
1. 📖 Giới thiệu
Bạn có bao giờ cảm thấy khó chịu và quá lười biếng để quản lý tất cả các khoản chi tiêu cá nhân của mình không? Tôi cũng vậy! Vì vậy, trong lớp học lập trình này, chúng ta sẽ xây dựng một trợ lý quản lý chi tiêu cá nhân dựa trên Gemini 2.5 để thực hiện mọi công việc cho chúng ta! Từ việc quản lý biên nhận đã tải lên cho đến phân tích xem bạn đã chi quá nhiều tiền để mua cà phê hay chưa!
Bạn có thể truy cập vào trợ lý này thông qua trình duyệt web dưới dạng giao diện web trò chuyện. Trong giao diện này, bạn có thể giao tiếp với trợ lý, tải một số hình ảnh biên nhận lên và yêu cầu trợ lý lưu trữ những hình ảnh đó, hoặc có thể muốn tìm kiếm một số biên nhận để lấy tệp và phân tích chi phí. Tất cả những điều này đều được xây dựng dựa trên khung Google Agent Development Kit
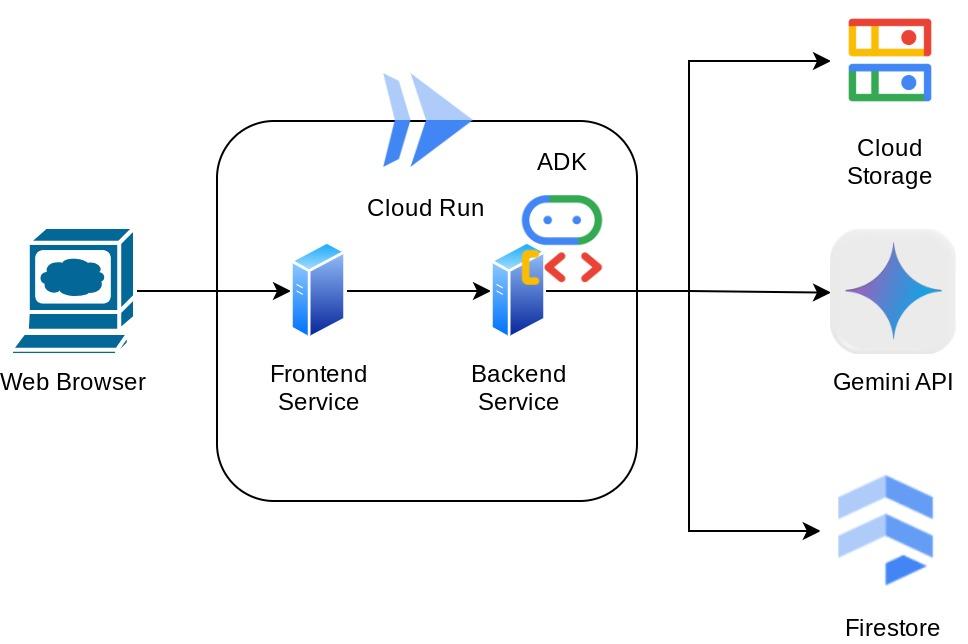
Bản thân ứng dụng được chia thành 2 dịch vụ: giao diện người dùng và phần phụ trợ; cho phép bạn tạo một nguyên mẫu nhanh và dùng thử, đồng thời hiểu rõ hợp đồng API trông như thế nào để tích hợp cả hai.
Trong lớp học lập trình này, bạn sẽ sử dụng phương pháp từng bước như sau:
- Chuẩn bị dự án Google Cloud và Bật tất cả API bắt buộc trên dự án đó
- Thiết lập bộ chứa trên Google Cloud Storage và cơ sở dữ liệu trên Firestore
- Tạo chỉ mục Firestore
- Thiết lập không gian làm việc cho môi trường lập trình
- Cấu trúc mã nguồn, công cụ, câu lệnh, v.v. của tác nhân ADK
- Kiểm thử tác nhân bằng giao diện người dùng phát triển web cục bộ ADK
- Xây dựng dịch vụ giao diện người dùng – giao diện trò chuyện bằng thư viện Gradio, để gửi một số truy vấn và tải hình ảnh biên nhận lên
- Xây dựng dịch vụ phụ trợ – máy chủ HTTP bằng FastAPI, nơi chứa mã tác nhân ADK, SessionService và Artifact Service
- Quản lý các biến môi trường và thiết lập các tệp bắt buộc cần thiết để triển khai ứng dụng vào Cloud Run
- Triển khai ứng dụng lên Cloud Run
Tổng quan về cấu trúc
Điều kiện tiên quyết
- Thoải mái khi làm việc với Python
- Hiểu biết về cấu trúc cơ bản của ngăn xếp đầy đủ bằng cách sử dụng dịch vụ HTTP
Kiến thức bạn sẽ học được
- Tạo mẫu web giao diện người dùng bằng Gradio
- Phát triển dịch vụ phụ trợ bằng FastAPI và Pydantic
- Thiết kế tác nhân ADK trong khi tận dụng một số chức năng của tác nhân này
- Mức sử dụng công cụ
- Quản lý phiên và cấu phần phần mềm
- Sử dụng lệnh gọi lại để sửa đổi dữ liệu đầu vào trước khi gửi đến Gemini
- Sử dụng BuiltInPlanner để cải thiện việc thực thi nhiệm vụ bằng cách lập kế hoạch
- Gỡ lỗi nhanh thông qua giao diện web cục bộ ADK
- Chiến lược tối ưu hoá hoạt động tương tác đa phương thức thông qua việc phân tích cú pháp và truy xuất thông tin thông qua thiết kế câu lệnh và sửa đổi yêu cầu của Gemini bằng lệnh gọi lại ADK
- Tạo sinh tăng cường khả năng truy xuất dựa trên tác nhân bằng cách sử dụng Firestore làm Cơ sở dữ liệu vectơ
- Quản lý các biến môi trường trong tệp YAML bằng Pydantic-settings
- Triển khai ứng dụng lên Cloud Run bằng Dockerfile và cung cấp các biến môi trường bằng tệp YAML
Bạn cần có
- Trình duyệt web Chrome
- Tài khoản Gmail
- Một Dự án trên đám mây đã bật tính năng thanh toán
Lớp học lập trình này được thiết kế cho nhà phát triển ở mọi cấp độ (kể cả người mới bắt đầu), sử dụng Python trong ứng dụng mẫu. Tuy nhiên, bạn không cần có kiến thức về Python để hiểu các khái niệm được trình bày.
2. 🚀 Trước khi bắt đầu
Chọn dự án đang hoạt động trong Cloud Console
Lớp học lập trình này giả định rằng bạn đã có một dự án trên Google Cloud có bật tính năng thanh toán. Nếu chưa có, bạn có thể làm theo hướng dẫn bên dưới để bắt đầu.
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
Chuẩn bị cơ sở dữ liệu Firestore
Tiếp theo, chúng ta cũng cần tạo một Cơ sở dữ liệu Firestore. Firestore ở chế độ Native là một cơ sở dữ liệu dạng tài liệu NoSQL được xây dựng để hỗ trợ việc tự động cấp tài nguyên bổ sung, duy trì hiệu suất cao và tạo điều kiện dễ dàng cho việc phát triển ứng dụng. Đây cũng có thể là một cơ sở dữ liệu vectơ có thể hỗ trợ kỹ thuật Tạo thông tin tăng cường để truy xuất cho phòng thí nghiệm của chúng tôi.
- Tìm kiếm "firestore" trên thanh tìm kiếm rồi nhấp vào sản phẩm Firestore
- Sau đó, hãy nhấp vào nút Create A Firestore Database (Tạo cơ sở dữ liệu Firestore)
- Sử dụng (mặc định) làm tên mã cơ sở dữ liệu và giữ nguyên lựa chọn Standard Edition (Phiên bản chuẩn). Để minh hoạ trong phòng thí nghiệm này, hãy sử dụng Firestore Native với các quy tắc bảo mật Mở.
- Bạn cũng sẽ nhận thấy rằng cơ sở dữ liệu này thực sự có Mức sử dụng miễn phí YEAY! Sau đó, hãy nhấp vào Nút Tạo cơ sở dữ liệu
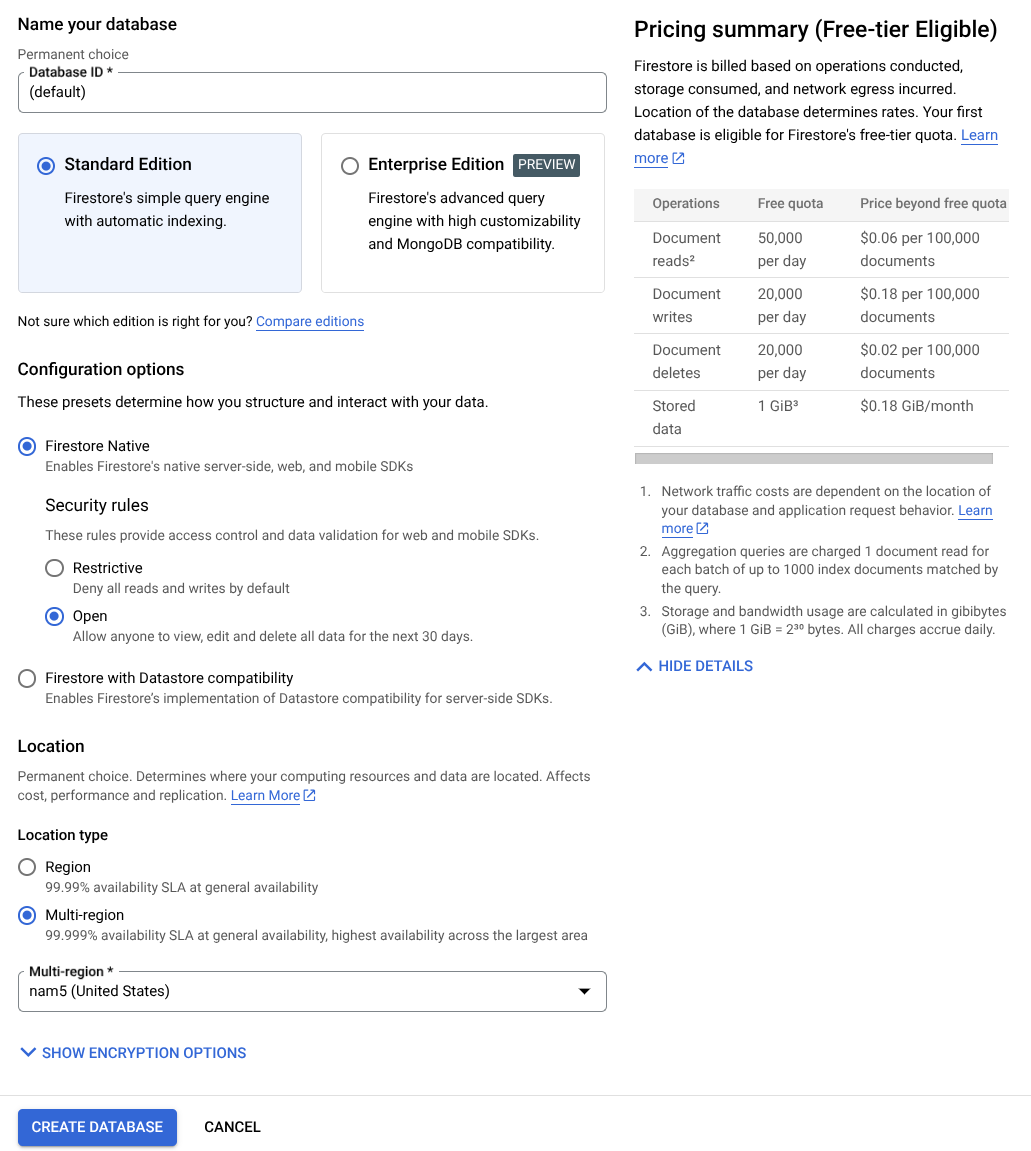
Sau các bước này, bạn sẽ được chuyển hướng đến Cơ sở dữ liệu Firestore mà bạn vừa tạo
Thiết lập dự án trên Cloud trong thiết bị đầu cuối Cloud Shell
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud và được tải sẵn bq. Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.
- Sau khi kết nối với Cloud Shell, bạn có thể kiểm tra để đảm bảo rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt:
gcloud config set project <YOUR_PROJECT_ID>
Ngoài ra, bạn cũng có thể xem mã PROJECT_ID trong bảng điều khiển
Nhấp vào đó, bạn sẽ thấy tất cả dự án và mã dự án ở bên phải
- Bật các API bắt buộc thông qua lệnh bên dưới. Quá trình này có thể mất vài phút, vì vậy, vui lòng kiên nhẫn chờ đợi.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Khi thực thi lệnh thành công, bạn sẽ thấy một thông báo tương tự như thông báo dưới đây:
Operation "operations/..." finished successfully.
Bạn có thể thay thế lệnh gcloud bằng cách tìm kiếm từng sản phẩm trên bảng điều khiển hoặc sử dụng đường liên kết này.
Nếu bỏ lỡ API nào, bạn luôn có thể bật API đó trong quá trình triển khai.
Tham khảo tài liệu để biết các lệnh và cách sử dụng gcloud.
Chuẩn bị bộ chứa Google Cloud Storage
Tiếp theo, từ cùng một thiết bị đầu cuối, chúng ta sẽ cần chuẩn bị bộ chứa GCS để lưu trữ tệp đã tải lên. Chạy lệnh sau để tạo bộ chứa. Bạn sẽ cần một tên bộ chứa duy nhất nhưng phù hợp với biên nhận của trợ lý chi tiêu cá nhân. Do đó, chúng ta sẽ sử dụng tên bộ chứa sau kết hợp với mã dự án của bạn
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Kết quả sẽ như sau
Creating gs://personal-expense-{your-project-id}
Bạn có thể xác minh điều này bằng cách chuyển đến Trình đơn điều hướng ở trên cùng bên trái của trình duyệt rồi chọn Bộ nhớ đám mây -> Nhóm tài nguyên
Tạo chỉ mục Firestore để tìm kiếm
Firestore là một cơ sở dữ liệu NoSQL gốc, mang lại hiệu suất và tính linh hoạt vượt trội trong mô hình dữ liệu, nhưng có những hạn chế khi nói đến các truy vấn phức tạp. Vì dự định sử dụng một số truy vấn kết hợp nhiều trường và tìm kiếm vectơ, nên trước tiên, chúng ta cần tạo một số chỉ mục. Bạn có thể đọc thêm về thông tin chi tiết trong tài liệu này
- Chạy lệnh sau để tạo chỉ mục nhằm hỗ trợ các truy vấn kết hợp
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- Và chạy lệnh này để hỗ trợ tìm kiếm vectơ
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
Bạn có thể kiểm tra chỉ mục đã tạo bằng cách truy cập vào Firestore trong bảng điều khiển đám mây, nhấp vào phiên bản cơ sở dữ liệu (mặc định) rồi chọn Chỉ mục trên thanh điều hướng
Chuyển đến Cloud Shell Editor và thiết lập thư mục làm việc của ứng dụng
Bây giờ, chúng ta có thể thiết lập trình soạn thảo mã để thực hiện một số việc liên quan đến lập trình. Chúng ta sẽ sử dụng Trình chỉnh sửa Cloud Shell cho việc này
- Nhấp vào nút Open Editor (Mở trình chỉnh sửa). Thao tác này sẽ mở Cloud Shell Editor. Chúng ta có thể viết mã tại đây
- Tiếp theo, chúng ta cũng cần kiểm tra xem shell đã được định cấu hình thành PROJECT ID chính xác mà bạn có hay chưa. Nếu thấy có giá trị bên trong ( ) trước biểu tượng $ trong thiết bị đầu cuối ( trong ảnh chụp màn hình bên dưới, giá trị là "adk-multimodal-tool"), thì giá trị này cho biết dự án đã định cấu hình cho phiên shell đang hoạt động của bạn.

Nếu giá trị được hiển thị đã chính xác, bạn có thể bỏ qua lệnh tiếp theo. Tuy nhiên, nếu không chính xác hoặc bị thiếu, hãy chạy lệnh sau
gcloud config set project <YOUR_PROJECT_ID>
- Tiếp theo, hãy sao chép thư mục làm việc của mẫu cho lớp học lập trình này từ GitHub bằng cách chạy lệnh sau. Thao tác này sẽ tạo thư mục làm việc trong thư mục personal-expense-assistant
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- Sau đó, hãy chuyển đến phần trên cùng của Cloud Shell Editor rồi nhấp vào File->Open Folder (Tệp->Mở thư mục), tìm thư mục username (tên người dùng) và tìm thư mục personal-expense-assistant (trợ lý chi tiêu cá nhân), sau đó nhấp vào nút OK. Thao tác này sẽ đặt thư mục đã chọn làm thư mục làm việc chính. Trong ví dụ này, tên người dùng là alvinprayuda, do đó, đường dẫn thư mục sẽ xuất hiện bên dưới

Giờ đây, Cloud Shell Editor sẽ có dạng như sau
Thiết lập môi trường
Chuẩn bị môi trường ảo Python
Bước tiếp theo là chuẩn bị môi trường phát triển. Thiết bị đầu cuối đang hoạt động hiện tại của bạn phải nằm trong thư mục làm việc personal-expense-assistant. Chúng ta sẽ sử dụng Python 3.12 trong lớp học lập trình này và sẽ dùng trình quản lý dự án uv python để đơn giản hoá nhu cầu tạo và quản lý phiên bản python cũng như môi trường ảo
- Nếu bạn chưa mở cửa sổ dòng lệnh, hãy mở bằng cách nhấp vào Terminal (Cửa sổ dòng lệnh) -> New Terminal (Cửa sổ dòng lệnh mới) hoặc sử dụng tổ hợp phím Ctrl + Shift + C. Thao tác này sẽ mở một cửa sổ dòng lệnh ở phần dưới cùng của trình duyệt

- Bây giờ, hãy khởi tạo môi trường ảo bằng
uv, chạy các lệnh này
cd ~/personal-expense-assistant
uv sync --frozen
Thao tác này sẽ tạo thư mục .venv và cài đặt các phần phụ thuộc. Xem nhanh pyproject.toml sẽ cung cấp cho bạn thông tin về các phần phụ thuộc xuất hiện như sau
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Thiết lập tệp cấu hình
Bây giờ, chúng ta cần thiết lập các tệp cấu hình cho dự án này. Chúng tôi sử dụng pydantic-settings để đọc cấu hình từ tệp YAML.
Chúng ta đã cung cấp mẫu tệp trong settings.yaml.example , chúng ta sẽ cần sao chép tệp và đổi tên thành settings.yaml. Chạy lệnh này để tạo tệp
cp settings.yaml.example settings.yaml
Sau đó, hãy sao chép giá trị sau đây vào tệp
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
Trong lớp học lập trình này, chúng ta sẽ sử dụng các giá trị được định cấu hình sẵn cho GCLOUD_LOCATION, BACKEND_URL, và DB_COLLECTION_NAME .
Giờ đây, chúng ta có thể chuyển sang bước tiếp theo, đó là tạo tác nhân rồi đến các dịch vụ
3. 🚀 Xây dựng Tác nhân bằng Google ADK và Gemini 2.5
Giới thiệu về Cấu trúc thư mục ADK
Hãy bắt đầu bằng cách khám phá những tính năng mà ADK cung cấp và cách tạo tác nhân. Bạn có thể truy cập vào tài liệu đầy đủ về ADK tại URL này . ADK cung cấp cho chúng ta nhiều tiện ích trong quá trình thực thi lệnh CLI. Sau đây là một số ví dụ :
- Thiết lập cấu trúc thư mục tác nhân
- Nhanh chóng thử tương tác thông qua đầu vào và đầu ra của CLI
- Thiết lập nhanh giao diện web của giao diện người dùng phát triển cục bộ
Bây giờ, hãy tạo cấu trúc thư mục tác nhân bằng lệnh CLI. Chạy lệnh sau.
uv run adk create expense_manager_agent
Khi được hỏi, hãy chọn mô hình gemini-2.5-flash và phần phụ trợ Vertex AI. Sau đó, trình hướng dẫn sẽ yêu cầu bạn nhập mã dự án và vị trí. Bạn có thể chấp nhận các lựa chọn mặc định bằng cách nhấn phím Enter hoặc thay đổi các lựa chọn đó nếu cần. Hãy kiểm tra kỹ để đảm bảo bạn đang sử dụng đúng mã dự án đã tạo trước đó trong phòng thí nghiệm này. Kết quả đầu ra sẽ có dạng như sau:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Thao tác này sẽ tạo cấu trúc thư mục tác nhân sau
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Nếu kiểm tra init.py và agent.py, bạn sẽ thấy mã này
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Bây giờ, bạn có thể kiểm thử bằng cách chạy
uv run adk run expense_manager_agent
Bất cứ khi nào kiểm thử xong, bạn có thể thoát khỏi tác nhân bằng cách nhập exit hoặc nhấn tổ hợp phím Ctrl+D.
Xây dựng tác nhân Trình quản lý chi phí
Hãy tạo tác nhân quản lý chi phí của chúng ta! Mở tệp expense_manager_agent/agent.py rồi sao chép đoạn mã bên dưới. Đoạn mã này sẽ chứa root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Giải thích mã
Tập lệnh này chứa quá trình khởi tạo tác nhân của chúng tôi, trong đó chúng tôi khởi tạo những điều sau:
- Đặt mô hình sẽ dùng thành
gemini-2.5-flash - Thiết lập nội dung mô tả và hướng dẫn cho tác nhân làm câu lệnh hệ thống đang được đọc từ
task_prompt.md - Cung cấp các công cụ cần thiết để hỗ trợ chức năng của tác nhân
- Cho phép lập kế hoạch trước khi tạo câu trả lời hoặc thực thi cuối cùng bằng cách sử dụng khả năng tư duy của Gemini 2.5 Flash
- Thiết lập lệnh gọi lại chặn trước khi gửi yêu cầu đến Gemini để giới hạn số lượng dữ liệu hình ảnh được gửi trước khi đưa ra dự đoán
4. 🚀 Định cấu hình Công cụ dành cho nhân viên
Tác nhân quản lý chi phí của chúng tôi sẽ có những chức năng sau:
- Trích xuất dữ liệu từ hình ảnh biên nhận, đồng thời lưu trữ dữ liệu và tệp
- Tìm kiếm chính xác dữ liệu chi phí
- Tìm kiếm theo ngữ cảnh trên dữ liệu chi phí
Do đó, chúng ta cần các công cụ phù hợp để hỗ trợ chức năng này. Tạo một tệp mới trong thư mục expense_manager_agent và đặt tên là tools.py
touch expense_manager_agent/tools.py
Mở expense_manage_agent/tools.py, sau đó sao chép đoạn mã bên dưới
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Giải thích mã
Trong quá trình triển khai chức năng công cụ này, chúng tôi thiết kế các công cụ dựa trên 2 ý tưởng chính sau:
- Phân tích cú pháp dữ liệu biên nhận và liên kết với tệp gốc bằng cách sử dụng phần giữ chỗ chuỗi mã nhận dạng hình ảnh
[IMAGE-ID <hash-of-image-1>] - Lưu trữ và truy xuất dữ liệu bằng cơ sở dữ liệu Firestore
Công cụ "store_receipt_data"
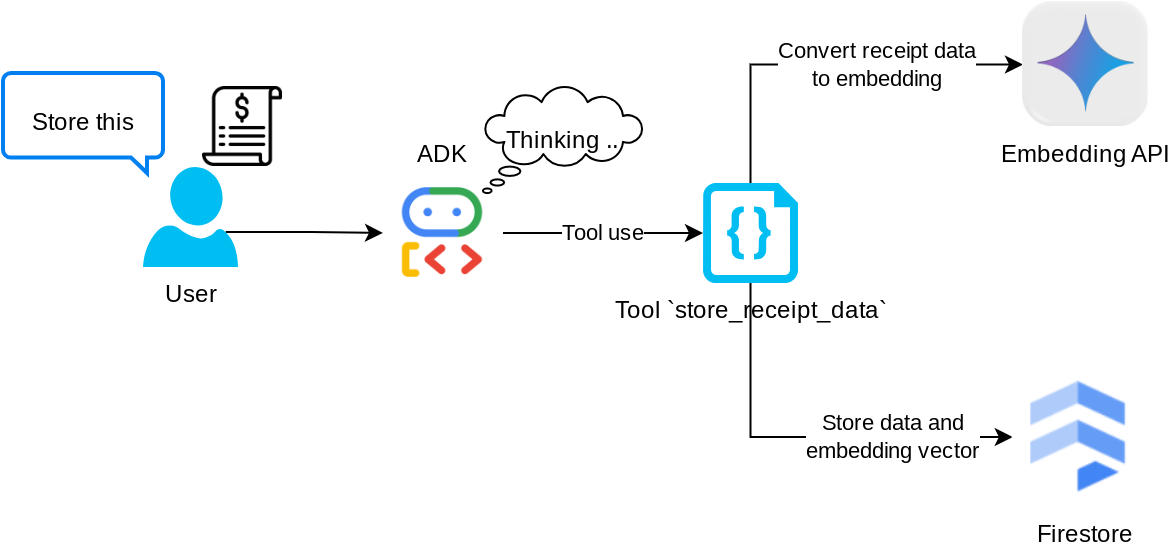
Công cụ này là công cụ Nhận dạng ký tự quang học. Công cụ này sẽ phân tích cú pháp thông tin bắt buộc từ dữ liệu hình ảnh, cùng với việc nhận dạng chuỗi mã nhận dạng hình ảnh và liên kết chúng với nhau để lưu trữ trong cơ sở dữ liệu Firestore.
Ngoài ra, công cụ này cũng chuyển đổi nội dung của biên nhận thành dữ liệu nhúng bằng cách sử dụng text-embedding-004 để tất cả siêu dữ liệu và dữ liệu nhúng được lưu trữ và lập chỉ mục cùng nhau. Cho phép truy xuất linh hoạt bằng cách tìm kiếm theo cụm từ hoặc theo ngữ cảnh.
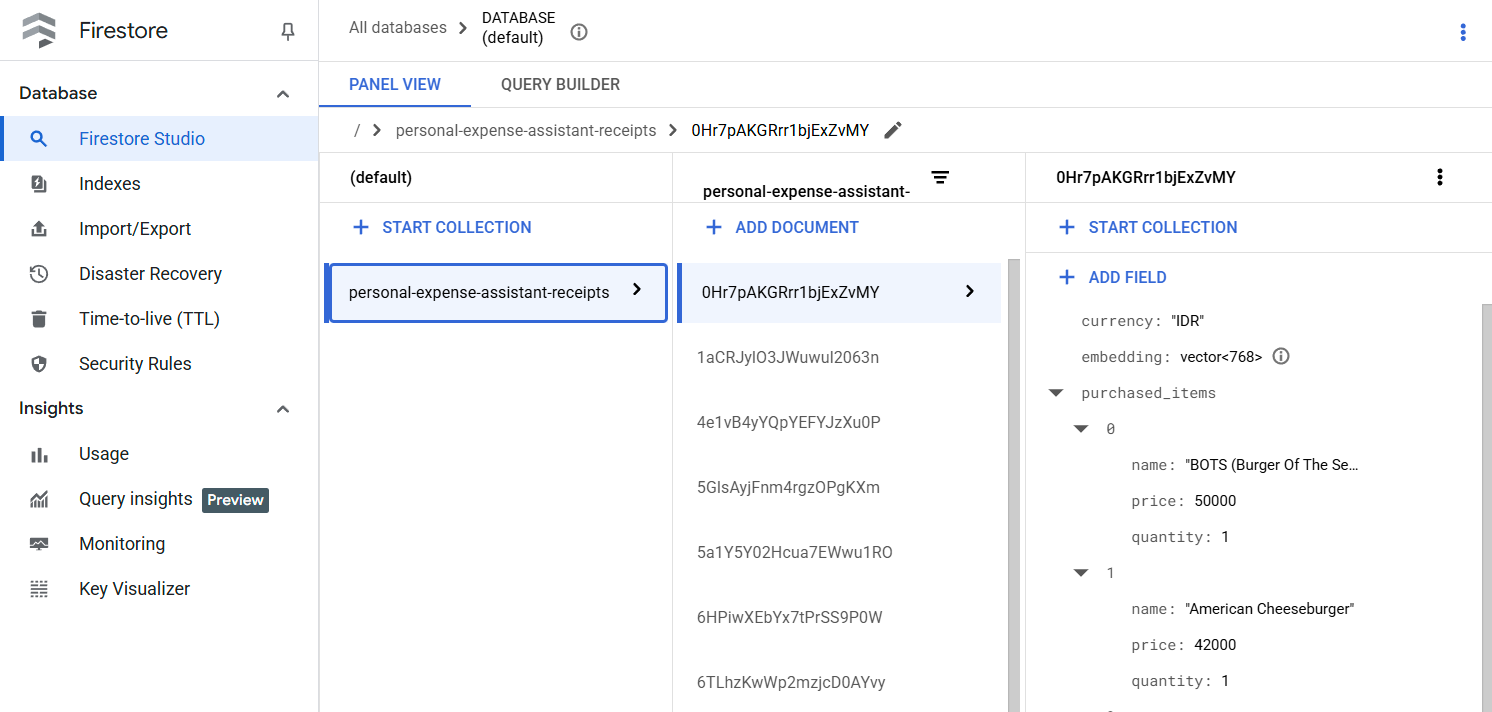
Sau khi thực thi thành công công cụ này, bạn có thể thấy dữ liệu biên nhận đã được lập chỉ mục trong cơ sở dữ liệu Firestore như minh hoạ bên dưới
Công cụ "search_receipts_by_metadata_filter"
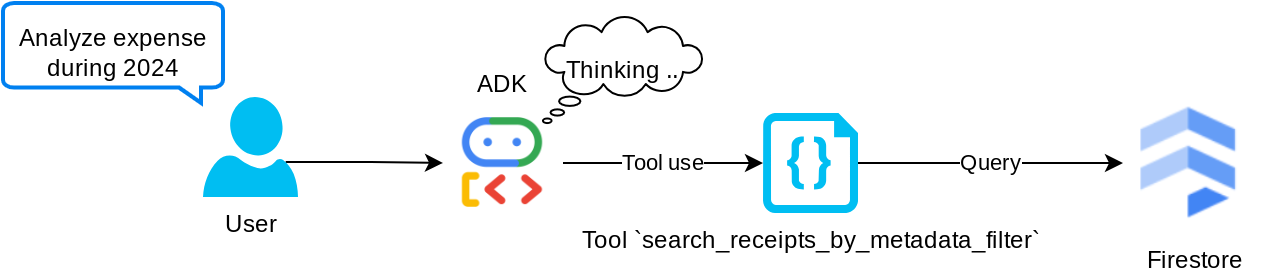
Công cụ này chuyển đổi truy vấn của người dùng thành bộ lọc truy vấn siêu dữ liệu, hỗ trợ tìm kiếm theo phạm vi ngày và/hoặc tổng giao dịch. Thao tác này sẽ trả về tất cả dữ liệu biên nhận trùng khớp, trong đó chúng tôi sẽ loại bỏ trường nhúng vì tác nhân không cần trường này để hiểu ngữ cảnh
Công cụ "search_relevant_receipts_by_natural_language_query"
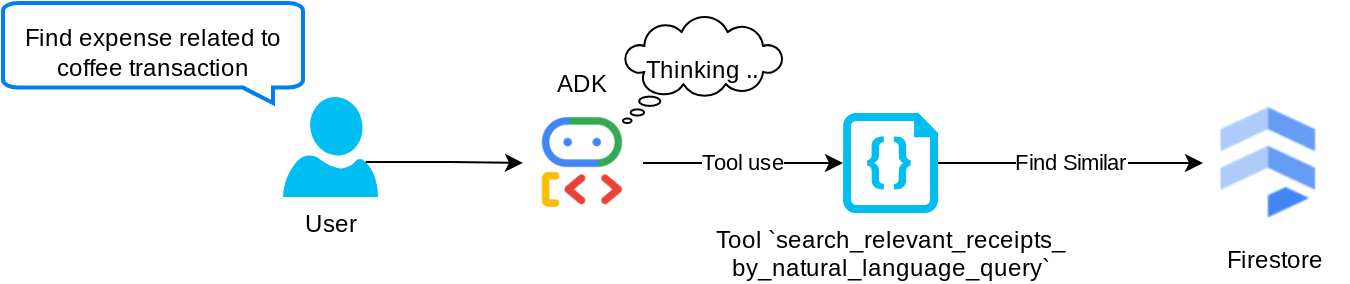
Đây là công cụ Tạo sinh tăng cường truy xuất (RAG) của chúng tôi. Tác nhân của chúng tôi có khả năng thiết kế truy vấn riêng để truy xuất các biên nhận có liên quan từ cơ sở dữ liệu vectơ và cũng có thể chọn thời điểm sử dụng công cụ này. Khái niệm cho phép tác nhân đưa ra quyết định độc lập về việc có sử dụng công cụ RAG này hay không và thiết kế truy vấn của riêng mình là một trong những định nghĩa về phương pháp RAG dựa trên tác nhân.
Không chỉ cho phép mô hình này tạo truy vấn riêng, mà còn cho phép mô hình này chọn số lượng tài liệu có liên quan mà mô hình muốn truy xuất. Kết hợp với thiết kế câu lệnh phù hợp, ví dụ:
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Điều này sẽ khiến công cụ này trở thành một công cụ mạnh mẽ có khả năng tìm kiếm gần như mọi thứ, mặc dù công cụ này có thể không trả về tất cả kết quả như mong đợi do bản chất không chính xác của tìm kiếm lân cận gần nhất.
5. 🚀 Sửa đổi bối cảnh cuộc trò chuyện thông qua lệnh gọi lại
Google ADK cho phép chúng ta "chặn" thời gian chạy của tác nhân ở nhiều cấp độ. Bạn có thể đọc thêm về chức năng chi tiết này trong tài liệu này . Trong phòng thí nghiệm này, chúng ta sẽ sử dụng before_model_callback để sửa đổi yêu cầu trước khi gửi đến LLM nhằm xoá dữ liệu hình ảnh trong bối cảnh nhật ký cuộc trò chuyện cũ ( chỉ bao gồm dữ liệu hình ảnh trong 3 lượt tương tác gần đây nhất của người dùng) để tăng hiệu quả
Tuy nhiên, chúng tôi vẫn muốn nhân viên hỗ trợ có được bối cảnh dữ liệu hình ảnh khi cần. Do đó, chúng tôi thêm một cơ chế để thêm phần giữ chỗ mã nhận dạng hình ảnh dạng chuỗi sau mỗi dữ liệu byte hình ảnh trong cuộc trò chuyện. Điều này sẽ giúp tác nhân liên kết mã nhận dạng hình ảnh với dữ liệu tệp thực tế của mã nhận dạng đó. Dữ liệu này có thể được sử dụng cả khi lưu trữ hoặc truy xuất hình ảnh. Cấu trúc sẽ có dạng như sau
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
Và khi dữ liệu byte trở nên lỗi thời trong nhật ký trò chuyện, giá trị nhận dạng chuỗi vẫn còn đó để vẫn cho phép quyền truy cập dữ liệu nhờ việc sử dụng công cụ. Ví dụ về cấu trúc nhật ký sau khi xoá dữ liệu hình ảnh
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Hãy bắt đầu! Tạo một tệp mới trong thư mục expense_manager_agent và đặt tên là callbacks.py
touch expense_manager_agent/callbacks.py
Mở tệp expense_manager_agent/callbacks.py, sau đó sao chép đoạn mã bên dưới
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 Câu lệnh
Để thiết kế một tác nhân có khả năng tương tác và các chức năng phức tạp, chúng ta cần tìm một câu lệnh đủ tốt để hướng dẫn tác nhân sao cho tác nhân có thể hoạt động theo cách chúng ta muốn.
Trước đây, chúng tôi có một cơ chế xử lý dữ liệu hình ảnh trong nhật ký trò chuyện, đồng thời có những công cụ có thể không dễ sử dụng, chẳng hạn như search_relevant_receipts_by_natural_language_query.. Chúng tôi cũng muốn nhân viên hỗ trợ có thể tìm kiếm và truy xuất hình ảnh biên nhận chính xác cho chúng tôi. Điều này có nghĩa là chúng ta cần truyền tải tất cả thông tin này một cách phù hợp trong cấu trúc câu lệnh phù hợp
Chúng tôi sẽ yêu cầu tác nhân sắp xếp đầu ra theo định dạng markdown sau đây để phân tích quy trình suy nghĩ, câu trả lời cuối cùng và tệp đính kèm ( nếu có)
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Hãy bắt đầu bằng câu lệnh sau để đạt được kỳ vọng ban đầu về hành vi của tác nhân quản lý chi phí. Tệp task_prompt.md phải đã có trong thư mục làm việc hiện tại, nhưng chúng ta cần di chuyển tệp này vào thư mục expense_manager_agent. Chạy lệnh sau để di chuyển
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Kiểm thử tác nhân
Bây giờ, hãy thử giao tiếp với tác nhân thông qua CLI bằng cách chạy lệnh sau
uv run adk run expense_manager_agent
Công cụ này sẽ cho ra kết quả như thế này, trong đó bạn có thể trò chuyện lần lượt với tác nhân, tuy nhiên, bạn chỉ có thể gửi văn bản thông qua giao diện này
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
Giờ đây, ngoài việc tương tác với CLI, ADK cũng cho phép chúng ta có một giao diện người dùng phát triển để tương tác và kiểm tra những gì đang diễn ra trong quá trình tương tác. Chạy lệnh sau để khởi động máy chủ giao diện người dùng phát triển cục bộ
uv run adk web --port 8080
Lệnh này sẽ tạo ra kết quả như ví dụ sau, tức là chúng ta đã có thể truy cập vào giao diện web
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
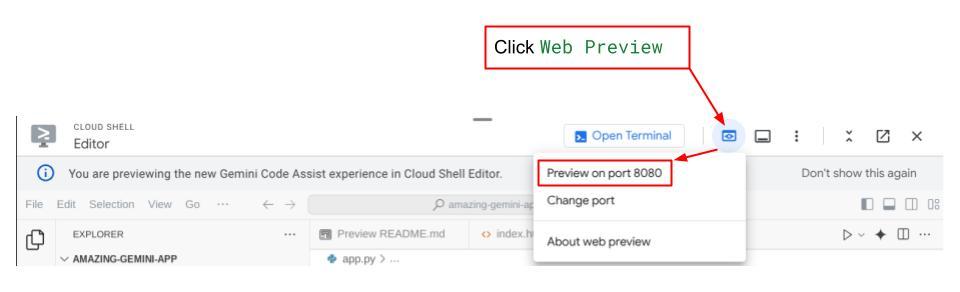
Bây giờ, để kiểm tra, hãy nhấp vào nút Web Preview (Xem trước trên web) ở khu vực trên cùng của Cloud Shell Editor rồi chọn Preview on port 8080 (Xem trước trên cổng 8080)
Bạn sẽ thấy trang web sau đây, nơi bạn có thể chọn các tác nhân có sẵn trên nút thả xuống ở trên cùng bên trái ( trong trường hợp của chúng ta, đó phải là expense_manager_agent) và tương tác với bot. Bạn sẽ thấy nhiều thông tin về chi tiết nhật ký trong thời gian chạy của tác nhân ở cửa sổ bên trái
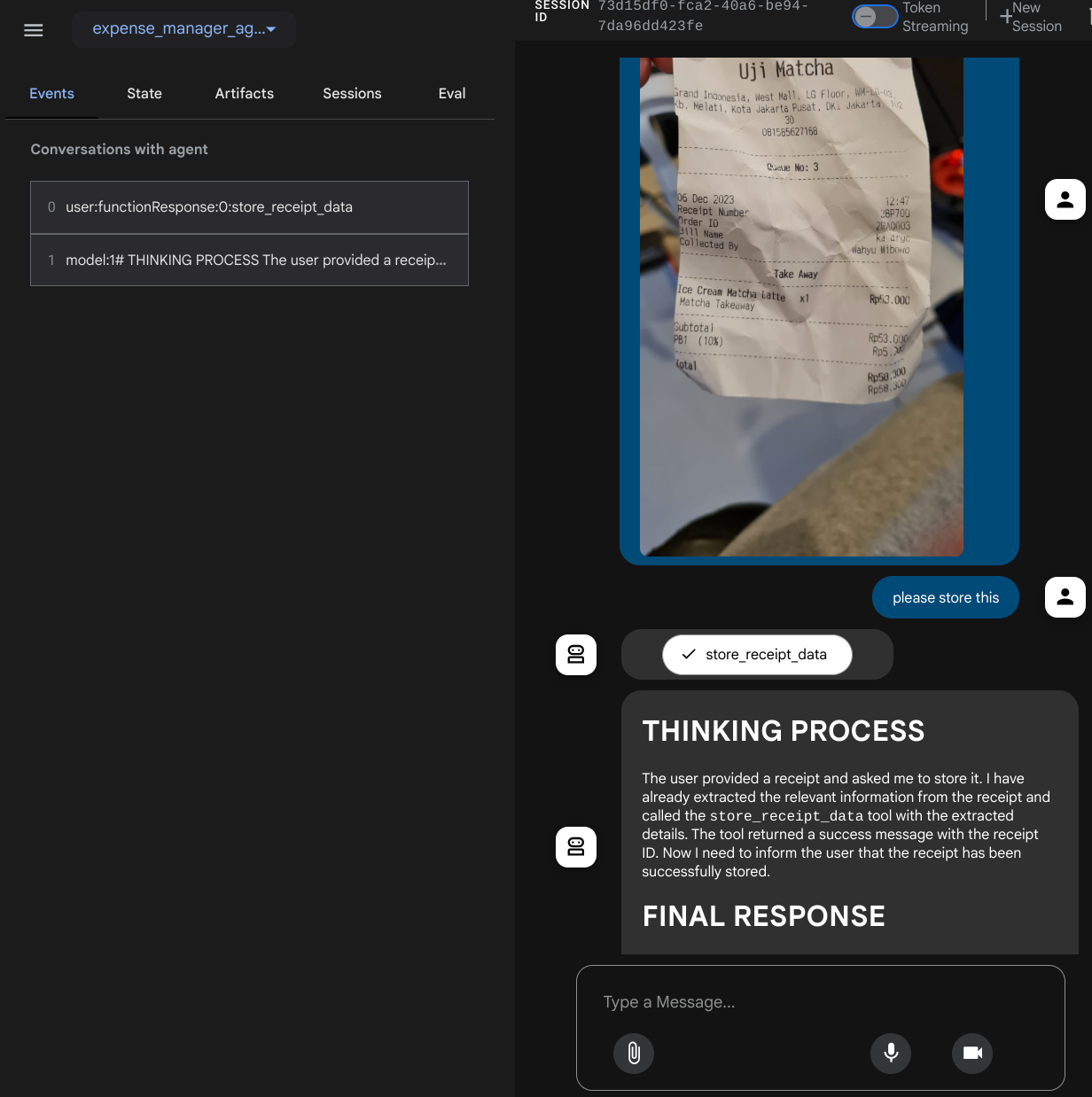
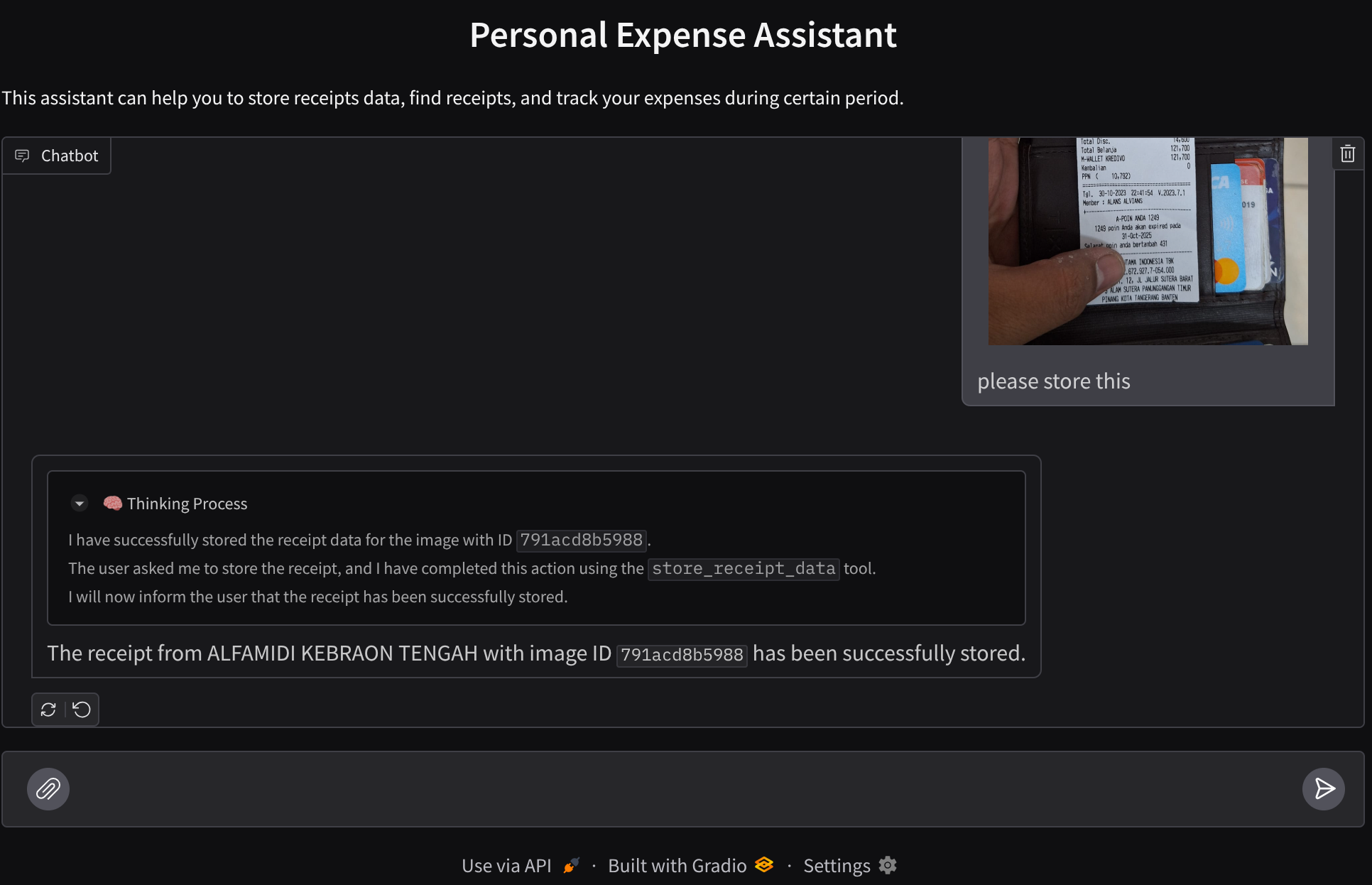
Hãy thử một số thao tác! Tải 2 biên nhận mẫu này lên ( nguồn : Tập dữ liệu Hugging Face mousserlane/id_receipt_dataset) . Nhấp chuột phải vào từng hình ảnh rồi chọn Lưu hình ảnh dưới dạng... ( thao tác này sẽ tải hình ảnh biên nhận xuống), sau đó tải tệp lên bot bằng cách nhấp vào biểu tượng "đoạn trích" và cho biết rằng bạn muốn lưu trữ những biên nhận này


Sau đó, hãy thử các truy vấn sau để tìm kiếm hoặc truy xuất tệp
- Cho biết bảng chi tiết về các khoản chi phí và tổng chi phí trong năm 2023
- "Give me receipt file from Indomaret" (Gửi cho tôi tệp biên nhận của Indomaret)
Khi sử dụng một số công cụ, bạn có thể kiểm tra những gì đang diễn ra trong giao diện người dùng phát triển
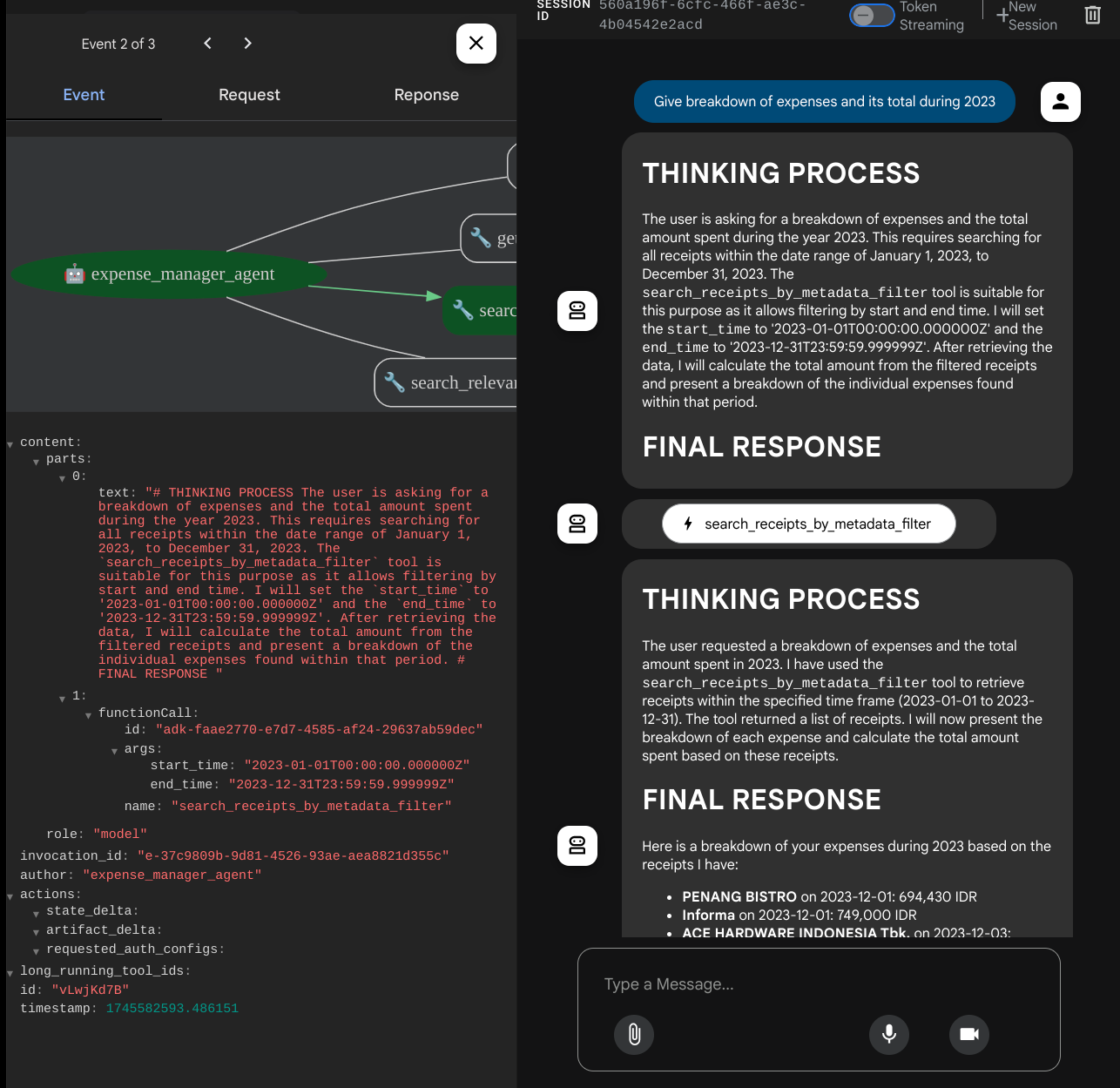
Xem cách mà trợ lý phản hồi bạn và kiểm tra xem trợ lý có tuân thủ tất cả các quy tắc được cung cấp trong câu lệnh bên trong task_prompt.py hay không. Xin chúc mừng! Bây giờ, bạn đã có một tác nhân phát triển hoạt động hoàn chỉnh.
Giờ là lúc hoàn tất việc này bằng giao diện người dùng phù hợp và đẹp mắt, cũng như các chức năng tải lên và tải tệp hình ảnh xuống.
8. 🚀 Xây dựng dịch vụ giao diện người dùng bằng Gradio
Chúng ta sẽ xây dựng một giao diện web trò chuyện có dạng như sau
Ứng dụng này có giao diện trò chuyện với một trường nhập dữ liệu để người dùng gửi văn bản và tải(các) tệp hình ảnh biên nhận lên.
Chúng ta sẽ tạo dịch vụ giao diện người dùng bằng Gradio.
Tạo tệp mới và đặt tên là frontend.py
touch frontend.py
sau đó sao chép mã sau và lưu lại
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Sau đó, chúng ta có thể thử chạy dịch vụ giao diện người dùng bằng lệnh sau. Đừng quên đổi tên tệp main.py thành frontend.py
uv run frontend.py
Bạn sẽ thấy kết quả tương tự như kết quả này trong Cloud Console
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Sau đó, bạn có thể kiểm tra giao diện web khi nhấn ctrl+nhấp vào đường liên kết URL cục bộ. Ngoài ra, bạn cũng có thể truy cập vào ứng dụng giao diện người dùng bằng cách nhấp vào nút Xem trước trên web ở phía trên cùng bên phải của Cloud Editor, rồi chọn Xem trước trên cổng 8080
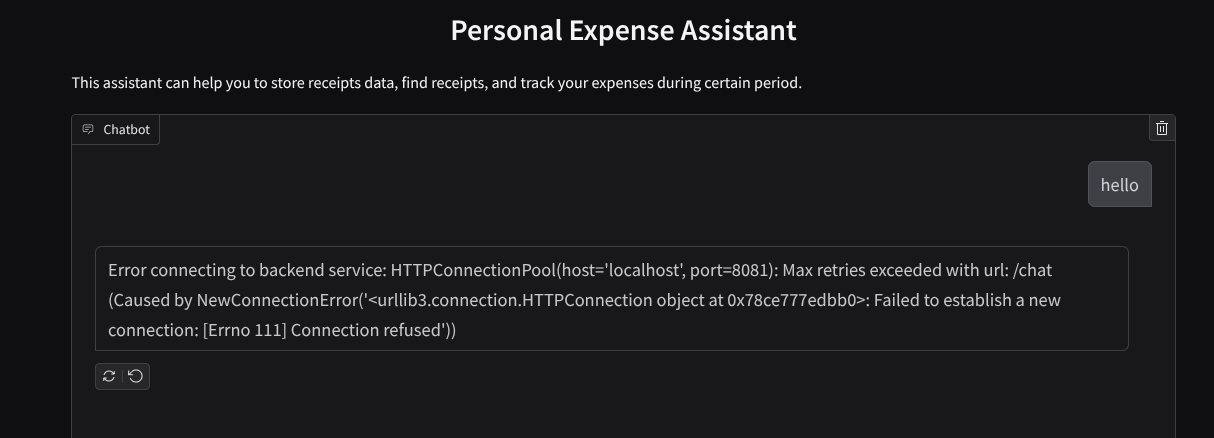
Bạn sẽ thấy giao diện web, tuy nhiên, bạn sẽ gặp phải lỗi dự kiến khi cố gắng gửi tin nhắn trò chuyện do dịch vụ phụ trợ chưa được thiết lập
Bây giờ, hãy chạy dịch vụ và đừng tắt dịch vụ ngay. Chúng ta sẽ chạy dịch vụ phụ trợ trong một thẻ dòng lệnh khác
Giải thích mã
Trong mã giao diện người dùng này, trước tiên, chúng ta cho phép người dùng gửi văn bản và tải nhiều tệp lên. Gradio cho phép chúng ta tạo loại chức năng này bằng phương thức gr.ChatInterface kết hợp với gr.MultimodalTextbox
Bây giờ, trước khi gửi tệp và văn bản đến phần phụ trợ, chúng ta cần xác định loại MIME của tệp vì phần phụ trợ cần loại MIME này. Chúng ta cũng cần mã hoá byte của tệp hình ảnh thành base64 và gửi cùng với loại MIME.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
Giản đồ dùng cho hoạt động tương tác giữa giao diện người dùng và phần phụ trợ được xác định trong schema.py. Chúng tôi sử dụng Pydantic BaseModel để thực thi việc xác thực dữ liệu trong lược đồ
Khi nhận được phản hồi, chúng tôi đã tách riêng phần nào là quy trình suy nghĩ, phản hồi cuối cùng và tệp đính kèm. Do đó, chúng ta có thể sử dụng thành phần Gradio để hiển thị từng thành phần bằng thành phần giao diện người dùng.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Xây dựng dịch vụ phụ trợ bằng FastAPI
Tiếp theo, chúng ta sẽ cần xây dựng phần phụ trợ có thể khởi động Agent cùng với các thành phần khác để có thể thực thi thời gian chạy của tác nhân.
Tạo tệp mới và đặt tên là backend.py
touch backend.py
Sao chép mã sau
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Sau đó, chúng ta có thể thử chạy dịch vụ phụ trợ. Hãy nhớ rằng ở bước trước, chúng ta đã chạy dịch vụ giao diện người dùng, giờ đây, chúng ta sẽ cần mở một thiết bị đầu cuối mới và thử chạy dịch vụ phụ trợ này
- Tạo một thiết bị đầu cuối mới. Chuyển đến thiết bị đầu cuối ở khu vực dưới cùng và tìm nút "+" để tạo một thiết bị đầu cuối mới. Hoặc bạn có thể nhấn tổ hợp phím Ctrl + Shift + C để mở thiết bị đầu cuối mới

- Sau đó, hãy đảm bảo rằng bạn đang ở trong thư mục làm việc personal-expense-assistant rồi chạy lệnh sau
uv run backend.py
- Nếu thành công, bạn sẽ thấy kết quả như sau
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Giải thích mã
Khởi động ADK Agent, SessionService và ArtifactService
Để chạy tác nhân trong dịch vụ phụ trợ, chúng ta cần tạo một Runner (Trình chạy) lấy cả SessionService và tác nhân của chúng ta. SessionService sẽ quản lý nhật ký và trạng thái trò chuyện. Do đó, khi được tích hợp với Runner, dịch vụ này sẽ giúp tác nhân của chúng tôi có khả năng nhận được ngữ cảnh của các cuộc trò chuyện đang diễn ra.
Chúng tôi cũng sử dụng ArtifactService để xử lý tệp đã tải lên. Bạn có thể đọc thêm thông tin chi tiết về Phiên và Hiện vật của ADK tại đây
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
Trong bản minh hoạ này, chúng ta sẽ sử dụng InMemorySessionService và GcsArtifactService để tích hợp với Runner của tác nhân. Vì nhật ký trò chuyện được lưu trữ trong bộ nhớ, nên nhật ký này sẽ bị mất khi dịch vụ phụ trợ bị tắt hoặc khởi động lại. Chúng ta sẽ khởi tạo các thành phần này trong vòng đời của ứng dụng FastAPI để được chèn dưới dạng phần phụ thuộc trong tuyến đường /chat.
Tải lên và tải hình ảnh xuống bằng GcsArtifactService
Tất cả hình ảnh được tải lên sẽ được lưu trữ dưới dạng cấu phần phần mềm bằng GcsArtifactService, bạn có thể kiểm tra cấu phần phần mềm này trong hàm format_user_request_to_adk_content_and_store_artifacts bên trong utils.py
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Tất cả các yêu cầu sẽ được trình chạy tác nhân xử lý đều cần được định dạng thành loại types.Content. Bên trong hàm, chúng ta cũng xử lý từng dữ liệu hình ảnh và trích xuất mã nhận dạng của dữ liệu đó để thay thế bằng phần giữ chỗ Mã nhận dạng hình ảnh.
Cơ chế tương tự được dùng để tải tệp đính kèm xuống sau khi trích xuất mã nhận dạng hình ảnh bằng biểu thức chính quy:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Kiểm thử tích hợp
Giờ đây, bạn sẽ có nhiều dịch vụ chạy trong các thẻ bảng điều khiển đám mây khác nhau:
- Dịch vụ giao diện người dùng chạy ở cổng 8080
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Dịch vụ phụ trợ chạy ở cổng 8081
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Ở trạng thái hiện tại, bạn có thể tải hình ảnh biên nhận lên và trò chuyện liền mạch với trợ lý từ ứng dụng web trên cổng 8080.
Nhấp vào nút Xem trước trên web ở khu vực trên cùng của Cloud Shell Editor rồi chọn Xem trước trên cổng 8080
Bây giờ, hãy tương tác với trợ lý!
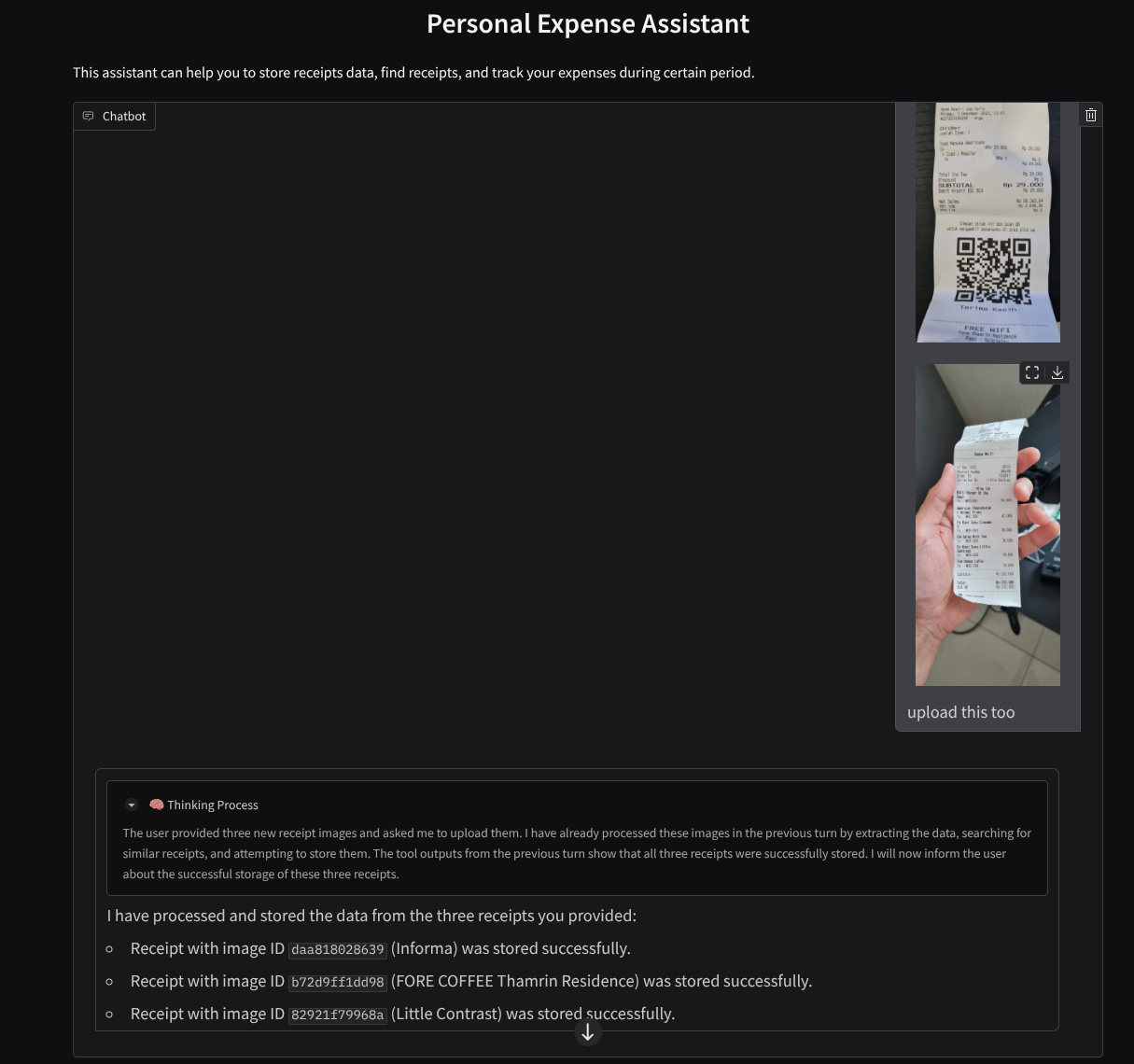
Tải các biên nhận sau xuống. Phạm vi ngày của dữ liệu biên nhận này là từ năm 2023 đến năm 2024 và yêu cầu trợ lý lưu trữ/tải dữ liệu đó lên
- Receipt Drive ( nguồn dữ liệu Hugging Face
mousserlane/id_receipt_dataset)
Hỏi nhiều điều
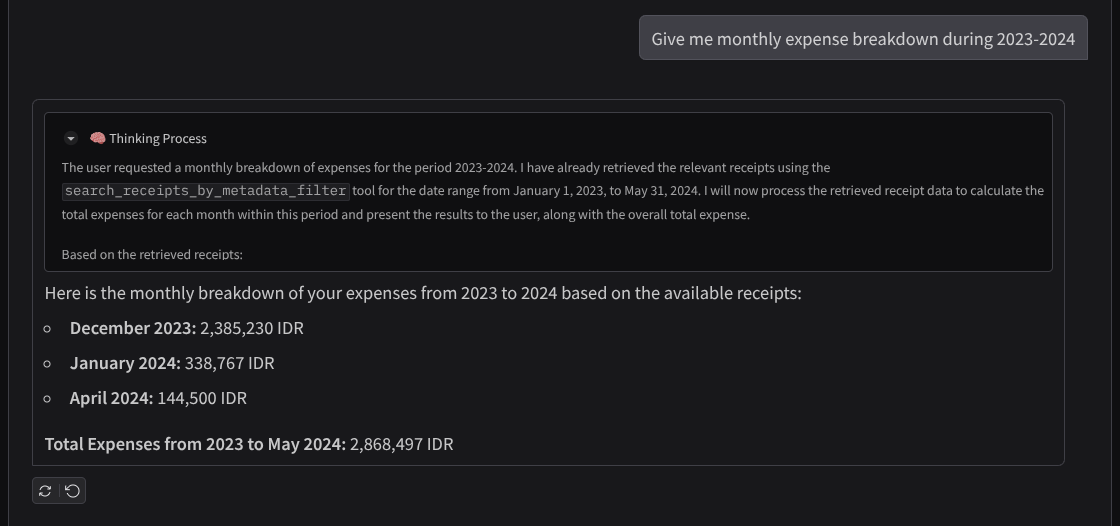
- Cho tôi xem bảng chi tiết chi phí hằng tháng trong khoảng thời gian từ năm 2023 đến năm 2024
- Cho tôi xem biên nhận của giao dịch mua cà phê
- "Give me receipt file from Yakiniku Like" (Gửi cho tôi tệp biên nhận của Yakiniku Like)
- Etc
Sau đây là một đoạn tương tác thành công
11. 🚀 Triển khai lên Cloud Run
Tất nhiên, chúng ta muốn truy cập vào ứng dụng tuyệt vời này ở mọi nơi. Để làm như vậy, chúng ta có thể đóng gói ứng dụng này và triển khai ứng dụng đó trên Cloud Run. Để minh hoạ, dịch vụ này sẽ được cung cấp dưới dạng một dịch vụ công khai mà người khác có thể truy cập. Tuy nhiên, hãy lưu ý rằng đây không phải là phương pháp hay nhất cho loại ứng dụng này vì nó phù hợp hơn với các ứng dụng cá nhân
Trong lớp học lập trình này, chúng ta sẽ đặt cả dịch vụ giao diện người dùng và dịch vụ phụ trợ vào 1 vùng chứa. Chúng ta sẽ cần sự trợ giúp của supervisord để quản lý cả hai dịch vụ. Bạn có thể kiểm tra tệp supervisord.conf và kiểm tra Dockerfile mà chúng tôi đặt supervisord làm điểm truy cập.
Đến đây, chúng ta đã có tất cả các tệp cần thiết để triển khai ứng dụng lên Cloud Run. Hãy triển khai ứng dụng. Chuyển đến Cloud Shell Terminal và đảm bảo dự án hiện tại được định cấu hình cho dự án đang hoạt động của bạn. Nếu không, bạn phải dùng lệnh gcloud configure để đặt mã dự án:
gcloud config set project [PROJECT_ID]
Sau đó, hãy chạy lệnh sau để triển khai ứng dụng này vào Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Nếu bạn được nhắc xác nhận việc tạo một sổ đăng ký hiện vật cho kho lưu trữ docker, hãy trả lời Y. Xin lưu ý rằng chúng tôi đang cho phép truy cập chưa xác thực tại đây vì đây là một ứng dụng minh hoạ. Bạn nên sử dụng phương thức xác thực phù hợp cho các ứng dụng doanh nghiệp và ứng dụng phát hành công khai.
Sau khi quá trình triển khai hoàn tất, bạn sẽ nhận được một đường liên kết tương tự như đường liên kết bên dưới:
https://personal-expense-assistant-*******.us-central1.run.app
Hãy tiếp tục sử dụng ứng dụng của bạn trong cửa sổ Ẩn danh hoặc trên thiết bị di động. Sản phẩm này đã được bán.
12. 🎯 Thách thức
Giờ là lúc bạn thể hiện và trau dồi kỹ năng khám phá của mình. Bạn có đủ khả năng để thay đổi mã sao cho phần phụ trợ có thể đáp ứng nhiều người dùng không? Bạn cần cập nhật những thành phần nào?
13. 🧹 Dọn dẹp
Để tránh phát sinh phí cho tài khoản Google Cloud của bạn đối với các tài nguyên được dùng trong lớp học lập trình này, hãy làm theo các bước sau:
- Trong bảng điều khiển Cloud, hãy chuyển đến trang Quản lý tài nguyên.
- Trong danh sách dự án, hãy chọn dự án mà bạn muốn xoá, rồi nhấp vào Xoá.
- Trong hộp thoại, hãy nhập mã dự án rồi nhấp vào Tắt để xoá dự án.
- Ngoài ra, bạn có thể chuyển đến Cloud Run trên bảng điều khiển, chọn dịch vụ bạn vừa triển khai rồi xoá.