
1. 📖 Введение
Вы когда-нибудь испытывали разочарование и лень самостоятельно управлять всеми своими личными расходами? Я тоже! Поэтому в этом практическом занятии мы создадим личного помощника по управлению расходами — на базе Gemini 2.5, который будет выполнять все эти задачи за нас! От управления загруженными чеками до анализа того, не потратили ли вы уже слишком много на кофе!
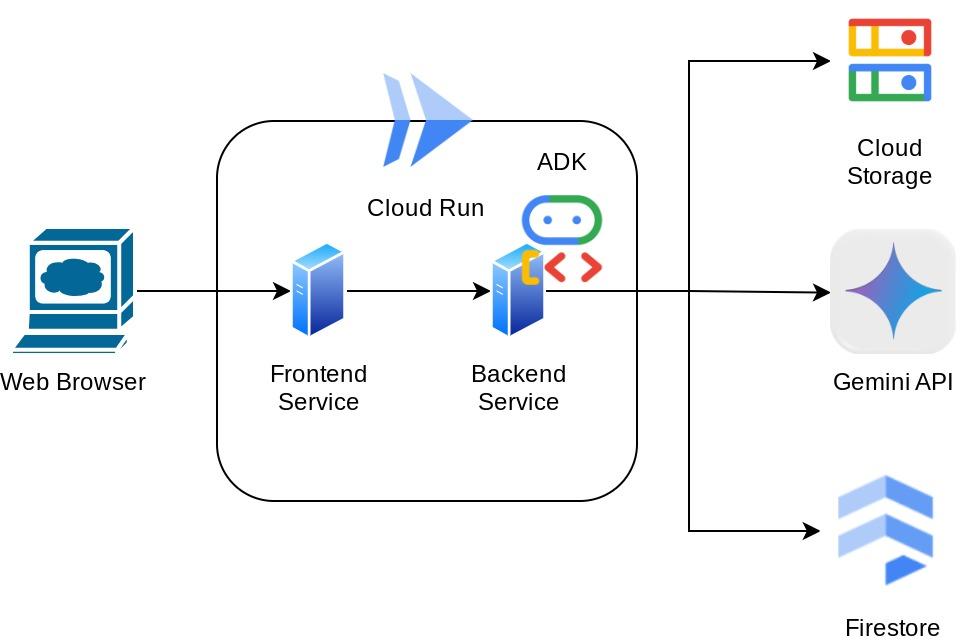
Этот помощник будет доступен через веб-браузер в виде веб-интерфейса чата, в котором вы сможете общаться с ним, загружать изображения чеков и просить помощника сохранить их, или, например, искать чеки, чтобы получить файл и провести анализ расходов. И все это построено на основе фреймворка Google Agent Development Kit.
Само приложение разделено на две части: фронтенд и бэкенд; это позволяет быстро создать прототип, оценить его функциональность, а также понять, как выглядит API-контракт для интеграции обеих частей.
В ходе выполнения практического задания вы будете использовать следующий пошаговый подход:
- Подготовьте свой проект в Google Cloud и включите в него все необходимые API.
- Настройте хранилище данных в Google Cloud Storage и базу данных в Firestore.
- Создание индекса Firestore
- Настройте рабочее пространство для вашей среды программирования.
- Структурирование исходного кода агента ADK, инструментов, командной строки и т. д.
- Тестирование агента с использованием локального пользовательского интерфейса веб-разработки ADK.
- Создайте фронтенд-сервис — интерфейс чата с использованием библиотеки Gradio , для отправки запросов и загрузки изображений чеков.
- Создайте серверную часть — HTTP-сервер с использованием FastAPI , в котором разместятся код нашего ADK-агента, SessionService и Artifact Service.
- Управление переменными среды и настройка необходимых файлов для развертывания приложения в облаке.
- Разверните приложение в облаке.
Обзор архитектуры
Предварительные требования
- Уверенно работаю с Python.
- Понимание базовой архитектуры полного стека с использованием HTTP-сервисов.
Что вы узнаете
- Фронтенд-прототипирование веб-сайтов с помощью Gradio
- Разработка бэкэнд-сервисов с использованием FastAPI и Pydantic.
- Разработка архитектуры агента ADK с использованием его многочисленных возможностей.
- Использование инструментов
- Управление сессиями и артефактами
- Использование функции обратного вызова для изменения входных данных перед отправкой в Gemini.
- Использование BuiltInPlanner для повышения эффективности выполнения задач за счет планирования.
- Быстрая отладка через локальный веб-интерфейс ADK.
- Стратегия оптимизации мультимодального взаимодействия посредством анализа и извлечения информации с использованием оперативной разработки и модификации запросов Gemini с помощью обратного вызова ADK.
- Расширенная генерация с использованием системы Agentic Retrieval на основе Firestore в качестве векторной базы данных.
- Управление переменными окружения в YAML-файле с помощью Pydantic-settings
- Разверните приложение в Cloud Run с помощью Dockerfile и укажите переменные среды в YAML-файле.
Что вам понадобится
- Веб-браузер Chrome
- Аккаунт Gmail
- Облачный проект с включенной функцией выставления счетов.
Этот практический урок, разработанный для разработчиков всех уровней (включая начинающих), использует Python в качестве примера приложения. Однако знание Python не требуется для понимания представленных концепций.
2. 🚀 Перед началом
Выберите активный проект в облачной консоли.
В этом практическом задании предполагается, что у вас уже есть проект Google Cloud с включенной оплатой. Если у вас его еще нет, вы можете следовать инструкциям ниже, чтобы начать работу.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Подготовка базы данных Firestore
Далее нам также потребуется создать базу данных Firestore. Firestore в нативном режиме — это документоориентированная база данных NoSQL, созданная для автоматического масштабирования, высокой производительности и упрощения разработки приложений. Она также может выступать в качестве векторной базы данных, которая поддерживает технику дополненной генерации (Retrieval Augmented Generation) для нашей лабораторной работы.
- Введите в поисковую строку « firestore» и выберите продукт Firestore.
- Затем нажмите кнопку «Создать базу данных Firestore».
- Используйте (по умолчанию) в качестве имени идентификатора базы данных и оставьте выбранным Standard Edition . Для целей этой лабораторной работы используйте Firestore Native с правилами безопасности Open .
- Вы также заметите, что эта база данных фактически доступна в бесплатном режиме! Ура! После этого нажмите кнопку «Создать базу данных».
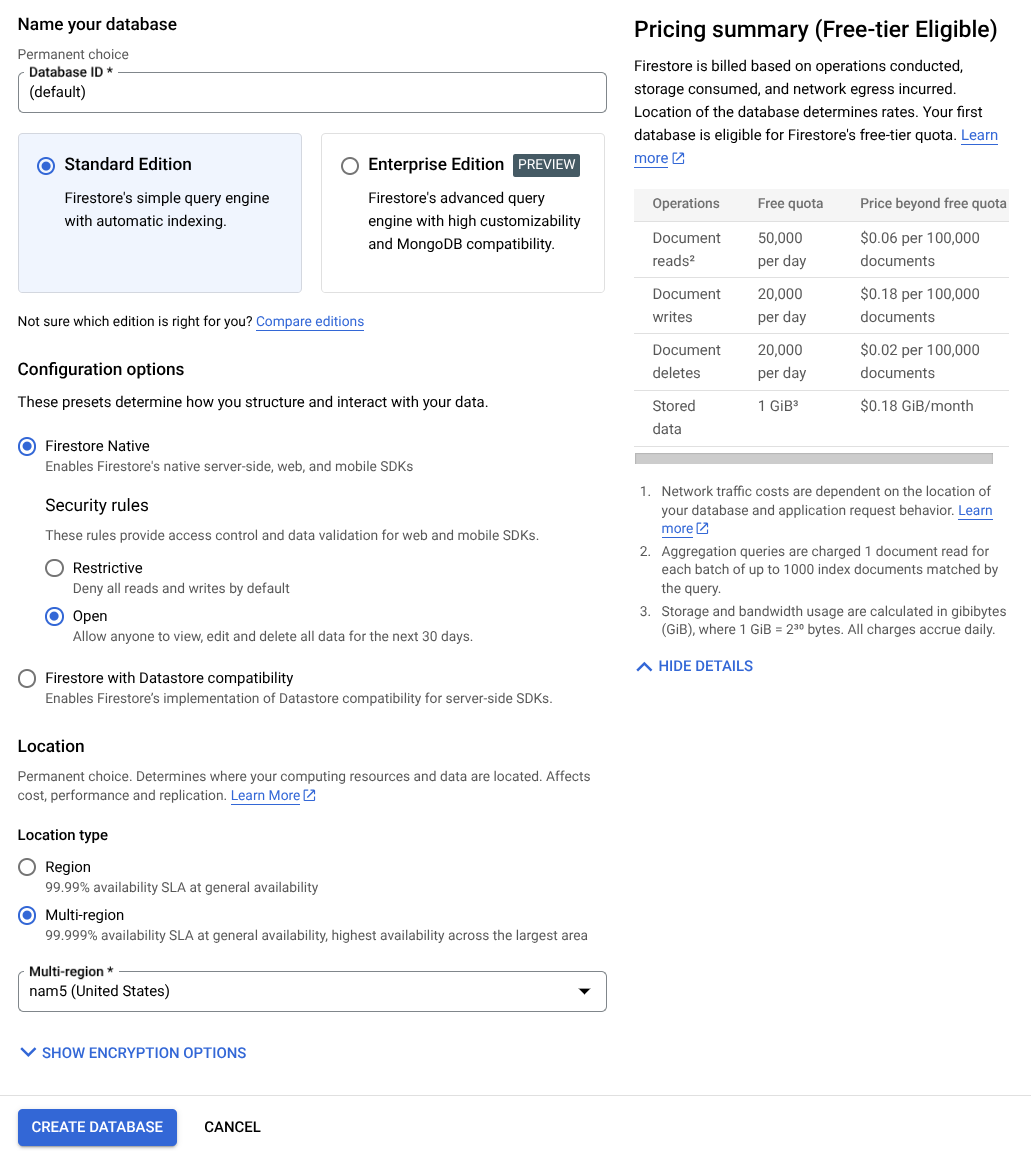
После выполнения этих шагов вы должны быть перенаправлены на созданную вами базу данных Firestore.
Настройка облачного проекта в терминале Cloud Shell
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud и поставляемую с предустановленным bq. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.
- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
В качестве альтернативы, вы также можете увидеть идентификатор PROJECT_ID в консоли.
Нажмите на него, и справа отобразятся все ваши проекты и их идентификаторы.
- Включите необходимые API с помощью команды, указанной ниже. Это может занять несколько минут, поэтому, пожалуйста, наберитесь терпения.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
После успешного выполнения команды вы должны увидеть сообщение, похожее на показанное ниже:
Operation "operations/..." finished successfully.
Альтернативой команде gcloud является поиск каждого продукта в консоли или использование этой ссылки .
Если какой-либо API отсутствует, вы всегда можете включить его в процессе реализации.
Для получения информации о командах gcloud и их использовании обратитесь к документации .
Подготовьте корзину Google Cloud Storage.
Далее, в том же терминале нам нужно будет подготовить хранилище GCS для хранения загруженного файла. Выполните следующую команду для создания хранилища; потребуется уникальное, но соответствующее имя хранилища, относящееся к квитанциям помощника по личным расходам, поэтому мы будем использовать следующее имя хранилища в сочетании с идентификатором вашего проекта.
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
В результате будет показан следующий результат.
Creating gs://personal-expense-{your-project-id}
Вы можете убедиться в этом, перейдя в меню навигации в левом верхнем углу браузера и выбрав «Облачное хранилище» -> «Корзина».
Создание индекса Firestore для поиска
Firestore — это NoSQL-база данных, которая изначально предлагает превосходную производительность и гибкость в модели данных, но имеет ограничения при работе со сложными запросами. Поскольку мы планируем использовать составные многопольные запросы и векторный поиск, нам сначала потребуется создать индексы. Подробнее об этом можно прочитать в этой документации.
- Выполните следующую команду, чтобы создать индекс для поддержки составных запросов.
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- И запустите этот скрипт для поддержки векторного поиска.
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
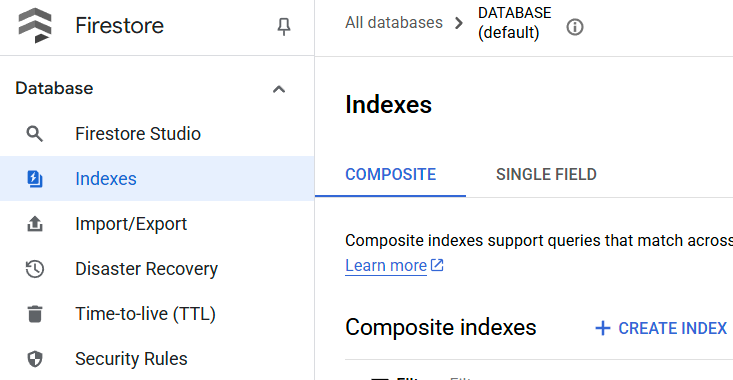
Проверить созданный индекс можно, посетив Firestore в облачной консоли, щелкнув экземпляр базы данных (по умолчанию) и выбрав «Индексы» на панели навигации.
Перейдите в редактор Cloud Shell и настройте рабочий каталог приложения.
Теперь мы можем настроить наш редактор кода для выполнения некоторых действий по программированию. Для этого мы будем использовать редактор Cloud Shell.
- Нажмите кнопку «Открыть редактор», это откроет редактор Cloud Shell, где мы можем писать свой код.
- Далее нам также необходимо проверить, настроена ли оболочка уже для правильного идентификатора проекта (PROJECT ID ). Если вы видите значение внутри скобок ( ) перед значком $ в терминале (на скриншоте ниже значение — "adk-multimodal-tool" ), это значение показывает настроенный проект для вашей активной сессии оболочки.

Если отображаемое значение уже верное , вы можете пропустить следующую команду . Однако, если оно неверно или отсутствует, выполните следующую команду.
gcloud config set project <YOUR_PROJECT_ID>
- Далее, давайте клонируем рабочую директорию шаблона для этого практического задания с Github и выполним следующую команду. Она создаст рабочую директорию в каталоге personal-expense-assistant.
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- После этого перейдите в верхнюю часть редактора Cloud Shell и нажмите «Файл» -> «Открыть папку», найдите каталог с вашим именем пользователя , затем найдите каталог personal-expense-assistant и нажмите кнопку «ОК» . Это сделает выбранный каталог основным рабочим каталогом. В этом примере имя пользователя — alvinprayuda , поэтому путь к каталогу показан ниже.

Теперь ваш редактор Cloud Shell должен выглядеть так.
Настройка среды
Подготовка виртуальной среды Python
Следующий шаг — подготовка среды разработки. Ваш текущий активный терминал должен находиться в рабочей директории personal-expense-assistant . В этом практическом занятии мы будем использовать Python 3.12 и менеджер проектов uv python , чтобы упростить создание и управление версиями Python и виртуальными средами.
- Если вы еще не открыли терминал, откройте его, щелкнув «Терминал» -> «Новый терминал» или используя сочетание клавиш Ctrl + Shift + C — это откроет окно терминала в нижней части браузера.

- Теперь инициализируем виртуальное окружение с помощью
uv. Выполните следующие команды.
cd ~/personal-expense-assistant
uv sync --frozen
Это создаст каталог .venv и установит зависимости. Быстрый просмотр файла pyproject.toml предоставит вам информацию о зависимостях, которая будет выглядеть примерно так.
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Настройка конфигурационных файлов
Теперь нам нужно будет настроить конфигурационные файлы для этого проекта. Мы используем pydantic-settings для чтения конфигурации из YAML-файла.
Шаблон файла уже предоставлен в файле settings.yaml.example , нам нужно скопировать этот файл и переименовать его в settings.yaml . Выполните эту команду, чтобы создать файл.
cp settings.yaml.example settings.yaml
Затем скопируйте следующее значение в файл.
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
Для этой практической работы мы будем использовать предварительно настроенные значения для GCLOUD_LOCATION , BACKEND_URL , DB_COLLECTION_NAME .
Теперь мы можем перейти к следующему шагу: созданию агента, а затем и сервисов.
3. 🚀 Создайте агента, используя Google ADK и Gemini 2.5.
Введение в структуру каталогов ADK
Начнём с изучения возможностей ADK и способов создания агента. Полную документацию по ADK можно найти по этому адресу . ADK предлагает множество утилит в рамках выполнения команд CLI. Некоторые из них:
- Настройка структуры каталогов агента
- Быстро попробуйте взаимодействие через ввод/вывод командной строки.
- Быстрая настройка локального веб-интерфейса для разработки.
Теперь давайте создадим структуру каталогов агента с помощью команды CLI. Выполните следующую команду.
uv run adk create expense_manager_agent
При появлении запроса выберите модель gemini-2.5-flash и бэкенд Vertex AI . Затем мастер запросит идентификатор проекта и его местоположение. Вы можете принять параметры по умолчанию, нажав Enter, или изменить их по мере необходимости. Просто убедитесь, что вы используете правильный идентификатор проекта, созданный ранее в этой лабораторной работе. Результат будет выглядеть примерно так:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
В результате будет создана следующая структура каталогов агентов.
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
А если вы изучите файлы init.py и agent.py, то увидите следующий код.
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Теперь вы можете проверить это, запустив команду.
uv run adk run expense_manager_agent
По завершении тестирования вы можете выйти из агента, набрав команду exit или нажав Ctrl+D .
Создание агента по управлению расходами
Давайте создадим нашего агента для управления расходами! Откройте файл expense_manager_agent / agent.py и скопируйте приведенный ниже код, который будет содержать root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Пояснение к коду
Этот скрипт содержит инициализацию нашего агента, в ходе которой мы выполняем следующие действия:
- Установите модель для использования:
gemini-2.5-flash - Установите описание агента и инструкции в качестве системной подсказки, считываемой из
task_prompt.md - Предоставьте необходимые инструменты для поддержки функциональности агента.
- Используйте возможности экспресс-анализа Gemini 2.5, чтобы обеспечить планирование перед формированием окончательного ответа или его выполнением.
- Перед отправкой запроса в Gemini настройте перехват обратного вызова, чтобы ограничить количество отправляемых данных изображения перед выполнением прогнозирования.
4. 🚀 Настройка инструментов агента
Наш специалист по управлению расходами будет обладать следующими возможностями:
- Извлеките данные из изображения чека, сохраните данные и файл.
- Точный поиск по данным о расходах.
- Контекстный поиск по данным о расходах.
Следовательно, нам необходимы соответствующие инструменты для поддержки этой функциональности. Создайте новый файл в каталоге expense_manager_agent и назовите его tools.py.
touch expense_manager_agent/tools.py
Откройте файл expense_manage_agent/tools.py и скопируйте приведенный ниже код.
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Пояснение к коду
В данной реализации функциональных инструментов мы проектируем их, основываясь на двух основных идеях:
- Анализ данных чека и сопоставление их с исходным файлом с использованием строкового заполнителя Image ID
[IMAGE-ID <hash-of-image-1>] - Хранение и извлечение данных с использованием базы данных Firestore.
Инструмент "store_receipt_data"
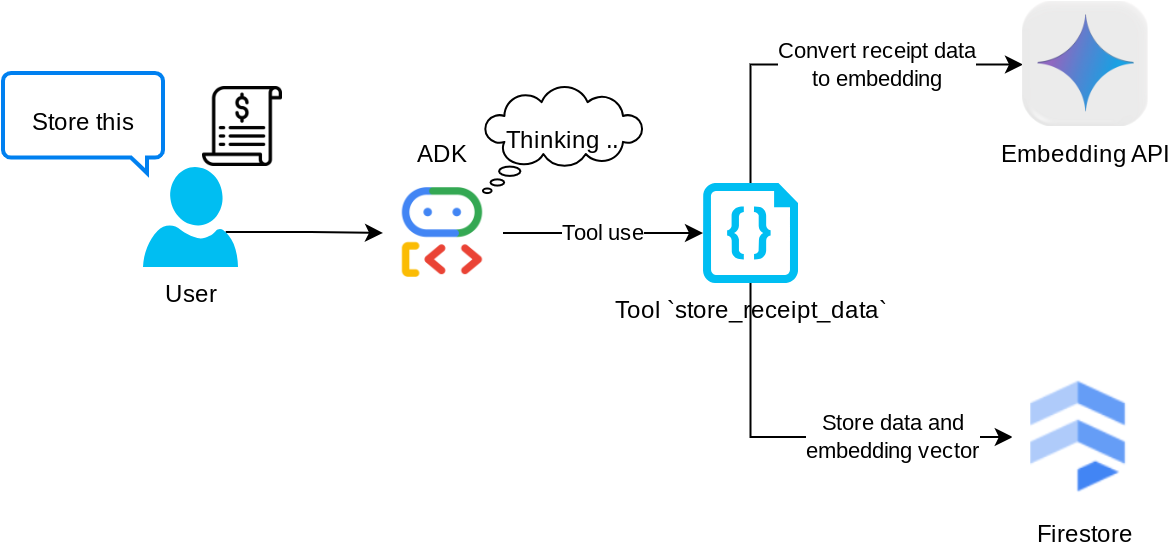
Этот инструмент представляет собой систему оптического распознавания символов. Он извлекает необходимую информацию из данных изображения, распознает строку идентификатора изображения и сопоставляет их для сохранения в базе данных Firestore.
Кроме того, этот инструмент также преобразует содержимое чека в встраивание с помощью text-embedding-004 так что все метаданные и встраивание хранятся и индексируются вместе. Это обеспечивает гибкость поиска как по запросу, так и по контекстному поиску.
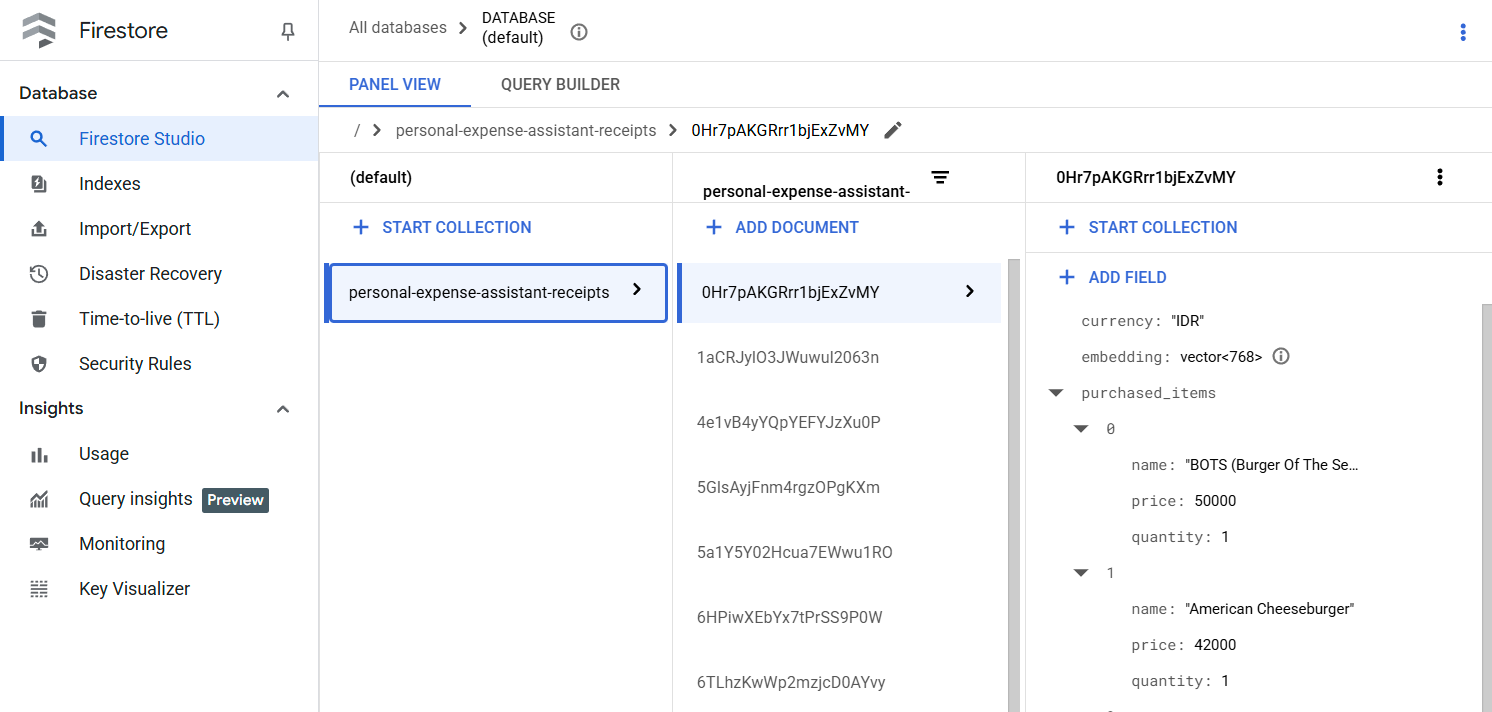
После успешного выполнения этой процедуры вы увидите, что данные чека уже проиндексированы в базе данных Firestore, как показано ниже.
Инструмент «search_receipts_by_metadata_filter»
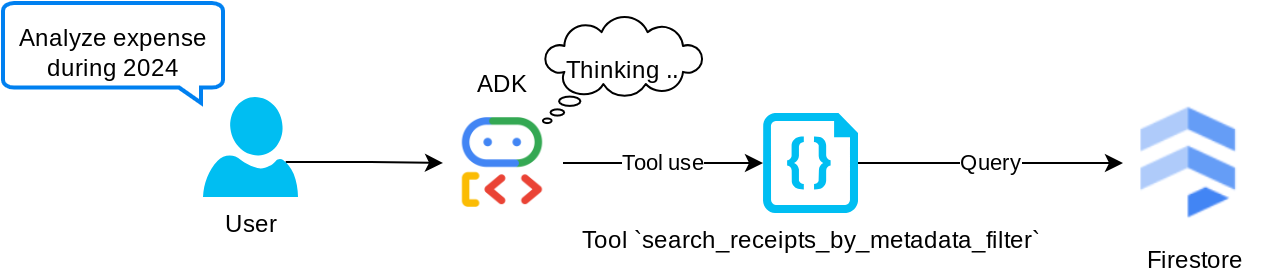
Этот инструмент преобразует пользовательский запрос в фильтр метаданных, поддерживающий поиск по диапазону дат и/или общей сумме транзакций. Он вернет все соответствующие данные чека, при этом поле встраивания будет удалено, поскольку оно не требуется агенту для контекстного понимания.
Инструмент "search_relevant_receipts_by_natural_language_query"
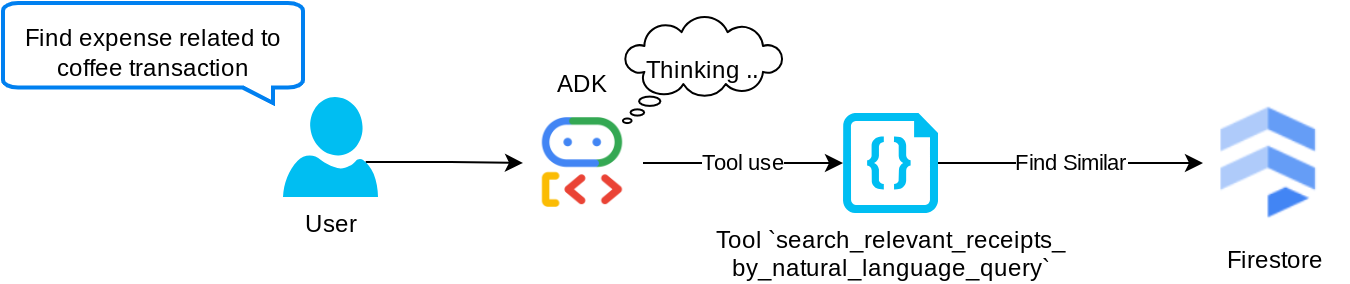
Это наш инструмент расширенной генерации запросов (Retrieval Augmented Generation, RAG). Наш агент способен создавать собственные запросы для извлечения релевантных квитанций из векторной базы данных, а также выбирать, когда использовать этот инструмент. Возможность для агента самостоятельно принимать решение об использовании инструмента RAG и создании собственного запроса является одним из определений подхода Agentic RAG .
Мы не только позволяем ему формировать собственный запрос, но и даем возможность выбирать, сколько релевантных документов он хочет получить. В сочетании с правильной разработкой подсказок, например,
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Это сделает данный инструмент мощным средством, способным искать практически что угодно, хотя он может не выдавать всех ожидаемых результатов из-за неточности метода ближайшего соседа .
5. 🚀 Изменение контекста разговора с помощью обратных вызовов
Google ADK позволяет нам «перехватывать» выполнение агента на различных уровнях. Подробнее об этой возможности можно прочитать в этой документации . В этой лабораторной работе мы используем before_model_callback для изменения запроса, отправляемого в LLM, чтобы удалить данные изображений из старого контекста истории разговора (включать только данные изображений из последних 3 взаимодействий с пользователем) для повышения эффективности.
Однако мы по-прежнему хотим, чтобы агент имел контекст данных изображения, когда это необходимо. Поэтому мы добавляем механизм для добавления строкового идентификатора изображения после каждого байта данных изображения в диалоге. Это поможет агенту связать идентификатор изображения с фактическими данными файла, что можно использовать как при сохранении, так и при извлечении изображения. Структура будет выглядеть следующим образом.
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
И даже когда байтовые данные в истории переписки устаревают, строковый идентификатор всё ещё остаётся, позволяя получить доступ к данным с помощью инструментов. Пример структуры истории после удаления данных изображения.
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Начнём! Создайте новый файл в директории expense_manager_agent и назовите его callbacks.py.
touch expense_manager_agent/callbacks.py
Откройте файл expense_manager_agent/callbacks.py и скопируйте приведенный ниже код.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 Подсказка
Разработка агента со сложным взаимодействием и возможностями требует от нас найти достаточно подходящую подсказку, которая направит агента к желаемому поведению.
Ранее у нас был механизм обработки изображений в истории переписки, а также инструменты, которые могли быть не совсем удобны в использовании, например, search_relevant_receipts_by_natural_language_query. Мы также хотим, чтобы агент мог искать и получать для нас нужное изображение чека. Это означает, что нам необходимо корректно передавать всю эту информацию в правильной структуре запроса.
Мы попросим агента структурировать вывод в следующий формат Markdown, чтобы отобразить ход мыслей, окончательный ответ и прикрепленные файлы (если таковые имеются).
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Начнём со следующего запроса, чтобы добиться желаемого поведения агента управления расходами. Файл task_prompt.md уже должен существовать в нашей рабочей директории, но нам нужно переместить его в директорию expense_manager_agent . Выполните следующую команду, чтобы переместить его.
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Тестирование агента
Теперь попробуем связаться с агентом через командную строку, выполнив следующую команду.
uv run adk run expense_manager_agent
В результате вы увидите примерно такой вывод, где сможете общаться с агентом в чате, однако отправлять текст через этот интерфейс можно только в текстовом формате.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
Теперь, помимо взаимодействия через командную строку, ADK также позволяет использовать пользовательский интерфейс для разработки, позволяющий взаимодействовать с программным обеспечением и отслеживать происходящее. Выполните следующую команду, чтобы запустить локальный сервер пользовательского интерфейса для разработки.
uv run adk web --port 8080
Результат будет выглядеть примерно так, как в следующем примере, это означает, что мы уже можем получить доступ к веб-интерфейсу.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Чтобы проверить это, нажмите кнопку « Предварительный просмотр веб-страниц» в верхней части редактора Cloud Shell и выберите «Предварительный просмотр на порту 8080».
Вы увидите следующую веб-страницу, где сможете выбрать доступных агентов в выпадающем списке в верхнем левом углу (в нашем случае это должен быть expense_manager_agent ) и взаимодействовать с ботом. В левом окне вы увидите подробную информацию о логах во время работы агента.
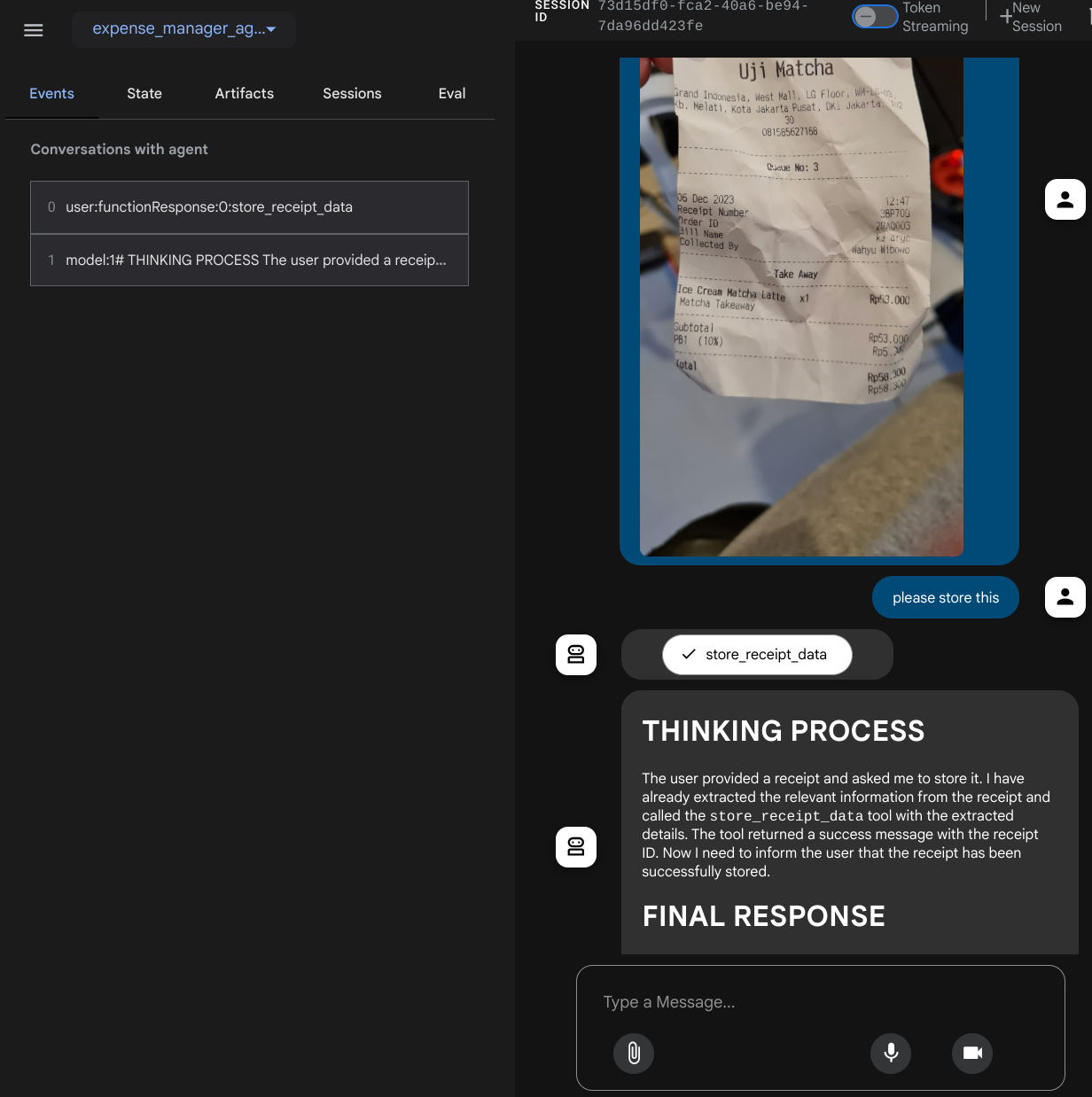
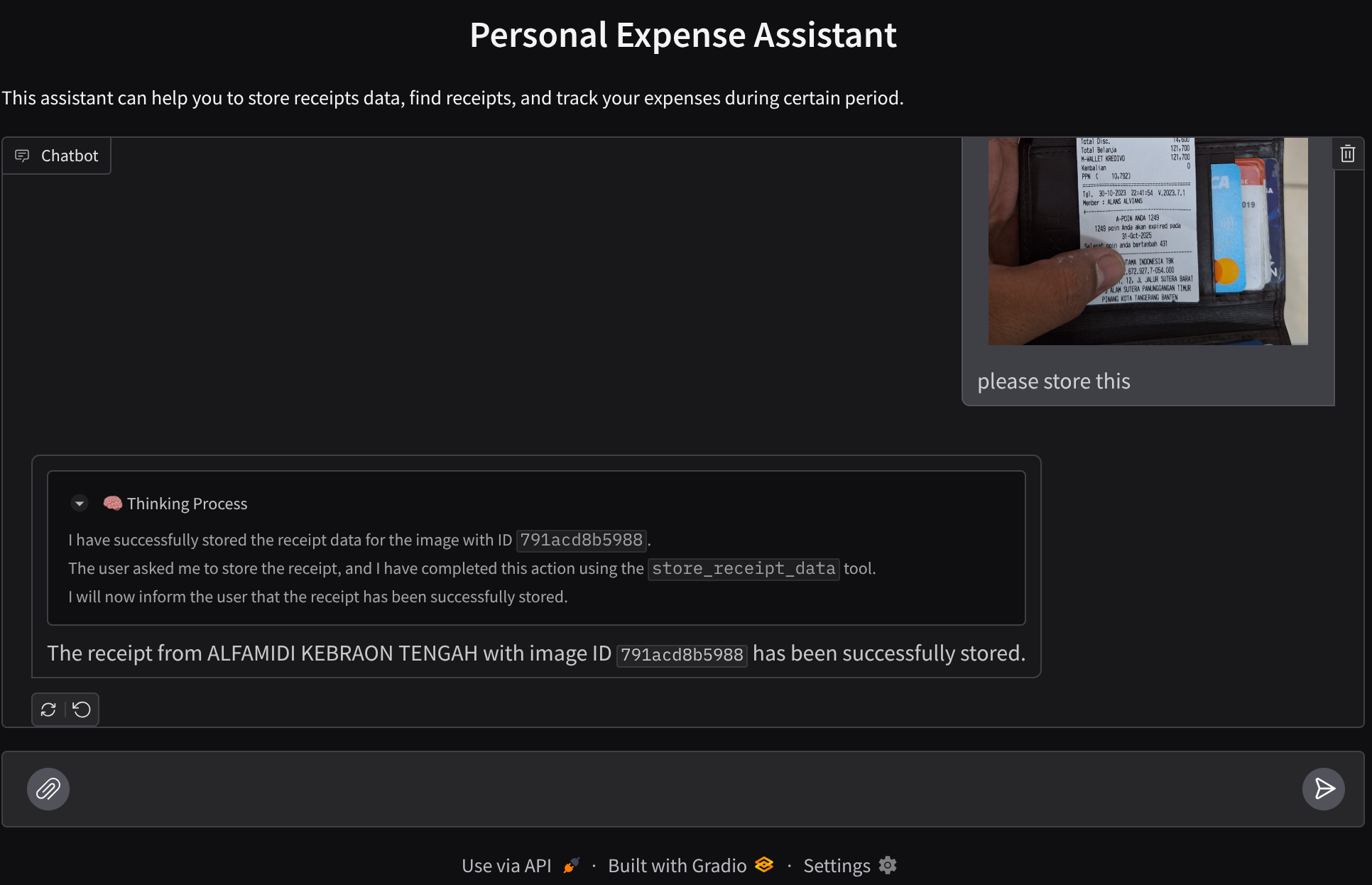
Давайте попробуем выполнить несколько действий! Загрузите эти 2 примера чеков (источник: набор данных Hugging face mousserlane/id_receipt_dataset ). Щелкните правой кнопкой мыши по каждому изображению и выберите «Сохранить изображение как...» (это загрузит изображение чека), затем загрузите файл в бота, нажав на значок «клипа» , и укажите, что вы хотите сохранить эти чеки.


После этого попробуйте следующие запросы для поиска или извлечения файлов.
- «Предоставьте подробную разбивку расходов и их общую сумму за 2023 год».
- "Предоставьте мне квитанцию из компании Indomaret"
При использовании некоторых инструментов можно проверить, что происходит в пользовательском интерфейсе разработчика.
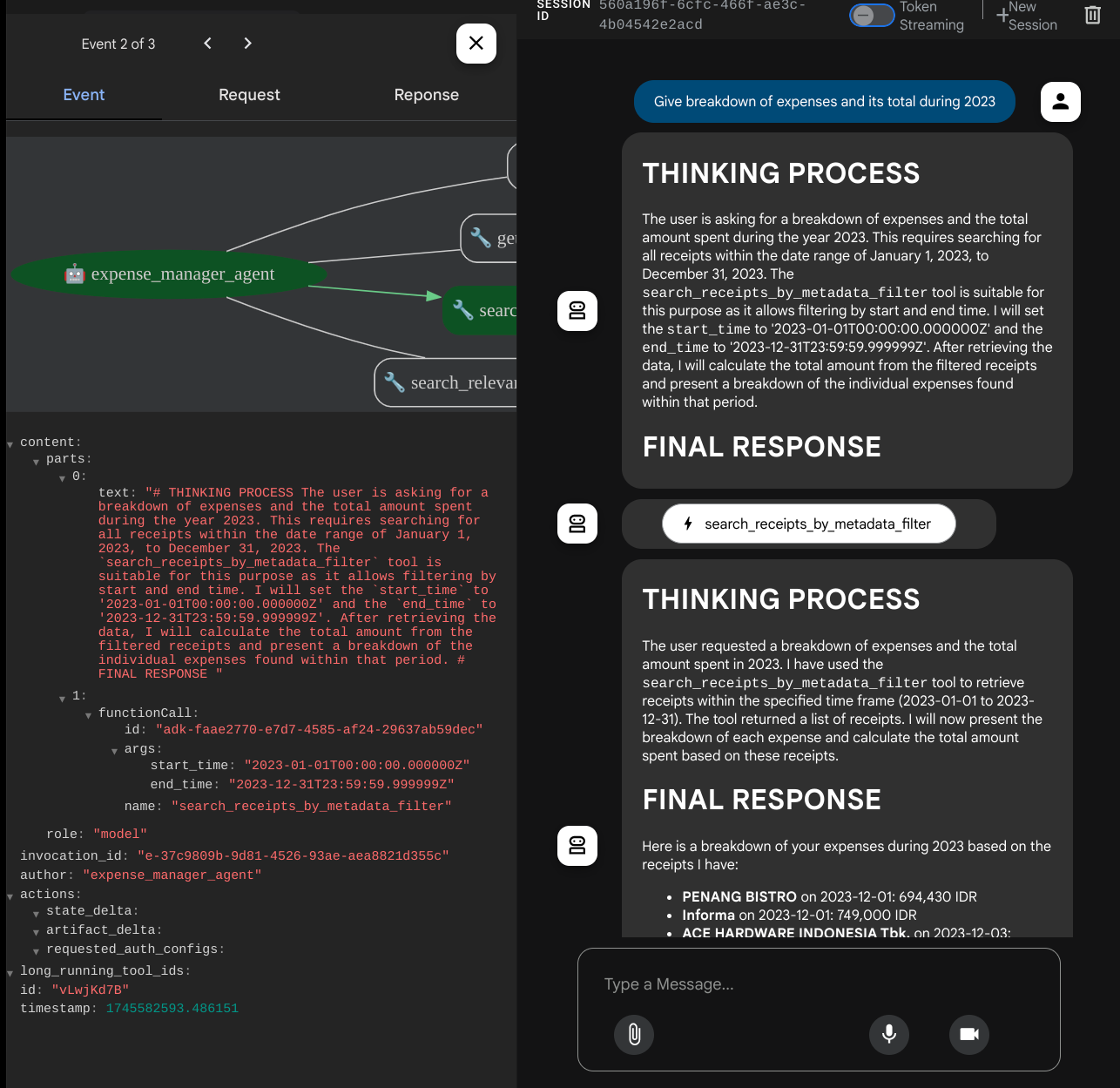
Посмотрите, как агент отвечает вам, и проверьте, соответствует ли он всем правилам, указанным в подсказке внутри файла task_prompt.py. Поздравляем! Теперь у вас есть полностью рабочий агент разработки.
Теперь пришло время дополнить его удобным и приятным пользовательским интерфейсом, а также возможностями загрузки и скачивания файлов изображений.
8. 🚀 Создайте фронтенд-сервис с помощью Gradio
Мы создадим веб-интерфейс для чата, который будет выглядеть следующим образом.
Он содержит интерфейс чата с полем ввода, где пользователи могут отправлять текст и загружать файлы изображений чеков.
Мы будем создавать фронтенд-сервис с помощью Gradio .
Создайте новый файл и назовите его frontend.py.
touch frontend.py
Затем скопируйте следующий код и сохраните его.
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
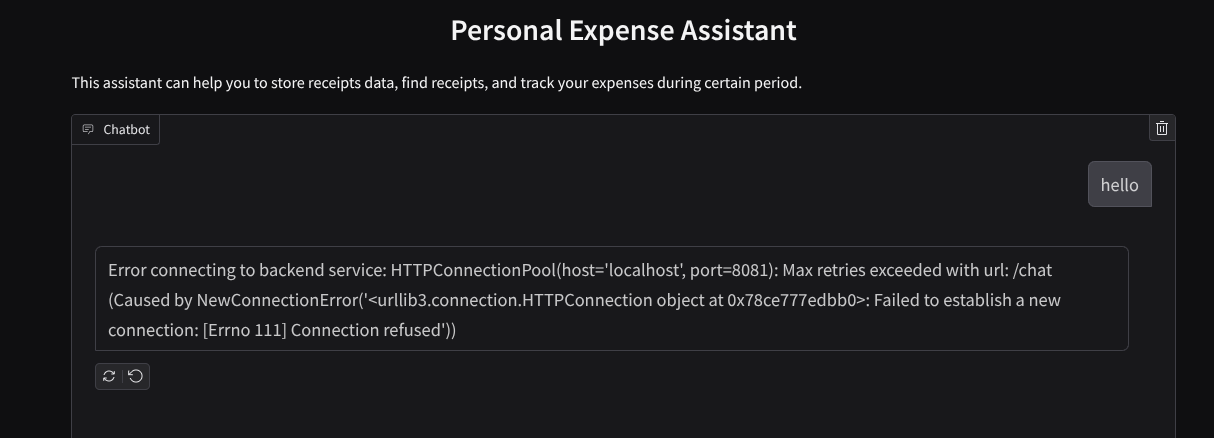
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
После этого можно попробовать запустить фронтенд-сервис с помощью следующей команды. Не забудьте переименовать файл main.py в frontend.py.
uv run frontend.py
В консоли вашего облака вы увидите результат, похожий на этот.
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
После этого вы можете проверить веб-интерфейс, щелкнув по локальной ссылке с помощью Ctrl+клик . Также вы можете получить доступ к фронтенд-приложению, нажав кнопку « Предварительный просмотр веб-страниц» в правом верхнем углу облачного редактора и выбрав «Предварительный просмотр на порту 8080».
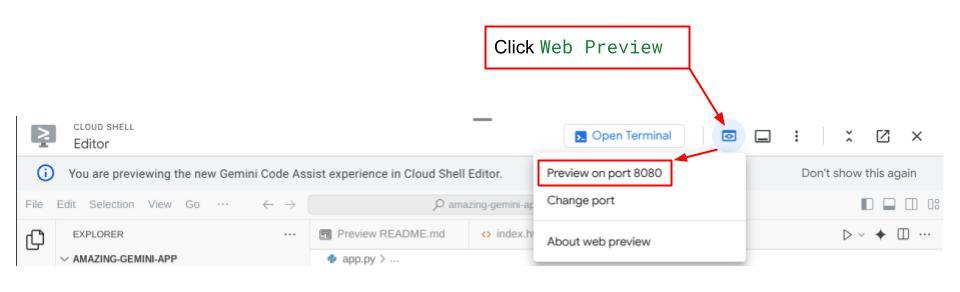
Вы увидите веб-интерфейс, однако при попытке отправить сообщение в чат вы получите ожидаемую ошибку, поскольку серверная часть еще не настроена.
Теперь дайте службе работать и пока не останавливайте её. Мы запустим серверную часть в другой вкладке терминала.
Пояснение к коду
В этом коде фронтенда мы сначала даем пользователю возможность отправлять текст и загружать несколько файлов. Gradio позволяет нам создать подобную функциональность с помощью метода gr.ChatInterface в сочетании с gr.MultimodalTextbox.
Прежде чем отправлять файл и текст на серверную часть, нам необходимо определить MIME-тип файла, поскольку он необходим серверу. Также нам нужно закодировать байты файла изображения в base64 и отправить их вместе с MIME-типом.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
Схема, используемая для взаимодействия между фронтендом и бэкендом, определена в файле schema.py . Для проверки данных в схеме мы используем Pydantic BaseModel.
Получив ответ, мы уже разделили его на этапы: мыслительный процесс, окончательный ответ и вложение. Таким образом, мы можем использовать компонент Gradio для отображения каждого из этих этапов вместе с компонентами пользовательского интерфейса.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Создайте бэкэнд-сервис с использованием FastAPI
Далее нам потребуется создать бэкэнд, который сможет инициализировать нашего агента вместе с другими компонентами, чтобы иметь возможность запускать среду выполнения агента.
Создайте новый файл и назовите его backend.py.
touch backend.py
И скопируйте следующий код.
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
После этого можно попробовать запустить бэкэнд-сервис. Помните, что на предыдущем шаге мы запустили фронтенд-сервис, верно? Теперь нам нужно открыть новое окно терминала и попробовать запустить этот бэкэнд-сервис.
- Создайте новый терминал. Перейдите в меню терминала внизу и найдите кнопку «+», чтобы создать новый терминал. Также вы можете нажать Ctrl + Shift + C, чтобы открыть новый терминал.

- После этого убедитесь, что вы находитесь в рабочей директории personal-expense-assistant, а затем выполните следующую команду.
uv run backend.py
- В случае успеха будет показан следующий результат.
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Пояснение к коду
Инициализация ADK Agent, SessionService и ArtifactService.
Для запуска агента в бэкэнд-сервисе нам потребуется создать Runner, который будет принимать как SessionService , так и нашего агента. SessionService будет управлять историей и состоянием диалогов, поэтому при интеграции с Runner он предоставит нашему агенту возможность получать контекст текущих диалогов.
Мы также используем ArtifactService для обработки загруженных файлов. Подробнее об этом, а также о сессиях ADK и артефактах, можно прочитать здесь.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
В этой демонстрации мы используем InMemorySessionService и GcsArtifactService для интеграции с нашим агентом Runner. Поскольку история переписки хранится в памяти, она будет потеряна после завершения или перезапуска серверной части. Мы инициализируем эти сервисы внутри жизненного цикла приложения FastAPI, чтобы внедрить их в качестве зависимостей в маршрут /chat .
Загрузка и скачивание изображений с помощью GcsArtifactService
Все загруженные изображения будут сохранены в качестве артефактов сервисом GcsArtifactService . Вы можете проверить это в функции format_user_request_to_adk_content_and_store_artifacts в файле utils.py.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Все запросы, которые будут обрабатываться агентом-раннером, должны быть отформатированы в тип `types.Content` . Внутри функции мы также обрабатываем данные каждого изображения и извлекаем его идентификатор, который затем заменяется заполнителем `Image ID`.
Аналогичный механизм используется для загрузки вложений после извлечения идентификаторов изображений с помощью регулярных выражений:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Интеграционный тест
Теперь у вас должно быть запущено несколько сервисов в разных вкладках облачной консоли:
- Фронтенд-сервис работает на порту 8080.
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Серверная служба работает на порту 8081.
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
В текущем состоянии вы должны иметь возможность загружать изображения чеков и беспрепятственно общаться с ассистентом через веб-приложение на порту 8080.
Нажмите кнопку « Предварительный просмотр веб-страницы» в верхней части редактора Cloud Shell и выберите «Предварительный просмотр на порту 8080».
Теперь давайте пообщаемся с ассистентом!
Загрузите следующие чеки. Данные по этим чекам охватывают период с 2023 по 2024 год. Попросите помощника сохранить/загрузить их.
- Receipt Drive (источник: набор данных Hugging face
mousserlane/id_receipt_dataset)
Задавайте разные вопросы.
- «Предоставьте мне разбивку ежемесячных расходов за 2023-2024 годы».
- "Покажите чек за покупку кофе"
- "Пришлите мне файл с чеком от Yakiniku Like"
- И т. д
Вот небольшой фрагмент успешного взаимодействия.
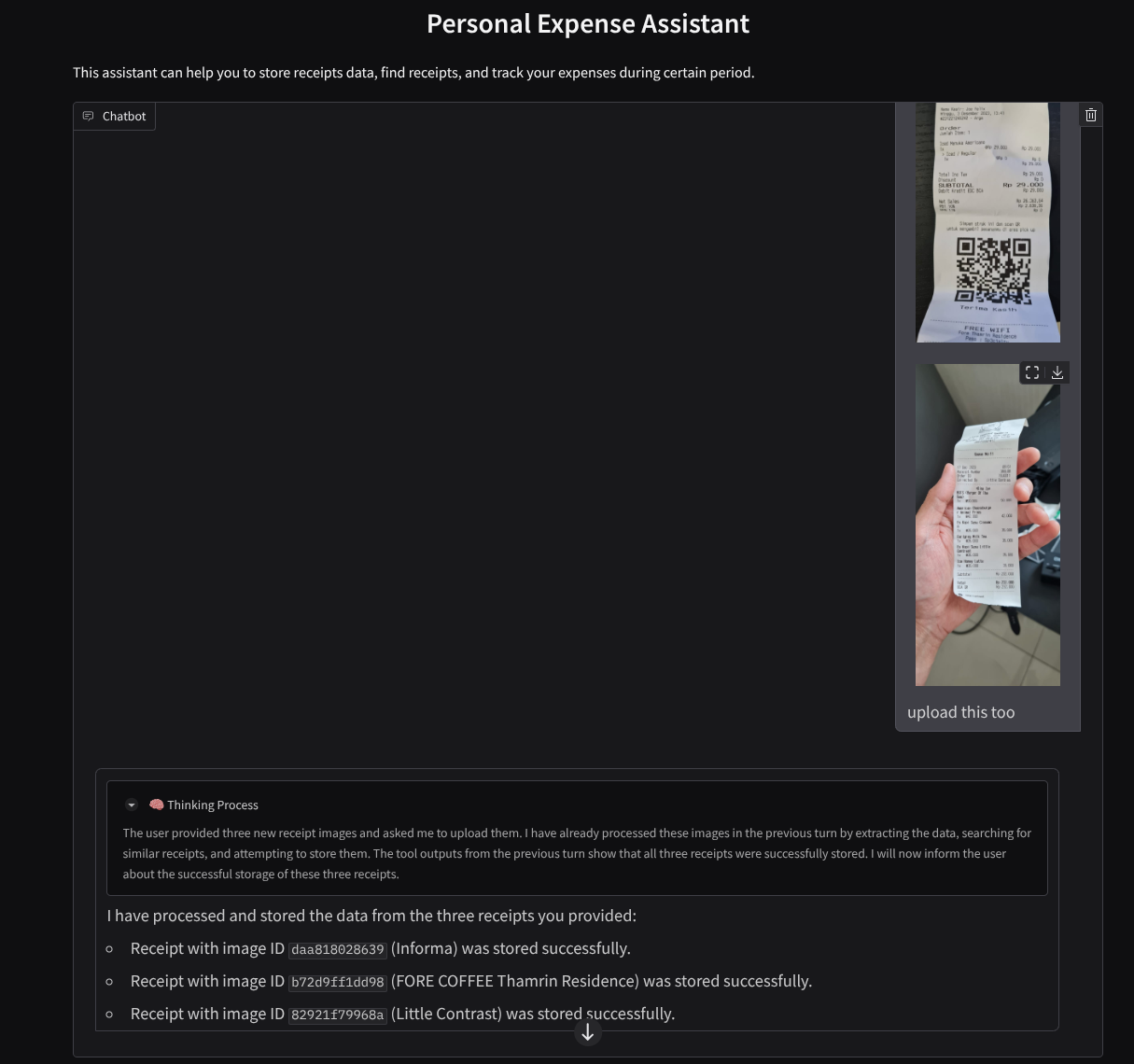
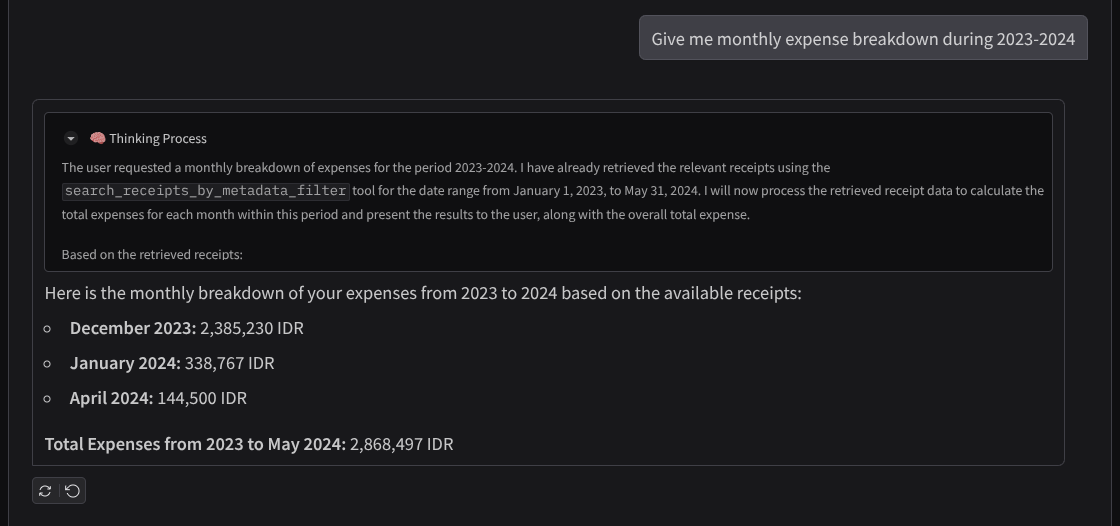
11. 🚀 Развертывание в Cloud Run
Конечно, теперь нам нужно получить доступ к этому замечательному приложению из любой точки мира. Для этого мы можем упаковать это приложение и развернуть его в Cloud Run. В рамках этой демонстрации данный сервис будет предоставлен как общедоступный сервис, к которому смогут получить доступ другие пользователи. Однако следует помнить, что это не лучшая практика для приложений такого типа, поскольку она больше подходит для личных приложений.
В этом практическом задании мы разместим фронтенд и бэкенд сервисы в одном контейнере. Для управления обоими сервисами нам понадобится supervisord . Вы можете изучить файл supervisord.conf и проверить Dockerfile , где мы указали supervisord в качестве точки входа.
На данном этапе у нас уже есть все необходимые файлы для развертывания наших приложений в Cloud Run, давайте приступим к развертыванию. Перейдите в терминал Cloud Shell и убедитесь, что текущий проект настроен на ваш активный проект. Если это не так, используйте команду gcloud configure для установки идентификатора проекта:
gcloud config set project [PROJECT_ID]
Затем выполните следующую команду, чтобы развернуть его в Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Если появится запрос на подтверждение создания реестра артефактов для репозитория Docker, просто ответьте «Да». Обратите внимание, что мы разрешаем неаутентифицированный доступ, поскольку это демонстрационное приложение. Рекомендуется использовать соответствующую аутентификацию для ваших корпоративных и производственных приложений.
После завершения развертывания вы должны получить ссылку, похожую на приведенную ниже:
https://personal-expense-assistant-*******.us-central1.run.app
Смело используйте приложение в режиме инкогнито или на мобильном устройстве. Оно уже должно быть запущено.
12. 🎯 Вызов
Теперь настало ваше время проявить себя и отточить свои навыки исследования. Сможете ли вы изменить код, чтобы бэкэнд мог поддерживать работу нескольких пользователей? Какие компоненты необходимо обновить?
13. 🧹 Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом задании, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
- В качестве альтернативы вы можете перейти в Cloud Run в консоли, выбрать только что развернутую службу и удалить ее.