
1. 📖 Wprowadzenie
Czy kiedykolwiek frustrowało Cię zarządzanie wszystkimi wydatkami osobistymi? Ja też! Dlatego w tym ćwiczeniu stworzymy osobistego asystenta do zarządzania wydatkami, który będzie oparty na Gemini 2.5 i wykona za nas wszystkie zadania. Od zarządzania przesłanymi paragonami po analizowanie, czy nie wydajesz za dużo na kawę.
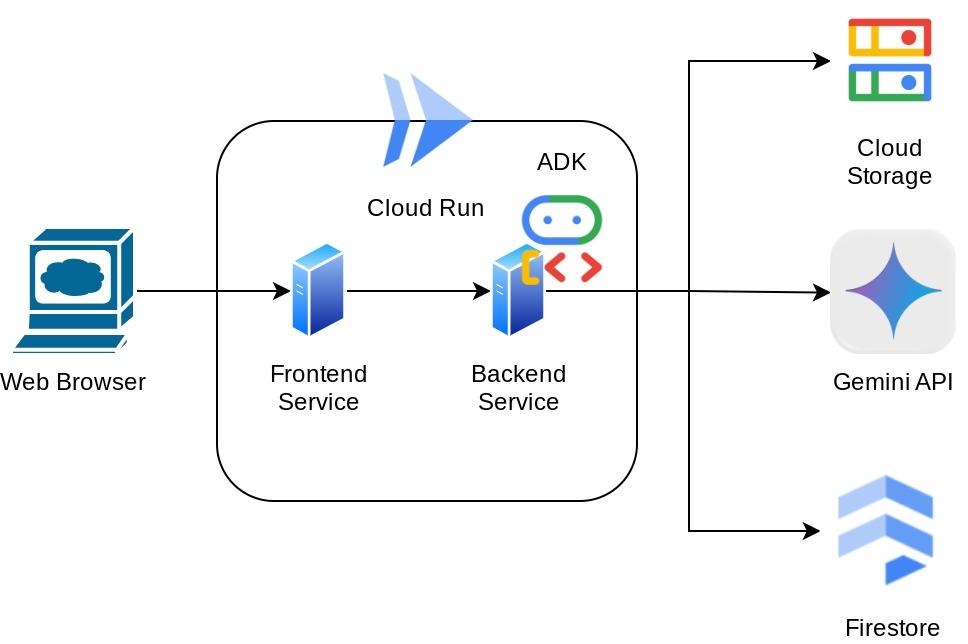
Ten asystent będzie dostępny w przeglądarce internetowej w formie interfejsu czatu, w którym możesz się z nim komunikować, przesyłać zdjęcia paragonów i prosić go o ich przechowywanie lub wyszukiwać paragony, aby uzyskać plik i przeprowadzić analizę wydatków. Wszystko to jest oparte na platformie Google Agent Development Kit.
Aplikacja jest podzielona na 2 usługi: frontend i backend. Dzięki temu możesz szybko utworzyć prototyp i sprawdzić, jak działa, a także dowiedzieć się, jak wygląda umowa API, aby zintegrować obie usługi.
W ramach ćwiczeń z programowania będziesz wykonywać kolejne czynności:
- Przygotowywanie projektu Google Cloud i włączanie w nim wszystkich wymaganych interfejsów API
- Konfigurowanie zasobnika w Google Cloud Storage i bazy danych w Firestore
- Tworzenie indeksowania Firestore
- Konfigurowanie obszaru roboczego dla środowiska programistycznego
- Strukturyzowanie kodu źródłowego, narzędzi, promptu itp. agenta ADK
- Testowanie agenta za pomocą lokalnego interfejsu internetowego ADK
- Utwórz usługę frontendu – interfejs czatu za pomocą biblioteki Gradio, aby wysyłać zapytania i przesyłać obrazy paragonów.
- Zbuduj usługę backendu – serwer HTTP za pomocą FastAPI, w której znajdują się kod agenta ADK, usługa SessionService i usługa Artifact Service.
- zarządzać zmiennymi środowiskowymi i konfigurować wymagane pliki potrzebne do wdrożenia aplikacji w Cloud Run,
- Wdrażanie aplikacji w Cloud Run
Omówienie architektury
Wymagania wstępne
- znajomość języka Python;
- Znajomość podstawowej architektury pełnego stosu z użyciem usługi HTTP
Czego się nauczysz
- Prototypowanie frontendu za pomocą Gradio
- Tworzenie usługi backendu za pomocą FastAPI i Pydantic
- Projektowanie agenta ADK z wykorzystaniem jego różnych funkcji
- Korzystanie z narzędzia
- Zarządzanie sesjami i artefaktami
- Wykorzystanie wywołania zwrotnego do modyfikowania danych wejściowych przed wysłaniem ich do Gemini
- Wykorzystywanie BuiltInPlanner do poprawy wykonywania zadań przez planowanie
- Szybkie debugowanie za pomocą lokalnego interfejsu internetowego ADK
- Strategia optymalizacji interakcji multimodalnej za pomocą analizowania i pobierania informacji za pomocą inżynierii promptów oraz modyfikowania żądań Gemini za pomocą wywołania zwrotnego ADK
- Generowanie wspomagane wyszukiwaniem z użyciem agentów z bazą wektorową Firestore
- Zarządzanie zmiennymi środowiskowymi w pliku YAML za pomocą Pydantic-settings
- Wdrażanie aplikacji w Cloud Run przy użyciu pliku Dockerfile i podawanie zmiennych środowiskowych za pomocą pliku YAML
Czego potrzebujesz
- Przeglądarka Chrome
- konto Gmail,
- Projekt w chmurze z włączonymi płatnościami
To ćwiczenie, przeznaczone dla deweloperów na wszystkich poziomach zaawansowania (w tym dla początkujących), wykorzystuje w przykładowej aplikacji język Python. Znajomość języka Python nie jest jednak wymagana do zrozumienia przedstawionych koncepcji.
2. 🚀 Zanim zaczniesz
Wybieranie aktywnego projektu w Cloud Console
W tym samouczku zakładamy, że masz już projekt Google Cloud z włączonymi płatnościami. Jeśli jeszcze go nie masz, możesz zacząć, wykonując czynności opisane poniżej.
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Przygotuj bazę danych Firestore
Następnie musimy utworzyć bazę danych Firestore. Firestore w trybie natywnym to baza danych dokumentów NoSQL zaprojektowana pod kątem automatycznego skalowania, wysokiej wydajności i łatwego tworzenia aplikacji. Może też pełnić funkcję bazy danych wektorowych, która będzie obsługiwać technikę generowania z wyszukiwaniem w naszym laboratorium.
- Na pasku wyszukiwania wpisz firestore i kliknij usługę Firestore.
- Następnie kliknij przycisk Utwórz bazę danych Firestore.
- Użyj (default) jako nazwy identyfikatora bazy danych i pozostaw wybraną wersję Standard. Na potrzeby tej wersji demonstracyjnej użyj natywnej bazy danych Firestore z otwartymi regułami zabezpieczeń.
- Zauważysz też, że ta baza danych ma bezpłatny poziom wykorzystania. Następnie kliknij przycisk Utwórz bazę danych.
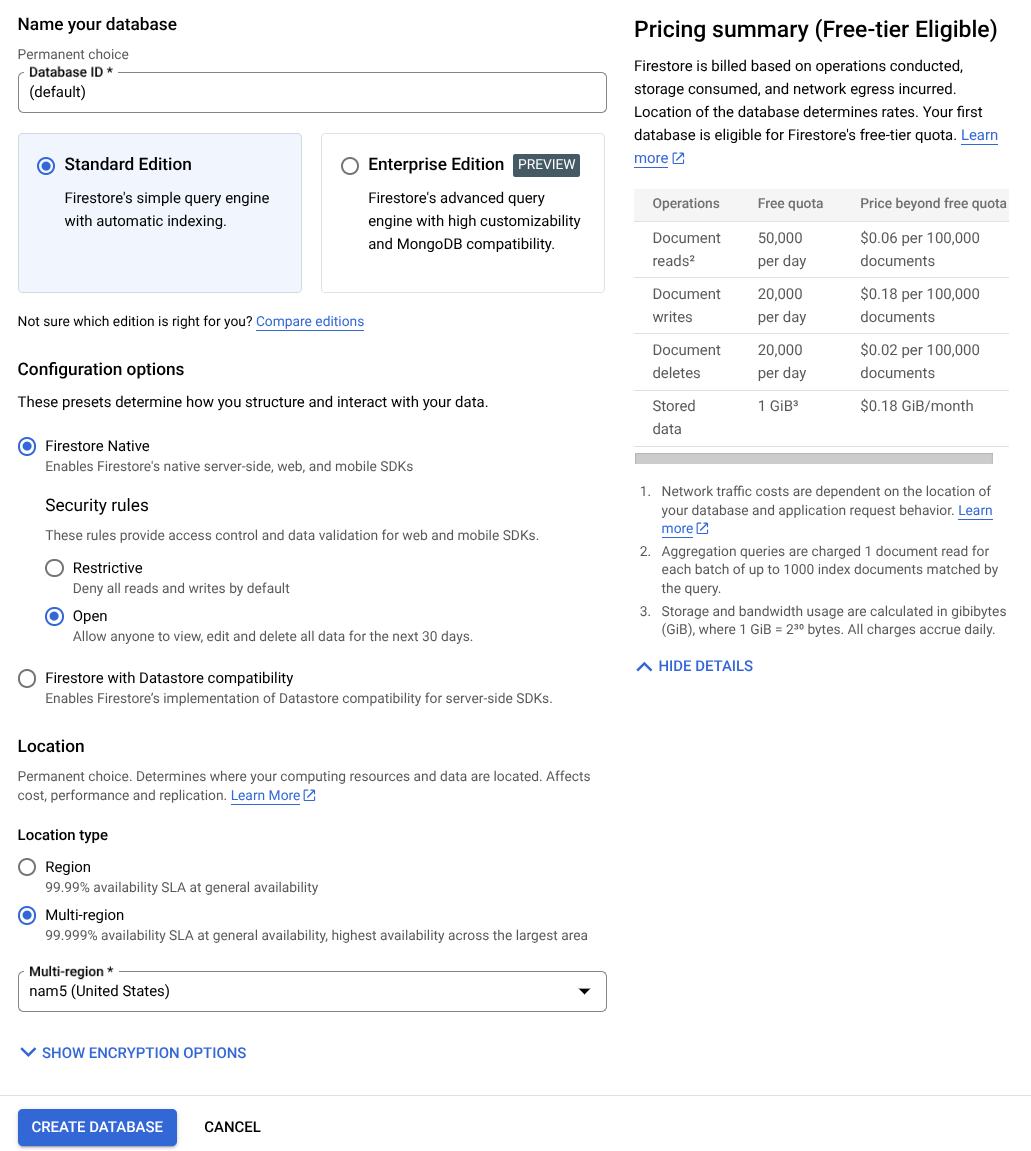
Po wykonaniu tych czynności nastąpi przekierowanie do utworzonej przed chwilą bazy danych Firestore.
Konfigurowanie projektu w Cloud Shell Terminal
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud, które jest wstępnie załadowane narzędziem bq. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
Możesz też zobaczyć identyfikator PROJECT_ID w konsoli.
Kliknij go, a po prawej stronie zobaczysz wszystkie projekty i identyfikator projektu.
- Włącz wymagane interfejsy API za pomocą polecenia pokazanego poniżej. Może to potrwać kilka minut, więc zachowaj cierpliwość.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
Alternatywą dla polecenia gcloud jest wyszukanie poszczególnych usług w konsoli lub skorzystanie z tego linku.
Jeśli pominiesz jakiś interfejs API, możesz go włączyć w trakcie wdrażania.
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
Przygotowywanie zasobnika Cloud Storage w Google Cloud Storage
Następnie w tym samym terminalu musimy przygotować zasobnik GCS do przechowywania przesłanego pliku. Aby utworzyć zasobnik, uruchom to polecenie. Będzie potrzebna unikalna, ale odpowiednia nazwa zasobnika związana z rachunkami asystenta wydatków osobistych. Dlatego użyjemy tej nazwy zasobnika w połączeniu z identyfikatorem projektu.
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Wyświetli te dane wyjściowe
Creating gs://personal-expense-{your-project-id}
Możesz to sprawdzić, otwierając menu nawigacyjne w lewym górnym rogu przeglądarki i wybierając Cloud Storage –> Zasobnik.
Tworzenie indeksu Firestore na potrzeby wyszukiwania
Firestore to natywna baza danych NoSQL, która zapewnia doskonałą wydajność i elastyczność w zakresie modelu danych, ale ma ograniczenia, jeśli chodzi o złożone zapytania. Planujemy używać zapytań złożonych obejmujących wiele pól i wyszukiwania wektorowego, dlatego musimy najpierw utworzyć indeks. Więcej informacji znajdziesz w tej dokumentacji.
- Aby utworzyć indeks obsługujący zapytania złożone, uruchom to polecenie:
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- Uruchom to polecenie, aby obsługiwać wyszukiwanie wektorowe.
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
Utworzony indeks możesz sprawdzić, otwierając Firestore w konsoli Google Cloud. Kliknij instancję bazy danych (default) i na pasku nawigacyjnym wybierz Indeksy.
Otwórz edytor Cloud Shell i skonfiguruj katalog roboczy aplikacji
Teraz możemy skonfigurować edytor kodu, aby wykonywać pewne czynności związane z kodowaniem. W tym celu użyjemy edytora Cloud Shell.
- Kliknij przycisk Otwórz edytor. Spowoduje to otwarcie edytora Cloud Shell, w którym możesz pisać kod.
- Następnie musimy sprawdzić, czy powłoka jest już skonfigurowana z prawidłowym IDENTYFIKATOREM PROJEKTU. Jeśli w terminalu przed ikoną $ widzisz wartość w nawiasach ( ) ( na zrzucie ekranu poniżej jest to „adk-multimodal-tool”), oznacza to, że w aktywnej sesji powłoki skonfigurowany jest projekt.

Jeśli wyświetlana wartość jest już prawidłowa, możesz pominąć następne polecenie. Jeśli jednak jest nieprawidłowy lub go brakuje, uruchom to polecenie:
gcloud config set project <YOUR_PROJECT_ID>
- Następnie sklonujmy z GitHuba katalog roboczy szablonu na potrzeby tego ćwiczenia. W tym celu wykonaj to polecenie: W katalogu personal-expense-assistant zostanie utworzony katalog roboczy.
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- Następnie przejdź do górnej sekcji edytora Cloud Shell i kliknij Plik –> Otwórz folder. Znajdź katalog nazwa_użytkownika, a w nim katalog personal-expense-assistant,a potem kliknij przycisk OK. Spowoduje to ustawienie wybranego katalogu jako głównego katalogu roboczego. W tym przykładzie nazwa użytkownika to alvinprayuda, dlatego ścieżka do katalogu jest widoczna poniżej.

Edytor Cloud Shell powinien teraz wyglądać tak:
Konfiguracja środowiska
Przygotowywanie środowiska wirtualnego Pythona
Następnym krokiem jest przygotowanie środowiska programistycznego. Bieżący aktywny terminal powinien znajdować się w katalogu roboczym personal-expense-assistant. W tym ćwiczeniu użyjemy Pythona 3.12 i menedżera projektów Pythona uv, aby uprościć tworzenie i zarządzanie wersją Pythona oraz środowiskiem wirtualnym.
- Jeśli terminal nie jest jeszcze otwarty, otwórz go, klikając Terminal –> Nowy terminal lub używając skrótu Ctrl + Shift + C. Spowoduje to otwarcie okna terminala w dolnej części przeglądarki.

- Teraz zainicjuj środowisko wirtualne za pomocą polecenia
uv. Uruchom te polecenia:
cd ~/personal-expense-assistant
uv sync --frozen
Spowoduje to utworzenie katalogu .venv i zainstalowanie zależności. Szybki podgląd pliku pyproject.toml pozwoli Ci uzyskać informacje o zależnościach, które będą wyświetlane w ten sposób:
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Konfigurowanie plików konfiguracyjnych
Teraz musimy skonfigurować pliki konfiguracji dla tego projektu. Do odczytywania konfiguracji z pliku YAML używamy biblioteki pydantic-settings.
Szablon pliku znajduje się już w pliku settings.yaml.example. Musimy skopiować ten plik i zmienić jego nazwę na settings.yaml. Uruchom to polecenie, aby utworzyć plik
cp settings.yaml.example settings.yaml
Następnie skopiuj do pliku tę wartość:
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
W tym samouczku użyjemy wstępnie skonfigurowanych wartości GCLOUD_LOCATION, BACKEND_URL, i DB_COLLECTION_NAME .
Teraz możemy przejść do następnego kroku, czyli utworzenia agenta, a potem usług.
3. 🚀 Tworzenie agenta za pomocą pakietu Google ADK i modelu Gemini 2.5
Wprowadzenie do struktury katalogów ADK
Zacznijmy od poznania możliwości ADK i sposobu tworzenia agenta. Pełną dokumentację pakietu ADK znajdziesz pod tym adresem URL . ADK oferuje wiele narzędzi w ramach wykonywania poleceń interfejsu CLI. Oto niektóre z nich :
- Konfigurowanie struktury katalogu agenta
- Szybkie wypróbowanie interakcji za pomocą danych wejściowych i wyjściowych interfejsu wiersza poleceń
- Szybkie konfigurowanie lokalnego interfejsu internetowego
Teraz utwórzmy strukturę katalogów agenta za pomocą polecenia interfejsu wiersza poleceń. Uruchom podane niżej polecenie.
uv run adk create expense_manager_agent
Gdy pojawi się pytanie, wybierz model gemini-2.5-flash i backend Vertex AI. Kreator poprosi Cię o podanie identyfikatora projektu i lokalizacji. Możesz zaakceptować opcje domyślne, naciskając Enter, lub w razie potrzeby je zmienić. Sprawdź tylko, czy używasz prawidłowego identyfikatora projektu utworzonego wcześniej w tym laboratorium. Dane wyjściowe będą wyglądać tak:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Spowoduje to utworzenie tej struktury katalogów agenta:
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Jeśli sprawdzisz pliki init.py i agent.py, zobaczysz ten kod:
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Możesz teraz przetestować ten kod, uruchamiając
uv run adk run expense_manager_agent
Gdy skończysz testowanie, możesz zamknąć agenta, wpisując exit lub naciskając Ctrl+D.
Tworzenie agenta do zarządzania wydatkami
Zbudujmy agenta do zarządzania wydatkami. Otwórz plik expense_manager_agent/agent.py i skopiuj poniższy kod, który będzie zawierać root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Wyjaśnienie kodu
Ten skrypt zawiera inicjację agenta, w której inicjujemy te elementy:
- Ustaw model, który ma być używany, na
gemini-2.5-flash - Skonfiguruj opis i instrukcje agenta jako prompt systemowy odczytywany z
task_prompt.md - zapewniać niezbędne narzędzia do obsługi funkcji agenta;
- Włącz planowanie przed wygenerowaniem ostatecznej odpowiedzi lub wykonaniem działania za pomocą funkcji myślenia Gemini 2.5 Flash
- Skonfiguruj przechwytywanie wywołania zwrotnego przed wysłaniem żądania do Gemini, aby ograniczyć liczbę danych obrazu wysyłanych przed dokonaniem prognozy.
4. 🚀 Konfigurowanie narzędzi agenta
Nasz agent do zarządzania wydatkami będzie mieć te możliwości:
- Wyodrębnianie danych z obrazu rachunku i przechowywanie danych oraz pliku
- Dokładne wyszukiwanie danych o wydatkach
- Wyszukiwanie kontekstowe danych o wydatkach
Dlatego potrzebujemy odpowiednich narzędzi, które będą obsługiwać tę funkcję. Utwórz nowy plik w katalogu expense_manager_agent i nadaj mu nazwę tools.py.
touch expense_manager_agent/tools.py
Otwórz plik expense_manage_agent/tools.py, a następnie skopiuj poniższy kod.
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Wyjaśnienie kodu
W ramach tej funkcji narzędzia projektujemy je w oparciu o 2 główne założenia:
- Analizowanie danych z paragonu i mapowanie ich na oryginalny plik za pomocą ciągu znaków zastępujących identyfikator obrazu
[IMAGE-ID <hash-of-image-1>] - Przechowywanie i pobieranie danych z zastosowaniem bazy danych Firestore
Narzędzie „store_receipt_data”
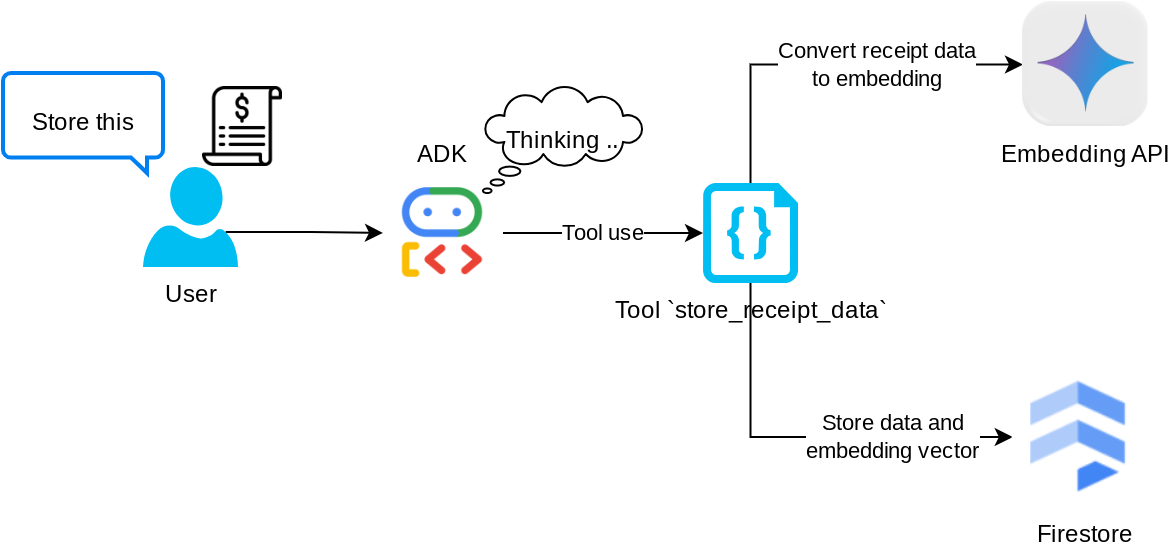
To narzędzie do optycznego rozpoznawania znaków (OCR) przeanalizuje wymagane informacje z danych obrazu, rozpozna ciąg identyfikatora obrazu i powiąże je ze sobą, aby zapisać je w bazie danych Firestore.
Dodatkowo to narzędzie przekształca treść paragonu w wektor dystrybucyjny za pomocą text-embedding-004, dzięki czemu wszystkie metadane i wektor dystrybucyjny są przechowywane i indeksowane razem. Umożliwia pobieranie elastyczności za pomocą zapytania lub wyszukiwania kontekstowego.
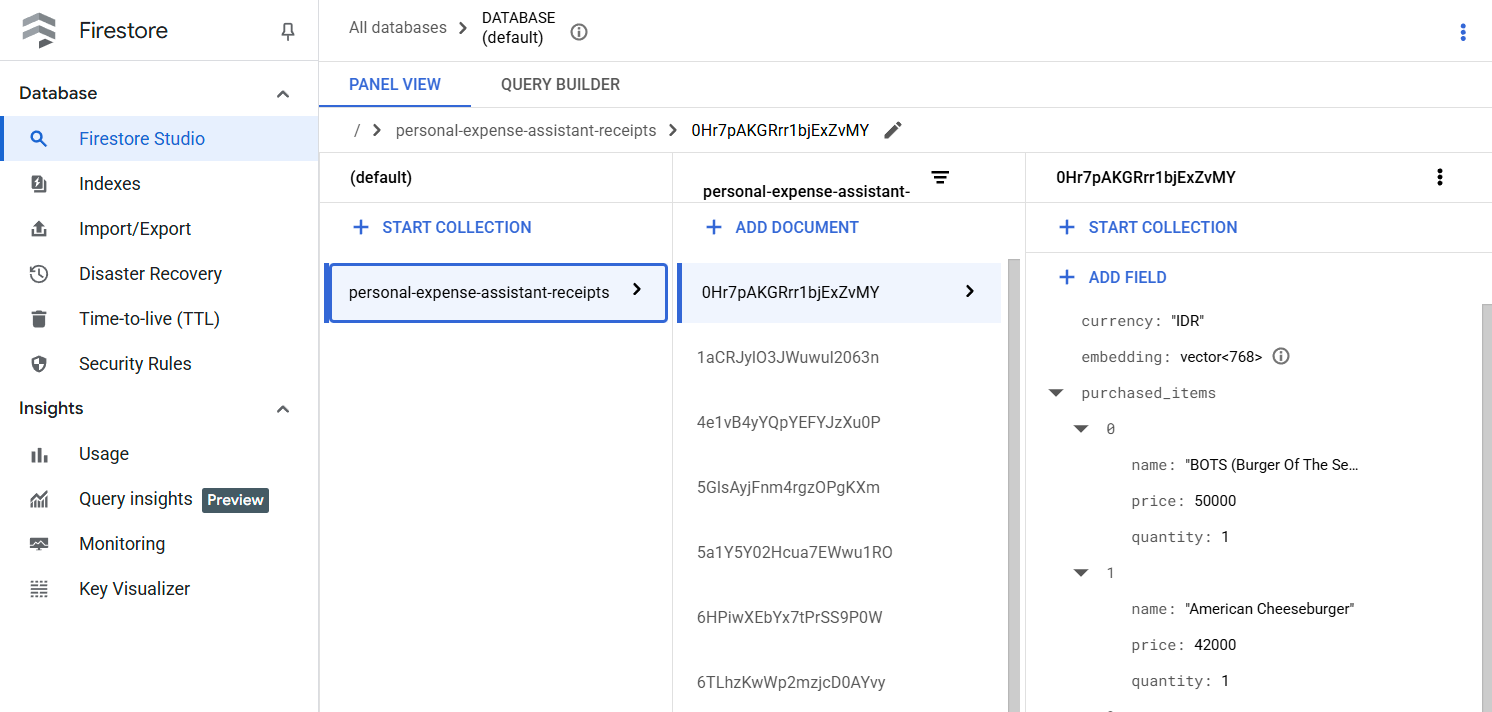
Po pomyślnym uruchomieniu tego narzędzia możesz zobaczyć, że dane z paragonu są już indeksowane w bazie danych Firestore, jak pokazano poniżej.
Narzędzie „search_receipts_by_metadata_filter”
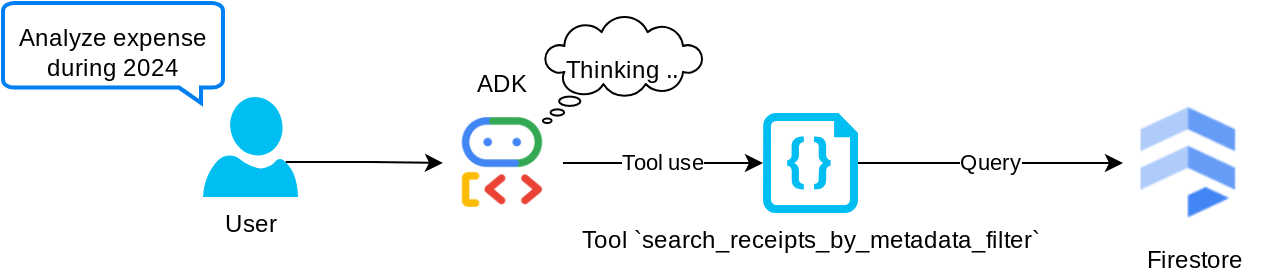
To narzędzie przekształca zapytanie użytkownika w filtr zapytania o metadane, który umożliwia wyszukiwanie według zakresu dat lub łącznej transakcji. Zwróci wszystkie pasujące dane z paragonu, przy czym usuniemy pole osadzania, ponieważ nie jest ono potrzebne agentowi do zrozumienia kontekstu.
Narzędzie „search_relevant_receipts_by_natural_language_query”
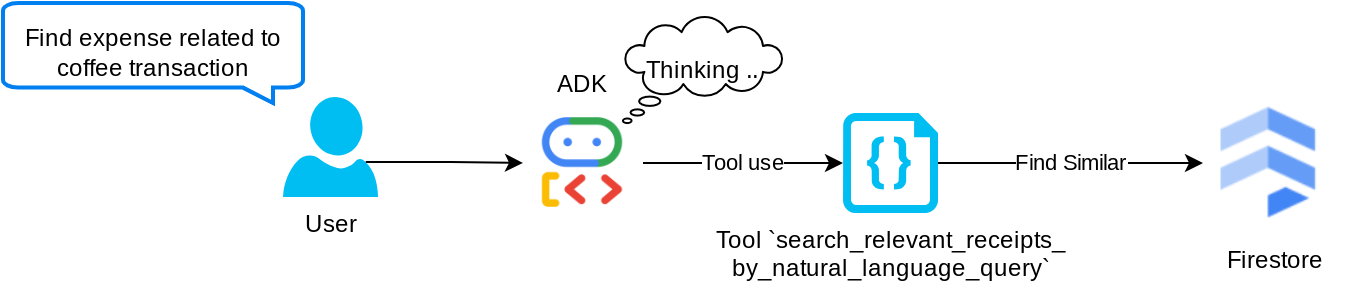
To nasze narzędzie do generowania wspomaganego wyszukiwaniem (RAG). Nasz agent może samodzielnie tworzyć zapytania, aby pobierać z bazy wektorowej odpowiednie rachunki, i samodzielnie decydować, kiedy używać tego narzędzia. Koncepcja umożliwienia agentowi samodzielnego podejmowania decyzji o tym, czy użyć tego narzędzia RAG, i tworzenia własnych zapytań jest jedną z definicji podejścia Agentic RAG.
Umożliwiamy mu nie tylko tworzenie własnych zapytań, ale też wybieranie liczby dokumentów, które chce pobrać. W połączeniu z odpowiednim inżynierem promptów, np.
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Dzięki temu narzędzie będzie bardzo przydatne i umożliwi wyszukiwanie niemal wszystkiego, ale ze względu na nieprecyzyjny charakter wyszukiwania najbliższego sąsiada może nie zwracać wszystkich oczekiwanych wyników.
5. 🚀 Modyfikowanie kontekstu rozmowy za pomocą wywołań zwrotnych
Google ADK umożliwia nam „przechwytywanie” czasu działania agenta na różnych poziomach. Więcej informacji o tej funkcji znajdziesz w tej dokumentacji . W tym module używamy before_model_callback, aby zmodyfikować żądanie przed wysłaniem go do LLM w celu usunięcia danych obrazu ze starej historii rozmów ( uwzględniamy tylko dane obrazu z 3 ostatnich interakcji użytkownika) dla większej wydajności.
Chcemy jednak, aby w razie potrzeby agent miał kontekst danych obrazu. Dlatego dodajemy mechanizm, który po każdych danych bajtowych obrazu w rozmowie dodaje ciąg znaków będący identyfikatorem obrazu. Pomoże to agentowi powiązać identyfikator obrazu z rzeczywistymi danymi pliku, które można wykorzystać podczas przechowywania lub pobierania obrazu. Struktura będzie wyglądać tak:
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
Gdy dane w postaci bajtów w historii rozmów stają się przestarzałe, identyfikator w postaci ciągu znaków nadal umożliwia dostęp do danych za pomocą narzędzia. Przykładowa struktura historii po usunięciu danych obrazu
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Rozpocznij Utwórz nowy plik w katalogu expense_manager_agent i nadaj mu nazwę callbacks.py.
touch expense_manager_agent/callbacks.py
Otwórz plik expense_manager_agent/callbacks.py, a następnie skopiuj poniższy kod.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 Prompt
Projektowanie agenta z zaawansowanymi interakcjami i możliwościami wymaga znalezienia odpowiedniego promptu, który będzie nim sterował, aby zachowywał się w pożądany sposób.
Wcześniej mieliśmy mechanizm obsługi danych obrazów w historii rozmów, a także narzędzia, które mogły być trudne w użyciu, np. search_relevant_receipts_by_natural_language_query. Chcemy też, aby agent mógł wyszukiwać i pobierać odpowiedni obraz paragonu. Oznacza to, że musimy przekazać wszystkie te informacje w odpowiedniej strukturze promptu.
Poprosimy agenta o sformatowanie danych wyjściowych w tym formacie Markdown, aby przeanalizować proces myślowy, ostateczną odpowiedź i załącznik ( jeśli występuje).
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Zacznijmy od tego prompta, aby osiągnąć początkowe oczekiwania dotyczące działania agenta do zarządzania wydatkami. Plik task_prompt.md powinien już znajdować się w naszym bieżącym katalogu roboczym, ale musimy go przenieść do katalogu expense_manager_agent. Aby go przenieść, uruchom to polecenie:
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Testowanie agenta
Teraz spróbujmy komunikować się z agentem za pomocą interfejsu wiersza poleceń. Uruchom to polecenie:
uv run adk run expense_manager_agent
Wyświetli się taki wynik, w którym możesz na zmianę rozmawiać z agentem, ale w tym interfejsie możesz wysyłać tylko tekst.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
Oprócz interakcji z interfejsem CLI ADK umożliwia też korzystanie z interfejsu programistycznego, który pozwala wchodzić w interakcje i sprawdzać, co się dzieje podczas interakcji. Aby uruchomić lokalny serwer interfejsu programistycznego, wykonaj to polecenie:
uv run adk web --port 8080
Wygeneruje to dane wyjściowe podobne do poniższego przykładu, co oznacza, że możemy już uzyskać dostęp do interfejsu internetowego.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
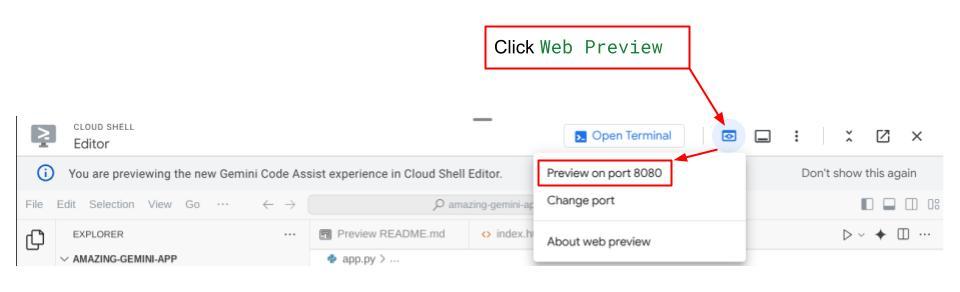
Aby to sprawdzić, kliknij przycisk Podgląd w przeglądarce w górnej części edytora Cloud Shell i wybierz Podejrzyj na porcie 8080.
Wyświetli się strona internetowa, na której w lewym górnym rogu możesz wybrać dostępnych agentów ( w naszym przypadku powinien to być expense_manager_agent) i interagować z botem. W oknie po lewej stronie zobaczysz wiele informacji o szczegółach logu podczas działania agenta.
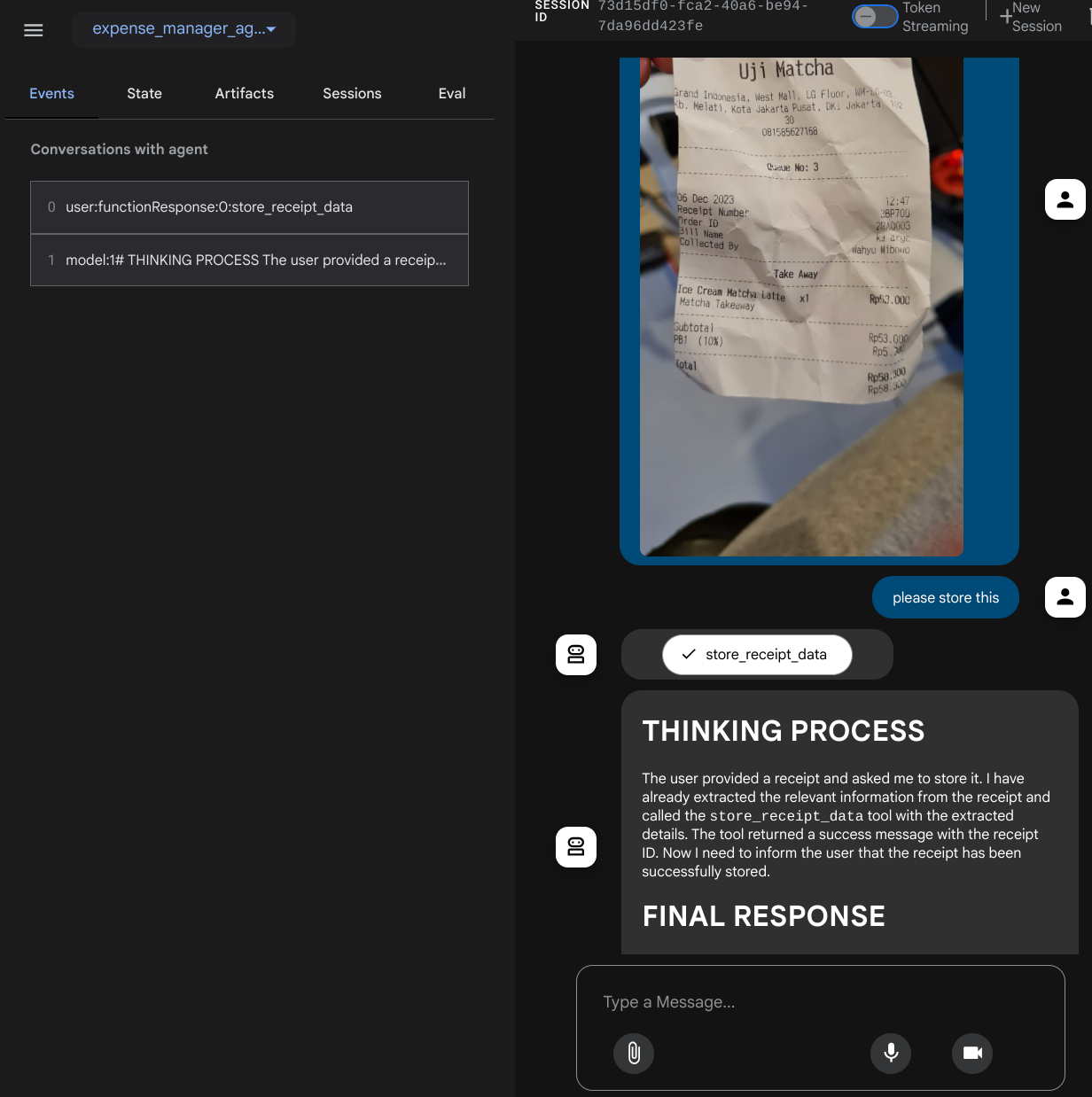
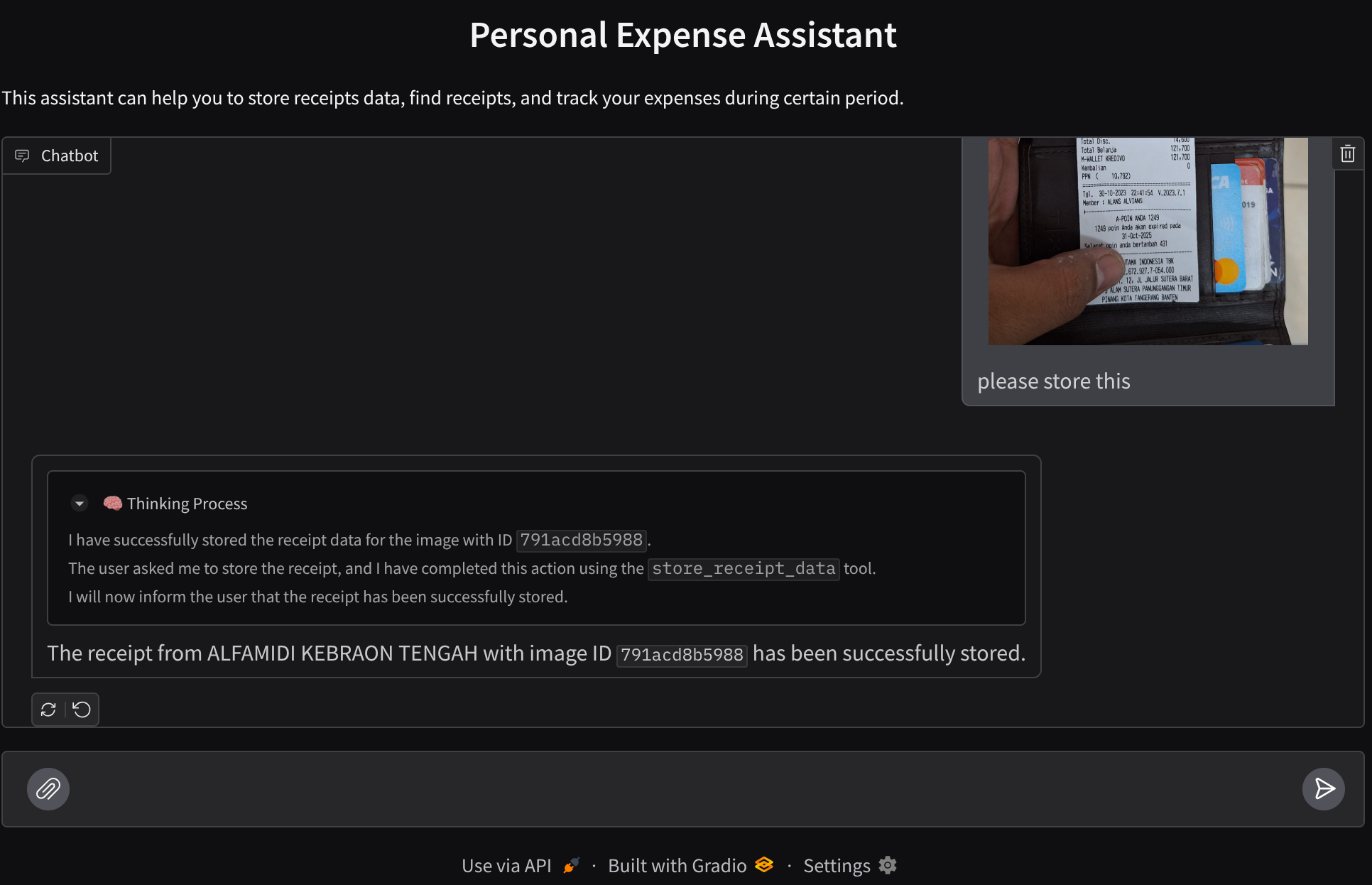
Wypróbujmy kilka działań. Prześlij te 2 przykładowe paragony ( źródło : Hugging Face Datasets mousserlane/id_receipt_dataset) . Kliknij każdy obraz prawym przyciskiem myszy i wybierz Zapisz obraz jako. ( spowoduje to pobranie obrazu paragonu), a następnie prześlij plik do bota, klikając ikonę „spinacza” i informując, że chcesz przechowywać te paragony.


Następnie wypróbuj te zapytania, aby wyszukać lub pobrać pliki:
- „Give breakdown of expenses and its total during 2023” (Podaj zestawienie wydatków i ich łączną kwotę w 2023 r.)
- „Wyślij mi plik z paragonem z Indomaretu”
Gdy używasz niektórych narzędzi, możesz sprawdzić, co się dzieje w interfejsie programowania.
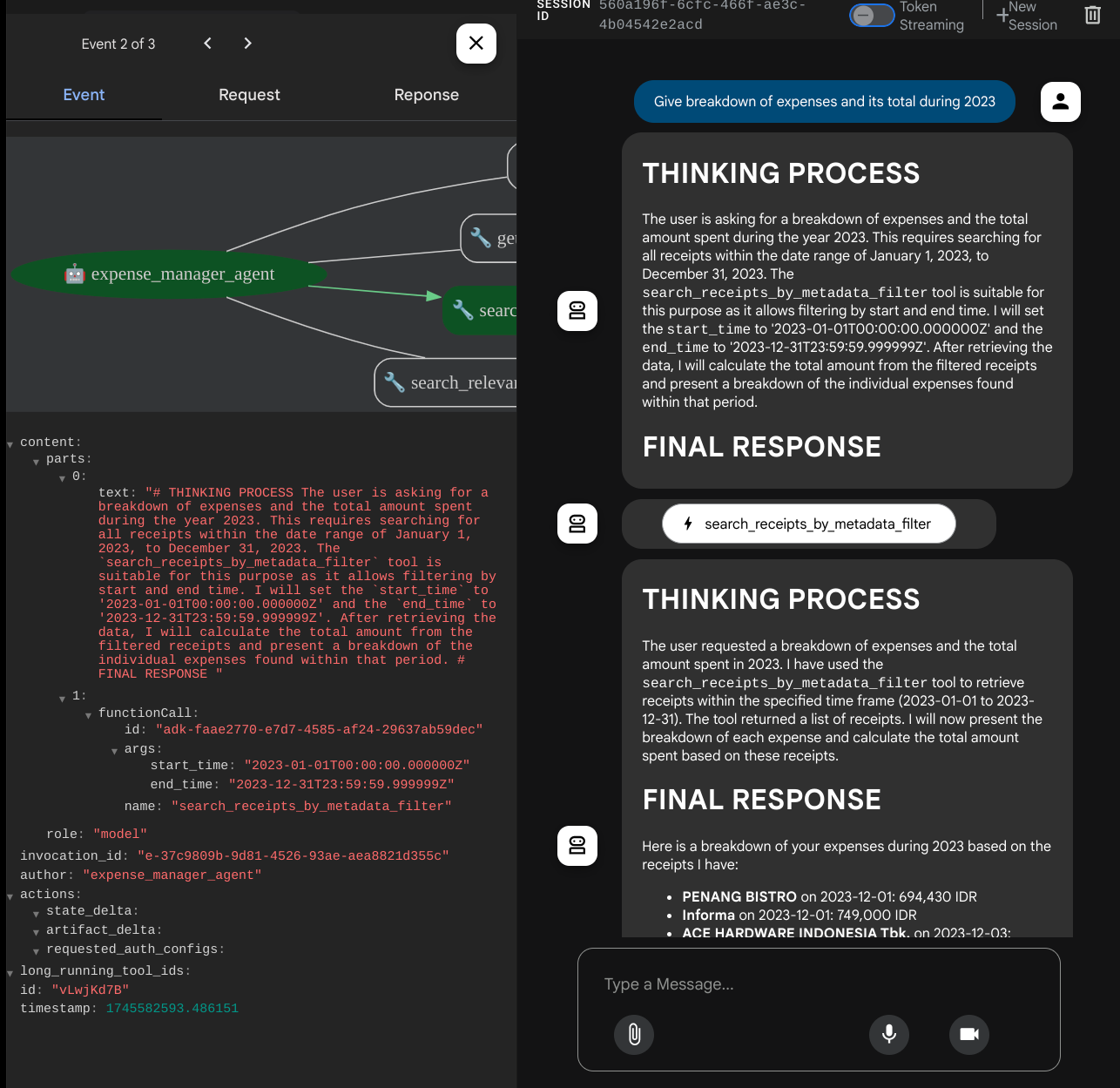
Sprawdź, jak agent odpowiada na Twoje pytania, i upewnij się, że przestrzega wszystkich reguł podanych w prompcie w pliku task_prompt.py. Gratulacje! Masz teraz w pełni działającego agenta programistycznego.
Teraz czas uzupełnić go o odpowiedni i przyjemny interfejs oraz funkcje przesyłania i pobierania pliku obrazu.
8. 🚀 Tworzenie usługi frontendu za pomocą Gradio
Utworzymy internetowy interfejs czatu, który będzie wyglądać tak:
Zawiera interfejs czatu z polem do wprowadzania danych, w którym użytkownicy mogą wysyłać tekst i przesyłać pliki z obrazami paragonów.
Usługę frontendu utworzymy za pomocą Gradio.
Utwórz nowy plik i nadaj mu nazwę frontend.py.
touch frontend.py
następnie skopiuj ten kod i zapisz go.
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Następnie możemy spróbować uruchomić usługę frontendu za pomocą tego polecenia. Nie zapomnij zmienić nazwy pliku main.py na frontend.py.
uv run frontend.py
W konsoli Google Cloud zobaczysz dane wyjściowe podobne do tych:
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Następnie możesz sprawdzić interfejs internetowy, klikając z naciśniętym klawiszem Ctrl lokalny link do adresu URL. Możesz też otworzyć aplikację frontendową, klikając przycisk Podgląd w przeglądarce w prawym górnym rogu Cloud Editor i wybierając Podejrzyj na porcie 8080.
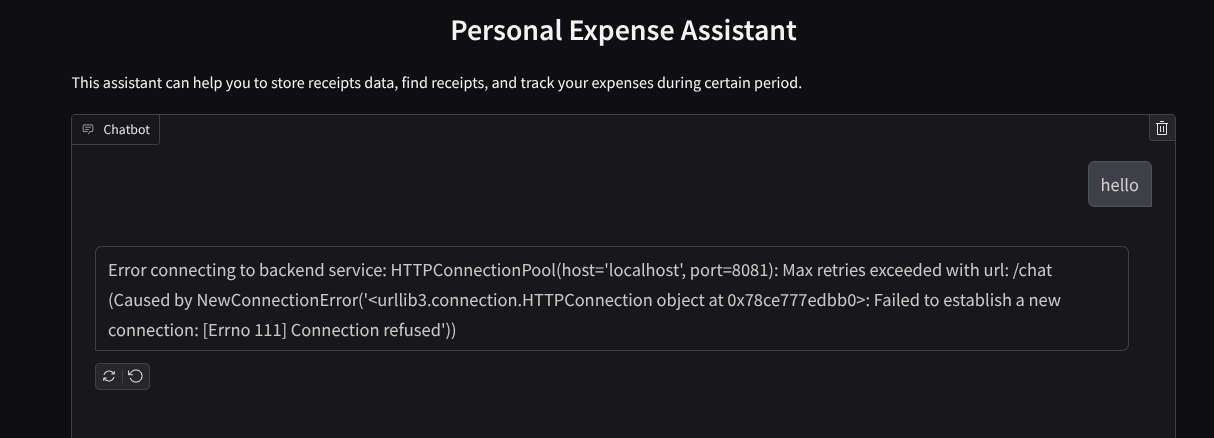
Zobaczysz interfejs internetowy, ale podczas próby przesłania czatu pojawi się oczekiwany błąd, ponieważ usługa backendu nie została jeszcze skonfigurowana.
Teraz pozwól usłudze działać i nie zamykaj jej. Usługę backendu uruchomimy w innej karcie terminala.
Wyjaśnienie kodu
W tym kodzie interfejsu najpierw umożliwiamy użytkownikowi wysyłanie tekstu i przesyłanie wielu plików. Gradio umożliwia tworzenie tego typu funkcji za pomocą metody gr.ChatInterface w połączeniu z gr.MultimodalTextbox.
Zanim wyślemy plik i tekst do backendu, musimy określić typ MIME pliku, ponieważ jest on wymagany przez backend. Musimy też zakodować bajty pliku obrazu w formacie base64 i wysłać je razem z typem MIME.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
Schemat używany do interakcji między frontendem a backendem jest zdefiniowany w pliku schema.py. Do wymuszania weryfikacji danych w schemacie używamy klasy Pydantic BaseModel.
Gdy otrzymujemy odpowiedź, od razu rozdzielamy proces myślowy, ostateczną odpowiedź i załącznik. Dlatego możemy użyć komponentu Gradio, aby wyświetlić każdy komponent za pomocą komponentu interfejsu.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Tworzenie usługi backendu za pomocą FastAPI
Następnie musimy zbudować backend, który może zainicjować agenta wraz z innymi komponentami, aby umożliwić wykonanie środowiska wykonawczego agenta.
Utwórz nowy plik i nadaj mu nazwę backend.py.
touch backend.py
Skopiuj ten kod:
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Następnie możemy spróbować uruchomić usługę backendu. Pamiętaj, że w poprzednim kroku uruchomiliśmy usługę frontendową. Teraz musimy otworzyć nowy terminal i spróbować uruchomić tę usługę backendową.
- Utwórz nowy terminal. Przejdź do terminala w dolnej części i kliknij przycisk „+”, aby utworzyć nowy terminal. Możesz też nacisnąć Ctrl + Shift + C, aby otworzyć nowy terminal.

- Następnie upewnij się, że jesteś w katalogu roboczym personal-expense-assistant, i uruchom to polecenie:
uv run backend.py
- Jeśli się uda, zobaczysz taki wynik:
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Wyjaśnienie kodu
Inicjowanie agenta ADK, usługi SessionService i usługi ArtifactService
Aby uruchomić agenta w usłudze backendu, musimy utworzyć Runnera, który przyjmuje zarówno SessionService, jak i naszego agenta. SessionService będzie zarządzać historią i stanem rozmowy, więc po zintegrowaniu z Runnerem umożliwi naszemu agentowi otrzymywanie kontekstu bieżących rozmów.
Do obsługi przesłanego pliku używamy też usługi ArtifactService. Więcej informacji o sesji i artefaktach w ADK znajdziesz tutaj.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
W tej wersji demonstracyjnej używamy usług InMemorySessionService i GcsArtifactService, które są zintegrowane z naszym agentem Runner. Historia rozmowy jest przechowywana w pamięci, więc zostanie utracona po zamknięciu lub ponownym uruchomieniu usługi backendu. Inicjujemy je w cyklu życia aplikacji FastAPI, aby można było je wstrzykiwać jako zależności w /chat.
Przesyłanie i pobieranie obrazu za pomocą GcsArtifactService
Wszystkie przesłane obrazy będą przechowywane jako artefakty przez GcsArtifactService. Możesz to sprawdzić w funkcji format_user_request_to_adk_content_and_store_artifacts w pliku utils.py.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Wszystkie żądania, które będą przetwarzane przez agenta, muszą być sformatowane jako types.Content. W funkcji przetwarzamy też dane każdego obrazu i wyodrębniamy jego identyfikator, który zastępujemy obiektem zastępczym identyfikatora obrazu.
Podobny mechanizm jest używany do pobierania załączników po wyodrębnieniu identyfikatorów obrazów za pomocą wyrażeń regularnych:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Test integracyjny
Teraz w różnych kartach konsoli Google Cloud powinno działać kilka usług:
- Usługa frontend działa na porcie 8080.
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Usługa backendu działa na porcie 8081.
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Obecnie możesz przesyłać zdjęcia paragonów i płynnie rozmawiać z asystentem w aplikacji internetowej na porcie 8080.
W górnej części edytora Cloud Shell kliknij przycisk Podgląd w przeglądarce i wybierz Podejrzyj na porcie 8080.
Teraz wejdźmy w interakcję z asystentem.
Pobierz te rachunki. Zakres dat tych danych z paragonów to lata 2023–2024. Poproś asystenta o ich zapisanie lub przesłanie.
- Receipt Drive ( źródło: zbiory danych Hugging Face
mousserlane/id_receipt_dataset)
Zadawanie różnych pytań
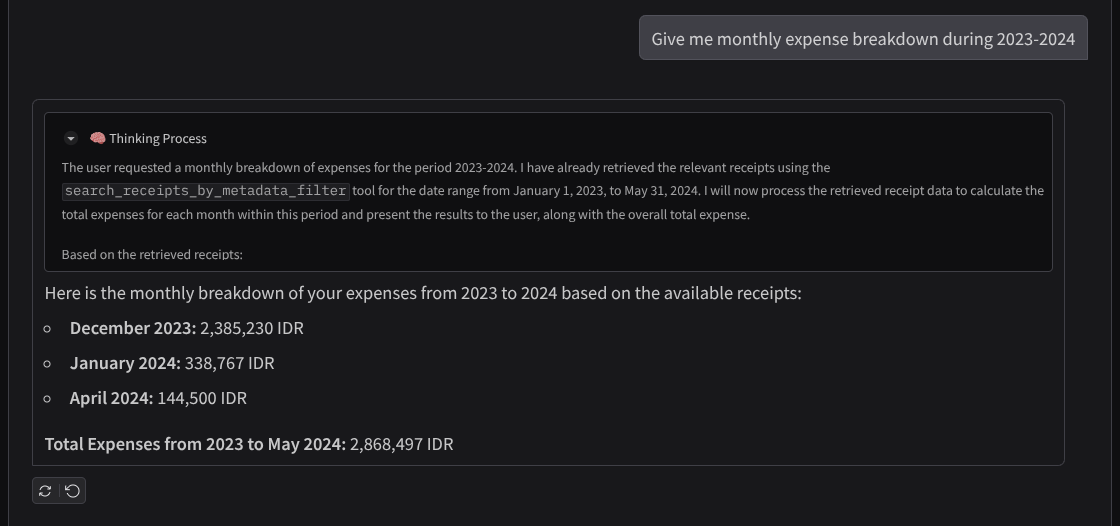
- „Podaj mi miesięczne zestawienie wydatków w latach 2023–2024”.
- „Pokaż mi rachunek za transakcję zakupu kawy”
- „Prześlij mi plik z paragonem z Yakiniku Like”
- itd.
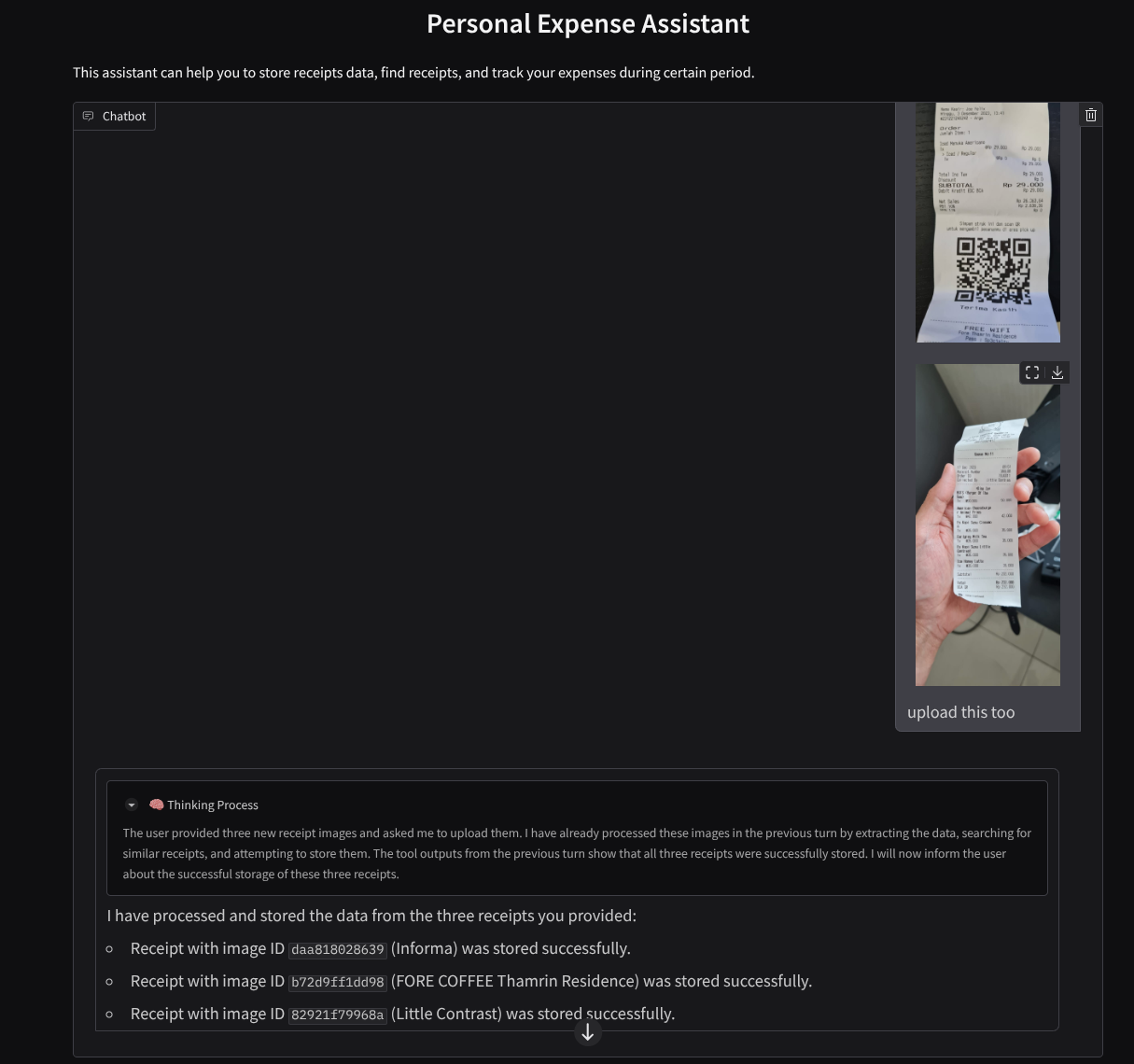
Oto fragment udanej interakcji
11. 🚀 Wdrażanie w Cloud Run
Oczywiście chcemy mieć dostęp do tej wspaniałej aplikacji z dowolnego miejsca. Aby to zrobić, możemy spakować tę aplikację i wdrożyć ją w Cloud Run. Na potrzeby tej prezentacji usługa będzie udostępniana jako usługa publiczna, do której dostęp będą miały inne osoby. Pamiętaj jednak, że nie jest to najlepsza metoda w przypadku tego typu aplikacji, ponieważ lepiej sprawdza się w przypadku aplikacji osobistych.
W tym ćwiczeniu umieścimy zarówno usługę frontendu, jak i usługę backendu w 1 kontenerze. Do zarządzania obiema usługami potrzebujemy pomocy supervisord. Możesz sprawdzić plik supervisord.conf i Dockerfile, w którym ustawiliśmy supervisord jako punkt wejścia.
Mamy już wszystkie pliki potrzebne do wdrożenia aplikacji w Cloud Run. Możemy więc to zrobić. Otwórz terminal Cloud Shell i sprawdź, czy bieżący projekt jest skonfigurowany jako aktywny. Jeśli nie, użyj polecenia gcloud configure, aby ustawić identyfikator projektu:
gcloud config set project [PROJECT_ID]
Następnie uruchom to polecenie, aby wdrożyć go w Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Jeśli pojawi się prośba o potwierdzenie utworzenia rejestru artefaktów dla repozytorium Dockera, wpisz Y. Pamiętaj, że w tym przypadku zezwalamy na nieuwierzytelniony dostęp, ponieważ jest to aplikacja demonstracyjna. Zalecamy stosowanie odpowiedniego uwierzytelniania w przypadku aplikacji firmowych i produkcyjnych.
Po zakończeniu wdrażania powinien pojawić się link podobny do tego poniżej:
https://personal-expense-assistant-*******.us-central1.run.app
Możesz teraz używać aplikacji w oknie incognito lub na urządzeniu mobilnym. Powinien być już widoczny.
12. 🎯 Wyzwanie
Teraz możesz zabłysnąć i podszkolić swoje umiejętności eksploracyjne. Czy masz umiejętności, które pozwolą Ci zmienić kod tak, aby backend mógł obsługiwać wielu użytkowników? Które komponenty wymagają aktualizacji?
13. 🧹 Zwalnianie miejsca
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym laboratorium, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
- Możesz też otworzyć Cloud Run w konsoli, wybrać wdrożoną usługę i ją usunąć.