yayında kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın:
- Google Cloud Console'da Kaynak Yöneticisi sayfasına gidin.
- Proje listesinde silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- İletişim kutusunda proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.
- Alternatif olarak, KÜMEYİ SİL düğmesini tıklayarak bu proje için yeni oluşturduğumuz AlloyDB kümesini silebilirsiniz (yapılandırma sırasında küme için us-central1'i seçmediyseniz bu köprüdeki konumu değiştirin).
9. Tebrikler
Tebrikler! Yüksek performans için AlloyDB'nin gelişmiş vektör arama özelliğiyle bağlamsal patent arama sorgunuzu başarıyla oluşturdunuz ve sorgunuzu gerçekten anlam odaklı hale getirdiniz. Burada bahsettiğimiz tüm AlloyDB özelliklerini ve ADK'yı kullanarak yüksek performanslı ve kaliteli bir Patent Vector Search & Analyzer Agent oluşturmak için kalite kontrollü bir çoklu araçlı aracı uygulaması geliştirdim. Bu uygulamayı şu bağlantıdan inceleyebilirsiniz: https://youtu.be/Y9fvVY0yZTY
Bu tür bir ajan oluşturmayı öğrenmek istiyorsanız lütfen bu codelab'e bakın.