
1. 📖 Introduction
Vous êtes-vous déjà senti frustré et trop paresseux pour gérer toutes vos dépenses personnelles ? Moi aussi ! C'est pourquoi, dans cet atelier de programmation, nous allons créer un assistant de gestion des dépenses personnelles, optimisé par Gemini 2.5, pour faire toutes les tâches à notre place. Gérez les reçus importés pour analyser si vous avez déjà dépensé trop d'argent pour acheter un café.
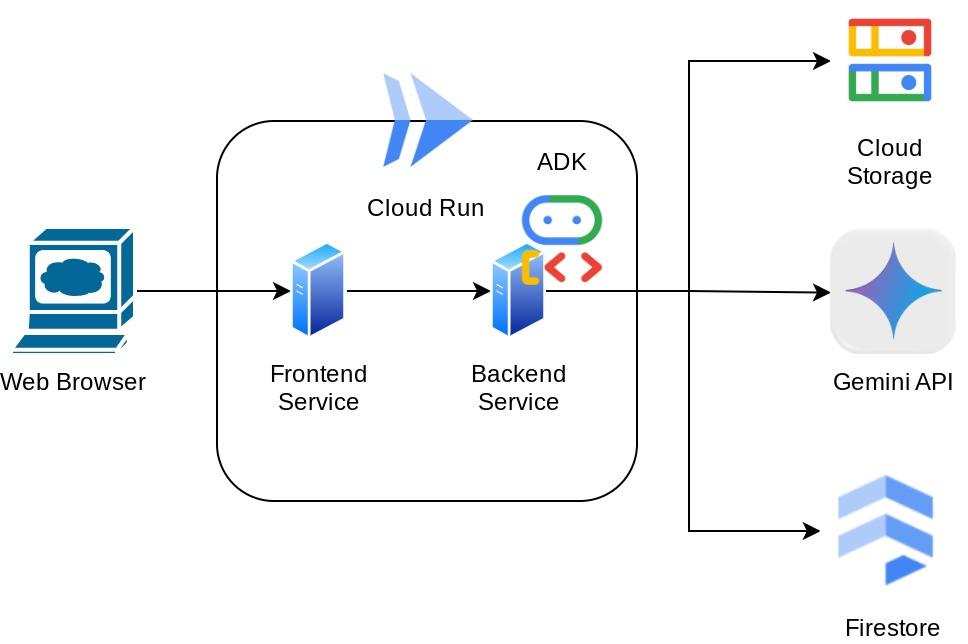
Cet assistant sera accessible via un navigateur Web sous la forme d'une interface Web de chat. Vous pourrez communiquer avec lui, importer des images de reçus et lui demander de les stocker, ou encore rechercher des reçus pour obtenir le fichier et effectuer une analyse des dépenses. Tout cela est basé sur le framework Google Agent Development Kit.
L'application elle-même est divisée en deux services : frontend et backend. Cela vous permet de créer un prototype rapide et de le tester, mais aussi de comprendre à quoi ressemble le contrat d'API pour les intégrer tous les deux.
Dans cet atelier de programmation, vous allez suivre une approche par étapes :
- Préparez votre projet Google Cloud et activez toutes les API requises.
- Configurer un bucket sur Google Cloud Storage et une base de données sur Firestore
- Créer l'indexation Firestore
- Configurer un espace de travail pour votre environnement de programmation
- Structurer le code source, les outils, les invites, etc. de l'agent ADK
- Tester l'agent à l'aide de l'UI de développement Web local de l'ADK
- Créez le service d'interface utilisateur (interface de chat) à l'aide de la bibliothèque Gradio pour envoyer des requêtes et importer des images de reçus.
- Créez le service de backend (serveur HTTP) à l'aide de FastAPI, où résident notre code d'agent ADK, SessionService et Artifact Service.
- Gérer les variables d'environnement et configurer les fichiers requis pour déployer l'application sur Cloud Run
- Déployer l'application sur Cloud Run
Présentation de l'architecture
Prérequis
- Vous êtes à l'aise avec Python.
- Comprendre l'architecture full stack de base à l'aide du service HTTP
Points abordés
- Prototyper une interface Web avec Gradio
- Développement de services de backend avec FastAPI et Pydantic
- Concevoir un agent ADK en utilisant ses différentes fonctionnalités
- Utilisation des outils
- Gestion des sessions et des artefacts
- Utilisation du rappel pour la modification des entrées avant l'envoi à Gemini
- Utiliser BuiltInPlanner pour améliorer l'exécution des tâches en planifiant
- Débogage rapide via l'interface Web locale ADK
- Stratégie pour optimiser l'interaction multimodale via l'analyse et la récupération d'informations à l'aide de l'ingénierie des prompts et de la modification des requêtes Gemini à l'aide du rappel ADK
- Génération augmentée par récupération agentique à l'aide de Firestore comme base de données vectorielle
- Gérer les variables d'environnement dans un fichier YAML avec Pydantic-settings
- Déployer une application sur Cloud Run à l'aide d'un fichier Dockerfile et fournir des variables d'environnement avec un fichier YAML
Prérequis
- Navigateur Web Chrome
- Un compte Gmail
- Un projet Cloud pour lequel la facturation est activée
Cet atelier de programmation, conçu pour les développeurs de tous niveaux (y compris les débutants), utilise Python dans son exemple d'application. Toutefois, vous n'avez pas besoin de maîtriser Python pour comprendre les concepts présentés.
2. 🚀 Avant de commencer
Sélectionner le projet actif dans la console Cloud
Cet atelier de programmation suppose que vous disposez déjà d'un projet Google Cloud pour lequel la facturation est activée. Si vous ne l'avez pas encore, vous pouvez suivre les instructions ci-dessous pour commencer.
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Préparer la base de données Firestore
Nous devrons ensuite créer une base de données Firestore. Firestore en mode natif est une base de données de documents NoSQL conçue pour le scaling automatique, les hautes performances et la convivialité de développement des applications. Il peut également servir de base de données vectorielle pour prendre en charge la technique de génération augmentée par récupération dans notre laboratoire.
- Recherchez firestore dans la barre de recherche, puis cliquez sur le produit Firestore.
- Cliquez ensuite sur le bouton Create A Firestore Database (Créer une base de données Firestore).
- Utilisez (par défaut) comme nom d'ID de base de données et conservez l'option Édition Standard sélectionnée. Pour la démonstration de cet atelier, utilisez Firestore Native avec des règles de sécurité ouvertes.
- Vous remarquerez également que cette base de données dispose de la fonctionnalité YEAY ! Utilisation du niveau sans frais. Cliquez ensuite sur le bouton Créer une base de données.
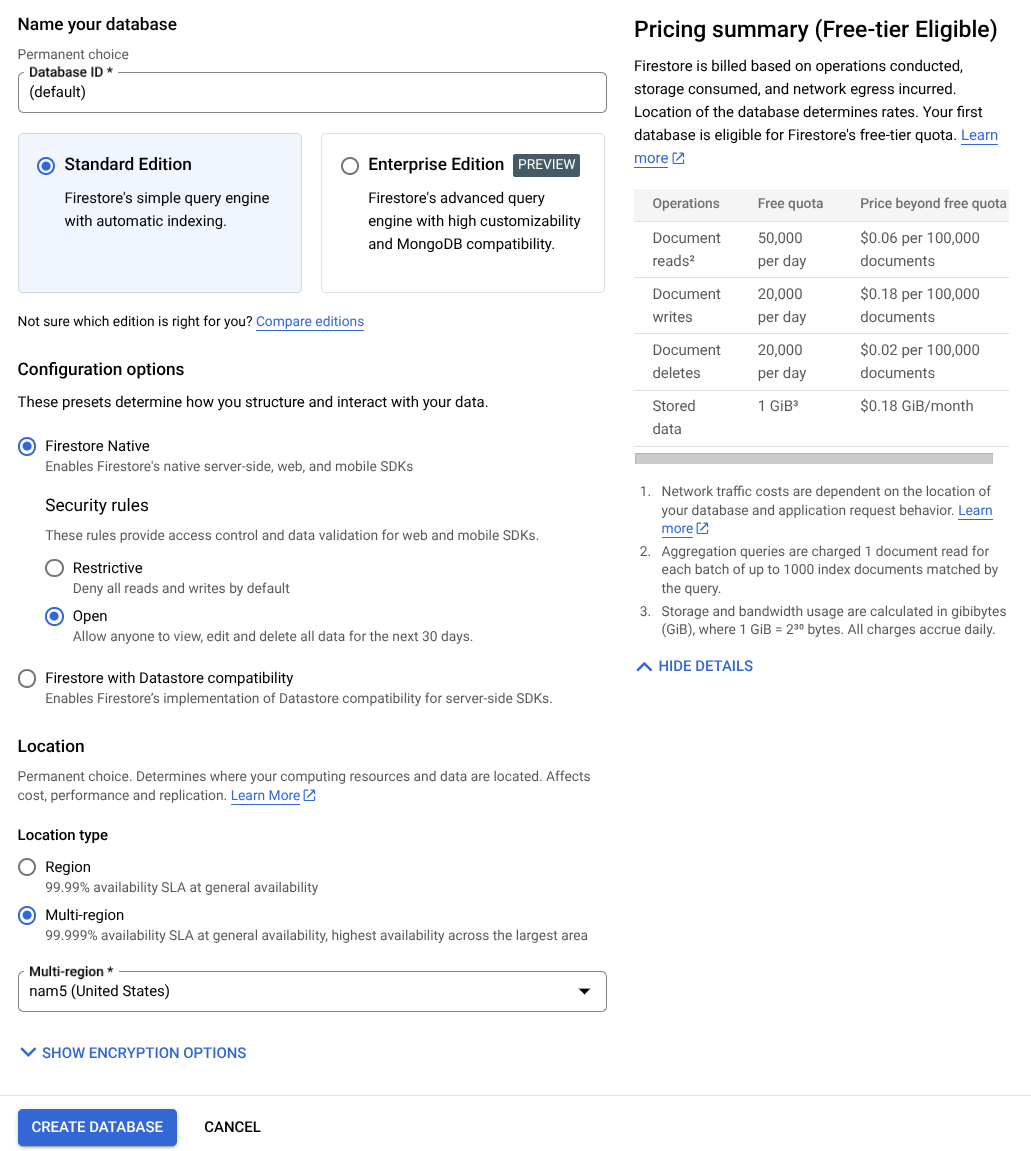
Après ces étapes, vous devriez déjà être redirigé vers la base de données Firestore que vous venez de créer.
Configurer un projet Cloud dans le terminal Cloud Shell
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud et fourni avec bq. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.
- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
Vous pouvez également voir l'ID PROJECT_ID dans la console.
Cliquez dessus pour afficher tous vos projets et l'ID du projet sur la droite.
- Activez les API requises à l'aide de la commande ci-dessous. Cette opération peut prendre quelques minutes. Merci de patienter.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Si la commande s'exécute correctement, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
Vous pouvez également accéder à la console en recherchant chaque produit ou en utilisant ce lien.
Si vous oubliez d'activer une API, vous pourrez toujours le faire au cours de l'implémentation.
Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
Préparer le bucket Google Cloud Storage
Ensuite, à partir du même terminal, nous devrons préparer le bucket GCS pour stocker le fichier importé. Exécutez la commande suivante pour créer le bucket. Vous aurez besoin d'un nom de bucket unique et pertinent pour les reçus de l'assistant de dépenses personnelles. Nous utiliserons donc le nom de bucket suivant combiné à l'ID de votre projet.
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Le résultat suivant s'affiche :
Creating gs://personal-expense-{your-project-id}
Pour le vérifier, accédez au menu de navigation en haut à gauche du navigateur et sélectionnez Cloud Storage > Bucket.
Créer un index Firestore pour la recherche
Firestore est une base de données NoSQL native qui offre des performances et une flexibilité supérieures en termes de modèle de données, mais qui présente des limites en ce qui concerne les requêtes complexes. Comme nous prévoyons d'utiliser des requêtes multifield complexes et la recherche vectorielle, nous devrons d'abord créer des index. Pour en savoir plus, consultez cette documentation.
- Exécutez la commande suivante pour créer un index permettant d'accepter les requêtes composées.
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- Exécutez celui-ci pour prendre en charge la recherche vectorielle.
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
Vous pouvez vérifier l'index créé en accédant à Firestore dans la console Cloud, en cliquant sur l'instance de base de données (par défaut), puis en sélectionnant Index dans la barre de navigation.
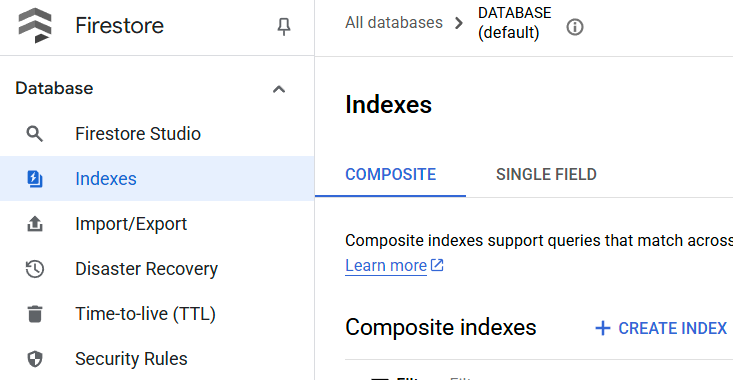
Accéder à l'éditeur Cloud Shell et configurer le répertoire de travail de l'application
Nous pouvons maintenant configurer notre éditeur de code pour effectuer certaines tâches de codage. Pour cela, nous allons utiliser l'éditeur Cloud Shell.
- Cliquez sur le bouton "Ouvrir l'éditeur". Un éditeur Cloud Shell s'ouvre. Vous pouvez y écrire votre code
 .
. - Ensuite, nous devons également vérifier si le shell est déjà configuré avec le bon ID DE PROJET. Si une valeur est indiquée entre parenthèses avant l'icône $ dans le terminal (dans la capture d'écran ci-dessous, la valeur est "adk-multimodal-tool"), cela indique le projet configuré pour votre session de shell active.

Si la valeur affichée est déjà correcte, vous pouvez ignorer la commande suivante. Toutefois, si elle est incorrecte ou manquante, exécutez la commande suivante :
gcloud config set project <YOUR_PROJECT_ID>
- Ensuite, clonons le répertoire de travail du modèle pour cet atelier de programmation à partir de GitHub en exécutant la commande suivante. Il créera le répertoire de travail dans le répertoire personal-expense-assistant.
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- Ensuite, accédez à la section supérieure de l'éditeur Cloud Shell et cliquez sur File->Open Folder (Fichier > Ouvrir le dossier), recherchez votre répertoire nom d'utilisateur, puis le répertoire personal-expense-assistant et cliquez sur le bouton OK. Le répertoire choisi deviendra le répertoire de travail principal. Dans cet exemple, le nom d'utilisateur est alvinprayuda. Le chemin d'accès au répertoire est donc indiqué ci-dessous.

Votre éditeur Cloud Shell devrait maintenant se présenter comme suit :
Configuration de l'environnement
Préparer l'environnement virtuel Python
L'étape suivante consiste à préparer l'environnement de développement. Votre terminal actif actuel doit se trouver dans le répertoire de travail personal-expense-assistant. Dans cet atelier de programmation, nous utiliserons Python 3.12 et le gestionnaire de projets Python uv pour simplifier la création et la gestion de la version Python et de l'environnement virtuel.
- Si vous n'avez pas encore ouvert le terminal, ouvrez-le en cliquant sur Terminal > Nouveau terminal ou en utilisant le raccourci clavier Ctrl+Maj+C. Une fenêtre de terminal s'ouvre alors en bas du navigateur.

- Initialisons maintenant l'environnement virtuel à l'aide de
uv. Exécutez ces commandes :
cd ~/personal-expense-assistant
uv sync --frozen
Cela créera le répertoire .venv et installera les dépendances. Un petit aperçu rapide du fichier pyproject.toml vous donnera des informations sur les dépendances, comme ceci :
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Configurer les fichiers de configuration
Nous devons maintenant configurer les fichiers de configuration pour ce projet. Nous utilisons pydantic-settings pour lire la configuration à partir du fichier YAML.
Nous avons déjà fourni le modèle de fichier dans settings.yaml.example. Nous devons copier le fichier et le renommer en settings.yaml. Exécutez cette commande pour créer le fichier.
cp settings.yaml.example settings.yaml
Ensuite, copiez la valeur suivante dans le fichier.
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
Pour cet atelier de programmation, nous allons utiliser les valeurs préconfigurées pour GCLOUD_LOCATION, BACKEND_URL, et DB_COLLECTION_NAME .
Nous pouvons maintenant passer à l'étape suivante, qui consiste à créer l'agent, puis les services.
3. 🚀 Créer l'agent à l'aide de Google ADK et de Gemini 2.5
Présentation de la structure de répertoires d'ADK
Commençons par explorer ce que l'ADK a à offrir et comment créer l'agent. La documentation complète de l'ADK est disponible sur cette URL . ADK propose de nombreux utilitaires dans l'exécution des commandes CLI. En voici quelques-uns :
- Configurer la structure du répertoire de l'agent
- Essayer rapidement l'interaction via l'entrée/sortie de la CLI
- Configurer rapidement l'interface utilisateur Web de développement local
À présent, créons la structure de répertoire de l'agent à l'aide de la commande CLI. Exécutez la commande ci-dessous.
uv run adk create expense_manager_agent
Lorsque vous y êtes invité, choisissez le modèle gemini-2.5-flash et le backend Vertex AI. L'assistant vous demandera ensuite l'ID et l'emplacement du projet. Vous pouvez accepter les options par défaut en appuyant sur Entrée ou les modifier si nécessaire. Vérifiez simplement que vous utilisez le bon ID de projet créé précédemment dans cet atelier. Le résultat doit se présenter comme suit :
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Il créera la structure de répertoire d'agent suivante :
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Si vous inspectez init.py et agent.py, vous verrez ce code
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Vous pouvez maintenant le tester en exécutant
uv run adk run expense_manager_agent
Lorsque vous avez terminé les tests, vous pouvez quitter l'agent en saisissant exit ou en appuyant sur Ctrl+D.
Créer notre agent Expense Manager
Créons notre agent de gestion des dépenses ! Ouvrez le fichier expense_manager_agent/agent.py et copiez le code ci-dessous, qui contiendra le root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Explication du code
Ce script contient l'initialisation de notre agent, où nous initialisons les éléments suivants :
- Définissez le modèle à utiliser sur
gemini-2.5-flash. - Configurez la description et les instructions de l'agent comme le prompt système qui est lu à partir de
task_prompt.md. - Fournir les outils nécessaires pour prendre en charge la fonctionnalité d'agent
- Activer la planification avant de générer la réponse finale ou l'exécution à l'aide des capacités de réflexion de Gemini 2.5 Flash
- Configurer l'interception de rappel avant d'envoyer une requête à Gemini pour limiter le nombre de données d'image envoyées avant d'effectuer une prédiction
4. 🚀 Configurer les outils de l'agent
Notre agent de gestion des dépenses sera capable de :
- Extraire les données de l'image du reçu et stocker les données et le fichier
- Recherche exacte sur les données de dépenses
- Recherche contextuelle sur les données de dépenses
Nous avons donc besoin des outils appropriés pour prendre en charge cette fonctionnalité. Créez un fichier sous le répertoire expense_manager_agent et nommez-le tools.py.
touch expense_manager_agent/tools.py
Ouvrez expense_manage_agent/tools.py, puis copiez le code ci-dessous.
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Explication du code
Dans cette implémentation de la fonction d'outils, nous concevons les outils autour de ces deux idées principales :
- Analyser les données des reçus et les mapper au fichier d'origine à l'aide de l'espace réservé pour la chaîne d'ID d'image
[IMAGE-ID <hash-of-image-1>] - Stocker et récupérer des données à l'aide de la base de données Firestore
Outil "store_receipt_data"
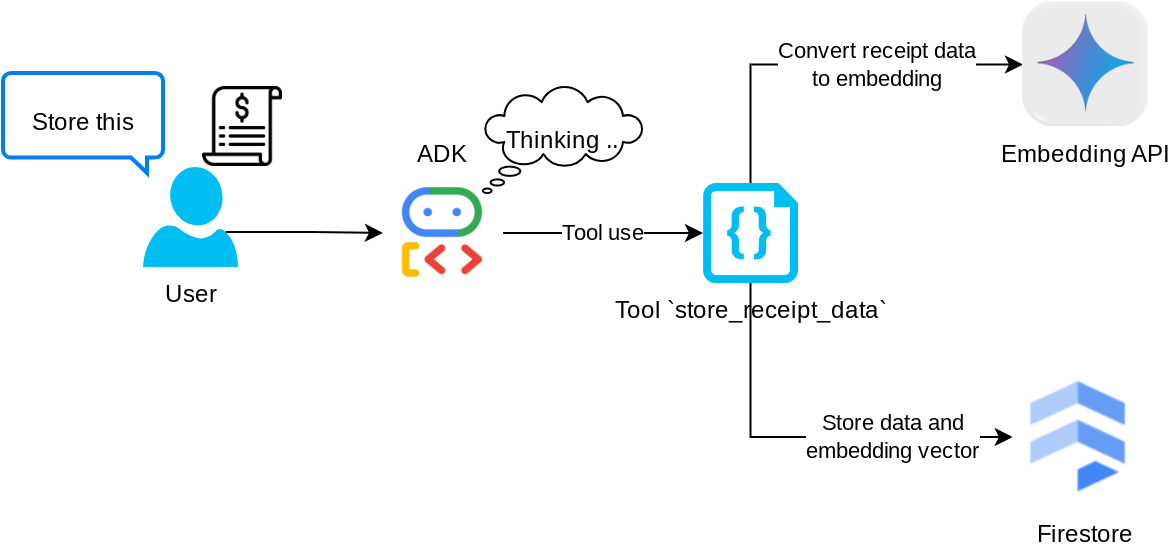
Cet outil est l'outil de reconnaissance optique des caractères. Il analysera les informations requises à partir des données d'image, reconnaîtra la chaîne d'ID d'image et les mappera ensemble pour les stocker dans la base de données Firestore.
En outre, cet outil convertit également le contenu du reçu en embedding à l'aide de text-embedding-004 afin que toutes les métadonnées et l'embedding soient stockés et indexés ensemble. Permet de récupérer la flexibilité par requête ou par recherche contextuelle.
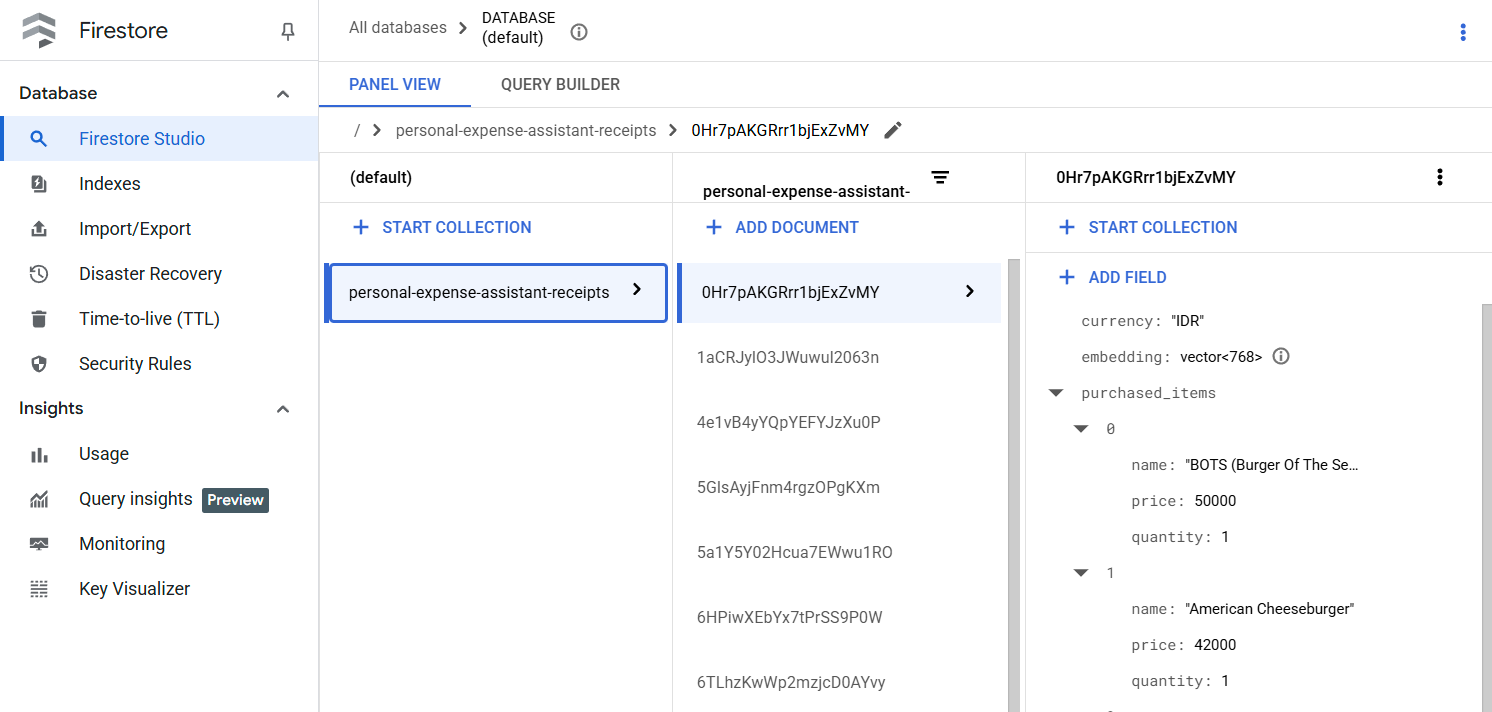
Une fois cet outil exécuté, vous pouvez voir que les données de reçus sont déjà indexées dans la base de données Firestore, comme indiqué ci-dessous.
Outil "search_receipts_by_metadata_filter"
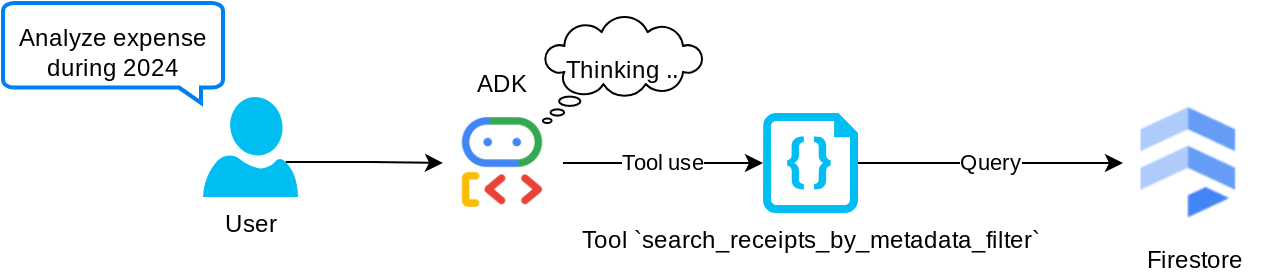
Cet outil convertit la requête utilisateur en filtre de requête de métadonnées, qui permet d'effectuer des recherches par plage de dates et/ou par transaction totale. Il renverra toutes les données de reçus correspondantes, et nous supprimerons le champ d'intégration, car l'agent n'en a pas besoin pour comprendre le contexte.
Outil "search_relevant_receipts_by_natural_language_query"
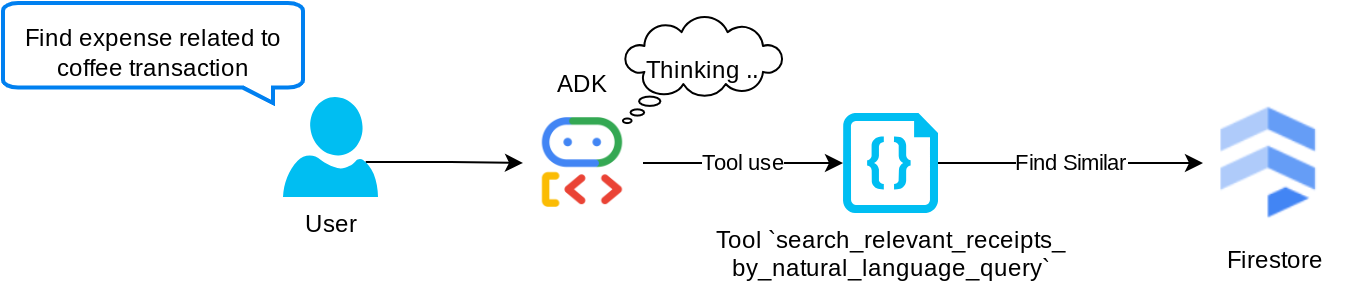
Il s'agit de notre outil de génération augmentée par récupération (RAG). Notre agent est capable de concevoir sa propre requête pour récupérer les reçus pertinents de la base de données vectorielle. Il peut également choisir quand utiliser cet outil. La notion de permettre à l'agent de décider de manière indépendante s'il utilisera ou non cet outil RAG et de concevoir sa propre requête est l'une des définitions de l'approche Agentic RAG.
Nous lui permettons non seulement de créer sa propre requête, mais aussi de sélectionner le nombre de documents pertinents qu'il souhaite récupérer. Combiné à une ingénierie des requêtes appropriée, par exemple :
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Cet outil deviendra ainsi un outil puissant capable de rechercher presque n'importe quoi, même s'il ne renverra peut-être pas tous les résultats attendus en raison de la nature non exacte de la recherche des voisins les plus proches.
5. 🚀 Modification du contexte de conversation via des rappels
Le Google ADK nous permet d'"intercepter" l'exécution de l'agent à différents niveaux. Pour en savoir plus sur cette fonctionnalité détaillée, consultez cette documentation . Dans cet atelier, nous utilisons before_model_callback pour modifier la requête avant de l'envoyer au LLM afin de supprimer les données d'image dans l'ancien contexte de l'historique des conversations ( n'incluez les données d'image que dans les trois dernières interactions utilisateur) pour plus d'efficacité.
Toutefois, nous souhaitons que l'agent dispose du contexte des données d'image si nécessaire. Nous ajoutons donc un mécanisme permettant d'ajouter un espace réservé pour l'ID de l'image sous forme de chaîne après chaque octet de données d'image dans la conversation. Cela aidera l'agent à associer l'ID de l'image à ses données de fichier réelles, qui peuvent être utilisées lors du stockage ou de la récupération de l'image. La structure se présente comme suit :
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
Lorsque les données d'octets deviennent obsolètes dans l'historique des conversations, l'identifiant de chaîne est toujours là pour permettre l'accès aux données à l'aide de l'outil. Exemple de structure de l'historique après la suppression des données d'image
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Commencer Créez un fichier sous le répertoire expense_manager_agent et nommez-le callbacks.py.
touch expense_manager_agent/callbacks.py
Ouvrez le fichier expense_manager_agent/callbacks.py, puis copiez le code ci-dessous.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 La requête
Pour concevoir un agent doté d'interactions et de capacités complexes, nous devons trouver un prompt suffisamment efficace pour le guider et lui permettre de se comporter comme nous le souhaitons.
Auparavant, nous disposions d'un mécanisme pour gérer les données d'image dans l'historique des conversations, ainsi que d'outils qui n'étaient pas forcément simples à utiliser, tels que search_relevant_receipts_by_natural_language_query. Nous souhaitons également que l'agent puisse rechercher et récupérer la bonne image de reçu pour nous. Cela signifie que nous devons transmettre correctement toutes ces informations dans une structure de requête appropriée.
Nous demanderons à l'agent de structurer la sortie au format Markdown suivant pour analyser le processus de réflexion, la réponse finale et la pièce jointe ( le cas échéant).
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Commençons par le prompt suivant pour répondre à nos attentes initiales concernant le comportement de l'agent de gestion des dépenses. Le fichier task_prompt.md devrait déjà exister dans notre répertoire de travail, mais nous devons le déplacer dans le répertoire expense_manager_agent. Exécutez la commande suivante pour le déplacer :
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Tester l'agent
Essayons maintenant de communiquer avec l'agent via la CLI. Exécutez la commande suivante :
uv run adk run expense_manager_agent
Le résultat sera semblable à celui-ci, où vous pourrez discuter à tour de rôle avec l'agent. Toutefois, vous ne pourrez envoyer que du texte via cette interface.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
En plus de l'interaction avec la CLI, l'ADK nous permet également de disposer d'une interface utilisateur de développement pour interagir et inspecter ce qui se passe pendant l'interaction. Exécutez la commande suivante pour démarrer le serveur d'interface utilisateur de développement local :
uv run adk web --port 8080
Il générera une sortie semblable à l'exemple suivant, ce qui signifie que nous pouvons déjà accéder à l'interface Web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
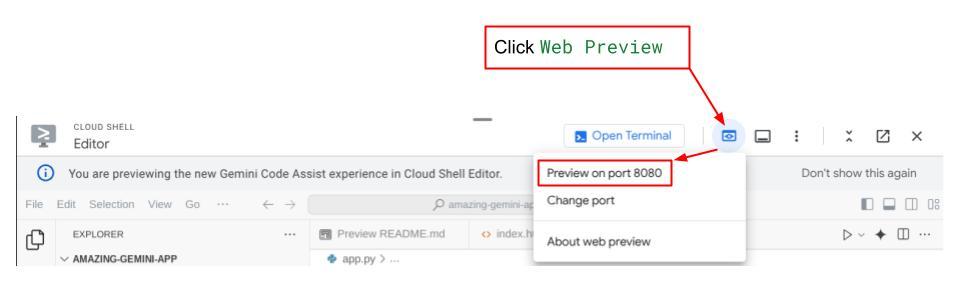
Pour le vérifier, cliquez sur le bouton Aperçu Web en haut de l'éditeur Cloud Shell, puis sélectionnez Prévisualiser sur le port 8080.
La page Web suivante s'affiche. Vous pouvez y sélectionner les agents disponibles dans le menu déroulant en haut à gauche ( dans notre cas, il devrait s'agir de expense_manager_agent) et interagir avec le bot. De nombreuses informations sur les détails du journal s'affichent dans la fenêtre de gauche pendant l'exécution de l'agent.
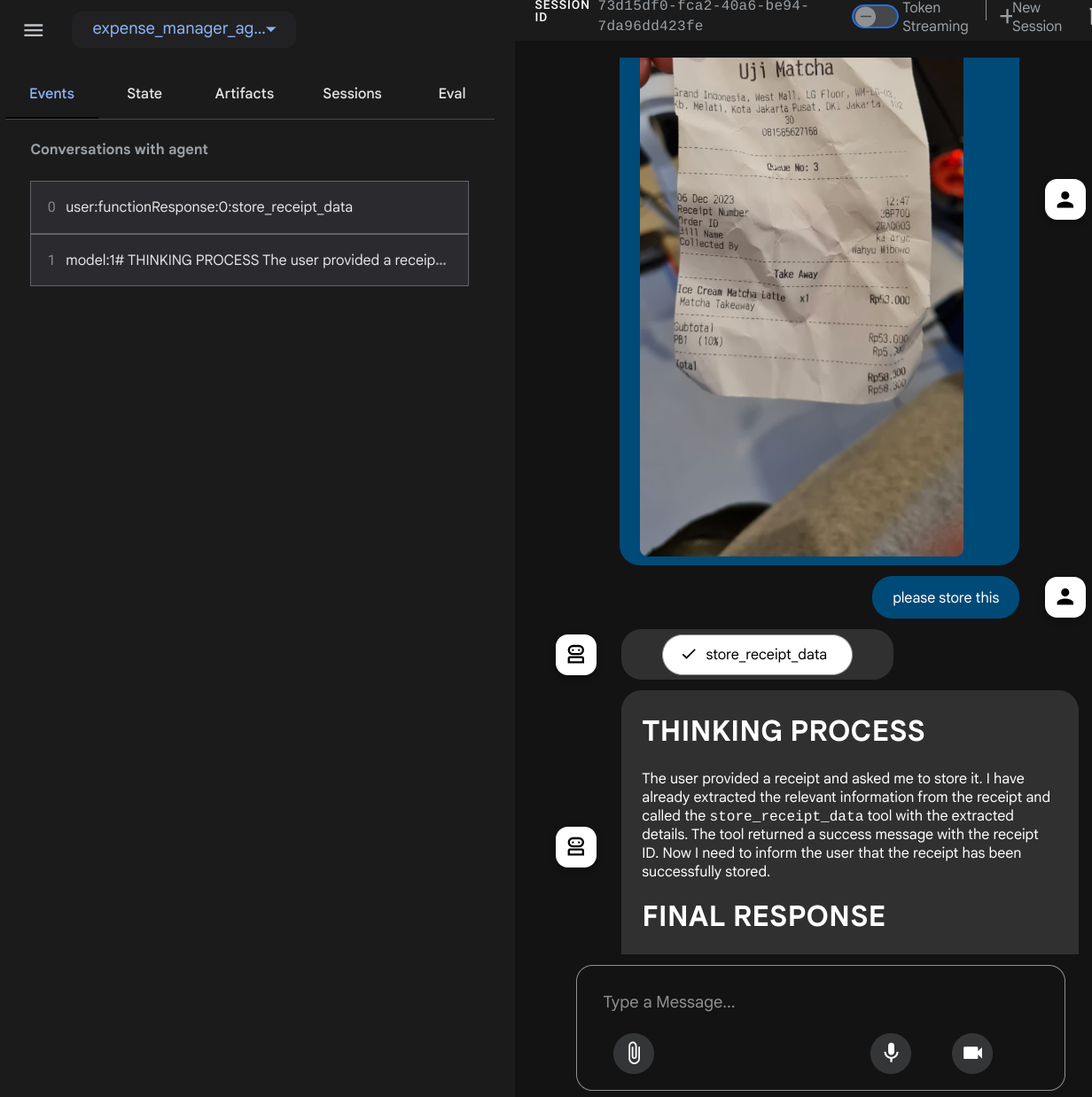
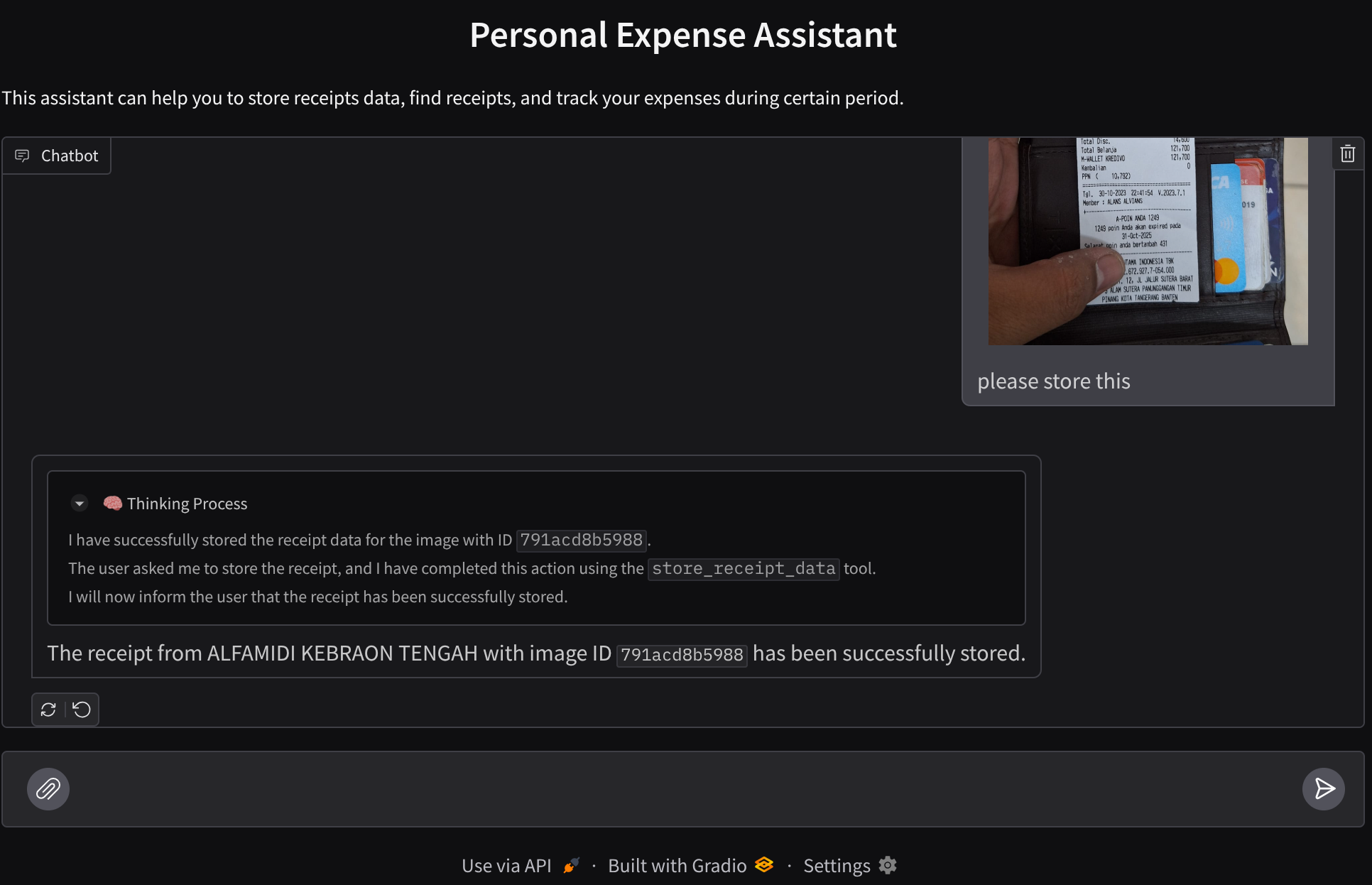
Essayons quelques actions ! Importez ces deux exemples de reçus ( source : ensembles de données Hugging Face mousserlane/id_receipt_dataset) . Effectuez un clic droit sur chaque image, puis sélectionnez Enregistrer l'image sous. ( l'image du reçu sera téléchargée). Ensuite, importez le fichier dans le bot en cliquant sur l'icône en forme de trombone et indiquez que vous souhaitez stocker ces reçus.


Ensuite, essayez les requêtes suivantes pour effectuer des recherches ou récupérer des fichiers.
- "Détaille les dépenses et leur total pour l'année 2023"
- "Donne-moi le fichier du reçu d'Indomaret"
Lorsque vous utilisez certains outils, vous pouvez inspecter ce qui se passe dans l'UI de développement.
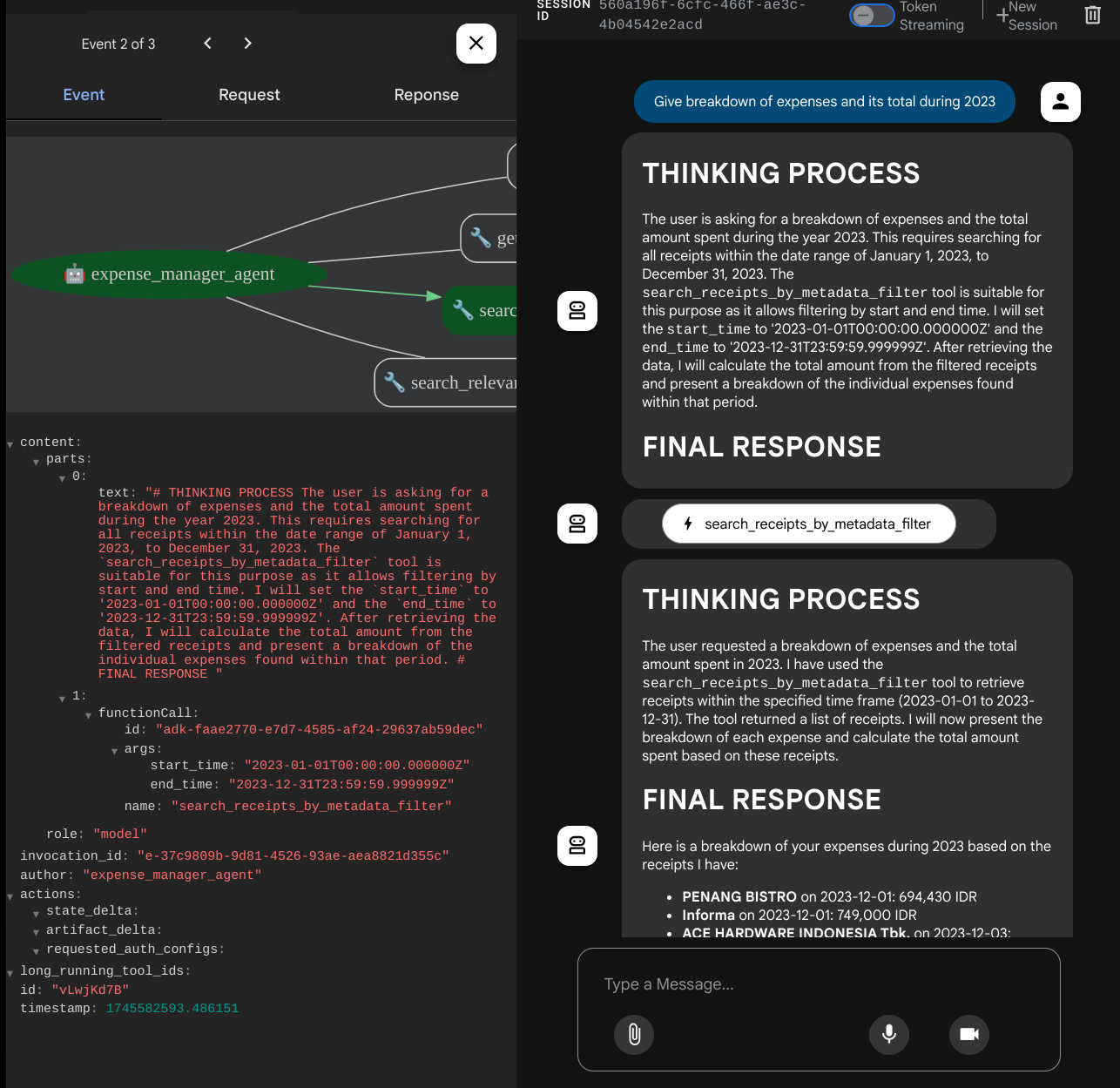
Observez la réponse de l'agent et vérifiez qu'elle respecte toutes les règles fournies dans le prompt à l'intérieur de task_prompt.py. Félicitations ! Vous disposez désormais d'un agent de développement fonctionnel complet.
Il est maintenant temps de le compléter avec une interface utilisateur appropriée et agréable, ainsi que des fonctionnalités permettant d'importer et de télécharger le fichier image.
8. 🚀 Créer un service d'interface utilisateur à l'aide de Gradio
Nous allons créer une interface Web de chat qui ressemble à ceci :
Elle contient une interface de chat avec un champ de saisie permettant aux utilisateurs d'envoyer du texte et d'importer le ou les fichiers image du reçu.
Nous allons créer le service de frontend à l'aide de Gradio.
Créez un fichier et nommez-le frontend.py.
touch frontend.py
Copiez ensuite le code suivant et enregistrez-le.
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Ensuite, nous pouvons essayer d'exécuter le service de frontend avec la commande suivante. N'oubliez pas de renommer le fichier main.py en frontend.py.
uv run frontend.py
Un résultat semblable à celui-ci s'affiche dans la console Cloud.
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Vous pouvez ensuite consulter l'interface Web en cliquant sur la touche Ctrl et en cliquant sur le lien de l'URL locale. Vous pouvez également accéder à l'application frontend en cliquant sur le bouton Aperçu sur le Web en haut à droite de Cloud Editor, puis en sélectionnant Prévisualiser sur le port 8080.
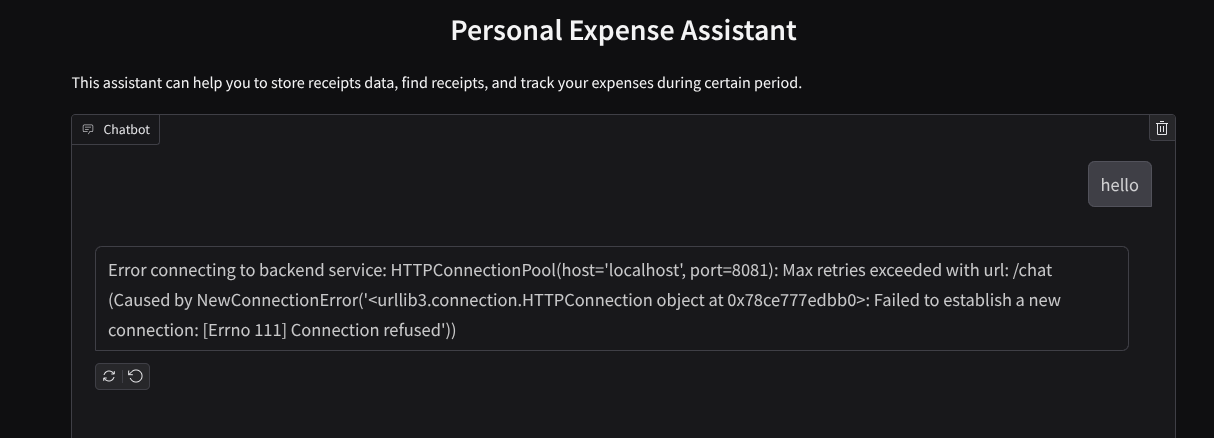
L'interface Web s'affiche, mais vous obtenez une erreur attendue lorsque vous essayez d'envoyer un chat, car le service backend n'est pas encore configuré.
Laissez le service s'exécuter et ne l'arrêtez pas tout de suite. Nous allons exécuter le service de backend dans un autre onglet de terminal.
Explication du code
Dans ce code de frontend, nous permettons d'abord à l'utilisateur d'envoyer du texte et d'importer plusieurs fichiers. Gradio nous permet de créer ce type de fonctionnalité avec la méthode gr.ChatInterface combinée à gr.MultimodalTextbox.
Avant d'envoyer le fichier et le texte au backend, nous devons déterminer le type MIME du fichier, car le backend en a besoin. Nous devons également encoder les octets du fichier image en base64 et les envoyer avec le type MIME.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
Le schéma utilisé pour l'interaction entre le frontend et le backend est défini dans schema.py. Nous utilisons Pydantic BaseModel pour appliquer la validation des données dans le schéma.
Lorsque nous recevons la réponse, nous séparons déjà la partie qui correspond au processus de réflexion, à la réponse finale et à la pièce jointe. Nous pouvons donc utiliser le composant Gradio pour afficher chaque composant avec le composant d'interface utilisateur.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Créer un service de backend avec FastAPI
Nous devons ensuite créer le backend qui peut initialiser notre agent avec les autres composants pour pouvoir exécuter le runtime de l'agent.
Créez un fichier et nommez-le backend.py.
touch backend.py
Copiez le code suivant :
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Ensuite, nous pouvons essayer d'exécuter le service de backend. N'oubliez pas que nous avons exécuté le service frontend à l'étape précédente. Nous devons maintenant ouvrir un nouveau terminal et essayer d'exécuter ce service backend.
- Créez un terminal. Accédez à votre terminal dans la zone inférieure et recherchez le bouton "+" pour créer un terminal. Vous pouvez également appuyer sur Ctrl+Maj+C pour ouvrir un nouveau terminal.

- Ensuite, assurez-vous d'être dans le répertoire de travail personal-expense-assistant, puis exécutez la commande suivante :
uv run backend.py
- Si l'opération réussit, un résultat semblable à celui-ci s'affiche :
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Explication du code
Initialisation d'ADK Agent, SessionService et ArtifactService
Pour exécuter l'agent dans le service de backend, nous devons créer un Runner qui prend à la fois SessionService et notre agent. SessionService gérera l'historique et l'état des conversations. Par conséquent, lorsqu'il sera intégré à Runner, il permettra à notre agent de recevoir le contexte des conversations en cours.
Nous utilisons également ArtifactService pour gérer le fichier importé. Pour en savoir plus sur les sessions et les artefacts ADK, cliquez ici.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
Dans cette démonstration, nous utilisons InMemorySessionService et GcsArtifactService pour l'intégration à notre Runner d'agent. L'historique des conversations étant stocké en mémoire, il sera perdu une fois que le service backend sera arrêté ou redémarré. Nous les initialisons dans le cycle de vie de l'application FastAPI pour les injecter en tant que dépendance dans la route /chat.
Importer et télécharger des images avec GcsArtifactService
Toutes les images importées seront stockées en tant qu'artefacts par GcsArtifactService. Vous pouvez le vérifier dans la fonction format_user_request_to_adk_content_and_store_artifacts de utils.py.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Toutes les requêtes qui seront traitées par l'exécuteur d'agent doivent être mises au format types.Content. Dans la fonction, nous traitons également chaque donnée d'image et extrayons son ID pour le remplacer par un espace réservé d'ID d'image.
Un mécanisme similaire est utilisé pour télécharger les pièces jointes après avoir extrait les ID d'image à l'aide d'expressions régulières :
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Test d'intégration
Vous devriez maintenant avoir plusieurs services exécutés dans différents onglets de la console Cloud :
- Le service de frontend s'exécute sur le port 8080.
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Le service de backend s'exécute sur le port 8081.
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
À l'heure actuelle, vous devriez pouvoir importer vos images de reçus et discuter facilement avec l'assistant depuis l'application Web sur le port 8080.
Cliquez sur le bouton Aperçu sur le Web en haut de l'éditeur Cloud Shell, puis sélectionnez Prévisualiser sur le port 8080.
Maintenant, interagissons avec l'assistant.
Téléchargez les reçus suivants. La plage de dates de ces données de reçus est comprise entre 2023 et 2024. Demande à l'assistant de les stocker/importer.
- Receipt Drive ( source : ensembles de données Hugging Face
mousserlane/id_receipt_dataset)
Poser des questions variées
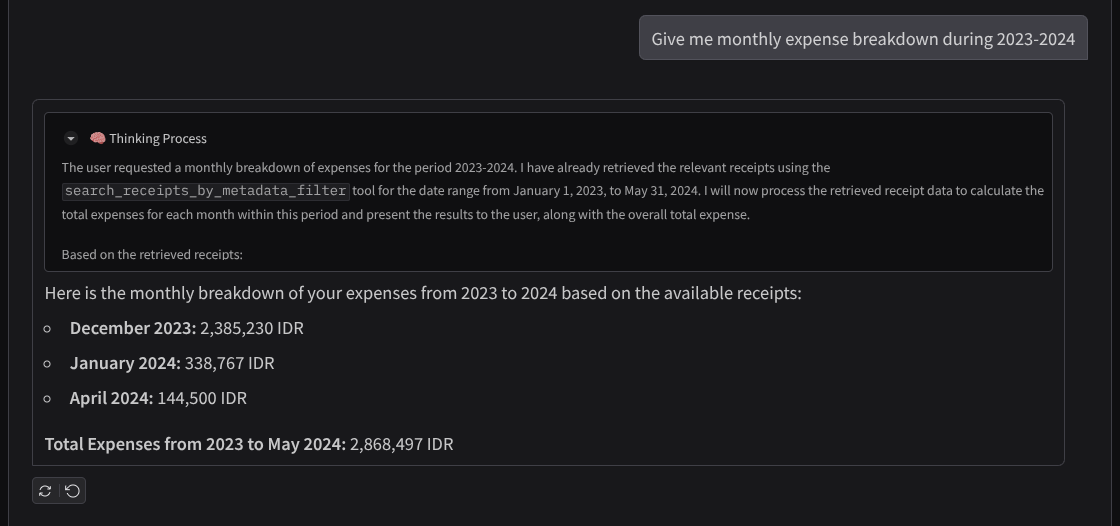
- "Donne-moi le détail de mes dépenses mensuelles pour 2023-2024."
- "Montre-moi le reçu de la transaction pour le café"
- "Donne-moi le fichier du reçu de Yakiniku Like"
- Etc
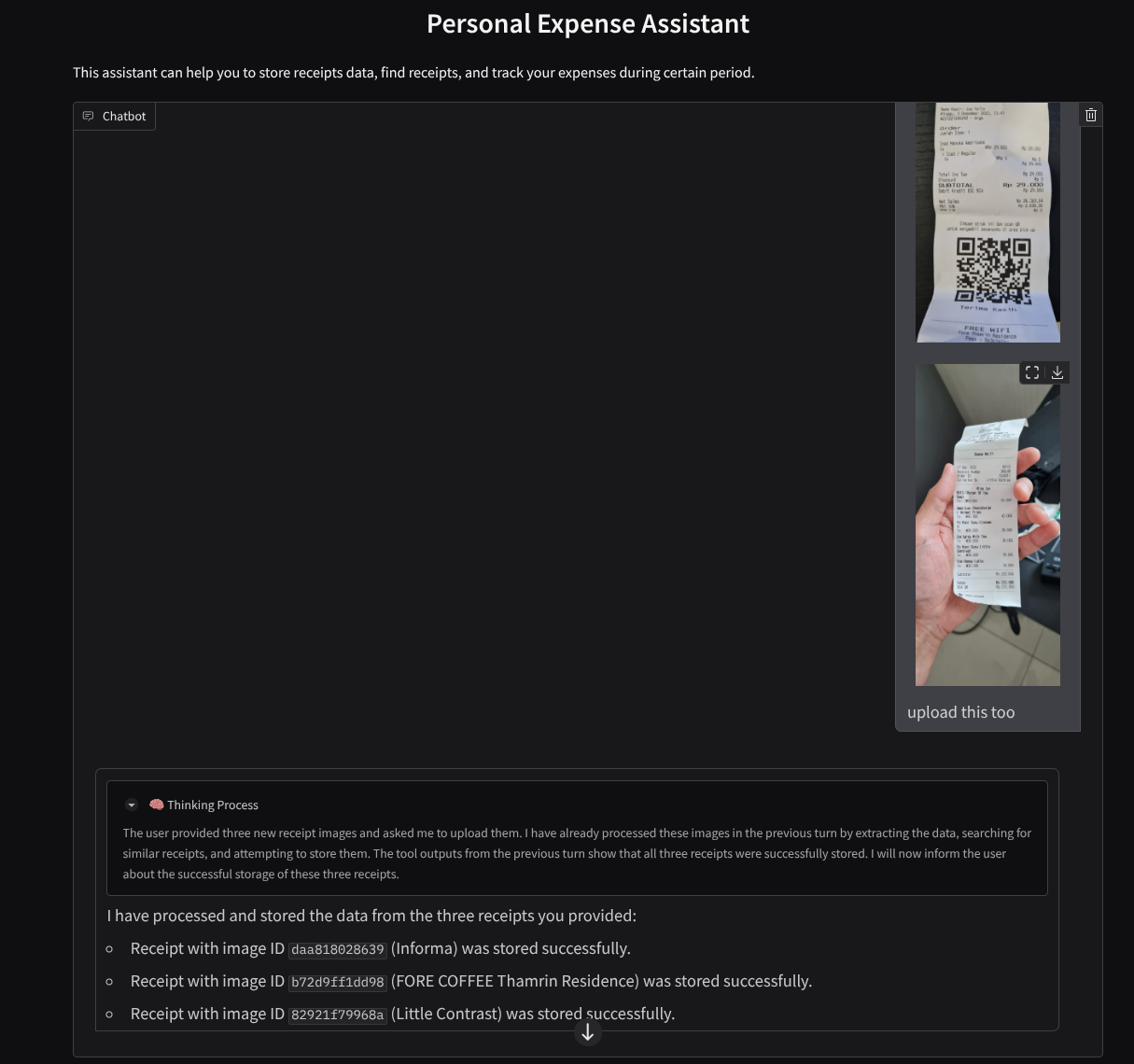
Voici un extrait d'une interaction réussie :
11. 🚀 Déployer sur Cloud Run
Bien sûr, nous voulons accéder à cette application incroyable depuis n'importe où. Pour ce faire, nous pouvons empaqueter cette application et la déployer sur Cloud Run. Pour cette démonstration, ce service sera exposé en tant que service public accessible à tous. Toutefois, n'oubliez pas que ce n'est pas la meilleure pratique pour ce type d'application, car elle est plus adaptée aux applications personnelles.
Dans cet atelier de programmation, nous allons placer les services de frontend et de backend dans un seul conteneur. Nous aurons besoin de l'aide de supervisord pour gérer les deux services. Vous pouvez inspecter le fichier supervisord.conf et vérifier le Dockerfile dans lequel nous avons défini supervisord comme point d'entrée.
À ce stade, nous disposons déjà de tous les fichiers nécessaires pour déployer nos applications sur Cloud Run. Déployons-les. Accédez au terminal Cloud Shell et assurez-vous que le projet actuel est configuré sur votre projet actif. Si ce n'est pas le cas, utilisez la commande gcloud configure pour définir l'ID du projet :
gcloud config set project [PROJECT_ID]
Exécutez ensuite la commande suivante pour le déployer sur Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Si vous êtes invité à confirmer la création d'un dépôt Docker Artifact Registry, répondez simplement Y. Notez que nous autorisons ici l'accès non authentifié, car il s'agit d'une application de démonstration. Nous vous recommandons d'utiliser une authentification appropriée pour vos applications d'entreprise et de production.
Une fois le déploiement terminé, vous devriez obtenir un lien semblable à celui ci-dessous :
https://personal-expense-assistant-*******.us-central1.run.app
N'hésitez pas à utiliser votre application depuis la fenêtre de navigation privée ou votre appareil mobile. Il devrait déjà être en ligne.
12. 🎯 Défi
Il est maintenant temps de briller et de perfectionner vos compétences en matière d'exploration. Avez-vous les compétences nécessaires pour modifier le code afin que le backend puisse accueillir plusieurs utilisateurs ? Quels composants doivent être mis à jour ?
13. 🧹 Nettoyer
Pour éviter que les ressources utilisées dans cet atelier de programmation soient facturées sur votre compte Google Cloud :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
- Vous pouvez également accéder à Cloud Run dans la console, sélectionner le service que vous venez de déployer, puis le supprimer.