
1. Einführung
Das Potenzial von generativer KI für die Erstellung von Testplänen beruht auf ihrer Fähigkeit, zwei der größten Herausforderungen in der modernen Qualitätssicherung zu lösen: Geschwindigkeit und Vollständigkeit. In den schnellen agilen und DevOps-Zyklen von heute ist das manuelle Erstellen detaillierter Testpläne ein erheblicher Engpass, der den gesamten Testprozess verzögert. Ein auf generativer KI basierender Agent kann User-Storys und technische Anforderungen aufnehmen und in wenigen Minuten einen umfassenden Testplan erstellen. So kann der QA-Prozess mit der Entwicklung Schritt halten. Außerdem ist KI hervorragend geeignet, komplexe Szenarien, Grenzfälle und negative Pfade zu erkennen, die ein Mensch möglicherweise übersieht. Dies führt zu einer erheblich verbesserten Testabdeckung und einer deutlichen Reduzierung von Fehlern, die in die Produktion gelangen.
In diesem Codelab erfahren Sie, wie Sie einen solchen Agenten erstellen, der die Produktspezifikationen aus Confluence abrufen, konstruktives Feedback geben und einen umfassenden Testplan generieren kann, der in eine CSV-Datei exportiert werden kann.
In diesem Codelab gehen Sie schrittweise so vor:
- Google Cloud-Projekt vorbereiten und alle erforderlichen APIs aktivieren
- Arbeitsbereich für Ihre Programmierumgebung einrichten
- Lokalen MCP-Server für Confluence vorbereiten
- ADK-Agenten-Quellcode, Prompt und Tools zum Herstellen einer Verbindung mit dem MCP-Server strukturieren
- Auslastung von Artifact Service und Tool-Kontexten
- Agenten mit der lokalen Web-Entwicklungs-UI des ADK testen
- Umgebungsvariablen verwalten und erforderliche Dateien einrichten, die zum Bereitstellen der Anwendung in Cloud Run benötigt werden
- Anwendung in Cloud Run bereitstellen
Architekturübersicht
Voraussetzungen
- Vertrautheit mit Python
- Grundkenntnisse der Full-Stack-Architektur mit HTTP-Dienst
Lerninhalte
- ADK-Agenten mit den verschiedenen Funktionen entwickeln
- Tool-Nutzung mit benutzerdefiniertem Tool und MCP
- Dateiausgabe durch Agent mithilfe der Artifact Service-Verwaltung einrichten
- BuiltInPlanner nutzen, um die Ausführung von Aufgaben zu verbessern, indem die Thinking-Funktionen von Gemini 2.5 Flash für die Planung verwendet werden
- Interaktion und Debugging über die ADK-Weboberfläche
- Anwendung mit Dockerfile in Cloud Run bereitstellen und Umgebungsvariablen angeben
Voraussetzungen
- Chrome-Webbrowser
- Ein Gmail-Konto
- Ein Cloud-Projekt mit aktivierter Abrechnung
- (Optional) Confluence-Bereich mit Seiten für Produktanforderungsdokumente
In diesem Codelab, das sich an Entwickler*innen aller Erfahrungsstufen (auch Anfänger*innen) richtet, wird Python in der Beispielanwendung verwendet. Python-Kenntnisse sind jedoch nicht erforderlich, um die vorgestellten Konzepte zu verstehen. Wenn Sie keinen Confluence-Arbeitsbereich haben, ist das kein Problem. Wir stellen Anmeldedaten für dieses Codelab zur Verfügung.
2. Hinweis
Aktives Projekt in der Cloud Console auswählen
In diesem Codelab wird davon ausgegangen, dass Sie bereits ein Google Cloud-Projekt mit aktivierter Abrechnung haben. Wenn Sie noch kein Konto haben, können Sie der Anleitung unten folgen, um eines zu erstellen.
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud-Projekt im Cloud Shell-Terminal einrichten
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.
- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
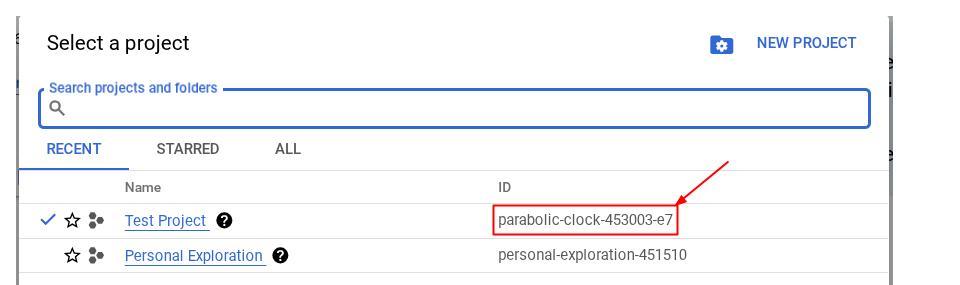
Alternativ können Sie die PROJECT_ID-ID auch in der Console sehen.
Klicken Sie darauf. Rechts sehen Sie dann alle Ihre Projekte und die Projekt-ID.
- Aktivieren Sie die erforderlichen APIs mit dem unten gezeigten Befehl. Das kann einige Minuten dauern.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Bei erfolgreicher Ausführung des Befehls sollte eine Meldung wie die unten gezeigte angezeigt werden:
Operation "operations/..." finished successfully.
Alternativ zum gcloud-Befehl können Sie in der Konsole nach den einzelnen Produkten suchen oder diesen Link verwenden.
Wenn eine API fehlt, können Sie sie jederzeit während der Implementierung aktivieren.
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
Cloud Shell-Editor aufrufen und Arbeitsverzeichnis der Anwendung einrichten
Jetzt können wir unseren Code-Editor für einige Programmieraufgaben einrichten. Dazu verwenden wir den Cloud Shell-Editor.
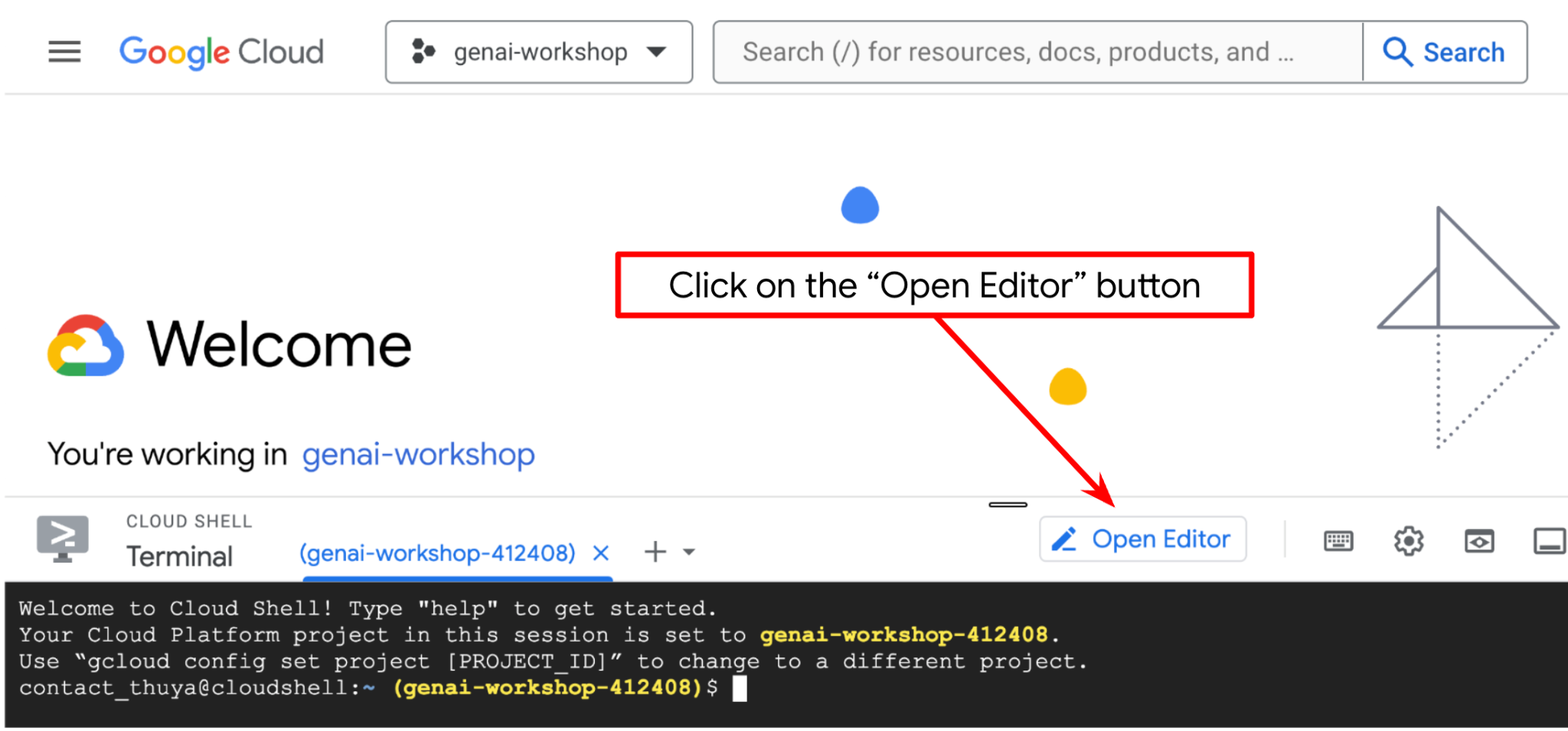
- Klicken Sie auf die Schaltfläche „Editor öffnen“, um den Cloud Shell-Editor zu öffnen. Hier können Sie Ihren Code schreiben
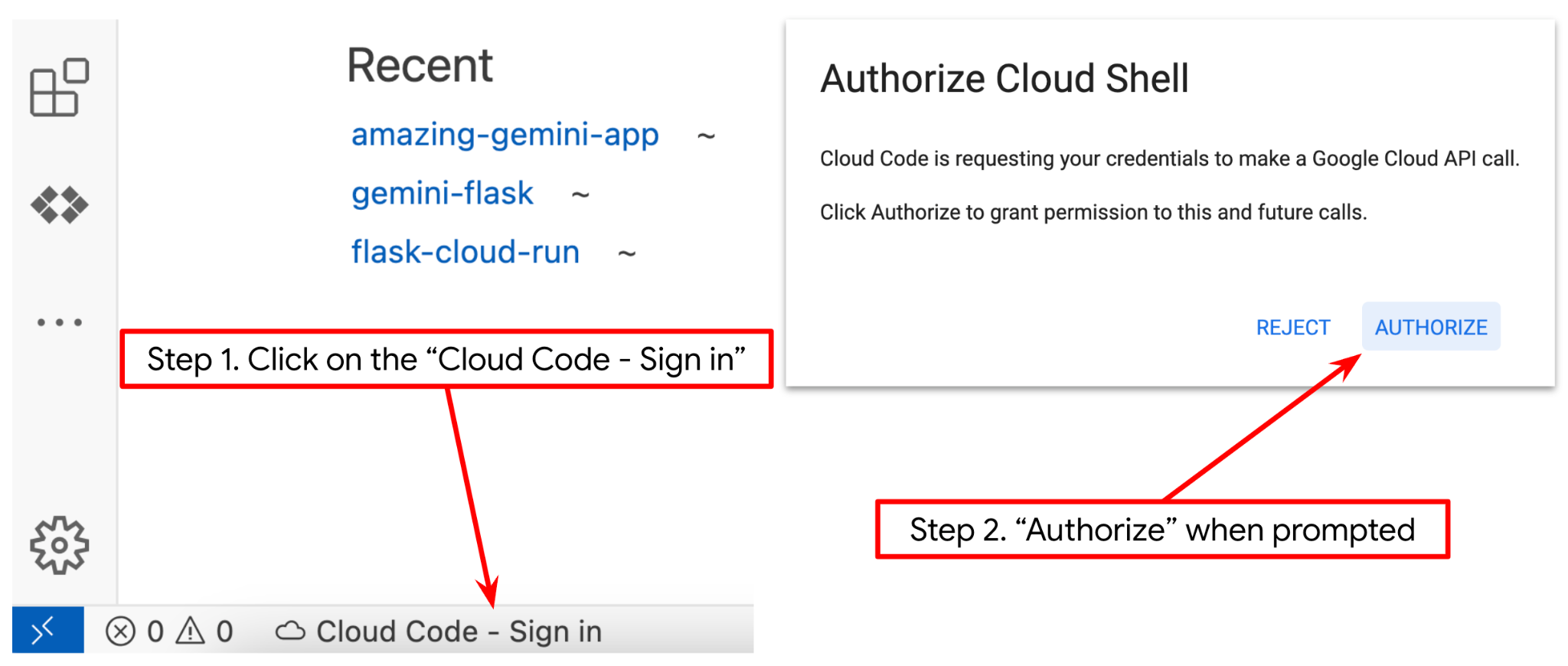
- Achten Sie darauf, dass das Cloud Code-Projekt in der Statusleiste unten links im Cloud Shell-Editor festgelegt ist, wie im Bild unten dargestellt, und auf das aktive Google Cloud-Projekt festgelegt ist, in dem die Abrechnung aktiviert ist. Autorisieren, wenn Sie dazu aufgefordert werden. Wenn Sie den vorherigen Befehl bereits ausgeführt haben, wird die Schaltfläche möglicherweise direkt auf Ihr aktiviertes Projekt verwiesen, anstatt auf die Schaltfläche „Anmelden“.
- Klonen Sie als Nächstes das Arbeitsverzeichnis der Vorlage für dieses Codelab von GitHub. Führen Sie dazu den folgenden Befehl aus. Das Arbeitsverzeichnis wird im Verzeichnis qa-test-planner-agent erstellt.
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
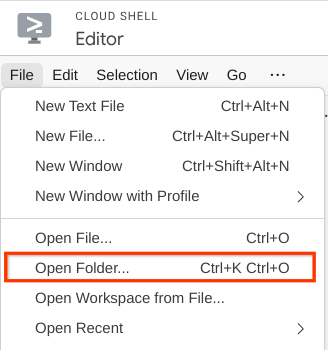
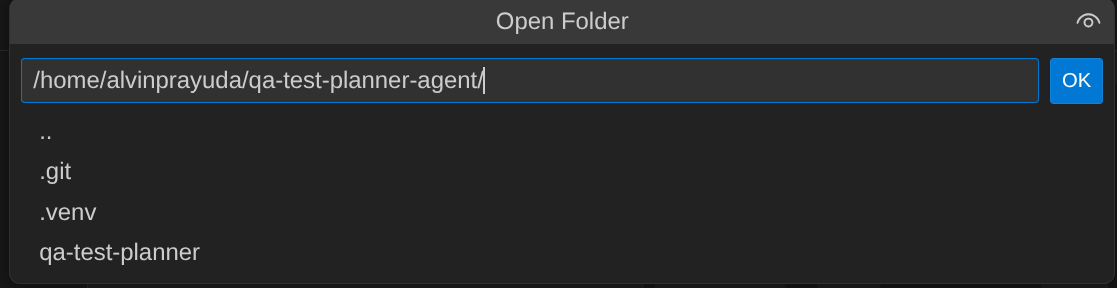
- Klicken Sie dann oben im Cloud Shell-Editor auf Datei –> Ordner öffnen, suchen Sie nach Ihrem Nutzernamen und dann nach dem Verzeichnis qa-test-planner-agent und klicken Sie auf die Schaltfläche „OK“. Dadurch wird das ausgewählte Verzeichnis zum Hauptarbeitsverzeichnis. In diesem Beispiel ist der Nutzername alvinprayuda. Der Verzeichnispfad wird unten angezeigt.
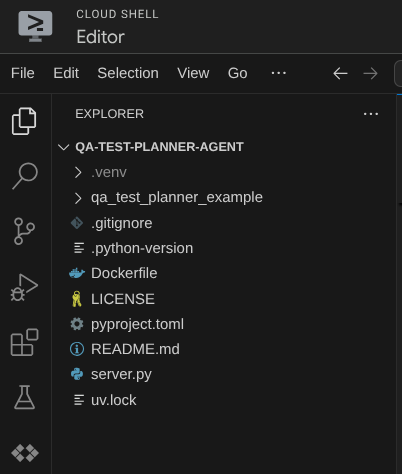
Der Cloud Shell Editor sollte jetzt so aussehen:
Umgebung einrichten
Virtuelle Python-Umgebung vorbereiten
Im nächsten Schritt bereiten Sie die Entwicklungsumgebung vor. Ihr aktuelles aktives Terminal sollte sich im Arbeitsverzeichnis qa-test-planner-agent befinden. In diesem Codelab verwenden wir Python 3.12 und den uv-Python-Projektmanager, um das Erstellen und Verwalten von Python-Versionen und virtuellen Umgebungen zu vereinfachen.
- Wenn Sie das Terminal noch nicht geöffnet haben, klicken Sie auf Terminal > Neues Terminal oder verwenden Sie Strg + Umschalt + C. Dadurch wird ein Terminalfenster im unteren Bereich des Browsers geöffnet.

- Laden Sie
uvherunter und installieren Sie Python 3.12 mit dem folgenden Befehl:
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- Initialisieren wir nun die virtuelle Umgebung mit
uv. Führen Sie dazu den folgenden Befehl aus:
uv sync --frozen
Dadurch wird das Verzeichnis .venv erstellt und die Abhängigkeiten werden installiert. Ein kurzer Blick in die Datei pyproject.toml gibt Ihnen Informationen zu den Abhängigkeiten, die so angezeigt werden:
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- Um die virtuelle Umgebung zu testen, erstellen Sie die neue Datei main.py und kopieren Sie den folgenden Code.
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- Führen Sie dann den folgenden Befehl aus:
uv run main.py
Die Ausgabe sollte in etwa so aussehen:
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
Das zeigt, dass das Python-Projekt richtig eingerichtet wird.
Nun können wir mit dem nächsten Schritt fortfahren und den Agent und dann die Dienste erstellen.
3. Agent mit Google ADK und Gemini 2.5 erstellen
Einführung in die ADK-Verzeichnisstruktur
Sehen wir uns zuerst an, was das ADK zu bieten hat und wie Sie den Agent erstellen. Die vollständige ADK-Dokumentation finden Sie unter dieser URL . Das ADK bietet viele Dienstprogramme für die Ausführung von CLI-Befehlen. Einige davon sind :
- Agentenverzeichnisstruktur einrichten
- Schnelles Ausprobieren der Interaktion über die CLI-Ein- und -Ausgabe
- Schnelle Einrichtung der Web-Benutzeroberfläche für die lokale Entwicklung
Erstellen wir nun die Verzeichnisstruktur des Agents mit dem CLI-Befehl. Führen Sie den folgenden Befehl aus:
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
Damit wird die folgende Agent-Verzeichnisstruktur in Ihrem aktuellen Arbeitsverzeichnis erstellt:
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
Wenn Sie init.py und agent.py untersuchen, sehen Sie diesen Code.
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
QA-Testplaner-Agent erstellen
Lassen Sie uns unseren QA Test Planner Agent erstellen. Öffnen Sie die Datei qa_test_planner/agent.py und kopieren Sie den folgenden Code, der den root_agent enthält.
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
Konfigurationsdateien einrichten
Jetzt müssen wir zusätzliche Konfigurationen für dieses Projekt hinzufügen, da dieser Agent Zugriff auf Confluence benötigt.
Öffnen Sie qa_test_planner/.env und fügen Sie die folgenden Umgebungsvariablenwerte hinzu. Die resultierende .env-Datei sollte so aussehen:
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
Leider kann dieser Confluence-Bereich nicht öffentlich gemacht werden. Sie können die Dateien jedoch mit den oben genannten Anmeldedaten aufrufen, um die verfügbaren Produktspezifikationen zu lesen.
Erläuterung zum Code
Dieses Skript enthält unsere Agent-Initialisierung, in der wir Folgendes initialisieren:
- Legen Sie das zu verwendende Modell auf
gemini-2.5-flashfest. - Confluence MCP-Tools einrichten, die über Stdio kommunizieren
write_test_tool-Tool zum Schreiben von Testplänen und zum Exportieren von CSV-Dateien in Artefakte einrichten- Beschreibung und Anleitung für den Agenten einrichten
- Planung vor der Generierung der endgültigen Antwort oder Ausführung mit den Thinking-Funktionen von Gemini 2.5 Flash aktivieren
Der Agent selbst, wenn er von einem Gemini-Modell mit integrierten Thinking-Funktionen unterstützt und mit den planner-Argumenten konfiguriert wird, kann seine Thinking-Funktionen zeigen und wird auch auf der Weboberfläche angezeigt. Der Code zum Konfigurieren dieser Einstellung ist unten zu sehen.
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
Und bevor es Maßnahmen ergreift, können wir seinen Denkprozess nachvollziehen.
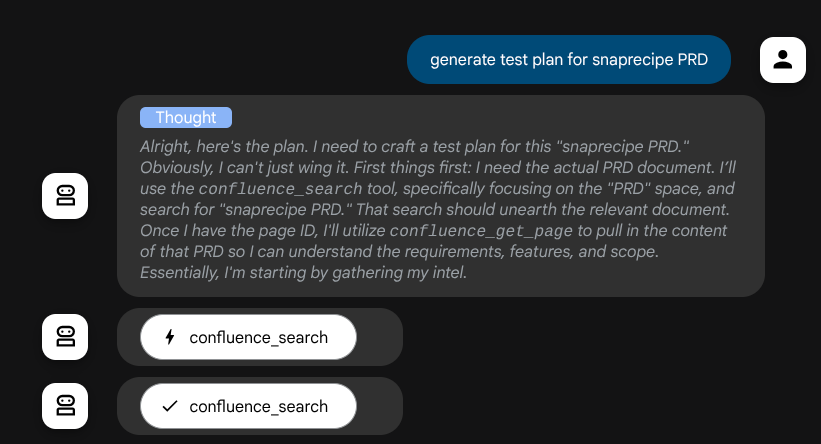
Das Confluence MCP-Tool
Um eine Verbindung zum MCP-Server über das ADK herzustellen, müssen wir MCPToolSet verwenden, das aus dem Modul google.adk.tools.mcp_tool.mcp_toolset importiert werden kann. Der Code, der hier initialisiert wird, ist unten zu sehen ( aus Effizienzgründen gekürzt).
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
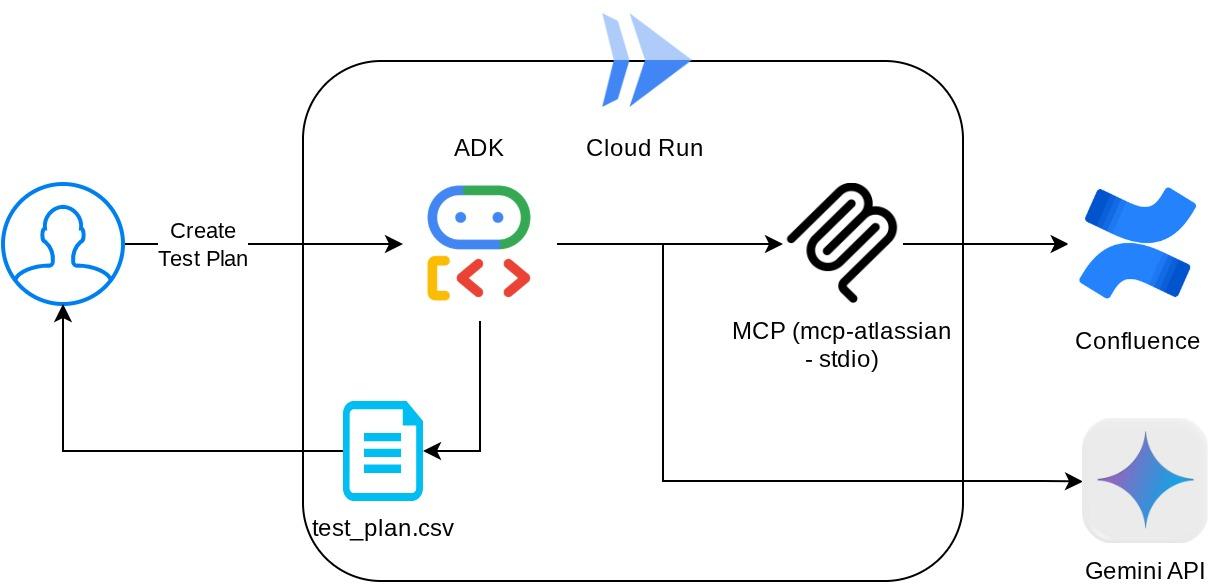
Bei dieser Konfiguration initialisiert der KI-Agent den Confluence-MCP-Server als separaten Prozess und verarbeitet die Kommunikation mit diesen Prozessen über Studio I/O. Dieser Ablauf wird im folgenden Bild der MCP-Architektur im roten Feld dargestellt.
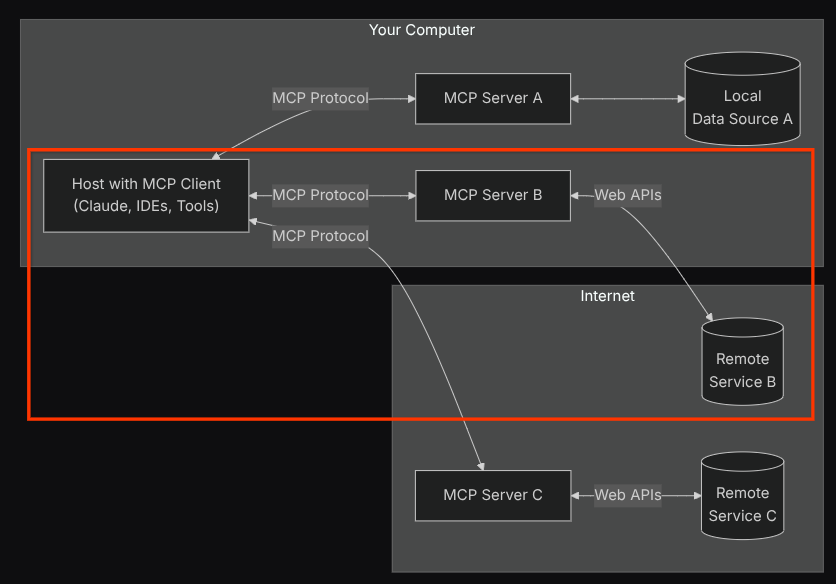
Außerdem beschränken wir in den Befehlsargumenten der MCP-Initialisierung die Tools, die verwendet werden können, auf confluence_search, confluence_get_page und confluence_get_page_children, die unsere Anwendungsfälle für QA-Test-Agents unterstützen. Für dieses Codelab verwenden wir den von der Community beigesteuerten Atlassian MCP-Server ( vollständige Dokumentation).
Write Test Tool
Nachdem der Kundenservicemitarbeiter Kontext vom Confluence MCP Tool erhalten hat, kann er den erforderlichen Testplan für den Nutzer erstellen. Wir möchten jedoch eine Datei erstellen, die diesen Testplan enthält, damit er gespeichert und mit der anderen Person geteilt werden kann. Dazu stellen wir das benutzerdefinierte Tool write_test_tool unten zur Verfügung.
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
Die oben deklarierte Funktion unterstützt die folgenden Funktionen:
- Prüfen Sie den erstellten Testplan, damit er den Spezifikationen für Pflichtfelder entspricht. Wir prüfen ihn mit dem Pydantic-Modell. Wenn ein Fehler auftritt, geben wir die Fehlermeldung an den Agent zurück.
- Ergebnis mit Pandas-Funktionen in eine CSV-Datei exportieren
- Die generierte Datei wird dann als Artefakt mit den Funktionen des Artifact Service gespeichert, auf die über das ToolContext-Objekt zugegriffen werden kann, das bei jedem Tool-Aufruf verfügbar ist.
Wenn wir die generierten Dateien als Artefakt speichern, wird dies in der ADK-Laufzeit als Ereignis markiert und kann später in der Web-Benutzeroberfläche in der Agent-Interaktion angezeigt werden.
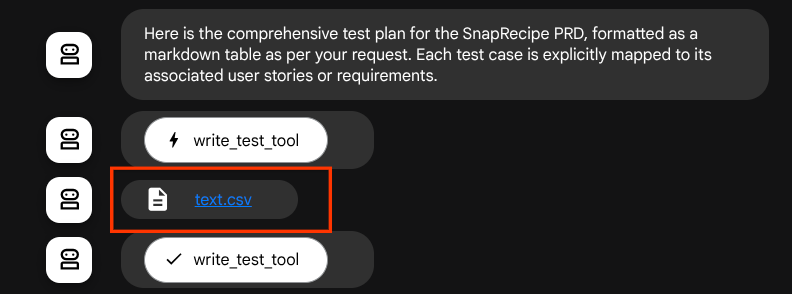
So können wir die Dateiantwort des KI-Agents dynamisch einrichten, damit sie dem Nutzer zur Verfügung gestellt wird.
4. Agent testen
Versuchen wir nun, über die Befehlszeile mit dem Agenten zu kommunizieren. Führen Sie dazu den folgenden Befehl aus:
uv run adk run qa_test_planner
Es wird eine Ausgabe wie diese angezeigt, in der Sie abwechselnd mit dem Agent chatten können. Über diese Schnittstelle können Sie jedoch nur Text senden.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
Es ist schön, dass man über die Befehlszeile mit dem Agenten chatten kann. Noch besser ist es aber, wenn wir einen schönen Webchat mit ihm haben, und das können wir auch! Mit dem ADK können wir auch eine Entwicklungs-UI erstellen, um zu interagieren und zu prüfen, was während der Interaktion passiert. Führen Sie den folgenden Befehl aus, um den lokalen Entwicklungsserver für die Benutzeroberfläche zu starten:
uv run adk web --port 8080
Es wird eine Ausgabe wie im folgenden Beispiel erzeugt. Das bedeutet, dass wir bereits auf die Weboberfläche zugreifen können.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
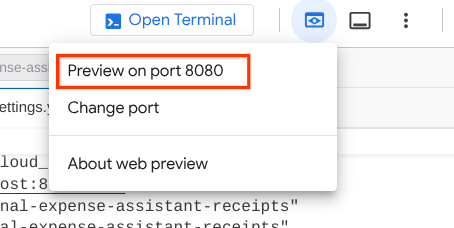
Klicken Sie nun oben im Cloud Shell Editor auf die Schaltfläche Webvorschau und wählen Sie Vorschau auf Port 8080 aus, um die Vorschau aufzurufen.
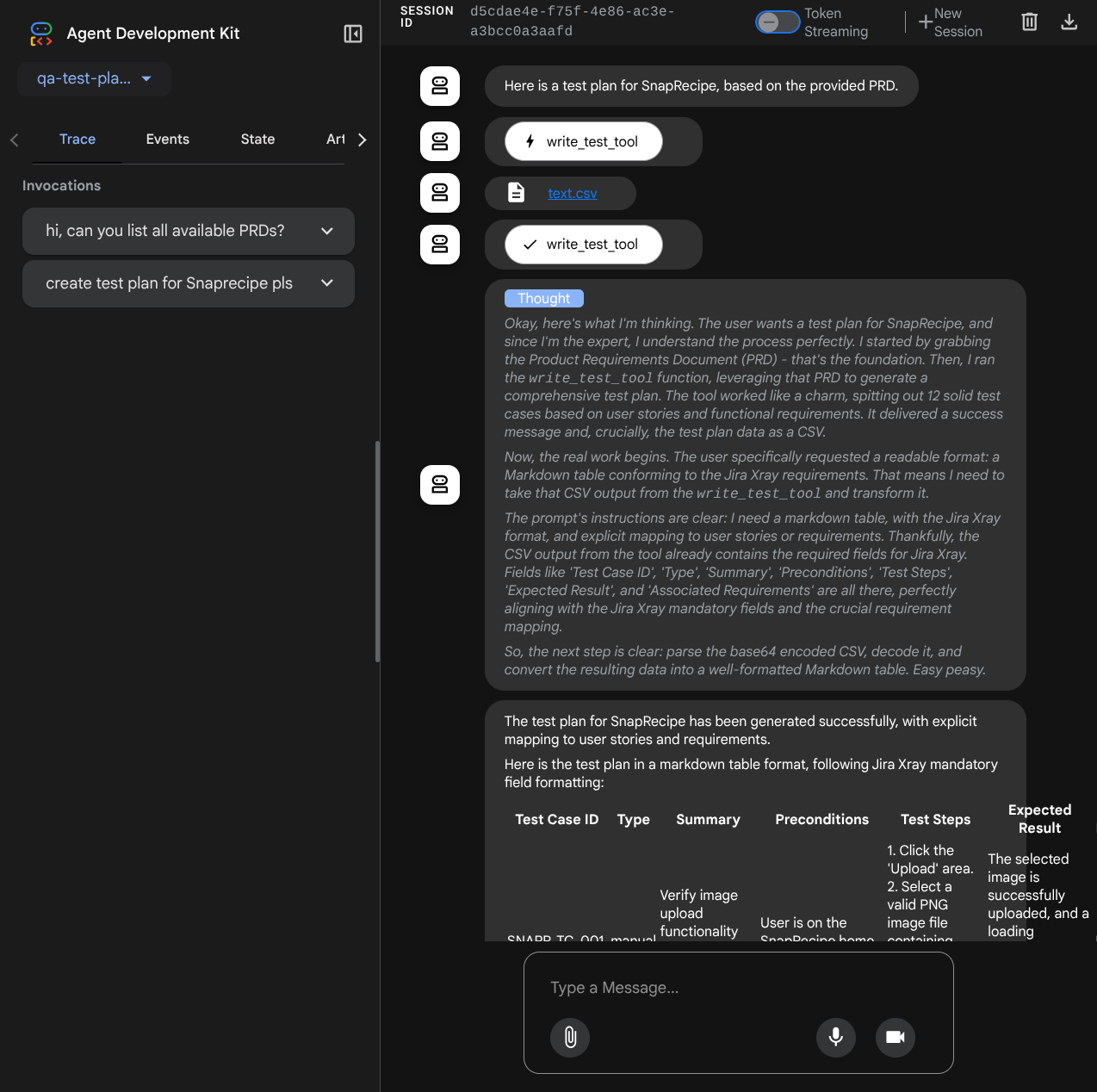
Sie sehen die folgende Webseite, auf der Sie oben links im Drop-down-Menü verfügbare Agents auswählen können ( in unserem Fall sollte es qa_test_planner sein) und mit dem Bot interagieren können. Im linken Fenster werden während der Laufzeit des Agents viele Informationen zu den Protokolldetails angezeigt.
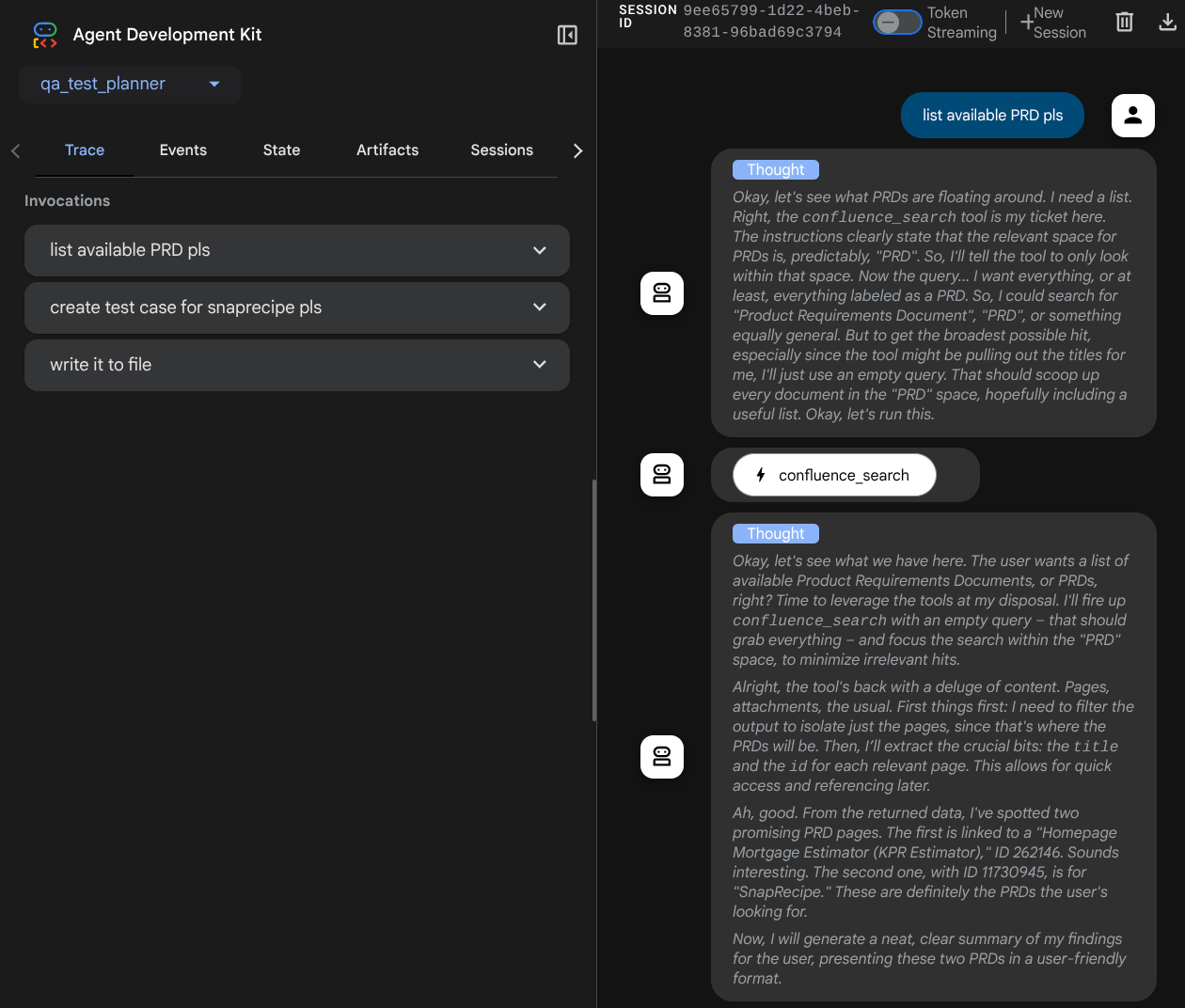
Probieren wir einige Aktionen aus. Chatten Sie mit den Agenten mit diesen Prompts:
- „Bitte liste alle verfügbaren PRDs auf.“
- „Write test plan for Snaprecipe PRD“ (Schreibe einen Testplan für das Snaprecipe-PRD)
Bei der Verwendung einiger Tools können Sie in der Entwickler-UI sehen, was passiert.
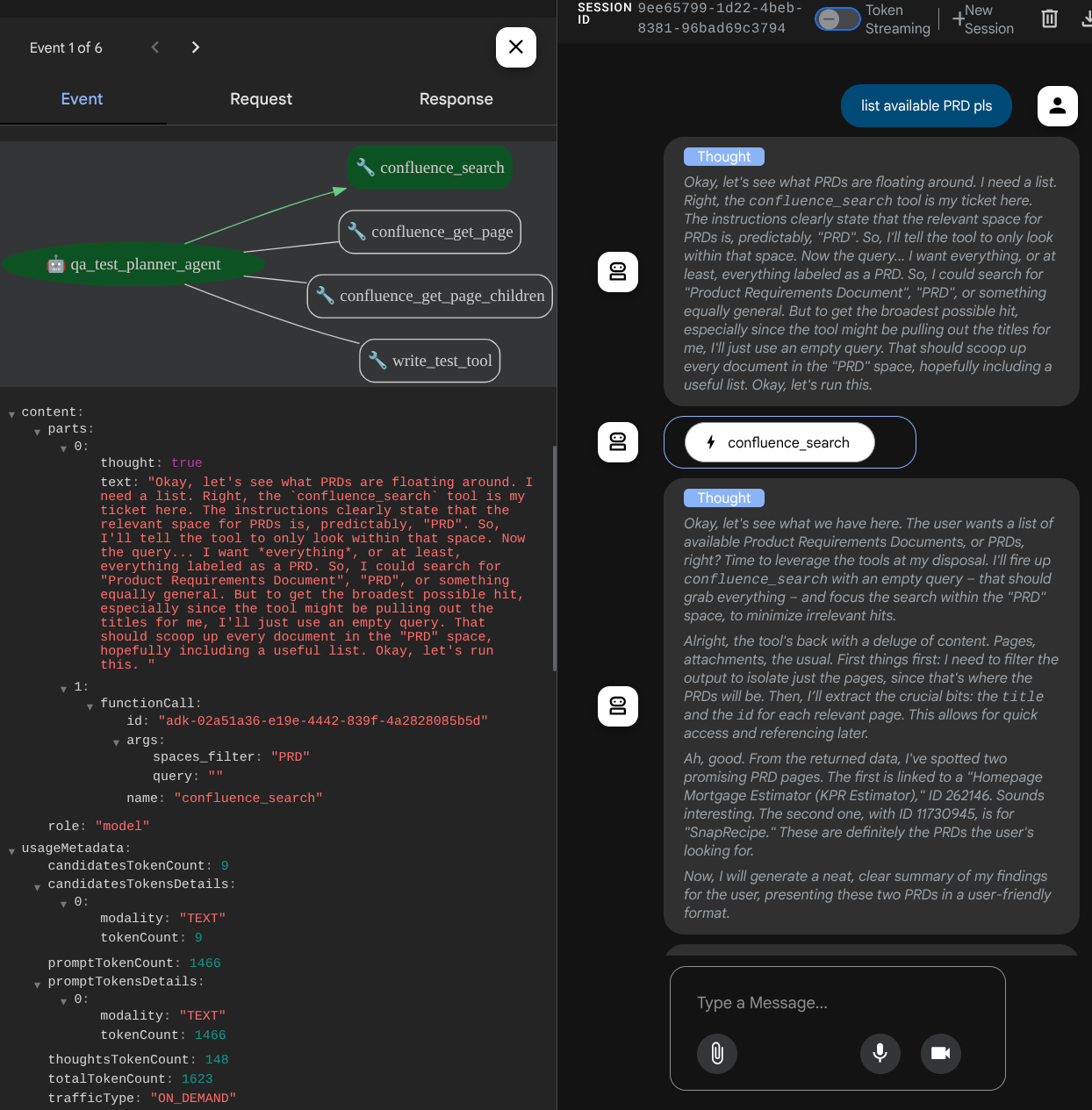
Sehen Sie sich an, wie der Agent auf Sie reagiert, und prüfen Sie, wann wir nach einer Testdatei fragen. In diesem Fall wird der Testplan als Artefakt in einer CSV-Datei generiert.
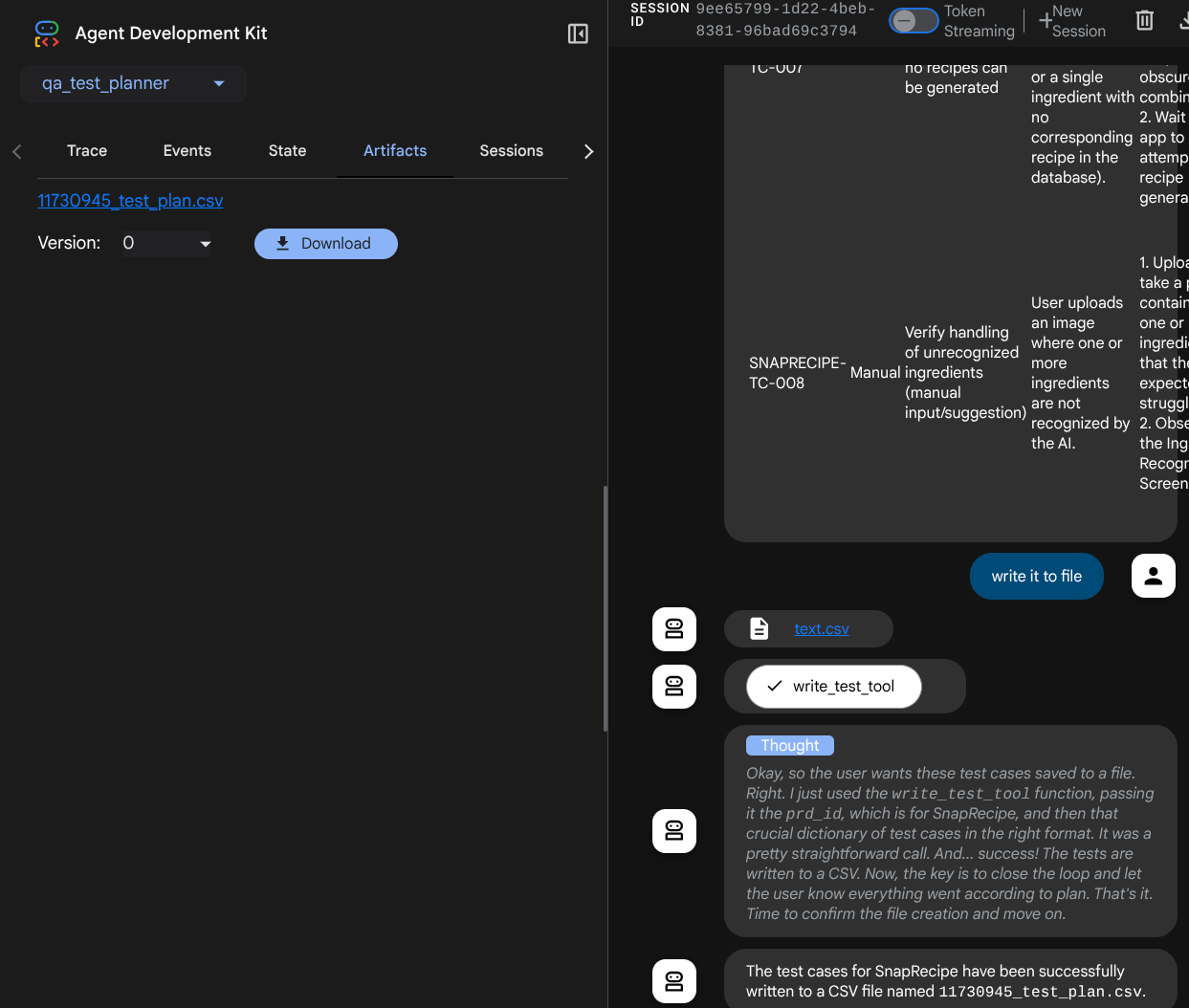
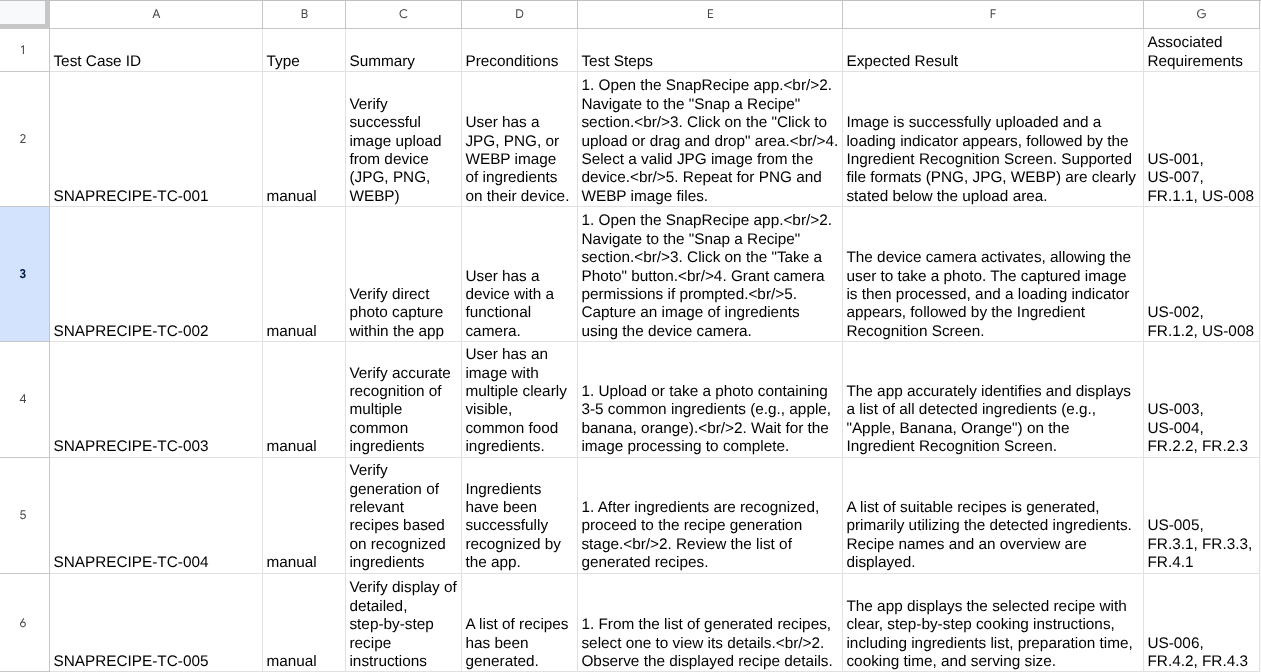
Sie können den Inhalt der CSV-Datei jetzt prüfen, indem Sie sie beispielsweise in Google Tabellen importieren.
Glückwunsch! Sie haben jetzt einen funktionierenden QA Test Planner-Agent, der lokal ausgeführt wird. Sehen wir uns nun an, wie wir sie in Cloud Run bereitstellen können, damit auch andere sie nutzen können.
5. In Cloud Run bereitstellen
Natürlich möchten wir von überall auf diese tolle App zugreifen können. Dazu können wir diese Anwendung verpacken und in Cloud Run bereitstellen. Im Rahmen dieser Demo wird dieser Dienst als öffentlicher Dienst bereitgestellt, auf den andere zugreifen können. Beachten Sie jedoch, dass dies nicht die beste Vorgehensweise ist.
In Ihrem aktuellen Arbeitsverzeichnis sind bereits alle Dateien vorhanden, die zum Bereitstellen unserer Anwendungen in Cloud Run erforderlich sind: das Agent-Verzeichnis, Dockerfile und server.py (das Hauptdienstskript). Stellen wir die Anwendung jetzt bereit. Rufen Sie das Cloud Shell-Terminal auf und prüfen Sie, ob das aktuelle Projekt für Ihr aktives Projekt konfiguriert ist. Falls nicht, müssen Sie die Projekt-ID mit dem Befehl „gcloud configure“ festlegen:
gcloud config set project [PROJECT_ID]
Führen Sie dann den folgenden Befehl aus, um die Anwendung in Cloud Run bereitzustellen.
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
Wenn Sie aufgefordert werden, die Erstellung eines Artifact Registry-Repositorys für Docker zu bestätigen, antworten Sie einfach mit Y. Hinweis: Wir erlauben hier den nicht authentifizierten Zugriff, da es sich um eine Demoanwendung handelt. Wir empfehlen, für Ihre Unternehmens- und Produktionsanwendungen eine geeignete Authentifizierung zu verwenden.
Nach Abschluss der Bereitstellung sollten Sie einen Link ähnlich dem folgenden erhalten:
https://qa-test-planner-agent-*******.us-central1.run.app
Wenn Sie auf die URL zugreifen, wird die Web-Entwickler-UI aufgerufen, ähnlich wie bei einem lokalen Test. Sie können die Anwendung nun über das Inkognitofenster oder Ihr Mobilgerät verwenden. Sie sollte bereits aktiv sein.
Sehen wir uns nun an, was passiert, wenn wir diese verschiedenen Prompts nacheinander ausprobieren:
- " Kannst du das PRD für den Hypothekenrechner finden? "
- „Gib mir Feedback dazu, was wir daran verbessern können.“
- „Schreibe den Testplan dafür.“
Da wir den Agenten als FastAPI-App ausführen, können wir außerdem alle API-Routen über die Route /docs aufrufen. Wenn Sie beispielsweise über die URL https://qa-test-planner-agent-*******.us-central1.run.app/docs auf die Dokumentation zugreifen, wird die Swagger-Dokumentationsseite wie unten dargestellt angezeigt.
Erläuterung zum Code
Sehen wir uns nun an, welche Datei wir hier für das Deployment benötigen. Beginnen wir mit server.py.
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Mit der Funktion get_fast_api_app können wir unseren Agenten ganz einfach in eine FastAPI-App umwandeln. In dieser Funktion können wir verschiedene Funktionen einrichten, z. B. den Sitzungsdienst, den Artefaktdienst oder sogar das Senden von Tracing-Daten in die Cloud.
Wenn Sie möchten, können Sie hier auch den Anwendungslebenszyklus festlegen. Danach können wir uvicorn verwenden, um die Fast API-Anwendung auszuführen.
Danach enthält das Dockerfile die erforderlichen Schritte zum Ausführen der Anwendung.
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. Herausforderung
Jetzt ist es an der Zeit, Ihr Wissen zu vertiefen und Ihre Fähigkeiten zu verbessern. Kannst du auch ein Tool erstellen, mit dem Feedback zur PRD-Überprüfung in eine Datei geschrieben wird?
7. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
- Alternativ können Sie in der Console zu Cloud Run wechseln, den gerade bereitgestellten Dienst auswählen und löschen.