
1. 📖 Introdução
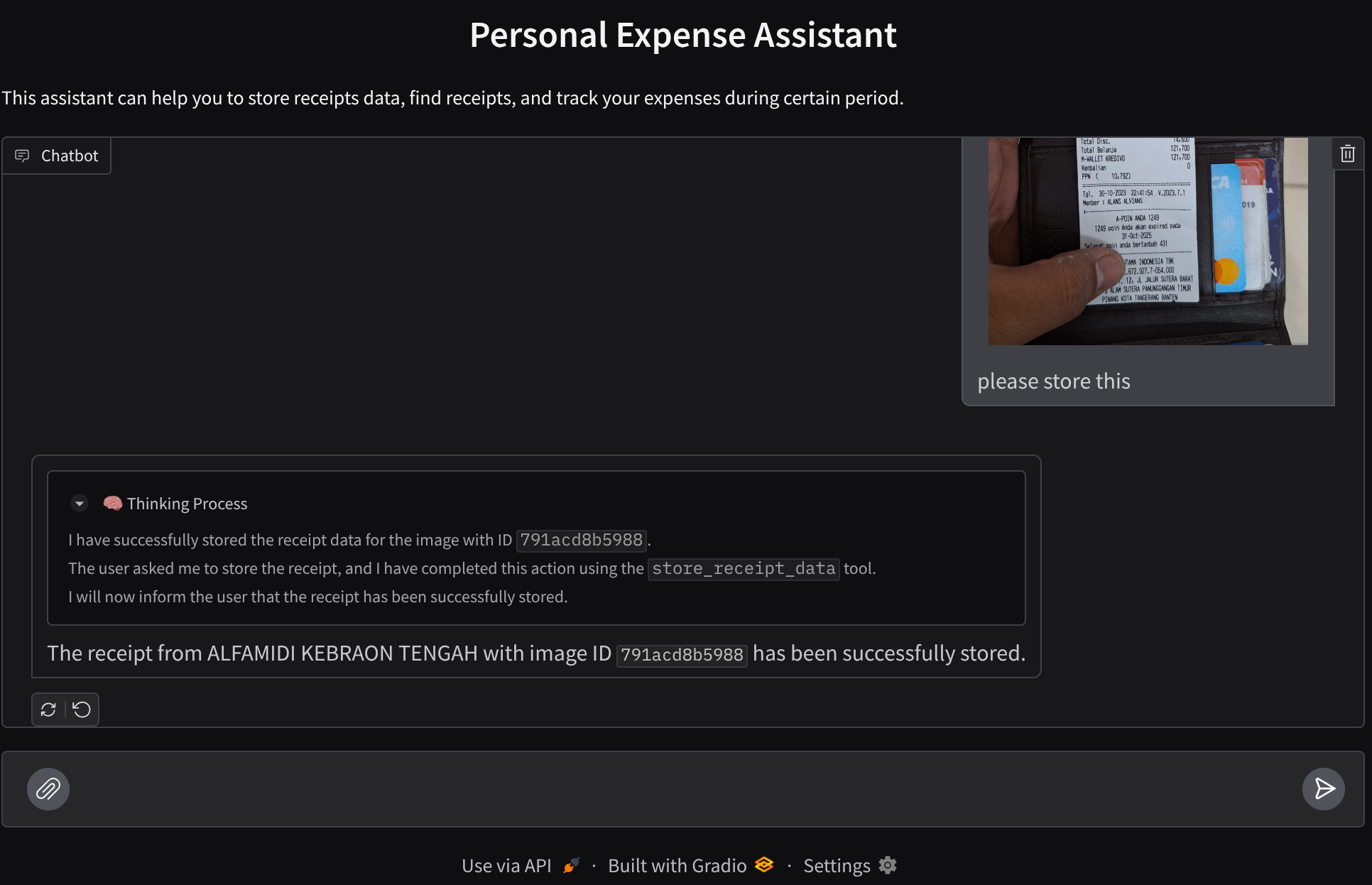
Você já ficou frustrado e com preguiça de gerenciar todas as suas despesas pessoais? E eu também! Por isso, neste codelab, vamos criar um assistente pessoal de gerenciamento de despesas com tecnologia do Gemini 2.5 para fazer todas as tarefas por nós. Desde o gerenciamento dos recibos enviados até a análise de se você já gastou demais para comprar um café!
Esse assistente vai estar acessível por um navegador da web na forma de uma interface da web de chat. Nela, você pode se comunicar com ele, fazer upload de algumas imagens de recibos e pedir para o assistente armazená-las. Também é possível buscar alguns recibos para receber o arquivo e fazer uma análise de despesas. Tudo isso é criado com base no framework do Kit de Desenvolvimento de Agente do Google.
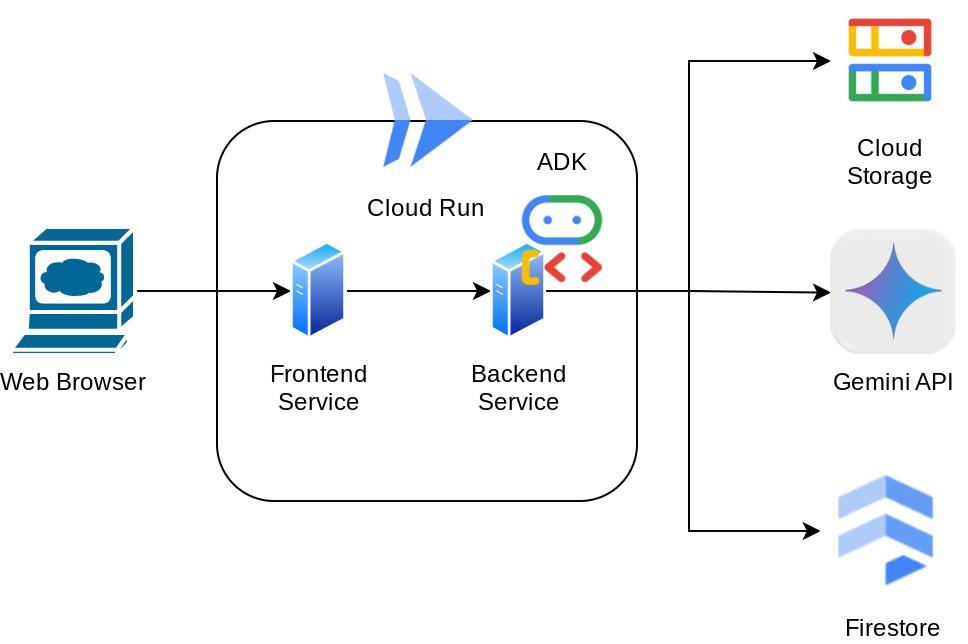
O aplicativo em si é separado em dois serviços: front-end e back-end. Isso permite criar um protótipo rápido e testar como ele funciona, além de entender como o contrato de API se parece para integrar os dois.
Durante o codelab, você vai usar uma abordagem gradual da seguinte forma:
- Prepare seu projeto na nuvem do Google Cloud e ative todas as APIs necessárias nele.
- Configurar o bucket no Google Cloud Storage e o banco de dados no Firestore
- Criar indexação do Firestore
- Configurar o espaço de trabalho para seu ambiente de programação
- Estruturar o código-fonte, as ferramentas, o comando etc. do agente do ADK
- Testar o agente usando a interface de desenvolvimento da Web local do ADK
- Crie o serviço de front-end (interface de chat) usando a biblioteca Gradio para enviar consultas e fazer upload de imagens de recibos.
- Crie o serviço de back-end (servidor HTTP) usando o FastAPI, que é onde residem o código do agente do ADK, o SessionService e o Artifact Service.
- Gerenciar variáveis de ambiente e configurar os arquivos necessários para implantar o aplicativo no Cloud Run
- Implante o aplicativo no Cloud Run.
Visão geral da arquitetura
Pré-requisitos
- Conhecimento de Python
- Conhecimento básico da arquitetura full-stack usando o serviço HTTP
O que você vai aprender
- Prototipagem da Web de front-end com o Gradio
- Desenvolvimento de serviços de back-end com FastAPI e Pydantic
- Arquitetar o agente do ADK usando os vários recursos dele
- Uso da ferramenta
- Gerenciamento de sessões e artefatos
- Uso de callback para modificação de entrada antes de enviar ao Gemini
- Usar o BuiltInPlanner para melhorar a execução de tarefas fazendo planejamento
- Depuração rápida pela interface da web local do ADK
- Estratégia para otimizar a interação multimodal por meio da análise e recuperação de informações com engenharia de comandos e modificação de solicitações do Gemini usando o callback do ADK
- Geração aumentada de recuperação com agentes usando o Firestore como banco de dados vetorial
- Gerenciar variáveis de ambiente em arquivos YAML com Pydantic-settings
- Implante o aplicativo no Cloud Run usando o Dockerfile e forneça variáveis de ambiente com o arquivo YAML
O que é necessário
- Navegador da Web Google Chrome
- Uma conta do Gmail
- Um projeto do Cloud com faturamento ativado
Este codelab, criado para desenvolvedores de todos os níveis (inclusive iniciantes), usa Python no aplicativo de exemplo. No entanto, não é necessário ter conhecimento de Python para entender os conceitos apresentados.
2. 🚀 Antes de começar
Selecionar projeto ativo no console do Cloud
Este codelab pressupõe que você já tenha um projeto na nuvem do Google Cloud com o faturamento ativado. Se você ainda não tem, siga as instruções abaixo para começar.
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Preparar o banco de dados do Firestore
Em seguida, também vamos precisar criar um banco de dados do Firestore. O Firestore no modo nativo é um banco de dados de documentos NoSQL criado para escalonamento automático, alto desempenho e facilidade no desenvolvimento de aplicativos. Ele também pode atuar como um banco de dados de vetores que oferece suporte à técnica de Geração Aprimorada de Recuperação para nosso laboratório.
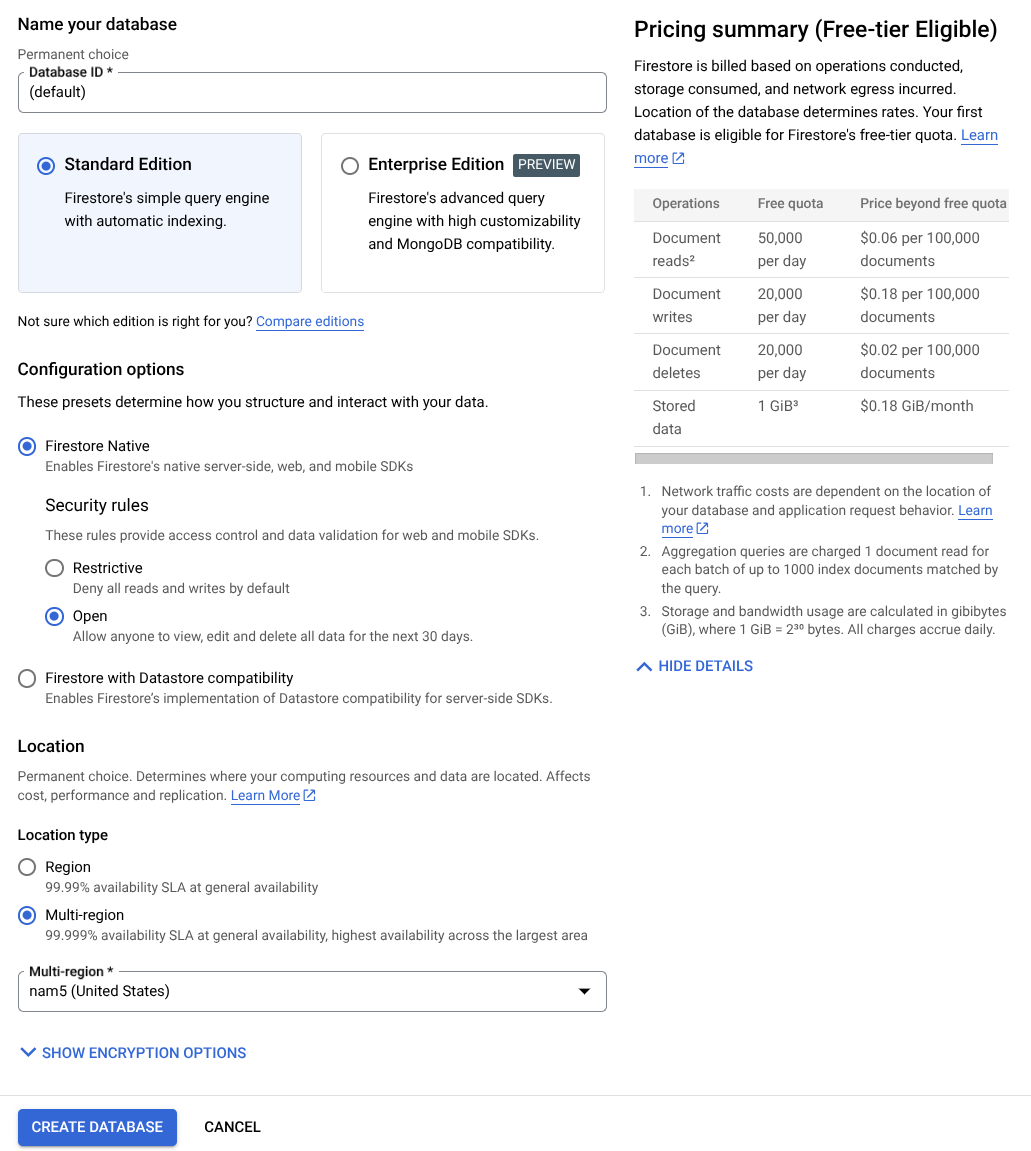
- Pesquise firestore na barra de pesquisa e clique no produto Firestore.
- Em seguida, clique no botão Criar um banco de dados do Firestore.
- Use (padrão) como o nome do ID do banco de dados e mantenha a Standard Edition selecionada. Para esta demonstração do laboratório, use o Firestore Native com regras de segurança abertas.
- Você também vai notar que esse banco de dados tem o Uso do nível sem custo financeiro YEAY! Depois disso, clique no botão Criar banco de dados.
Depois dessas etapas, você já será redirecionado para o banco de dados do Firestore que acabou de criar.
Configurar o projeto do Cloud no terminal do Cloud Shell
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com bq. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.
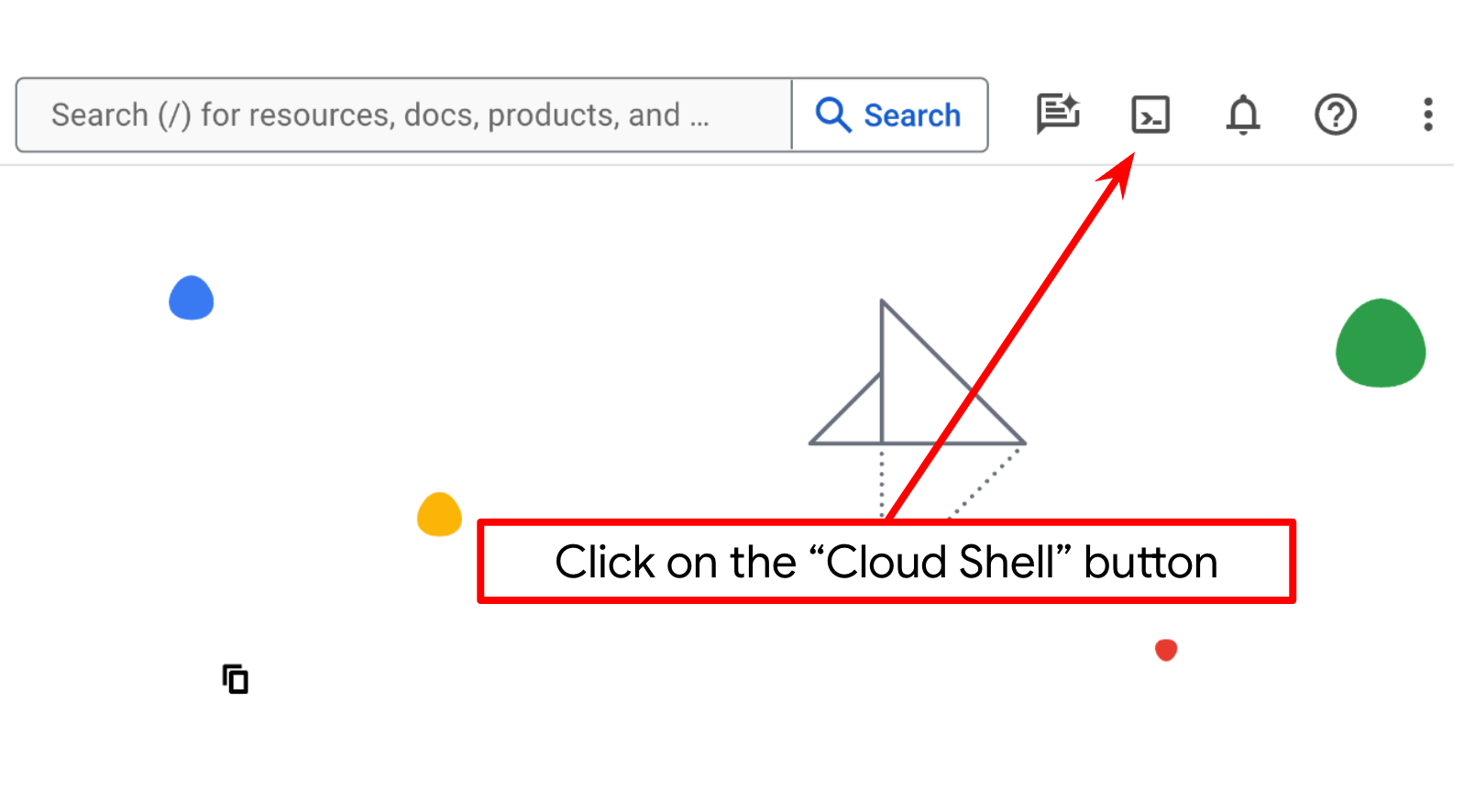
- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com o ID do seu projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
Também é possível conferir o ID do PROJECT_ID no console.
Clique nele para ver todos os seus projetos e o ID do projeto no lado direito.
- Ative as APIs necessárias com o comando mostrado abaixo. Isso pode levar alguns minutos. Aguarde.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Após a execução do comando, você vai ver uma mensagem semelhante à mostrada abaixo:
Operation "operations/..." finished successfully.
A alternativa ao comando gcloud é usar o console. Para isso, pesquise cada produto ou use este link.
Se alguma API for esquecida, você sempre poderá ativá-la durante a implementação.
Consulte a documentação para ver o uso e os comandos gcloud.
Preparar o bucket do Cloud Storage
Em seguida, no mesmo terminal, vamos preparar o bucket do GCS para armazenar o arquivo enviado. Execute o comando a seguir para criar o bucket. Um nome exclusivo e relevante para recibos do assistente de despesas pessoais será necessário. Por isso, vamos usar o nome de bucket a seguir combinado com o ID do projeto.
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Ele vai mostrar esta saída
Creating gs://personal-expense-{your-project-id}
Para verificar isso, acesse o menu de navegação no canto superior esquerdo do navegador e selecione Cloud Storage -> Bucket.
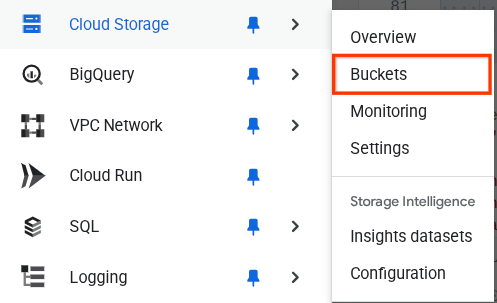
Como criar um índice do Firestore para pesquisa
O Firestore é um banco de dados NoSQL nativo, que oferece desempenho e flexibilidade superiores no modelo de dados, mas tem limitações quando se trata de consultas complexas. Como planejamos usar algumas consultas compostas de vários campos e pesquisa vetorial, primeiro precisamos criar um índice. Leia mais detalhes nesta documentação.
- Execute o comando a seguir para criar um índice que ofereça suporte a consultas compostas:
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- E execute este para oferecer suporte à pesquisa vetorial
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
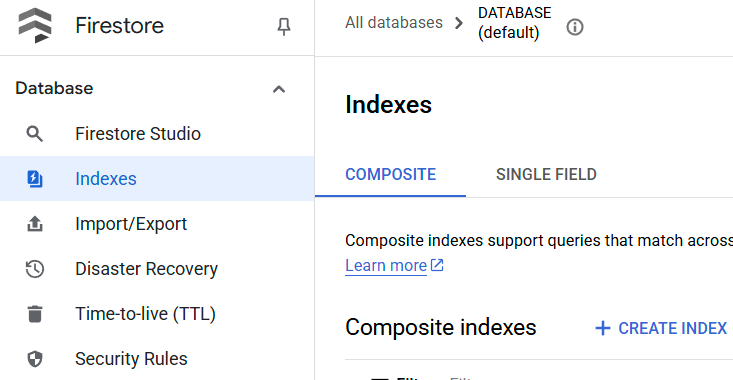
Para verificar o índice criado, acesse o Firestore no console do Cloud, clique na instância de banco de dados (padrão) e selecione Índices na barra de navegação.
Acessar o editor do Cloud Shell e configurar o diretório de trabalho do aplicativo
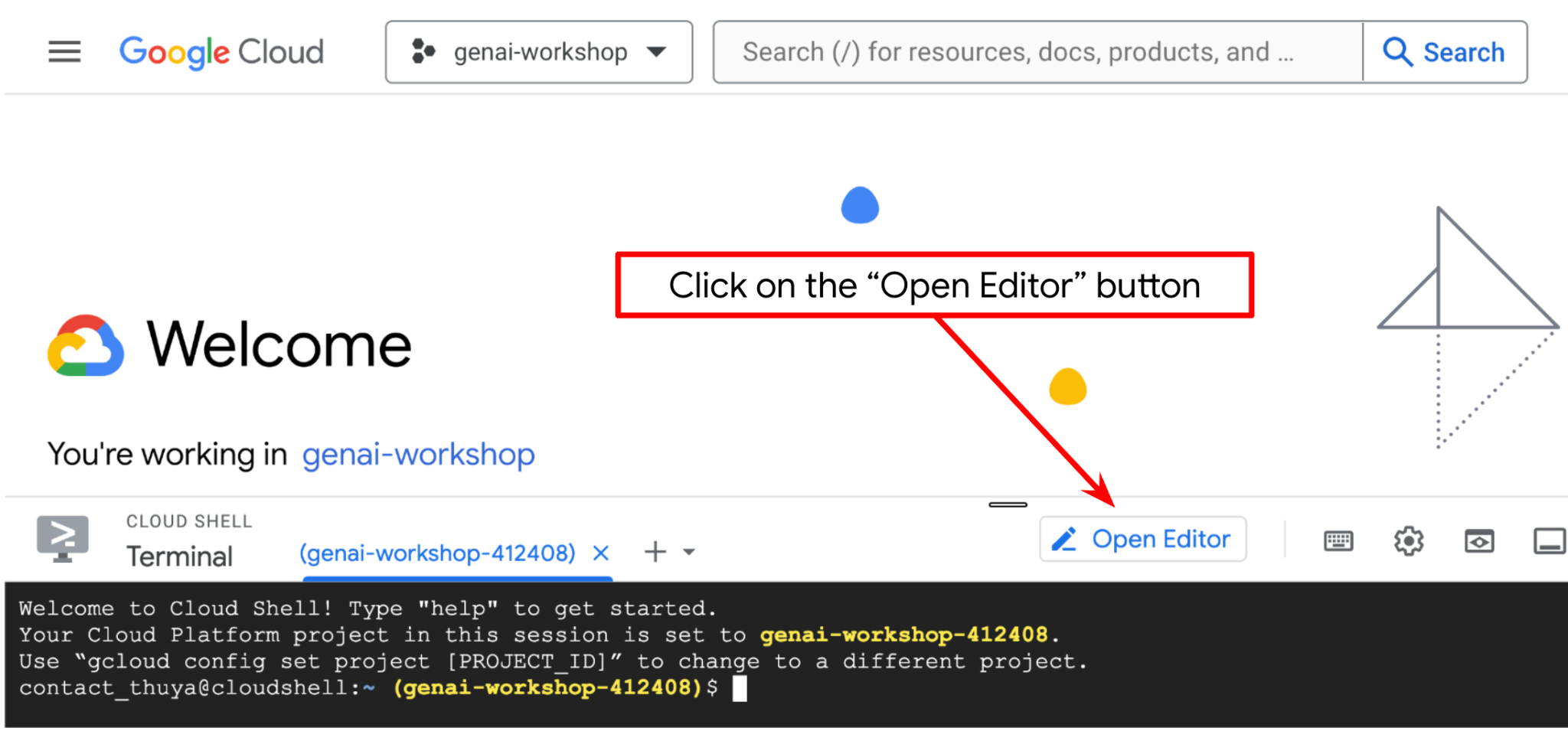
Agora, podemos configurar nosso editor de código para fazer algumas coisas de programação. Vamos usar o editor do Cloud Shell para isso.
- Clique no botão "Abrir editor" para abrir um editor do Cloud Shell. Podemos escrever nosso código aqui
- Em seguida, também precisamos verificar se o shell já está configurado para o ID DO PROJETO correto. Se você vir um valor entre parênteses antes do ícone $ no terminal (na captura de tela abaixo, o valor é "adk-multimodal-tool"), esse valor mostra o projeto configurado para sua sessão de shell ativa.

Se o valor mostrado já estiver correto, pule o próximo comando. No entanto, se não estiver correto ou estiver faltando, execute o seguinte comando:
gcloud config set project <YOUR_PROJECT_ID>
- Em seguida, vamos clonar o diretório de trabalho do modelo para este codelab do GitHub. Execute o seguinte comando: Isso vai criar o diretório de trabalho no diretório personal-expense-assistant.
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
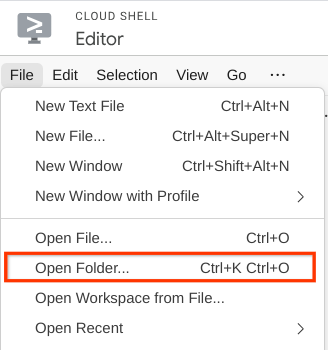
- Depois disso, acesse a seção superior do editor do Cloud Shell e clique em Arquivo->Abrir pasta, encontre o diretório nome de usuário e o diretório personal-expense-assistant. Em seguida, clique no botão OK. Isso vai definir o diretório escolhido como o principal. Neste exemplo, o nome de usuário é alvinprayuda. Portanto, o caminho do diretório é mostrado abaixo.

Agora, o editor do Cloud Shell vai ficar assim:
Configuração do ambiente
Preparar o ambiente virtual do Python
A próxima etapa é preparar o ambiente de desenvolvimento. O terminal ativo atual precisa estar no diretório de trabalho personal-expense-assistant. Vamos usar o Python 3.12 neste codelab e o gerenciador de projetos Python uv para simplificar a necessidade de criar e gerenciar a versão do Python e o ambiente virtual.
- Se você ainda não abriu o terminal, clique em Terminal -> Novo terminal ou use Ctrl + Shift + C. Isso vai abrir uma janela do terminal na parte de baixo do navegador.

- Agora vamos inicializar o ambiente virtual usando
uv. Execute estes comandos:
cd ~/personal-expense-assistant
uv sync --frozen
Isso vai criar o diretório .venv e instalar as dependências. Uma rápida olhada no pyproject.toml vai mostrar informações sobre as dependências, assim:
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Configurar arquivos de configuração
Agora precisamos configurar os arquivos de configuração para esse projeto. Usamos pydantic-settings para ler a configuração do arquivo YAML.
Já fornecemos o modelo de arquivo em settings.yaml.example. Agora , copie o arquivo e renomeie para settings.yaml. Execute este comando para criar o arquivo:
cp settings.yaml.example settings.yaml
Em seguida, copie o seguinte valor no arquivo:
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
Neste codelab, vamos usar os valores pré-configurados para GCLOUD_LOCATION, BACKEND_URL, e DB_COLLECTION_NAME .
Agora podemos passar para a próxima etapa, criando o agente e depois os serviços.
3. 🚀 Crie o agente usando o ADK do Google e o Gemini 2.5
Introdução à estrutura de diretórios do ADK
Vamos começar analisando o que o ADK tem a oferecer e como criar o agente. A documentação completa do ADK pode ser acessada neste URL . O ADK oferece muitas utilidades na execução de comandos da CLI. Alguns deles são :
- Configurar a estrutura de diretórios do agente
- Teste rapidamente a interação por entrada e saída da CLI
- Configurar rapidamente a interface da Web da IU de desenvolvimento local
Agora, vamos criar a estrutura de diretórios do agente usando o comando da CLI. Execute o comando a seguir.
uv run adk create expense_manager_agent
Quando solicitado, escolha o modelo gemini-2.5-flash e o back-end Vertex AI. Em seguida, o assistente vai pedir o ID do projeto e o local. Você pode aceitar as opções padrão pressionando Enter ou mudá-las conforme necessário. Verifique se você está usando o ID do projeto correto criado anteriormente neste laboratório. A saída será semelhante ao seguinte:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Ela vai criar a seguinte estrutura de diretório do agente
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Se você inspecionar init.py e agent.py, verá este código:
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Agora você pode testar executando
uv run adk run expense_manager_agent
Quando terminar de testar, saia do agente digitando exit ou pressionando Ctrl+D.
Como criar nosso agente do Expense Manager
Vamos criar nosso agente de gerenciamento de despesas! Abra o arquivo expense_manager_agent/agent.py e copie o código abaixo, que vai conter o root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Explicação do código
Esse script contém a inicialização do agente, em que inicializamos o seguinte:
- Defina o modelo a ser usado como
gemini-2.5-flash. - Defina a descrição e a instrução do agente como o comando do sistema que está sendo lido de
task_prompt.md - Fornecer as ferramentas necessárias para oferecer suporte à funcionalidade do agente
- Ativar o planejamento antes de gerar a resposta final ou a execução usando os recursos de raciocínio do Gemini 2.5 Flash
- Configure a interceptação de callback antes de enviar a solicitação ao Gemini para limitar o número de dados de imagem enviados antes de fazer a previsão.
4. 🚀 Como configurar as ferramentas do agente
Nosso agente de gerenciamento de despesas terá as seguintes capacidades:
- Extrair dados da imagem do recibo e armazenar os dados e o arquivo
- Pesquisa exata nos dados de despesas
- Pesquisa contextual nos dados de despesas
Por isso, precisamos das ferramentas adequadas para oferecer suporte a essa funcionalidade. Crie um arquivo no diretório expense_manager_agent e nomeie-o como tools.py.
touch expense_manager_agent/tools.py
Abra o arquivo expense_manage_agent/tools.py e copie o código abaixo.
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Explicação do código
Nessa implementação de função de ferramentas, projetamos as ferramentas com base nestas duas ideias principais:
- Analisar dados de recibo e mapear para o arquivo original usando o marcador de posição da string do ID da imagem
[IMAGE-ID <hash-of-image-1>] - Armazenamento e recuperação de dados usando o banco de dados do Firestore
Ferramenta "store_receipt_data"
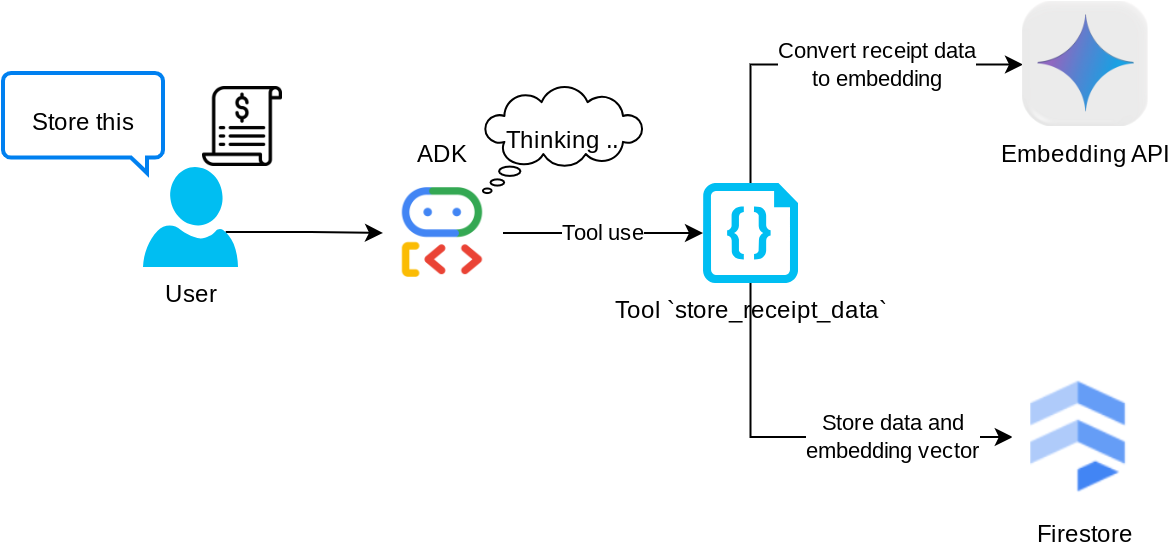
Essa ferramenta é o reconhecimento óptico de caracteres (OCR, na sigla em inglês). Ela vai analisar as informações necessárias dos dados de imagem, além de reconhecer a string do ID da imagem e mapeá-las para serem armazenadas no banco de dados do Firestore.
Além disso, essa ferramenta também converte o conteúdo do recibo em incorporação usando text-embedding-004 para que todos os metadados e a incorporação sejam armazenados e indexados juntos. Permitindo que a flexibilidade seja recuperada por consulta ou pesquisa contextual.
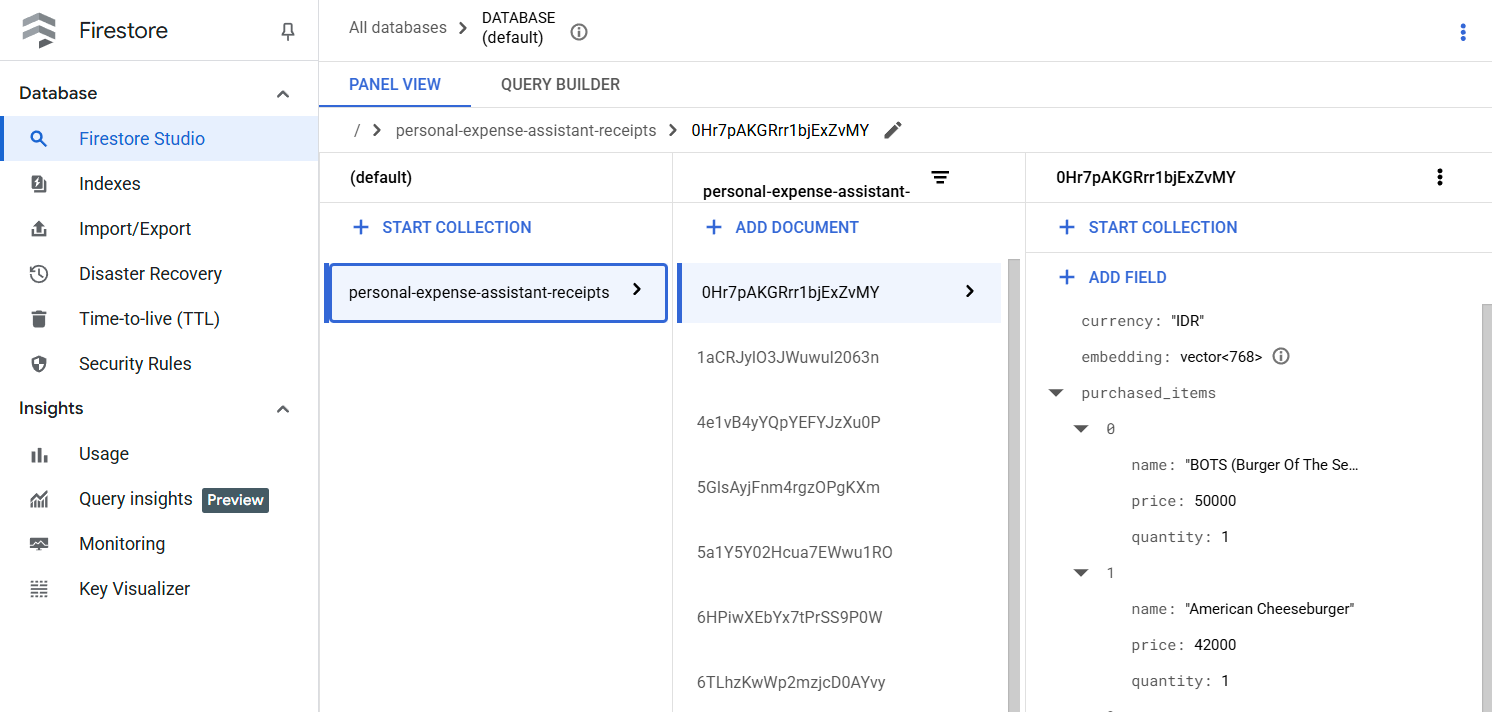
Depois de executar essa ferramenta, você vai ver que os dados do recibo já estão indexados no banco de dados do Firestore, conforme mostrado abaixo.
Ferramenta "search_receipts_by_metadata_filter"
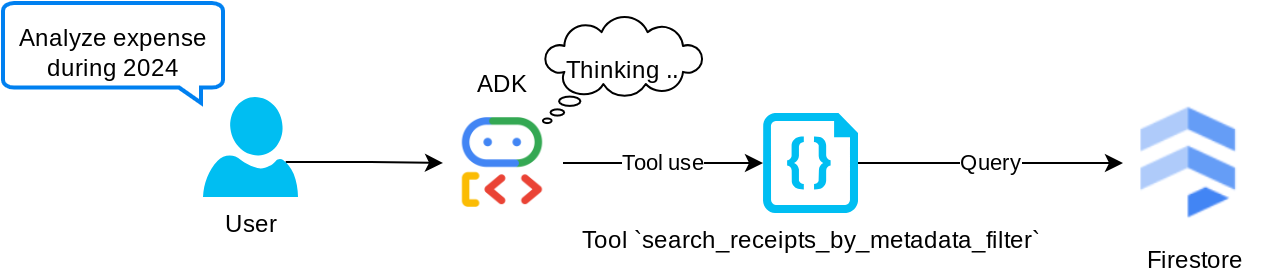
Essa ferramenta converte a consulta do usuário em um filtro de consulta de metadados que permite pesquisar por período e/ou transação total. Ele vai retornar todos os dados de recibos correspondentes, e no processo vamos descartar o campo de incorporação, já que ele não é necessário para o agente entender o contexto.
Ferramenta "search_relevant_receipts_by_natural_language_query"
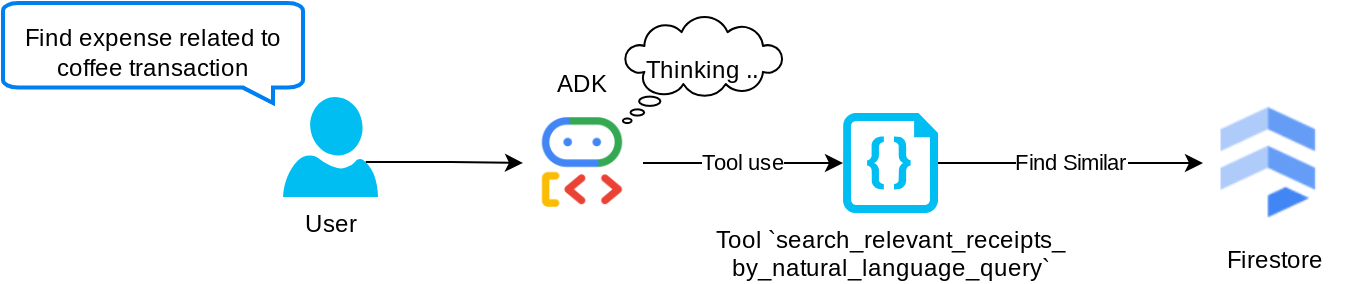
Essa é nossa ferramenta de geração aumentada por recuperação (RAG). Nosso agente tem a capacidade de criar a própria consulta para recuperar recibos relevantes do banco de dados vetorial e também pode escolher quando usar essa ferramenta. A ideia de permitir que o agente tome decisões independentes sobre usar ou não essa ferramenta de RAG e crie a própria consulta é uma das definições da abordagem de RAG com agente.
Além de permitir que ele crie a própria consulta, também é possível selecionar quantos documentos relevantes ele quer recuperar. Combinado com uma engenharia de comando adequada, por exemplo:
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Isso torna a ferramenta muito útil, já que ela pode pesquisar quase tudo, mas talvez não retorne todos os resultados esperados devido à natureza não exata da pesquisa de vizinho mais próximo.
5. 🚀 Modificação do contexto da conversa por callbacks
O ADK do Google permite "interceptar" o tempo de execução do agente em vários níveis. Leia mais sobre esse recurso detalhado nesta documentação . Neste laboratório, usamos o before_model_callback para modificar a solicitação antes de enviá-la ao LLM e remover os dados de imagem no contexto do histórico de conversas antigo ( incluindo apenas os dados de imagem nas últimas três interações do usuário) para aumentar a eficiência.
No entanto, ainda queremos que o agente tenha o contexto dos dados de imagem quando necessário. Por isso, adicionamos um mecanismo para incluir um marcador de posição de ID de imagem de string após cada dado de byte de imagem na conversa. Isso ajuda o agente a vincular o ID da imagem aos dados reais do arquivo, que podem ser usados no momento do armazenamento ou da recuperação da imagem. A estrutura terá esta aparência:
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
E quando os dados de bytes ficam obsoletos no histórico de conversas, o identificador de string ainda está lá para permitir o acesso aos dados com a ajuda do uso da ferramenta. Exemplo de estrutura do histórico após a remoção dos dados de imagem
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Vamos começar! Crie um arquivo no diretório expense_manager_agent e nomeie-o como callbacks.py.
touch expense_manager_agent/callbacks.py
Abra o arquivo expense_manager_agent/callbacks.py e copie o código abaixo.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 O comando
Para criar um agente com interação e recursos complexos, precisamos encontrar um comando bom o suficiente para orientá-lo e fazer com que ele se comporte da maneira que queremos.
Antes, tínhamos um mecanismo para processar dados de imagens no histórico de conversas e ferramentas que não eram tão fáceis de usar, como search_relevant_receipts_by_natural_language_query.. Também queremos que o agente possa pesquisar e recuperar a imagem correta do recibo. Isso significa que precisamos transmitir todas essas informações em uma estrutura de comando adequada.
Vamos pedir ao agente para estruturar a saída no seguinte formato Markdown para analisar o processo de pensamento, a resposta final e o anexo ( se houver).
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Vamos começar com o seguinte comando para alcançar nossa expectativa inicial de comportamento do agente do gerenciador de despesas. O arquivo task_prompt.md já existe no diretório de trabalho, mas precisamos movê-lo para o diretório expense_manager_agent. Execute o comando a seguir para movê-lo
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Testar o agente
Agora vamos tentar nos comunicar com o agente pela CLI. Execute o seguinte comando:
uv run adk run expense_manager_agent
Ele vai mostrar uma saída como esta, em que você pode conversar com o agente, mas só é possível enviar texto por essa interface.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
Agora, além da interação com a CLI, o ADK também permite ter uma interface de desenvolvimento para interagir e inspecionar o que está acontecendo durante a interação. Execute o comando a seguir para iniciar o servidor da interface de desenvolvimento local:
uv run adk web --port 8080
Ele vai gerar uma saída como o exemplo a seguir, o que significa que já podemos acessar a interface da Web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
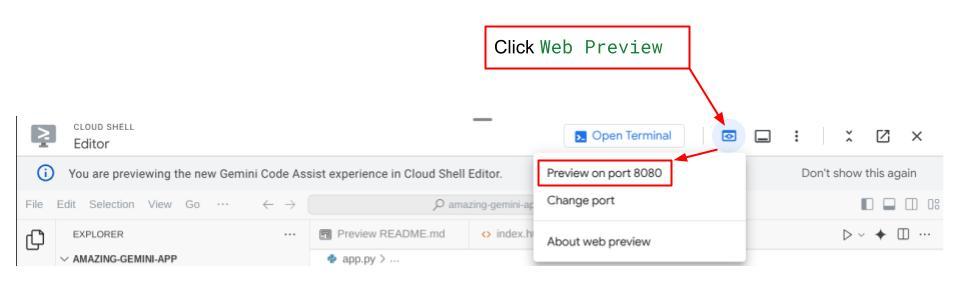
Para verificar, clique no botão Visualização da Web na parte superior do Editor do Cloud Shell e selecione Visualizar na porta 8080.
Você vai ver a seguinte página da Web, em que é possível selecionar os agentes disponíveis no botão suspenso no canto superior esquerdo ( no nosso caso, expense_manager_agent) e interagir com o bot. Você vai ver muitas informações sobre os detalhes do registro durante o tempo de execução do agente na janela à esquerda.
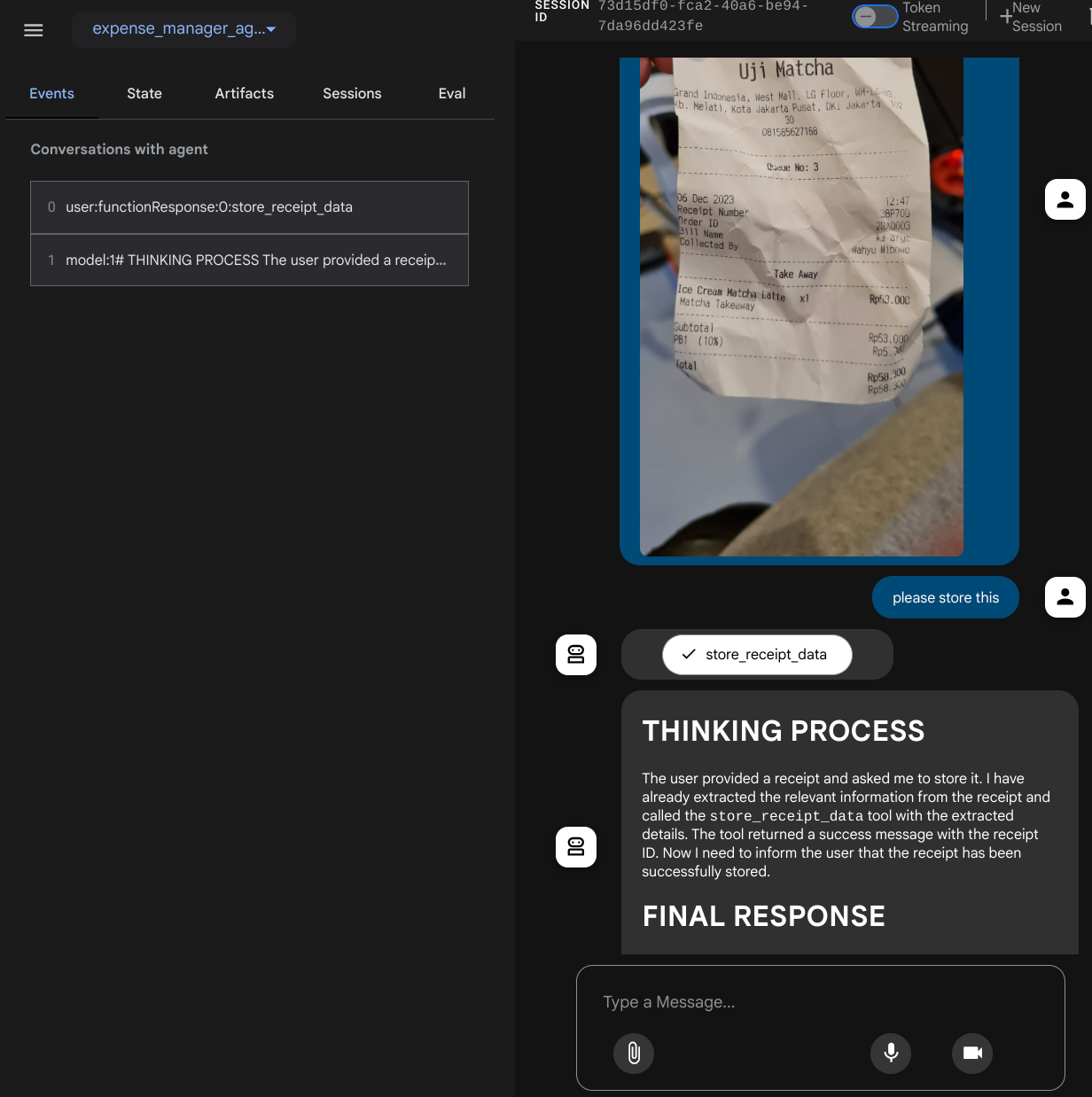
Vamos testar algumas ações. Faça upload destes dois exemplos de recibos ( fonte : conjuntos de dados do Hugging Face mousserlane/id_receipt_dataset) . Clique com o botão direito do mouse em cada imagem e escolha Salvar imagem como… ( isso vai baixar a imagem do recibo) e faça upload do arquivo para o bot clicando no ícone de "clipe" e diga que você quer armazenar esses recibos.


Depois disso, tente as seguintes consultas para fazer alguma pesquisa ou recuperação de arquivos
- "Mostre o detalhamento das despesas e o total delas em 2023"
- "Me dê o arquivo de recibo da Indomaret"
Ao usar algumas ferramentas, é possível inspecionar o que está acontecendo na interface de desenvolvimento.
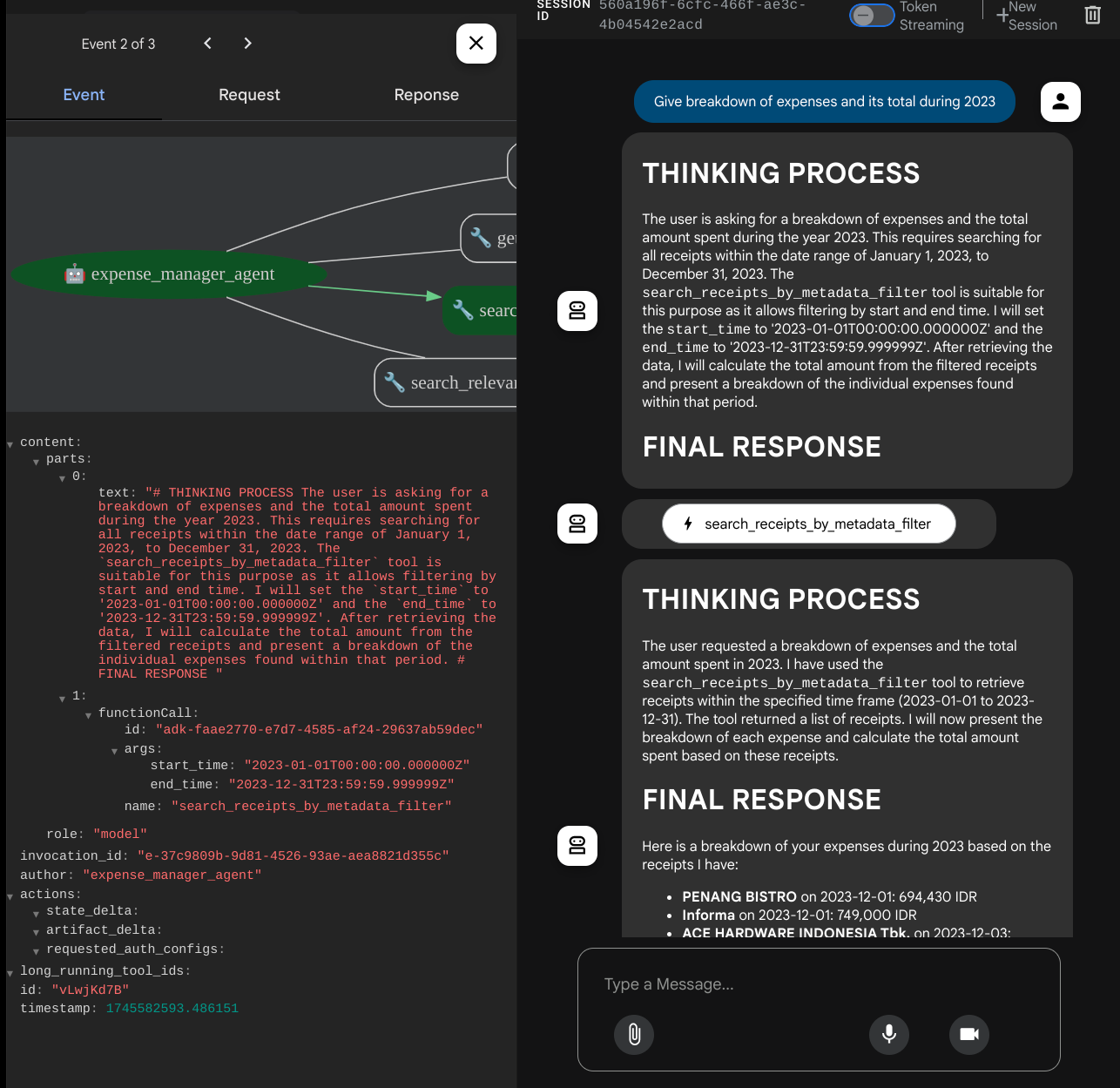
Confira como o agente responde a você e verifique se ele obedece a todas as regras fornecidas no comando em task_prompt.py. Parabéns! Agora você tem um agente de desenvolvimento completo e funcional.
Agora é hora de concluir com uma interface e recursos adequados e agradáveis para fazer upload e download do arquivo de imagem.
8. 🚀 Criar o serviço de front-end usando o Gradio
Vamos criar uma interface da Web de chat parecida com esta
Ela contém uma interface de chat com um campo de entrada para os usuários enviarem texto e fazer upload dos arquivos de imagem do recibo.
Vamos criar o serviço de front-end usando o Gradio.
Crie um arquivo e nomeie-o como frontend.py.
touch frontend.py
Em seguida, copie e salve o código a seguir:
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Depois disso, tente executar o serviço de front-end com o seguinte comando. Não se esqueça de renomear o arquivo main.py para frontend.py.
uv run frontend.py
Você vai ver uma saída semelhante a esta no console do Cloud
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Depois disso, você pode verificar a interface da Web ao ctrl+clicar no link do URL local. Como alternativa, clique no botão Visualização da Web, no canto superior direito do Cloud Editor, e selecione Visualizar na porta 8080 para acessar o aplicativo de front-end.
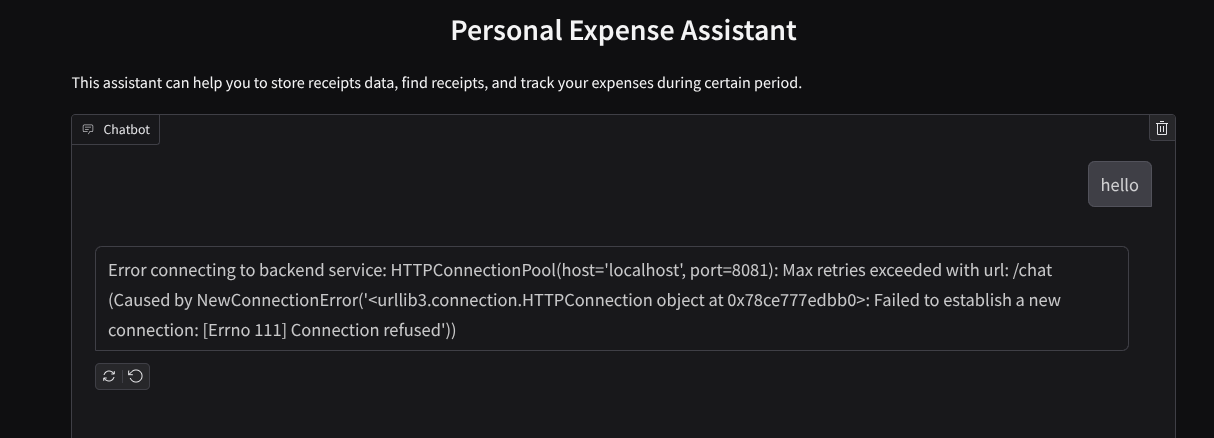
A interface da Web vai aparecer, mas você vai receber um erro esperado ao tentar enviar uma conversa devido a um serviço de back-end que ainda não foi configurado.
Agora, deixe o serviço ser executado e não o encerre ainda. Vamos executar o serviço de back-end em outra guia do terminal.
Explicação do código
Neste código de front-end, primeiro permitimos que o usuário envie texto e faça upload de vários arquivos. O Gradio permite criar esse tipo de funcionalidade com o método gr.ChatInterface combinado com gr.MultimodalTextbox.
Antes de enviar o arquivo e o texto para o back-end, precisamos descobrir o mimetype do arquivo, já que ele é necessário para o back-end. Também precisamos codificar o byte do arquivo de imagem em base64 e enviá-lo junto com o mimetype.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
O esquema usado para interação entre front-end e back-end é definido em schema.py. Usamos o Pydantic BaseModel para aplicar a validação de dados no esquema.
Ao receber a resposta, já separamos qual parte é o processo de pensamento, a resposta final e o anexo. Assim, podemos usar o componente Gradio para mostrar cada componente com o componente de interface.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Criar um serviço de back-end usando o FastAPI
Em seguida, vamos criar o back-end, que pode inicializar nosso agente com os outros componentes para executar o tempo de execução do agente.
Crie um arquivo e nomeie-o como backend.py.
touch backend.py
e copie o seguinte código:
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Depois disso, podemos tentar executar o serviço de back-end. Na etapa anterior, executamos o serviço de front-end corretamente. Agora, vamos precisar abrir um novo terminal e tentar executar o serviço de back-end.
- Crie um novo terminal. Navegue até o terminal na área de baixo e encontre o botão "+" para criar um novo terminal. Ou pressione Ctrl + Shift + C para abrir um novo terminal.

- Depois disso, verifique se você está no diretório de trabalho personal-expense-assistant e execute o seguinte comando:
uv run backend.py
- Se for bem-sucedido, a saída será semelhante a esta:
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Explicação do código
Inicializando o agente do ADK, o SessionService e o ArtifactService
Para executar o agente no serviço de back-end, precisamos criar um Runner que use o SessionService e nosso agente. O SessionService gerencia o histórico e o estado da conversa. Portanto, quando integrado ao Runner, ele dá ao nosso agente a capacidade de receber o contexto das conversas em andamento.
Também usamos o ArtifactService para processar o arquivo enviado. Leia mais detalhes sobre sessão e artefatos do ADK.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
Nesta demonstração, usamos InMemorySessionService e GcsArtifactService para integração com nosso Runner de agente. Como o histórico de conversas é armazenado na memória, ele será perdido quando o serviço de back-end for encerrado ou reiniciado. Inicializamos esses elementos no ciclo de vida do aplicativo FastAPI para serem injetados como dependência na rota /chat.
Como fazer upload e download de imagens com o GcsArtifactService
Todas as imagens enviadas serão armazenadas como artefato pelo GcsArtifactService. É possível verificar isso na função format_user_request_to_adk_content_and_store_artifacts em utils.py.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Todas as solicitações que serão processadas pelo executor do agente precisam ser formatadas no tipo types.Content. Dentro da função, também processamos cada dado de imagem e extraímos o ID dele para ser substituído por um marcador de posição de ID de imagem.
Um mecanismo semelhante é usado para baixar os anexos depois de extrair os IDs de imagem usando regex:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Teste de integração
Agora, você terá vários serviços executados em diferentes guias do console do Cloud:
- Serviço de front-end executado na porta 8080
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Serviço de back-end executado na porta 8081
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
No estado atual, você pode fazer upload das imagens dos recibos e conversar com o assistente no aplicativo da Web na porta 8080.
Clique no botão Visualização da Web na parte superior do editor do Cloud Shell e selecione Visualizar na porta 8080.
Agora vamos interagir com o assistente!
Faça o download dos seguintes recibos. O período desses dados de recibo é entre 2023 e 2024. Peça ao assistente para armazenar/fazer upload deles.
- Receipt Drive ( fonte: conjuntos de dados do Hugging Face
mousserlane/id_receipt_dataset)
Perguntar várias coisas
- "Mostre o detalhamento das despesas mensais de 2023 a 2024"
- "Mostre o recibo da transação de café"
- "Me dê o arquivo de recibo da Yakiniku Like"
- Etc.
Aqui está um trecho de uma interação bem-sucedida
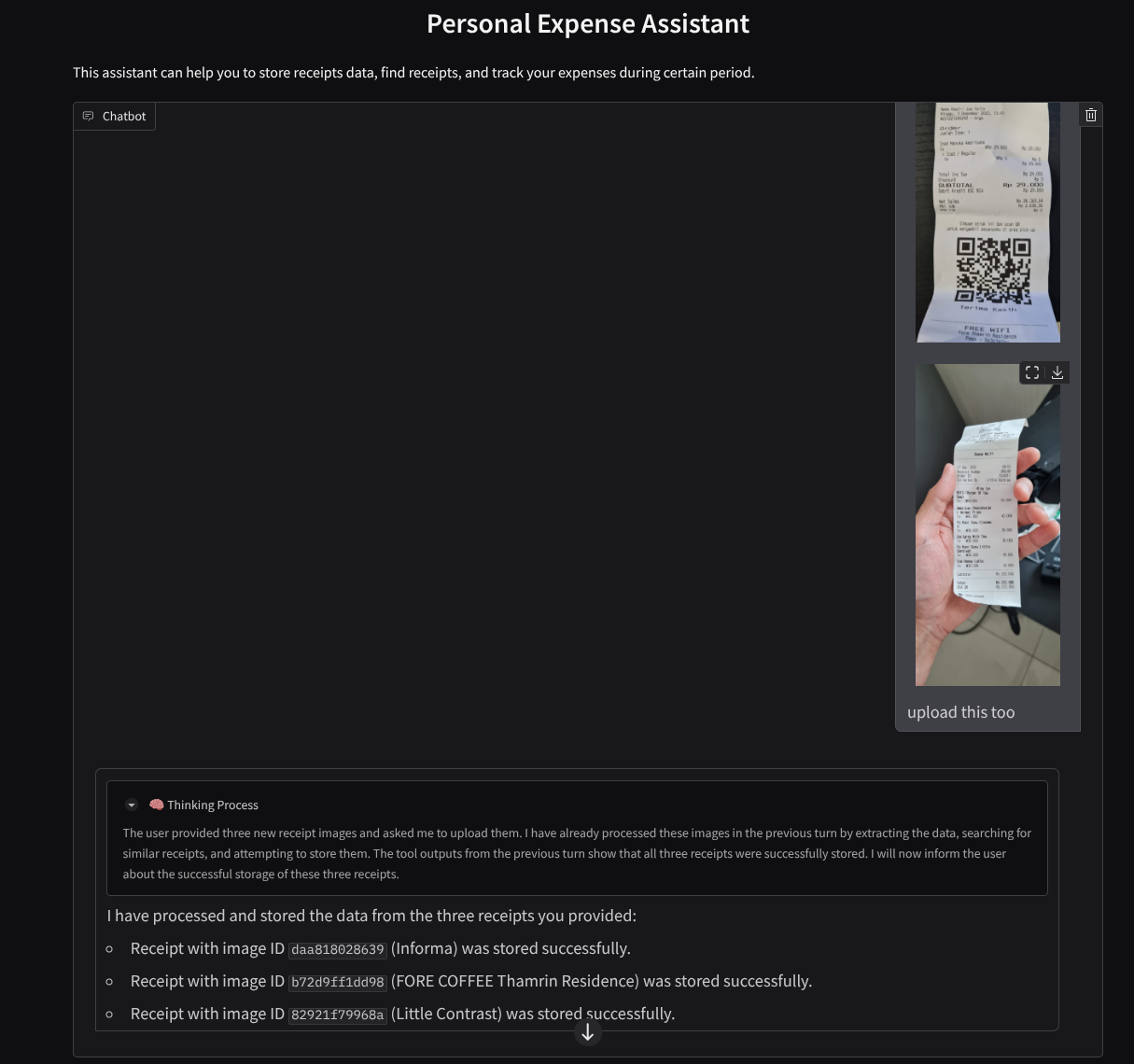
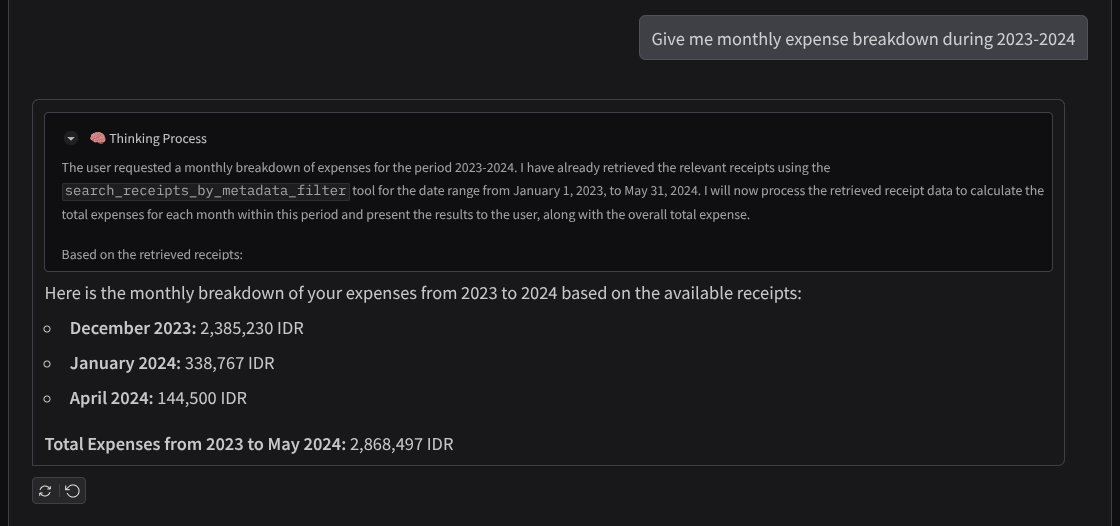
11. 🚀 Como implantar no Cloud Run
Agora, é claro que queremos acessar esse app incrível de qualquer lugar. Para isso, podemos empacotar e implantar o aplicativo no Cloud Run. Para fins desta demonstração, esse serviço será exposto como um serviço público que pode ser acessado por outras pessoas. No entanto, essa não é a prática recomendada para esse tipo de aplicativo, já que é mais adequada para aplicativos pessoais.
Neste codelab, vamos colocar o serviço de front-end e o serviço de back-end em um contêiner. Vamos precisar da ajuda do supervisord para gerenciar os dois serviços. É possível inspecionar o arquivo supervisord.conf e verificar o Dockerfile em que definimos o supervisord como o ponto de entrada.
Neste ponto, já temos todos os arquivos necessários para implantar nossos aplicativos no Cloud Run. Vamos fazer isso. Navegue até o terminal do Cloud Shell e verifique se o projeto atual está configurado para seu projeto ativo. Caso contrário, use o comando gcloud configure para definir o ID do projeto:
gcloud config set project [PROJECT_ID]
Em seguida, execute o comando abaixo para implantar no Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Se você precisar confirmar a criação de um registro de artefato para o repositório do Docker, responda Y. Estamos permitindo o acesso não autenticado porque este é um aplicativo de demonstração. Recomendamos usar a autenticação adequada para seus aplicativos empresariais e de produção.
Quando a implantação for concluída, você vai receber um link semelhante a este:
https://personal-expense-assistant-*******.us-central1.run.app
Use o aplicativo na janela anônima ou no dispositivo móvel. Ele já deve estar ativo.
12. 🎯 Desafio
Agora é sua vez de brilhar e aprimorar suas habilidades de análise detalhada. Você tem o que é preciso para mudar o código e permitir que o back-end acomode vários usuários? Quais componentes precisam ser atualizados?
13. 🧹 Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste codelab, siga estas etapas:
- No console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
- Ou acesse Cloud Run no console do Google Cloud, selecione o serviço que você acabou de implantar e exclua.