
1. 📖 Giriş
Kişisel harcamalarınızın tamamını yönetmekten sıkılıp üşendiğiniz oldu mu? Ben de! Bu nedenle bu codelab'de, tüm işleri bizim için yapacak Gemini 2.5 destekli kişisel bir gider yöneticisi asistanı oluşturacağız. Yüklenen makbuzları yönetmekten kahve satın almak için çok fazla para harcayıp harcamadığınızı analiz etmeye kadar birçok konuda yardımcı olur.
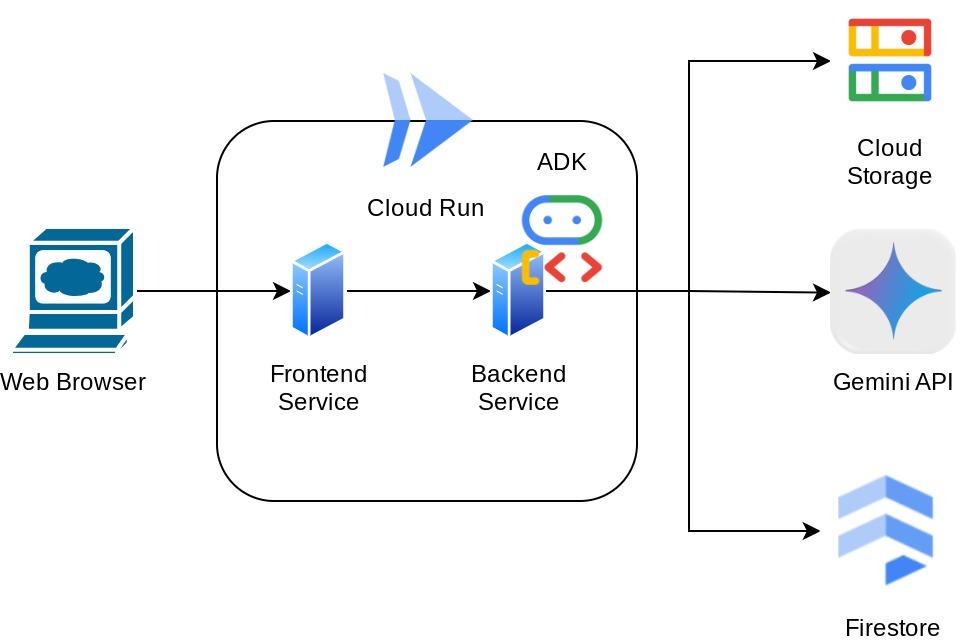
Bu asistana, web tarayıcısı üzerinden sohbet web arayüzü şeklinde erişebilirsiniz. Bu arayüzde asistanla iletişim kurabilir, bazı makbuz resimlerini yükleyip saklamasını isteyebilir veya dosya almak ve bazı gider analizleri yapmak için makbuz arayabilirsiniz. Tüm bunlar Google Agent Development Kit çerçevesi üzerine kurulmuştur.
Uygulama, ön uç ve arka uç olmak üzere 2 hizmete ayrılmıştır. Bu sayede hızlı bir prototip oluşturabilir, nasıl bir deneyim sunacağını deneyebilir ve API sözleşmesinin her ikisini de entegre etmek için nasıl göründüğünü anlayabilirsiniz.
Bu codelab'de aşağıdaki gibi adım adım bir yaklaşım kullanacaksınız:
- Google Cloud projenizi hazırlayın ve gerekli tüm API'leri etkinleştirin.
- Google Cloud Storage'da paket ve Firestore'da veritabanı oluşturma
- Firestore dizin oluşturma işlemi oluşturma
- Kodlama ortamınız için çalışma alanı oluşturma
- ADK temsilcisi kaynak kodunu, araçlarını, istemini vb. yapılandırma
- ADK yerel web geliştirme kullanıcı arayüzünü kullanarak temsilciyi test etme
- Gradio kitaplığını kullanarak ön uç hizmetini (sorgu göndermek ve makbuz resimleri yüklemek için kullanılan sohbet arayüzü) oluşturun.
- Arka uç hizmetini oluşturun: ADK aracısı kodumuzun, SessionService'in ve Artifact Service'in bulunduğu FastAPI kullanan HTTP sunucusu
- Ortam değişkenlerini yönetme ve uygulamayı Cloud Run'a dağıtmak için gereken dosyaları ayarlama
- Uygulamayı Cloud Run'a dağıtma
Mimariye Genel Bakış
Ön koşullar
- Python ile rahatça çalışabilme
- HTTP hizmetini kullanan temel tam yığın mimarisi hakkında bilgi sahibi olmak
Neler öğreneceksiniz?
- Gradio ile ön uç web prototipi oluşturma
- FastAPI ve Pydantic ile arka uç hizmeti geliştirme
- ADK aracısını, çeşitli özelliklerinden yararlanarak tasarlama
- Araç kullanımı
- Oturum ve Yapı Yönetimi
- Gemini'a gönderilmeden önce giriş değişikliği için geri çağırma kullanımı
- Planlama yaparak görev yürütmeyi iyileştirmek için BuiltInPlanner'ı kullanma
- ADK yerel web arayüzü üzerinden hızlı hata ayıklama
- ADK geri çağırma işlevi kullanılarak istem mühendisliği ve Gemini isteği değişikliği aracılığıyla bilgi ayrıştırma ve alma yoluyla çok formatlı etkileşimi optimize etme stratejisi
- Vektör veritabanı olarak Firestore'u kullanan, ajan tabanlı almayla artırılmış üretim
- Pydantic-settings ile YAML dosyasındaki ortam değişkenlerini yönetme
- Dockerfile kullanarak uygulamayı Cloud Run'a dağıtma ve YAML dosyasıyla ortam değişkenleri sağlama
Gerekenler
- Chrome web tarayıcısı
- Gmail hesabı
- Faturalandırmanın etkin olduğu bir Cloud projesi
Her seviyeden geliştirici (yeni başlayanlar dahil) için tasarlanan bu codelab'de örnek uygulamada Python kullanılır. Ancak sunulan kavramları anlamak için Python bilgisi gerekmez.
2. 🚀 Başlamadan önce
Cloud Console'da Etkin Projeyi Seçme
Bu codelab'de, faturalandırmanın etkin olduğu bir Google Cloud projenizin olduğu varsayılır. Henüz kullanmıyorsanız başlamak için aşağıdaki talimatları uygulayabilirsiniz.
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Firestore veritabanını hazırlama
Ardından, bir Firestore veritabanı oluşturmamız da gerekecek. Yerel moddaki Firestore; otomatik ölçeklendirme, yüksek performans ve uygulama geliştirme kolaylığı için oluşturulmuş NoSQL belge veritabanıdır. Ayrıca, laboratuvarımızda Retrieval Augmented Generation tekniğini destekleyebilecek bir vektör veritabanı olarak da kullanılabilir.
- Arama çubuğunda "firestore" ifadesini arayın ve Firestore ürününü tıklayın.
- Ardından, Create A Firestore Database (Firestore Veritabanı Oluştur) düğmesini tıklayın.
- Veritabanı kimliği adı olarak (varsayılan) seçeneğini kullanın ve Standard Edition'ı seçili tutun. Bu laboratuvar demosunda Açık güvenlik kurallarıyla Firestore Native'i kullanın.
- Ayrıca bu veritabanının Free-tier Usage YEAY! (Ücretsiz katman kullanımı YEAY!) özelliğine sahip olduğunu da göreceksiniz. Ardından Veritabanı Oluştur Düğmesi'ni tıklayın.
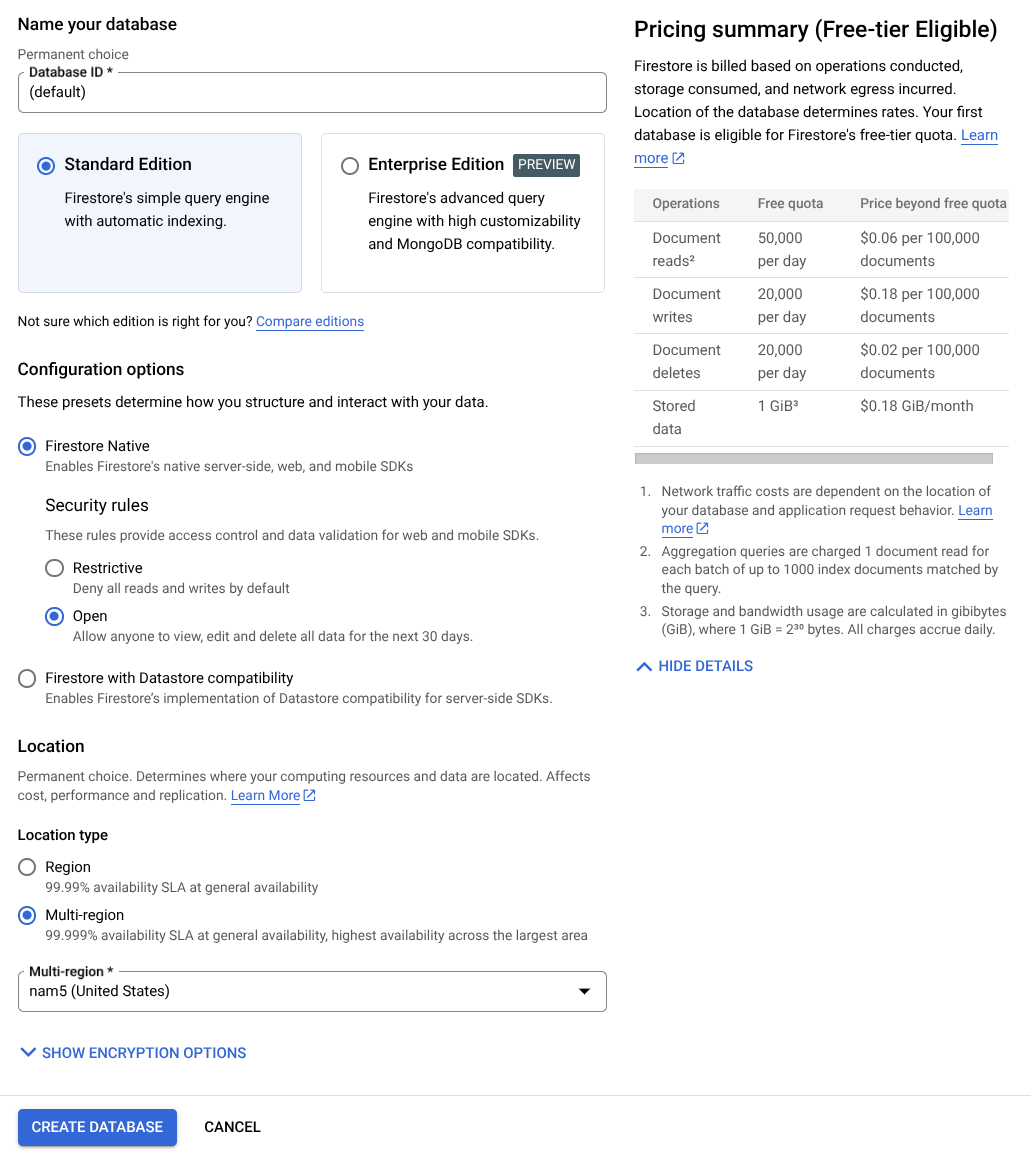
Bu adımlardan sonra, yeni oluşturduğunuz Firestore veritabanına yönlendirilmiş olmanız gerekir.
Cloud Shell Terminal'de Cloud projesi ayarlama
- bq'nun önceden yüklendiği, Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.
- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
gcloud config set project <YOUR_PROJECT_ID>
Alternatif olarak, PROJECT_ID kimliğini konsolda da görebilirsiniz.
Bu seçeneği tıkladığınızda sağ tarafta tüm projenizi ve proje kimliğini görürsünüz.
- Aşağıdaki komutu kullanarak gerekli API'leri etkinleştirin. Bu işlem birkaç dakika sürebilir. Lütfen bekleyin.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Komut başarıyla yürütüldüğünde aşağıda gösterilene benzer bir mesaj görürsünüz:
Operation "operations/..." finished successfully.
Gcloud komutuna alternatif olarak, her ürünü arayarak veya bu bağlantıyı kullanarak konsolu kullanabilirsiniz.
Herhangi bir API atlanırsa uygulama sırasında istediğiniz zaman etkinleştirebilirsiniz.
gcloud komutları ve kullanımı için belgelere bakın.
Google Cloud Storage paketini hazırlama
Ardından, aynı terminalden yüklenen dosyayı depolamak için GCS paketini hazırlamamız gerekir. Paketi oluşturmak için aşağıdaki komutu çalıştırın. Kişisel harcama asistanı makbuzlarıyla ilgili benzersiz ancak alakalı bir paket adı gerekir. Bu nedenle, proje kimliğinizle birlikte aşağıdaki paket adını kullanacağız.
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Şu çıkış gösterilir:
Creating gs://personal-expense-{your-project-id}
Bunu doğrulamak için tarayıcının sol üst kısmındaki gezinme menüsüne gidip Cloud Storage -> Bucket'ı (Cloud Storage -> Paket) seçebilirsiniz.
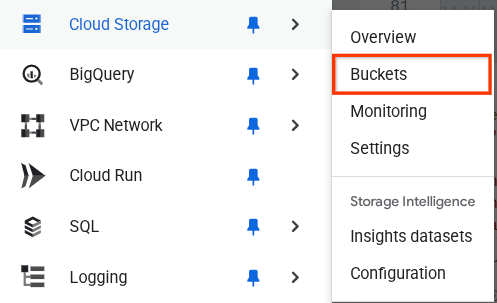
Arama için Firestore dizini oluşturma
Firestore, yerel olarak NoSQL veritabanıdır. Veri modelinde üstün performans ve esneklik sunar ancak karmaşık sorgular konusunda sınırlamaları vardır. Bazı bileşik çok alanlı sorguları ve Vector Search'ü kullanmayı planladığımız için önce bazı dizinler oluşturmamız gerekiyor. Ayrıntılar hakkında daha fazla bilgiyi bu belgede bulabilirsiniz.
- Bileşik sorguları desteklemek için dizin oluşturmak üzere aşağıdaki komutu çalıştırın
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- Vektör aramasını desteklemek için bu komutu çalıştırın.
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
Oluşturulan dizini kontrol etmek için Cloud Console'da Firestore'u ziyaret edip (varsayılan) veritabanı örneğini tıklayın ve gezinme çubuğunda Dizinler'i seçin.
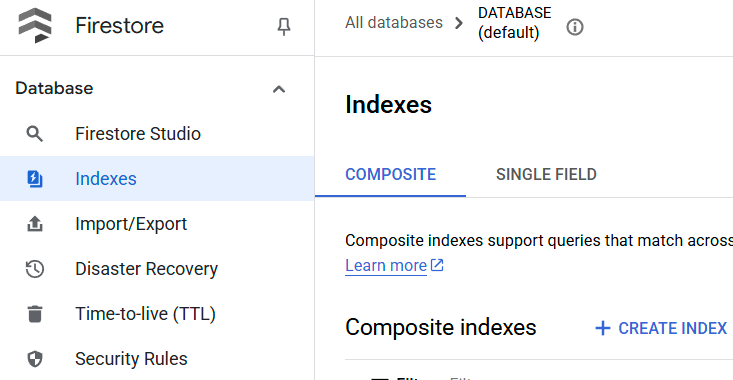
Cloud Shell Düzenleyici'ye gidin ve uygulama çalışma dizinini ayarlayın
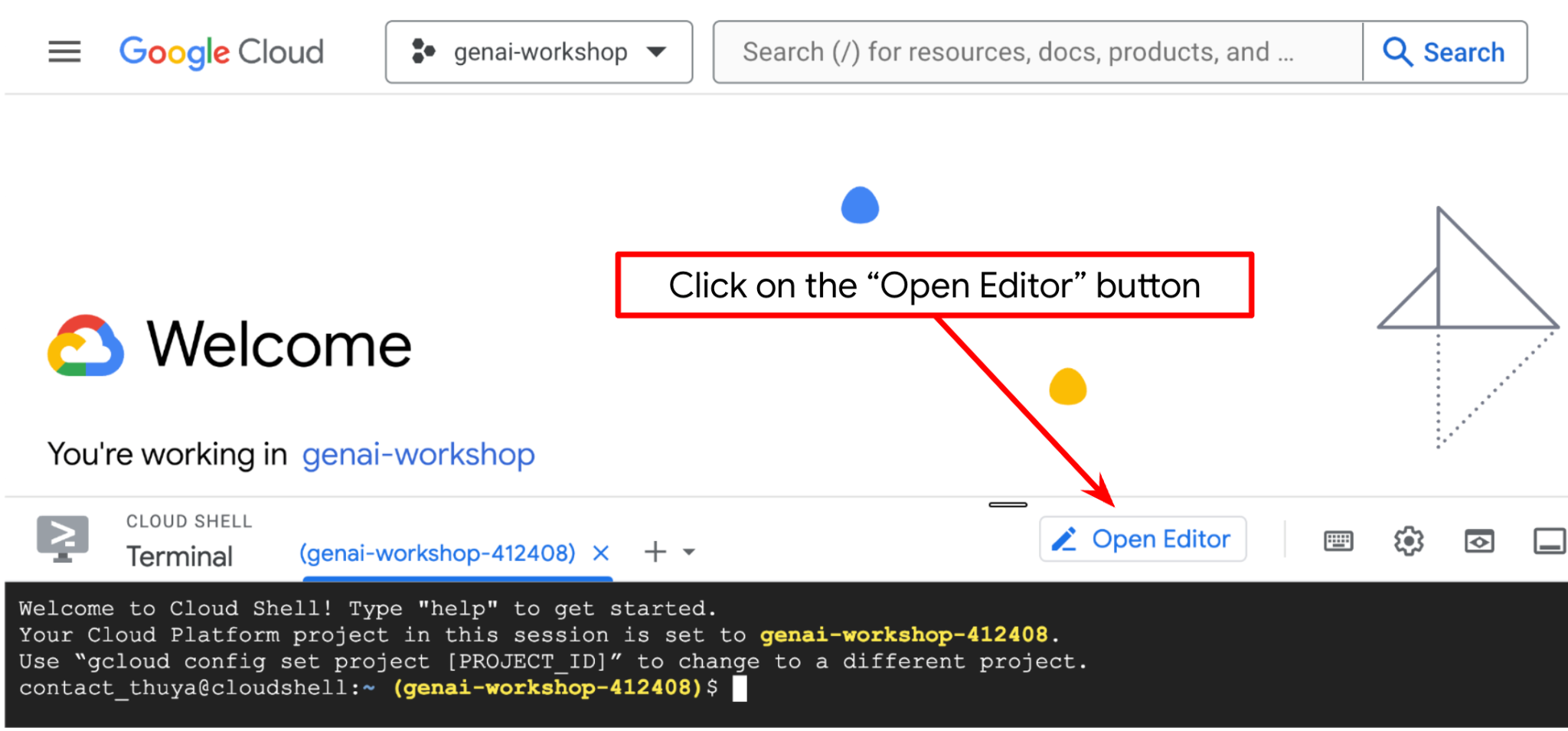
Şimdi kod düzenleyicimizi bazı kodlama işlemleri yapacak şekilde ayarlayabiliriz. Bu işlem için Cloud Shell Düzenleyici'yi kullanacağız.
- Open Editor (Düzenleyiciyi Aç) düğmesini tıklayın. Bu işlemle Cloud Shell Editor açılır. Kodumuzu burada yazabiliriz.
- Ardından, kabuğun doğru PROJE KİMLİĞİ ile yapılandırılıp yapılandırılmadığını da kontrol etmemiz gerekir. Terminalde $simgesinden önce ( ) içinde değer görüyorsanız ( aşağıdaki ekran görüntüsünde değer "adk-multimodal-tool") bu değer, etkin kabuk oturumunuz için yapılandırılmış projeyi gösterir.

Gösterilen değer zaten doğruysa sonraki komutu atlayabilirsiniz. Ancak doğru değilse veya eksikse aşağıdaki komutu çalıştırın.
gcloud config set project <YOUR_PROJECT_ID>
- Ardından, bu codelab için şablon çalışma dizinini GitHub'dan klonlayalım. Bunun için aşağıdaki komutu çalıştırın. Çalışma dizini, personal-expense-assistant dizininde oluşturulur.
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- Ardından Cloud Shell Düzenleyici'nin üst bölümüne gidip File->Open Folder'ı (Dosya->Klasör Aç) tıklayın, username (kullanıcı adı) dizininizi ve personal-expense-assistant (kişisel harcama asistanı) dizinini bulun,ardından OK (Tamam) düğmesini tıklayın. Bu işlem, seçilen dizini ana çalışma dizini yapar. Bu örnekte kullanıcı adı alvinprayuda olduğundan dizin yolu aşağıda gösterilmiştir.
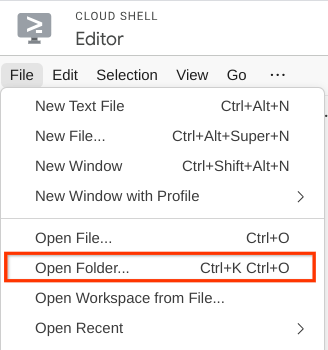

Cloud Shell Düzenleyiciniz artık aşağıdaki gibi görünmelidir.
Ortam Kurulumu
Python sanal ortamını hazırlama
Bir sonraki adım, geliştirme ortamını hazırlamaktır. Mevcut etkin terminaliniz personal-expense-assistant çalışma dizininde olmalıdır. Bu codelab'de Python 3.12'yi kullanacağız. Python sürümü ve sanal ortam oluşturma ve yönetme ihtiyacını basitleştirmek için uv python proje yöneticisini kullanacağız.
- Terminali henüz açmadıysanız Terminal -> Yeni Terminal'i tıklayarak açın veya Ctrl + Üst Karakter + C tuşlarını kullanın. Bu tuşlar, tarayıcının alt kısmında bir terminal penceresi açar.

- Şimdi
uvkullanarak sanal ortamı başlatalım. Bu komutları çalıştırın.
cd ~/personal-expense-assistant
uv sync --frozen
Bu işlem, .venv dizinini oluşturur ve bağımlılıkları yükler. pyproject.toml dosyasına hızlıca göz atarak, bağımlılıklar hakkında aşağıdaki gibi bilgiler edinebilirsiniz.
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Yapılandırma dosyalarını ayarlama
Şimdi bu proje için yapılandırma dosyalarını ayarlamamız gerekiyor. YAML dosyasındaki yapılandırmayı okumak için pydantic-settings kullanılır.
Dosya şablonunu settings.yaml.example içinde zaten sağladık. Dosyayı kopyalayıp settings.yaml olarak yeniden adlandırmamız gerekiyor. Dosyayı oluşturmak için bu komutu çalıştırın.
cp settings.yaml.example settings.yaml
Ardından, aşağıdaki değeri dosyaya kopyalayın.
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
Bu codelab'de GCLOUD_LOCATION, BACKEND_URL, ve DB_COLLECTION_NAME için önceden yapılandırılmış değerleri kullanacağız .
Şimdi bir sonraki adıma geçebiliriz: önce aracıyı, ardından hizmetleri oluşturma
3. 🚀 Google ADK ve Gemini 2.5'i kullanarak temsilci oluşturma
ADK dizin yapısına giriş
ADK'nın sunduğu özelliklere ve temsilcinin nasıl oluşturulacağına göz atarak başlayalım. ADK'nın tam dokümanına bu URL'den erişebilirsiniz . ADK, KSA komut yürütme özelliğiyle bize birçok yardımcı program sunar. Bunlardan bazıları şunlardır :
- Aracı dizin yapısını ayarlama
- KSA giriş çıkışı üzerinden etkileşimi hızlıca deneme
- Yerel geliştirme kullanıcı arayüzü web arayüzünü hızlıca kurma
Şimdi CLI komutunu kullanarak aracı dizin yapısını oluşturalım. Aşağıdaki komutu çalıştırın.
uv run adk create expense_manager_agent
İstendiğinde modeli gemini-2.5-flash ve Vertex AI arka ucunu seçin. Ardından sihirbaz, proje kimliğini ve konumunu ister. Enter tuşuna basarak varsayılan seçenekleri kabul edebilir veya bunları gerektiği gibi değiştirebilirsiniz. Bu laboratuvarda daha önce oluşturulan doğru proje kimliğini kullandığınızdan emin olun. Çıkış şu şekilde görünür:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Aşağıdaki aracı dizin yapısını oluşturur.
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Ayrıca init.py ve agent.py dosyalarını incelerseniz bu kodu görürsünüz.
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Artık aşağıdaki komutu çalıştırarak
uv run adk run expense_manager_agent
Testi tamamladığınızda exit yazarak veya Ctrl+D tuşlarına basarak aracıdan çıkabilirsiniz.
Building Our Expense Manager Agent
Harcama yöneticisi temsilcimizi oluşturalım. expense_manager_agent/agent.py dosyasını açın ve root_agent'ı içeren aşağıdaki kodu kopyalayın.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Kod Açıklaması
Bu komut dosyası, aşağıdaki öğeleri başlattığımız aracı başlatma kodumuzu içerir:
- Kullanılacak modeli
gemini-2.5-flasholarak ayarlayın. - Temsilci açıklamasını ve talimatını,
task_prompt.mdkonumundan okunan sistem istemi olarak ayarlayın. - Temsilci işlevini desteklemek için gerekli araçları sağlama
- Gemini 2.5 Flash'in düşünme özelliklerini kullanarak nihai yanıtı oluşturmadan veya yürütmeden önce planlamayı etkinleştirme
- Tahmin yapmadan önce gönderilen resim verilerinin sayısını sınırlamak için Gemini'a istek göndermeden önce geri arama yakalama ayarlayın.
4. 🚀 Aracı Araçlarını Yapılandırma
Gider yöneticisi temsilcimiz aşağıdaki özelliklere sahip olacak:
- Makbuz resminden veri çıkarma ve verileri ile dosyayı depolama
- Gider verilerinde tam arama
- Gider verilerinde bağlama dayalı arama
Bu nedenle, bu işlevi desteklemek için uygun araçlara ihtiyacımız var. expense_manager_agent dizininde yeni bir dosya oluşturun ve bu dosyayı tools.py olarak adlandırın.
touch expense_manager_agent/tools.py
expense_manage_agent/tools.py dosyasını açın ve aşağıdaki kodu kopyalayın.
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Kod Açıklaması
Bu araç işlevi uygulamasında, araçları şu iki ana fikir etrafında tasarlıyoruz:
- Resim kimliği dizesi yer tutucusunu kullanarak makbuz verilerini ayrıştırma ve orijinal dosyayla eşleme
[IMAGE-ID <hash-of-image-1>] - Firestore veritabanını kullanarak veri depolama ve alma
"store_receipt_data" aracı
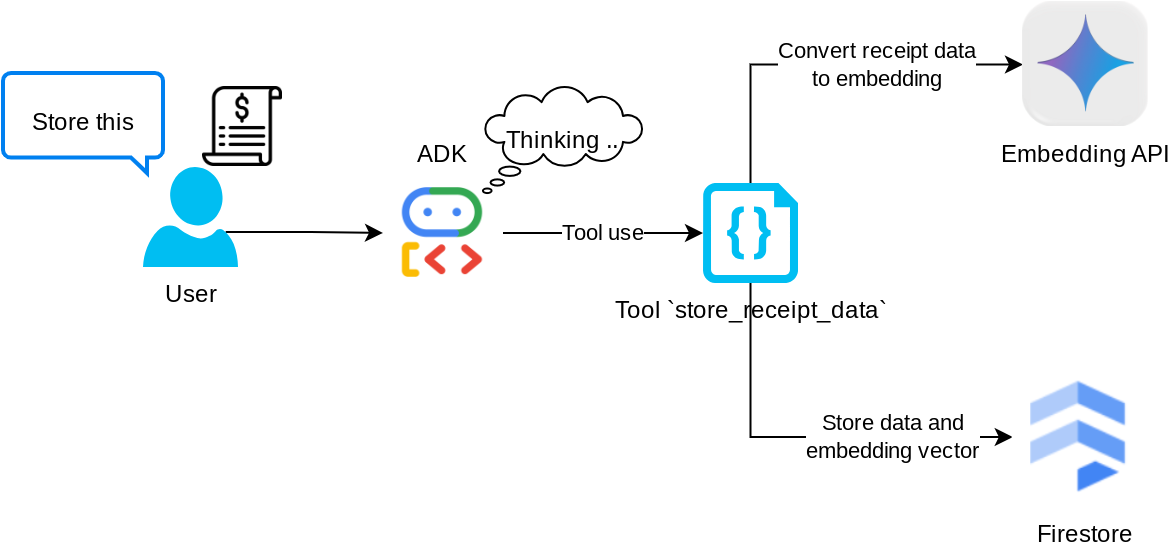
Bu araç, optik karakter tanıma aracıdır. Görüntü kimliği dizesini tanıyıp Firestore veritabanında depolanmak üzere birlikte eşleştirmenin yanı sıra, görüntü verilerindeki gerekli bilgileri ayrıştırır.
Ayrıca bu araç, makbuzun içeriğini text-embedding-004 kullanarak yerleştirmeye dönüştürür. Böylece tüm meta veriler ve yerleştirme birlikte depolanır ve dizine eklenir. Sorgu veya bağlamsal arama ile alınabilme esnekliği sağlar.
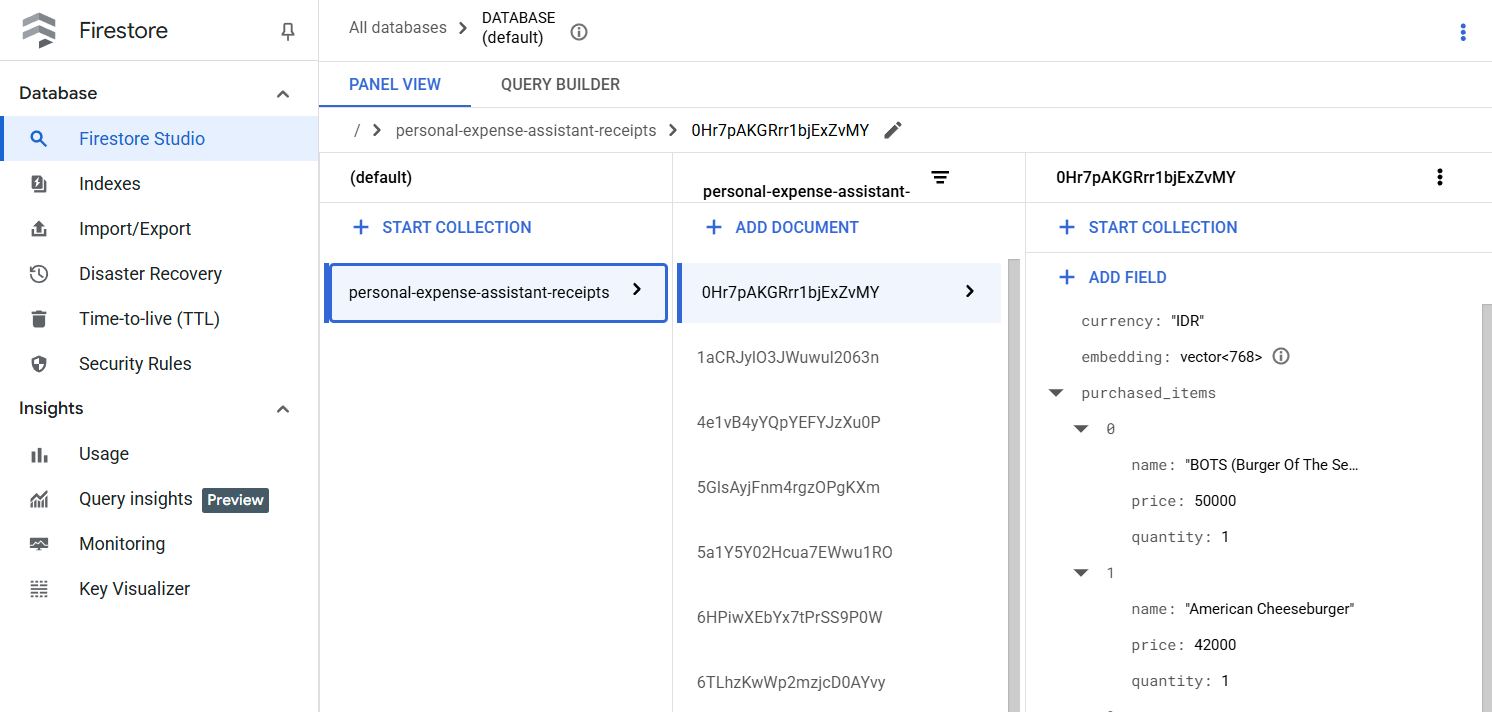
Bu araç başarıyla çalıştırıldıktan sonra, Firestore veritabanında daha önce dizine eklenmiş olan makbuz verilerinin aşağıdaki gibi göründüğünü görebilirsiniz.
"search_receipts_by_metadata_filter" aracı
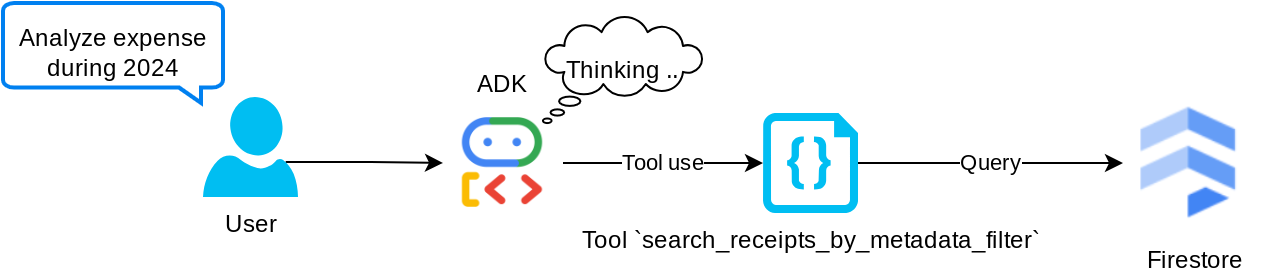
Bu araç, kullanıcı sorgusunu tarih aralığına ve/veya toplam işleme göre aramayı destekleyen bir meta veri sorgu filtresine dönüştürür. Bu işlemde, bağlamsal anlayış için ajanın ihtiyacı olmadığından yerleştirme alanı bırakılır ve eşleşen tüm makbuz verileri döndürülür.
"search_relevant_receipts_by_natural_language_query" aracı
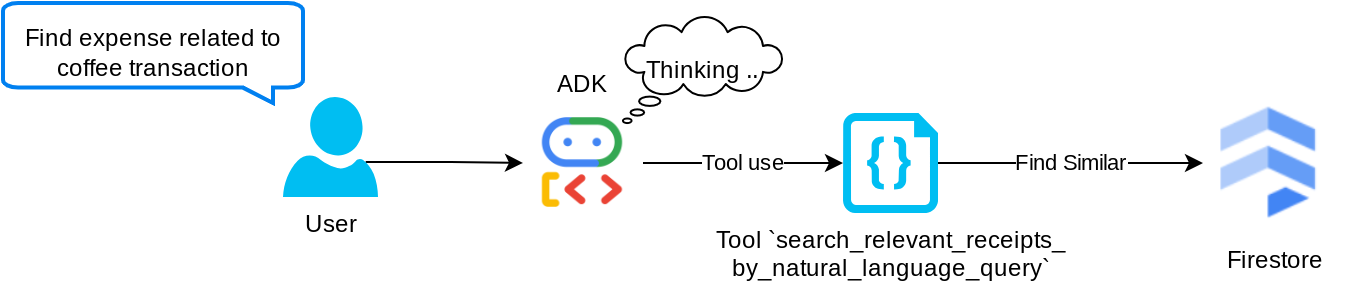
Bu, almayla artırılmış üretim (RAG) aracımızdır. Ajanımız, vektör veritabanından ilgili makbuzları almak için kendi sorgusunu tasarlayabilir ve bu aracı ne zaman kullanacağını seçebilir. Aracının bu RAG aracını kullanıp kullanmayacağına bağımsız olarak karar vermesine ve kendi sorgusunu tasarlamasına izin verme kavramı, Agentic RAG yaklaşımının tanımlarından biridir.
Modelin kendi sorgusunu oluşturmasına izin vermenin yanı sıra kaç alakalı doküman almak istediğini seçmesine de izin veriyoruz. Uygun istem mühendisliğiyle birlikte kullanılmalıdır. Örneğin:
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Bu sayede araç, en yakın komşu aramasının tam olarak eşleşme içermeyen yapısı nedeniyle beklenen tüm sonuçları döndürmese de neredeyse her şeyi arayabilen güçlü bir araç haline gelir.
5. 🚀 Geri aramalar aracılığıyla görüşme bağlamını değiştirme
Google ADK, aracı çalışma zamanını çeşitli düzeylerde "yakalamamıza" olanak tanır. Bu ayrıntılı özellik hakkında daha fazla bilgiyi bu belgede bulabilirsiniz . Bu laboratuvarda, eski görüşme geçmişi bağlamındaki görüntü verilerini kaldırmak için ( yalnızca son 3 kullanıcı etkileşimindeki görüntü verilerini dahil edin) isteği LLM'ye gönderilmeden önce değiştirmek üzere before_model_callback kullanıyoruz.
Ancak, gerektiğinde temsilcinin resim verisi bağlamına erişebilmesini istiyoruz. Bu nedenle, görüşmedeki her resim bayt verisinden sonra bir dize resim kimliği yer tutucusu eklemek için bir mekanizma ekliyoruz. Bu, aracının resim kimliğini gerçek dosya verilerine bağlamasına yardımcı olur. Bu veriler, resim depolama veya alma sırasında kullanılabilir. Yapı şu şekilde görünür:
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
Ayrıca, görüşme geçmişinde bayt verileri eski hale geldiğinde, araç kullanımı yardımıyla veri erişimini etkinleştirmek için dize tanımlayıcı kullanılmaya devam eder. Resim verileri kaldırıldıktan sonraki örnek geçmiş yapısı
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Başlayalım! expense_manager_agent dizininde yeni bir dosya oluşturun ve callbacks.py olarak adlandırın.
touch expense_manager_agent/callbacks.py
expense_manager_agent/callbacks.py dosyasını açın ve aşağıdaki kodu kopyalayın.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 İstem
Karmaşık etkileşim ve özelliklere sahip bir ajan tasarlamak için ajanı yönlendirecek yeterince iyi bir istem bulmamız gerekir. Böylece ajan, istediğimiz şekilde davranabilir.
Daha önce, görüşme geçmişindeki resim verilerinin nasıl işleneceğiyle ilgili bir mekanizmamız vardı ve search_relevant_receipts_by_natural_language_query. gibi, kullanımı kolay olmayan araçlarımız da vardı. Ayrıca, temsilcinin doğru makbuz resmini arayıp bize getirebilmesini de istiyoruz. Bu nedenle, tüm bu bilgileri uygun bir istem yapısında doğru şekilde aktarmamız gerekir.
Düşünme sürecini, nihai yanıtı ve ekleri ( varsa) ayrıştırmak için aracının çıktıyı aşağıdaki Markdown biçiminde yapılandırmasını isteyeceğiz.
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Harcama yöneticisi aracısının davranışıyla ilgili ilk beklentimizi karşılamak için aşağıdaki istemle başlayalım. task_prompt.md dosyası mevcut çalışma dizinimizde bulunuyor olmalıdır ancak bu dosyayı expense_manager_agent dizinine taşımamız gerekir. Taşımak için aşağıdaki komutu çalıştırın:
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Temsilciyi Test Etme
Şimdi de KSA üzerinden aracıyla iletişim kurmayı deneyelim. Aşağıdaki komutu çalıştırın:
uv run adk run expense_manager_agent
Bu arayüzde, sırayla ajanla sohbet edebilirsiniz. Ancak bu arayüz üzerinden yalnızca metin gönderebilirsiniz.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
ADK, CLI etkileşiminin yanı sıra etkileşim sırasında neler olduğunu inceleyip etkileşimde bulunabileceğimiz bir geliştirme kullanıcı arayüzü de sunar. Yerel geliştirme kullanıcı arayüzü sunucusunu başlatmak için aşağıdaki komutu çalıştırın.
uv run adk web --port 8080
Aşağıdaki örnekteki gibi bir çıktı oluşturulur. Bu, web arayüzüne erişebildiğimiz anlamına gelir.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
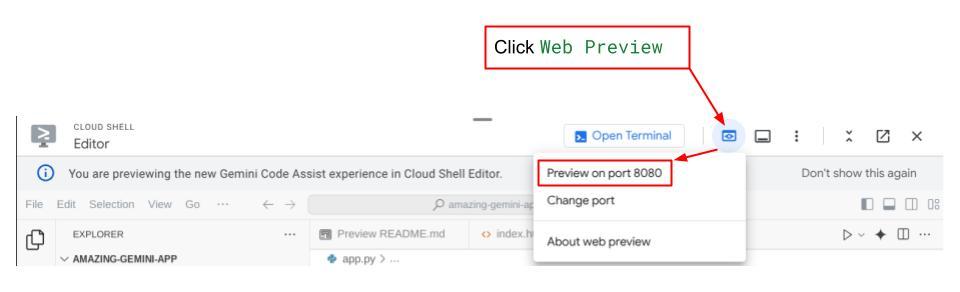
Şimdi bunu kontrol etmek için Cloud Shell Düzenleyicinizin üst kısmındaki Web Önizlemesi düğmesini tıklayın ve 8080 bağlantı noktasında önizle'yi seçin.
Sol üstteki açılır düğmeden ( bizim durumumuzda expense_manager_agent olmalıdır) kullanılabilir aracıları seçebileceğiniz ve bot ile etkileşim kurabileceğiniz aşağıdaki web sayfasını görürsünüz. Sol pencerede, temsilci çalışma zamanı sırasında günlük ayrıntılarıyla ilgili birçok bilgi görürsünüz.
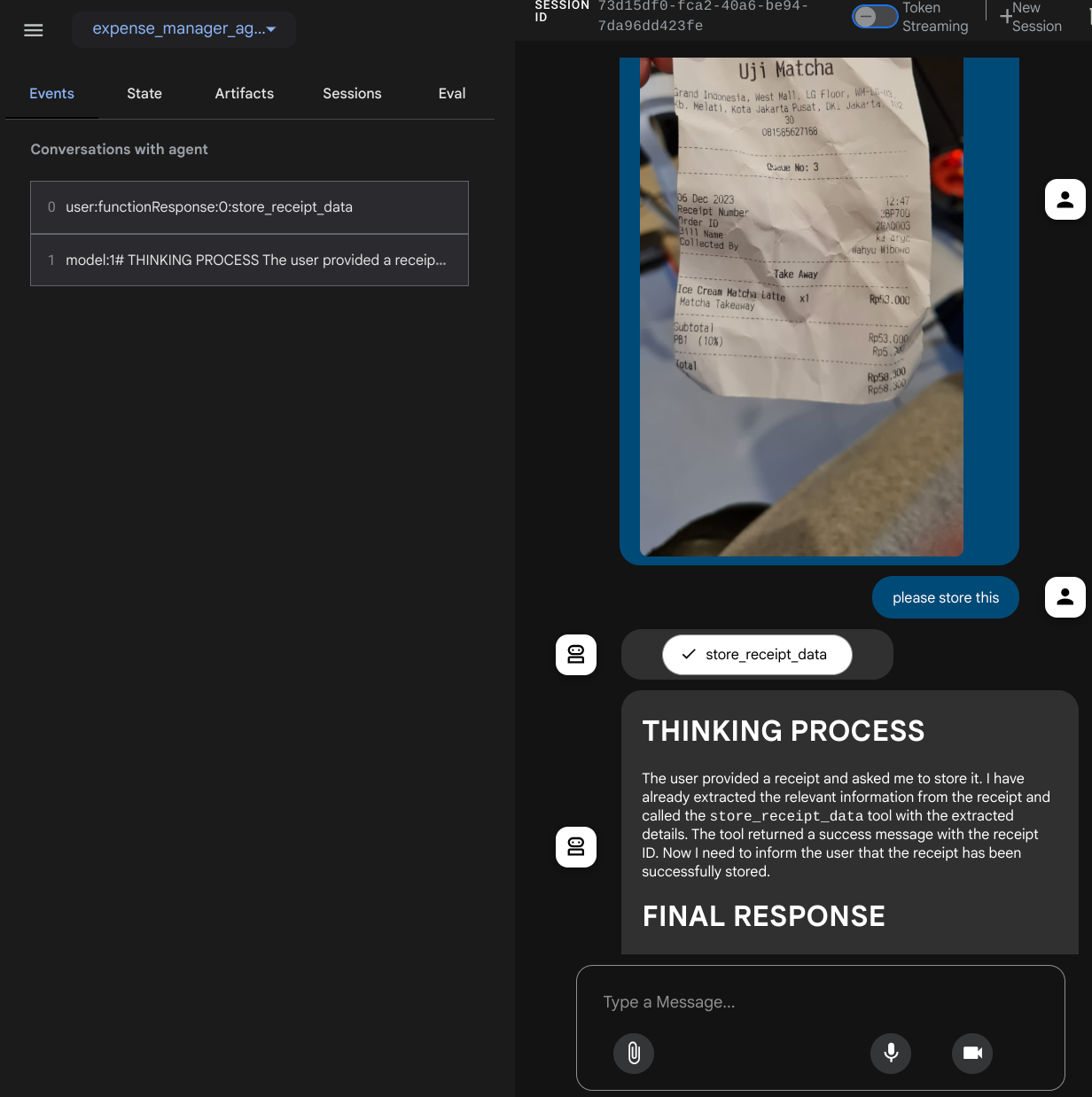
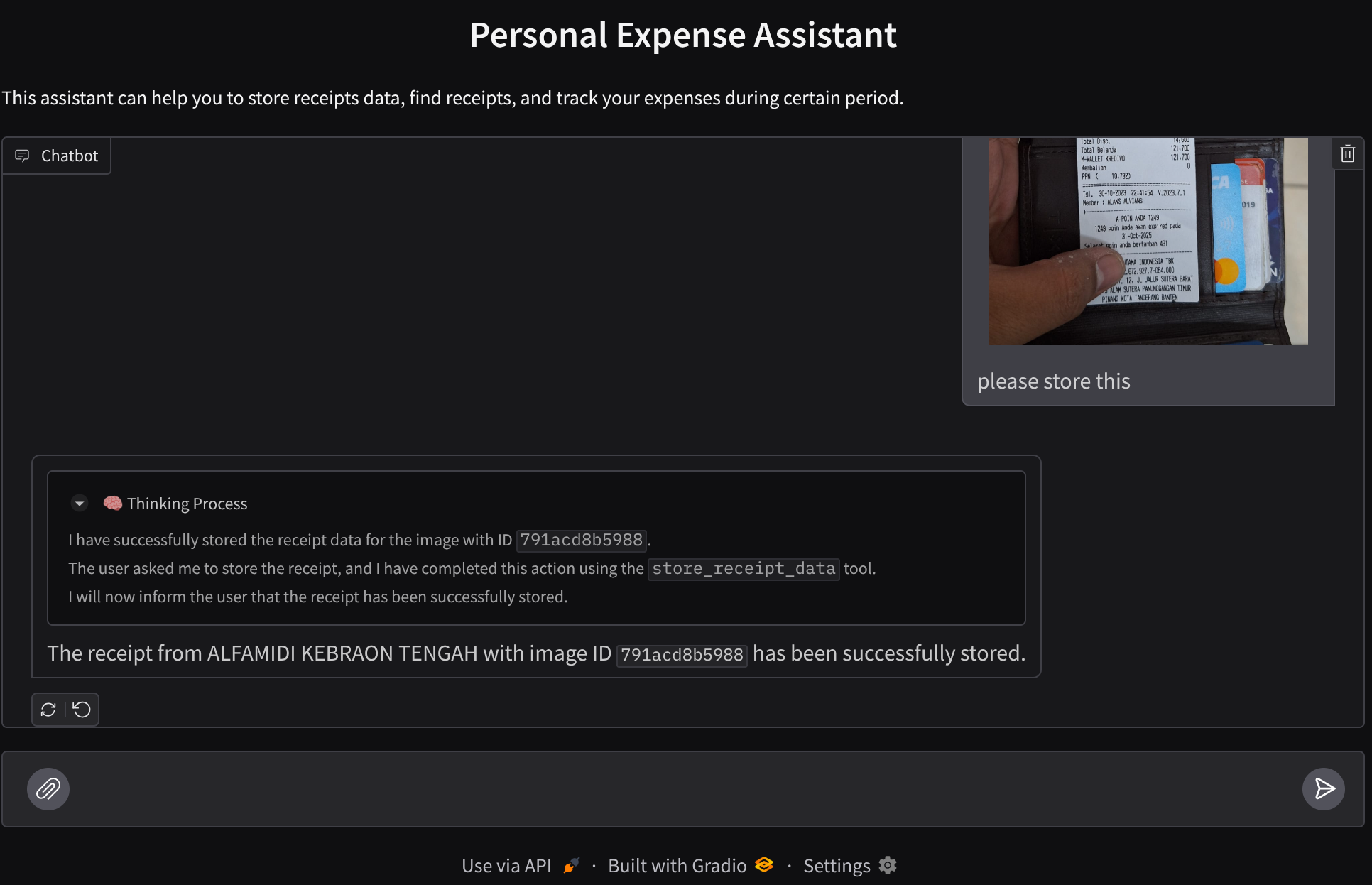
Bazı işlemleri deneyelim. Bu 2 örnek makbuzu yükleyin ( kaynak : Hugging Face veri kümeleri mousserlane/id_receipt_dataset) . Her resmi sağ tıklayıp Resmi farklı kaydet... seçeneğini belirleyin. ( Bu işlem, makbuz resmini indirir.) Ardından, "ataç" simgesini tıklayarak dosyayı bota yükleyin ve bu makbuzları saklamak istediğinizi söyleyin.


Ardından, arama yapmak veya dosya almak için aşağıdaki sorguları deneyin.
- "2023'teki harcamaların dökümünü ve toplamını ver"
- "Indomaret'ten aldığım fişin dosyasını göster"
Bazı araçları kullanırken geliştirme kullanıcı arayüzünde neler olduğunu inceleyebilirsiniz.
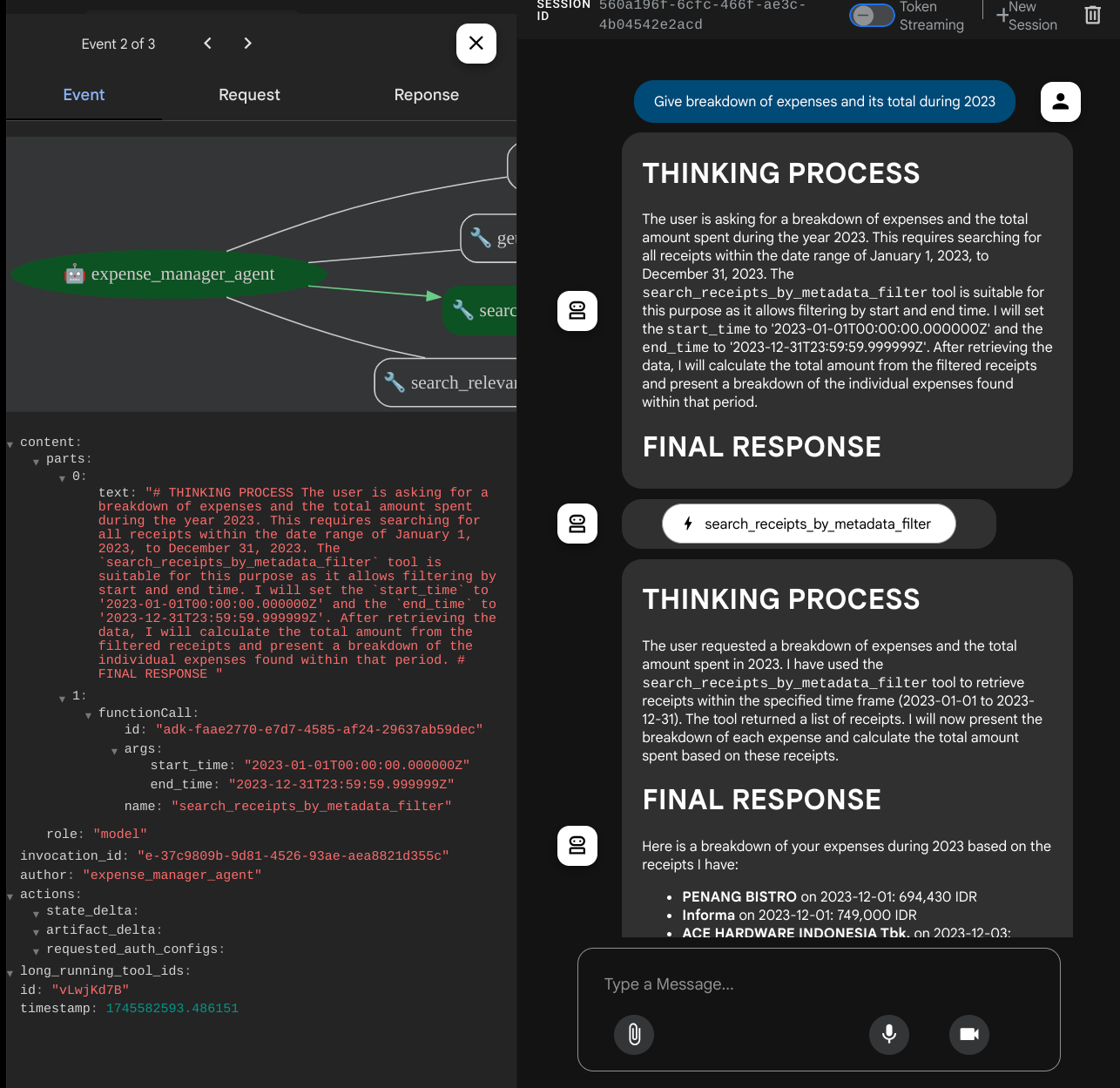
Aracının size nasıl yanıt verdiğini görün ve task_prompt.py dosyasındaki istemde belirtilen tüm kurallara uyup uymadığını kontrol edin. Tebrikler! Artık tamamen çalışan bir geliştirme aracınız var.
Şimdi de uygun ve güzel bir kullanıcı arayüzüyle, resim dosyasını yükleme ve indirme özellikleriyle tamamlamanın zamanı.
8. 🚀 Gradio kullanarak ön uç hizmeti oluşturma
Aşağıdaki gibi bir sohbet web arayüzü oluşturacağız.
Kullanıcıların metin göndermesi ve makbuz resmi dosyalarını yüklemesi için bir giriş alanı içeren bir sohbet arayüzü içerir.
Ön uç hizmetini Gradio kullanarak oluşturacağız.
Yeni bir dosya oluşturun ve frontend.py olarak adlandırın.
touch frontend.py
ardından aşağıdaki kodu kopyalayıp kaydedin.
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Ardından, ön uç hizmetini aşağıdaki komutla çalıştırmayı deneyebiliriz. main.py dosyasını frontend.py olarak yeniden adlandırmayı unutmayın.
uv run frontend.py
Cloud Console'unuzda buna benzer bir çıkış görürsünüz.
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Ardından, yerel URL bağlantısını Ctrl+tıklayarak web arayüzünü kontrol edebilirsiniz. Alternatif olarak, Cloud Editor'ün sağ üst tarafındaki Web Önizlemesi düğmesini tıklayıp 8080 bağlantı noktasında önizle'yi seçerek de ön uç uygulamasına erişebilirsiniz.
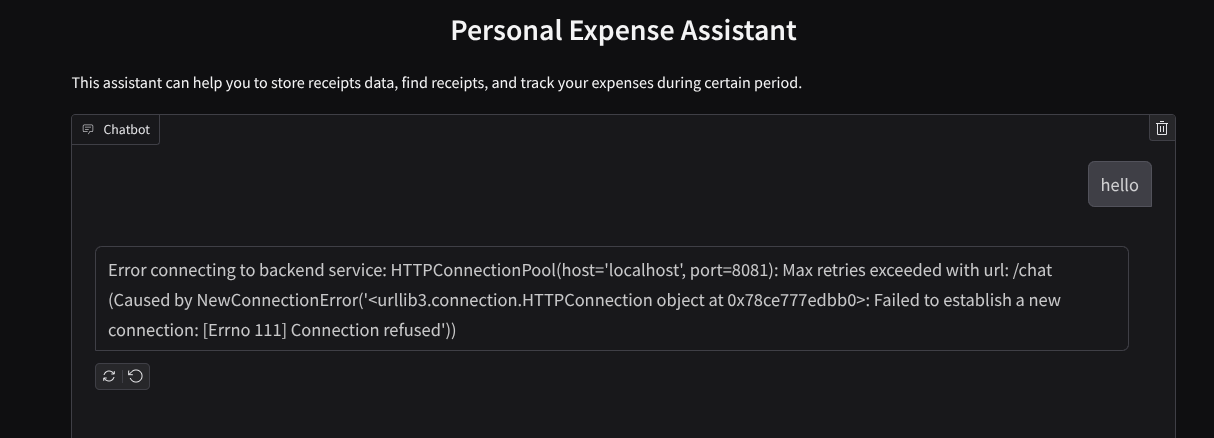
Web arayüzünü görürsünüz ancak henüz ayarlanmamış arka uç hizmeti nedeniyle sohbet göndermeye çalışırken beklenen hatayı alırsınız.
Şimdi hizmetin çalışmasına izin verin ve henüz sonlandırmayın. Arka uç hizmetini başka bir terminal sekmesinde çalıştıracağız.
Kod Açıklaması
Bu ön uç kodunda, önce kullanıcının metin göndermesine ve birden fazla dosya yüklemesine olanak tanıyoruz. Gradio, gr.ChatInterface yöntemi ile gr.MultimodalTextbox'ı birleştirerek bu tür işlevler oluşturmamıza olanak tanır.
Şimdi dosyayı ve metni arka uca göndermeden önce, arka ucun ihtiyaç duyduğu dosyanın MIME türünü bulmamız gerekiyor. Ayrıca, resim dosyası baytını base64 olarak kodlamamız ve MIME türüyle birlikte göndermemiz gerekir.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
Ön uç ile arka uç etkileşimi için kullanılan şema schema.py dosyasında tanımlanır. Şemada veri doğrulamayı zorunlu kılmak için Pydantic BaseModel'i kullanırız.
Yanıtı alırken düşünce sürecinin, nihai yanıtın ve eklerin hangi bölümler olduğunu zaten ayırırız. Bu nedenle, her bileşeni kullanıcı arayüzü bileşeniyle birlikte görüntülemek için Gradio bileşenini kullanabiliriz.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 FastAPI kullanarak arka uç hizmeti oluşturma
Ardından, ajan çalışma zamanını yürütebilmek için ajanımızı diğer bileşenlerle birlikte başlatabilecek arka ucu oluşturmamız gerekir.
Yeni bir dosya oluşturun ve backend.py olarak adlandırın.
touch backend.py
Aşağıdaki kodu kopyalayın.
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Ardından arka uç hizmetini çalıştırmayı deneyebiliriz. Önceki adımda ön uç hizmetini doğru şekilde çalıştırdığımızı hatırlayın. Şimdi yeni bir terminal açıp bu arka uç hizmetini çalıştırmayı denememiz gerekiyor.
- Yeni bir terminal oluşturun. Alt kısımdaki terminalinize gidin ve yeni bir terminal oluşturmak için "+" düğmesini bulun. Alternatif olarak, yeni terminali açmak için Ctrl + Üst Karakter + C tuşlarına basabilirsiniz.

- Ardından, personal-expense-assistant çalışma dizininde olduğunuzdan emin olun ve aşağıdaki komutu çalıştırın.
uv run backend.py
- İşlem başarılı olursa aşağıdaki gibi bir çıkış gösterilir.
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Kod Açıklaması
ADK Temsilcisi, SessionService ve ArtifactService'i başlatma
Aracı arka uç hizmetinde çalıştırmak için hem SessionService hem de aracımızı alan bir Runner oluşturmamız gerekir. SessionService, görüşme geçmişini ve durumunu yönetir. Bu nedenle Runner ile entegre edildiğinde temsilcimize devam eden görüşmelerin bağlamını alma olanağı tanır.
Yüklenen dosyayı işlemek için ArtifactService'i de kullanırız. ADK Oturumu ve Yapay Nesneler hakkında daha fazla bilgiyi burada bulabilirsiniz.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
Bu demoda, aracımız Runner ile entegre etmek için InMemorySessionService ve GcsArtifactService'i kullanıyoruz. Konuşma geçmişi bellekte saklandığından arka uç hizmeti sonlandırıldığında veya yeniden başlatıldığında kaybolur. Bunları, /chat rotasına bağımlılık olarak yerleştirilmek üzere FastAPI uygulama yaşam döngüsünde başlatırız.
GcsArtifactService ile Görüntü Yükleme ve İndirme
Yüklenen tüm resimler GcsArtifactService tarafından yapıt olarak saklanır. Bunu utils.py içindeki format_user_request_to_adk_content_and_store_artifacts işlevinde kontrol edebilirsiniz.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Aracı çalıştırıcı tarafından işlenecek tüm isteklerin types.Content türünde biçimlendirilmesi gerekir. Fonksiyonun içinde her görüntü verisini de işleriz ve görüntü kimliği yer tutucusuyla değiştirilecek kimliğini ayıklarız.
Resim kimliklerini normal ifade kullanarak ayıklamanın ardından ekleri indirmek için benzer bir mekanizma kullanılır:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Entegrasyon Testi
Artık farklı Cloud Console sekmelerinde birden fazla hizmet çalıştırıyor olmanız gerekir:
- Frontend hizmeti 8080 numaralı bağlantı noktasında çalıştırılır.
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Arka uç hizmeti 8081 numaralı bağlantı noktasında çalıştırılır.
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Şu anda, makbuz resimlerinizi yükleyebilmeniz ve 8080 bağlantı noktasındaki web uygulamasından asistanla sorunsuz bir şekilde sohbet edebilmeniz gerekir.
Cloud Shell Düzenleyicinizin üst kısmındaki Web Önizlemesi düğmesini tıklayın ve 8080 bağlantı noktasında önizle'yi seçin.
Şimdi Asistan ile etkileşime geçelim.
Aşağıdaki makbuzları indirin. Bu makbuz verilerinin tarih aralığı 2023-2024 yılları arasındadır ve asistandan bunları saklamasını/yüklemesini isteyin.
- Receipt Drive ( kaynak: Hugging Face veri kümeleri
mousserlane/id_receipt_dataset)
Çeşitli şeyler sorun
- "2023-2024 dönemindeki aylık harcama dökümünü göster."
- "Kahve işlemiyle ilgili makbuzu göster"
- "Yakiniku Like'tan aldığım makbuz dosyasını göster"
- Vb.
Başarılı etkileşimden bir snippet
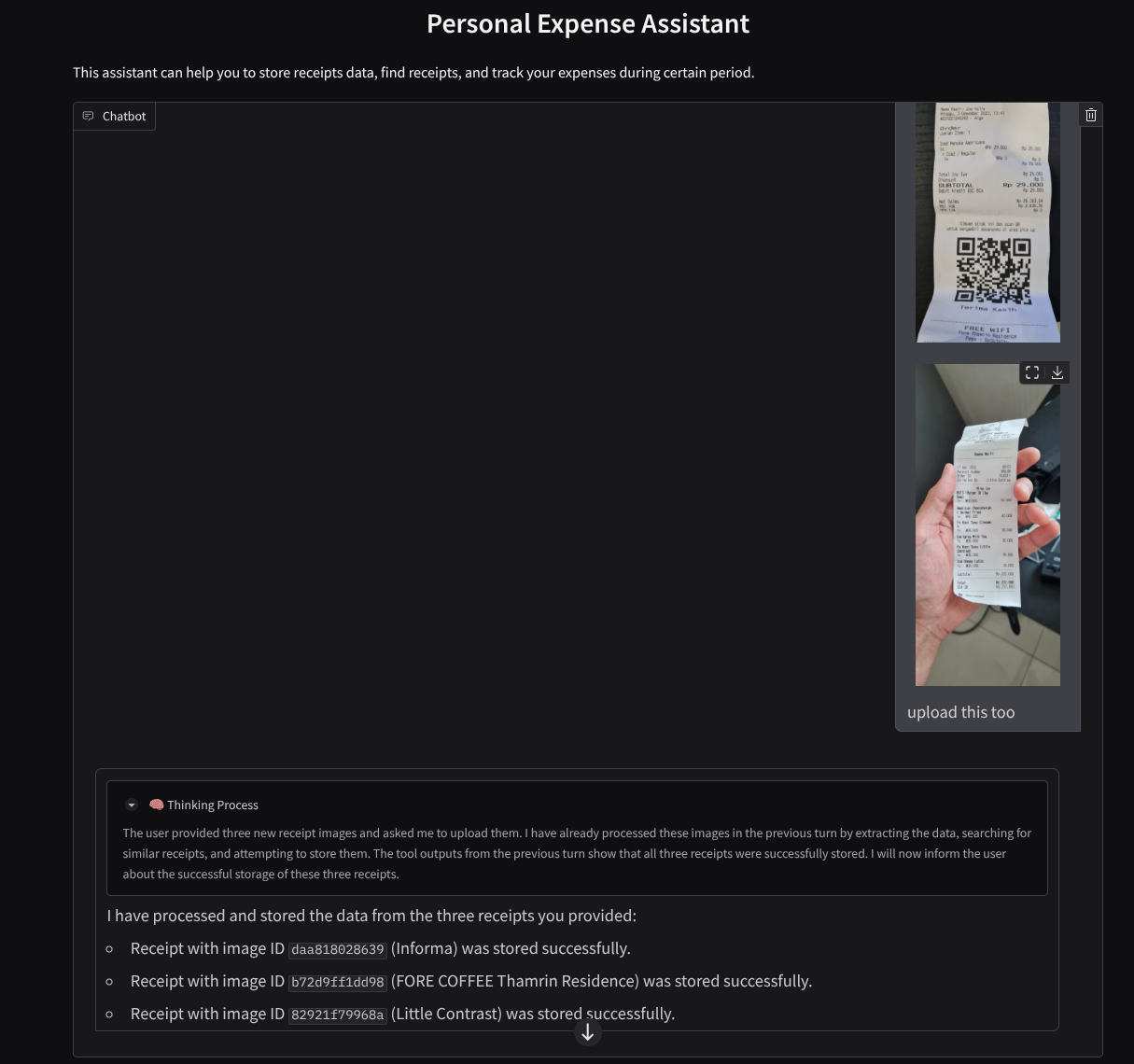
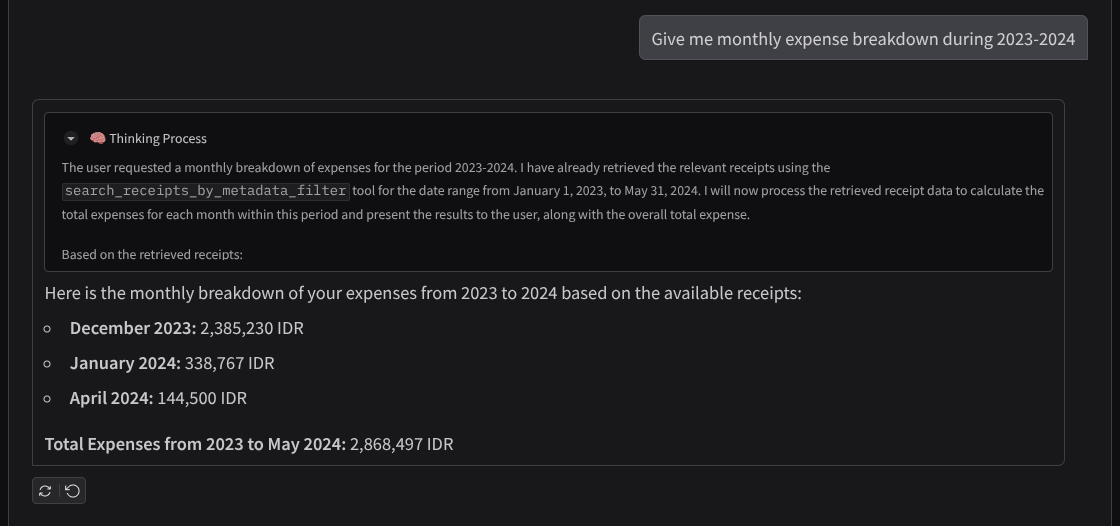
11. 🚀 Cloud Run'a dağıtma
Elbette bu harika uygulamaya her yerden erişmek istiyoruz. Bunu yapmak için bu uygulamayı paketleyip Cloud Run'a dağıtabiliriz. Bu demoda, bu hizmet başkalarının erişebileceği herkese açık bir hizmet olarak sunulacaktır. Ancak bunun, kişisel uygulamalar için daha uygun olduğundan bu tür uygulamalar için en iyi uygulama olmadığını unutmayın.
Bu codelab'de hem ön uç hem de arka uç hizmetini tek bir kapsayıcıya yerleştireceğiz. Her iki hizmeti de yönetmek için supervisord'un yardımına ihtiyacımız olacak. supervisord.conf dosyasını inceleyebilir ve giriş noktası olarak supervisord'u ayarladığımız Dockerfile'ı kontrol edebilirsiniz.
Bu noktada, uygulamalarımızı Cloud Run'a dağıtmak için gereken tüm dosyalara sahibiz. Şimdi dağıtalım. Cloud Shell Terminali'ne gidin ve mevcut projenin etkin projeniz olarak yapılandırıldığından emin olun. Aksi takdirde, proje kimliğini ayarlamak için gcloud configure komutunu kullanmanız gerekir:
gcloud config set project [PROJECT_ID]
Ardından, Cloud Run'a dağıtmak için aşağıdaki komutu çalıştırın.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Docker deposu için bir Artifact Registry oluşturmayı onaylamanız istenirse Y yanıtını verin. Bunun bir demo uygulaması olması nedeniyle burada kimliği doğrulanmamış erişime izin verildiğini unutmayın. Kurumsal ve üretim uygulamalarınız için uygun kimlik doğrulama yöntemini kullanmanız önerilir.
Dağıtım tamamlandığında aşağıdakine benzer bir bağlantı alırsınız:
https://personal-expense-assistant-*******.us-central1.run.app
Uygulamanızı Gizli penceresinden veya mobil cihazınızdan kullanmaya devam edebilirsiniz. Bu özellik zaten kullanıma sunulmuş olmalıdır.
12. 🎯 Görev
Şimdi keşif becerilerinizi geliştirme ve parlatma zamanı. Arka ucun birden fazla kullanıcıyı destekleyebilmesi için kodu değiştirecek bilgiye sahip misiniz? Hangi bileşenlerin güncellenmesi gerekiyor?
13. 🧹 Temizleme
Bu codelab'de kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın:
- Google Cloud Console'da Kaynakları yönetin sayfasına gidin.
- Proje listesinde silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- İletişim kutusunda proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.
- Alternatif olarak, konsolda Cloud Run'a gidebilir, yeni dağıttığınız hizmeti seçip silebilirsiniz.