
1. Introducción
El potencial de usar la IA generativa para crear planes de pruebas radica en su capacidad de resolver dos de los mayores desafíos en el control de calidad moderno: la velocidad y la exhaustividad. En los ciclos rápidos de Agile y DevOps actuales, la creación manual de planes de prueba detallados es un cuello de botella importante que retrasa todo el proceso de prueba. Un agente potenciado por IA generativa puede procesar historias de usuarios y requisitos técnicos para producir un plan de pruebas detallado en minutos, no en días, lo que garantiza que el proceso de QA siga el ritmo del desarrollo. Además, la IA se destaca por identificar situaciones complejas, casos extremos y rutas negativas que una persona podría pasar por alto, lo que lleva a una cobertura de pruebas muy mejorada y a una reducción significativa de los errores que se filtran a la producción.
En este codelab, exploraremos cómo crear un agente de este tipo que pueda recuperar los documentos de requisitos del producto de Confluence y que sea capaz de brindar comentarios constructivos, así como generar un plan de pruebas integral que se pueda exportar a un archivo CSV.
En el codelab, seguirás un enfoque paso a paso de la siguiente manera:
- Prepara tu proyecto de Google Cloud y habilita todas las APIs necesarias en él
- Configura el espacio de trabajo para tu entorno de programación
- Cómo preparar el servidor de mcp local para Confluence
- Estructura del código fuente, la instrucción y las herramientas del agente del ADK para conectarse al servidor de MCP
- Comprensión del uso de los contextos de Artifact Service y Tool
- Prueba del agente con la IU web de desarrollo local del ADK
- Administrar variables de entorno y configurar los archivos necesarios para implementar la aplicación en Cloud Run
- Implementa la aplicación en Cloud Run
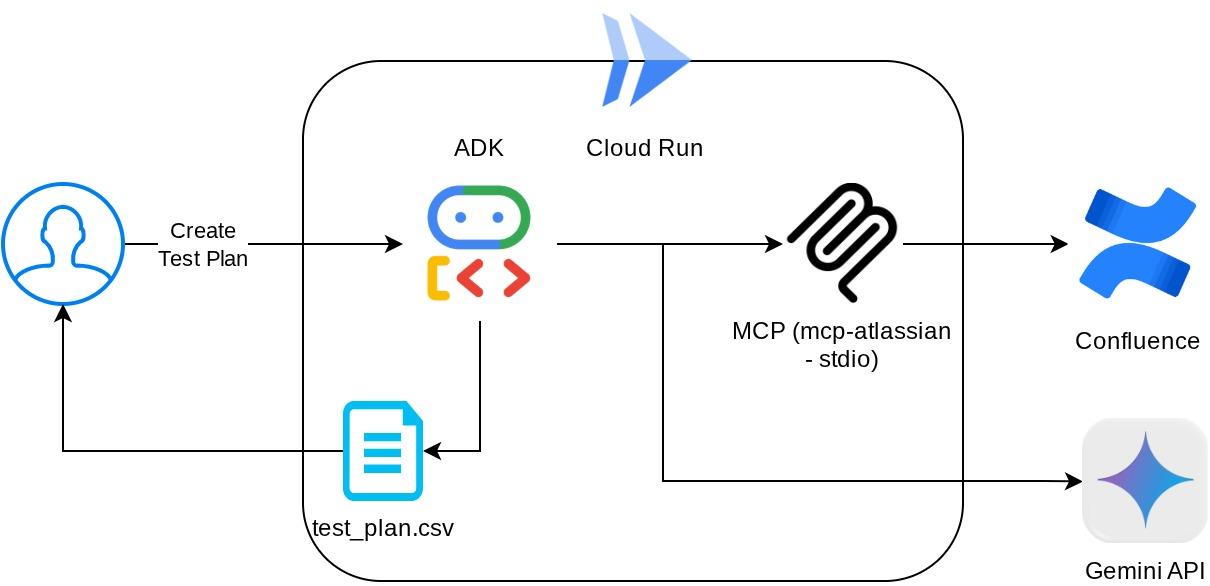
Descripción general de la arquitectura
Requisitos previos
- Comodidad para trabajar con Python
- Conocimiento de la arquitectura básica de pila completa con el servicio HTTP
Qué aprenderás
- Diseño de la arquitectura del agente del ADK y aprovechamiento de sus diversas capacidades
- Uso de la herramienta con la herramienta personalizada y el MCP
- Configura la salida de archivos por parte del agente con la administración del servicio de artefactos
- Utilizar BuiltInPlanner para mejorar la ejecución de tareas a través de la planificación con las capacidades de pensamiento de Gemini 2.5 Flash
- Interacción y depuración a través de la interfaz web del ADK
- Implementa la aplicación en Cloud Run con Dockerfile y proporciona variables de entorno
Requisitos
- Navegador web Chrome
- Una cuenta de Gmail
- Un proyecto de Cloud con la facturación habilitada
- (Opcional) Espacio de Confluence con páginas de documentos de requisitos del producto
Este codelab, diseñado para desarrolladores de todos los niveles (incluidos los principiantes), usa Python en su aplicación de ejemplo. Sin embargo, no es necesario tener conocimientos de Python para comprender los conceptos presentados. No te preocupes por el espacio de Confluence si no tienes uno. Te proporcionaremos credenciales para probar este codelab.
2. Antes de comenzar
Selecciona el proyecto activo en la consola de Cloud
En este codelab, se supone que ya tienes un proyecto de Google Cloud con la facturación habilitada. Si aún no la tienes, puedes seguir las instrucciones que se indican a continuación para comenzar.
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información sobre cómo verificar si la facturación está habilitada en un proyecto.
Configura el proyecto de Cloud en la terminal de Cloud Shell
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
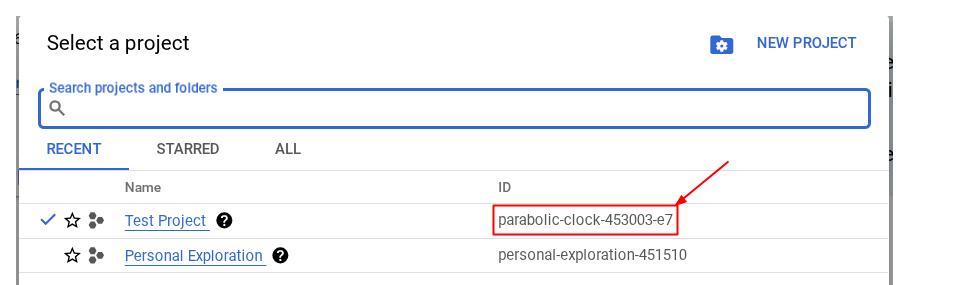
Como alternativa, también puedes ver el ID de PROJECT_ID en la consola.
Haz clic en él y verás todos tus proyectos y el ID del proyecto en el lado derecho.
- Habilita las APIs requeridas con el comando que se muestra a continuación. Este proceso puede tardar unos minutos, así que ten paciencia.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Cuando el comando se ejecute correctamente, deberías ver un mensaje similar al que se muestra a continuación:
Operation "operations/..." finished successfully.
La alternativa al comando de gcloud es buscar cada producto en la consola o usar este vínculo.
Si olvidas alguna API, puedes habilitarla durante el proceso de implementación.
Consulta la documentación para ver los comandos y el uso de gcloud.
Ve al editor de Cloud Shell y configura el directorio de trabajo de la aplicación
Ahora, podemos configurar nuestro editor de código para hacer algunas cosas de programación. Usaremos el editor de Cloud Shell para esto.
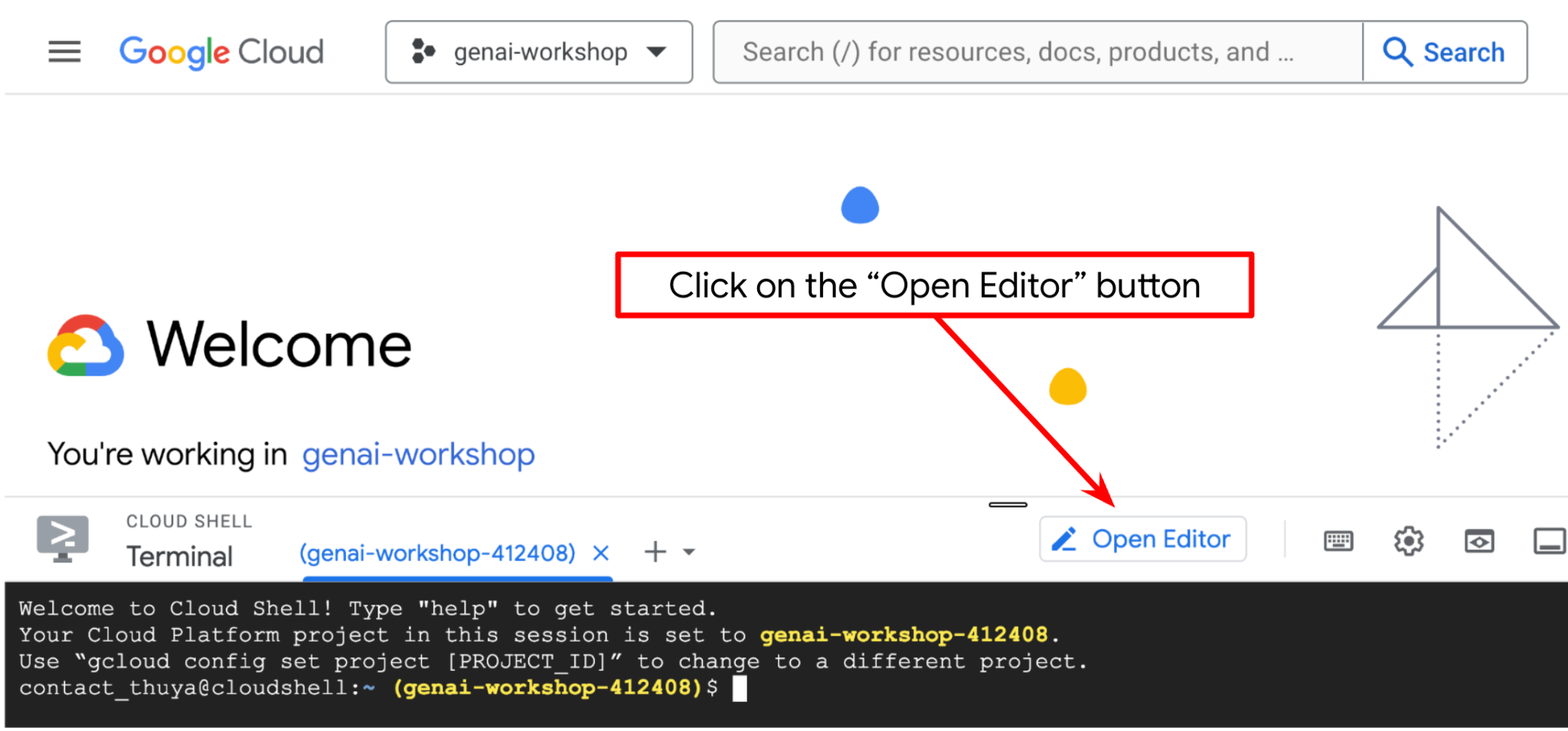
- Haz clic en el botón Open Editor para abrir un editor de Cloud Shell en el que puedes escribir tu código
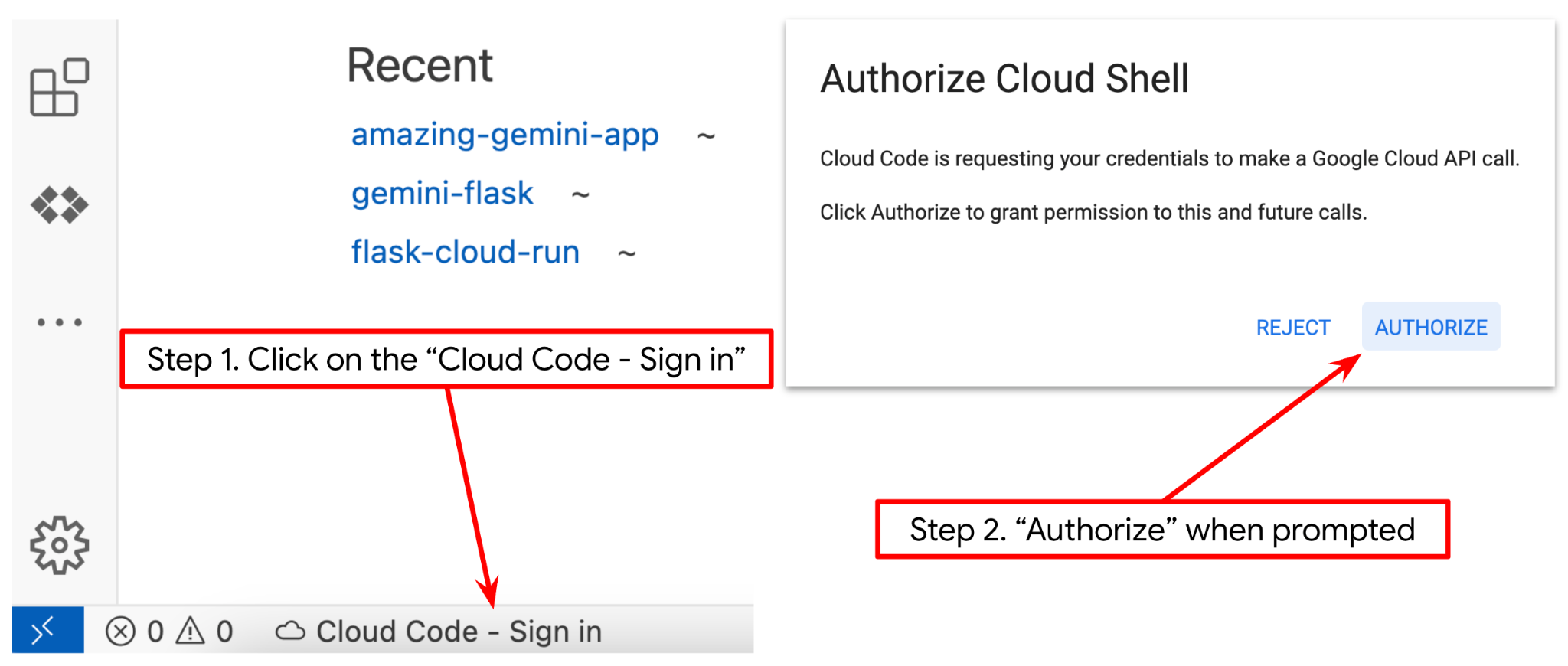
- Asegúrate de que el proyecto de Cloud Code esté configurado en la esquina inferior izquierda (barra de estado) del editor de Cloud Shell, como se destaca en la siguiente imagen, y que esté configurado en el proyecto activo de Google Cloud en el que tienes habilitada la facturación. Haz clic en Autorizar si se te solicita. Si ya seguiste el comando anterior, es posible que el botón también apunte directamente a tu proyecto activado en lugar del botón de acceso.
- A continuación, clonemos el directorio de trabajo de la plantilla para este codelab desde GitHub. Para ello, ejecuta el siguiente comando. Se creará el directorio de trabajo en el directorio qa-test-planner-agent.
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
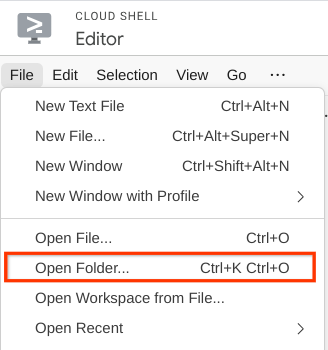
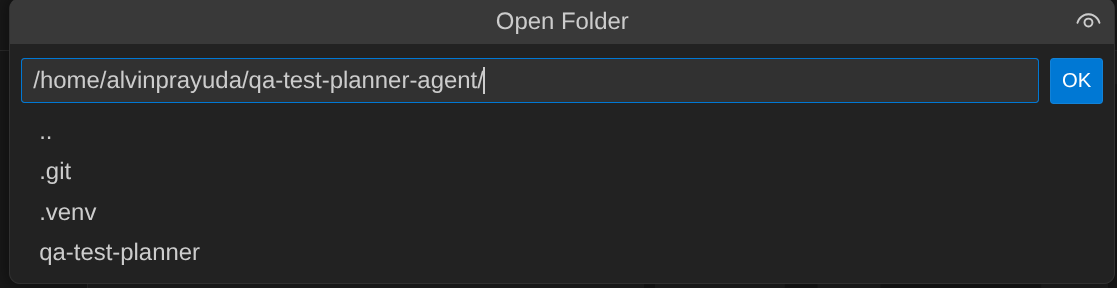
- Después, ve a la sección superior del editor de Cloud Shell y haz clic en File->Open Folder, busca tu directorio de username y el directorio qa-test-planner-agent, y, luego, haz clic en el botón Aceptar. Esto convertirá el directorio elegido en el directorio de trabajo principal. En este ejemplo, el nombre de usuario es alvinprayuda, por lo que la ruta de acceso del directorio se muestra a continuación.
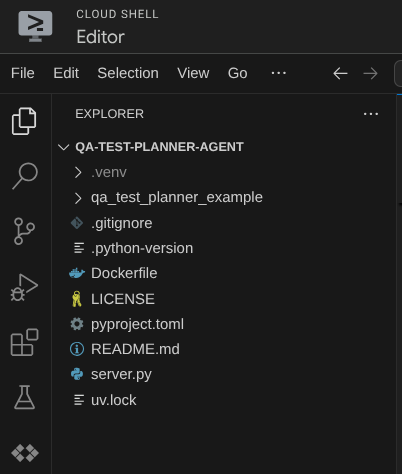
Ahora, tu editor de Cloud Shell debería verse así:
Configuración del entorno
Prepara el entorno virtual de Python
El siguiente paso es preparar el entorno de desarrollo. Tu terminal activa actual debe estar dentro del directorio de trabajo qa-test-planner-agent. En este codelab, usaremos Python 3.12 y uv python project manager para simplificar la necesidad de crear y administrar la versión de Python y el entorno virtual.
- Si aún no abriste la terminal, haz clic en Terminal -> New Terminal o usa Ctrl + Mayúsculas + C para abrir una ventana de terminal en la parte inferior del navegador.

- Descarga
uvy, luego, instala Python 3.12 con el siguiente comando:
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- Ahora , inicialicemos el entorno virtual con
uv. Ejecuta este comando:
uv sync --frozen
Esto creará el directorio .venv y, luego, instalará las dependencias. Un vistazo rápido a pyproject.toml te brindará información sobre las dependencias que se muestran de esta manera:
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- Para probar el entorno virtual, crea un archivo nuevo main.py y copia el siguiente código:
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- Luego, ejecuta el siguiente comando:
uv run main.py
Obtendrás un resultado como el que se muestra a continuación.
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
Esto demuestra que el proyecto de Python se está configurando correctamente.
Ahora podemos pasar al siguiente paso, que es compilar el agente y, luego, los servicios.
3. Compila el agente con el ADK de Google y Gemini 2.5
Introducción a la estructura de directorios del ADK
Comencemos por explorar lo que el ADK tiene para ofrecer y cómo compilar el agente. Puedes acceder a la documentación completa del ADK en esta URL . El ADK nos ofrece muchas utilidades dentro de la ejecución de su comando de CLI. Algunos de ellos son los siguientes :
- Configura la estructura del directorio del agente
- Probar rápidamente la interacción a través de la entrada y salida de la CLI
- Configura rápidamente la interfaz web de la IU de desarrollo local
Ahora, crearemos la estructura de directorios del agente con el comando de la CLI. Ejecuta el siguiente comando:
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
Se creará la siguiente estructura de directorio del agente en tu directorio de trabajo actual:
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
Si inspeccionas init.py y agent.py, verás este código:
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Cómo crear nuestro agente de planificación de pruebas de QA
Creemos nuestro agente de planificación de pruebas de QA. Abre el archivo qa_test_planner/agent.py y copia el siguiente código que contendrá el root_agent.
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
Configura archivos de configuración
Ahora, deberemos agregar una configuración adicional para este proyecto, ya que este agente necesitará acceso a Confluence.
Abre qa_test_planner/.env y agrega los siguientes valores de variables de entorno. Asegúrate de que el archivo .env resultante se vea de la siguiente manera:
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
Lamentablemente, este espacio de Confluence no se puede hacer público, por lo que puedes inspeccionar estos archivos para leer los documentos de requisitos del producto disponibles, que estarán disponibles con las credenciales anteriores.
Explicación del código
Este script contiene la inicialización de nuestro agente, en la que inicializamos los siguientes elementos:
- Establece el modelo que se usará en
gemini-2.5-flash. - Configura las herramientas de MCP de Confluence que se comunicarán a través de Stdio.
- Configura la herramienta personalizada
write_test_toolpara escribir el plan de pruebas y volcar el CSV en el artefacto - Configura la descripción y las instrucciones del agente
- Habilita la planificación antes de generar la respuesta final o la ejecución con las capacidades de pensamiento de Gemini 2.5 Flash
El agente en sí, cuando está potenciado por un modelo de Gemini con capacidades de Pensar integradas y configurado con los argumentos del planificador, puede mostrar sus capacidades de Pensar y también aparecer en la interfaz web. A continuación, se muestra el código para configurar esto.
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
Y antes de tomar medidas, podemos ver su proceso de pensamiento.
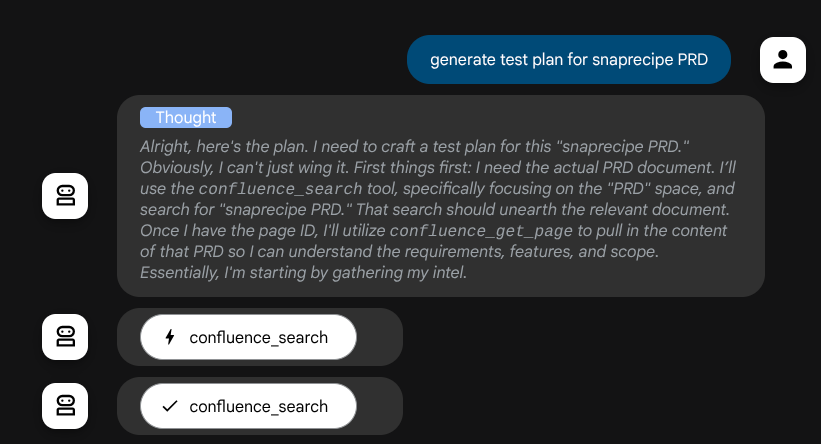
La herramienta de MCP de Confluence
Para conectarnos al servidor de MCP desde el ADK, debemos utilizar MCPToolSet, que se puede importar desde el módulo google.adk.tools.mcp_tool.mcp_toolset. El código que se inicializó aquí se muestra a continuación ( truncado para mayor eficiencia):
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
Con esta configuración, el agente inicializará el servidor de MCP de Confluence como un proceso independiente y controlará la comunicación con esos procesos a través de Studio I/O. Este flujo se ilustra en la siguiente imagen de la arquitectura del MCP, marcada dentro del cuadro rojo que se muestra a continuación.
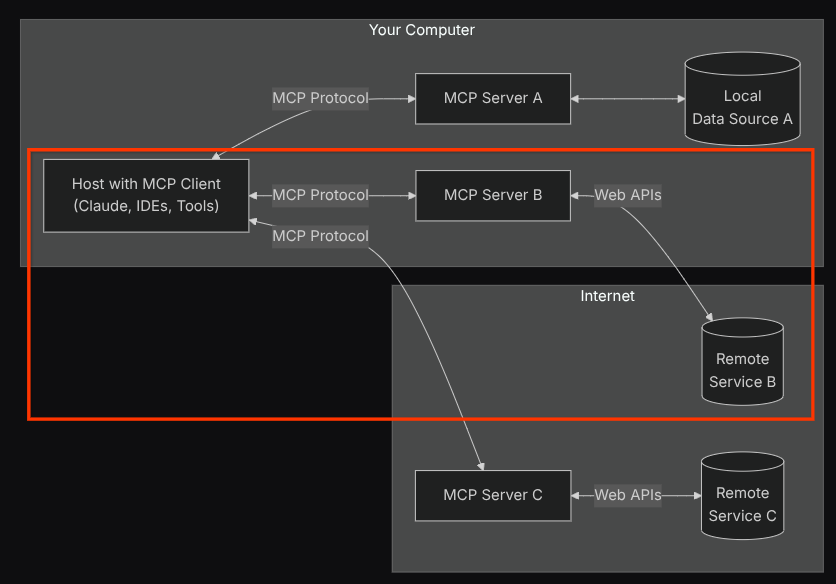
Además, dentro de los argumentos de comando de la inicialización de MCP, también limitamos las herramientas que se pueden utilizar solo a estas: confluence_search, confluence_get_page y confluence_get_page_children, que admiten nuestros casos de uso del agente de prueba de QA. En este instructivo del codelab, utilizamos el servidor de MCP de Atlassian aportado por la comunidad ( consulta la documentación completa para obtener más detalles).
Herramienta de escritura de pruebas
Después de que el agente recibe contexto de la herramienta de MCP de Confluence, puede crear el plan de prueba necesario para el usuario. Sin embargo, queremos producir un archivo que contenga este plan de pruebas para que se pueda conservar y compartir con la otra persona. Para admitir esta función, proporcionamos la herramienta personalizada write_test_tool a continuación.
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
La función declarada anteriormente admite las siguientes funcionalidades:
- Verifica el plan de pruebas generado para que cumpla con las especificaciones de los campos obligatorios. Para ello, usamos el modelo de Pydantic y, si se produce un error, le proporcionamos el mensaje de error al agente.
- Volcar el resultado en un archivo CSV con la funcionalidad de Pandas
- Luego, el archivo generado se guarda como artefacto con las capacidades del servicio de artefactos, al que se puede acceder con el objeto ToolContext que se puede acceder en cada llamada a la herramienta.
Si guardamos los archivos generados como artefacto, se marcará como evento en el tiempo de ejecución del ADK y se mostrará en la interacción del agente más adelante en la interfaz web.
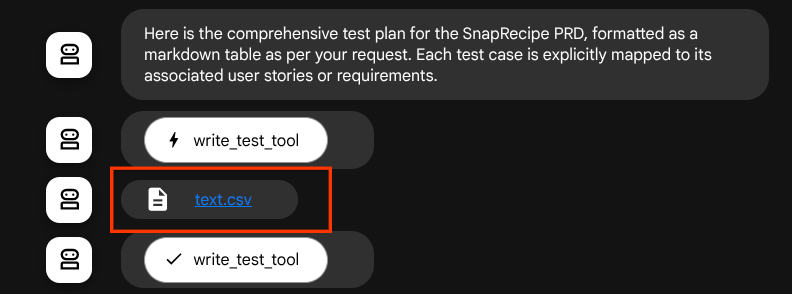
Con esto, podemos configurar de forma dinámica la respuesta del archivo del agente para que se le proporcione al usuario.
4. Prueba del agente
Ahora, intentemos comunicarnos con el agente a través de la CLI. Para ello, ejecuta el siguiente comando:
uv run adk run qa_test_planner
Se mostrará un resultado como este, en el que puedes chatear con el agente por turnos, pero solo puedes enviar texto a través de esta interfaz.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
Es bueno poder chatear con el agente a través de la CLI. Pero sería aún mejor si tuviéramos un buen chat web con él, y también podemos hacerlo. El ADK también nos permite tener una IU de desarrollo para interactuar y ver qué sucede durante la interacción. Ejecuta el siguiente comando para iniciar el servidor de la IU de desarrollo local:
uv run adk web --port 8080
Se generará un resultado similar al siguiente ejemplo, lo que significa que ya podemos acceder a la interfaz web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
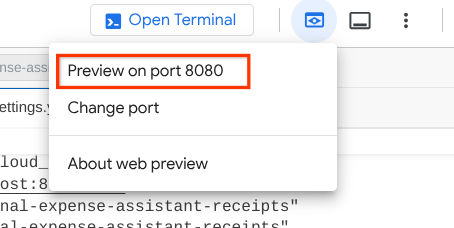
Ahora, para verificarlo, haz clic en el botón Vista previa en la Web en la parte superior del editor de Cloud Shell y selecciona Vista previa en el puerto 8080.
Verás la siguiente página web en la que puedes seleccionar los agentes disponibles en el botón desplegable de la parte superior izquierda ( en nuestro caso, debería ser qa_test_planner) y, luego, interactuar con el bot. En la ventana de la izquierda, verás mucha información sobre los detalles del registro durante el tiempo de ejecución del agente.
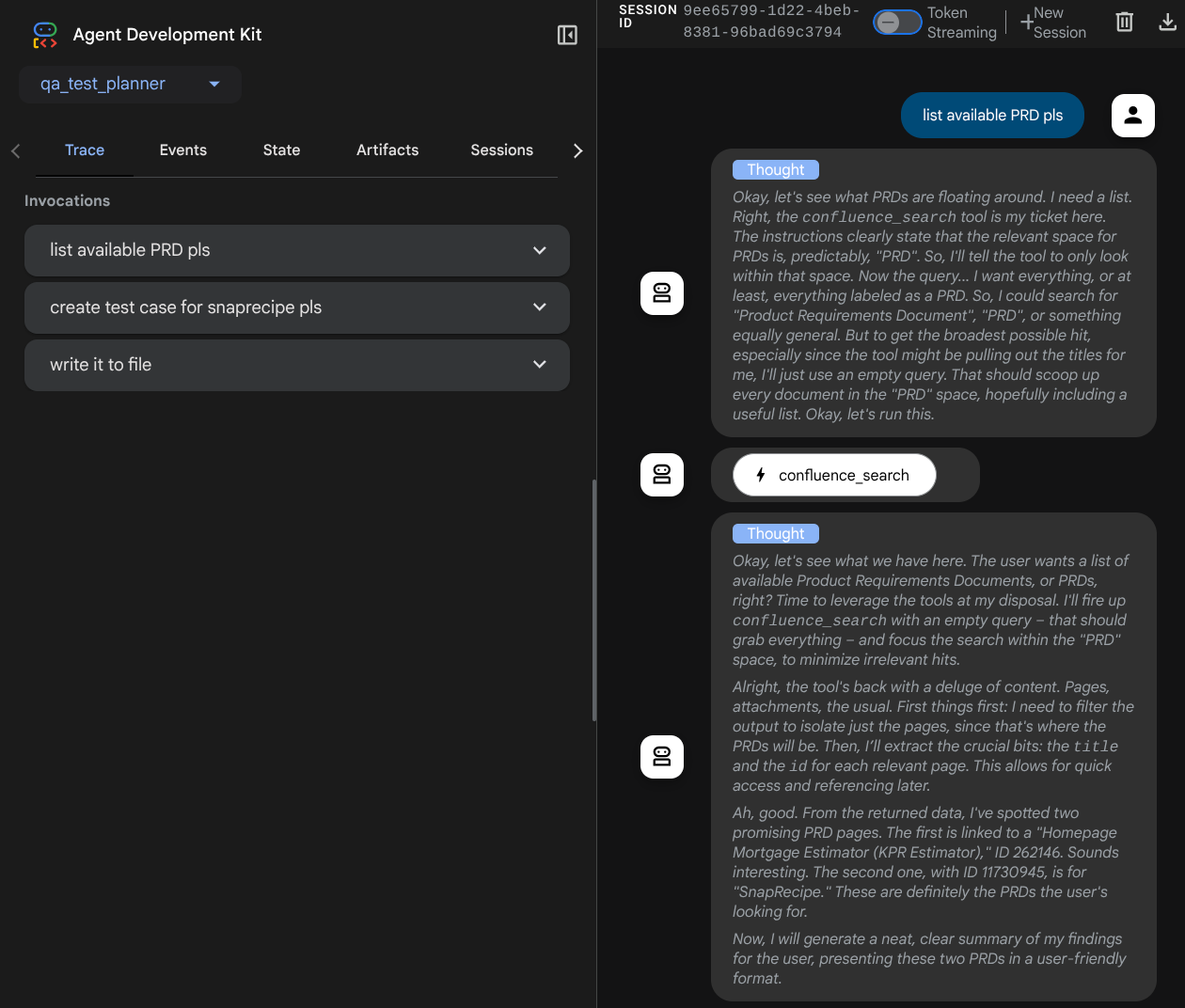
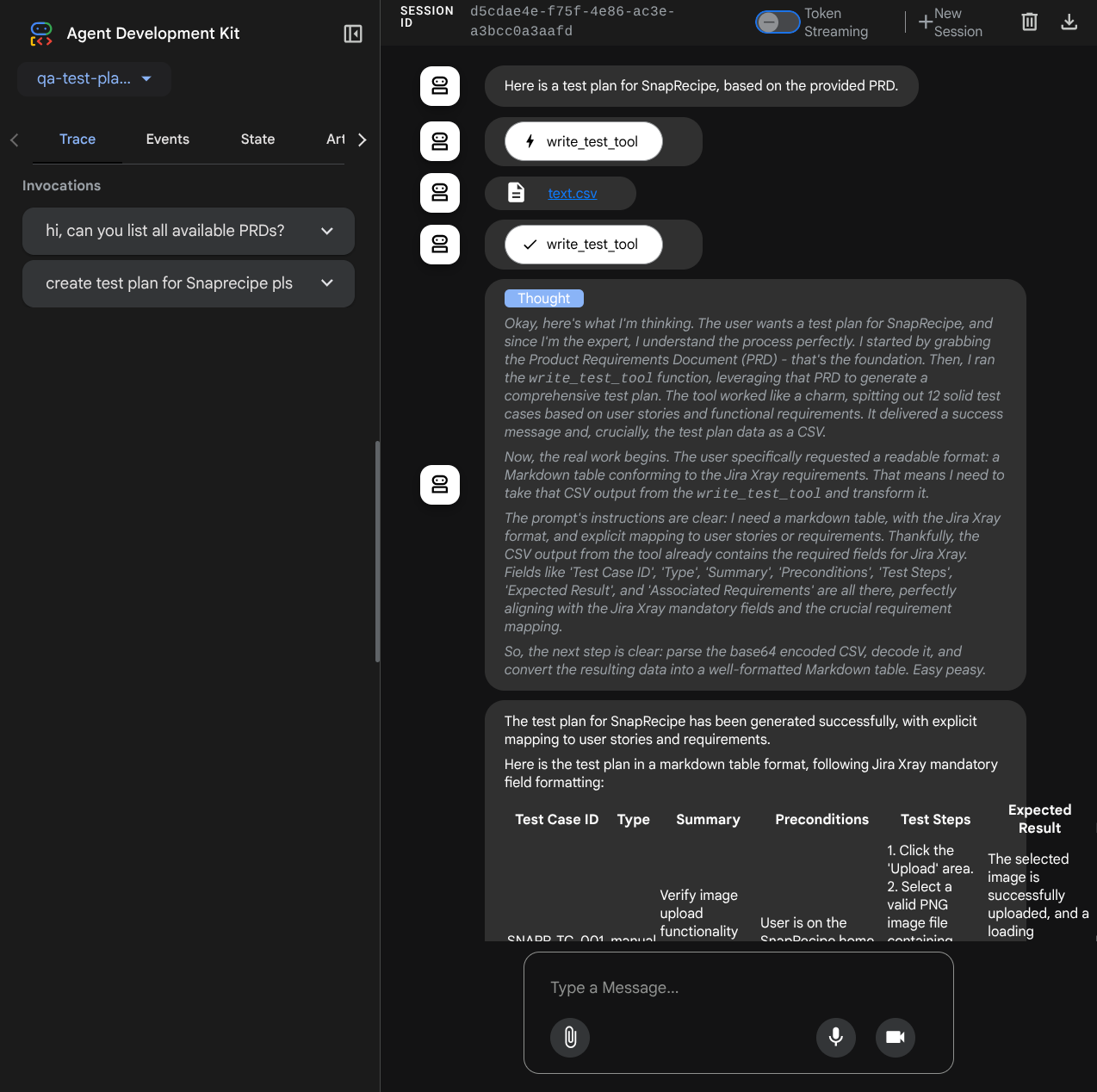
Probemos algunas acciones. Chatea con los agentes con estas instrucciones:
- "Enumera todos los PRD disponibles ".
- "Escribe un plan de pruebas para el PRD de Snaprecipe ".
Cuando usas algunas herramientas, puedes inspeccionar lo que sucede en la IU de desarrollo.
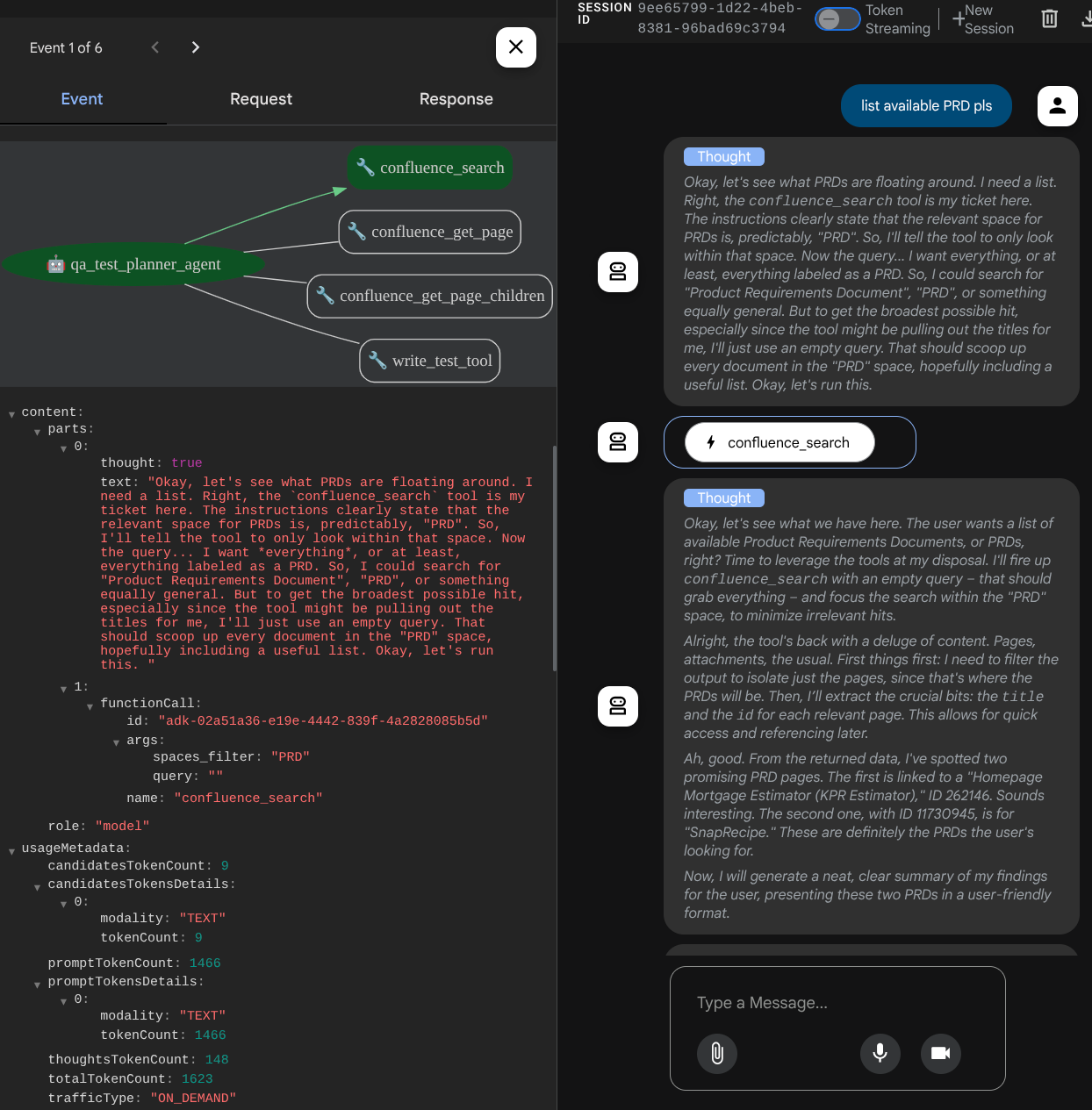
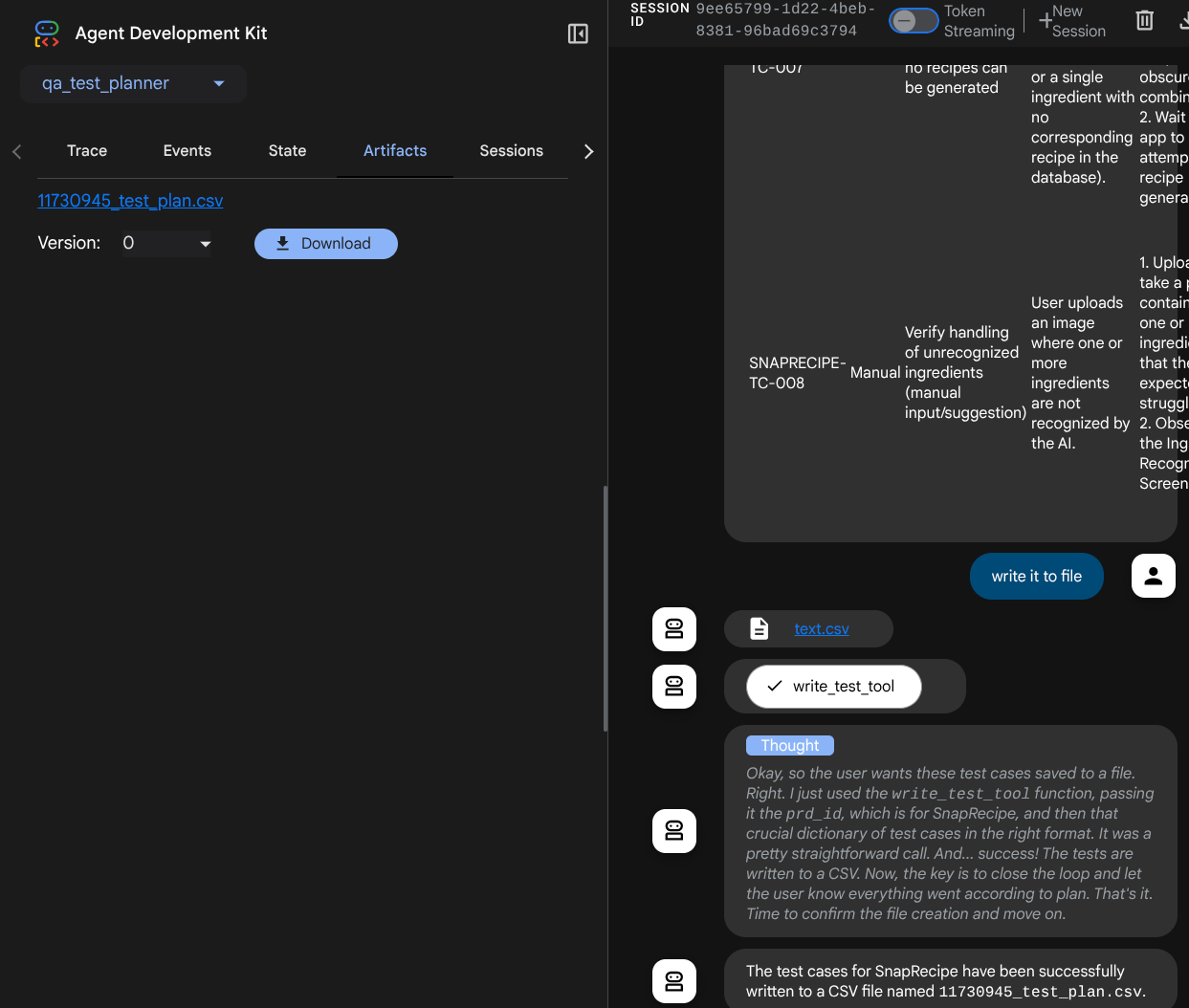
Observa cómo te responde el agente y también inspecciona cuándo te pedimos el archivo de prueba. Se generará el plan de prueba en un archivo CSV como artefacto.
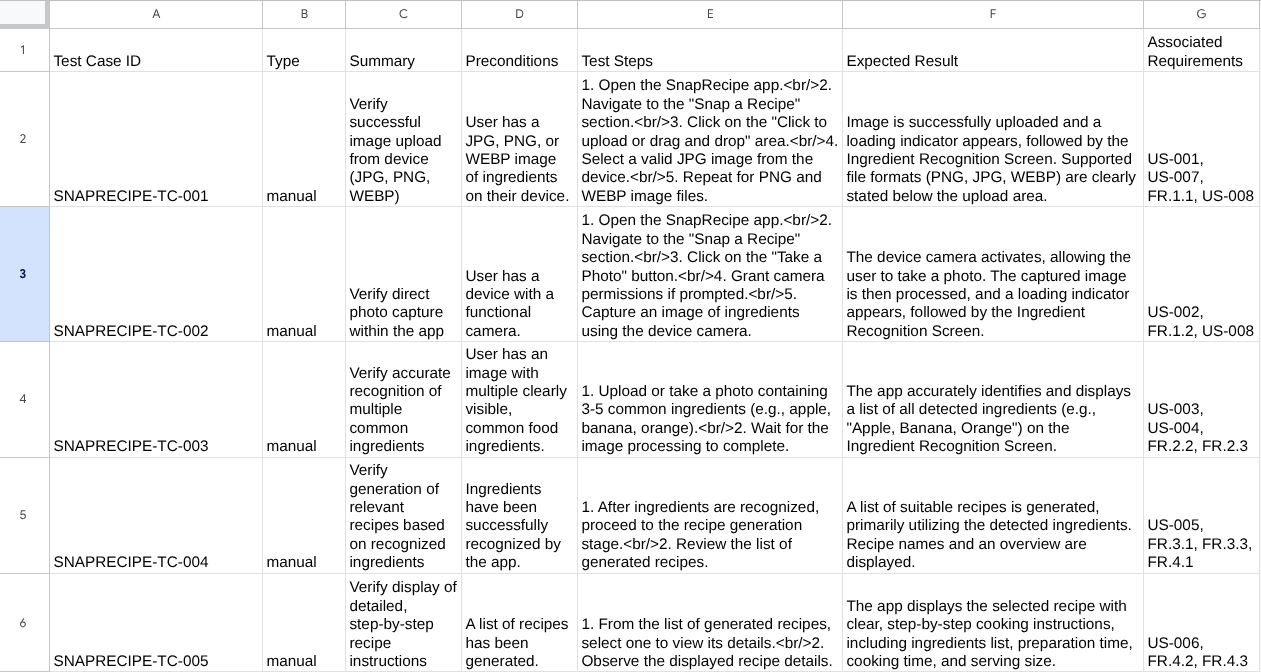
Ahora, puedes verificar el contenido del CSV importándolo a una hoja de cálculo de Google, por ejemplo.
¡Felicitaciones! Ahora tienes un agente de QA Test Planner que funciona de forma local. Ahora veamos cómo podemos implementarlo en Cloud Run para que otras personas también puedan usarlo.
5. Implementa en Cloud Run
Por supuesto, queremos acceder a esta increíble app desde cualquier lugar. Para ello, podemos empaquetar esta aplicación y, luego, implementarla en Cloud Run. Para los fines de esta demostración, este servicio se expondrá como un servicio público al que pueden acceder otras personas. Sin embargo, ten en cuenta que esta no es la mejor práctica.
En tu directorio de trabajo actual, ya tenemos todos los archivos necesarios para implementar nuestras aplicaciones en Cloud Run: el directorio del agente, el Dockerfile y server.py (la secuencia de comandos principal del servicio). Implementémoslos. Navega a la terminal de Cloud Shell y asegúrate de que el proyecto actual esté configurado en tu proyecto activo. Si no es así, usa el comando gcloud config para establecer el ID del proyecto:
gcloud config set project [PROJECT_ID]
Luego, ejecuta el siguiente comando para implementarlo en Cloud Run.
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
Si se te solicita que confirmes la creación de un registro de artefactos para el repositorio de Docker, responde Y. Ten en cuenta que permitimos el acceso no autenticado aquí porque se trata de una aplicación de demostración. Se recomienda usar la autenticación adecuada para tus aplicaciones empresariales y de producción.
Una vez que se complete la implementación, deberías obtener un vínculo similar al siguiente:
https://qa-test-planner-agent-*******.us-central1.run.app
Cuando accedas a la URL, ingresarás a la IU de desarrollo web, de manera similar a cuando la pruebas de forma local. Continúa y usa tu aplicación desde la ventana de incógnito o tu dispositivo móvil. Ya debería estar disponible.
Ahora, probemos estas diferentes instrucciones nuevamente, de forma secuencial, para ver qué sucede:
- "¿Puedes encontrar el PRD relacionado con el Estimador de hipotecas? "
- "Dame comentarios sobre qué podemos mejorar".
- "Escribe el plan de pruebas para ello".
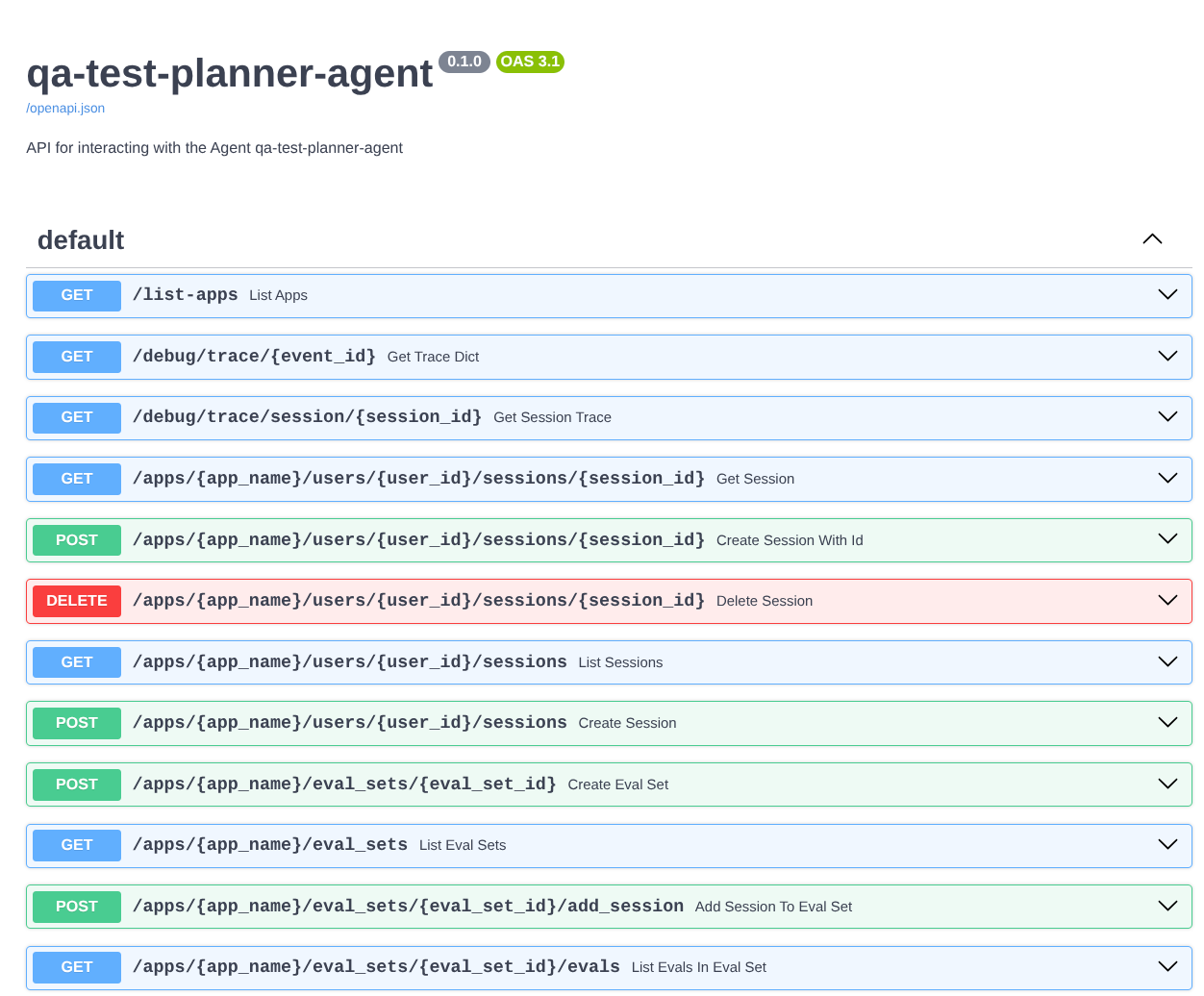
Además, como ejecutamos el agente como una app de FastAPI, también podemos inspeccionar todas las rutas de la API en la ruta /docs. Por ejemplo, si accedes a la URL de esta manera https://qa-test-planner-agent-*******.us-central1.run.app/docs, verás la página de documentación de Swagger como se muestra a continuación.
Explicación del código
Ahora, inspeccionemos qué archivo necesitamos aquí para la implementación, comenzando con server.py.
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Podemos convertir fácilmente nuestro agente en una app de FastAPI con la función get_fast_api_app. En esta función, podemos configurar varias funcionalidades, por ejemplo, configurar el servicio de sesión, el servicio de artefactos o incluso rastrear datos en la nube.
Si quieres, también puedes establecer el ciclo de vida de la aplicación aquí. Después de eso, podemos usar Uvicorn para ejecutar la aplicación de la API de Fast.
Después, el Dockerfile nos proporcionará los pasos necesarios para ejecutar la aplicación.
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. Desafío
Ahora es tu momento de brillar y pulir tus habilidades de exploración. ¿También puedes crear una herramienta para que los comentarios de la revisión del PRD se escriban en un archivo?
7. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este codelab:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
- Como alternativa, puedes ir a Cloud Run en la consola, seleccionar el servicio que acabas de implementar y borrarlo.