
1. Введение
Потенциал использования генеративного ИИ для создания планов тестирования обусловлен его способностью решать две самые большие проблемы в современном обеспечении качества: скорость и всесторонность. В современных быстрых циклах Agile и DevOps ручное составление подробных планов тестирования является существенным узким местом, замедляющим весь процесс тестирования. Агент, работающий на основе генеративного ИИ, может обрабатывать пользовательские истории и технические требования для создания подробного плана тестирования за считанные минуты, а не дни, обеспечивая соответствие процесса обеспечения качества темпам разработки. Кроме того, ИИ превосходно выявляет сложные сценарии, граничные случаи и негативные пути, которые человек может упустить из виду, что приводит к значительному улучшению тестового покрытия и существенному сокращению количества ошибок, попадающих в производственную среду.
В этом практическом занятии мы рассмотрим, как создать агента, способного получать документы с требованиями к продукту из Confluence, предоставлять конструктивную обратную связь, а также генерировать подробный план тестирования, который можно экспортировать в CSV-файл.
В ходе выполнения практического задания вы будете использовать следующий пошаговый подход:
- Подготовьте свой проект в Google Cloud и включите в него все необходимые API.
- Настройте рабочее пространство для вашей среды программирования.
- Подготовка локального mcp-сервера для Confluence
- Структурирование исходного кода агента ADK, командной строки и инструментов для подключения к серверу MCP.
- Понимание использования контекстов сервисов артефактов и инструментов.
- Тестирование агента с использованием локального пользовательского интерфейса веб-разработки ADK.
- Управление переменными среды и настройка необходимых файлов для развертывания приложения в облаке.
- Разверните приложение в облаке.
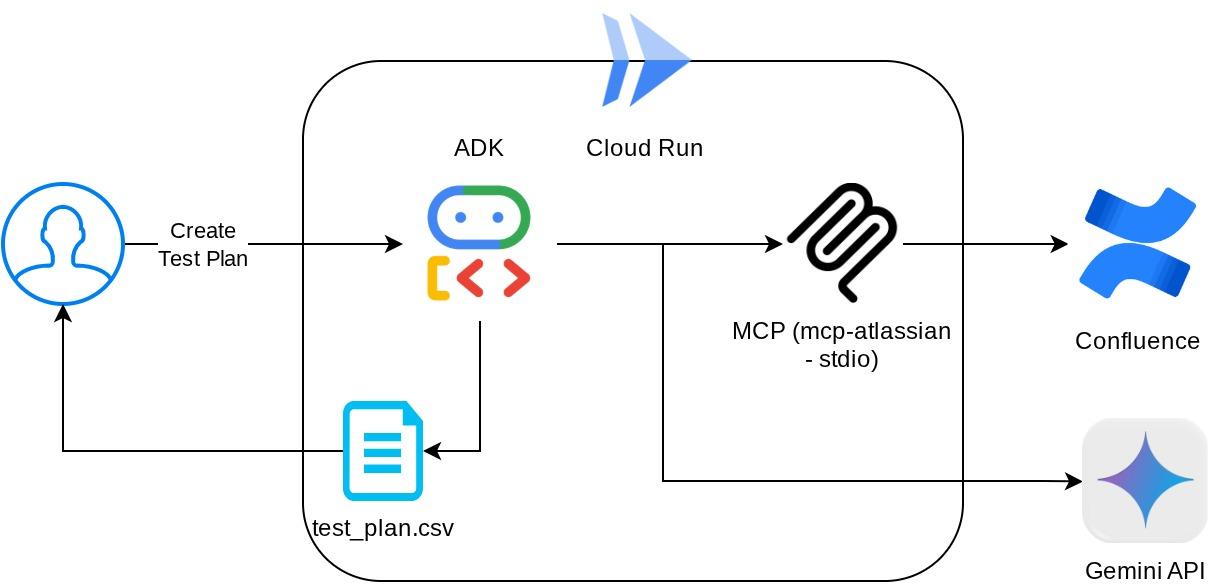
Обзор архитектуры
Предварительные требования
- Уверенно работаю с Python.
- Понимание базовой архитектуры полного стека с использованием HTTP-сервисов.
Что вы узнаете
- Разработка архитектуры агента ADK с использованием его многочисленных возможностей.
- Использование инструментов с пользовательским инструментом и MCP.
- Настройка вывода файлов агентом с использованием управления службой артефактов.
- Использование BuiltInPlanner для повышения эффективности выполнения задач путем планирования с помощью возможностей быстрого мышления Gemini 2.5.
- Взаимодействие и отладка через веб-интерфейс ADK.
- Разверните приложение в Cloud Run с помощью Dockerfile и укажите переменные среды.
Что вам понадобится
- Веб-браузер Chrome
- Аккаунт Gmail
- Облачный проект с включенной функцией выставления счетов.
- (Необязательно) Пространство Confluence со страницей(ами) документов с требованиями к продукту.
Этот практический урок, разработанный для разработчиков всех уровней (включая начинающих), использует Python в своем примере приложения. Однако знание Python не требуется для понимания представленных концепций. Не беспокойтесь, если у вас нет учетной записи в Confluence, мы предоставим вам учетные данные для участия в этом практическом уроке.
2. Прежде чем начать
Выберите активный проект в облачной консоли.
В этом практическом задании предполагается, что у вас уже есть проект Google Cloud с включенной оплатой. Если у вас его еще нет, вы можете следовать инструкциям ниже, чтобы начать работу.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Настройка облачного проекта в терминале Cloud Shell
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.
- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
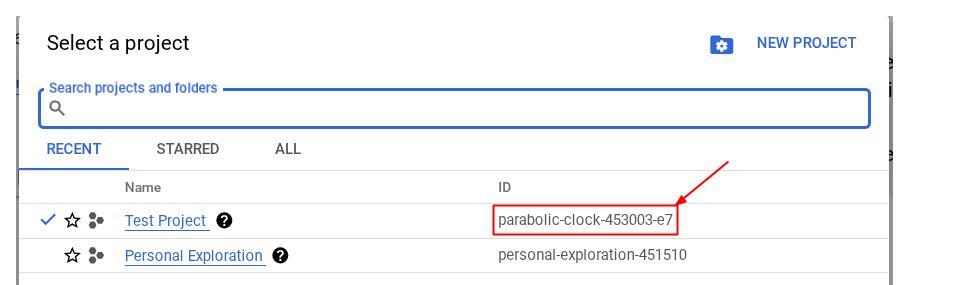
В качестве альтернативы, вы также можете увидеть идентификатор PROJECT_ID в консоли.
Нажмите на него, и справа отобразятся все ваши проекты и их идентификаторы.
- Включите необходимые API с помощью команды, указанной ниже. Это может занять несколько минут, поэтому, пожалуйста, наберитесь терпения.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
После успешного выполнения команды вы должны увидеть сообщение, похожее на показанное ниже:
Operation "operations/..." finished successfully.
Альтернативой команде gcloud является поиск каждого продукта в консоли или использование этой ссылки .
Если какой-либо API отсутствует, вы всегда можете включить его в процессе реализации.
Для получения информации о командах gcloud и их использовании обратитесь к документации .
Перейдите в редактор Cloud Shell и настройте рабочий каталог приложения.
Теперь мы можем настроить наш редактор кода для выполнения некоторых действий по программированию. Для этого мы будем использовать редактор Cloud Shell.
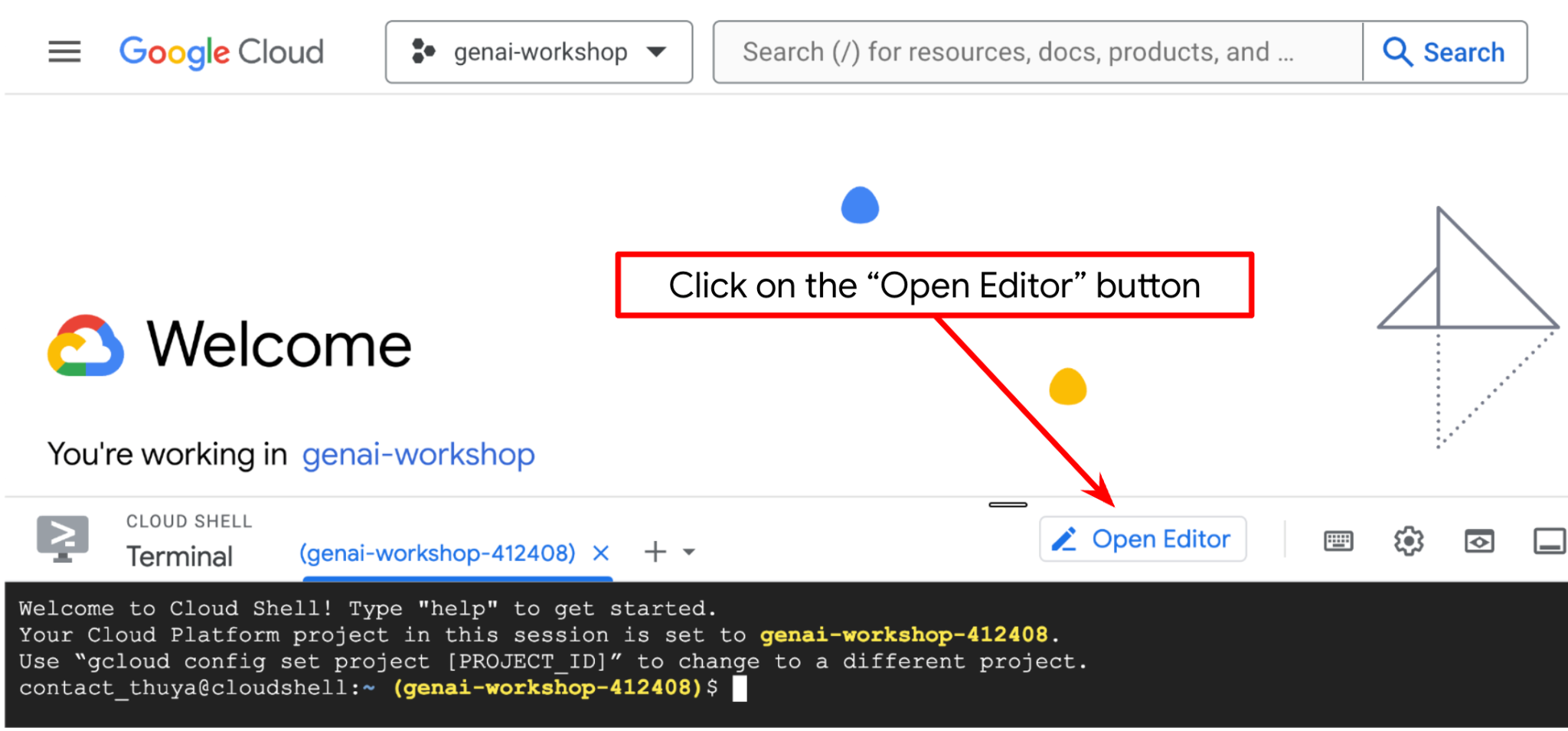
- Нажмите кнопку «Открыть редактор», это откроет редактор Cloud Shell, где мы можем писать свой код.
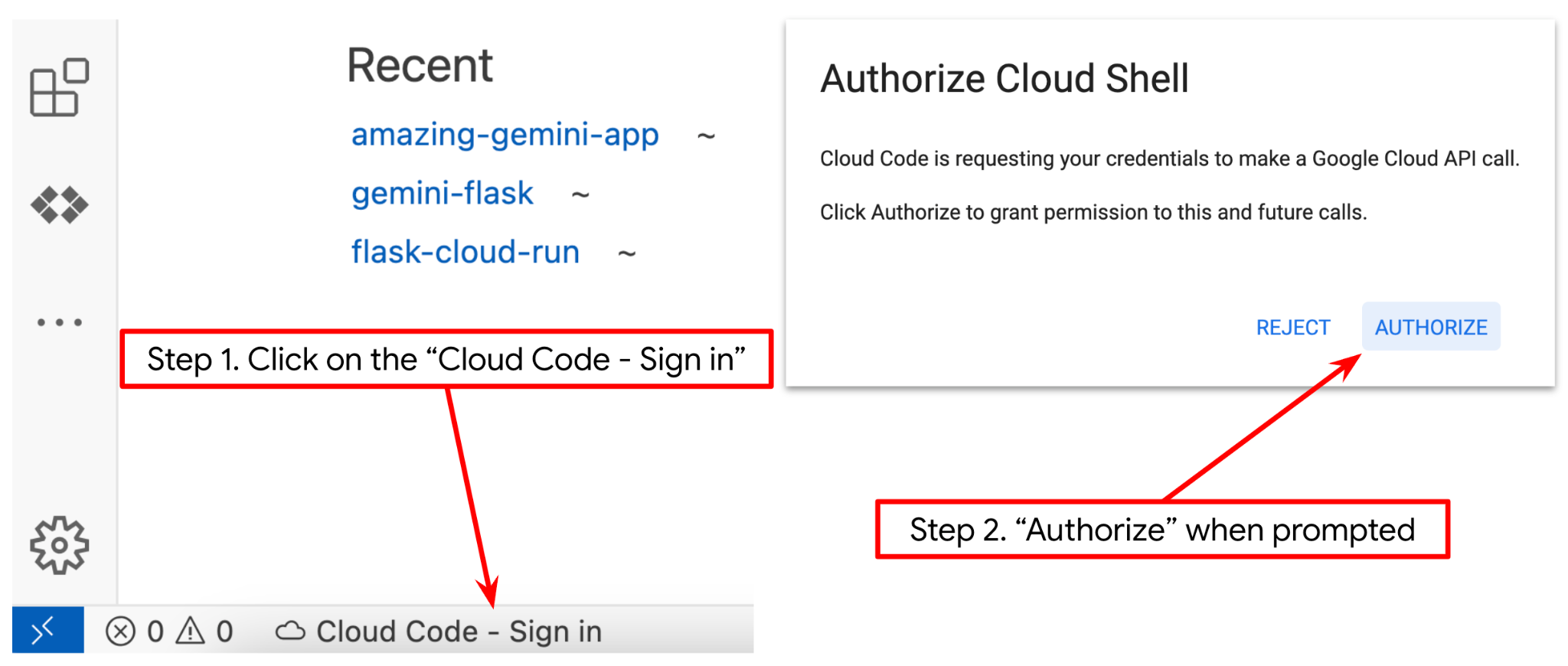
- Убедитесь, что проект Cloud Code указан в левом нижнем углу (строке состояния) редактора Cloud Shell, как показано на изображении ниже, и что он соответствует активному проекту Google Cloud, в котором включена оплата. Авторизуйтесь, если потребуется. Если вы уже выполнили предыдущую команду, кнопка может также указывать непосредственно на ваш активированный проект, а не на кнопку входа в систему.
- Далее, давайте клонируем рабочий каталог шаблона для этого практического задания с Github и выполним следующую команду. Она создаст рабочий каталог в директории qa-test-planner-agent.
git clone https://github.com/alphinside/qa-test-planner-agent.git qa-test-planner-agent
- После этого перейдите в верхнюю часть редактора Cloud Shell и нажмите «Файл» -> «Открыть папку», найдите каталог с вашим именем пользователя и найдите каталог qa-test-planner-agent, затем нажмите кнопку «ОК». Это сделает выбранный каталог основным рабочим каталогом. В этом примере имя пользователя — alvinprayuda , поэтому путь к каталогу показан ниже.
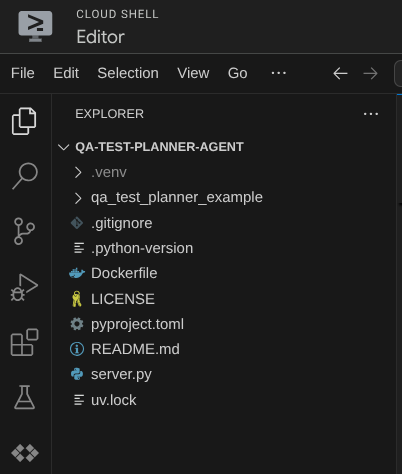
Теперь ваш редактор Cloud Shell должен выглядеть так.
Настройка среды
Подготовка виртуальной среды Python
Следующий шаг — подготовка среды разработки. Ваш текущий активный терминал должен находиться в рабочей директории qa-test-planner-agent . В этом практическом занятии мы будем использовать Python 3.12 и менеджер проектов uv python , чтобы упростить создание и управление версиями Python и виртуальными средами.
- Если вы еще не открыли терминал, откройте его, щелкнув «Терминал» -> «Новый терминал» или используя сочетание клавиш Ctrl + Shift + C — это откроет окно терминала в нижней части браузера.

- Загрузите
uvи установите Python 3.12 с помощью следующей команды.
curl -LsSf https://astral.sh/uv/0.7.19/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- Теперь инициализируем виртуальное окружение с помощью
uv. Выполните эту команду.
uv sync --frozen
Это создаст каталог .venv и установит зависимости. Быстрый просмотр файла pyproject.toml предоставит вам информацию о зависимостях, которая будет выглядеть примерно так.
dependencies = [
"google-adk>=1.5.0",
"mcp-atlassian>=0.11.9",
"pandas>=2.3.0",
"python-dotenv>=1.1.1",
]
- Для тестирования виртуальной среды создайте новый файл main.py и скопируйте в него следующий код.
def main():
print("Hello from qa-test-planner-agent")
if __name__ == "__main__":
main()
- Затем выполните следующую команду.
uv run main.py
В результате вы получите результат, показанный ниже.
Using CPython 3.12 Creating virtual environment at: .venv Hello from qa-test-planner-agent!
Это свидетельствует о том, что проект на Python настроен правильно.
Теперь мы можем перейти к следующему шагу: созданию агента, а затем и сервисов.
3. Создайте агента, используя Google ADK и Gemini 2.5.
Введение в структуру каталогов ADK
Начнём с изучения возможностей ADK и способов создания агента. Полную документацию по ADK можно найти по этому адресу . ADK предлагает множество утилит в рамках выполнения команд CLI. Некоторые из них:
- Настройка структуры каталогов агента
- Быстро попробуйте взаимодействие через ввод/вывод командной строки.
- Быстрая настройка локального веб-интерфейса для разработки.
Теперь давайте создадим структуру каталогов агента с помощью команды CLI. Выполните следующую команду.
uv run adk create qa_test_planner \
--model gemini-2.5-flash \
--project {your-project-id} \
--region global
В результате в текущем рабочем каталоге будет создана следующая структура каталогов агента.
qa_test_planner/ ├── __init__.py ├── .env ├── agent.py
А если вы изучите файлы init.py и agent.py, то увидите следующий код.
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Создание нашего агента планирования тестирования качества
Давайте создадим нашего агента для планирования тестирования! Откройте файл qa_test_planner / agent.py и скопируйте приведенный ниже код, который будет содержать root_agent.
# qa_test_planner/agent.py
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
from google.adk.planners import BuiltInPlanner
from google.genai import types
from dotenv import load_dotenv
import os
from pathlib import Path
from pydantic import BaseModel
from typing import Literal
import tempfile
import pandas as pd
from google.adk.tools import ToolContext
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
class TestPlan(BaseModel):
test_case_key: str
test_type: Literal["manual", "automatic"]
summary: str
preconditions: str
test_steps: str
expected_result: str
associated_requirements: str
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
description="You are an expert QA Test Planner and Product Manager assistant",
instruction=f"""
Help user search any product requirement documents on Confluence. Furthermore you also can provide the following capabilities when asked:
- evaluate product requirement documents and assess it, then give expert input on what can be improved
- create a comprehensive test plan following Jira Xray mandatory field formatting, result showed as markdown table. Each test plan must also have explicit mapping on
which user stories or requirements identifier it's associated to
Here is the Confluence space ID with it's respective document grouping:
- "{os.getenv("CONFLUENCE_PRD_SPACE_ID")}" : space to store Product Requirements Documents
Do not making things up, Always stick to the fact based on data you retrieve via tools.
""",
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
)
Настройка конфигурационных файлов
Теперь нам потребуется добавить дополнительные параметры конфигурации для этого проекта, поскольку этому агенту потребуется доступ к Confluence.
Откройте файл qa_test_planner/.env и вставьте в него следующие значения переменных окружения. Убедитесь, что полученный файл .env выглядит следующим образом.
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT={YOUR-CLOUD-PROJECT-ID}
GOOGLE_CLOUD_LOCATION=global
CONFLUENCE_URL={YOUR-CONFLUENCE-DOMAIN}
CONFLUENCE_USERNAME={YOUR-CONFLUENCE-USERNAME}
CONFLUENCE_TOKEN={YOUR-CONFLUENCE-API-TOKEN}
CONFLUENCE_PRD_SPACE_ID={YOUR-CONFLUENCE-SPACE-ID}
К сожалению, это пространство Confluence не может быть общедоступным, поэтому вы можете просмотреть эти файлы, чтобы ознакомиться с доступными документами с требованиями к продукту, которые будут доступны с использованием указанных выше учетных данных.
Пояснение к коду
Этот скрипт содержит инициализацию нашего агента, в ходе которой мы выполняем следующие действия:
- Установите модель для использования:
gemini-2.5-flash - Настройте инструменты Confluence MCP, которые будут взаимодействовать через Stdio.
- Настройте пользовательский инструмент
write_test_toolдля записи плана тестирования и сохранения его в формате CSV в артефакт. - Настройте описание и инструкции для агента.
- Используйте возможности экспресс-анализа Gemini 2.5, чтобы обеспечить планирование перед формированием окончательного ответа или его выполнением.
Сам агент, работающий на основе модели Gemini со встроенными аналитическими способностями и настроенный с использованием аргументов планировщика, может демонстрировать свои аналитические способности, которые также отображаются в веб-интерфейсе. Код для настройки показан ниже.
# qa-test-planner/agent.py
from google.adk.planners import BuiltInPlanner
from google.genai import types
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
include_thoughts=True,
thinking_budget=2048,
)
),
...
А перед принятием решения мы можем увидеть ход мыслительных процессов.
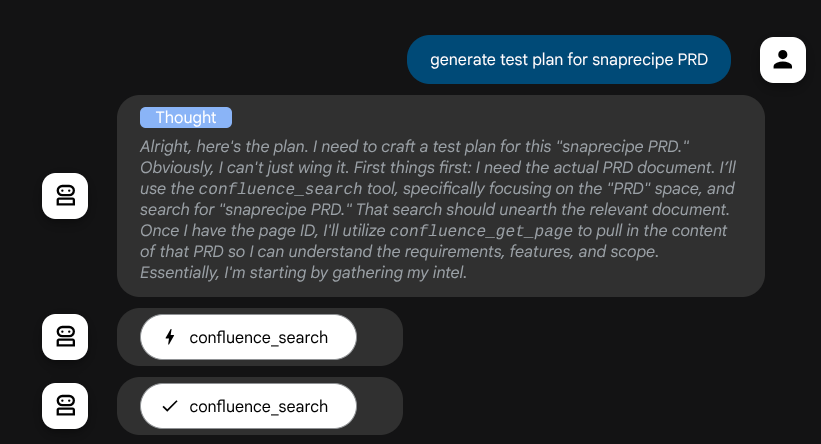
Инструмент Confluence MCP
Для подключения к MCP-серверу из ADK необходимо использовать MCPToolSet , который можно импортировать из модуля google.adk.tools.mcp_tool.mcp_toolset . Код инициализации показан ниже (сокращен для эффективности).
# qa-test-planner/agent.py
from google.adk.tools.mcp_tool.mcp_toolset import (
MCPToolset,
StdioConnectionParams,
StdioServerParameters,
)
...
# Initialize the Confluence MCP Tool via Stdio Output
confluence_tool = MCPToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=[
"mcp-atlassian",
f"--confluence-url={os.getenv('CONFLUENCE_URL')}",
f"--confluence-username={os.getenv('CONFLUENCE_USERNAME')}",
f"--confluence-token={os.getenv('CONFLUENCE_TOKEN')}",
"--enabled-tools=confluence_search,confluence_get_page,confluence_get_page_children",
],
env={},
),
timeout=60,
),
)
...
# Provide the confluence tool to agent
root_agent = Agent(
model="gemini-2.5-flash",
name="qa_test_planner_agent",
...,
tools=[confluence_tool, write_test_tool],
...
При такой конфигурации агент инициализирует сервер Confluence MCP как отдельный процесс и будет обрабатывать взаимодействие с этими процессами через интерфейс ввода-вывода Studio. Этот процесс показан на изображении архитектуры MCP, отмеченном красным прямоугольником ниже.
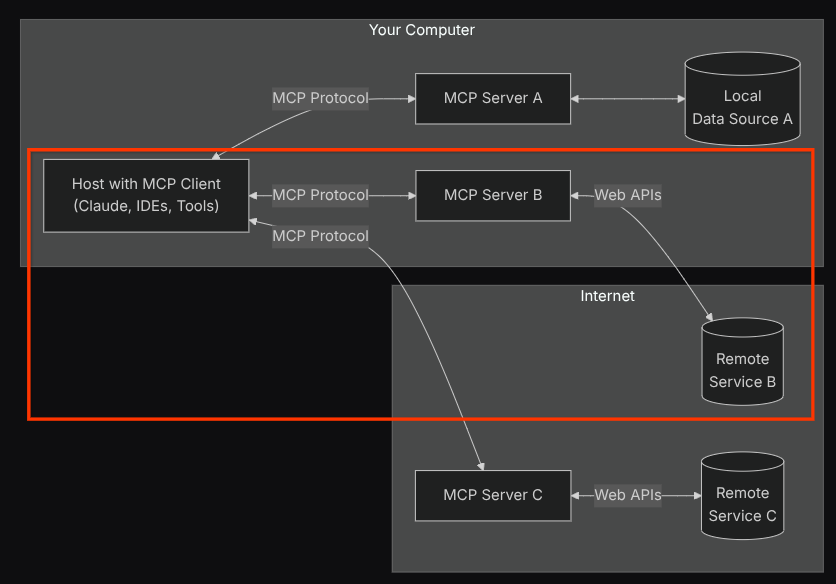
Кроме того, в аргументах команды инициализации MCP мы также ограничиваем список используемых инструментов только следующими: confluence_search, confluence_get_page и confluence_get_page_children , которые поддерживают сценарии использования нашего агента тестирования QA. Для этого практического занятия мы используем сервер Atlassian MCP, разработанный сообществом (подробнее см. в полной документации ).
Инструмент для написания тестов
После получения контекста от инструмента Confluence MCP, агент может составить необходимый план тестирования для пользователя. Однако мы хотим создать файл, содержащий этот план тестирования, чтобы его можно было сохранить и передать другому пользователю. Для этого мы предлагаем пользовательский инструмент write_test_tool описанный ниже.
# qa-test-planner/agent.py
...
async def write_test_tool(
prd_id: str, test_cases: list[dict], tool_context: ToolContext
):
"""A tool to write the test plan into file
Args:
prd_id: Product requirement document ID
test_cases: List of test case dictionaries that should conform to these fields:
- test_case_key: str
- test_type: Literal["manual","automatic"]
- summary: str
- preconditions: str
- test_steps: str
- expected_result: str
- associated_requirements: str
Returns:
A message indicating success or failure of the validation and writing process
"""
validated_test_cases = []
validation_errors = []
# Validate each test case
for i, test_case in enumerate(test_cases):
try:
validated_test_case = TestPlan(**test_case)
validated_test_cases.append(validated_test_case)
except Exception as e:
validation_errors.append(f"Error in test case {i + 1}: {str(e)}")
# If validation errors exist, return error message
if validation_errors:
return {
"status": "error",
"message": "Validation failed",
"errors": validation_errors,
}
# Write validated test cases to CSV
try:
# Convert validated test cases to a pandas DataFrame
data = []
for tc in validated_test_cases:
data.append(
{
"Test Case ID": tc.test_case_key,
"Type": tc.test_type,
"Summary": tc.summary,
"Preconditions": tc.preconditions,
"Test Steps": tc.test_steps,
"Expected Result": tc.expected_result,
"Associated Requirements": tc.associated_requirements,
}
)
# Create DataFrame from the test case data
df = pd.DataFrame(data)
if not df.empty:
# Create a temporary file with .csv extension
with tempfile.NamedTemporaryFile(suffix=".csv", delete=False) as temp_file:
# Write DataFrame to the temporary CSV file
df.to_csv(temp_file.name, index=False)
temp_file_path = temp_file.name
# Read the file bytes from the temporary file
with open(temp_file_path, "rb") as f:
file_bytes = f.read()
# Create an artifact with the file bytes
await tool_context.save_artifact(
filename=f"{prd_id}_test_plan.csv",
artifact=types.Part.from_bytes(data=file_bytes, mime_type="text/csv"),
)
# Clean up the temporary file
os.unlink(temp_file_path)
return {
"status": "success",
"message": (
f"Successfully wrote {len(validated_test_cases)} test cases to "
f"CSV file: {prd_id}_test_plan.csv"
),
}
else:
return {"status": "warning", "message": "No test cases to write"}
except Exception as e:
return {
"status": "error",
"message": f"An error occurred while writing to CSV: {str(e)}",
}
...
Вышеуказанная функция предназначена для поддержки следующих возможностей:
- Проверьте составленный план тестирования на соответствие обязательным полям, используя модель Pydantic, и в случае возникновения ошибки отправьте сообщение об ошибке обратно агенту.
- Выведите результат в CSV-файл, используя функциональность pandas.
- Сгенерированный файл затем сохраняется как артефакт с использованием возможностей службы артефактов, доступ к которой осуществляется через объект ToolContext, доступный при каждом вызове инструмента.
Если мы сохраним сгенерированные файлы как артефакты, они будут помечены как событие в среде выполнения ADK и смогут отображаться в дальнейшем при взаимодействии с агентом через веб-интерфейс.
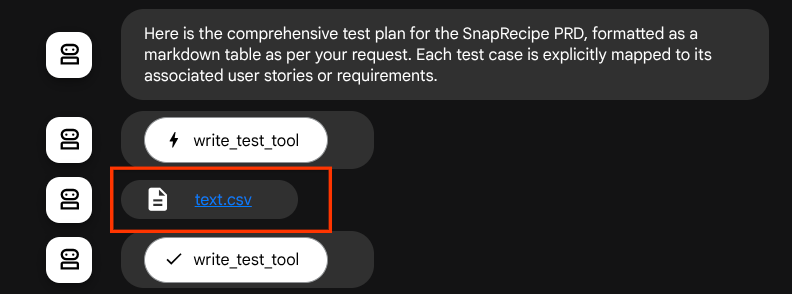
Благодаря этому мы можем динамически настраивать файл-ответ от агента, который будет отправлен пользователю.
4. Тестирование агента
Теперь попробуем связаться с агентом через командную строку, выполнив следующую команду.
uv run adk run qa_test_planner
В результате вы увидите примерно такой вывод, где сможете общаться с агентом в чате, однако отправлять текст через этот интерфейс можно только в текстовом формате.
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent qa_test_planner_agent, type exit to exit. user: hello [qa_test_planner_agent]: Hello there! How can I help you today? user:
Приятно иметь возможность общаться с агентом через командную строку. Но еще лучше, если у нас будет удобный веб-чат, и это тоже возможно! ADK также позволяет нам использовать пользовательский интерфейс для разработки, чтобы взаимодействовать и отслеживать происходящее во время общения. Выполните следующую команду, чтобы запустить локальный сервер пользовательского интерфейса для разработки.
uv run adk web --port 8080
Результат будет выглядеть примерно так, как в следующем примере, это означает, что мы уже можем получить доступ к веб-интерфейсу.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
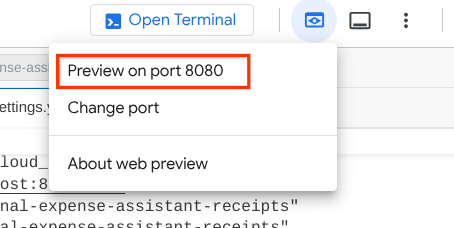
Чтобы проверить это, нажмите кнопку « Предварительный просмотр веб-страниц» в верхней части редактора Cloud Shell и выберите «Предварительный просмотр на порту 8080».
Вы увидите следующую веб-страницу, где в верхнем левом углу в выпадающем списке (в нашем случае это должен быть qa_test_planner ) можно выбрать доступных агентов и взаимодействовать с ботом. В левом окне вы увидите подробную информацию о логах во время работы агента.
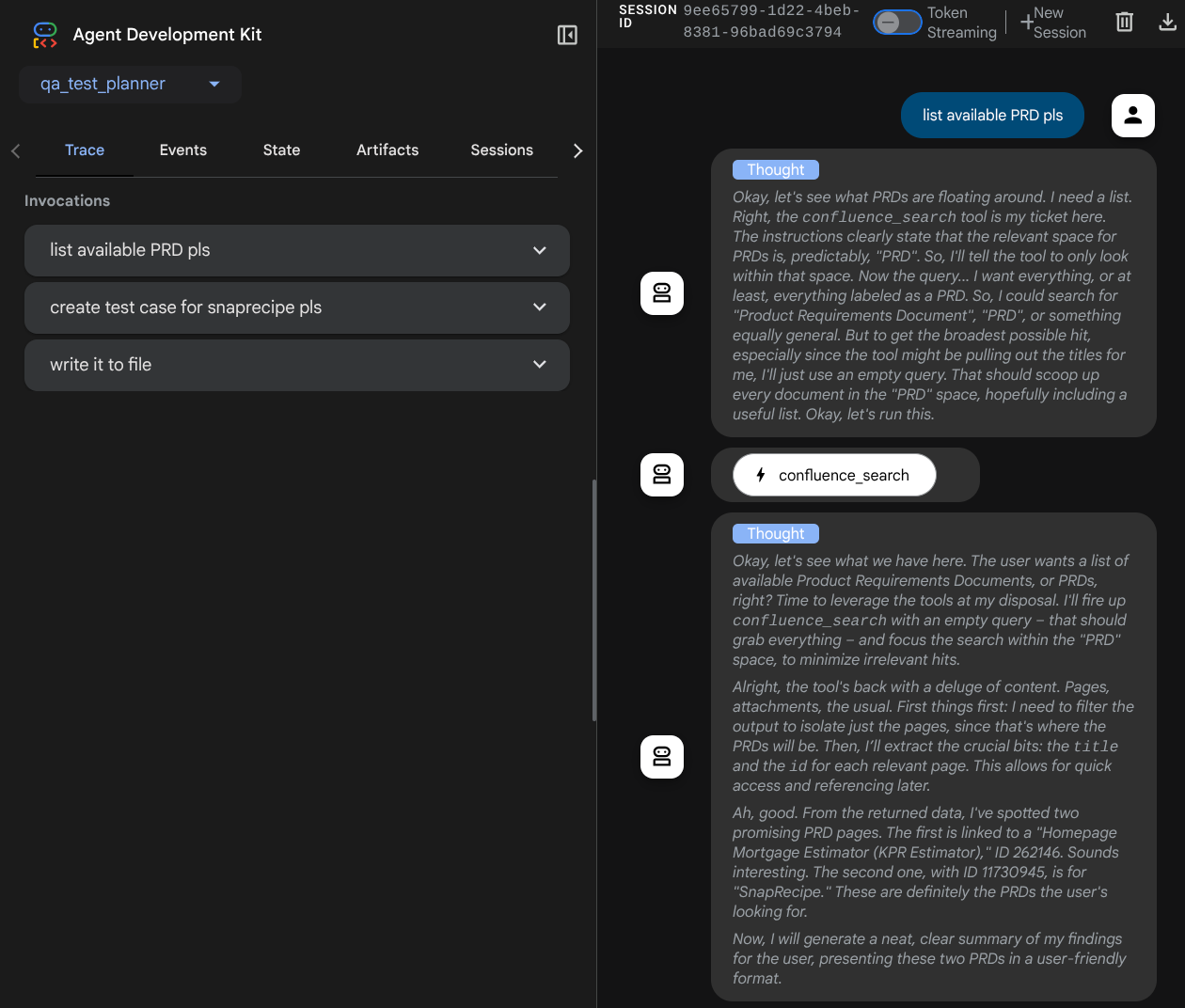
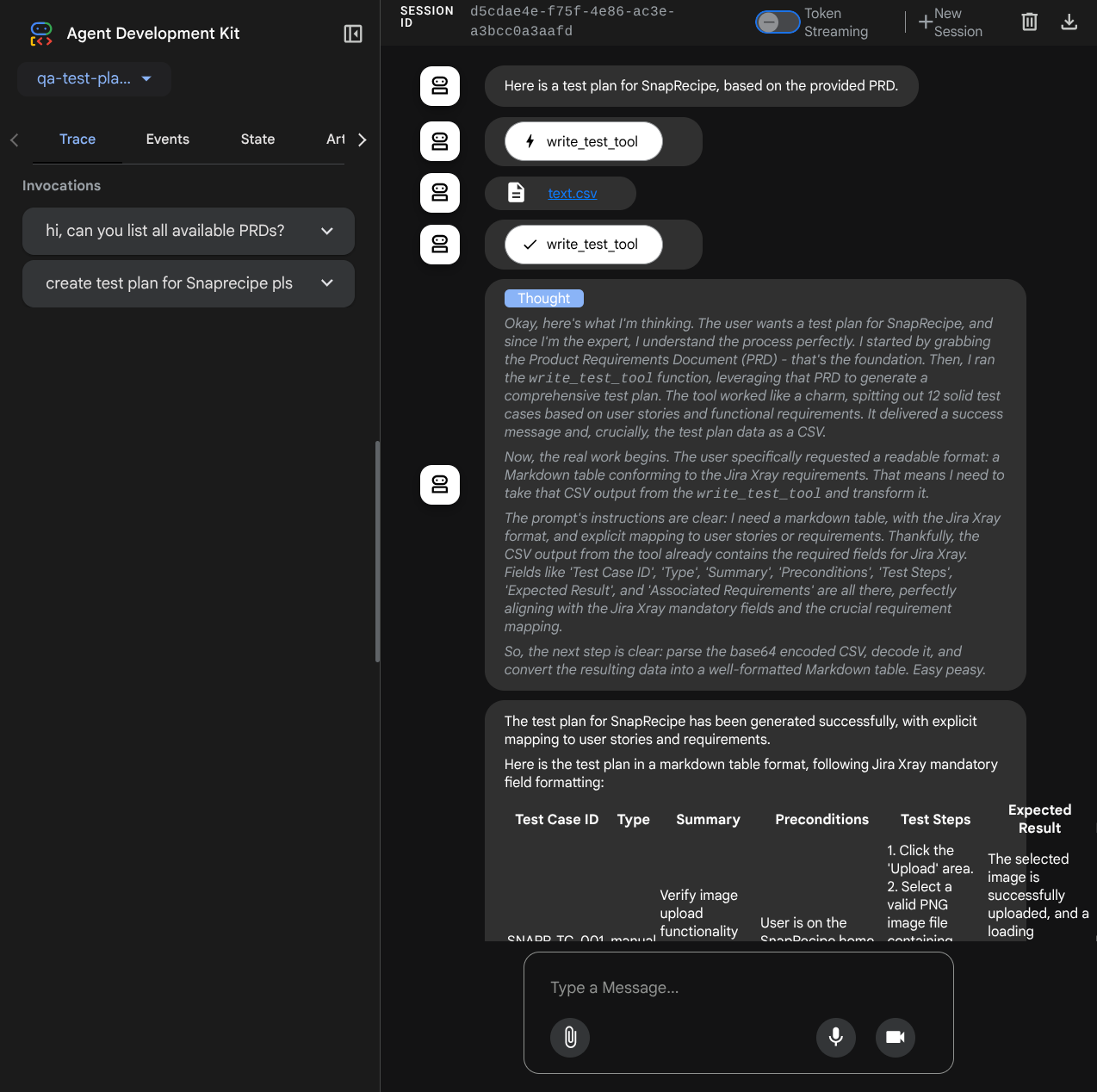
Давайте попробуем выполнить несколько действий! Пообщайтесь с агентами, используя следующие подсказки:
- "Пожалуйста, перечислите все доступные PRD."
- "Напишите план тестирования для Snaprecipes PRD"
При использовании некоторых инструментов можно проверить, что происходит в пользовательском интерфейсе разработчика.
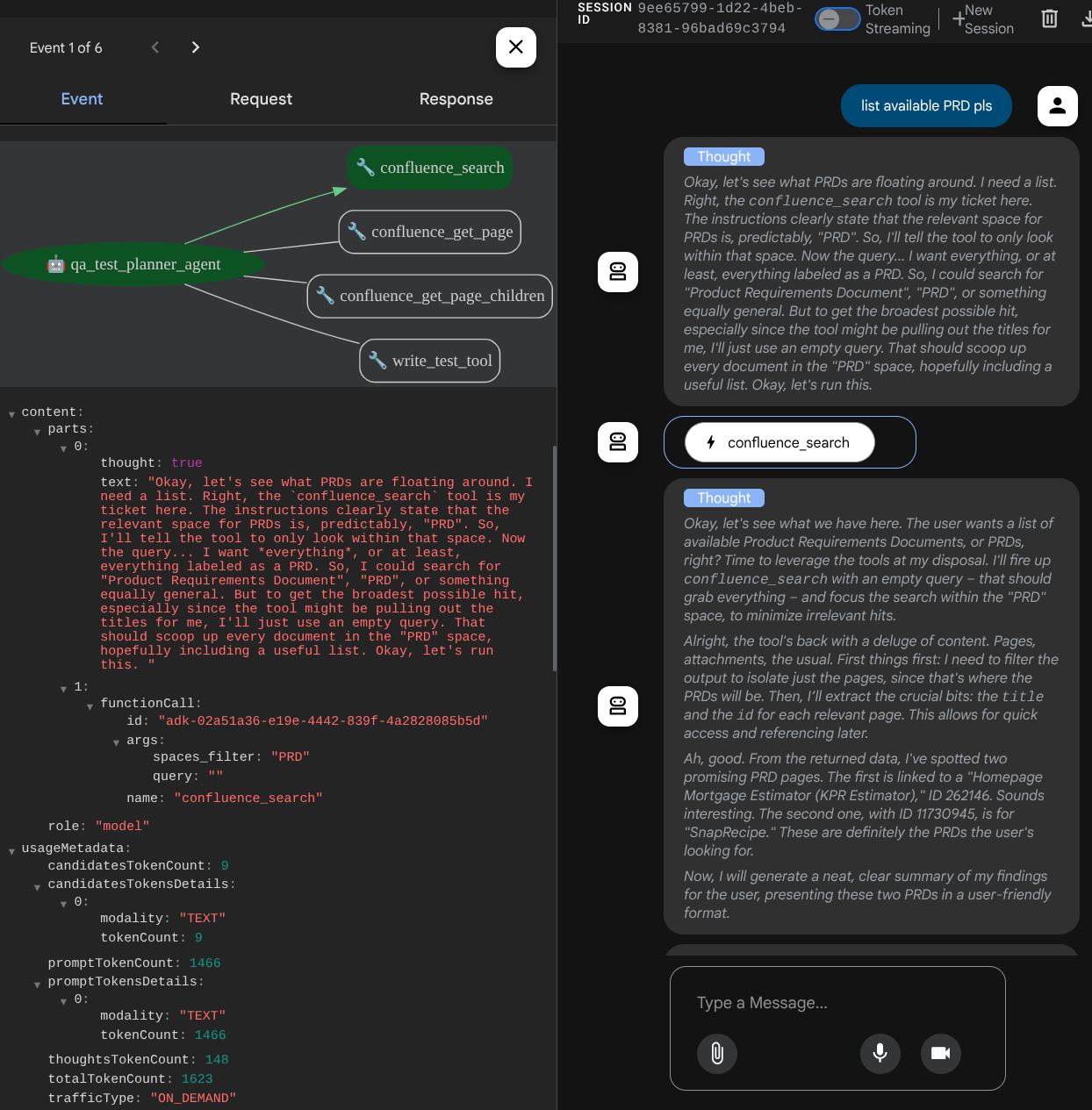
Посмотрите, как агент отвечает вам, а также проверьте, когда мы запрашиваем тестовый файл, генерируется план тестирования в формате CSV в качестве артефакта.
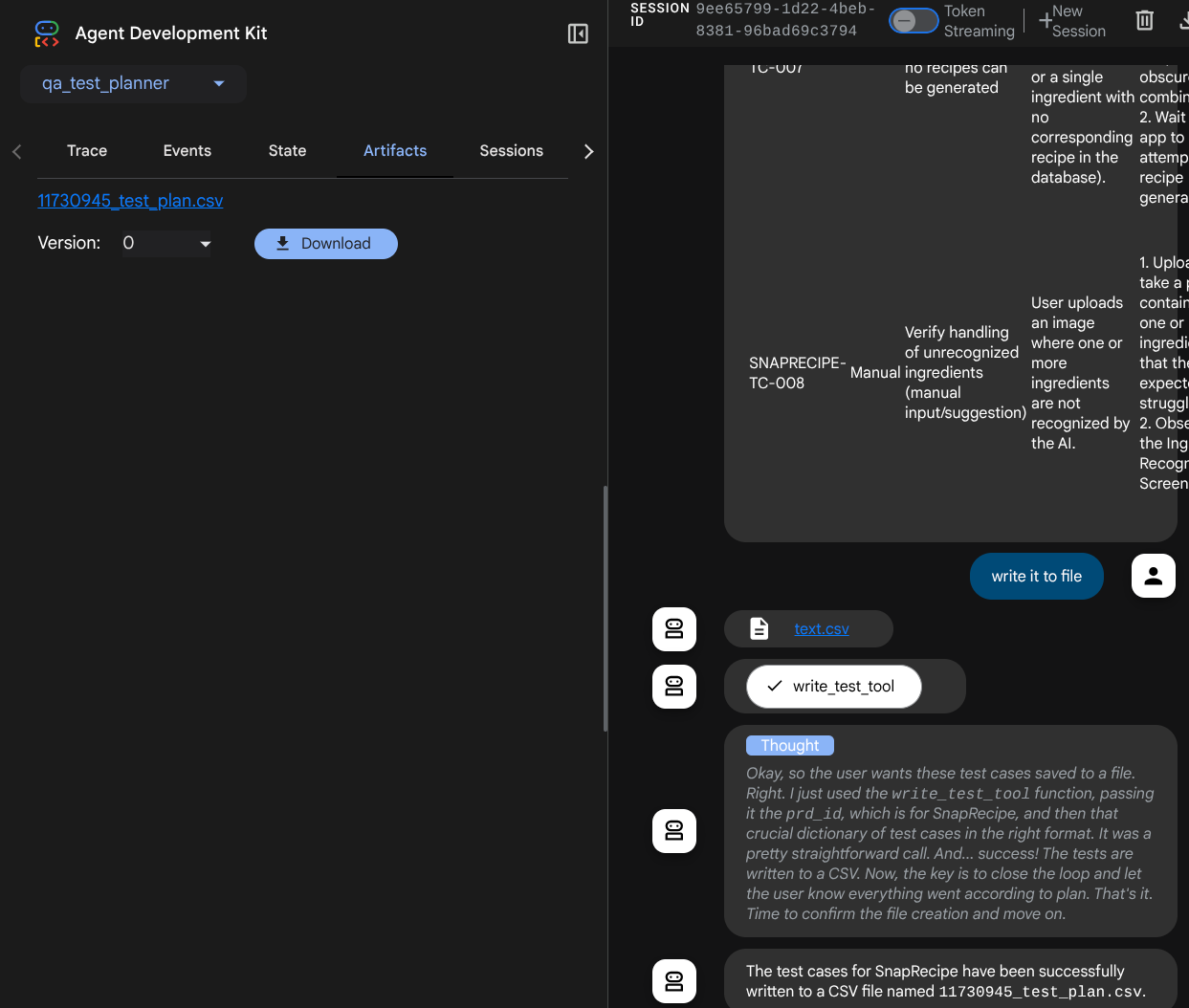
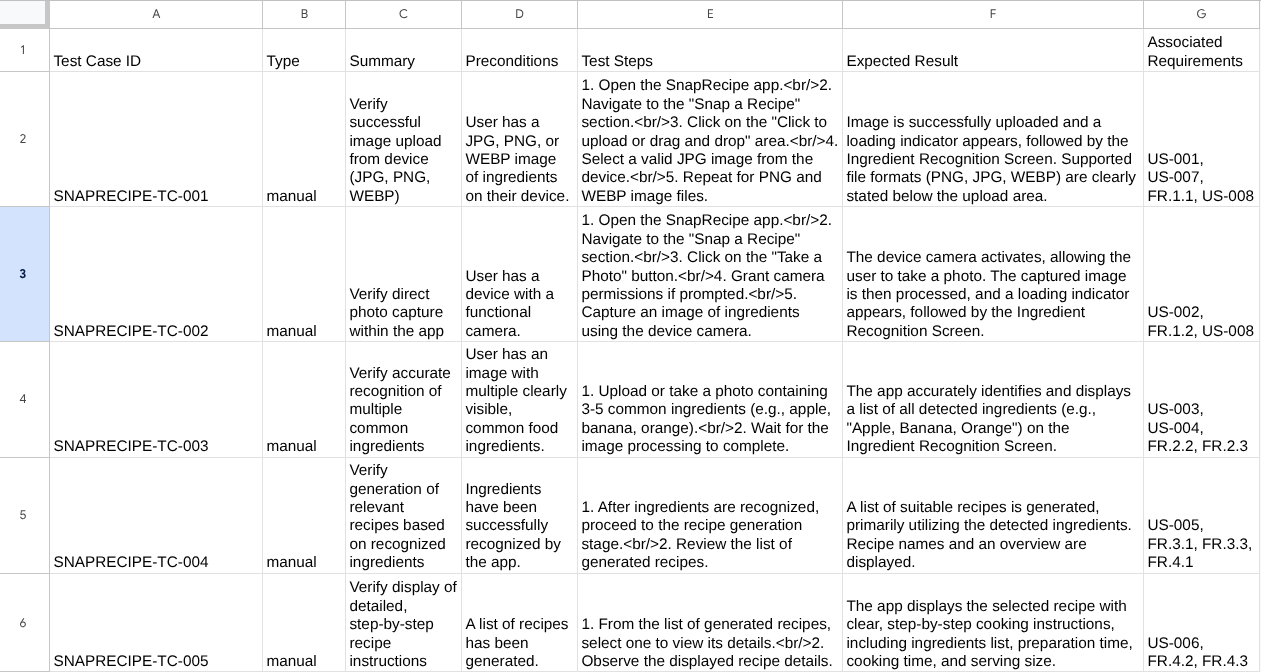
Теперь вы можете проверить содержимое CSV-файла, импортировав его, например, в Google Таблицы.
Поздравляем! Теперь у вас есть работающий локально агент QA Test Planner! Давайте посмотрим, как развернуть его в Cloud Run, чтобы им могли пользоваться и другие пользователи!
5. Развертывание в Cloud Run
Конечно, теперь нам нужно иметь доступ к этому замечательному приложению из любой точки мира. Для этого мы можем упаковать это приложение и развернуть его в Cloud Run. В рамках этой демонстрации данный сервис будет предоставлен как общедоступный сервис, к которому смогут получить доступ другие пользователи. Однако имейте в виду, что это не самая лучшая практика!
В текущей рабочей директории у нас уже есть все необходимые файлы для развертывания наших приложений в Cloud Run — директория агента, Dockerfile и server.py (основной скрипт сервиса) , давайте развернем их. Перейдите в терминал Cloud Shell и убедитесь, что текущий проект настроен на ваш активный проект. Если нет, используйте команду gcloud configure для установки идентификатора проекта:
gcloud config set project [PROJECT_ID]
Затем выполните следующую команду, чтобы развернуть его в Cloud Run.
gcloud run deploy qa-test-planner-agent \
--source . \
--port 8080 \
--project {YOUR_PROJECT_ID} \
--allow-unauthenticated \
--region us-central1 \
--update-env-vars GOOGLE_GENAI_USE_VERTEXAI=1 \
--update-env-vars GOOGLE_CLOUD_PROJECT={YOUR_PROJECT_ID} \
--update-env-vars GOOGLE_CLOUD_LOCATION=global \
--update-env-vars CONFLUENCE_URL={YOUR_CONFLUENCE_URL} \
--update-env-vars CONFLUENCE_USERNAME={YOUR_CONFLUENCE_USERNAME} \
--update-env-vars CONFLUENCE_TOKEN={YOUR_CONFLUENCE_TOKEN} \
--update-env-vars CONFLUENCE_PRD_SPACE_ID={YOUR_PRD_SPACE_ID} \
--memory 1G
Если появится запрос на подтверждение создания реестра артефактов для репозитория Docker, просто ответьте «Да». Обратите внимание, что мы разрешаем неаутентифицированный доступ, поскольку это демонстрационное приложение. Рекомендуется использовать соответствующую аутентификацию для ваших корпоративных и производственных приложений.
После завершения развертывания вы должны получить ссылку, похожую на приведенную ниже:
https://qa-test-planner-agent-*******.us-central1.run.app
При переходе по URL-адресу вы попадете в пользовательский интерфейс веб-разработчика, аналогичный тому, что вы используете локально. Смело используйте свое приложение в режиме инкогнито или на мобильном устройстве. Оно уже должно быть запущено.
Теперь давайте попробуем еще раз эти разные подсказки — последовательно, посмотрим, что произойдет:
- "Можно ли найти PRD, связанный с калькулятором ипотеки?"
- «Пожалуйста, дайте мне знать, что мы можем улучшить в этом плане».
- "Напишите для этого план тестирования"
Кроме того, поскольку мы запускаем агент как приложение FastAPI, мы также можем проверить все маршруты API в маршруте /docs . Например, если вы перейдете по URL-адресу следующим образом : https://qa-test-planner-agent-*******.us-central1.run.app/docs, вы увидите страницу документации Swagger, как показано ниже.
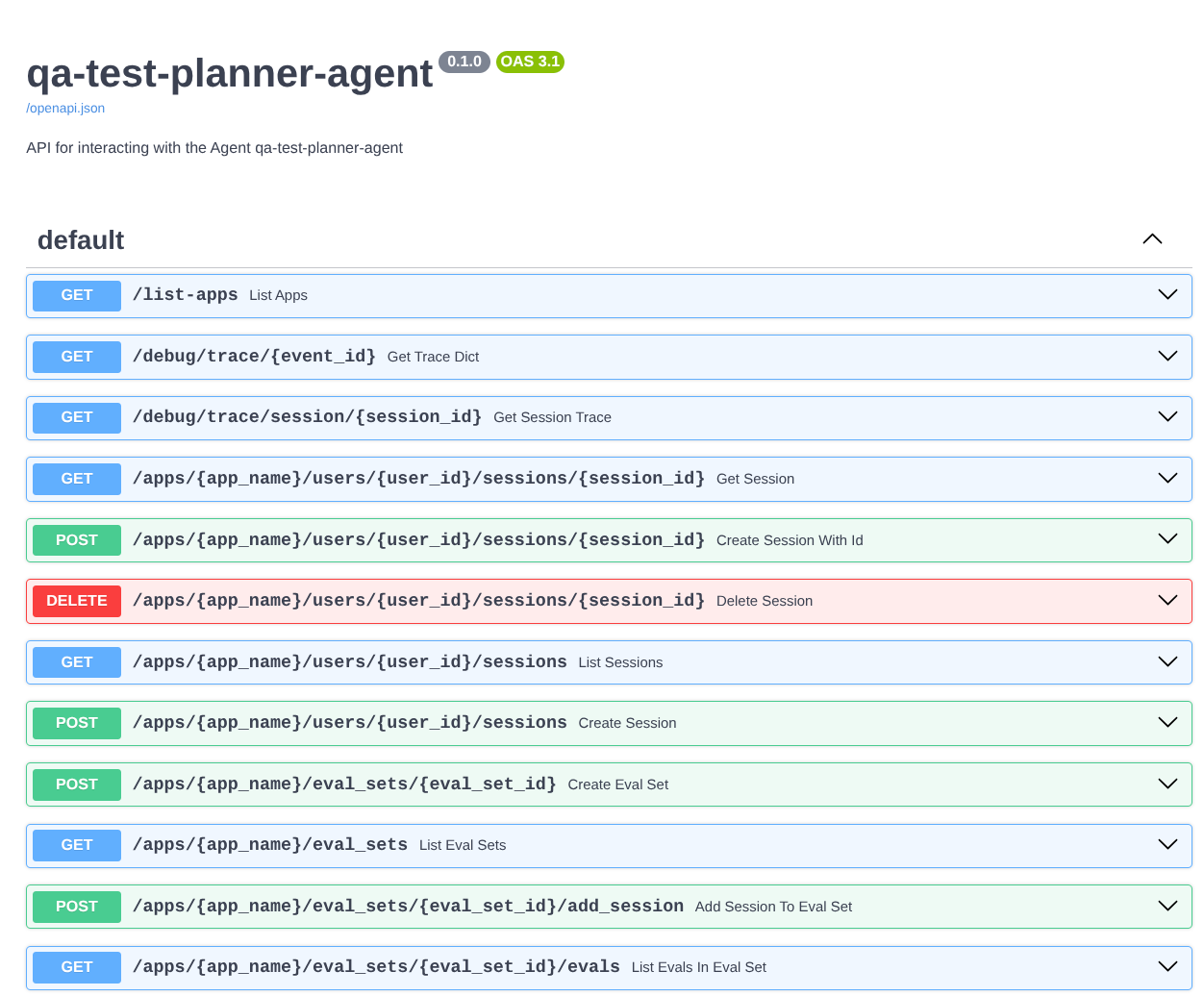
Пояснение к коду
Теперь давайте посмотрим, какой файл нам нужен для развертывания, начиная с server.py.
# server.py
import os
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
app_args = {"agents_dir": AGENT_DIR, "web": True}
app: FastAPI = get_fast_api_app(**app_args)
app.title = "qa-test-planner-agent"
app.description = "API for interacting with the Agent qa-test-planner-agent"
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Мы можем легко преобразовать наш агент в приложение fastapi, используя функцию get_fast_api_app . В этой функции мы можем настроить различные функции, например, службу сессий, службу артефактов или даже трассировку данных в облако.
При желании вы также можете установить здесь жизненный цикл приложения. После этого мы можем использовать uvicorn для запуска приложения Fast API.
После этого Dockerfile предоставит нам необходимые шаги для запуска приложения.
# Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
6. Вызов
Теперь настала ваша очередь проявить себя и отточить навыки исследования. А можете ли вы также создать инструмент, который позволит записывать отзывы по результатам проверки PRD в отдельный файл?
7. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом задании, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
- В качестве альтернативы вы можете перейти в Cloud Run в консоли, выбрать только что развернутую службу и удалить ее.