
1. Introdução
O potencial de usar a IA generativa para criar planos de teste decorre da capacidade dela de resolver dois dos maiores desafios no controle de qualidade moderno: velocidade e abrangência. Nos ciclos rápidos de Agile e DevOps de hoje, a criação manual de planos de teste detalhados é um gargalo significativo, atrasando todo o processo de teste. Um agente com tecnologia de IA generativa pode ingerir histórias de usuários e requisitos técnicos para produzir um plano de teste completo em minutos, não em dias, garantindo que o processo de controle de qualidade acompanhe o desenvolvimento. Além disso, a IA é excelente para identificar cenários complexos, casos extremos e caminhos negativos que um humano pode ignorar, o que leva a uma cobertura de teste muito melhor e a uma redução significativa de bugs que escapam para a produção.
Neste codelab, vamos mostrar como criar um agente que pode recuperar os documentos de requisitos do produto do Confluence, dar feedback construtivo e gerar um plano de teste abrangente que pode ser exportado para um arquivo CSV.
Durante o codelab, você vai usar uma abordagem gradual da seguinte forma:
- Prepare seu projeto na nuvem do Google Cloud e ative todas as APIs necessárias nele.
- Configurar o espaço de trabalho para seu ambiente de programação
- Como preparar o mcp-server local para o Confluence
- Estruturar o código-fonte, o comando e as ferramentas do agente do ADK para se conectar ao servidor MCP
- Entender a utilização de contextos de serviço de artefato e de ferramenta
- Testar o agente usando a interface de desenvolvimento da Web local do ADK
- Gerenciar variáveis de ambiente e configurar os arquivos necessários para implantar o aplicativo no Cloud Run
- Implante o aplicativo no Cloud Run.
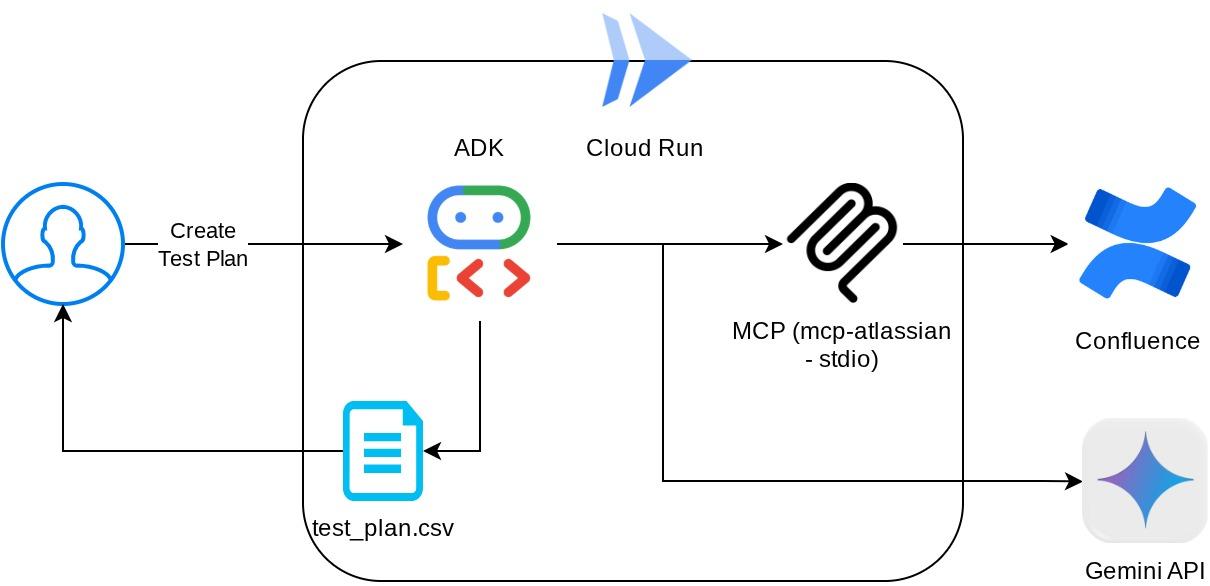
Visão geral da arquitetura
Pré-requisitos
- Conhecimento de Python
- Conhecimento básico da arquitetura full-stack usando o serviço HTTP
O que você vai aprender
- Arquitetar o agente do ADK usando os vários recursos dele
- Uso de ferramentas com a ferramenta personalizada e o MCP
- Configurar a saída de arquivos pelo agente usando o gerenciamento do serviço de artefatos
- Usar o BuiltInPlanner para melhorar a execução de tarefas fazendo planejamento com os recursos de raciocínio do Gemini 2.5 Flash
- Interação e depuração pela interface da Web do ADK
- Implantar o aplicativo no Cloud Run usando o Dockerfile e fornecer variáveis de ambiente
O que é necessário
- Navegador da Web Google Chrome
- Uma conta do Gmail
- Um projeto do Cloud com faturamento ativado
- (Opcional) Espaço do Confluence com páginas de documentos de requisitos do produto
Este codelab, criado para desenvolvedores de todos os níveis (inclusive iniciantes), usa Python no aplicativo de exemplo. No entanto, não é necessário ter conhecimento de Python para entender os conceitos apresentados. Não se preocupe se você não tiver um espaço do Confluence. Vamos fornecer credenciais para testar este codelab.
2. Antes de começar
Selecionar projeto ativo no console do Cloud
Este codelab pressupõe que você já tenha um projeto na nuvem do Google Cloud com o faturamento ativado. Se você ainda não tem, siga as instruções abaixo para começar.
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Configurar o projeto do Cloud no terminal do Cloud Shell
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.
- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com o ID do seu projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
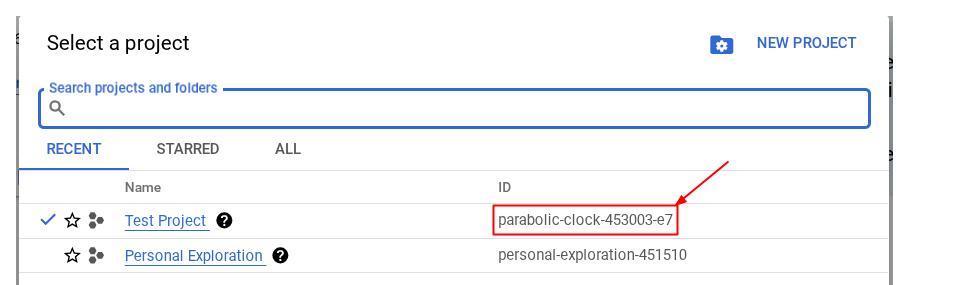
Também é possível conferir o ID do PROJECT_ID no console.
Clique nele para ver todos os seus projetos e o ID do projeto no lado direito.
- Ative as APIs necessárias com o comando mostrado abaixo. Isso pode levar alguns minutos. Aguarde.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Após a execução do comando, você vai ver uma mensagem semelhante à mostrada abaixo:
Operation "operations/..." finished successfully.
A alternativa ao comando gcloud é usar o console. Para isso, pesquise cada produto ou use este link.
Se alguma API for esquecida, você sempre poderá ativá-la durante a implementação.
Consulte a documentação para ver o uso e os comandos gcloud.
Acessar o editor do Cloud Shell e configurar o diretório de trabalho do aplicativo
Agora, podemos configurar nosso editor de código para fazer algumas coisas de programação. Vamos usar o editor do Cloud Shell para isso.
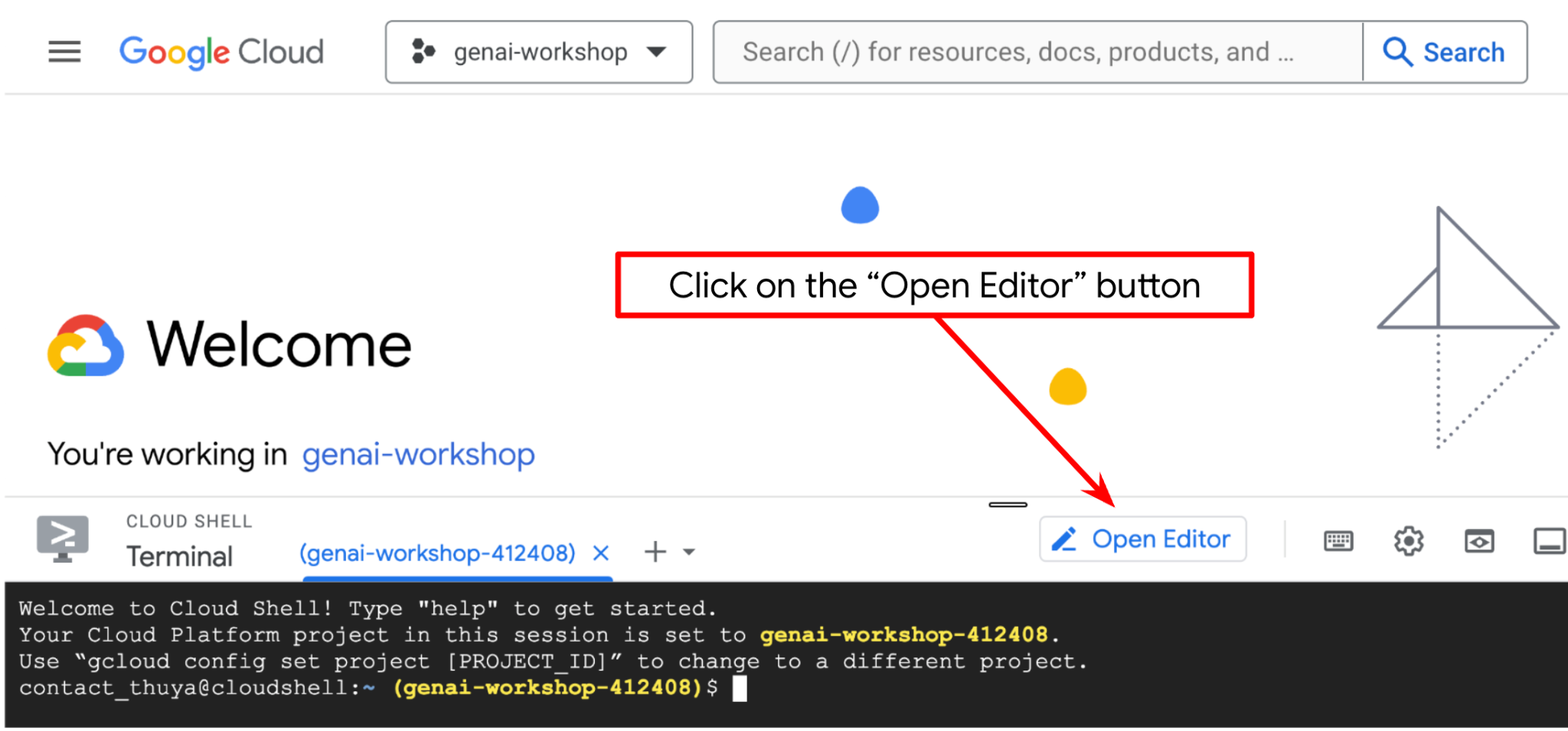
- Clique no botão "Abrir editor" para abrir um editor do Cloud Shell. Podemos escrever nosso código aqui
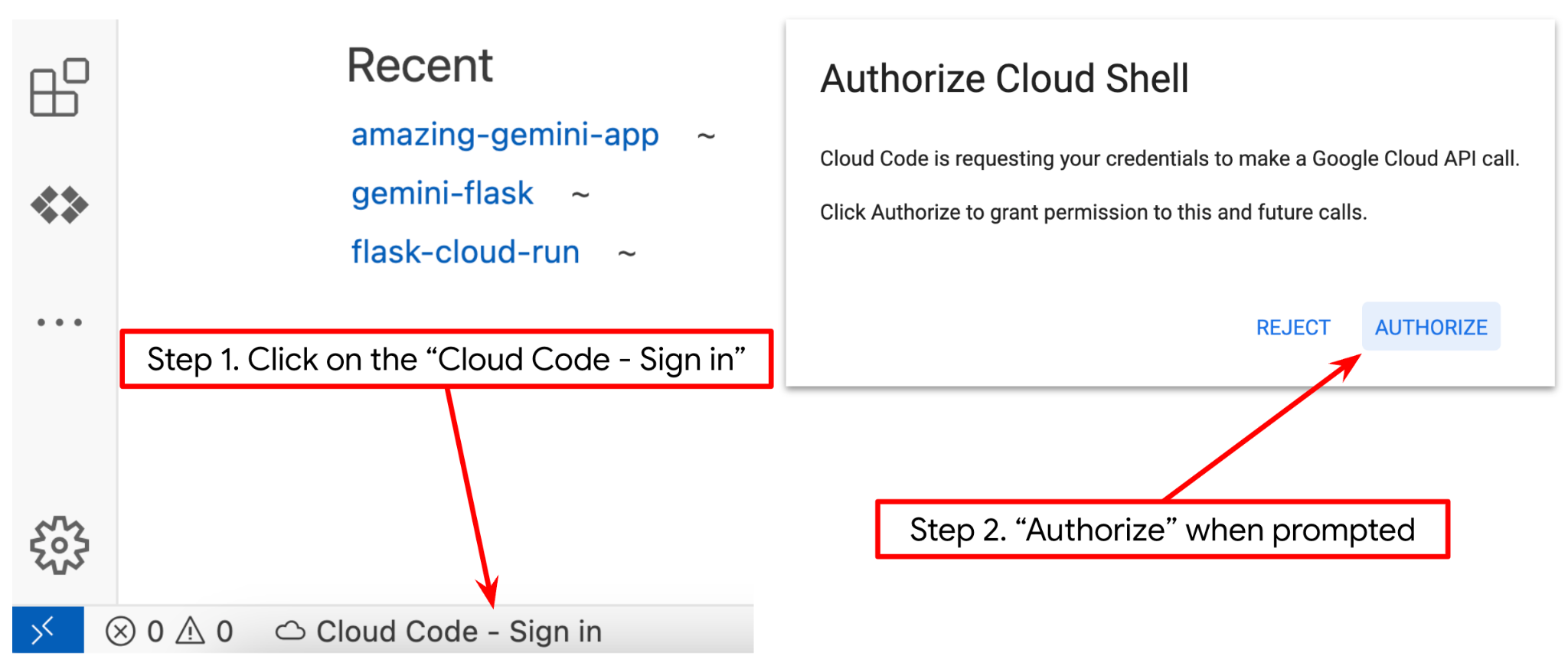
- Verifique se o projeto do Cloud Code está definido no canto inferior esquerdo (barra de status) do editor do Cloud Shell, conforme destacado na imagem abaixo, e se ele está definido como o projeto ativo do Google Cloud em que o faturamento está ativado. Autorize se for solicitado. Se você já tiver seguido o comando anterior, o botão também poderá apontar diretamente para o projeto ativado em vez do botão de login.
- Em seguida, vamos clonar o diretório de trabalho do modelo para este codelab do GitHub. Execute o seguinte comando: Ele vai criar o diretório de trabalho no diretório qa-test-planner-agent.
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
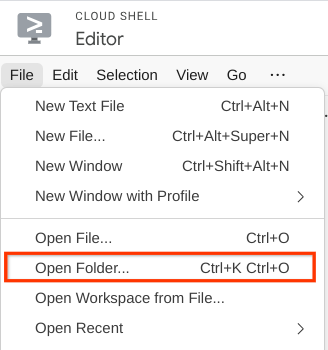
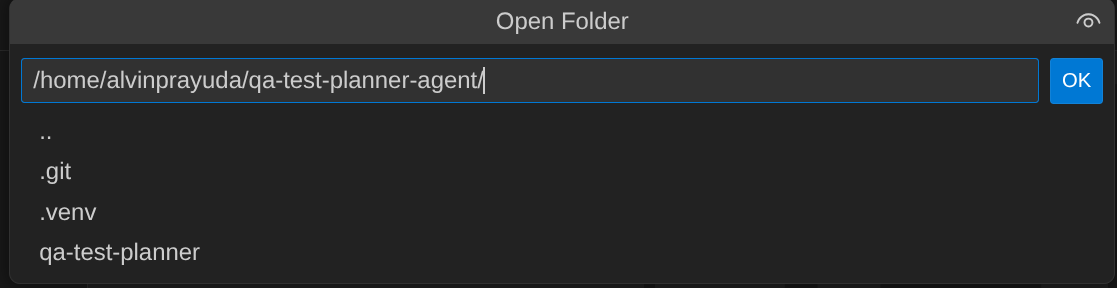
- Depois disso, acesse a seção superior do editor do Cloud Shell e clique em Arquivo->Abrir pasta, encontre o diretório username e o diretório qa-test-planner-agent. Em seguida, clique no botão "OK". Isso vai definir o diretório escolhido como o principal. Neste exemplo, o nome de usuário é alvinprayuda. Portanto, o caminho do diretório é mostrado abaixo.
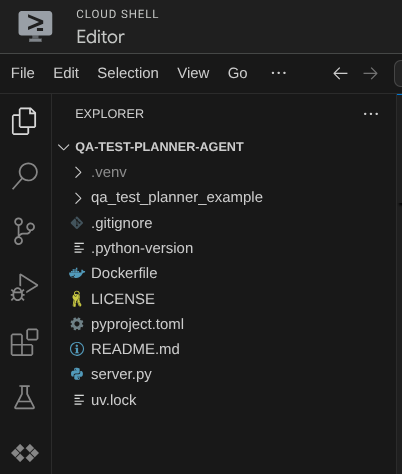
Agora, o editor do Cloud Shell vai ficar assim:
Configuração do ambiente
Preparar o ambiente virtual do Python
A próxima etapa é preparar o ambiente de desenvolvimento. O terminal ativo atual precisa estar no diretório de trabalho qa-test-planner-agent. Vamos usar o Python 3.12 neste codelab e o gerenciador de projetos Python uv para simplificar a necessidade de criar e gerenciar a versão do Python e o ambiente virtual.
- Se você ainda não abriu o terminal, clique em Terminal -> Novo terminal ou use Ctrl + Shift + C. Isso vai abrir uma janela do terminal na parte de baixo do navegador.

- Faça o download do
uve instale o Python 3.12 com o seguinte comando:
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- Agora vamos inicializar o ambiente virtual usando
uv. Execute este comando:
uv sync --frozen
Isso vai criar o diretório .venv e instalar as dependências. Uma rápida olhada no pyproject.toml vai mostrar informações sobre as dependências, assim:
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- Para testar o ambiente virtual, crie um arquivo main.py e copie o seguinte código:
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- Em seguida, execute o comando abaixo.
uv run main.py
Você vai receber uma saída como a mostrada abaixo
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
Isso mostra que o projeto Python está sendo configurado corretamente.
Agora podemos passar para a próxima etapa, criando o agente e depois os serviços.
3. Criar o agente usando o Google ADK e o Gemini 2.5
Introdução à estrutura de diretórios do ADK
Vamos começar analisando o que o ADK tem a oferecer e como criar o agente. A documentação completa do ADK pode ser acessada neste URL . O ADK oferece muitas utilidades na execução de comandos da CLI. Alguns deles são :
- Configurar a estrutura de diretórios do agente
- Teste rapidamente a interação por entrada e saída da CLI
- Configurar rapidamente a interface da Web da IU de desenvolvimento local
Agora, vamos criar a estrutura de diretórios do agente usando o comando da CLI. Execute este comando
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
Ele vai criar a seguinte estrutura de diretório do agente no seu diretório de trabalho atual:
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
Se você inspecionar init.py e agent.py, verá este código:
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Como criar nosso agente de planejamento de testes de controle de qualidade
Vamos criar nosso agente planejador de testes de controle de qualidade! Abra o arquivo qa_test_planner/agent.py e copie o código abaixo, que vai conter o root_agent.
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
Configurar arquivos de configuração
Agora, precisamos adicionar mais configurações para esse projeto, já que o agente precisa de acesso ao Confluence.
Abra o arquivo qa_test_planner/.env e adicione os seguintes valores de variáveis de ambiente. Verifique se o arquivo .env resultante está assim:
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
Infelizmente, esse espaço do Confluence não pode ser tornado público. Portanto, você pode inspecionar esses arquivos para ler os documentos de requisitos do produto disponíveis, que estarão acessíveis usando as credenciais acima.
Explicação do código
Esse script contém a inicialização do agente, em que inicializamos o seguinte:
- Defina o modelo a ser usado como
gemini-2.5-flash. - Configurar as ferramentas do MCP do Confluence, que se comunicam via Stdio
- Configurar a ferramenta personalizada
write_test_toolpara escrever um plano de teste e despejar CSV no artefato - Configurar a descrição e as instruções do agente
- Ativar o planejamento antes de gerar a resposta final ou a execução usando os recursos de raciocínio do Gemini 2.5 Flash
O próprio agente, quando alimentado pelo modelo do Gemini com recursos de raciocínio integrados e configurado com os argumentos do planner, pode mostrar seus recursos de raciocínio e ser exibido na interface da Web. Confira o código para configurar isso abaixo:
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
Antes de tomar medidas, podemos ver o processo de pensamento
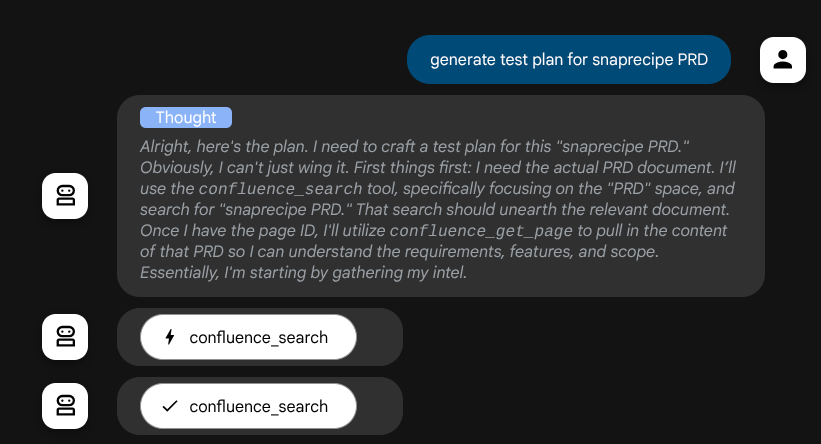
Ferramenta MCP do Confluence
Para se conectar ao servidor MCP do ADK, precisamos usar o MCPToolSet, que pode ser importado do módulo google.adk.tools.mcp_tool.mcp_toolset. O código a ser inicializado aqui é mostrado abaixo ( truncado para eficiência):
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
Com essa configuração, o agente vai inicializar o servidor MCP do Confluence como um processo separado e vai processar a comunicação com esses processos usando a E/S do Studio. Esse fluxo é ilustrado na imagem de arquitetura do MCP marcada dentro da caixa vermelha abaixo.
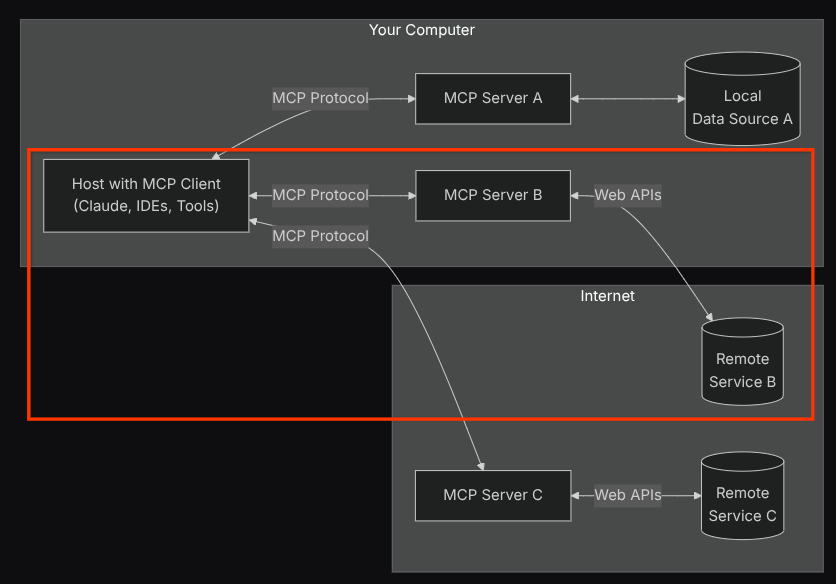
Além disso, nos argumentos de comando da inicialização do MCP, limitamos as ferramentas que podem ser usadas apenas a estas: confluence_search, confluence_get_page e confluence_get_page_children, que oferecem suporte aos casos de uso do nosso agente de teste de QA. Usamos o servidor MCP da Atlassian contribuído pela comunidade ( consulte a documentação completa para mais detalhes) neste tutorial do codelab.
Ferramenta de teste de gravação
Depois que o agente recebe o contexto da ferramenta MCP do Confluence, ele pode criar o plano de teste necessário para o usuário. No entanto, queremos produzir um arquivo que contenha esse plano de teste para que ele possa ser mantido e compartilhado com a outra pessoa. Para isso, fornecemos a ferramenta personalizada write_test_tool abaixo.
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
A função declarada acima é para oferecer suporte às seguintes funcionalidades:
- Verifique se o plano de teste produzido está de acordo com as especificações de campo obrigatório. Fazemos essa verificação usando o modelo Pydantic. Se ocorrer um erro, vamos fornecer a mensagem de erro de volta ao agente.
- Despejar o resultado em CSV usando a funcionalidade do pandas
- O arquivo gerado é salvo como um artefato usando os recursos do serviço de artefatos, que podem ser acessados usando o objeto ToolContext em todas as chamadas de ferramentas.
Se salvarmos os arquivos gerados como artefato, eles serão marcados como evento no tempo de execução do ADK e poderão ser exibidos na interação do agente mais tarde na interface da Web.
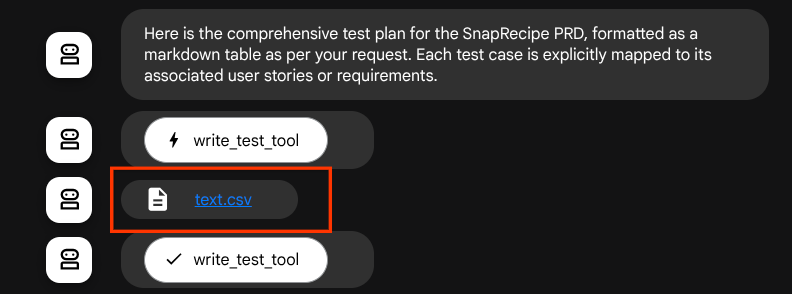
Assim, podemos configurar dinamicamente a resposta do arquivo do agente para o usuário.
4. Testar o agente
Agora vamos tentar nos comunicar com o agente pela CLI. Execute o seguinte comando:
uv run adk run qa_test_planner
Ele vai mostrar uma saída como esta, em que você pode conversar com o agente, mas só é possível enviar texto por essa interface.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
É bom poder conversar com o agente pela CLI. Mas é ainda melhor se tivermos um bom chat na Web com ele, e isso também é possível. O ADK também permite ter uma interface de desenvolvimento para interagir e inspecionar o que está acontecendo durante a interação. Execute o comando a seguir para iniciar o servidor da interface de desenvolvimento local:
uv run adk web --port 8080
Ele vai gerar uma saída como o exemplo a seguir, o que significa que já podemos acessar a interface da Web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Para verificar, clique no botão Visualização da Web na parte superior do Editor do Cloud Shell e selecione Visualizar na porta 8080.
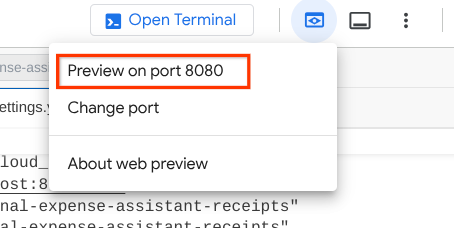
A seguinte página da Web vai aparecer. Nela, você pode selecionar os agentes disponíveis no botão suspenso no canto superior esquerdo ( no nosso caso, qa_test_planner) e interagir com o bot. Você vai ver muitas informações sobre os detalhes do registro durante o tempo de execução do agente na janela à esquerda.
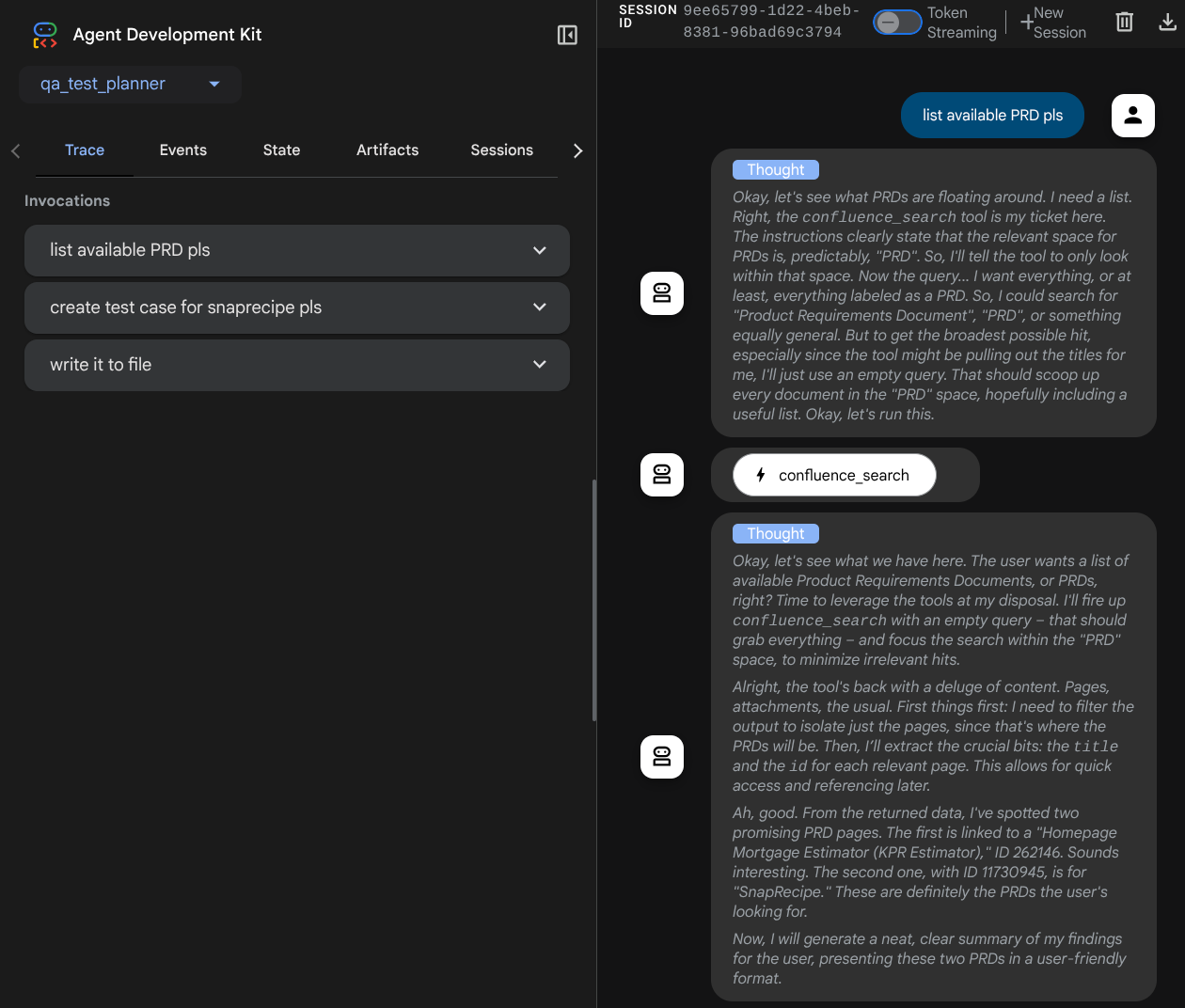
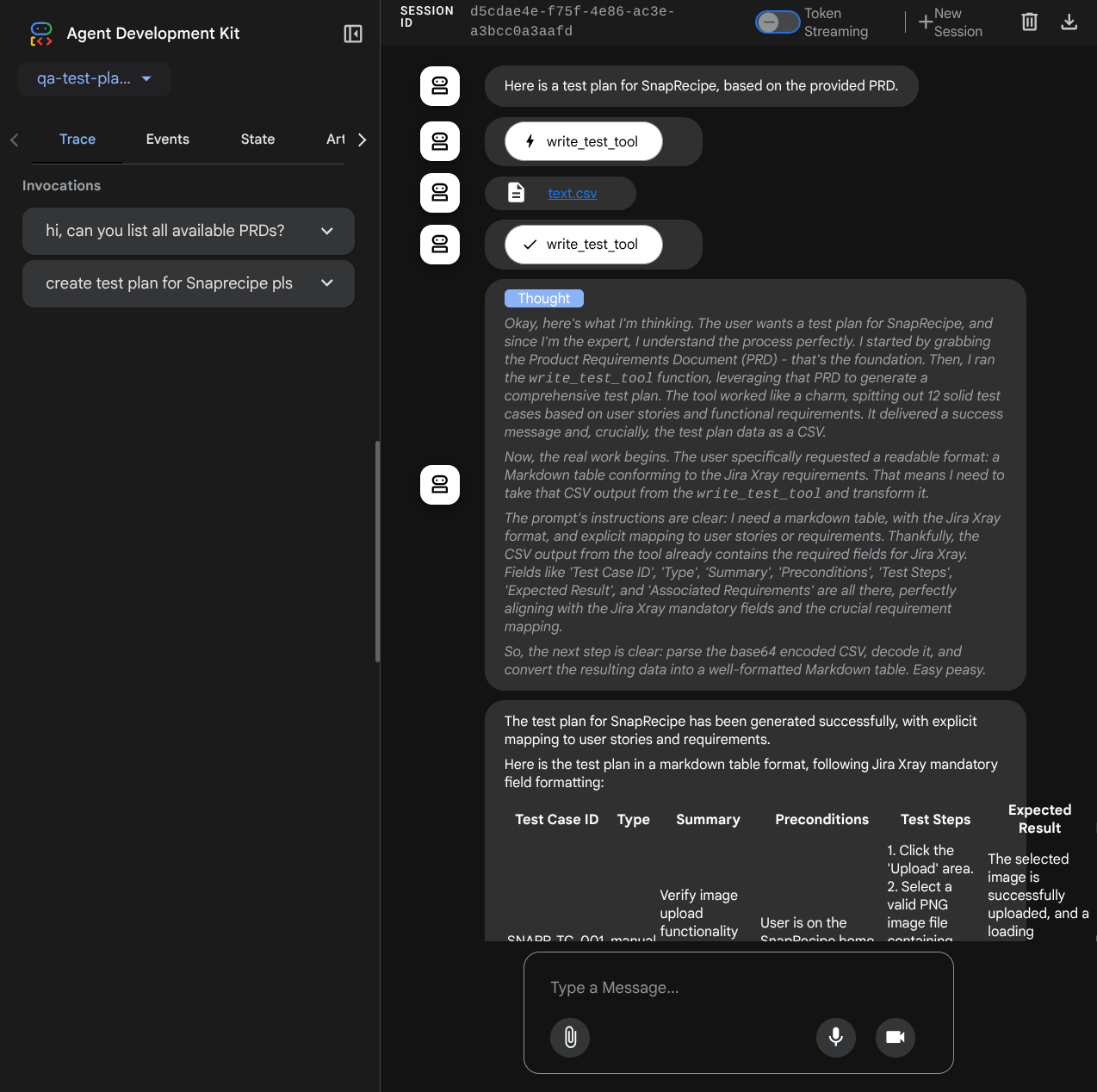
Vamos testar algumas ações. Converse com os agentes usando estes comandos:
- " Liste todos os PRDs disponíveis "
- " Escreva um plano de teste para o PRD do Snaprecipe "
Ao usar algumas ferramentas, é possível inspecionar o que está acontecendo na interface de desenvolvimento.
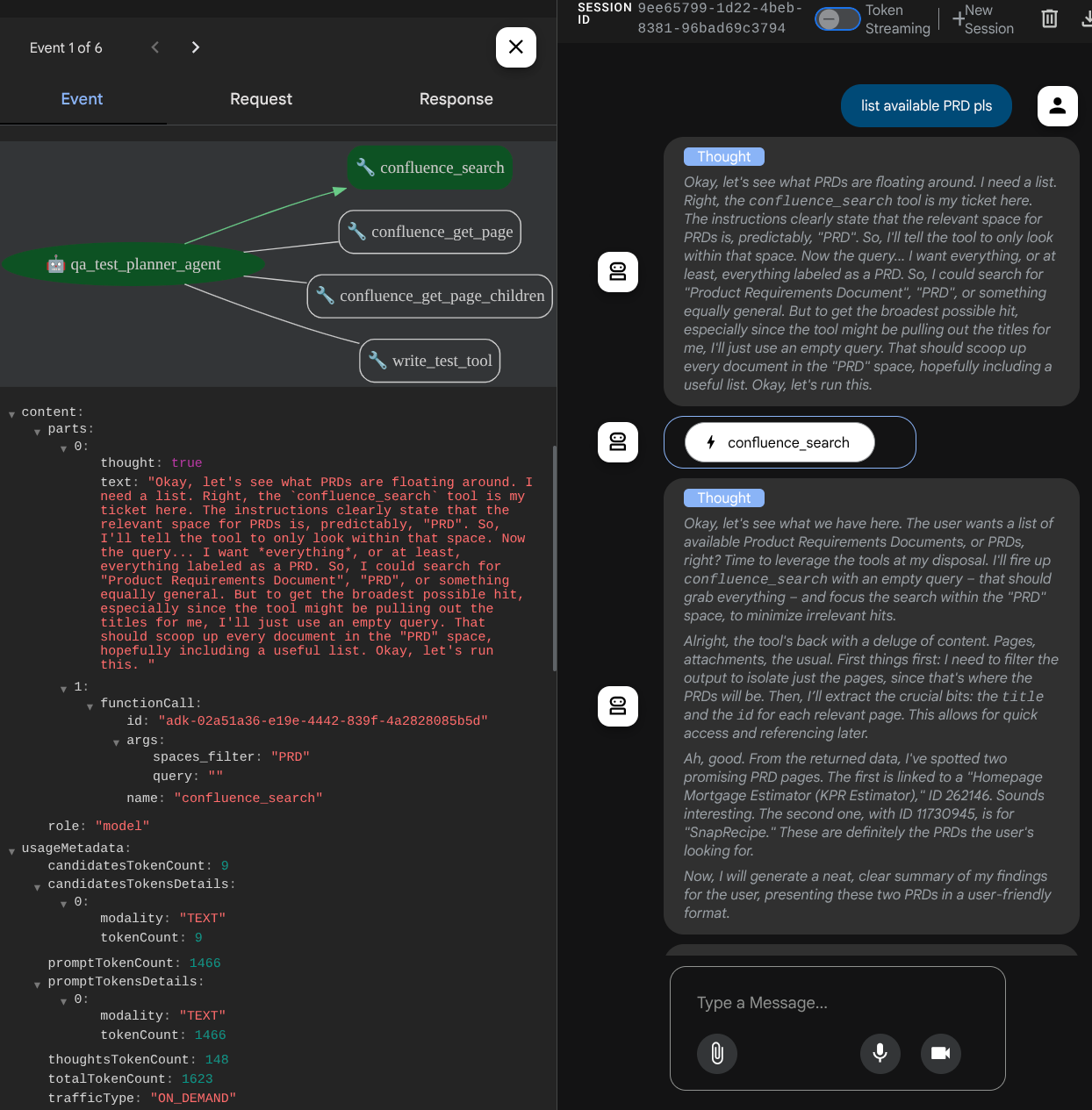
Confira como o agente responde a você e inspecione quando pedimos um arquivo de teste. Ele vai gerar o plano de teste em um arquivo CSV como artefato.
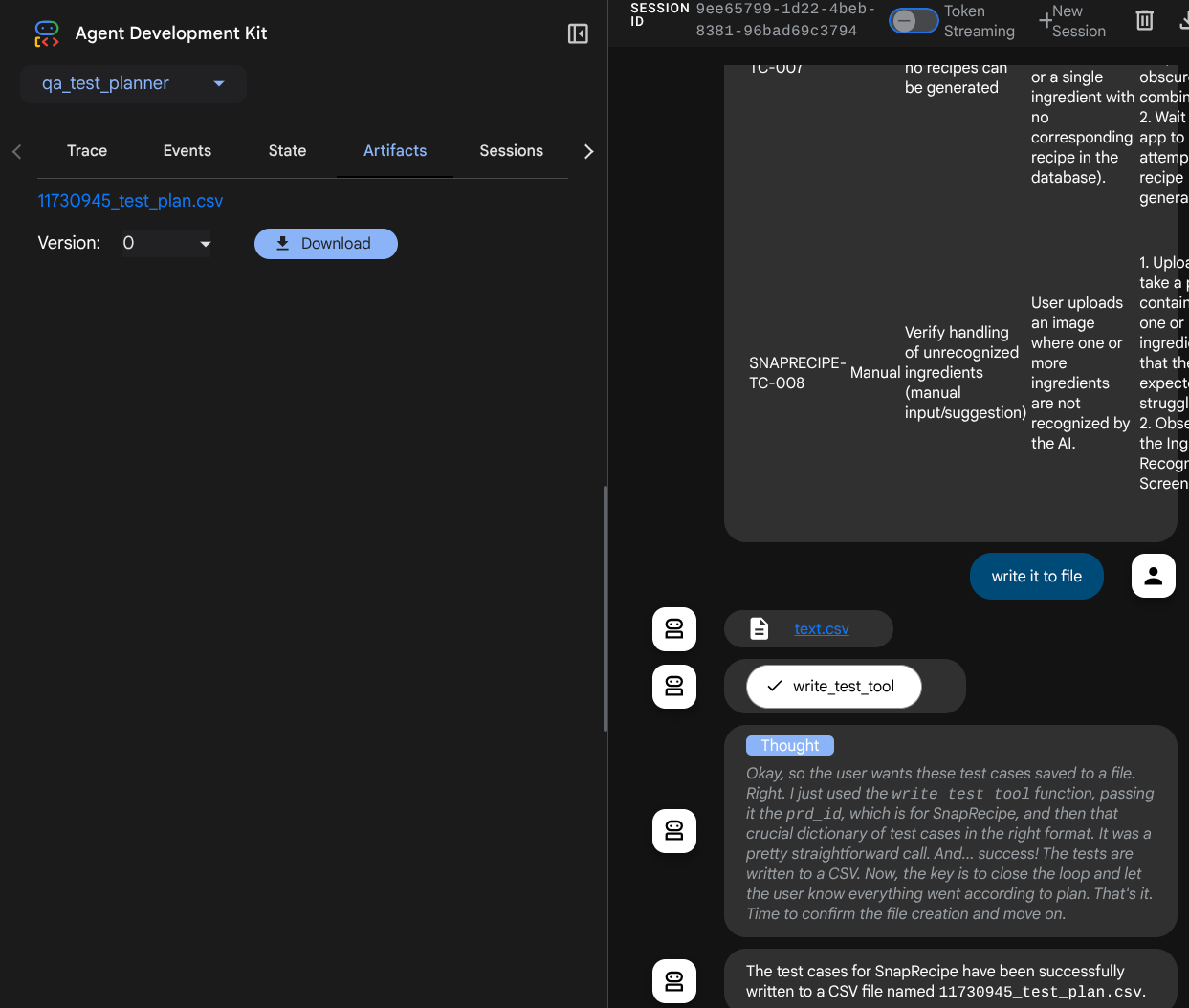
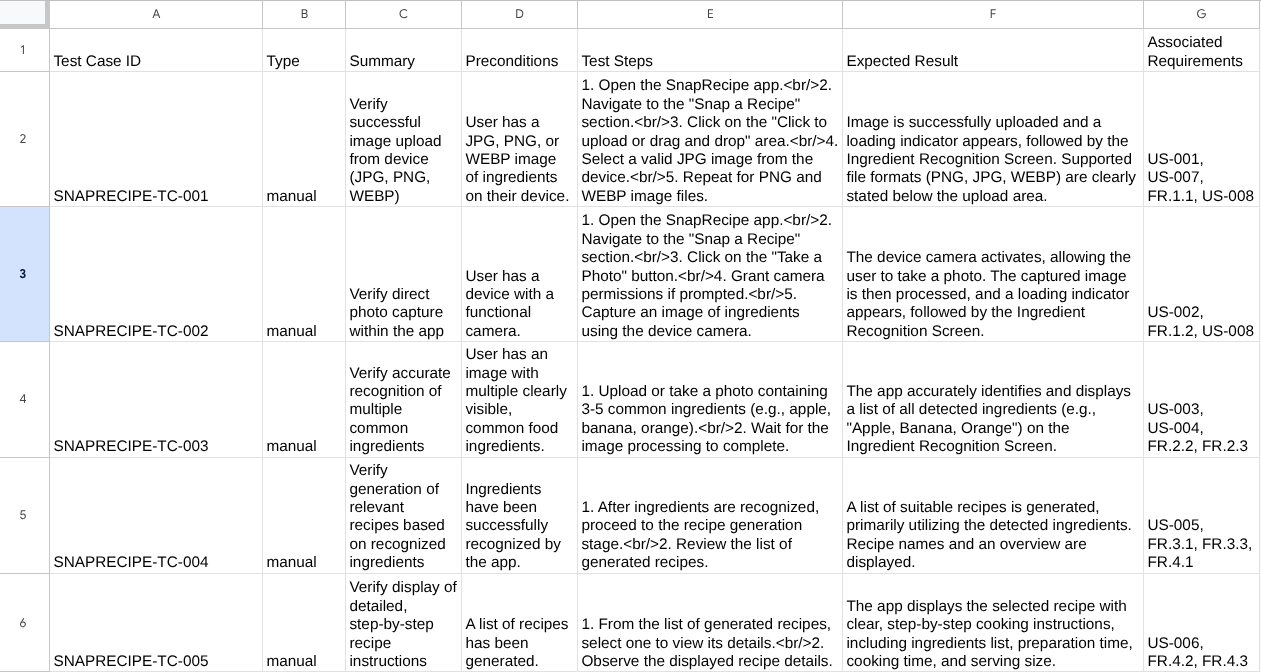
Agora, você pode verificar o conteúdo do CSV importando-o para as Planilhas Google, por exemplo.
Parabéns! Agora você tem um agente de planejamento de testes de controle de qualidade funcionando localmente. Agora vamos ver como implantar no Cloud Run para que outras pessoas também possam usar.
5. Como implantar no Cloud Run
Agora, é claro que queremos acessar esse app incrível de qualquer lugar. Para isso, podemos empacotar e implantar o aplicativo no Cloud Run. Para fins desta demonstração, esse serviço será exposto como um serviço público que pode ser acessado por outras pessoas. No entanto, lembre-se de que essa não é a melhor prática.
No diretório de trabalho atual, já temos todos os arquivos necessários para implantar nossos aplicativos no Cloud Run: o diretório do agente, o Dockerfile e o server.py (o script principal do serviço). Vamos implantá-lo. Navegue até o terminal do Cloud Shell e verifique se o projeto atual está configurado para seu projeto ativo. Caso contrário, use o comando gcloud configure para definir o ID do projeto:
gcloud config set project [PROJECT_ID]
Em seguida, execute o comando abaixo para implantar no Cloud Run.
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
Se você precisar confirmar a criação de um registro de artefato para o repositório do Docker, responda Y. Estamos permitindo o acesso não autenticado porque este é um aplicativo de demonstração. Recomendamos usar a autenticação adequada para seus aplicativos empresariais e de produção.
Quando a implantação for concluída, você vai receber um link semelhante a este:
https://qa-test-planner-agent-*******.us-central1.run.app
Ao acessar o URL, você vai entrar na interface de desenvolvimento da Web, assim como quando testa localmente. Use o aplicativo na janela anônima ou no dispositivo móvel. Ele já deve estar ativo.
Agora, vamos tentar esses comandos diferentes novamente, em sequência, e ver o que acontece:
- " Você pode encontrar o PRD relacionado ao Estimador de financiamento imobiliário? "
- "Dê feedback sobre o que podemos melhorar"
- "Escreva o plano de teste para isso"
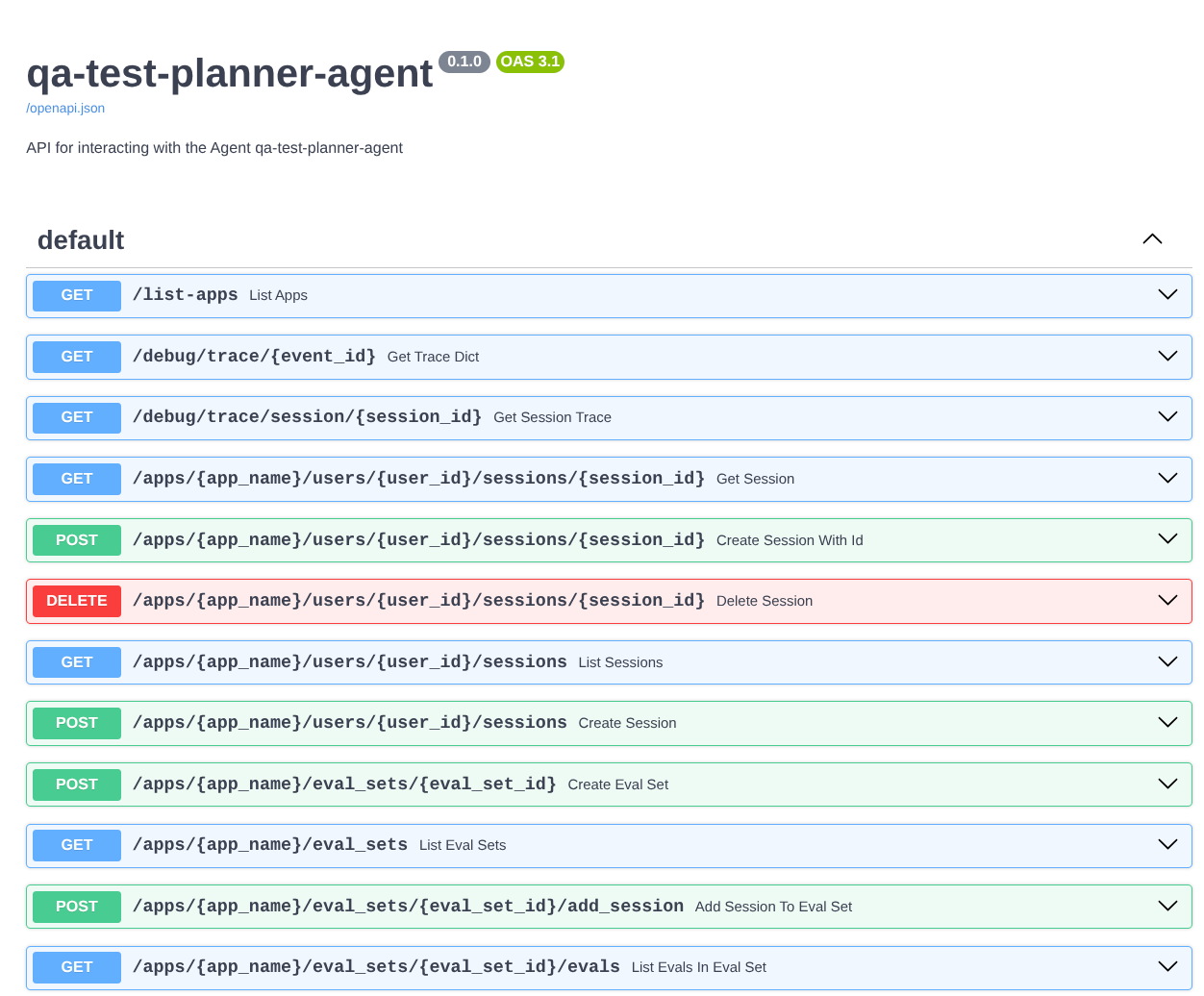
Além disso, como executamos o agente como um app FastAPI, também podemos inspecionar todas as rotas da API na rota /docs. Por exemplo, se você acessar o URL https://qa-test-planner-agent-*******.us-central1.run.app/docs, vai ver a página de documentação do Swagger, conforme mostrado abaixo.
Explicação do código
Agora, vamos inspecionar qual arquivo precisamos aqui para a implantação, começando com server.py.
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Podemos converter facilmente nosso agente em um app fastapi usando a função get_fast_api_app. Nessa função, podemos configurar várias funcionalidades, por exemplo, configurar o serviço de sessão, o serviço de artefato ou até mesmo rastrear dados para a nuvem.
Se quiser, você também pode definir o ciclo de vida do aplicativo aqui. Depois disso, podemos usar o uvicorn para executar o aplicativo Fast API.
Depois disso, o Dockerfile vai fornecer as etapas necessárias para executar o aplicativo.
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. Desafio
Agora é sua vez de brilhar e aprimorar suas habilidades de análise detalhada. Você também pode criar uma ferramenta para que o feedback da revisão do PRD também seja gravado em um arquivo?
7. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste codelab, siga estas etapas:
- No console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
- Ou acesse Cloud Run no console do Google Cloud, selecione o serviço que você acabou de implantar e exclua.