
1. परिचय
टेस्ट प्लान बनाने के लिए जनरेटिव एआई का इस्तेमाल करने की क्षमता, क्वालिटी अश्योरेंस से जुड़ी दो सबसे बड़ी चुनौतियों को हल करने की क्षमता से मिलती है. ये चुनौतियां हैं: तेज़ी और पूरी जानकारी. आजकल, तेज़ी से काम करने वाले एजाइल और DevOps साइकल में, टेस्ट प्लान को मैन्युअल तरीके से तैयार करना एक बड़ी समस्या है. इससे टेस्टिंग की पूरी प्रोसेस में देरी होती है. जन एआई की मदद से काम करने वाला एजेंट, उपयोगकर्ता की कहानियों और तकनीकी ज़रूरतों को समझकर, कुछ ही मिनटों में टेस्ट प्लान तैयार कर सकता है. इससे QA प्रोसेस, डेवलपमेंट के साथ-साथ चलती रहती है. इसके अलावा, एआई ऐसे मुश्किल मामलों, असामान्य स्थितियों, और नेगेटिव पाथ की पहचान करने में बेहतर होता है जिन्हें कोई व्यक्ति नज़रअंदाज़ कर सकता है. इससे टेस्ट कवरेज में काफ़ी सुधार होता है और प्रोडक्शन में आने वाले बग की संख्या में काफ़ी कमी आती है.
इस कोडलैब में, हम ऐसे एजेंट को बनाने का तरीका जानेंगे जो Confluence से प्रॉडक्ट की ज़रूरी शर्तों वाले दस्तावेज़ों को वापस पा सकता है. साथ ही, वह काम के सुझाव दे सकता है. इसके अलावा, वह एक ऐसा टेस्ट प्लान भी जनरेट कर सकता है जिसे CSV फ़ाइल में एक्सपोर्ट किया जा सकता है.
कोडलैब के ज़रिए, आपको यहां दिया गया तरीका अपनाना होगा:
- अपना Google Cloud प्रोजेक्ट तैयार करें और उस पर सभी ज़रूरी एपीआई चालू करें
- कोडिंग एनवायरमेंट के लिए Workspace सेट अप करना
- Confluence के लिए लोकल mcp-server तैयार किया जा रहा है
- एमसीपी सर्वर से कनेक्ट करने के लिए, एडीके एजेंट के सोर्स कोड, प्रॉम्प्ट, और टूल को स्ट्रक्चर करना
- आर्टफ़ैक्ट सेवा और टूल के कॉन्टेक्स्ट के इस्तेमाल को समझना
- ADK के लोकल वेब डेवलपमेंट यूज़र इंटरफ़ेस का इस्तेमाल करके एजेंट की जांच करना
- Cloud Run पर ऐप्लिकेशन को डिप्लॉय करने के लिए, एनवायरमेंट वैरिएबल और ज़रूरी फ़ाइलों को मैनेज करना
- ऐप्लिकेशन को Cloud Run पर डिप्लॉय करें
आर्किटेक्चर की खास जानकारी
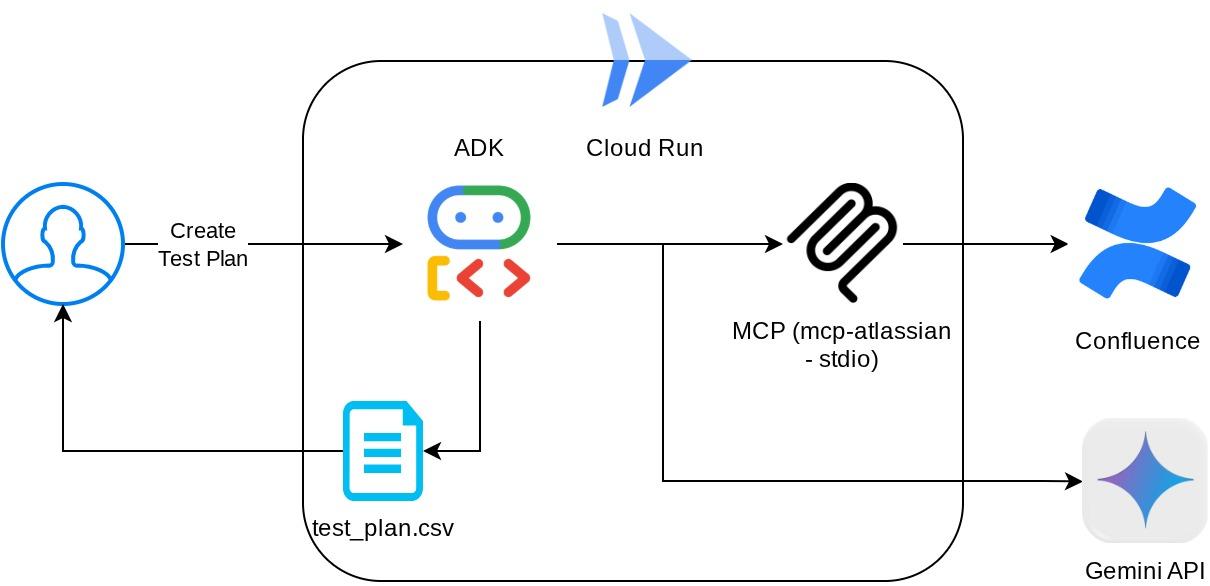
ज़रूरी शर्तें
- Python के साथ काम करने में सहज हों
- एचटीटीपी सेवा का इस्तेमाल करके, बुनियादी फ़ुल-स्टैक आर्किटेक्चर के बारे में जानकारी
आपको क्या सीखने को मिलेगा
- ADK एजेंट को डिज़ाइन करना और उसकी कई क्षमताओं का इस्तेमाल करना
- कस्टम टूल और एमसीपी के साथ टूल का इस्तेमाल करना
- Artifact Service Management का इस्तेमाल करके, एजेंट के ज़रिए फ़ाइल आउटपुट सेट अप करना
- Gemini 2.5 Flash की सोच-विचार करने की क्षमताओं का इस्तेमाल करके, BuiltInPlanner की मदद से टास्क को बेहतर तरीके से पूरा करना
- ADK के वेब इंटरफ़ेस के ज़रिए इंटरैक्शन और डीबग करना
- Dockerfile का इस्तेमाल करके, Cloud Run पर ऐप्लिकेशन डिप्लॉय करें और एनवायरमेंट वैरिएबल उपलब्ध कराएं
आपको इन चीज़ों की ज़रूरत होगी
- Chrome वेब ब्राउज़र
- Gmail खाता
- ऐसा Cloud प्रोजेक्ट जिसमें बिलिंग की सुविधा चालू हो
- (ज़रूरी नहीं) Confluence Space, जिसमें प्रॉडक्ट की ज़रूरी शर्तों की जानकारी देने वाले दस्तावेज़ के पेज हों
यह कोडलैब, सभी लेवल के डेवलपर के लिए बनाया गया है. इसमें शुरुआती डेवलपर भी शामिल हैं. इसमें सैंपल ऐप्लिकेशन में Python का इस्तेमाल किया गया है. हालांकि, यहां दिए गए कॉन्सेप्ट को समझने के लिए, Python के बारे में जानकारी होना ज़रूरी नहीं है. अगर आपके पास Confluence स्पेस नहीं है, तो चिंता न करें. हम आपको इस कोडलैब को आज़माने के लिए क्रेडेंशियल देंगे
2. शुरू करने से पहले
Cloud Console में चालू प्रोजेक्ट चुनना
इस कोडलैब में यह माना गया है कि आपके पास पहले से ही बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट है. अगर आपके पास यह सुविधा अभी तक नहीं है, तो इसे इस्तेमाल करने के लिए यहां दिया गया तरीका अपनाएं.
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell टर्मिनल में क्लाउड प्रोजेक्ट सेट अप करना
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
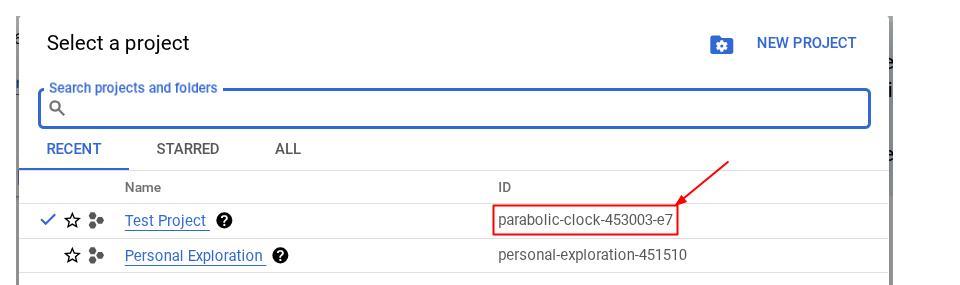
इसके अलावा, PROJECT_ID आईडी को कंसोल में भी देखा जा सकता है
इस पर क्लिक करने से, आपको अपने सभी प्रोजेक्ट और प्रोजेक्ट आईडी दाईं ओर दिखेंगे
- नीचे दिए गए निर्देश का इस्तेमाल करके, ज़रूरी एपीआई चालू करें. इसमें कुछ मिनट लग सकते हैं. इसलिए, कृपया इंतज़ार करें.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
कमांड के सही तरीके से लागू होने पर, आपको यहां दिखाए गए मैसेज जैसा कोई मैसेज दिखेगा:
Operation "operations/..." finished successfully.
gcloud कमांड के बजाय, कंसोल का इस्तेमाल करके भी ऐसा किया जा सकता है. इसके लिए, हर प्रॉडक्ट को खोजें या इस लिंक का इस्तेमाल करें.
अगर कोई एपीआई छूट जाता है, तो उसे लागू करने के दौरान कभी भी चालू किया जा सकता है.
gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
Cloud Shell Editor पर जाएं और ऐप्लिकेशन की वर्किंग डायरेक्ट्री सेट अप करें
अब हम कोडिंग से जुड़े कुछ काम करने के लिए, कोड एडिटर सेट अप कर सकते हैं. इसके लिए, हम Cloud Shell Editor का इस्तेमाल करेंगे
- 'एडिटर खोलें' बटन पर क्लिक करें. इससे Cloud Shell Editor खुल जाएगा. यहां हम अपना कोड लिख सकते हैं
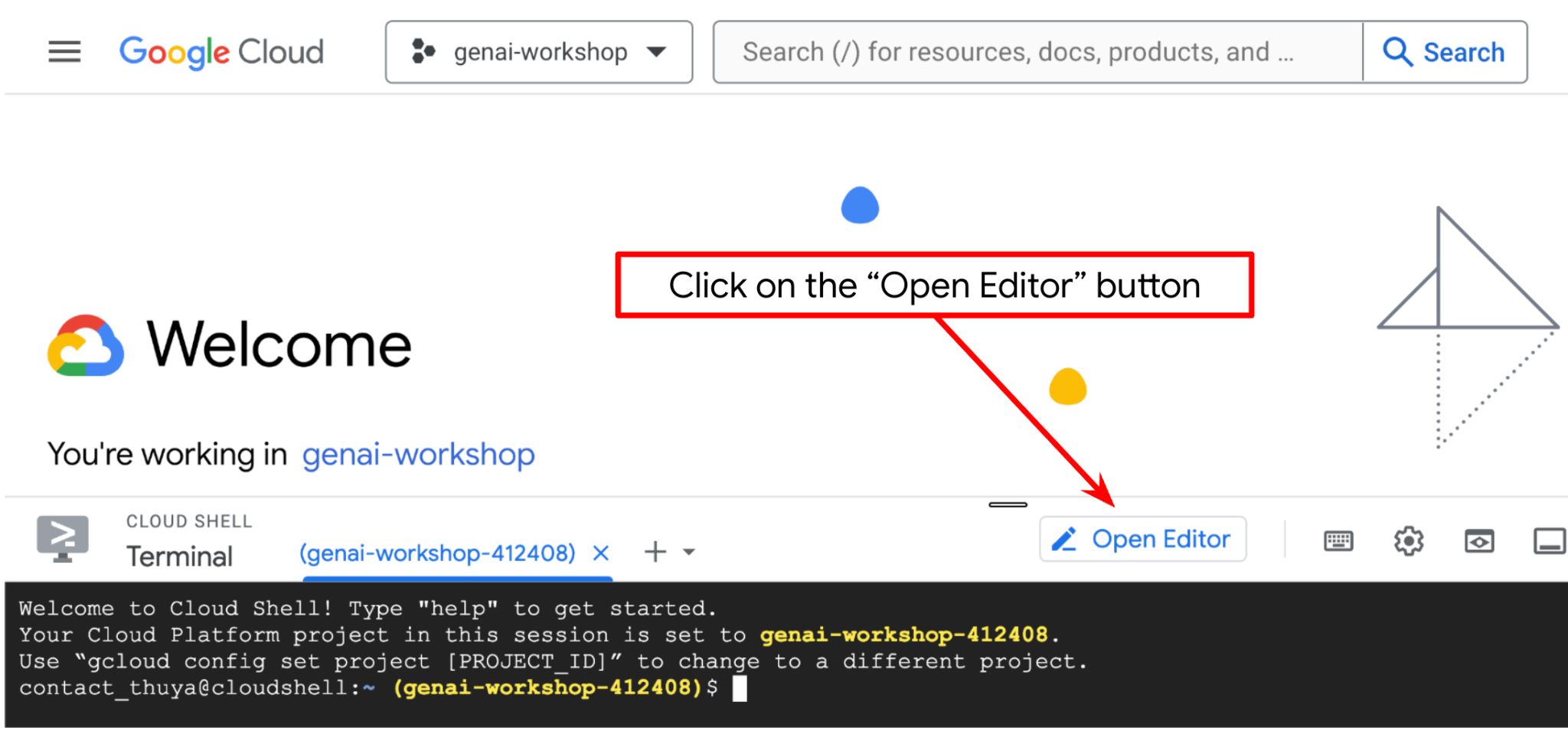
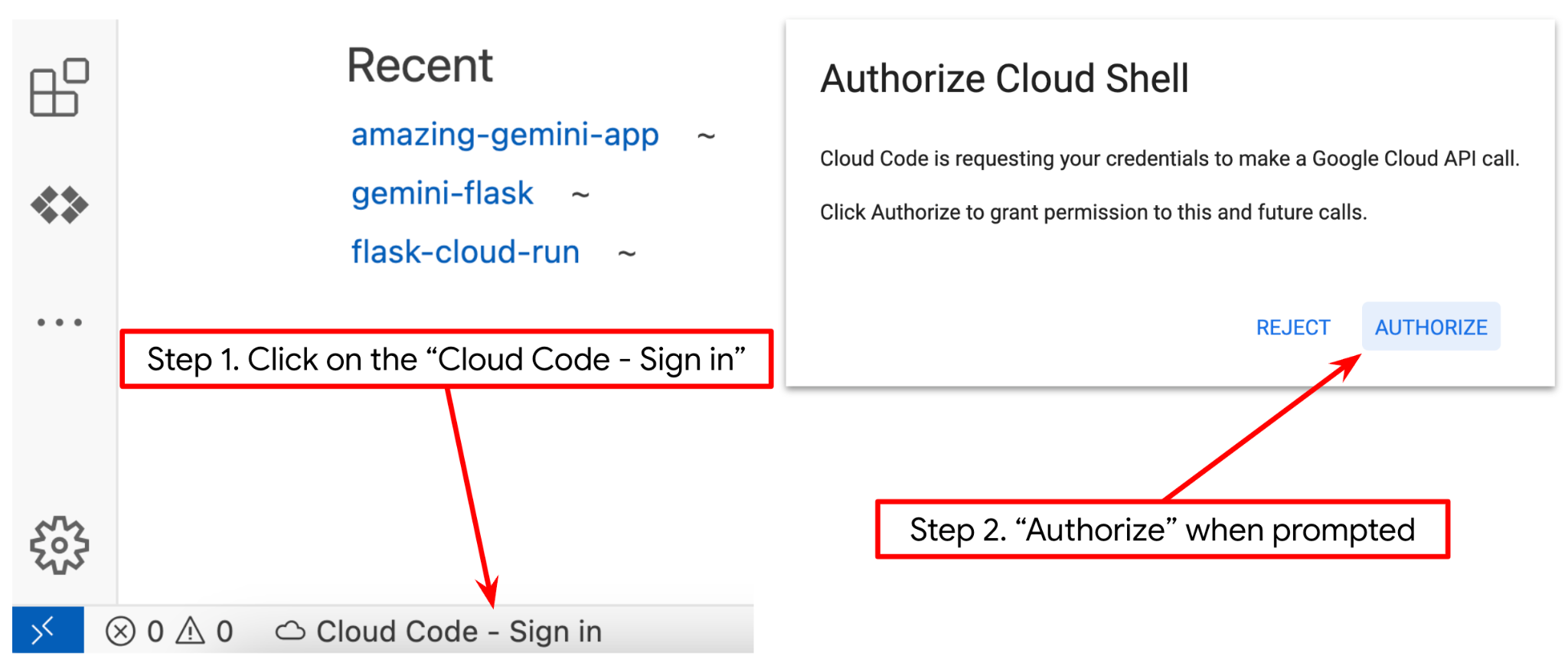
- पक्का करें कि Cloud Code प्रोजेक्ट, Cloud Shell एडिटर के सबसे नीचे बाईं ओर (स्टेटस बार) में सेट हो. जैसा कि नीचे दी गई इमेज में हाइलाइट किया गया है. साथ ही, यह उस चालू Google Cloud प्रोजेक्ट पर सेट हो जिसके लिए बिलिंग की सुविधा चालू है. अगर कहा जाए, तो अनुमति दें पर क्लिक करें. अगर आपने पहले से ही पिछले निर्देश का पालन किया है, तो बटन, साइन इन बटन के बजाय सीधे आपके चालू किए गए प्रोजेक्ट पर भी ले जा सकता है
- इसके बाद, कोड सीखने की इस लैब के लिए, टेंप्लेट की वर्किंग डायरेक्ट्री को Github से क्लोन करें. इसके लिए, यहां दिया गया निर्देश चलाएं. इससे qa-test-planner-agent डायरेक्ट्री में वर्किंग डायरेक्ट्री बन जाएगी
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
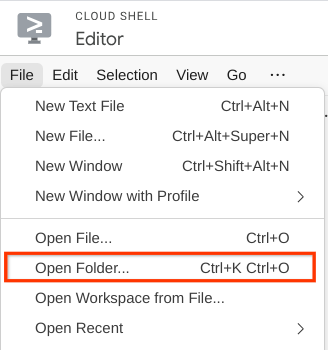
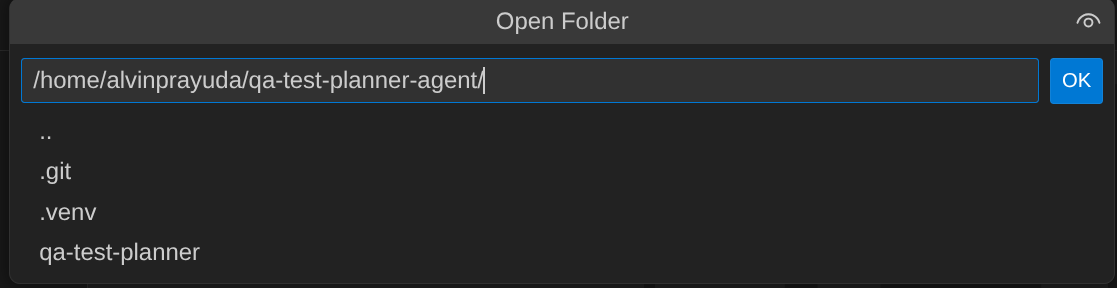
- इसके बाद, Cloud Shell Editor के सबसे ऊपर वाले सेक्शन पर जाएं और File->Open Folder पर क्लिक करें. इसके बाद, अपनी username डायरेक्ट्री ढूंढें और qa-test-planner-agent डायरेक्ट्री ढूंढें. इसके बाद, OK बटन पर क्लिक करें. इससे चुनी गई डायरेक्ट्री, मुख्य वर्किंग डायरेक्ट्री बन जाएगी. इस उदाहरण में, उपयोगकर्ता नाम alvinprayuda है. इसलिए, डायरेक्ट्री का पाथ यहां दिखाया गया है
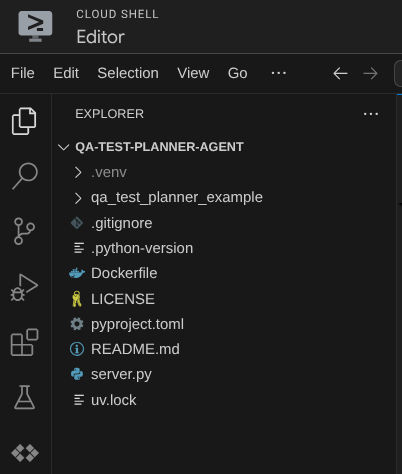
अब आपका Cloud Shell Editor ऐसा दिखना चाहिए
एनवायरमेंट सेटअप करना
Python वर्चुअल एनवायरमेंट तैयार करना
अगला चरण, डेवलपमेंट एनवायरमेंट तैयार करना है. आपका मौजूदा ऐक्टिव टर्मिनल, qa-test-planner-agent वर्किंग डायरेक्ट्री में होना चाहिए. इस कोडलैब में, Python 3.12 का इस्तेमाल किया जाएगा. साथ ही, Python के वर्शन और वर्चुअल एनवायरमेंट को बनाने और मैनेज करने की ज़रूरत को आसान बनाने के लिए, हम uv python project manager का इस्तेमाल करेंगे
- अगर आपने अब तक टर्मिनल नहीं खोला है, तो टर्मिनल -> नया टर्मिनल पर क्लिक करके इसे खोलें. इसके अलावा, Ctrl + Shift + C का इस्तेमाल करके भी इसे खोला जा सकता है. इससे ब्राउज़र के सबसे नीचे एक टर्मिनल विंडो खुलेगी

uvडाउनलोड करें और python 3.12 को इस कमांड के साथ इंस्टॉल करें
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- अब
uvका इस्तेमाल करके वर्चुअल एनवायरमेंट शुरू करें. यह निर्देश चलाएं
uv sync --frozen
इससे .venv डायरेक्ट्री बन जाएगी और डिपेंडेंसी इंस्टॉल हो जाएंगी. pyproject.toml की झलक से, आपको इस तरह दिखाई गई डिपेंडेंसी के बारे में जानकारी मिलेगी
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- वर्चुअल एनवायरमेंट की जांच करने के लिए, नई फ़ाइल main.py बनाएं और इस कोड को कॉपी करें
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- इसके बाद, यह कमांड चलाएं
uv run main.py
आपको नीचे दिखाए गए जैसा आउटपुट मिलेगा
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
इससे पता चलता है कि Python प्रोजेक्ट को सही तरीके से सेट अप किया जा रहा है.
अब हम अगले चरण पर जा सकते हैं. इसमें एजेंट और फिर सेवाएं बनाई जाएंगी
3. Google ADK और Gemini 2.5 का इस्तेमाल करके एजेंट बनाना
ADK के डायरेक्ट्री स्ट्रक्चर के बारे में जानकारी
आइए, सबसे पहले यह जानते हैं कि ADK में क्या-क्या सुविधाएं उपलब्ध हैं और एजेंट कैसे बनाया जाता है. ADK के पूरे दस्तावेज़ को इस यूआरएल पर ऐक्सेस किया जा सकता है . ADK, सीएलआई कमांड को लागू करने के लिए कई सुविधाएं देता है. इनमें से कुछ यहां दिए गए हैं :
- एजेंट डायरेक्ट्री स्ट्रक्चर सेट अप करना
- सीएलआई के इनपुट और आउटपुट के ज़रिए, बातचीत करने की सुविधा को तुरंत आज़माएं
- लोकल डेवलपमेंट यूज़र इंटरफ़ेस (यूआई) वेब इंटरफ़ेस को तुरंत सेटअप करना
अब, CLI कमांड का इस्तेमाल करके एजेंट डायरेक्ट्री स्ट्रक्चर बनाते हैं. यह कमांड चलाएं
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
इससे आपकी मौजूदा वर्किंग डायरेक्ट्री में, एजेंट डायरेक्ट्री का यह स्ट्रक्चर बन जाएगा
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
init.py और agent.py की जांच करने पर, आपको यह कोड दिखेगा
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
QA टेस्ट प्लानर एजेंट बनाना
चलिए, क्यूए टेस्ट प्लानर एजेंट बनाते हैं! qa_test_planner/agent.py फ़ाइल खोलें और नीचे दिया गया कोड कॉपी करें. इसमें root_agent शामिल होगा.
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
कॉन्फ़िगरेशन फ़ाइलें सेट अप करना
अब हमें इस प्रोजेक्ट के लिए, अतिरिक्त कॉन्फ़िगरेशन सेटअप करना होगा. ऐसा इसलिए, क्योंकि इस एजेंट को Confluence का ऐक्सेस चाहिए होगा
qa_test_planner/.env फ़ाइल खोलें और इसमें यहां दी गई एनवायरमेंट वैरिएबल की वैल्यू डालें. पक्का करें कि .env फ़ाइल इस तरह दिखे
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
माफ़ करें, इस Confluence स्पेस को सार्वजनिक नहीं किया जा सकता. इसलिए, उपलब्ध प्रॉडक्ट की ज़रूरी शर्तों वाले दस्तावेज़ पढ़ने के लिए, इन फ़ाइलों की जांच करें. ये दस्तावेज़, ऊपर दिए गए क्रेडेंशियल का इस्तेमाल करके उपलब्ध होंगे.
कोड के बारे में जानकारी
इस स्क्रिप्ट में, एजेंट को शुरू करने की सुविधा शामिल है. इसमें हम इन चीज़ों को शुरू करते हैं:
- इस्तेमाल किए जाने वाले मॉडल को
gemini-2.5-flashपर सेट करें - Confluence MCP Tools सेट अप करें, जो Studio के ज़रिए कम्यूनिकेट करेगा
- टेस्ट प्लान लिखने और CSV को आर्टफ़ैक्ट में डंप करने के लिए,
write_test_toolकस्टम टूल सेटअप करें - एजेंट की जानकारी और निर्देश सेट अप करना
- Gemini 2.5 Flash की सूझ-बूझ वाली क्षमताओं का इस्तेमाल करके, फ़ाइनल जवाब जनरेट करने या टास्क पूरा करने से पहले प्लानिंग की सुविधा चालू करना
Gemini मॉडल की मदद से काम करने वाला एजेंट, सोचने की क्षमता के साथ काम करता है. साथ ही, प्लानर आर्ग्युमेंट के साथ कॉन्फ़िगर किया जाता है. इससे एजेंट, सोचने की क्षमता दिखा पाता है. साथ ही, इसे वेब इंटरफ़ेस पर भी दिखाया जाता है. इसे कॉन्फ़िगर करने का कोड यहां दिया गया है
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
कार्रवाइयां करने से पहले, हम इसकी सोचने की प्रोसेस देख सकते हैं
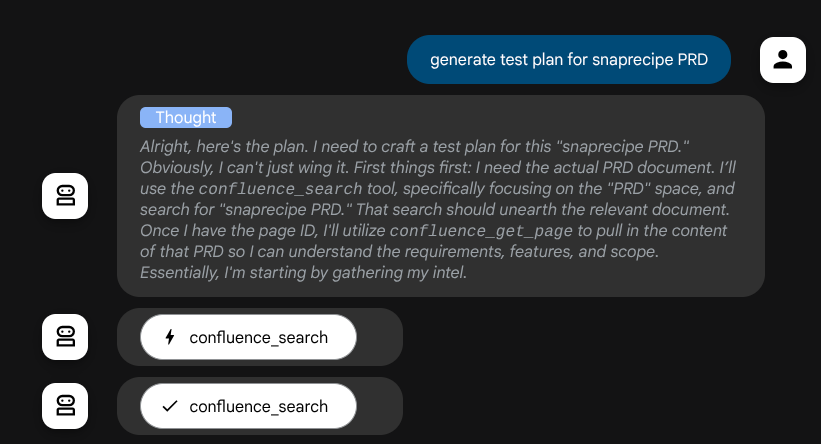
Confluence MCP टूल
ADK से एमसीपी सर्वर से कनेक्ट करने के लिए, हमें MCPToolSet का इस्तेमाल करना होगा. इसे google.adk.tools.mcp_tool.mcp_toolset मॉड्यूल से इंपोर्ट किया जा सकता है. यहां शुरू किया गया कोड नीचे दिखाया गया है ( इसे छोटा किया गया है)
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
इस कॉन्फ़िगरेशन की मदद से, एजेंट Confluence MCP Server को एक अलग प्रोसेस के तौर पर शुरू करेगा. साथ ही, Studio I/O के ज़रिए उन प्रोसेस के साथ कम्यूनिकेट करेगा. इस फ़्लो को नीचे दी गई एमसीपी आर्किटेक्चर की इमेज में दिखाया गया है. यह इमेज, लाल बॉक्स में मार्क की गई है.
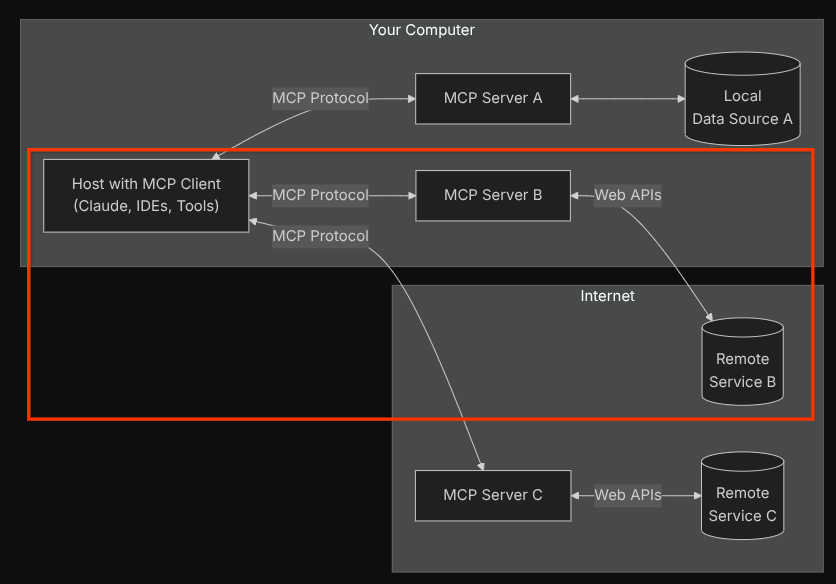
इसके अलावा, एमसीपी को शुरू करने के लिए इस्तेमाल किए जाने वाले कमांड आर्ग्युमेंट में, हम सिर्फ़ इन टूल का इस्तेमाल करने की अनुमति देते हैं: confluence_search, confluence_get_page, और confluence_get_page_children. ये टूल, QA टेस्ट एजेंट के इस्तेमाल के मामलों के साथ काम करते हैं. इस कोडलैब ट्यूटोरियल के लिए, हम कम्यूनिटी के योगदान वाले Atlassian MCP Server का इस्तेमाल करते हैं. ज़्यादा जानकारी के लिए, पूरे दस्तावेज़ देखें.
लिखने की जांच करने वाला टूल
Confluence MCP टूल से कॉन्टेक्स्ट मिलने के बाद, एजेंट उपयोगकर्ता के लिए ज़रूरी टेस्ट प्लान बना सकता है. हालांकि, हमें एक ऐसी फ़ाइल बनानी है जिसमें यह टेस्ट प्लान शामिल हो, ताकि इसे सेव किया जा सके और दूसरे व्यक्ति के साथ शेयर किया जा सके. इसके लिए, हम यहां कस्टम टूल write_test_tool उपलब्ध करा रहे हैं
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
ऊपर दिए गए फ़ंक्शन का इस्तेमाल इन कामों के लिए किया जाता है:
- तैयार किए गए टेस्ट प्लान की जांच करें, ताकि यह पक्का किया जा सके कि यह ज़रूरी फ़ील्ड की खास बातों के मुताबिक है. हम Pydantic मॉडल का इस्तेमाल करके इसकी जांच करते हैं. अगर कोई गड़बड़ी होती है, तो हम एजेंट को गड़बड़ी का मैसेज भेजते हैं
- pandas की सुविधा का इस्तेमाल करके, नतीजे को CSV में डंप करना
- इसके बाद, जनरेट की गई फ़ाइल को आर्टफ़ैक्ट के तौर पर सेव किया जाता है. इसके लिए, आर्टफ़ैक्ट सेवा की सुविधाओं का इस्तेमाल किया जाता है. इसे ToolContext ऑब्जेक्ट का इस्तेमाल करके ऐक्सेस किया जा सकता है. इसे हर टूल कॉल पर ऐक्सेस किया जा सकता है
अगर जनरेट की गई फ़ाइलों को आर्टफ़ैक्ट के तौर पर सेव किया जाता है, तो ADK रनटाइम में उन्हें इवेंट के तौर पर मार्क किया जाएगा. साथ ही, इन्हें बाद में एजेंट इंटरैक्शन के दौरान वेब इंटरफ़ेस पर दिखाया जा सकता है
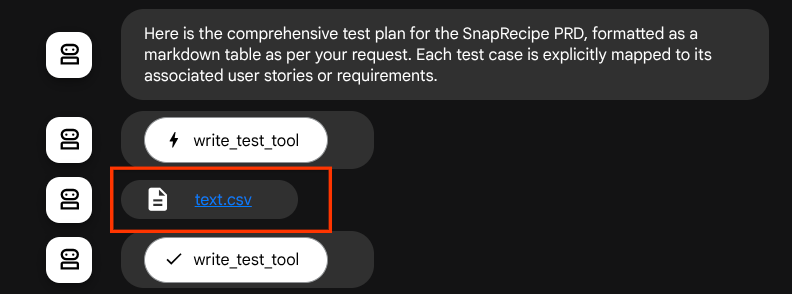
इसकी मदद से, हम एजेंट से मिले फ़ाइल रिस्पॉन्स को डाइनैमिक तरीके से सेटअप कर सकते हैं, ताकि उसे उपयोगकर्ता को दिया जा सके.
4. एजेंट की टेस्टिंग
अब सीएलआई के ज़रिए एजेंट से कम्यूनिकेट करने की कोशिश करें. इसके लिए, यह निर्देश चलाएं
uv run adk run qa_test_planner
आपको इस तरह का आउटपुट दिखेगा. इसमें एजेंट के साथ बारी-बारी से चैट की जा सकती है. हालांकि, इस इंटरफ़ेस के ज़रिए सिर्फ़ टेक्स्ट भेजा जा सकता है
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
सीएलआई के ज़रिए एजेंट से चैट करने की सुविधा अच्छी है. हालांकि, अगर हम इसके साथ वेब चैट कर पाएं, तो यह और भी बेहतर होगा. हम ऐसा भी कर सकते हैं! ADK की मदद से, हमें डेवलपमेंट यूज़र इंटरफ़ेस (यूआई) मिलता है. इससे हम बातचीत के दौरान, यह देख पाते हैं कि क्या हो रहा है. लोकल डेवलपमेंट यूज़र इंटरफ़ेस (यूआई) सर्वर शुरू करने के लिए, यह कमांड चलाएं
uv run adk web --port 8080
इससे आपको इस उदाहरण जैसा आउटपुट मिलेगा. इसका मतलब है कि अब वेब इंटरफ़ेस को ऐक्सेस किया जा सकता है
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
अब इसे देखने के लिए, Cloud Shell Editor के सबसे ऊपर मौजूद वेब प्रीव्यू बटन पर क्लिक करें. इसके बाद, पोर्ट 8080 पर प्रीव्यू करें को चुनें
आपको यह वेब पेज दिखेगा. इसमें सबसे ऊपर बाईं ओर मौजूद ड्रॉप-डाउन बटन से, उपलब्ध एजेंट चुने जा सकते हैं. हमारे मामले में, यह qa_test_planner होना चाहिए. इसके बाद, बॉट से इंटरैक्ट किया जा सकता है. आपको बाईं ओर मौजूद विंडो में, एजेंट के रनटाइम के दौरान लॉग की जानकारी के बारे में कई तरह की जानकारी दिखेगी
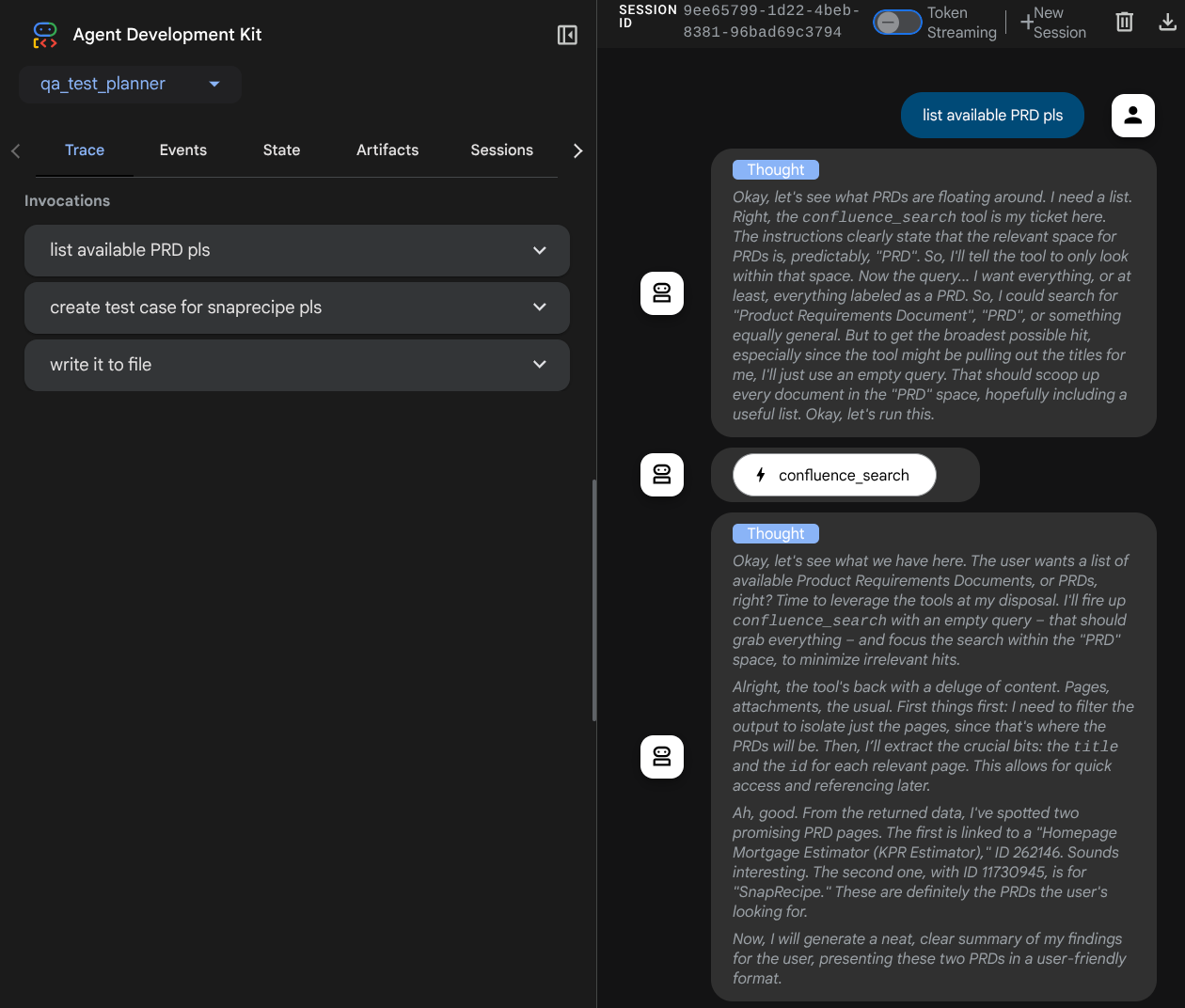
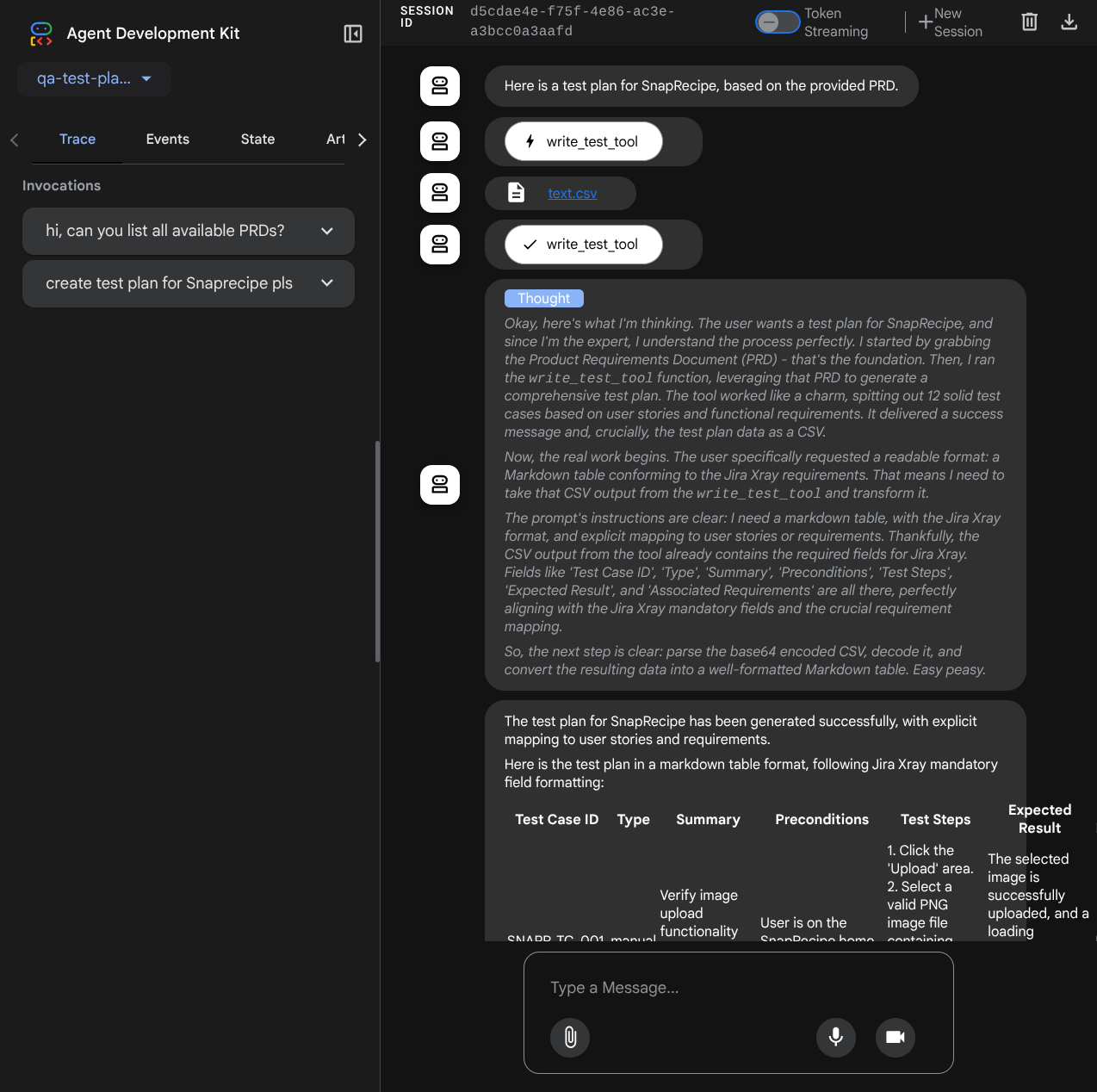
आइए, कुछ कार्रवाइयाँ करके देखते हैं! इन प्रॉम्प्ट का इस्तेमाल करके, एजेंट से चैट करें:
- " कृपया सभी उपलब्ध पीआरडी की सूची बनाएं "
- " Snaprecipe PRD के लिए टेस्ट प्लान लिखो "
कुछ टूल का इस्तेमाल करते समय, डेवलपमेंट यूज़र इंटरफ़ेस (यूआई) में चल रही प्रोसेस की जांच की जा सकती है
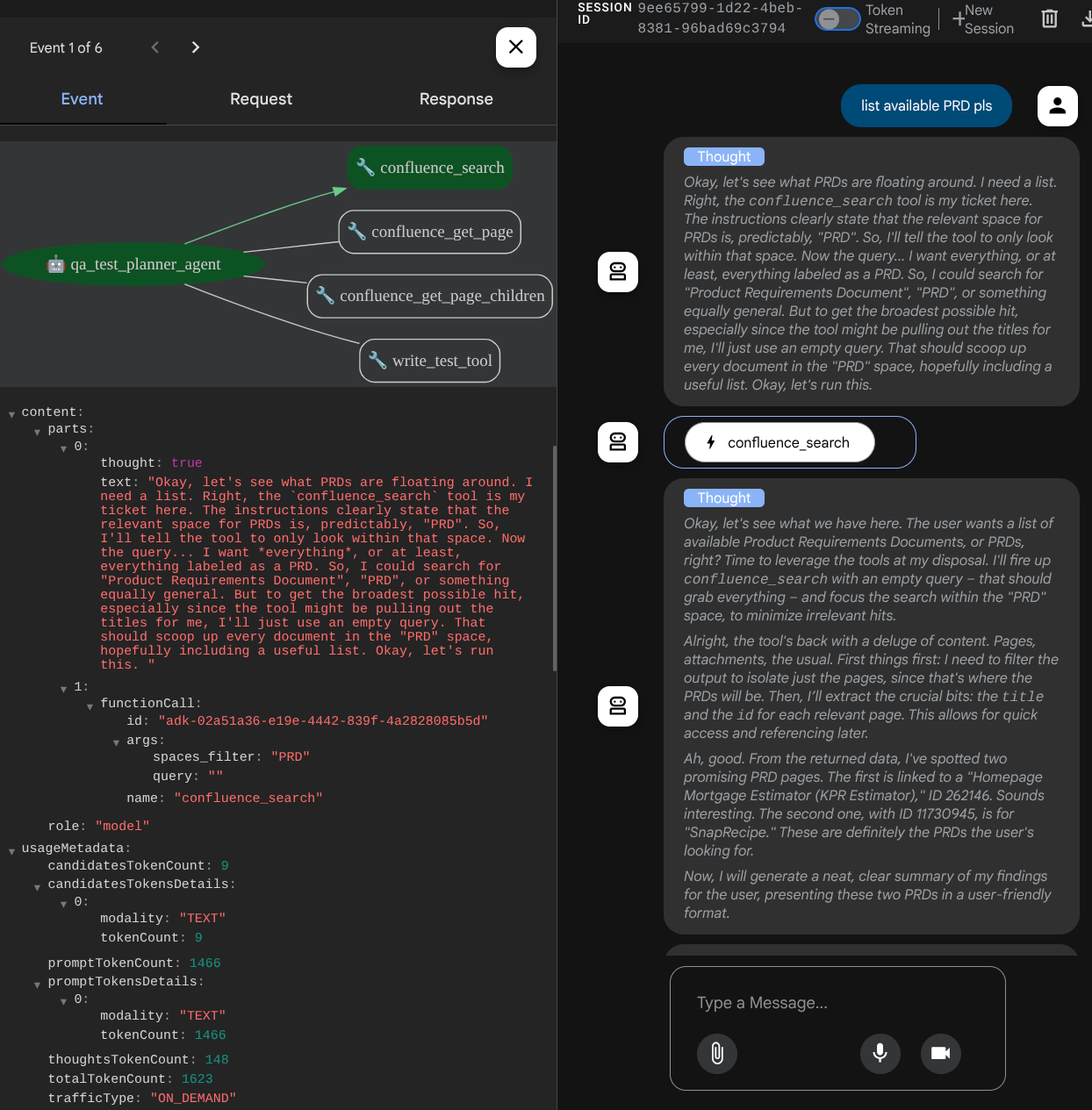
देखें कि एजेंट आपको कैसे जवाब देता है. साथ ही, यह भी देखें कि जब हम टेस्ट फ़ाइल के लिए प्रॉम्प्ट करते हैं, तो यह CSV फ़ाइल में टेस्ट प्लान को आर्टफ़ैक्ट के तौर पर जनरेट करेगा
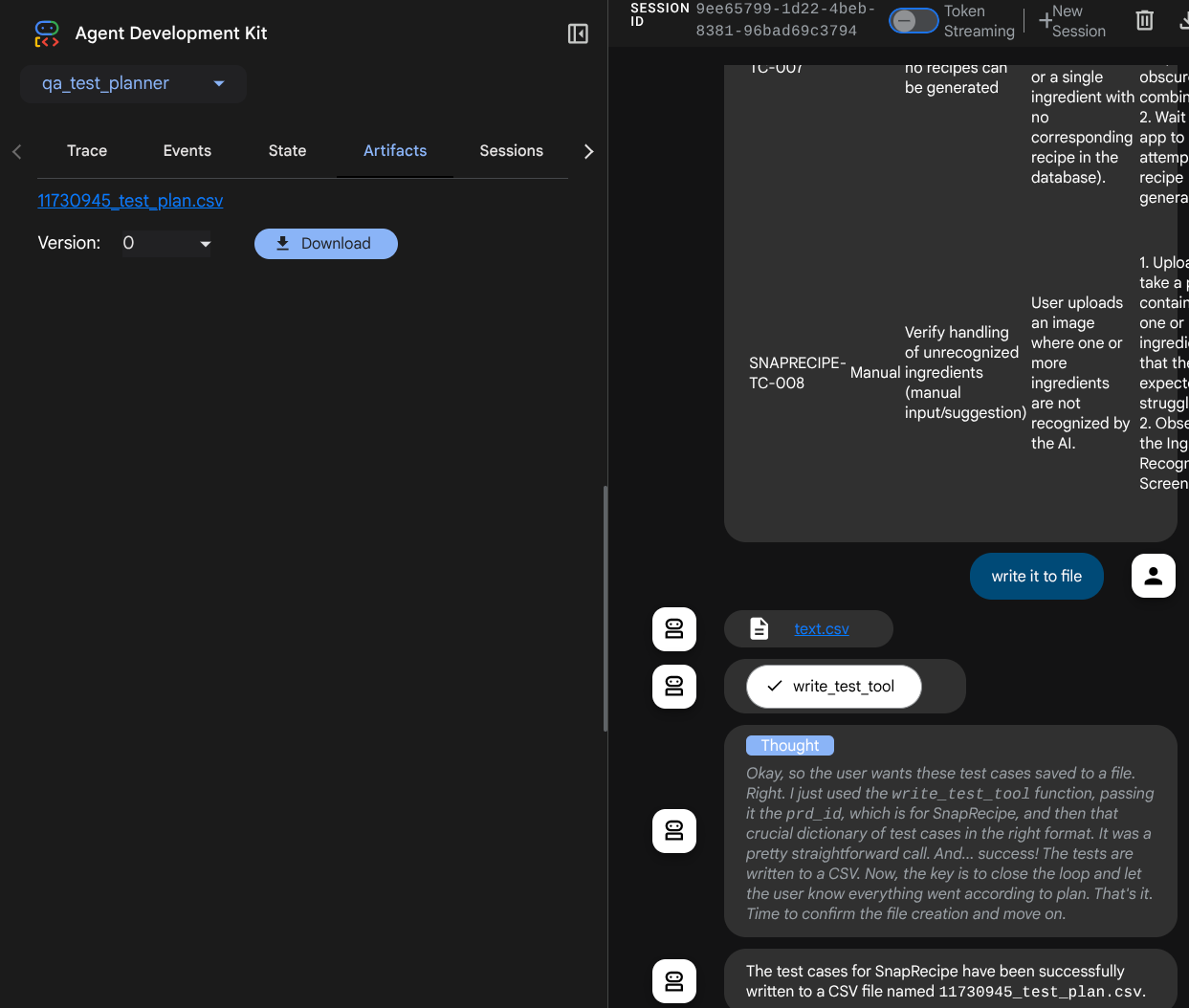
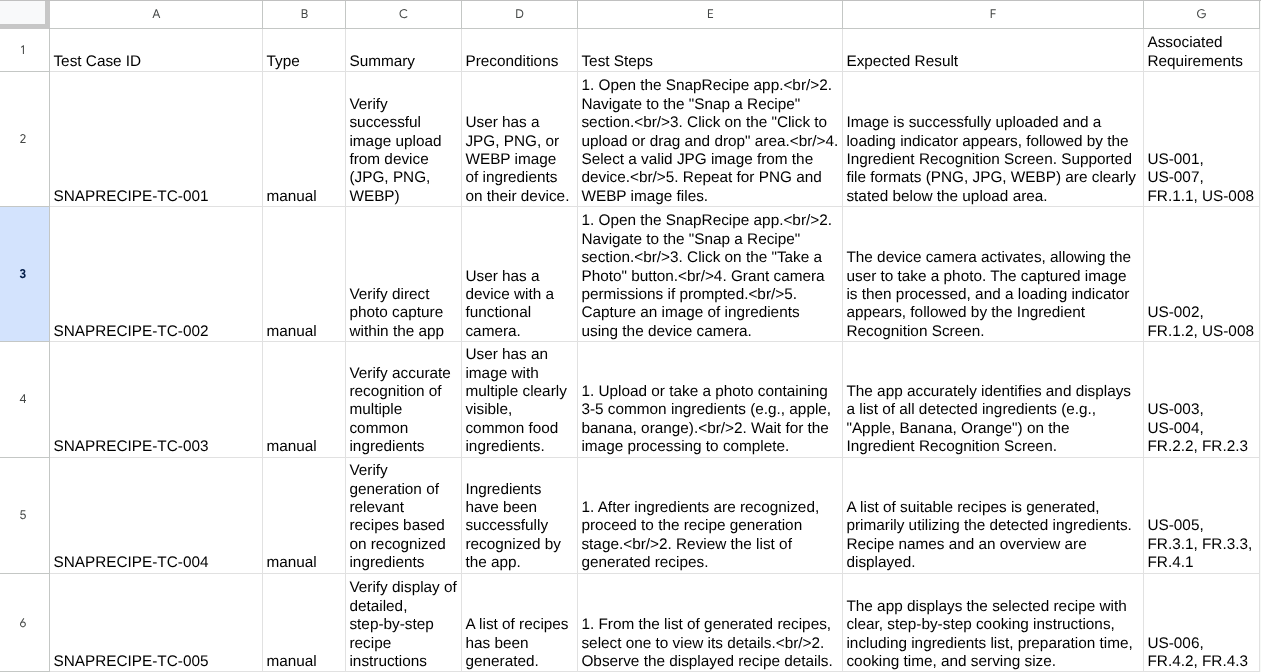
अब, CSV फ़ाइल के कॉन्टेंट को Google शीट में इंपोर्ट करके देखा जा सकता है
बधाई हो! अब आपके पास स्थानीय तौर पर काम करने वाला QA Test Planner एजेंट है! अब देखते हैं कि इसे Cloud Run में कैसे डिप्लॉय किया जा सकता है, ताकि दूसरे लोग भी इसका इस्तेमाल कर सकें!
5. Cloud Run पर डिप्लॉय करना
अब हम इस बेहतरीन ऐप्लिकेशन को कहीं से भी ऐक्सेस करना चाहते हैं. इसके लिए, हम इस ऐप्लिकेशन को पैकेज कर सकते हैं और इसे Cloud Run पर डिप्लॉय कर सकते हैं. इस डेमो के लिए, इस सेवा को सार्वजनिक सेवा के तौर पर दिखाया जाएगा. इसे अन्य लोग ऐक्सेस कर सकते हैं. हालांकि, ध्यान रखें कि यह सबसे सही तरीका नहीं है!
हमारी मौजूदा वर्किंग डायरेक्ट्री में, Cloud Run पर हमारे ऐप्लिकेशन डिप्लॉय करने के लिए ज़रूरी सभी फ़ाइलें पहले से मौजूद हैं. जैसे, एजेंट डायरेक्ट्री, Dockerfile, और server.py (मुख्य सेवा स्क्रिप्ट). अब इसे डिप्लॉय करते हैं. Cloud Shell टर्मिनल पर जाएं और पक्का करें कि मौजूदा प्रोजेक्ट, आपके एक्टिव प्रोजेक्ट के लिए कॉन्फ़िगर किया गया हो. अगर ऐसा नहीं है, तो प्रोजेक्ट आईडी सेट करने के लिए, gcloud configure कमांड का इस्तेमाल करें:
gcloud config set project [PROJECT_ID]
इसके बाद, इसे Cloud Run पर डिप्लॉय करने के लिए, यहां दिया गया कमांड चलाएं.
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
अगर आपको Docker इमेज के लिए आर्टफ़ैक्ट रजिस्ट्री बनाने की पुष्टि करने के लिए कहा जाता है, तो बस Y जवाब दें. ध्यान दें कि हम यहां बिना पुष्टि किए ऐक्सेस करने की अनुमति दे रहे हैं, क्योंकि यह एक डेमो ऐप्लिकेशन है. हमारा सुझाव है कि आप अपने एंटरप्राइज़ और प्रोडक्शन ऐप्लिकेशन के लिए, पुष्टि करने के सही तरीके का इस्तेमाल करें.
डप्लॉयमेंट पूरा होने के बाद, आपको यहां दिए गए लिंक जैसा लिंक मिलेगा:
https://qa-test-planner-agent-*******.us-central1.run.app
यूआरएल को ऐक्सेस करने पर, आपको वेब डेवलपर यूज़र इंटरफ़ेस (यूआई) दिखेगा. यह यूआई, स्थानीय तौर पर इसे आज़माते समय दिखने वाले यूआई जैसा ही होगा. अब गुप्त विंडो या अपने मोबाइल डिवाइस से ऐप्लिकेशन का इस्तेमाल करें. यह पहले से ही लाइव होना चाहिए.
अब इन अलग-अलग प्रॉम्प्ट को क्रम से फिर से आज़माएं और देखें कि क्या होता है:
- " क्या आपको मॉर्टगेज का अनुमान लगाने वाले टूल से जुड़ा पीआरडी मिल सकता है? "
- "हमें इसमें क्या सुधार करने चाहिए, इस बारे में सुझाव दो"
- "इसके लिए टेस्ट प्लान लिखो"
इसके अलावा, एजेंट को FastAPI ऐप्लिकेशन के तौर पर चलाने की वजह से, हम /docs रूट में सभी एपीआई रूट की जांच भी कर सकते हैं. उदाहरण के लिए, अगर आपने इस यूआरएल को ऐक्सेस किया https://qa-test-planner-agent-*******.us-central1.run.app/docs, तो आपको Swagger का दस्तावेज़ पेज दिखेगा. यह पेज यहां दिखाया गया है
कोड के बारे में जानकारी
अब देखते हैं कि डिप्लॉयमेंट के लिए, हमें यहां कौनसी फ़ाइल की ज़रूरत है. इसकी शुरुआत server.py से करते हैं
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
हम get_fast_api_app फ़ंक्शन का इस्तेमाल करके, अपने एजेंट को आसानी से fastapi ऐप्लिकेशन में बदल सकते हैं. इस फ़ंक्शन में, हम कई तरह की सुविधाएं सेट अप कर सकते हैं. उदाहरण के लिए, सेशन सेवा, आर्टफ़ैक्ट सेवा को कॉन्फ़िगर करना या क्लाउड पर डेटा को ट्रेस करना.
अगर आपको ऐप्लिकेशन का लाइफ़साइकल सेट करना है, तो यहां भी किया जा सकता है. इसके बाद, हम Fast API ऐप्लिकेशन को चलाने के लिए uvicorn का इस्तेमाल कर सकते हैं
इसके बाद, Dockerfile हमें ऐप्लिकेशन चलाने के लिए ज़रूरी चरणों के बारे में बताएगा
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. चुनौती
अब आपको अपनी खोज करने की क्षमता को बेहतर बनाने का मौका मिला है. क्या ऐसा टूल भी बनाया जा सकता है जिससे पीआरडी की समीक्षा से जुड़ा सुझाव/राय भी किसी फ़ाइल में लिखा जा सके?
7. व्यवस्थित करें
इस कोडलैब में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेज करें पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
- इसके अलावा, कंसोल पर Cloud Run पर जाकर, अभी-अभी डिप्लॉय की गई सेवा को चुनें और मिटाएं.