
1. 📖 Introduzione
Ti è mai capitato di essere frustrato e troppo pigro per gestire tutte le tue spese personali? Anch'io! Per questo motivo, in questo codelab creeremo un assistente per la gestione delle spese personali, basato su Gemini 2.5, che svolgerà tutte le attività per noi. Dalla gestione delle ricevute caricate all'analisi per capire se hai già speso troppo per comprare un caffè.
Questo assistente sarà accessibile tramite browser web sotto forma di interfaccia web di chat, in cui potrai comunicare con lui, caricare alcune immagini di ricevute e chiedere all'assistente di memorizzarle o magari cercare alcune ricevute per ottenere il file ed eseguire un'analisi delle spese. Il tutto basato sul framework Google Agent Development Kit.
L'applicazione stessa è suddivisa in due servizi: frontend e backend, che ti consentono di creare un prototipo rapido e provare l'esperienza, nonché di capire come appare il contratto API per integrarli entrambi.
Nel codelab, seguirai un approccio passo passo come segue:
- Prepara il tuo progetto cloud Google e abilita tutte le API richieste
- Configura il bucket su Google Cloud Storage e il database su Firestore
- Crea l'indicizzazione Firestore
- Configurare lo spazio di lavoro per l'ambiente di programmazione
- Strutturazione del codice sorgente, degli strumenti, del prompt e così via dell'agente ADK
- Test dell'agente utilizzando l'interfaccia utente di sviluppo web locale di ADK
- Crea il servizio frontend, l'interfaccia di chat, utilizzando la libreria Gradio per inviare alcune query e caricare immagini di ricevute.
- Crea il servizio di backend, ovvero il server HTTP, utilizzando FastAPI, in cui risiedono il codice dell'agente ADK, SessionService e Artifact Service.
- Gestisci le variabili di ambiente e configura i file richiesti necessari per eseguire il deployment dell'applicazione in Cloud Run
- Esegui il deployment dell'applicazione in Cloud Run
Panoramica dell'architettura

Prerequisiti
- Avere familiarità con Python
- Comprensione dell'architettura full-stack di base utilizzando il servizio HTTP
Cosa imparerai a fare
- Prototipazione web frontend con Gradio
- Sviluppo del servizio di backend con FastAPI e Pydantic
- Progettare l'agente ADK utilizzando le sue diverse funzionalità
- Utilizzo dello strumento
- Gestione di sessioni e artefatti
- Utilizzo dei callback per la modifica dell'input prima dell'invio a Gemini
- Utilizzare BuiltInPlanner per migliorare l'esecuzione delle attività tramite la pianificazione
- Debug rapido tramite l'interfaccia web locale dell'ADK
- Strategia per ottimizzare l'interazione multimodale tramite l'analisi e il recupero delle informazioni tramite l'ingegneria dei prompt e la modifica delle richieste Gemini utilizzando il callback ADK
- Generazione aumentata dal recupero agentico utilizzando Firestore come database vettoriale
- Gestisci le variabili di ambiente nel file YAML con Pydantic-settings
- Esegui il deployment dell'applicazione in Cloud Run utilizzando Dockerfile e fornisci le variabili di ambiente con il file YAML
Che cosa ti serve
- Browser web Chrome
- Un account Gmail
- Un progetto cloud con fatturazione abilitata
Questo codelab, progettato per sviluppatori di tutti i livelli (inclusi i principianti), utilizza Python nella sua applicazione di esempio. Tuttavia, la conoscenza di Python non è necessaria per comprendere i concetti presentati.
2. 🚀 Prima di iniziare
Seleziona il progetto attivo in Cloud Console
Questo codelab presuppone che tu abbia già un progetto Google Cloud con la fatturazione abilitata. Se non l'hai ancora fatto, puoi seguire le istruzioni riportate di seguito per iniziare.
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Prepara il database Firestore
Successivamente, dovremo creare anche un database Firestore. Firestore in modalità nativa è un database di documenti NoSQL creato per offrire scalabilità automatica, prestazioni elevate e facilità di sviluppo delle applicazioni. Può anche fungere da database vettoriale che può supportare la tecnica Retrieval Augmented Generation per il nostro lab.
- Cerca "firestore" nella barra di ricerca e fai clic sul prodotto Firestore.
- Quindi, fai clic sul pulsante Crea un database Firestore.
- Utilizza (default) come nome dell'ID database e mantieni selezionata l'edizione Standard. Ai fini di questa demo del lab, utilizza Firestore Native con regole di sicurezza Open.
- Noterai anche che questo database ha effettivamente l'utilizzo del livello senza costi YEAY! Dopodiché, fai clic sul pulsante Crea database.
Dopo questi passaggi, dovresti già essere reindirizzato al database Firestore che hai appena creato.
Configura il progetto cloud nel terminale Cloud Shell
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud precaricato con bq. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
In alternativa, puoi anche visualizzare l'ID PROJECT_ID nella console.
Fai clic e vedrai tutti i tuoi progetti e l'ID progetto sul lato destro.
- Abilita le API richieste tramite il comando mostrato di seguito. L'operazione potrebbe richiedere alcuni minuti.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Se il comando viene eseguito correttamente, dovresti visualizzare un messaggio simile a quello mostrato di seguito:
Operation "operations/..." finished successfully.
L'alternativa al comando gcloud è tramite la console, cercando ogni prodotto o utilizzando questo link.
Se manca un'API, puoi sempre abilitarla durante l'implementazione.
Consulta la documentazione per i comandi e l'utilizzo di gcloud.
Prepara il bucket Cloud Storage
Successivamente, dallo stesso terminale, dovremo preparare il bucket GCS per archiviare il file caricato. Esegui il comando seguente per creare il bucket. Avrai bisogno di un nome univoco e pertinente per il bucket, che sia rilevante per le ricevute dell'assistente per le spese personali. Pertanto, utilizzeremo il seguente nome del bucket combinato con l'ID progetto
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Verrà visualizzato questo output
Creating gs://personal-expense-{your-project-id}
Puoi verificarlo andando al menu di navigazione in alto a sinistra del browser e selezionando Cloud Storage -> Bucket.
Creazione dell'indice Firestore per la ricerca
Firestore è un database NoSQL nativo, che offre prestazioni e flessibilità superiori nel modello dei dati, ma presenta limitazioni per quanto riguarda le query complesse. Poiché prevediamo di utilizzare alcune query multi-campo composte e la ricerca vettoriale, dovremo prima creare alcuni indici. Per saperne di più, consulta questa documentazione.
- Esegui questo comando per creare l'indice per supportare le query composte
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- E questo per supportare la ricerca vettoriale
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
Puoi controllare l'indice creato visitando Firestore nella console Google Cloud, facendo clic sull'istanza del database (default) e selezionando Indici nella barra di navigazione.
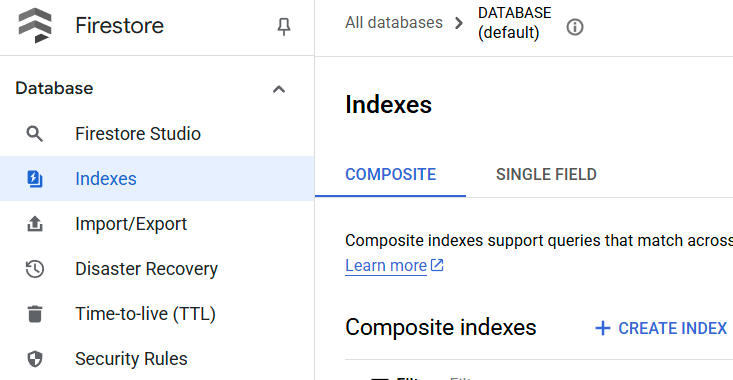
Vai all'editor di Cloud Shell e configura la directory di lavoro dell'applicazione
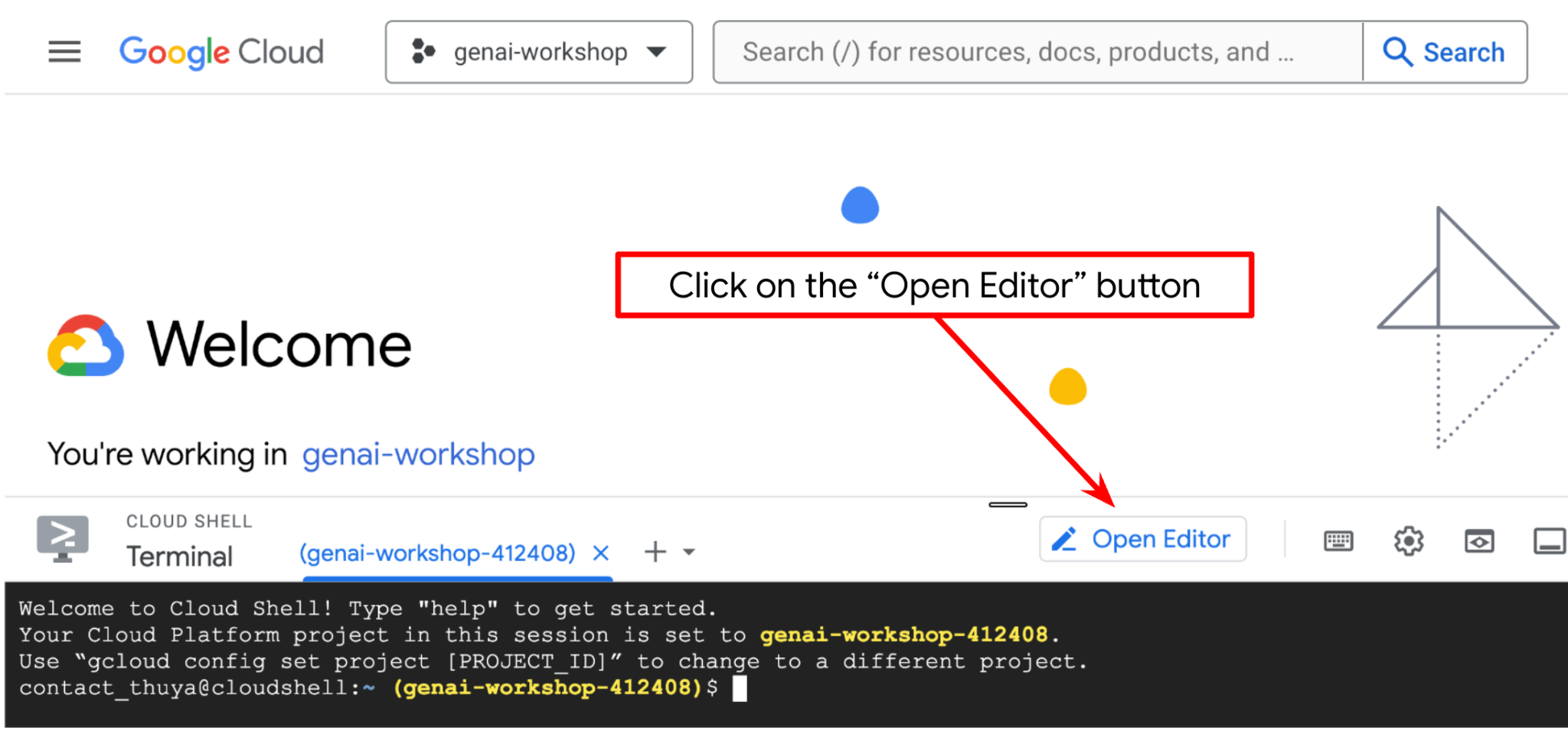
Ora possiamo configurare l'editor di codice per svolgere alcune attività di programmazione. Per questo utilizzeremo l'editor di Cloud Shell
- Fai clic sul pulsante Apri editor per aprire un editor di Cloud Shell, dove puoi scrivere il codice
- Successivamente, dobbiamo anche verificare se la shell è già configurata con l'ID PROGETTO corretto. Se vedi un valore tra parentesi ( ) prima dell'icona $ nel terminale ( nella schermata riportata di seguito, il valore è "adk-multimodal-tool"), questo valore mostra il progetto configurato per la sessione shell attiva.

Se il valore mostrato è già corretto, puoi saltare il comando successivo. Tuttavia, se non è corretto o è mancante, esegui il seguente comando
gcloud config set project <YOUR_PROJECT_ID>
- Successivamente, cloniamo la directory di lavoro del modello per questo codelab da GitHub eseguendo il seguente comando. Verrà creata la directory di lavoro nella directory personal-expense-assistant
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- Dopodiché, vai alla sezione superiore dell'editor di Cloud Shell e fai clic su File->Apri cartella, individua la directory username e la directory personal-expense-assistant, quindi fai clic sul pulsante Ok. In questo modo, la directory scelta diventerà la directory di lavoro principale. In questo esempio, il nome utente è alvinprayuda, quindi il percorso della directory è mostrato di seguito
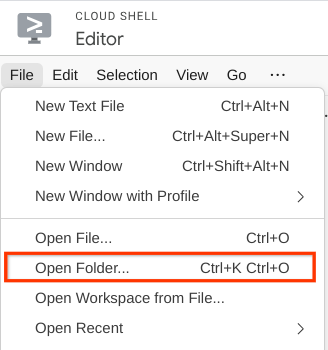

Ora, Cloud Shell Editor dovrebbe avere il seguente aspetto
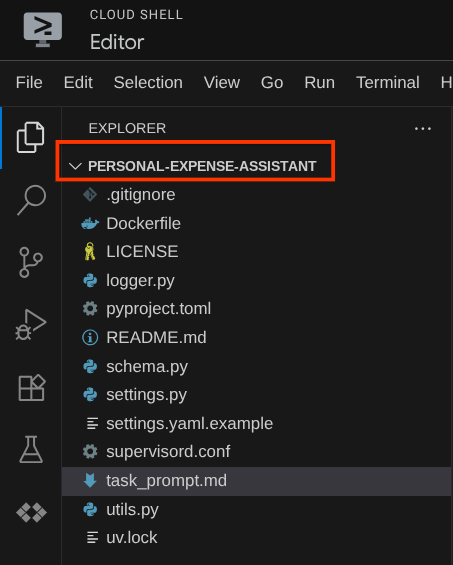
Configurazione dell'ambiente
Prepara l'ambiente virtuale Python
Il passaggio successivo consiste nel preparare l'ambiente di sviluppo. Il terminale attivo corrente deve trovarsi nella directory di lavoro personal-expense-assistant. In questo codelab utilizzeremo Python 3.12 e uv python project manager per semplificare la necessità di creare e gestire la versione di Python e l'ambiente virtuale.
- Se non hai ancora aperto il terminale, aprilo facendo clic su Terminale -> Nuovo terminale o utilizza Ctrl + Maiusc + C, che aprirà una finestra del terminale nella parte inferiore del browser.

- Ora inizializziamo l'ambiente virtuale utilizzando
uv. Esegui questi comandi:
cd ~/personal-expense-assistant
uv sync --frozen
Verranno create la directory .venv e installate le dipendenze. Una rapida anteprima di pyproject.toml ti fornirà informazioni sulle dipendenze visualizzate in questo modo
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
File di configurazione dell'installazione
Ora dobbiamo configurare i file di configurazione per questo progetto. Utilizziamo pydantic-settings per leggere la configurazione dal file YAML.
Abbiamo già fornito il modello di file all'interno di settings.yaml.example. Dovremo copiare il file e rinominarlo in settings.yaml. Esegui questo comando per creare il file
cp settings.yaml.example settings.yaml
Poi copia il seguente valore nel file
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
Per questo codelab, utilizzeremo i valori preconfigurati per GCLOUD_LOCATION, BACKEND_URL, e DB_COLLECTION_NAME .
Ora possiamo passare al passaggio successivo, ovvero la creazione dell'agente e poi dei servizi
3. 🚀 Crea l'agente utilizzando Google ADK e Gemini 2.5
Introduzione alla struttura delle directory dell'ADK
Iniziamo esplorando le funzionalità dell'ADK e come creare l'agente. La documentazione completa dell'ADK è disponibile in questo URL . L'ADK ci offre molte utilità nell'esecuzione dei comandi della CLI. Alcuni di questi sono :
- Configura la struttura delle directory dell'agente
- Prova rapidamente l'interazione tramite input/output della CLI
- Configurare rapidamente l'interfaccia web dell'interfaccia utente di sviluppo locale
Ora creiamo la struttura di directory dell'agente utilizzando il comando CLI. Esegui questo comando.
uv run adk create expense_manager_agent
Quando ti viene chiesto, scegli il modello gemini-2.5-flash e il backend Vertex AI. La procedura guidata ti chiederà l'ID progetto e la posizione. Puoi accettare le opzioni predefinite premendo Invio o modificarle in base alle tue esigenze. Verifica di utilizzare l'ID progetto corretto creato in precedenza in questo lab. L'output sarà simile al seguente:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Verrà creata la seguente struttura di directory dell'agente
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Se ispezioni init.py e agent.py, vedrai questo codice
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Ora puoi testarlo eseguendo
uv run adk run expense_manager_agent
Al termine del test, puoi uscire dall'agente digitando exit o premendo Ctrl+D.
Creazione dell'agente Expense Manager
Creiamo il nostro agente per la gestione delle spese. Apri il file expense_manager_agent/agent.py e copia il codice riportato di seguito, che conterrà root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Spiegazione del codice
Questo script contiene l'inizializzazione dell'agente, in cui inizializziamo quanto segue:
- Imposta il modello da utilizzare su
gemini-2.5-flash - Configura la descrizione e le istruzioni dell'agente come prompt di sistema letto da
task_prompt.md - Fornire gli strumenti necessari per supportare la funzionalità dell'agente
- Attivare la pianificazione prima di generare la risposta finale o l'esecuzione utilizzando le funzionalità di ragionamento di Gemini 2.5 Flash
- Configura l'intercettazione del callback prima di inviare la richiesta a Gemini per limitare il numero di dati immagine inviati prima di fare la previsione
4. 🚀 Configurazione degli strumenti dell'agente
Il nostro agente di gestione delle spese avrà le seguenti funzionalità:
- Estrai i dati dall'immagine della ricevuta e memorizza i dati e il file
- Ricerca esatta sui dati delle spese
- Ricerca contestuale sui dati delle spese
Pertanto, abbiamo bisogno degli strumenti appropriati per supportare questa funzionalità. Crea un nuovo file nella directory expense_manager_agent e chiamalo tools.py.
touch expense_manager_agent/tools.py
Apri expense_manage_agent/tools.py, poi copia il codice riportato di seguito.
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Spiegazione del codice
Nell'implementazione di questa funzione di strumenti, progettiamo gli strumenti intorno a queste due idee principali:
- Analizzare i dati delle ricevute e mapparli al file originale utilizzando il segnaposto della stringa dell'ID immagine
[IMAGE-ID <hash-of-image-1>] - Archiviazione e recupero dei dati utilizzando il database Firestore
Strumento "store_receipt_data"
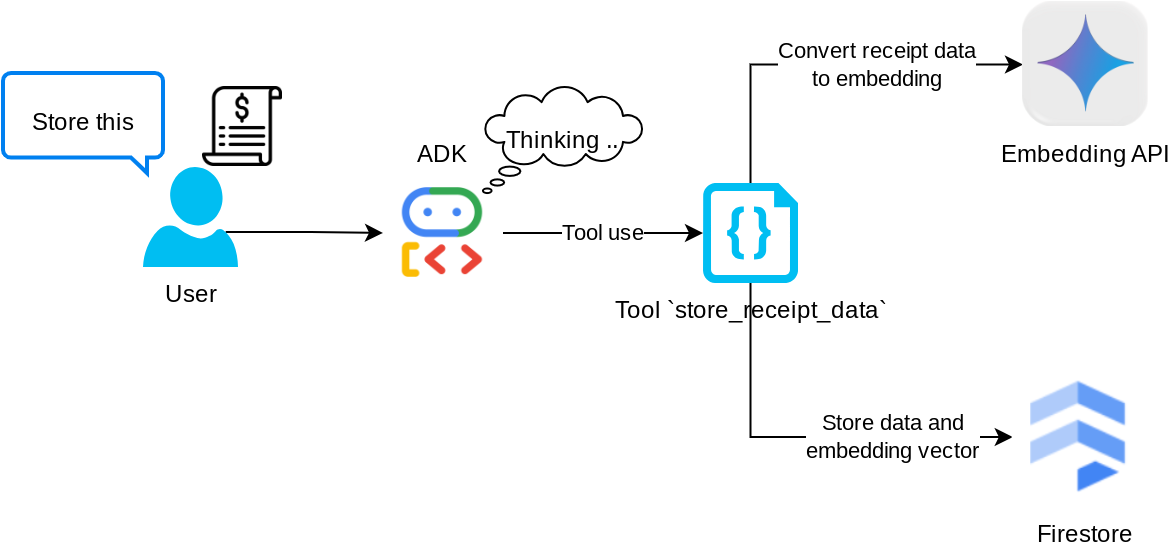
Questo strumento è il riconoscimento ottico dei caratteri, che analizzerà le informazioni richieste dai dati dell'immagine, riconoscerà la stringa dell'ID immagine e le mapperà insieme per essere archiviate nel database Firestore.
Inoltre, questo strumento converte anche il contenuto della ricevuta in incorporamento utilizzando text-embedding-004, in modo che tutti i metadati e l'incorporamento vengano archiviati e indicizzati insieme. Consentendo la flessibilità di essere recuperati tramite query o ricerca contestuale.
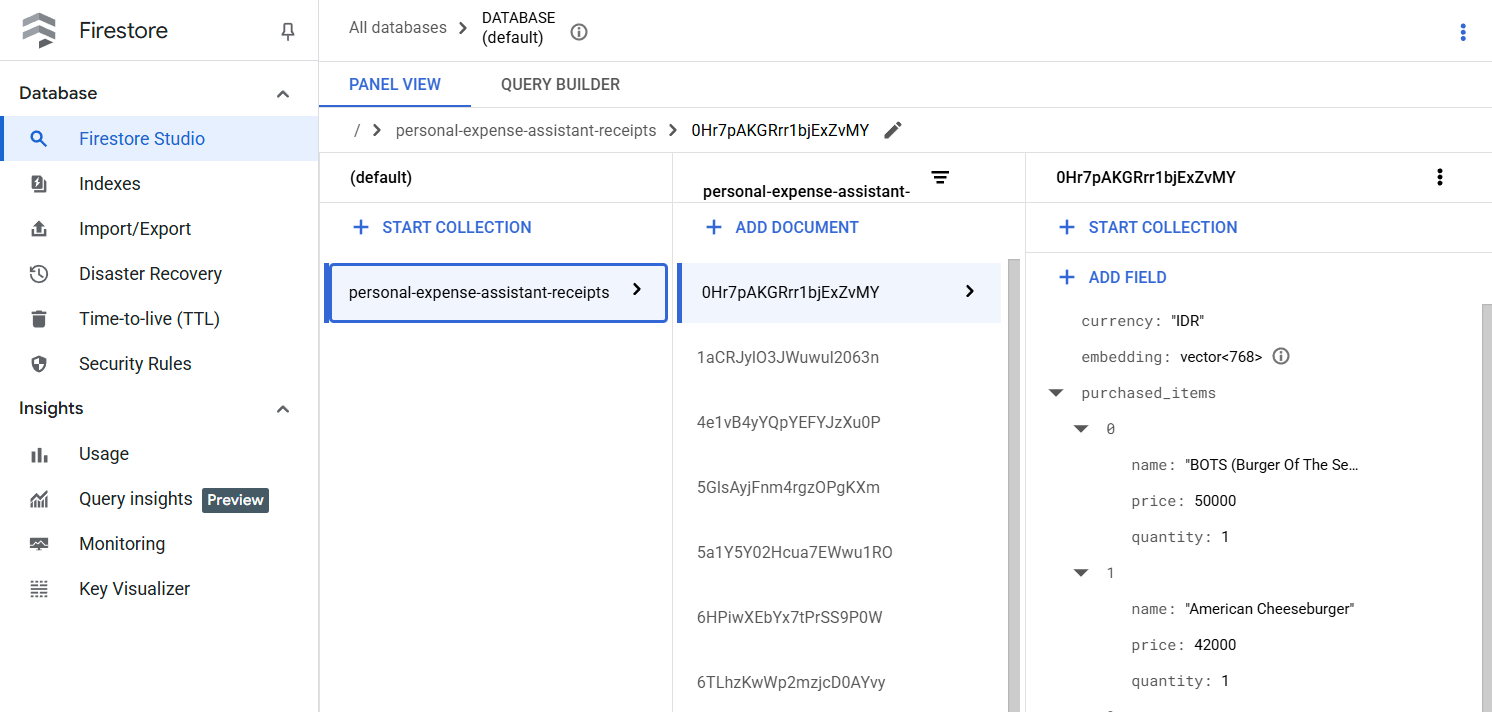
Dopo aver eseguito correttamente questo strumento, puoi vedere che i dati delle ricevute sono già indicizzati nel database Firestore, come mostrato di seguito
Strumento "search_receipts_by_metadata_filter"
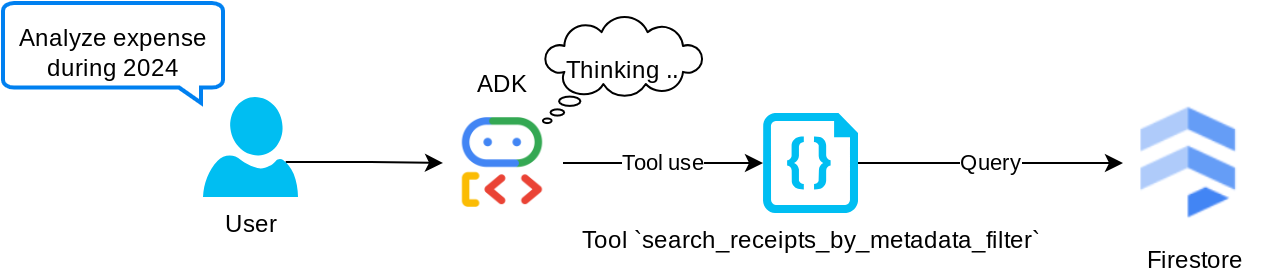
Questo strumento converte la query dell'utente in un filtro di query sui metadati che supporta la ricerca per intervallo di date e/o transazione totale. Restituirà tutti i dati delle ricevute corrispondenti, mentre nel processo elimineremo il campo di incorporamento perché non è necessario all'agente per la comprensione contestuale
Strumento "search_relevant_receipts_by_natural_language_query"
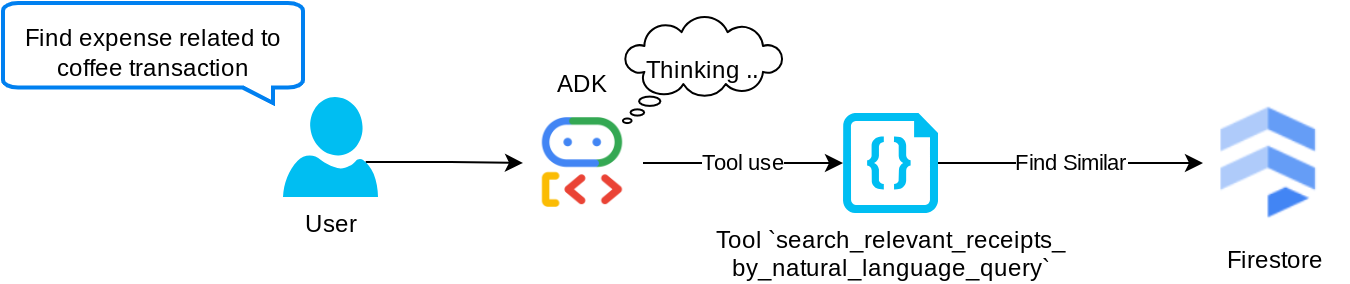
Questo è il nostro strumento Retrieval-Augmented Generation (RAG). Il nostro agente è in grado di progettare la propria query per recuperare le ricevute pertinenti dal database vettoriale e può anche scegliere quando utilizzare questo strumento. La nozione di consentire all'agente di decidere autonomamente se utilizzare o meno questo strumento RAG e progettare la propria query è una delle definizioni dell'approccio RAG agentico.
Non solo gli consentiamo di creare la propria query, ma anche di selezionare il numero di documenti pertinenti che vuole recuperare. Se combinato con un prompt engineering adeguato, ad esempio
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
In questo modo, questo strumento diventa uno strumento potente in grado di cercare quasi qualsiasi cosa, anche se potrebbe non restituire tutti i risultati previsti a causa della natura non esatta della ricerca del vicino più prossimo.
5. 🚀 Modifica del contesto della conversazione tramite callback
Google ADK ci consente di "intercettare" l'runtime dell'agente a vari livelli. Per saperne di più su questa funzionalità dettagliata, consulta questa documentazione . In questo lab, utilizziamo before_model_callback per modificare la richiesta prima dell'invio all'LLM per rimuovere i dati delle immagini nel contesto della cronologia delle conversazioni precedente ( includi i dati delle immagini solo nelle ultime 3 interazioni dell'utente) per efficienza.
Tuttavia, vogliamo comunque che l'agente abbia il contesto dei dati delle immagini quando necessario. Pertanto, aggiungiamo un meccanismo per inserire un segnaposto per l'ID immagine stringa dopo ogni byte di dati dell'immagine nella conversazione. In questo modo, l'agente potrà collegare l'ID immagine ai dati del file effettivo, che possono essere utilizzati sia al momento dell'archiviazione che del recupero dell'immagine. La struttura sarà simile a questa
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
Quando i dati dei byte diventano obsoleti nella cronologia delle conversazioni, l'identificatore della stringa è ancora presente per consentire l'accesso ai dati con l'aiuto dell'utilizzo dello strumento. Esempio di struttura della cronologia dopo la rimozione dei dati delle immagini
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Inizia. Crea un nuovo file nella directory expense_manager_agent e chiamalo callbacks.py.
touch expense_manager_agent/callbacks.py
Apri il file expense_manager_agent/callbacks.py, quindi copia il codice riportato di seguito.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 Il prompt
La progettazione di un agente con interazioni e funzionalità complesse richiede di trovare un prompt sufficientemente buono per guidarlo in modo che si comporti nel modo desiderato.
In precedenza avevamo un meccanismo per gestire i dati delle immagini nella cronologia delle conversazioni e anche strumenti che potrebbero non essere semplici da usare, come search_relevant_receipts_by_natural_language_query. Vogliamo anche che l'agente sia in grado di cercare e recuperare l'immagine della ricevuta corretta. Ciò significa che dobbiamo trasmettere correttamente tutte queste informazioni in una struttura di prompt adeguata
Chiederemo all'agente di strutturare l'output nel seguente formato Markdown per analizzare il processo di pensiero, la risposta finale e l'eventuale allegato
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Iniziamo con il seguente prompt per raggiungere la nostra aspettativa iniziale sul comportamento dell'agente di gestione delle spese. Il file task_prompt.md dovrebbe già esistere nella nostra directory di lavoro esistente, ma dobbiamo spostarlo nella directory expense_manager_agent. Esegui questo comando per spostarlo
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Test dell'agente
Ora proviamo a comunicare con l'agente tramite la CLI. Esegui il seguente comando
uv run adk run expense_manager_agent
Verrà visualizzato un output simile a questo, in cui puoi chattare a turno con l'agente, ma puoi inviare solo testo tramite questa interfaccia
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
Oltre all'interazione con la CLI, l'ADK ci consente anche di avere un'interfaccia utente di sviluppo per interagire e ispezionare ciò che accade durante l'interazione. Esegui questo comando per avviare il server dell'interfaccia utente di sviluppo locale
uv run adk web --port 8080
Verrà generato un output simile al seguente esempio, il che significa che possiamo già accedere all'interfaccia web
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Ora, per verificarlo, fai clic sul pulsante Anteprima web nella parte superiore di Cloud Shell Editor e seleziona Anteprima sulla porta 8080.
Vedrai la seguente pagina web in cui puoi selezionare gli agenti disponibili nel pulsante a discesa in alto a sinistra ( nel nostro caso dovrebbe essere expense_manager_agent) e interagire con il bot. Nella finestra a sinistra vedrai molte informazioni sui dettagli del log durante il runtime dell'agente.
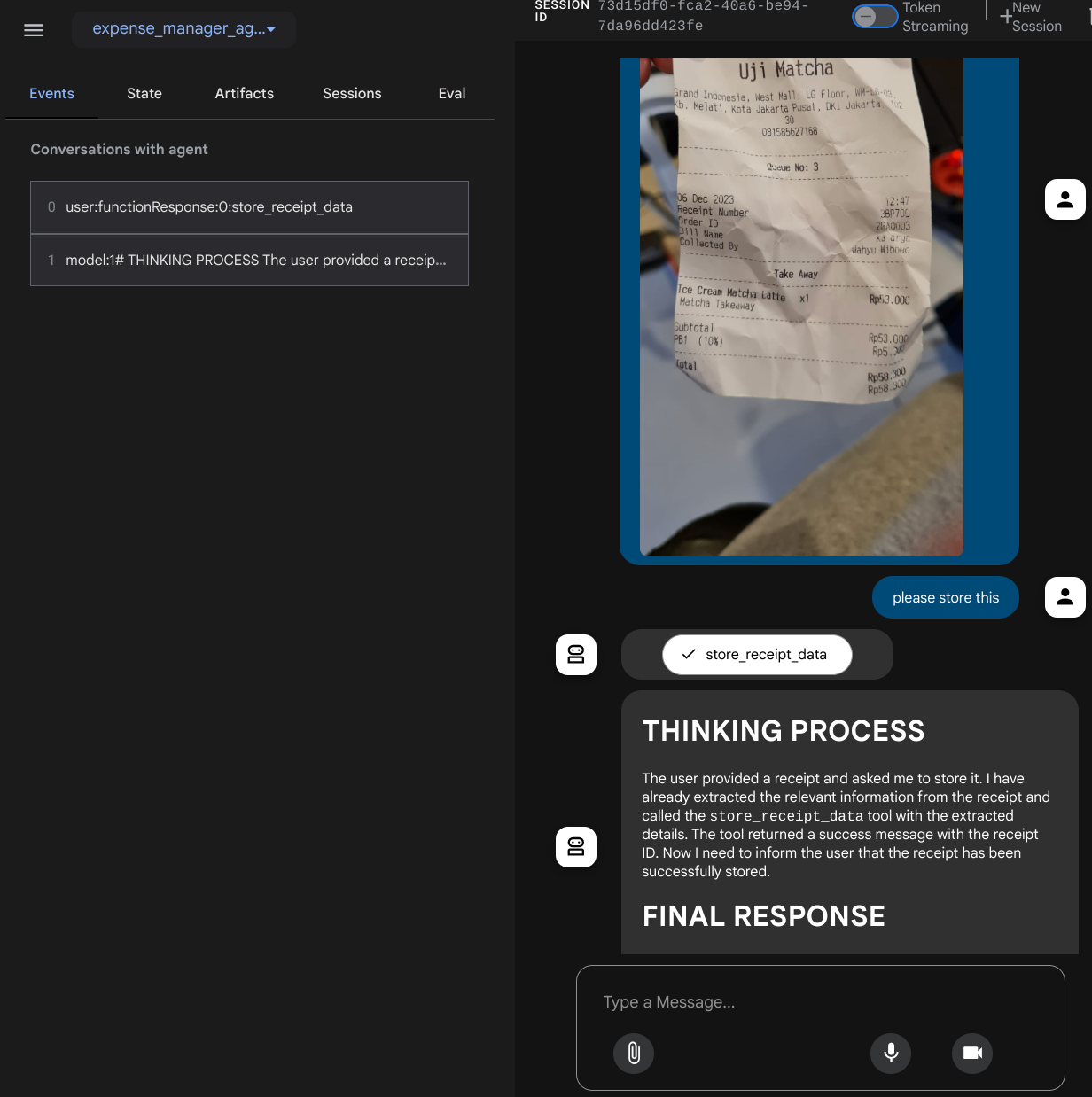
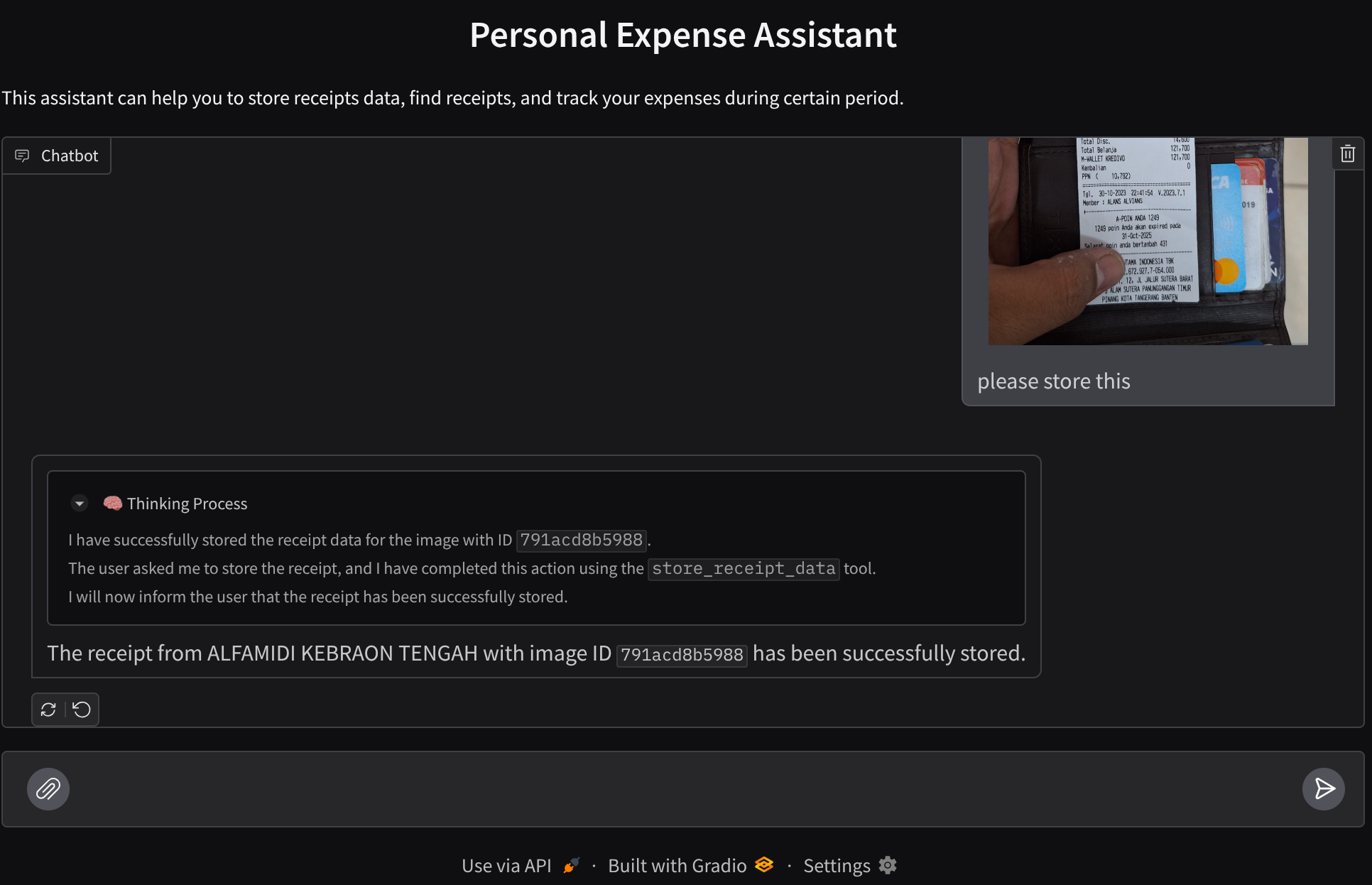
Proviamo alcune azioni. Carica queste due ricevute di esempio ( origine : set di dati Hugging Face mousserlane/id_receipt_dataset) . Fai clic con il tasto destro del mouse su ogni immagine e scegli Salva immagine con nome… ( in questo modo verrà scaricata l'immagine della ricevuta), poi carica il file sul bot facendo clic sull'icona a forma di "graffetta" e indica che vuoi archiviare queste ricevute.


Dopodiché, prova le seguenti query per eseguire ricerche o recuperare file.
- "Fornisci la suddivisione delle spese e il relativo totale nel 2023"
- "Dammi il file della ricevuta di Indomaret"
Quando utilizzi alcuni strumenti, puoi esaminare cosa succede nella UI di sviluppo
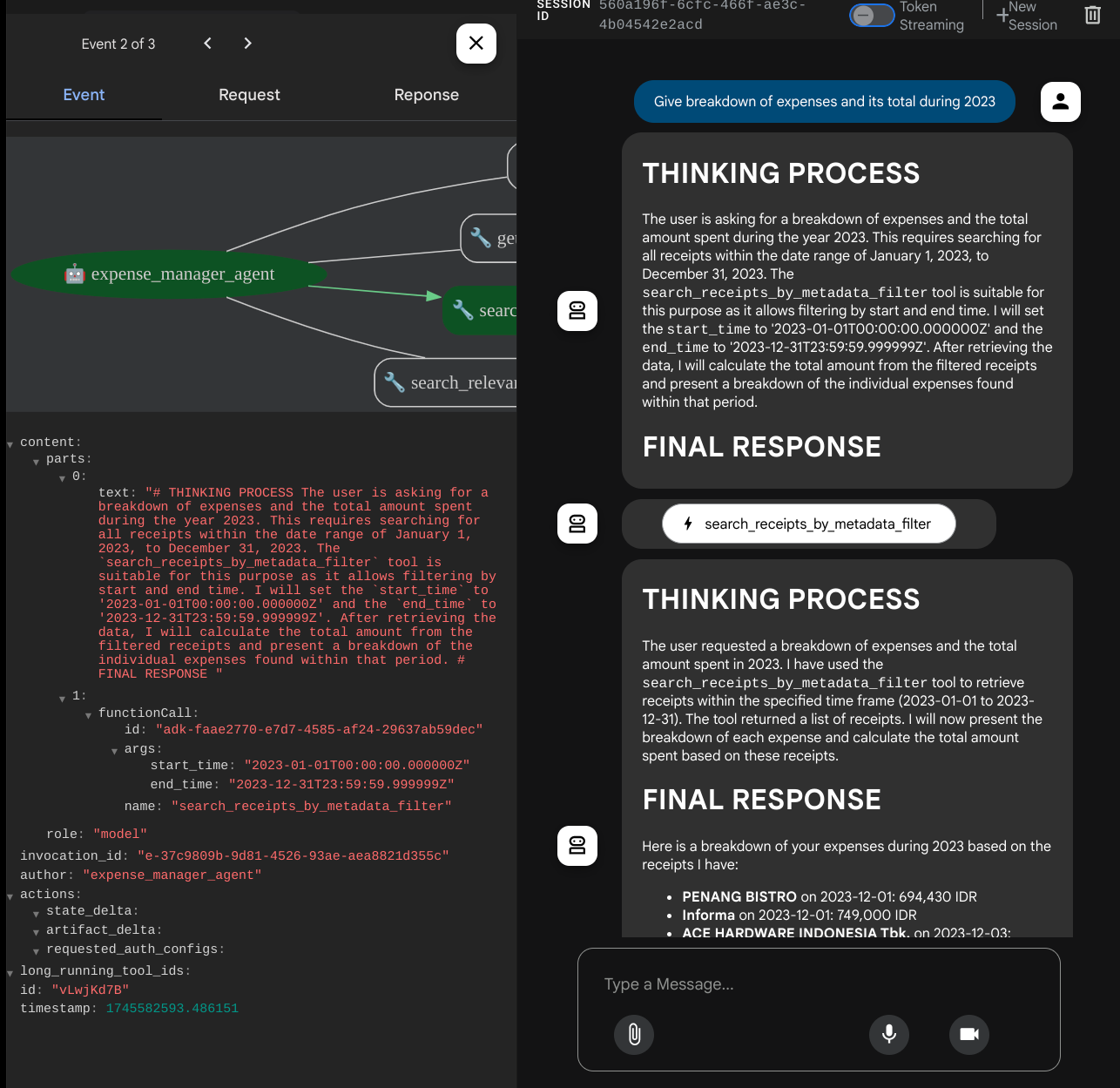
Guarda come risponde l'agente e controlla se rispetta tutte le regole fornite nel prompt all'interno di task_prompt.py. Complimenti! Ora hai un agente di sviluppo funzionante completo.
Ora è il momento di completarlo con una UI e funzionalità adeguate e piacevoli per caricare e scaricare il file immagine.
8. 🚀 Crea il servizio frontend utilizzando Gradio
Creeremo un'interfaccia web di chat simile a questa
Contiene un'interfaccia di chat con un campo di immissione in cui gli utenti possono inviare testo e caricare i file immagine delle ricevute.
Creeremo il servizio frontend utilizzando Gradio.
Crea un nuovo file e chiamalo frontend.py.
touch frontend.py
quindi copia il seguente codice e salvalo.
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Dopodiché, possiamo provare a eseguire il servizio di frontend con il seguente comando. Non dimenticare di rinominare il file main.py in frontend.py.
uv run frontend.py
Nella console Google Cloud vedrai un output simile a questo
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Dopodiché, puoi controllare l'interfaccia web quando Ctrl+fai clic sul link dell'URL locale. In alternativa, puoi accedere all'applicazione frontend facendo clic sul pulsante Anteprima web in alto a destra in Cloud Editor e selezionando Anteprima sulla porta 8080.
Vedrai l'interfaccia web, ma riceverai un errore previsto quando provi a inviare la chat a causa del servizio di backend che non è ancora stato configurato
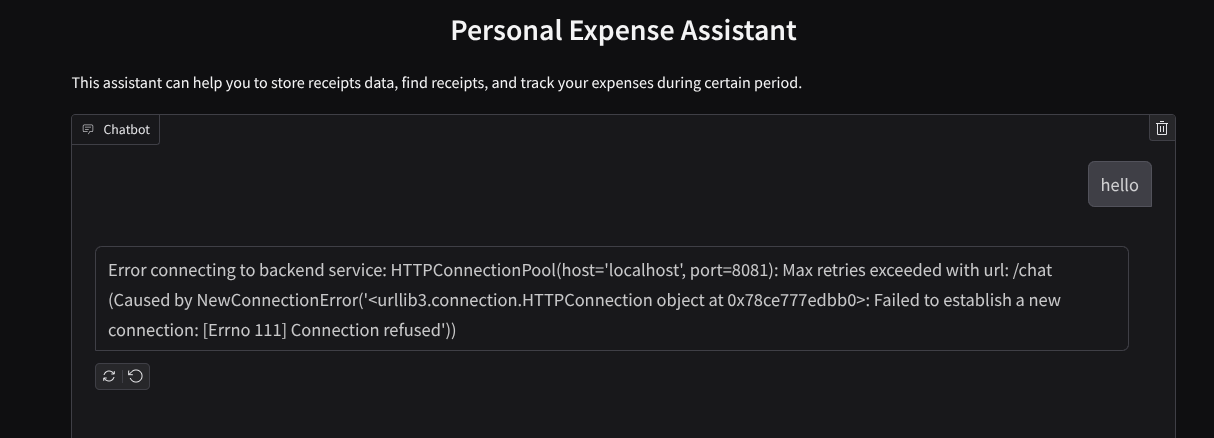
Ora lascia in esecuzione il servizio e non terminarlo ancora. Eseguiamo il servizio di backend in un'altra scheda del terminale
Spiegazione del codice
In questo codice frontend, prima consentiamo all'utente di inviare testo e caricare più file. Gradio ci consente di creare questo tipo di funzionalità con il metodo gr.ChatInterface combinato con gr.MultimodalTextbox
Prima di inviare il file e il testo al backend, dobbiamo capire il tipo MIME del file, poiché è necessario per il backend. Dobbiamo anche codificare il byte del file immagine in base64 e inviarlo insieme al tipo MIME.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
Lo schema utilizzato per l'interazione frontend-backend è definito in schema.py. Utilizziamo Pydantic BaseModel per applicare la convalida dei dati nello schema
Quando ricevi la risposta, separiamo già la parte relativa al processo di pensiero, la risposta finale e l'allegato. Pertanto, possiamo utilizzare il componente Gradio per visualizzare ogni componente con il componente UI.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Crea un servizio di backend utilizzando FastAPI
Successivamente, dovremo creare il backend che può inizializzare l'agente insieme agli altri componenti per poter eseguire Agent Runtime.
Crea un nuovo file e chiamalo backend.py.
touch backend.py
e copia il seguente codice
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Dopodiché, possiamo provare a eseguire il servizio di backend. Ricorda che nel passaggio precedente abbiamo eseguito il servizio frontend. Ora dobbiamo aprire un nuovo terminale e provare a eseguire questo servizio di backend.
- Crea un nuovo terminale. Vai al terminale nella parte inferiore e trova il pulsante "+" per creare un nuovo terminale. In alternativa, puoi premere Ctrl + Maiusc + C per aprire un nuovo terminale.

- Dopodiché, assicurati di trovarti nella directory di lavoro personal-expense-assistant ed esegui questo comando
uv run backend.py
- In caso di esito positivo, l'output sarà simile a questo
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Spiegazione del codice
Initializing ADK Agent, SessionService and ArtifactService
Per eseguire l'agente nel servizio di backend, dobbiamo creare un Runner che accetti sia SessionService sia il nostro agente. SessionService gestirà la cronologia e lo stato delle conversazioni, quindi, se integrato con Runner, consentirà al nostro agente di ricevere il contesto delle conversazioni in corso.
Utilizziamo anche ArtifactService per gestire il file caricato. Puoi leggere ulteriori dettagli su ADK Session e Artifacts qui.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
In questa demo, utilizziamo InMemorySessionService e GcsArtifactService per l'integrazione con il nostro agente Runner. Poiché la cronologia delle conversazioni è memorizzata nella memoria, andrà persa una volta interrotto o riavviato il servizio di backend. Li inizializziamo all'interno del ciclo di vita dell'applicazione FastAPI per essere inseriti come dipendenza nella route /chat.
Caricamento e download di immagini con GcsArtifactService
Tutte le immagini caricate verranno archiviate come artefatto da GcsArtifactService. Puoi verificarlo all'interno della funzione format_user_request_to_adk_content_and_store_artifacts in utils.py.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Tutte le richieste che verranno elaborate da agent runner devono essere formattate nel tipo types.Content. All'interno della funzione, elaboriamo anche i dati di ogni immagine ed estraiamo il relativo ID da sostituire con un segnaposto ID immagine.
Un meccanismo simile viene utilizzato per scaricare gli allegati dopo aver estratto gli ID immagine utilizzando le espressioni regolari:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Test di integrazione
Ora dovresti avere più servizi in esecuzione in diverse schede della console Cloud:
- Servizio frontend eseguito sulla porta 8080
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Servizio di backend eseguito sulla porta 8081
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Nello stato attuale, dovresti essere in grado di caricare le immagini delle ricevute e chattare senza problemi con l'assistente dall'applicazione web sulla porta 8080.
Fai clic sul pulsante Anteprima web nella parte superiore di Cloud Shell Editor e seleziona Anteprima sulla porta 8080.
Ora interagiamo un po' con l'assistente.
Scarica le seguenti ricevute. L'intervallo di date di questi dati delle ricevute è compreso tra gli anni 2023 e 2024. Chiedi all'assistente di archiviarli/caricarli.
- Receipt Drive ( origine: set di dati Hugging Face
mousserlane/id_receipt_dataset)
Chiedere varie cose
- "Dammi la suddivisione delle spese mensili nel periodo 2023-2024"
- "Mostrami la ricevuta della transazione del caffè"
- "Dammi il file della ricevuta di Yakiniku Like"
- Etc
Ecco un frammento di un'interazione riuscita
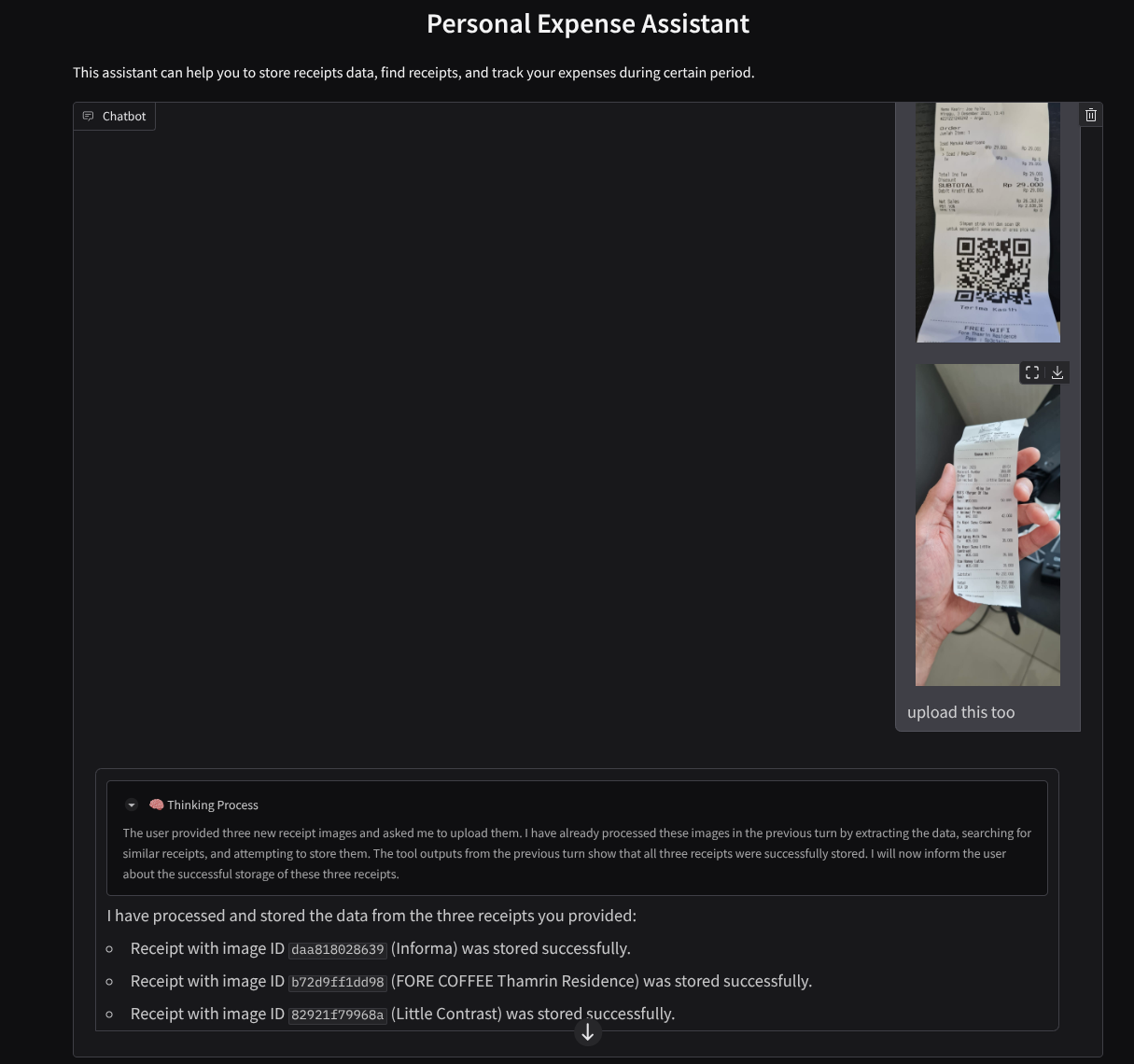
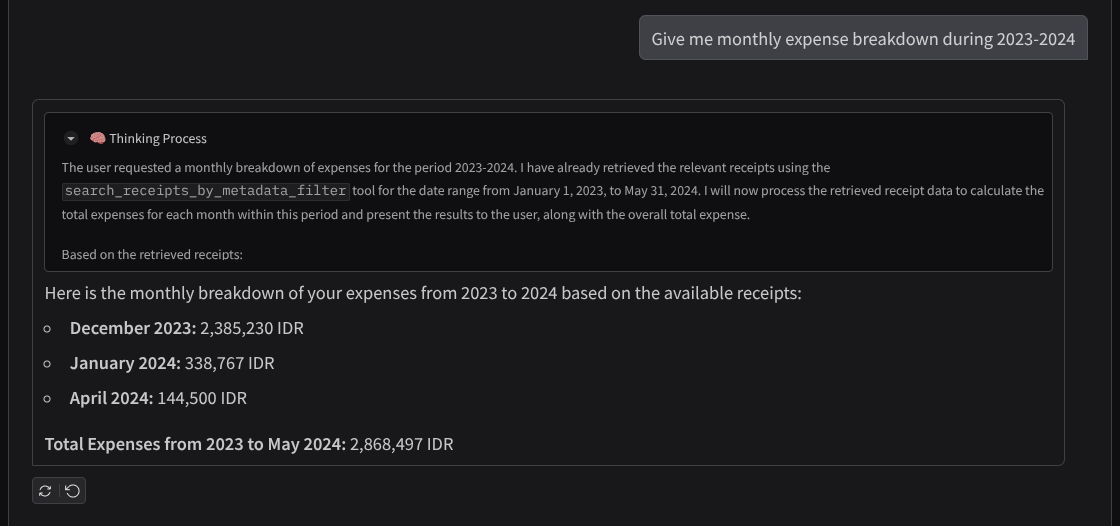
11. 🚀 Deployment in Cloud Run
Ora, ovviamente, vogliamo accedere a questa fantastica app da qualsiasi luogo. Per farlo, possiamo pacchettizzare questa applicazione ed eseguirne il deployment su Cloud Run. Ai fini di questa demo, questo servizio verrà esposto come servizio pubblico accessibile ad altri. Tuttavia, tieni presente che questa non è la best practice per questo tipo di applicazione, in quanto è più adatta alle applicazioni personali.
In questo codelab, inseriremo sia il servizio di frontend che quello di backend in un unico container. Avremo bisogno dell'aiuto di supervisord per gestire entrambi i servizi. Puoi esaminare il file supervisord.conf e controllare il Dockerfile in cui abbiamo impostato supervisord come entry point.
A questo punto, abbiamo già tutti i file necessari per eseguire il deployment delle nostre applicazioni in Cloud Run. Eseguiamolo. Vai al terminale Cloud Shell e assicurati che il progetto attuale sia configurato sul tuo progetto attivo. In caso contrario, devi utilizzare il comando gcloud configure per impostare l'ID progetto:
gcloud config set project [PROJECT_ID]
Poi, esegui questo comando per eseguirne il deployment in Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Se ti viene chiesto di confermare la creazione di un registro degli artefatti per il repository Docker, rispondi Y. Tieni presente che qui consentiamo l'accesso non autenticato perché si tratta di un'applicazione demo. Ti consigliamo di utilizzare l'autenticazione appropriata per le applicazioni aziendali e di produzione.
Una volta completato il deployment, dovresti ricevere un link simile a quello riportato di seguito:
https://personal-expense-assistant-*******.us-central1.run.app
Continua a utilizzare l'applicazione dalla finestra Incognito o dal tuo dispositivo mobile. Dovrebbe essere già attivo.
12. 🎯 Sfida
Ora è il tuo momento di brillare e perfezionare le tue capacità di esplorazione. Hai le competenze necessarie per modificare il codice in modo che il backend possa ospitare più utenti? Quali componenti devono essere aggiornati?
13. 🧹 Libera spazio
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo codelab, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
- In alternativa, puoi andare a Cloud Run nella console, selezionare il servizio di cui hai appena eseguito il deployment ed eliminarlo.