
1. 📖 מבוא
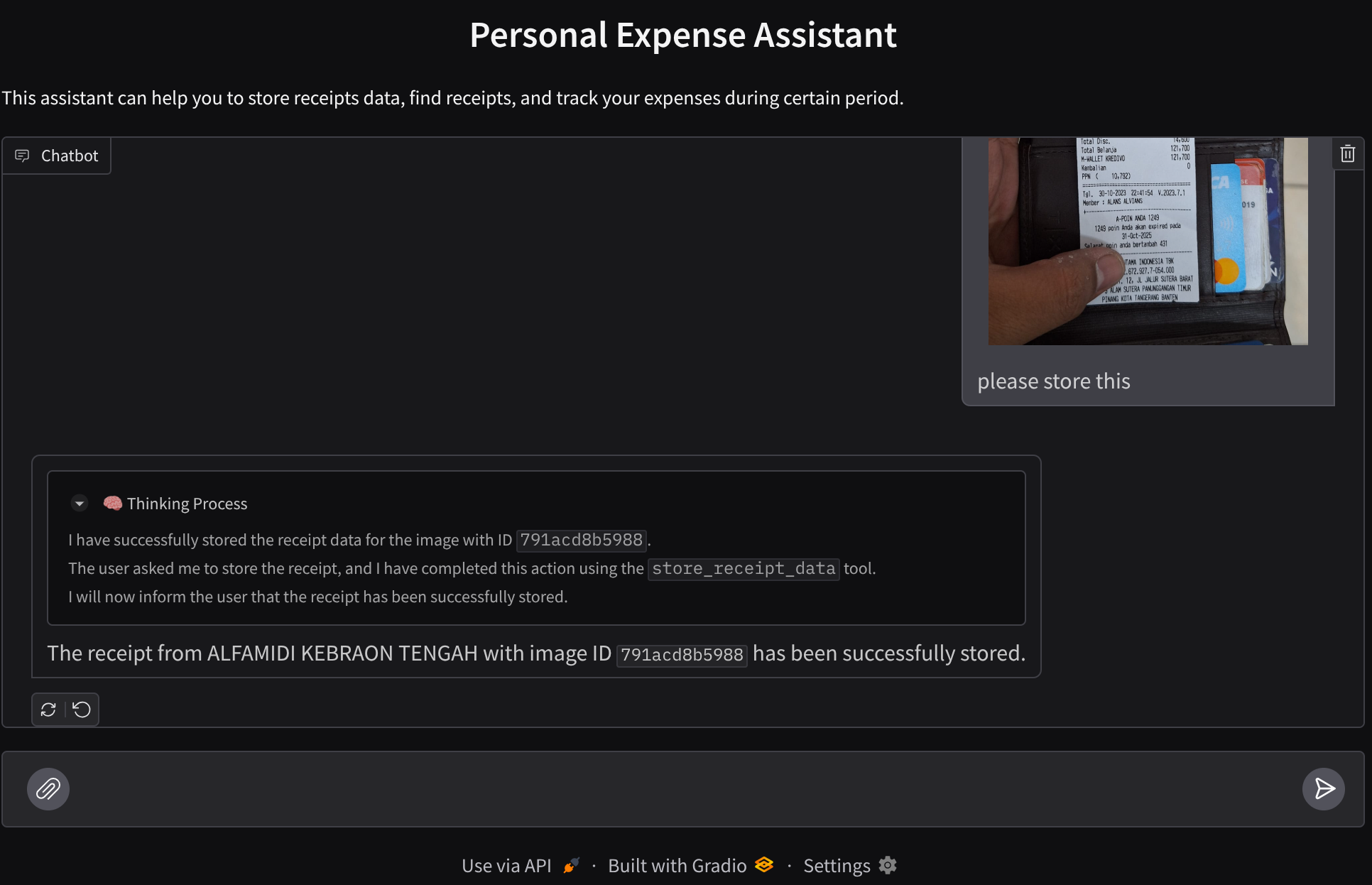
האם קרה לך שהיית מתוסכל מדי ופשוט לא היה לך כוח לנהל את כל ההוצאות האישיות שלך? גם אני! לכן, בשיעור Codelab הזה, ניצור עוזר אישי לניהול הוצאות – מבוסס על Gemini 2.5 – שיבצע בשבילנו את כל המשימות. האפליקציה מאפשרת לנהל את הקבלות שהועלו כדי לנתח אם כבר הוצאתם יותר מדי כסף על קפה.
תהיה לכם גישה לעוזר הזה דרך דפדפן אינטרנט, בצורה של ממשק אינטרנט לצ'אט. תוכלו לתקשר איתו, להעלות תמונות של קבלות ולבקש מהעוזר לאחסן אותן, או אולי לחפש קבלות כדי לקבל את הקובץ ולבצע ניתוח של ההוצאות. כל זה מבוסס על מסגרת Google Agent Development Kit
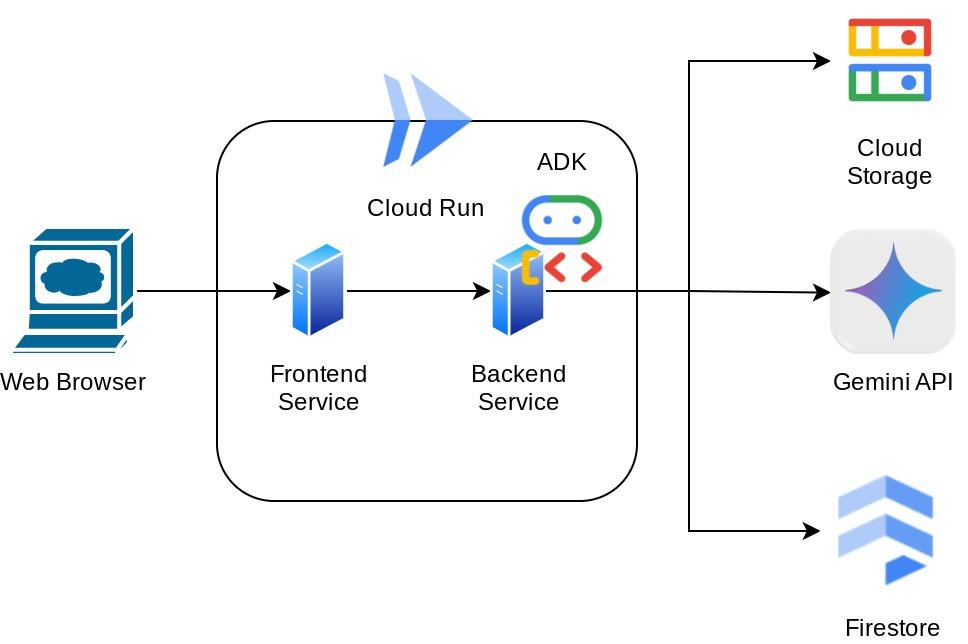
האפליקציה עצמה מחולקת ל-2 שירותים: קצה קדמי (frontend) וקצה אחורי (backend). כך תוכלו ליצור אב טיפוס במהירות ולנסות את האפליקציה, וגם להבין איך נראה חוזה ה-API לשילוב של שני השירותים.
במהלך ה-codelab, תשתמשו בגישה שלב אחר שלב באופן הבא:
- הכנת הפרויקט ב-Google Cloud והפעלת כל ממשקי ה-API הנדרשים בו
- הגדרת קטגוריה ב-Google Cloud Storage ומסד נתונים ב-Firestore
- יצירת אינדקסים ב-Firestore
- הגדרת סביבת עבודה לסביבת התכנות
- מבנה של קוד מקור, כלים, הנחיה וכו' של סוכן ADK
- בדיקת הסוכן באמצעות ממשק משתמש מקומי לפיתוח אתרים ב-ADK
- בונים את שירות הקצה הקדמי – ממשק צ'אט באמצעות ספריית Gradio, כדי לשלוח שאילתה ולהעלות תמונות של קבלות
- פיתוח שירות לקצה העורפי – שרת HTTP באמצעות FastAPI שבו נמצאים קוד הסוכן של ADK, SessionService ו-Artifact Service
- ניהול משתני הסביבה והגדרת הקבצים הנדרשים לפריסת האפליקציה ב-Cloud Run
- פריסת האפליקציה ב-Cloud Run
סקירה כללית של הארכיטקטורה
דרישות מוקדמות
- ניסיון בעבודה עם Python
- הבנה של ארכיטקטורת full-stack בסיסית באמצעות שירות HTTP
מה תלמדו
- יצירת אב טיפוס לאתרים עם Gradio
- פיתוח שירות לקצה העורפי באמצעות FastAPI ו-Pydantic
- תכנון סוכן ADK תוך שימוש בכמה מהיכולות שלו
- שימוש בכלי
- ניהול סשנים ופריטי מידע שנוצרו בתהליך פיתוח (Artifacts)
- שימוש בפונקציית Callback לשינוי הקלט לפני שהוא נשלח ל-Gemini
- שימוש ב-BuiltInPlanner כדי לשפר את ביצוע המשימות באמצעות תכנון
- ניפוי באגים מהיר באמצעות ממשק אינטרנט מקומי של ADK
- אסטרטגיה לאופטימיזציה של אינטראקציה מולטי-מודאלית באמצעות ניתוח מידע ואחזור מידע באמצעות הנדסת הנחיות ושינוי בקשות ל-Gemini באמצעות קריאה חוזרת (callback) של ADK
- יצירה משולבת-אחזור (RAG) באמצעות סוכנים עם Firestore כמסד נתונים וקטורי
- ניהול משתני סביבה בקובץ YAML באמצעות Pydantic-settings
- פריסת אפליקציה ב-Cloud Run באמצעות Dockerfile ומתן משתני סביבה באמצעות קובץ YAML
מה תצטרכו
- דפדפן האינטרנט Chrome
- חשבון Gmail
- פרויקט ב-Cloud עם חיוב מופעל
בשיעור Codelab הזה, שמיועד למפתחים בכל הרמות (כולל מתחילים), נעשה שימוש ב-Python באפליקציה לדוגמה. עם זאת, לא נדרש ידע ב-Python כדי להבין את המושגים שמוצגים.
2. 🚀 לפני שמתחילים
בחירת פרויקט פעיל ב-Cloud Console
ב-Codelab הזה אנחנו יוצאים מנקודת הנחה שכבר יש לכם פרויקט בענן ב-Google Cloud עם חיוב מופעל. אם עדיין אין לכם חשבון, אתם יכולים לפעול לפי ההוראות שבהמשך כדי להתחיל.
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הכנת מסד נתונים ב-Firestore
בשלב הבא, נצטרך גם ליצור מסד נתונים של Firestore. Firestore במצב Native הוא מסד נתונים מסוג NoSQL לאחסון מסמכים שמיועד להתאמה לעומס (automatic scaling), לביצועים גבוהים ולפיתוח אפליקציות בקלות. הוא יכול לשמש גם כמאגר נתונים וקטורי שיכול לתמוך בטכניקת יצירה משופרת באמצעות אחזור (RAG) במעבדה שלנו.
- בסרגל החיפוש, מחפשים firestore ולוחצים על המוצר Firestore.
- לאחר מכן, לוחצים על הלחצן יצירת מסד נתונים של Firestore.
- משתמשים ב(ברירת מחדל) כשם מזהה מסד הנתונים ומשאירים את האפשרות Standard Edition מסומנת. לצורך ההדגמה הזו, משתמשים ב-Firestore Native עם כללי אבטחה מסוג Open.
- אפשר גם לראות שבמסד הנתונים הזה יש שימוש בתוכנית בחינם. אחרי כן, לוחצים על לחצן יצירת מסד נתונים.
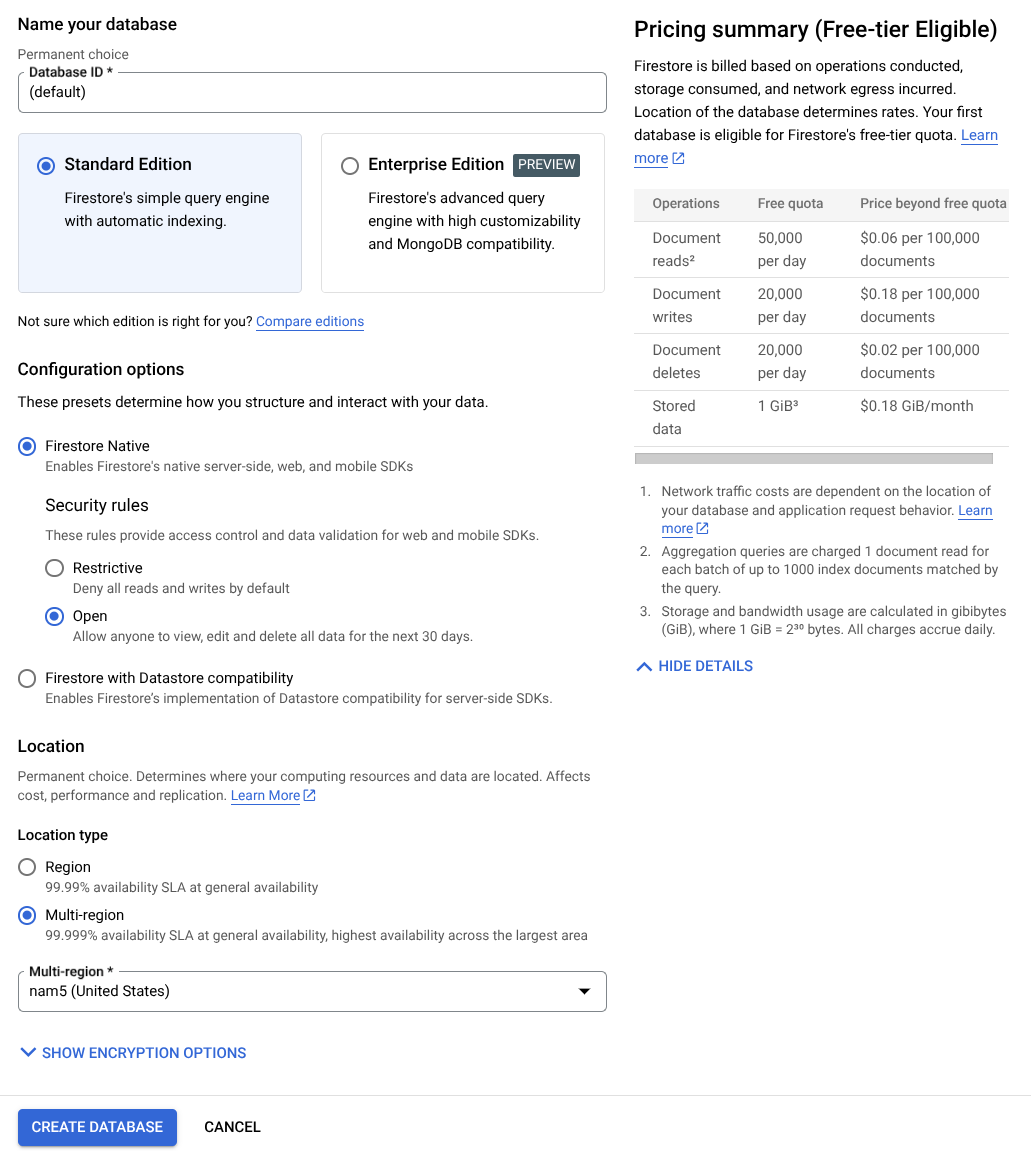
אחרי השלבים האלה, אמורה להיות הפניה אוטומטית למסד הנתונים של Firestore שיצרתם.
הגדרת פרויקט בענן בטרמינל Cloud Shell
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud ומגיעה עם bq שנטען מראש. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.
- אחרי שמתחברים ל-Cloud Shell, אפשר לבדוק שכבר בוצע אימות ושהפרויקט מוגדר לפי מזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
gcloud config set project <YOUR_PROJECT_ID>
אפשר גם לראות את המזהה PROJECT_ID במסוף
לוחצים עליו וכל הפרויקטים ומזהה הפרויקט יופיעו בצד שמאל.
- מפעילים את ממשקי ה-API הנדרשים באמצעות הפקודה שמוצגת למטה. זה יימשך כמה דקות, אז כדאי לחכות בסבלנות.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
אם הפקודה תפעל בהצלחה, תוצג הודעה שדומה לזו שמופיעה בהמשך:
Operation "operations/..." finished successfully.
אפשר גם לחפש כל מוצר במסוף או להשתמש בקישור הזה במקום בפקודת gcloud.
אם פספסתם API כלשהו, תמיד תוכלו להפעיל אותו במהלך ההטמעה.
אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
הכנת קטגוריה של Cloud Storage ב-Google Cloud
בשלב הבא, מאותו מסוף, נצטרך להכין את קטגוריית ה-GCS לאחסון הקובץ שהועלה. מריצים את הפקודה הבאה כדי ליצור את הקטגוריה. צריך שם ייחודי ורלוונטי לקטגוריה שקשור לקבלות של עוזר הוצאות אישיות, ולכן נשתמש בשם הקטגוריה הבא בשילוב עם מזהה הפרויקט שלכם
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
יוצג הפלט הבא
Creating gs://personal-expense-{your-project-id}
כדי לוודא זאת, עוברים לתפריט הניווט בפינה הימנית העליונה של הדפדפן ובוחרים באפשרות Cloud Storage -> Bucket.
יצירת אינדקס של Firestore לחיפוש
Firestore הוא מסד נתונים NoSQL באופן מובנה, שמציע ביצועים מעולים וגמישות במודל הנתונים, אבל יש לו מגבלות כשמדובר בשאילתות מורכבות. אנחנו מתכננים להשתמש בכמה שאילתות מורכבות עם כמה שדות ובחיפוש וקטורי, ולכן נצטרך ליצור קודם אינדקס. פרטים נוספים זמינים במאמר הזה
- מריצים את הפקודה הבאה כדי ליצור אינדקס לתמיכה בשאילתות מורכבות
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- מריצים את הפקודה הזו כדי לתמוך בחיפוש וקטורי
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
כדי לבדוק את האינדקס שנוצר, נכנסים ל-Firestore במסוף Cloud, לוחצים על מופע מסד הנתונים (default) ובוחרים באפשרות Indexes בסרגל הניווט.
כניסה אל Cloud Shell Editor והגדרת ספריית העבודה של האפליקציה
עכשיו אפשר להגדיר את עורך הקוד כדי לבצע פעולות שקשורות לקוד. נשתמש ב-Cloud Shell Editor לצורך זה
- לוחצים על הלחצן Open Editor (פתיחת העורך). כך ייפתח Cloud Shell Editor, שבו אפשר לכתוב את הקוד
- בנוסף, צריך לבדוק אם ה-Shell כבר מוגדר למזהה הפרויקט הנכון שיש לכם. אם מופיע ערך בתוך ( ) לפני הסמל $ במסוף ( בצילום המסך שלמטה, הערך הוא "adk-multimodal-tool"), הערך הזה מציין את הפרויקט שהוגדר עבור סשן ה-Shell הפעיל.

אם הערך שמוצג כבר נכון, אפשר לדלג על הפקודה הבאה. אבל אם הוא לא נכון או חסר, מריצים את הפקודה הבאה
gcloud config set project <YOUR_PROJECT_ID>
- לאחר מכן, משכפלים מ-GitHub את ספריית העבודה של התבנית בשביל ה-codelab הזה, ומריצים את הפקודה הבאה. הסקריפט ייצור את ספריית העבודה בספרייה personal-expense-assistant.
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- אחרי זה, עוברים לקטע העליון של Cloud Shell Editor ולוחצים על File->Open Folder (קובץ > פתיחת תיקייה), מאתרים את ספריית שם המשתמש ואת הספרייה personal-expense-assistant ואז לוחצים על הלחצן OK (אישור). הפעולה הזו תגרום לכך שהספרייה שנבחרה תהפוך לספריית העבודה הראשית. בדוגמה הזו, שם המשתמש הוא alvinprayuda, ולכן נתיב הספרייה מוצג למטה

עכשיו Cloud Shell Editor אמור להיראות כך
הגדרת הסביבה
הכנת סביבה וירטואלית של Python
השלב הבא הוא הכנת סביבת הפיתוח. הטרמינל הפעיל הנוכחי צריך להיות בתוך ספריית העבודה personal-expense-assistant. בשיעור Codelab הזה נשתמש ב-Python 3.12 וב-uv python project manager כדי לפשט את הצורך ליצור ולנהל גרסת Python וסביבה וירטואלית.
- אם עדיין לא פתחתם את הטרמינל, פותחים אותו על ידי לחיצה על Terminal (טרמינל) -> New Terminal (טרמינל חדש), או באמצעות Ctrl + Shift + C. חלון הטרמינל ייפתח בחלק התחתון של הדפדפן.

- עכשיו מאתחלים את הסביבה הווירטואלית באמצעות
uv. מריצים את הפקודות הבאות
cd ~/personal-expense-assistant
uv sync --frozen
תיקיית .venv תיצור ותתקין את יחסי התלות. תצוגה מקדימה מהירה של pyproject.toml תיתן לכם מידע על התלות שמוצגת כך
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
הגדרת קובצי תצורה
עכשיו נצטרך להגדיר קובצי הגדרה לפרויקט הזה. אנחנו משתמשים ב-pydantic-settings כדי לקרוא את ההגדרות מקובץ ה-YAML.
כבר סיפקנו את תבנית הקובץ בתוך settings.yaml.example , ועכשיו צריך להעתיק את הקובץ ולשנות את השם שלו ל-settings.yaml. מריצים את הפקודה הזו כדי ליצור את הקובץ
cp settings.yaml.example settings.yaml
אחר כך מעתיקים את הערך הבא לקובץ
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
ב-codelab הזה, נשתמש בערכים שהוגדרו מראש עבור GCLOUD_LOCATION, BACKEND_URL, ו-DB_COLLECTION_NAME .
עכשיו אפשר לעבור לשלב הבא, בניית הסוכן ואז השירותים
3. 🚀 יצירת סוכן באמצעות Google ADK ו-Gemini 2.5
מבוא למבנה הספריות של ADK
נתחיל בסקירה של האפשרויות ש-ADK מציע ושל אופן בניית הסוכן. אפשר לגשת לתיעוד המלא של ADK בכתובת ה-URL הזו . חבילת ה-ADK מציעה לנו הרבה כלי עזר בביצוע פקודות ה-CLI שלה. לדוגמה :
- הגדרת מבנה הספריות של הסוכן
- ניסיון מהיר של אינטראקציה באמצעות קלט ופלט של CLI
- הגדרה מהירה של ממשק משתמש מקומי לפיתוח
עכשיו ניצור את מבנה הספריות של הסוכן באמצעות פקודת ה-CLI. מריצים את הפקודה הבאה.
uv run adk create expense_manager_agent
כשמתבקשים, בוחרים את המודל gemini-2.5-flash ואת הקצה העורפי Vertex AI. אחרי כן, באשף תתבקשו להזין את מזהה הפרויקט והמיקום. אפשר לאשר את אפשרויות ברירת המחדל על ידי הקשה על Enter, או לשנות אותן לפי הצורך. חשוב לוודא שאתם משתמשים במזהה הפרויקט הנכון שיצרתם קודם במעבדה הזו. הפלט ייראה כך:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
המבנה הבא של ספריית הסוכן ייווצר
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
אם בודקים את הקבצים init.py ו-agent.py, אפשר לראות את הקוד הזה
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
עכשיו אפשר להריץ את הפקודה הבאה כדי לבדוק את זה
uv run adk run expense_manager_agent
בסיום הבדיקה, אפשר להקליד exit או ללחוץ על Ctrl+D כדי לצאת מהסוכן.
יצירת סוכן לניהול הוצאות
נתחיל ליצור את הסוכן לניהול הוצאות. פותחים את הקובץ expense_manager_agent/agent.py ומעתיקים את הקוד שבהמשך, שיכלול את root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
הסבר על הקוד
הסקריפט הזה מכיל את ההפעלה של הנציג, שבה אנחנו מאתחלים את הדברים הבאים:
- הגדרת המודל שבו רוצים להשתמש ל-
gemini-2.5-flash - הגדרת תיאור הסוכן וההוראות כהנחיית המערכת שנקראת מ-
task_prompt.md - לספק את הכלים הדרושים לתמיכה בפונקציונליות של הסוכן
- הפעלת תכנון לפני יצירת התשובה הסופית או הביצוע באמצעות יכולות החשיבה של Gemini 2.5 Flash
- הגדרת חסימת קריאה חוזרת (callback) לפני שליחת בקשה ל-Gemini כדי להגביל את כמות נתוני התמונות שנשלחים לפני יצירת התחזית
4. 🚀 הגדרת כלי הסוכן
הסוכן שלנו לניהול הוצאות יוכל לבצע את הפעולות הבאות:
- חילוץ נתונים מתמונת הקבלה ואחסון הנתונים והקובץ
- חיפוש מדויק בנתוני ההוצאות
- חיפוש לפי הקשר בנתוני ההוצאות
לכן אנחנו צריכים את הכלים המתאימים כדי לתמוך בפונקציונליות הזו. יוצרים קובץ חדש בספרייה expense_manager_agent ונותנים לו את השם tools.py.
touch expense_manager_agent/tools.py
פותחים את expense_manage_agent/tools.py ומעתיקים את הקוד שבהמשך.
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
הסבר על הקוד
ביישום הפונקציה של הכלים האלה, אנחנו מתכננים את הכלים סביב 2 הרעיונות העיקריים האלה:
- ניתוח נתוני הקבלה ומיפוי לקובץ המקורי באמצעות מציין המיקום של מחרוזת מזהה התמונה
[IMAGE-ID <hash-of-image-1>] - אחסון ואחזור נתונים באמצעות מסד נתונים ב-Firestore
הכלי store_receipt_data
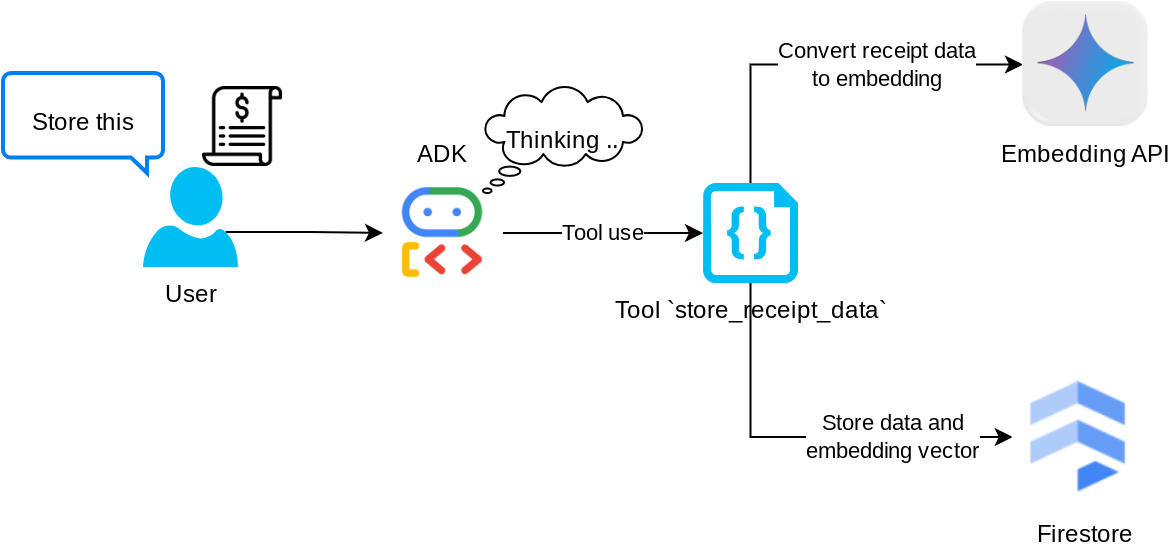
הכלי הזה הוא כלי לזיהוי תווים אופטי (OCR). הוא ינתח את המידע הנדרש מנתוני התמונה, יזהה את מחרוזת מזהה התמונה וימפה אותם יחד כדי לאחסן אותם במסד הנתונים של Firestore.
בנוסף, הכלי הזה ממיר את תוכן הקבלה להטמעה באמצעות text-embedding-004, כך שכל המטא-נתונים וההטמעה נשמרים ומאונדקסים יחד. הגמישות מאפשרת לאחזר את המידע באמצעות שאילתה או חיפוש הקשרי.
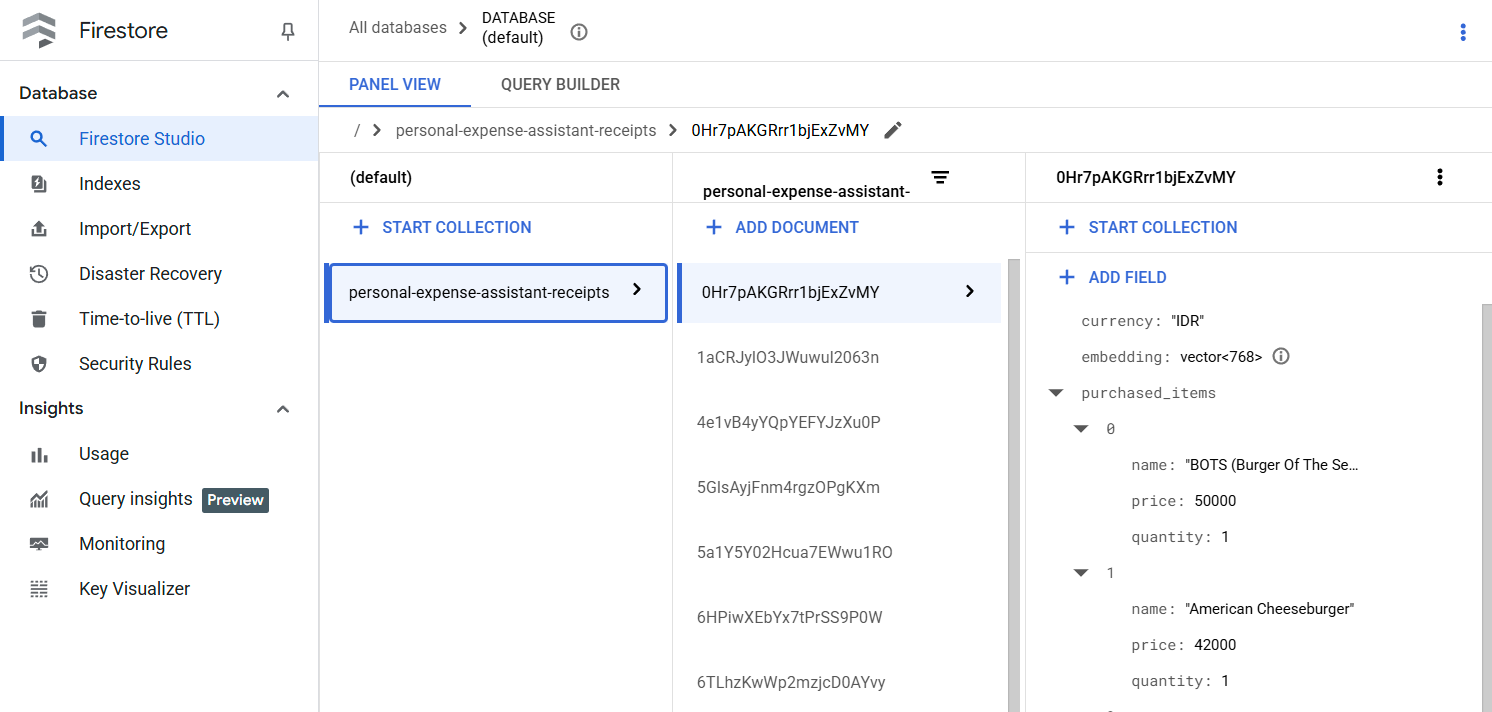
אחרי שמריצים את הכלי הזה בהצלחה, אפשר לראות שנתוני הקבלה כבר עברו אינדוקס במסד הנתונים של Firestore, כמו שמוצג בהמשך
הכלי search_receipts_by_metadata_filter
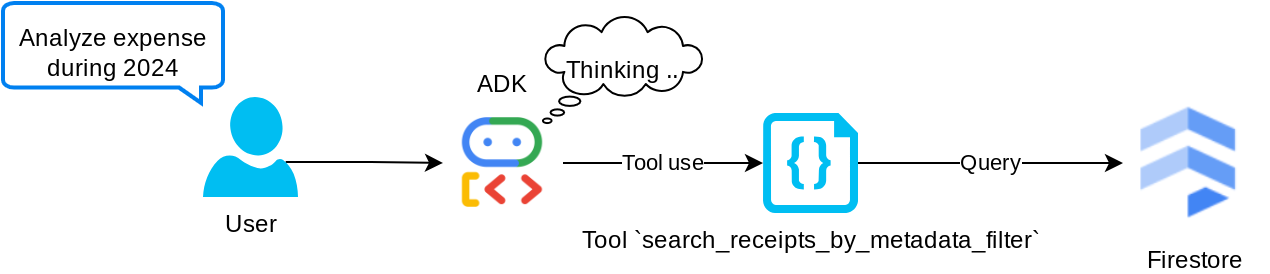
הכלי הזה ממיר את שאילתת המשתמש למסנן של שאילתת מטא-נתונים, שתומך בחיפוש לפי טווח תאריכים או לפי סכום העסקה הכולל. היא תחזיר את כל נתוני הקבלה התואמים, ובמהלך התהליך נשמיט את שדה ההטמעה כי הסוכן לא צריך אותו כדי להבין את ההקשר
הכלי search_relevant_receipts_by_natural_language_query
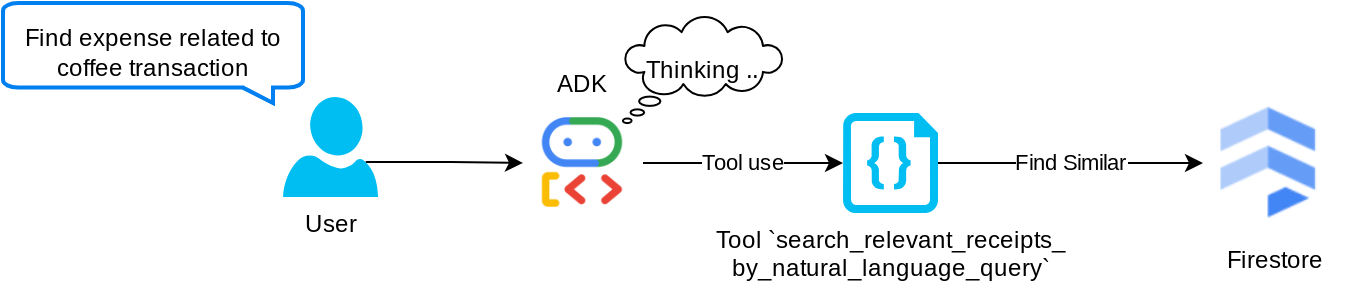
זהו כלי Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG). הסוכן שלנו יכול לעצב שאילתה משלו כדי לאחזר קבלות רלוונטיות ממסד הנתונים הווקטורי, והוא גם יכול לבחור מתי להשתמש בכלי הזה. המושג של מתן אפשרות לסוכן לקבל החלטה עצמאית אם להשתמש בכלי RAG הזה או לא, ולנסח שאילתה משלו, הוא אחת ההגדרות של גישת Agentic RAG.
אנחנו לא רק מאפשרים לו ליצור שאילתה משלו, אלא גם לבחור כמה מסמכים רלוונטיים הוא רוצה לאחזר. בשילוב עם הנדסת הנחיות נכונה, למשל:
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
הכלי הזה יהיה כלי רב עוצמה שיוכל לחפש כמעט כל דבר, אבל יכול להיות שהוא לא יחזיר את כל התוצאות הצפויות בגלל האופי הלא מדויק של חיפוש השכן הקרוב ביותר.
5. 🚀 שינוי הקשר של השיחה באמצעות קריאות חוזרות (callback)
Google ADK מאפשר לנו 'ליירט' את זמן הריצה של הסוכן ברמות שונות. מידע נוסף על היכולת המפורטת הזו זמין במאמרי עזרה אלה . בשיעור ה-Lab הזה נשתמש ב-before_model_callback כדי לשנות את הבקשה לפני שהיא נשלחת ל-LLM, כדי להסיר נתוני תמונות מההקשר של היסטוריית השיחות הישנה ( כולל נתוני תמונות רק ב-3 האינטראקציות האחרונות עם המשתמש) לצורך יעילות.
עם זאת, אנחנו עדיין רוצים שהסוכן יקבל את ההקשר של נתוני התמונה כשצריך. לכן אנחנו מוסיפים מנגנון להוספת placeholder של מזהה תמונה במחרוזת אחרי כל נתון בייט של תמונה בשיחה. כך הסוכן יוכל לקשר את מזהה התמונה לנתוני הקובץ בפועל, שאפשר להשתמש בהם בזמן אחסון התמונה או בזמן אחזור שלה. המבנה ייראה כך
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
גם כשהנתונים בבייט מתיישנים בהיסטוריית השיחות, מזהה המחרוזת עדיין נמצא שם ומאפשר גישה לנתונים בעזרת השימוש בכלי. דוגמה למבנה ההיסטוריה אחרי הסרת נתוני התמונות
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
אפשר להתחיל! יוצרים קובץ חדש בספרייה expense_manager_agent ונותנים לו את השם callbacks.py.
touch expense_manager_agent/callbacks.py
פותחים את הקובץ expense_manager_agent/callbacks.py ומעתיקים את הקוד שבהמשך.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 ההנחיה
כדי לעצב נציג עם אינטראקציה ויכולות מורכבות, צריך למצוא הנחיה טובה מספיק שתנחה את הנציג כך שהוא יתנהג כמו שאנחנו רוצים.
בעבר היה לנו מנגנון לטיפול בנתוני תמונות בהיסטוריית השיחות, והיו לנו גם כלים שאולי לא היו פשוטים לשימוש, כמו search_relevant_receipts_by_natural_language_query. We also want the agent to be able to search and retrieve the correct receipt image to us. כלומר, אנחנו צריכים להעביר את כל המידע הזה במבנה הנכון של ההנחיה.
נבקש מהסוכן לבנות את הפלט בפורמט Markdown הבא כדי לנתח את תהליך החשיבה, התגובה הסופית והקובץ המצורף ( אם יש)
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
נתחיל עם ההנחיה הבאה כדי להשיג את ההתנהגות הראשונית שציפינו לה מסוכן ניהול ההוצאות. הקובץ task_prompt.md אמור כבר להיות בספריית העבודה הקיימת, אבל צריך להעביר אותו לספרייה expense_manager_agent. מריצים את הפקודה הבאה כדי להעביר אותו
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 בדיקת הסוכן
עכשיו ננסה לתקשר עם הסוכן באמצעות ה-CLI. מריצים את הפקודה הבאה:
uv run adk run expense_manager_agent
יוצג פלט כמו זה, שבו תוכלו לשוחח עם הסוכן בתורכם, אבל תוכלו לשלוח טקסט רק דרך הממשק הזה
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
בנוסף לאינטראקציה עם CLI, ערכת ה-ADK מאפשרת לנו גם להשתמש בממשק משתמש לפיתוח כדי לבצע אינטראקציה עם התוסף ולבדוק מה קורה במהלך האינטראקציה. מריצים את הפקודה הבאה כדי להפעיל את שרת ממשק המשתמש של הפיתוח המקומי
uv run adk web --port 8080
יוצג פלט כמו בדוגמה הבאה, כלומר כבר יש לנו גישה לממשק האינטרנט
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
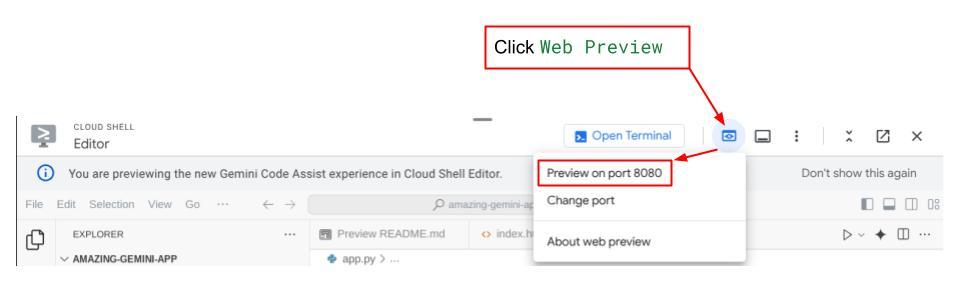
כדי לבדוק את זה, לוחצים על הלחצן Web Preview (תצוגה מקדימה של אתר) בחלק העליון של Cloud Shell Editor ובוחרים באפשרות Preview on port 8080 (תצוגה מקדימה ביציאה 8080).
יוצג דף אינטרנט שבו תוכלו לבחור סוכנים זמינים באמצעות הלחצן הנפתח בפינה הימנית העליונה ( במקרה שלנו, האפשרות שצריך לבחור היא expense_manager_agent) ולנהל אינטראקציה עם הבוט. בחלון הימני יוצגו פרטים רבים על יומן הרישום במהלך זמן הריצה של הסוכן
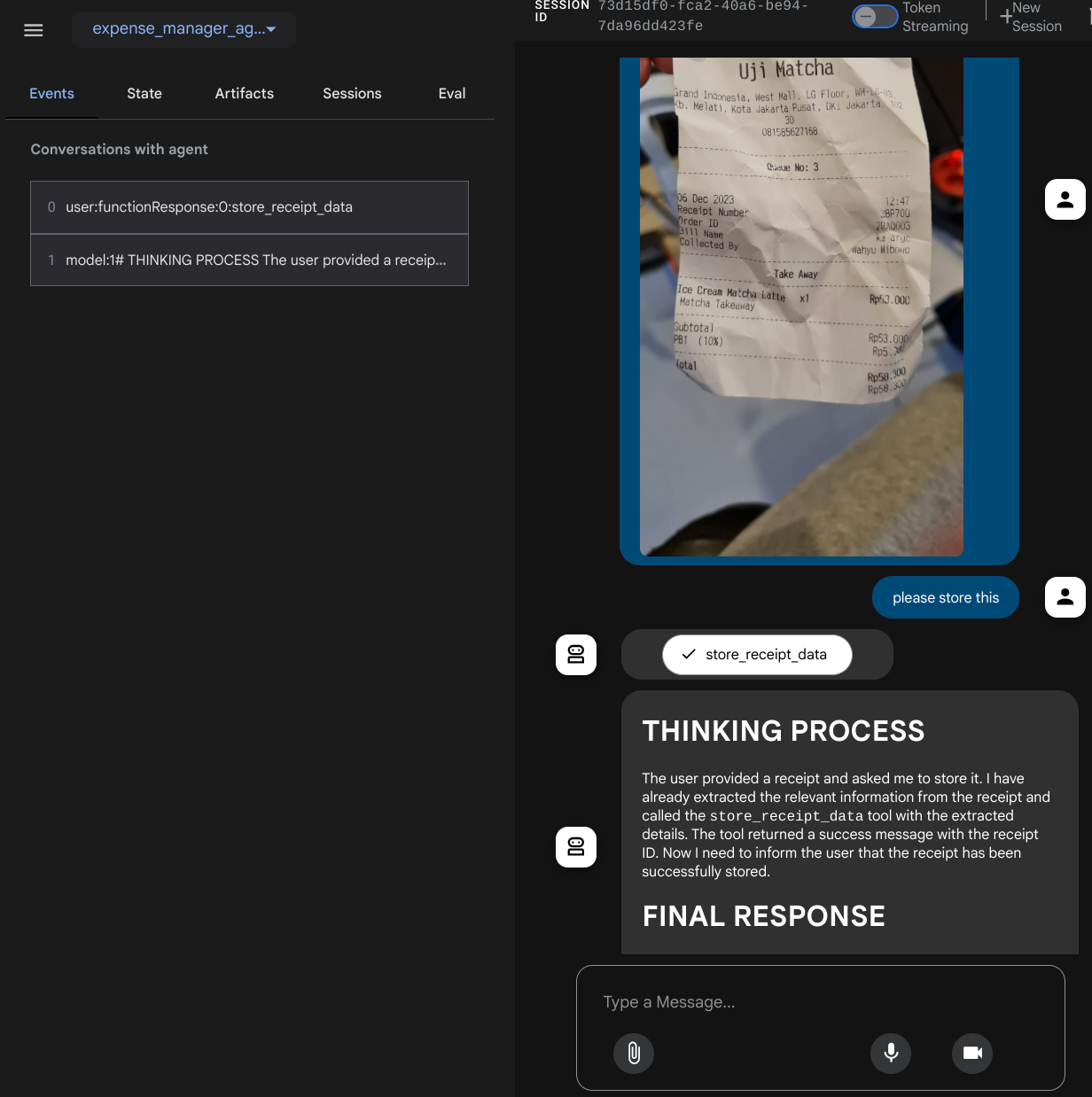
אפשר לנסות כמה פעולות. מעלים את 2 קבלות לדוגמה האלה ( מקור : מערכי נתונים של Hugging Face mousserlane/id_receipt_dataset) . לוחצים לחיצה ימנית על כל תמונה ובוחרים באפשרות שמירת תמונה בשם. ( הפעולה הזו תוריד את תמונת הקבלה), ואז מעלים את הקובץ לבוט על ידי לחיצה על סמל המהדק ומציינים שרוצים לשמור את הקבלות האלה.


אחרי זה, נסו להשתמש בשאילתות הבאות כדי לבצע חיפוש או לאחזר קובץ
- "Give breakdown of expenses and its total during 2023" (תן פירוט של ההוצאות והסכום הכולל שלהן במהלך שנת 2023)
- "Give me receipt file from Indomaret" (תביא לי קובץ קבלה מ-Indomaret)
כשמשתמשים בכלים מסוימים, אפשר לבדוק מה קורה בממשק המשתמש של הפיתוח
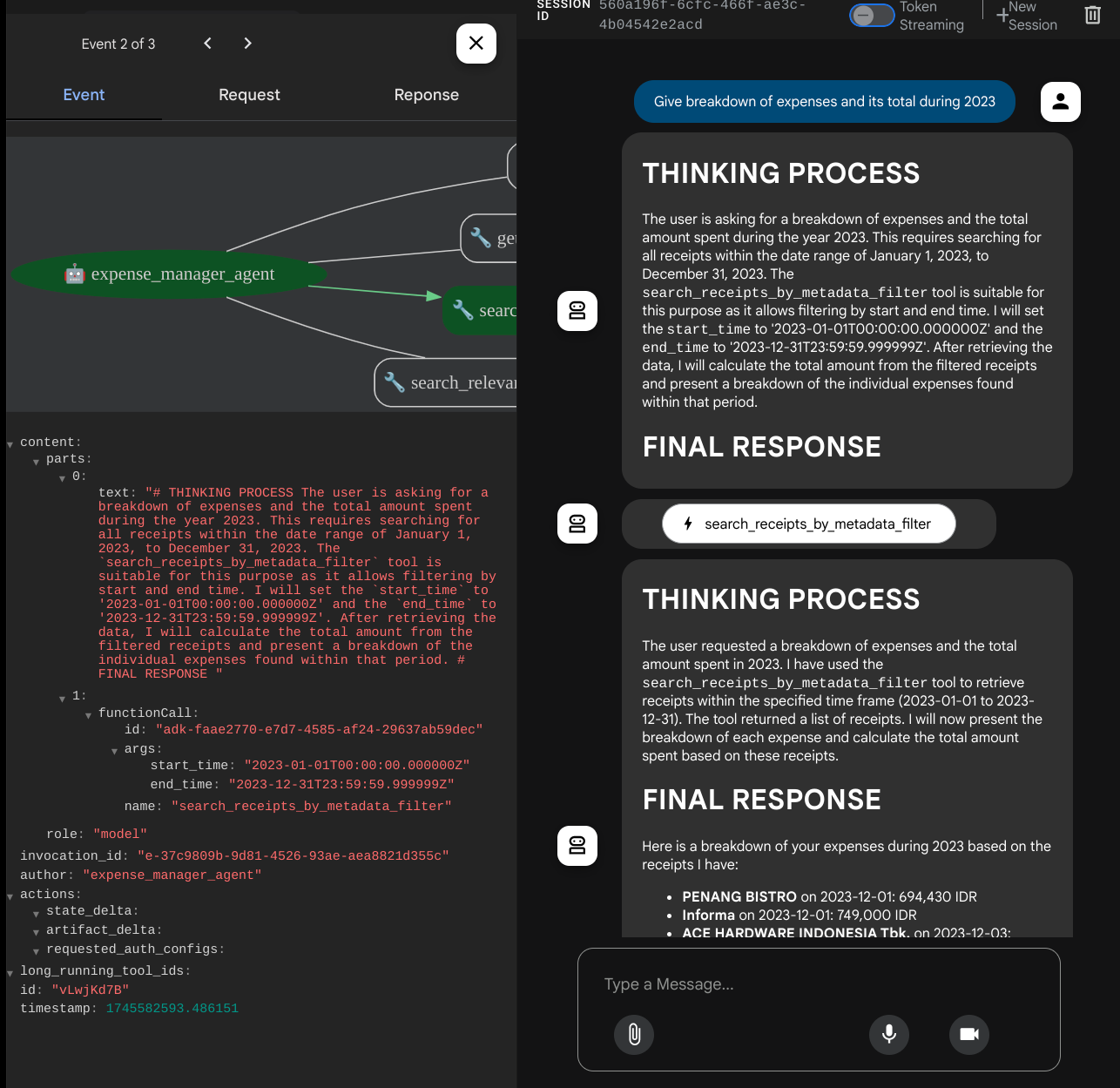
בודקים איך הסוכן מגיב לכם ומוודאים שהוא עומד בכל הכללים שצוינו בהנחיה בקובץ task_prompt.py. מזל טוב! עכשיו יש לכם סוכן פיתוח שעובד באופן מלא.
עכשיו הגיע הזמן להשלים אותו עם ממשק משתמש מתאים ונעים, ועם יכולות להעלות ולהוריד את קובץ התמונה.
8. 🚀 יצירת שירות Frontend באמצעות Gradio
אנחנו ניצור ממשק אינטרנט לצ'אט שייראה כך
הוא כולל ממשק צ'אט עם שדה להזנת קלט שבו המשתמשים יכולים לשלוח טקסט ולהעלות את קובצי התמונות של הקבלות.
ניצור את שירות ה-Frontend באמצעות Gradio.
יוצרים קובץ חדש ונותנים לו את השם frontend.py.
touch frontend.py
אחר כך מעתיקים את הקוד הבא ושומרים אותו
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
אחרי זה, אפשר לנסות להריץ את שירות ה-frontend באמצעות הפקודה הבאה. לא לשכוח לשנות את השם של הקובץ main.py ל-frontend.py
uv run frontend.py
במסוף Google Cloud יופיע פלט דומה לזה:
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
אחרי זה אפשר לבדוק את ממשק האינטרנט כשמבצעים Ctrl+click על הקישור לכתובת ה-URL המקומית. אפשר גם לגשת לאפליקציית חזית הלקוח על ידי לחיצה על הלחצן תצוגה מקדימה באינטרנט בפינה השמאלית העליונה של Cloud Editor, ואז על תצוגה מקדימה ביציאה 8080.
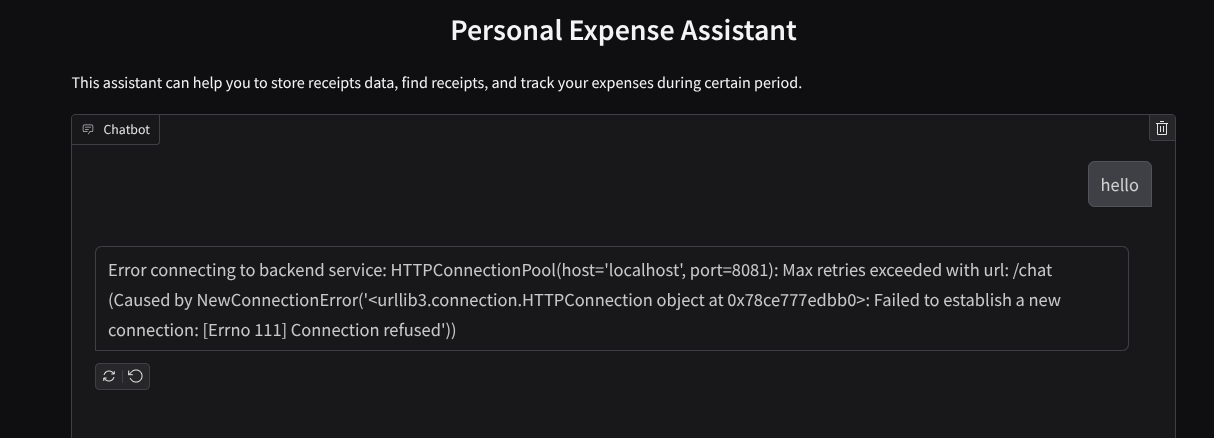
ממשק האינטרנט יוצג, אבל אם תנסו לשלוח צ'אט תקבלו שגיאה צפויה כי שירות לקצה העורפי עדיין לא הוגדר
עכשיו, נותנים לשירות לפעול ולא מפסיקים אותו עדיין. נפעיל את שירות לקצה העורפי בכרטיסיית מסוף אחרת
הסבר על הקוד
בקוד הקצה הקדמי הזה, קודם כל אנחנו מאפשרים למשתמש לשלוח טקסט ולהעלות כמה קבצים. Gradio מאפשר לנו ליצור פונקציונליות כזו באמצעות השיטה gr.ChatInterface בשילוב עם gr.MultimodalTextbox
לפני ששולחים את הקובץ והטקסט אל ה-backend, צריך לגלות את סוג ה-MIME של הקובץ, כי הוא נדרש על ידי ה-backend. צריך גם לקודד את בייט קובץ התמונה ל-base64 ולשלוח אותו יחד עם סוג ה-MIME.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
הסכימה שמשמשת לאינטראקציה בין חזית העורפית מוגדרת בקובץ schema.py. אנחנו משתמשים ב-Pydantic BaseModel כדי לאכוף אימות נתונים בסכימה
כשאנחנו מקבלים את התשובה, אנחנו כבר מפרידים בין החלק של תהליך החשיבה, התשובה הסופית והקובץ המצורף. לכן אנחנו יכולים להשתמש ברכיב Gradio כדי להציג כל רכיב עם רכיב ממשק המשתמש.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 יצירת שירות לקצה העורפי באמצעות FastAPI
בשלב הבא נצטרך ליצור את הקצה העורפי שיכול לאתחל את הסוכן שלנו יחד עם הרכיבים האחרים כדי להפעיל את זמן הריצה של הסוכן.
יוצרים קובץ חדש ונותנים לו את השם backend.py.
touch backend.py
מעתיקים את הקוד הבא
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
אחרי זה אפשר לנסות להפעיל את שירות ה-Backend. זוכרים שבשלב הקודם הפעלנו את שירות ה-frontend? עכשיו נצטרך לפתוח מסוף חדש ולנסות להפעיל את שירות ה-backend הזה.
- יוצרים טרמינל חדש. עוברים לטרמינל באזור התחתון ולוחצים על הלחצן '+' כדי ליצור טרמינל חדש. אפשר גם להקיש על Ctrl + Shift + C כדי לפתוח טרמינל חדש.

- אחרי זה, מוודאים שאתם בספריית העבודה personal-expense-assistant ומריצים את הפקודה הבאה
uv run backend.py
- אם הפעולה תצליח, יוצג פלט כמו זה
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
הסבר על הקוד
Initializing ADK Agent, SessionService and ArtifactService
כדי להריץ את הסוכן בשירות הקצה העורפי, צריך ליצור Runner שמקבל גם SessionService וגם את הסוכן שלנו. SessionService ינהל את היסטוריית השיחות והמצב שלהן, ולכן כשמשלבים אותו עם Runner, הוא מאפשר לסוכן שלנו לקבל את ההקשר של השיחות המתנהלות.
אנחנו גם משתמשים ב-ArtifactService כדי לטפל בקובץ שהועלה. כאן מפורט מידע נוסף על Artifacts ועל Session ב-ADK
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
בהדגמה הזו, אנחנו משתמשים ב-InMemorySessionService וב-GcsArtifactService כדי לשלב אותם עם הסוכן Runner שלנו. היסטוריית השיחות נשמרת בזיכרון, ולכן היא תימחק אם שירות לקצה העורפי יופסק או יופעל מחדש. אנחנו מאתחלים אותם בתוך מחזור החיים של אפליקציית FastAPI כדי להחדיר אותם כתלות במסלול /chat.
העלאה והורדה של תמונה באמצעות GcsArtifactService
כל התמונות שמועלות יישמרו כארטיפקט על ידי GcsArtifactService. אפשר לבדוק את זה בפונקציה format_user_request_to_adk_content_and_store_artifacts בתוך utils.py.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
כל הבקשות שיעובדו על ידי agent runner צריכות להיות בפורמט של סוג types.Content. בתוך הפונקציה, אנחנו גם מעבדים כל נתוני תמונה ומחלצים את המזהה שלה כדי להחליף אותו במחזיק מקום של מזהה תמונה.
מנגנון דומה משמש להורדת הקבצים המצורפים אחרי חילוץ מזהי התמונות באמצעות ביטוי רגולרי:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 בדיקת אינטגרציה
עכשיו אמורים לפעול כמה שירותים בכרטיסיות שונות במסוף הענן:
- שירות Frontend פועל ביציאה 8080
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- שירות לקצה העורפי פועל ביציאה 8081
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
במצב הנוכחי, אמורה להיות לך אפשרות להעלות תמונות של קבלות ולנהל שיחה חלקה עם העוזר הדיגיטלי מאפליקציית האינטרנט בפורט 8080.
לוחצים על הלחצן Web Preview (תצוגה מקדימה של אתר) בחלק העליון של Cloud Shell Editor ובוחרים באפשרות Preview on port 8080 (תצוגה מקדימה ביציאה 8080).
עכשיו נתחיל אינטראקציה עם העוזר הדיגיטלי.
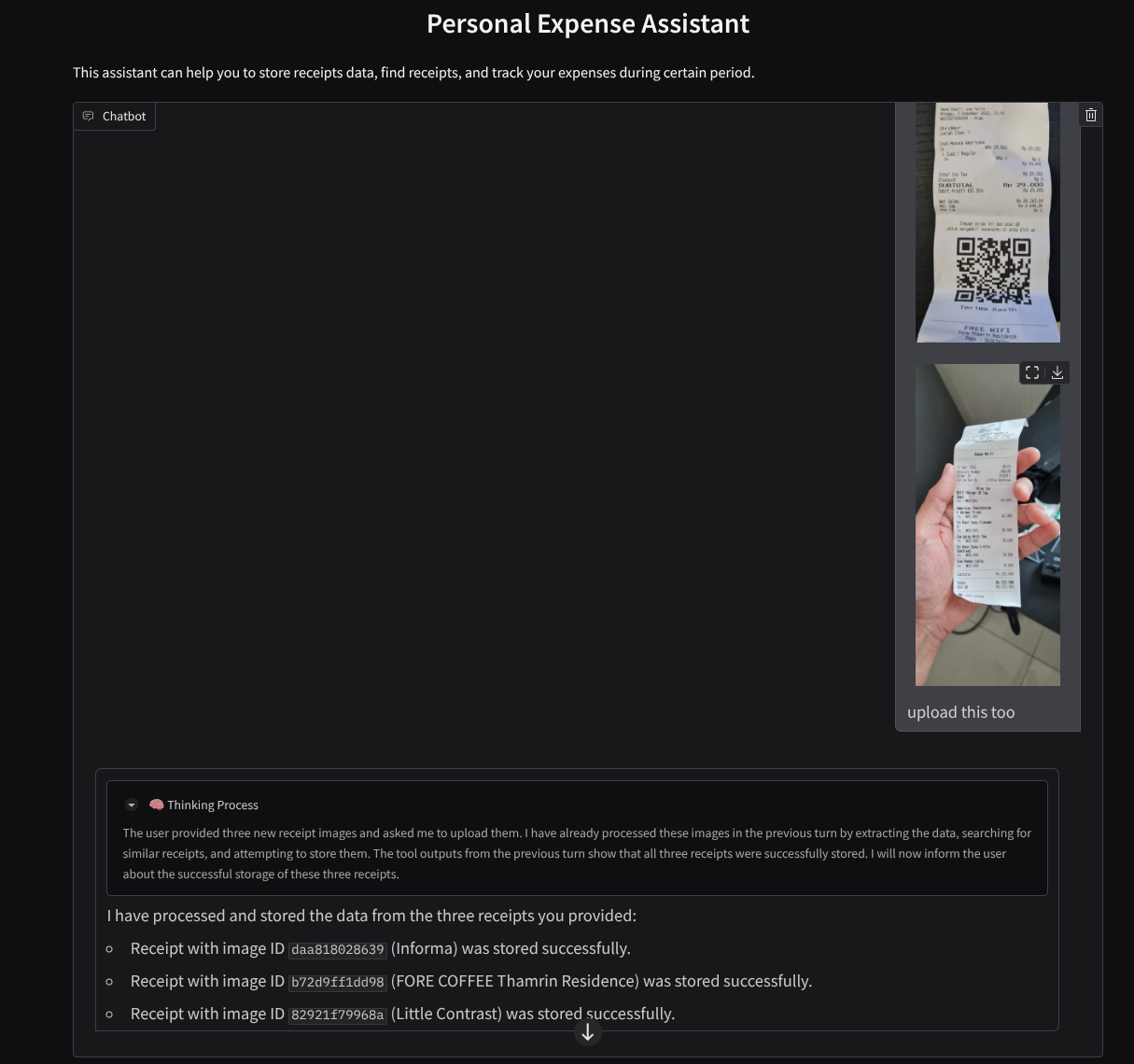
הורדת הקבלות הבאות. טווח התאריכים של נתוני הקבלה האלה הוא בין השנים 2023-2024, ומבקשים מהעוזר הדיגיטלי לאחסן או להעלות אותם
- Receipt Drive ( מקור: מערכי נתונים של Hugging Face
mousserlane/id_receipt_dataset)
לשאול שאלות שונות
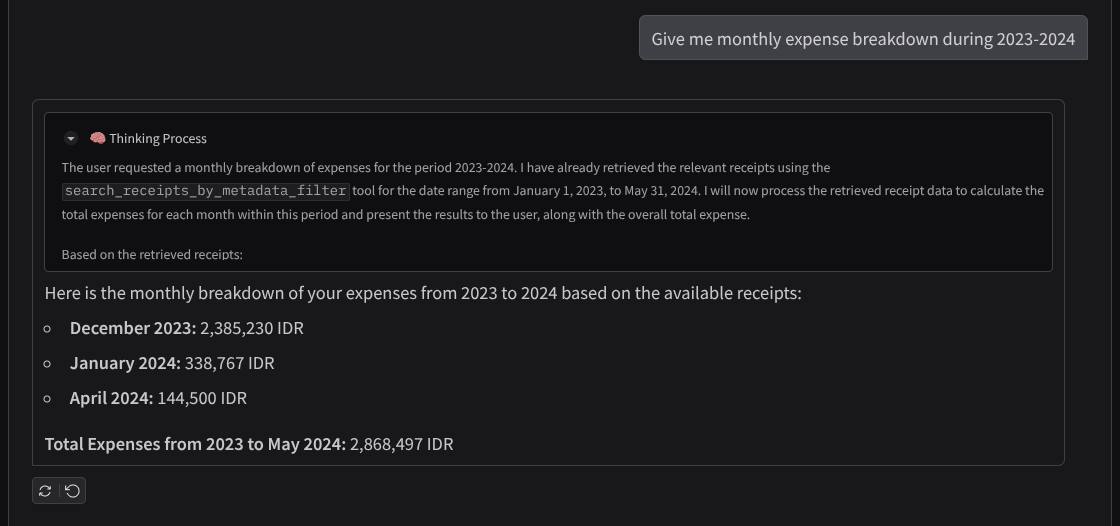
- "Give me monthly expense breakdown during 2023-2024" (תספק לי פירוט של ההוצאות החודשיות במהלך השנים 2023-2024)
- "Show me receipt for coffee transaction" (הצגת קבלה על עסקת קפה)
- "Give me receipt file from Yakiniku Like" (תביא לי קובץ קבלה מ-Yakiniku Like)
- וכו'
הנה קטע קצר של אינטראקציה מוצלחת
11. 🚀 פריסה ב-Cloud Run
עכשיו, ברור שאנחנו רוצים לגשת לאפליקציה המדהימה הזו מכל מקום. כדי לעשות זאת, אפשר לארוז את האפליקציה הזו ולפרוס אותה ב-Cloud Run. לצורך ההדגמה הזו, השירות הזה יהיה שירות ציבורי שאנשים אחרים יוכלו לגשת אליו. עם זאת, חשוב לזכור שזו לא השיטה המומלצת לסוג הזה של אפליקציה, כי היא מתאימה יותר לאפליקציות אישיות
ב-Codelab הזה נכניס את שירותי ה-frontend ושירותי הקצה העורפי ל-1 container. כדי לנהל את שני השירותים, נצטרך את העזרה של supervisord. אפשר לבדוק את הקובץ supervisord.conf ואת Dockerfile שהגדרנו את supervisord כנקודת הכניסה.
בשלב הזה, יש לנו כבר את כל הקבצים שנדרשים לפריסת האפליקציות ב-Cloud Run, אז נבצע את הפריסה. עוברים לטרמינל Cloud Shell ומוודאים שהפרויקט הנוכחי מוגדר לפרויקט הפעיל שלכם. אם לא, צריך להשתמש בפקודה gcloud configure כדי להגדיר את מזהה הפרויקט:
gcloud config set project [PROJECT_ID]
לאחר מכן, מריצים את הפקודה הבאה כדי לפרוס אותו ב-Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
אם מוצגת בקשה לאישור יצירה של מאגר ארטיפקטים עבור מאגר Docker, פשוט עונים Y. שימו לב שאנחנו מאפשרים כאן גישה לא מאומתת כי זו אפליקציית הדגמה. מומלץ להשתמש באימות מתאים לאפליקציות הארגוניות ולאפליקציות הייצור.
אחרי שהפריסה תושלם, תקבלו קישור שדומה לקישור שבהמשך:
https://personal-expense-assistant-*******.us-central1.run.app
אפשר להשתמש באפליקציה מהחלון הפרטי או מהנייד. הוא כבר אמור להיות פעיל.
12. 🎯 אתגר
עכשיו הגיע הזמן שלכם לזרוח ולשפר את מיומנויות החיפוש שלכם. האם יש לך את הידע הנדרש כדי לשנות את הקוד כך שהקצה העורפי יוכל לתמוך בכמה משתמשים? אילו רכיבים צריך לעדכן?
13. 🧹 ניקוי
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם ב-Code Lab הזה:
- במסוף Google Cloud, עוברים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
- לחלופין, אפשר לעבור אל Cloud Run במסוף, לבחור את השירות שפרסתם ולמחוק אותו.