
1. 📖 Introducción
¿Alguna vez te frustraste y te dio pereza administrar todos tus gastos personales? A mí también. Por eso, en este codelab, crearemos un asistente personal para administrar gastos, potenciado por Gemini 2.5 para que haga todas las tareas por nosotros. Desde administrar los recibos subidos hasta analizar si ya gastaste demasiado para comprar un café
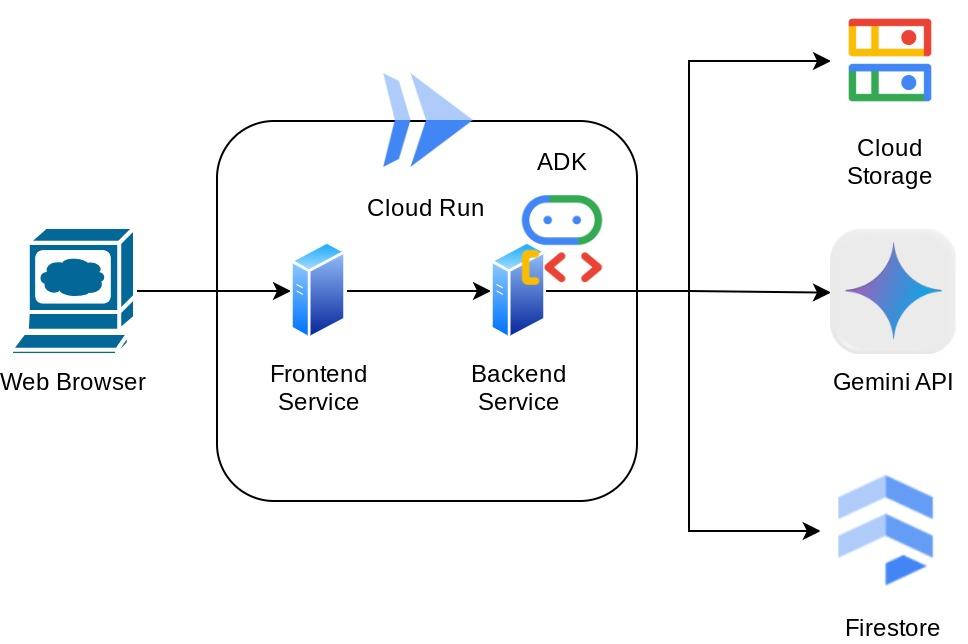
Se podrá acceder a este asistente a través del navegador web en forma de una interfaz web de chat, en la que podrás comunicarte con él, subir algunas imágenes de recibos y pedirle que las almacene, o tal vez quieras buscar algunos recibos para obtener el archivo y hacer un análisis de gastos. Todo esto se basa en el framework del Kit de desarrollo de agentes de Google.
La aplicación en sí está separada en 2 servicios: frontend y backend, lo que te permite compilar un prototipo rápido y probar cómo se siente, y también comprender cómo se ve el contrato de API para integrar ambos.
En el codelab, seguirás un enfoque paso a paso de la siguiente manera:
- Prepara tu proyecto de Google Cloud y habilita todas las APIs necesarias en él
- Configura el bucket en Google Cloud Storage y la base de datos en Firestore
- Crea la indexación de Firestore
- Configura el espacio de trabajo para tu entorno de programación
- Estructura del código fuente, las herramientas, las instrucciones, etc., del agente del ADK
- Prueba del agente con la IU web de desarrollo local del ADK
- Compila el servicio de frontend: interfaz de chat con la biblioteca Gradio para enviar algunas consultas y subir imágenes de recibos.
- Compila el servicio de backend: servidor HTTP con FastAPI, donde residen el código del agente del ADK, SessionService y Artifact Service.
- Administrar variables de entorno y configurar los archivos necesarios para implementar la aplicación en Cloud Run
- Implementa la aplicación en Cloud Run
Descripción general de la arquitectura
Requisitos previos
- Comodidad para trabajar con Python
- Conocimiento de la arquitectura básica de pila completa con el servicio HTTP
Qué aprenderás
- Prototipado web de frontend con Gradio
- Desarrollo de servicios de backend con FastAPI y Pydantic
- Diseño de la arquitectura del agente del ADK y aprovechamiento de sus diversas capacidades
- Uso de herramientas
- Administración de sesiones y artefactos
- Utilización de devolución de llamada para la modificación de la entrada antes de enviarla a Gemini
- Cómo usar BuiltInPlanner para mejorar la ejecución de tareas a través de la planificación
- Depuración rápida a través de la interfaz web local del ADK
- Estrategia para optimizar la interacción multimodal a través del análisis y la recuperación de información con la ingeniería de instrucciones y la modificación de solicitudes de Gemini con la devolución de llamada del ADK
- Generación mejorada por recuperación con agentes que usa Firestore como base de datos de vectores
- Administra variables de entorno en un archivo YAML con Pydantic-settings
- Implementa la aplicación en Cloud Run con Dockerfile y proporciona variables de entorno con un archivo YAML
Requisitos
- Navegador web Chrome
- Una cuenta de Gmail
- Un proyecto de Cloud con la facturación habilitada
Este codelab, diseñado para desarrolladores de todos los niveles (incluidos los principiantes), usa Python en su aplicación de ejemplo. Sin embargo, no es necesario tener conocimientos de Python para comprender los conceptos presentados.
2. 🚀 Antes de comenzar
Selecciona el proyecto activo en la consola de Cloud
En este codelab, se supone que ya tienes un proyecto de Google Cloud con la facturación habilitada. Si aún no la tienes, puedes seguir las instrucciones que se indican a continuación para comenzar.
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información sobre cómo verificar si la facturación está habilitada en un proyecto.
Prepara la base de datos de Firestore
A continuación, también deberemos crear una base de datos de Firestore. Firestore en modo nativo es una base de datos de documentos NoSQL creada para proporcionar ajuste de escala automático, alto rendimiento y facilidad de desarrollo de aplicaciones. También puede actuar como una base de datos de vectores que admita la técnica de generación aumentada por recuperación para nuestro lab.
- Busca "firestore" en la barra de búsqueda y haz clic en el producto de Firestore.
- Luego, haz clic en el botón Crear una base de datos de Firestore.
- Usa (predeterminado) como el nombre del ID de la base de datos y mantén seleccionada la Edición estándar. Para los fines de esta demostración del lab, usa Firestore Native con reglas de seguridad Open.
- También notarás que esta base de datos tiene el mensaje Free-tier Usage YEAY! Luego, haz clic en el botón Crear base de datos.
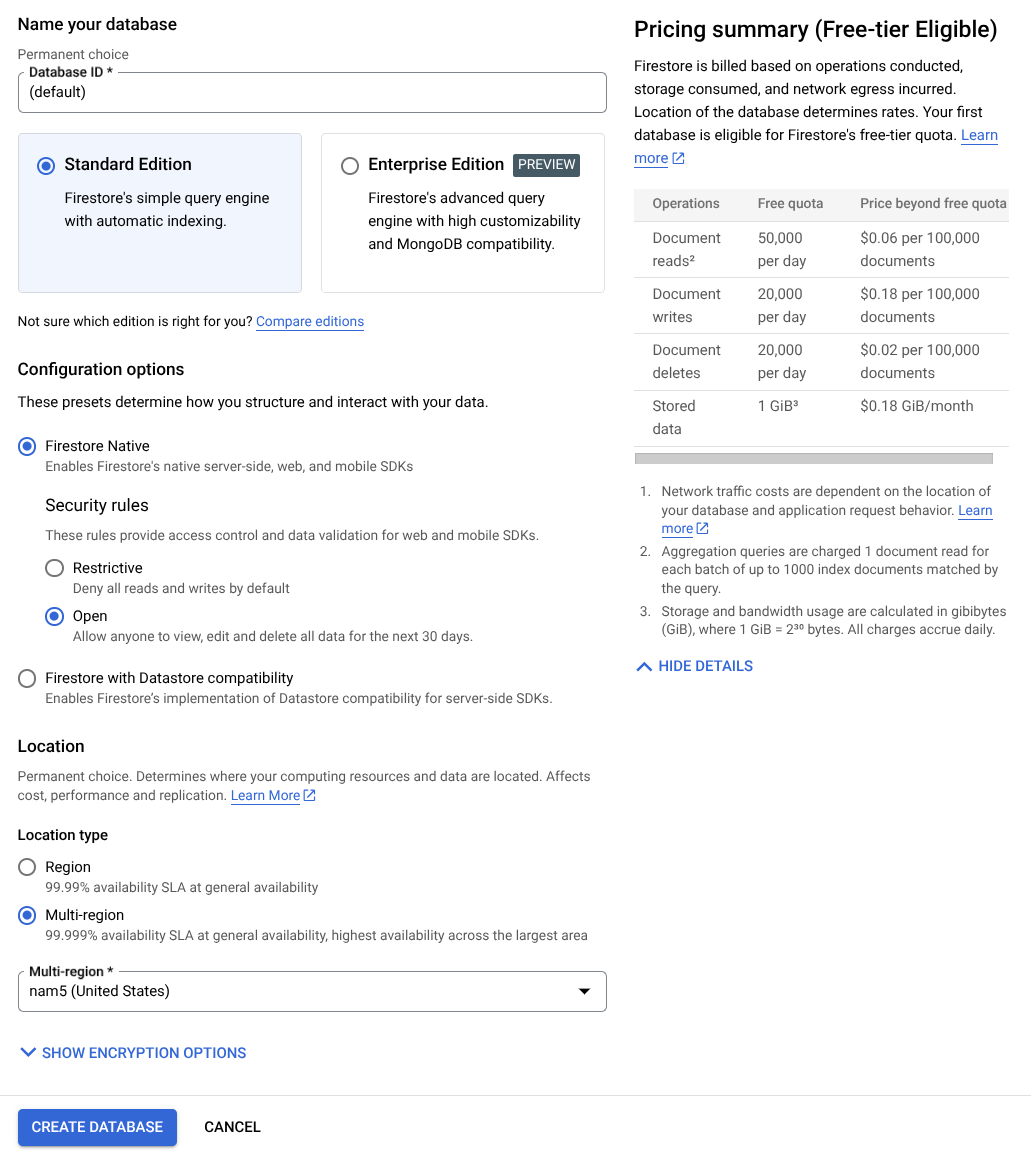
Después de seguir estos pasos, ya deberías haber sido redireccionado a la base de datos de Firestore que acabas de crear.
Configura el proyecto de Cloud en la terminal de Cloud Shell
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con bq. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
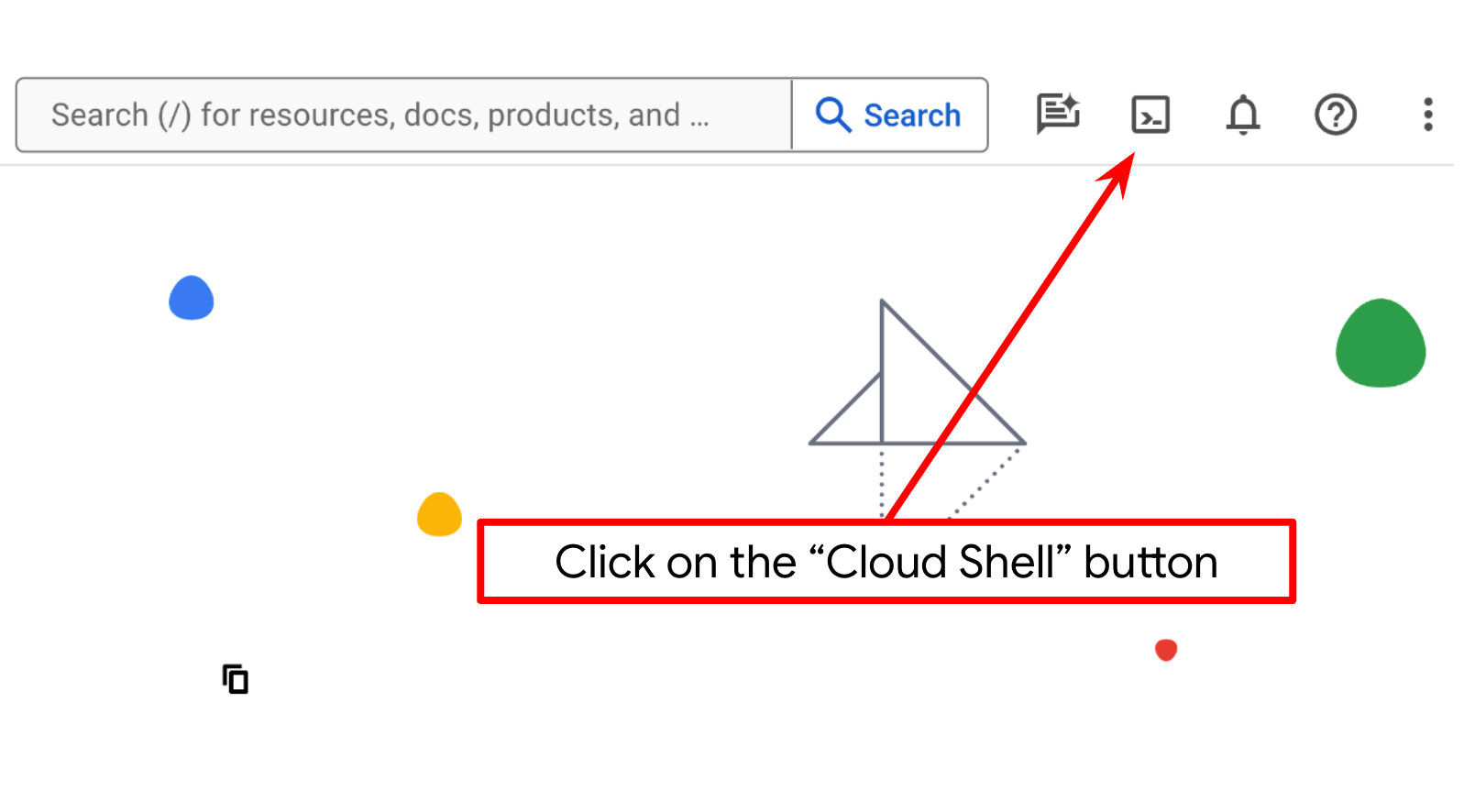
- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
Como alternativa, también puedes ver el ID de PROJECT_ID en la consola.
Haz clic en él y verás todos tus proyectos y el ID del proyecto en el lado derecho.
- Habilita las APIs requeridas con el comando que se muestra a continuación. Este proceso puede tardar unos minutos, así que ten paciencia.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Cuando el comando se ejecute correctamente, deberías ver un mensaje similar al que se muestra a continuación:
Operation "operations/..." finished successfully.
La alternativa al comando de gcloud es buscar cada producto en la consola o usar este vínculo.
Si olvidas alguna API, puedes habilitarla durante el proceso de implementación.
Consulta la documentación para ver los comandos y el uso de gcloud.
Prepara el bucket de Cloud Storage
A continuación, desde la misma terminal, deberemos preparar el bucket de GCS para almacenar el archivo subido. Ejecuta el siguiente comando para crear el bucket. Se necesitará un nombre de bucket único y pertinente para los recibos del asistente de gastos personales. Por lo tanto, utilizaremos el siguiente nombre de bucket combinado con tu ID del proyecto.
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Se mostrará este resultado
Creating gs://personal-expense-{your-project-id}
Para verificarlo, ve al menú de navegación en la parte superior izquierda del navegador y selecciona Cloud Storage -> Bucket.
Cómo crear un índice de Firestore para la búsqueda
Firestore es una base de datos NoSQL nativa que ofrece un rendimiento y una flexibilidad superiores en el modelo de datos, pero tiene limitaciones cuando se trata de consultas complejas. Como planeamos utilizar algunas búsquedas vectoriales y consultas compuestas de varios campos, primero tendremos que crear algunos índices. Puedes obtener más información en esta documentación.
- Ejecuta el siguiente comando para crear un índice que admita consultas compuestas:
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- Y ejecuta este para admitir la búsqueda de vectores
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
Para verificar el índice creado, visita Firestore en la consola de Cloud, haz clic en la instancia de base de datos (predeterminada) y selecciona Índices en la barra de navegación.
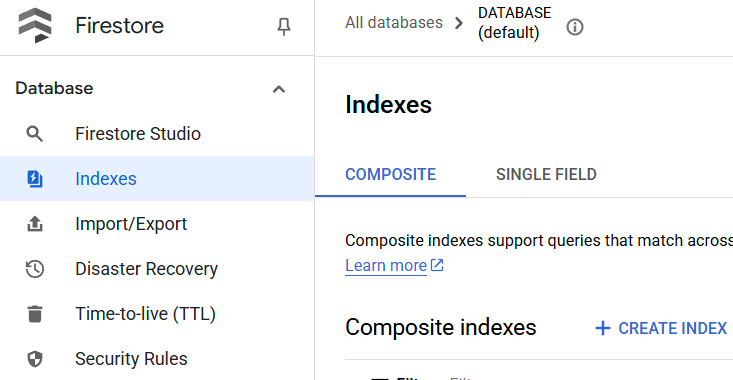
Ve al editor de Cloud Shell y configura el directorio de trabajo de la aplicación
Ahora, podemos configurar nuestro editor de código para hacer algunas cosas de programación. Usaremos el editor de Cloud Shell para esto.
- Haz clic en el botón Open Editor para abrir un editor de Cloud Shell en el que puedes escribir tu código
- A continuación, también debemos verificar si la shell ya está configurada con el ID DEL PROYECTO correcto que tienes. Si ves que hay un valor dentro de ( ) antes del ícono $ en la terminal ( en la captura de pantalla a continuación, el valor es "adk-multimodal-tool"), este valor muestra el proyecto configurado para tu sesión de shell activa.

Si el valor que se muestra ya es correcto, puedes omitir el siguiente comando. Sin embargo, si no es correcto o falta, ejecuta el siguiente comando:
gcloud config set project <YOUR_PROJECT_ID>
- A continuación, clonemos el directorio de trabajo de la plantilla para este codelab desde GitHub. Para ello, ejecuta el siguiente comando. Se creará el directorio de trabajo en el directorio personal-expense-assistant.
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- Después, ve a la sección superior del Editor de Cloud Shell y haz clic en File->Open Folder, busca tu directorio de nombre de usuario y el directorio personal-expense-assistant y, luego, haz clic en el botón OK. Esto convertirá el directorio elegido en el directorio de trabajo principal. En este ejemplo, el nombre de usuario es alvinprayuda, por lo que la ruta de acceso del directorio se muestra a continuación.

Ahora, tu editor de Cloud Shell debería verse así:
Configuración del entorno
Prepara el entorno virtual de Python
El siguiente paso es preparar el entorno de desarrollo. Tu terminal activa actual debe estar dentro del directorio de trabajo personal-expense-assistant. En este codelab, usaremos Python 3.12 y uv python project manager para simplificar la necesidad de crear y administrar la versión de Python y el entorno virtual.
- Si aún no abriste la terminal, haz clic en Terminal -> New Terminal o usa Ctrl + Mayúsculas + C para abrir una ventana de terminal en la parte inferior del navegador.

- Ahora , inicialicemos el entorno virtual con
uv. Ejecuta estos comandos:
cd ~/personal-expense-assistant
uv sync --frozen
Esto creará el directorio .venv y, luego, instalará las dependencias. Un vistazo rápido a pyproject.toml te brindará información sobre las dependencias que se muestran de esta manera:
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Configura archivos de configuración
Ahora, deberemos configurar los archivos de configuración para este proyecto. Usamos pydantic-settings para leer la configuración del archivo YAML.
Ya proporcionamos la plantilla de archivo dentro de settings.yaml.example. Deberemos copiar el archivo y cambiarle el nombre a settings.yaml. Ejecuta este comando para crear el archivo.
cp settings.yaml.example settings.yaml
Luego, copia el siguiente valor en el archivo:
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
Para este codelab, usaremos los valores preconfigurados para GCLOUD_LOCATION, BACKEND_URL, y DB_COLLECTION_NAME .
Ahora podemos pasar al siguiente paso, que es compilar el agente y, luego, los servicios.
3. 🚀 Compila el agente con el ADK de Google y Gemini 2.5
Introducción a la estructura de directorios del ADK
Comencemos por explorar lo que el ADK tiene para ofrecer y cómo compilar el agente. Puedes acceder a la documentación completa del ADK en esta URL . El ADK nos ofrece muchas utilidades dentro de la ejecución de su comando de CLI. Algunos de ellos son los siguientes :
- Configura la estructura del directorio del agente
- Probar rápidamente la interacción a través de la entrada y salida de la CLI
- Configura rápidamente la interfaz web de la IU de desarrollo local
Ahora, crearemos la estructura de directorios del agente con el comando de la CLI. Ejecuta el siguiente comando.
uv run adk create expense_manager_agent
Cuando se te solicite, elige el modelo gemini-2.5-flash y el backend Vertex AI. Luego, el asistente te pedirá el ID del proyecto y la ubicación. Puedes presionar Intro para aceptar las opciones predeterminadas o cambiarlas según sea necesario. Solo verifica que estés usando el ID del proyecto correcto que creaste anteriormente en este lab. El resultado se verá así:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Se creará la siguiente estructura de directorios del agente
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Si inspeccionas init.py y agent.py, verás este código:
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Ahora puedes probarlo ejecutando
uv run adk run expense_manager_agent
Cuando termines de probar el agente, puedes salir de él escribiendo exit o presionando Ctrl+D.
Cómo crear nuestro agente de Expense Manager
Creemos nuestro agente de administración de gastos. Abre el archivo expense_manager_agent/agent.py y copia el siguiente código que contendrá el root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Explicación del código
Este script contiene la inicialización de nuestro agente, en la que inicializamos los siguientes elementos:
- Establece el modelo que se usará en
gemini-2.5-flash - Configura la descripción y las instrucciones del agente como la instrucción del sistema que se lee desde
task_prompt.md. - Proporciona las herramientas necesarias para admitir la funcionalidad del agente
- Habilita la planificación antes de generar la respuesta final o la ejecución con las capacidades de pensamiento de Gemini 2.5 Flash
- Configura la interceptación de devolución de llamada antes de enviar la solicitud a Gemini para limitar la cantidad de datos de imagen enviados antes de realizar la predicción.
4. 🚀 Configura las herramientas del agente
Nuestro agente de administración de gastos tendrá las siguientes capacidades:
- Extraer datos de la imagen del recibo y almacenar los datos y el archivo
- Búsqueda exacta en los datos de gastos
- Búsqueda contextual en los datos de gastos
Por lo tanto, necesitamos las herramientas adecuadas para admitir esta funcionalidad. Crea un archivo nuevo en el directorio expense_manager_agent y asígnale el nombre tools.py.
touch expense_manager_agent/tools.py
Abre expense_manage_agent/tools.py y, luego, copia el siguiente código:
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Explicación del código
En esta implementación de la función de herramientas, diseñamos las herramientas en torno a estas 2 ideas principales:
- Analiza los datos del recibo y asígnalos al archivo original con el marcador de posición de cadena del ID de imagen
[IMAGE-ID <hash-of-image-1>] - Almacenamiento y recuperación de datos con la base de datos de Firestore
Herramienta "store_receipt_data"
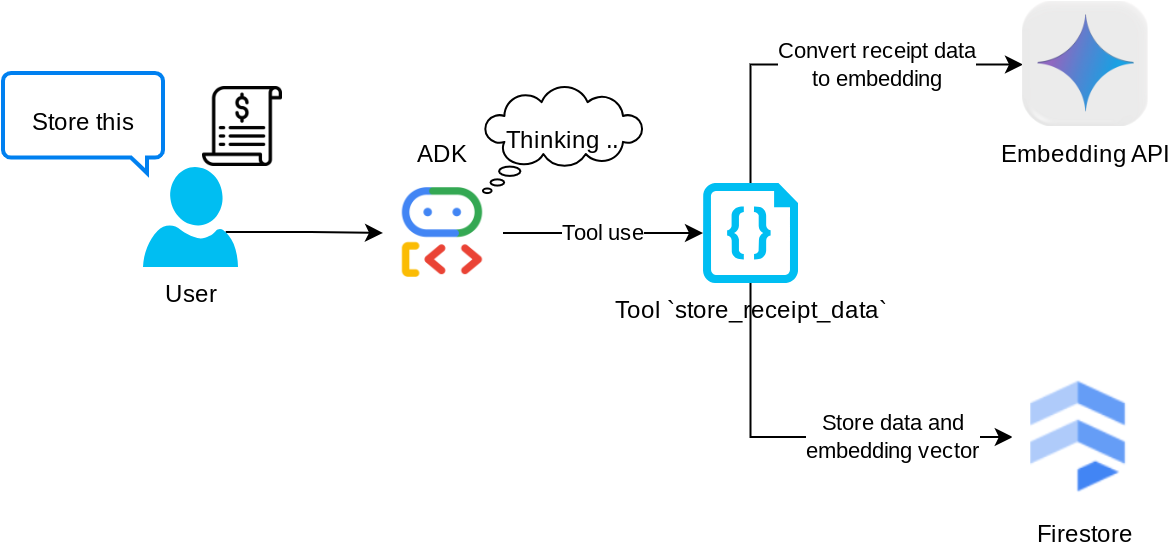
Esta herramienta es la de reconocimiento óptico de caracteres, que analizará la información requerida de los datos de la imagen, reconocerá la cadena del ID de la imagen y las asignará para que se almacenen en la base de datos de Firestore.
Además, esta herramienta también convierte el contenido del recibo en una incorporación con text-embedding-004 para que todos los metadatos y la incorporación se almacenen y se indexen juntos. Permite recuperar la flexibilidad a través de la búsqueda contextual o por consulta.
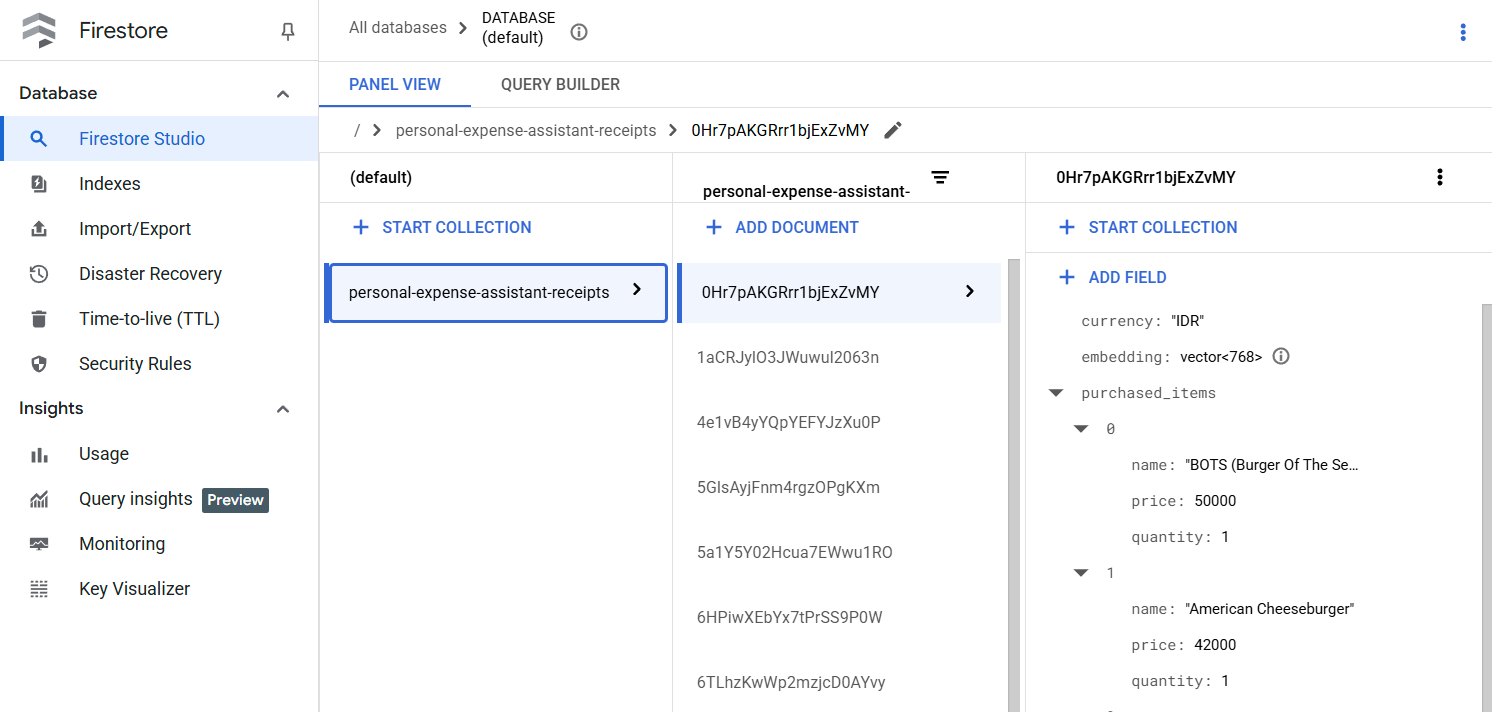
Después de ejecutar esta herramienta correctamente, puedes ver que los datos del recibo ya están indexados en la base de datos de Firestore, como se muestra a continuación.
Herramienta "search_receipts_by_metadata_filter"
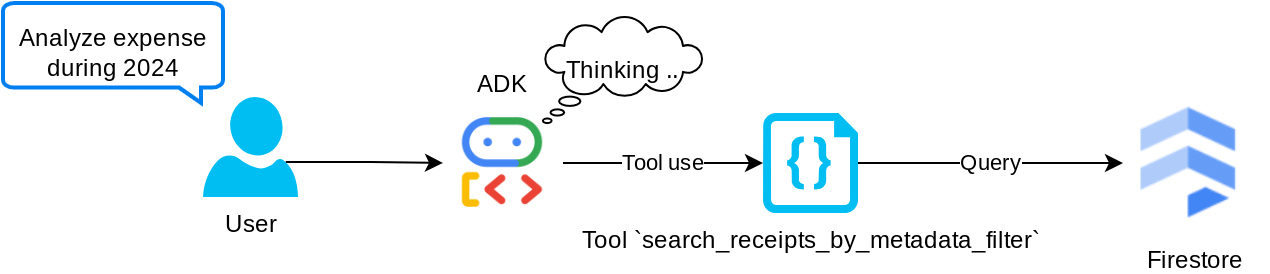
Esta herramienta convierte la búsqueda del usuario en un filtro de búsqueda de metadatos que admite la búsqueda por rango de fechas o transacción total. Devolverá todos los datos de recibos coincidentes, y, en el proceso, descartaremos el campo de incorporación, ya que el agente no lo necesita para la comprensión contextual.
Herramienta "search_relevant_receipts_by_natural_language_query"
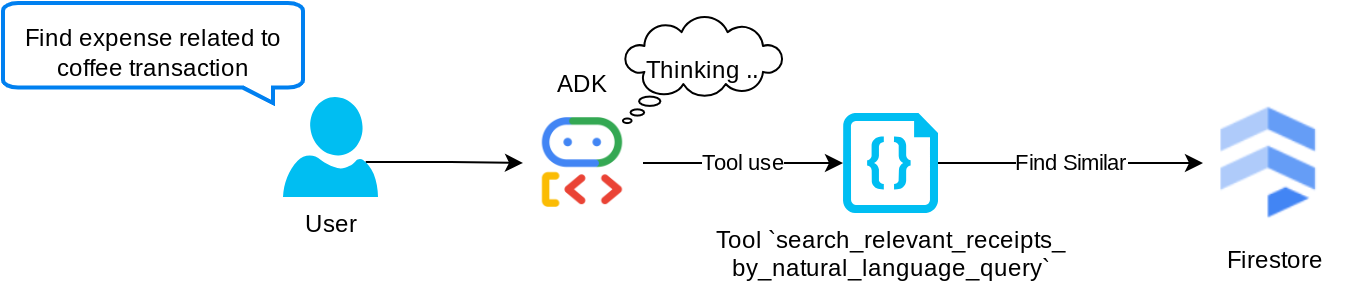
Esta es nuestra herramienta de generación mejorada por recuperación (RAG). Nuestro agente tiene la capacidad de diseñar su propia consulta para recuperar recibos relevantes de la base de datos de vectores y también puede elegir cuándo usar esta herramienta. La idea de permitir que el agente tome decisiones independientes sobre si usará esta herramienta de RAG o no y diseñe su propia búsqueda es una de las definiciones del enfoque de RAG agentic.
No solo le permitimos crear su propia búsqueda, sino que también le permitimos seleccionar cuántos documentos relevantes desea recuperar. Combinado con una ingeniería de instrucciones adecuada, p.ej.,
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Esto hará que la herramienta sea poderosa y capaz de buscar casi cualquier cosa, aunque es posible que no devuelva todos los resultados esperados debido a la naturaleza no exacta de la búsqueda de vecinos más cercanos.
5. 🚀 Modificación del contexto de la conversación a través de devoluciones de llamadas
El ADK de Google nos permite "interceptar" el tiempo de ejecución del agente en varios niveles. Puedes obtener más información sobre esta capacidad detallada en esta documentación . En este lab, utilizamos before_model_callback para modificar la solicitud antes de enviarla al LLM y quitar los datos de imágenes del contexto del historial de conversaciones anterior ( solo se incluyen los datos de imágenes de las últimas 3 interacciones del usuario) para mejorar la eficiencia.
Sin embargo, queremos que el agente tenga el contexto de los datos de la imagen cuando sea necesario. Por lo tanto, agregamos un mecanismo para agregar un marcador de posición de ID de imagen de cadena después de cada dato de bytes de imagen en la conversación. Esto ayudará al agente a vincular el ID de la imagen con los datos reales del archivo, que se pueden utilizar tanto en el momento del almacenamiento como de la recuperación de la imagen. La estructura se verá de la siguiente manera:
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
Además, cuando los datos de bytes se vuelven obsoletos en el historial de conversación, el identificador de cadena sigue presente para permitir el acceso a los datos con la ayuda del uso de herramientas. Ejemplo de la estructura del historial después de quitar los datos de imágenes
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
¡Comencemos! Crea un archivo nuevo en el directorio expense_manager_agent y asígnale el nombre callbacks.py.
touch expense_manager_agent/callbacks.py
Abre el archivo expense_manager_agent/callbacks.py y, luego, copia el siguiente código:
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 La instrucción
Para diseñar un agente con capacidades y una interacción complejas, debemos encontrar una instrucción lo suficientemente buena para guiar al agente de modo que se comporte de la manera que queremos.
Anteriormente, teníamos un mecanismo para controlar los datos de imágenes en el historial de conversaciones y también herramientas que podrían no ser fáciles de usar, como search_relevant_receipts_by_natural_language_query.. También queremos que el agente pueda buscar y recuperar la imagen del recibo correcta. Esto significa que debemos transmitir toda esta información de forma adecuada en una estructura de instrucción correcta.
Le pediremos al agente que estructure el resultado en el siguiente formato de Markdown para analizar el proceso de pensamiento, la respuesta final y el adjunto ( si corresponde).
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Comencemos con la siguiente instrucción para lograr nuestra expectativa inicial del comportamiento del agente de administración de gastos. El archivo task_prompt.md ya debería existir en nuestro directorio de trabajo existente, pero debemos moverlo al directorio expense_manager_agent. Ejecuta el siguiente comando para moverlo:
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Prueba del agente
Ahora, intentemos comunicarnos con el agente a través de la CLI. Para ello, ejecuta el siguiente comando:
uv run adk run expense_manager_agent
Se mostrará un resultado como este, en el que puedes chatear con el agente por turnos, pero solo puedes enviar texto a través de esta interfaz.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
Ahora, además de la interacción con la CLI, el ADK también nos permite tener una IU de desarrollo para interactuar y analizar lo que sucede durante la interacción. Ejecuta el siguiente comando para iniciar el servidor de la IU de desarrollo local:
uv run adk web --port 8080
Se generará un resultado similar al siguiente ejemplo, lo que significa que ya podemos acceder a la interfaz web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
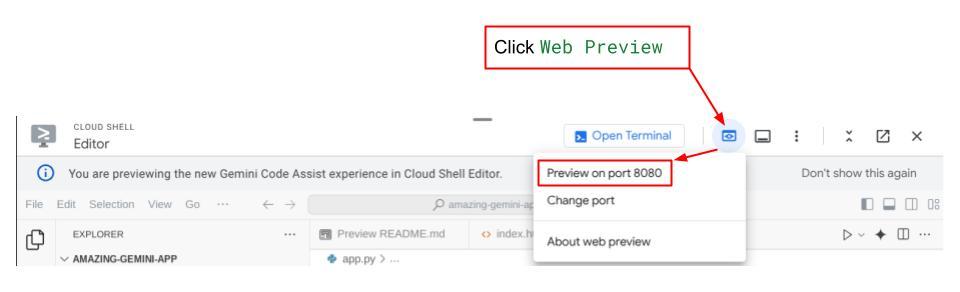
Ahora, para verificarlo, haz clic en el botón Vista previa en la Web en la parte superior del editor de Cloud Shell y selecciona Vista previa en el puerto 8080.
Verás la siguiente página web en la que puedes seleccionar los agentes disponibles en el botón del menú desplegable de la esquina superior izquierda ( en nuestro caso, debería ser expense_manager_agent) y, luego, interactuar con el bot. En la ventana de la izquierda, verás mucha información sobre los detalles del registro durante el tiempo de ejecución del agente.
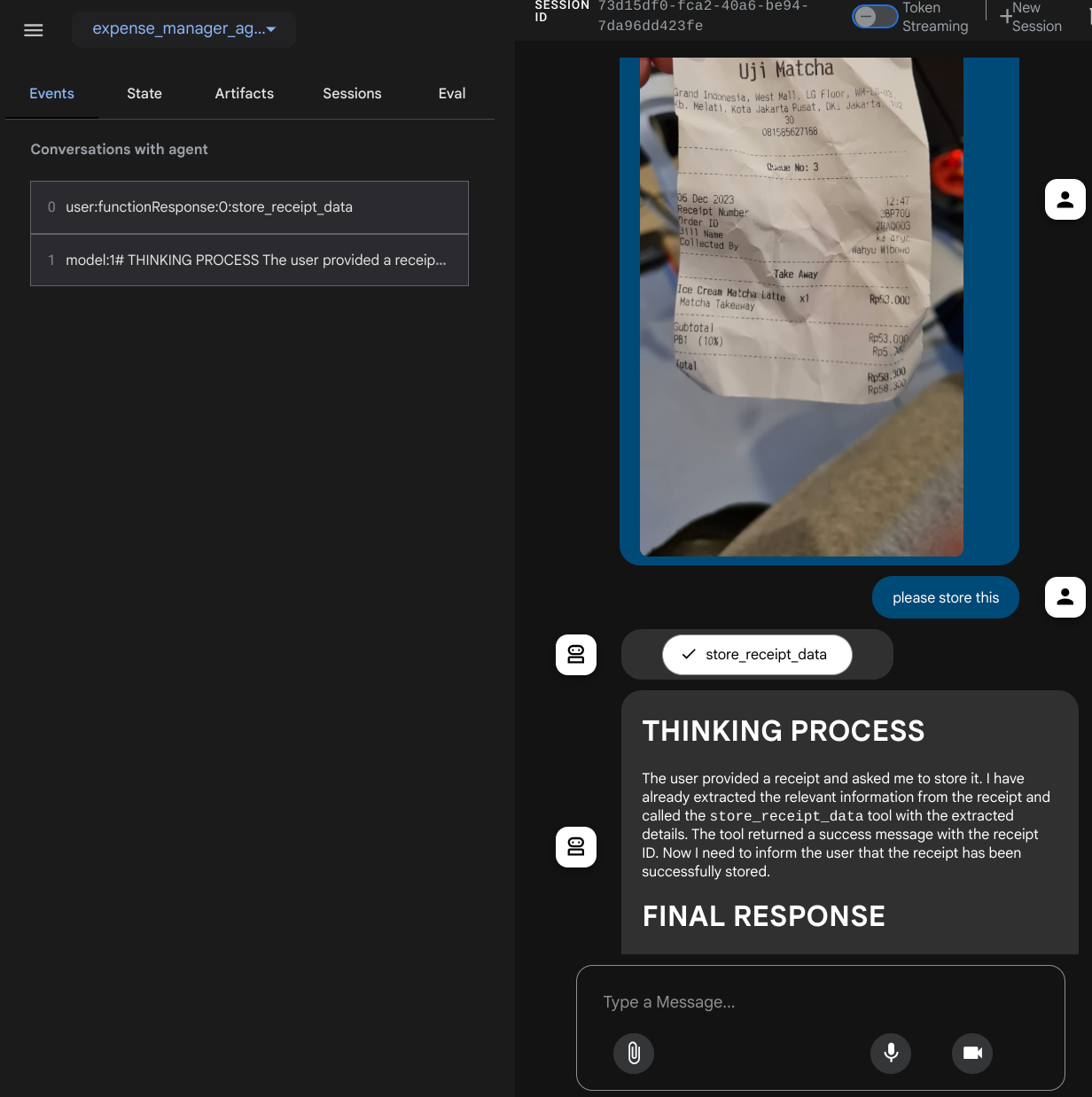
Probemos algunas acciones. Sube estos 2 recibos de ejemplo ( fuente : conjuntos de datos de Hugging Face mousserlane/id_receipt_dataset) . Haz clic con el botón derecho en cada imagen y selecciona Guardar imagen como… ( se descargará la imagen del recibo). Luego, haz clic en el ícono de "clip" y sube el archivo al bot. Indica que quieres almacenar esos recibos.


Después, prueba las siguientes consultas para realizar búsquedas o recuperar archivos.
- "Desglosa los gastos y su total durante el 2023".
- "Dame el archivo de recibo de Indomaret".
Cuando usas algunas herramientas, puedes inspeccionar lo que sucede en la IU de desarrollo.
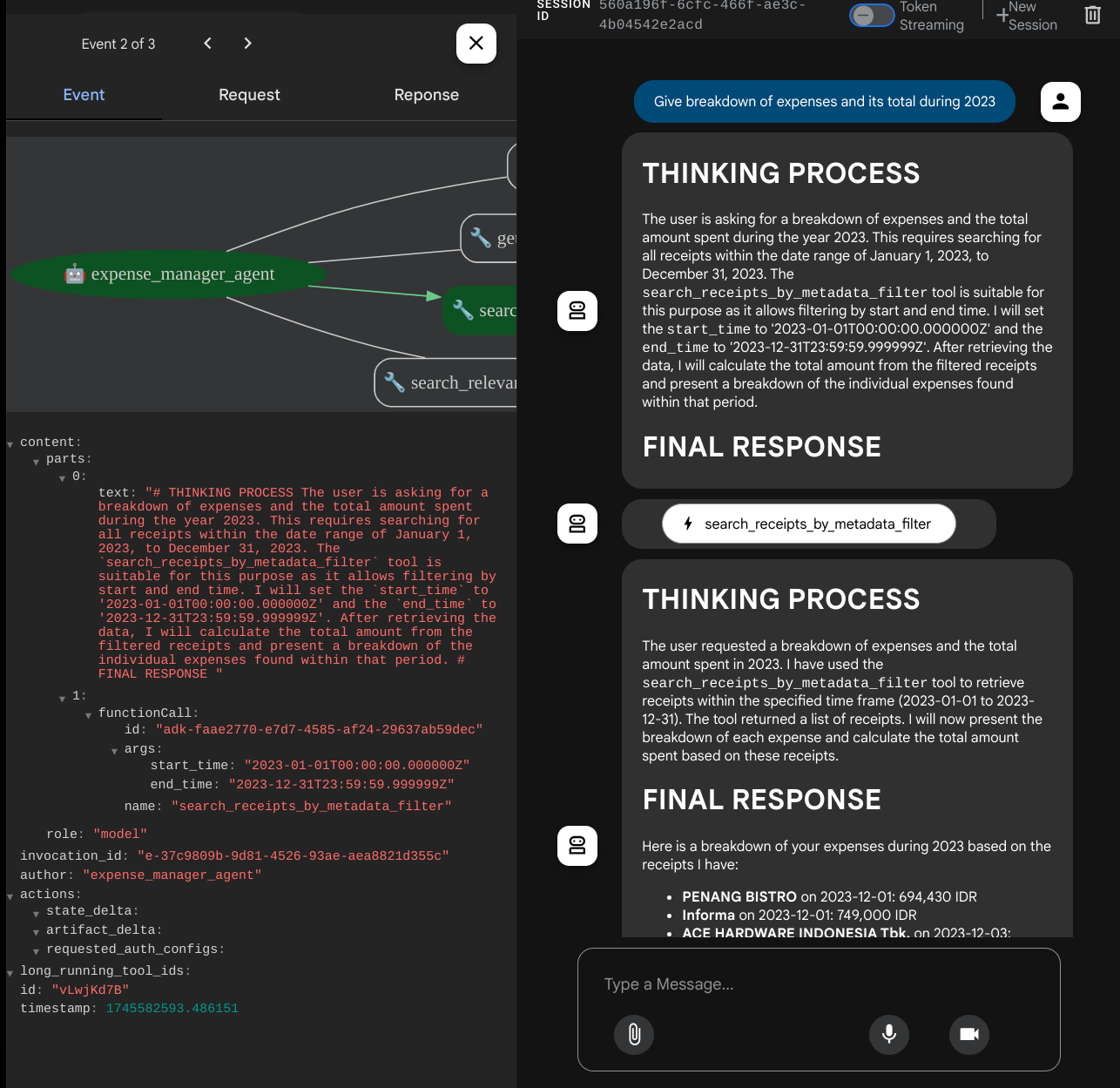
Observa cómo te responde el agente y verifica si cumple con todas las reglas proporcionadas en la instrucción dentro de task_prompt.py. ¡Felicitaciones! Ahora tienes un agente de desarrollo completo y en funcionamiento.
Ahora es momento de completarlo con una IU y capacidades adecuadas y agradables para subir y descargar el archivo de imagen.
8. 🚀 Compila el servicio de frontend con Gradio
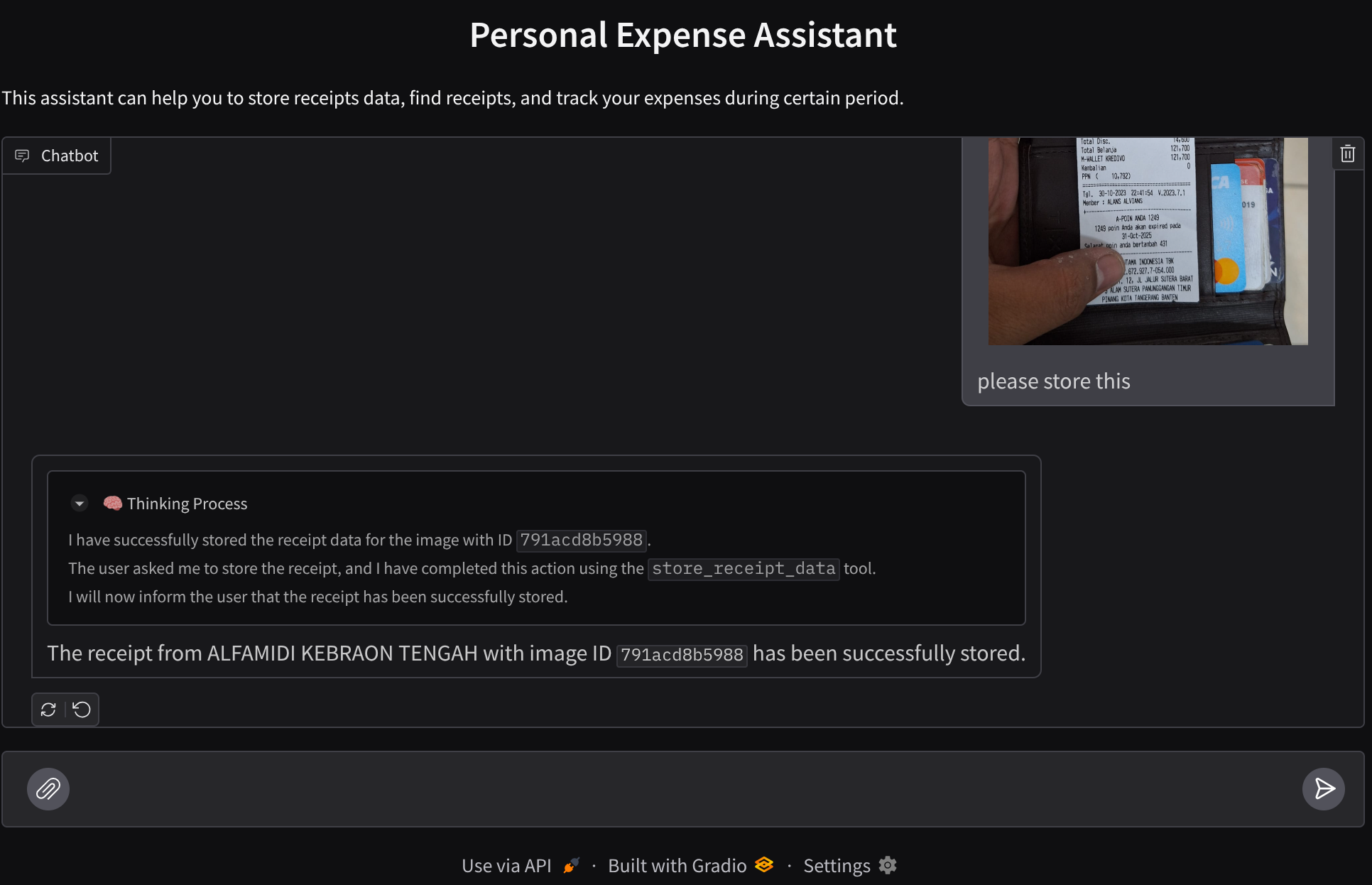
Compilaremos una interfaz web de chat que se verá así:
Contiene una interfaz de chat con un campo de entrada para que los usuarios envíen texto y suban los archivos de imagen de los recibos.
Compilaremos el servicio de frontend con Gradio.
Crea un archivo nuevo y asígnale el nombre frontend.py.
touch frontend.py
Luego, copia el siguiente código y guárdalo.
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Después, podemos intentar ejecutar el servicio de frontend con el siguiente comando. No olvides cambiar el nombre del archivo main.py a frontend.py.
uv run frontend.py
Verás un resultado similar a este en tu consola de Cloud
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Después, puedes verificar la interfaz web cuando presiones Ctrl y hagas clic en el vínculo de la URL local. También puedes acceder a la aplicación de frontend haciendo clic en el botón Vista previa en la Web en la parte superior derecha del editor de Cloud y seleccionando Vista previa en el puerto 8080.
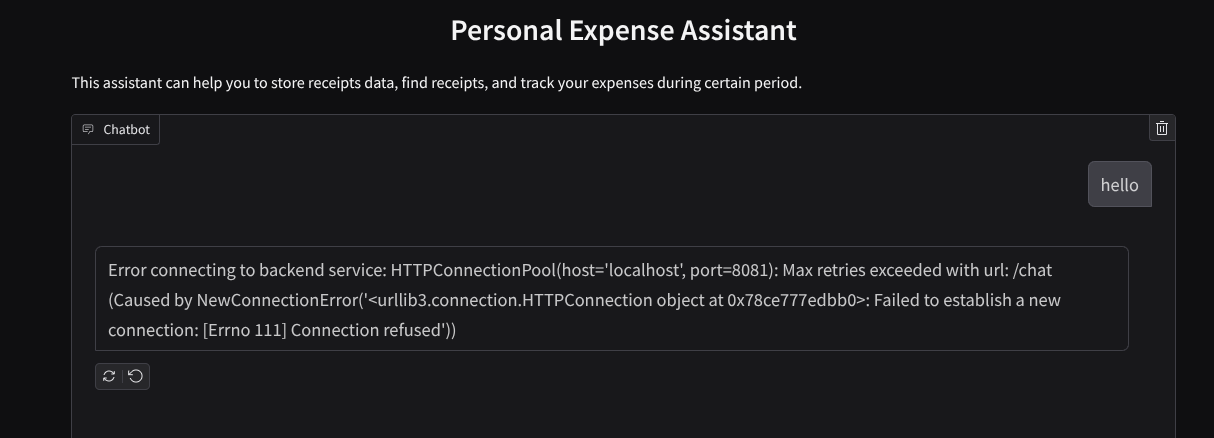
Verás la interfaz web, pero recibirás un error esperado cuando intentes enviar el chat debido a que el servicio de backend aún no está configurado.
Ahora, deja que el servicio se ejecute y no lo detengas todavía. Ejecutaremos el servicio de backend en otra pestaña de la terminal
Explicación del código
En este código de frontend, primero habilitamos al usuario para que envíe texto y suba varios archivos. Gradio nos permite crear este tipo de funcionalidad con el método gr.ChatInterface combinado con gr.MultimodalTextbox.
Ahora, antes de enviar el archivo y el texto al backend, debemos determinar el tipo de MIME del archivo, ya que el backend lo necesita. También debemos codificar el byte del archivo de imagen en base64 y enviarlo junto con el tipo de MIME.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
El esquema que se usa para la interacción entre el frontend y el backend se define en schema.py. Utilizamos Pydantic BaseModel para aplicar la validación de datos en el esquema.
Cuando recibimos la respuesta, ya separamos qué parte es el proceso de pensamiento, la respuesta final y el adjunto. Por lo tanto, podemos utilizar el componente Gradio para mostrar cada componente con el componente de IU.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Compila un servicio de backend con FastAPI
A continuación, tendremos que compilar el backend que puede inicializar nuestro agente junto con los demás componentes para poder ejecutar el tiempo de ejecución del agente.
Crea un archivo nuevo y asígnale el nombre backend.py.
touch backend.py
Copia el siguiente código:
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Después de eso, podemos intentar ejecutar el servicio de backend. Recuerda que, en el paso anterior, ejecutamos el servicio de frontend correctamente. Ahora, deberemos abrir una nueva terminal y tratar de ejecutar este servicio de backend.
- Crea una terminal nueva. Navega a la terminal en el área inferior y busca el botón "+" para crear una terminal nueva. También puedes presionar Ctrl + Mayúsculas + C para abrir una terminal nueva.

- Después de eso, asegúrate de estar en el directorio de trabajo personal-expense-assistant y, luego, ejecuta el siguiente comando:
uv run backend.py
- Si se ejecuta de forma correcta, se mostrará un resultado como el siguiente:
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Explicación del código
Inicialización de ADK Agent, SessionService y ArtifactService
Para ejecutar el agente en el servicio de backend, deberemos crear un ejecutor que tome tanto SessionService como nuestro agente. SessionService administrará el historial y el estado de la conversación, por lo que, cuando se integre con Runner, le dará a nuestro agente la capacidad de recibir el contexto de las conversaciones en curso.
También usamos ArtifactService para controlar el archivo subido. Puedes leer más detalles sobre la sesión y los artefactos del ADK aquí.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
En esta demostración, usamos InMemorySessionService y GcsArtifactService para integrarlos en nuestro Runner del agente. Como el historial de conversación se almacena en la memoria, se perderá una vez que se detenga o reinicie el servicio de backend. Inicializamos estos elementos dentro del ciclo de vida de la aplicación FastAPI para que se inserten como dependencia en la ruta /chat.
Cómo subir y descargar imágenes con GcsArtifactService
Todas las imágenes subidas se almacenarán como artefactos en GcsArtifactService. Puedes verificar esto en la función format_user_request_to_adk_content_and_store_artifacts dentro de utils.py.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Todas las solicitudes que procesará el ejecutor de agentes deben tener el formato del tipo types.Content. Dentro de la función, también procesamos cada dato de imagen y extraemos su ID para sustituirlo por un marcador de posición de ID de imagen.
Se emplea un mecanismo similar para descargar los archivos adjuntos después de extraer los IDs de las imágenes con regex:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Prueba de integración
Ahora, deberías tener varios servicios ejecutándose en diferentes pestañas de la consola de Cloud:
- El servicio de frontend se ejecuta en el puerto 8080
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- El servicio de backend se ejecuta en el puerto 8081
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
En el estado actual, deberías poder subir las imágenes de tus recibos y chatear sin problemas con el asistente desde la aplicación web en el puerto 8080.
Haz clic en el botón Vista previa en la Web en la parte superior del editor de Cloud Shell y selecciona Vista previa en el puerto 8080.
Ahora, interactuemos con el asistente.
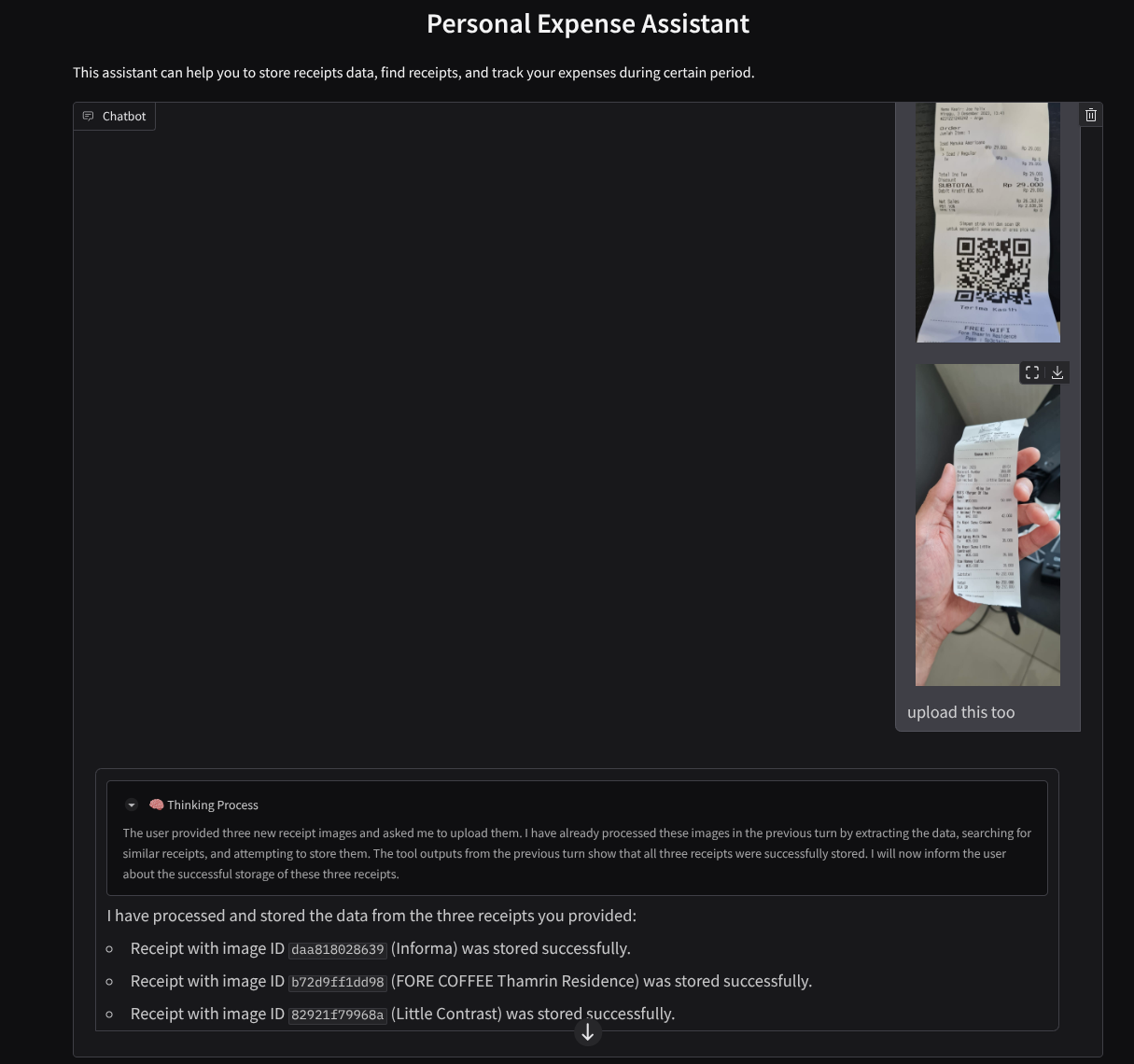
Descarga los siguientes recibos. El período de estos datos de recibos abarca los años 2023 y 2024, y se le pide al asistente que los almacene o suba.
- Receipt Drive ( fuente de conjuntos de datos de Hugging Face
mousserlane/id_receipt_dataset)
Preguntar varias cosas
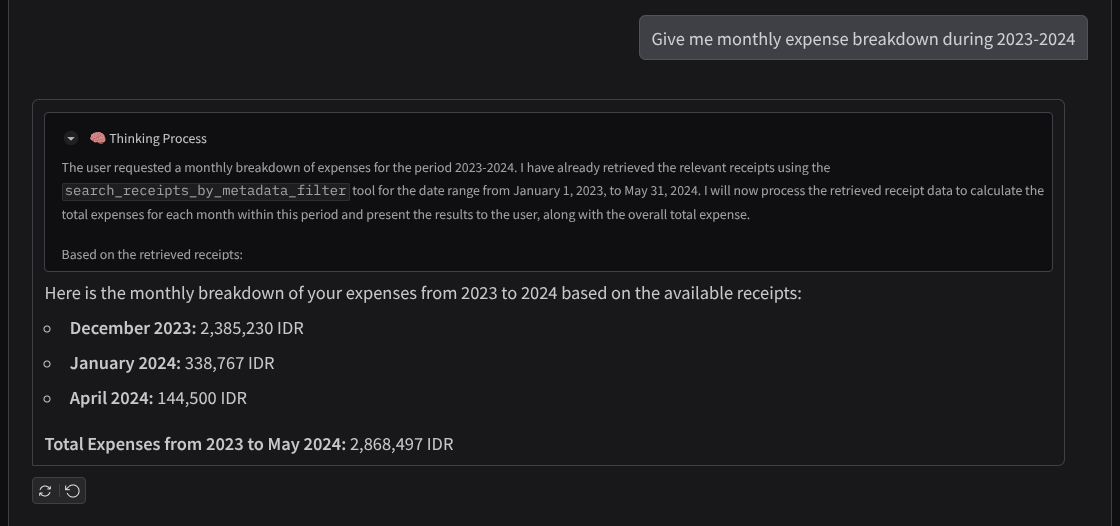
- “Dame un desglose de los gastos mensuales entre 2023 y 2024”.
- Muéstrame el recibo de la transacción de café.
- "Dame el archivo de recibo de Yakiniku Like".
- Etc.
A continuación, se muestra un fragmento de una interacción exitosa:
11. 🚀 Implementación en Cloud Run
Por supuesto, queremos acceder a esta increíble app desde cualquier lugar. Para ello, podemos empaquetar esta aplicación y, luego, implementarla en Cloud Run. Para los fines de esta demostración, este servicio se expondrá como un servicio público al que pueden acceder otras personas. Sin embargo, ten en cuenta que esta no es la mejor práctica para este tipo de aplicación, ya que es más adecuada para aplicaciones personales.
En este codelab, colocaremos el servicio de frontend y el de backend en 1 contenedor. Necesitaremos la ayuda de supervisord para administrar ambos servicios. Puedes inspeccionar el archivo supervisord.conf y verificar el Dockerfile en el que configuramos supervisord como el punto de entrada.
En este punto, ya tenemos todos los archivos necesarios para implementar nuestras aplicaciones en Cloud Run. Implementémosla. Navega a la terminal de Cloud Shell y asegúrate de que el proyecto actual esté configurado en tu proyecto activo. Si no es así, usa el comando gcloud config para establecer el ID del proyecto:
gcloud config set project [PROJECT_ID]
Luego, ejecuta el siguiente comando para implementarlo en Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Si se te solicita que confirmes la creación de un registro de artefactos para el repositorio de Docker, responde Y. Ten en cuenta que permitimos el acceso no autenticado aquí porque se trata de una aplicación de demostración. Se recomienda usar la autenticación adecuada para tus aplicaciones empresariales y de producción.
Una vez que se complete la implementación, deberías obtener un vínculo similar al siguiente:
https://personal-expense-assistant-*******.us-central1.run.app
Continúa y usa tu aplicación desde la ventana de incógnito o tu dispositivo móvil. Ya debería estar disponible.
12. 🎯 Desafío
Ahora es tu momento de brillar y pulir tus habilidades de exploración. ¿Tienes lo que se necesita para cambiar el código de modo que el backend pueda admitir varios usuarios? ¿Qué componentes deben actualizarse?
13. 🧹 Limpieza
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este codelab:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
- Como alternativa, puedes ir a Cloud Run en la consola, seleccionar el servicio que acabas de implementar y borrarlo.