
1. Wprowadzenie
Podczas tej praktycznej sesji wyjdziesz poza podstawowe, bezstanowe chatboty i utworzysz inteligentnego konsjerża kawiarni – agenta AI opartego na Gemini, który będzie pełnił rolę przyjaznego baristy. Przyjmuje zamówienia na kawę śledzone w stanie sesji, zapamiętuje długoterminowe preferencje żywieniowe w stanie ograniczonym do użytkownika i zapisuje wszystko w bazie danych Cloud SQL PostgreSQL. Dzięki temu agent zapamięta, że masz nietolerancję laktozy, nawet po ponownym uruchomieniu aplikacji i rozpoczęciu nowej rozmowy.
Oto architektura systemu, którą zbudujemy
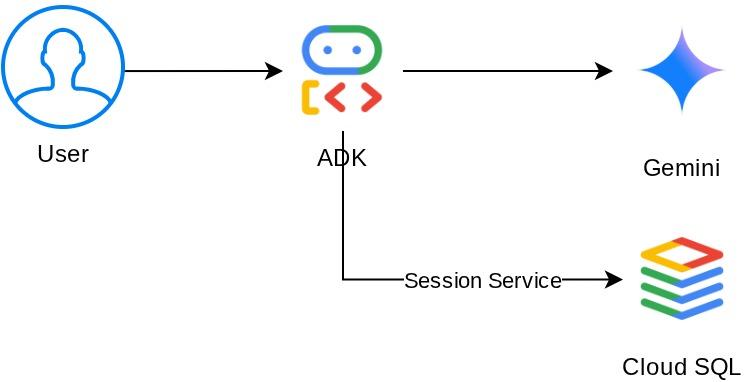
Wymagania wstępne
- Konto Google Cloud z próbnym kontem rozliczeniowym
- podstawowa znajomość Pythona,
- Nie jest wymagane wcześniejsze doświadczenie z pakietem ADK, agentami AI ani Cloud SQL
Czego się nauczysz
- Tworzenie agenta AI za pomocą pakietu Agent Development Kit (ADK) od Google z użyciem narzędzi niestandardowych
- Określ narzędzia, które odczytują i zapisują stan sesji za pomocą funkcji
ToolContext. - Rozróżnianie stanu ograniczonego do sesji i stanu ograniczonego do użytkownika (prefiks
user:) - Aprowizowanie instancji Cloud SQL PostgreSQL i łączenie się z nią z Cloud Shell
- Przenieś dane z pamięci lokalnej (która jest domyślna, gdy używasz polecenia
adk web) doDatabaseSessionService, aby uzyskać pamięć trwałą w dedykowanej bazie danych. - Sprawdź, czy pamięć agenta jest zachowywana po ponownym uruchomieniu aplikacji i w różnych sesjach rozmowy.
Czego potrzebujesz
- działający komputer i stabilne połączenie z internetem.
- przeglądarka, np. Chrome, do otwierania konsoli Google Cloud;
- ciekawość i chęć do nauki;
2. Konfigurowanie środowiska
Ten krok przygotowuje środowisko Cloud Shell i konfiguruje projekt Google Cloud.
Otwieranie Cloud Shell
Otwórz Cloud Shell w przeglądarce. Cloud Shell zapewnia wstępnie skonfigurowane środowisko ze wszystkimi narzędziami potrzebnymi do tego ćwiczenia. Gdy pojawi się prośba o autoryzację, kliknij Autoryzuj.
Interfejs powinien wyglądać podobnie do tego:
Będzie to nasz główny interfejs: IDE u góry, terminal u dołu.
Konfigurowanie katalogu roboczego
Utwórz katalog roboczy. Cały kod, który napiszesz w tym module, będzie przechowywany tutaj – oddzielnie od repozytorium referencyjnego:
# Create your working directory
mkdir -p ~/build-agent-adk-cloudsql
# Change cloudshell workspace and working directory into previously created dir
cloudshell workspace ~/build-agent-adk-cloudsql && cd ~/build-agent-adk-cloudsql
Aby otworzyć terminal, kliknij Widok –> Terminal.
Konfigurowanie projektu Google Cloud i początkowych zmiennych środowiskowych
Pobierz skrypt konfiguracji projektu do katalogu roboczego:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
Uruchom skrypt. Weryfikuje próbne konto rozliczeniowe, tworzy nowy projekt (lub weryfikuje istniejący), zapisuje identyfikator projektu w pliku .env w bieżącym katalogu i ustawia aktywny projekt w terminalu.
bash setup_verify_trial_project.sh && source .env
Podczas uruchamiania tego polecenia pojawi się sugestia nazwy identyfikatora projektu. Aby kontynuować, możesz nacisnąć Enter.
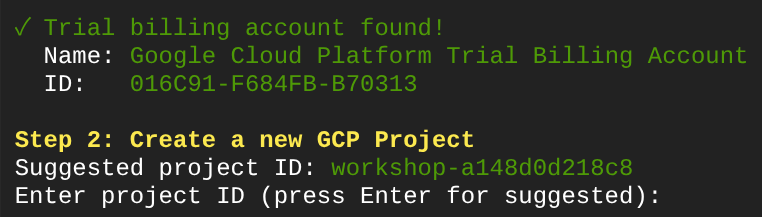
Jeśli po pewnym czasie w konsoli zobaczysz te dane wyjściowe, możesz przejść do następnego kroku. 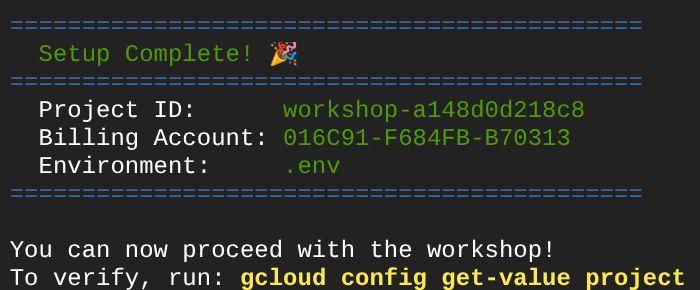
Wykonany skrypt wykonuje te czynności:
- Sprawdź, czy masz aktywne konto rozliczeniowe w wersji próbnej
- Sprawdź, czy w
.envistnieje projekt (jeśli tak) - Utwórz nowy projekt lub użyj istniejącego.
- Połącz próbne konto rozliczeniowe z projektem
- Zapisywanie identyfikatora projektu w pliku .env
- Ustaw projekt jako aktywny projekt gcloud.
Sprawdź, czy projekt jest prawidłowo ustawiony, sprawdzając żółty tekst obok katalogu roboczego w wierszu poleceń terminala Cloud Shell. Powinien wyświetlać identyfikator projektu.

Włącz wymagane interfejsy API
Włącz interfejsy Google Cloud API potrzebne w tym laboratorium:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
- Vertex AI API (
aiplatform.googleapis.com) – agent korzysta z modeli Gemini za pomocą Vertex AI. - Cloud SQL Admin API (
sqladmin.googleapis.com) – możesz udostępniać instancję PostgreSQL i nią zarządzać na potrzeby pamięci trwałej. - Compute Engine API (
compute.googleapis.com) – wymagany do tworzenia instancji Cloud SQL.
Konfigurowanie regionu Gemini i usług w Google Cloud
Zanim przejdziemy dalej, skonfigurujmy też niezbędne ustawienia lokalizacji/regionu dla produktu, z którym będziemy wchodzić w interakcję. Dodaj do pliku .env tę konfigurację:
# This is for our Gemini endpoint
echo "GOOGLE_CLOUD_LOCATION=global" >> .env
# This is for our other Cloud products
echo "REGION=us-central1" >> .env
source .env
Przejdźmy do następnego kroku
3. Konfigurowanie Cloud SQL
Ten krok powoduje udostępnienie instancji Cloud SQL PostgreSQL i przełączenie agenta z pamięci na pamięć opartą na bazie danych. Tworzenie instancji trwa kilka minut, więc najpierw ją uruchomimy, a w międzyczasie możemy przejść do następnego tematu.
Rozpoczęcie tworzenia instancji
Dodaj hasło do bazy danych do pliku .env i ponownie go wczytaj. Jako hasła użyjemy cafe-agent-pwd-2025.
echo "DB_PASSWORD=cafe-agent-pwd-2025" >> .env
source .env
Aby utworzyć instancję Cloud SQL PostgreSQL, uruchom to polecenie. Może to potrwać kilka minut. Pozostaw urządzenie włączone i przejdź do następnej sekcji.
gcloud sql instances create cafe-concierge-db \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--region=${REGION} \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} \
--tier=db-f1-micro \
--root-password=${DB_PASSWORD} \
--quiet &
Kilka uwag na temat powyższego polecenia:
db-f1-microto najmniejsza (i najtańsza) warstwa Cloud SQL, która wystarczy na potrzeby tego laboratorium.--root-passwordustawia hasło domyślnego użytkownika Postgres.- Sufiks
&w poleceniu uruchamia je w tle, dzięki czemu możesz kontynuować pracę.
Proces będzie działać w tle, ale dane wyjściowe konsoli będą od czasu do czasu wyświetlane w bieżącym terminalu. Otwórzmy nową kartę terminala w Cloud Shell (kliknij ikonę +) dla większej wygody.

Ponownie przejdź do katalogu roboczego i aktywuj projekt za pomocą poprzedniego skryptu konfiguracji.
cd ~/build-agent-adk-cloudsql
bash setup_verify_trial_project.sh && source .env
Następnie przejdźmy do następnej sekcji.
4. Tworzenie agenta Cafe Concierge
W tym kroku utworzysz strukturę projektu dla agenta ADK i zdefiniujesz podstawowego konsjerża kawiarni z narzędziem do obsługi menu.
Inicjowanie projektu w Pythonie
W tym ćwiczeniu używamy uv, szybkiego menedżera pakietów Pythona, który obsługuje środowiska wirtualne i zależności w jednym narzędziu. Jest ono już zainstalowane w Cloud Shell.
Zainicjuj projekt w Pythonie i dodaj pakiet ADK jako zależność:
uv init
uv add google-adk==1.25.0 asyncpg
uv init tworzy pyproject.toml i środowisko wirtualne. uv dodaje zależność i zapisuje ją w pliku pyproject.toml.
Inicjowanie struktury projektu agenta
ADK oczekuje określonego układu folderów: katalogu o nazwie agenta zawierającego pliki __init__.py, agent.py i .env w katalogu agenta.
ADK ma wbudowane polecenie, które pomaga szybko to zrobić. Uruchom to polecenie:
uv run adk create cafe_concierge \
--model gemini-2.5-flash \
--project ${GOOGLE_CLOUD_PROJECT} \
--region ${GOOGLE_CLOUD_LOCATION}
To polecenie utworzy strukturę agenta z gemini-2.5-flash jako mózgiem. Twój katalog powinien teraz wyglądać tak:
build-agent-adk-cloudsql/ ├── cafe_concierge/ │ ├── __init__.py │ ├── agent.py │ └── .env ├── pyproject.toml ├── .env ├── .venv/ └── ...
Napisz agenta
Otwórz plik cafe_concierge/agent.py w edytorze Cloud Shell.
cloudshell edit cafe_concierge/agent.py
i zastąp plik tym kodem:
# cafe_concierge/agent.py
from google.adk.agents import LlmAgent
from google.adk.tools import ToolContext
CAFE_MENU = {
"espresso": {
"price": 3.50,
"description": "Rich and bold single shot",
"tags": ["vegan", "dairy-free", "gluten-free"],
},
"latte": {
"price": 5.00,
"description": "Espresso with steamed milk",
"tags": ["gluten-free"],
},
"oat milk latte": {
"price": 5.50,
"description": "Espresso with steamed oat milk",
"tags": ["vegan", "dairy-free", "gluten-free"],
},
"cappuccino": {
"price": 4.50,
"description": "Espresso with equal parts steamed milk and foam",
"tags": ["gluten-free"],
},
"cold brew": {
"price": 4.00,
"description": "Slow-steeped for 12 hours, served over ice",
"tags": ["vegan", "dairy-free", "gluten-free"],
},
"matcha latte": {
"price": 5.50,
"description": "Ceremonial grade matcha with steamed milk",
"tags": ["gluten-free"],
},
"croissant": {
"price": 3.00,
"description": "Buttery, flaky French pastry",
"tags": [],
},
"banana bread": {
"price": 3.50,
"description": "Homemade with walnuts",
"tags": ["vegan"],
},
}
def get_menu() -> dict:
"""Returns the full cafe menu with prices, descriptions, and dietary tags.
Use this tool when the customer asks what's available, wants to see
the menu, or asks about specific items.
"""
return CAFE_MENU
root_agent = LlmAgent(
name="cafe_concierge",
model="gemini-2.5-flash",
instruction="""You are a friendly and knowledgeable barista at "The Cloud Cafe".
Your job:
- Help customers browse the menu and answer questions about items.
- Take coffee and food orders.
- Remember and respect dietary preferences.
Be conversational, warm, and concise. If a customer mentions a dietary
restriction, acknowledge it and suggest suitable options from the menu.
""",
tools=[get_menu],
)
Definiuje to podstawowego agenta z 1 narzędziem: get_menu(). Agent może odpowiadać na pytania dotyczące menu, ale nie może jeszcze śledzić zamówień ani zapamiętywać preferencji.
Sprawdzanie, czy agent jest uruchomiony
Uruchom interfejs programisty ADK z katalogu roboczego:
cd ~/build-agent-adk-cloudsql
uv run adk web
Otwórz adres URL wyświetlany w terminalu (zwykle http://localhost:8000) za pomocą funkcji podglądu w przeglądarce Cloud Shell. W menu agenta w lewym górnym rogu kliknij cafe_concierge.
Wpisz na pasku czatu ten tekst i sprawdź, czy agent odpowie pozycjami menu i cenami.
What's on the menu?
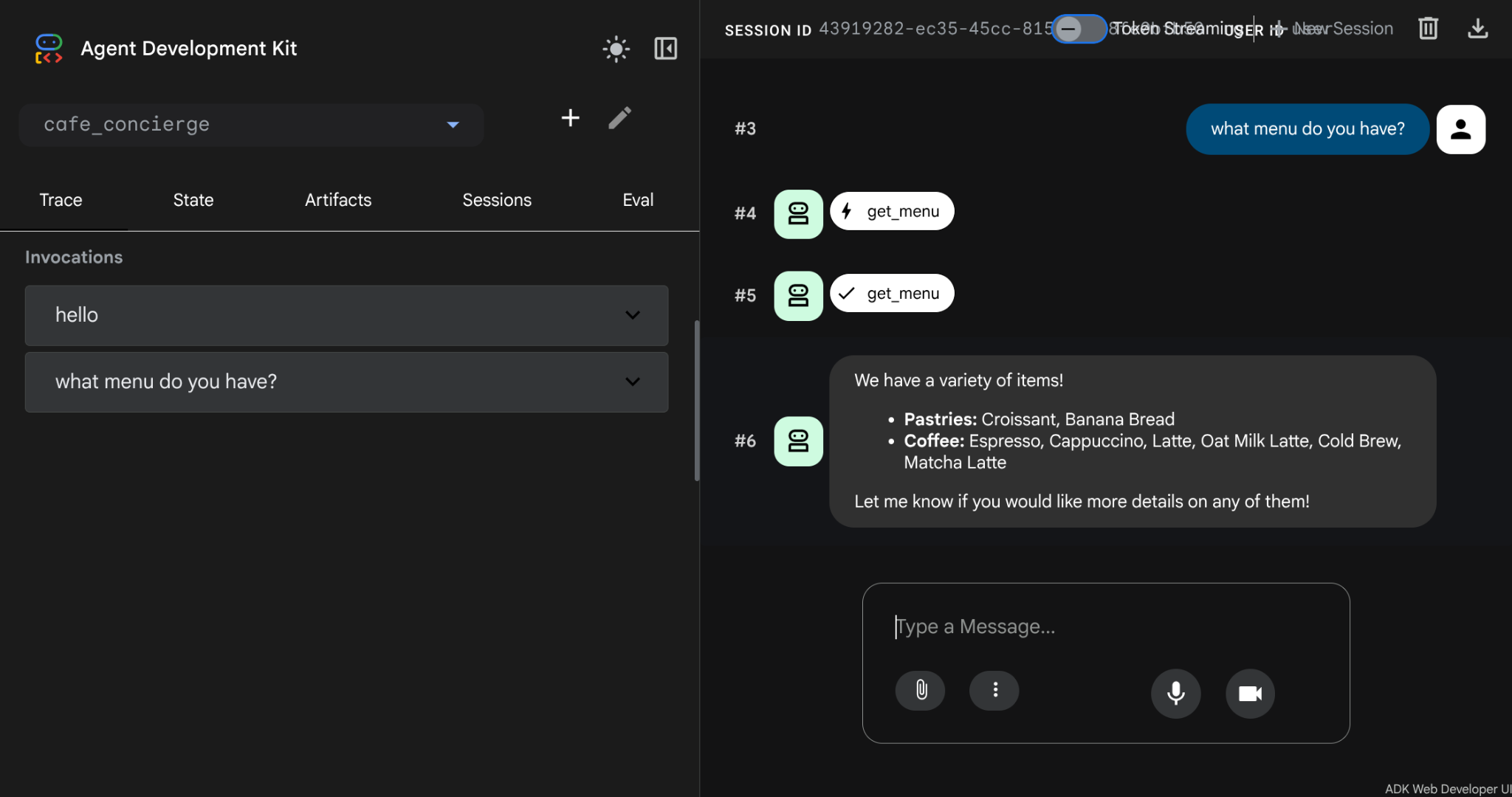
Przed kontynuowaniem zatrzymaj interfejs programisty, naciskając Ctrl+C.
5. Dodawanie Zarządzania zamówieniami z zachowaniem stanu
Agent może wyświetlić menu, ale nie może przyjmować zamówień ani zapamiętywać preferencji. Ten krok dodaje 4 narzędzia, które korzystają z systemu stanów ADK do śledzenia zamówień w ramach rozmowy i przechowywania preferencji żywieniowych w różnych rozmowach.
Informacje o zdarzeniach i stanie sesji
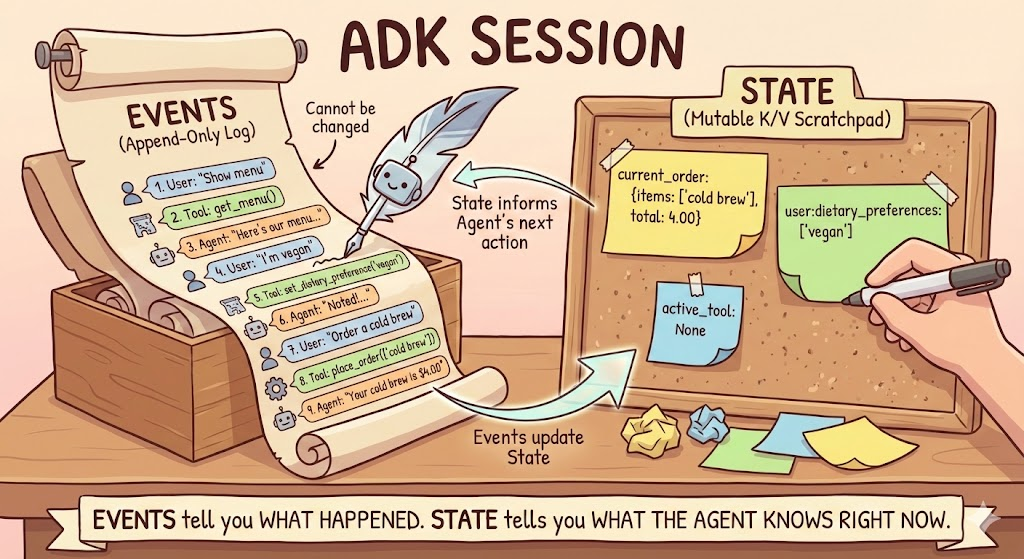
Każda rozmowa ADK znajduje się w obiekcie Session. Sesja śledzi 2 różne elementy: zdarzenia i stan. Zrozumienie tej różnicy jest kluczowe do tworzenia agentów, którzy zapamiętują odpowiednie informacje we właściwy sposób.
Zdarzenia to chronologiczny dziennik wszystkich działań w rozmowie. Każda wiadomość użytkownika, każda odpowiedź agenta, każde wywołanie narzędzia i jego wartość zwracana są rejestrowane jako Event i dodawane do listy events sesji. Zdarzenia są niezmienne: po zarejestrowaniu nigdy się nie zmieniają. Zdarzenia to pełna transkrypcja rozmowy.
Stan to obszar roboczy z parami klucz-wartość, z którego agent odczytuje i do którego zapisuje informacje podczas rozmowy. W odróżnieniu od zdarzeń stan jest zmienny – wartości zmieniają się w miarę rozwoju rozmowy. Stan to miejsce, w którym agent przechowuje dane strukturalne potrzebne do działania: bieżące zamówienie, preferencje klienta, bieżącą sumę. Stan można porównać do karteczek samoprzylepnych, które agent trzyma obok transkrypcji.
Oto jak się ze sobą wiążą:
Narzędzia odczytują i zapisują stan za pomocą obiektu ToolContext, który pakiet ADK automatycznie wstrzykuje do każdej funkcji narzędzia, która deklaruje go jako parametr. Nie tworzysz go samodzielnie. Za pomocą tool_context.state narzędzie może odczytywać i zapisywać obszar roboczy stanu sesji. Pakiet ADK sprawdza sygnaturę funkcji: parametry typu ToolContext są wstrzykiwane, a wszystkie pozostałe parametry są wypełniane przez LLM na podstawie rozmowy.
Gdy narzędzie zapisuje dane w tool_context.state, ADK rejestruje tę zmianę jako state_delta w zdarzeniu. SessionService następnie stosuje deltę do bieżącego stanu sesji. Oznacza to, że zmiany stanu zawsze można powiązać ze zdarzeniem, które je spowodowało. Dotyczy to również innych form kontekstu, takich jak callback_context
Omówienie prefiksów stanów
Klucze stanu używają prefiksów do kontrolowania ich zakresu:
Prefiks | Zakres | Czy przetrwa ponowne uruchomienie? (z bazą danych) |
(brak) | Tylko bieżąca sesja | Tak |
| Wszystkie sesje tego użytkownika | Tak |
| Wszystkie sesje, wszyscy użytkownicy | Tak |
| Tylko bieżące wywołanie | Nie |
W tym ćwiczeniu użyjesz 2 z tych prefiksów: kluczy bez prefiksu w przypadku danych ograniczonych do sesji (bieżące zamówienie – istotne tylko w tej rozmowie) i kluczy z prefiksem user: w przypadku danych ograniczonych do użytkownika (preferencje żywieniowe – istotne we wszystkich rozmowach tego użytkownika).
Dodawanie narzędzi stanowych
Otwórz plik cafe_concierge/agent.py w edytorze Cloud Shell.
cloudshell edit cafe_concierge/agent.py
Następnie dodaj te 4 funkcje nad definicją root_agent:
# cafe_concierge/agent.py (add below get_menu, above root_agent)
def place_order(tool_context: ToolContext, items: list[str]) -> dict:
"""Places an order for the specified menu items.
Use this tool when the customer confirms they want to order something.
Args:
tool_context: Provided automatically by ADK.
items: A list of menu item names the customer wants to order.
"""
valid_items = []
invalid_items = []
total = 0.0
for item in items:
item_lower = item.lower()
if item_lower in CAFE_MENU:
valid_items.append(item_lower)
total += CAFE_MENU[item_lower]["price"]
else:
invalid_items.append(item)
if not valid_items:
return {"error": f"None of these items are on our menu: {invalid_items}"}
order = {"items": valid_items, "total": round(total, 2)}
tool_context.state["current_order"] = order
result = {"order": order}
if invalid_items:
result["warning"] = f"These items are not on our menu: {invalid_items}"
return result
def get_order_summary(tool_context: ToolContext) -> dict:
"""Returns the current order summary for this session.
Use this tool when the customer asks about their current order,
wants to review what they ordered, or asks for the total.
Args:
tool_context: Provided automatically by ADK.
"""
order = tool_context.state.get("current_order")
if order:
return {"order": order}
return {"message": "No order has been placed yet in this session."}
def set_dietary_preference(tool_context: ToolContext, preference: str) -> dict:
"""Saves a dietary preference that persists across all conversations.
Use this tool when the customer mentions a dietary restriction or
preference (e.g., "I'm vegan", "I'm lactose intolerant",
"I have a nut allergy").
Args:
tool_context: Provided automatically by ADK.
preference: The dietary preference to save (e.g., "vegan",
"lactose intolerant", "nut allergy").
"""
existing = tool_context.state.get("user:dietary_preferences", [])
if not isinstance(existing, list):
existing = []
preference_lower = preference.lower().strip()
if preference_lower not in existing:
existing.append(preference_lower)
tool_context.state["user:dietary_preferences"] = existing
return {
"saved": preference_lower,
"all_preferences": existing,
}
def get_dietary_preferences(tool_context: ToolContext) -> dict:
"""Retrieves the customer's saved dietary preferences.
Use this tool when you need to check the customer's dietary
restrictions before making recommendations.
Args:
tool_context: Provided automatically by ADK.
"""
preferences = tool_context.state.get("user:dietary_preferences", [])
if preferences:
return {"preferences": preferences}
return {"message": "No dietary preferences saved yet."}
Dwie rzeczy, na które warto zwrócić uwagę:
place_orderiget_order_summaryużywają kluczy bez prefiksu (current_order). Ten stan jest powiązany z bieżącą sesją – nowa rozmowa rozpoczyna się od pustego zamówienia.set_dietary_preferenceiget_dietary_preferencesużywają prefiksuuser:(user:dietary_preferences). Ten stan jest wspólny dla wszystkich sesji tego samego użytkownika.
Aktualizowanie agenta za pomocą nowych narzędzi i instrukcji
Zastąp istniejącą definicję root_agent na dole pliku tym kodem:
# cafe_concierge/agent.py (replace the existing root_agent)
root_agent = LlmAgent(
name="cafe_concierge",
model="gemini-2.5-flash",
instruction="""You are a friendly and knowledgeable barista at "The Cloud Cafe".
Your job:
- Help customers browse the menu and answer questions about items.
- Take coffee and food orders.
- Remember and respect dietary preferences.
The customer's saved dietary preferences are: {user:dietary_preferences?}
IMPORTANT RULES:
- When a customer mentions a dietary restriction, ALWAYS save it using the
set_dietary_preference tool before doing anything else.
- Before recommending items, check the customer's dietary preferences. If they
have preferences saved, only recommend items compatible with those
restrictions. Check the menu item tags to determine compatibility.
- When placing an order, confirm the items and total with the customer.
Be conversational, warm, and concise.
""",
tools=[
get_menu,
place_order,
get_order_summary,
set_dietary_preference,
get_dietary_preferences,
],
)
Instrukcja korzysta z szablonu wstrzykiwania stanu {user:dietary_preferences?}, aby wstrzyknąć zapisane preferencje klienta bezpośrednio do promptu.
Weryfikacja całego pliku
Konto cafe_concierge/agent.py powinno teraz zawierać:
- Słownik
CAFE_MENU - 5 funkcji narzędzi:
get_menu,place_order,get_order_summary,set_dietary_preference,get_dietary_preferences - Definicja
root_agentz użyciem wszystkich 5 narzędzi
6. Testowanie agenta za pomocą interfejsu programisty ADK
Ten krok uruchamia agenta i wykorzystuje wszystkie funkcje stanu: zamawianie, śledzenie preferencji i pamięć między sesjami (w ramach tego samego procesu). Możesz też sprawdzić panele Zdarzenia i Stan, aby zobaczyć, jak ADK śledzi rozmowę wewnętrznie.
Uruchamianie interfejsu programisty
cd ~/build-agent-adk-cloudsql
uv run adk web
Otwórz podgląd w przeglądarce na porcie 8000 i wybierz cafe_concierge z menu.
Rozmowa 1. Składanie zamówienia i ustawianie preferencji
Wypróbuj te prompty w kolejności:
What's on the menu?
I'm lactose intolerant
What would you recommend?
I'll have an oat milk latte and a banana bread
What's my order?
Sprawdzanie zdarzeń sesji
Wszystkie zdarzenia zostaną zarejestrowane i wyświetlone w interfejsie internetowym. W oknie czatu zobaczysz nie tylko swój prompt i odpowiedź, ale też tool_call i tool_response.
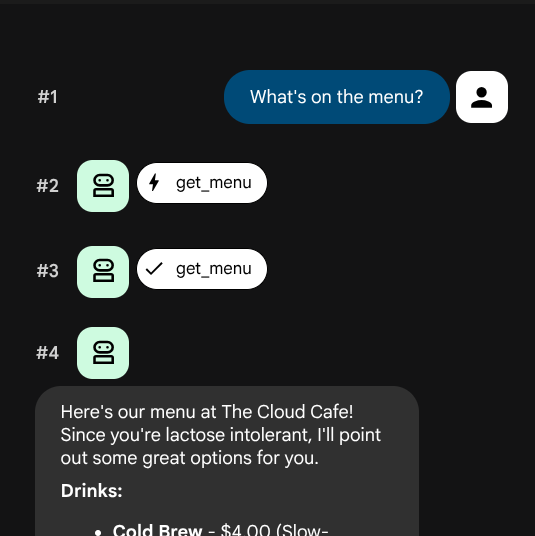
Powinna pojawić się lista wydarzeń w odpowiedniej kolejności. Każde zdarzenie ma autora (osobę, która je wywołała) i typ (rodzaj interakcji, którą reprezentuje):
Autor | Typ | Co to oznacza |
|
| Wiadomość wpisana przez Ciebie na czacie |
|
| Odpowiedź tekstowa agenta |
|
| Agent zdecydował się wywołać narzędzie (wyświetla nazwę funkcji i argumenty) |
|
| Wartość zwracana z wywołania narzędzia |
Kliknij jedno ze zdarzeń tool_call, np. połączenie set_dietary_preference. Zobaczysz, że:
- Nazwa funkcji:
set_dietary_preference - Argumenty:
{"preference": "lactose intolerant"}
Teraz kliknij odpowiednie wydarzenie tool_response bezpośrednio pod nim. Powinna się wyświetlić wartość zwracana:
- Odpowiedź:
{"saved": "lactose intolerant", "all_preferences": ["lactose intolerant"]}
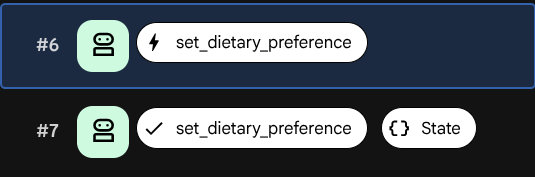
W zdarzeniu tool_response znajdź pole state_delta. Pokazuje to dokładnie, jaki stan uległ zmianie w wyniku wywołania narzędzia:
state_delta: {"user:dietary_preferences": ["lactose intolerant"]}
Każda zmiana stanu jest powiązana z określonym zdarzeniem. W ten sposób ADK zapewnia synchronizację obszaru roboczego stanu z historią rozmowy.
Sprawdzanie stanu sesji
Kliknij kartę Stan. W przeciwieństwie do dziennika zdarzeń (który zawiera pełną historię) karta stanu pokazuje zrzut informacji, które ma obecnie agent – bieżącą wartość każdego klucza stanu.
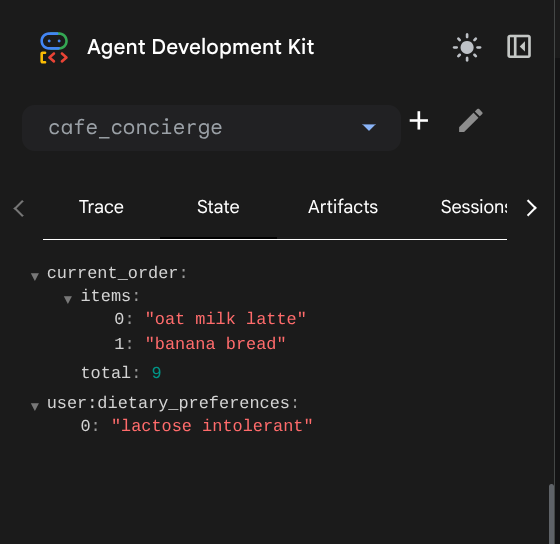
Powinny się wyświetlić 2 wpisy:
current_order–{"items": ["oat milk latte", "banana bread"], "total": 9.0}user:dietary_preferences–["lactose intolerant"]
Zwróć uwagę na różnicę w nazwach kluczy:
current_ordernie ma prefiksu, ponieważ jest ograniczony do sesji. Istnieje tylko w tej rozmowie i znika po zakończeniu sesji.user:dietary_preferencesma prefiksuser:, co oznacza, że jest to wymiar ograniczony do użytkownika. Jest on udostępniany w każdej sesji tego użytkownika.
W kodzie to rozróżnienie jest niewidoczne (oba typy używają tool_context.state), ale określa, jak daleko docierają dane. Zobaczysz to w następnym teście.
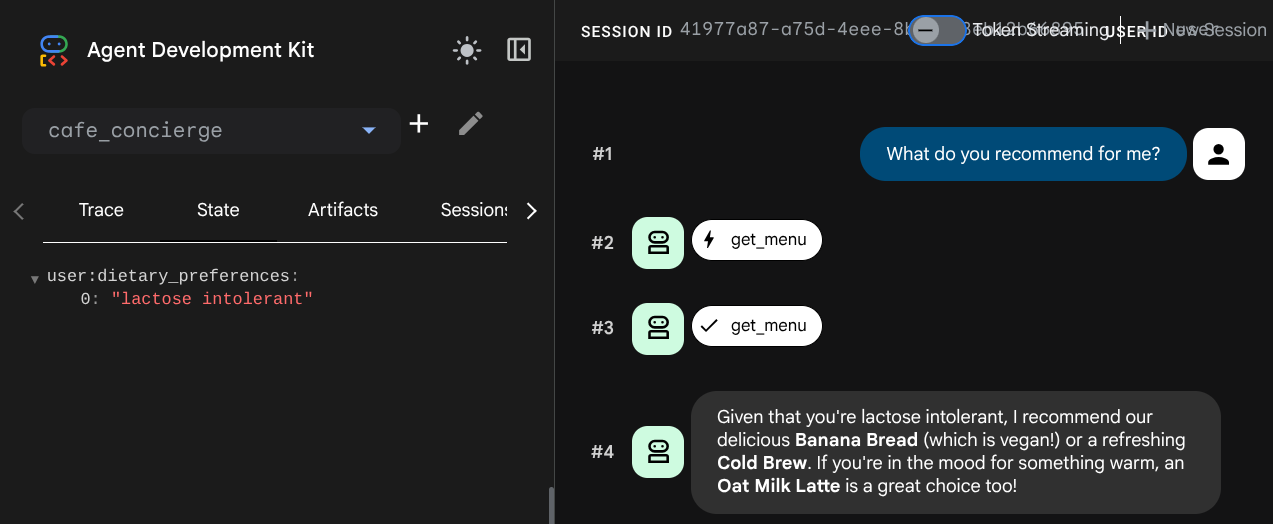
Rozmowa 2. Weryfikowanie stanu użytkownika w różnych sesjach
Aby rozpocząć nową rozmowę, w interfejsie programisty kliknij przycisk Nowa sesja. Spowoduje to utworzenie nowej sesji dla tego samego użytkownika.

Wypróbuj ten prompt:
What do you recommend for me?
Sprawdź kartę Stan w nowej sesji. Klucz user:dietary_preferences jest przenoszony, ale current_order już nie – ten stan był powiązany z poprzednią sesją.
7. Przestrzeganie ograniczeń pamięci lokalnej
Agent zapamiętuje preferencje w różnych sesjach, ale tylko wtedy, gdy istnieje pamięć lokalna. Ten krok pokazuje podstawowe ograniczenie pamięci lokalnej.
Ponowne uruchomienie agenta
W poprzednim kroku interfejs programisty został zatrzymany. Teraz usuńmy pamięć lokalną i uruchommy ją ponownie, aby zasymulować środowisko bezserwerowe, które nie przechowuje stanu:
cd ~/build-agent-adk-cloudsql
rm -f cafe_concierge/.adk/session.db
uv run adk web
Teraz otwórz podgląd w przeglądarce na porcie 8000 i wybierz cafe_concierge.
Testowanie zapamiętywania preferencji
Typ:
Do you remember my dietary preferences?
Agent nie pamięta. Preferencje żywieniowe, historia zamówień – wszystko zniknęło.
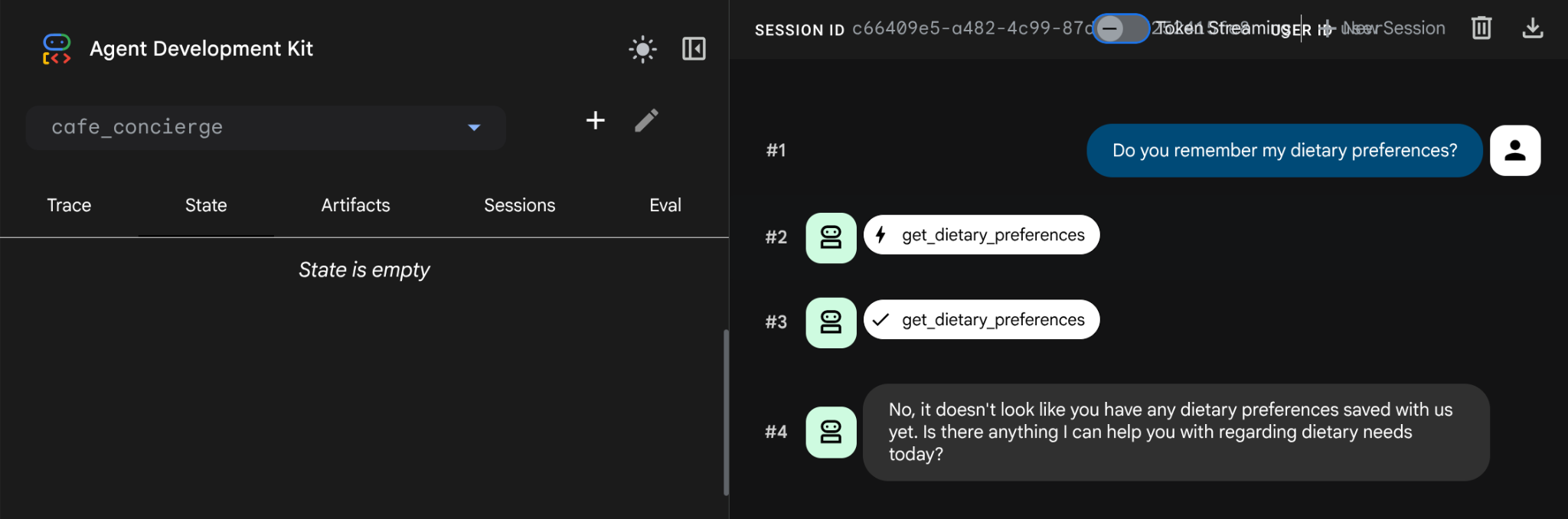
Po usunięciu pamięci lokalnej wszystko zostało wyczyszczone, co zwykle zdarzało się w środowisku bezserwerowym. session.db przechowuje wszystkie stany w pamięci procesu. Usunięcie go spowoduje wymazanie wszystkich danych.
Rozwiązanie: określ DatabaseSessionService, które w tym samouczku będzie przechowywać wszystkie dane sesji w bazie danych PostgreSQL w Cloud SQL. Kod agenta i narzędzia pozostają bez zmian – zmienia się tylko backend pamięci masowej.
Przed kontynuowaniem zatrzymaj interfejs programisty, naciskając Ctrl+C.
8. Ponowne sprawdzanie konfiguracji bazy danych
W tym momencie tworzenie instancji bazy danych powinno być już zakończone. Sprawdźmy to, uruchamiając to polecenie:
gcloud sql instances describe cafe-concierge-db --format="value(state)"
Powinny pojawić się te dane wyjściowe. Oznacz je jako gotowe.
RUNNABLE
Tworzenie bazy danych
Utwórz dedykowaną bazę danych na potrzeby danych sesji agenta:
gcloud sql databases create agent_db --instance=cafe-concierge-db
Uruchamianie serwera proxy uwierzytelniania Cloud SQL
Serwer proxy uwierzytelniania Cloud SQL zapewnia bezpieczne, uwierzytelnione połączenie z Cloud Shell do instancji Cloud SQL bez konieczności dodawania adresów IP do listy dozwolonych. Jest już zainstalowane w Cloud Shell.
cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:${REGION}:cafe-concierge-db --port 5432 &
Sufiks & w poleceniu powoduje, że serwer proxy działa w tle. Powinny się wyświetlić dane wyjściowe potwierdzające, że serwer proxy jest gotowy, jak pokazano poniżej.
[your-project-id:your-region:cafe-concierge-db] Listening on 127.0.0.1:5432 The proxy has started successfully and is ready for new connections!
Weryfikowanie połączenia
Sprawdź, czy możesz połączyć się z bazą danych przez serwer proxy:
psql "host=127.0.0.1 port=5432 dbname=agent_db user=postgres password=$DB_PASSWORD" -c "SELECT 'Connection ok' AS status;"
Zobaczysz, że:
status --------------------- Connection ok (1 row)
9. Sprawdzanie trwałej pamięci w różnych sesjach
Ten krok potwierdza, że pamięć agenta przetrwa resetowanie, gdy upewnimy się, że cafe_concierge/.adk/session_db (lokalna baza danych) zostanie usunięta i będzie obejmować sesje rozmowy.
Uruchom agenta
Sprawdź, czy serwer proxy uwierzytelniania Cloud SQL nadal działa (sprawdź zadania). Jeśli nie, uruchom go ponownie:
if ss -tlnp | grep -q ':5432 '; then
echo "Cloud SQL Auth Proxy is already running."
else
cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:${REGION}:cafe-concierge-db --port 5432 &
fi
Następnie uruchom interfejs programisty ADK, określając bazę danych jako usługę sesji.
uv run adk web --session_service_uri postgresql+asyncpg://postgres:${DB_PASSWORD}@127.0.0.1:5432/agent_db
Otwórz podgląd w przeglądarce na porcie 8000 i wybierz cafe_concierge.
Test 1. Złóż zamówienie i ustaw preferencje
W pierwszej sesji wykonaj te czynności:
Show me the menu
I'm vegan
What can I eat?
I'll have a cold brew and banana bread
Test 2. Przetrwanie ponownego uruchomienia
Zatrzymaj interfejs programisty, naciskając Ctrl+C, i upewnij się, że lokalny znak session.db został usunięty.
rm -f cafe_concierge/.adk/session.db
Następnie ponownie uruchom serwer interfejsu programisty.
uv run adk web --session_service_uri postgresql+asyncpg://postgres:${DB_PASSWORD}@127.0.0.1:5432/agent_db
Otwórz podgląd w przeglądarce na porcie 8000, kliknij cafe_concierge i rozpocznij nową sesję. Następnie zadaj pytanie.
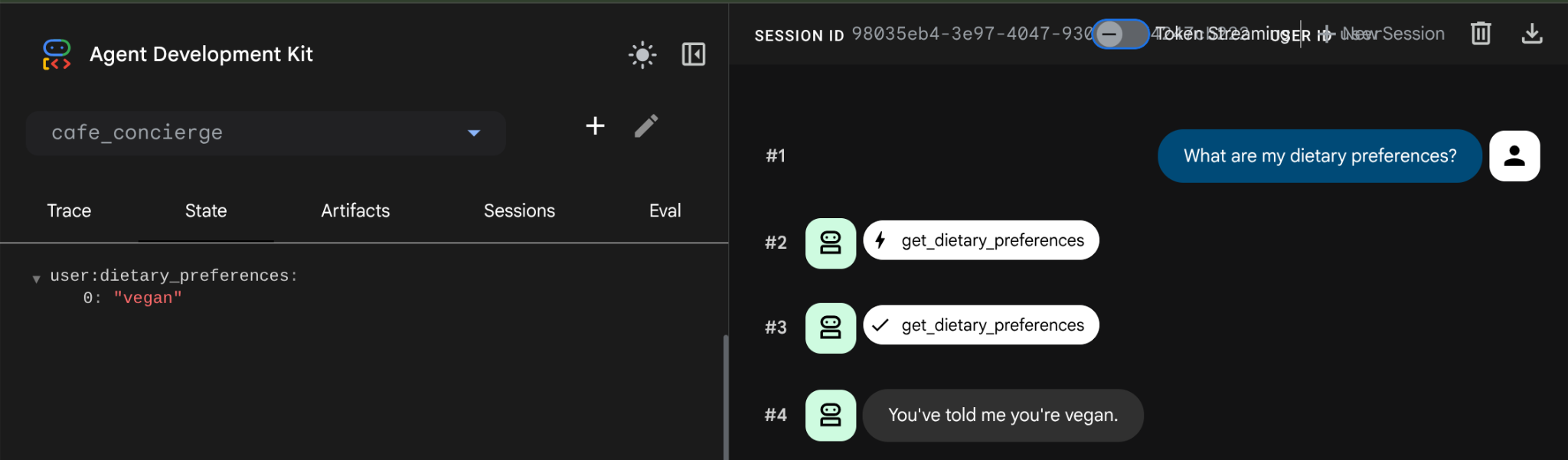
What are my dietary preferences?
Pracownik obsługi klienta odpowiada, podając zapisane preferencje – wegańskie. Dane przetrwały ponowne uruchomienie, ponieważ są teraz przechowywane w PostgreSQL, a nie w pamięci lokalnej. Podobnie będzie w przypadku utworzenia nowej sesji, ponieważ stan user: jest przenoszony do każdej nowej sesji tego użytkownika.
Bezpośrednie sprawdzanie bazy danych
Otwórz nową kartę terminala w Cloud Shell i wyślij zapytanie do bazy danych, aby wyświetlić przechowywane dane:
psql "host=127.0.0.1 port=5432 dbname=agent_db user=postgres password=$DB_PASSWORD" -c "\dt"
Powinny być widoczne tabele utworzone automatycznie przez ADK do przechowywania sesji, zdarzeń i stanu, np. tak jak w tym przykładzie.
List of relations Schema | Name | Type | Owner --------+-----------------------+-------+---------- public | adk_internal_metadata | table | postgres public | app_states | table | postgres public | events | table | postgres public | sessions | table | postgres public | user_states | table | postgres (5 rows)
Podsumowanie działania stanu
Klucz stanu | Prefiks | Zakres | Współdzielone w ramach sesji? |
| (brak) | Sesja | Nie |
|
| Użytkownik | Tak |
10. Gratulacje / Czyszczenie
Gratulacje! Udało Ci się utworzyć trwałego, stanowego agenta AI za pomocą pakietu ADK i Cloud SQL.
Czego się nauczysz
- Tworzenie agenta ADK z narzędziami niestandardowymi, które odczytują i zapisują stan sesji
- Różnica między stanem ograniczonym do sesji (bez prefiksu) a stanem ograniczonym do użytkownika (z prefiksem
user:). - Dlaczego domyślny lokalny pakiet ADK
session.dbnadaje się tylko do programowania – wszystkie dane są tracone po usunięciu (i łatwo je usunąć, nie ma kopii zapasowej), nie nadaje się do wdrożenia bezserwerowego, które jest bezstanowe - Jak utworzyć instancję Cloud SQL PostgreSQL i połączyć się z nią za pomocą serwera proxy uwierzytelniania Cloud SQL
- Jak połączyć się z usługą DatabaseSessionService za pomocą PostgreSQL w Cloud SQL przy minimalnych zmianach w kodzie – te same narzędzia, ten sam agent, inne zaplecze
- Jak stan ograniczony do użytkownika jest zachowywany w różnych sesjach rozmowy
Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami, zwalniaj miejsce zajmowane przez zasoby utworzone w tym ćwiczeniu.
Opcja 1. Usuwanie projektu (zalecane)
Najprostszym sposobem na zwolnienie miejsca jest usunięcie projektu. Spowoduje to usunięcie wszystkich zasobów powiązanych z projektem.
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
Opcja 2. Usuwanie poszczególnych zasobów
Jeśli chcesz zachować projekt, ale usunąć tylko zasoby utworzone w tym laboratorium:
gcloud sql instances delete cafe-concierge-db --quiet