
1. 📖 Einführung
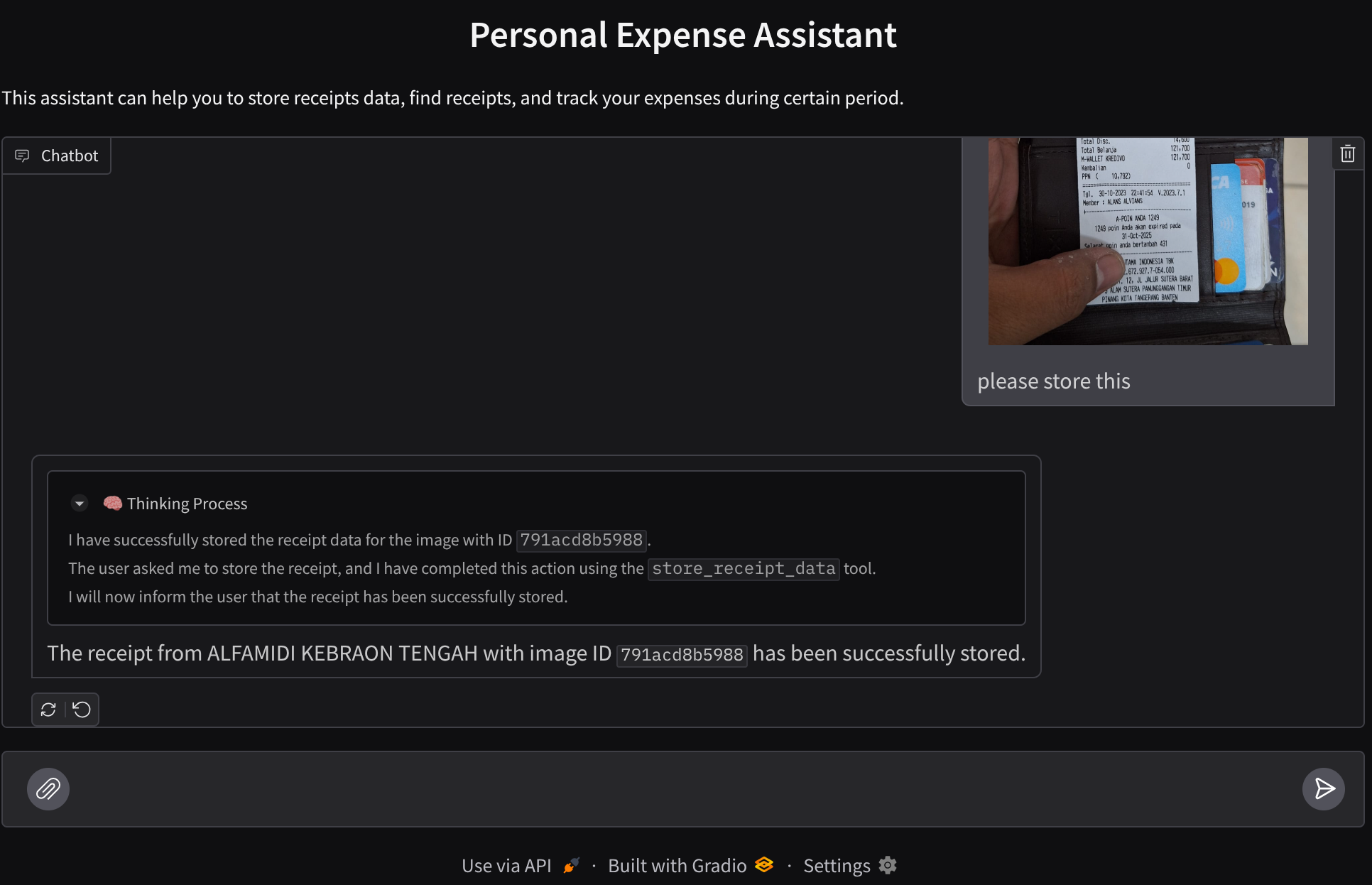
Haben Sie sich schon einmal geärgert, weil Sie zu faul waren, alle Ihre persönlichen Ausgaben zu verwalten? Und ich ebenfalls! In diesem Codelab entwickeln wir daher einen persönlichen Assistenten zur Ausgabenverwaltung, der auf Gemini 2.5 basiert und alle Aufgaben für uns erledigt. Sie können hochgeladene Belege verwalten und analysieren, ob Sie schon zu viel für einen Kaffee ausgegeben haben.
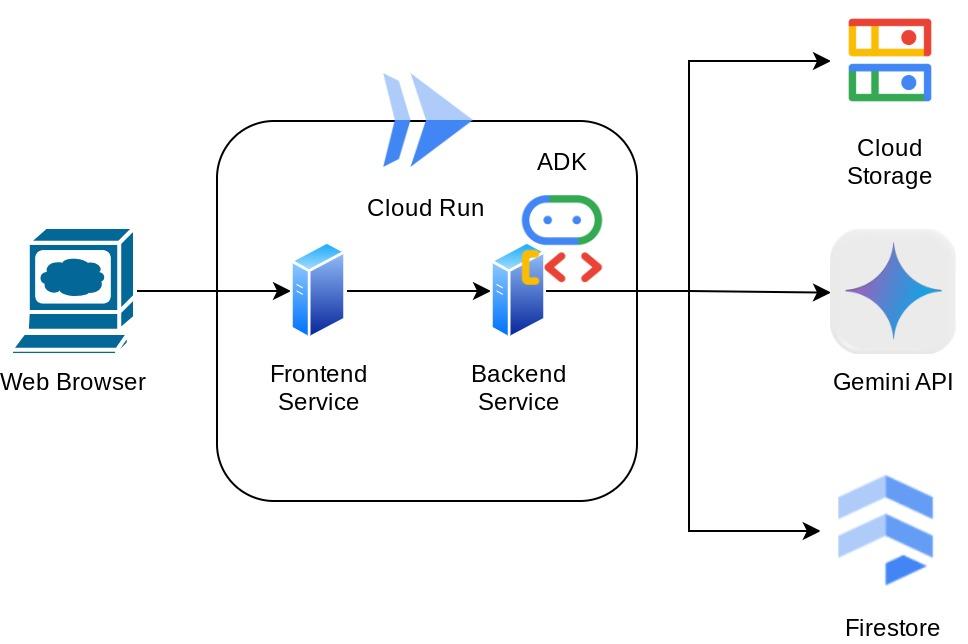
Dieser Assistent ist über einen Webbrowser in Form einer Chat-Weboberfläche zugänglich. Sie können mit ihm kommunizieren, einige Belegbilder hochladen und den Assistenten bitten, sie zu speichern, oder vielleicht nach einigen Belegen suchen, um die Datei zu erhalten und eine Ausgabenanalyse durchzuführen. All das basiert auf dem Google Agent Development Kit-Framework.
Die Anwendung selbst ist in zwei Dienste unterteilt: Frontend und Backend. So können Sie schnell einen Prototyp erstellen und ausprobieren und auch nachvollziehen, wie der API-Vertrag für die Integration beider Dienste aussieht.
In diesem Codelab gehen Sie schrittweise so vor:
- Google Cloud-Projekt vorbereiten und alle erforderlichen APIs aktivieren
- Bucket in Google Cloud Storage und Datenbank in Firestore einrichten
- Firestore-Indexierung erstellen
- Arbeitsbereich für Ihre Programmierumgebung einrichten
- ADK-Agent-Quellcode, Tools, Prompt usw. strukturieren
- Agenten mit der lokalen Web-Entwicklungs-UI des ADK testen
- Erstellen Sie den Frontend-Dienst – die Chat-Oberfläche – mit der Gradio-Bibliothek, um Anfragen zu senden und Belegbilder hochzuladen.
- Backend-Dienst erstellen – HTTP-Server mit FastAPI, auf dem sich unser ADK-Agent-Code, SessionService und Artifact Service befinden
- Umgebungsvariablen verwalten und erforderliche Dateien einrichten, die zum Bereitstellen der Anwendung in Cloud Run benötigt werden
- Anwendung in Cloud Run bereitstellen
Architekturübersicht
Voraussetzungen
- Vertrautheit mit Python
- Grundkenntnisse der Full-Stack-Architektur mit HTTP-Dienst
Lerninhalte
- Frontend-Webprototyping mit Gradio
- Entwicklung von Backend-Diensten mit FastAPI und Pydantic
- ADK-Agenten mit den verschiedenen Funktionen entwickeln
- Tool-Nutzung
- Sitzungs- und Artefaktverwaltung
- Callback-Nutzung zur Eingabemodifizierung vor dem Senden an Gemini
- „BuiltInPlanner“ zur Verbesserung der Aufgabenausführung durch Planung nutzen
- Schnelle Fehlerbehebung über die lokale ADK-Weboberfläche
- Strategie zur Optimierung der multimodalen Interaktion durch das Parsen und Abrufen von Informationen über Prompt-Engineering und die Änderung von Gemini-Anfragen mithilfe des ADK-Callbacks
- Agentic Retrieval Augmented Generation mit Firestore als Vektordatenbank
- Umgebungsvariablen in der YAML-Datei mit Pydantic-settings verwalten
- Anwendung mit Dockerfile in Cloud Run bereitstellen und Umgebungsvariablen mit YAML-Datei bereitstellen
Voraussetzungen
- Chrome-Webbrowser
- Ein Gmail-Konto
- Ein Cloud-Projekt mit aktivierter Abrechnung
In diesem Codelab, das sich an Entwickler*innen aller Erfahrungsstufen (auch Anfänger*innen) richtet, wird Python in der Beispielanwendung verwendet. Python-Kenntnisse sind jedoch nicht erforderlich, um die vorgestellten Konzepte zu verstehen.
2. 🚀 Vorbereitung
Aktives Projekt in der Cloud Console auswählen
In diesem Codelab wird davon ausgegangen, dass Sie bereits ein Google Cloud-Projekt mit aktivierter Abrechnung haben. Wenn Sie noch kein Konto haben, können Sie der Anleitung unten folgen, um eines zu erstellen.
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Firestore-Datenbank vorbereiten
Als Nächstes müssen wir auch eine Firestore-Datenbank erstellen. Firestore im nativen Modus ist eine NoSQL-Dokumentdatenbank, die auf automatische Skalierung, hohe Leistung und einfache Anwendungsentwicklung ausgelegt ist. Sie kann auch als Vektordatenbank fungieren, die die Retrieval Augmented Generation-Technik für unser Labor unterstützt.
- Suchen Sie in der Suchleiste nach firestore und klicken Sie auf das Firestore-Produkt.
- Klicken Sie dann auf die Schaltfläche Firestore-Datenbank erstellen.
- Verwenden Sie (default) als Namen der Datenbank-ID und lassen Sie die Standard Edition ausgewählt. Verwenden Sie für diese Lab-Demo Firestore Native mit Offenen Sicherheitsregeln.
- Sie werden auch feststellen, dass diese Datenbank tatsächlich die Meldung Free-tier Usage YEAY! enthält. Klicken Sie dann auf Datenbank erstellen.
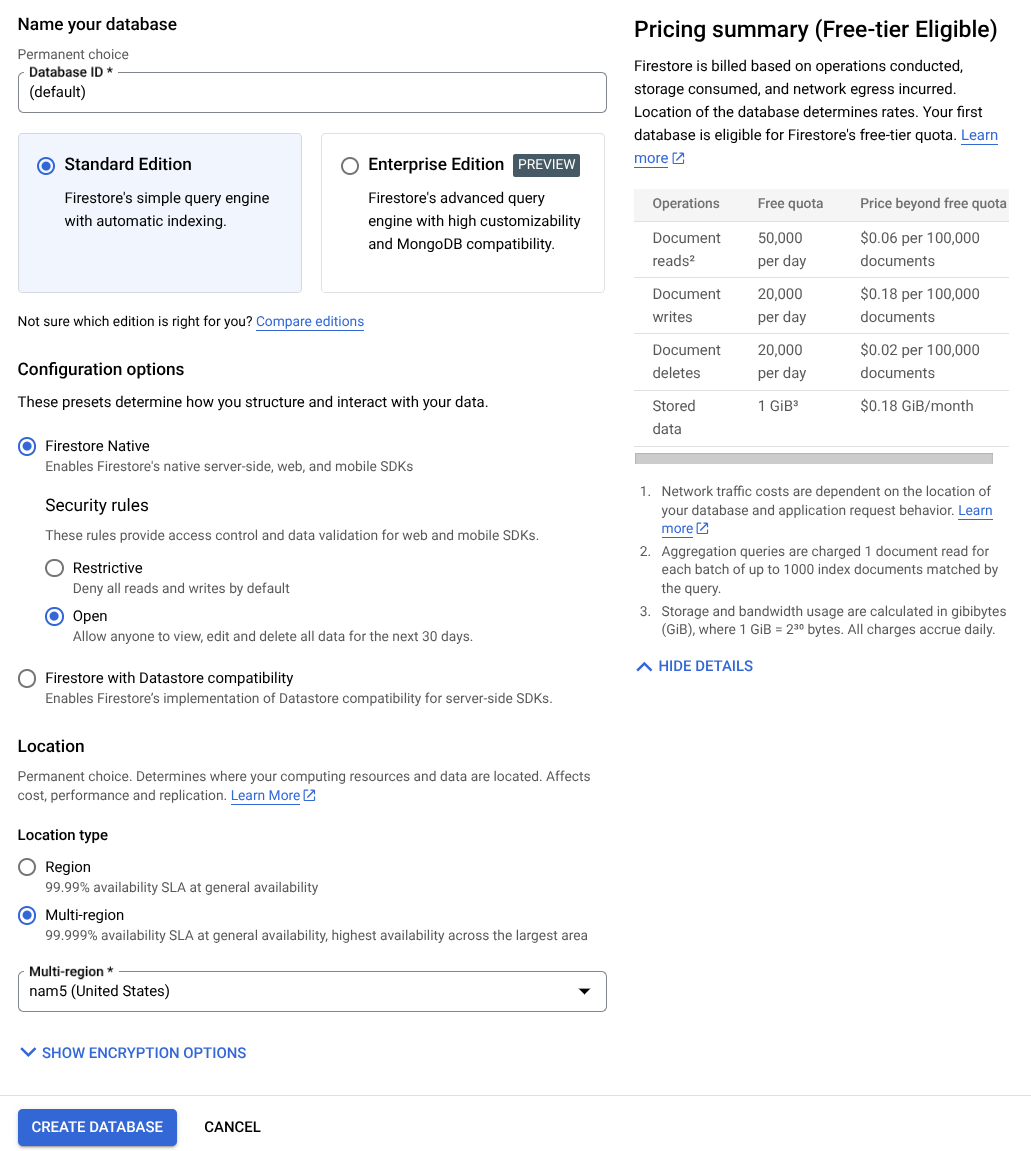
Danach sollten Sie bereits zur Firestore-Datenbank weitergeleitet werden, die Sie gerade erstellt haben.
Cloud-Projekt im Cloud Shell-Terminal einrichten
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der bq vorinstalliert ist. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.
- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
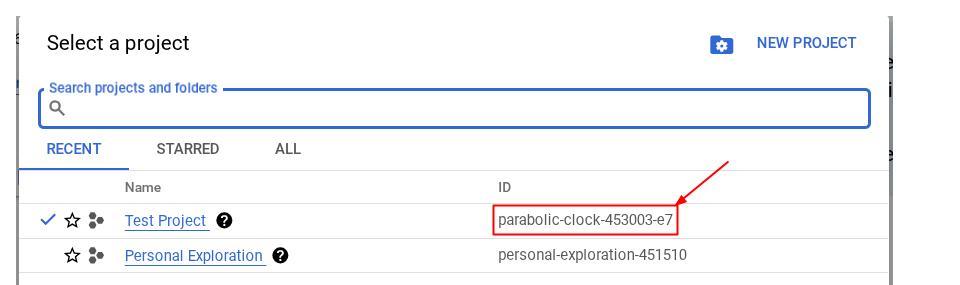
Alternativ können Sie die PROJECT_ID-ID auch in der Console sehen.
Klicken Sie darauf. Rechts sehen Sie dann alle Ihre Projekte und die Projekt-ID.
- Aktivieren Sie die erforderlichen APIs mit dem unten gezeigten Befehl. Das kann einige Minuten dauern.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Bei erfolgreicher Ausführung des Befehls sollte eine Meldung wie die unten gezeigte angezeigt werden:
Operation "operations/..." finished successfully.
Alternativ zum gcloud-Befehl können Sie in der Konsole nach den einzelnen Produkten suchen oder diesen Link verwenden.
Wenn eine API fehlt, können Sie sie jederzeit während der Implementierung aktivieren.
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
Google Cloud Storage-Bucket vorbereiten
Als Nächstes müssen wir im selben Terminal den GCS-Bucket vorbereiten, in dem die hochgeladene Datei gespeichert werden soll. Führen Sie den folgenden Befehl aus, um den Bucket zu erstellen. Sie benötigen einen eindeutigen, aber relevanten Bucket-Namen für Belege des persönlichen Ausgabenassistenten. Daher verwenden wir den folgenden Bucket-Namen in Kombination mit Ihrer Projekt-ID.
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Es wird folgende Ausgabe angezeigt:
Creating gs://personal-expense-{your-project-id}
Sie können dies überprüfen, indem Sie im Browser oben links auf das Navigationsmenü klicken und Cloud Storage -> Bucket auswählen.
Firestore-Index für die Suche erstellen
Firestore ist eine native NoSQL-Datenbank, die eine hervorragende Leistung und Flexibilität im Datenmodell bietet, aber Einschränkungen bei komplexen Abfragen hat. Da wir einige zusammengesetzte Abfragen mit mehreren Feldern und die Vektorsuche verwenden möchten, müssen wir zuerst einige Indexe erstellen. Weitere Informationen finden Sie in dieser Dokumentation
- Führen Sie den folgenden Befehl aus, um einen Index zur Unterstützung von zusammengesetzten Abfragen zu erstellen.
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- Führen Sie diesen aus, um die Vektorsuche zu unterstützen.
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
Sie können den erstellten Index prüfen, indem Sie in der Cloud Console Firestore aufrufen, auf die Datenbankinstanz (default) klicken und in der Navigationsleiste Indexe auswählen.
Cloud Shell-Editor aufrufen und Arbeitsverzeichnis der Anwendung einrichten
Jetzt können wir unseren Code-Editor für einige Programmieraufgaben einrichten. Dazu verwenden wir den Cloud Shell-Editor.
- Klicken Sie auf die Schaltfläche „Editor öffnen“, um den Cloud Shell-Editor zu öffnen. Hier können Sie Ihren Code schreiben
- Als Nächstes müssen wir prüfen, ob die Shell bereits für die richtige PROJECT ID konfiguriert ist. Wenn im Terminal vor dem Symbol „$“ ein Wert in Klammern angezeigt wird (im Screenshot unten ist der Wert "adk-multimodal-tool"), gibt dieser Wert das konfigurierte Projekt für Ihre aktive Shell-Sitzung an.

Wenn der angezeigte Wert bereits korrekt ist, können Sie den nächsten Befehl überspringen. Wenn sie nicht korrekt ist oder fehlt, führen Sie den folgenden Befehl aus:
gcloud config set project <YOUR_PROJECT_ID>
- Klonen Sie als Nächstes das Arbeitsverzeichnis der Vorlage für dieses Codelab von GitHub. Führen Sie dazu den folgenden Befehl aus. Das Arbeitsverzeichnis wird im Verzeichnis personal-expense-assistant erstellt.
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- Klicken Sie dann oben im Cloud Shell-Editor auf Datei > Ordner öffnen, suchen Sie nach dem Verzeichnis username und dann nach dem Verzeichnis personal-expense-assistant und klicken Sie auf die Schaltfläche OK. Dadurch wird das ausgewählte Verzeichnis zum Hauptarbeitsverzeichnis. In diesem Beispiel ist der Nutzername alvinprayuda. Der Verzeichnispfad wird unten angezeigt.

Der Cloud Shell Editor sollte jetzt so aussehen:
Umgebung einrichten
Virtuelle Python-Umgebung vorbereiten
Im nächsten Schritt bereiten Sie die Entwicklungsumgebung vor. Ihr aktuelles aktives Terminal sollte sich im Arbeitsverzeichnis personal-expense-assistant befinden. In diesem Codelab verwenden wir Python 3.12 und den uv-Python-Projektmanager, um das Erstellen und Verwalten von Python-Versionen und virtuellen Umgebungen zu vereinfachen.
- Wenn Sie das Terminal noch nicht geöffnet haben, klicken Sie auf Terminal > Neues Terminal oder verwenden Sie Strg + Umschalt + C. Dadurch wird ein Terminalfenster im unteren Bereich des Browsers geöffnet.

- Initialisieren wir nun die virtuelle Umgebung mit
uv. Führen Sie diese Befehle aus:
cd ~/personal-expense-assistant
uv sync --frozen
Dadurch wird das Verzeichnis .venv erstellt und die Abhängigkeiten werden installiert. Ein kurzer Blick in die Datei pyproject.toml gibt Ihnen Informationen zu den Abhängigkeiten, die so angezeigt werden:
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Konfigurationsdateien einrichten
Als Nächstes müssen wir Konfigurationsdateien für dieses Projekt einrichten. Wir verwenden pydantic-settings, um die Konfiguration aus der YAML-Datei zu lesen.
Wir haben die Dateivorlage bereits in settings.yaml.example bereitgestellt. Wir müssen die Datei kopieren und in settings.yaml umbenennen. Führen Sie diesen Befehl aus, um die Datei zu erstellen.
cp settings.yaml.example settings.yaml
Kopieren Sie dann den folgenden Wert in die Datei.
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
In diesem Codelab verwenden wir die vorkonfigurierten Werte für GCLOUD_LOCATION, BACKEND_URL, und DB_COLLECTION_NAME .
Nun können wir mit dem nächsten Schritt fortfahren und den Agent und dann die Dienste erstellen.
3. 🚀 Agent mit Google ADK und Gemini 2.5 erstellen
Einführung in die ADK-Verzeichnisstruktur
Sehen wir uns zuerst an, was das ADK zu bieten hat und wie Sie den Agent erstellen. Die vollständige ADK-Dokumentation finden Sie unter dieser URL . Das ADK bietet viele Dienstprogramme für die Ausführung von CLI-Befehlen. Einige davon sind :
- Agentenverzeichnisstruktur einrichten
- Schnelles Ausprobieren der Interaktion über die CLI-Ein- und -Ausgabe
- Schnelle Einrichtung der Web-Benutzeroberfläche für die lokale Entwicklung
Erstellen wir nun die Verzeichnisstruktur des Agents mit dem CLI-Befehl. Führen Sie den folgenden Befehl aus:
uv run adk create expense_manager_agent
Wählen Sie bei Aufforderung das Modell gemini-2.5-flash und das Backend Vertex AI aus. Der Assistent fragt dann nach der Projekt-ID und dem Standort. Sie können die Standardoptionen übernehmen, indem Sie die Eingabetaste drücken, oder sie nach Bedarf ändern. Achten Sie nur darauf, dass Sie die richtige Projekt-ID verwenden, die Sie zuvor in diesem Lab erstellt haben. Die Ausgabe sieht so aus:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Dadurch wird die folgende Agent-Verzeichnisstruktur erstellt:
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Wenn Sie init.py und agent.py untersuchen, sehen Sie diesen Code.
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Sie können dies prüfen, indem Sie folgenden Befehl ausführen:
uv run adk run expense_manager_agent
Wenn Sie mit dem Testen fertig sind, können Sie den Agenten beenden, indem Sie exit eingeben oder Strg + D drücken.
Expense Manager-Agent erstellen
Lassen Sie uns unseren Ausgabenmanager-Agenten erstellen. Öffnen Sie die Datei expense_manager_agent/agent.py und kopieren Sie den folgenden Code, der den root_agent enthält.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Erläuterung zum Code
Dieses Skript enthält unsere Agent-Initialisierung, in der wir Folgendes initialisieren:
- Legen Sie das zu verwendende Modell auf
gemini-2.5-flashfest. - Richten Sie die Beschreibung und Anleitung des Agents als System-Prompt ein, der aus
task_prompt.mdgelesen wird. - Notwendige Tools zur Unterstützung der Agent-Funktionalität bereitstellen
- Planung vor der Generierung der endgültigen Antwort oder Ausführung mit den Thinking-Funktionen von Gemini 2.5 Flash aktivieren
- Callback-Intercept einrichten, bevor die Anfrage an Gemini gesendet wird, um die Anzahl der Bilddaten zu begrenzen, die vor der Vorhersage gesendet werden
4. 🚀 Agent-Tools konfigurieren
Unser Ausgabenmanager-Agent bietet folgende Funktionen:
- Daten aus dem Belegbild extrahieren und die Daten und die Datei speichern
- Genaue Suche in den Ausgabendaten
- Kontextbezogene Suche in den Ausgabendaten
Daher benötigen wir die entsprechenden Tools, um diese Funktion zu unterstützen. Erstellen Sie eine neue Datei im Verzeichnis expense_manager_agent und nennen Sie sie tools.py.
touch expense_manager_agent/tools.py
Öffnen Sie expense_manage_agent/tools.py und kopieren Sie den folgenden Code.
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Erläuterung zum Code
Bei der Implementierung der Tools-Funktion orientieren wir uns an diesen beiden Hauptideen:
- Belegdaten parsen und der Originaldatei zuordnen, indem Sie den Platzhalter für den Bild-ID-String
[IMAGE-ID <hash-of-image-1>]verwenden - Daten mit der Firestore-Datenbank speichern und abrufen
Tool „store_receipt_data“
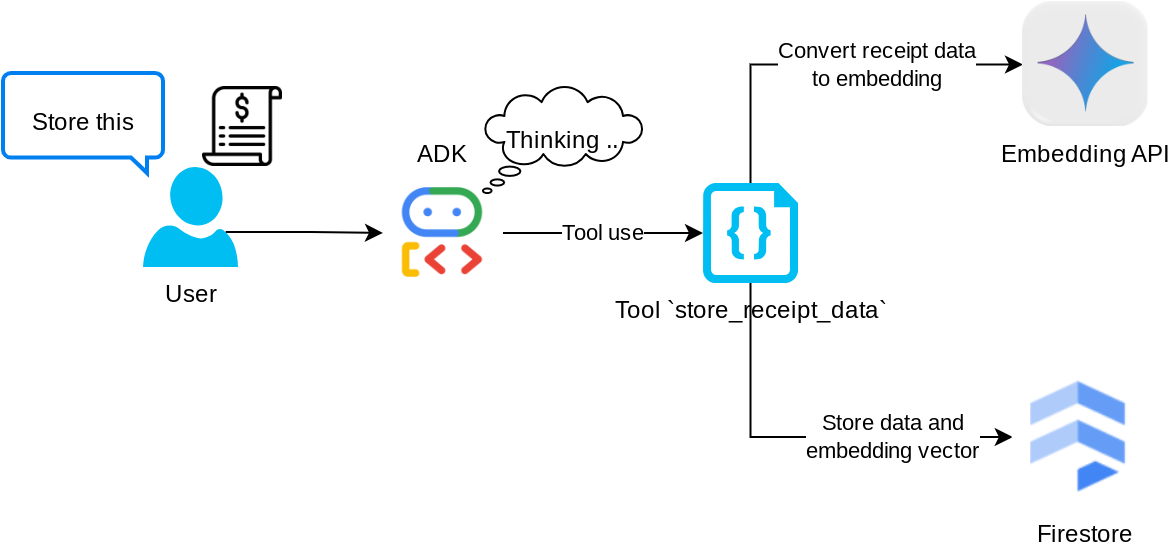
Dieses Tool ist das Tool für optische Zeichenerkennung (OCR). Es parst die erforderlichen Informationen aus den Bilddaten, erkennt den Bild-ID-String und ordnet sie einander zu, um in der Firestore-Datenbank gespeichert zu werden.
Außerdem wird mit diesem Tool der Inhalt des Belegs mithilfe von text-embedding-004 in eine Einbettung umgewandelt, sodass alle Metadaten und die Einbettung zusammen gespeichert und indexiert werden. Die Flexibilität kann entweder durch eine Abfrage oder eine kontextbezogene Suche abgerufen werden.
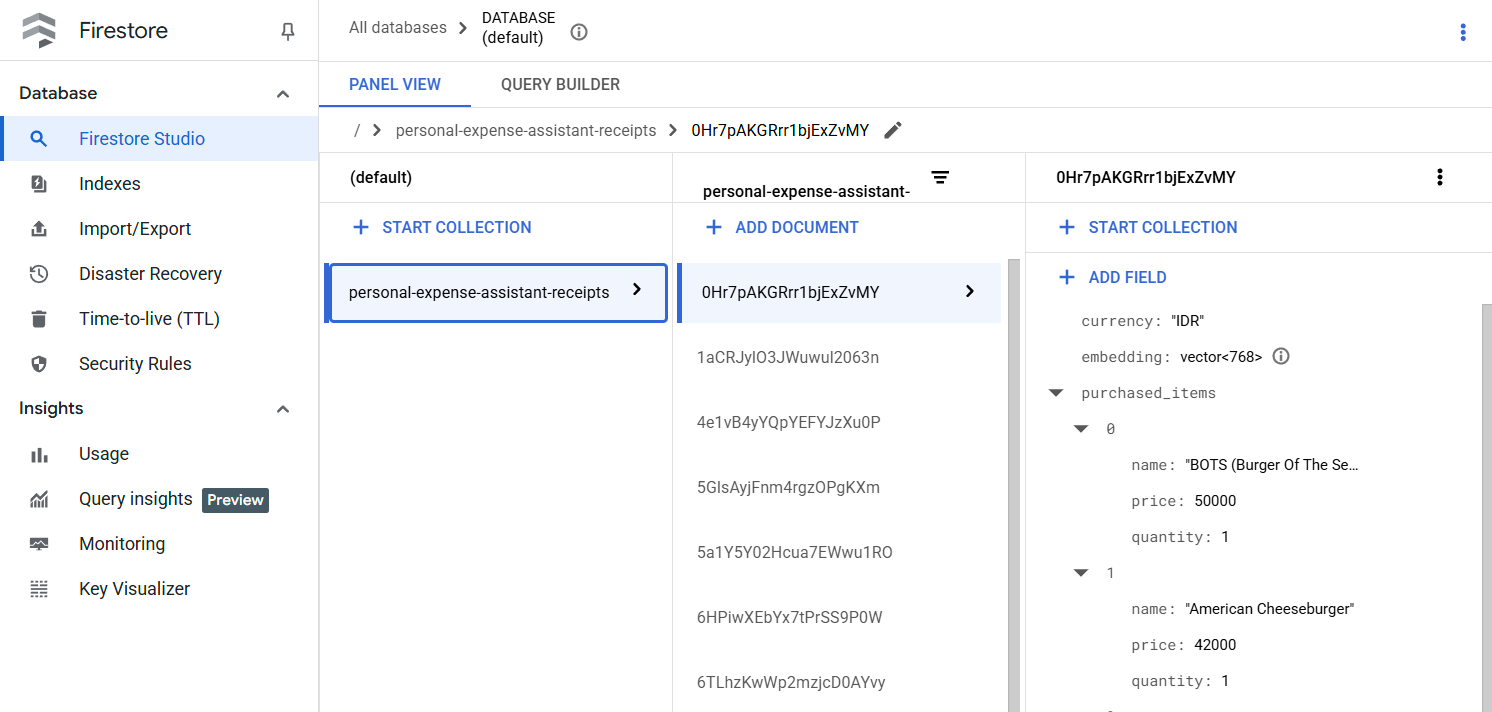
Nachdem Sie dieses Tool erfolgreich ausgeführt haben, sehen Sie, dass die Belegdaten bereits in der Firestore-Datenbank indexiert wurden, wie unten dargestellt.
Tool „search_receipts_by_metadata_filter“
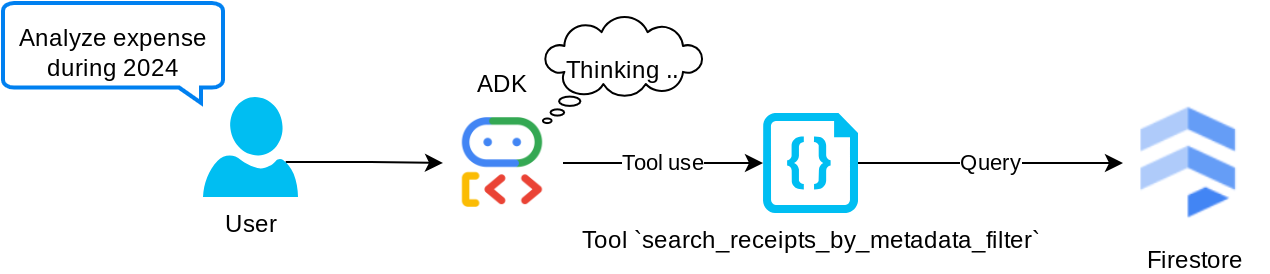
Mit diesem Tool wird die Nutzeranfrage in einen Metadaten-Abfragefilter umgewandelt, der die Suche nach Zeitraum und/oder Gesamtvorgang unterstützt. Es werden alle übereinstimmenden Belegdaten zurückgegeben. Dabei wird das Einbettungsfeld entfernt, da es vom Agent nicht für das kontextbezogene Verständnis benötigt wird.
Tool „search_relevant_receipts_by_natural_language_query“
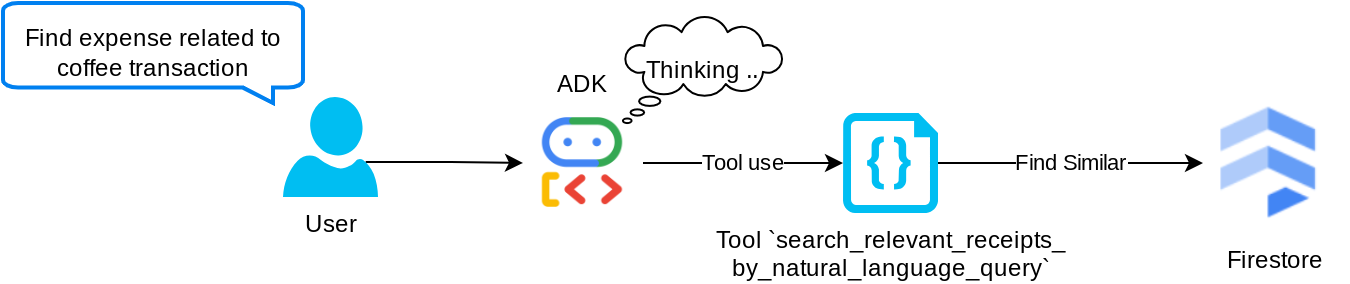
Das ist unser Tool für Retrieval-Augmented Generation (RAG). Unser Agent kann eigene Abfragen entwerfen, um relevante Belege aus der Vektordatenbank abzurufen, und er kann auch selbst entscheiden, wann er dieses Tool verwendet. Die Idee, dass der Agent unabhängig entscheiden kann, ob er dieses RAG-Tool verwendet oder nicht, und seine eigene Anfrage entwerfen kann, ist eine der Definitionen des Agentic RAG-Ansatzes.
Das Modell kann nicht nur eigene Anfragen erstellen, sondern auch auswählen, wie viele relevante Dokumente abgerufen werden sollen. In Kombination mit einem geeigneten Prompt Engineering, z.B.
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Dadurch wird dieses Tool zu einem leistungsstarken Tool, mit dem sich fast alles durchsuchen lässt. Aufgrund der nicht exakten Natur der Nearest-Neighbor-Suche werden jedoch möglicherweise nicht alle erwarteten Ergebnisse zurückgegeben.
5. 🚀 Kontext von Unterhaltungen über Callbacks ändern
Mit dem Google ADK können wir die Laufzeit von Agenten auf verschiedenen Ebenen „abfangen“. Weitere Informationen zu dieser detaillierten Funktion finden Sie in dieser Dokumentation . In diesem Lab verwenden wir before_model_callback, um die Anfrage zu ändern, bevor sie an das LLM gesendet wird. So werden Bilddaten im alten Unterhaltungsverlauf entfernt ( Bilddaten werden nur in den letzten drei Nutzerinteraktionen berücksichtigt).
Wir möchten jedoch, dass der Kundenservicemitarbeiter bei Bedarf Zugriff auf den Kontext der Bilddaten hat. Daher fügen wir nach jedem Bildbyte in der Unterhaltung einen Platzhalter für die String-Bild-ID hinzu. So kann der Agent die Bild-ID mit den tatsächlichen Dateidaten verknüpfen, die sowohl beim Speichern als auch beim Abrufen von Bildern verwendet werden können. Die Struktur sieht so aus:
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
Wenn die Byte-Daten im Unterhaltungsverlauf veraltet sind, ist die String-Kennung weiterhin vorhanden, um den Datenzugriff mithilfe der Tool-Nutzung zu ermöglichen. Beispiel für die Verlaufsstruktur nach dem Entfernen von Bilddaten
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Los geht's! Erstellen Sie eine neue Datei im Verzeichnis expense_manager_agent und nennen Sie sie callbacks.py.
touch expense_manager_agent/callbacks.py
Öffnen Sie die Datei expense_manager_agent/callbacks.py und kopieren Sie den folgenden Code.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 Der Prompt
Wenn wir einen Agent mit komplexen Interaktionen und Funktionen entwickeln, müssen wir einen Prompt finden, der den Agent so anleitet, dass er sich wie gewünscht verhält.
Bisher hatten wir einen Mechanismus für den Umgang mit Bilddaten im Unterhaltungsverlauf und auch Tools, die möglicherweise nicht einfach zu verwenden sind, z. B. search_relevant_receipts_by_natural_language_query.. Außerdem soll der Kundenservicemitarbeiter in der Lage sein, das richtige Belegbild zu suchen und abzurufen. Das bedeutet, dass wir alle diese Informationen in einer geeigneten Prompt-Struktur richtig vermitteln müssen.
Wir bitten den Agenten, die Ausgabe im folgenden Markdown-Format zu strukturieren, um den Denkprozess, die endgültige Antwort und den Anhang ( falls vorhanden) zu analysieren.
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Beginnen wir mit dem folgenden Prompt, um unser ursprüngliches Ziel für das Verhalten des Ausgabenmanager-Agents zu erreichen. Die Datei task_prompt.md sollte bereits in unserem vorhandenen Arbeitsverzeichnis vorhanden sein. Wir müssen sie jedoch in das Verzeichnis expense_manager_agent verschieben. Führen Sie dazu den folgenden Befehl aus:
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Agent testen
Versuchen wir nun, über die Befehlszeile mit dem Agenten zu kommunizieren. Führen Sie dazu den folgenden Befehl aus:
uv run adk run expense_manager_agent
Es wird eine Ausgabe wie diese angezeigt, in der Sie abwechselnd mit dem Agent chatten können. Über diese Schnittstelle können Sie jedoch nur Text senden.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
Neben der CLI-Interaktion bietet das ADK auch eine Entwickler-UI, über die wir interagieren und prüfen können, was während der Interaktion passiert. Führen Sie den folgenden Befehl aus, um den lokalen Entwicklungsserver für die Benutzeroberfläche zu starten:
uv run adk web --port 8080
Es wird eine Ausgabe wie im folgenden Beispiel erzeugt. Das bedeutet, dass wir bereits auf die Weboberfläche zugreifen können.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Klicken Sie nun oben im Cloud Shell Editor auf die Schaltfläche Webvorschau und wählen Sie Vorschau auf Port 8080 aus, um die Vorschau aufzurufen.
Auf der folgenden Webseite können Sie oben links im Drop-down-Menü verfügbare Agents auswählen ( in unserem Fall sollte es expense_manager_agent sein) und mit dem Bot interagieren. Im linken Fenster werden während der Laufzeit des Agents viele Informationen zu den Protokolldetails angezeigt.
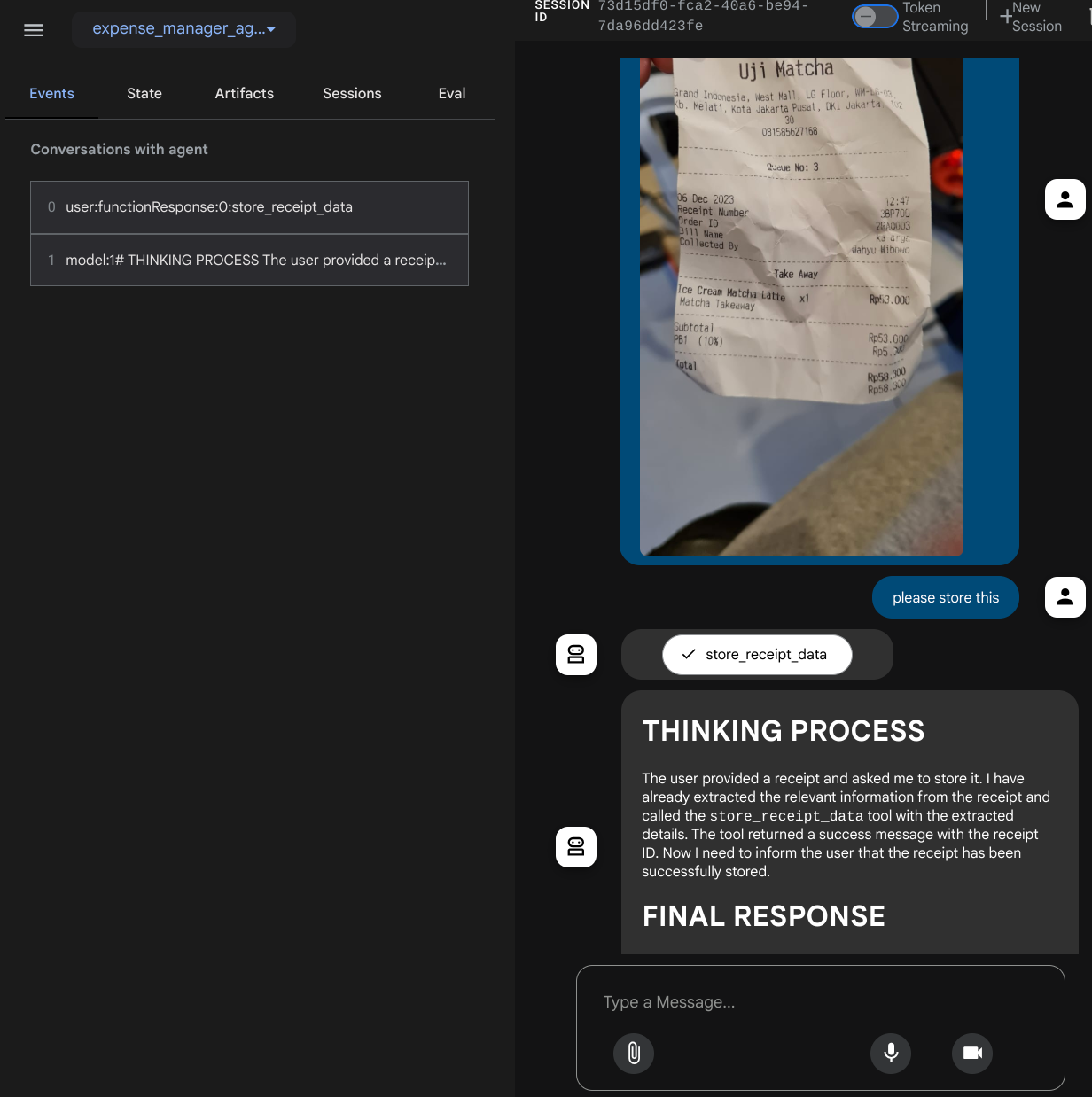
Probieren wir einige Aktionen aus. Laden Sie diese beiden Beispielbelege hoch ( Quelle : Hugging Face Datasets mousserlane/id_receipt_dataset) . Klicken Sie mit der rechten Maustaste auf die einzelnen Bilder und wählen Sie Bild speichern unter… aus. Dadurch wird das Bild des Belegs heruntergeladen. Laden Sie die Datei dann in den Bot hoch, indem Sie auf das Büroklammersymbol klicken und angeben, dass Sie diese Belege speichern möchten.


Versuchen Sie danach, mit den folgenden Anfragen zu suchen oder Dateien abzurufen.
- „Gib eine Aufschlüsselung der Ausgaben und die Gesamtausgaben für 2023 an.“
- „Gib mir die Belegdatei von Indomaret.“
Bei der Verwendung einiger Tools können Sie in der Entwickler-UI sehen, was passiert.
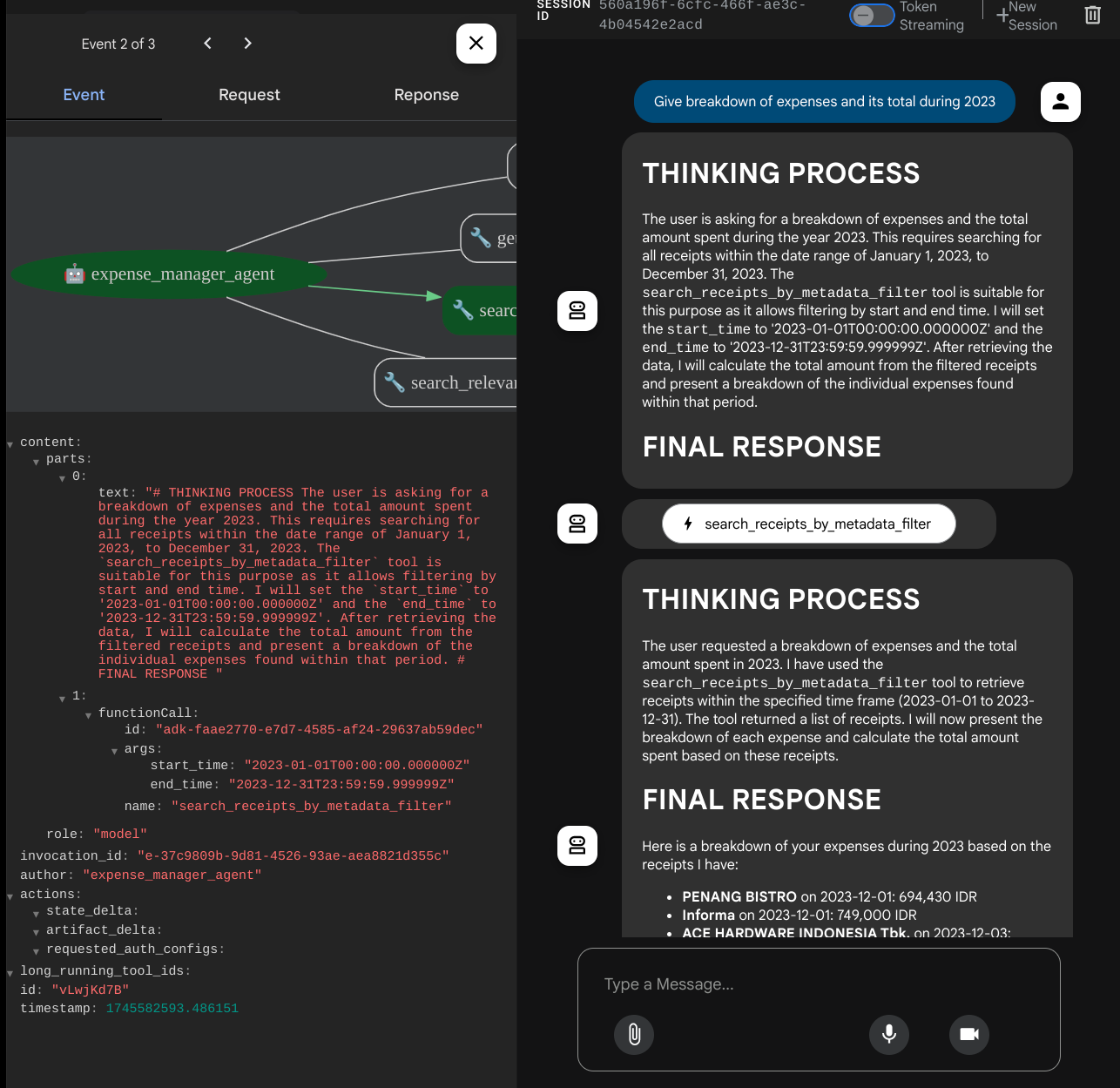
Sehen Sie sich an, wie der Agent auf Sie reagiert, und prüfen Sie, ob er alle Regeln einhält, die im Prompt in task_prompt.py angegeben sind. Glückwunsch! Sie haben jetzt einen vollständig funktionierenden Entwicklungs-Agent.
Jetzt ist es an der Zeit, die Benutzeroberfläche zu gestalten und Funktionen zum Hoch- und Herunterladen der Bilddatei zu implementieren.
8. 🚀 Frontend-Dienst mit Gradio erstellen
Wir erstellen eine Chat-Weboberfläche, die so aussieht:
Es enthält eine Chatoberfläche mit einem Eingabefeld, in dem Nutzer Text senden und die Bilddatei(en) des Belegs hochladen können.
Wir erstellen den Front-End-Dienst mit Gradio.
Erstellen Sie eine neue Datei mit dem Namen frontend.py.
touch frontend.py
Kopieren Sie dann den folgenden Code und speichern Sie ihn.
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Anschließend können wir versuchen, den Frontend-Dienst mit dem folgenden Befehl auszuführen. Vergessen Sie nicht, die Datei main.py in frontend.py umzubenennen.
uv run frontend.py
In der Cloud Console wird eine ähnliche Ausgabe angezeigt:
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Danach können Sie die Weboberfläche aufrufen, indem Sie Strg+Klick auf den lokalen URL-Link ausführen. Alternativ können Sie auch auf die Frontend-Anwendung zugreifen, indem Sie oben rechts im Cloud Editor auf die Schaltfläche Webvorschau klicken und Vorschau auf Port 8080 auswählen.
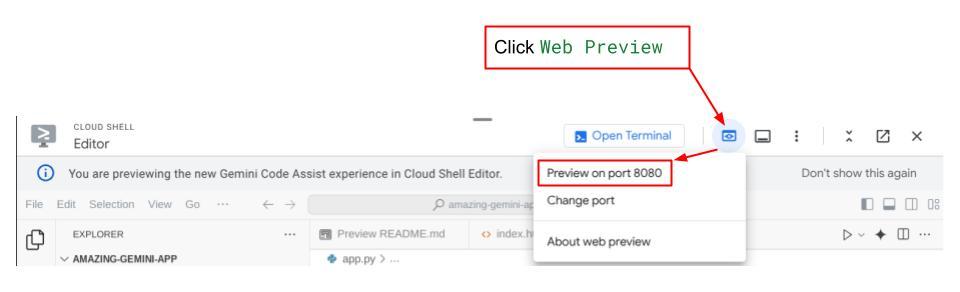
Sie sehen die Weboberfläche, erhalten aber einen erwarteten Fehler, wenn Sie versuchen, einen Chat zu senden, da der Backend-Dienst noch nicht eingerichtet ist.
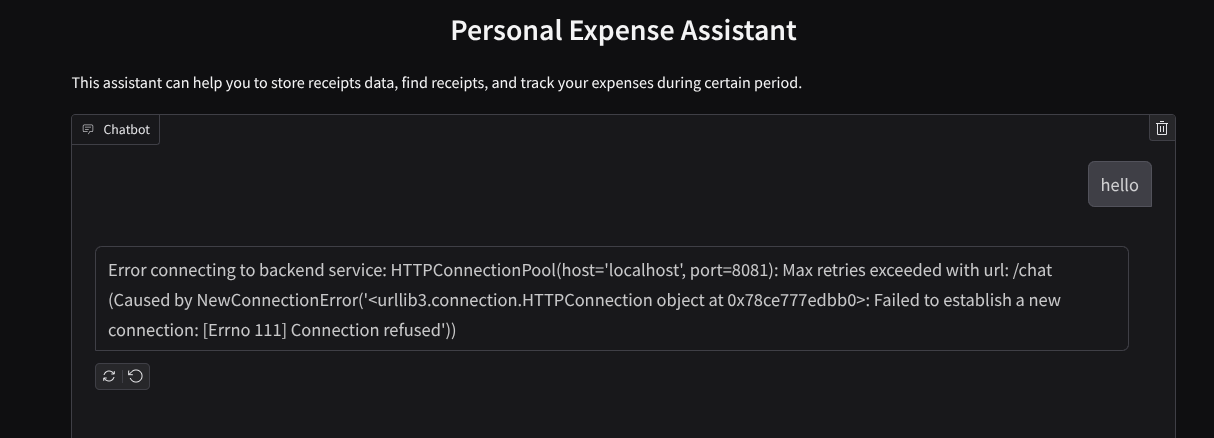
Lassen Sie den Dienst jetzt laufen und beenden Sie ihn noch nicht. Wir führen den Backend-Dienst auf einem anderen Terminaltab aus.
Erläuterung zum Code
In diesem Frontend-Code ermöglichen wir dem Nutzer zuerst, Text zu senden und mehrere Dateien hochzuladen. Mit Gradio können wir diese Art von Funktion mit der Methode gr.ChatInterface in Kombination mit gr.MultimodalTextbox erstellen.
Bevor wir die Datei und den Text an das Backend senden, müssen wir den MIME-Typ der Datei ermitteln, da er vom Backend benötigt wird. Außerdem müssen wir das Byte der Bilddatei in Base64 codieren und zusammen mit dem MIME-Typ senden.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
Das Schema, das für die Interaktion zwischen Frontend und Backend verwendet wird, ist in schema.py definiert. Wir verwenden Pydantic BaseModel, um die Datenvalidierung im Schema zu erzwingen.
Wenn wir die Antwort erhalten, trennen wir bereits den Denkprozess, die endgültige Antwort und die Anlage. So können wir die Gradio-Komponente verwenden, um jede Komponente mit der UI-Komponente darzustellen.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Backend-Dienst mit FastAPI erstellen
Als Nächstes müssen wir das Backend erstellen, das unseren Agenten zusammen mit den anderen Komponenten initialisieren kann, um die Agent-Laufzeit auszuführen.
Erstellen Sie eine neue Datei mit dem Namen backend.py.
touch backend.py
Kopieren Sie den folgenden Code.
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Danach können wir versuchen, den Backend-Dienst auszuführen. Im vorherigen Schritt haben wir den Frontend-Dienst ausgeführt. Jetzt müssen wir ein neues Terminal öffnen und versuchen, diesen Backend-Dienst auszuführen.
- Erstellen Sie ein neues Terminal. Gehen Sie unten zu Ihrem Terminal und suchen Sie nach der Schaltfläche „+“, um ein neues Terminal zu erstellen. Alternativ können Sie Strg + Umschalt + C drücken, um ein neues Terminal zu öffnen.

- Achten Sie darauf, dass Sie sich im Arbeitsverzeichnis personal-expense-assistant befinden, und führen Sie dann den folgenden Befehl aus:
uv run backend.py
- Bei Erfolg wird eine Ausgabe wie diese angezeigt:
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Erläuterung zum Code
ADK-Agent, SessionService und ArtifactService initialisieren
Damit der Agent im Backend-Dienst ausgeführt werden kann, müssen wir einen Runner erstellen, der sowohl den SessionService als auch unseren Agenten verwendet. SessionService verwaltet den Unterhaltungsverlauf und den Status. Wenn er also in Runner integriert ist, kann unser Agent den Kontext der laufenden Unterhaltungen empfangen.
Wir verwenden auch ArtifactService, um die hochgeladene Datei zu verarbeiten. Weitere Informationen zu ADK-Sitzungen und Artefakten finden Sie hier.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
In dieser Demo verwenden wir InMemorySessionService und GcsArtifactService, die in unseren Agent Runner integriert werden. Da der Unterhaltungsverlauf im Arbeitsspeicher gespeichert wird, geht er verloren, sobald der Backend-Dienst beendet oder neu gestartet wird. Wir initialisieren diese im FastAPI-Anwendungslebenszyklus, um sie als Abhängigkeit in die /chat-Route einzufügen.
Bild mit GcsArtifactService hochladen und herunterladen
Alle hochgeladenen Bilder werden vom GcsArtifactService als Artefakt gespeichert. Sie können dies in der Funktion format_user_request_to_adk_content_and_store_artifacts in utils.py prüfen.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Alle Anfragen, die vom Agent-Runner verarbeitet werden, müssen als types.Content formatiert werden. Innerhalb der Funktion verarbeiten wir auch die einzelnen Bilddaten und extrahieren die ID, die durch einen Platzhalter für die Bild-ID ersetzt werden soll.
Ein ähnlicher Mechanismus wird verwendet, um die Anhänge herunterzuladen, nachdem die Bild-IDs mit regulären Ausdrücken extrahiert wurden:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Integrationstest
Jetzt sollten mehrere Dienste in verschiedenen Cloud Console-Tabs ausgeführt werden:
- Frontend-Dienst wird an Port 8080 ausgeführt
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Backend-Dienst wird auf Port 8081 ausgeführt
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Sie sollten jetzt in der Lage sein, Ihre Belegbilder hochzuladen und nahtlos mit dem Assistenten über die Webanwendung auf Port 8080 zu chatten.
Klicken Sie oben im Cloud Shell Editor auf die Schaltfläche Webvorschau und wählen Sie Vorschau auf Port 8080 aus.
Jetzt interagieren wir mit dem Assistenten.
Laden Sie die folgenden Belege herunter. Der Zeitraum für diese Belegdaten liegt zwischen 2023 und 2024. Bitte den Assistenten, sie zu speichern/hochzuladen.
- Receipt Drive ( Quelle: Hugging Face-Datasets
mousserlane/id_receipt_dataset)
Verschiedene Dinge fragen
- „Gib mir eine monatliche Aufschlüsselung der Ausgaben für 2023–2024.“
- Zeig mir den Beleg für die Kaffeetransaktion
- „Gib mir die Belegdatei von Yakiniku Like.“
- ETC
Hier ist ein Ausschnitt einer erfolgreichen Interaktion:
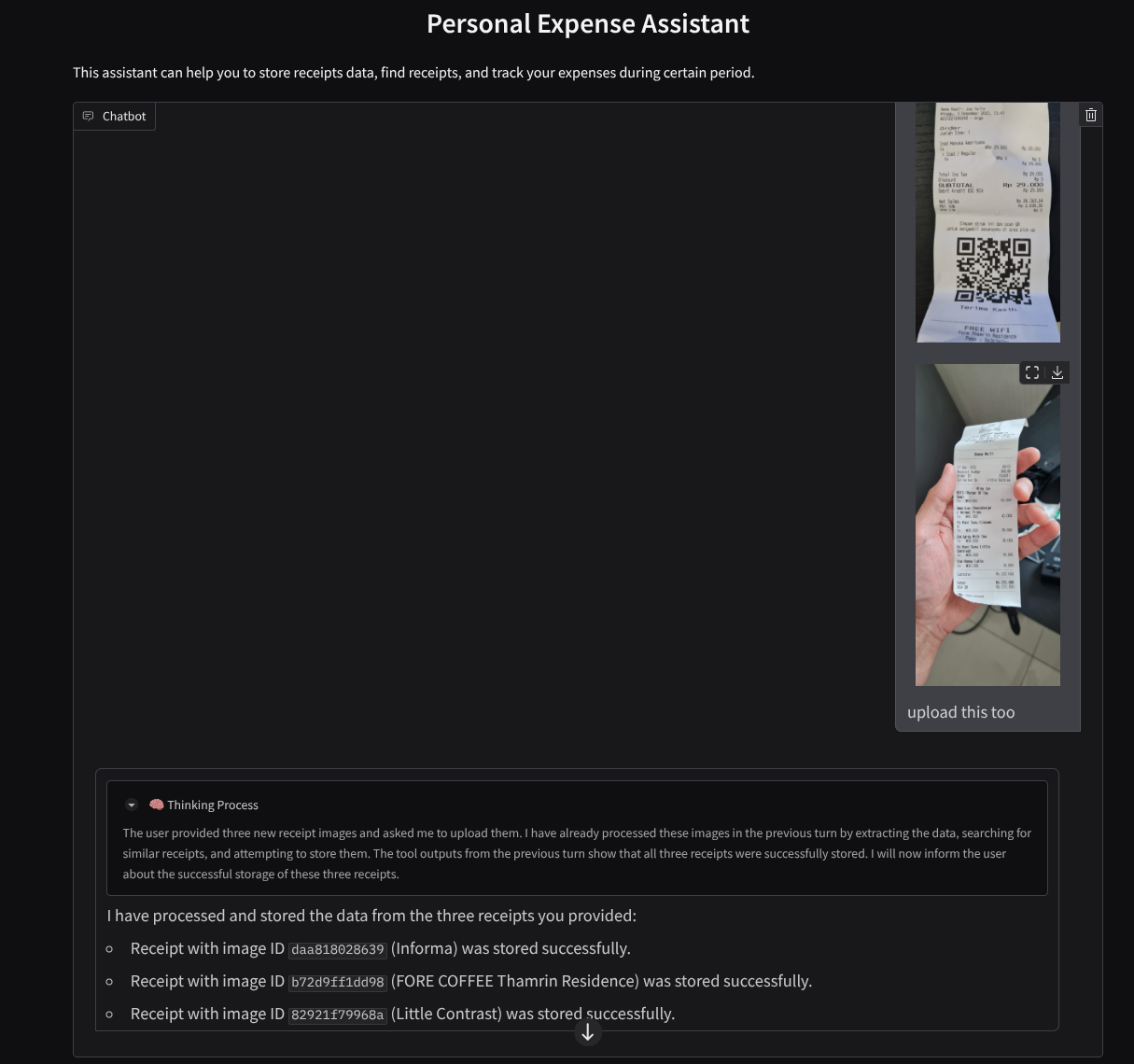
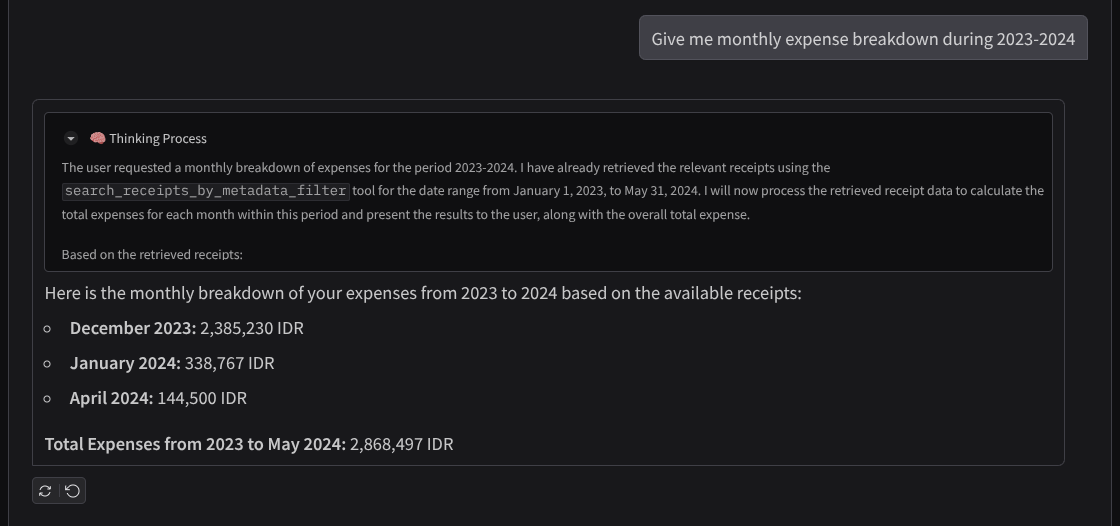
11. 🚀 In Cloud Run bereitstellen
Natürlich möchten wir von überall auf diese tolle App zugreifen können. Dazu können wir diese Anwendung verpacken und in Cloud Run bereitstellen. Im Rahmen dieser Demo wird dieser Dienst als öffentlicher Dienst bereitgestellt, auf den andere zugreifen können. Das ist jedoch nicht die beste Vorgehensweise für diese Art von Anwendung, da sie eher für private Anwendungen geeignet ist.
In diesem Codelab werden wir sowohl den Frontend- als auch den Backend-Dienst in einem Container unterbringen. Wir benötigen die Hilfe von supervisord, um beide Dienste zu verwalten. Sie können die Datei supervisord.conf und das Dockerfile ansehen, in dem wir supervisord als Einstiegspunkt festgelegt haben.
Wir haben jetzt alle Dateien, die zum Bereitstellen unserer Anwendungen in Cloud Run erforderlich sind. Stellen wir sie also bereit. Rufen Sie das Cloud Shell-Terminal auf und prüfen Sie, ob das aktuelle Projekt für Ihr aktives Projekt konfiguriert ist. Falls nicht, müssen Sie die Projekt-ID mit dem Befehl „gcloud configure“ festlegen:
gcloud config set project [PROJECT_ID]
Führen Sie dann den folgenden Befehl aus, um die Anwendung in Cloud Run bereitzustellen.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Wenn Sie aufgefordert werden, die Erstellung eines Artifact Registry-Repositorys für Docker zu bestätigen, antworten Sie einfach mit Y. Hinweis: Wir erlauben hier den nicht authentifizierten Zugriff, da es sich um eine Demoanwendung handelt. Wir empfehlen, für Ihre Unternehmens- und Produktionsanwendungen eine geeignete Authentifizierung zu verwenden.
Nach Abschluss der Bereitstellung sollten Sie einen Link ähnlich dem folgenden erhalten:
https://personal-expense-assistant-*******.us-central1.run.app
Sie können die Anwendung nun über das Inkognitofenster oder Ihr Mobilgerät verwenden. Sie sollte bereits aktiv sein.
12. 🎯 Herausforderung
Jetzt ist es an der Zeit, Ihr Wissen zu vertiefen und Ihre Fähigkeiten zu verbessern. Haben Sie das Zeug dazu, den Code so zu ändern, dass das Backend mehrere Nutzer unterstützen kann? Welche Komponenten müssen aktualisiert werden?
13. 🧹 Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
- Alternativ können Sie in der Console zu Cloud Run wechseln, den gerade bereitgestellten Dienst auswählen und löschen.