
1. Wprowadzenie
Możliwości wykorzystania generatywnej AI do tworzenia planów testów wynikają z jej zdolności do rozwiązywania dwóch największych problemów we współczesnym zapewnianiu jakości: szybkości i kompleksowości. W dzisiejszych szybkich cyklach Agile i DevOps ręczne tworzenie szczegółowych planów testów jest znaczącym wąskim gardłem, które opóźnia cały proces testowania. Agent oparty na generatywnej AI może przetwarzać historie użytkowników i wymagania techniczne, aby w ciągu kilku minut, a nie dni, tworzyć szczegółowy plan testów, dzięki czemu proces kontroli jakości będzie nadążać za rozwojem. Ponadto AI doskonale radzi sobie z identyfikowaniem złożonych scenariuszy, przypadków skrajnych i negatywnych ścieżek, które człowiek może przeoczyć. Prowadzi to do znacznego zwiększenia pokrycia testami i znacznego zmniejszenia liczby błędów, które trafiają do środowiska produkcyjnego.
W tym ćwiczeniu pokażemy, jak utworzyć takiego agenta, który może pobierać dokumenty z wymaganiami dotyczącymi produktów z Confluence, przekazywać konstruktywne opinie, a także generować kompleksowy plan testów, który można wyeksportować do pliku CSV.
W ramach ćwiczeń z programowania będziesz wykonywać kolejne czynności:
- Przygotowywanie projektu Google Cloud i włączanie w nim wszystkich wymaganych interfejsów API
- Konfigurowanie obszaru roboczego środowiska programistycznego
- Przygotowywanie lokalnego serwera MCP na potrzeby Confluence
- Strukturyzowanie kodu źródłowego, promptu i narzędzi agenta pakietu ADK w celu połączenia z serwerem MCP
- Wykorzystanie usługi artefaktów i kontekstów narzędzi
- Testowanie agenta za pomocą lokalnego interfejsu internetowego ADK
- zarządzać zmiennymi środowiskowymi i konfigurować wymagane pliki potrzebne do wdrożenia aplikacji w Cloud Run,
- Wdrażanie aplikacji w Cloud Run
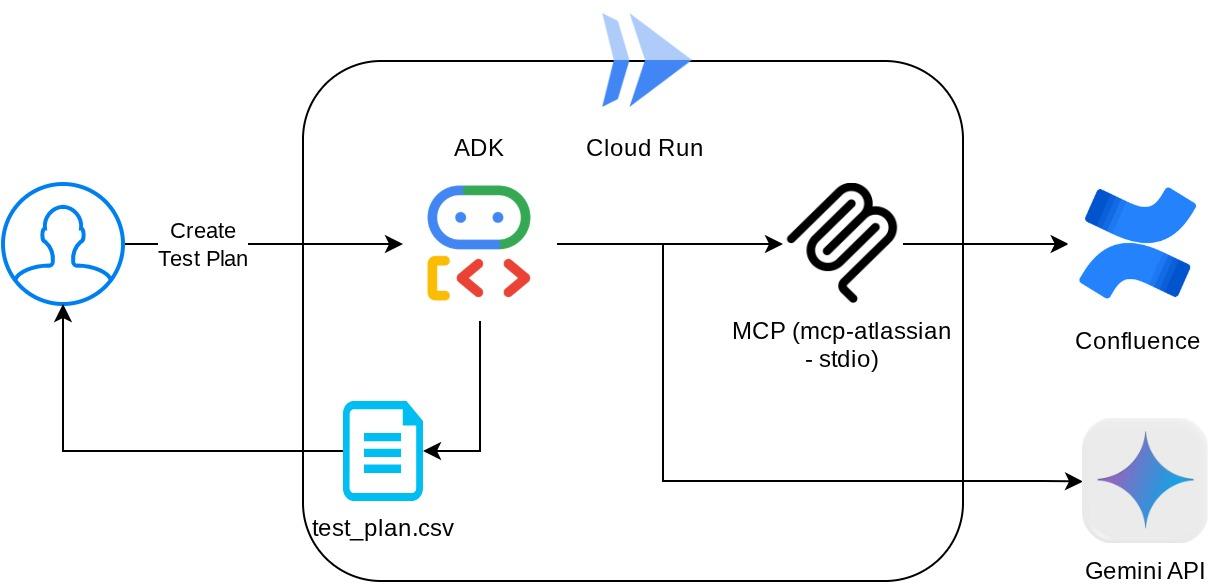
Omówienie architektury
Wymagania wstępne
- znajomość języka Python;
- Znajomość podstawowej architektury pełnego stosu z użyciem usługi HTTP
Czego się nauczysz
- Projektowanie agenta ADK z wykorzystaniem jego różnych funkcji
- Korzystanie z narzędzia w przypadku narzędzia niestandardowego i MCP
- Konfigurowanie danych wyjściowych pliku przez agenta za pomocą zarządzania usługą Artifact Service
- Wykorzystanie wbudowanego planisty do ulepszania wykonywania zadań przez planowanie z użyciem funkcji myślenia modelu Gemini 2.5 Flash
- Interakcja i debugowanie za pomocą interfejsu internetowego ADK
- Wdrażanie aplikacji w Cloud Run za pomocą pliku Dockerfile i przekazywanie zmiennych środowiskowych
Czego potrzebujesz
- przeglądarki Chrome,
- konto Gmail,
- Projekt Cloud z włączonymi płatnościami
- (Opcjonalnie) Przestrzeń Confluence ze stronami dokumentów wymagań usługi
To ćwiczenie jest przeznaczone dla programistów na wszystkich poziomach zaawansowania (w tym dla początkujących). W przykładowej aplikacji używa się języka Python. Znajomość Pythona nie jest jednak wymagana do zrozumienia przedstawionych koncepcji. Nie musisz się martwić, jeśli nie masz przestrzeni Confluence. Udostępnimy Ci dane logowania, aby umożliwić Ci wypróbowanie tego codelabu.
2. Zanim zaczniesz
Wybieranie aktywnego projektu w Cloud Console
W tym ćwiczeniu zakładamy, że masz już projekt Google Cloud z włączonymi płatnościami. Jeśli jeszcze go nie masz, możesz zacząć, wykonując czynności opisane poniżej.
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Konfigurowanie projektu w Cloud Shell Terminal
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
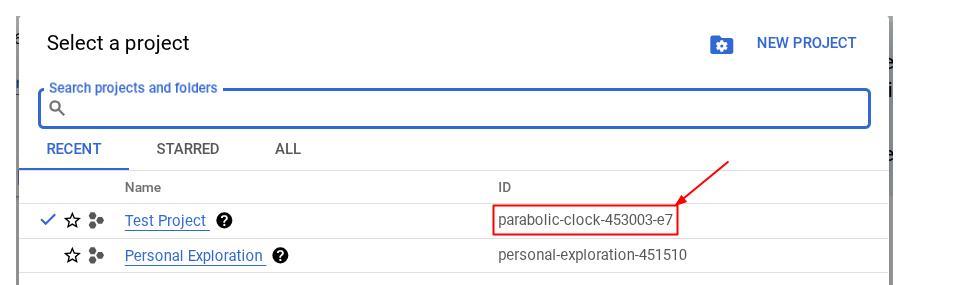
Możesz też zobaczyć PROJECT_ID id w konsoli.
Kliknij go, a po prawej stronie zobaczysz wszystkie swoje projekty i identyfikator projektu.
- Włącz wymagane interfejsy API za pomocą polecenia pokazanego poniżej. Może to potrwać kilka minut, więc prosimy o cierpliwość.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
Alternatywą dla polecenia gcloud jest wyszukanie poszczególnych usług w konsoli lub skorzystanie z tego linku.
Jeśli pominiesz jakiś interfejs API, możesz go włączyć w trakcie wdrażania.
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
Otwórz edytor Cloud Shell i skonfiguruj katalog roboczy aplikacji
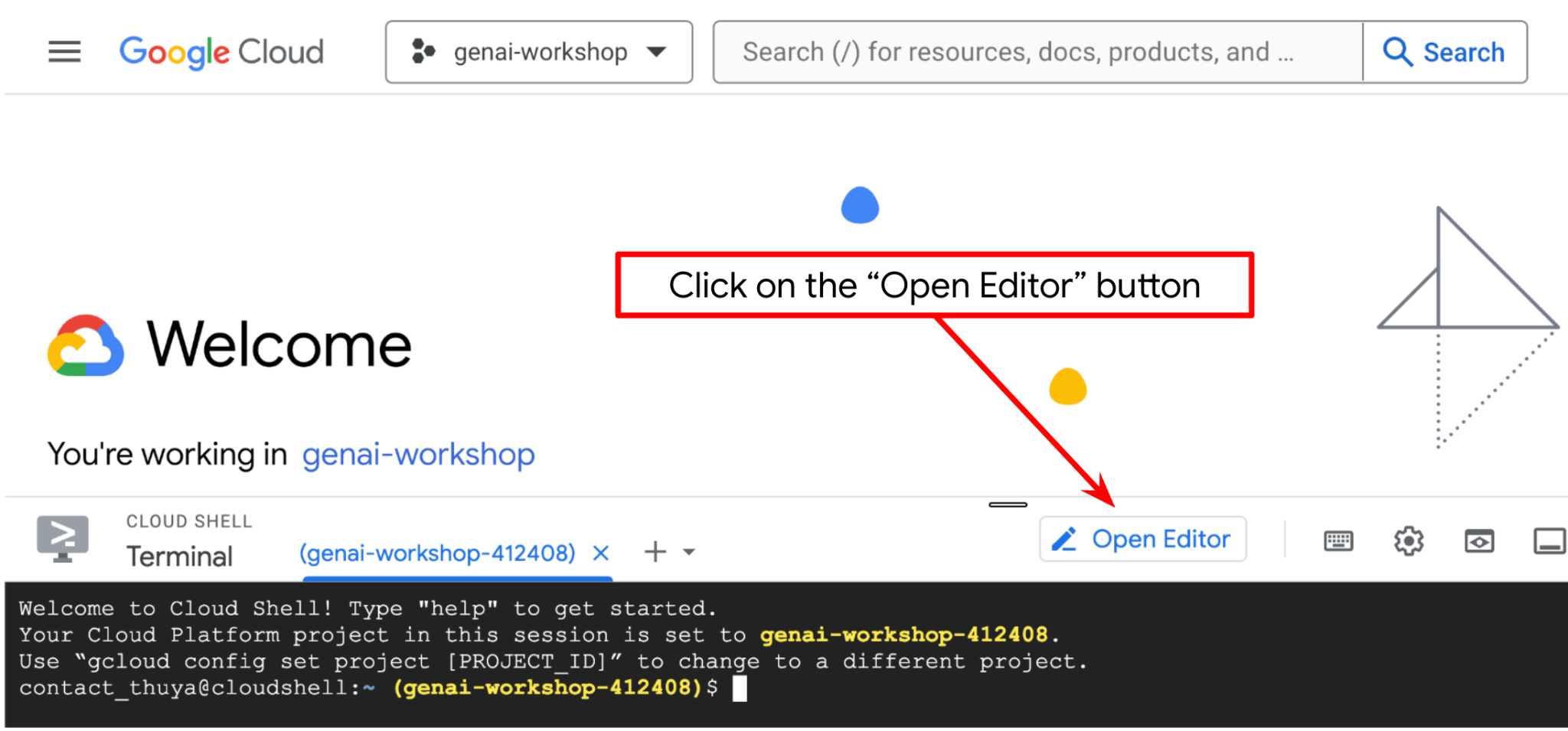
Teraz możemy skonfigurować edytor kodu, aby wykonywać różne czynności związane z kodowaniem. W tym celu użyjemy edytora Cloud Shell.
- Kliknij przycisk Otwórz edytor. Spowoduje to otwarcie edytora Cloud Shell, w którym możesz pisać kod.
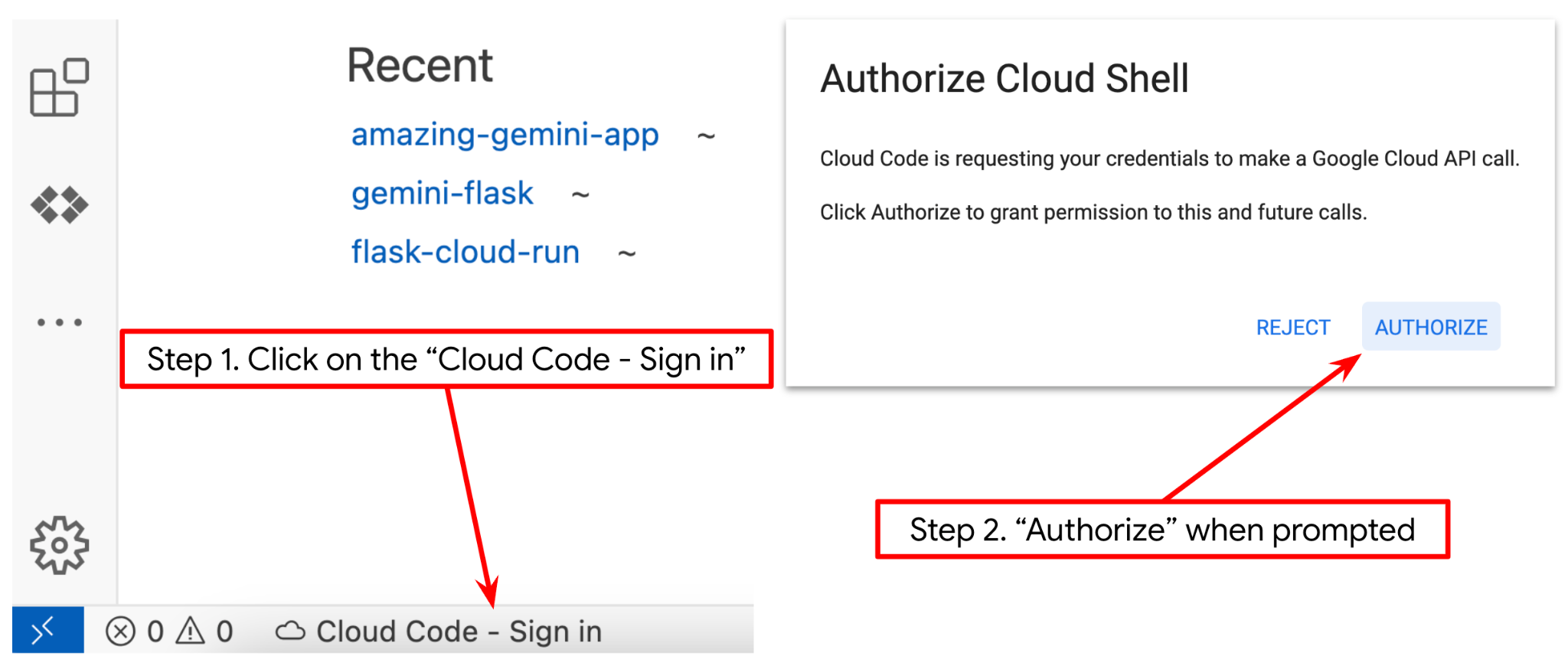
- Sprawdź, czy projekt Cloud Code jest ustawiony w lewym dolnym rogu (na pasku stanu) edytora Cloud Shell, jak pokazano na ilustracji poniżej, i czy jest ustawiony jako aktywny projekt Google Cloud, w którym masz włączone płatności. W razie potrzeby kliknij Autoryzuj. Jeśli wykonasz poprzednie polecenie, przycisk może też prowadzić bezpośrednio do aktywowanego projektu zamiast do przycisku logowania.
- Następnie sklonuj z GitHuba katalog roboczy szablonu dla tego ćwiczenia, wykonując to polecenie: W katalogu qa-test-planner-agent zostanie utworzony katalog roboczy.
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
- Następnie przejdź do górnej sekcji edytora Cloud Shell i kliknij File->Open Folder (Plik –>Otwórz folder), znajdź katalog nazwa_użytkownika i katalog qa-test-planner-agent,a potem kliknij OK. Wybrany katalog stanie się głównym katalogiem roboczym. W tym przykładzie nazwa użytkownika to alvinprayuda, więc ścieżka do katalogu jest widoczna poniżej.
Edytor Cloud Shell powinien teraz wyglądać tak:
Konfiguracja środowiska
Przygotowywanie wirtualnego środowiska Pythona
Następnym krokiem jest przygotowanie środowiska programistycznego. Aktywny terminal powinien znajdować się w katalogu roboczym qa-test-planner-agent. W tym ćwiczeniu użyjemy Pythona 3.12 i menedżera projektów Pythona uv, aby uprościć tworzenie i zarządzanie wersją Pythona oraz środowiskiem wirtualnym.
- Jeśli terminal nie jest jeszcze otwarty, otwórz go, klikając Terminal –> Nowy terminal lub użyj skrótu Ctrl + Shift + C. W dolnej części przeglądarki otworzy się okno terminala.

- Pobierz
uvi zainstaluj Pythona 3.12 za pomocą tego polecenia:
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- Teraz zainicjuj środowisko wirtualne za pomocą polecenia
uv. Uruchom to polecenie:
uv sync --frozen
Spowoduje to utworzenie katalogu .venv i zainstalowanie zależności. Szybki podgląd pyproject.toml dostarczy Ci informacji o zależnościach, które będą wyglądać tak:
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- Aby przetestować środowisko wirtualne, utwórz nowy plik main.py i skopiuj do niego ten kod:
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- Następnie uruchom to polecenie:
uv run main.py
Otrzymasz dane wyjściowe podobne do tych poniżej.
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
Oznacza to, że projekt w Pythonie jest prawidłowo konfigurowany.
Teraz możemy przejść do następnego kroku, czyli utworzenia agenta, a potem usług.
3. Tworzenie agenta za pomocą pakietu Google ADK i modelu Gemini 2.5
Wprowadzenie do struktury katalogów ADK
Zacznijmy od omówienia możliwości ADK i sposobu tworzenia agenta. Pełną dokumentację pakietu ADK znajdziesz pod tym adresem URL . ADK oferuje wiele narzędzi w ramach wykonywania poleceń interfejsu CLI. Oto niektóre z nich :
- Konfigurowanie struktury katalogu agenta
- Szybkie wypróbowanie interakcji za pomocą danych wejściowych i wyjściowych interfejsu wiersza poleceń
- Szybkie konfigurowanie lokalnego interfejsu internetowego
Teraz utwórzmy strukturę katalogów agenta za pomocą polecenia interfejsu wiersza poleceń. Uruchom to polecenie:
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
W bieżącym katalogu roboczym zostanie utworzona ta struktura katalogów agenta:
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
Jeśli sprawdzisz pliki init.py i agent.py, zobaczysz ten kod:
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Tworzenie agenta do planowania testów kontroli jakości
Zacznijmy tworzyć agenta do planowania testów kontroli jakości. Otwórz plik qa_test_planner/agent.py i skopiuj poniższy kod, który będzie zawierać root_agent.
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
Konfigurowanie plików konfiguracji
Teraz musimy dodać dodatkową konfigurację tego projektu, ponieważ ten agent będzie potrzebować dostępu do Confluence.
Otwórz plik qa_test_planner/.env i dodaj do niego wartości tych zmiennych środowiskowych. Upewnij się, że wynikowy plik .env wygląda tak:
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
Niestety nie możemy udostępnić tej przestrzeni Confluence publicznie, dlatego możesz przejrzeć te pliki, aby przeczytać dostępne dokumenty z wymaganiami dotyczącymi produktu, które będą dostępne przy użyciu powyższych danych logowania.
Wyjaśnienie kodu
Ten skrypt zawiera inicjację agenta, w której inicjujemy te elementy:
- Ustaw model, który ma być używany, na
gemini-2.5-flash. - Skonfiguruj narzędzia MCP Confluence, które będą komunikować się za pomocą Stdio.
- Skonfiguruj
write_test_toolniestandardowe narzędzie do pisania planu testów i eksportowania pliku CSV do artefaktu. - Skonfiguruj opis i instrukcje agenta
- Włącz planowanie przed wygenerowaniem ostatecznej odpowiedzi lub wykonaniem działania za pomocą funkcji myślenia Gemini 2.5 Flash
Sam agent, gdy jest oparty na modelu Gemini z wbudowanymi funkcjami myślenia i skonfigurowany z argumentami planera, może pokazywać swoje możliwości myślenia, które są też wyświetlane w interfejsie internetowym. Kod do skonfigurowania tej funkcji znajdziesz poniżej.
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
Zanim podejmie działania, możemy zobaczyć jego proces myślowy.
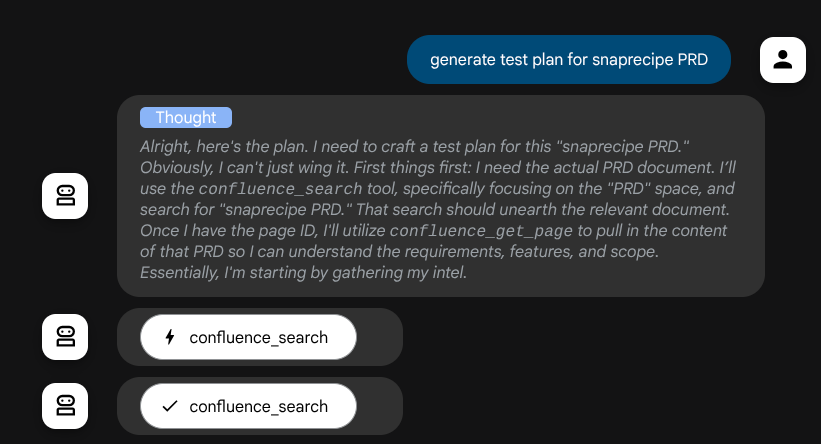
Narzędzie MCP w Confluence
Aby połączyć się z serwerem MCP z ADK, musimy użyć MCPToolSet, który można zaimportować z modułu google.adk.tools.mcp_tool.mcp_toolset. Kod do zainicjowania pokazany poniżej ( skrócony dla wygody):
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
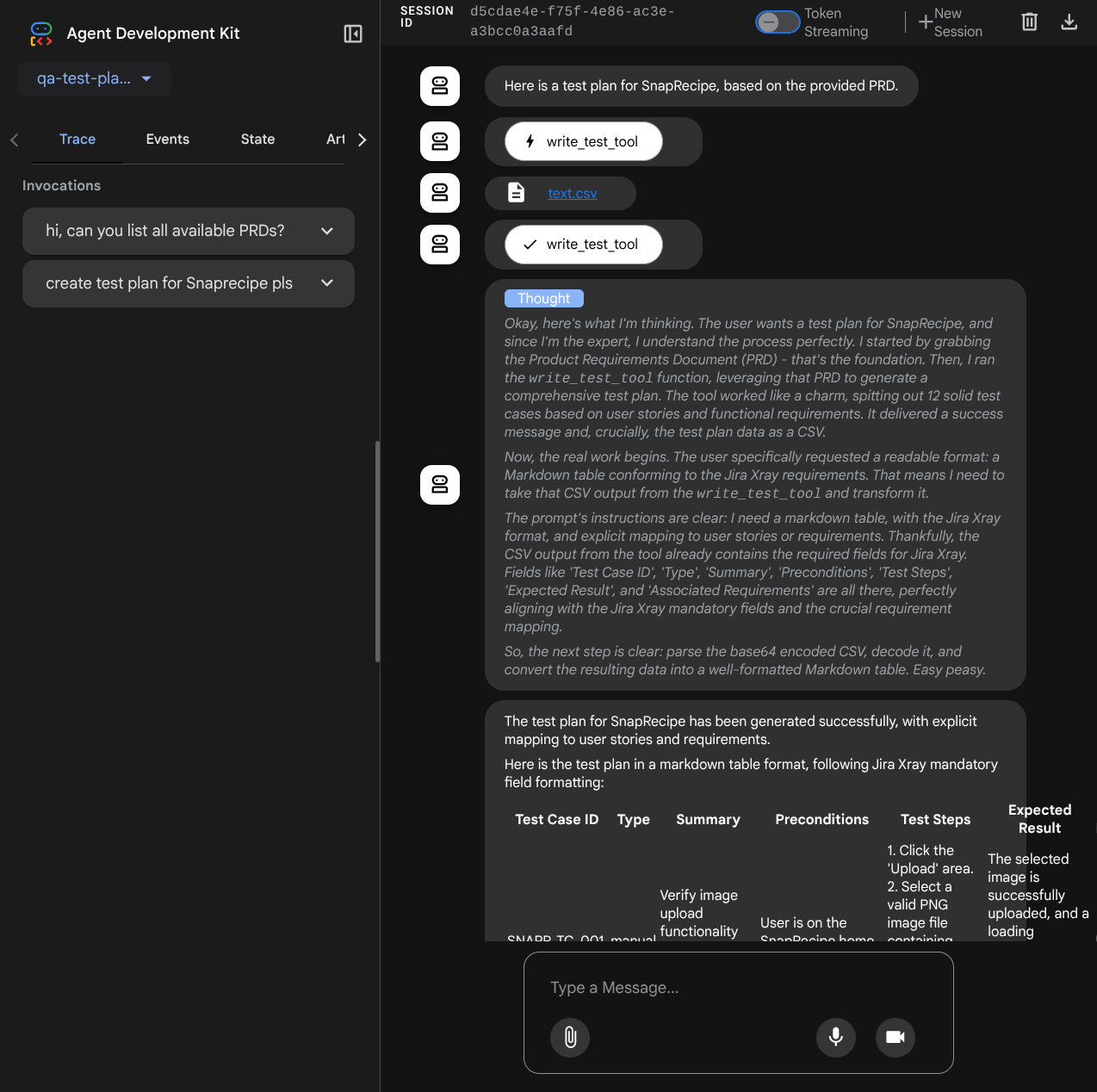
W tej konfiguracji agent zainicjuje serwer MCP Confluence jako osobny proces i będzie obsługiwać komunikację z tymi procesami za pomocą Studio I/O. Ten proces jest przedstawiony na poniższym schemacie architektury MCP w czerwonej ramce.
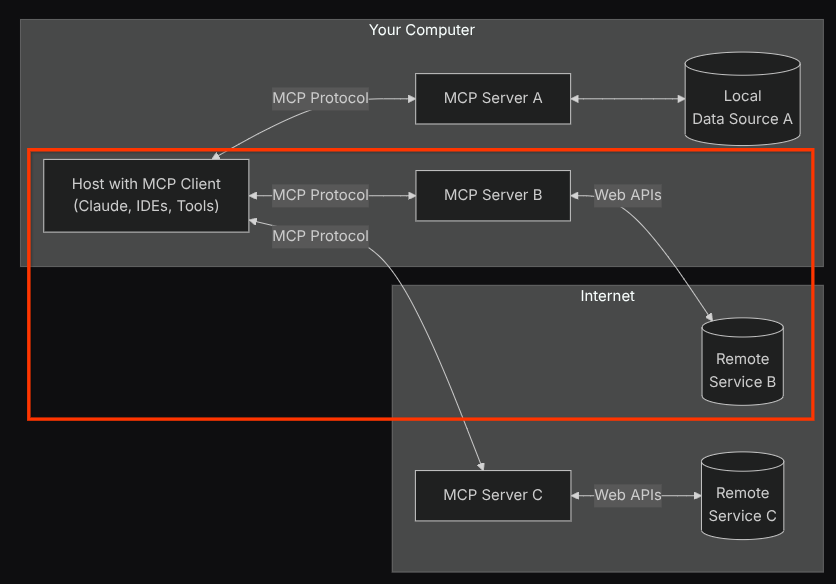
Dodatkowo w argumentach polecenia inicjowania MCP ograniczamy narzędzia, które mogą być używane, do tych: confluence_search, confluence_get_page i confluence_get_page_children, które obsługują przypadki użycia agenta testów jakości. W tym samouczku dotyczącym ćwiczeń z programowania korzystamy z serwera Atlassian MCP Server, który został opracowany przez społeczność ( więcej informacji znajdziesz w pełnej dokumentacji).
Narzędzie do pisania testów
Gdy agent otrzyma kontekst z narzędzia Confluence MCP, może utworzyć dla użytkownika niezbędny plan testów. Chcemy jednak utworzyć plik zawierający ten plan testów, aby można go było zapisać i udostępnić innej osobie. Aby to umożliwić, udostępniamy poniżej narzędzie niestandardowe write_test_tool.
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
Funkcja zadeklarowana powyżej obsługuje te funkcje:
- Sprawdź wygenerowany plan testów, aby upewnić się, że jest zgodny ze specyfikacjami pól obowiązkowych. Sprawdzamy to za pomocą modelu Pydantic. Jeśli wystąpi błąd, przekazujemy agentowi komunikat o błędzie.
- Zapisz wynik w pliku CSV za pomocą funkcji biblioteki pandas.
- Wygenerowany plik jest następnie zapisywany jako artefakt za pomocą funkcji usługi Artifact Service, do których można uzyskać dostęp za pomocą obiektu ToolContext, który jest dostępny w przypadku każdego wywołania narzędzia.
Jeśli zapiszemy wygenerowane pliki jako artefakty, zostaną one oznaczone jako zdarzenie w środowisku wykonawczym ADK i będą później wyświetlane w interfejsie internetowym.
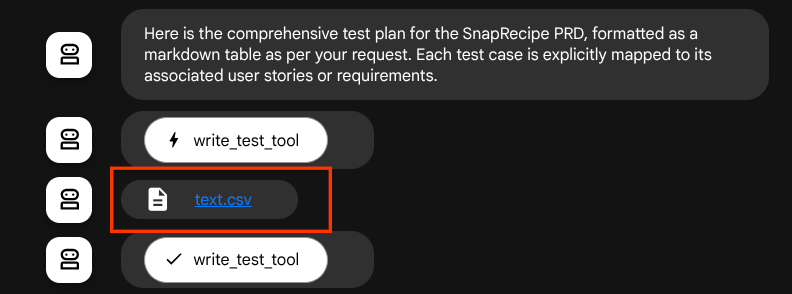
Dzięki temu możemy dynamicznie konfigurować odpowiedź agenta w postaci pliku, która będzie przekazywana użytkownikowi.
4. Testowanie agenta
Teraz spróbujmy komunikować się z agentem za pomocą interfejsu wiersza poleceń. Uruchom to polecenie:
uv run adk run qa_test_planner
Wyświetli się wynik podobny do tego poniżej, w którym możesz na zmianę rozmawiać z agentem. W tym interfejsie możesz jednak wysyłać tylko tekst.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
Możliwość czatowania z pracownikiem obsługi klienta za pomocą interfejsu wiersza poleceń jest bardzo przydatna. Jeszcze lepiej, jeśli będziemy mogli prowadzić z nim rozmowę na czacie w internecie. To też jest możliwe. ADK umożliwia też korzystanie z interfejsu programistycznego, który pozwala wchodzić w interakcje i sprawdzać, co się dzieje podczas interakcji. Aby uruchomić lokalny serwer interfejsu programistycznego, wykonaj to polecenie:
uv run adk web --port 8080
Wygeneruje to dane wyjściowe podobne do poniższego przykładu, co oznacza, że możemy już uzyskać dostęp do interfejsu internetowego.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
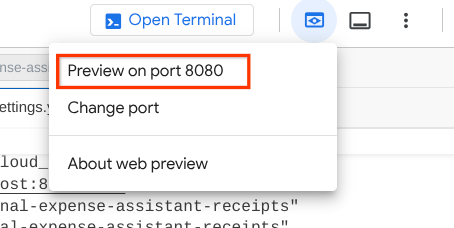
Aby to sprawdzić, kliknij przycisk Podgląd w przeglądarce w górnej części edytora Cloud Shell i wybierz Podejrzyj na porcie 8080.
Wyświetli się strona internetowa, na której w lewym górnym rogu możesz wybrać dostępnych agentów ( w naszym przypadku powinien to być qa_test_planner) i interagować z botem. W oknie po lewej stronie zobaczysz wiele informacji o szczegółach logu podczas działania agenta.
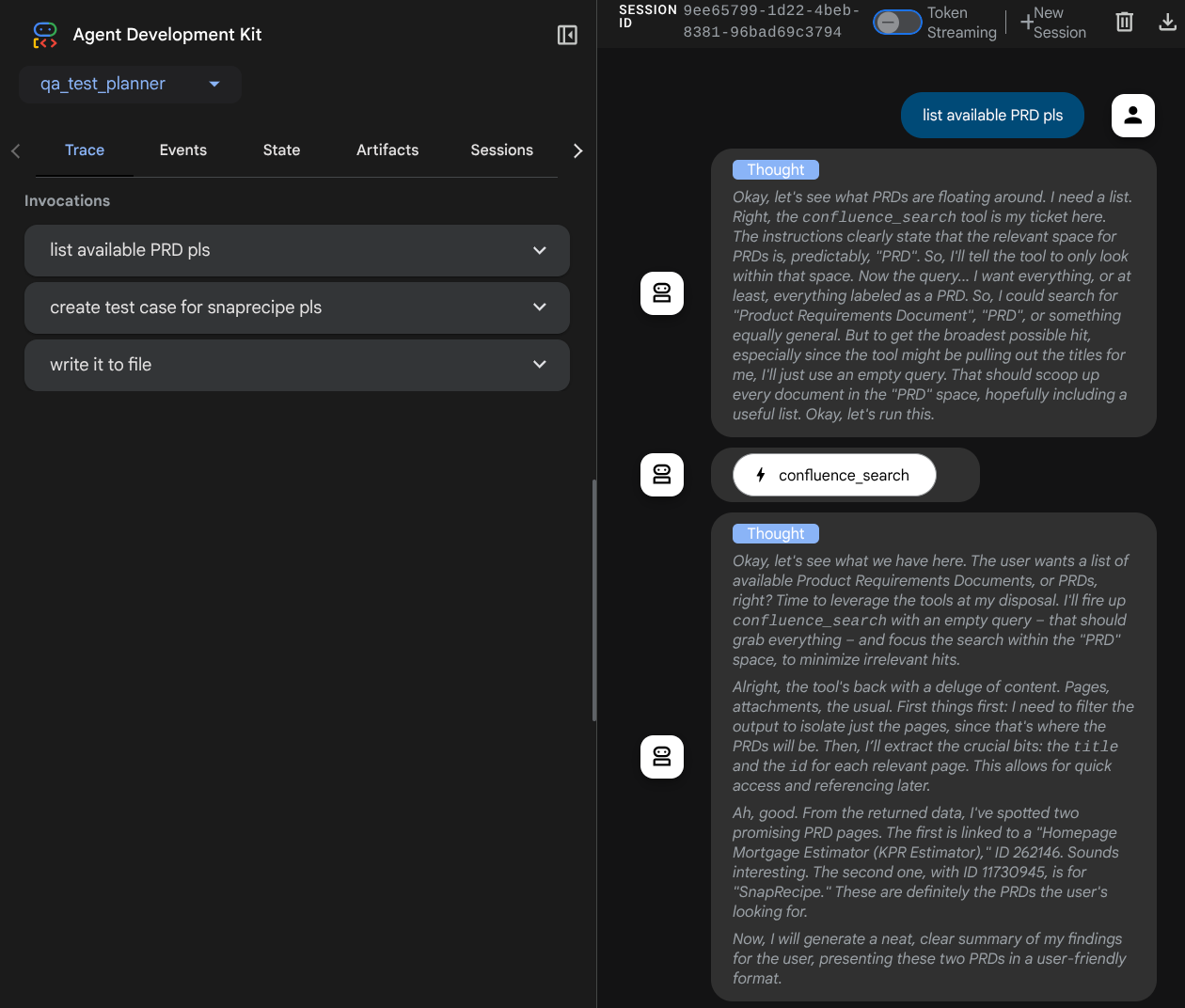
Wypróbujmy kilka działań. Porozmawiaj na czacie z pracownikami obsługi klienta, używając tych promptów:
- „ Proszę o podanie wszystkich dostępnych PRD ”
- „Napisz plan testów dla dokumentu PRD Snaprecipe”.
Gdy używasz niektórych narzędzi, możesz sprawdzić, co się dzieje w interfejsie programowania.
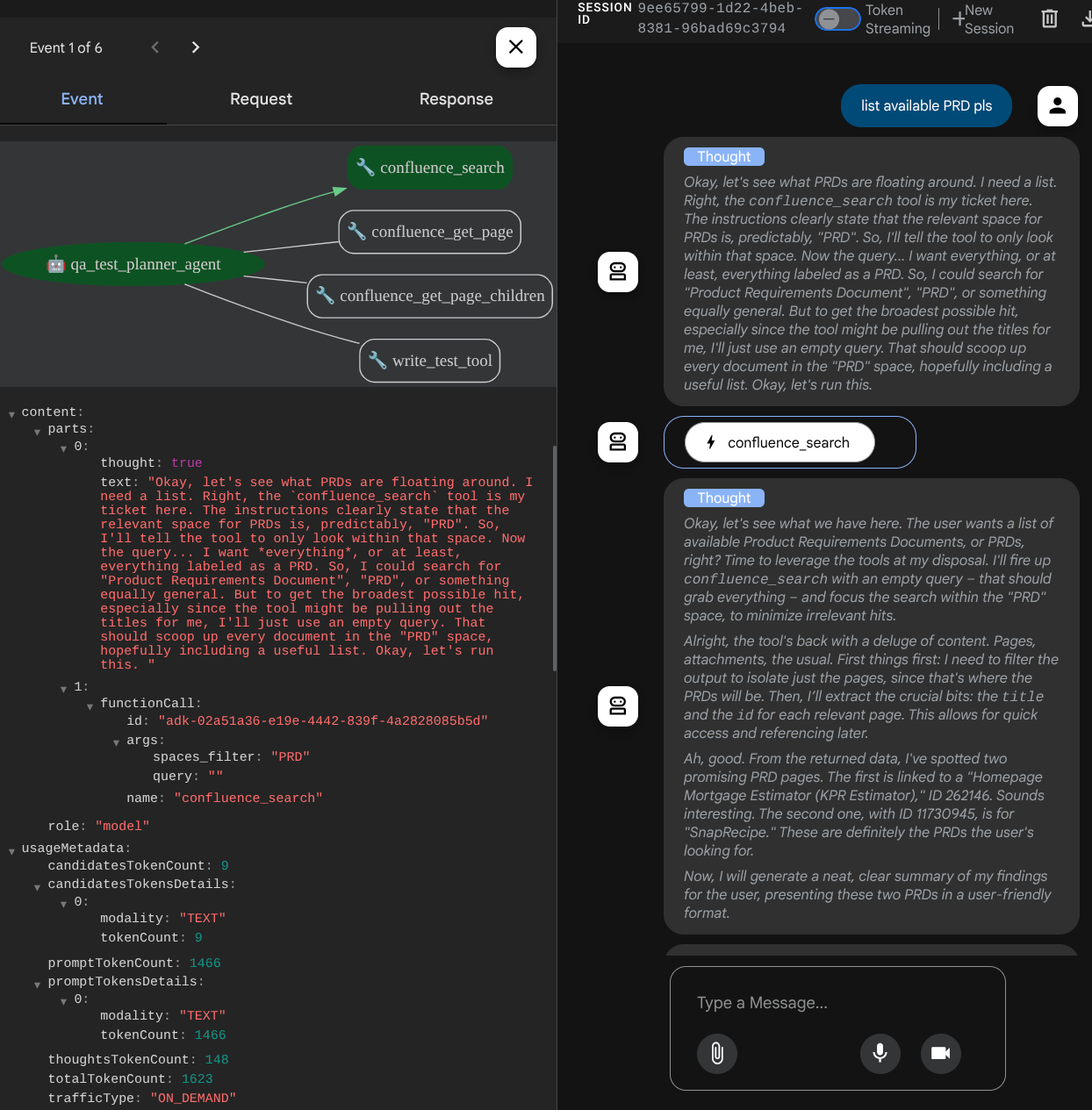
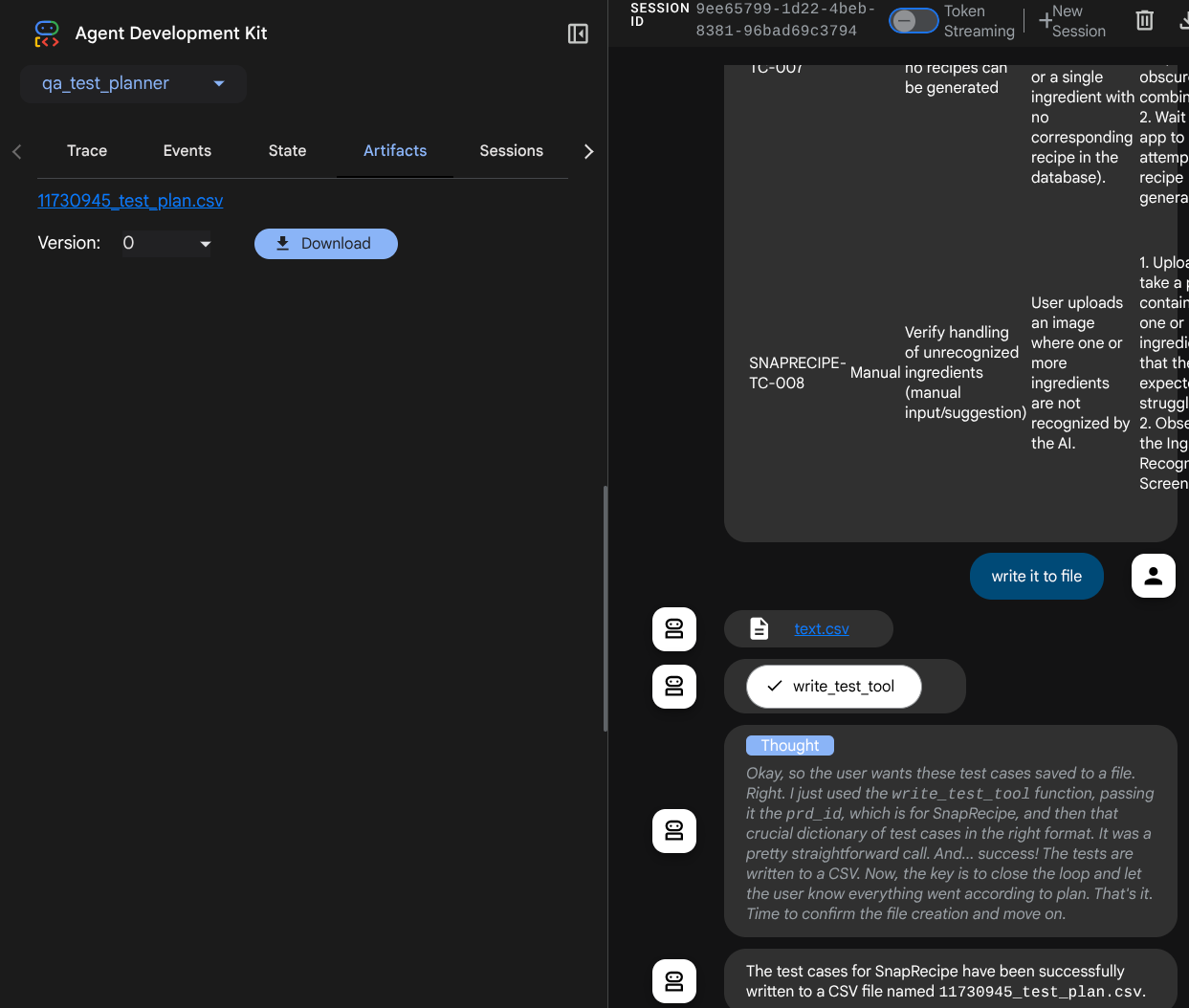
Sprawdź, jak odpowiada agent, a także kiedy poprosimy o plik testowy, wygeneruje on plan testów w pliku CSV jako artefakt.
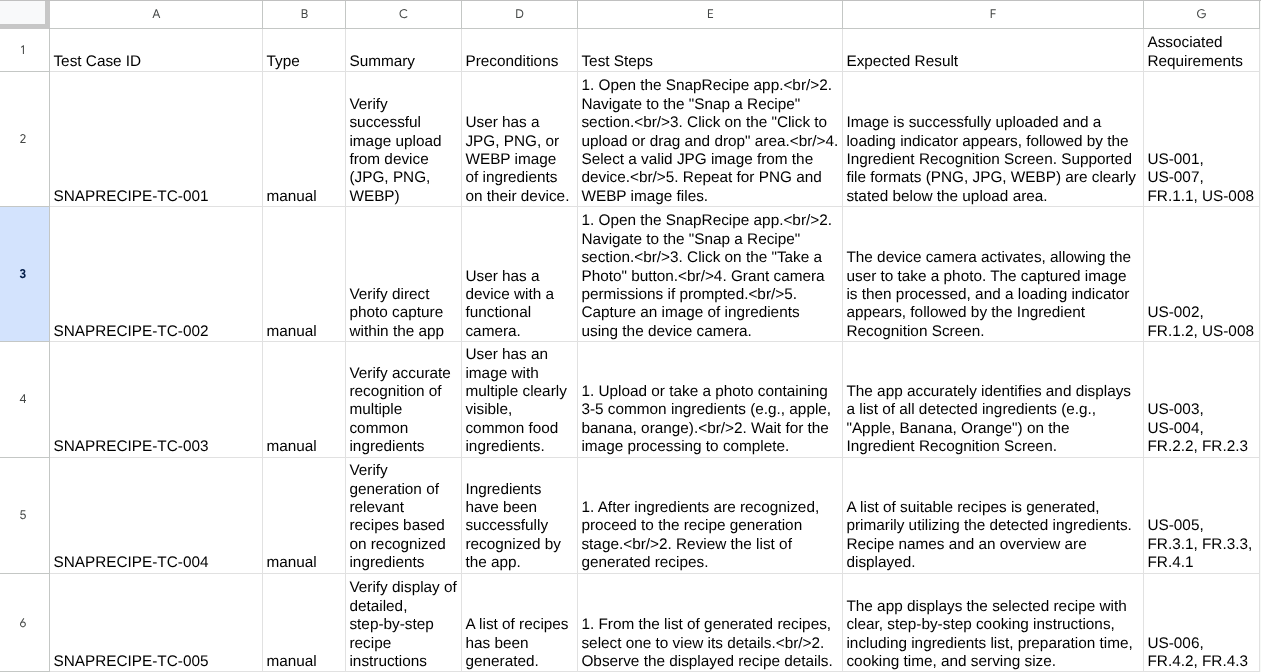
Teraz możesz sprawdzić zawartość pliku CSV, importując go na przykład do Arkuszy Google.
Gratulacje! Masz teraz działającego lokalnie agenta do planowania testów kontroli jakości. Zobaczmy teraz, jak wdrożyć go w Cloud Run, aby inni też mogli z niego korzystać.
5. Wdrażanie w Cloud Run
Oczywiście chcemy mieć dostęp do tej wspaniałej aplikacji z dowolnego miejsca. Aby to zrobić, możemy spakować tę aplikację i wdrożyć ją w Cloud Run. Na potrzeby tej wersji demonstracyjnej usługa będzie udostępniana jako usługa publiczna, do której inne osoby będą miały dostęp. Pamiętaj jednak, że nie jest to najlepsze rozwiązanie.
W bieżącym katalogu roboczym mamy już wszystkie pliki potrzebne do wdrożenia aplikacji w Cloud Run: katalog agenta, plik Dockerfile i server.py (główny skrypt usługi). Wdróżmy je. Otwórz terminal Cloud Shell i sprawdź, czy bieżący projekt jest skonfigurowany jako aktywny. Jeśli nie, użyj polecenia gcloud configure, aby ustawić identyfikator projektu:
gcloud config set project [PROJECT_ID]
Następnie uruchom to polecenie, aby wdrożyć go w Cloud Run.
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
Jeśli pojawi się prośba o potwierdzenie utworzenia repozytorium Artifact Registry dla Dockera, wpisz Y. Pamiętaj, że w tym przypadku zezwalamy na nieuwierzytelniony dostęp, ponieważ jest to aplikacja demonstracyjna. Zalecamy stosowanie odpowiedniego uwierzytelniania w przypadku aplikacji firmowych i produkcyjnych.
Po zakończeniu wdrażania powinien pojawić się link podobny do tego:
https://qa-test-planner-agent-*******.us-central1.run.app
Gdy otworzysz adres URL, zobaczysz interfejs programisty podobny do tego, który pojawia się podczas testowania lokalnego. Możesz teraz korzystać z aplikacji w oknie incognito lub na urządzeniu mobilnym. Powinien być już widoczny.
Spróbujmy teraz ponownie tych różnych promptów – po kolei, aby zobaczyć, co się stanie:
- „ Czy możesz znaleźć dokument PRD związany z kalkulatorem kredytów hipotecznych? ”
- „Prześlij opinię o tym, co możemy w tym zakresie poprawić”.
- „Napisz plan testów”.
Dodatkowo, ponieważ uruchamiamy agenta jako aplikację FastAPI, możemy też sprawdzić wszystkie trasy API w ramach trasy /docs. Jeśli np.otworzysz adres URL https://qa-test-planner-agent-*******.us-central1.run.app/docs, zobaczysz stronę dokumentacji Swaggera, jak pokazano poniżej.
Wyjaśnienie kodu
Teraz sprawdźmy, jakiego pliku potrzebujemy do wdrożenia, zaczynając od server.py.
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Za pomocą funkcji get_fast_api_app możemy łatwo przekształcić agenta w aplikację FastAPI. W tej funkcji możemy skonfigurować różne funkcje, np. usługę sesji, usługę artefaktów, a nawet śledzenie danych w chmurze.
Jeśli chcesz, możesz też ustawić tutaj cykl życia aplikacji. Następnie możemy użyć uvicorn do uruchomienia aplikacji Fast API.
Następnie Dockerfile dostarczy nam niezbędne kroki do uruchomienia aplikacji.
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. Wyzwanie
Teraz możesz zabłysnąć i podszkolić swoje umiejętności eksploracyjne. Czy możesz też utworzyć narzędzie, które zapisuje w pliku opinie dotyczące PRD?
7. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym laboratorium, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
- Możesz też otworzyć Cloud Run w konsoli, wybrać wdrożoną usługę i ją usunąć.