
1. Introduction
Le potentiel de l'IA générative pour la création de plans de test réside dans sa capacité à résoudre deux des plus grands défis de l'assurance qualité moderne : la rapidité et l'exhaustivité. Dans les cycles Agile et DevOps rapides d'aujourd'hui, la création manuelle de plans de test détaillés constitue un goulot d'étranglement important qui retarde l'ensemble du processus de test. Un agent optimisé par l'IA générative peut ingérer des user stories et des exigences techniques pour produire un plan de test complet en quelques minutes, et non en quelques jours. Le processus d'assurance qualité reste ainsi au même rythme que le développement. De plus, l'IA excelle dans l'identification de scénarios complexes, de cas extrêmes et de chemins négatifs qu'un humain pourrait manquer. Cela permet d'améliorer considérablement la couverture des tests et de réduire considérablement le nombre de bugs qui passent en production.
Dans cet atelier de programmation, nous allons explorer comment créer un agent capable de récupérer les documents de spécifications produit depuis Confluence, de fournir des commentaires constructifs et de générer un plan de test complet pouvant être exporté dans un fichier CSV.
Dans cet atelier de programmation, vous allez suivre une approche par étapes :
- Préparez votre projet Google Cloud et activez toutes les API requises.
- Configurer un espace de travail pour votre environnement de programmation
- Préparer le serveur MCP local pour Confluence
- Structurer le code source, l'invite et les outils de l'agent ADK pour se connecter au serveur MCP
- Comprendre l'utilisation du service d'artefacts et des contextes d'outils
- Tester l'agent à l'aide de l'UI de développement Web local de l'ADK
- Gérer les variables d'environnement et configurer les fichiers requis pour déployer l'application sur Cloud Run
- Déployer l'application sur Cloud Run
Présentation de l'architecture
Prérequis
- Vous êtes à l'aise avec Python.
- Comprendre l'architecture full stack de base à l'aide du service HTTP
Points abordés
- Concevoir un agent ADK en utilisant ses différentes fonctionnalités
- Utilisation des outils avec l'outil personnalisé et MCP
- Configurer la sortie de fichier par l'agent à l'aide de la gestion du service Artifact
- Utiliser BuiltInPlanner pour améliorer l'exécution des tâches en planifiant avec les capacités de réflexion de Gemini 2.5 Flash
- Interaction et débogage via l'interface Web ADK
- Déployer une application sur Cloud Run à l'aide d'un fichier Dockerfile et fournir des variables d'environnement
Prérequis
- Navigateur Web Chrome
- Un compte Gmail
- Un projet Cloud pour lequel la facturation est activée
- (Facultatif) Espace Confluence avec une ou plusieurs pages de documents sur les exigences du produit
Cet atelier de programmation, conçu pour les développeurs de tous niveaux (y compris les débutants), utilise Python dans son exemple d'application. Toutefois, vous n'avez pas besoin de maîtriser Python pour comprendre les concepts présentés. Ne vous inquiétez pas si vous n'avez pas d'espace Confluence. Nous vous fournirons des identifiants pour essayer cet atelier de programmation.
2. Avant de commencer
Sélectionner le projet actif dans la console Cloud
Cet atelier de programmation suppose que vous disposez déjà d'un projet Google Cloud pour lequel la facturation est activée. Si vous ne l'avez pas encore, vous pouvez suivre les instructions ci-dessous pour commencer.
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Configurer un projet Cloud dans le terminal Cloud Shell
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.
- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
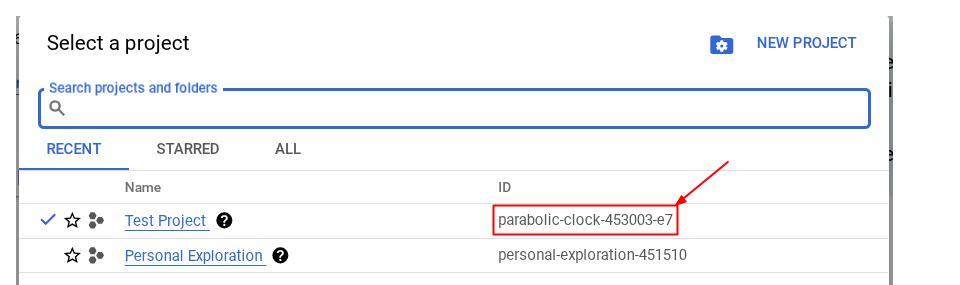
Vous pouvez également voir l'ID PROJECT_ID dans la console.
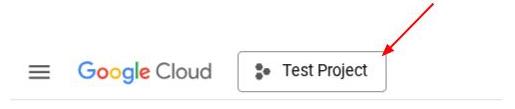
Cliquez dessus pour afficher tous vos projets et l'ID du projet sur la droite.
- Activez les API requises à l'aide de la commande ci-dessous. Cette opération peut prendre quelques minutes. Merci de patienter.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Si la commande s'exécute correctement, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
Vous pouvez également accéder à la console en recherchant chaque produit ou en utilisant ce lien.
Si vous oubliez d'activer une API, vous pourrez toujours le faire au cours de l'implémentation.
Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
Accéder à l'éditeur Cloud Shell et configurer le répertoire de travail de l'application
Nous pouvons maintenant configurer notre éditeur de code pour effectuer certaines tâches de codage. Pour cela, nous allons utiliser l'éditeur Cloud Shell.
- Cliquez sur le bouton "Ouvrir l'éditeur". Un éditeur Cloud Shell s'ouvre. Vous pouvez y écrire votre code
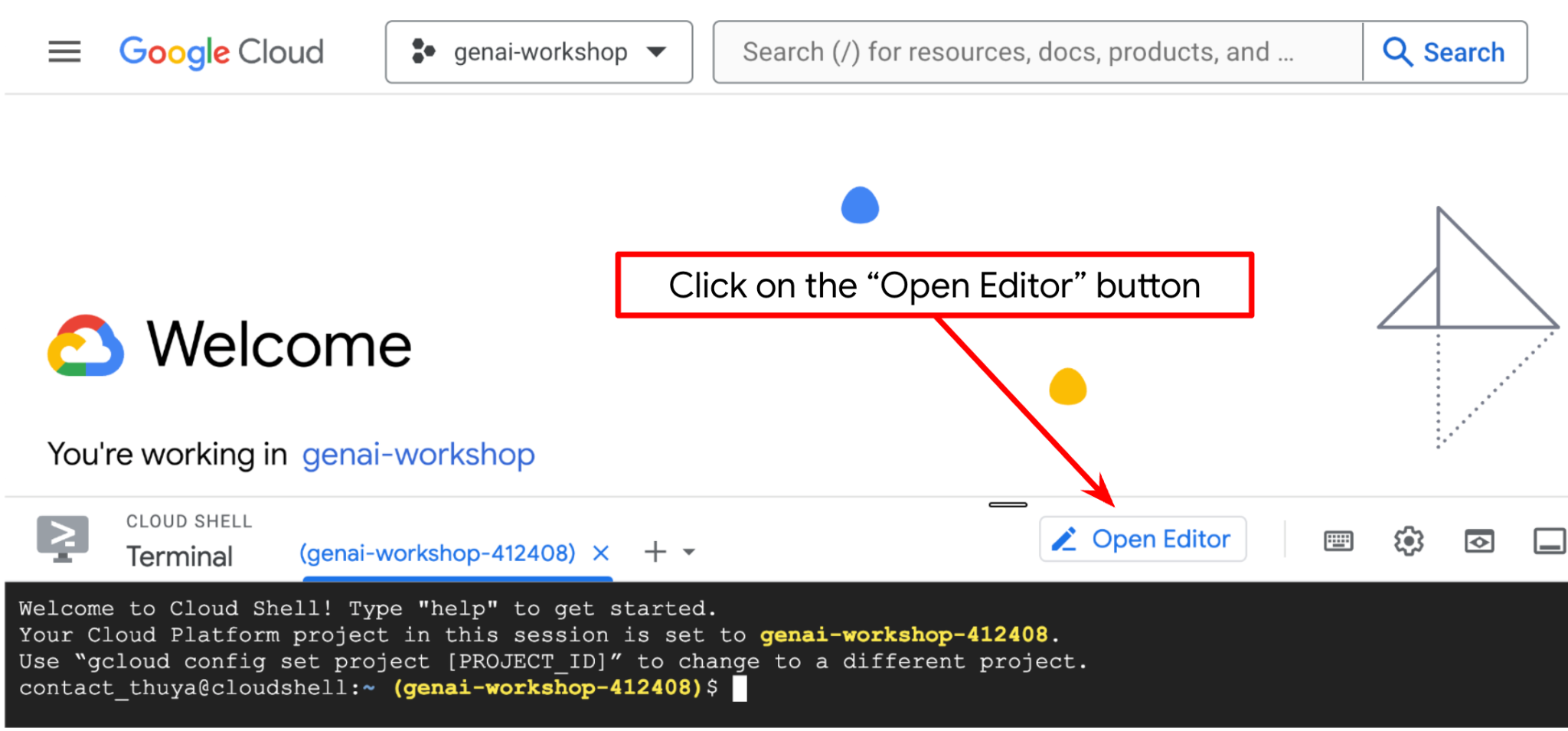 .
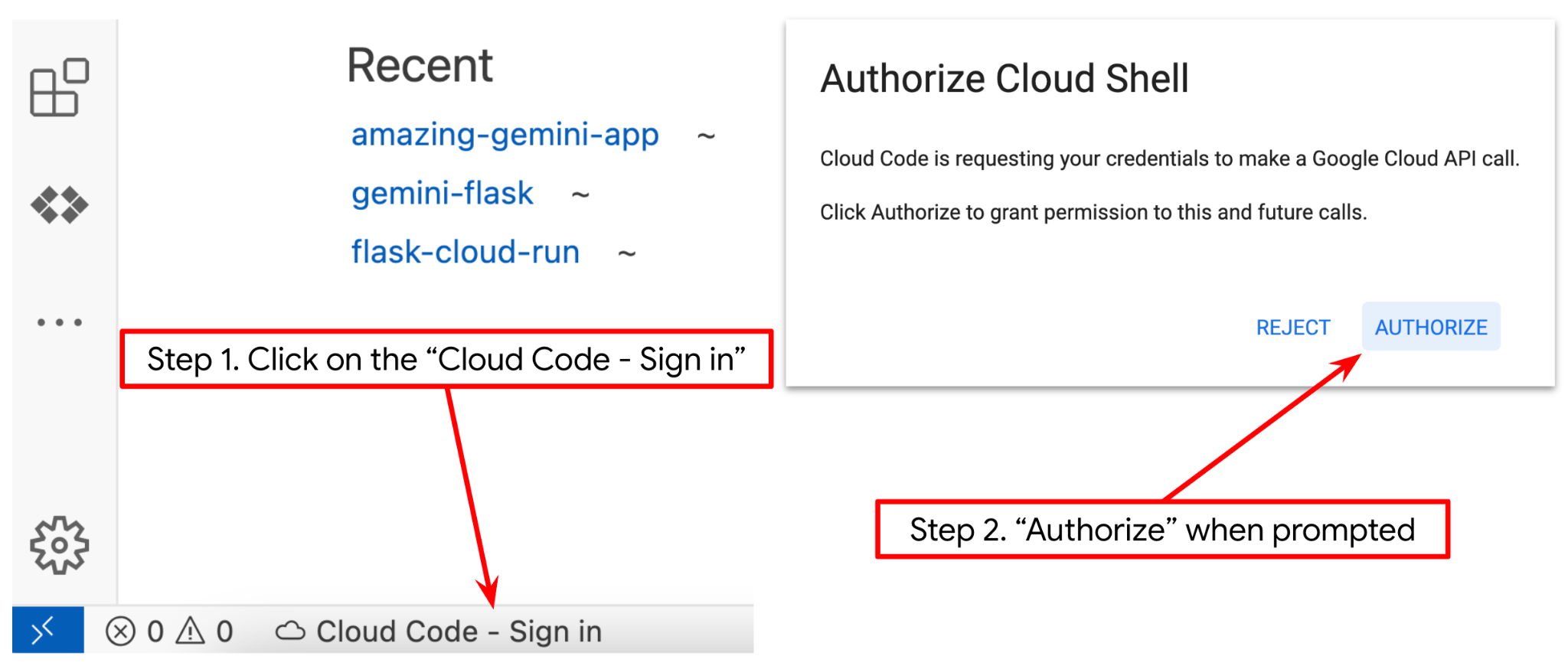
. - Assurez-vous que le projet Cloud Code est défini en bas à gauche (barre d'état) de l'éditeur Cloud Shell, comme indiqué dans l'image ci-dessous, et qu'il est défini sur le projet Google Cloud actif pour lequel la facturation est activée. Cliquez sur Autoriser si vous y êtes invité. Si vous avez déjà suivi la commande précédente, le bouton peut également pointer directement vers votre projet activé au lieu du bouton de connexion.
- Ensuite, clonons le répertoire de travail du modèle pour cet atelier de programmation à partir de GitHub en exécutant la commande suivante. Il créera le répertoire de travail dans le répertoire qa-test-planner-agent.
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
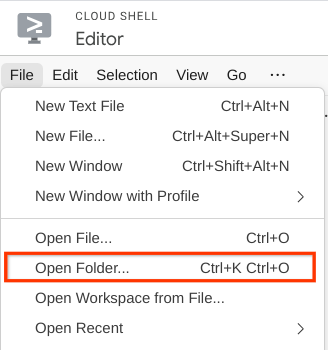
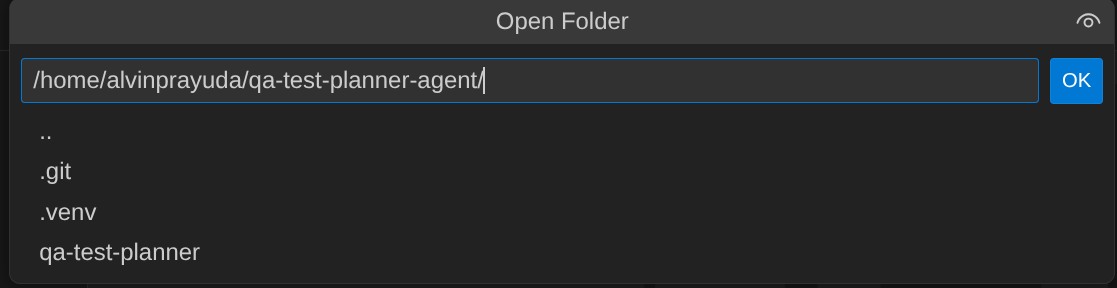
- Ensuite, accédez à la section supérieure de l'éditeur Cloud Shell et cliquez sur File->Open Folder (Fichier > Ouvrir le dossier), recherchez votre répertoire nom d'utilisateur, puis le répertoire qa-test-planner-agent, puis cliquez sur le bouton OK. Le répertoire choisi deviendra le répertoire de travail principal. Dans cet exemple, le nom d'utilisateur est alvinprayuda. Le chemin d'accès au répertoire est donc indiqué ci-dessous.
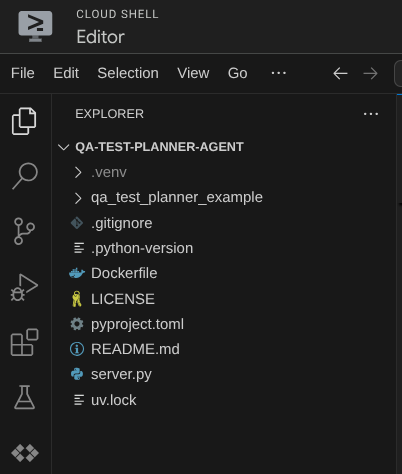
Votre éditeur Cloud Shell devrait maintenant se présenter comme suit :
Configuration de l'environnement
Préparer l'environnement virtuel Python
L'étape suivante consiste à préparer l'environnement de développement. Votre terminal actif actuel doit se trouver dans le répertoire de travail qa-test-planner-agent. Dans cet atelier de programmation, nous utiliserons Python 3.12 et le gestionnaire de projets Python uv pour simplifier la création et la gestion de la version Python et de l'environnement virtuel.
- Si vous n'avez pas encore ouvert le terminal, ouvrez-le en cliquant sur Terminal > Nouveau terminal ou en utilisant le raccourci clavier Ctrl+Maj+C. Une fenêtre de terminal s'ouvre alors en bas du navigateur.

- Téléchargez
uvet installez Python 3.12 avec la commande suivante :
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- Initialisons maintenant l'environnement virtuel à l'aide de
uv. Exécutez cette commande :
uv sync --frozen
Cela créera le répertoire .venv et installera les dépendances. Un petit aperçu rapide du fichier pyproject.toml vous donnera des informations sur les dépendances, comme ceci :
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- Pour tester l'environnement virtuel, créez un fichier main.py et copiez-y le code suivant :
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- Exécutez ensuite la commande suivante :
uv run main.py
Vous obtiendrez un résultat semblable à celui-ci :
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
Cela montre que le projet Python est correctement configuré.
Nous pouvons maintenant passer à l'étape suivante, qui consiste à créer l'agent, puis les services.
3. Créer l'agent à l'aide de Google ADK et de Gemini 2.5
Présentation de la structure de répertoires d'ADK
Commençons par explorer ce que l'ADK a à offrir et comment créer l'agent. La documentation complète de l'ADK est disponible sur cette URL . ADK propose de nombreux utilitaires dans l'exécution des commandes CLI. En voici quelques-uns :
- Configurer la structure du répertoire de l'agent
- Essayer rapidement l'interaction via l'entrée/sortie de la CLI
- Configurer rapidement l'interface utilisateur Web de développement local
À présent, créons la structure de répertoire de l'agent à l'aide de la commande CLI. Exécutez la commande suivante :
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
Il crée la structure de répertoire d'agent suivante dans votre répertoire de travail actuel :
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
Si vous inspectez init.py et agent.py, vous verrez ce code
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Créer notre agent de planification des tests d'assurance qualité
Créons notre agent de planification de tests d'assurance qualité ! Ouvrez le fichier qa_test_planner/agent.py et copiez le code ci-dessous, qui contiendra le root_agent.
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
Configurer les fichiers de configuration
Nous devons maintenant ajouter une configuration supplémentaire pour ce projet, car cet agent aura besoin d'accéder à Confluence.
Ouvrez le fichier qa_test_planner/.env et ajoutez-y les valeurs des variables d'environnement suivantes. Assurez-vous que le fichier .env obtenu ressemble à ceci :
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
Malheureusement, cet espace Confluence ne peut pas être rendu public. Vous pouvez donc inspecter ces fichiers pour lire les documents de spécifications produit disponibles à l'aide des identifiants ci-dessus.
Explication du code
Ce script contient l'initialisation de notre agent, où nous initialisons les éléments suivants :
- Définissez le modèle à utiliser sur
gemini-2.5-flash. - Configurer les outils MCP Confluence qui communiqueront via Stdio
- Configurer l'outil personnalisé
write_test_toolpour rédiger un plan de test et exporter le fichier CSV vers un artefact - Configurer la description et les instructions de l'agent
- Activer la planification avant de générer la réponse finale ou l'exécution à l'aide des capacités de réflexion de Gemini 2.5 Flash
L'agent lui-même, lorsqu'il est optimisé par le modèle Gemini avec des capacités de réflexion intégrées et configuré avec les arguments planner, peut afficher ses capacités de réflexion sur l'interface Web. Le code permettant de configurer cette option est présenté ci-dessous.
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
Avant de passer à l'action, nous pouvons voir son processus de réflexion.
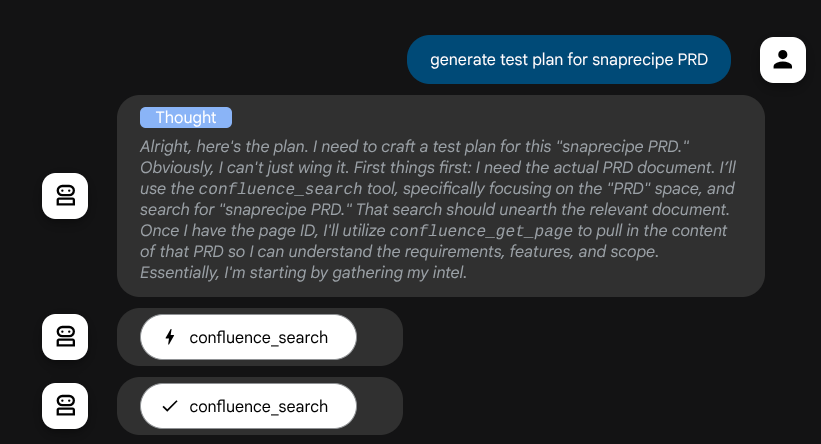
L'outil MCP Confluence
Pour se connecter au serveur MCP depuis ADK, nous devons utiliser MCPToolSet, qui peut être importé depuis le module google.adk.tools.mcp_tool.mcp_toolset. Le code à initialiser ici est présenté ci-dessous ( tronqué pour plus d'efficacité).
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
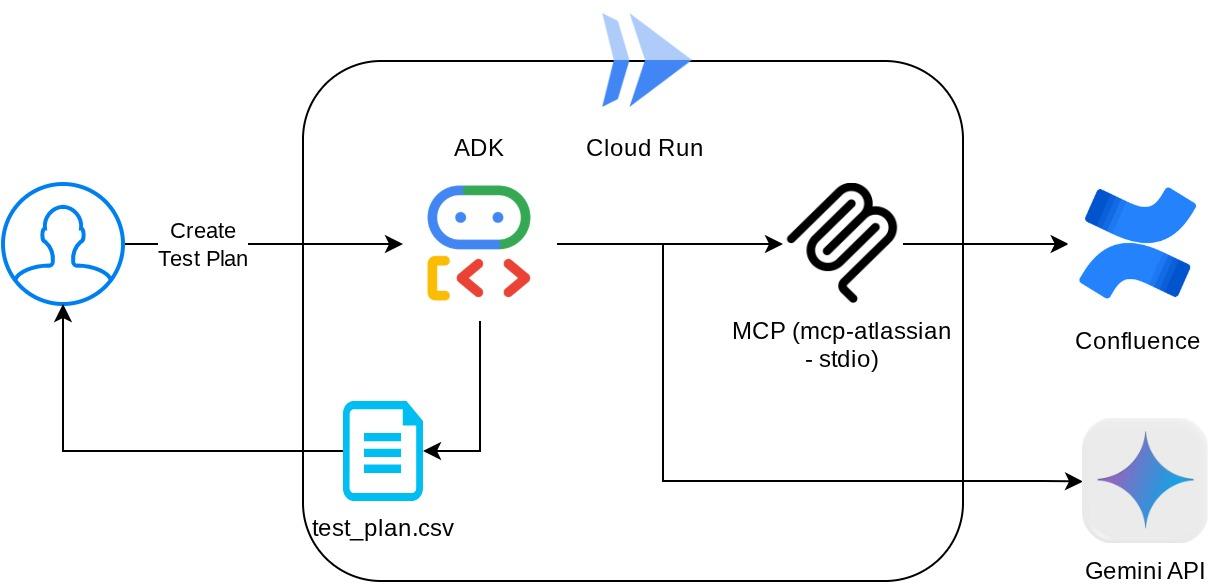
Avec cette configuration, l'agent initialisera le serveur Confluence MCP en tant que processus distinct et gérera la communication avec ces processus via Studio I/O. Ce flux est illustré dans l'image de l'architecture MCP ci-dessous, dans l'encadré rouge.
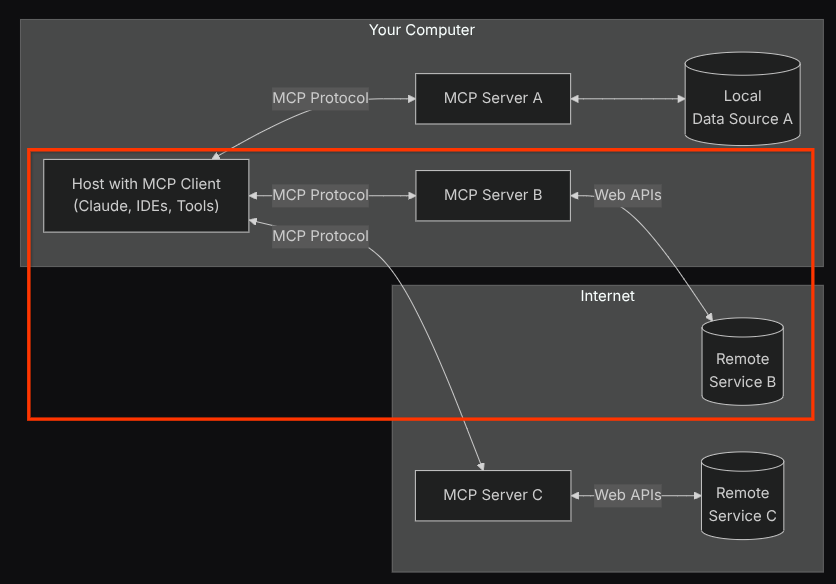
De plus, dans les arguments de commande de l'initialisation MCP, nous limitons également les outils qui peuvent être utilisés à confluence_search, confluence_get_page et confluence_get_page_children, qui prennent en charge nos cas d'utilisation des agents de test QA. Pour cet atelier de programmation, nous utilisons le serveur MCP Atlassian fourni par la communauté ( consultez la documentation complète pour en savoir plus).
Outil Write Test
Une fois que l'agent a reçu le contexte de l'outil MCP Confluence, il peut élaborer le plan de test nécessaire pour l'utilisateur. Cependant, nous souhaitons produire un fichier contenant ce plan de test afin qu'il puisse être conservé et partagé avec l'autre personne. Pour ce faire, nous fournissons l'outil personnalisé write_test_tool ci-dessous.
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
La fonction déclarée ci-dessus permet de prendre en charge les fonctionnalités suivantes :
- Vérifiez que le plan de test produit est conforme aux spécifications des champs obligatoires. Nous effectuons cette vérification à l'aide du modèle Pydantic. En cas d'erreur, nous renvoyons le message d'erreur à l'agent.
- Exporter le résultat au format CSV à l'aide de la fonctionnalité Pandas
- Le fichier généré est ensuite enregistré en tant qu'artefact à l'aide des fonctionnalités du service d'artefacts, accessibles à l'aide de l'objet ToolContext, lui-même accessible à chaque appel d'outil.
Si nous enregistrons les fichiers générés en tant qu'artefact, ils seront marqués comme événement dans le runtime ADK et pourront être affichés dans l'interaction de l'agent ultérieurement dans l'interface Web.
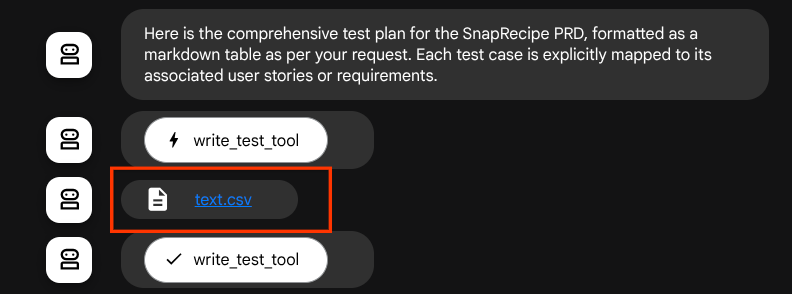
Cela nous permet de configurer dynamiquement la réponse de fichier de l'agent, qui sera fournie à l'utilisateur.
4. Tester l'agent
Essayons maintenant de communiquer avec l'agent via la CLI. Exécutez la commande suivante :
uv run adk run qa_test_planner
Le résultat sera semblable à celui-ci, où vous pourrez discuter à tour de rôle avec l'agent. Toutefois, vous ne pourrez envoyer que du texte via cette interface.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
C'est agréable de pouvoir discuter avec l'agent via la CLI. Mais c'est encore mieux si nous avons un chat Web agréable avec lui, et nous pouvons le faire aussi ! L'ADK nous permet également de disposer d'une UI de développement pour interagir et inspecter ce qui se passe pendant l'interaction. Exécutez la commande suivante pour démarrer le serveur d'interface utilisateur de développement local :
uv run adk web --port 8080
Il générera une sortie semblable à l'exemple suivant, ce qui signifie que nous pouvons déjà accéder à l'interface Web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
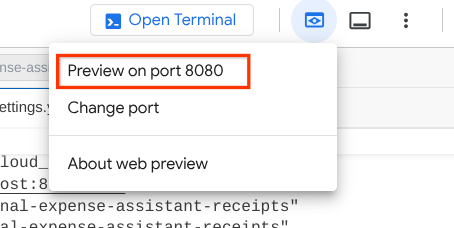
Pour le vérifier, cliquez sur le bouton Aperçu Web en haut de l'éditeur Cloud Shell, puis sélectionnez Prévisualiser sur le port 8080.
La page Web suivante s'affiche. Vous pouvez y sélectionner les agents disponibles dans le menu déroulant en haut à gauche ( dans notre cas, il s'agit de qa_test_planner) et interagir avec le bot. De nombreuses informations sur les détails du journal s'affichent dans la fenêtre de gauche pendant l'exécution de l'agent.
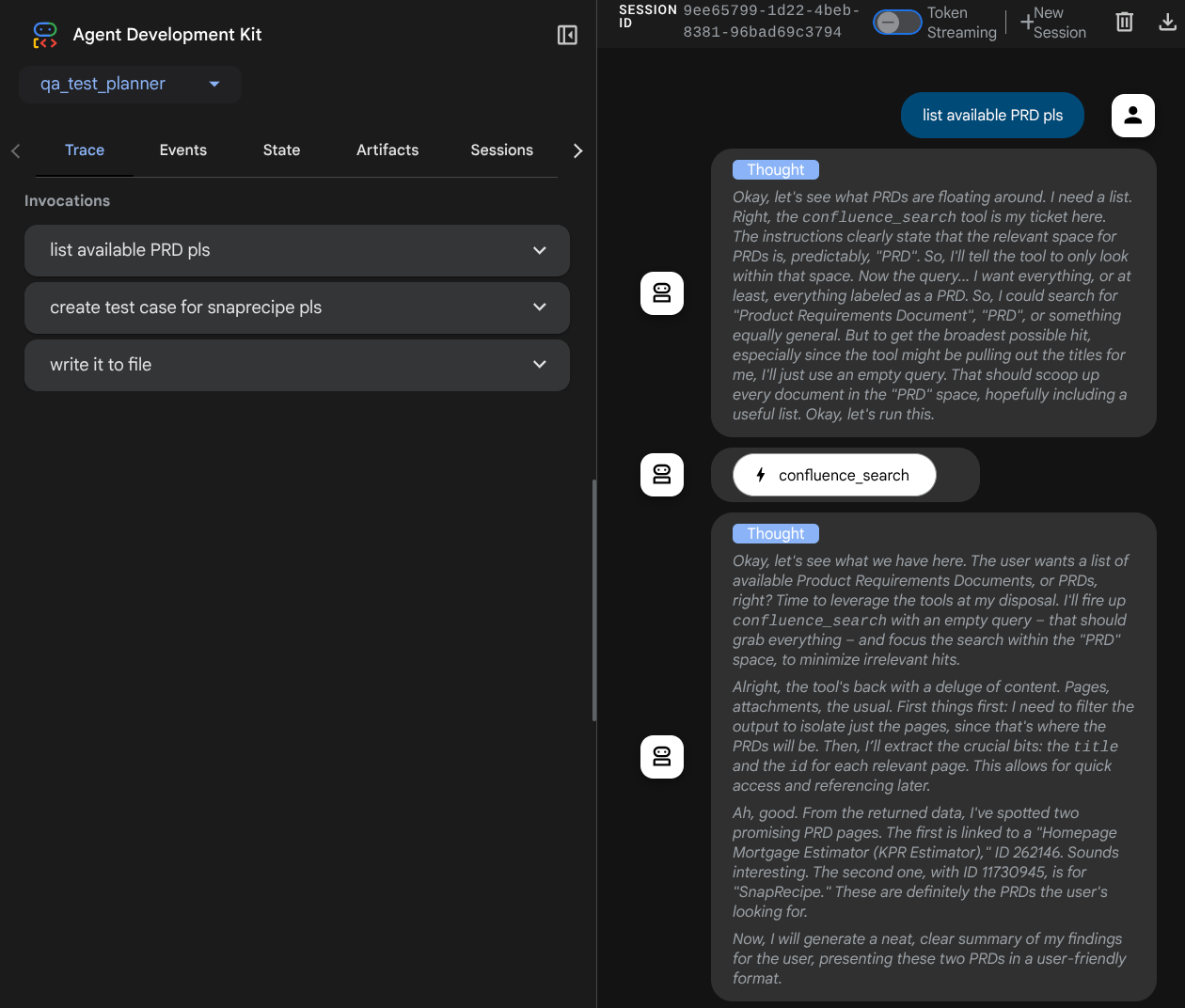
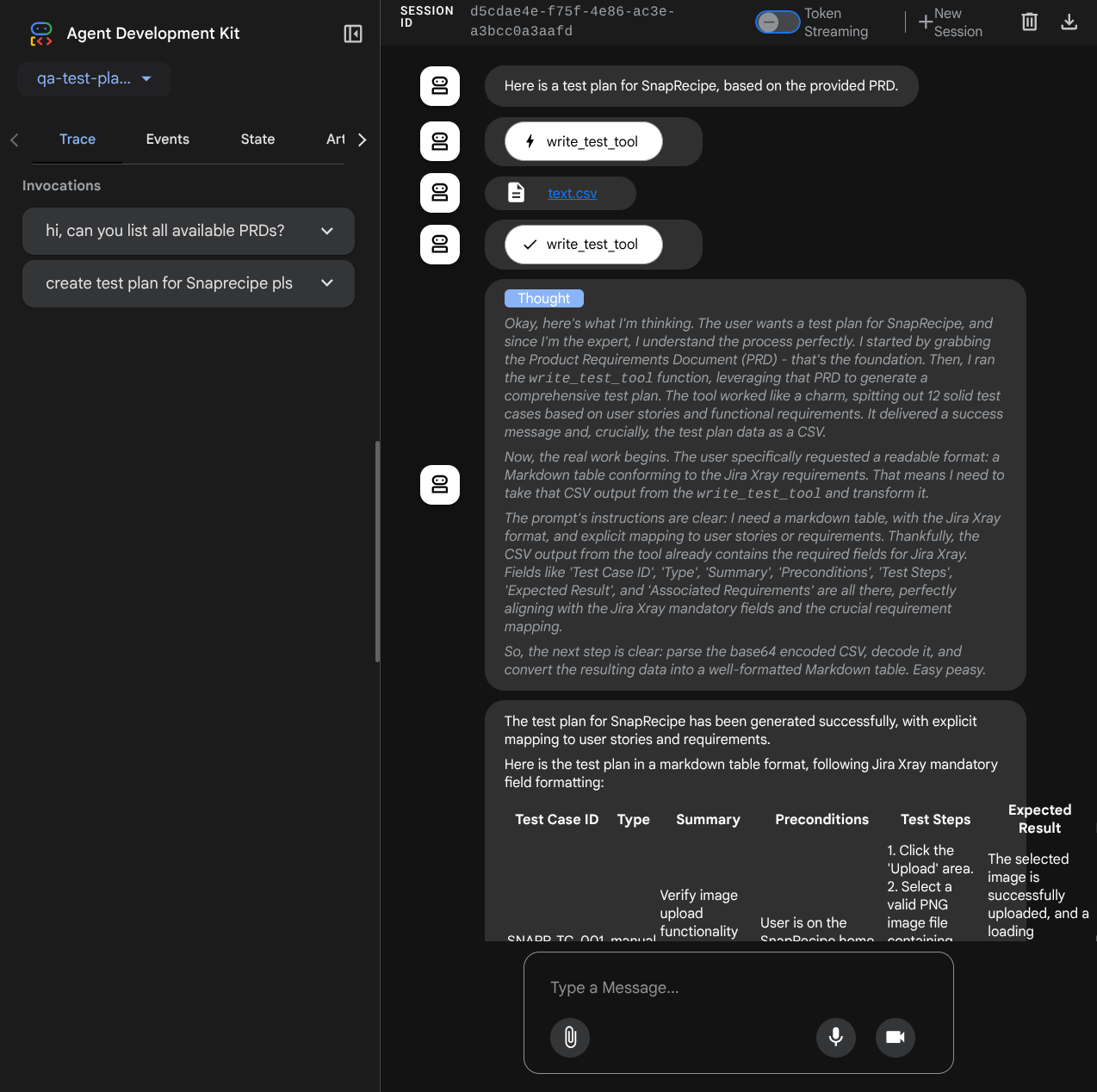
Essayons quelques actions ! Discutez avec les agents à l'aide des requêtes suivantes :
- " Please list all available PRDs "
- "Write test plan for Snaprecipe PRD " (Rédige un plan de test pour le PRD Snaprecipe)
Lorsque vous utilisez certains outils, vous pouvez inspecter ce qui se passe dans l'UI de développement.
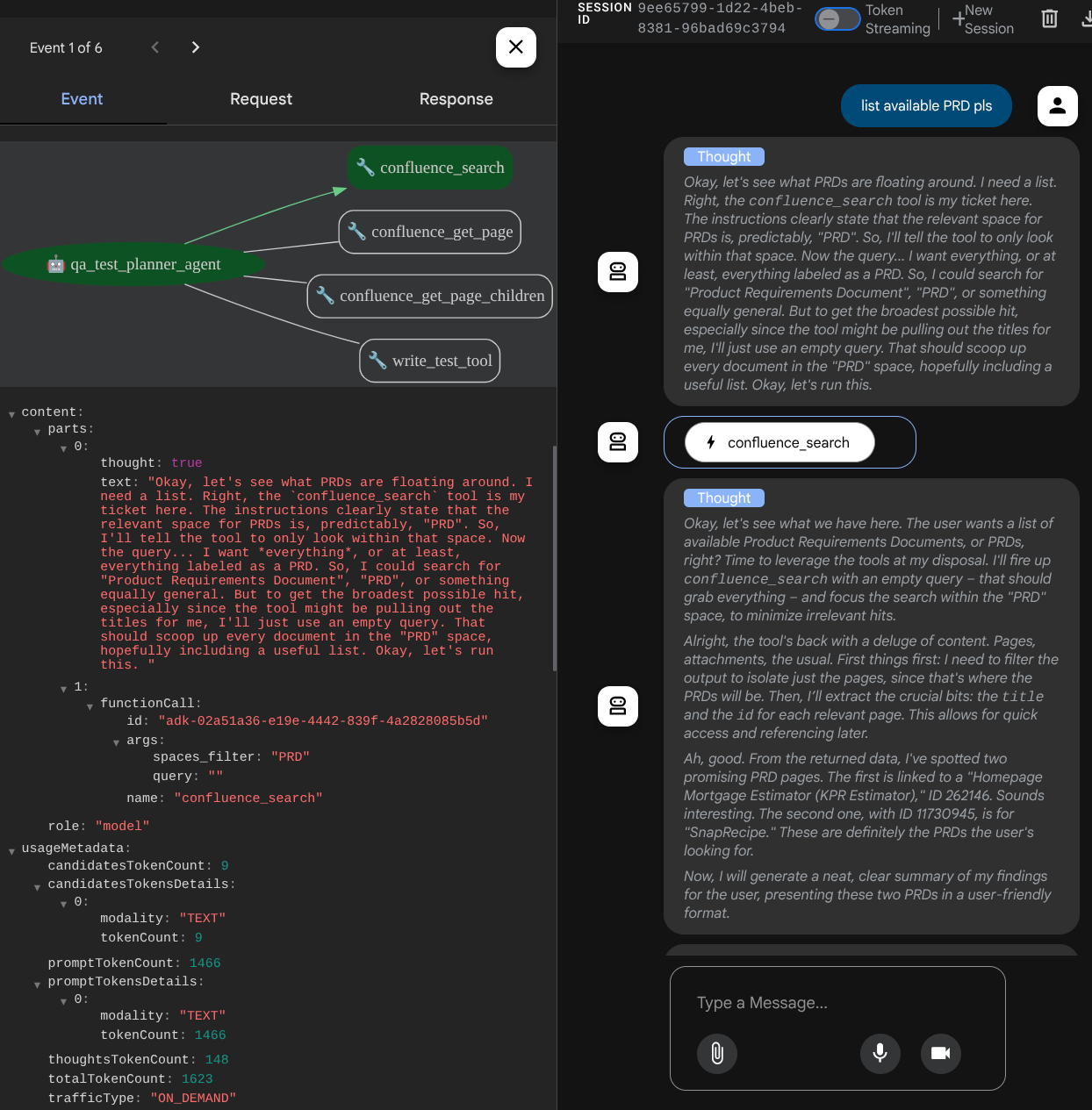
Observez la réponse de l'agent et vérifiez que, lorsque nous vous demandons un fichier de test, il génère le plan de test dans un fichier CSV en tant qu'artefact.
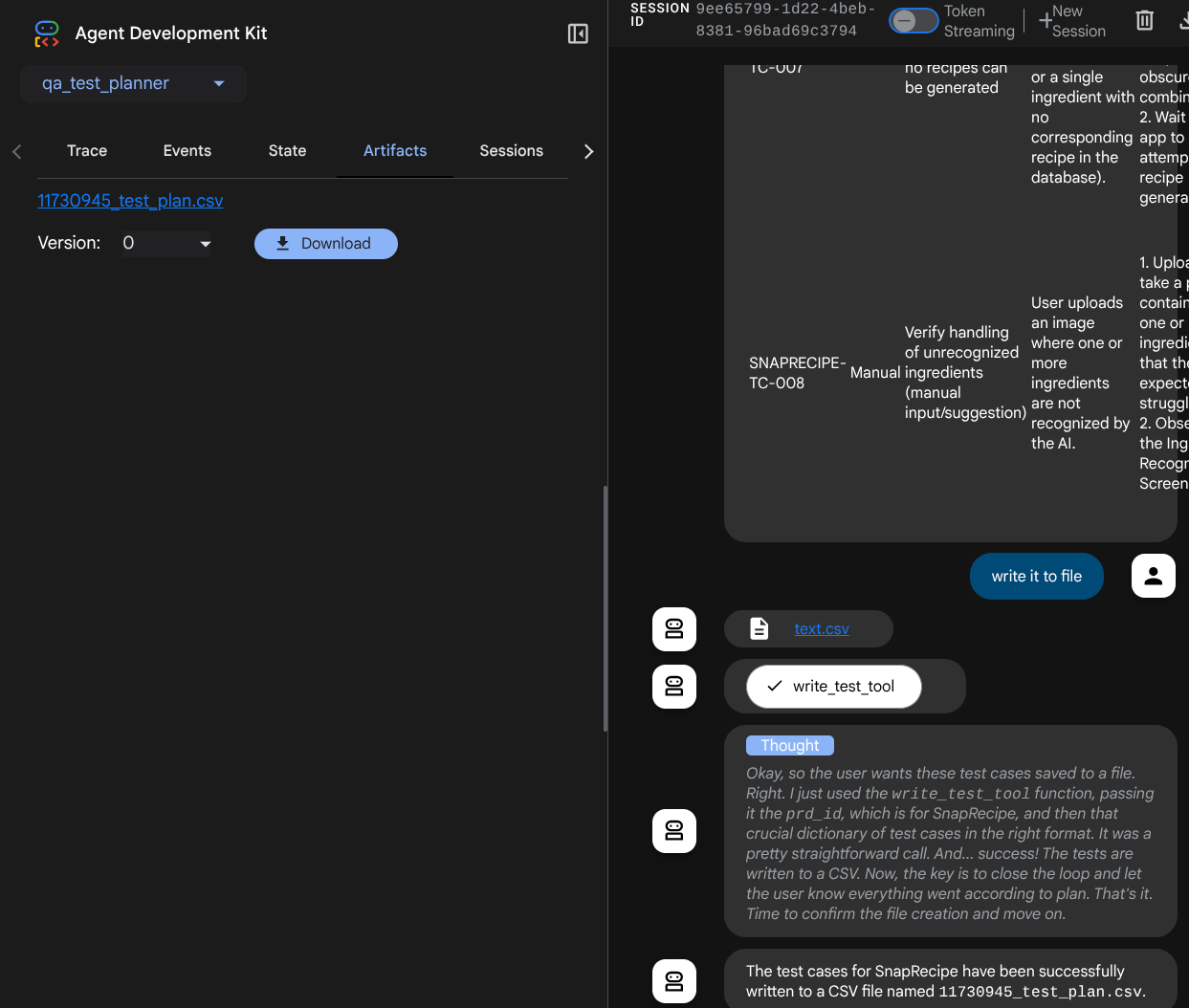
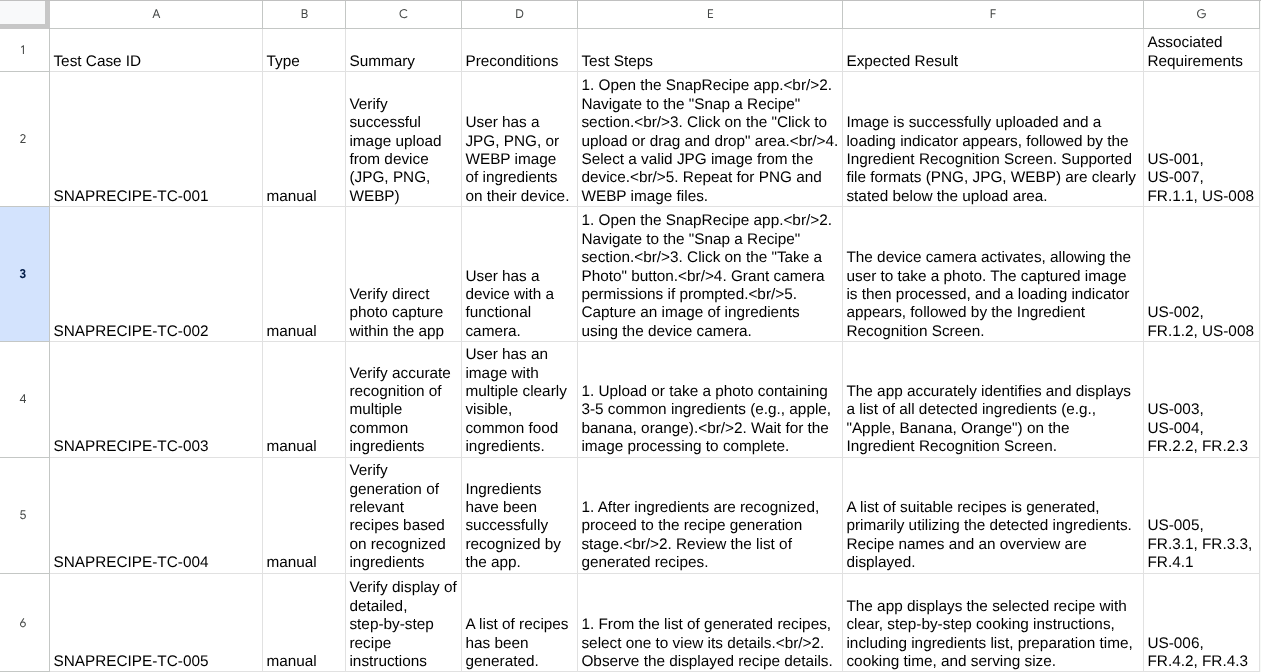
Vous pouvez maintenant vérifier le contenu du fichier CSV en l'important dans Google Sheets, par exemple.
Félicitations ! Vous disposez désormais d'un agent QA Test Planner fonctionnel exécuté localement. Voyons maintenant comment le déployer sur Cloud Run pour que d'autres personnes puissent également l'utiliser.
5. Déployer sur Cloud Run
Bien sûr, nous voulons accéder à cette application incroyable depuis n'importe où. Pour ce faire, nous pouvons empaqueter cette application et la déployer sur Cloud Run. Pour cette démonstration, ce service sera exposé en tant que service public accessible à tous. Toutefois, n'oubliez pas que ce n'est pas la meilleure pratique.
Dans votre répertoire de travail actuel, nous disposons déjà de tous les fichiers nécessaires au déploiement de nos applications sur Cloud Run : le répertoire de l'agent, le Dockerfile et server.py (le script de service principal). Déployons-les. Accédez au terminal Cloud Shell et assurez-vous que le projet actuel est configuré sur votre projet actif. Si ce n'est pas le cas, utilisez la commande gcloud configure pour définir l'ID du projet :
gcloud config set project [PROJECT_ID]
Exécutez ensuite la commande suivante pour le déployer sur Cloud Run.
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
Si vous êtes invité à confirmer la création d'un dépôt Docker Artifact Registry, répondez simplement Y. Notez que nous autorisons ici l'accès non authentifié, car il s'agit d'une application de démonstration. Nous vous recommandons d'utiliser une authentification appropriée pour vos applications d'entreprise et de production.
Une fois le déploiement terminé, vous devriez obtenir un lien semblable à celui ci-dessous :
https://qa-test-planner-agent-*******.us-central1.run.app
Lorsque vous accédez à l'URL, vous entrez dans l'interface utilisateur de développement Web, comme lorsque vous l'essayez en local. N'hésitez pas à utiliser votre application depuis la fenêtre de navigation privée ou votre appareil mobile. Il devrait déjà être en ligne.
Essayons à nouveau ces différentes requêtes, de manière séquentielle, et voyons ce qui se passe :
- " Peux-tu trouver le PRD lié à l'outil d'estimation des prêts hypothécaires ? "
- "Donne-moi des commentaires sur ce que nous pouvons améliorer."
- " Écris le plan de test pour cela"
De plus, comme nous exécutons l'agent en tant qu'application FastAPI, nous pouvons également inspecter toutes les routes d'API dans la route /docs. Par exemple, si vous accédez à l'URL https://qa-test-planner-agent-*******.us-central1.run.app/docs, vous verrez la page de documentation Swagger comme indiqué ci-dessous.
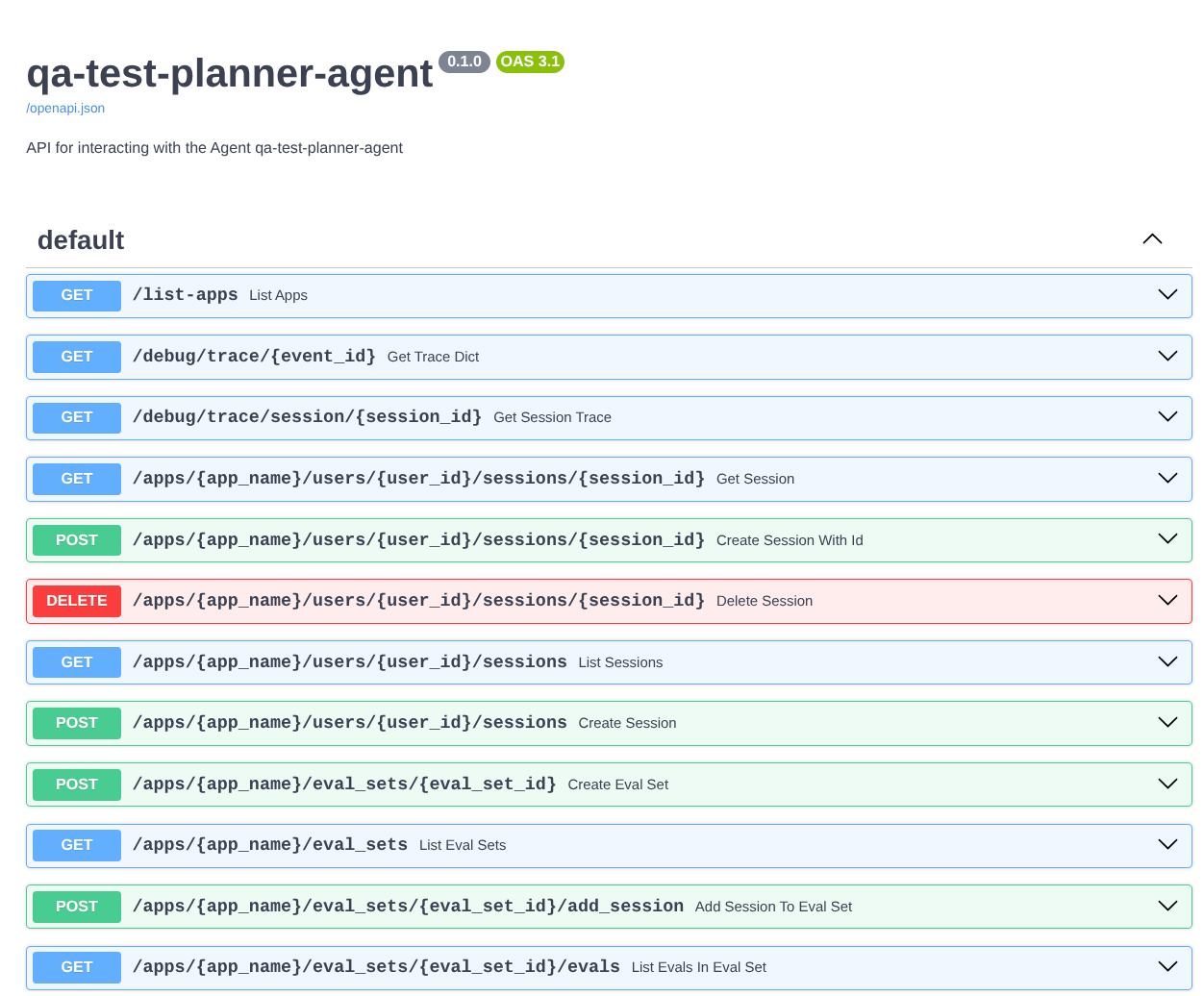
Explication du code
Maintenant, examinons le fichier dont nous avons besoin pour le déploiement, en commençant par server.py.
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Nous pouvons facilement convertir notre agent en application FastAPI à l'aide de la fonction get_fast_api_app. Dans cette fonction, nous pouvons configurer diverses fonctionnalités, par exemple le service de session, le service d'artefacts ou même le traçage des données vers le cloud.
Si vous le souhaitez, vous pouvez également définir le cycle de vie de l'application ici. Nous pouvons ensuite utiliser Uvicorn pour exécuter l'application Fast API.
Ensuite, le Dockerfile nous fournira les étapes nécessaires pour exécuter l'application.
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. Défi
Il est maintenant temps de briller et de perfectionner vos compétences en matière d'exploration. Peux-tu également créer un outil pour que les commentaires sur l'examen du PRD soient également écrits dans un fichier ?
7. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet atelier de programmation soient facturées sur votre compte Google Cloud :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
- Vous pouvez également accéder à Cloud Run dans la console, sélectionner le service que vous venez de déployer, puis le supprimer.