
1. 소개
테스트 계획 생성에 생성형 AI를 사용할 수 있는 이유는 최신 품질 보증의 가장 큰 두 가지 과제인 속도와 포괄성을 해결할 수 있기 때문입니다. 오늘날의 신속한 애자일 및 DevOps 사이클에서는 세부적인 테스트 계획을 수동으로 작성하는 것이 전체 테스트 프로세스를 지연시키는 심각한 병목 현상입니다. 생성형 AI 기반 에이전트는 사용자 스토리와 기술 요구사항을 수집하여 며칠이 아닌 몇 분 만에 철저한 테스트 계획을 수립할 수 있으므로 QA 프로세스가 개발 속도를 따라갈 수 있습니다. 또한 AI는 사람이 간과할 수 있는 복잡한 시나리오, 특이 사례, 부정적인 경로를 식별하는 데 탁월하여 테스트 범위가 크게 개선되고 프로덕션으로 유출되는 버그가 크게 줄어듭니다.
이 Codelab에서는 Confluence에서 제품 요구사항 문서를 가져오고 건설적인 의견을 제공할 수 있으며 CSV 파일로 내보낼 수 있는 포괄적인 테스트 계획을 생성할 수 있는 에이전트를 빌드하는 방법을 살펴봅니다.
Codelab을 통해 다음과 같이 단계별 접근 방식을 사용합니다.
- Google Cloud 프로젝트를 준비하고 필요한 API를 모두 사용 설정합니다.
- 코딩 환경의 작업공간 설정
- Confluence용 로컬 mcp-server 준비
- MCP 서버에 연결하기 위한 ADK 에이전트 소스 코드, 프롬프트, 도구 구조화
- 아티팩트 서비스 및 도구 컨텍스트 사용량 이해
- ADK 로컬 웹 개발 UI를 사용하여 에이전트 테스트
- 환경 변수를 관리하고 애플리케이션을 Cloud Run에 배포하는 데 필요한 파일을 설정합니다.
- Cloud Run에 애플리케이션 배포
아키텍처 개요
기본 요건
- Python 사용에 능숙함
- HTTP 서비스를 사용한 기본 풀 스택 아키텍처에 대한 이해
학습할 내용
- 여러 기능을 활용하면서 ADK 에이전트 설계
- 맞춤 도구 및 MCP를 사용한 도구 사용
- 아티팩트 서비스 관리를 사용하여 에이전트의 파일 출력 설정
- Gemini 2.5 Flash 사고 기능을 사용하여 계획을 수립하여 BuiltInPlanner를 활용해 작업 실행 개선
- ADK 웹 인터페이스를 통한 상호작용 및 디버깅
- Dockerfile을 사용하여 Cloud Run에 애플리케이션을 배포하고 환경 변수 제공
필요한 항목
- Chrome 웹브라우저
- Gmail 계정
- 결제가 사용 설정된 Cloud 프로젝트
- (선택사항) 제품 요구사항 문서 페이지가 있는 Confluence 스페이스
이 Codelab은 초보자를 포함한 모든 수준의 개발자를 대상으로 하며 샘플 애플리케이션에서 Python을 사용합니다. 하지만 제시된 개념을 이해하는 데 Python 지식이 필요하지는 않습니다. Confluence 스페이스가 없어도 걱정하지 마세요. 이 Codelab을 사용해 볼 수 있는 사용자 인증 정보를 제공해 드립니다.
2. 시작하기 전에
Cloud 콘솔에서 활성 프로젝트 선택
이 Codelab에서는 결제가 사용 설정된 Google Cloud 프로젝트가 이미 있다고 가정합니다. 아직 설치하지 않았다면 아래 안내에 따라 시작하세요.
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있어야 하므로 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 터미널에서 Cloud 프로젝트 설정
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.
- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
또는 콘솔에서 PROJECT_ID ID를 확인할 수도 있습니다.
클릭하면 오른쪽에 모든 프로젝트와 프로젝트 ID가 표시됩니다.
- 아래에 표시된 명령어를 통해 필수 API를 사용 설정합니다. 몇 분 정도 걸릴 수 있으니 잠시 기다려 주세요.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
명령어가 성공적으로 실행되면 아래와 비슷한 메시지가 표시됩니다.
Operation "operations/..." finished successfully.
gcloud 명령의 대안은 콘솔을 통해 각 제품을 검색하거나 이 링크를 사용하는 것입니다.
API가 누락된 경우 구현 과정에서 언제든지 사용 설정할 수 있습니다.
gcloud 명령어 및 사용법은 문서를 참조하세요.
Cloud Shell 편집기로 이동하여 애플리케이션 작업 디렉터리 설정
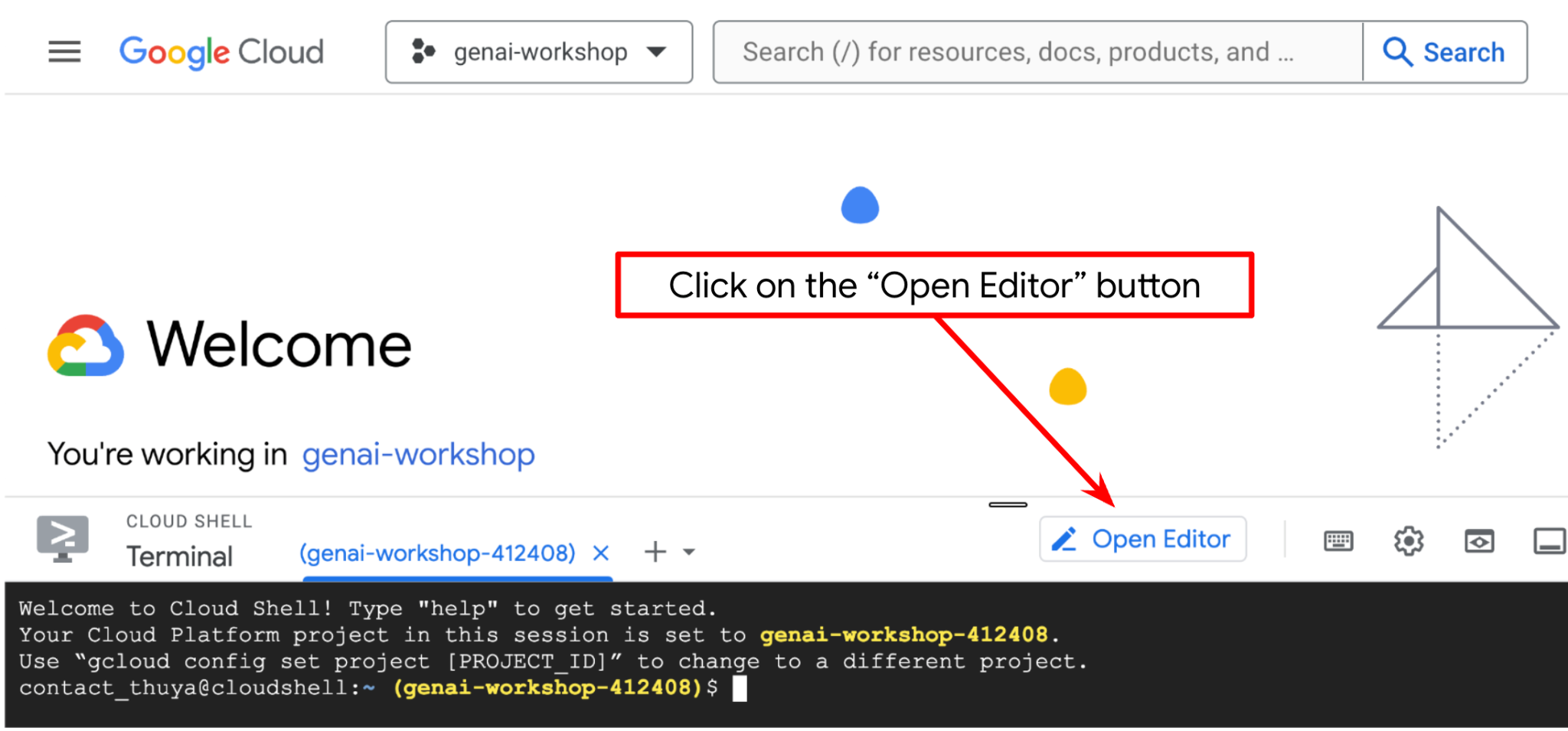
이제 코드 편집기를 설정하여 코딩 작업을 할 수 있습니다. 이를 위해 Cloud Shell 편집기를 사용합니다.
- 편집기 열기 버튼을 클릭하면 Cloud Shell 편집기가 열립니다. 여기에 코드를 작성할 수 있습니다.
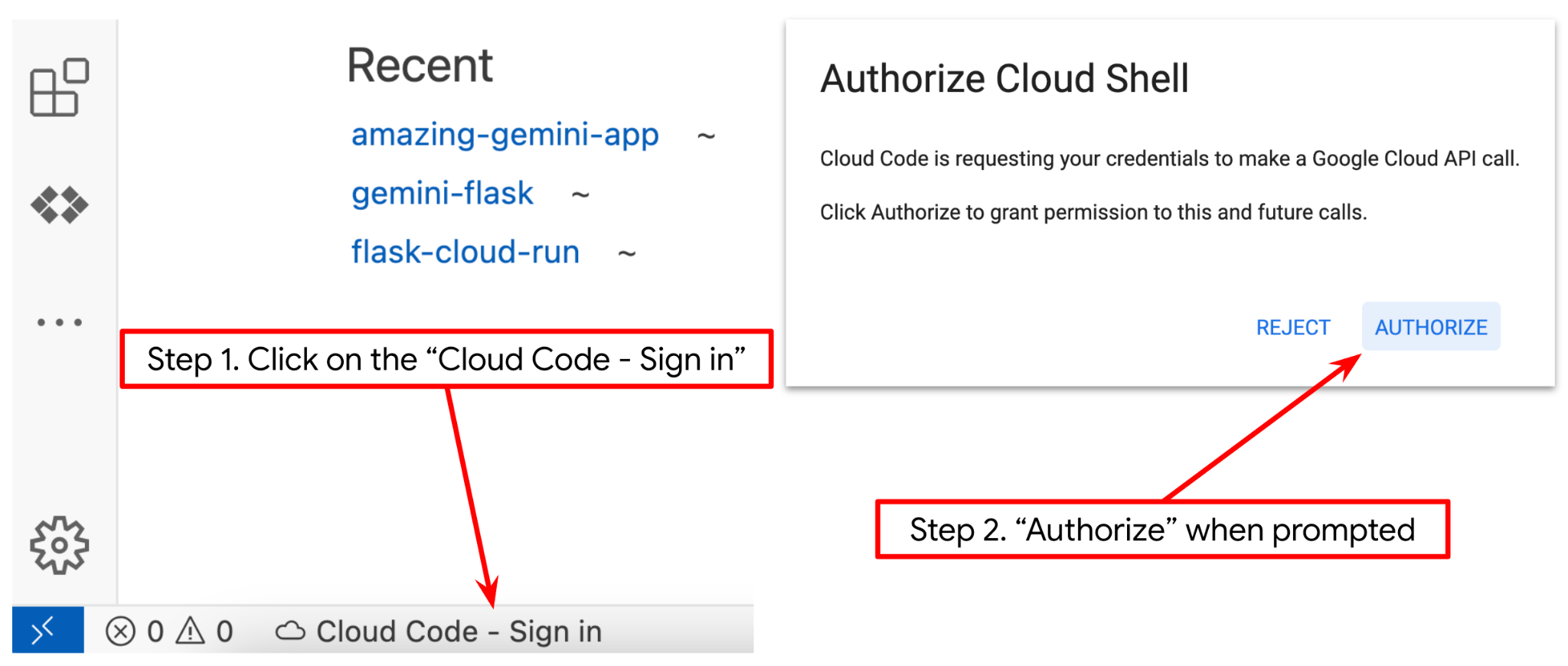
- 아래 이미지에 강조 표시된 것처럼 Cloud Shell 편집기의 왼쪽 하단 (상태 표시줄)에 Cloud Code 프로젝트가 설정되어 있고 결제가 사용 설정된 활성 Google Cloud 프로젝트로 설정되어 있는지 확인합니다. 메시지가 표시되면 승인을 클릭합니다. 이전 명령어를 이미 따른 경우 버튼이 로그인 버튼 대신 활성화된 프로젝트를 직접 가리킬 수도 있습니다.
- 다음으로 GitHub에서 이 Codelab의 템플릿 작업 디렉터리를 클론하고 다음 명령어를 실행합니다. qa-test-planner-agent 디렉터리에 작업 디렉터리가 생성됩니다.
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
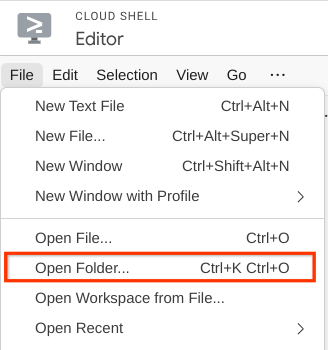
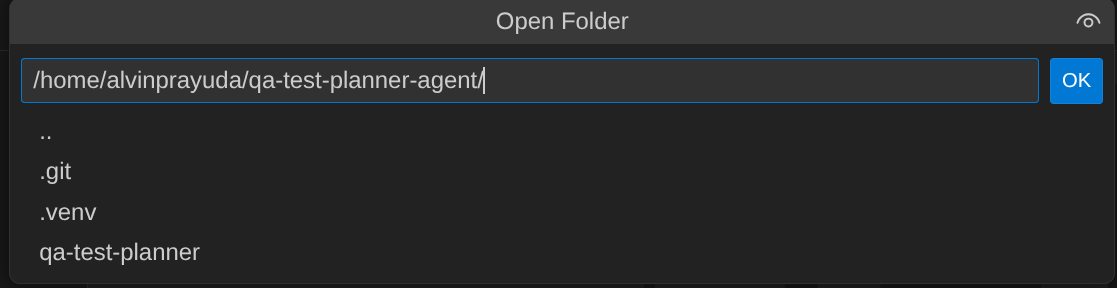
- 그런 다음 Cloud Shell 편집기의 상단 섹션으로 이동하여 File->Open Folder를 클릭하고 username 디렉터리를 찾아 qa-test-planner-agent 디렉터리를 찾은 다음 OK 버튼을 클릭합니다. 이렇게 하면 선택한 디렉터리가 기본 작업 디렉터리가 됩니다. 이 예시에서 사용자 이름은 alvinprayuda이므로 디렉터리 경로는 아래와 같습니다.
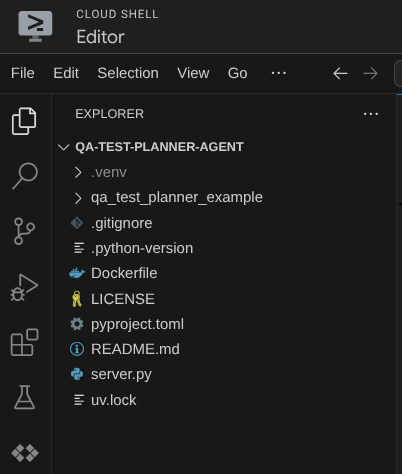
이제 Cloud Shell 편집기가 다음과 같이 표시됩니다.
환경 설정
Python 가상 환경 준비
다음 단계는 개발 환경을 준비하는 것입니다. 현재 활성 터미널은 qa-test-planner-agent 작업 디렉터리 내에 있어야 합니다. 이 Codelab에서는 Python 3.12를 사용하고 uv python 프로젝트 관리자를 사용하여 Python 버전과 가상 환경을 만들고 관리할 필요성을 간소화합니다.
- 터미널을 아직 열지 않은 경우 터미널 -> 새 터미널을 클릭하여 열거나 Ctrl + Shift + C를 사용합니다. 그러면 브라우저 하단에 터미널 창이 열립니다.

uv를 다운로드하고 다음 명령어를 사용하여 python 3.12를 설치합니다.
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- 이제
uv를 사용하여 가상 환경을 초기화해 보겠습니다. 다음 명령어를 실행하세요.
uv sync --frozen
이렇게 하면 .venv 디렉터리가 생성되고 종속 항목이 설치됩니다. pyproject.toml을 간단히 살펴보면 다음과 같이 표시된 종속 항목에 관한 정보를 확인할 수 있습니다.
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- 가상 환경을 테스트하려면 새 파일 main.py를 만들고 다음 코드를 복사합니다.
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- 그런 다음 다음 명령어를 실행합니다.
uv run main.py
아래와 같은 출력이 표시됩니다.
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
이는 Python 프로젝트가 올바르게 설정되고 있음을 보여줍니다.
이제 다음 단계인 에이전트와 서비스 빌드로 넘어갈 수 있습니다.
3. Google ADK 및 Gemini 2.5를 사용하여 에이전트 빌드
ADK 디렉터리 구조 소개
먼저 ADK에서 제공하는 기능과 에이전트를 빌드하는 방법을 살펴보겠습니다. ADK 전체 문서는 이 URL에서 확인할 수 있습니다 . ADK는 CLI 명령어 실행 내에서 다양한 유틸리티를 제공합니다. 일부 예는 다음과 같습니다.
- 에이전트 디렉터리 구조 설정
- CLI 입력 출력을 통해 상호작용을 빠르게 시도해 보세요.
- 로컬 개발 UI 웹 인터페이스를 빠르게 설정
이제 CLI 명령어를 사용하여 에이전트 디렉터리 구조를 만들어 보겠습니다. 다음 명령어를 실행합니다.
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
그러면 현재 작업 디렉터리에 다음과 같은 에이전트 디렉터리 구조가 생성됩니다.
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
init.py 및 agent.py를 검사하면 다음 코드가 표시됩니다.
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
QA 테스트 플래너 에이전트 빌드
QA 테스트 플래너 에이전트를 빌드해 보겠습니다. qa_test_planner/agent.py 파일을 열고 root_agent가 포함된 아래 코드를 복사합니다.
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
설정 구성 파일
이제 이 에이전트가 Confluence에 액세스해야 하므로 이 프로젝트에 추가 구성 설정을 추가해야 합니다.
qa_test_planner/.env를 열고 다음 환경 변수 값을 추가하여 결과 .env 파일이 다음과 같이 표시되는지 확인합니다.
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
안타깝게도 이 Confluence 스페이스는 공개할 수 없으므로 위 사용자 인증 정보를 사용하여 제공되는 제품 요구사항 문서를 검토할 수 있습니다.
코드 설명
이 스크립트에는 다음 항목을 초기화하는 에이전트 초기화가 포함되어 있습니다.
- 사용할 모델을
gemini-2.5-flash로 설정합니다. - Stdio를 통해 통신하는 Confluence MCP 도구 설정
- 테스트 계획을 작성하고 CSV를 아티팩트에 덤프하는
write_test_tool맞춤 도구 설정 - 에이전트 설명 및 요청 사항 설정
- Gemini 2.5 Flash 사고 능력을 사용하여 최종 응답 또는 실행을 생성하기 전에 계획을 수립합니다.
사고 기능이 내장된 Gemini 모델로 구동되고 플래너 인수로 구성된 에이전트 자체도 사고 기능을 보여주고 웹 인터페이스에 표시될 수 있습니다. 이를 구성하는 코드는 아래와 같습니다.
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
조치를 취하기 전에 사고 과정을 확인할 수 있습니다.
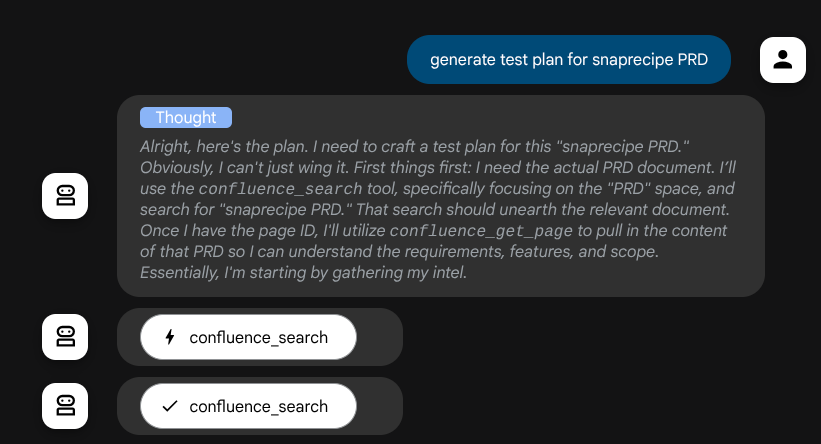
Confluence MCP 도구
ADK에서 MCP 서버에 연결하려면 google.adk.tools.mcp_tool.mcp_toolset 모듈에서 가져올 수 있는 MCPToolSet를 활용해야 합니다. 여기에서 초기화할 코드는 아래와 같습니다 ( 효율성을 위해 잘림).
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
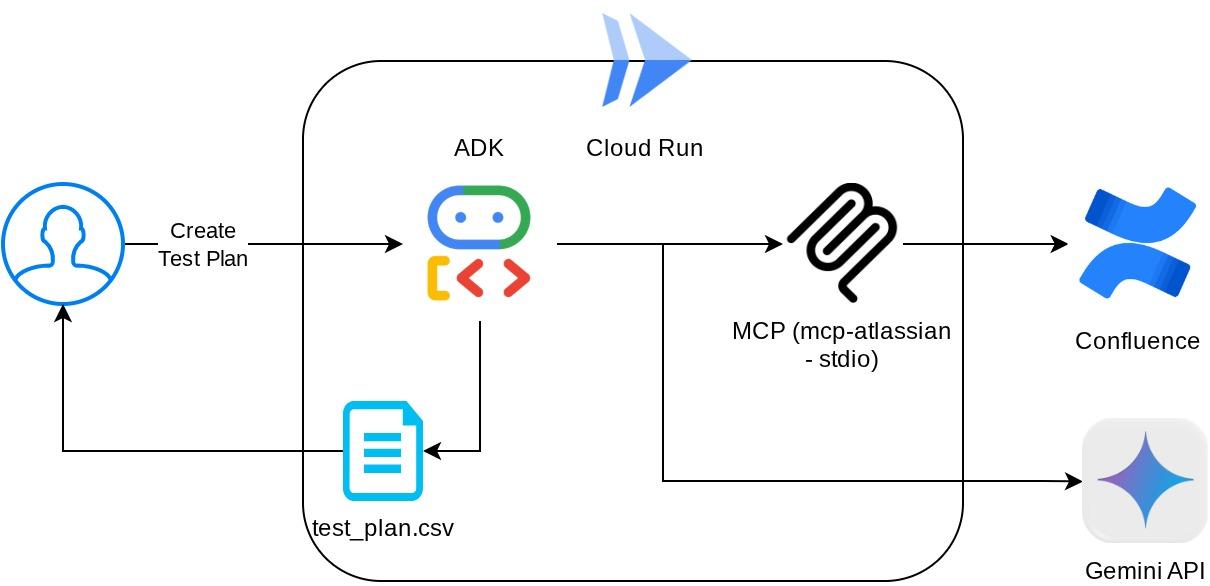
이 구성에서 에이전트는 Confluence MCP 서버를 별도의 프로세스로 초기화하고 Studio I/O를 통해 이러한 프로세스와의 통신을 처리합니다. 이 흐름은 아래 빨간색 상자 안에 표시된 다음 MCP 아키텍처 이미지에 나와 있습니다.
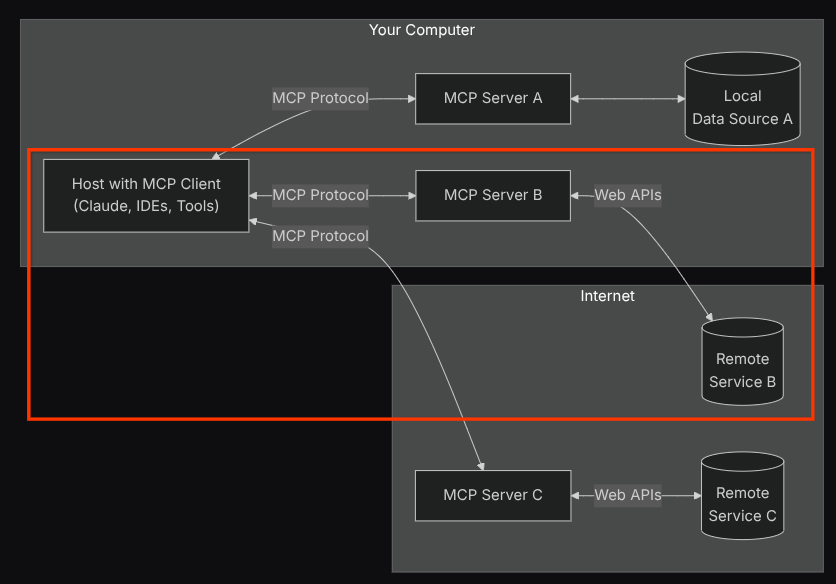
또한 MCP 초기화의 명령 인수 내에서 활용할 수 있는 도구를 QA 테스트 에이전트 사용 사례를 지원하는 confluence_search, confluence_get_page, confluence_get_page_children 도구로만 제한합니다. 이 Codelab 튜토리얼에서는 커뮤니티에서 제공한 Atlassian MCP 서버 ( 자세한 내용은 전체 문서 참고)를 사용합니다.
쓰기 테스트 도구
상담사가 Confluence MCP 도구에서 컨텍스트를 수신하면 사용자를 위해 필요한 테스트 계획을 구성할 수 있습니다. 하지만 이 테스트 계획이 포함된 파일을 생성하여 저장하고 다른 사람과 공유할 수 있도록 하고 싶습니다. 이를 지원하기 위해 아래에 맞춤 도구 write_test_tool를 제공합니다.
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
위에서 선언된 함수는 다음 기능을 지원합니다.
- 생성된 테스트 계획이 필수 필드 사양을 준수하는지 확인합니다. Pydantic 모델을 사용하여 확인하며 오류가 발생하면 오류 메시지를 에이전트에게 다시 제공합니다.
- pandas 기능을 사용하여 결과를 CSV로 덤프
- 생성된 파일은 모든 도구 호출에서 액세스할 수 있는 ToolContext 객체를 사용하여 액세스할 수 있는 Artifact Service 기능을 사용하여 아티팩트로 저장됩니다.
생성된 파일을 아티팩트로 저장하면 ADK 런타임에서 이벤트로 표시되며 나중에 웹 인터페이스의 에이전트 상호작용에 표시될 수 있습니다.
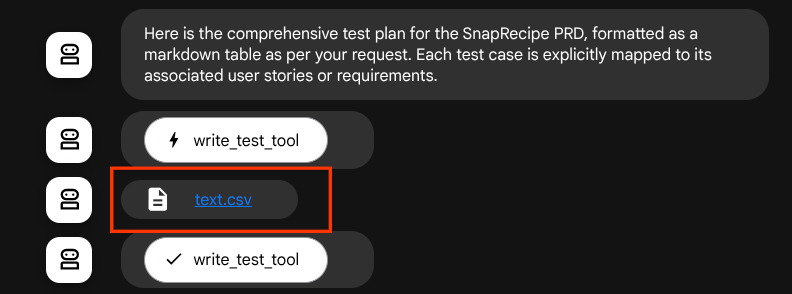
이를 통해 사용자에게 제공되는 에이전트의 파일 응답을 동적으로 설정할 수 있습니다.
4. 에이전트 테스트
이제 CLI를 통해 에이전트와 통신해 보겠습니다. 다음 명령어를 실행하세요.
uv run adk run qa_test_planner
다음과 같은 출력이 표시되며, 여기서 에이전트와 번갈아 채팅할 수 있습니다. 하지만 이 인터페이스를 통해서는 텍스트만 전송할 수 있습니다.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
CLI를 통해 에이전트와 채팅할 수 있어 좋습니다. 하지만 웹 채팅을 통해 문제를 해결할 수 있다면 더 좋겠죠. ADK를 사용하면 상호작용 중에 발생하는 상황을 상호작용하고 검사할 수 있는 개발 UI도 사용할 수 있습니다. 다음 명령어를 실행하여 로컬 개발 UI 서버를 시작합니다.
uv run adk web --port 8080
다음 예와 같은 출력이 생성됩니다. 이는 웹 인터페이스에 이미 액세스할 수 있음을 의미합니다.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
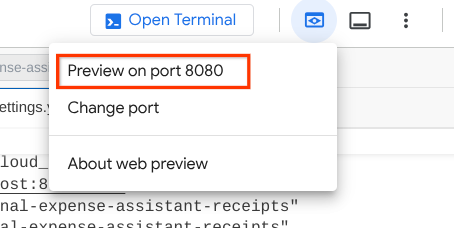
이제 이를 확인하려면 Cloud Shell 편집기의 상단 영역에 있는 웹 미리보기 버튼을 클릭하고 포트 8080에서 미리보기를 선택합니다.
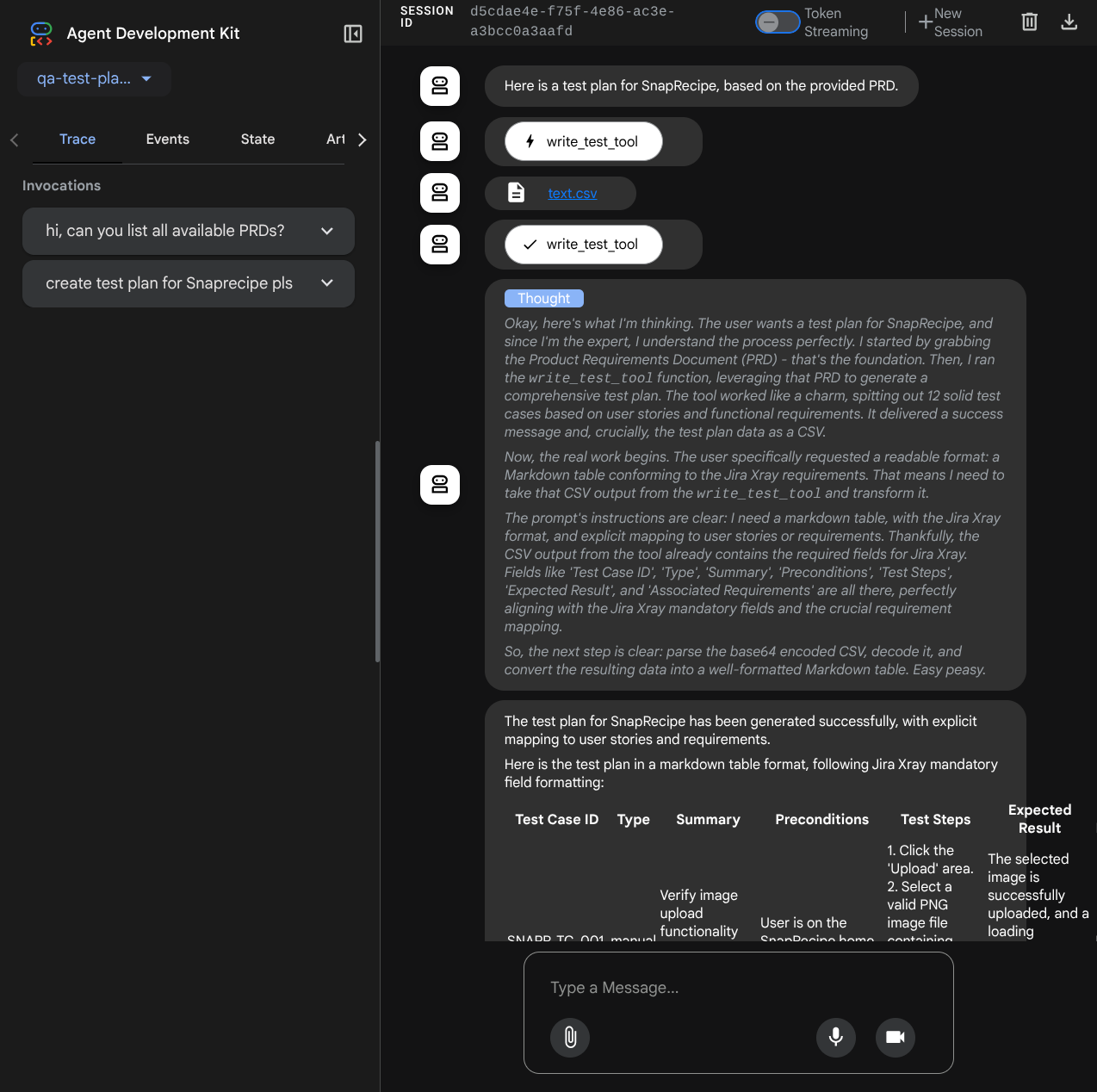
다음 웹페이지에서 왼쪽 상단의 드롭다운 버튼 ( 이 경우 qa_test_planner)을 통해 사용 가능한 에이전트를 선택하고 봇과 상호작용할 수 있습니다. 왼쪽 창에는 에이전트 런타임 중 로그 세부정보에 관한 많은 정보가 표시됩니다.
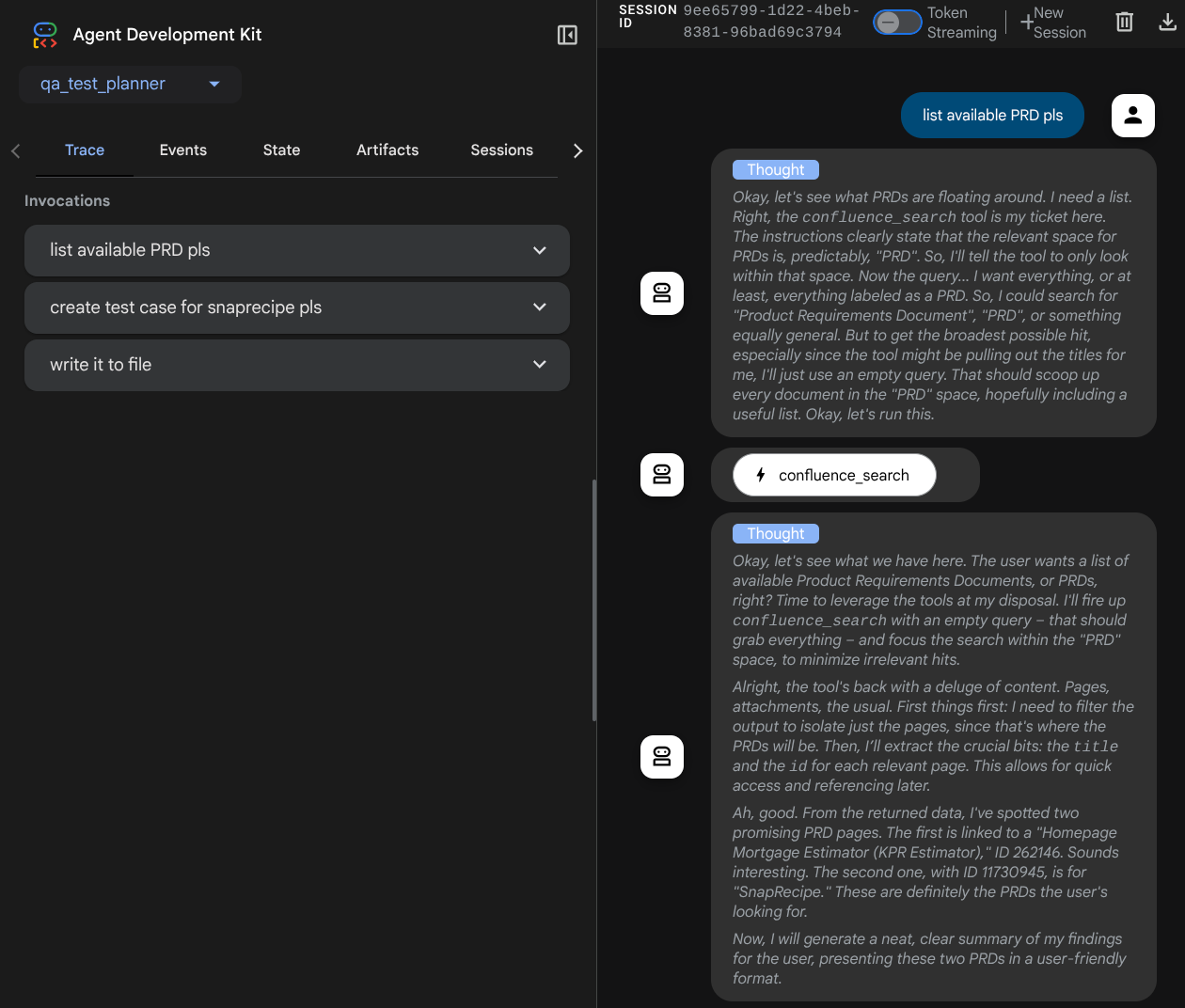
몇 가지 작업을 시도해 보겠습니다. 다음 프롬프트로 상담사와 채팅합니다.
- '사용 가능한 모든 PRD를 나열해 줘'
- 'Snaprecipe PRD의 테스트 계획을 작성해 줘.'
일부 도구를 사용하면 개발 UI에서 어떤 일이 일어나고 있는지 검사할 수 있습니다.
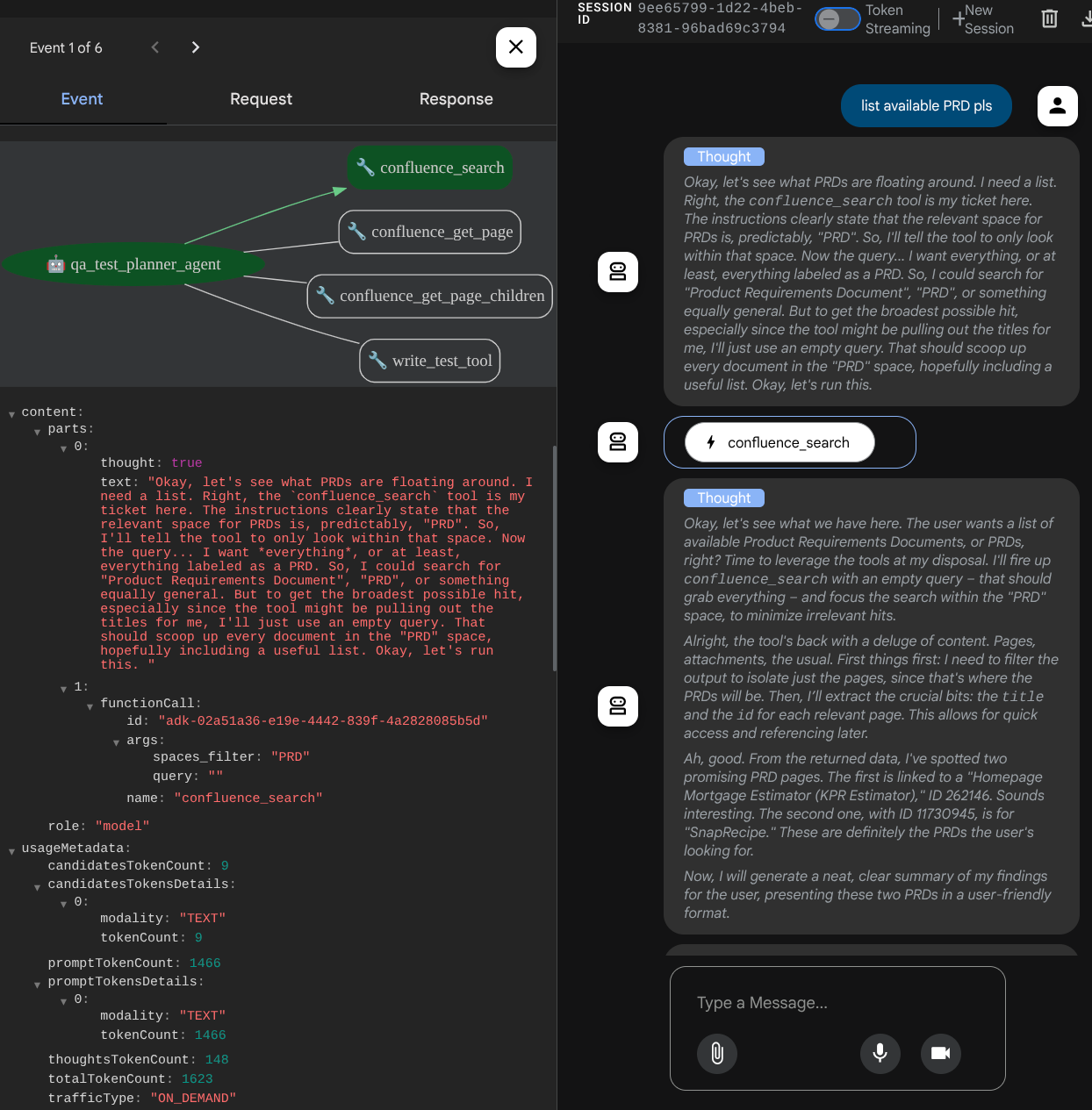
에이전트가 어떻게 대답하는지 확인하고 테스트 파일을 요청할 때 아티팩트로 CSV 파일에 테스트 계획이 생성되는지 검사합니다.
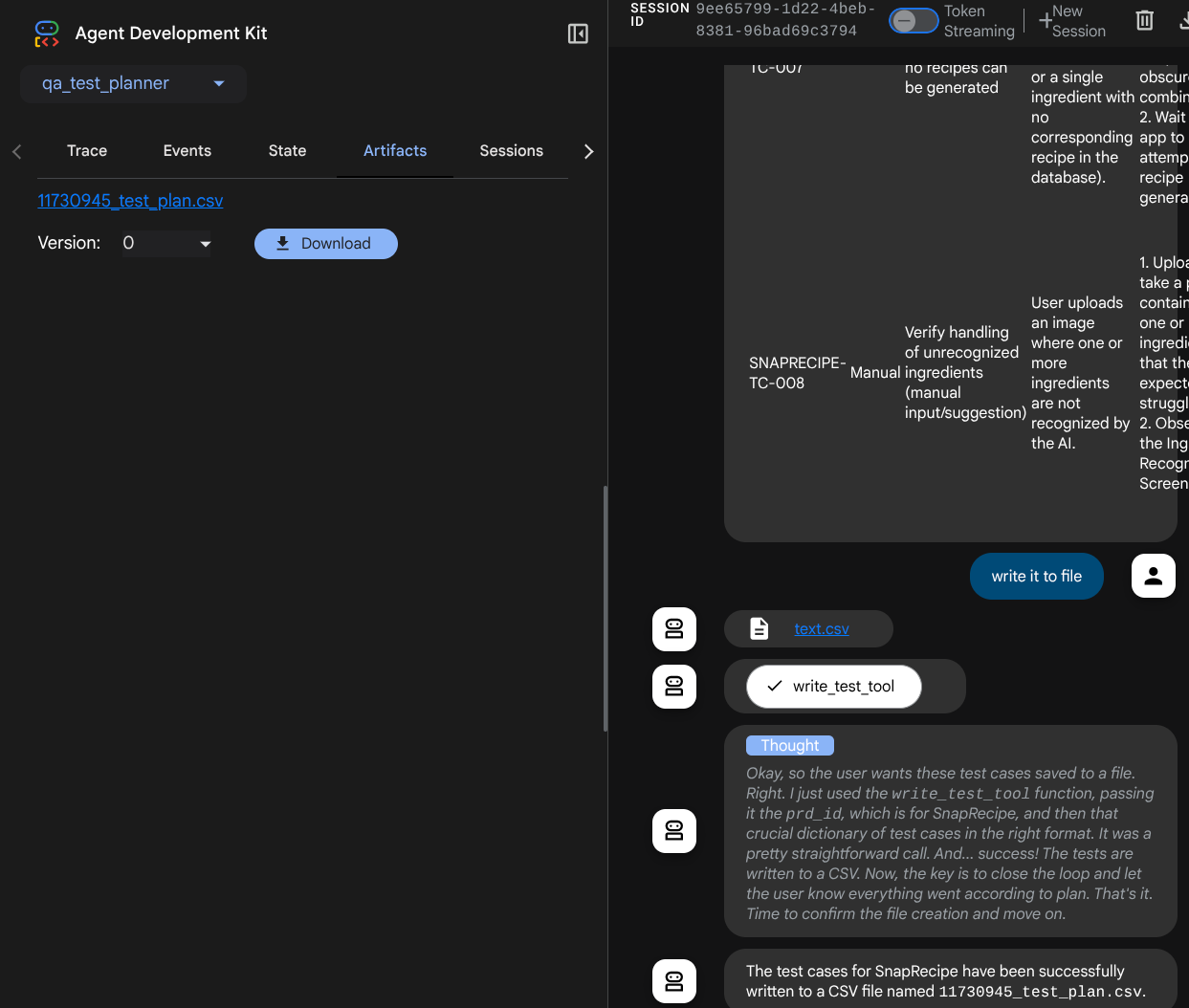
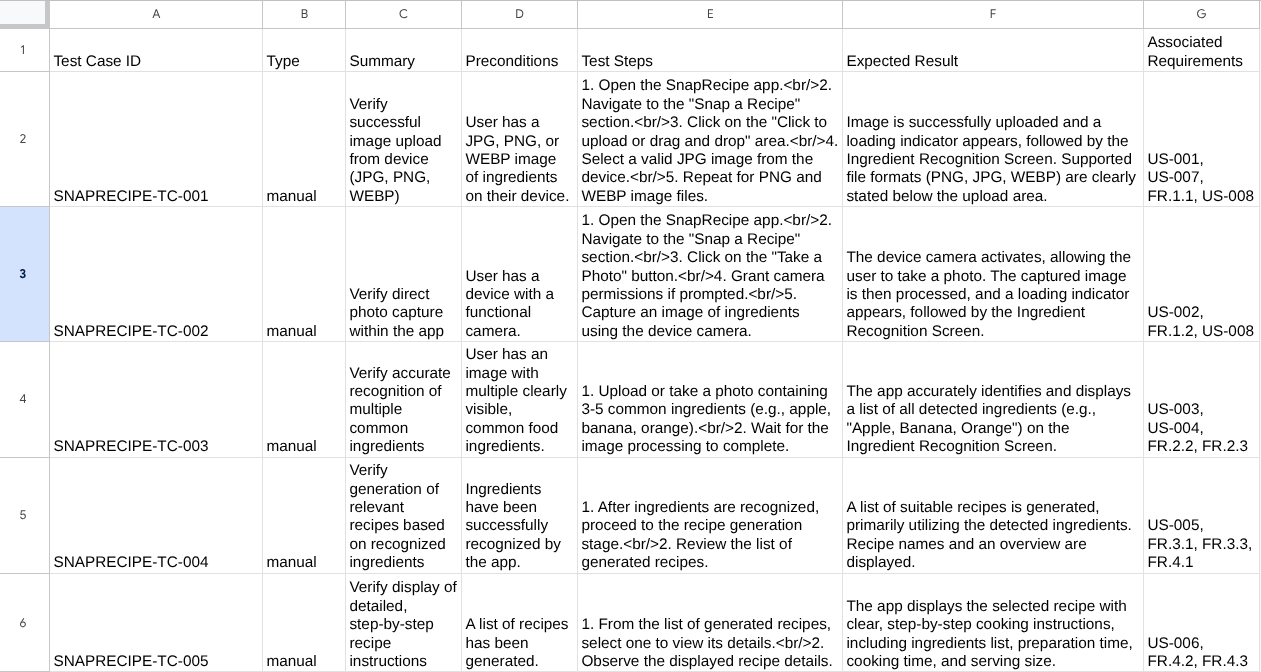
이제 CSV를 Google 시트로 가져와 콘텐츠를 확인할 수 있습니다.
축하합니다. 이제 로컬에서 실행되는 QA 테스트 계획자 에이전트가 있습니다. 이제 다른 사람도 사용할 수 있도록 Cloud Run에 배포하는 방법을 알아보겠습니다.
5. Cloud Run에 배포
이제 어디서나 이 멋진 앱에 액세스할 수 있습니다. 이렇게 하려면 이 애플리케이션을 패키징하여 Cloud Run에 배포하면 됩니다. 이 데모에서는 이 서비스가 다른 사용자가 액세스할 수 있는 공개 서비스로 노출됩니다. 하지만 이는 권장사항이 아닙니다.
현재 작업 디렉터리에는 Cloud Run에 애플리케이션을 배포하는 데 필요한 모든 파일(에이전트 디렉터리, Dockerfile, server.py(기본 서비스 스크립트))이 이미 있습니다. 배포해 보겠습니다. Cloud Shell 터미널로 이동하여 현재 프로젝트가 활성 프로젝트로 구성되어 있는지 확인합니다. 그렇지 않은 경우 gcloud configure 명령어를 사용하여 프로젝트 ID를 설정해야 합니다.
gcloud config set project [PROJECT_ID]
그런 다음 다음 명령어를 실행하여 Cloud Run에 배포합니다.
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
Docker 저장소용 Artifact Registry를 만들 것인지 묻는 메시지가 표시되면 Y라고 답합니다. 데모 애플리케이션이므로 여기서는 인증되지 않은 액세스를 허용합니다. 엔터프라이즈 및 프로덕션 애플리케이션에 적절한 인증을 사용하는 것이 좋습니다.
배포가 완료되면 다음과 비슷한 링크가 표시됩니다.
https://qa-test-planner-agent-*******.us-central1.run.app
URL에 액세스하면 로컬에서 시도할 때와 유사한 웹 개발자 UI가 표시됩니다. 시크릿 창이나 휴대기기에서 애플리케이션을 사용하세요. 이미 게시되었을 것입니다.
이제 이러한 다양한 프롬프트를 순차적으로 다시 시도하여 어떤 결과가 나오는지 확인해 보겠습니다.
- '주택담보대출 견적 도구와 관련된 PRD를 찾을 수 있어?' "
- '이 부분에서 개선할 점에 대한 의견을 알려 줘'
- '테스트 계획을 작성해 줘'
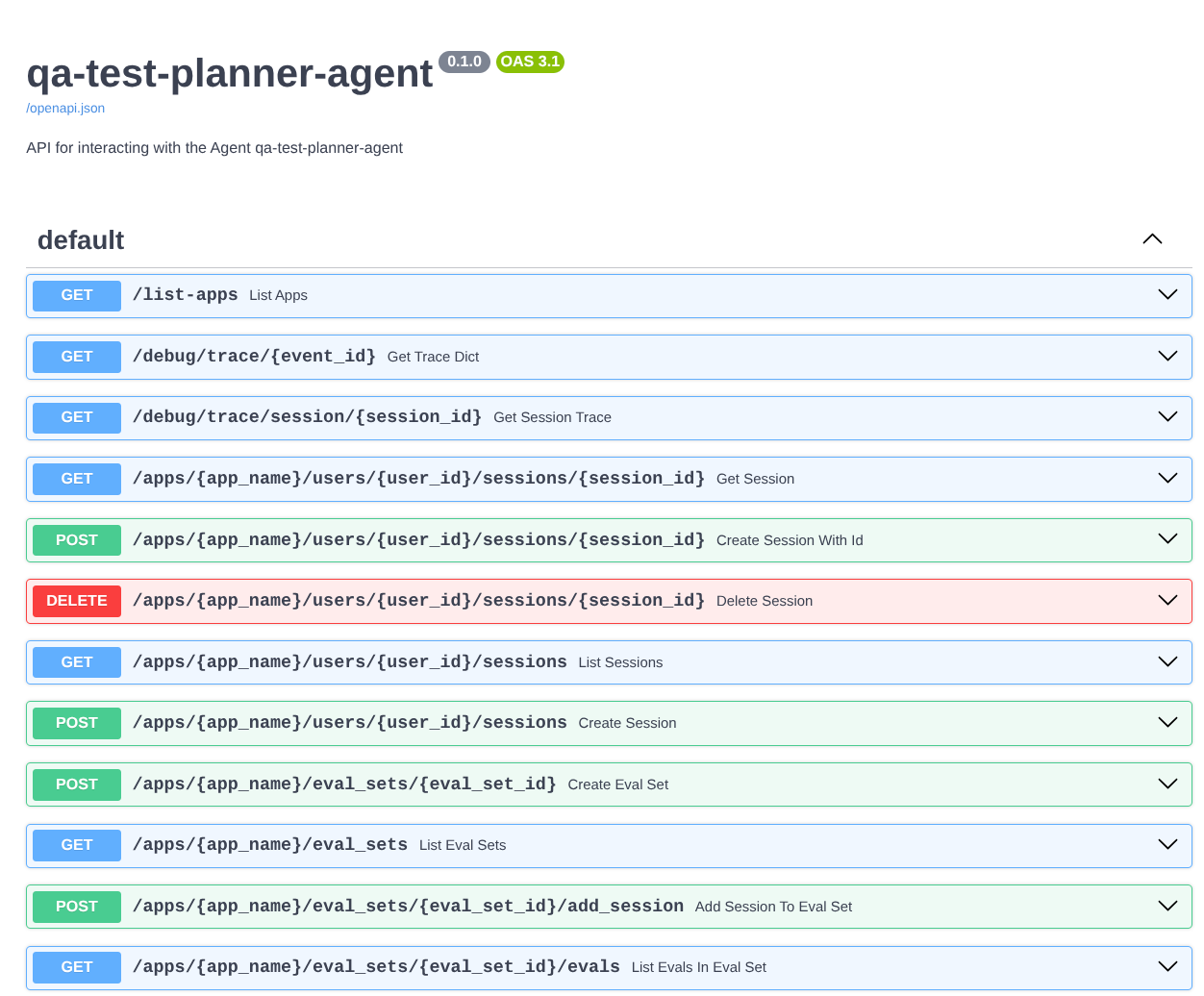
또한 에이전트를 FastAPI 앱으로 실행하므로 /docs 경로에서 모든 API 경로를 검사할 수 있습니다. 예를 들어 https://qa-test-planner-agent-*******.us-central1.run.app/docs와 같은 URL에 액세스하면 아래와 같은 Swagger 문서 페이지가 표시됩니다.
코드 설명
이제 server.py부터 시작하여 배포에 필요한 파일을 살펴보겠습니다.
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
get_fast_api_app 함수를 사용하여 에이전트를 fastapi 앱으로 쉽게 변환할 수 있습니다. 이 함수에서는 세션 서비스, 아티팩트 서비스 구성, 클라우드로의 데이터 추적 등 다양한 기능을 설정할 수 있습니다.
원하는 경우 여기에서 애플리케이션 수명 주기를 설정할 수도 있습니다. 그런 다음 uvicorn을 사용하여 Fast API 애플리케이션을 실행할 수 있습니다.
그런 다음 Dockerfile에서 애플리케이션을 실행하는 데 필요한 단계를 제공합니다.
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. 도전과제
이제 탐색 기술을 연마하고 빛을 발할 때입니다. PRD 검토 의견도 파일에 작성되도록 도구를 만들어 줄 수 있나요?
7. 삭제
이 Codelab에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 따르세요.